Clover Serverに対するOracle Endecaの補足
この補足では、Clover ServerをOracle Endeca Integrator Serverとして使用する場合のサポートと制限事項に関する特定の情報を示します。
サポートされるコンテナ
Oracle Endeca Integrator Serverは、次のコンテナでのみサポートされます。
- Apache Tomcat
- Oracle WebLogic
Clover Serverは他のコンテナにインストール可能ですが、Oracle Endeca Integrator Serverでは、他のコンテナへのインストールはサポートされません。
第1章 CloverETL Serverの概要
CloverETL Server (CS)は、CloverETL製品ファミリの統合メンバーです。強力なCloverツールを企業アプリケーションの世界に導入します。CloverETL Server自体は、エンタープライズ・クラスのアプリケーションであり、WARファイル(WARはWeb Archiveの略)として出荷されます。CSは、Apache Tomcat、Jetty、IBM Websphere、Sun Glassfish、JBoss、Oracle Weblogicなど幅広いアプリケーション・サーバーで動作が保証されています。基本的に、CSはグラフのランタイム環境であり、Cloverを独自のソフトウェアと統合する新たな可能性をもたらします。Clover Engineは組込みライブラリとしてしか統合できませんが、CSでは複数のインタフェースを実装し、HTTPなどの共通プロトコルを使用して他のアプリケーションによって呼び出すことができます。また、CSではスレッドとメモリー管理の最適化も一部実装されます。
表1.1. CloverETL ServerとCloverETL Engineの比較
| CloverETL Server | 実行可能ツールとしてのCloverEngine | |
|---|---|---|
| グラフ実行の機能 | http (またはJMX、その他)のAPIをコール(詳細は第14章「簡易HTTP API」(76ページ)を参照してください。) | 外部プロセスを実行、またはJava APIをコール |
| エンジンの初期化 | サーバーの起動時 | グラフを実行するたびにinitがコールされます |
| スレッドとメモリーの最適化 | スレッドのリサイクル、グラフ・キャッシュ、その他 | 未実装 |
| スケジューリング | タイムテーブル、ワンタイム・トリガー、ロギングなどによりスケジューリング | 外部ツール(Cronなど)を使用可 |
| 統計 | 各グラフを実行するたびに独自のログ・ファイルが作成されて結果ステータスが格納され、CSによりトリガーされた各イベントが記録されます | 未実装 |
| 監視 | グラフが失敗した場合、イベント・リスナーに通知されます。電子メールを送信し、シェル・コマンドを実行するか、他のグラフを実行する場合があります。詳細は第7章「グラフ・イベント・リスナー」(55ページ)を参照してください。また、サーバーはサーバー/グラフ・ステータスの監視に使用できる各種のAPI (HTTPおよびJMX)を実装します。 | グラフの実行中にJMX mBeanを使用できます |
| グラフと関連ファイルの格納 | グラフはサーバー・ファイルシステム上で、いわゆるサンドボックスに格納されます | |
| セキュリティと認可のサポート | CSはユーザー/グループの管理をサポートするため、各サンドボックスには独自のアクセス権セットを指定できます。すべてのインタフェースは認証を必要とします。詳細は第3章「サーバー側ジョブ・ファイル - サンドボックス」(25ページ)を参照してください。 | ユーザーが入力したパスワードを暗号化できます |
| 統合機能 | CSには、HTTPなどの共通プロトコルを使用してコールできるAPIがあります。詳細は第14章「簡易HTTP API」(76ページ)を参照してください。 | CloverEngineライブラリを、クライアントのJavaコードの組込みライブラリとして使用することも、グラフごとに個別のOSプロセスとして実行することもできます。 |
| グラフの開発 | CSは1つのプロジェクト(サンドボックス)に対するチーム作業をサポートします。今後のバージョンでは、CloverETL DesignerがCSに統合されます。 | |
| スケーラビリティ | CSは変換リクエストの水平方向のスケーラビリティと、データ・スケーラビリティを実装します。詳細は第24章「クラスタリング」(115ページ)を参照してください。また、CloverEngineの実装にはネイティブで垂直方向のスケーラビリティがあります。 | Clover Engineが垂直方向のスケーラビリティを実装します |
| ジョブフロー | CSは各種のジョブフロー・コンポーネントを実装します。詳細はCloverETLのマニュアルを参照してください。 | Clover Engine自体が限定的にジョブフローをサポートします。 |
第2章 インストール
次の各項では、2つのタイプのインストールについて説明します。「評価サーバー」(3ページ)の項では構成を行わない迅速で簡単なインストールを扱い、「エンタープライズ・サーバー」(4ページ)の項では、選択したアプリケーション・コンテナとデータベースでのテストと本番を扱います。
評価サーバー
CloverETL Serverのデフォルト・インストールでは、追加のデータベース・サーバーは必要ありません。組込みのApache Derby DBが使用されます。また、後続の構成も不要です。CloverETL Serverは、最初の起動時に自動的に構成されます。データベース表と必要なレコードの一部が、最初の起動時に空のデータベース上に自動的に作成されます。Web GUIの「サンドボックス」セクションで、サンドボックスとデモ用のいくつかのグラフが作成されたことを確認できます。
なんらかの構成、たとえば電子メールの送信、LDAP認証、クラスタリングなどの変更を必要とするCloverETl Serverの機能を評価する必要がある場合、またはTomcat以外のアプリケーション・コンテナでCloverETL Serverを評価する必要がある場合は、「エンタープライズ・サーバー」(4ページ)の項で説明されている一般的なインストールに進んでください。
Apache Tomcatのインストール
CloverETL Serverを実行するには、Apache Tomcatバージョン6.0.xが必要です。
Apache Tomcatがすでにインストールされている場合は、この項をスキップできます。
- http://tomcat.apache.org/download-60.cgiから、バイナリのディストリビューションを含むZIPをダウンロードします。Tomcatは、Windows OSのサービスとしてインストールすることもできますが、ファイルシステムへのアクセスに問題が生じる可能性があり、評価の目的用としてはお薦めしません。
- ダウンロードしたzipファイルを解凍します。
- [tomcat_home]/bin/startup.sh (または、Windows OSの場合は[tomcat_home]/bin/startup.bat)で、Tomcatを実行します。
- http://localhost:8080/のURLで、Tomcatが実行中かどうかを確認します。Apache Tomcatの情報ページが開きます。
- Apache Tomcatがインストールされます。
CloverETL Serverのインストール
- 次の前提条件を満たしているかどうかを確認します。
- JDKまたはJRE v. 1.6.x以上
- JAVA_HOMEまたはJRE_HOMEの環境変数が設定されていること。
- Apache Tomcat 6.0.xがインストールされていること。詳細は「Apache Tomcatのインストール」(3ページ)を参照してください。
-
メモリー制限、その他のスイッチを設定します。詳細は「メモリー設定」(23ページ)の項を参照してください。
setenvファイルを作成します。
Unixライクなシステムの場合: [tomcat]/bin/setenv.sh
export CATALINA_OPTS="$CATALINA_OPTS -XX:MaxPermSize=512m -Xms128m -Xmx2048m" export CATALINA_OPTS="$CATALINA_OPTS -Dderby.system.home=$CATALINA_HOME/temp -server" echo "Using CATALINA_OPTS: $CATALINA_OPTS"Windowsシステムの場合: [tomcat]/bin/setenv.bat
set CATALINA_OPTS="%CATALINA_OPTS% -XX:MaxPermSize=512m -Xms128m -Xmx2048m" set CATALINA_OPTS="%CATALINA_OPTS% -Dderby.system.home=%CATALINA_HOME%/temp -server" echo "Using CATALINA_OPTS: %CATALINA_OPTS% - Apache Tomcat用のCloverETL Serverを含むWebアーカイブ・ファイル(clover.war)と、有効なライセンス・ファイルを含むclover-license.warをダウンロードします。
-
両方のWARファイル、clover.warとclover-license.warを[tomcat_home]/webappsディレクトリにデプロイします。
デプロイメント上の問題を回避するために、コピー中はTomcatを停止してください。
- [tomcat_home]/bin/startup.sh (または、Windows OSの場合は[tomcat_home]/bin/startup.bat)で、Tomcatを実行します。
- 次のURLで、CloverETL Serverが実行中かどうかを確認します。
-
Webアプリケーション・ルート
http://[host]:[port]/[contextPath]
httpコネクタのデフォルトのTomcatポートは8080で、CloverETL ServerのデフォルトのcontextPathはcloverです。したがって、デフォルトのURLは次のようになります。 http://localhost:8080/clover/ -
Web GUI
http://[host]:[port]/[contextPath]/gui http://localhost:8080/clover/gui
デフォルトの管理者資格証明を使用してWeb GUIにアクセスします。ユーザー名はclover、パスワードはcloverです。
- CloverETL Serverがインストールされ、基本的な評価の準備ができます。各種の変換デモがインストールされた2つのサンドボックスがあります。
エンタープライズ・サーバー
この項では、各種のアプリケーション・サーバーにおけるCloverETL Serverのインストールの詳細を説明し、またサーバーの構成方法についても説明します。簡単にCloverETL Serverの機能を評価する以外に構成が不要な場合は、評価インストールが適しています。「評価サーバー」(3ページ)の項を参照してください。
エンタープライズ環境用のCloverETL Serverは、Webアプリケーション・アーカイブ(WARファイル)として出荷されます。そのため、アプリケーション・サーバーにWebアプリケーションをデプロイする標準的な方法を使用できます。ただし、アプリケーション・サーバーごとに動作と機能はそれぞれ異なります。それぞれのインストールと構成の詳細は、次の各項に記載されています。
対応するコンテナのリスト:
- 「Apache Tomcat」(5ページ)
- 「Jetty」(8ページ)
- 「IBM Websphere」(10ページ)
- 「Glassfish / Sun Java System Application Server」(13ページ)
- 「JBoss」(15ページ)
- 「Oracle WebLogic Server」(17ページ)
Apache Tomcat
Apache Tomcatのインストール
CloverETL Serverを実行するには、Apache Tomcatバージョン6.0.xが必要です。
Apache Tomcatがすでにインストールされている場合は、この項をスキップできます。
- http://tomcat.apache.org/download-60.cgiから、バイナリのディストリビューションを含むZIPをダウンロードします。
- ダウンロードしたzipファイルを解凍します。
- [tomcat_home]/bin/startup.sh (または、Windows OSの場合は[tomcat_home]/bin/startup.bat)で、Tomcatを実行します。
- http://localhost:8080/のURLで、Tomcatが実行中かどうかを確認します。Apache Tomcatの情報ページが開きます。
-
Apache Tomcatがインストールされます。
CloverETL Serverのインストール
- Apache Tomcat用のCloverETL Serverを含むWebアーカイブ・ファイル(clover.war)をダウンロードします。
-
次の前提条件を満たしているかどうかを確認します。
- JDKまたはJRE v. 1.6.x以上
- JAVA_HOMEまたはJRE_HOMEの環境変数が設定されていること。
- Apache Tomcat 6.0.xがインストールされていること。CloverETL Serverは、Apache Tomcat 6.0.xコンテナに対応して開発とテストが行われています(想定されていない他のバージョンでも動作する場合があります)。詳細は「Apache Tomcatのインストール」(5ページ)を参照してください。
-
ヒープとperm genのメモリー領域に対するデフォルトの制限は変更することをお薦めします。
詳細は「メモリー設定」(23ページ)の項を参照してください。
"Xms"と"Xmx"のJVMパラメータを調整して、メモリー・ヒープの最小サイズと最大サイズを設定できます。[TOMCAT_HOME]/bin/setenv.shファイル(存在しない場合は作成できます)で環境変数JAVA_OPTSを設定すると、TomcatのJVMパラメータを設定できます。
setenvファイルを作成します。
Unixライクなシステムの場合: [tomcat]/bin/setenv.sh
export CATALINA_OPTS="$CATALINA_OPTS -XX:MaxPermSize=512m -Xms128m -Xmx1024m" export CATALINA_OPTS="$CATALINA_OPTS -Dderby.system.home=$CATALINA_HOME/temp -server" echo "Using CATALINA_OPTS: $CATALINA_OPTS"Windowsシステムの場合: [tomcat]/bin/setenv.bat
set CATALINA_OPTS="%CATALINA_OPTS% -XX:MaxPermSize=512m -Xms128m -Xmx1024m" set CATALINA_OPTS="%CATALINA_OPTS% -Dderby.system.home=%CATALINA_HOME%/temp -server" echo "Using CATALINA_OPTS: %CATALINA_OPTS%"前述の設定でもわかるように、-serverというスイッチもあります。パフォーマンス上の理由により、コンテナはサーバー・モードで実行することをお薦めします。 - clover.war (Tomcat用に作成されています)を[tomcat_home]/webappsディレクトリにコピーします。
- Tomcatを再起動しなくても、WARファイルは自動的に検出されてデプロイされます。
- 次のURLで、CloverETL Serverが実行中かどうかを確認します。
-
Webアプリケーション・ルート
http://[host]:[port]/[contextPath]
httpコネクタのデフォルトのTomcatポートは8080で、CloverETL ServerのデフォルトのcontextPathはcloverです。したがって、デフォルトのURLは次のようになります。 http://localhost:8080/clover/ -
Web GUI
http://[host]:[port]/[contextPath]
httpコネクタのデフォルトのTomcatポートは8080で、CloverETL ServerのデフォルトのcontextPathはcloverです。したがって、デフォルトのURLは次のようになります。 http://localhost:8080/clover/gui デフォルトの管理者資格証明を使用してWeb GUIにアクセスします。ユーザー名はclover、パスワードはcloverです。
コピーはアトミック操作ではありません。Tomcatの実行中は、コピー・プロセスの長さに注意してください。コピー時間が長すぎると、デプロイ中に失敗の原因になることがあります。これは、Tomcatが不完全なファイルのデプロイを試行するためです。かわりに、Tomcatが実行中でないときにファイルを操作してください。
Apache TomcatでのCloverETL Serverの構成
デフォルトのインストール(構成なし)が推奨されるのは評価を目的とする場合のみです。本番では、少なくともDBデータ・ソースとSMTPサーバーの構成をお薦めします。
構成プロパティを設定するには、いくつかの方法があります。
コンテキスト・パラメータ(Apache Tomcatで使用可能)
アプリケーション・サーバーによっては、WARファイルを変更せずにコンテキスト・パラメータを設定できます。Tomcatの場合は、この構成方法をお薦めします。
Tomcatでは、コンテキスト構成ファイル([tomcat_home]/ conf/Catalina/localhost/clover.xml)でコンテキスト・パラメータを指定できます。ファイルは、CloverETL Server Webアプリケーションのデプロイ直後に自動的に作成されます。
プロパティを指定するには、次の要素を追加します。
<Parameter name="[propertyName]" value="[propertyValue]" override="false" />
Tomcatコンテキスト・パラメータを変更するには、次をコンテキスト構成ファイルに追加します(資格証明もあわせて変更します)。
<Parameter name="jdbc.driverClassName" value="..." override="false" />
<Parameter name="jdbc.url" value="..." />
<Parameter name="jdbc.username" value="..." override="false" />
<Parameter name="jdbc.password" value="..." override="false" />
<Parameter name="jdbc.dialect" value="..." override="false" />
 注意
注意
コンテキスト・ファイルで特殊文字を入力する場合は、XMLエンティティとして指定する必要があります。たとえば、アンパサンド&を表す&などです。
指定した場所のプロパティ・ファイル
このようなファイルの例をあげます。
jdbc.driverClassName=...
jdbc.url=...
jdbc.username=...
jdbc.password=...
jdbc.dialect=...
共通プロパティ・ファイルのロード元となる場所は、システム・プロパティまたは環境変数clover_config_file (clover.config.file)によって指定できます。アプリケーション・サーバーでコンテキスト・パラメータを設定できない場合は、この構成方法をお薦めします。
Apache Tomcatのシステム・プロパティは、[TOMCAT_HOME]/bin/setenv.shファイル(存在しない場合は作成できます)で設定できます。単にJAVA_OPTS="$JAVA_OPTS -Dclover_config_file=/path/ to/cloverServer.properties"を追加します。
CloverETL Serverライセンスのインストール
グラフを実行するには、CloverETL Serverに有効なライセンスが必要です。ライセンスがなくてもCloverETL Serverはインストールできますが、グラフは実行できません。
Tomcatにライセンスをインストールするには、2つの方法があります。簡単なのは、別のWebアプリケーションclover-license.warを使用する方法です。ただしクラスタ環境の場合は、プレーン・ライセンス・ファイルの構成を実行する必要があります(すべてのアプリケーション・コンテナで共通)。
a) 個別のライセンスWAR
- Webアーカイブ・ファイルclover-license.warをダウンロードします。
- clover-license.warファイルを[tomcat_home]/webappsディレクトリにコピーします。
- Tomcatを再起動しなくても、WARファイルは自動的に検出されてデプロイされます。
- 次のURLで、ライセンスのWebアプリケーションが実行中かどうかを確認します。
http://[host]:[port]/clover-license/ (注意: contextPath clover-licenseは必須であり、変更できません)
b) license.fileのプロパティ
または、サーバーの"license.file"プロパティを構成します。その値を、license.datファイルのフルパスに設定します。
注意
CloverETLのライセンスは、clover-license.warファイルを再デプロイすることによって、いつでも変更できます。後から、ライセンスを変更したことをCloverETL Serverに認識させる必要があります。
- サーバーのWeb GUI→「監視」→「ライセンス」に移動します。
- ライセンスの再ロードをクリックします。
- あるいは、CloverETL Serverアプリケーションを再起動する方法もあります。
警告: WARファイルを再デプロイする際には、ディレクトリ[tomcat_home]/ webapps/[contextPath]を削除する必要があります。Tomcatが実行中の場合は自動的に行われます。その場合でも手動で確認するようにしてください。そうしないと、変更が反映されません。
IBM AS/400 (iSeries)のApache Tomcat
iSeriesプラットフォームでCloverETL Serverを実行する場合は、いくつか追加の設定があります。
- 32ビット版のJava 6.0を使用していることを宣言します
- パラメータ-Djava.awt.headless=trueを指定してJavaを実行します
JAVA_HOME=/QOpenSys/QIBM/ProdData/JavaVM/jdk50/32bit
JAVA_OPTS="$JAVA_OPTS -Djava.awt.headless=true"
Jetty
CloverETL Serverのインストール
- Jetty用に作成されたCloverETL Serverアプリケーションを含むWebアーカイブ・ファイル(clover.war)をダウンロードします。
- 次の前提条件を満たしているかどうかを確認します。
- JDKまたはJREバージョン1.6.x以上
- Jetty 6.1.x (サポートされるのはこの特定のバージョンのみ)
- メモリー割当て設定
- clover.warを[JETTY_HOME]/webappsにコピーします。
-
[JETTY_HOME]/contextsにコンテキスト・ファイルclover.xmlを作成し、そこに次の行を記述します。
<?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE Configure PUBLIC "-//Jetty//Configure//EN" "http://www.eclipse.org/jetty/configure.dtd"> <Configure class="org.mortbay.jetty.webapp.WebAppContext"> <Set name="contextPath">/clover</Set> <Set name="war"><SystemProperty name="jetty.home" default="."/>/webapps/clover.war</Set> </Configure>Jettyによってclover.xmlが検出され、アプリケーションが自動的にロードされます。
- [JETTY_HOME]/bin/jetty.sh start (Windows OSの場合は[JETTY_HOME]/bin/Jetty-Service.exe)を実行します。
jetty-6リリースはすべて、http://jetty.codehaus.org/jetty/から入手できます。Jetty 7はサポートされていません(Jetty 7は、Eclipse Foundationによって運営されているためディストリビューション・パッケージに大きい違いがあります)。
これに関係するのは、JVMパラメータの-Xms -Xmx (ヒープ・メモリー)と、-XX:MaxPermSize (クラスローダー・メモリー制限)です。詳細は「メモリー設定」(23ページ)の項を参照してください。
パラメータを設定するには、次の行
JAVA_OPTIONS='$JAVA_OPTIONS -Xms128m -Xmx1024m -XX:MaxPermSize=256m'
を[JETTY_HOME]/bin/jetty.shに追加します
最後に、http://localhost:8080/test/でサーバーが稼働しているかどうかを確認します。
JettyでのCloverETL Serverの構成
デフォルトのインストール(構成なし)が推奨されるのは評価を目的とする場合のみです。本番では、少なくともDBデータ・ソースとSMTPサーバーの構成をお薦めします。
構成プロパティを設定するには、いくつかの方法がありますが、最も一般的なのは、指定した場所のプロパティ・ファイルです。
指定した場所のプロパティ・ファイル
このようなファイルの例をあげます。
jdbc.driverClassName=...
jdbc.url=...
jdbc.username=...
jdbc.password=...
jdbc.dialect=...
license.file=/path/to/license.dat
共通プロパティ・ファイルは、環境/システム・プロパティclover_config_fileまたはclover.config.fileによって指定された場所からロードされます。これが、Jettyを構成する推奨の方法です。
Jettyのシステム・プロパティは、[JETTY_HOME]/bin/jetty.shファイルで設定できます。次を追加します。
JAVA_OPTIONS="$JAVA_OPTIONS -Dclover_config_file=/path/to/cloverServer.properties"
CloverETL Serverライセンスのインストール
グラフを実行するには、CloverETL Serverに有効なライセンス・ファイルが必要です。ライセンスがなくてもCloverETL Serverはインストールできますが、グラフは実行できません。
- license.datファイルを取得します。
- CloverETL Serverのlicense.fileパラメータを、license.datのパスに設定します。
- "license.file"プロパティを構成プロパティ・ファイルに追加します(「JettyでのCloverETL Serverの構成」(9ページ)の説明を参照)。その値を、license.datファイルのフルパスに設定します。
- Jettyを再起動します。
ライセンスを構成するには、いくつかの方法があります。すべての方法の詳細は、第18章「構成」(96ページ)を参照してください。
![]() 注意
注意
CloverETLのライセンスは、license.datファイルを置き換えることによって、いつでも変更できます。後から、ライセンスを変更したことをCloverETL Serverに認識させる必要があります。
- サーバーのWeb GUI→「監視」→「ライセンス」に移動します。
- ライセンスの再ロードをクリックします。
- あるいは、CloverETL Serverアプリケーションを再起動する方法もあります。
IBM Websphere
CloverETL Serverのインストール
- Websphere用に作成されたCloverETL Serverアプリケーションを含むWebアーカイブ・ファイル(clover.war)をダウンロードします。
- 次の前提条件を満たしているかどうかを確認します。
- JDKまたはJREバージョン1.6.x以上
- IBM Websphere 7.0 (http://www.ibm.com/developerworks/downloads/ws/was/を参照)
- メモリー割当て設定
- 「サーバー」→「アプリケーション・サーバー」→[server1] (その他、使用しているサーバーの名前)→「プロセス管理」→「Java仮想マシン」に移動します。
- 「最大ヒープ・サイズ」というフィールドがあります。デフォルト値は256 MBですが、ETL変換には不十分です。
- 同じページに、汎用のJVM引数があります。次のような恒久領域の制限を追加します。
- サーバーを再起動して変更を確定します。
- WARファイルをデプロイします
- Integrated Solutions Consoleに移動します。
- 「アプリケーション」→「新しいアプリケーション」→新しいエンタープライズ・アプリケーションに移動します。
- ロギングを構成します
- Websphereディレクトリに構成ファイルを追加します: AppServer/profiles/AppSrv01/properties/ commons-logging.properties
- 次の行をファイルに挿入します。
- clover.war/WEB-INF/libアーカイブからAppServer/libディレクトリにjarファイルをコピーします。commons-logging-*.jarおよびlog4j-*.jarなどのファイルをすべてコピーしてください。
- サーバーが稼働しているかどうかを確認します
これに関係するのは、JVMパラメータの-Xms -Xmxと、-XX:MaxPermSizeです。詳細は「メモリー設定」(23ページ)の項を参照してください。ヒープ・サイズと恒久領域は、IBM WebsphereのIntegrated Solutions Consoleで設定できます(デフォルトではhttp://[host]:10003//ibm/console/)でアクセスできます。

図2.1 「最大ヒープ・サイズ」制限の調整
-XX:MaxPermSize=512M
(http://localhost:9060/ibm/console/)
デフォルトでは、Websphereログ出力はlog4jを使用しません。これが原因でCloverETL Serverのロギングが正しく構成されない場合があります。したがって、CloverETL Engineの一部のメッセージではグラフ実行ログが欠落しています。そのため、log4jを使用するようにWebsphereを正しく構成することをお薦めします。
priority=1
org.apache.commons.logging.LogFactory=org.apache.commons.logging.impl.LogFactoryImpl
org.apache.commons.logging.Log=org.apache.commons.logging.impl.Log4JLogger
cloverコンテキスト・パスで実行されるアプリケーションとしてclover.warを設定していると仮定します。次のようにポート番号が変更されています。
IBM WebsphereでのCloverETL Serverの構成
デフォルトのインストール(構成なし)が推奨されるのは評価を目的とする場合のみです。本番では、少なくともDBデータ・ソースとSMTPサーバーの構成をお薦めします。
構成プロパティを設定するには、いくつかの方法があります。最も一般的なのは、指定した場所のプロパティ・ファイルです。
指定した場所のプロパティ・ファイル
このようなファイルの例をあげます。
jdbc.driverClassName=...
jdbc.url=...
jdbc.username=...
jdbc.password=...
jdbc.dialect=...
license.file=/path/to/license.dat
構成プロパティ・ファイルを示すシステム・プロパティ(または環境変数)clover_config_fileを設定します。
- Integrated Solutions Consoleに移動します。
- 「サーバー」→「アプリケーション・サーバー」→[サーバー名]→Javaおよびプロセス管理→「プロセス定義」→「環境エントリ」に移動します。
- clover_config_fileという名前のシステム・プロパティを作成します。この値が、たとえばcloverServer.propertiesなど、ファイルシステム上の構成ファイルのフルパスです。
- この変更には、IBM Websphereの再起動が必要です。
(http://localhost:9060/ibm/console/)
CloverETL Serverライセンスのインストール
CloverETL Serverでグラフを実行するには、有効なライセンスが必要です。ライセンスがなくてもCloverETL Serverはインストールできますが、グラフは実行できません。
- license.datファイルを取得します。
- CloverETL Serverのlicense.fileパラメータを、license.datファイルのパスに設定します。
- license.fileプロパティを構成プロパティ・ファイルに追加します(「IBM WebsphereでのCloverETL Serverの構成」(12ページ)の説明を参照)。プロパティの値は、license.datファイルのフルパスである必要があります。
- CloverETL Serverを再起動します。
これを行うには、他の方法もあります。最も直接的なのは、システム・プロパティまたは環境変数clover_license_fileを設定する方法です。(すべての方法の詳細は、第18章「構成」(96ページ)を参照してください。)
![]() 注意
注意
適切に構成されたCloverETLのライセンスは、ファイルlicense.datを置き換えることによって、いつでも変更できます。この場合、ライセンスを変更したことをCloverETL Serverに認識させる必要があります。
- Web GUI→「監視」セクション→「ライセンス」タブに移動します。
- ライセンスの再ロードボタンをクリックします。
- あるいは、CloverETL Serverアプリケーションを再起動する方法もあります。
Glassfish / Sun Java System Application Server
CloverETL Serverのインストール
- Glassfish (Tomcat)用に作成されたCloverETL Server Webアーカイブ・ファイル(clover.war)を取得します。
- 次の前提条件を満たしているかどうかを確認します
- JDKまたはJREバージョン1.6.x以上
- Glassfish (CloverETL ServerはV2.1で動作確認済)
- メモリー割当て設定
- WARファイルをデプロイします
- WARファイルをサーバー・ファイルシステムにコピーします。CloverETL Serverは、約100 MBのWARファイルとして圧縮されているので、管理コンソールを使用してローカル・ファイルシステムから直接アップロードすることはできません。
- 「アプリケーション名」と「コンテキスト・ルート」の属性にcloverを入力します。サーバー・ファイルシステムでWARファイルのパスを指定します。
- Glassfish管理コンソールに移動します。
- 「アプリケーション」→「Webアプリケーション」に移動し、「デプロイ」をクリックします。
- フォームを発行します
これに関係するのは、JVMパラメータの-Xms -Xmxと-XX:MaxPermSizeです。詳細は「メモリー設定」(23ページ)の項を参照してください。
ヒープ・サイズと恒久領域は、XMLファイル[glassfish]/domains/domain1/config/ domain.xmlで設定できます。次の下位要素を<java-config>に追加します。
<jvm-options>-XX:MaxPermSize=512m</jvm-options>
<jvm-options>-Xmx2048m</jvm-options>
この変更には、Glassfishの再起動が必要です。
デフォルトではhttp://localhost:4848/でアクセスでき、デフォルトのユーザー名/パスワードは、admin/adminadminです
GlassfishでのCloverETL Serverの構成
デフォルトのインストール(構成なし)が推奨されるのは評価を目的とする場合のみです。本番では、少なくともDBデータ・ソースとSMTPサーバーの構成をお薦めします。
構成プロパティを設定するには、いくつかの方法があります。最も一般的なのは、指定した場所のプロパティ・ファイルです。
指定した場所のプロパティ・ファイル
このようなファイルの例をあげます。
jdbc.driverClassName=...
jdbc.url=...
jdbc.username=...
jdbc.password=...
jdbc.dialect=...
license.file=/path/to/license.dat
構成プロパティ・ファイルを示すシステム・プロパティ(または環境変数)clover_config_fileを設定します。
デフォルトではhttp://localhost:4848/でアクセスでき、ユーザー名/パスワードは、admin/adminadminです
CloverETL Serverライセンスのインストール
CloverETL Serverでグラフを実行するには、有効なライセンスが必要です。ライセンスがなくてもCloverETL Serverはインストールできますが、グラフは実行できません。
ライセンスの構成は、WebSphere(10ページ)とほぼ同様です。
- license.datファイルを取得します。
- CloverETL Serverのlicense.fileパラメータを、license.datのパスに設定します。
- 「指定した場所のプロパティ・ファイル」(14ページ)の説明に従って、license.fileプロパティを構成プロパティ・ファイルに追加します。その値を、license.datファイルのフルパスに設定します。
- CloverETL Serverを再起動します。
- Web GUI→「監視」→「ライセンス」に移動します
- ライセンスの再ロードをクリックします。
- あるいは、CloverETL Serverを再起動する方法もあります。
これを行うには、他の方法もあります。最も直接的なのは、システム・プロパティまたは環境変数clover_license_fileを設定する方法です。(すべての方法の詳細は、(第18章「構成」(96ページ)を参照してください。)
![]() 注意
注意
適切に構成されたCloverETLのライセンスは、license.datを置き換えることによって、いつでも変更できます。次に、ライセンスを変更したことをCloverETL Serverに認識させる必要があります。
JBoss
CloverETL Serverのインストール
- JBoss用に作成されたCloverETL Server Webアーカイブ・ファイル(clover.war)を取得します。
- 次の前提条件を満たしているかどうかを確認します
- JDKまたはJREバージョン1.6.x以上
- JBoss 6.0またはJBoss 5.1 (http://www.jboss.org/jbossas/downloadsを参照してください)
- jboss javaプロセスのメモリー設定。詳細は「メモリー設定」(23ページ)の項を参照してください。
-
DBデータ・ソースの構成
JBossは組込みのDerby DBでは動作しないため、常にDB接続を構成する必要があります。この例では、MySQLを使用しました。
- データ・ソース構成ファイル[jboss-home]/server/default/deploy/mysql-ds.xmlを作成します
<datasources> <local-tx-datasource> <jndi-name>CloverETLServerDS</jndi-name> <connection-url>jdbc:mysql://localhost:3306/cloverServerDB</connection-url> <driver-class>com.mysql.jdbc.Driver</driver-class> <user-name>root</user-name> <password></password> </local-tx-datasource> </datasources> 注意
XMLファイルで特殊文字を使用する場合は、XMLエンティティとして入力する必要があります。たとえば、アンパサンド&を表す&などです。
JNDI名は、正確にCloverETLServerDSとする必要があります。ここで行うのは、作成したデータベースにDB接続パラメータ(connection-url、driver-class、user-name、password)を設定することです。データベースは、最初に実行する前に空である必要があり、サーバーが自動的に表を作成します。
JNDIデータ・ソースは、JBossでCloverETL ServerのDB接続を構成する唯一の手段です。
- 使用しているDBに対応するJDBCドライバを、アプリケーション・サーバーのクラスパスに指定します。
ここでは、JDBCドライバmysql-connectorjava-5.1.5-bin.jarを[jboss-home]/server/default/libにコピーしました。 - 次の項(16ページ)の説明に従って、CloverETL Serverを構成します。
-
WARファイルをデプロイします
clover.warを[jboss-home]/server/default/deployにコピーします
-
[jboss-home]/bin/run.sh(Windows OSの場合はrun.bat)を使用してjbossを起動します。
すべてのアプリケーションが起動するまでに数分間かかる場合があります。
- JBossの応答とCloverETL Serverの応答を確認します
- デフォルトでは、JBoss管理コンソールにはhttp://localhost:8080/でアクセスできます。デフォルトのユーザー名/パスワードは、admin/adminです
- デフォルトでは、http://localhost:8080/でCloverETL Serverにアクセスできます。
-
必要な場合、デフォルトとサンプルのサンドボックス(tempディレクトリに自動的に作成される)をファイルシステム上で適切なディレクトリに移動します。
- これらのサンドボックスは、最初のデプロイ時に自動的に作成され、web-appディレクトリに配置されます。このディレクトリは、特定のデプロイごとに固有です。なんらかの理由でWebアプリケーションをデプロイした場合に、このディレクトリが作成されます。このため、サンドボックスは変化しない場所に移動することをお薦めします。
[jboss-home]/bin/run.conf (Windows OSの場合はrun.conf.bat)で、メモリー制限を設定できます。
JAVA_OPTS="$JAVA_OPTS -XX:MaxPermSize=512m -Xms128m -Xmx2048m"
Windowsの場合も、前述と同様な手順を実行します。
JBossでのCloverETL Serverの構成
デフォルトのインストール(構成なし)が推奨されるのは評価を目的とする場合のみです。本番では、少なくともDBデータ・ソースとSMTPサーバーの構成をお薦めします。
構成プロパティを設定するには、いくつかの方法があります。最も一般的なのは、指定した場所のプロパティ・ファイルです。
指定した場所のプロパティ・ファイル
- cloverServer.propertiesを適切なディレクトリに作成します
datasource.type=JNDI datasource.jndiName=java:/CloverETLServerDS jdbc.dialect=org.hibernate.dialect.MySQLDialect license.file=/home/clover/config/license.datdatasource.typeとdatasource.jndiNameのプロパティは変更せず、使用しているDBサーバーに応じて正しいJDBC言語を設定してください(第18章「構成」(96ページ)を参照)。また、ライセンス・ファイルのパスも設定します。
- システム・プロパティ(または環境変数) clover_config_fileを設定します。
これには、前の手順で作成したcloverServer.propertiesファイルのフルパスを指定する必要があります。
最も簡単なのは、次のように[jboss-home]/bin/run.shでJavaのパラメータを設定する方法です。
export JAVA_OPTS="$JAVA_OPTS -Dclover_config_file=/home/clover/config/cloverServer.properties"JAVA_OPTSプロパティの他の設定、つまり前述したメモリー設定はオーバーライドしないでください。
Windows OSの場合は、[jboss-home]/bin/run.conf.batを編集し、JVMにオプションが渡されるセクションに次の行を追加します。
set JAVA_OPTS=%JAVA_OPTS% -Dclover_config_file=C:\JBoss6\cloverServer.properties - この変更には、JBossの再起動が必要です。
CloverETL Serverライセンスのインストール
CloverETL Serverでグラフを実行するには、有効なライセンスが必要です。ライセンスがなくてもCloverETL Serverはインストールできますが、グラフは実行できません。
- license.datファイルを取得します。
- CloverETL Serverのパラメータlicense.fileに、license.datのパスを指定します。
-
構成を変更するには、アプリケーション・サーバーの再起動が必要です。
注意
CloverETLのライセンスは、ファイルlicense.datファイルを置き換えることによって、いつでも変更できます。この場合、ライセンスを変更したことをCloverETL Serverに認識させる必要があります。
- Web GUI→「監視」→「ライセンス」に移動します
- ライセンスの再ロードをクリックします。
- あるいは、CloverETL Serverアプリケーションを再起動する方法もあります。
clover_license.warのみある場合は、それを通常のzipアーカイブと同様に解凍すると、WEB-INFサブディレクトリにlicense.datが見つかります。
ライセンスを構成するには、前の項で説明されているようにcloverServer.propertiesファイルでlicense.fileプロパティを設定するのが最も確実です。
これを行うには、他の方法もあります。(すべての方法の詳細は、第18章「構成」(96ページ)を参照してください。)
Oracle WebLogic Server
CloverETL Serverのインストール
- WebLogic用に作成されたCloverETL Server Webアーカイブ・ファイル(clover.war)を取得します。
- 次の前提条件を満たしているかどうかを確認します
- JDKまたはJREバージョン1.6.x以上
- WebLogic (CloverETL Serverは10.3.6で動作確認済です。http://www.oracle.com/technetwork/middleware/ ias/downloads/wls-main-097127.htmlを参照してください)
-
メモリー割当て設定
これに関係するのは、JVMパラメータの-Xms -Xmxと-XX:MaxPermSizeです。
詳細は「メモリー設定」(23ページ)の項を参照してください。
-
HTTP基本認証の構成を変更します
- HTTPリクエストで"Authentication"ヘッダーが検出されると、WebLogicはそれ自体のレルムでユーザーを検索しようとします。CloverETLでユーザーを認証するためには、この動作を停止する必要があります。
- 構成ファイル[domainHome]/config/config.xmlを修正します。<enforce-validbasic-auth-credentials>false</enforce-valid-basic-auth-credentials>という要素を、<security-configuration>という要素(終了タグの直前)に追加します。
-
WARファイル(またはアプリケーション・ディレクトリ)をデプロイします
- WebLogic Server管理コンソールを使用して、clover.warをデプロイします。詳細は、『Oracle Fusion Middleware管理者ガイド』(http://docs.oracle.com/cd/E23943_01/core.1111/e10105/toc.htm)を参照してください。
-
ライセンス(およびその他の構成プロパティ)を構成します
- 後述の別項(18ページ)を参照してください。
-
CloverETL ServerのURLを確認します
Webアプリケーションは、デプロイ後に自動的に起動するため、稼働していることを確認できます。
- デフォルトでは、http://host:7001/cloverでCloverETL Serverにアクセスできます。ポート7001は、デフォルトのWebLogic HTTPコネクタ・ポートです。
WebLogicが稼働している必要があり、ドメインを構成する必要があります。これは、http://hostname:7001/console/ (7001はHTTPのデフォルト・ポート)で管理コンソールに接続して確認できます。ユーザー名とパスワードは、インストール中に指定します。
これは、次の内容を追加して設定できます。
export JAVA_OPTIONS='$JAVA_OPTIONS -Xms128m -Xmx2048m -XX:MaxPermSize=512m' to the start script
この変更には、ドメインの再起動が必要です。
WeblogicでのCloverETL Serverの構成
デフォルトのインストール(構成なし)が推奨されるのは評価を目的とする場合のみです。本番では、少なくともDBデータ・ソースとSMTPサーバーの構成をお薦めします。
構成プロパティを設定するには、いくつかの方法があります。最も一般的なのは、指定した場所のプロパティ・ファイルです。
指定した場所のプロパティ・ファイル
cloverServer.propertiesを適切なディレクトリに作成します。
構成ファイルには、DBデータ・ソースの構成、SMTP接続の構成などが含まれます。
構成プロパティ・ファイルを示すシステム・プロパティ(または環境変数)clover_config_fileを設定します
- WebLogicドメイン起動スクリプト[domainHome]/startWebLogic.shで、JAVA_OPTIONS変数を設定します
JAVA_OPTIONS="${JAVA_OPTIONS} -Dclover_config_file=/path/to/clover-config.properties
CloverETL Serverライセンスのインストール
CloverETL Serverでグラフを実行するには、有効なライセンスが必要です。ライセンスがなくてもCloverETL Serverはインストールできますが、グラフは実行できません。
- license.datファイルを取得します。
- CloverETL Serverのパラメータlicense.fileに、license.datファイルのパスを指定します
-
構成を変更するには、アプリケーション・サーバーの再起動が必要です。
注意
適切に構成されたCloverETLのライセンスは、ファイルlicense.datを置き換えることによって、いつでも変更できます。この場合、ライセンスを変更したことをCloverETL Serverに認識させる必要があります。
- Web GUI→「監視」→「ライセンス」に移動します
- ライセンスの再ロードをクリックします。
- あるいは、CloverETL Serverアプリケーションを再起動する方法もあります。
clover_license.warのみある場合は、それを通常のzipアーカイブと同様に解凍すると、WEB-INFサブディレクトリにlicense.datファイルが見つかります。
ライセンスを構成するには、前の項で説明されているようにcloverServer.propertiesファイルでlicense.fileプロパティを設定するのが最も確実です。
これを行うには、他の方法もあります。(すべての方法の詳細は、第18章「構成」(96ページ)を参照してください。)
インストール中に想定される問題
CloverETL Serverは、様々なアプリケーション・サーバー、データベースおよびJVM実装で動作するユニバーサルJEEアプリケーションとして位置付けられているため、インストール中に問題が発生する可能性があります。それらは、サーバー環境の適切な構成によって解決できます。この項では、構成に関するヒントについて説明します。
Derbyにおけるメモリーの問題
これまで正常に稼働していたサーバーが突然、大量のリソース(CPU、メモリー)を消費し始めた場合は、内部Derby DBの実行が原因になっている可能性があります。代表的な原因は、Apache Tomcatの不正または不完全なシャットダウンと、Apache Tomcatのパラレル(再)起動です。
解決方法: 標準(スタンドアロン)データベースに移行します。
修正方法: CloverETL Serverを再デプロイします。
- Apache Tomcatを停止し、他のインスタンスが実行中でないことを確認します。実行中の場合は、強制終了します。
- webapps/clover/WEB-INFとclover/WEB-INF/sandboxesから、config.propertiesをバックアップします(そこにデータがある場合)。
- webapps/cloverディレクトリを削除します。
- Apache Tomcatサーバーを起動します。自動的にClover Serverが再デプロイされます。
- DesignerからもWebからも接続できることを確認します。
- Apache Tomcatをシャットダウンします。
- config.propertiesをリストアし、通常のデータベースを指定します。
- Apache Tomcatを起動します。
JAVA_HOMEまたはJRE_HOME環境変数が定義されていない
アプリケーション・サーバー(大部分はTomcat)を起動しようとしてこのエラー・メッセージが表示された場合は、次の処理を実行してください。
Linuxの場合:
次の2つのコマンドを使用して、サーバー上の変数のパスを設定します。
- [root@server /] export JAVA_HOME=/usr/local/java
- [root@server /] export JRE_HOME=/usr/local/jdk
最後に、アプリケーション・サーバーを再起動します。
Windows OSの場合:
JAVA_HOMEを、JDKインストール・ディレクトリ、たとえばC:\Program Files\java\jdk1.6.0に設定します。オプションで、JRE_HOMEもJREのベース・ディレクトリ、たとえばC:\Program Files\java\jre6に設定します。
![]() 重要
重要
JREのみインストールしている場合は、JRE_HOMEのみを指定します。
Tomcatのログ・ファイルcatalina.outがWindows上で欠落
Windows用のTomcat起動バッチ・ファイルは、アプリケーションの標準出力を含むcatalina.outファイルを作成するように構成されていません。Tomcatをコンソールで起動せず、なんらかの問題が発生した場合は、catalina.outが重要になることがあります。あるいは、Tomcatをコンソールで実行している場合でも、エラー・メッセージの表示後、すぐ自動的に閉じることがあります。
次の手順を実行して、catalina.outの作成を有効にしてください。
-
[tomcat_home]/bin/catalina.batを変更します。"_EXECJAVA"変数が設定されている行に、パラメータ/Bを追加します。該当する行は2行です。次のようになります。
set _EXECJAVA=start /B [行の残り]
パラメータ/Bを指定すると、startコマンドで新しいコンソール・ウィンドウが開かず、コマンドをそれ自身のコンソール・ウィンドウで実行します。
-
次の1行のみを含む新しい起動ファイル、たとえば[tomcat_home]/bin/startupLog.batを作成します。
catalina.bat start > ..\logs\catalina.out 2<&1
これでTomcatは通常のように実行されますが、標準出力がコンソールではなくcatalina.outファイルに変更されます。
次に、[tomcat_home]/bin/startup.batのかわりに新しい起動ファイルを使用します
JVMを待機中にタイムアウト
Jettyアプリケーション・サーバーが正常に起動し、Clover Serverを起動できない場合は、ラッパーのJVMに対する待機時間が長すぎた可能性があります(これはメモリー不足の問題とみなされます)。[JETTY_HOME]\logs \jetty-service.logで、次のような行があるかどうかを調べてください。
Startup failed: Timed out waiting for signal from JVM.
あった場合は[JETTY_HOME]\bin\jetty-service.confを編集し、次の行を追加します。
wrapper.startup.timeout=60
wrapper.shutdown.timeout=60
これで問題が解決しない場合は、両方の値を120に設定してみます。デフォルトのタイムアウトは、どちらも30です。
clover.warがWebsphereでデフォルトのコンテキスト(Windows OS)
コンテキスト・パスを指定せずにclover.warをIBM Websphereサーバーにデプロイしている場合は、コンテキスト・ルートで他のアプリケーションが実行中でないかを確認する必要があります。WebsphereでClover Serverを起動できない場合は、ログを確認して次のようなメッセージがあるかどうか調べます。
com.ibm.ws.webcontainer.exception.WebAppNotLoadedException:
Failed to load webapp: Failed to load webapp: Context root /* is already bound.
Cannot start application CloverETL
あった場合は、ここで説明する場合に該当しています。問題を解決する最も簡単な方法は、他の(サンプル)アプリケーションをすべて停止し、サーバーでclover.warのみが実行されている状態にすることです。これによって、これ以降はコンテキスト・ルート(例: http://localhost:9080/)でサーバーが稼働するようになります。

図2.2 IBM Websphereで稼働しているアプリケーションがClover Serverのみの場合
Linux上のTomcat 6.0 -デフォルトDB
Linuxで内部(デフォルト)データベースを使用している場合、Clover Serverが特に理由もなく最初の起動時にエラーになることがあります。可能性としては、/var/lib/tomcat6/databasesディレクトリが作成されていない場合があります(親フォルダに対するアクセス権が原因)。
解決方法: 自分でディレクトリを作成し、サーバーを再起動してみます。単純な修正ですが、Tomcat Web管理者を介してWARファイルとしてデプロイされたClover Serverに対しては有効であることが確認されています。
derby.system.homeにアクセスできない
サーバーを起動できない場合は、ログに次のようなメッセージがあります。
java.sql.SQLException: Failed to start database 'databases/cloverserver'
この場合、次の例外で詳細を確認します。その後、derby.system.homeシステム・プロパティの設定を確認します。そこでアクセスできないディレクトリが指定されているか、ファイルが他のプロセスによってロックされている可能性があります。特定のディレクトリをシステム・プロパティで設定してください。
複数の環境変数と複数のCloverETL Serverインスタンスが1つのマシン上に存在
clover_license_fileまたはclover_config_fileなどの環境変数を設定している場合、複数のCloverETL Serverは実行できないことに注意してください。したがって、複数のインスタンスを同時に実行する必要がある場合は、別の方法でパラメータを設定してください(詳細は、第18章「構成」(96ページ)を参照)。これは、環境変数はすべてのアプリケーションによって共有され、構成も共有するため、予期しないエラーが発生するためです。環境変数のかわりに、システム・プロパティ(-D接頭辞を含むパラメータ-Dclover_config_fileを使用してアプリケーション・コンテナ・プロセスに渡されます)を使用できます。
パスに特殊文字とスラッシュ
サーバーを操作する際には、通常より厳格にフォルダの命名規則に従う必要があります。サーバー・パスに特殊文字は使用しないでください。空白、アクセント記号、発音符号などはすべて非推奨です。Windowsシステムでは命名によく使用される文字です。ただしこれは問題の原因になり、しかも特定が困難です。奇妙なエラーが発生し、その原因を特定できない場合は、アプリケーション・サーバーを次のように確実な場所にインストールしてみてください。
C:\JBoss6\
同様に、たとえばClover Serverライセンス・ファイルを指定する場合などで、*.propertiesファイル内部のパスにはスラッシュを使用し、円記号は使用しないでください。誤って円記号を使用するとエスケープ文字と解釈され、サーバーが正常に動作しないことがあります。次に正しいパスの例を示します。
license.file=C:/CoverETL/Server/license.dat
JAXBおよびそれ以前のバージョンのJVM 1.6
バージョン1.3以降のCloverETL Serverには、jaxb 2.1のライブラリが含まれています。これが、jaxb 2.0を含むJVM1.6の初期バージョンでは競合の原因になることがあります。ただし、JDK6 Update 4リリースでは最終的にjaxb 2.1が含まれるようになったため、これより新しいバージョンのJVMに更新すれば、競合の可能性は解決されます。
ファイルシステムの権限
アプリケーション・サーバーは、ファイルシステム上で適切な読取り/書込み権限を持つOSユーザーが実行する必要があります。アプリケーション・サーバーが初めてルート・ユーザーによって実行された場合に問題が発生することがあり、ログおよびその他の一時ファイルはルート・ユーザーによって作成されます。同じアプリケーション・サーバーを別のユーザーが実行すると、ルートのファイルには書き込めないためエラーになります。
JMS APIとJMSのサード・パーティ製ライブラリ
JMSライブラリが欠落していてもサーバーの起動には失敗しませんが、アプリケーション・サーバーへのデプロイ時には問題になるため、この項で取り上げることにします。
clover.war自体にはjms.jarが含まれていないので、アプリケーション・サーバーのクラスパスに指定する必要があります。ほとんどのアプリケーション・サーバーにはデフォルトでjms.jarがありますが、Tomcatなどにはjms.jarがありません。そのため、JMS機能が必要な場合は、jms.jarを明示的に追加する必要があります。
JMSタスク機能を使用する場合、サーバーのクラスパスにはサード・パーティ製ライブラリも必要です。JMS Reader/Writerコンポーネントで外部ライブラリの指定が許可される場合でも、同じアプローチが推奨されます。これらのライブラリにはたびたびメモリー・リークが存在し、それが原因で"OutOfMemoryError: PermGen space"が発生するためです。
メモリー設定
Java仮想マシンの現在の実装では、JVMシステム・プロセスに対してはグローバルなメモリー構成のみが可能です。そのため、アプリケーション・サーバー全体が、そこで実行されるWARやEARまで含めて、1つのメモリー領域を共有します。
JVMメモリーのデフォルト設定は、CloverETL Serverとアプリケーション・コンテナを実行するには小さすぎます。IBM Websphereなど一部のアプリケーション・サーバーは独自にJVMのデフォルトを増やしますが、それでもまだメモリー設定は十分ではありません。
最適なメモリー上限は多くの条件、たとえばCloverETLで実行される変換などにより異なります。最大の上限は、恒久的に割り当てられるメモリー量ではなく、超えてはならない上限です。この上限を超えた場合、OutOfMemoryErrorが発生します。
XmsとXmxのJVMパラメータを調整して、メモリー・ヒープの最小サイズと最大サイズを設定できます。使用するアプリケーション・コンテナによって、設定の変更方法は様々です。
変換に必要なメモリー量がわからない場合は、最大1から2 GBのヒープ・メモリーを推奨します。変換の作成中にOutOfMemoryErrorが発生した場合は、この上限をさらに増やすことができます。
クラスをロードするためのメモリー領域(いわゆるPermGen領域)は、ヒープ・メモリーと区別されているため、JVMパラメータ-XX:MaxPermSizeで設定できます。デフォルトでは、これが64 MBしかなく、エンタープライズ・アプリケーションには十分ではありません。ここでも、適切なメモリー上限は様々な条件で異なりますが、512 MBを指定しておくとほとんどの場合に十分です。PermGen領域の最大値が低すぎる場合は、OutOfMemoryError: PermGen spaceが発生することがあります。
設定方法の詳細は、個々のコンテナに関する項を参照してください。
新しいバージョンへのサーバーのアップグレード
新しいバージョンの起動
- 新しいビルドのCloverETL Serverで、Webアーカイブ・ファイル(WAR)を取得します。
- Webアプリケーションを再デプロイします。その方法はアプリケーション・サーバーによって異なります。サポートされているすべてのサーバーのインストールについては、「エンタープライズ・サーバー」(4ページ)を参照してください。再デプロイすると、新しいサーバーが以前のバージョンの構成に基づいて構成されます。
- データベース・スキーマに対する変更が必要な場合は、新しいサーバーを最初に起動したとき自動的にその変更が行われます。アップグレードの前にデータベースをバックアップすることをお薦めします。
サーバー・ライセンスのアップグレード
-
ライセンス・ファイルは、一意の文字列セットを含むテキストとして出荷されます。次の場合に応じて操作してください。
- 新しいライセンスをファイル(*.dat)として受け取った場合は、単に古いライセンス・ファイルを上書きします。
- ライセンス・テキストを電子メールなどで送信された場合は、ライセンスの内容(CompanyとEND LICENSEの間の全テキスト)をclover-license.datという新規ファイルにコピーします。次に、古いライセンス・ファイルを新しいライセンス・ファイルで上書きします。
- Clover Serverの構成で、必要に応じてフルパスを新しいライセンス・ファイルに変更します。
- サーバーのWeb GUI→「監視」→「ライセンス」で、ライセンスの再ロードをクリックします。あるいは、CloverETL Serverを再起動します。
評価バージョンの場合- ライセンスをアップグレードするだけでは十分ではありません。評価サーバーからエンタープライズ・サーバーに移行する場合は、デフォルトの構成とデータベースは使用しないでください。かわりに、時間はかかりますが本番環境に応じてClover Serverを構成してください。
第3章 サーバー側ジョブ・ファイル - サンドボックス
サンドボックスは、プロジェクトのベースの格納単位です。実際のサンドボックスは、CloverETL Designerプロジェクトに相当するサーバー側の機能です。CloverETL Designerには、CloverETL Serverへのコネクタがあるので、Designerプロジェクトとサーバーのサンドボックスを相互にリンクきます。このリモートCloverETL Designerプロジェクトは、見かけも動作も通常のローカル・プロジェクトと類似していますが、すべてのファイルがサーバー側に格納され、すべての操作がサーバー側で実行されます。サーバーへの接続の構成の詳細は、CloverETL Designerのマニュアルを参照してください。
技術的には、サンドボックスはサーバーのファイルシステム上の専用ディレクトリです。サンドボックスに他のサンドボックスを含めることはできません。1つのディレクトリをサンドボックス・コンテナとし、各サンドボックスに対してはサブディレクトリを作成することをお薦めします。サンドボックスの中のファイルとディレクトリは、アプリケーション・サーバーのJVMによって読み込まれます。したがって、これらのディレクトリはすべて、アプリケーション・サーバーのJVMを実行するOSユーザーからアクセスできる必要があります。たとえば、Apache Tomcatが"tomcat"というユーザーによってOSサービスとして実行される場合、すべてのサンドボックスはこのユーザーからアクセスできる必要があります。
クラスタ・モードでは、共有、ローカル、パーティション化の3タイプのサンドボックスがあります。詳細は、第24章「クラスタリング」(115ページ)を参照してください。

図3.1 CloverETL Server Web GUIの「サンドボックス」セクション
各サンドボックスは、次の属性で定義されます。
表3.1. サンドボックスの属性
| ID | サンドボックスの一意な名前。サンドボックスを識別するためにサーバーAPIで使用されます。識別子の一般的なルールを満たしている必要があります。サンドボックスを作成する際にユーザーによって指定され、後から変更も可能です。 注意: いずれかのCS APIクライアントですでに使用されている可能性があるため、変更は推奨されません。 |
| 名前 | 表示用にのみ使用されるサンドボックス名。サンドボックスを作成する際にユーザーによって指定され、後から変更も可能です。 |
| ルート・パス | サーバー側ファイルシステムにおけるサンドボックス・ルートの絶対パス。サンドボックスを作成する際にユーザーによって指定され、後から変更も可能です。この属性はスタンドアロン・モードでのみ使用されます。クラスタ・モードの詳細は、第24章「クラスタリング」(115ページ)を参照してください。 |
| 所有者 | サンドボックスを作成する際に自動的に設定されます。後から変更も可能です。 |

図3.2 CloverETL Server Web GUIのサンドボックスの詳細
ETLグラフまたはジョブフローからのファイルの参照
一部のコンポーネントでは、ファイルシステム上のリソースへの参照として、ファイルのURL属性を指定できます。また、ファイルシステム上のファイルへの参照として、外部メタデータ、ルックアップまたはDB接続定義も指定されます。CloverETL Serverでは、この関係を指定する方法がいくつかあります。
- 相対パス
- sandbox:// URLs
グラフにおける相対パスはすべて、ジョブ・ファイル(ETLグラフまたはジョブフロー)を含む同じサンドボックスのルートへの相対パスとみなされます。
サンドボックスのURLを指定すると、スタンドアロンのCloverETL Serverまたはクラスタで異なるサンドボックスからリソースを参照できます。クラスタ環境では、特定のクラスタ・ノードでしかリソースにアクセスできない場合に、CloverETL Serverがリモート・ストリーミングを透過的に管理します。
サンドボックスのURLの詳細は、「コンポーネント・データ・ソースとしてのサンドボックス・リソースの使用」(119ページ)を参照してください。
サンドボックスの内容のセキュリティと権限
各サンドボックスには、サンドボックスの作成時に所有者が設定されます。このサンドボックスに対して、所有者であるユーザーと管理者が無制限の権限を持ちます。サンドボックスの設定によっては、他のユーザーがアクセス権を持つ場合もあります。
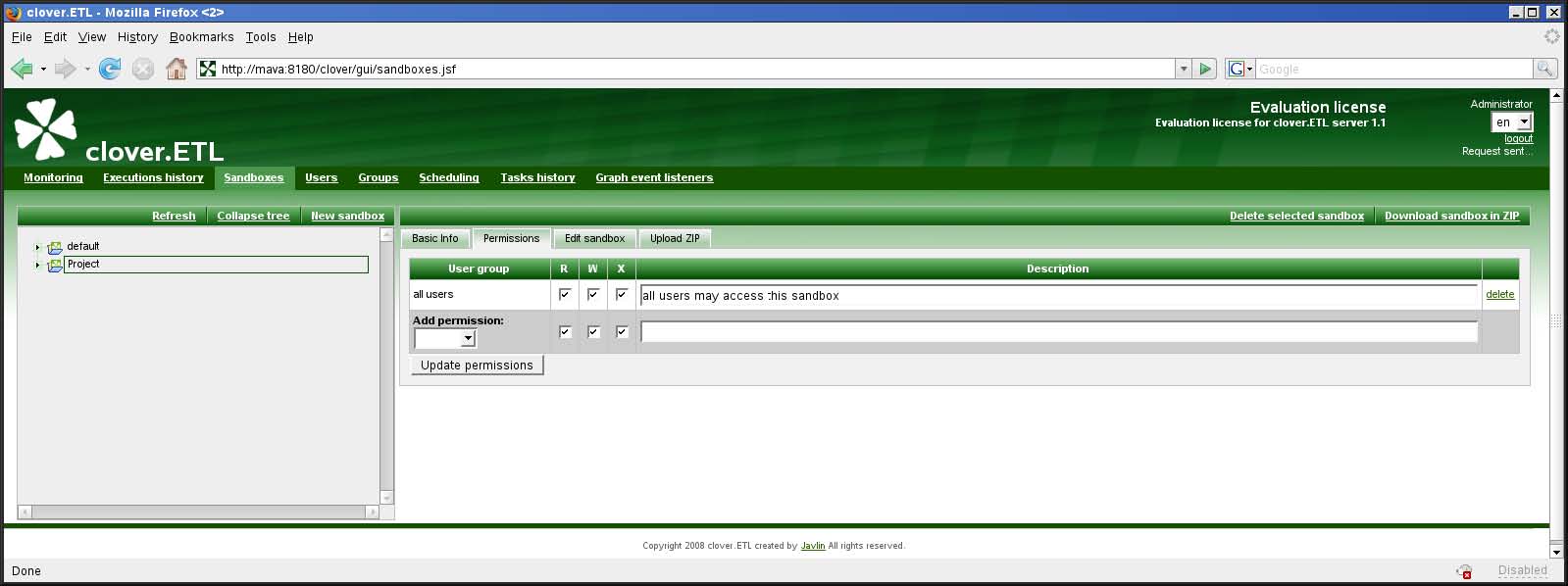
図3.3 CloverETL Server Web GUIの「サンドボックス」の「権限」
特定のサンドボックスに対する権限は、サンドボックスの詳細の「権限」タブで変更が可能です。このタブで、指定したユーザー・グループに特定の操作の実行を許可できます。
3タイプの操作があります。
表3.2. サンドボックスの権限
| R - 読取り | ユーザーは、サンドボックスのリストでこのサンドボックスを表示できます。 |
| W - 書込み | ユーザーは、CS APIを介してサンドボックスの中のファイルを変更できます。 |
| X - 実行 | ユーザーは、このサンドボックスの中のグラフを実行できます。 注意: グラフ・イベント・リスナーによって実行されるグラフは、実際には、イベントのソースであるグラフと同じユーザーによって実行されます。詳細は「グラフ・イベント・リスナー」を参照してください。スケジュール・トリガーによって実行されるグラフは、実際にはスケジュール所有者によって実行されます。詳細は第6章「スケジューリング」(45ページ)を参照してください。 |
これらの権限によって、特定のサンドボックスの内容に対するアクセス権が変更されます。また、サンドボックスの構成に関する操作、たとえばサンドボックスの作成、編集、削除などを実行する権限を構成することもできます。詳細は、第5章「ユーザーとグループ」(38ページ)を参照してください。
サンドボックスの内容
サンドボックスには、ジョブフロー、グラフ、メタデータ、外部接続、および関連するすべてのファイルが含まれます。ファイル、特にグラフやジョブフローのファイルは、サンドボックス・ルートからの相対パスで識別されます。したがって、特定のジョブ・ファイルを識別するには、サンドボックスとサンドボックスにおけるパスの2つの値が必要です。ジョブフローまたはETLグラフのパスを、通常は「ジョブ・ファイル」と呼びます。

図3.4 Web GUI - 「サンドボックス」セクション - サンドボックスのポップアップ・メニュー
Web GUIの「サンドボックス」セクションはファイル・マネージャではありませんが、サンドボックス管理に便利な機能があります。

図3.5 Web GUI - 「サンドボックス」セクション - フォルダのポップアップ・メニュー
ZIPでのサンドボックスのダウンロード
左パネルでサンドボックスを選択すると、Web GUI右側のツールバーに、ZIPでのサンドボックスのダウンロード・ボタンが表示されます。
作成したZIPには、ファイルシステムと同じ階層にある読取り可能なサンドボックス・ファイルがすべて含まれます。このZIPファイルを使用して、同じサンドボックス、または別のサーバー・インスタンスにある他のサンドボックスにファイルをアップロードできます。

図3.6 Web GUI - ZIPでのサンドボックスのダウンロード
サンドボックスへのZIPのアップロード
左パネルでサンドボックスを選択します。選択したサンドボックスに対して、書込み権限が必要です。次に、右パネルでZIPのアップロード・タブを選択します。ZIPのアップロードにはスイッチとなるパラメータがいくつかあり、それについては後述します。+ Upload ZIPのアップロード・ボタンで、共通ファイル選択ダイアログを開きます。ZIPファイルを選択すると、すぐサーバーにアップロードされて、結果のメッセージが表示されます。結果メッセージの各行に、アップロードされたファイルごとの説明が示されます。選択したオプションに応じて、ファイルがスキップ、更新、作成または削除されます。

図3.7 Web GUI - サンドボックスへのZIPのアップロード

図3.8 Web GUI - ZIPアップロードの結果
表3.3. Zipアップロード・パラメータ
| ラベル | 説明 |
| 圧縮ファイル名のエンコード | 特殊文字(非ASCII文字)を含むファイル名がエンコードされます。この選択ボックスでファイル名が適切にデコードされるように正しいエンコードを選択します。 |
| 既存ファイルの上書き | このスイッチを選択すると、サンドボックスの同じパスに同じファイル名で格納しようとした場合に、既存のファイルが新規ファイルで上書きされます。 |
| サンドボックスの内容の置換え | このオプションを選択すると、アップロードしたZIPファイルに含まれず、アップロード先のサンドボックスに存在するファイルがすべて削除されます。このオプションを使用するとデータが失われる可能性があるので、これを有効にするには、アップロードしたZIPに含まれないファイルを削除できる特別な権限が必要です。 |
ZIPでのファイルのダウンロード
左パネルでファイルを選択すると、Web GUI右側のツールバーに、ZIPでのファイルのダウンロード・ボタンが表示されます。
作成されるZIPには、選択したファイルのみが含まれます。この機能は、Web GUIで直接表示できない大きいファイル(入力ファイルや出力ファイルなど)で便利です。ユーザーはそれをダウンロードできます。
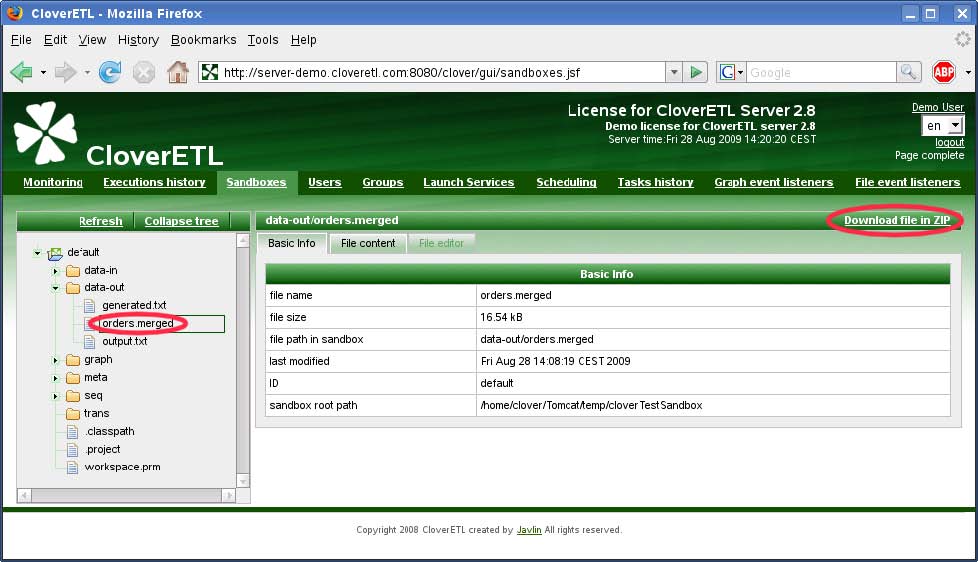
図3.9 Web GUI - ZIPでのファイルのダウンロード
HTTP APIファイルのダウンロード
簡単なHTTP GETのリクエストによってダウンロード・サーブレットにアクセスするサンドボックス・ファイルをダウンロードまたは表示することができます。
http://[host]:[port]/[Clover Context]/downloadFile?[Parameters]
サーバーにはHTTP基本認証が必要です。LinuxコマンドラインのHTTPクライアントwgetの場合は、次のようになります。
wget --user=clover --password=clover
http://localhost:8080/clover/downloadFile?sandbox=default\&file=data-out/data.dat
アンパサンド文字は円記号でエスケープします。そうしないと、コマンドライン・システムでプロセスのフォークを示す演算子として解釈されます。
URLのパラメータ
- sandbox - サンドボックス・コード。必須パラメータです。
- file - サンドボックス・ルートからのファイルの相対パス。必須パラメータです。
- zip - trueに設定すると、ファイルがZIPとして返され、レスポンスのコンテンツ・タイプはapplication/x-zip-compressedになります。デフォルトではfalseで、レスポンスのコンテンツ・タイプはfileです。
ジョブ構成プロパティ
ETLグラフまたはジョブフローごとに構成プロパティを設定でき、それが実行中に適用されます。プロパティは、Web GUIの「サンドボックス」セクションで編集可能です。ジョブ・ファイルを選択し、「構成プロパティ」タブに移動します。
各サンドボックスに対して同じ構成プロパティを編集することもできます。サンドボックスに指定した値はサンドボックスの各ジョブにも適用されますが、ジョブに対して指定した構成プロパティより優先度は低くなります。
サンドボックスにもジョブにも構成プロパティが指定されない場合は、メインのサーバー構成のデフォルトが適用されます。ジョブ構成プロパティに関連するグローバルな構成プロパティには、executionという接頭辞が付きます。たとえば、サーバー・プロパティexecutor.classpathは、ジョブ構成プロパティclasspathのデフォルトです。(詳細は、第18章「構成」(96ページ)を参照してください。)
また、追加のジョブ・パラメータを指定でき、これはジョブのXMLでプレースホルダとして使用されます。このプレースホルダは、XMLファイルのダウンロードおよび解析中に解決されるので、このようなジョブを保存することはできません。
表3.4. ジョブ構成パラメータ
| tracking_interval | 2000 | 変換の実行時にノード・ステータスをサンプリングする間隔(ミリ秒単位) |
| max_running_concurrently | unlimited | この変換の同時実行インスタンス数。 |
| enqueue_executions | false | ブール値。trueの場合、max_running_concurrentlyを超える実行はエンキューされ、falseの場合、max_running_concurrently超える実行は失敗します。 |
| log_level | INFO | このグラフ実行のLog4jログ・レベル。(ALL | TRACE | DEBUG | INFO | WARN | ERROR | FATAL)。低レベル(ALL、TRACE、DEBUG)については、ルート・ログ出力レベルも低レベルに設定する必要があります。ルート・ログ出力のログ・レベルはデフォルトでINFOなので、ジョブ構成パラメータlog_levelが適切に設定されている場合、変換の実行ログにINFOを超える詳細メッセージは含まれません。log4jの構成の詳細は、第21章「ロギング」(110ページ)を参照してください。 |
| max_graph_instance_age | 0 | サーバーのキャッシュで、変換のインスタンスが持続する時間を表す間隔(ミリ秒単位)。0の場合、実行するたびに変換が初期化され解放されます。状況によっては、変換をプールに保存して再利用することができない場合があります(変換では、動的に指定されるパラメータを使用するプレースホルダが使用されます)。 |
| classpath | ジョブ・ファイルで使用される外部クラス(変換、ジェネレータ、JMSプロセッサ)を含むパスまたはjarファイルのリスト。セパレータは、エンジンのプロパティDEFAULT_PATH_SEPARATOR_REGEXで指定します。ディレクトリ・パスは常にスラッシュ文字"/"で終わる必要があります。そうしないと、ClassLoaderでディレクトリであることを認識されません。サーバーは常にジョブのサンドボックスのtransサブディレクトリを追加するので、明示的に追加する必要はありません。 | |
| skip_check_config | デフォルト値はエンジン・プロパティから取得 | 変換を実行する前に構成チェックを実行するかどうかを指定するスイッチです。 |
| password | エンコードされたDB接続パスワードのデコードに使用するパスワード。 | |
| verbose_mode | true | trueの場合、ジョブ実行の詳細なログが生成されます。 |
| use_jmx | true | trueの場合、ジョブ・エグゼキュータは実行中の変換のJMX mBeanを登録します。 |
| debug_mode | false | trueの場合、デバッグを有効にしたエッジがデバッグ・ディレクトリのファイルにデータを格納します。プロパティgraph.debug_pathを参照してください。明示的に設定しない場合、サーバー統合に伴うDesignerからグラフを実行するとdebug_modeがtrueに設定されます。一方、サーバー・コンソールからグラフを実行するとdebug_modeはfalseに設定されます。 |
| executor.use_local_context_url | trueの場合、実行中のジョブのコンテキストURLはローカルの"file:" URLになります。そうでない場合は、"sandbox:" URLが使用されます。 | false |
| executor.jobflow_token_tracking | falseの場合、ジョブフロー実行時におけるトークンのトラッキングが無効になります。 | true |
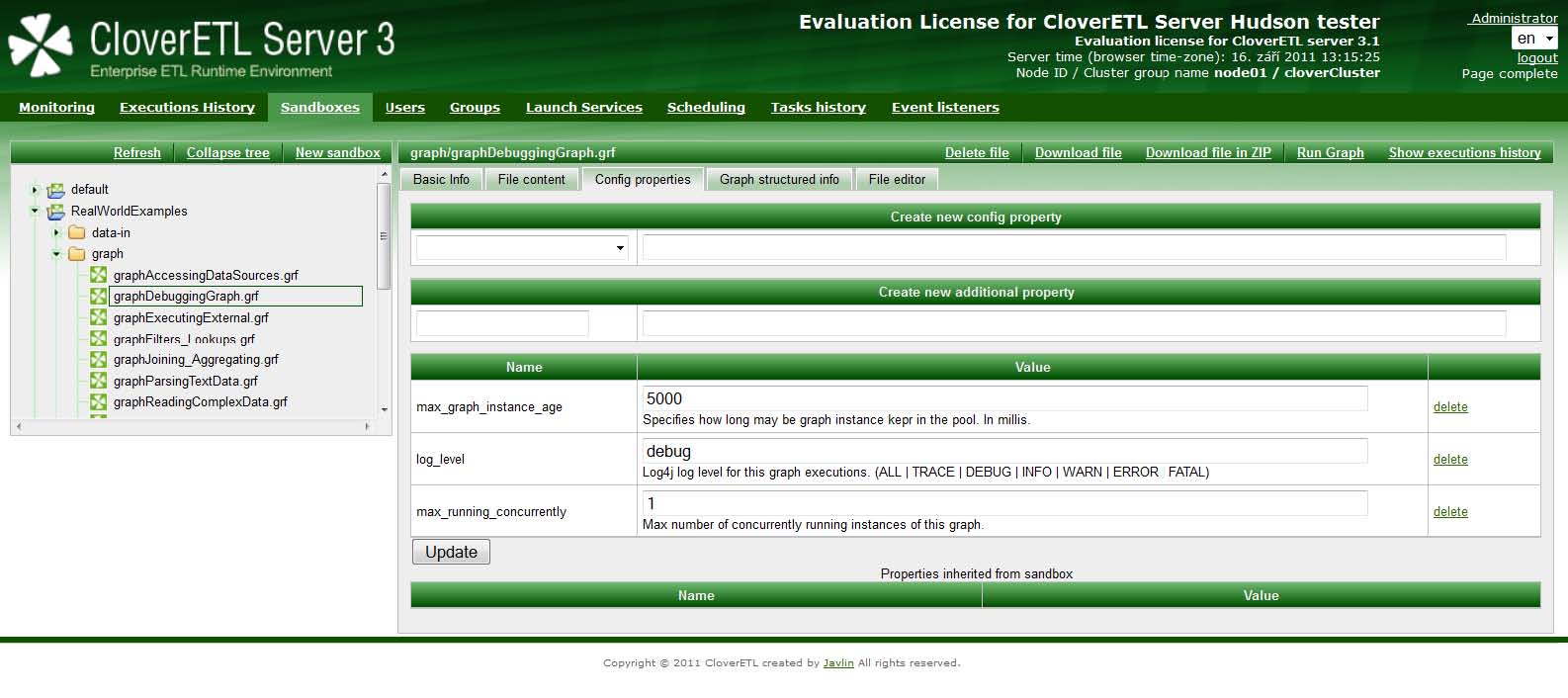
図3.10 ジョブ構成プロパティ
第4章 ジョブ実行の表示 - 実行履歴
「実行履歴」セクションには、永続的なジョブの実行がすべて表示されます。表に掲載されるのは、実行ID、ジョブ・ファイル、現在のステータス、実行時刻、その他の便利なリンクなど、ジョブに関する基本的な情報のみです。
フィルタリングと並替え
表のレコードは、実行ID、ジョブ・ファイル、実行日時、ステータス、ジョブを実行したユーザーなど様々な基準でフィルタリングできます。また、子の実行はデフォルトでフィルタで除外されていますが、それも表示できます(パーティション化された実行や、ジョブフローから実行されたジョブのワーカーなど)。
デフォルトでは、直前のジョブが最上位に表示されます。
ジョブによっては、パフォーマンスを優先するために永続性が無効になっている場合があります。一般的には起動サービスによって実行されるジョブがこれに該当します。実行に関する詳細情報よりパフォーマンスのほうが重要なためです。

図4.1 実行履歴 - 実行処理表
表でジョブの実行を選択すると、右側に詳細情報が表示されます。
表4.1. 永続化実行記録属性
| 属性 | 説明 |
| 実行ID | ジョブの実行を一意に識別する数字。サーバーAPIは通常、実行リクエストに対する単純なレスポンスとしてこの数字を返します。ジョブ実行の指定に対する後続のコールのパラメータとして使用すると便利です。 |
| 実行タイプ | サーバーによって認識されるジョブのタイプ。ETLグラフの場合はSTANDALONE、ジョブフローの場合はJOBFLOW、クラスタでパーティション化された実行のメイン・レコードの場合はMASTER、クラスタでパーティション化された実行のワーカー・レコードの場合はPARTITIONED_WORKER |
| 親実行ID | 親ジョブの実行ID。通常は、このジョブを実行したジョブフロー、またはこのワーカー実行をカプセル化するマスター実行です。 |
| ルート実行ID | ルート親ジョブの実行ID。別の親ジョブによって実行されなかったジョブ実行です。 |
| ネストしたジョブ | このジョブ実行に子の実行があるかどうかを示します。 |
| ノード | クラスタ・モードで、この実行が実行されるクラスタ・ノードのIDを示します。 |
| 実行者 | ジョブを実行するユーザー。直接API/GUIを使用するか、スケジューリングまたはイベント・リスナーを間接的に使用します。 |
| サンドボックス | ジョブ・ファイルを含むサンドボックス。実行リクエストとともに送信されるジョブの場合、ジョブ・ファイルがサーバー・サイトに存在しないため、デフォルトのサンドボックスに設定されます。 |
| ジョブ・ファイル | サンドボックスのルートから相対的に示したジョブ・ファイルのパス。実行リクエストとともに送信されるジョブの場合、ジョブ・ファイルがサーバー・サイトに存在しないため、生成された文字列に設定されます。 |
| ジョブ・バージョン | ジョブ・ファイルのリビジョン。CloverETL Designerによって生成され、ジョブ・ファイルに格納される文字列。 |
| ステータス | ジョブ実行のステータス。READY - 実行の開始を待機中、RUNNING - ジョブを処理中、FINISHED OK - ジョブがエラーなしで完了、ABORTED - 直接API/GUIを使用して、または親ジョブフローによってジョブが中断された、ERROR - ジョブが失敗、N/A (使用不可) - サーバー・プロセスが突然終了しジョブを中断できなかったため、再起動後にステータス不明のジョブがN/Aに設定された |
| 起動済 | 実行開始のサーバー日時(およびタイムゾーン)。 |
| 終了 | 実行完了のサーバー日時(およびタイムゾーン)。 |
| 期間 | 実行の期間 |
| コンポーネントIDのエラー | コンポーネントのエラーが原因でジョブが失敗した場合、このフィールドにそのコンポーネントのIDが入ります。 |
| コンポーネント・タイプのエラー | コンポーネントのエラーが原因でジョブが失敗した場合、このフィールドにそのコンポーネントのタイプが入ります。 |
| エラー・メッセージ | ジョブが失敗した場合、このフィールドにエラーの説明が入ります。 |
| 例外 | ジョブが失敗した場合、このフィールドにエラー・スタック・トレースが入ります。 |
| 入力パラメータ | ジョブに渡される入力パラメータのリスト。パラメータはジョブ・ファイルからのロード中に適用されるため、ジョブ・ファイルはキャッシュできません。デフォルトでは、ジョブ・ファイルはキャッシュされません。 |
| 入力ディクショナリ | ジョブに渡されるディクショナリ要素のリスト。ディクショナリは、ジョブ・ファイルのキャッシュとは独立して使用されます。 |
| 出力ディクショナリ | ジョブ終了時のディクショナリ要素のリスト。 |
子の実行があるジョブ、たとえばパーティション化されたジョブやジョブフローの場合、実行階層も表示されます。
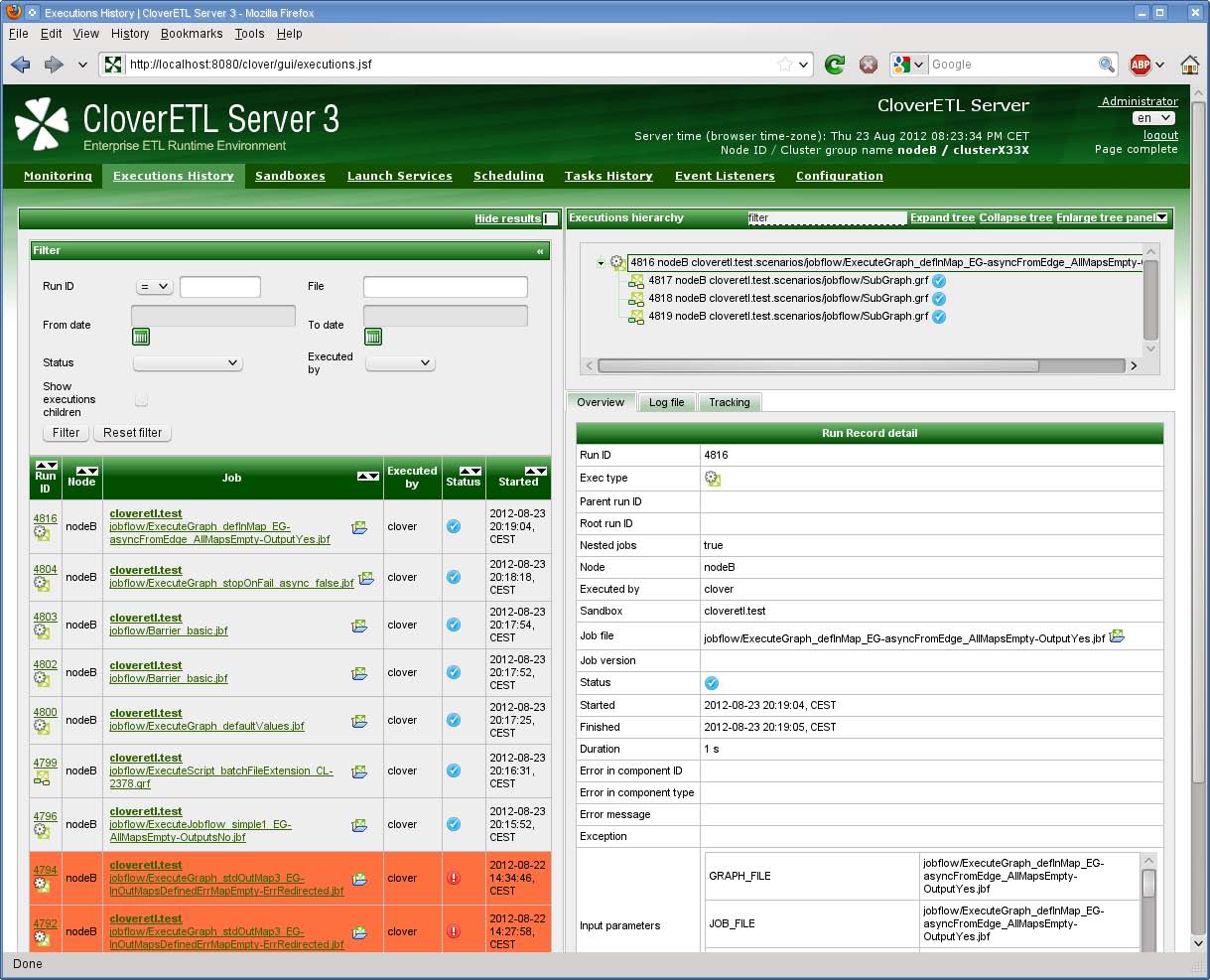
図4.2 実行履歴 - 全体の概要
詳細パネルとジョブのログは大きくなる場合があるので、詳細パネルを広げられるように、左側の表を非表示にすると便利です。リスト・パネルの上部で結果の非表示リンクをクリックすると、パネルが非表示になります。リスト・パネルを再表示するには、左にある「結果の表示」ボタンをクリックします。

図4.3 実行階層とドッキング表示されたジョブ・リスト
実行階層は多少複雑になる場合があるので、全文フィルタでツリーの内容をフィルタできます。ただし、フィルタを使用すると、選択した実行は階層構造ではなくなります。
第5章 ユーザーとグループ
CloverETL Serverにはセキュリティ・モジュールが実装されており、これでユーザーとグループが管理されます。セキュリティ・モジュールは、全体的にオフにすることもできますが(詳細は第18章「構成」(96ページ)を参照)、デフォルトではオンで、すべてのインタフェースにはユーザー名とパスワードによるクライアント認証が必要です。ユーザーとグループの関係はN:Mで、1つのユーザーを複数のグループに割り当てることも、1つのグループを複数のユーザーに割り当てることもできます。
ユーザーとグループの関係は、Web GUIの「ユーザー」セクションと「グループ」セクションで構成します。
どちらのセクションも、アクセスできるのはユーザーのリスト(またはグループのリスト)権限のあるユーザーのみです。ユーザー/グループを変更するには、「作成」、「編集」および「削除」権限が必要です。
LDAP認証
3.2から、ユーザー認証にLDAPサーバーを使用するようにCloverETL Serverを構成できるようになりました。そのため、任意のCloverETL Serverインタフェース(APIまたはGUI)への認証に、LDAPに登録されているユーザーの資格証明を使用できます。
ただし、認可(サンドボックスの内容に対するアクセス・レベルと操作の権限)は引き続きCloverのセキュリティ・モジュールによって処理されます。各ユーザーは、LDAP認証を使用してログインした場合でも、CloverETLセキュリティ・モジュールに独自のユーザー・レコード(および関連グループ)が必要です。したがって、同じユーザー名とドメインのユーザーをLDAPに設定する必要があります。そのようなユーザー・レコードが存在しない場合は、CloverETLの構成に従って自動的に作成されます。
LDAPユーザーを認証するためのCloverETLの動作
- Web GUIのログイン・フォームで、LDAPの資格証明を指定します。
- CloverETL ServerがLDAPに接続し、ユーザーが存在するかどうかを確認します(指定した検索を使用してLDAPをルックアップします)。
- LDAPにユーザーが存在する場合、CloverETL Serverは認証を実行します。
- 成功すると、CloverETL ServerはLDAPユーザーのグループを検索します。
- CloverETL Serverは、CloverにログインできるLDAPグループにそのユーザーが割り当てられているかどうかを確認します。
- Cloverのユーザー・レコードは、現在のLDAP値に従って作成/更新されます。
- Cloverユーザーは、LDAPグループへの現在の割当てに従ってCloverグループに割り当てられます。
- ユーザーがログインします
注意
ドメインの切替え:
- ユーザーをLDAPで作成してからcloverドメインに切り替えた場合は、「パスワードの変更」タブでそのユーザーのパスワードを設定します。
- cloverとしてユーザーを作成してから、LDAPドメインに切り替えた場合は、cloverドメインのパスワードがありますが、LDAPのパスワードでオーバーライドされます。cloverドメインに戻ると、元のパスワードが再利用されます。必要な場合(パスワードを忘れた場合など)は、「パスワードの変更」タブでリセットできます。
構成
デフォルトでは、CloverETL Serverで認証に使用できるのは、独自の内部メカニズムのみです。LDAPでの認証を有効にするには、構成プロパティ"security.authentication.allowed_domains"を適切に設定します。これは、認証に使用されるユーザー・ドメインのリストです。
現在、"LDAP"と"clover"の2つの認証メカニズムが実装されています("clover"はCloverETLの内部認証の識別子で、security.default_domainプロパティによって変更できますが、ホワイトレーベル化の目的に限られます)。LDAP認証を有効にするには、値を"LDAP" (LDAPのみ)、または"clover,LDAP"に設定します。どちらのドメインのユーザーもログインできます。LDAPが適切に構成されるまでは、両方のメカニズムを同時に許可しておくことをお薦めします。管理者ユーザーは、LDAP接続が適切に構成されていない場合でもWeb GUIに引き続きログインできます。
LDAP接続の基本的なプロパティ
# Implementation of context factory
security.ldap.ctx_factory=com.sun.jndi.ldap.LdapCtxFactory
# timeout for all queries sent to LDAP server
security.ldap.timeout=5000
# limit for number of records returned from LDAP
security.ldap.records_limit=50
# URL of LDAP server
security.ldap.url=ldap://hostname:port
# Some generic UserDN which allows lookup for the user and groups.
security.ldap.userDN=
# Password for the user specified above
security.ldap.password=
ユーザー・ルックアップの構成
指定した値は、次の特定のLDAPツリーで有効です。
- cn=admins (objectClass=groupOfNames,member=(uid=smith,dc=company,dc=com),member=(uid=jones,dc=company,dc=com))
- cn=developers (objectClass=groupOfNames,member=(uid=smith,dc=company,dc=com))
-
cn=consultants (objectClass=groupOfNames,member=(uid=jones,dc=company,dc=com))
- uid=smith (fn=John,sn=Smith,mail=smith@company.com)
- uid=jones (fn=Bob,sn=Jones,mail=jones@company.com)
LDAPユーザーをそのユーザー名でルックアップする場合は、次のプロパティが必須です。(前述のログイン・プロセスのステップ[2]を参照)
# Base specifies the node of LDAP tree where the search starts
security.ldap.user_search.base=dc=company,dc=eu
# Filter expression for searching the user by his username.
# Please note, that this search query must return just one record.
# Placeholder ${username} will be replaced by username specified by the logging user.
security.ldap.user_search.filter=(uid=${username})
# Scope specifies type of search in "base". There are three possible values: SUBTREE | ONELEVEL | OBJECT
# http://download.oracle.com/javase/6/docs/api/javax/naming/directory/SearchControls.html
security.ldap.user_search.scope=SUBTREE
次のプロパティは、定義した検索の属性の名前です。Cloverセキュリティ・モジュールによるユーザー・レコードの作成/更新が必要になった場合に、LDAPユーザーに関する基本的な情報を取得するために使用されます(前述のログイン・プロセスのステップ[6]を参照)。
security.ldap.user_search.attribute.firstname=fn
security.ldap.user_search.attribute.lastname=sn
security.ldap.user_search.attribute.email=mail
# This property is related to the following step "searching for groups".
# Groups may be obtained from specified user's attribute, or found by filter (see next paragraph)
# Please leave this property empty if the user doesn't have such attribute.
security.ldap.user_search.attribute.groups=memberO
次のステップでは、ユーザーが割り当てられているグループをcloverが検索しようとします。(前述のログイン・プロセスのステップ[4]を参照)。ユーザーが割り当てられているグループのリストを取得するには、2つの方法があります。ユーザーとグループの関係をユーザー側で指定します。ユーザー・レコードは、グループのリストに関する属性を持ちます。通常はmemberOf属性です。または、ユーザーとグループの関係をグループ側で指定します。グループ・レコードは、割り当てられているユーザーのリストに関する属性を持ちます。通常はmember属性です。
関係をユーザー側で指定する場合は、適切なプロパティを指定してください。
security.ldap.user_search.attribute.groups=memberOf
そうでない場合は、空のままにします。
関係をグループ側で指定する場合は、検索のプロパティを指定してください。
security.ldap.groups_search.base=dc=company,dc=com
# Placeholder ${userDN} will be replaced by user DN found by the search above
# If the filter is empty, searching will be skipped.
security.ldap.groups_search.filter=(&(objectClass=groupOfNames)(member=${userDN}))
security.ldap.groups_search.scope=SUBTREE
そうでない場合は、security.ldap.groups_search.filterプロパティを空のままにして、検索をスキップするようにします。
Cloverユーザー・レコードは、検索(または属性)で見つかったLDAPグループに従ってcloverグループに割り当てられます。(グループ・チェックは、ログインごとに実行されます)
# Value of the following attribute will be used for lookup for the Clover group by its code.
# So the user will be assigned to the Clover group with the same "code"
security.ldap.groups_search.attribute.group_code=cn
CloverにログインできるLDAPグループを指定することもできます。(前述のログイン・プロセスのステップ[5]を参照)
# Semicolon separated list of LDAP group DNs (distinguished names).
# LDAP user must be assigned to one or more of these groups, otherwise new clover user can't be created.
# Special value "_ANY_" disables this check and basically any LDAP user may login.
# If the LDAP group DNs are configured, also security.ldap.groups_search.* properties must be configured.
# value could be e.g. "cn=developers,dc=company,dc=com;cn=admins,dc=company,dc=com"
security.ldap.allowed_ldap_groups=_ANY_
Web GUIの「ユーザー」セクション
これは、ユーザー管理のためのセクションです。このセクションの機能はユーザーの権限に依存します。したがって、ユーザーによっては、このセクションを表示できても何も変更できません。あるいは、変更は可能でも新規のユーザーは作成できません。
「ユーザー」セクションで使用できる機能
- 新規ユーザーの作成
- 基本データの変更
- パスワードの変更
- ユーザーの有効化/無効化
- グループへのユーザーの割当て - グループに割り当てると、ユーザーに適切な権限が付与されます。
表5.1. 前述の空のDBのデフォルト・インストール後に作成される2つのユーザー
| ユーザー名 | 説明 |
| clover | cloverユーザーは管理権限を持ちます。したがって、デフォルトのパスワードcloverは、インストール後に必ず変更してください。 |
| system | systemユーザーは、他のユーザーを使用できない場合、たとえばセキュリティがグローバルにオフになっている場合に、共通ユーザーではなくアプリケーションによって使用されます。このユーザーは削除できず、このユーザーでログインすることもできません。 |
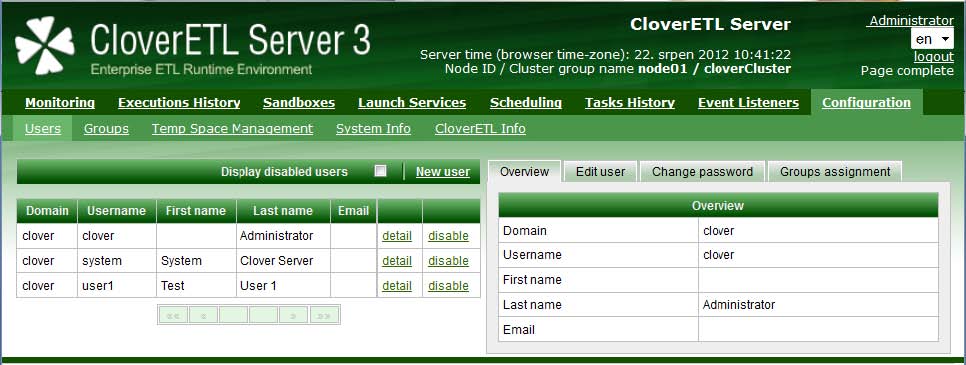
図5.1 Web GUI - 「構成」の「ユーザー」セクション
表5.2. ユーザー属性
| 属性 | 説明 |
| username | 共通ユーザーの識別子。一意である必要があり、空白や特殊文字は使用できません。英数字のみです。 |
| password | 大/小文字が区別されるパスワード。ユーザーがパスワードを忘れた場合は、新しいパスワードを設定する必要があります。セキュリティ上の理由でパスワードは暗号化して格納されます。したがって、データベースから取り出すことはできず、その操作を行う適切な権限のあるユーザーが変更する必要があります。 |
| first name | |
| last name | |
| CloverETL管理者またはCloverETLサーバーが自動通知に使用できる電子メール。詳細は「タスク - 電子メールの送信」(57ページ)を参照してください。 |
ユーザー・レコードの編集
「ユーザーの作成」権限または「ユーザーの編集」権限のあるユーザーは、このフォームを使用して基本的なユーザー・パラメータを設定できます。
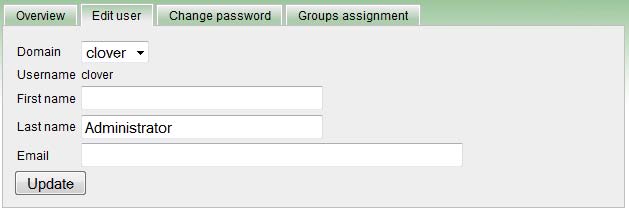
図5.2 Web GUI - 「ユーザーの編集」
ユーザー・パスワードの変更
ユーザーがパスワードを忘れた場合は、新しいパスワードを設定する必要があります。「パスワードの変更」権限のあるユーザーは、このフォームを使用してパスワードを変更できます。
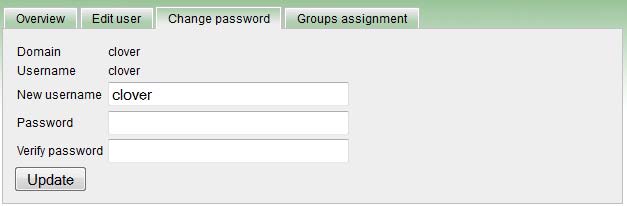
図5.3 Web GUI - 「パスワードの変更」
グループの割当て
グループに割り当てると、ユーザーに適切な権限が付与されます。このフォームを使用して、ユーザーを割り当てるグループを指定できるのは、グループの割当て権限でログインしているユーザーのみです。権限の詳細は、「Web GUIの「グループ」セクション」(43ページ)を参照してください。
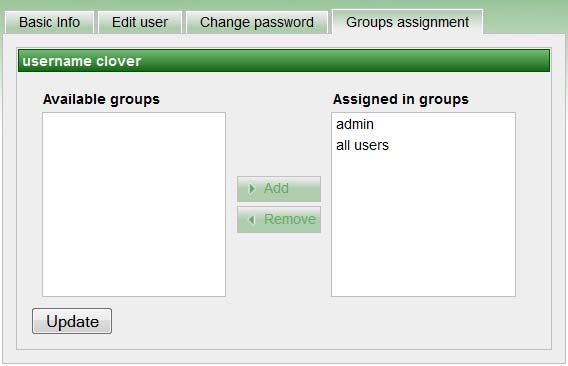
図5.4 Web GUI - グループの割当て
ユーザーの有効化/無効化
ユーザー・レコードは、ログおよび履歴レコードと様々に関係しているため、削除はできません。かわりに、無効化することができます。つまり、基本的にレコードはリストに表示されず、ユーザーはログインもできません。
ただし、無効化したユーザーは再度有効化できます。無効化したユーザーはグループから削除されるので、再度有効化してから必要に応じてグループに割り当てる必要があります。
Web GUIの「グループ」セクション
グループとはユーザーの抽象セットであり、グループに割り当てられたユーザーは一定の権限を付与されます。したがって、個々のユーザーに権限を指定することは必ずしも必要ではありません。
CloverETL Serverには、複数レベルの権限が実装されています。
- サンドボックスでの読取り/書込み/実行権限 - サンドボックスの所有者は、グループごとに異なる権限を指定できます。詳細は「サンドボックスの内容のセキュリティと権限」(26ページ)を参照してください。
- 一定の操作を実行する権限 - 操作権限「権限の割当て」を持つユーザーは、特定の権限を既存のグループに割り当てることができます。
- 特定のサービスを起動する権限 - 詳細は、第17章「起動サービス」(89ページ)を参照してください。
表5.3. インストール中に作成されるデフォルトのグループ
| グループ名 | 説明 |
| admins | このグループは「すべて」の操作権限、つまり無制限の権限を持ちます。デフォルトのユーザーcloverはこのグループに割り当てられ、管理者となります。 |
| all users | CloverETLの各ユーザーは、デフォルトでこのグループに割り当てられます。このグループからユーザーを削除することは可能ですが、推奨はされません。このグループは、サンドボックスまたは一定の操作の権限など、例外なくすべてのユーザーに付与する権限があるときに便利です。 |
図5.5 Web GUI -「グループ」セクション
ユーザーの割当て
ユーザーとグループの関係はN:Mです。つまり、グループをユーザーに割り当てる場合でも、ユーザーをグループに割り当てる場合でも、方法は変わりません。

図5.6 Web GUI - グループの割当て
グループ権限
グループ権限はツリーとして構造化され、権限はルートからリーフへと継承されます。つまり、ある権限(ツリー・ノード)が有効(青い丸)である場合、サブツリーの権限もすべて自動的に有効(白い丸)になります。赤い×印の権限は無効です。
adminグループには「すべて」権限が割り当てられるので、サブツリーの個別の権限は自動的に割り当てられます。

図5.7 権限のツリー
第6章 スケジューリング
スケジューリングにより、手動でトリガーしない場合の操作用の独自のタイムテーブルを作成できます。各スケジュールは、区切られたタイムテーブルを表すとともに、基本的には、いつ何をする必要があるかに関する仕様を表します。
クラスタ環境では、スケジューリングはマスター・ノードに対してのみ処理されるため、タスクはマスター・ノードに対してのみトリガーされます。

図6.1 Web GUI - 「スケジューリング」セクション - 新規作成
タイムテーブル設定
この項では、スケジュールをいつトリガーする必要があるかを指定する方法について説明します。正確なトリガー時間が保証されるわけではないことに注意してください。数秒の遅れが生じる可能性があります。スケジュール自体は様々な方法で指定できます。
- 「ワンタイム・スケジュール」(45ページ)
- 「間隔別の定期的スケジュール」(46ページ)
- 「タイムテーブル別の定期的スケジュール(cron式)」(47ページ)
ワンタイム・スケジュール
このスケジュールが1回のみトリガーされることは明白です。
表6.1. ワンタイム・スケジュールの属性
| タイプ | ワンタイム |
| 開始日付/時間 | 分単位の精度で指定した日付および時間。 |

図6.2 Web GUI - ワンタイム・スケジュール・フォーム

図6.3 Web GUI - スケジュール・フォーム - カレンダ
間隔別の定期的スケジュール
このタイプのスケジュールは、最も簡単な定期的タイプです。トリガー時間は、次の属性によって指定されます。
| タイプ | 定期的 |
| 周期性 | 間隔 |
| 開始日付/時間 | 分単位の精度で指定した日付および時間。 |
| 終了日付/時間 | 分単位の精度で指定した日付および時間。 |
| 間隔 | 2つのトリガー時間の間隔を指定します。次のタスクは、前のタスクがまだ実行中でもトリガーされます。 |
| 正しく起動していないイベントを即時起動するスイッチ | 選択すると、トリガー時間がなんらかの理由により欠落している場合(サーバーの再起動など)、可能であれば、即時トリガーされます。それ以外の場合は、無視され、次のスケジュール時にトリガーされます。 |

図6.4 Web GUI - 定期的スケジュール・フォーム
タイムテーブル別の定期的スケジュール(cron式)
タイムテーブルは、強力な(ただし少々扱いにくい) cron式によって指定します。
| タイプ | 定期的 |
| 周期性 | 間隔 |
| 開始日付/時間 | 分単位の精度で指定した日付および時間。 |
| 終了日付/時間 | 分単位の精度で指定した日付および時間。 |
| cron式 | cronは、スケジューリング用として独自の書式を使用する強力なツールです。この書式は、UNIX管理者の間で広く知れ渡っています(たとえば、「0 0/2 4-23 * * ?」は、「4:00amと11:59pmの間で2分ごと」を意味します)。 |
| 正しく起動していないイベントを即時起動するスイッチ | 選択すると、トリガー時間がなんらかの理由により欠落している場合(サーバーの再起動など)、可能であれば、即時トリガーされます。それ以外の場合は、無視され、次のスケジュール時にトリガーされます。 |
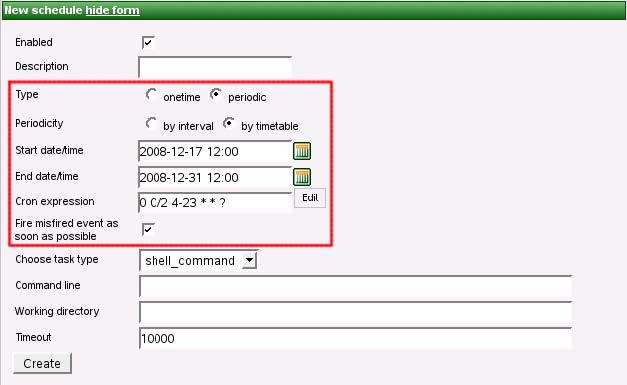
図6.5 cron定期的スケジュール・フォーム
タスク
基本的に、タスクにより、トリガー時に何を行うかを指定します。スケジュール用、およびグラフ・イベント・リスナー用として、次のような複数のタスクが実装されています。
- 「タスク - グラフの実行」(48ページ)
- 「タスク - ジョブフローの実行」(49ページ)
- 「タスク - ジョブの強制終了」(50ページ)
- 「タスク - シェル・コマンドの実行」(51ページ)
- 「タスク - 電子メールの送信」(52ページ)
- 「タスク - Groovyコードの実行」(52ページ)
- 「タスク - レコードのアーカイブ」(53ページ)
タスク - グラフの実行
このタスク・タイプの動作は「タスク - ジョブフローの実行」(49ページ)とほとんど同じです。
表6.4. グラフの実行タスクの属性
| タスク・タイプ | グラフの実行 | サンドボックス | この選択ボックスには、ログ出力ユーザーによる読取りが可能なサンドボックスが含まれます。実行するグラフが含まれるサンドボックスを選択します。 | グラフ | この選択ボックスには、選択したサンドボックスでアクセス可能なすべてのグラフ・ファイルが入力されます。 | パラメータ |
実行対象ジョブにパラメータとして渡されるキーと値のペア。また、このタスクがジョブ(グラフまたはジョブフロー)イベントによってトリガーされる場合、ソース・ジョブ・パラメータを指定できます。これらのパラメータは、ソース・ジョブから実行対象ジョブに渡されます。たとえば、イベント・ソースには、次のパラメータがあるとします: 値"val2"を持つparamName2、値"val3"を持つparamName3、値"val5"を持つparamName5。タスクでは、「パラメータ」属性が次のように設定されています。
paramName1=paramValue1
paramName2=
paramName3
paramName4
このため、実行対象ジョブは、次のパラメータおよび値を取得します: 値"paramValue1"を持つparamName1 (タスク構成で明示的に指定されています)、値""を持つparamName2 (タスク構成で明示的に指定されている空の文字列により、イベント・ソース・パラメータがオーバーライドされます)、値"val3"を持つparamName3 (値はイベント・ソースから取得されます)。次のパラメータは渡されません: paramName4は、イベント・ソース内に値がないため、渡されません。paramName5は、渡すパラメータとしてタスク内に指定されていないため、渡されません。EVENT_RUN_RESULTやEVENT_RUN_IDなどのイベント・パラメータは、制限なしで実行対象ジョブに渡されます。 |
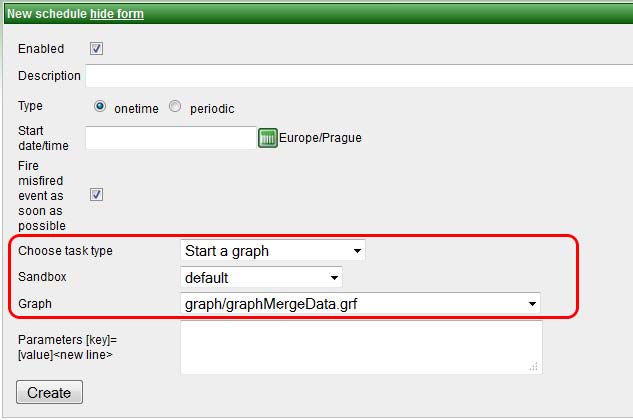
図6.6 Web GUI - グラフ実行タスク
タスク - ジョブフローの実行
このタスク・タイプの動作は「タスク - グラフの実行」(48ページ)とほとんど同じです。
表6.5. ジョブフローの実行タスクの属性
| タスク・タイプ | ジョブフローの実行 |
| サンドボックス | この選択ボックスには、ログ出力ユーザーによる読取りが可能なサンドボックスが含まれます。実行するジョブフローが含まれるサンドボックスを選択します。 |
| ジョブフロー | この選択ボックスには、選択したサンドボックスでアクセス可能なすべてのジョブフロー・ファイルが入力されます。 |
| パラメータ | "実行対象ジョブにパラメータとして渡されるキーと値のペア。また、このタスクがジョブ(グラフまたはジョブフロー)イベントによってトリガーされる場合、ソース・ジョブ・パラメータを指定できます。これらのパラメータは、ソース・ジョブから実行対象ジョブに渡されます。たとえば、イベント・ソースには、次のパラメータがあるとします: 値"val2"を持つparamName2、値"val3"を持つparamName3、値"val5"を持つparamName5。タスクでは、「パラメータ」属性が次のように設定されています。
paramName1=paramValue1
paramName2=
paramName3
paramName4
このため、実行対象ジョブは、次のパラメータおよび値を取得します: 値"paramValue1"を持つparamName1 (タスク構成で明示的に指定されています)、値""を持つparamName2 (タスク構成で明示的に指定されている空の文字列により、イベント・ソース・パラメータがオーバーライドされます)、値"val3"を持つparamName3 (値はイベント・ソースから取得されます)。次のパラメータは渡されません: paramName4は、イベント・ソース内に値がないため、渡されません。paramName5は、渡すパラメータとしてタスク内に指定されていないため、渡されません。
EVENT_RUN_RESULTやEVENT_RUN_IDなどのイベント・パラメータは、制限なしで実行対象ジョブに渡されます。" |

図6.7 Web GUI - ジョブフロー実行タスク
タスク - ジョブの強制終了
このタスクをアクティブ化すると、指定したジョブ(ETLグラフまたはジョブフロー)が現在実行されている場合、このジョブを強制終了/中断します。
表6.6. ジョブの強制終了タスクの属性
| タスク・タイプ | ジョブの強制終了 |
|---|---|
| イベントのソースの強制終了 | このスイッチがオンである場合、このタスクをアクティブ化した、イベントのソースであるジョブが強制終了されます。属性サンドボックスおよびジョブは無視されます。 |
| サンドボックス | 強制終了するジョブが含まれるサンドボックスを選択します。この属性が機能するのは、イベントのソースの強制終了スイッチがオフである場合のみです。 |
| ジョブ | この選択ボックスには、選択したサンドボックスでアクセス可能なすべてのジョブが入力されます。現在実行されている、選択したジョブのすべてのインスタンスが強制終了されます。この属性が機能するのは、イベントのソースの強制終了スイッチがオフである場合のみです。 |

図6.8 Web GUI - ジョブの強制終了
タスク - シェル・コマンドの実行
表6.7. シェル・コマンド・タスクの属性
| タスク・タイプ | シェル・コマンド |
| コマンドライン | 外部プロセスを実行するためのコマンドライン。 |
| 作業ディレクトリ | プロセスの作業ディレクトリ。設定されていない場合は、アプリケーション・サーバー・プロセスの作業ディレクトリが使用されます。 |
| タイムアウト | タイムアウト(ミリ秒)。この数値によって指定した時間が経過した後、外部プロセスが終了し、すべての結果がログに記録されます。 |

図6.9 Web GUI - シェル・コマンド
タスク - 電子メールの送信
このタスクは非常に便利ですが、現在はグラフ・イベントに対するレスポンスとしてのみ使用されています。これは、監視用として非常に強力な機能です。(このタスク・タイプの詳細は、第7章「グラフ・イベント・リスナー」(55ページ)を参照してください)。
注意: 電子メールを定期的に送信するのは無意味であるように思われますが、現在のサーバー・ステータスや日次の概要を送信できます。これらの機能は将来のバージョンで実装されます。
タスク - Groovyコードの実行
このタスク・タイプを使用すると、スクリプト言語Groovyで作成されたコードを実行できます。いくつかの変数も使用できます。このタスクの唯一のパラメータは、Groovyで作成されたソース・コードです。
表6.8. Groovyコードで使用可能な変数のリスト
| 変数 | クラス | 説明 | 可用性 |
|---|---|---|---|
| event | com.cloveretl.server.events.AbstractServerEvent | 毎回 | |
| task | com.cloveretl.server.persistent.Task | 毎回 | |
| now | java.util.Date | 現在時 | 毎回 |
| parametersjava.util.Properties | タスクのプロパティ | 毎回 | |
| user | com.cloveretl.server.persistent.User | event.getUser()と同様 | 毎回 |
| run | com.cloveretl.server.persistent.RunRecord | イベントがGraphServerEventのインスタンスである場合 | |
| tracking | com.cloveretl.server.persistent.TrackingGraph | run.getTrackingGraph()と同様 | イベントがGraphServerEventのインスタンスである場合 |
| sandbox | com.cloveretl.server.persistent.Sandbox | run.getSandbox()と同様 | イベントがGraphServerEventのインスタンスである場合 |
| schedule | com.cloveretl.server.persistent.Schedule | ((ScheduleServerEvent)event).getSchedule()と同様 | イベントがScheduleServerEventのインスタンスである場合 |
| servletContext | javax.servlet.ServletContext | 毎回 | |
| cloverConfiguration | com.cloveretl.server.spring.CloverConfiguration | CloverETL Serverの構成値 | 毎回 |
| serverFacade | com.cloveretl.server.facade.api.ServerFacade | ファサード・インタフェースの参照。CloverETL Serverコアをコールする際に役立ちます。WARファイルには、ファサードAPIのJavaDocが含まれます。このファイルは、URL: http://host:port/clover/ javadoc/index.htmlからアクセスできます | 毎回 |
| sessionTokenString | イベントを所有するユーザーの有効なセッション・トークン。ファサード・インタフェースの認可用として役立ちます。 | 毎回 |
変数run、trackingおよびsandboxが使用可能なのは、イベントがGraphServerEventクラスのインスタンスである場合のみです。変数scheduleは、イベント変数クラスとしてのScheduleServerEventに対してのみ使用可能です。
Groovyスクリプトの使用例
この例は、終了したグラフを記述するテキスト・ファイルを作成するスクリプトを示しています。これは、run変数の使用を示しています。
import com.cloveretl.server.persistent.RunRecord;
String dir = "/tmp/";
RunRecord rr = (RunRecord)run;
String fileName = "report"+rr.getId()+"_finished.txt";
FileWriter fw = new FileWriter(new File(dir+fileName));
fw.write("Run ID :"+rr.getId()+"\n");
fw.write("Graph ID :"+rr.getGraphId()+"\n");
fw.write("Sandbox :"+rr.getSandbox().getName()+"\n");
fw.write("\n");
fw.write("Start time :"+rr.getStartTime()+"\n");
fw.write("Stop time :"+rr.getStopTime()+"\n");
fw.write("Duration :"+rr.getDurationString()+"\n");
fw.write("Final status :"+rr.getFinalStatus()+"\n");
タスク - レコードのアーカイブ
名前が示すように、このタスクでは、DBから不要になったレコードをアーカイブ(または削除)できます。
表6.9. レコードのアーカイブ・タスクの属性
| タスク・タイプ | アーカイバ |
| 次より古い | 時間(分): 不要と評価されたレコードを指定します。指定した間隔より古いレコードがアーカイブに格納されます。 |
| アーカイバ・タイプ | archiveまたはdeleteという2つの値を使用できます。削除する場合、UNDO操作は一切不可能な状態でレコードを削除します。アーカイブする場合、レコードがDBから削除されますが、削除されたデータが含まれるCSVファイルを使用してZIPパッケージが作成されます。 |
| アーカイブの出力パス | この属性が有効なのは、アーカイブ・タイプに対してのみです。 |
| 実行履歴を含める | |
| ステータスのある実行レコード | ステータスが選択されている場合、指定したステータスを持つ実行レコードのみがアーカイブされます。これが役立つのは、たとえば、正常に終了したジョブのレコードを削除するが、失敗したジョブを将来の調査用として保持する場合などです。 |
| 一時ファイルを含める | |
| レコード・ステータスのある一時ファイル | ステータスが選択されている場合、選択したステータスを持つ実行レコードに関連する一時ファイルのみがアーカイブされます。これが役立つのは、たとえば、正常に終了したジョブのファイルを削除するが、失敗したジョブを将来の調査用として保持する場合などです。 |
| タスク履歴を含める | 選択すると、実行レコードがアーカイバに含まれます。グラフ実行のログ・ファイルも含まれます。 |
| タスク・タイプ | このタスク・タイプを選択すると、選択したタスク・タイプのログのみがアーカイブされます。 |
| タスク結果マスク | タスク・ログ結果属性にマスクが適用されます。結果がこのマスクと一致するレコードのみがアーカイブされます。ワイルドカードなしで文字列を指定します。指定した文字列が「結果」属性に含まれる各タスク・ログが削除/アーカイブされます。大/小文字が区別されるかどうかは、データベース照合によって異なります。 |
| デバッグ・ファイルを含める | 選択すると、「次より古い」属性に定義されている特定のタイムスタンプより古いグラフ・デバッグ・ファイルがすべて削除されます。 |
| ディクショナリ・ファイルを含める | 選択すると、「次より古い」属性に定義されている特定のタイムスタンプより古いディクショナリ一時ファイルがすべて削除されます。 |

図6.10 Web GUI - レコードのアーカイブ
第7章 グラフ・イベント・リスナー
グラフ・イベント・リスナーは、ETLグラフ実行の成功または失敗を監視できる強力な機能です。また、各実行間の関係を作成したり、グラフの成功または失敗に応じてバックアップ・スクリプトを実行することもできます。
グラフ・イベント・リスナーの機能は、多くの用途においてジョブフロー・イベント・リスナーと非常に類似しています(第8章「ジョブフロー・イベント・リスナー」(63ページ))。これは、ETLグラフとジョブフローは、CloverETL Serverの観点からは両方ともジョブであるためです。
クラスタ環境では、イベントは、ジョブフローを実行するクラスタ・ノード上にのみ存在します。このため、ノードが明示的に指定されていない場合、タスクは同じノードでトリガーされます。
グラフ・イベント
各イベントには、イベントのソースであるグラフのプロパティが設定されています。イベント・リスナーが指定されている場合、タスクではこれらのプロパティを使用できます。つまり、チェーン内の次のグラフでは、チェーン内の最初のグラフをアクティブ化するEVENT_FILE_NAMEプレースホルダを使用できます。グラフ実行(つまり、RUN_ID)ごとに明確に設定されているグラフ・プロパティは、最後のグラフによってオーバーライドされます。
現時点では、次のタイプのグラフ・イベントが存在します。
- 「グラフ開始」(55ページ)
- 「グラフ・フェーズ終了」(55ページ)
- 「グラフ正常終了」(55ページ)
- 「グラフ・エラー」(55ページ)
- 「グラフ中断」(56ページ)
- 「グラフ・タイムアウト」(56ページ)
- 「グラフ・ステータス不明」(56ページ)
グラフ開始
ETLグラフ実行が正常に開始された場合、このタイプのイベントが作成されます。
グラフ・フェーズ終了
グラフ・フェーズが終了し、すべてのノードがステータスFINISHED_OKで終了するたびに、このタイプのイベントが作成されます。
グラフ正常終了
グラフのすべてのフェーズおよびノードがステータスFINISHED_OKで終了した場合、このタイプのイベントが作成されます。
グラフ・エラー
なんらかの理由によりグラフを実行できない場合、またはグラフの任意のノードに障害が発生した場合、このタイプのイベントが作成されます。
グラフ中断
グラフが明示的に中断された場合、このタイプのイベントが作成されます。
グラフ・タイムアウト
指定した間隔より長くグラフが実行された場合、このタイプのイベントが作成されます。このため、グラフ・タイムアウト・イベントのリスナーごとにジョブ・タイムアウト間隔属性を指定する必要があります。この間隔は、秒、分または時単位で指定できます。

図7.1 Web GUI - グラフ・タイムアウト・イベント
グラフ・ステータス不明
起動時に、実行履歴内で未定義のステータスの実行レコードが検出された場合、このタイプのイベントが作成されます。未定義のステータスとは、グラフの実行時にサーバーが強制終了されたことを意味します。グラフの状態は自動的に「使用不可」に変更され、「グラフ・ステータス不明」イベントが送信されます。このように機能するのは、実行履歴内に永続レコードがある実行の場合のみです。実行履歴内に永続レコードがなくても変換を実行することはできますが、これは通常、パフォーマンスを向上させたり変換を高速に実行する場合などです(たとえば、起動サービスを使用する場合など)。
リスナー
指定したイベント・タイプおよびグラフ(またはサンドボックス内のすべてのグラフ)に対してリスナーを作成できます。リスナーは実際に、グラフ・イベントとタスク間の接続として機能します。この場合、グラフ・イベントによっていつ実行するかが指定され、タスクによって何を実行するかが指定されます。
このため、処理は次のように進行します。
- イベントが作成されます
- このイベントのリスナーが通知されます
- 各リスナーによって関連タスクが実行されます
タスク
シェル・コマンドの実行、グラフの実行、およびアーカイバの各タスク・タイプの詳細は、「スケジューリング」の項を参照してください。これらのタスク・タイプの詳細は、この項を参照してください。特にグラフ・イベント・リスナーの場合に役立つタスク・タイプがもう1つあるため、これについてもここで説明します。これは、電子メールの送信タスク・タイプです。
注意: スケジューリングとグラフ・イベント・リスナーには両方とも、任意のタイプのタスクを使用できます。タスク・タイプの説明は、最も明白なユースケースを示すために2つの項に分けられています。
- 「タスク - 電子メールの送信」(57ページ)
- 「タスク - JMSメッセージ」(59ページ)
タスク - 電子メールの送信
このタスク・タイプは、グラフ実行の結果に関する通知用として役立ちます。つまり、指定したサンドボックス内の失敗または特定のグラフの失敗ごとに通知するリスナーをこのタスク・タイプを使用して作成できます。
表7.1. 電子メールの送信タスクの属性
| タスク・タイプ | 電子メール | |||||
|---|---|---|---|---|---|---|
| 電子メール・パターン | この選択ボックスには、事前定義された電子メール・パターンがすべて含まれます。これらのいずれかを選択すると、この下のすべてのフィールドにパターンの値が入力されます。 | |||||
| 宛先 | 受信者の電子メール・アドレス。複数のアドレスをカンマで区切って指定できます。また、プレースホルダを使用することもできます。 詳細は、「プレースホルダ」(58ページ)を参照してください。 | |||||
| Cc | Ccは、カーボン・コピーを表します。これらのアドレスに電子メールのコピーが送信されます。複数のアドレスをカンマで区切って指定できます。また、プレースホルダを使用することもできます。 詳細は、「プレースホルダ」(58ページ)を参照してください。 | |||||
| Bcc | Bccは、ブラインド・カーボン・コピーを表します。これはCcと同じですが、これらの受信者が電子メールのコピーを受信していることが他の受信者にはわかりません。 | |||||
| 返信先(送信者) | 送信者の電子メール・アドレス。これは、SMTPサーバーに応じて有効なアドレスである必要があります。また、プレースホルダを使用することもできます。 詳細は、「プレースホルダ」(58ページ)を参照してください。 | |||||
| 件名 | 電子メールの件名。また、プレースホルダを使用することもできます。詳細は、「プレースホルダ」(58ページ)を参照してください。 | |||||
| プレーン・テキスト | プレーン・テキスト形式の電子メールの本文。電子メールはマルチパートとして作成されるため、HTMLの本文が優先されます。プレーン・テキストの本文は、HTMLを表示しない電子メール・クライアント用です。また、プレースホルダを使用することもできます。 詳細は、「プレースホルダ」(58ページ)を参照してください。 | |||||
| HTML | HTML形式の電子メールの本文。電子メールはマルチパートとして作成されるため、HTMLの本文が優先されます。プレーン・テキストの本文は、HTMLを表示しない電子メール・クライアント用です。また、プレースホルダを使用することもできます。 詳細は、「プレースホルダ」(58ページ)を参照してください。 | |||||
| 添付としてのログ・ファイル | このスイッチを選択すると、電子メールには、関連するグラフ実行がパックされたログ・ファイルが添付されます。 | |||||

図7.2 Web GUI - 電子メールの送信
注意: SMTPサーバーへの接続を必ず構成してください(詳細は、第18章「構成」(96ページ)を参照してください)。
プレースホルダ
プレースホルダは、タスクの各種フィールドで使用できます。これらは特に、コンテキスト変数に応じて電子メールのコンテンツを生成できる、電子メール・タスクで便利です。
注意: ほとんどの場合、電子メール・パターンを使用することによってこれを回避できます(詳細は、電子メール・タスクを参照)。
これらのフィールドは、Apache Velocityテンプレート・エンジンによって事前に処理されます。構文の詳細は、VelocityプロジェクトのURL (http://velocity.apache.org/)を参照してください。
プレースホルダで使用できる他にループおよび条件の作成にも使用できるコンテキスト変数が複数用意されています。
- event
- now
- user
- run
- sandbox
これらの一部は、フィールドが処理される状況によっては空である場合があります。つまり、タスクがグラフ・イベントのために処理される場合、runおよびsandbox変数には関連データが含まれ、それ以外の場合は空になります。
表7.2. 電子メール・テンプレートで役立つプレースホルダ
| 変数名 | 内容 |
| now | 現在の日付/時間 |
| user | このイベントを引き起こしたユーザー。これは、スケジュールの所有者である場合や、グラフを実行したユーザーである場合があります。ドット表記法(例: ${user.email})を使用してアクセス可能なサブプロパティ(email、username、firstName、lastName、groups (値リスト))が含まれます |
| run | 1回のグラフ実行を表すデータ構造。ドット表記法(例: ${run.graphId})を使用してアクセス可能なサブプロパティ(graphId、finalStatus、startTime、stopTime、errNode、errMessage、errException、logLocation)が含まれます |
| tracking |
グラフ実行時のコンポーネントのステータスを表すデータ構造。ループおよび条件のVelocity構文を使用してアクセス可能なサブプロパティが含まれます。
#if (${tracking})
<table border="1" cellpadding="2" cellspacing="0">
#foreach ($phase in $tracking.trackingPhases)
<tr><td>phase: ${phase.phaseNumber}</td>
<td>${phase.execTime} ms</td>
<td></td><td></td><td></td></tr>
#foreach ($node in $phase.trackingNodes)
<tr><td>${node.nodeName}</td>
<td>${node.result}</td>
<td></td><td></td><td></td></tr>
#foreach ($port in $node.trackingPorts)
<tr><td></td><td></td>
<td>${port.portType}:${port.index}</td>
<td>${port.totalBytes} B</td>
<td>${port.totalRows} rows</td></tr>
#end
#end
#end
</table>
#end
}
|
| sandbox | 実行したグラフが含まれるサンドボックスを表すデータ構造。ドット表記法(例: ${sandbox.name})を使用してアクセス可能なサブプロパティ(name、code、rootPath)が含まれます |
| schedule | このタスクをトリガーしたスケジュールを表すデータ構造。ドット表記法(例: ${schedule.description})を使用してアクセス可能なサブプロパティ(description、startTime、endTime、lastEvent、nextEvent、fireMisfired)が含まれます |
タスク - JMSメッセージ
このタスク・タイプは、グラフ実行の結果に関する通知用として役立ちます。つまり、指定したサンドボックス内の失敗または特定のグラフの失敗ごとに通知するグラフ・イベント・リスナーをこのタスク・タイプを使用して作成できます。
JMSメッセージングには、JMS API (jms.jar)およびサード・パーティのライブラリが必要です。これらすべてのライブラリは、アプリケーション・サーバーのクラスパスで使用可能である必要があります。一部のアプリケーション・サーバーにはこれらのライブラリがデフォルトで含まれますが、一部のアプリケーション・サーバーには含まれません。このため、これらのライブラリは明示的に追加する必要があります。
表7.3. JMSメッセージ・タスクの属性
| タスク・タイプ | JMSメッセージ |
| 初期コンテキスト・クラス名 | javax.naming.InitialContext実装の完全クラス名。各JMSプロバイダには、独自の実装があります。たとえば、Apache MQの場合、これは、"org.apache.activemq.jndi.ActiveMQInitialContextFactory"です。空の場合、デフォルトの初期コンテキストが使用されます。 |
| コネクション・ファクトリJNDI名 | コネクション・ファクトリのJNDI名。JMSプロバイダによって異なります。 |
| 宛先 | サーバー上のメッセージ・キュー/トピックのJNDI名 |
| ユーザー名 | JMSメッセージ・ブローカに接続するためのユーザー名 |
| パスワード | JMSメッセージ・ブローカに接続するためのパスワード |
| URL | JMSメッセージ・ブローカのURL |
| JMSパターン | この選択ボックスには、事前定義されたJMSメッセージ・パターンがすべて含まれます。これらのいずれかを選択すると、その下にあるテキスト・フィールドにパターンの値が自動的に入力されます。 |
| テキスト | JMSメッセージの本文。また、プレースホルダを使用することもできます。詳細は、電子メールの送信タスクの「プレースホルダ」(58ページ)を参照してください。 |

図7.3 Web GUI - タスクJMSメッセージのエディタ
ユースケース
使用可能なユースケースは、次のとおりです。
- 「チェーン内のグラフの実行」(61ページ)
- 「グラフの失敗に関する電子メール通知」(61ページ)
- 「グラフの成功に関する電子メール通知」(62ページ)
- 「グラフによって処理されたデータのバックアップ」 (62ページ)
チェーン内のグラフの実行
たとえば、グラフBを実行するのは、別のグラフAがエラーなしで終了した場合であるとします。このため、これらのグラフ間にはなんらかの関係があります。このような動作を実現するには、グラフ・イベント・リスナーを作成します。グラフAのイベント「グラフ正常終了」に対してリスナーを作成し、グラフBが実行対象として指定された状態でタスク・タイプ「グラフ実行」を選択します。これで完了です。グラフCが実行対象として指定された状態でタスク「グラフ実行」を選択してグラフBに対してリスナーを作成すると、グラフのチェーンとして機能します。
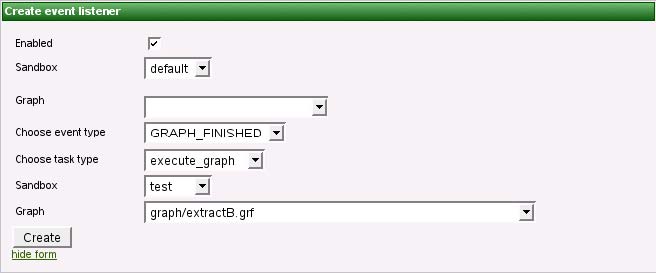
図7.4 イベント・ソース・グラフが指定されていないため、指定したサンドボックス内のすべてのグラフに対してリスナーが機能
グラフの失敗に関する電子メール通知

図7.5 Web GUI - グラフの失敗に関する電子メール通知
グラフの成功に関する電子メール通知

図7.6 Web GUI - グラフの成功に関する電子メール通知
グラフによって処理されたデータのバックアップ
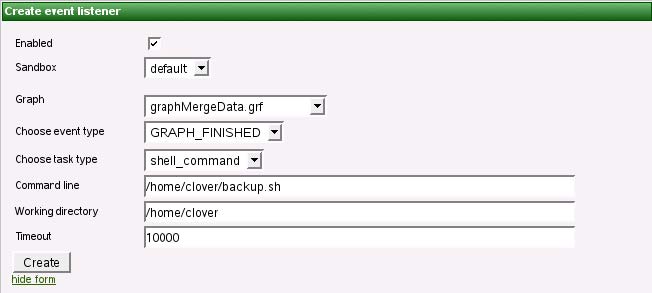
図7.7 Web GUI - グラフによって処理されたデータのバックアップ
第8章 ジョブフロー・イベント・リスナー
ジョブフロー・イベント・リスナーの機能は、多くの用途においてグラフ・イベント・リスナーと非常に類似しています(「タスク」(56ページ)の項)。これは、ETLグラフとジョブフローは、CloverETLサーバーの観点からは両方ともジョブであるためです。
クラスタ環境では、イベントは、ジョブフローを実行するクラスタ・ノード上にのみ存在します。このため、ノードが明示的に指定されていない場合、タスクは同じノードでトリガーされます。
ジョブフロー・イベント
各イベントには、イベント・ソース・ジョブのプロパティが含まれます。イベント・リスナーが指定されている場合、タスクではこれらのプロパティを使用できます。たとえば、チェーン内の次のジョブでは、チェーン内の最初のジョブをアクティブ化するEVENT_FILE_NAMEプレースホルダを使用できます。実行(たとえば、RUN_ID)ごとに明確に設定されているジョブ・プロパティは、最後のジョブによってオーバーライドされます。
次のタイプのジョブフロー・イベントがあります。
- 「ジョブフロー開始」(63ページ)
- 「ジョブフロー・フェーズ終了」(63ページ)
- 「ジョブフロー正常終了」(63ページ)
- 「ジョブフロー・エラー」(63ページ)
- 「ジョブフロー中断」(63ページ)
- 「ジョブフロー・タイムアウト」(64ページ)
- 「ジョブフロー・ステータス不明」(64ページ)
ジョブフロー開始
ジョブフロー実行が正常に開始された場合、このタイプのイベントが作成されます。
ジョブフロー・フェーズ終了
ジョブフロー・フェーズが終了し、すべてのノードがステータスFINISHED_OKで終了するたびに、このタイプのイベントが作成されます。
ジョブフロー正常終了
ジョブフローのすべてのフェーズおよびノードがステータスFINISHED_OKで終了した場合、このタイプのイベントが作成されます。
ジョブフロー・エラー
なんらかの理由によりジョブフローを実行できない場合、またはジョブフローの任意のノードに障害が発生した場合、このタイプのイベントが作成されます。
ジョブフロー中断
ジョブフローが明示的に中断された場合、このタイプのイベントが作成されます。
ジョブフロー・タイムアウト
指定した間隔より長くジョブフローが実行された場合、このタイプのイベントが作成されます。このため、ジョブフロー・タイムアウト・イベントのリスナーごとにジョブ・タイムアウト間隔属性を指定する必要があります。この間隔は、秒、分または時単位で指定できます。
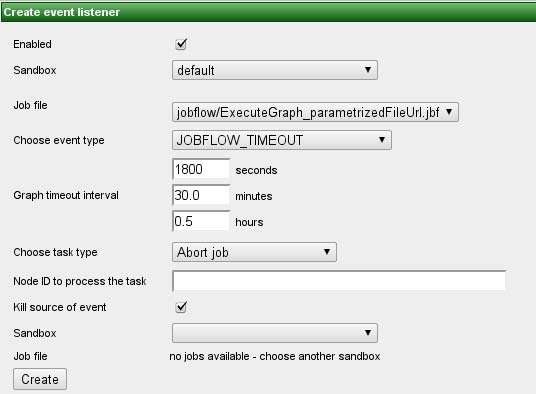
図8.1 Web GUI - ジョブフロー・タイムアウト・イベント
ジョブフロー・ステータス不明
起動時に、実行履歴内で未定義のステータスの実行レコードが検出された場合、このタイプのイベントが作成されます。未定義のステータスとは、ジョブフローの実行時にサーバーが強制終了されたことを意味します。ジョブフローの状態は自動的に「使用不可」に変更され、「ジョブフロー・ステータス不明」イベントが送信されます。このように機能するのは、実行履歴内に永続レコードがある実行の場合のみです。実行履歴内に永続レコードがなくても変換を実行することはできますが、これは通常、パフォーマンスを向上させたり変換を高速に実行する場合などです(たとえば、起動サービスを使用する場合など)。
リスナー
指定したイベント・タイプおよびジョブフロー(またはサンドボックス内のすべてのジョブフロー)に対してリスナーを作成できます。リスナーは実際に、ジョブフロー・イベントとタスク間の接続として機能します。この場合、ジョブフロー・イベントによっていつ実行するかが指定され、タスクによって何を実行するかが指定されます。
このため、処理は次のように進行します。
- イベントが作成されます
- このイベントのリスナーが通知されます
- 各リスナーによって関連タスクが実行されます
タスク
タスクにより、トリガーされたイベントに対する対応として実行する必要がある操作を指定します。
タスク・タイプの詳細は、「タスク」(48ページ)の項および「タスク」(56ページ)の項を参照してください。
注意: ジョブフロー・イベント・リスナーには、任意のタイプのタスクを使用できます。タスク・タイプの説明は、最も明白なユースケースを示すために2つの項に分けられています。
第9章 JMSメッセージ・リスナー
この機能を使用すると、受信JMSメッセージのリスナーを指定できます。これにより、このようなリスナーで、すべてのイベント・リスナーに対して事前定義されたタスクの1つを通常どおり処理できるようになります。このため、リスナーごとに、それぞれの受信JMSメッセージの結果として処理されるタスクおよびJMSメッセージ(JMSトピックまたはJMSキュー)のソースを指定します。
JMSメッセージングには、JMS API (jms.jar)およびサード・パーティのライブラリが必要です。これらすべてのライブラリは、アプリケーション・サーバーのクラスパスで使用可能である必要があります。一部のアプリケーション・サーバーにはこれらのライブラリがデフォルトで含まれますが、一部のアプリケーション・サーバーには含まれません。このため、これらのライブラリは明示的に追加する必要があります。
JMS自体については、このドキュメントの範囲を超えた非常に複雑なトピックです。この詳細は、SunのWebサイト(http://java.sun.com/j2ee/1.4/docs/tutorial/doc/JMS6.html)を参照してください。
表9.1. JMSメッセージ・タスクの属性
| 属性 | 説明 |
| イベントを処理するためのノードID | この属性が有効なのは、クラスタ環境の場合のみです。これは、リスナーを初期化する必要があるノードIDです。設定しない場合、リスナーはクラスタ内のすべてのノードで初期化されます。 |
| 初期コンテキスト・クラス名 | javax.naming.InitialContext実装の完全クラス名。JMSプロバイダごとに独自の実装があります。たとえば、Apache MQの場合はorg.apache.activemq.jndi.ActiveMQInitialContextFactoryです。空である場合、デフォルトの初期コンテキストが使用されます。指定したクラスは、web-appクラスパスまたはapplication-serverクラスパス上にある必要があります。これは通常、特定のJMSブローカ・プロバイダごとにJMS APIが実装された1つのライブラリ内にあります。 |
| コネクション・ファクトリJNDI名 | JMSプロバイダによって異なります。 |
| 宛先JNDI名 | サーバー上のメッセージ・キュー/トピックのJNDI名 |
| ユーザー名 | JMSメッセージ・ブローカに接続するためのユーザー名 |
| パスワード | JMSメッセージ・ブローカに接続するためのパスワード |
| URL | JMSメッセージ・ブローカのURL |
| 恒久サブスクライバ(トピック専用) | "falseである場合、メッセージ・コンシューマは、非恒久としてブローカに接続されます。このため、接続がアクティブであるときに送信されたメッセージのみを受信します。他のメッセージは失われます。trueである場合、コンシューマは恒久としてサブスクライブされるため、接続が非アクティブであるときに送信されたメッセージも受信します。このようなメッセージは、送信可能になるまで、または有効期限が切れるまで格納されます。このスイッチが有効なのはトピック宛先の場合のみです。これは、キュー宛先の場合、メッセージは送信可能になるまで、または有効期限が切れるまで常に格納されるためです。サーバーの再起動中や、JMSメッセージ・リスナーが更新される間の一瞬、コンシューマは非アクティブになるため、再度初期化する必要があります。サーバーの再起動中や、JMSメッセージ・リスナーが更新される間の一瞬、コンシューマは非アクティブになるため、再度初期化する必要があります。 サブスクリプションが恒久である場合、クライアントにはClientIdを指定する必要があります。この属性は、JMSプロバイダに応じて様々な方法で設定できます。たとえば、ActiveMQの場合は、URLパラメータtcp://localhost:1244?jms.clientID=TestClientIDとして設定されます。" |
| メッセージ・セレクタ | この問合せ文字列は、受信メッセージをフィルタするための条件の仕様として使用できます。構文の詳細は、Java EE APIのWebサイト(http://java.sun.com/j2ee/1.4/docs/api/javax/jms/Message.html)を参照してください。これは、コンシューマのタイプ(キュー/トピック)に応じて動作が異なります。キューの場合、フィルタで除外されたメッセージはキュー内に残ります。トピックの場合、トピック・サブスクライバのメッセージ・セレクタによってフィルタで除外されたメッセージがサブスクライバに送信されることはありません。サブスクライバの観点からは、これらは存在しません。 |
| Groovyコード | Groovyコードは、追加メッセージ処理やメッセージの拒否用として使用できます。これら両方の機能については次の説明を参照してください。 |
オプションのGroovyコード
Groovyコードは、追加メッセージ処理やメッセージの拒否用として使用できます。
- 追加メッセージ処理 Groovyコードにより、コンテナ「プロパティ」および「データ」に格納されている値を変更/追加/削除できます。
- メッセージの拒否/承認 GroovyコードからBoolean.FALSEが戻されると、メッセージは拒否されます。それ以外の場合、メッセージは承認されます。拒否されたメッセージを再送信することもできますが、JMSブローカにより、メッセージの再送信に関する制限が構成されている必要があります。Groovyコードによって例外がスローされた場合、コーディング・エラーとみなされ、これが原因でJMSメッセージは拒否されません。このため、例外によってメッセージの拒否が指示された場合、これはGroovyで処理する必要があります。
表9.2. Groovyコードでアクセス可能な変数
| タイプ | キー | 説明 |
|---|---|---|
| javax.jms.Message | msg | JMSメッセージのインスタンス |
| java.util.Properties | properties | 詳細は、次の説明を参照してください。メッセージから読み取られた値(文字列または文字列に変換されたもの)が含まれます。これは、タスクに渡され、タスクによってなんらかの方法で使用されます。たとえば、タスク「グラフ実行」の場合、これらのパラメータを実行対象グラフに渡します。 |
| java.util.Map<String, Object> | data | 詳細は、次の説明を参照してください。メッセージ・インスタンスから読み取られたかプロキシされた値(オブジェクト、ストリームなど)が含まれます。これは、タスクに渡され、タスクによってなんらかの方法で使用されます。たとえば、タスク「グラフ実行」の場合、これを「ディクショナリ・エントリ」として実行対象グラフに渡します。 |
| javax.servlet.ServletContext | servletContext | ServletContextのインスタンス |
| javax.jms.Message | msg | JMSメッセージのインスタンス |
| com.cloveretl.server.api.ServerFacade | serverFacade | CloverETL Serverコア機能をコールする場合に使用可能なserverFacadeのインスタンス。 |
| String | sessionToken | serverFacadeメソッドのコールに必要なsessionToken |
追加処理に使用可能なメッセージ・データ
JMSメッセージは処理され、これに含まれるデータは基本的に「プロパティ」と「データ」の2つのデータ構造に格納されます。
表9.3. 「プロパティ」要素
| キー | 説明 |
| JMS_PROP_[property key] | メッセージ・プロパティごとに、1つのエントリが作成されます。この場合、キーは接頭辞JMS_PROP_とプロパティ・キーを使用して作成されます。 |
| JMS_MAP_[map entry key] | メッセージがMapMessageのインスタンスである場合、マップ・エントリごとに1つのエントリが作成されます。この場合、キーは接頭辞JMS_MAP_とマップ・エントリ・キーを使用して作成されます。値はStringに変換されます。 |
| JMS_TEXT | メッセージがTextMessageのインスタンスである場合、このプロパティにはメッセージの内容が含まれます。 |
| JMS_MSG_CLASS | メッセージ実装のクラス名 |
| JMS_MSG_CORRELATIONID | 相関IDは、プロバイダ固有のメッセージIDまたはアプリケーション固有のString値です |
| JMS_MSG_DESTINATION | JMSDestinationヘッダー・フィールドには、メッセージの送信先である宛先が含まれます。 |
| JMS_MSG_MESSAGEID | JMSMessageIDは、履歴リポジトリ内のメッセージを識別するために一意キーとして機能する必要があるString値です。 一意性の正確な範囲はプロバイダによって定義されます。この範囲は少なくとも、プロバイダの特定のインストールに対するすべてのメッセージを網羅する必要があります。この場合、インストールとは、接続されたメッセージ・ルーターの集合です。 |
| JMS_MSG_REPLYTO | このメッセージに対する返信の送信先。 |
| JMS_MSG_TYPE | メッセージの送信時にクライアントによって提供されるメッセージ・タイプ識別子。 |
| JMS_MSG_DELIVERYMODE | このメッセージに指定されているDeliveryMode値。 |
| JMS_MSG_EXPIRATION | メッセージ期限が切れる時間。これは、クライアントによって指定される存続時間と送信時のGMTの合計です。 |
| JMS_MSG_PRIORITY | JMS APIにより、10レベルの優先度の値が定義されます。この場合、0が最も優先度が低く、9が最も高い値です。また、クライアントでは、優先度0-4を通常の優先度レベル、優先度5-9を優先される優先度レベルだとみなす必要があります。 |
| JMS_MSG_REDELIVERED | このメッセージが再配信される場合はtrue。 |
| JMS_MSG_TIMESTAMP | 送信先のプロバイダにメッセージが渡された時間。これは、メッセージが実際に送信された時間ではありません。実際には、トランザクションやメッセージのクライアント側のキューが原因で送信が遅れる可能性があるためです。 |
「プロパティ」構造内の値はすべて、数値であるかテキストであるかとは関係なく、Stringタイプです。
リストされているプロパティはすべて、下位互換性のために小文字のキーを使用してアクセスすることもできます。ただし、この方法は推奨されません。
表9.4. 「データ」要素
| キー | 説明 |
| JMS_MSG | javax.jms.Messageのインスタンス |
| JMS_DATA_STREAM | java.io.InputStreamのインスタンス。TextMessage、BytesMessage、StreamMessage、ObjectMessage (ペイロード・オブジェクトがStringのインスタンスである場合のみ)の場合のみアクセスできます。文字列はUTF-8でエンコードされます。 |
| JMS_DATA_TEXT | Stringのインスタンス。TextMessageおよびObjectMessage (ペイロード・オブジェクトがStringのインスタンスである場合)のみが対象です。 |
| JMS_DATA_OBJECT | java.lang.Objectのインスタンス - メッセージ・ペイロード。ObjectMessageのみが対象です。 |
「データ」コンテナは、タスクに渡され、タスクによって実装に応じてなんらかの方法で使用されます。たとえば、グラフの実行タスクの場合、これをディクショナリ・エントリとして実行対象グラフに渡します。これはシリアライズ可能ではありません。このため、タスクがこれに依存している場合、これを正しく処理できるのは、同じクラスタ・ノード上である場合のみです。
ディクショナリ・エントリは、一部のグラフ・コンポーネント属性で使用できます。たとえば、fileURL属性の場合は「dict:JMS_DATA_STREAM:discrete」のようになります。このため、データは、このプロキシ・ストリームを使用して受信JMSメッセージから直接読み取られます。
リストされているディクショナリ・エントリはすべて、下位互換性のために小文字のキーを使用してアクセスすることもできます。ただし、この方法は推奨されません。
第10章 ユニバーサル・イベント・リスナー
2.10以降
この機能を使用すると、イベントが作成されるタイミングを決定するGroovyコードを指定できます。後で、指定したタスクが処理されます。このため、リスナーごとに、Groovyコードによって処理が決定された場合に処理されるGroovyソース・コードおよびタスクを指定します。
表10.1. JMSメッセージ・タスクの属性
| 属性 | 説明 |
| イベントを処理するためのノードID | この属性が有効なのは、クラスタ環境の場合のみです。これは、リスナーを初期化する必要があるノードIDです。設定しない場合、リスナーはクラスタ内のすべてのノードで初期化されます。 |
| チェックインの間隔(秒) | Groovyコード実行の周期性。 |
| Groovyコード | Groovyコードは、イベントを作成する必要があるかどうかを決定するために使用されます。 コードの詳細は、次の説明を参照してください。 |
Groovyコード
Groovyコードは、イベントを作成する必要があるかどうかを決定するために使用されます。
たとえば、グラフの実行に不可欠のデータ・ソースの確認を行うことができます。または、実行グラフの複雑な確認を行い、これを強制終了することも決定できます。ServerFacadeインタフェース(詳細は、独自の章を参照)を使用してCloverETL Serverコア機能をコールすることもできます。
イベントの作成は簡単です。GroovyコードからBoolean.TRUEが戻されたら、イベントが作成され、指定したタスクが処理されます。それ以外の場合、何も行われません。Groovyコードによって例外がスローされた場合、コーディング・エラーとみなされ、これが原因でイベントは作成されません。このため、必要な場合、例外はGroovyコードで処理する必要があります。
表10.2. Groovyコードでアクセス可能な変数
| タイプ | キー | 説明 |
|---|---|---|
| java.util.Properties | properties | Groovyコード内のString-String型のキーと値のペアによって入力できる空のコンテナ。これは、タスクに渡され、タスクによってなんらかの方法で使用されます。たとえば、グラフの実行タスクの場合、これらのパラメータを実行対象グラフに渡します。 |
| java.util.Map<String, Object> | data | Groovyコード内のString-Object型のキーと値のペアによって入力できる空のコンテナ。これは、タスクに渡され、タスクによって実装に応じてなんらかの方法で使用されます。たとえば、グラフの実行タスクの場合、これをディクショナリ・エントリとして実行対象グラフに渡します。これはシリアライズ可能ではありません。このため、タスクがこれに依存している場合、これを正しく処理できるのは、同じクラスタ・ノード上である場合のみです。 |
| javax.servlet.ServletContext | servletContext | ServletContextのインスタンス |
| com.cloveretl.server.api.ServerFacade | serverFacade | CloverETL Serverコア機能をコールする場合に使用可能なserverFacadeのインスタンス。 |
| String | sessionToken | serverFacadeメソッドのコールに必要なsessionToken |
第11章 手動タスク実行
3.1以降
手動タスク実行を使用すると、タスク処理を呼び出すことができます。タスクは、ソース・イベントに対応する方法を表すエンティティです。このため、通常のタスクは、ソース・イベントに対応する方法としてのみ処理されます。3.1以降、タスク処理は手動で呼び出すことができます。
また、通常はタスク処理をトリガーするソース・イベントをシミュレートするためのパラメータを指定することもできます。次の図は、ファイル・イベントをシミュレートする方法を示しています。様々なイベント・ソースのパラメータは、「グラフ・パラメータ」の項を参照してください。
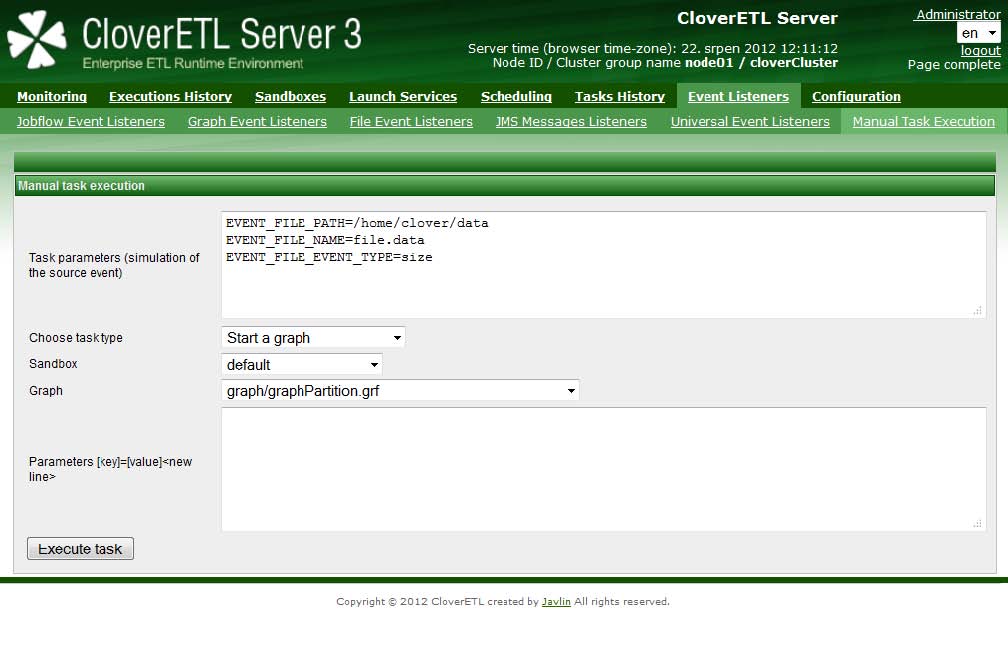
図11.1 Web GUI -手動タスク実行セクション
第12章 ファイル・イベント・リスナー
1.3以降
ファイル・イベント・リスナーを使用すると、サーバー・ファイルシステム上の変更を監視できます。ファイル・イベント・ソースとして監視する必要があるファイルシステム・リソースを定義できます。また、ファイルシステム上の変更に応じて処理する必要があるタスクを指定することもできます。
ファイルシステム上の変更に対する確認を実行するプロセスがあります。このプロセスは事前構成された周期で動作するため、確認の間隔は最小限に抑えられます。この最小限の間隔は、cloverプロパティclover.event.fileCheckMinIntervalによって設定できます。
クラスタ環境では、イベント・リスナーごとに、ローカル・ファイルシステムを確認するクラスタ・ノードを指定するノードID属性があります。スタンドアロン環境では、ノードID属性は無視されます。
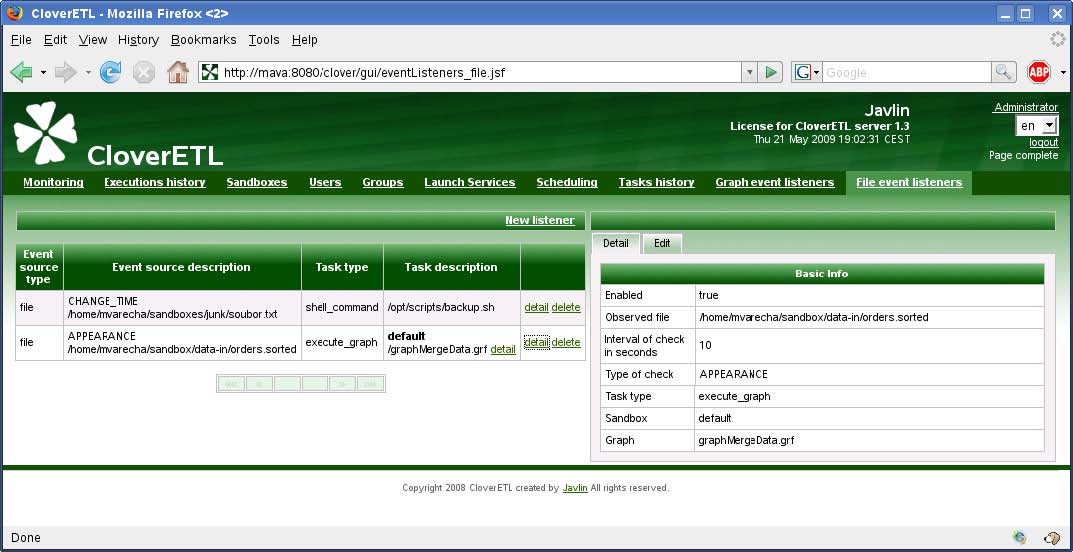
図12.1 Web GUI - ファイル・イベント・リスナー・セクション
監視対象ファイル
監視対象ファイルは、ディレクトリ・パスおよびファイル名パターンによって指定します。
厳密に1つのファイル名を指定することも、指定したディレクトリ内の複数の一致ファイルを監視するためにファイル名パターンを指定することもできます。パターンと一致する変更済ファイルが複数存在する場合、これらのファイルごとに個別イベントがトリガーされます。監視対象ファイルのファイル名パターンを指定する方法は3通りあります
完全一致
監視対象ファイルの厳密な名前を指定します。
ワイルドカード
ほとんどのオペレーティング・システムで一般的なワイルドカード(*や?など)を使用できます。
- * - 任意の文字の0以上のインスタンスと一致します
- ? - 任意の1文字のインスタンスと一致します
- [...] - 大カッコで囲まれた任意の文字と一致します
- \ - エスケープ文字
例
- *.csv - すべてのCSVファイルと一致します
- input_*.csv - input_001.csv、input_9.csvなどと一致します
- input_???.csv - input_001.csvとは一致しますが、input_9.csvとは一致しません
正規表現
例
- (.*?)\.(jpg|jpeg|png|gif)$ - イメージ・ファイルと一致します
注意
- 絶対パスを使用することをお薦めします。相対パスを使用することもできますが、作業ディレクトリはアプリケーション・サーバーに依存します。
- MS Windows OSの場合でも、ファイル・セパレータとしてフォワード・スラッシュを使用してください。バックスラッシュはエスケープ・シーケンスとみなされる可能性があります。
ファイル・イベント
リスナーごとに、該当するイベント・タイプを指定する必要があります。
次の4つのファイル・イベントがあります。
- 「ファイルAPPEARANCE」(72ページ)
- 「ファイルDISAPPEARANCE」(72ページ)
- 「ファイルSIZE」(73ページ)
- 「ファイルCHANGE_TIME」(73ページ)
ファイルAPPEARANCE
このタイプのイベントは、監視対象ファイルが2回の確認の間に別の場所から作成またはコピーされたときに発生します。このタイプのイベントは、新規ファイルが完成したかどうかとは関係なく、検出されると同時に発生することに注意してください。このため、ファイルがまだ不完全であっても完全なファイルを必要とする可能性があるタスクが実行されます。したがって、ファイルを別の場所に保存し、ファイルが完成したら、CloverETL Serverが検出できる監視対象場所に移動/名前変更することをお薦めします。ファイルの移動/名前変更はアトミック操作である必要があります。
このタイプのイベントは、ファイルが2回の確認の間に更新(タイムスタンプまたはサイズの変更)されている場合は発生しません。APPEARANCE (出現)とは、ファイルは前回の確認時には存在しなかったが、現在の確認時には存在することを意味します。
ファイルDISAPPEARANCE
このタイプのイベントは、監視対象ファイルが2回の確認の間に削除されたか別の場所に移動されたときに発生します。
ファイルSIZE
このタイプのイベントは、監視対象ファイルのサイズが2回の確認の間に変更されたときに発生します。このタイプのイベントは、ファイルが作成または削除された場合は発生しません。ファイルは両方の確認時に存在する必要があります。
ファイルCHANGE_TIME
このタイプのイベントは、監視対象ファイルの変更時間が2回の確認の間に変更されたときに発生します。このタイプのイベントは、ファイルが作成または削除された場合は発生しません。ファイルは両方の確認時に存在する必要があります。
確認間隔、タスクおよびユースケース
- 2回の確認の最小限の間隔を指定できます。これは秒単位で指定します。
- リスナーごとにタスクが定義され、これらのタスクはファイル・イベントに応じて処理されます。すべてのタスク・タイプおよびその属性の詳細は、「スケジューリング」および「グラフ・イベント・リスナー」の項を参照してください
- グラフ実行、入力データがアクセス可能な場合
- グラフ実行、入力データが更新された場合
- グラフ実行、生成データがあるファイルが削除され、再作成する必要がある場合
タスク処理時にイベントのソースを使用する方法
イベントの原因となる(イベントのソースとみなされる)ファイルは、タスク処理時に使用できます。つまり、グラフ変換のリーダー・コンポーネント/ライター・コンポーネントは、特別なプレースホルダによってこのファイルを参照できます。${EVENT_FILE_PATH}は、イベント・ソースが含まれるディレクトリへのパスです。${EVENT_FILE_NAME}は、イベント・ソースの名前です。
前のバージョンでは、小文字のプレースホルダを指定していました。バージョン3.3以降、プレースホルダは大文字です。ただし、下位互換性のために小文字も機能します。
たとえば、イベント・ソースが/home/clover/data/customers.csvである場合、プレースホルダにはEVENT_FILE_PATH - /home/clover/data、EVENT_FILE_NAME - customers.csvが含まれます
グラフの実行タスクの場合、これが機能するのは、グラフがプールされていない場合のみです。このため、保持プール間隔は0 (デフォルト値)に設定する必要があります。
第13章 WebDAV
3.1以降
WebDAV APIを使用すると、サンドボックスの内容を管理するために標準WebDAVクライアントを使用できます。
特に次の操作が可能です。
- ディレクトリ構造の参照
- ファイルの編集
- ファイル/フォルダの削除
- ファイル/フォルダの名前変更
- ファイル/フォルダの作成
- ファイルのコピー
- ファイルの移動
URL (http://[host]:[port]/clover/webdav)でアクセスできます。このURLは一般的なWWWブラウザで開くことができますが、これらのほとんどはリッチWebDAVクライアントではないため、アイテムのリストの表示のみが可能です。一般的なWWWブラウザでは、ディレクトリ構造は参照できません。
WebDAVクライアント
様々なオペレーティング・システムを対象としたWebDAVクライアントは多数存在し、一部のOSはWebDAVをネイティブでサポートしています。
LinuxライクなOS
Linuxシステム上で動作する優れたWebDAVクライアントはKonquerorです。URL (webdav:// [host]:[port]/clover/webdav)にある別のプロトコルを使用してください。
MS Windows
MS Windowsの最後のディストリビューション(Win XP以降)は、WebDAVをネイティブでサポートしています。ただし、これは多少不安定であるため、無料または市販のWebDAVクライアントを使用することをお薦めします。
- 弊社でテストした最良のWebDAVクライアントはBitKinex (http://www.bitkinex.com/webdavclient)です
- もう1つのオプションは、Total Commander (http://www.ghisler.com/index.htm)をWebDAVプラグイン (http:// www.ghisler.com/plugins.htm#filesys)とともに使用する方法です
Mac OS
Mac OSは、WebDAVをネイティブでサポートしており、この場合、問題は発生しません。「finder」アプリケーションを使用し、「Connect to the server ...」メニュー項目を選択し、HTTPプロトコルでURL (http://[host]:[port]/ clover/webdav)を使用します。
WebDAV認証/認可
CloverETL Server WebDAV APIでは、デフォルトでHTTP基本認証を使用します。ただし、HTTPダイジェスト認証を使用するよう再構成することもできます。詳細は、「構成」の項を参照してください。
一部のWebDAVクライアントはHTTP基本認証とは機能せず、ダイジェスト認証でのみ機能するため、ダイジェスト認証が役立つ場合があります。
HTTPダイジェスト認証は、バージョン3.1に追加された機能です。古いCloverETL Serverディストリビューションをアップグレードした場合、アップグレードの前に作成されたユーザーは、パスワードをリセットするまではHTTPダイジェスト認証を使用できません。このため、パスワードをリセット(または管理者がかわりにパスワードをリセット)すると、新規ユーザーと同様にダイジェスト認証を使用できるようになります。
第14章 簡易HTTP API
このAPIは、すべてのHTTPクライアントを対象としています(wgetツールのような最も簡単なものも対象です)。すべての操作は、HTTPのGETメソッドを使用してアクセスでき、プレーン・テキストを戻します。このため、レスポンスは簡単なツールによって解析できます。グローバル・セキュリティがオン(デフォルト設定)である場合、HTTP基本認証が必要です。CloverETL Serverユーザーは適切な権限を使用して使用してください。
ETLのグラフ関連操作であるgraph_run、graph_statusおよびgraph_killは、ジョブフローに対しても機能します。
URLには、次のパターンがあります。
http://[domain]:[port]/[context]/[servlet]/[operation]?[param1]=[value1]&[param2]=[value2]...
wgetクライアントの場合、次のコマンドラインを使用できます。
wget --user=$USER --password=$PASS -O ./$OUTPUT_FILE $REQUEST_URL
- 「help操作」(76ページ)
- 「graph_run操作」(77ページ)
- 「graph_status操作」(77ページ)
- 「graph_kill操作」(78ページ)
- 「server_jobs操作」(79ページ)
- 「sandbox_list操作」(79ページ)
- 「sandbox_content操作」(79ページ)
- 「executions_history操作」(79ページ)
- 「suspend操作」(81ページ)
- 「resume操作」(81ページ)
- 「sandbox_create操作」(82ページ)
- 「sandbox_add_location操作」(82ページ)
- 「sandbox_remove_location操作」(82ページ)
- 「cluster status」(83ページ)
help操作
パラメータ
なし
戻り値
使用可能な操作およびパラメータ(説明付き)のリスト
例
http://localhost:8080/clover/request_processor/help
graph_run操作
この操作をコールし、指定したジョブの実行を開始します。この操作は下位互換性のためにgraph_runと呼ばれますが、ETLグラフまたはジョブフローを実行できます。
パラメータ
表14.1. graph_runのパラメータ
| パラメータ名 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| graphID | はい | - | 指定したサンドボックス内で一意であるテキストID。サンドボックスのルートの相対ファイル・パスである場合があります |
| sandbox | はい | - | サンドボックスのテキストID |
| 追加グラフ・パラメータ | いいえ | param_接頭辞が付いたURLパラメータは、実行対象グラフに渡され、グラフXMLでプレースホルダとして使用できますが、param_接頭辞がない場合、たとえば、URLで指定されたparam_FILE_NAMEは、グラフ内で${FILE_NAME}として使用できます。これらのパラメータが解決されるのはグラフXMLのロード中のみであるため、グラフはプールできません。 | |
| nodeID | いいえ | - | クラスタ・モードの場合は、ジョブを実行する必要があるノードのID。ただし、これは最終ノードではありません。グラフが分散している場合や、ノードが切断されている場合、グラフは別のノードでも実行できます。 |
| verbose | いいえ | MESSAGE | MESSAGE | FULL - 可能性のあるエラー・メッセージの冗長性の程度。 |
戻り値
実行ID: 各実行リクエストを識別する増分番号
例
http://localhost:8080/clover/request_processor/graph_run?graphID=graph/graphDBExecute.grf&sandbox=mva
graph_status操作
この操作をコールし、指定したジョブ実行のステータスを取得します。この操作は下位互換性のためにgraph_statusと呼ばれますが、ETLグラフまたはジョブフローのステータスを戻すことができます。
パラメータ
表14.2. graph_statusのパラメータ
| パラメータ名 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| runID | はい | - | 各グラフ実行のID |
| returnType | いいえ | STATUS | STATUS | STATUS_TEXT | DESCRIPTION | DESCRIPTION_XML |
| waitForStatus | いいえ | - | 待機対象のステータス・コード。指定すると、この操作はグラフが必要なステータスになるまで待機します。 |
| waitTimeout | いいえ | 0 | waitForStatusが指定されている場合、指定したミリ秒数のみ待機します。デフォルトの0は永久を意味しますが、アプリケーション・サーバーの構成によって異なります。指定したタイムアウトの期限が切れたときに、グラフ実行がまだ必要なステータスになっていない場合、コード408 (リクエスト・タイムアウト)が戻されます。アプリケーション・サーバーのHTTPリクエスト・タイムアウトの期限が先に切れた場合も、408コードが戻される可能性があります。 |
| verbose | いいえ | MESSAGE | MESSAGE | FULL - 可能性のあるエラー・メッセージの冗長性の程度。 |
戻り値
指定したグラフのステータス。これは、オプションのパラメータreturnTypeに応じて、数値コード、テキスト・コードまたは複雑な説明である場合があります。説明は、セパレータとしてパイプが使用されたプレーン・テキストまたはXMLとして戻されます。XMLレスポンスのXML書式を表すスキーマには、CloverETL ServerのURL (http://[host]:[port]/clover/schemas/ executions.xsd)でアクセスできます。waitForStatusパラメータに応じて、結果は即時戻されるか、指定したステータスになってから戻されます。
例
http://localhost:8080/clover/request_processor/graph_status ->
-> ?runID=123456&returnType=DESCRIPTION&waitForStatus=FINISHED&waitTimeout=60000
graph_kill操作
この操作をコールし、ジョブ実行を中断/強制終了します。この操作は下位互換性のためにgraph_killと呼ばれますが、ETLグラフまたはジョブフローを中断/強制終了できます。
パラメータ
表14.3. graph_killのパラメータ
| パラメータ名 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| runID | はい | - | 各グラフ実行のID |
| returnType | いいえ | STATUS | STATUS | STATUS_TEXT | DESCRIPTION |
| verbose | いいえ | MESSAGE | MESSAGE | FULL - 可能性のあるエラー・メッセージの冗長性の程度。 |
戻り値
指定したグラフを強制終了しようとした後のグラフのステータス。これは、オプションのパラメータに応じて、数値コード、テキスト・コードまたは複雑な説明である場合があります。
例
http://localhost:8080/clover/request_processor/graph_kill?runID=123456&returnType=DESCRIPTION
server_jobs操作
パラメータ
なし
戻り値
現在実行されているジョブのrunIDのリスト。
例
http://localhost:8080/clover/request_processor/server_jobs
sandbox_list操作
パラメータ
なし
戻り値
すべてのサンドボックスのテキストIDのリスト。次のバージョンでは、アクセス可能なもののみが戻されます。
例
http://localhost:8080/clover/request_processor/sandbox_list
sandbox_content操作
パラメータ
表14.4. sandbox_contentのパラメータ
| パラメータ名 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| sandbox | はい | - | サンドボックスのテキストID |
| verbose | いいえ | MESSAGE | MESSAGE | FULL - 可能性のあるエラー・メッセージの冗長性の程度 |
戻り値
指定したサンドボックスのすべての要素のリスト。各要素は、サンドボックスのルートの相対ファイル・パスとして指定できます。
例
http://localhost:8080/clover/request_processor/sandbox_content?sandbox=mva
executions_history操作
パラメータ
表14.5. executions_historyのパラメータ
| パラメータ名 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| sandbox | はい | - | サンドボックスのテキストID |
| from | いいえ | 日時の下限。この日時以降のレコードのみが戻されます。書式: yyyy-MM-dd HH:mm (URLエンコードする必要があります) | |
| to | いいえ | 日時の下限。この日時以降のレコードのみが戻されます。書式: yyyy-MM-dd HH:mm (URLエンコードする必要があります)ステータス | |
| status | いいえ | 現在の実行ステータス。指定したSTATUSを持つレコードのみが戻されます。意味のある値は、RUNNING | ABORTED | FINISHED_OK | ERRORです。 | |
| sandbox | いいえ | サンドボックス・コード。指定したサンドボックスのグラフのレコードのみが戻されます。 | |
| graphId | いいえ | 指定したサンドボックス内で一意であるテキストID。サンドボックスのルートの相対ファイル・パス | |
| orderBy | いいえ | リスト順序の属性。使用可能な値: id | graphId | finalStatus | startTime | stopTime。デフォルトでは、順序はありません。 | |
| orderDescend | いいえ | true | 昇順または降順を指定するスイッチ。true (デフォルト)である場合、順序は降順です。 |
| returnType | いいえ | ID | 使用可能な値: IDs | DESCRIPTION | DESCRIPTION_XML |
| index | いいえ | 0 | レコード・セット全体で最初に戻されるレコードの索引。(開始元 |
| records | いいえ | infinite | 戻されるレコードの最大数。 |
| verbose | いいえ | MESSAGE | MESSAGE | FULL - 可能性のあるエラー・メッセージの冗長性の程度。 |
戻り値
フィルタ基準に応じた実行のリスト。
returnType==IDsである場合、runIDの簡単なリストを戻します(改行デリミタ付き)。
returnType==DESCRIPTIONの場合、選択した実行の現在のステータス、フェーズ、ノードおよびポートを表す複合レスポンスを戻します。
execution|[runID]|[status]|[username]|[sandbox]|[graphID]|[startedDatetime]|[finishedDatetime]|[clusterNode]|[graphVersion]
phase|[index]|[execTimeInMilis]
node|[nodeID]|[status]|[totalCpuTime]|[totalUserTime]|[cpuUsage]|[peakCpuUsage]|[userUsage]|[peakUserUsage]
port|[portType]|[index]|[avgBytes]|[avgRows]|[peakBytes]|[peakRows]|[totalBytes]|[totalRows]
リクエストの例
http://localhost:8080/clover/request_processor/executions_history ->
-> ?from=&to=2008-09-16+16%3A40&status=&sandbox=def&graphID=&index=&records=&returnType=DESCRIPTION
DESCRIPTION (プレーン・テキスト)レスポンスの例
execution|13108|FINISHED_OK|clover|def|test.grf|2008-09-16 11:11:19|2008-09-16 11:11:58|nodeA|2.4
phase|0|38733
node|DATA_GENERATOR1|FINISHED_OK|0|0|0.0|0.0|0.0|0.0
port|Output|0|0|0|0|0|130|10
node|TRASH0|FINISHED_OK|0|0|0.0|0.0|0.0|0.0
port|Input|0|0|0|5|0|130|10
node|SPEED_LIMITER0|FINISHED_OK|0|0|0.0|0.0|0.0|0.0
port|Input|0|0|0|0|0|130|10
port|Output|0|0|0|5|0|130|10
execution|13107|ABORTED|clover|def|test.grf|2008-09-16 11:11:19|2008-09-16 11:11:30
phase|0|11133
node|DATA_GENERATOR1|FINISHED_OK|0|0|0.0|0.0|0.0|0.0
port|Output|0|0|0|0|0|130|10
node|TRASH0|RUNNING|0|0|0.0|0.0|0.0|0.0
port|Input|0|5|0|5|0|52|4
node|SPEED_LIMITER0|RUNNING|0|0|0.0|0.0|0.0|0.0
port|Input|0|0|0|0|0|130|10
port|Output|0|5|0|5|0|52|4
returnType==DESCRIPTION_XMLの場合、選択した1つ以上の実行を表す複合データ構造をXML書式で戻します。XMLレスポンスのXML書式を表すスキーマには、CloverETL ServerのURL (http://[host]:[port]/clover/schemas/ executions.xsd)でアクセスできます。
suspend操作
サーバーまたはサンドボックスを一時停止します(指定されている場合)。一時停止とは、一時停止されているサーバー/サンドボックスでグラフを実行できないことを意味します。
パラメータ
表14.6. suspendのパラメータ
| パラメータ名 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| sandbox | いいえ | - | 一時停止するサンドボックスのテキストID。指定しない場合、サーバー全体を一時停止します。 |
| atonce | いいえ | このパラメータがtrueに設定されている場合、一時停止されているサーバー(またはサンドボックスのみ)から実行されているグラフが中断されます。それ以外の場合、一般的な方法で終了するまで実行できます。 |
戻り値
結果メッセージ
resume操作
パラメータ
表14.7. resumeのパラメータ
| パラメータ名 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| sandbox | いいえ | - | 再開するサンドボックスのテキストID。指定しない場合、サーバーは再開されます。 |
| verbose | いいえ | MESSAGE | MESSAGE | FULL - 可能性のあるエラー・メッセージの冗長性の程度。 |
戻り値
結果メッセージ
sandbox_create操作
この操作により、指定したサンドボックスが作成されます。これがpartitionedまたはlocalタイプのサンドボックスである場合、sandbox_add_location操作によって場所も作成されます。
パラメータ
表14.8. sandbox_createのパラメータ
| パラメータ名 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| sandbox | はい | - | 作成するサンドボックスのテキストID。 |
| path | いいえ | - | サーバーがスタンドアロン・モードで実行されている場合におけるサンドボックスのルートのパス。 |
| type | いいえ | shared | サンドボックス・タイプ: shared | partitioned | local。スタンドアロン・サーバーの場合、デフォルトのsharedが使用されるため、空のままである可能性があります。 |
| createDirs | いいえ | true | サンドボックスのディレクトリ構造を作成するかどうかのスイッチ(クラスタ環境のスタンドアロン・サーバーまたはsharedサンドボックスの場合のみ)。 |
| verbose | いいえ | MESSAGE | MESSAGE | FULL - 可能性のあるエラー・メッセージの冗長性の程度。 |
戻り値
結果メッセージ
sandbox_add_location操作
この操作により、指定したサンドボックスに場所が追加されます。partitionedまたはlocalタイプのサンドボックスに対してのみ使用可能です。
パラメータ
表14.9. sandbox_add_locationのパラメータ
| パラメータ名 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| sandbox | はい | - | 場所の追加先のサンドボックス。 |
| nodeId | はい | - | 場所属性 - この場所に直接アクセスできるノード。 |
| path | はい | - | 場所属性 - 指定したノード上の場所のルートへのパス。 |
| location | いいえ | - | 場所属性 - 場所記憶域ID。指定しない場合、新しい場所が生成されます。 |
| verbose | いいえ | MESSAGE | MESSAGE | FULL - 可能性のあるエラー・メッセージの冗長性の程度。 |
戻り値
結果メッセージ
sandbox_remove_location操作
この操作により、指定したサンドボックスから場所が削除されます。partitionedまたはlocalタイプのサンドボックスに対してのみ場所を関連付けることができます。
パラメータ
表14.10. sandbox_add_locationのパラメータ
| パラメータ名 | 必須 | デフォルト | 説明 |
|---|---|---|---|
| sandbox | はい | - | 指定したサンドボックスから場所を削除します。 |
| location | はい | - | 場所記憶域ID。指定した場所が指定したサンドボックスにアタッチされていない場合、サンドボックスは変更されません。 |
| verbose | いいえ | MESSAGE | MESSAGE | FULL - 可能性のあるエラー・メッセージの冗長性の程度。 |
戻り値
結果メッセージ
Cluster status
この操作により、クラスタのノードのリストが表示されます。
パラメータ
なし
戻り値
クラスタのノードのリスト。
第15章 JMX mBean
CloverETL ServerのJMX mBeanは、CloverETL Serverの内部ステータスの監視用として役立つAPIです。MBeanは、次の名前で登録されています。
com.cloveretl.server.api.jmx:name=cloverServerJmxMBean
JMX構成
アプリケーションのJMX MBeanには、デフォルトでは、JVMの外部からアクセスできません。これらにアクセスできるようにするには、アプリケーション・サーバー構成を変更する必要があります。
この項では、開発およびテスト用としてJMXコネクタを構成する方法について説明します。これにより、認証が無効になる可能性があります。本番デプロイメントの場合、認証を有効にする必要があります。これを実現する方法については、追加ドキュメント(http://java.sun.com/j2se/1.5.0/docs/guide/management/agent.html#auth)を参照してください。
構成および可能性のある問題:
- 「Apache TomcatでのJMXの構成方法」(84ページ)
- 「GlassfishでのJMXの構成方法」(85ページ)
- 「Websphere 7」(86ページ)
- 「可能性のある問題」(87ページ)
Apache TomcatでのJMXの構成方法
TomcatのJVMは、次の自明のパラメータを使用して実行する必要があります。
- -Dcom.sun.management.jmxremote=true
- -Dcom.sun.management.jmxremote.port=8686
- -Dcom.sun.management.jmxremote.ssl=false
- -Dcom.sun.management.jmxremote.authenticate=false UNIXライクなOSの場合、環境変数CATALINA_OPTSを次のように設定します。
export CATALINA_OPTS="-Dcom.sun.management.jmxremote=true
-Dcom.sun.management.jmxremote.port=8686
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false"
ファイルTOMCAT_HOME/bin/setenv.sh (存在しない場合は作成できます)またはTOMCAT_HOME/bin/catalina.sh
Windowsの場合は扱いにくい可能性があるため、各パラメータを個別に設定する必要があります。
set CATALINA_OPTS=-Dcom.sun.management.jmxremote=true
set CATALINA_OPTS=%CATALINA_OPTS% -Dcom.sun.management.jmxremote.port=8686
set CATALINA_OPTS=%CATALINA_OPTS% -Dcom.sun.management.jmxremote.authenticate=false
set CATALINA_OPTS=%CATALINA_OPTS% -Dcom.sun.management.jmxremote.ssl=false
ファイルTOMCAT_HOME/bin/setenv.bat (存在しない場合は作成できます)またはTOMCAT_HOME/bin/ catalina.bat
これらの値とともに、URLを使用して
service:jmx:rmi:///jndi/rmi://localhost:8686/jmxrmi
JVMのJMXサーバーに接続できます。ユーザー/パスワードは必要ありません
GlassfishでのJMXの構成方法
Glasfishの管理コンソール(デフォルトでは、http://localhost:4848でユーザー/パスワードとしてadmin/adminadminを使用してアクセスできます)に移動します
セクション「Configuration」>「Admin Service」>「system」に移動し、次のように属性を設定します。
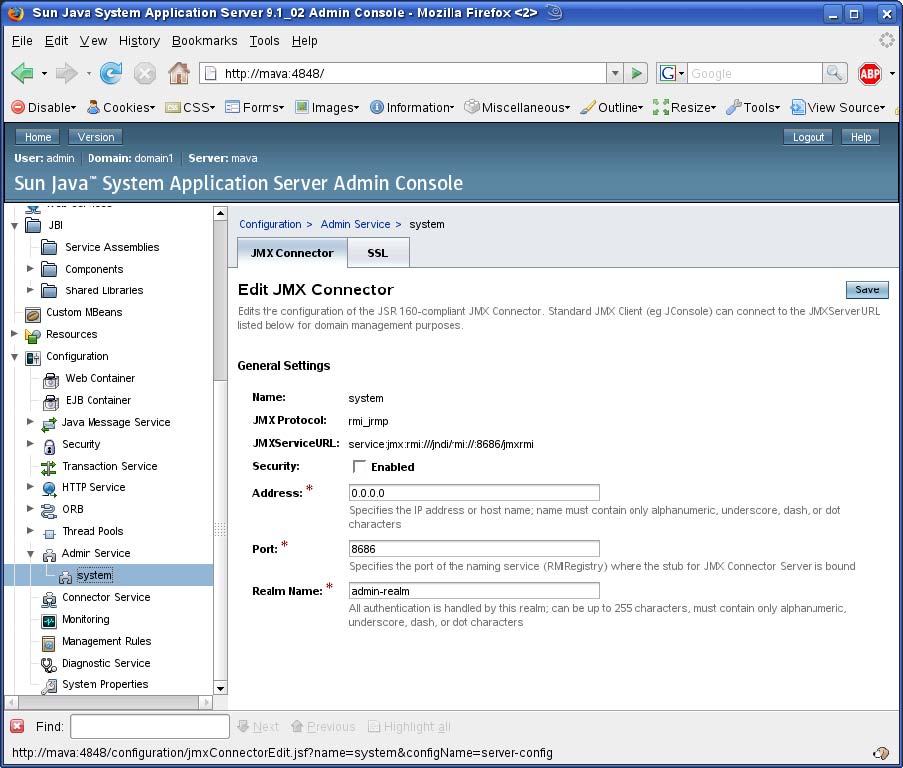
図15.1 Glassfish JMXコネクタ
これらの値とともに、URLを使用して
service:jmx:rmi:///jndi/rmi://localhost:8686/jmxrmi
JVMのJMXサーバーに接続できます。
ユーザー/パスワードとしてadmin/adminadminを使用します。(admin/adminadminはデフォルトのglassfish値です)
WebsphereでのJMXの構成方法
Websphereでは特別な構成は必要ありませんが、cloverのMBeanは、アプリケーション・サーバーの構成に依存する名前とともに登録されています。
com.cloveretl.server.api.jmx:cell=[cellName],name=cloverServerJmxMBean,node=[nodeName],
process=[instanceName]

図15.2 Websphere構成
Websphere 7
JMXサーバーに接続するためのURLは、次のとおりです。
service:jmx:iiop://[host]:[port]/jndi/JMXConnector
hostは接続先のホスト名、portはRMIポート番号です。デフォルトのWebsphereがインストールされている場合、1つのシステムにインストールされているサーバーの数、および接続先の特定のサーバーに応じて、JNDIポート番号は2809、2810、...のようになります。確実を期すには、次のような行がダンプされるので、ログを確認します
0000000a RMIConnectorC A ADMC0026I: The RMI Connector is available at port 2810
Websphere7でのJMXの構成方法
Websphereでは特別な構成は必要ありませんが、cloverのMBeanは、アプリケーション・サーバーの構成に依存する名前とともに登録されています。
com.cloveretl.server.api.jmx:cell=[cellName],name=cloverServerJmxMBean,node=[nodeName],
process=[instanceName]
図15.3 Websphere7構成
JMXサーバーに接続するためのURLは、次のとおりです。
service:jmx:iiop://[host]:[port]/jndi/JMXConnector
hostは接続先のホスト名、portはRMIポート番号です。デフォルトのWebsphereがインストールされている場合、1つのシステムにインストールされているサーバーの数、および接続先の特定のサーバーに応じて、JNDIポート番号は2809、2810、...のようになります。確実を期すには、次のような行がダンプされるので、ログを確認します
0000000a RMIConnectorC A ADMC0026I: The RMI Connector is available at port 2810
また、クラスパスで、Websphereのホーム・ディレクトリの次のjarファイルを設定する必要があります。
/runtimes/com.ibm.ws.admin.client_7.0.0.jar
/runtimes/com.ibm.ws.ejb.thinclient_7.0.0.jar
/runtimes/com.ibm.ws.orb_7.0.0.jar
可能性のある問題
- デフォルトのJMX mBeanサーバーでは、トランスポート・プロトコルとしてRMIを使用します。場合によっては、ピアの1つでJavaバージョン1.6が使用されているときにRMIがリモートで接続できない可能性があります。このソリューションは非常に簡単で、次の2つのシステム・プロパティを設定するだけです: -Djava.rmi.server.hostname=[hostname or IP address] -Djava.net.preferIPv4Stack=true
操作
操作の詳細は、MBeanインタフェースのJavaDocを参照してください。
JMX API MBeanのJavaDocは、URL (http://[host]:[port]/[contextPath]/javadoc-jmx/index.html)で、実行されているCloverETL Serverインスタンスからアクセスできます。
第16章 SOAPのWebサービスAPI
CloverETL Server SOAPのWebサービスはAPIで、これにより、クライアントはサンドボックスの内容を操作して、実行対象グラフなどのステータスを監視できるようになります。
サービスには、次のURLからアクセスできます。
http://[host]:[port]/clover/webservice
サービス・ディスクリプタには、次のURLからアクセスできます。
http://[host]:[port]/clover/webservice?wsdl
プロトコルHTTPは、Webサーバーの構成に応じてセキュアなHTTPSに変更できます。
SOAP WSクライアント
公開されているサービスは、様々なプログラミング言語のライブラリで広くサポートされている最も一般的なバインディング・スタイルdocument/literalを使用して実装されています。
このAPIのクライアントを作成するには、WSDLドキュメント(前述のURLを参照)とともに、プログラミング言語および開発環境に応じてなんらかの開発ツールが必要です。
関連するすべてのクラスを含むWebServiceインタフェースのJavaDocは、URL (http://[host]:[port]/[contextPath]/javadoc-ws/index.html)で、実行されているCloverETL Serverインスタンスからアクセスできます。
WebサーバーでHTTPSコネクタが構成されている場合、クライアントは、Webサーバーの構成に応じてセキュリティ要件も満たす必要があります。(クライアントの信頼性および正しく構成されたキーストアなど)
SOAP WS API認証/認可
公開されているサービスはステートレスであるため、認証sessionTokenをパラメータとして各操作に渡す必要があります。クライアントは、login操作をコールすることによって認証sessionTokenを取得できます。
第17章 起動サービス
起動サービスは、簡単なWebベースのインタフェースを介してCloverETLのグラフまたはジョブフローをリモートで実行する便利な方法を提供します。
起動サービスは、任意のHTTPクライアントとともに使用できます。これにより、必要に応じて、ジョブ実行を手軽に制御できる機能を外部ツールと簡単に統合できます(リクエストはカスタム・アプリケーションからも送信できます)。
起動サービスの概要
起動サービスのアーキテクチャは比較的シンプルであり、ブラウザを利用する複数層アプリケーションの基本設計に準拠しています。
起動サービスおよび基礎となるCloverETL Serverジョブは、任意のフロントエンドのバックエンドとして機能することもできます。これは、HTTPリクエストによってCloverETL Launch Serviceをコールするサード・パーティのアプリケーションでもクライアントのWebアプリケーションでもかまいません。このため、起動サービスを使用すると、Webの外観を完全にカスタマイズできます。たとえば、ユーザーがよく理解している用語でユーザーと通信する簡単なWebフォームを作成することもできます。

図17.1 Webアプリケーションのバックエンドとしての起動サービスおよびCloverETL Server
起動サービスでのグラフのデプロイ
起動サービスを介して特定のジョブにアクセスできるようにするには、複数のステップを実行する必要があります。
- ディクショナリを介してパラメータを渡すことができるようにジョブを設計する必要があります。
- CloverETL Serverの起動サービス・セクションでジョブを構成する必要があります。
- 起動サービスにデータを送信するフォームを作成する必要があります。
起動サービスへのジョブのデプロイメントは全体として、通常のジョブ開発プロセスと比べてもそれほど複雑ではありません。次の各章では、すべての手順について詳しく説明するとともに、基本的な例をいくつか示します。
起動サービスのETLグラフ/ジョブフローの設計
起動サービスからジョブを使用するには、パラメータをジョブに渡す必要があるときにジョブがディクショナリを使用する必要があります。ディクショナリは、CloverETLでのジョブの実行ごとに関連付けられたデータ記憶域です。ディクショナリの詳細は、CloverETL Designerのドキュメントのディクショナリに関する項を参照してください。
起動サービスからディクショナリを使用するには、ジョブのXMLソース・ファイル内のディクショナリのエントリを指定するためのジョブ作成者が必要です。ディクショナリのXML要素の詳細は、CloverETL Designerのドキュメントのディクショナリに関する項を参照してください。
ディクショナリの使用以外に、起動サービスによって実行されるジョブに課される他の制限はありません。したがって、ジョブは、CloverETLエンジンによって提供されるすべての機能を使用できます。
CloverETL ServerのWeb GUIでのジョブの構成
起動サービスのインタフェースを介して使用可能なジョブを起動サービスに通知するには、CloverETL ServerのGUIを使用して起動サービスを適切に構成する必要があります。
起動サービスでは、起動構成を使用して、各ジョブの実行方法に関する詳細を格納します。各起動構成には、ジョブのパラメータに関する完全な説明や、これらのパラメータをWebインタフェースから渡されるパラメータにマップする方法などが含まれます。
各起動構成は、名前、ユーザーおよびグループ制限によって識別されます。各構成のユーザーまたはグループ制限が異なるかぎり、同じ名前で複数の構成を作成してもかまいません。
ユーザー制限を使用すると、異なるユーザーによって同じ起動構成が使用されている場合でも、これらのユーザーごとに異なるジョブを起動できます(たとえば、開発者はジョブのデバッグ・バージョンを使用し、エンド・カスタマは本番ジョブを使用するということが可能です)。また、ユーザー制限を使用して、特定のユーザーが起動構成を実行できないようにすることもできます。
同様に、グループ制限を使用して、起動構成を実行するユーザーのグループ・メンバーシップに基づいてジョブを区別することもできます。
構成が起動されると、構成名、ユーザー仕様およびグループ仕様に基づいて正しい構成が選択されます。複数の構成が現在のユーザー/グループおよび構成名と一致する場合、最も適切な構成が選択されます(グループ名よりユーザー名の方が優先されます)。
新規起動構成の追加
新規起動構成を追加するには、CloverETL ServerのGUIの起動サービスタブ上の新規起動構成リンクをクリックします。

図17.2 起動サービス・セクション
構成が作成されると、左側にある表内に他の既存の構成とともに表示されます。構成を使用する前に、パラメータ・マッピングを追加する必要があります。パラメータ・マッピングを追加するには、新しく作成した構成の「詳細」リンクをクリックします。詳細は、ウィンドウの右側にある簡単な表に表示されます。

図17.3 「概要」タブ
「概要」タブには、起動構成に関する基本的な詳細が表示されます。これらは、「構成の編集」タブで変更できます。
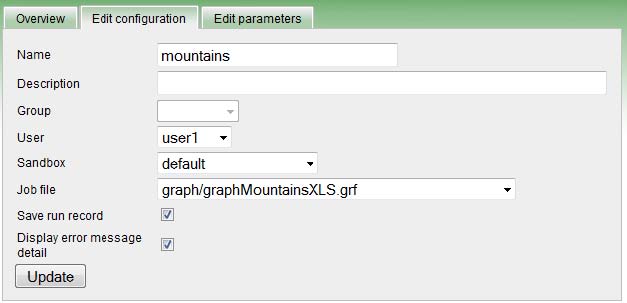
図17.4 「構成の編集」タブ
次のフィールドを変更できます。
- 名前 - Webから構成にアクセスする際の名前。
- 説明 - 構成の説明。
- グループ - 構成を特定のユーザーのグループに制限します。
- ユーザー - 構成を特定のユーザーに制限します。
- サンドボックス - 構成を起動するCloverETL Sandboxを選択します。
- ジョブ・ファイル - 構成の起動時に実行するジョブを選択します。
- 実行レコードの保存 - 選択すると、起動構成に関する詳細がCloverETL ServerのGUIの「実行履歴」に表示されます。選択しない場合、ジョブ実行はログに記録されず、「実行履歴」にも表示されません。
- エラー・メッセージ詳細の表示 - 選択すると、起動が失敗した場合に詳細なエラー・メッセージが表示されます。選択しない場合、簡単なメッセージのみが表示されます。
最後に、「パラメータの編集」タブを使用して、起動構成のパラメータ・マッピングを構成できます。起動リクエストで送信された値に基づいてパラメータ値を正しく割り当てるには、マッピングが必要です。

図17.5 新規パラメータの作成
新規パラメータ・マッピングを追加するには、「新規プロパティ」リンクをクリックします。ジョブに必要な各プロパティを作成する必要があります(内部ジョブ・プロパティの場合、マッピングは必要ありません)。

図17.6 「パラメータの編集」タブ
プロパティごとに次のフィールドを使用できます。
- 名前 - ジョブのディクショナリ内のプロパティの名前。
- リクエスト・パラメータ - リクエスト・ページによって生成された起動リクエストに指定されているパラメータの名前。この名前は、ジョブのディクショナリ内で使用されている名前と異なっていてもかまいません。
- 必須パラメータ - 選択すると、パラメータが必須になり、パラメータが省略されるとエラーがレポートされます。
- ジョブに渡す - 選択すると、パラメータは、追加パラメータ間のみでなくディクショナリ内でもジョブに渡されます。このような場合、パラメータは、ジョブのXMLファイル内で${ParameterName}として参照することもできます。追加パラメータはXMLファイルの解析時に解決されるため、この方法を使用するジョブをプールすることはできません。
- デフォルト値 - パラメータが起動リクエストで省略されたときに適用されるデフォルト値。
新規マッピングを作成するには、すべてのフィールドに入力した後に「作成」ボタンをクリックします。マッピングが作成されると、既存のマッピングのリスト内に表示されます。これは、適切なリンクをクリックすることによって後で編集または削除できます。
起動サービスへのデータの送信
起動サービスで使用するよう構成されているジョブを起動するには、起動リクエストを送信する必要があります。起動リクエストは、HTTP GETまたはPOSTメソッドを介して送信できます。起動リクエストは、ジョブに渡す必要があるすべてのパラメータの値が含まれる単なるURLです。リクエストURLは、複数の部分で構成されています。
[Clover Context]/launch/[Configuration name]?[Parameters]
- [Clover Context]は、CloverETLが実行されているコンテキストに対するURLです。通常、これは、CloverETL Serverに対する完全なURLです(たとえば、CloverETL Demo Serverの場合、これはhttp://serverdemo.cloveretl.com:8080/cloverのようになります)。
- [Configuration name]は、構成の作成時に指定された起動構成の名前です。この例では、これはNewMountainsに設定されます(大/小文字を区別することが重要です)。
- [Parameters]は、PHPなどによって使用される書式で構成に必要なパラメータのリストです。したがって、このパラメータのリストは、&文字によって区切られた名前と値のペアのリストです。名前と値の各ペアは、[name]=[value]として指定します。URLを確実に有効にするには、RFC 1738に応じてvalueを適切にエンコードする必要があります。
前述の設定に基づいて、mountainsを使用したこの例における起動リクエストの完全なURLは、http:// server-demo.cloveretl.com:8080/clover/launch/NewMountains?heightMin=4000のようになります。前述のリクエストでは、heightMinプロパティの値は4000に設定されます。
グラフ実行の結果
ジョブの実行が終了すると、結果がHTTPレスポンスのコンテンツとしてHTTPクライアントに戻されます。この出力は、ジョブのXMLファイルで宣言されているディクショナリに部分的に定義されています。ディクショナリでは、選択したパラメータを出力パラメータとしてマークできます。ジョブの実行が終了すると、すべての出力パラメータがユーザーに送信されます。
出力パラメータの数に応じて、次の出力がHTTPクライアントに送信されます。
- 出力パラメータなし - 概要ページのみが戻されます。概要ページの書式はカスタマイズできません。ページには、ジョブが開始された時間、終了した時間、ユーザー名などの詳細が表示されます。
- 1つの出力パラメータ - この場合、ディクショナリ内のプロパティ・タイプによってコンテンツ・タイプが定義されているHTTPクライアントに出力が送信されます。
- 複数の出力パラメータ - この場合、各出力パラメータがマルチパートHTTPレスポンスとしてHTTPクライアントに送信されます。レスポンスのコンテンツ・タイプは、HTTPクライアントに応じてmultipart/relatedまたはmultipart/x-mixed-replaceになります(クライアントは完全に自動検出されます)。multipart/relatedタイプはMicrosoft Internet Explorerに基づくブラウザに対して使用され、multipart/x-mixed-replaceはGeckoまたはWebkitに基づくブラウザに送信されます。
起動リクエストは、CloverETL Server構成内のlaunch.log.dirプロパティによって指定されているディレクトリ内のログ・ファイルに記録されます。起動構成ごとに、[Configuration name]#[Launch ID].logという名前のログ・ファイルが1つ作成されます。このファイルでは、起動リクエストごとに、次のタブ区切りフィールドを持つ1行のみが含まれます。
プロパティlaunch.log.dirが指定されていない場合、ログ・ファイルは一時ディレクトリ[java.io.tmpdir]/cloverlog/launch内に作成されます。java.io.tmpdirはシステム・プロパティです。
- 起動開始時間
- 起動終了時間
- ログイン・ユーザー名
- 実行ID
- 実行ステータス: FINISHED_OK、ERRORまたはABORTED
- クライアントの「IPアドレス」
- HTTPクライアントの「ユーザー・エージェント」
- 起動サービスに渡される「問合せ文字列」(現在の起動のパラメータの完全なリスト)
構成が有効でない場合、同じ起動詳細が同じディレクトリ内の_no_launch_config.logファイルに保存されます。未認証リクエストはすべて同じファイルに保存されます。
第18章 構成
デフォルトのインストール(構成なし)が推奨されるのは評価を目的とする場合のみです。本番では、少なくともDB接続とSMTPサーバーの構成をお薦めします。
構成ソースとその優先度
構成プロパティには複数のソースがあります。プロパティが設定されていない場合、アプリケーションのデフォルトが使用されます。
警告: 次に示すソースを結合しないでください。構成が混乱し、メンテナンスが困難になります。
コンテキスト・パラメータ(Apache Tomcatで使用可能)
アプリケーション・サーバーによっては、WARファイルを変更せずにコンテキスト・パラメータを設定できます。この方法による構成が可能で推奨されるのは、Tomcatの場合です。
Apache Tomcatの例
Tomcatでは、コンテキスト構成ファイルでコンテキスト・パラメータを指定できます。 これは、CloverETL Server Webアプリケーションのデプロイメント直後に自動的に作成される[tomcat_home]/conf/ Catalina/localhost/clover.xmlです。
次の要素を追加することにより、プロパティを指定できます。
<Parameter name="[propertyName]" value="[propertyValue]" override="false" />
環境変数
接頭辞cloverを使用して環境変数を設定します。例: (clover.config.file)
一部オペレーティング・システムではドット文字を使用できないことがあるため、ドット(.)のかわりに下線(_)を使用することもできます。このため、clover_config_fileも有効です。
システム・プロパティ
接頭辞cloverを使用してシステム・プロパティを設定します。例: (clover.config.file)
また、ドット(.)のかわりに下線(_)を使用することもできます。このため、clover_config_fileも有効です。
デフォルトの場所のプロパティ・ファイル
ソースは、共通プロパティ・ファイル(キーと値のペアを持つテキスト・ファイル)です。
[property-key]=[property-value]
デフォルトでは、CloverETLでは、構成ファイル[workingDir]/cloverServer.propertiesの検索が試行されます。
指定した場所のプロパティ・ファイル
前述の場合と同じですが、プロパティ・ファイルはデフォルトの場所からロードされません。これは、その場所が環境変数またはシステム・プロパティclover_config_fileまたはclover.config.fileによって指定されるためです。アプリケーション・サーバーでコンテキスト・パラメータを設定できない場合は、この構成方法をお薦めします。
web.xml内のコンテキスト・パラメータの変更
clover.warを解凍し、ファイルWEB-INF/web.xmlを変更し、次のコードを追加します。
<context-param>
<param-name>[property-name]</param-name>
<param-value>[property-value]</param-value>
</context-param>
この方法はお薦めしませんが、前述のいずれの方法も不可能である場合は役立つ場合があります。
構成ソースの優先度
構成ソースには、次の優先度があります。
- コンテキスト・パラメータ(アプリケーション・サーバー内に指定されるか、web.xmlに直接指定されます)
- CSによってこの順序で検索が試行される外部構成ファイル(これらの1つのみがロードされます):
- コンテキスト・パラメータconfig.fileによって指定されるパス
- システム・プロパティclover_config_fileまたはclover.config.fileによって指定されるパス
- 環境変数clover_config_fileまたはclover.config.fileによって指定されるパス
- デフォルトの場所([workingDir]/cloverServer.properties)
- システム・プロパティ
- 環境変数
- デフォルト値
DB接続構成の例
DB接続の構成はオプションです。デフォルトでは、組込みApache Derby DBが使用され、評価用としてはこれで十分です。ただし、本番デプロイメントの場合は、外部DB接続の構成をお薦めします。一般的なJDBC DB接続属性(URL、ユーザー名、パスワード)またはDB DataSourceのJNDIの場所を指定することもできます。
構成とその変更は、次のようになります。
- 「組込みApache Derby」(97ページ)
- 「MySQL」(98ページ)
- 「DB2」(98ページ)
- 「Oracle」(100ページ)
- 「MS SQL」(101ページ)
- 「Postgre SQL」(101ページ)
- 「JNDI DB DataSource」(101ページ)
組込みApache Derby
Apache Derbyの組込みDBは、デフォルトのCloverETL Serverインストールとともに使用されます。デフォルトでは、データの永続性のために作業ディレクトリが記憶域ディレクトリとして使用されます。この場合、一部のシステムでは問題が発生する可能性があります。Derby DBへの接続に関して問題が発生した場合は、外部DBへの接続を構成するか、少なくともDerbyのホーム・ディレクトリを指定することをお薦めします。
システム・プロパティderby.system.homeを設定し、アプリケーション・サーバーからアクセスできるパスを設定します。このシステム・プロパティは、次のJVM実行パラメータによって指定できます。
-Dderby.system.home=[derby_DB_files_root]
構成用のプロパティ・ファイルを使用する場合、jdbc.driverClassName、jdbc.url、jdbc.username、jdbc.password、jdbc.dialectという各パラメータを指定します。次はその例です。
jdbc.driverClassName=org.apache.derby.jdbc.EmbeddedDriver
jdbc.url=jdbc:derby:databases/cloverDb;create=true
jdbc.username=
jdbc.password=
jdbc.dialect=org.hibernate.dialect.DerbyDialect
jdbc.urlパラメータに注目してください。databases/cloverDbの部分は、DBデータのサブディレクトリを意味します。このサブディレクトリは、derby.system.homeとして設定されているディレクトリ(または、derby.system.homeが設定されていない場合は作業ディレクトリ)内に作成されます。値databases/cloverDbはデフォルト値であり、変更できます。
MySQL
CloverETL Serverには、MySql 5.xが必要です
構成用のプロパティ・ファイルを使用する場合、jdbc.driverClassName、jdbc.url、jdbc.username、jdbc.password、jdbc.dialectという各パラメータを指定します。次はその例です。
jdbc.driverClassName=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306/clover?useUnicode=true&characterEncoding=utf8
jdbc.username=root
jdbc.password=
jdbc.dialect=org.hibernate.dialect.MySQLDialect
3.0 JDBCドライバはCloverETL ServerのWebアーカイブに含まれないため、アプリケーション・サーバーのクラスパスに追加する必要があります。
次のように、正しいキャラクタ・セットを使用してDBを作成します。
CREATE DATABASE IF NOT EXISTS clover DEFAULT CHARACTER SET 'utf8';
DB2
Linux/Windows上のDB2
構成用のプロパティ・ファイルを使用する場合、jdbc.driverClassName、jdbc.url、jdbc.username、jdbc.password、jdbc.dialectという各パラメータを指定します。次はその例です。
jdbc.driverClassName=com.ibm.db2.jcc.DB2Driver
jdbc.url= jdbc:db2://localhost:50000/clover
jdbc.username=usr
jdbc.password=pwd
jdbc.dialect=org.hibernate.dialect.DB2Dialect
可能性のある問題
PAGESIZEが正しくない
データベースcloverは、適切なPAGESIZEを使用して作成する必要があります。DB2には、このプロパティに使用可能な値として4096、8192、16384または32768という複数の値があります。
CloverETL Serverは、PAGESIZEが16384または32768に設定された状態でDBを処理する必要があります。PAGESIZE値が正しく設定されていない場合、CloverETL Serverの起動に失敗した後ログ・ファイルにエラー・メッセージが表示されます。
ERROR:
DB2 SQL Error: SQLCODE=-286, SQLSTATE=42727, SQLERRMC=16384;
ROOT, DRIVER=3.50.152
SQLERRMCには、PAGESIZEに適した値が含まれます。
次のように、正しいPAGESIZEを使用してデータベースを作成できます。
CREATE DB clover PAGESIZE 32768;
表が再編成保留状態
ALTER TABLEコマンドの後、一部の表が再編成保留状態にある場合があります。この動作は、DB2に固有のものです。ALTER TABLE DDLコマンドが実行されるのは、新規CloverETL Serverバージョンの初回起動時のみです。
この問題のエラー・メッセージは、次のようになります。
DB2 SQL Error: SQLCODE=-668, SQLSTATE=57016, SQLERRMC=7;DB2INST2.RUN_RECORD, DRIVER=3.50.152
または、次のようになります
reorg table run_record
この場合、RUN_RECORDは再編成保留状態にある表名であり、DB2INST2はDBインスタンス名です。
これを解決するには、DB2コンソールに移動し、コマンドを(表run_recordに対して)実行します。
reorg table run_record
DB2コンソールの出力は、次のようになります。
db2 => connect to clover1
Database Connection Information
Database server = DB2/LINUX 9.7.0
SQL authorization ID = DB2INST2
Local database alias = CLOVER1
db2 => reorg table run_record
DB20000I The REORG command completed successfully.
db2 => disconnect clover1
DB20000I The SQL DISCONNECT command completed successfully.
"clover1"はDB名です
DB列の長さを切り捨てるALTER TABLEをDB2で使用不可。
この問題はDB2の構成に依存し、一部のAS400でのみ発生することがこれまでに判明しています。CloverETL Serverでは、アプリケーションのアップグレード後の初回インストール時に一連のDPパッチが適用されます。これらのパッチの一部により、テキスト列の長さを切り捨てる列変更が適用される場合があります。これらの変更によってデータが切り捨てられることはありません。ただし、DB2では、一部のデータが切り捨てられる可能性があるため、この処理は許可されません。DB2では、空のDB表内でもこれらの変更は拒否されます。解決策としては、データ切捨てに関するDB2の警告を無効にし、パッチを適用するCloverETL Serverを再起動してから、DB2の警告を再度有効にします。
AS/400上のDB2
AS/400での接続は若干異なる可能性があります。
構成用のプロパティ・ファイルを使用する場合、jdbc.driverClassName、jdbc.url、jdbc.username、jdbc.password、jdbc.dialectという各パラメータを指定します。次はその例です。
jdbc.driverClassName=com.ibm.as400.access.AS400JDBCDriver
jdbc.username=javlin
jdbc.password=clover
jdbc.url=jdbc:as400://host/cloversrv;libraries=cloversrv;date format=iso
jdbc.dialect=org.hibernate.dialect.DB2400Dialect
jdbc.usernameおよびjdbc.passwordに対してはOSユーザーの資格証明を使用します。前述のjdbc.urlのcloversrvは、DBスキーマの名前です。スキーマはAS/400コンソールで作成できます。
- コマンドSTRSQLを実行します(SQLコンソール)
- CREATE COLLECTION cloversrv IN ASP 1を実行します
- cloversrvはDBスキーマの名前であり、最大で10文字にすることができます
アプリケーション・サーバーのクラスパス内に正しいJDBCドライバが含まれる必要があります。
サーバー上の/QIBM/ProdData/Java400にあるJDBCドライバjt400ntv.jarを使用します。
JDBCドライバjt400ntv.jarを使用します。
TomcatのクラスパスにはJDBCドライバとともにjarを必ず追加してください。
Oracle
構成用のプロパティ・ファイルを使用する場合、jdbc.driverClassName、jdbc.url、jdbc.username、jdbc.password、jdbc.dialectという各パラメータを指定します。次はその例です。
jdbc.driverClassName=oracle.jdbc.OracleDriver
jdbc.url=jdbc:oracle:thin:@host:1521:db
jdbc.username=user
jdbc.password=pass
jdbc.dialect=org.hibernate.dialect.Oracle9Dialect
アプリケーション・サーバーのクラスパスにはJDBCドライバとともにjarを必ず追加してください。
CloverETL Serverバージョン1.2.1以降、言語org.hibernate.dialect.Oracle10gDialectは使用できません。
かわりにorg.hibernate.dialect.Oracle9Dialectを使用してください。
CloverETL Serverで使用されるスキーマに付与する必要がある権限は、次のとおりです。
CONNECT
CREATE SESSION
CREATE/ALTER/DROP TABLE
CREATE/ALTER/DROP SEQUENCE
QUOTA UNLIMITED ON <user_tablespace>;
QUOTA UNLIMITED ON <temp_tablespace>;
MS SQL
Ms SQLには、DBサーバーの構成が必要です。
- TCP/IP接続の許可:
- ツールSQL Server Configuration Managerを実行します
- 「クライアント プロトコル」に移動します
- TCP/IP (デフォルトのポートは1433です)をオンにします
- ツールSQL Server Management Studioを実行します
- 「データベース」に移動し、DB cloverを作成します
- 「セキュリティ/ログイン」に移動し、ユーザーを作成し、このユーザーをDB cloverの所有者として割り当てます
- 「セキュリティ」に移動し、「SQL Server 認証モードと Windows 認証モード」を選択します
構成用のプロパティ・ファイルを使用する場合、jdbc.driverClassName、jdbc.url、jdbc.username、jdbc.password、jdbc.dialectという各パラメータを指定します。次はその例です。
jdbc.driverClassName=com.microsoft.sqlserver.jdbc.SQLServerDriver
jdbc.url=jdbc:sqlserver://localhost:1433;databaseName=clover
jdbc.username=user
jdbc.password=pass
jdbc.dialect=org.hibernate.dialect.SybaseDialect
TomcatのクラスパスにはJDBCドライバとともにjarを必ず追加してください。
Postgre SQL
構成用のプロパティ・ファイルを使用する場合、jdbc.driverClassName、jdbc.url、jdbc.username、jdbc.password、jdbc.dialectという各パラメータを指定します。次はその例です。
jdbc.driverClassName=com.microsoft.sqlserver.jdbc.SQLServerDriver
jdbc.url=jdbc:postgresql://localhost/clover?charSet=UTF-8
jdbc.username=postgres
jdbc.password=
jdbc.dialect=org.hibernate.dialect.PostgreSQLDialect
TomcatのクラスパスにはJDBCドライバとともにjarを必ず追加してください。
JNDI DB DataSource
サーバーは、アプリケーション・サーバーまたはコンテナ内で構成されるJNDI DB DataSourceに接続できます。ただし、設定が必要なCloverETLパラメータがいくつか存在します。これらを設定しない場合、予期しない動作が行われる可能性があります。
datasource.type=JNDI # type of datasource; must be set, because default value is JDBC
datasource.jndiName=# JNDI location of DB DataSource; default value is java:comp/env/jdbc/clover_server #
jdbc.dialect=# Set dialect according to DB which DataSource is connected to.
The same dialect as in sections above. #
前述のパラメータは、(プロパティ・ファイルまたはTomcatコンテキスト・ファイル内の)他のパラメータと同じ方法で設定できます
Apache TomcatでのDataSource構成の例を示します。次のコードをコンテキスト・ファイルに追加します。
<Resource name="jdbc/clover_server" auth="Container"
type="javax.sql.DataSource" driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://192.168.1.100:3306/clover?useUnicode=true&characterEncoding=utf8"
username="root" password="" maxActive="20" maxIdle="10" maxWait="-1"/>
注意
コンテキスト・ファイルで特殊文字を入力する場合は、XMLエンティティとして指定する必要があります。アンパサンド&を表す&などです。
プロパティのリスト
表18.1. 一般構成
| キー | 説明 | デフォルト | |
|---|---|---|---|
| config.file | CloverETL Server構成ファイルの場所 | [working_dir]/ cloverServer.properties | |
| license.file | CloverETL Serverライセンス・ファイル(license.dat)の場所 | ||
| engine.config.file | CloverETLエンジン構成のプロパティ・ファイルの場所 | CloverETLとともに圧縮されたプロパティ・ファイル | |
| private.properties | CloverETL Serverコードによってのみ使用されるサーバー・プロパティのリスト。このため、これらのプロパティは、ServerFacadeの外部からはアクセスできません。デフォルトでは、パスワードが含まれる可能性があるプロパティがすべてリスト内に存在します。これは基本的に、これらの値がWeb GUIユーザーには表示されないことを意味します。各値は単一の星印"*"に置き換えられています。このリストを変更すると、一部のサーバーAPIで予期しない動作が行われる可能性があります。 | jdbc.password、executor.password、security.ldap.password、clover.smtp.password | |
| engine.plugins.src | このプロパティには、CloverETLエンジンの追加プラグインのソースに対する絶対パスがある場合があります。これらのプラグインは、WARに圧縮されているプラグインの代替ではありません。ソースは、ディレクトリでもzipファイルでもかまいません。ディレクトリとzipファイルには両方とも、各プラグインのサブディレクトリが含まれる必要があります。ディレクトリまたはZIPファイルの変更が適用されるのは、サーバーの再起動時のみです。詳細は、「拡張性 - エンジンのプラグイン」の項を参照してください。 | 空 | |
| datasource.type | CloverETL ServerでJNDIデータソースを使用してDBに接続する必要がある場合、これを明示的にJNDIに設定します。この場合、パラメータdatasource.jndiNameおよびjdbc.dialectを正しく設定する必要があります。使用可能な値: JNDI | JDBC | JDBC | |
| datasource.jndiName | DB DataSourceのJNDIの場所。これが適用されるのは、datasource.typeがJNDIに設定されている場合のみです。 | java:comp/env/jdbc/clover_server | |
| jdbc.driverClassName | JDBCドライバ名のクラス名 | ||
| jdbc.url | データを格納するためにCloverETL Serverによって使用されるJDBCのURL | ||
| jdbc.username | JDBCデータベースのユーザー名 | ||
| jdbc.password | JDBCデータベースのユーザー名 | ||
| jdbc.dialect | ORMで使用するHibernate言語 | ||
| quartz.driverDelegateClass | Quartz用のSQL言語。値は、jdbc.dialectプロパティ値から自動的に導出されます。 | ||
| security_enabled | true | false。falseに設定された場合、認証は必要なく、任意のユーザーに管理権限が付与されます。 | true | |
| security.default_domain | すべての新規ユーザーが含まれるドメイン。データベース内のユーザーのレコードに格納されます。cloverをホワイトレーベル化する必要がないかぎり、変更しないでください。 | clover | |
| security.basic_authentication.features_list | HTTPを使用してアクセスでき、HTTP基本認証によって保護する必要がある機能のセミコロン区切りのリスト。各機能は、サーブレット・パスによって指定します。 | /request_processor;/ simpleHttpApi;/ launch;/launchIt;/ downloadStorage;/ downloadFile;/ uploadSandboxFile;/ downloadLog | |
| security.basic_authentication.realm | HTTP基本認証のレルム文字列。 | CloverETL Server | |
| security.digest_authentication.features_list | HTTPを使用してアクセスでき、HTTPダイジェスト認証によって保護する必要がある機能のセミコロン区切りのリスト。各機能は、サーブレット・パスによって指定します。HTTPダイジェスト認証はバージョン3.1に追加された機能であることに注意してください。古いCloverETL Serverディストリビューションをアップグレードした場合、アップグレードの前に作成されたユーザーは、パスワードをリセットするまではHTTPダイジェスト認証を使用できません。このため、パスワードをリセット(または管理者がかわりにパスワードをリセット)すると、新規ユーザーと同様にダイジェスト認証を使用できるようになります。 | /webdav | |
| security.digest_authentication.realm | HTTPダイジェスト認証のレルム文字列。これが変更されると、すべてのユーザーがパスワードをリセットする必要があります。リセットしない場合、HTTPダイジェスト認証によって保護されているサーバー機能にアクセスできなくなります。 | CloverETL Server | |
| security.digest_authentication.nonce_validity | 秒単位で指定されたHTTPダイジェスト認証の有効間隔。この間隔が過ぎると、サーバーからクライアントに対して新規認証が求められます。これはほとんどのHTTPクライアントで自動的に行われます。 | 300 | |
| clover.event.fileCheckMinInterval | ファイル・チェックの間隔(ミリ秒)。詳細は、第12章「ファイル・イベント・リスナー」(71ページ)を参照してください。 | 1000 | |
| clover.smtp.host | SMTPサーバーのホスト名またはIPアドレス | ||
| clover.smtp.port | SMTPサーバーのポート | ||
| clover.smtp.authentication | true/false。falseの場合、ユーザー名およびパスワードは無視されます。 | ||
| clover.smtp.username | SMTPサーバーのユーザー名 | ||
| clover.smtp.password | SMTPサーバーのパスワード | ||
| logging.project_name | 製品名を指定する必要があるときにログ・メッセージで使用されます | CloverETL | |
| logging.default_subdir | すべてのサーバー・ログのデフォルトのサブディレクトリ名。システム・プロパティjava.io.tmpdirによって指定されるパスの相対パスです。絶対パスは指定しないでください。絶対パス用として使用されるプロパティを使用してください。 | cloverlogs | |
| launch.log.dir | サーバーが起動リクエスト・ログを格納する必要がある場所。詳細は、「起動サービス」の項を参照してください。 | ${java.io.tmpdir}/[logging. default_subdir]/launch。${java.io.tmpdir}はシステム・プロパティです | |
| graph.logs_path | サーバーがグラフ実行ログを格納する必要がある場所。詳細は、「ロギング」の項を参照してください。 | ${java.io.tmpdir}/[logging. default_subdir]/graph。${java.io.tmpdir}はシステム・プロパティです | |
| temp.default_subdir | サーバーの一時ファイルのデフォルトのサブディレクトリ名。システム・プロパティjava.io.tmpdirによって指定されるパスの相対パスです。 | clovertmp | |
| graph.debug_path | サーバーがグラフ・デバッグ情報を格納する必要がある場所。 | ${java.io.tmpdir}/[temp.default_subdir]/debug。${java.io.tmpdir}はシステム・プロパティです | |
| graph.dictionary_path | サーバーがグラフ・ディクショナリ一時ファイルを格納する必要がある場所。 | ${java.io.tmpdir}/[temp.default_subdir]/dictionary。${java.io.tmpdir}はシステム・プロパティです | |
| graph.pass_event_params_to_graph_in_old_style | 3.0以降。グラフ・イベントによって実行されるグラフにパラメータを渡すための下位互換性用のスイッチ。3.0より前のバージョンでは、すべてのパラメータが実行対象グラフに渡されていました。3.0以降は、指定したパラメータのみが渡されます。詳細は、「タスク - グラフの実行」(48ページ)を参照してください。 | false | |
| threadManager.pool.corePoolSize | 常にアクティブ(実行中またはアイドル中)であるスレッドの数。サーバー・イベントを処理するためのスレッド・プールに関連しています。 | 4 | |
| threadManager.pool.queueCapacity | スレッドを待機中のタスクが含まれるキュー(FIFO)の最大サイズ。サーバー・イベントを処理するためのスレッド・プールに関連しています。これは、queueCapacityより多い待機中のタスクがないことを意味します。たとえば、queueCapacity=0の場合、待機中のタスクはありません。各タスクは、使用可能なスレッドまたは新規スレッド内で即時実行されます。queueCapacity=1024の場合、キュー内で最大1024のタスクがcorePoolSizeから使用可能なスレッドを待機できます。 | 12 | |
| threadManager.pool.maxPoolSize | アクティブなスレッドの最大数。コア・プール内に使用可能なスレッドがなく、キュー容量を超えている場合、最大maxPoolSizeの新規スレッドがプール内に作成されます。maxPoolSizeを超える同時タスクが存在する場合、スレッド・マネージャによってその実行が拒否されます。このため、queueCapacityまたはmaxPoolSizeは十分大きい値に設定してください。 | 1024 | |
| task.archivator.batch_size | 1つのバッチ内で削除されるレコードの最大数。アーカイブされた実行レコードを削除するために使用されます。 | 50 | |
| launch.http_header_prefix | 起動サービスによってHTTPレスポンスに追加されるHTTPヘッダーの接頭辞。 | X-cloveretl | |
| task.archivator.archive_file_prefix | アーカイバによって作成されるアーカイブ・ファイルの接頭辞。 | cloverArchive_ | |
| license.context_names | ライセンスが含まれる可能性があるweb-appコンテキストのカンマ区切りのリスト。これらはそれぞれ先頭にスラッシュを付ける必要があります。Apache Tomcatの場合のみ機能します。 | /clover-license、/clover_license | |
| license.display_header | サーバーのWeb GUIにライセンス・ヘッダーを表示するかどうかを指定するスイッチ。 | false |
表18.2. ジョブ実行構成のデフォルト - 詳細は「ジョブ構成プロパティ」の項を参照
| キー | 説明 | デフォルト | |
|---|---|---|---|
| executor.tracking_interval | 実行中のグラフの現在のステータスをスキャンする間隔(ミリ秒)。間隔が短いほど、ログ・ファイルは大きくなります。 | 2000 | |
| executor.log_level | グラフ実行のログ・レベル。TRACE | DEBUG | INFO | WARN | ERROR | INFO | |
| executor.max_running_concurrently | 同時に存在(または実行)可能なグラフ・インスタンスの数。0は、制限がないことを意味します | 0 | |
| executor.max_graph_instance_age | 間隔(ミリ秒)。グラフ・インスタンスをメモリーから解放するまでアイドル状態にする時間を指定します。0は、制限がないことを意味します。このプロパティは2.8以降名前が変更されています。元の名前はexecutor.maxGraphInstanceAgeでした | 0 | |
| executor.classpath | グラフで使用される変換/プロセッサ・クラスのクラスパス。ディレクトリ[sandbox_root]/trans/は、グラフ実行クラスパスに自動的に追加されるため、ここにリストする必要はありません。 | ||
| executor.skip_check_config | グラフ構成の確認を無効にします。グラフ実行のパフォーマンスが向上します。グラフ開発時に役立つ場合があります。 | true | |
| executor.password | エンコードされたDB接続パスワードのデコードに使用するパスワード。 | ||
| executor.verbose_mode | trueの場合、グラフ実行の詳細なログが生成されます。 | true | |
| executor.use_jmx | trueの場合、グラフ・エグゼキュータは実行中のグラフのJMX mBeanを登録します。 | true | |
| executor.debug_mode | trueの場合、デバッグを有効にしたエッジがデバッグ・ディレクトリのファイルにデータを格納します。プロパティgraph.debug_pathを参照してください | false |
プロパティの詳細は、「クラスタリング」の項を参照してください。
第19章 グラフ・パラメータ
CloverETL Serverでは、グラフの実行ごとにパラメータ・セットが渡されます。プレースホルダ${paramName}が解決されるのはグラフXMLのロード中のみであるため、グラフの実行ごとにプレースホルダを解決する必要がある場合、グラフをプールできないことに注意してください。ただし、次のように、現在のパラメータ値には常にインラインJavaコードによってアクセスできます。
String runId = getGraph().getGraphProperties().getProperty("RUN_ID");
プロパティは、次のように、追加または置換できます。
getGraph().getGraphProperties().setProperty("new_property", value );
CloverETL Serverによって常に設定されるパラメータ・セットは、次のとおりです。
表19.1. グラフ実行構成のデフォルト - 詳細は「グラフ構成プロパティ」の項を参照
| キー | 説明 |
| SANDBOX_CODE | 実行対象グラフが含まれるサンドボックスのコード。 |
| JOB_FILE | サンドボックスのルート・パスの相対ファイル・パス。 |
| SANDBOX_ROOT | サンドボックスのルートの絶対パス。 |
| RUN_ID | グラフ実行のID。スタンドアロン・モードまたはクラスタ・モード。常に一意です。実行レコードが値0より永続的ではない場合、値0より小さくなる可能性があります。詳細は、「起動サービス」を参照してください。 |
実行のタイプに応じた別のパラメータ・セット
グラフの実行方法に応じたパラメータは他にもあります。
Web GUIからの実行
パラメータなし
起動サービスの呼出しによる実行
属性Pass to graphが有効であるサービス・パラメータは、ディクショナリ入力データとしてだけではなく、グラフ・パラメータとしてもグラフに渡されます。
HTTP API実行グラフ操作の呼出しによる実行
param_接頭辞が付いたURLパラメータは、実行対象グラフに渡されますが、この場合はparam_接頭辞は使用されません。たとえば、URLで指定されたparam_FILE_NAMEは、FILE_NAMEという名前のプロパティとしてグラフに渡されます。
RunGraphコンポーネントによる実行
3.0以降、paramsToPass属性によって指定されたパラメータのみがparentグラフから実行対象グラフに渡されます。ただし、一般的なプロパティ(RUN_ID、PROJECT_DIRなど)は新しい値によって上書きされます。
WS APIメソッドexecuteGraphの呼出しによる実行
値のあるパラメータを、実行リクエストによってグラフに渡すことができます。
スケジューラによるグラフの実行タスクによる実行
表19.2. 渡されるパラメータ
| キー | 説明 | ||||
|---|---|---|---|---|---|
| EVENT_SCHEDULE_EVENT_TYPE | スケジュールSCHEDULE_PERIODIC | SCHEDULE_ONETIMEのタイプ | ||||
| EVENT_SCHEDULE_LAST_EVENT | 前のイベントの日付/時間 | ||||
| EVENT_SCHEDULE_DESCRIPTION | Web GUIに表示されるスケジュールの説明 | ||||
| EVENT_USERNAME | イベントを所有するユーザー。スケジュールの場合、これは、スケジュールを作成したユーザーです | ||||
| EVENT_SCHEDULE_ID | グラフをトリガーしたスケジュールのID | ||||
JMSリスナーからの実行
受信メッセージのタイプに応じて、多くのグラフ・パラメータおよびディクショナリ・エントリが渡されます。詳細は、第9章「JMSメッセージ・リスナー」(65ページ)を参照してください。
グラフ・イベント・リスナーによるグラフの実行タスクによる実行
3.0以降、デフォルトでは、ソース・グラフから指定したプロパティのみが実行対象グラフに渡されます。この動作を変更し、ソース・グラフからすべてのパラメータが実行対象グラフに渡されるようにできるサーバー構成プロパティgraph.pass_event_params_to_graph_in_old_styleも用意されています。このスイッチは、下位互換性のために実装されています。デフォルトの動作については、グラフ・イベント・リスナーのエディタで渡すパラメータのリストを指定できます。詳細は、「タスク - グラフの実行」の項を参照してください。
ただし、現在の値を持つ次のパラメータは常にターゲット・グラフに渡されます
表19.3. 渡されるパラメータ
| キー | 説明 |
|---|---|
| EVENT_RUN_SANDBOX | イベントのソースであるグラフが含まれるサンドボックス |
| EVENT_GRAPH_EVENT_TYPE | GRAPH_STARTED | GRAPH_FINISHED | GRAPH_ERROR | GRAPH_ABORTED | GRAPH_TIMEOUT | GRAPH_STATUS_UNKNOWN |
| EVENT_RUN_GRAPH | イベントのソースであるグラフのグラフID |
| EVENT_RUN_ID | イベントのソースであるグラフ実行のID。 |
| EVENT_TIMEOUT | タイムアウトの間隔を指定するミリ秒数。timeoutグラフ・イベントの場合のみ有効です。 |
| EVENT_RUN_RESULT | イベントのソースである実行の結果(または現在のステータス)。 |
| EVENT_USERNAME | イベントを所有するユーザー。グラフ・イベントの場合、これは、グラフ・イベント・リスナーを作成したユーザーです |
ファイル・イベント・リスナーによるグラフの実行タスクによる実行
表19.4. 渡されるパラメータ
| キー | 説明 | |
|---|---|---|
| EVENT_FILE_PATH | イベントのソースであるファイルのパス。ファイル名は含まれません。末尾はファイル・セパレータではありません。 | |
| EVENT_FILE_NAME | イベントのソースであるファイルのファイル名。 | |
| EVENT_FILE_EVENT_TYPE | SIZE | CHANGE_TIME | APPEARANCE | DISAPPEARANCE | |
| EVENT_FILE_PATTERN | ファイル・イベント・リスナーで指定されるパターン | |
| EVENT_FILE_LISTENER_ID | ||
| EVENT_USERNAME | イベントを所有するユーザー。ファイル・イベントの場合、これは、ファイル・イベント・リスナーを作成したユーザーです |
別のグラフ・パラメータの追加方法
追加のグラフ構成パラメータ
選択したグラフまたは選択したサンドボックス内のすべてのグラフに対してWeb GUIのセクション「サンドボックス」で、いわゆる追加パラメータを追加できます。詳細は、「ジョブ構成プロパティ」(32ページ)の項を参照してください。
タスクexecute_graphのパラメータ
グラフの実行タスクは、スケジュール、グラフ・イベント・リスナーまたはファイル・イベント・リスナーによってトリガーできます。タスク・エディタを使用すると、実行対象グラフに渡されるキーと値のペアを指定できます。
第20章 変換開発者向けの推奨事項
app-serverクラスパスへの外部ライブラリの追加
接続(JDBC/JMS)には、サード・パーティのライブラリが必要な場合があります。これらのライブラリをapp-serverクラスパスに追加することをお薦めします。
CloverETLを使用すると、これらのライブラリをグラフ定義に直接指定できます。これにより、CloverETLでは、これらのライブラリを動的にロードできるようになります。ただしこの場合、外部ライブラリを使用すると、メモリー・リークが発生し、java.lang.OutOfMemoryError: PermGen spaceが発生する可能性があります。
また、app-serverのクラスパスにはJMS APIが必要ですが、多くの場合、サード・パーティのライブラリにはこのAPIもバンドルされています。このため、これらのライブラリが同じクラスローダーによってロードされていない場合、クラスロードの競合が発生する可能性があります。
RunGraphコンポーネントによって実行される別のグラフは同じJVMインスタンスでのみ実行可能
サーバー環境では、すべてのグラフが同じVMインスタンスで実行されます。RunGraphコンポーネントの属性same instanceをfalseに設定することはできません。
第21章 ロギング
メイン・ログ
CloverETL Serverでは、ロギング用としてlog4jライブラリが使用されます。WARファイルには、デフォルトのlog4j構成が含まれます。
デフォルトでは、ログ・ファイルは、システム・プロパティjava.io.tmpdirによって指定されるディレクトリ内のcloverlogsサブディレクトリ内に作成されます。
通常、java.io.tmpdirには、一般的なシステム一時ディレクトリ("/tmp")が含まれます。Tomcatの場合は通常、これは[TOMCAT_HOME]/tempです
デフォルトのロギング構成は、システム・プロパティlog4j.configurationによってオーバーライドされる可能性があります。このプロパティには、log4j構成ファイルのURLが含まれる必要があります。
log4j.configuration=file:/home/clover/config/log4j.xml
このような構成によってデフォルトの構成がオーバーライドされるため、グラフ実行ログに影響が及ぶ可能性があります。このため、グラフ実行ログを保持するために独自のログ構成に次のコード片が含まれる必要があります
<logger name="Tracking" additivity="false">
<level value="debug"/>
</logger>
これらのシステム・プロパティにより、HTTPリクエスト/レスポンスをstdoutに記録できるようになります。
クライアント側:
com.sun.xml.ws.transport.http.client.HttpTransportPipe.dump=true (詳細は、CloverETL Designerユーザーズ・ガイドの「CloverETL DesignerのCloverETL Serverとの統合」を参照してください)
サーバー側:
com.sun.xml.ws.transport.http.HttpAdapter.dump=tru
グラフ実行ログ
グラフ実行ごとに独自のログ・ファイルがあり、これは、Web GUIのセクション「実行履歴」でアクセスできます。
デフォルトでは、これらのログ・ファイルは、システム・プロパティjava.io.tmpdirによって指定されるディレクトリ内のサブディレクトリcloverLogs/graph内に作成されます。
CloverETLプロパティgraph.logs_pathにより、これらのログに対して別の場所を指定することもできます。このプロパティは、メイン・サーバー・ログには影響しません。
第22章 拡張性(組込みOSGiフレームワーク)
CloverETL Serverでは、APIの拡張が実装されるため、カスタムAPIを使用して機能を公開できます。現時点では、GroovyコードAPIとOSGiプラグインの2つを使用できます。
GroovyコードAPI
3.3以降
CloverETL ServerのGroovyコードAPIを使用すると、クライアントでは、HTTPリクエストによってサーバーに格納されているGroovyコードを実行できます。実行対象コードでは、serverFacade、インスタンスのHTTPリクエストおよびHTTPレスポンスにアクセスできるため、GroovyコードでカスタムCloverServer APIを実装できます。
コード・コールURLの実行の手順:
http://[host]:[port]/clover/groovy/[sandboxCode]/[pathToGroovyCodeFile]
プロトコルHTTPは、Webサーバーの構成に応じてセキュアなHTTPSに変更できます。
サーバーでは構成に応じて基本認証またはダイジェスト認証が使用されるため、ユーザーは、認可されているとともに、指定したサンドボックス内で実行する権限、およびGroovyコードAPIをコールする権限を持っている必要があります。
GroovyコードAPIをコール(および編集)する権限は非常に強力な権限です。これは通常、Groovyコードは、Javaコードと同じ処理を実行でき、アプリケーション・コンテナと同じシステム・プロセスとして実行されるためです。
Groovyコードでアクセス可能な変数
デフォルトでは、Groovyコードでアクセス可能な変数が複数あります。
表22.1. Groovyコードでアクセス可能な変数
| タイプ | キー | 説明 |
|---|---|---|
| javax.servlet.http.HttpServletRequest | request | コードをトリガーしたHTTPリクエストのインスタンス。 |
| javax.servlet.http.HttpServletResponse | response | スクリプトの終了時にクライアントに送信されるHTTPレスポンスのインスタンス。 |
| javax.servlet.http.HttpSession | session | HTTPセッションのインスタンス。 |
| javax.servlet.ServletConfig | servletConfig | ServletConfigのインスタンス |
| javax.servlet.ServletContext | servletContext | ServletContextのインスタンス |
| com.cloveretl.server.api.ServerFacade | serverFacade | CloverETL Serverコア機能をコールする場合に使用可能なserverFacadeのインスタンス。WARファイルには、ファサードAPIのJavaDocが含まれます。このファイルは、URL: http://host:port/clover/ javadoc/index.htmlからアクセスできます |
| String | sessionToken | serverFacadeメソッドのコールに必要なsessionToken |
コード例
コードにより、HTTPレスポンスのコンテンツとして戻される文字列が戻されたり、コード自体により、出力ライターに対する出力が構成される場合があります。
次のスクリプトの場合、独自の出力が作成されますが、何も戻されません。このため、基礎となるサーブレットによって出力は変更されません。この方法の利点は、出力を高速で構成し、クライアントに継続的に送信できることです。ただし、出力ストリーム(またはライター)がオープンされた場合、スクリプト処理時にエラーが発生してもエラー説明は送信されません。
response.getWriter().write("write anything to the output");
次のスクリプトの場合、文字列が戻されるため、基礎となるサーブレットにより、この文字列が出力に追加されます。この方法の利点は、コード処理時にエラーが発生した場合、完全なスタックトレースが戻されるため、スクリプトを修正できることです。ただし、構成された出力によってある程度のメモリーが消費される可能性があります。
String output = "write anything to the output";
return output;
次のスクリプトは、少々複雑になっています。この場合、構成されているすべてのスケジュールのリストとともにXMLが戻されます。これらのスケジュールをリストするには、権限が必要です。
// uses variables: response, sessionToken, serverFacade
import java.io.*;
import java.util.*;
import javax.xml.bind.*;
import com.cloveretl.server.facade.api.*;
import com.cloveretl.server.persistent.*;
import com.cloveretl.server.persistent.jaxb.*;
JAXBContext jc = JAXBContext.newInstance( "com.cloveretl.server.persistent:com.cloveretl.server.persistent.jaxb" );
Marshaller m = jc.createMarshaller();
m.setProperty(Marshaller.JAXB_ENCODING, "UTF-8");
m.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, Boolean.TRUE);
m.setProperty(Marshaller.JAXB_SCHEMA_LOCATION, "/clover/schemas/csc.xsd");
Response<List<Schedule>> list = serverFacade.findScheduleList(sessionToken, null);
SchedulesList xmlList = new SchedulesList();
xmlList.setSchedulesList(list.getBean());
m.marshal(xmlList, response.getWriter());
組込みOSGiフレームワーク
3.0以降
CloverETL Serverには、サーバーの新規API (またはGUI)として機能するプラグイン(OSGiバンドル)の実装を可能にし、リリースされているclover.warとは関係ない、組込みOSGiフレームワークが含まれます。
プラグインの可用性
プラグインは基本的に、起動サービス、HTTP API、WebサービスAPIと同様に新規サーバーAPIとして機能します。これは、単純なJSP、HttpServlet、または複雑なSOAP Webサービスである場合があります。このため、プラグインにHTTPサービスが含まれる場合、起動時に指定したURLでリスニングするために登録され、受信HTTPリクエストはWebコンテナからプラグインにブリッジされます。プラグイン自体は、ServerFacadeと呼ばれるCloverETL Serverの内部インタフェースにアクセスできます。ServerFacadeには、グラフ実行、グラフ・ステータスおよび実行履歴の取得、スケジューリング、リスナー、構成の操作などの多数の方法が用意されています。このため、APIは、特定のデプロイメントのニーズに応じてカスタマイズできます。
OSGiバンドルのデプロイ
OSGiフレームワークに関するCloverETL Serverの構成プロパティは2つあります。
- plugins.path - すべてのプラグイン(jarファイル)が含まれるディレクトリへの絶対パス。
- plugins.autostart - カンマ区切りのプラグイン名のリストです。これらのプラグインは、サーバーの起動時に起動されます。理論的には、OSGiフレームワークはOSGiバンドルをオンデマンドで起動できますが、サーブレット・コンテナへのサーブレット・ブリッジが使用される場合、このバンドルは信頼性が低くなります。このため、すべてのプラグインを指定することをお薦めします。
したがって、必ずプラグインをデプロイしてください。この場合、2つの構成プロパティを設定し、plugins.pathによって指定されるディレクトリにプラグインをコピーし、サーバーを再起動します。
第23章 拡張性 - CloverETL エンジンのプラグイン
3.1.2以降
CloverETL Serverでは、指定したソースからロードされる外部エンジン・プラグインを使用できます。ソースは、プロパティengine.plugins.srcをコピーすることによって指定します。
CloverETL構成の可用性の詳細は、第18章「構成」(96ページ)を参照してください。
このプロパティは、追加のCloverETLエンジン・プラグインが含まれるディレクトリまたはzipファイルの絶対パスである必要があります。ディレクトリとzipファイルには両方とも、各プラグインのサブディレクトリが含まれる必要があります。これらのプラグインは、WARに圧縮されているプラグインの代替ではありません。ディレクトリまたはZIPファイルの変更が適用されるのは、サーバーの再起動時のみです。
各プラグインには、デフォルトではparent-first計画を使用する独自のクラスローダーがあります。プラグインのクラスローダーの親は、web-appクラスローダー([WAR]/WEB-INF/libのコンテンツ)です。プラグインにサード・パーティのライブラリが使用されている場合、親クラスローダーのクラスパス上のライブラリとの競合が発生する可能性があります。これらは一般的な例外/エラーであり、クラスロードに問題があることを示しています。
- java.lang.ClassCastException
- java.lang.ClassNotFoundException
- java.lang.NoClassDefFoundError
- java.lang.LinkageError
このような競合を解消する方法はいくつかあります。
- 競合しているサード・パーティのライブラリを削除し、親クラスローダー(web-appまたはapp-serverクラスローダー)上のライブラリを使用します
- プラグインに対して異なるクラスロード計画を使用します。
- プラグイン記述子plugin.xmlで、要素pluginに属性greedyClassLoader="true"を設定します
- これは、プラグイン・クラスローダーでself-first計画が使用されることを意味します
- 選択したJavaパッケージに対して逆のクラスロード計画を設定します。
- プラグイン記述子plugin.xmlで、要素pluginに属性excludedPackagesを設定します
- これは、パッケージの接頭辞のカンマ区切りのリストです。例: excludedPackages="some.java.package,some.another.package"
- 前の例では、some.java.package、some.another.package、およびこれらのすべてのサブパッケージが逆のクラスロード計画を使用してロードされてから、プラグインのクラスパス上の残りのクラスがロードされます。
前述の提案は組み合せることもできます。これらの競合に対して最適な解決策を見つけることは容易ではなく、このような解決策は、app-serverクラスパス上のライブラリによって異なります。
より効率的にデバッグを行うには、関連するクラスローダーにTRACEログ・レベルを設定することが有用です。
<logger name="org.jetel.util.classloader.GreedyURLClassLoader">
<level value="trace"/>
</logger>
<logger name="org.jetel.plugin.PluginClassLoader">
<level value="trace"/>
</logger>
サーバーのlog4j構成のオーバーライドの詳細は、「ロギング」の項を参照してください。
第24章 クラスタリング
CloverETL Serverは、ユーザーのライセンスによって許可されている場合のみ、クラスタ内で動作します。
クラスタには、高可用性とスケーラビリティという2つの一般的な機能があります。これらは両方ともCloverETL Serverによって様々なレベルで実装されます。この項では、CloverETLクラスタリングの基礎について詳細を説明します。
高可用性
バージョン3.0以降、CloverETL Serverでは、クラスタ・ノード間の差異は認識されません。このため、マスター・ノードやスレーブ・ノードは存在しません。つまり、すべてのノードが実質的に対等です。CloverETLクラスタ自体には単一点障害(SPOF)はありません。ただし、SPOFは入力データや他の一部の外部要素内に存在する可能性があります。
クラスタリングにより、HTTPを介してアクセスできるすべての機能の高可用性(HA)が実現されます。これには、サンドボックスの参照、サービス構成(スケジューリング、起動サービス、リスナー)の変更、および主としてグラフ実行が含まれます。任意のクラスタ・ノードが受信HTTPリクエストを受け入れ、これらをそのノード自体が処理するか、別のノードに委任できます。
すべてのノードが対等であるため、任意のクラスタ・ノードがほとんどすべてのリクエストを処理できます。
- グラフ・ファイル、メタデータ・ファイルなどはすべて共有サンドボックス内にあります。このため、すべてのノードがこれらにアクセスできます。共有ファイルシステムはSPOFである場合があるため、レプリケートされたファイルシステムをかわりに使用することをお薦めします。
- データベースは、すべてのクラスタ・ノードによって共有されます。また、共有DBもSPOFである場合がありますが、これもクラスタ化できます。
ただし、まだなお、ノード自体がリクエストを処理できない可能性があります。このような場合、このリクエストは、これを処理できるノードに完全かつ透過的に委任されます。
1つ(または複数)のノードに制限されるリクエストは、次のとおりです。
- パーティション化されたサンドボックスまたはローカル・サンドボックスの内容に対するリクエスト。これらのサンドボックスはすべてのクラスタ・ノード間では共有されません。このようなリクエストは任意のクラスタ・ノードに向けられる可能性があります。この場合、このリクエストはターゲット・ノードに委任されますが、このターゲット・ノードが起動し実行中である必要があります。
- パーティション化されたサンドボックスまたはローカル・サンドボックスを使用するようグラフが構成されています。これらのグラフには、必要なサンドボックスに物理的にアクセスできるノードが必要です。
このため、パーティション化されたサンドボックスまたはローカル・サンドボックスにアクセスできない場合、リクエストによる障害が発生する可能性があります。ただし、
- 他のクラスタ・ノードに格納される冗長サンドボックスを構成することもできます。
- これらのタイプのサンドボックスは、次に示すデータ・レベルでのスケーラビリティを実現することのみを目的として使用されます。これは、CloverETLクラスタを使用する場合とは異なるアプローチです。
CloverETL自体には、グラフを実行するためのロード・バランサが実装されています。このため、特定のノードを対象として構成されていないグラフをクラスタ内の任意の場所で実行でき、CloverETLのロード・バランサにより、このグラフを処理するノードが現在の負荷に応じて決定されます。この処理はすべて透過的に実行されます。
HAを実現するには、独立したHTTPロード・バランサを使用することをお薦めします。独立したHTTPロード・バランサを使用すると、HTTPリクエストに対して透過的なフェイルオーバーが可能になります。これにより、実行中のノードにリクエストが送信されます。
スケーラビリティ
実装されるスケーラビリティには独立した2つのレベルがあります。変換リクエスト(および任意のHTTPリクエスト)のスケーラビリティとデータのスケーラビリティ(パラレル・データ処理)です。
これらのスケーラビリティ・レベルは両方とも水平です。水平スケーラビリティとは、クラスタにノードを追加することを意味します。一方、垂直スケーラビリティとは、単一ノードにリソースを追加することを意味します。垂直スケーラビリティは、CloverETLエンジンによってネイティブにサポートされており、ここでは説明しません。
変換リクエスト
基本的に、クラスタ内のノードが多いほど、一度に処理できる変換リクエスト(または一般的にはHTTPリクエスト)が多くなります。このタイプのスケーラビリティは、増大するクライアント数をサポートするためのCloverETL Serverの機能です。この機能は、前の項で説明したHTTPロード・バランサの使用と密接に関連しています。
パラレル・データ処理
変換がパラレルに処理される場合、グラフ全体(またはその一部)が複数のクラスタ・ノード上でパラレルに実行されます。この場合、各ノードによってデータの一部のみが処理されます。
このため、クラスタ内のノードが多いほど、指定した時間内に処理できるデータが多くなります。
データは、グラフ実行の前に分割(パーティション化)することも、高速でグラフ自体が分割することもできます。この結果生成されるデータは、パーティションに格納することも、収集して1つのデータ・グループとして格納することもできます。
スケーラビリティの曲線図は、変換のタイプによって異なる場合があります。これはほぼ直線になる場合があり、ほとんどの場合、これが理想的な形です。ただし、データ・ソースが単一であるために複数のリーダーによる読取りが不可能であることが原因でそれ以上のデータ変換の速度が制限される場合は例外です。このような場合、実際には入力データを待機することになるため、パラレル・データ処理を行う利点がなくなります。
ノード割当て
ノード割当ては、グラフを実行するクラスタ・ノード、およびクラスタ・ノードが実行するグラフの部分に関する仕様です。割当ては基本的に、グラフ・フェーズで使用されるパーティション化されたサンドボックスによって指定されます。各フェーズには、独自(1つのみ)の割当てを設定できます。基本的に、パーティション化されたサンドボックスごとに場所のリストがあります。グラフの一部がパラレルに実行される場合、パーティション化されたサンドボックスの場所ごとに1つのワーカーがあります。詳細は、「パーティション化されたサンドボックスおよびローカル・サンドボックス」(118ページ)の「パーティション化されたサンドボックス」を参照してください。
割当ては、次のいずれかによってグラフ内に指定されます。
- ワーカーによってこのパーティション化されたサンドボックスの独自の場所でパーティション化されたデータの読取り/書込みが行われる場合は、パーティション化されたサンドボックスを指し示すサンドボックス・リソース
- ワーカーによってパーティション化されたデータの読取り/書込みが行われないが、割当てが指定されている必要がある場合は、ノード属性node allocation。
競合が存在する場合、実行は失敗し、競合の説明を含むエラー・メッセージが表示されます。単一のフェーズで2つの異なる割当てを使用することによって1つの競合が発生する可能性があります。
データのパーティション化/収集
前述のとおり、データは複数の方法でパーティション化および収集できます。これは、グラフ実行の前に準備することも、高速でパーティション化することもできます。
高速でのパーティション化/収集
ClusterPartitionerおよびClusterGatherという2つの考慮が必要な特別なコンポーネントがあります。これらは両方とも同じように機能しますが、その方法は正反対です。
ClusterPartitionerは一般的なパーティショナと同様に機能しますが、node allocationはClusterPartitionerコンポーネントの後に同時に適用されます。ClusterPartitionerの前のコンポーネントはすべて1つのノードで実行されますが(このため、プライマリ・ワーカーと呼ばれます。後述参照)、ClusterPartitionerの後のコンポーネントはノード割当てに応じてパラレルに実行されます。このため、これらのノードはデータの一部のみを使用して機能します。これ以外にも、ラウンドロビン(デフォルト)、レコード・キー別、および負荷別などのパーティション化タイプがあります。
ClusterGatherは、正反対に機能します。収集の前のコンポーネントはパラレルに実行されますが、収集の後のコンポーネントは1つのノード(プライマリ・ワーカー)で実行されます。クラスタ収集コンポーネントの場合、SimpleGatherと同じ方法でレコードが収集され、その属性は同じです。デフォルトでは、入力レコードは一切ソートされません。これらは受け入れられた順序でそのまま収集されます。
プライマリ・ワーカー・ノード - パラレルに実行されるよう設計されたグラフの一部は、いずれの場合も単一ノードで実行できます(グラフによって単一リソースでデータの読取り/書込みが行われる部分)。これはそれぞれ、ClusterPartitionerの前の部分でも、ClusterGathererの後の部分でもかまいません。また、node allocationが一切指定されていないフェーズ内のすべてのコンポーネントに対する場合でもかまいません。各フェーズには、独自のプライマリ・ワーカーを設定できます。・グラフのプライマリ・ワーカーはすべて、主にフェーズで使用されるローカル・サンドボックス・データソースに応じてグラフの実行時に選択されます。基本的に、フェーズで使用されるサンドボックス・データソースに直接(ローカルで)アクセスできるノードは、プライマリ・ワーカーとして選択されます。ただし、異なるローカル・サンドボックス・データソースが複数存在したり、フェーズで使用されるローカル・サンドボックス・データソースが存在しない場合もあります。このような場合は、マイナー・パラメータを使用してプライマリ・ワーカーが選択されます。
これらのコンポーネントは両方とも、どのような方法でも単一フェーズに結合できますが、単一フェーズごとに唯一のノード割当てと唯一のプライマリ・ワーカーが設定されている必要があります。
次の例では、2つの異なるプライマリ・ワーカーで2つの異なるノード割当てによってデータを処理する方法を示します。
- フェーズ1の開始
- プライマリ・ワーカー(nodeA)でのデータの処理
- クラスタ・パーティショナ・コンポーネント
- データのパラレル処理(nodeA、nodeB、nodeC)
- クラスタ・ギャザラー・コンポーネント
- プライマリ・ワーカー(nodeA)でのデータの処理
- フェーズ1の終了
- フェーズ2の開始
- プライマリ・ワーカー(nodeA)でのデータの処理
- クラスタ・パーティショナ・コンポーネント
- データのパラレル処理(nodeB、nodeD)
- フェーズ2の終了
- フェーズ3の開始
- データのパラレル処理(nodeB、nodeD)
- クラスタ・ギャザラー・コンポーネント
- プライマリ・ワーカー(nodeD)でのデータの処理
- フェーズ3の終了
結果は、読取りを行うノード(nodeA)とは別のノード(nodeD)に格納され、データは実際には(nodeA、nodeB、nodeCからnodeB、nodeDへ)再パーティション化されます。
外部ツールによるデータのパーティション化/収集
高速でデータをパーティション化すると、場合によっては不要なボトルネックが発生する可能性があります。低レベルのツールを使用してデータを分割したほうが、スケーラビリティの観点からは効率的である場合があります。最適なのは、実行中のワーカーごとに独立したデータソースからデータが読み取られる状態です。このため、最初のフェーズにClusterPartitionerコンポーネントが存在する必要はなく、グラフは最初からパラレルに実行されます。
- フェーズ1の開始
- データのパラレル処理(nodeA、nodeB、nodeC)
- クラスタ・ギャザラー・コンポーネント
- プライマリ・ワーカー(nodeA)でのデータの処理
- フェーズ1の終了
または、グラフ全体がパラレルに実行されていてもかまいませんが、結果はパーティション化されます。
- フェーズ1の開始
- データのパラレル処理(nodeA、nodeB、nodeC)
- フェーズ1の終了
パーティション化されたサンドボックスおよびローカル・サンドボックス
パーティション化されたサンドボックスおよびローカル・サンドボックスについては、前述の項で説明しました。これらの新しいサンドボックス・タイプはバージョン3.0で導入されたもので、これらはパラレル・データ処理には不可欠です。
共有サンドボックスとあわせて、合計で3つのサンドボックス・タイプがあります。
共有サンドボックス
このタイプのサンドボックスは、すべてのクラスタ・ノードでアクセスできるすべてのデータに対して使用する必要があります。これには、HA (前述参照)をサポートする必要があるすべてのグラフ、グラフのメタデータ、接続、クラスおよび入力/出力データが含まれます。

図24.1 新規共有サンドボックスを作成するためのダイアログ・フォーム
前述のスクリーンショットからわかるように、ファイルシステムで任意のルート・パスを指定できるわけではありません。共有サンドボックスは、cluster.shared_sandboxes_pathによって指定されるディレクトリ内に格納されます。各共有サンドボックスの内部には、サンドボックスIDによって名前が付けられた独自のサブディレクトリがあります。
ローカル・サンドボックス
このサンドボックス・タイプは、特定のクラスタ・ノードによってのみアクセスできるデータを対象としています。これには、大量の入力/出力ファイルが含まれる可能性があります。これには次のような目的があります。つまり、任意のクラスタ・ノードがこのタイプのサンドボックスの内容にアクセスできるが、ローカル(高速)アクセスが可能なノードは1つのみであり、このノードはデータ提供のために起動し実行中である必要があります。グラフでは、物理的に異なるノードに格納されている複数のサンドボックスのリソースを使用できます。これは、クラスタ・ノードでは、リソースがローカル・ファイルであるかのようにネットワーク・ストリームを透過的に作成できるためです。詳細は、「コンポーネント・データ・ソースとしてのサンドボックス・リソースの使用」(119ページ)を参照してください。
ローカル・サンドボックスは一般的なプロジェクト・データ(グラフ、メタデータ、接続、ルックアップ、プロパティ・ファイルなど)には使用しないでください。予期できない動作が発生する可能性があります。かわりに共有サンドボックスを使用してください。

図24.2 新規ローカル・サンドボックスを作成するためのダイアログ・フォーム
パーティション化されたサンドボックス
このタイプのサンドボックスは実際には、通常は異なるクラスタ・ノード上に存在する一組の物理的な場所用の抽象ラッパーです。ただし、同じノード上に複数の場所が存在する場合もあります。パーティション化されたサンドボックスには2つ目的があり、これらは両方ともパラレル・データ処理と密接に関連しています。
- node allocation仕様 - パーティション化されたサンドボックスの場所により、グラフまたはグラフの一部を実行するワーカーが定義されます。このため、物理的な場所ごとに実行する単一のワーカーが実行されます。このワーカーは実際にデータをその場所に格納する必要はありません。これは、これらのノードでこのグラフ/フェーズをパラレルに実行するようCloverETL Serverに指示するための単なる手段です。
- パラレル・データ処理時の一部のデータの記憶域。物理的な場所ごとに一部のデータのみが含まれます。通常の使用方法の場合、より多くの入力ファイルに入力データを分割するため、各ファイルを異なる場所に配置し、ワーカーごとに独自のファイルが処理されます。
前述のスクリーンショットからわかるように、パーティション化されたサンドボックスの場合、異なるクラスタ・ノードで物理的な場所を1つ以上指定できます。
パーティション化されたサンドボックスは一般的なプロジェクト・データ(グラフ、メタデータ、接続、ルックアップ、プロパティ・ファイルなど)には使用しないでください。予期できない動作が発生する可能性があります。かわりに共有サンドボックスを使用してください。
コンポーネント・データ・ソースとしてのサンドボックス・リソースの使用
共有サンドボックス、ローカル・サンドボックスまたはパーティション化されたサンドボックス(またはスタンドアロン・サーバー上の通常のサンドボックス)であるかどうかとは関係なく、サンドボックス・リソースは、グラフ内で次のようないわゆるサンドボックスURLとしてfileURL属性の下に指定されます。
sandbox://data/path/to/file/file.dat
dataはサンドボックスのコードであり、path/to/file/file.datはサンドボックス・ルートからリソースへのパスです。URLはグラフの実行時にCloverETL Serverによって評価され、コンポーネント(リーダーまたはライター)により、サーバーからオープンされたストリームが取得されます。これは、ローカル・ファイルに対するストリームである場合や、他のリモート・リソースに対するストリームである場合があります。このため、グラフは、リソースに対してローカルでアクセスできるノードで実行する必要はありません。グラフ内でより多くのサンドボックス・リソースが使用され、これらの各リソースが異なるノード上にある場合もあります。このような場合、CloverETL Serverでは、リモート・ストリームを最小限に抑えるために最もローカルなリソースを持つノードが選択されます。
サンドボックスURLには、パラレル・データ処理用の特別な用途があります。パーティション化されたサンドボックス内のリソースがあるサンドボックスURLが使用される場合、グラフ/フェーズの一部は、パーティション化されたサンドボックスの場所のリストで指定されるノード割当てに応じてパラレルに実行されます。したがって、各ワーカーには独自のローカル・サンドボックス・リソースがあります。CloverETL Serverにより、各ワーカーのサンドボックスURLが評価され、ローカル・リソースに対するオープン・ストリームがコンポーネントに提供されます。
サンドボックスURLは、スタンドアロン・サーバーでも使用できます。グラフによって様々なサンドボックスからリソースが参照される場合、これは最適です。これには、メタデータ、ルックアップ定義または入力/出力データなどがあります。ただし、参照されるサンドボックスは、グラフを実行するユーザーがアクセスできる必要があります。
クラスタ・デプロイメントに関する推奨事項
- クラスタ内のすべてのノードでシステム日時を同期化する必要があります。
- すべてのノードで、共有ファイルシステムまたはレプリケートされたファイルシステムに格納されたサンドボックスが共有されます。すべてのノード間で共有されるファイルシステムは単一点障害です。したがって、レプリケートされたファイルシステムを使用することをお薦めします。
- すべてのノードでDBが共有されるため、トランザクションのサポートが必要になります。MySQL表エンジンのMyISAMはトランザクション型ではないため、このエンジンを使用すると予期しない動作が発生する可能性があります。
- すべてのノードでDBが共有される場合、これは単一点障害になります。クラスタ化されたDBを使用することをお薦めします。
- Tomcatでは、このプロパティのライセンスはlicense.fileとして構成してください。clover_license.warは使用しないでください。Tomcatでは、web-appが予期しない順序でロードされるため、クラスタについては、ライセンスをCloverETL Server自体の前にロードする必要があります。
図24.3 クラスタに結合されたノードのリスト
分散実行の例
次の図は、チェコ共和国内の複数の携帯電話ネットワークのプロバイダによって生成される請求書の解析に使用される変換グラフを示しています。

これらの入力ファイルのサイズは最大で数GBになる可能性があるため、クラスタ環境で動作するようグラフを設計することは非常に有用です。
変換設計例の詳細
グラフ内には、1つのフェーズと4つのクラスタ・コンポーネントがあります(赤枠で強調表示されています)。これらのコンポーネントによって変更ポイントであるnode allocationが定義されるため、これらのコンポーネントによって境界が定められるグラフ部分は赤い四角で強調表示されています。このグラフ部分では、データ処理がパラレルに実行されています。つまり、点線の四角内のコンポーネントは、グラフのこの部分のnode allocationに応じてクラスタ・ノード上で実行されます。
グラフの残りの部分は、プライマリ・ワーカーと呼ばれる1つのノード上でのみ実行されます。
node allocationの仕様
フェーズは1つのみであるため、グラフ全体において1つのプライマリ・ワーカーのみ、および1つのnode allocationのみが存在します。
- node allocationは、パラレルで実行されているコンポーネントのグループ(4つのクラスタ・コンポーネントによって境界が定められています)に適用されます。
- グラフの外側の部分は、単一ノードであるプライマリ・ワーカー上で実行されます。
プライマリ・ワーカーは、入力データのURLで使用されるサンドボックス・コードによって指定されます。次のダイアログは、ファイルURLの値としてsandbox://data/path-to-csv-fileを示しています。dataは、指定したファイルを含むサーバー・サンドボックスのIDです。また、グラフ内のプライマリ・ワーカーを定義するのは、dataローカル・サンドボックスです。

4つのクラスタ・コンポーネントによって境界が定められたグラフ部分では、ファイルURL属性によって割当てが指定されている場合もありますが、この部分はファイルを使用して機能しません。そのため、ファイルURLは存在しません。したがって、allocation属性を使用します。この部分のすべてのコンポーネントには同じ割当てが必要であるため、1つのコンポーネントに対して設定するのみで十分です。
次のダイアログのdataPartitionedもサンドボックスIDです。

これらのサンドボックスについて調べてみましょう。このプロジェクトには、data、dataPartitionedおよびPhoneChargesDistributedという3つのサンドボックスが必要です。
- data
- 入力および出力データが含まれます
- ローカル・サンドボックス(黄色いフォルダ)であるため、物理的な場所が1つのみ含まれます
- 指定したパス内のノードi-4cc9733bでのみアクセスできます
- dataPartitioned
- パーティション化されたサンドボックス(赤いフォルダ)であるため、異なるノード上に物理的な場所のリストがあります
- データが含まれず、グラフではこのサンドボックスで読取りまたは書込みが行われないため、ノード割当ての定義用としてのみ使用されます
- 次の図では、2つのクラスタ・ノードに対して割当てが構成されています
-
PhoneChargesDistributed
- グラフ・ファイル、メタデータおよび接続を含む一般的なサンドボックス
- 共有サンドボックス(青いフォルダ)であるため、すべてのクラスタ・ノードが同じファイルにアクセスできます

前の図のサンドボックス構成を使用してグラフが実行された場合、ノード割当ては次のようになります。
- プライマリ・ワーカー上でのみ実行されるコンポーネントは、dataサンドボックスの場所に応じてi-4cc9733bノードでのみ実行されます。
- dataPartitionedサンドボックスに応じた割当てを持つコンポーネントは、i-4cc9733bおよびi-52d05425ノード上で実行されます。
変換例のスケーラビリティ
変換例は、Amazon Cloud環境ですべての実行に対して次の条件を使用してテストされています。
- 同じマスター・ノード
- 同じ入力データ: 1、2GBの入力データ、2700万のレコード
- node allocationごとに3回の実行
- 2回の実行ごとにnode allocationの変更
- ノードはすべてc1.mediumタイプ
次の図は、クラスタ内のノード数に対するランタイムの機能の依存性を示しています。

図24.4 クラスタのスケーラビリティ
次の図は、クラスタ内のノード数に対する加速要因の依存性を示しています。加速要因は、1つのクラスタ・ノードを使用した場合の平均ランタイムとx個のクラスタ・ノードを使用した場合の平均ランタイムの比率です。つまり、次のようになります。
speedupFactor = avgRuntime(1ノード) / avgRuntime(xノード)
この結果から、最大4ノードが効率的であることがわかります。ノードを追加するたびにクラスタのパフォーマンスは向上しますが、向上の効果は減少します。9個以上のノードを使用すると、マイナスの影響も現れています。これは、これらのノードの管理によるオーバーヘッドのためにパフォーマンス上のメリットが失われるためです。
これらの結果は、変換ごとに固有のものであるため、変換の機能曲線が改善する場合や、あるいは悪化する場合もあります。

図24.5 加速要因
ランタイムの測定結果表:
| ノード数 | ランタイム1 [s] | ランタイム2 [s] | ランタイム3 [s] | 平均ランタイム[s] | 加速要因 |
|---|---|---|---|---|---|
| 1 | 861 | 861 | 861 | 861 | 1 |
| 2 | 467 | 465 | 466 | 466 | 1.85 |
| 3 | 317 | 319 | 314 | 316.67 | 2.72 |
| 4 | 236 | 233 | 233 | 234 | 3.68 |
| 5 | 208 | 204 | 204 | 205.33 | 4.19 |
| 6 | 181 | 182 | 182 | 181.67 | 4.74 |
| 7 | 168 | 168 | 168 | 168 | 5.13 |
| 8 | 172 | 159 | 162 | 164.33 | 5.24 |
クラスタ構成
クラスタが正しく機能するのは、各ノードが正しく構成されている場合のみです。クラスタリングが有効であり、各ノードのnodeIDが一意であり、すべてのノードが共有DBおよび共有サンドボックスにアクセスでき、ノード間の協調性に関するすべてのプロパティがネットワーク環境に応じて設定されていることが必要です。
プロパティおよび使用可能な構成は、次のとおりです。
- 「必須プロパティ」(125ページ)
- 「オプションのプロパティ」(126ページ)
- 「2ノードのクラスタ構成の例」(126ページ)
- 「ロード・バランシングのプロパティ」(127ページ)
必須プロパティ
必須クラスタ・プロパティ以外にも、license.file、データベース接続、およびクラスタ環境とは特に関係のない他の必須プロパティを設定する必要があります。
表24.1. 必須プロパティ - クラスタの各ノードで正しく設定する必要があるプロパティ
| プロパティ | タイプ | デフォルト |
| cluster.enabled | boolean | FALSE |
| 説明: | サーバーがクラスタに接続されるかどうかのスイッチ | |
| cluster.node.id | String | node01 |
| 説明: | クラスタ・ノードごとに一意のIDが必要です | |
| cluster.shared_sandboxes_path | String、パス | |
| 説明: | すべての共有サンドボックスがこのノードに格納されるパス。クラスタが有効である場合、すべてのサンドボックスが共有されます。このため、サンドボックスのrootPath属性は無視されます。サンドボックスのルート・ディレクトリへのパスは、[shared_sandboxes_path]/[sandboxID]のように作成されます | |
| cluster.jgroups.bind_address | String、IPアドレス | 127.0.0.1 |
| 説明: | イーサネット・インタフェースのIPアドレス。これは、別のクラスタ・ノードとの通信に使用されます。ノード間のメッセージングに必須です。 | |
| cluster.jgroups.start_port | int、ポート | 7800 |
| 説明: | ノード間のメッセージング用としてjGroupサーバーがリッスンするポート。 | |
| cluster.jgroups.tcpping.initial_hosts | String、形式: IPaddress1[port1],IPaddress2[port2] | 127.0.0.1[7800] |
| 説明: | ノードを実行およびリスニングしていることが想定されるIPアドレス(ポートあり)のリスト。これは、別のノードのbind_addressおよびstart_port属性に関連しています。つまり、bind_address1[start_port1],bind_address2[start_port2],…のようになります。クラスタのすべてのノードをリストする必要はありませんが、リストされているホスト:ポートの少なくとも1つが実行されている必要があります。ノード間のメッセージングに必須です。 | |
| cluster.http.url | String、URL | http://localhost:8080/clover |
| 説明: | 構成されているノードのWebアプリケーションのルートに対するURL。ノード間のメッセージングに必須です。この値は、クラスタ内の他のすべてのノードに送信され、このノードに接続する方法を伝えます。 |
オプションのプロパティ
表24.2. オプションのプロパティ - クラスタ構成に必須ではないプロパティ(デフォルト値で十分)
| プロパティ | タイプ | デフォルト | 説明 |
|---|---|---|---|
| cluster.node.sendinfo.interval | int | 5000 | ミリ秒単位の時間間隔; 各ノードにより、それ自体に関する情報が別のノードに送信されます。この間隔により、情報が設定される頻度が指定されます |
| cluster.node.remove.interval | int | 15000 | ミリ秒単位の時間間隔; この間隔内にノード情報が受信されない場合、ノードは失われたとみなされ、クラスタから削除されます |
| cluster.max_allowed_time_shift_between_nodes | int | 2000 | ノード間の最大許容時間シフト。これを時間シフトが超えると、ノードは無効として選択されます。 |
| cluster.group.name | String | cloverCluster | クラスタごとに一意のグループ名があります。同じネットワーク環境内に2つのクラスタが必要な場合、これらのクラスタごとに独自のグループ名が設定されます。 |
| cluster.max_allowed_time_shift_between_nodes | int | 2000 | クラスタ内のノード間の最大許容時間シフト(ミリ秒単位)。すべてのノードでシステム時間が同期化されている必要があります。そうでない場合、クラスタが正しく機能しない可能性があります。このため、このしきい値を超えると、ノードは無効として設定されます。 |
2ノードのクラスタ構成の例
この項には、CloverETLクラスタ・ノード構成の例が含まれます。また、次を構成することが必要です。
- ディレクトリ/home/clover/nfs_shared/sandboxesの共有またはレプリケーション
- 両ノードからの同じデータベースに対する接続
- HTTPロード・バランサ
192.168.1.131でのノードの構成
jdbc.dialect=org.hibernate.dialect.MySQLDialect
datasource.type=JNDI
datasource.jndiName=java:comp/env/jdbc/clover_server
cluster.enabled=true
cluster.node.id=node01
cluster.shared_sandboxes_path=/home/clover/nfs_shared/sandboxes
license.file=/home/clover/license/license.dat
cluster.group.name=cloverCluster
cluster.jgroups.bind_address=192.168.1.131
cluster.jgroups.start_port=7800
cluster.jgroups.tcpping.initial_hosts=192.168.1.13[7800]
cluster.http.url=http://192.168.1.131:8080/clover
192.168.1.13でのノードの構成
jdbc.dialect=org.hibernate.dialect.MySQLDialect
datasource.type=JNDI
datasource.jndiName=java:comp/env/jdbc/clover_server
cluster.enabled=true
cluster.node.id=node02
cluster.shared_sandboxes_path=/home/clover/nfs_shared/sandboxes
license.file=/home/clover/license/license.dat
cluster.group.name=cloverCluster
cluster.jgroups.bind_address=192.168.1.13
cluster.jgroups.start_port=7800
cluster.jgroups.tcpping.initial_hosts=192.168.1.131[7800]
cluster.http.url=http://192.168.1.13:8080/clover
ロード・バランシングのプロパティ
ロード・バランシング基準の乗法子です。ロード・バランサにより、グラフを実行するクラスタ・ノードが決定されます。つまり、任意のノードが実行のためのリクエストを処理できますが、グラフはノードの現在の負荷およびこれらの乗法子に応じて同じノードまたは異なるノード上で実行されます。
数値が大きいほど、決定に対する関連性が高くなります。乗法子はすべて0より大きい必要があります。
クラスタのノードごとにロード・バランシングのプロパティが異なる場合があります。任意のノードが変換実行のための受信リクエストを処理でき、各ノードが独自の構成に応じて異なる方法でロード・バランシングの基準を適用できます。
これらのプロパティはクラスタ構成に必須ではありません。デフォルト値で十分です
表24.3. ロード・バランシングのプロパティ
| プロパティ | タイプ | デフォルト | 説明 |
|---|---|---|---|
| cluster.lb.balance.running_graphs | float | 3 | ロード・バランシング用の実行グラフの重要度を指定します。 |
| cluster.lb.balance.memused | float | 0.5 | ロード・バランシング用の使用メモリーの重要度を指定します。 |
| cluster.lb.balance.cpus | float | 1.5 | ロード・バランシング用のCPU数の重要度を指定します。 |
| cluster.lb.balance.master_bonus | float | 1 | ノードがマスターである事実の重要度を指定します。通常、これは何も影響しません。このため、値を1に設定する場合、マスター・ノードを他のノードと同じものとみなすようロード・バランサに指示することになります |
| cluster.lb.balance.this_node | float | 2 | ノードが実行のためのリクエストを処理するものと同じノードである、という事実の重要度を指定します。これは、グラフを実行する場所を決定する同じノードです。この乗法子に十分大きい値を指定すると、実行のためのリクエストを処理するノードと同じノードでグラフが常に実行されるようになります。 |
第25章 一時領域管理
CloverETLで使用可能なコンポーネントの多くが正しく機能するには、一時ファイルまたはディレクトリが必要です。 一時領域は、これらのファイルまたはディレクトリが作成および保持されるローカル・ファイルシステム上の物理的な場所です。
概要
CloverETL Serverで定義されている一時領域の概要は、「構成」>一時領域管理>「概要」で参照できます。
図25.1 構成されている一時領域の概要 - クラスタ・ノードごとに1つのデフォルト一時領域
設定
一時領域管理には、一時領域を追加、一時停止、再開および削除するためのインタフェースが用意されています。これは、,「構成」>一時領域管理>「編集」からアクセスできます。
画面は、「グローバル構成」とノード構成当たりという2つのドロップダウン領域に分かれています。「グローバル構成」では、スタンドアロン・サーバーの一時領域を管理します。また、サーバー・クラスタの場合は、すべてのノード上の一時領域を管理します。ノード構成当たりを使用すると、ノードごとに一時領域を個別に保持できます。
初期化
CloverETL Serverが起動すると、一時領域構成が確認されます。一時領域が構成されていない場合、java.io.tmpdirシステム・プロパティが指し示すディレクトリ内にデフォルトの一時領域が新しく作成されます。ディレクトリの名前は、次のとおりです。
- ${java.io.tmpdir}/clover_temp (スタンドアロン・サーバーの場合)
- ${java.io.tmpdir}/clover_temp_<node_id> (サーバー・クラスタの場合)
一時領域の追加
新規一時領域を定義するには、表内の最後の行の下にあるテキスト・フィールドにパスを入力し、「追加」リンクをクリックします。パス内では環境変数およびシステム・プロパティを使用できます(例: ${VARIABLE_NAME}/ temp_space)。入力したディレクトリが存在しない場合は作成されます。
 注意
注意
環境変数は、同じ名前のシステム・プロパティより優先されます。変数が含まれるパスが解決されるのは、新規一時領域が追加された後のサーバーの起動中です。変数値が変更されている場合は、サーバーを再起動してこのような変更を有効にする必要があります。
ヒント
一時領域を追加する主な目的は、システム・スループットを高めることにあります。したがって、I/Oのパフォーマンスを最大限に高めるには、入力したパスが別の物理デバイス上にあるディレクトリを指し示している必要があります。
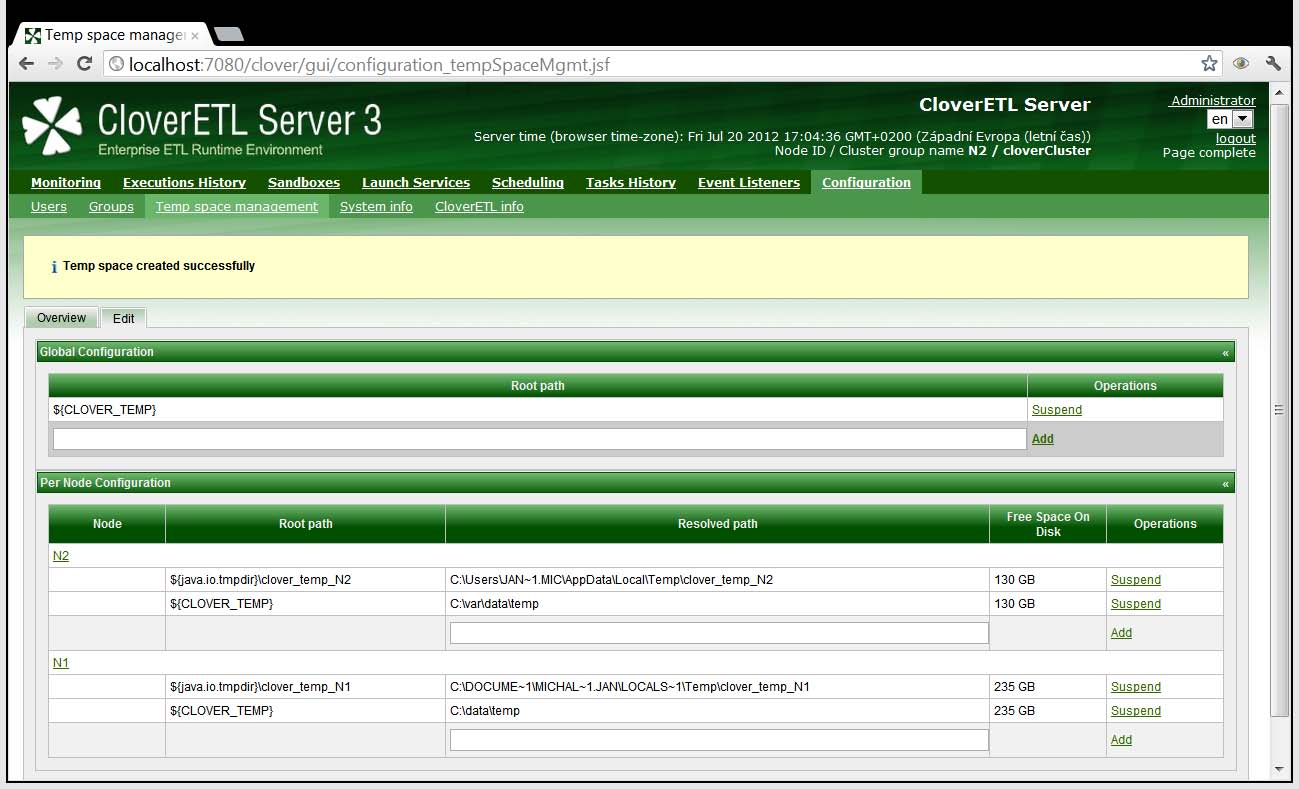
図25.2 両ノードに設定された環境プロパティを使用して新しく追加されたグローバル一時領域。
一時領域の一時停止
一時領域を一時停止するには、パネル内の「一時停止」リンクをクリックします。前または現在のグラフ実行から残されたファイルがある場合、通知が表示されます。一時領域が一時停止された後は、一時領域で一時ファイルが新規作成されなくなりますが、すでに作成されているファイルはそれまでどおり実行ジョブによる使用が可能です。
注意
一時領域は少なくとも1つがアクティブである(一時停止されていない)よう保持されます。

図25.3 実行中のジョブのデータが存在する場合に一時停止操作によって求められる確認。
一時領域の再開
一時領域を再開するには、パネル内の「再開」リンクをクリックします。再開された一時領域はアクティブです。つまり、一時ファイルおよびディレクトリの作成用として使用できます。
一時領域の削除
一時領域を再開するには、パネル内の「削除」リンクをクリックします。一時停止されている一時領域のみを削除できます。一時領域を使用している実行中のジョブが存在する場合、削除は許可されません。一時領域ディレクトリ内にファイルが残されている場合、表示された通知パネルでこれらを削除できます。使用可能なオプションは、次のとおりです。
- 削除 - システムから一時領域を削除しますが、内容は保持します
- 削除および抹消 - システムから一時領域とその内容を削除します
- 取消 - 操作を続行しません

図25.4 一時領域内にデータが存在する場合に削除操作によって求められる確認。
著作権および免責事項
Copyright © 2003, 2013, Oracle and/or its affiliates.All rights reserved.
OracleおよびJavaはOracle Corporationおよびその関連企業の登録商標です。その他の名称は、それぞれの所有者の商標または登録商標です。UNIXは、The Open Groupの登録商標です。
このソフトウェアおよび関連ドキュメントの使用と開示は、ライセンス契約の制約条件に従うものとし、知的財産に関する法律により保護されています。ライセンス契約で明示的に許諾されている場合もしくは法律によって認められている場合を除き、形式、手段に関係なく、いかなる部分も使用、複写、複製、翻訳、放送、修正、ライセンス供与、送信、配布、発表、実行、公開または表示することはできません。このソフトウェアのリバース・エンジニアリング、逆アセンブル、逆コンパイルは互換性のために法律によって規定されている場合を除き、禁止されています。
ここに記載された情報は予告なしに変更される場合があります。また、誤りが無いことの保証はいたしかねます。誤りを見つけた場合は、オラクル社までご連絡ください。
このソフトウェアまたは関連ドキュメントを、米国政府機関もしくは米国政府機関に代わってこのソフトウェアまたは関連ドキュメントをライセンスされた者に提供する場合は、次の通知が適用されます。
U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations.As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs.No other rights are granted to the U.S. Government.
このソフトウェアもしくはハードウェアは様々な情報管理アプリケーションでの一般的な使用のために開発されたものです。このソフトウェアもしくはハードウェアは、危険が伴うアプリケーション(人的傷害を発生させる可能性があるアプリケーションを含む)への用途を目的として開発されていません。このソフトウェアもしくはハードウェアを危険が伴うアプリケーションで使用する際、安全に使用するために、適切な安全装置、バックアップ、冗長性(redundancy)、その他の対策を講じることは使用者の責任となります。このソフトウェアもしくはハードウェアを危険が伴うアプリケーションで使用したことに起因して損害が発生しても、オラクル社およびその関連会社は一切の責任を負いかねます。
このソフトウェアまたはハードウェア、そしてドキュメントは、第三者のコンテンツ、製品、サービスへのアクセス、あるいはそれらに関する情報を提供することがあります。オラクル社およびその関連会社は、第三者のコンテンツ、製品、サービスに関して一切の責任を負わず、いかなる保証もいたしません。オラクル社およびその関連会社は、第三者のコンテンツ、製品、サービスへのアクセスまたは使用によって損失、費用、あるいは損害が発生しても一切の責任を負いかねます。