10 Oracle Utilities Data Model Data Mining Model
This chapter provides reference information about the data mining models provided with Oracle Utilities Data Model.
This chapter includes the following sections:
About Data Mining in Oracle Utilities Data Model
Oracle Utilities Data Model data mining includes data mining intra-ETL package, data mining core package, source data views, apply data views, target tables, support tables, and setting tables. The source views are defined on source derived tables. These source views are used to train the models. The target tables contain the mining model rules and mining prediction results. Data mining core package builds mining models using data in source views as training data, and applies mining models on the data in apply views. Mining target tables are populated with mining model rules and prediction results. The data in the target tables can be presented in reports.
As shown in Table 10-1, the Oracle Utilities Data Model mining models use the specified algorithms for the specific mining problem.
Table 10-1 Oracle Utilities Data Model Algorithm Used
| Model | Algorithms Used by Data Mining Model |
|---|---|
|
Model 1: Customer Savings and Customer Profile by DR Program |
Decision Tree (DT), Support Vector Machine (SVM) |
Understanding the Mining Architecture
Figure 10-1 shows the architecture of data mining in Oracle Utilities Data Model. Oracle Utilities Data Model schema, oudm_sys, includes the following:
-
Mining Model Source Views: Views defined on source derived table,
DWD_CUST_DR_PROG_PROFILE. These views are used to train mining models. -
Mining Model Apply Views: Views defined on source derived tables,
DWD_CUST_DR_PROG_PROFILE. These views are used to apply trained mining models. -
Mining Model Support Tables: Mining algorithm settings for different algorithms used in Oracle Utilities Data Model are stored in the support tables. These support tables start with "
DM". Building a mining model creates few tables and views which start with "DM$".
Note:
Do not delete tables and views that start with "DM" and "DM$". Deleting "DM$" tables and views would also delete the trained mining model.-
Mining Model Target Tables: Mining model target tables used for storing mining model rules and prediction results. Mining model rules are generated from the trained model and predictions results are produced when a trained model is applied on apply data.
-
Mining Model Core Package: This is the core package for Oracle Utilities Data Model data mining. Each mining model has separate procedure in this package. Each procedure builds, tests, and applied mining model. It uses source views as training data, and applies trained model on apply views.
Figure 10-1 Oracle utilities Data Model Mining Packages Tables and Views
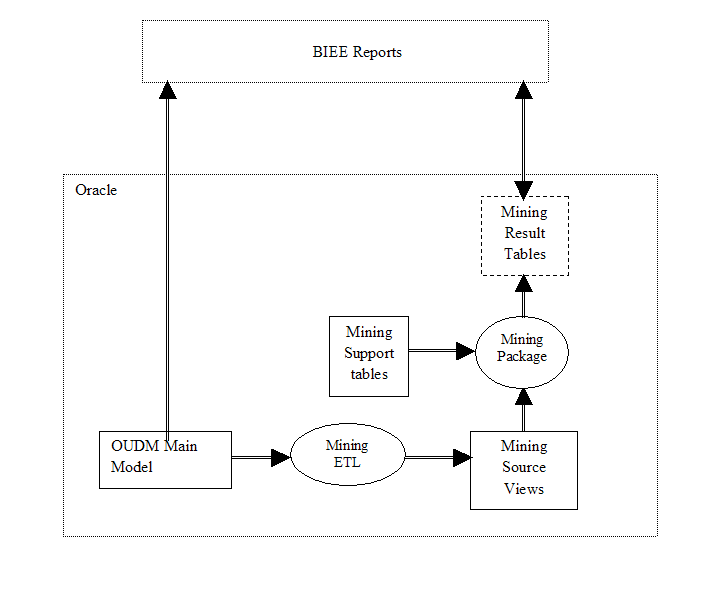
Description of "Figure 10-1 Oracle utilities Data Model Mining Packages Tables and Views"
Oracle Utilities Data Model Mining Result Tables
Table 10-2 shows the DWR_CUST_SGMNT table.
Table 10-2 DWR_CUST_SGMNT Data Mining Model Details Table
| Name | Data Type | Description |
|---|---|---|
|
DEMAND_RESPN_PROG_KEY |
NUMBER(30) |
Surrogate key of demand response program |
|
CUST_SGMNT_KEY |
NUMBER (30,0) |
Surrogate key for customer segment |
|
CUST_SGMNT_CD |
VARCHAR2 (120) |
Natural key for customer segment |
|
CUST_SGMNT_MDL_KEY |
NUMBER (30,0) |
Customer segment model key |
|
PRNT_CUST_SGMNT_KEY |
NUMBER (30,0) |
Parent segment key |
|
CUST_SGMNT_NAME |
VARCHAR2 (400) |
Customer segment name |
|
SGMNT_CRTRA_KEY |
NUMBER (30,0) |
Segment criteria key |
|
CUST_SGMNT_DSCR |
VARCHAR2 (1000) |
Customer segment description |
|
IS_LEAF_IND |
CHAR (1) |
Indicates whether the node is a leaf indicator. The prediction of lead node is the final prediction |
|
TREE_LVL |
NUMBER (4,0) |
Tree level |
|
SGMNT_DISPRSN |
VARCHAR2 (500) |
Segment dispersion, which is also known as intra cluster distance |
|
SPPRTG_REC_CNT |
NUMBER (16,0) |
Supporting record count - number of customers in the segment |
|
STAT_CD |
VARCHAR2 (120) |
Status code of the record |
|
EFF_FROM_DT |
DATE |
Effective from date |
|
EFF_TO_DT |
DATE |
Effective to date |
Table 10-2 shows the DWR_CUST_SGMNT_DTL table.
Table 10-3 DWR_CUST_SGMNT_DTL Data Mining Model Details Table
| Name | Data Type | Description |
|---|---|---|
|
DEMAND_RESPN_PROG_KEY |
NUMBER(30) |
Surrogate key of demand response program |
|
SGMNT_ID |
NUMBER |
Customer segment Identifier |
|
ATTRIBUTE_NAME |
VARCHAR2(4000) |
Name of customer attribute |
|
MEAN |
NUMBER |
Mean of the customer attribute if the attribute is numeric |
|
MODE_VALUE |
VARCHAR2(4000) |
Model of the customer attribute if the attribute is categorical |
Model 1: Customer Savings and Customer Profile by DR Program
Customers can reduce their usage by participating in a Demand Response (DR) program. The utility company needs to let customers know the savings the customer can obtain by participating in the demand response program. For this purpose, there is the need to segment whole customer population in two steps.
-
STEP1: Segmentation Using Oracle Data Mining Clustering Algorithm based on customers' demographic attributes. This will be done using Oracle Data Mining clustering algorithm (K-means or Hierarchical clustering)
-
STEP2 Segmentation and Customer Saving Calculation For each STEP1 segment, segment based on customers' participation in DR programs:
-
Customers participating in DR programs.
-
Customers not participating in DR programs.
-
For each segment in STEP1, determine the average actual usage of customers not participating in DR program during the time of DR program instance; let us call it Average actual usage of non participants. In the same segment, for each participant customer determine delta (Average actual usage of non participants - customer actual usage) as a percentage of Average actual usage of non participants during the time of DR program instance.
%saving = 100*(Average actual usage of non participants - customer actual usage)/Average actual usage of non participants
"%saving" measure gives the energy saved by customer during the time of DR program instance due to participation.
STEP1: Segmentation Using Oracle Data Mining Clustering Algorithm
In this segmentation, the complete customer population is segmented into a predefined number of segments using customers' demographic attributes. By default, Oracle Data Mining chooses K-Means algorithm as the clustering function and 10 as number of segments. The default settings can be overridden using a setting a table.
Table 10-4 shows the structure of source table, which is used as training data.
Table 10-4 DWD_CUST_DR_PROG_PROFILE
| Attribute Name | Description | Column Name | Source Table | Mapping |
|---|---|---|---|---|
|
Customer Key |
Customer Identifier |
CUST_KEY |
DWR_CUST |
CUST_KEY |
|
Demand Response Program Key |
DR program Identifier |
DEMAND_RESPN_PROG_KEY |
||
|
DEMOGRAPHIC ATTRIBUTES |
||||
|
Customer Kind |
Kind of Customer |
CUST_KIND_CD |
DWR_CUST |
CUST_KIND_CD |
|
Customer Type |
Type of customer. For example: Industrial, Commercial, Residential |
CUST_TYP_CD |
DWR_CUST |
CUST_TYP_CD |
|
Dwelling Type |
Facility Type |
DWLNG_TYP |
DWR_CUST |
DWLNG_TYP |
|
Dwelling Status |
Facility Status |
DWLNG_STAT |
DWR_CUST |
DWLNG_STAT |
|
Dwelling Size |
Facility Size |
DWLNG_SZ |
DWR_CUST |
DWLNG_SZ |
|
Dwelling Tenure |
Facility Tenure |
DWLNG_TENR |
DWR_CUST |
DWLNG_TENR |
|
Income Group |
Income Group |
INCM_GRP |
DWR_HH |
INCM_GRP |
|
Number of Children |
Number of children in the household |
NBR_OF_CHLDRN |
DWR_HH |
NBR_OF_CHLDRN |
|
Number of Teens |
Number of teens in the household |
NBR_OF_TEENS |
DWR_HH |
NBR_OF_TEENS |
|
Number of Adults |
Number of adults in the household |
NBR_OF_ADLTS |
DWR_HH |
NBR_OF_ADLTS |
|
Number of Seniors |
Number of seniors in the household |
NBR_OF_SNRS |
DWR_HH |
NBR_OF_SNRS |
|
Number of Persons |
Number of persons in the household |
NBR_OF_PRSN |
DWR_HH |
NBR_OF_PRSN |
|
Number of Earners |
Number of earners in the household |
NBR_OF_ERNR |
DWR_HH |
NBR_OF_ERNR |
|
Business Legal Status |
The legal status of the company. For example: Public, Private, and so on. |
BSNS_LEGAL_STAT_CD |
DWR_CUST |
BSNS_LEGAL_STAT_CD |
|
Customer Revenue Band |
Customer Revenue Band |
CUST_RVN_BND_CD |
DWR_CUST |
CUST_RVN_BND_CD (Derive it from payment and cost) |
|
Nationality |
Nationality |
NTNLTY_CD |
DWR_CUST |
NTNLTY_CD |
|
Education |
Education Qualification |
EDU_CD |
DWR_CUST |
EDU_CD |
|
Marital Status |
Marital Status |
MRTL_STAT_CD |
DWR_CUST |
MRTL_STAT_CD |
|
Gender |
Gender |
GNDR_CD |
DWR_CUST |
GNDR_CD |
|
Job Position |
Job Position |
JB_POSN |
DWR_CUST |
JB_POSN |
|
Annual Revenue |
Annual Revenue |
ANNUAL_RVN |
DWR_CUST |
ANNUAL_RVN (o for residential customers) |
|
Annual Sales |
Annual Sales |
ANNUAL_SL |
DWR_CUST |
ANNUAL_SL (o for residential customers) |
|
Equity Amount |
Equity Amount |
EQTY_AMT |
DWR_CUST |
EQTY_AMT (o for residential customers) |
|
City |
City |
CITY |
DWR_CUST |
CITY |
|
State |
State |
STATE |
DWR_CUST |
STATE |
|
Country |
Country |
COUNTRY |
DWR_CUST |
COUNTRY |
|
Ethnic Background |
Ethnic Background |
ETHNIC_BCKGRND |
DWR_CUST |
ETHNIC_BCKGRND |
|
Source of Income |
Source of Income |
SRC_OF_INCM |
DWR_CUST |
SRC_OF_INCM |
|
Special Need |
Special Need |
SPL_NEED |
DWR_CUST |
SPL_NEED |
|
Economically Active Indicator |
Economically Active Indicator |
ECNMCLY_ACTV_IND |
DWR_CUST |
ECNMCLY_ACTV_IND |
|
Domestic Indicator |
Domestic company Indicator |
DMSTC_IND |
DWR_CUST |
DMSTC_IND |
|
Mail Allowed Indicator |
Mail Allowed Indicator |
MAIL_ALWD_IND |
DWR_CUST |
MAIL_ALWD_IND |
|
Third Party Marketing Allowed Indicator |
Third Party Marketing Allowed Indicator |
THIRD_PRTY_MKTG_ALWD_IND |
DWR_CUST |
THIRD_PRTY_MKTG_ALWD_IND |
|
Customer Payment Responsible Indicator |
Customer Payment Responsible Indicator |
CUST_PYMT_RESPBL_IND |
DWR_CUST |
CUST_PYMT_RESPBL_IND |
|
VIP |
VIP Flag |
VIP |
DWR_CUST |
VIP |
|
TARGET/OUTPUT ATTRIBUTES |
||||
|
Customer Segment Code |
Customer Segment Code |
CUST_SGMNT_CD |
||
|
TECHNICAL QUALITY |
||||
|
Creation Date |
Date when this record is created |
CREATED_DT |
SYSDATE |
|
|
Created By |
User who created this record |
CREATED_BY |
USER |
|
|
Updated Date |
Date when this record updated |
UPDATE_DT |
SYSDATE |
|
|
Updated By |
User who updated this record |
UPDATE_BY |
USER |
|
|
Effective from Date |
Date from when this record is effective |
EFF_FROM_DT |
SYSDATE |
|
|
Effective to Date |
Date until when the record is effective |
EFF_TO_DT |
NULL |
|
|
Current Indicator |
Whether this record is current or not. 'Y' - Yes, 'N' - No |
CURR_IND |
'Y' |
|
|
Status Code |
Status of this record. 'A' - Active, 'I' - Inactive |
STAT_CD |
'A' |
Algorithm Setting Table
DM_STNG_CUST_PROFILE is the setting table used for STEP1 segmentation using Oracle Data Mining segmentation algorithm. Following table shows the different settings used:
Table 10-5 shows setting values for STEP1 segmentation.
STEP2 Segmentation and Customer Saving Calculation
As mentioned earlier, each STEP1 segment can have both DR program participant customers and non-participant customers. Each STEP1 segment is further segmented into two segments using customer participation indicator; that is, one sub-segment for participant customers and the other sub-segment for non-participant customers.
For each STEP1 segment:
-
Calculate the average of actual usage of non-participant customers during the DR program, let us call it Average actual usage of non participants
-
For each participant customer, compute %saving as follows:
%saving =
Description of the illustration dm_calc1.png
For each participant customer, PERCNT_CUST_SAVNG column in mining target table DWD_CUST_DR_PROG_PROFILE is updated with the calculated %saving.
Oracle Utilities Data Model Mining Setting Tables
Use the algorithm settings tables to override default values of different settings of mining algorithms.
The following two setting tables have the same structure:
-
DM_STNG_USER_ALL -
DM_STNG_PROFILE_KMEANS
Table 10-6 shows the structure of the two setting tables.