| Oracle® Big Data Applianceソフトウェア・ユーザーズ・ガイド リリース2 (2.2.1) E48217-02 |
|


 前 |
 次 |
この章では、Oracle Big Data Applianceにインストールされるソフトウェアおよびサービスについて説明します。次の項について説明します。
Oracle Enterprise Managerプラグインでは、Oracle Exadata Database Machineや他のOracle Databaseインストールに使用するのと同じシステム監視ツールをOracle Big Data Applianceに使用できます。プラグインを使用して、インストールされたソフトウェア・コンポーネントのステータスを表や図式を使用した形式で表示したり、これらのソフトウェア・サービスの起動や停止を行えます。ネットワークおよびラック・コンポーネントの状態を監視することもできます。
Oracle Enterprise Manager Webインタフェースを開いてログインし、ターゲット・クラスタを選択すると、次の主要領域へドリルダウンできます。
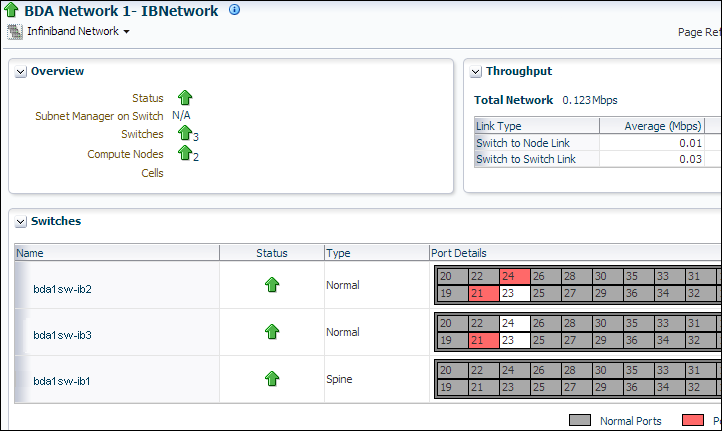
インフィニバンド・ネットワーク: インフィニバンド・スイッチとポートのネットワーク・トポロジとステータス。図2-1を参照してください。
Hadoopクラスタ: HDFS、MapReduceおよびZooKeeperのソフトウェア・サービス。
Oracle Big Data Applianceラック: サーバー・ホスト、Oracle Integrated Lights Out Manager (Oracle ILOM)サーバー、配電ユニット(PDU)、イーサネット・スイッチなどのハードウェア・ステータス。
図2-1に、インフィニバンド・スイッチについて表示された情報の一部を示します。
Oracle Enterprise Managerを使用してOracle Big Data Applianceを監視するには、次の手順を実行します。
プラグインをダウンロードしてインストールします。『Oracle Enterprise Manager System Monitoring Plug-inインストレーション・ガイドfor Oracle Big Data Appliance』を参照してください。
管理ユーザーとしてOracle Enterprise Managerにログインします。
「ターゲット」メニューから「ビッグ・データ・アプライアンス」を選択し、ビッグ・データ・ページを表示します。Oracle Enterprise Managerによって検出済のターゲットの全体的なステータスが表示されます。
詳細ページを表示するターゲット・クラスタを選択します。
ターゲット・ナビゲーション・ツリーを展開し、コンポーネントを表示します。すべてのレベルで情報を使用可能です。
ツリーでコンポーネントを選択し、ホーム・ページを表示します。
表示を変更するには、メイン表示領域の左上部にあるドロップダウン・メニューから項目を選択します。
|
関連項目: インストール手順と使用例については、『Oracle Enterprise Manager System Monitoring Plug-inインストレーション・ガイドfor Oracle Big Data Appliance』を参照してください。 |
Enterprise Managerコマンドライン・インタフェース(emcli)はOracle Big Data Applianceに、他のすべてのソフトウェアとともにインストールされます。このインタフェースは、Webインタフェースと同じように機能します。Oracle Management Serverに接続するための資格証明を入力する必要があります。
ヘルプを表示するには、emcli helpと入力してください。
|
関連項目: 『Oracle Enterprise Managerコマンドライン・インタフェース・ガイド』 |
Oracle Big Data ApplianceにインストールされるCloudera Managerは、Cloudera's Distribution including Apache Hadoop (CDH)の操作に役立ちます。Cloudera Managerは、Hadoopクラスタの一部として構成されたすべてのOracle Big Data Applianceサーバーを対象とする単一の管理インタフェースを備えています。
Cloudera Managerを使用すると、次の管理タスクを簡単に行うことができます。
ジョブおよびサービスの監視
サービスの開始および停止
セキュリティ資格証明とKerberos資格証明の管理
ユーザー・アクティビティの監視
システムの状態の監視
パフォーマンス・メトリックの監視
ハードウェアの使用状況の追跡(ディスク、CPU、RAM)
Cloudera Managerは、JobTrackerノード(node03)上で動作し、ポート7180上で使用できます。
Cloudera Managerを使用するには、次の手順を実行します。
ブラウザを開き、次のようにURLを入力します。
http://bda1node03.example.com:7180
この例で、bda1はアプライアンス名、node03はサーバー名、example.comはドメイン、7180はデフォルトのポート番号(それぞれCloudera Managerで使用)を示します。
Cloudera Managerのユーザー名とパスワードでログインします。設定を変更できるのは、管理者権限を持つユーザーのみです。その他のCloudera Managerユーザーは、Oracle Big Data Applianceのステータスを表示できます。
|
関連項目: Cloudera Manager Monitoring and Diagnostics Guideまたは、Cloudera Managerの「Help」メニューで、「Help」をクリックしてください |
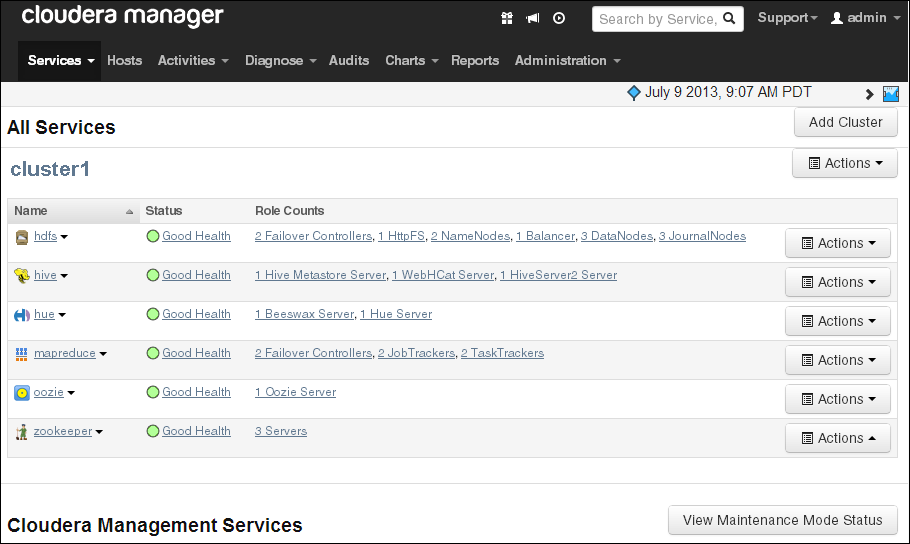
Cloudera Managerでは、画面上部のメニュー・バーから、次に示す任意のページを選択できます。
Services: Oracle Big Data Appliance上で実行されているサービスのステータスと状態を監視します。サービス名をクリックすると、詳細情報にドリル・ダウンされます。
Hosts: すべてのサーバーの状態、ディスク使用量、負荷、物理メモリー、スワップ領域などの統計情報を監視します。
Activities: 指定期間に実行されているすべてのMapReduceジョブを監視します。
Logs: システムおよびサービスの履歴情報を収集します。選択したサーバー、サービス、および期間を対象に、特定の句を検索できます。また、ログ・メッセージの最小重大度(TRACE、DEBUG、INFO、WARN、ERRORまたはFATAL)を選択して、検索に含めることもできます。
Events: 状態の変化やその他の注意すべきイベントの発生を記録します。選択したサーバー、サービス、および期間を対象に、1つ以上のキーワードを検索できます。また、イベント・タイプ(Audit Event、Activity Event、Health CheckまたはLog Message)を選択することもできます。
Charts: Cloudera Managerの時系列データ・ストアからメトリックを表示します。折れ線グラフ棒グラフなど、様々なタイプのグラフを選択できます。
Reports: ディスクおよびMapReduceの使用状況に関するレポートをオンデマンドで生成します。
Audits: 選択した時間範囲の監査履歴ログを表示します。ユーザー名、サービスまたはその他の条件によって結果を絞り込み、CSVファイルとしてログをダウンロードできます。
図2-2は、Cloudera Managerのオープニング画面(「Services」ページ)を示しています。
MapReduceジョブを監視するために、Cloudera Managerのユーザー名とパスワードは必要ありません。
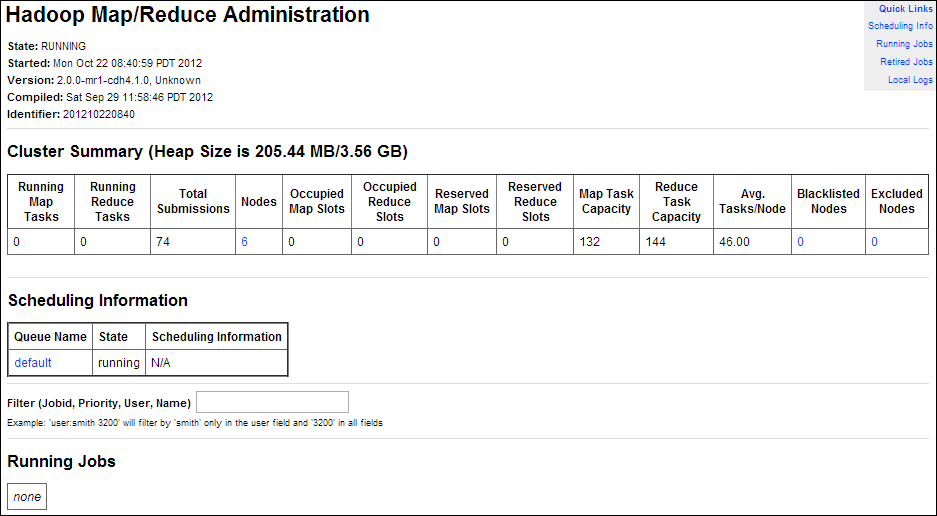
Hadoop Map/Reduce Administrationでは、Oracle Big Data ApplianceのJobTrackerノード(node03)のポート50030で実行されるJobTrackerを監視します。
JobTrackerを監視するには、次の手順を実行します。
ブラウザを開き、次のようにURLを入力します。
http://bda1node03.example.com:50030
この例で、bda1はアプライアンス名、node03はサーバー名、50030はデフォルトのポート番号(それぞれHadoop Map/Reduce Administrationで使用)を示します。
図2-3は、「Hadoop Map/Reduce Administration」画面の一部を示しています。
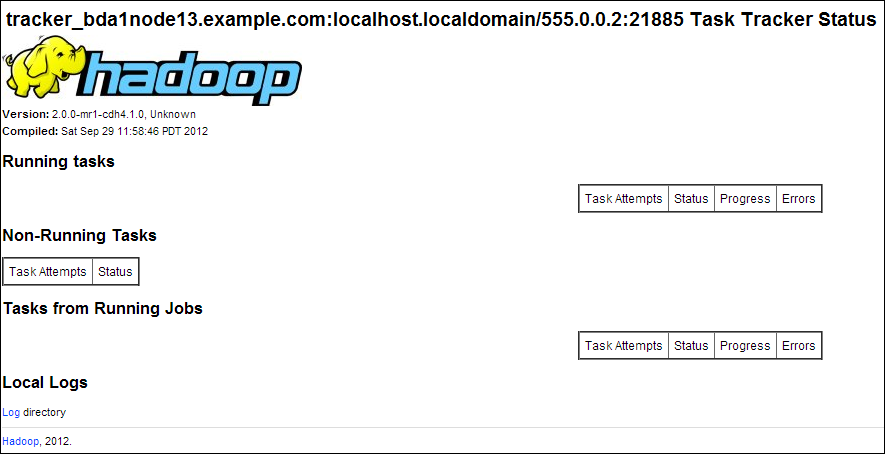
Task Tracker Statusインタフェースでは、単一ノード上のTaskTrackerを監視します。Oracle Big Data Appliance内にあるすべての非クリティカル・ノード(node04からnode18)のポート50060上で使用できます。6ノードのクラスタの場合、TaskTrackerはnode01とnode02でも実行されます。
TaskTrackerを監視するには、次の手順を実行します。
ブラウザを開き、次のように特定のノードのURLを入力します。
http://bda1node13.example.com:50060
この例で、bda1はラック名、node13はサーバー名、50060はデフォルトのポート番号(それぞれTask Tracker Statusインタフェースで使用)を示します。
図2-4は、Task Tracker Statusインタフェースを示しています。
Hueはブラウザで動作し、複数のアプリケーションに使いやすいインタフェースを提供して、HadoopとHDFSの操作をサポートします。Hueを使用すると、次のタスクを実行できます。
Hiveデータ・ストアの問合せ
Hive表の作成、ロードおよび削除
HDFSファイルおよびディレクトリの操作
MapReduceジョブの作成、発行および監視
MapReduceジョブの監視
Oozieダッシュボードを使用したワークフローの作成、編集および発行
ユーザーおよびグループの管理
HueはJobTrackerノード(node03)のポート8888上で動作します。
Hueを使用するには、次の手順を実行します。
この例で示したようなアドレスを使用し、ブラウザでHueを開きます。
http://bda1node03.example.com:8888
この例で、bda1はクラスタ名、node03はサーバー名、example.comはドメインをそれぞれ示します。
Hue資格証明を使用してログインします。
Oracle Big Data Applianceは、初期設定では特定のHueユーザー・アカウントを使用するよう構成されていません。Hueに最初に接続するユーザーは、任意のユーザー名とパスワードでログインでき、自動的に管理者になります。このユーザーは、他のユーザーと管理者アカウントを作成できます。
上部のアイコンを使用して、ユーティリティを開きます。
図2-5は、Hive問合せを入力するためのBeeswax Query Editorを示しています。
|
関連項目: Oracle Big Data Applianceにすでにインストールおよび構成されているHueの使用方法の詳細は、次のサイトで『Hue Installation Guide』を参照してください |
次の各項では、Oracle Big Data Applianceにインストールされるソフトウェアと、そのラック内での実行場所について説明します。一部のコンポーネントは、Oracle Database 11.2.0.2以降のリリースで動作します。
次のソフトウェア・コンポーネントは、Oracle Big Data Applianceのラック内にある18台すべてのサーバーにインストールされます。Oracle Linux、必須ドライバ、ファームウェアおよびハードウェア検証ユーティリティは工場出荷時にインストール済です。その他のソフトウェアはすべて、Mammothユーティリティを使用してオンサイトでインストールします。オプションのソフトウェア・コンポーネントは、インストールで構成されない場合があります。
|
注意: Oracle Big Data Applianceに追加のソフトウェアをインストールする必要はありません。これを行うと、保証やサポートの対象外となる可能性があります。詳細は、『Oracle Big Data Applianceオーナーズ・ガイド』を参照してください。 |
ベースとなるイメージ・ソフトウェア:
Java HotSpot Virtual Machine 6 Update 51
Oracle R Distribution 2.15.1
MySQL Server 5.5.17 Advanced Edition
Puppet、ファームウェア、ユーティリティ
Mammothインストール:
Cloudera's Distribution including Apache Hadoop Release 4 Update 3 (4.3)
Oracle Database Instant Client 11.2.0.3
Oracle NoSQL Database Community EditionまたはEnterprise Edition 11g Release 2.0 (オプション)
Oracle Big Data Connectors 2.2 (オプション):
|
関連項目: Mammothユーティリティの詳細は、『Oracle Big Data Applianceオーナーズ・ガイド』を参照してください。 |
図2-6は、主要コンポーネント間の関係を示しています。
各サーバーには12基のディスクが搭載されています。重要なオペレーティング・システムはディスク1および2に格納されます。
表2-1に、ディスク・パーティションの内容を示します。
この項の内容は次のとおりです。
Cloudera Managerを使用すると、Oracle Big Data Appliance上のCDHサービスを監視できます。
サービスを監視するには、次の手順を実行します。
Cloudera Managerで、ページ上部にある「Services」タブをクリックして、「Services」ページを表示します。
サービス名をクリックすると、その詳細ページが表示されます。サービスの「Status」ページが開きます。
確認するページのリンク(「Status」、「Instances」、「Commands」、「Configuration」または「Audits」)をクリックします。
すべてのサービスはCDHクラスタ内の全ノード上にインストールされますが、個々のサービスは指定されたノードでのみ実行されます。サービスの場所は、クラスタの構成によって多少異なります。
表2-2は、シングル・ラック内に構成されたCDHクラスタ内のサービスを示したものです(6ノードを使用したスタータ・ラックやクラスタを含む)。Node01はクラスタ内の最初のサーバー(サーバー1、7または10)で、nodexxはクラスタ内の最後のサーバー(サーバー6、9、12または18)です。
表2-2 シングル・ラック内にある1つ以上のCDHクラスタのサービス・ロケーション
| node01 | node02 | node03 | Node04 | Node05~nn |
|---|---|---|---|---|
|
バランサ |
||||
|
Hive、Hue、Oozie |
||||
|
Cloudera Manager Agent |
Cloudera Manager Agent |
Cloudera Manager Agent |
Cloudera Manager Agent |
Cloudera Manager Agent |
|
Cloudera Manager Server |
||||
|
DataNode |
DataNode |
DataNode |
DataNode |
DataNode |
|
Failover Controller |
Failover Controller |
Failover Controller |
Failover Controller |
|
|
JournalNode |
JournalNode |
JournalNode |
||
|
MySQL Backup |
MySQL Primary |
|||
|
NameNode 1 |
NameNode 2 |
|||
|
Oracle Data Integratorエージェント |
||||
|
Puppet |
Puppet |
Puppet |
Puppet |
Puppet |
|
Puppet Master |
||||
|
JobTracker 1 |
JobTracker 2 |
|||
|
Task Tracker脚注 1 |
Task Tracker脚注 1 |
TaskTracker |
TaskTracker |
TaskTracker |
|
ZooKeeper Server |
ZooKeeper Server |
ZooKeeper Server |
脚注 1 スタータ・ラックと6ノード・クラスタのみ
複数のラックが単一のCDHクラスタとして構成されている場合、一部の重要なサービスが第2ラックの第1サーバーへと移動されます。
第2ラックの第1サーバーで実行される重要なサービス:
バランサ
Failover Controller
Journal Node
NameNode 1
ZooKeeper Server
DataNode、Cloudera Manager AgentおよびPuppetサービスもこのサーバーで実行されます。
表2-3は、マルチラック・クラスタの最初のラックで実行されるサービスの場所を示したものです。
表2-3 マルチラックCDHクラスタの最初のラックでのサービス・ロケーション
| node01 | node02 | node03 | Node04 | Node05~nn脚注 1 |
|---|---|---|---|---|
|
Cloudera Manager Agent |
Cloudera Manager Agent |
Cloudera Manager Agent |
Cloudera Manager Agent |
Cloudera Manager Agent |
|
Cloudera Manager Server |
||||
|
DataNode |
DataNode |
DataNode |
DataNode |
DataNode |
|
Failover Controller |
Failover Controller |
Failover Controller |
||
|
Hive、Hue、Oozie |
||||
|
JournalNode |
JournalNode |
|||
|
MySQL Backup |
MySQL Primary |
|||
|
NameNode 2 |
||||
|
Oracle Data Integratorエージェント |
||||
|
Puppet |
Puppet |
Puppet |
Puppet |
Puppet |
|
Puppet Master |
||||
|
JobTracker 1 |
JobTracker 2 |
|||
|
TaskTracker |
TaskTracker |
TaskTracker |
TaskTracker |
|
|
ZooKeeper Server |
ZooKeeper Server |
脚注 1 nnには追加ラック内のサーバーが含まれます。
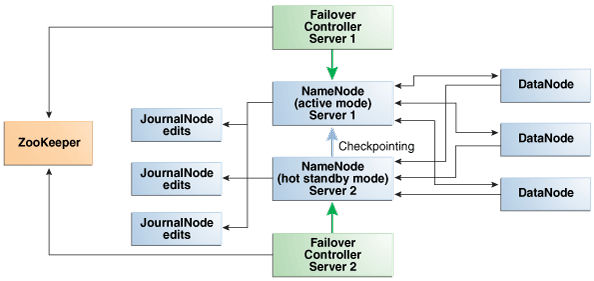
NameNodeは、すべてのデータの場所を追跡するため、最も重要なプロセスです。正常に機能しているNameNodeがないと、クラスタ全体に障害が発生します。Apache Hadoop v0.20.2以前のバージョンは、ネームノードが1つしかないため、障害に対して脆弱です。
Cloudera's Distribution including Apache Hadoopのバージョン4 (CDH4)では、NameNodeの冗長性を維持することにより、この脆弱性が軽減されています。次に示すように、データは通常の運用時にレプリケートされます。
CDHは、最初の2つのノード上でNameNodeの冗長性を維持します。NameNodeの一方はアクティブ・モード、もう一方のNameNodeはホット・スタンバイ・モードです。アクティブNameNodeに障害が発生すると、そのアクティブNameNodeのロールは自動的にスタンバイNameNodeにフェイルオーバーされます。
NameNodeのデータはミラー化されたパーティションに書き込まれるので、1つのディスクが失われても耐障害性が確保されます。このミラー化の処理は、オペレーティング・システムのインストールの一環として工場出荷時に行われます。
アクティブNameNodeでは、ファイル・システム・メタデータへのすべての変更を2つ以上のJournalNodeプロセスに記録し、これをスタンバイNameNodeが読み取ります。3つのJournalNodeがあり、それらは各クラスタの最初の3つのノードで実行されます。
ジャーナルに記録された変更は、チェックポインティングと呼ばれるプロセスで単一のfsimageファイルに定期的に統合されます。
|
注意: Oracle Big Data Appliance 2.0以降のリリースでは、バックアップ用の外部NFSフィルタをサポートしておらず、NameNodeのフェデレーションを使用しません。 |
図2-7は、NameNodeの自動フェイルオーバーをサポートしているプロセス間の関係を示しています。
図2-7 Oracle Big Data ApplianceでのNameNodeの自動フェイルオーバー
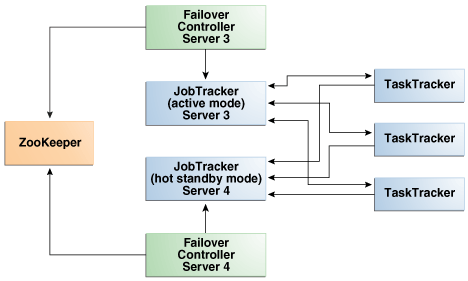
JobTrackerは、MapReduceタスクをクラスタ全体に分散します。NameNodeと同様、JobTrackerはノードの重要な障害ポイントです。JobTrackerで障害が起きると、すべてのジョブが実行を停止します。
Oracle Big Data Appliance 2.2以降のリリースでは、この脆弱性を緩和するためにCDH4でのJobTracker High Availableがサポートされています。
CDHは、node03と-04上の冗長なJobTrackerサービスを管理します。それらのサービスの1つがアクティブ・モードになり、その他のサービスはホット・スタンバイ・モードになります。サービスの状態は、2つのノード上のフェイルオーバー・コントローラによって監視されます。アクティブ・サービスに障害が発生すると、そのアクティブJobTrackerのロールは自動的にスタンバイJobTrackerにフェイルオーバーされます。
図2-7は、NameNodeの自動フェイルオーバーをサポートしているプロセス間の関係を示しています。
図2-8 Oracle Big Data ApplianceでのJobTrackerの自動フェイルオーバー
次のツールのRPMインストール・ファイルは、Oracle Big Data Appliance上で提供されます。これらは、Cloudera Webサイトからはダウンロードしないでください。ただし、これらは必ずインストールして構成する必要があります。
各クラスタの最初のサーバー上のRPMファイルは、/opt/oracle/BDAMammoth/bdarepo/RPMS/noarchにあります。
|
関連項目: 構成の手順の詳細は、次のサイトで『CDH4 Installation and Configuration Guide』を参照してください |
クラスタ内の各ノードには、同時実行を許可されるマップ・タスクとリデュース・タスクの最大数があります。表2-4は、Oracle Big Data Appliance X3-2でのMapReduceサービスのデフォルトのリソース構成を示したものです。
表2-4 Oracle Big Data Appliance X3-2でのマップおよびリデュース・タスクの最大数
| ノード | 6ノード・クラスタ | より大規模なクラスタ脚注 1 |
|---|---|---|
|
Node01とNode02 |
14マップ 8リデュース |
なし |
|
Node03とNode04 |
10マップ 6リデュース |
10マップ 6リデュース |
|
Node05~Nodenn |
20マップ 13リデュース |
20マップ 13リデュース |
脚注 1 9ノード以上
表2-5は、Oracle Big Data Appliance Sun Fire X4270 M2ベース・ラックでのMapReduceサービスのデフォルトのリソース構成を示したものです。
表2-5 Sun Fire X4270 M2ベース・ラックでのマップおよびリデュース・タスクの最大数
| ノード | 6ノード・クラスタ | より大規模なクラスタ脚注 1 |
|---|---|---|
|
Node01とNode02 |
10マップ 6リデュース |
なし |
|
Node03とNode04 |
7マップ 4リデュース |
7マップ 4リデュース |
|
Node05~Nodenn |
15マップ 10リデュース |
15マップ 10リデュース |
脚注 1 9ノード以上
HBaseは、CDHで提供される、オープンソースの列指向データベースです。HBaseは、Oracle Big Data Applianceでは自動的には構成されません。別のシステム上のHBaseクライアントからアクセスできるようにするには、事前にHBaseを設定および構成する必要があります。
HBaseサービスを作成するには、次の手順に従います。
次のようなURLを使用して、ブラウザでCloudera Managerを開きます:
http://bda1node03.example.com:7180
この例で、bda1はアプライアンス名、node03はサーバー名、example.comはドメイン、7180はデフォルトのポート番号(それぞれCloudera Managerで使用)を示します。
「All Services」ページで、「Add a Service」をクリックします。
サービスのリストからHBaseを選択し、「Continue」をクリックします。
zookeeperを選択し、「Continue」をクリックします。
ホスト割当てページで「Continue」をクリックします。
レビュー・ページで「Accept」をクリックします。
これで、HBaseを構成できる状態になります。
Oracle Big Data Appliance上でHBaseを構成するには、次の手順に従います。
Cloudera Managerの「All Services」ページで、「hbase1」をクリックします。
「hbase1」ページで、「Configuration」をクリックします。
左の「Category」ペインで、「Service-Wide」の「Advanced」を選択します。
右のペインで、hbase-site.xmlプロパティのHBase Service Configuration Safety Valveを探し、「Value」セルをクリックします。
次のXMLプロパティ説明を入力します。
<property> <name>hbase.master.ipc.address</name> <value>0.0.0.0</value> </property> <property> <name>hbase.regionserver.ipc.address</name> <value>0.0.0.0</value> </property>
「Save Changes」ボタンをクリックします。
HBaseサーバーの現在のステータスに応じて、「Actions」メニューから「Start」または「Restart」を選択します。
Cloudera Managerからログアウトします。
サーバー障害の影響は、CDHクラスタ内におけるサーバーの機能によって異なります。Oracle Big Data Applianceサーバーは、コモディティ・ハードウェアよりも堅牢なため、ハードウェア障害が発生することはほとんどありません。この項では、プライマリ・ラックの様々なサーバー上で実行される重要性の高いサービスに焦点を当てています。完全なリストは、「CDHサービスの実行場所」を参照してください。
クリティカル・ノードは、クラスタが正常に動作し、すべてのサービスをユーザーに提供するために必要です。これとは対照的に、非クリティカル・ノードに障害が発生しても、クラスタはサービスを失うことなく動作し続けます。
シングルラック・クラスタでは、重要なサービスはクラスタの最初の4つのノードに初期インストールされます。残りのノード(node05から最大でnode18まで)は重要性の低いサービスのみを実行します。クリティカル・ノードのいずれかでハードウェア障害が発生した場合は、別の非クリティカル・サーバーにサービスを移行できます。たとえば、node02に障害が発生した場合、重要なサービスをnode05に移行できます。表2-2は、シングル・ラック上に構成されたクラスタのサービスの初期ロケーションを示したものです。
マルチラック・クラスタでは、一部の重要なサービスが第2ラックの第1サーバーで実行されます。「CDHサービスの実行場所」を参照してください。
クリティカル・ノードを移行するには、すべてのクライアントが新しいノードのアドレスで再構成されている必要があります。もう1つの方法としては、障害が発生したサーバーの復旧を待ちます。サービスの喪失とクライアントを再構成する不便さとを比較検討する必要があります。
表2-6 重要なサービスの場所
| ノード名 | 初期ノードの場所 | 重要な機能 |
|---|---|---|
|
第1NameNode |
node01 |
ZooKeeper脚注 1 、第1 NameNode脚注 1、フェイルオーバー・コントローラ脚注 1、バランサ脚注 1、Puppetマスター |
|
第2NameNode |
node02 |
ZooKeeper、第2NameNode、フェイルオーバー・コントローラ、MySQLバックアップ・サーバー |
|
第1 JobTrackerノード |
node03 |
ZooKeeper、第1 JobTracker、フェイルオーバー・コントローラ、Cloudera Managerサーバー、MySQLプライマリ・サーバー |
|
第2 JobTrackerノード |
Node04 |
第2 JobTracker、フェイルオーバー・コントローラ、Oracle Data Integratorエージェント、Hue、Hive、Oozie |
脚注 1 マルチラック・クラスタでは、このサービスは第2ラックの第1サーバー上に初期インストールされます。
NameNodeインスタンスの1つは、初期設定ではnode01上で実行されます。このノードに障害が発生するか、オフライン(再起動など)になると、第2NameNode (node02)が自動的に引き継いで、クラスタの正常なアクティビティを維持します。
または、第2NameNodeがすでにアクティブな場合は、バックアップなしで動作し続けます。NameNodeが1つのみの場合、クラスタは障害に対して脆弱です。クラスタが、自動フェイルオーバーに必要な冗長性を失うためです。
Puppetマスターもこのノードで実行されます。MammothユーティリティではPuppetを使用するので、たとえばラック内の別の場所にあるディスク・ドライブを交換する必要がある場合、ソフトウェアのインストールまたは再インストールはできません。
|
注意: マルチラック・クラスタでは、NameNodeサービスは第2ラックの第1サーバーにインストールされます。 |
NameNodeインスタンスの1つは、初期設定ではnode02上で実行されます。このノードに障害が発生すると、NameNodeの機能は第1NameNode (node01)にフェイルオーバーされるか、そのままバックアップなしで動作し続けます。ただし、第1NameNodeにも障害が発生すると、クラスタは自動ファイルオーバーに必要な冗長性を失っています。
MySQLバックアップ・データベースもこのノードで実行されます。MySQL Serverは動作を継続しますが、マスター・データベースのバックアップはありません。
JobTrackerインスタンスの1つは、初期設定ではnode03上で実行されます。このノードに障害が発生するか、このノードが(再起動などによって)オフラインになると、第2 JobTracker (node04) が自動的に機能を引き継ぎ、MapReduceタスクをクラスタの特定のノードへと分配します。
または、第2 JobTrackerがすでにアクティブな場合は、バックアップなしで動作し続けます。JobTrackerが1つのみの場合、クラスタは障害に対して脆弱です。クラスタが、自動フェイルオーバーに必要な冗長性を失うためです。
次のサービスも影響を受けます。
Cloudera Manager: このツールは、CDHクラスタ全体の一元管理機能を提供します。このツールがない場合は、「Hadoop監視ユーティリティの使用方法」で説明したユーティリティを使用すれば、引き続きアクティビティを監視できます。
MySQL Master Database: Cloudera Manager、Oracle Data Integrator、HiveおよびOozieはMySQLデータベースを使用しています。データは自動的にレプリケートされますが、マスター・データベース・サーバーが停止していると、それにはアクセスできません。
JobTrackerインスタンスの1つは、初期設定ではnode04上で実行されます。このノードに障害が発生すると、JobTrackerの機能は第1 JobTracker (node03)にフェイルオーバーされるか、そのままバックアップなしで動作し続けます。ただし、第1 JobTrackerにも障害が発生すると、クラスタは自動フェイルオーバーに必要な冗長性を失っています。
次のサービスも影響を受けます。
Oracle Data Integrator: このサービスは、Oracle Data Integrator Application Adapter for Hadoopをサポートしています。JobTrackerノードが停止している場合、このコネクタは使用できません。
Hive: Hiveは、HDFSに格納されているデータへのSQLライクなインタフェースを備えています。Oracle Big Data Connectorsの多くは、Hive表にアクセスできますが、このノードが動作していない場合は使用できません。
Oozie: このワークフローおよび調整サービスはJobTrackerノードで実行され、このノードがダウンしているときには使用できません。
CDHの問題のトラブルシューティングを行うために、Oracleサポートのアドバイスが必要な場合は、まずbdadiagユーティリティをcmオプションを指定して使用し、診断情報を収集してください。
診断情報を収集するには、次の手順を実行します。
Oracle Big Data Applianceサーバーにrootとしてログインします。
少なくともcmオプションを指定してbdadiagを実行します。必要に応じてコマンドに他のオプションを含めることができます。bdadiagの構文の詳細は、『Oracle Big Data Applianceオーナーズ・ガイド』を参照してください。
# bdadiag cm
コマンド出力によって、診断ファイルの名前と場所が識別されます。
My Oracle Support (http://support.oracle.com)へ移動します。
サービス・リクエスト(SR)を開きます(まだ開いていない場合)。
SRにbz2ファイルをアップロードします。ファイルのサイズが大きすぎる場合は、sftp.oracle.comにアップロードしてください(次の手順を参照)。
診断情報をftp.oracle.comにアップロードするには、次の手順を実行します。
SFTPクライアントを開き、sftp.oracle.comに接続します。ポート2021とリモート・ディレクトリ/support/incoming/targetを指定します(targetは、Oracle Supportにより指定されたフォルダ名です)。
コマンドラインSFTPクライアントを使用している場合は、例2-1を参照してください。
Oracle Single Sign-Onのアカウントとパスワードでログインします。
診断ファイルを新しいディレクトリにアップロードします。
このフル・パスおよびファイル名でSRを更新します。
例2-1は、SFTPコマンド・インタフェースを使用して、診断情報をアップロードするコマンドを示しています。
例2-1 FTPを使用した診断情報のアップロード
$ sftp -o port=2021 my.user.name@oracle.com@sftp.oracle.com Connecting to sftp.oracle.com... . . . Enter password for my.user.name@oracle.com Password: password sftp> cd support/incoming/SR123456 sftp> put /tmp/bdadiag_bda1node01_1216FM5497_2013_07_18_07_33.tar.bz2 Uploading bdadiag_bda1node01_1216FM5497_2013_07_18_07_33.tar.bz2 to //support/incoming/create_table.sql bdadiag_bda1node01_1216FM5497_2013_07_18_07_33.tar.bz2 to support/incoming/create_table.sql 100% 311 0.3KB/s 00:00 sftp> exit $
Oracle Big Data Applianceではソフトウェアやデータの不正利用を防ぐための予防策を取ることができます。
Oracle Big Data Applianceにインストールされるオープンソース・パッケージごとに、1つ以上のユーザーおよびグループが作成されます。このようなユーザーのほとんどは、ログイン権限、シェル、またはホーム・ディレクトリを持っていません。これらはデーモンによって使用され、各ユーザー向けのインタフェースとしては設計されていません。たとえば、Hadoopはhdfsユーザーとして、MapReduceはmapredとして、Hiveはhiveとしてそれぞれ動作します。
Oracle Big Data Applianceソフトウェアのインストール直後にHadoopおよびHiveジョブを実行するには、oracle IDを使用できます。このユーザー・アカウントは、ログイン権限、シェル、およびホーム・ディレクトリを保持しています。
Oracle NoSQL DatabaseおよびOracle Data Integratorはoracleユーザーとして実行します。プライマリ・グループはoinstallです。
|
注意: インストール時に作成されたユーザーは、ソフトウェアの操作に必要なため、削除や変更はしないでください。 |
表2-7に、Oracle Big Data Applianceソフトウェアのインストール時に自動的に作成され、CDHコンポーネントおよびその他のソフトウェア・パッケージによって使用されるオペレーティング・システム・ユーザーおよびグループを示します。
表2-7 オペレーティング・システム・ユーザーおよびグループ
| ユーザー名 | グループ | 使用者 | ログイン権限 |
|---|---|---|---|
|
|
Flume親およびノード |
なし |
|
|
|
HBaseプロセス |
なし |
|
|
|
なし |
||
|
|
なし |
||
|
|
Hueプロセス |
なし |
|
|
|
JobTracker、TaskTracker、Hive Thriftデーモン |
あり |
|
|
|
|
あり |
|
|
|
Oozieサーバー |
なし |
|
|
Oracle NoSQL Database、Oracle Loader for Hadoop、Oracle Data IntegratorおよびOracle DBA |
あり |
||
|
|
Puppet親( |
なし |
|
|
|
Sqoopメタストア |
なし |
|
|
自動サービス・リクエスト |
なし |
||
|
|
ZooKeeperプロセス |
なし |
表2-8に、CDH用のポート番号の他に使用される可能性のあるポート番号を示します。
特定のサーバー上で使用されるポート番号を確認するには、次の手順を実行します。
Cloudera Managerで、ページ上部にある「Hosts」タブをクリックして、「Hosts」ページを表示します。
「Name」列でサーバーのリンクをクリックすると、その詳細ページが表示されます。
「Ports」セクションまで下方向にスクロールします。
|
関連項目: CDHのポート番号の詳細なリストは、次に示すClouderaのWebサイトを参照してください。 |
Apache Hadoopは、本質的に安全なシステムではありません。ネットワーク・セキュリティによってのみ保護されています。接続が確立されると、クライアントはシステムに対して完全なアクセス権限を取得します。
Cloudera's Distribution including Apache Hadoop (CDH)では、Kerberosネットワーク認証プロトコルをサポートし、悪意のある偽装攻撃を防ぎます。Kerberosをインストールして構成し、Kerberos Key Distribution Centerおよびレルムを設定する必要があります。その後で、CDHの各種コンポーネントでKerberosを使用するように構成します。
Kerberosを使用するように構成された場合、CDHは次のセキュリティを提供します。
CDHマスター・ノード、NameNodeおよびJobTrackerでグループ名を解決し、ユーザーがグループのメンバーシップを操作できないようにします。
マップ・タスクはジョブを発行したユーザーのアイデンティティの下で実行されます。
|
関連項目: 次のマニュアルは、http://oracle.cloudera.comで入手できます。
|
Puppetノード・サービス(puppetd)は、すべてのサーバー上でrootとして継続的に実行されます。Puppetマスターに対する更新リクエストのトリガーとなるキック・リクエストを、ポート8139上でリスニングします。このポート上で更新は受信しません。
Puppetマスター・サービス(puppetmasterd)は、Oracle Big Data Applianceのプライマリ・ラックの第1サーバー上で、Puppetユーザーとして継続的に実行されます。ポート8140上で、Puppetノードに更新をプッシュするリクエストをリスニングします。
Puppetノードは、ソフトウェアのインストール時に初期登録するため、証明書を生成してPuppetマスターに送信します。ソフトウェアのアップデートの場合は、PuppetマスターからPuppetノードに信号(キック)が送信され、そこから登録先のPuppetマスター・ノードに対して、すべての構成変更がリクエストされます。
Puppetマスターは、既知の有効な証明書を保持しているPuppetノードに対してのみ更新を送信します。Puppetノードは、初期登録されたPuppetマスターのホスト名からの更新のみを受け付けます。Oracle Big Data Applianceでは、ラック内の通信に内部ネットワークを使用するため、Puppetマスターのホスト名は、/etc/hostsを使用して、内部のプライベートIPアドレスに解決されます。