Oracle® Insurance Rules Palette
The Identifier field data type is typically used in the following situations:
to generate identification numbers using alphabetic and/or numeric parts. The numeric parts may be incremented in order to provide a unique ID constructed with the same elements. An example would be the generation of a claim number for a death claim process that is unique among other claim numbers.
to generate a value built from variable data values. An example would be the generation of a classification of payments by its source (Payment-Cash, Payment-EFT, Payment-Rollover).
![]()
Identifier Option in Palette Window
When setting up a new Identifier, you must insert the first record into the AsSequence table, then add the database component that allows it to work correctly. The scripts required for each type of database are provided below.
ALL (ORACLE, DB2, SQL):
Insert into ASSEQUENCE (SEQUENCENAME, SEQUENCEINTEGER, SEQUENCEDESCRIPTION, DATABASESEQUENCENAME)
Values ('ConfirmationNumber', 1, 'ConfirmationNumber', 'ConfirmationNumber')
Insert into ASSEQUENCE (SEQUENCENAME, SEQUENCEINTEGER, SEQUENCEDESCRIPTION, DATABASESEQUENCENAME)
Values ('ConfirmationNumberMV', 1, 'ConfirmationNumberMV', 'ConfirmationNumberMV')
ORACLE and DB2 Only:
Create sequence ConfirmationNumber start with 1 increment by 1 maxvalue 999999999 cache 200
Create sequence ConfirmationNumberMV start with 1 increment by 1 maxvalue 999999999 cache 200
Keep in mind the following points when configuring Identifier field types.
The Identifier field data type is applicable in any component that may contain the common entry Fields definition (screens, activity fields section). It does NOT apply where data must pass from one component to another as in spawns and updating business rules (CopyTo...) or in Math and ScreenMath.
An Identifier field cannot be used in ScreenMath. The field’s value is generated when the component is saved to the data store and is therefore not always available for ScreenMath.
Once an Identifier field has been generated using its unique set of attributes, it is treated as a text value everywhere else.
An identifier field may be passed to another activity through a spawn or updated to a component in an APE rule. The receiving field is defined as a text field and the data is passed as if it were text.
An identifier field may be source data for a math variable. It is treated as a text field with the math variable defined as a text data type.
The total character length of the identifier field is limited to the same size as a field of data type TEXT.
Each type is added to the Parts node in the Rules Palette Identifier Field - Parts window. Each type translates to a <Part> element in the XML.
Identifier Field configuration supports the use of the <ClearOnRecycle> sub-element. When <ClearOnRecycle> is set to Yes, the value of the Identifier Field will be on-load cleared if the activity is manually recycled. If the activity is re-done due to system-generated undo/redo, then the original Identifier Field value is retained.
Drag and drop the Identifier field from the Palette window onto the Fields Pane. The Field Properties window will open, which provides the means for configuring the field. Enter the field information such as field name, display name, etc., by clicking in the field and typing the information.
Scroll down to the Parts line and click the box to the right of that line. This will open the Parts window, where the individual components of the unique identifier can be created. An explanation of each type is given in the section below.
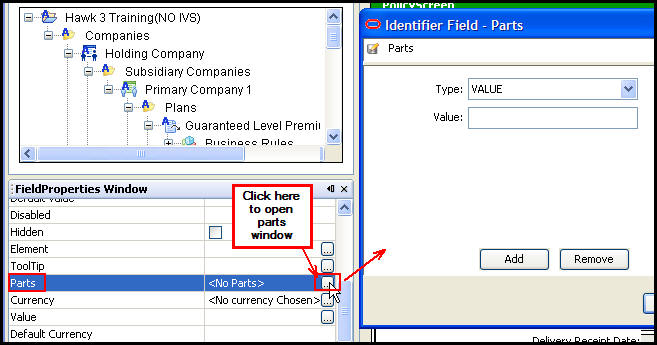
Field Properties Window for Identifier Field
The following list explains the various Identifier Parts options. Each type is listed, along with the configuration options that accompany the type. Each type translates to a <Part> element in the XML.
When Type=Value is selected:
The value of the <Part> element is the literal text that is concatenated to the identifier field.
When Type=SystemDate is selected:
Format: Portions of the system date or all of the system date may be concatenated to the identifier field. The required attribute FORMAT defines the portions that will make up the resulting value to concatenate. The following is a list of the attribute’s values and what they accomplish.
YY and YYYY results in 2 and 4 digit years, respectively.
MM results in a 2 digit month.
DD results in a 2 digit day.
YYMM and YYYYMM results in a 2 digit year, 2 digit month value or a 4 digit year, 2 digit month value, respectively. Both create a value in year-month order.
YYYYMMDD results is a full date value with a 4 digit year in year-month-day order.
YYMMDD results is a full date value with a 2 digit year in year-month-day order.
When Type=Sequence is selected:
A sequence number is generated from a sequence set identified by the sequence name referenced in the <Part> element’s value. Once a sequence number becomes part of the Identifier field’s value, it cannot be duplicated by any subsequent Identifier field using the same sequence set. A sequence number becomes part of the Identifier field’s value as the screen component or Activity Detail screen is persisted in the data store. Concurrent accesses to the same sequence will yield different sequence values.
A required FORMAT attribute specifies the padding characters and length of the output that is concatenated to the identifier field. The padding character may be any visible character or mix of characters that define the padding character(s). The length of the output is defined by the number of characters in the FORMAT attribute's value. For example, if FORMAT=”000”, the complete length of the <Part> value is 3. If the sequence number is 1, then the output is 001. If the sequence number is 100, then the output is 100.
An optional SEQUENCEDATE attribute filters the sequence records for a specific sequence set. It may be used to restart the sequence numbering as of a specific date. The value of the attribute indicates the data source for the date. One data source for the attribute’s value is a field name. The field must be defined prior to the identifier field and must be a date data type. Other data sources for the attribute's value may be the system date and an activity's effective date. The latter is applicable to transaction configuration only.
The following image shows data that resides in the sequence data store for a specific sequence set.
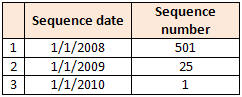
Sequence Data Store for a Sequence Set
For any date value provided to SEQUENCEDATE that falls between 1/1/2008 and 12/31/2008, inclusively, record #1 is used to supply sequence numbers. The next number is 501.
For any date value provided to SEQUENCEDATE that falls between 1/1/2009 to 12/31/2009, inclusively, record #2 is used to supply sequence numbers. The next number is 25.
For any date value provided to SEQUENCEDATE that is equal to or greater than 1/1/2010, record #3 is used. The next number is 1.
Any positive integer value may be used as a starting value. Maximum value for a sequence number is about 2.1 billion.
Field
Parse: select Left, Right, Mid and enter a Parse Value. These indicators are used to tell the system what part of the value to concatenate to the identifier's field value. A sample of each option is given below:
Left & Parse Value: specifies the number of characters extracted from the start of the field’s value. Ex: If the Field value is12345, then LEFT with Parse Value=2 would mean that 12 is extracted and concatenated to the identifier's value.
Right & Parse Value: specifies the number of characters extracted from the end of the field’s value. Ex: If the Field value is 12345, then RIGHT with Parse Value=2 would mean that 45 is concatenated to the identifier's value.
Mid & Parse Value: specifies the starting and ending location in the field’s value from which to extract the value. Ex: If the Field value is 12345, then MID with Parse Value 2 and 5 would mean that 2345 is concatenated to the identifier's value.
Format: indicates the padding character and the length of the resulting value. Any character or mixture of characters define the padding character(s). The length of the output is defined by the number of characters in the FORMAT attribute's value. Padding will always occur to the left of the parsed value to create a result that is the length of FORMAT attribute. For example, FieldA contains the value of Mon. FieldB is an identifier data type field with a Part type of Field defined with a FORMAT=ddddd. The resulting value is ddMon, which is then concatenated to the identifier field’s value. The padding character is d and the resulting value’s length is 5 because d was repeated 5 times in the FORMAT attribute's value.
Value: The value of the Part element of TYPE="FIELD" is the name of the field whose value may be parsed and padded then concatenated to the identifier field's value.
Copyright © 2009, 2013, Oracle and/or its affiliates. All rights reserved. Legal Notices