| Oracle® Real User Experience Insightユーザーズ・ガイド 12c リリース3 (12.1.0.4) for Linux x86-64 E49732-01 |
|


 前 |
 次 |
| Oracle® Real User Experience Insightユーザーズ・ガイド 12c リリース3 (12.1.0.4) for Linux x86-64 E49732-01 |
|
前 |
次 |
この付録では、RUEI内で用意されている、XPath問合せを使用するためのサポートについて詳しく説明します。これらはコンテンツ・メッセージ、クライアント識別、カスタム・ディメンション、およびページ識別とサービス識別の定義の一部として使用できます。
XPath(XML Path言語)は、XML文書からノードを選択したり、値を計算するのに使用できる問合せ言語です。RUEIにおけるXPathバージョン1.0のサポートはlibxml2に基づきます。詳細は次のサイトを参照してください。
http://xmlsoft.org/
XPath言語の仕様の詳細は、次のサイトを参照してください。
http://www.w3.org/TR/xpath
重要:
RUEIでは、すべてのトラフィックのコンテンツに対して、実際にそれがXML形式であるかどうかにかかわらず、XPath一致が適用されます。このため、正確な結果を取得するには、すべてのXPath式が整形式XHTMLコードに対して実行されるようにし、F.5項「XPathスキャンの最適化」の情報を確認することを強くお薦めします。また、XPath式では大/小文字が区別されることに注意してください。
XML名前空間を使用すると、XML文書内の要素および属性に一意の名前を付けることができます。XMLインスタンスには、複数のXMLボキャブラリからの要素名または属性名が含まれている場合があります。各ボキャブラリに名前空間が割り当てられている場合は、同じ名前の要素間または属性間のあいまいさを解決できます。
RUEIでは、XPath問合せで使用するすべての名前空間が明示的に定義されている必要があります。名前空間を問合せで使用する場合は、定義されていないと機能しません。名前空間を定義する手順は、次のとおりです。
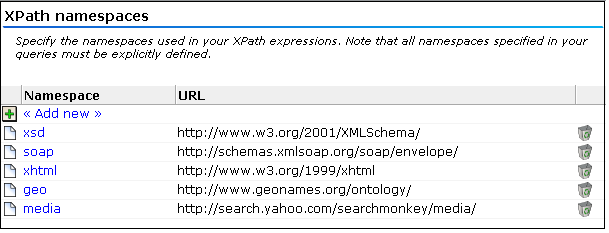
「構成」→「一般」→「詳細設定」→「XPathネームスペース」の順に選択します。図F-1に示すウィンドウが表示されます。
このウィンドウは、XPathベースのコンテンツ・メッセージ、カスタム・ディメンション、ユーザー識別、およびページ識別とサービス識別の定義を指定するときに、「ネームスペース」タブをクリックしても表示できます。
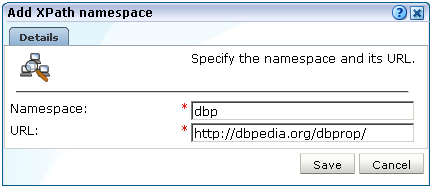
「新規追加」をクリックして新しい名前空間を定義するか、または既存の定義をクリックして変更します。図F-2に示すダイアログが表示されます。
監視対象のXML文書内で使用する名前空間接頭辞および対応する基本URLを指定します。名前を一意にする必要があります。名前空間と接頭辞の使用方法に関する重要な情報は、F.3項「名前空間の接頭辞およびURLの概要」を参照してください。名前空間の定義はグローバルで、すべての監視対象トラフィックに適用されます。
次に、「保存」をクリックします。新しい定義または既存の定義の変更は、5分以内に有効になります。
|
注意: 定義済のネームスペースを削除する場合、トラフィックの監視で必要ないことを確認することをお薦めします。 |
名前空間は接頭辞(ローカル・バインディングの形式とみなすことができる)とURLで構成されます。これは、実際の名前空間を定義する文書の場所を示します。たとえば、my_ns1=http://www.w3.org/1999/xhtmlのようになります。
名前空間はそのURL(または該当する場所にある文書のコンテンツ)によって定義されることを理解しておく必要があります。接頭辞は単に、XMLノードおよび要素内で名前空間URLへの参照を示します。このため、同じ名前空間を複数の接頭辞にバインドしたり、これらの接頭辞を文書内に混在させることができます。その結果、すべての接頭辞が同じURLを指すことにより、すべての要素が同じ名前空間に配置される可能性があります。
別の文書の異なる名前空間に同じ接頭辞がバインドされる場合があります。さらに、XMLでは、同一文書内で異なる複数のURLに同じ接頭辞をバインドできます。
異なる複数の名前空間、同一の接頭辞
次の例を考えてみます。
<parent xmlns:ns1="foo">
<child xmlns:ns2="bar">
<ns2:some_element>
</child>
<child xmlns:ns2="baz">
<ns2:some_element>
</child>
</parent>
ここでは、2つの子ノードが2つの異なる名前空間(barとbaz)を使用していますが、ローカルでのバインドには同じ接頭辞を使用してしています。このため、<some_element>ノードは、2つの子ノードにおいてそれぞれ異なる意味を持ちます。
2番目の<some_element>ノードを選択することを考えてみます。XPath式//ns2:some_elementの使用を考慮します。ただし、RUEIでns2接頭辞が最初の定義(bar)または2番目(baz)を参照するかどうかを判別できないため、これは機能しません。
ここで、これらのノードを両方とも一致させる場合について考えてみます。可能性としては、名前空間の定義をまったく無視して、ワイルドカード式を使用する方法が考えられます。次に例を示します。
//*[local-name()='some_element']
ただし、この式では、関係ない名前空間にバインドされたものまで含むすべての<some_element>ノードが検出されます。実際の接頭辞名は意味を持たないことを理解しておく必要があります。接頭辞は定義されている文書の一部に対してローカルであるため、対象の場所で有効な名前空間に接頭辞がバインドされている限り、XPath式でどの接頭辞を使用するかは問題になりません。このため、次のXPath式は、
//ns2:some_element
(ns2はbazを指す)2番目の<some_element>ノードに一致します。ただし、XPath式に指定された実際の接頭辞は文書で使用されている接頭辞と一致する必要がないので、次のXPath式も使用できます。
//boo:some_element
booはbarを指します。この場合、XPath式では、名前空間bazにローカルでバインドされているノードを検出し、booを使用してXPath式内の該当する名前空間を参照します。RUEIでは、この式がロードされると、booが指している名前空間(この場合はbaz)を参照し、名前空間baz内で<some_element>という名前のノードを検出する必要があることを記録します。その時点で、接頭辞はもう必要ありません。RUEIでは、文書のスキャン時に<some_element>要素を検出するたびに、ローカルで定義された接頭辞を介して現在の名前空間を取得して、XPath式に定義された名前空間と比較します。両方ともbazであれば、一致が検出されます。
前述の内容を踏まえ、次のXPath式を使用して両方のノードが抽出されるようにRUEIを構成できます。
//boo:some_element where boo=bar//hoo:some_element where hoo=baz
その他の例
次のXML文書について考えてみます。
<parent xmlns:ns2="foo">
<child xmlns:ns2="bar">
<ns2:some_element>
</child>
</parent>
この例では、親ノードと子ノードが異なる名前空間を使用していますが、両方とも同じ接頭辞(ns2)にバインドされています。名前空間の定義はローカルであるため、これは有効です。<some_element>ノードの内容を検出するには、次のXPath式を使用できます。
/p_parent:parent/p_child:child/p_child:some_element
p_parentはfooで、p_childはbar(または、任意のローカル接頭辞文字列)です。
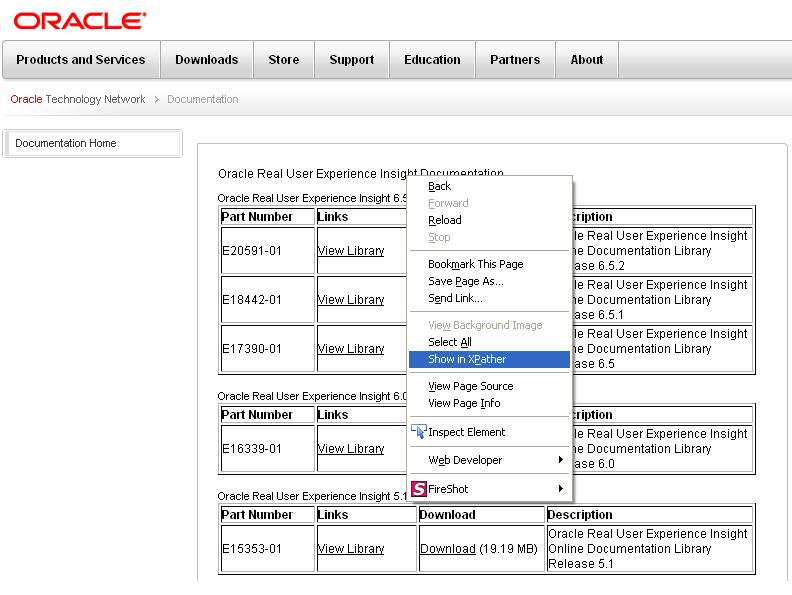
利便性向上のため、Mozilla FirefoxのXPather拡張など、サード・パーティのXPathツールを使用して、RUEI内で使用可能なXPath式を作成できるようになっています。このXPather拡張は、次のサイトから入手可能です。
http://xpath.alephzarro.com/index
インストールすると、ページ内で右クリックしてXpatherで表示オプションを選択できるようになります。例を図F-3に示します。
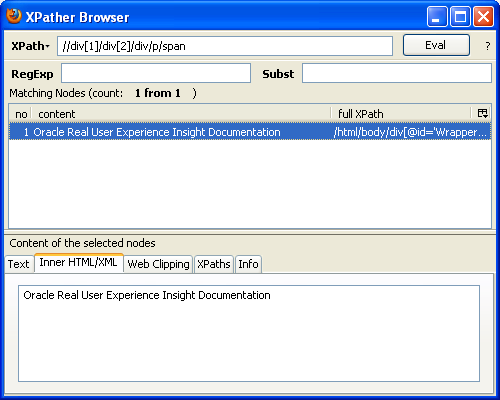
次に、XPatherブラウザ(図F-4を参照)内でXPath式をコピーすれば、RUEIでのXPath問合せのベースとして使用できます。必ず、生成されたXPath式を確認して、前述の制限事項に準拠していることを確認してください。
|
注意: ページ内の基礎となるXHTMLコードが整形式でない場合、XPatherによって生成されたXPath式はRUEI内で正常に機能しない場合があります。 |
この項では、XMLスキャンの最適化方法およびコレクタ・システムの過剰なメモリーおよびCPU使用率が生じる可能性がある多数のドキュメントの不要なスキャンを防ぐ方法について説明します。
定義済のXPath定義に対してスキャンするドキュメントは、次の方法で決定されます。
ドキュメントが強制オブジェクトの場合、スキャンされません。強制オブジェクトとみなされるファイル拡張子および構成方法の詳細は、12.15項「ページとしてのオブジェクトのレポートの制御」を参照してください。
それ以外の場合は、ドキュメントのContent-TypeヘッダーでHTMLまたはXMLを指定すると、HTMLまたはXMLファイルとしてスキャンされます。
ドキュメントのContent-Typeがhtmlまたはxml以外の場合またはドキュメントにContent-Typeヘッダーが含まれない場合、メッセージ・コンテンツの開始が事前定義済のコンテンツ文字列と比較され、一致するとドキュメントがHTMLまたはXMLコンテンツに対してスキャンされます。
最後に、事前定義済のコンテンツ文字列が一致せず、デフォルトのコンテンツ・タイプ(HTMLまたはXML)が構成されている場合、指定されたデフォルト・タイプでもドキュメントがスキャンされます。
XML/HTMLコンテンツ文字列
Content-Typeヘッダーがドキュメントに見つからない場合またはHTMLまたはXML以外が指定されている場合、メッセージ・コンテンツの開始が事前定義済の文字列と比較され、一致するとHTMLまたはXMLドキュメントでもスキャンされます。デフォルトのコンテンツ文字列を表F-1に示します。
XMLコンテンツ文字列は大/小文字が区別され、HTML文字列は区別されません。
コレクタ・システムでRUEI_USERユーザーとして次のコマンドを発行して、追加のコンテンツ文字列を定義できます。
execsql config_set_prj_value wg xpath-optionstypeadd "content-string"
構造の各要素の意味は、次のとおりです。
typeでは、ドキュメントをHTML(html-magic)またはXML(xml-magic)としてスキャンするかどうかを指定します。
content-stringでは、ドキュメントの開始を比較する文字列を指定します。
次に例を示します。
execsql config_set_prj_value wg xpath-options xml-magic add "<soap:"
デフォルトのコンテンツ・タイプ
定義されたコンテンツ文字列が一致しない場合、スキャンするためにデフォルトのコンテンツ・タイプをこれらのドキュメントに割り当てることができます。それには、コレクタ・システムでRUEI_USERユーザーとして次のコマンドを発行します。
execsql config_set_prj_value wg xpath-options default-content-type add "type"
typeは、xmlまたはhtmlです。