7 Understanding the Oracle Unified Directory Replication Model
This chapter provides a general introduction to Oracle Unified Directory replication in the directory server, including basic concepts and a description of the replication architecture.
Note:
The architectural topics described in this chapter are targeted at developers and at users who want to understand the internal replication mechanism. You do not have to read these topics to configure and use replication. For information about configuring and using replication, see Chapter 32, "Replicating Directory Data."This chapter includes the following sections:
7.1 Overview of the Replication Architecture
Replication enables copies of identical data to be available across multiple servers. Oracle Unified Directory uses a a loosely consistent multi-master replication model, which means that all the directory servers within a replication topology can accept read and write operations.
Replication is built around a centralized publish-subscribe architecture. Each directory server communicates with a central service, and uses the central service to publish its own changes and to receive notification about changes on other directory servers. This central service is called the replication service.
The replication service can be made highly available by using multiple server instances running on multiple hosts. Within the replication architecture, a server instance that provides the replication service is called a replication server. A server instance that provides the directory service is called a directory server.
The parties in a replication session authenticate to each other using SSL certificates. A connection is accepted if the certificate that is presented is in the ADS trust store. No access control or privileges are enforced.
The topics in this section describe the replication architecture and the various elements comprise this architecture.
7.1.1 Basic Replication Architecture
The basic replication architecture is shown in the following illustration.
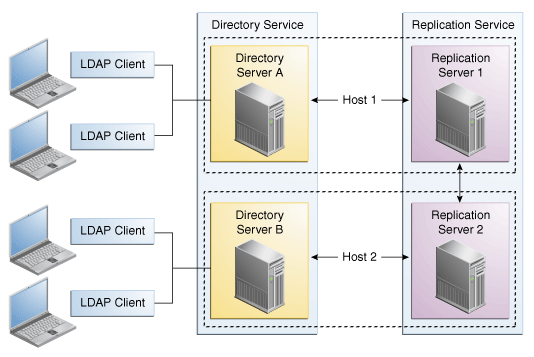
Description of the illustration ''basic-repl-architecture.gif''
At startup time, each directory server selects a single replication server and connects to it. The directory server sends all changes that it processes to that replication server, and receives all changes from other servers in the topology through that replication server. Each replication server is connected to every other replication server in the topology.
Note:
In a replication architecture, each replication server is connected to every other replication server in the topology.When a replication server receives a change from a directory server, the replication server forwards the change to all the other replication servers in the topology. These replication servers in turn forward the change to all the directory servers to which they are connected. When a replication server receives a change from another replication server, the replication server forwards the change to the directory servers to which it is connected, but not to other replication servers. A directory server never sends a change directly to another directory server. This architecture ensures that all changes are forwarded to all servers without requiring complex negotiation.
Every change is assigned a change number by the directory server that originally processed the change. The change number is used to identify the change throughout its processing. A replication server maintains changes in persistent storage so that older changes can be resent to directory servers that were not connected when the change occurred or that fell behind, becoming temporarily unable to receive all the changes at the time they were processed. For more information, see Chapter 7, "Replication Change Numbers."
The current update state of each directory server is maintained by keeping a record of the last changes that the directory server processed. When a directory server connects to a replication server, the replication server uses this record to determine the first change in the list of updates to send to the directory server.
Because multiple directory servers can process updates simultaneously, an update operation on one directory server can conflict with another update operation that affects the same entries on another directory server. Each directory server resolves conflicts when it replays operations from other directory servers, so that all directory server data eventually converges.
Conflicts can occur because of conflicting modify operations, called modify conflicts. Conflicts can also occur because of conflicting add, delete, or modRDN operations, called naming conflicts. To resolve conflicts in a coherent way, directory servers maintain a history of successive changes to each entry. This history is called historical information. Historical information is stored as an operational attribute inside the entry on which the changes occurred. For more information, see Section 7.3, "Historical Information and Conflict Resolution."
7.1.2 Replication Servers
A replication server performs the following tasks:
-
Manages connections from directory servers
-
Connects to other replication servers
-
Listens for connections from other replication servers
-
Receives changes from directory servers
-
Forwards changes to directory servers and other replication servers
-
Saves changes to stable storage, which includes trimming older operations
Replication servers are different from directory servers. However, like directory servers, replication servers use a configuration file, and they can be configured, monitored online, backed up, and restored. Replication servers are therefore always LDAP servers or JMX servers, even though replication servers do not store directory data.
When you configure a directory server instance for replication, a replication server is created automatically, unless you specify otherwise. The replication server and the directory server can run in the same JVM, or in separate JVMs.
In a small topology (up to four directory servers) it makes sense to configure each server to function as both a directory server and a replication server. In a large topology (more than twenty directory servers) it is advisable to separate the directory server and replication server instances into separate JVMs, and to limit the number of replication servers.
Between these two extremes, you can decided on the configuration that works best for your requirements. Having all servers functioning as both directory servers and replication servers is generally a simpler topology and easier to administer. Separating the directory servers and replication servers lowers the disk requirements of the directory server instances because they do not need to store a replication change log.
7.1.3 Replication Change Numbers
Change numbers uniquely identify changes that are made on an LDAP directory server. Change numbers also provide a consistent ordering of changes. The change number order is used to resolve conflicts and to determine the order in which forwarded changes should be replayed.
A change number consists of the following elements:
-
Time stamp, in milliseconds. Time stamps are generated using the system clock. The change number is also generated such that each change number is always greater than all the change numbers that have already been processed by the server. Constantly increasing change numbers guarantees that operations that depend on previous operations are consistently replayed in the correct order. An example of an operation that depends on a previous operation is a modify operation that directly follows the add operation for that entry.
-
Sequence number. A sequential number, increment for each change that occurs within the same millisecond.
-
Replica identifier. A unique integer identifier that is assigned to each replica in a topology. (A replication topology is the set of all replicas of a given data set. For example, the replication topology for
example.commight be all copies of thedc=example,dc=comsuffix across a directory service.)The replica identifier ensures that two different servers do not assign the same identifier to two different changes. In a future directory server release, an algorithm might be used to assign replica identifiers automatically.
7.1.4 Replication Server State
When a directory server connects to a replication server, the replication server must determine how up to date the directory server data is before the replication server can send changes that the directory server has not yet seen. This "up to date" state of the directory server is called the replication server state.
A server might have missed relatively old changes from another remote server, yet might already have seen and processed more recent changes from a server that is close by. Server state is therefore maintained by recording the last change number processed by each replica, according to the replica identifier.
Because administrators can stop and restart servers, the server state must be saved to stable storage. Ideally saving the server state would be done after each local or replicated change is made. Saving information to the database after each change would add significant overhead, however. Server state is therefore kept in memory and saved to the database on a regular basis, and when the server is properly shut down.
A severe interruption to the server connection, such as a kill operation or a system failure, can cause the server to lose track of changes that have already been processed. This can result in the need to fix inconsistencies when the server restarts. For an explanation of how crash recovery is managed, see Section 7.2.6, "Directory Server Crashes."
7.1.5 Operation Dependencies
Sometimes an operation cannot be replayed until another operation is complete. For example, when an add operation is followed by a modify operation on the same entry, the server must wait for the add operation to be completed before starting the modify operation.
Such dependencies are quite rare and are generally necessary for a few operations only. Usually operations do not have dependencies, since they are modify operations. Therefore, in such cases, it is necessary to replay operations in parallel to obtain the best performance with multi-CPU servers.
The replication model is built on the assumption that operation dependencies are rare. The replication mechanism therefore always tries to replay operations in parallel, and only switches to processing operation dependencies if an operation fails to replay.
7.2 How Replication Works
The topics in this section describe the mechanics involved in the replication process and how specific functionality is achieved.
7.2.1 Replication Initialization
Before a server can participate in a replicated topology, you must initialize that server with data. That is, a complete data set must be copied onto the server. For information about the methods for initializing a server with data, see Section 32.6, "Initializing a Replicated Server With Data."
7.2.1.1 Replicating Configuration Data Manually
Replication is automatic for data, but it has to be manually triggered for configuration.
Oracle Unified Directory configuration is specified in the file instance-path/config/config.ldif. This section lists the specific configuration attributes that you must replicate from the old instance to the new instance manually.
You can migrate the values of the following configuration attributes:
-
Global configuration attributes, for instance writability mode, size and time limit, and so on.
-
Security configuration attributes, for instance crypto manager, key manager, trust manager, ID mapping, and SASL.
-
Connection handlers.
-
Performance tuning attributes, for instance cache, threads, and other database configuration parameters.
-
Replication configuration attributes.
-
Password policy configuration attributes.
-
Plug-In configuration attributes.
-
Feature configuration attributes, for instance identity mapping, indexes, and so on.
7.2.2 Directory Server Change Processing
When a modification occurs on a directory server, replication code on the directory server performs the following tasks:
-
Assigns a change number
-
Generates historical information
-
Forwards the change to a replication server
-
Updates the server state
Historical information is stored in the entry and must therefore be included in the operation before the server writes to the back end. The server uses the change number when generating historical information. The change number is therefore generated before the historical information. Both the change number and the historical information are performed as part of the pre-operation phase.
The operation is sent to the replication server before an acknowledgment for the update is sent to the client application that requested the operation. This ensures that a synchronous, assured replication mode can be implemented. For more information, see Section 7.7, "Assured Replication." The acknowledgment is therefore sent as part of the post-operation phase.
Changes are sent in the order defined by their change numbers. The correct order enables replication servers to ensure that all the changes are forwarded to other directory servers.
Because a directory server is multi-threaded, post-operation plug-ins can be called in a different order to pre-operation plug-ins, for the same operation. The replication code maintains a list of pending changes. This list includes changes that have started, and for which change numbers have already been generated, but that have not yet been sent to the replication server. Changes are added to the list of pending changes in the pre-operation phase. Changes are removed from the list when they are sent to the replication server. If a specific operation reaches the post-operation phase ahead of its change number-defined position, that operation waits until previous operations are sent before being sent to the replication server.
The server state is updated when the operation is sent to the replication server. For more information, see Section 7.1.4, "Replication Server State."
7.2.3 Replication Server Selection
When a directory server starts (or when the replication server to which it is connected is stopped), the directory server selects a suitable replication server for publishing and receiving changes. This section describes how the replication server is selected.
7.2.3.1 Replication Server Selection Algorithm
The directory server uses the following principles to select a suitable replication server:
-
Filtering. To begin, the directory server creates a list of eligible replication servers, from all of the configured replication servers in the topology. The list is created based on the following criteria:
-
Replication servers that have the same group ID (or geographic identifier) as the directory server.
-
Replication servers that have the same generation ID (initial data set) as the directory server.
-
Replication servers that include all of the latest updates that were generated from the directory server.
-
Replication servers that run in the same virtual machine as the directory server.
Note:
These criteria are listed in order of preference. So, for example, if a replication server has the same generation ID (criterion 2) as the directory server but does not have the same group ID (criterion 1), it will not be included in the list, unless no replication server in the topology has the same group ID as the directory server. -
-
Load Balancing. When the directory server has compiled a list of eligible replication servers, it selects a replication server in a manner that balances the load across all the replication servers in the topology. This selection is made in accordance with the replication server weight in the topology. For more information, see Section 7.2.3.2, "Replication Server Load Balancing."
7.2.3.2 Replication Server Load Balancing
In large topologies with several directory servers and several replication servers, it is more efficient to spread the directory servers out across the replication servers in a predefined manner. This approach is particularly important if the replication servers run on different types of machines, with different capabilities. If the estimated "global power" of the machines differs significantly from one replication server to another, it is useful to balance the load on the replication servers according to their power.
You can configure the proportional weight of a replication server so that the number of directory servers connecting to each replication server is balanced efficiently. Replication server weight is defined as an integer (1..n). Each replication server in a topology has a default weight of 1. This weight only has meaning in its comparison to the weights of other replication servers in the topology.
The replication server weight determines the proportion of the directory servers currently in the topology that should connect to this particular replication server. The replication server weight is configured as a fraction of the estimated global power of all the replication servers in the topology. For example, if replication server A is estimated to be twice as powerful as replication server B, the weight of replication server A should be twice the weight of replication server B.
The percentage of load of a particular replication server can be represented as (n/d) where n is the weight of the replication server and d is the sum of the weights of all the replication servers in the topology.
For information about configuring the replication server weight, see Section 32.5.12, "Configuring the Replication Server Weight."
7.2.4 Change Replay
The replay of changes on replicated directory servers is efficient on multi-core and multi-CPU systems. On a directory server, multiple threads read the changes sent by the replication server.
Dependency information is used to decide whether an operation can be replayed immediately. The server checks the server state and the list of operations on which the current operation depends to determine whether those operations have been replayed. If the operations have not been replayed, the server puts the operation in a queue that holds dependency operations. If the operation can be replayed, the server builds an internal operation from information sent by replication servers. The server then runs the internal replay operation.
Internal replay operations built from the operations that are sent by a replication server can conflict with prior operations. Such internal operations cannot therefore always be replayed as if they were taking place on the original directory server. The server checks for conflicts when processing the handleConflictResolution phase.
In the majority of cases, the internal replay operations do not conflict with prior operations. In such cases, the handleConflictResolution phase does nothing. The replication code is therefore optimized to return quickly.
When a conflict does occur, the handleConflictResolution code takes the appropriate action to resolve the conflict. For modify conflicts, the handleConflictResolution code changes the modifications to retain the most recent changes.
When conflict resolution is handled, historical information is updated as for local operations. The operation can then be processed by the core server. Finally, at the end of the operation, the server state is updated.
After completing an operation, the server thread processing the operation checks whether an operation in the dependency queue was waiting for the current operation to complete. If so, that operation is eligible to be replayed, so the thread starts the replay process for the eligible operation. If not, the thread listens for further operations from the replication server.
7.2.5 Auto Repair
Despite efforts to keep servers synchronized, directory servers can begin to show incoherent data. Typically, this occurs in the following circumstances:
-
A disk error taints the stored data
-
A memory error leads to an error in processing data
-
A software bug leads to bad data or missing changes
In such cases, tracking and replaying changes is not sufficient to synchronize the incoherent data.
An automatic repair mechanism is provided, which leverages historical information inside entries to determine what the coherent data should be. The replication mechanism then repairs the data on directory servers where the data is bad or missing. The auto repair mechanism is implemented as an LDAP application, and runs on the hosts that run replication servers.
The auto repair application can run in different modes. Depending on the mode in which it is run, the auto repair application performs the following tasks:
-
Repairs inconsistencies manifested as an error when the server was replaying modifications
-
Repairs inconsistencies detected by the administrator
-
Periodically scans directory entries to detect and repair inconsistencies
Note:
In the current directory server release, the auto repair mechanism must be run manually. For more information, see Section 32.11, "Detecting and Resolving Replication Inconsistencies."7.2.6 Directory Server Crashes
If a directory server crashes, its connection to the replication server is lost. Recent changes that the directory server has processed and committed to its database might not yet have been transmitted to any replication server.
When a directory server restarts, therefore, it must compare its state with the server state of the replication servers to which the directory server connects. If the directory server detects that changes are missing and not yet sent to a replication server, the directory server constructs fake operations from historical information. The directory server sends these fake operations to its replication server.
Because the local server state is not saved after each operation, the directory server cannot trust its saved server state after a crash. Instead, it recalculates its server update state, based on historical information.
7.2.7 Replication Server Crashes
If a replication server crashes, directory servers connect to another replication server in the topology. The directory servers then check for and, if necessary, resend missing changes.
7.3 Historical Information and Conflict Resolution
The topics in this section describe how historical information is retained and used to resolve replication conflicts.
7.3.1 What is a Replication Conflict?
A conflict occurs when one or more entries are updated simultaneously on multiple servers and the changes are incompatible, or causes some interaction between the updates. Conflict occurs because no update operation is carried out simultaneously on every replica in the replication topology. Instead, updates are first processed on one server, then replicated to other servers.
The following example describes a conflict that occurs when an attribute is modified at the same time on two different directory servers.
Consider a topology with two read/write replicas. A modify operation changes the surname, sn, attribute of an entry to Smith on one server. Before the server that is processing the change can synchronize with the other server, the sn attribute value for that entry is replaced with the value Jones on the other server. Unless the conflict is managed, replication would replay the change (Smith) on the server that now contains the value Jones. At the same time, replication would replay the change (Jones) on the server that contains the value Smith. The servers would therefore end up with inconsistent values for the sn attribute on the modified entry.
The following list describes additional conflicts that can occur.
-
An entry is deleted on one server while one of its attribute values is modified on another server.
-
An entry is renamed on one server while one of its attribute values is remodified on another server.
-
An entry is deleted and another entry with the same Distinguished Name (DN) is added on one server while one of its attribute values is modified on another server.
-
A parent entry is deleted and a child of that entry is created on another server, either through an add operation or a rename operation.
-
Two different entries with the same DN are added at the same time on two different servers.
-
Two different values are used to replace a single-valued attribute on the same entry on different servers at the same time.
Conflicts that involve only modifications of the same entry are called modify conflicts. Conflicts that involve at least one operation other than modify are called naming conflicts.
All modify conflicts and the vast majority of naming conflicts can be solved automatically by replaying the operations in their order of occurrence. However, the following naming conflicts, which have very little chance of occurring, cannot be solved automatically.
-
Two entries with the same DN are created at the same time on different servers, either by adding new entries or by renaming existing entries.
-
A parent entry is deleted and a child of the parent entry is created at the same time. The child entry can be created either when a new entry is added or when an existing entry is renamed.
7.3.2 Resolving Modify Conflicts
Modify conflicts only occur with modification operations.
Operations are globally and logically ordered to determine the outcome of a given set of operations. Change numbers are used to define the order.
The replication conflict resolution functionality ensures that all servers eventually reach the same state, as if all operations were replayed everywhere in the order defined by the change numbers. This remains true even though changes might be replayed in a different order on different servers. In the modify conflict example with the sn values of Smith and Jones, described previously, assume that the value was set to Jones on the second server after it was set to Smith on the first server. The resulting attribute value should be Jones on both servers, even after the replace modification of Smith is replayed on the second server.
Historical information about each entry is retained to check whether a conflicting operation has already been played using a change number newer than that of a current conflicting operation. For each modify operation, historical information is used, first to check if there is a conflict, and, if there is a conflict, to determine the correct result of the operation.
When a modify conflict occurs, the server determines whether the current attribute values must be retained or whether the modification must be applied. The current attribute values alone are not sufficient to make this assessment. The server also determines when (at which change number) prior modifications were made. Historical information therefore includes the following elements:
-
The date when the attribute was last deleted
-
The date when a given value was last added
-
The date when a given value was last deleted
When an attribute is deleted or fully replaced, older information is no longer relevant. At that point the older historical information is removed.
Historical information undergoes the following processing:
-
Saved in the
ds-sync-histattribute (can be viewed only by an administrator) -
Updated (but not used) for normal operations
-
Updated and used for replicated operations
Conflict resolution is carried out when operations are replayed, after the pre-operation during the handleConflictResolution phase.
Conflict resolution is carried out by changing the List<Modification> field of the modifyOperation to match the actual modifications required on the user attributes of the entry, and to change the ds-sync-hist attribute that is used to store historical information.
7.3.3 Resolving Naming Conflicts
Naming conflicts only happen for replayed operations. The server uses the following methods to resolve naming conflicts:
-
Uses unique IDs to identify entries, including entries that have been renamed
-
Tries to replay each operation first and only takes action if a conflict occurs
-
Checks during the pre-operation phase for conflicts that cannot be detected when operations are replayed
-
Retains no tombstone entries, which are entries that have been marked for deletion but not yet removed
Because directory entries can be renamed, the DN is not an immutable value of the entry. DNs cannot therefore be used to identify the entry for replication purposes. A unique and immutable identifier is therefore generated when an entry is created, and added as an operational attribute of the entry. This unique ID is used, instead of the DN, to identify the entry in changes that are sent between directory servers and replication servers.
A replication context is attached to the operation. The replication context stores private replication information such as change number, entry ID, and parent entry ID that is required to solve the conflict.
7.3.4 Purging Historical Information
Historical information is stored in the server database. Historical information therefore consumes space, I/O bandwidth, and cache efficiency. Historical information can be removed as soon as more recent changes have been seen from all the other servers in the topology.
Historical information is purged in the following ways:
-
When a new change is performed on the entry.
-
By a purge process that can be triggered at regular intervals. The purge process saves space, at the cost of more CPU for processing the purge. The purge process is therefore configurable. For more information, see Section 32.5.2, "Changing the Replication Purge Delay."
7.4 Schema Replication
This section describe how schema replication is implemented. and is aimed at users who require an in-depth understanding of the schema replication architecture.
Schema describe the entries that can be stored in a directory server. Schema management is a core feature of the directory service. Replication is also a central feature of the directory service and is essential to a scalable, highly available service.
Any changes made to the schema of an individual directory server must therefore be replicated on all the directory servers that contribute to the same service.
Schema replication occurs when the schema is modified in any of the following ways:
-
By modifying the
cn=schemasuffix when the server is online -
By using a dedicated task to perform dynamic schema updates by means of a file when the server is online
-
By modifying the underlying back-end files directly when the server is offline
Generally, schema modifications occur only when deploying new applications or new types of data. The rate of change for schema is therefore low. For this reason, the schema replication implementation favors simplicity over scalability.
Schema replication is enabled by default. In certain specific cases, it might be necessary to have different schema on different directory servers, even when the servers share all or part of their data. In such cases you can disable schema replication, or specify a restricted list of servers that participate in schema replication. For more information, see Section 32.9, "Configuring Schema Replication."
7.4.1 Schema Replication Architecture
The schema replication architecture relies on the general replication architecture. You should therefore have an understanding of the general replication architecture before reading this section. For more information, see Section 7.1, "Overview of the Replication Architecture."
Directory servers notify replication servers about any changes to their local schema. As with data replication, the replication servers propagate schema changes to other replication servers, which in turn replay the changes on the other directory servers in the topology.
Schema replication shares the same replication configuration used for any subtree:
dn: cn=example,cn=domains,cn=Multimaster Synchronization,\ cn=Synchronization Providers,cn=config objectClass: top objectClass: ds-cfg-replication-domain cn: example ds-cfg-base-dn: cn=schema ds-cfg-replication-server: <server1>:<port1> ds-cfg-replication-server: <server2>:<port2> ds-cfg-server-id: <unique-server-id>
Schema replication differs from data replication in the following ways:
-
Entry Unique ID. A unique ID is required for data replication because entries can be renamed or deleted.
In the schema, there is only one entry and that entry cannot be deleted or renamed. The unique ID used for the schema entry is therefore the DN of the schema entry.
-
Historical information. Historical information is used to save a history of relevant modifications to an entry. This information makes it possible to solve modification conflicts.
For schema replication, the only possible operations are adding values and deleting values. Historical information is therefore not maintained for modifications to the schema.
-
Persistent server state. When a directory server starts up, the replication plug-in establishes a connection with a replication server. The replication server looks for changes in its change log and sends any changes that have not yet been applied to the directory server.
To know where to start in the change log, the replication plug-in stores information that is persistent across server stop and start operations. This persistent information is stored in the replication
base-dnentry.The schema back end allows the specific operational attribute used to store the persistent state,
ds-sync-state, to be modified.
7.5 Replication Status
A replication domain is a directory server that contains data. Each replicated domain in a replicated topology has a certain replication status. The replication status is determined by the replication domain connections within the topology, and by how up-to-date the replication domain is based on the changes that have occurred throughout the topology.
Knowledge of a domain's replication status enables a replicated topology to do the following:
-
Manage certain aspects of assured replication
-
Enable certain administrative tasks
-
Administer and monitor replication effectively
For more information, see Section 35.7, "Monitoring a Replicated Topology."
The following sections outline the different statuses that a replicated domain can have.
7.5.1 Replication Status Definitions
For directory servers that contain data (replication domains), the status can be one of the following
-
Normal. The connection to a replication server is established with the correct data set. Replication is working. If assured mode is used, then acknowledgments from this directory server are sent.
-
Late. The connection to a replication server is established with the correct data set. Replication is marked Late when the number of missing changes for the directory server exceeds the threshold defined in the replication server configuration. When the number of changes goes below this threshold, the status will go back to Normal.
-
Full Update. The connection to a replication server is established and a new data set is received from this connection (online import), to initialize the local back end.
-
Bad Data Set. The connection to a replication server is established with a data set that is different from the rest of the topology. Replication is not working. Either the other directory servers of the topology should be initialized with a compatible data set, or this server should be initialized with another data set that is compatible with the other servers.
-
Not Connected. The directory server is not connected to any replication server.
-
Unknown. The status cannot be determined. This occurs mainly when the server is down or unreachable but it is referenced in the monitoring of another server.
-
Invalid. This is for internal use. If the directory server changes its state and the transition is impossible according to state machine, then
INVALID_STATUSis returned.
7.5.2 Degraded Status
A directory server that is slow in replaying changes is assigned a DEGRADED_STATUS. The stage at which the server is regarded as "too slow" is defined by the degraded status threshold and is configurable, based on the number of updates queued in the replication server for that directory server.
When the degraded status threshold is reached, the directory server assumes a degraded status and is considered to be unable to send acknowledgments in time. A server with this status can have an impact on assured replication, as replication servers no longer wait for an acknowledgment from this server before returning their own acknowledgments.
7.5.3 Full Update Status and Bad Generation ID Status
Apart from being assigned a degraded status, a directory server can change status if an administrator performs one of the following tasks on the topology:
-
Full update. When a replicated domain is initialized online from another server in the topology, the directory server status for that domain changes to
FULL_UPDATE_STATUS. When the full update has completed, the directory server reinitializes its connection to the topology, and the status is reset toNORMAL_STATUS. -
Local import or restore. When a replicated domain is reinitialized by using a local import or restore procedure, the directory server status for that domain changes to
NOT_CONNECTED_STATUS. -
Resetting the generation ID. If a replicated domain connects to a replication server with a generation ID that is different from its own, the domain is assigned a
BAD_GEN_IDstatus. A domain can also be assigned this status if a reconnection occurs after a full online update, a local import, or a restore with a set of data that has a different generation ID to that of the replication server.In addition, you might need to reset the generation ID of all the replication servers in the topology by running the reset generation ID task on the directory server. This causes all the replication servers in the topology to have a different ID to the ID of the directory servers to which they are connected. In this case, the directory servers are assigned a
BAD_GEN_IDstatus.
7.6 Replication Groups
Replication groups are designed to support multi-data center deployments and disaster recovery scenarios. Replication groups are defined by a group ID. A group ID is a unique number that is assigned to a replicated domain on a directory server (one group ID per replicated domain). A group ID is also assigned to a replication server (one group ID for the whole replication server).
Group IDs determine how a directory server domain connects to an available replication server. From the list of configured replication servers, a directory server first tries to connect to a replication server that has the same group ID as that of the directory server. If no replication server with a compatible group ID is available, the directory server connects to a replication server with a different group ID. The next section describes this selection process in greater detail.
For information about how to configure replication groups, see Section 32.5.8, "Configuring Replication Groups."
Note:
Assured replication does not cross group boundaries. For more information, see Section 7.7, "Assured Replication."7.7 Assured Replication
Before you read the following sections, you should have an understanding of basic replication concepts. You must know what a replication server is, as opposed to a directory server, and have an understanding of how replication servers work in a replicated topology. If this is not the case, read at least the Section 7.1, "Overview of the Replication Architecture" to obtain an understanding of how regular replication works in the directory server.
In a standard replicated topology, changes are replayed to other replicated servers in a "best effort" mode. A change made on an LDAP server is replayed on the other servers in the topology as soon as possible, but in an unsynchronized manner. This is convenient for performance but does not ensure that a change has been propagated to other servers when the initial LDAP client call is finished.
In some deployments this might be acceptable, that is, the time period between the change on the first server and the replay on peer servers might be short enough to fulfill the requirements of the deployment. For example, an international organization might store employee user accounts in a replicated topology across various geographical locations. If a new employee is hired and a new account is created for him on one LDAP server in a specific location, it might be acceptable that the replay of the creation occurs in other LDAP servers a few milliseconds after the LDAP client call terminates. The user is unlikely to perform a host login that would access one of the other LDAP servers in the same second that the user account is created.
However, there might be cases in which more synchronization is required from the replication process. If a specific host fails, it might be imperative that any changes made on that host have been propagated elsewhere in the topology. In addition, the deployment might require assurance that once the LDAP client call of a change is returned by a server, all of the peer servers in the topology have received that change. Any other clients that read the entry from anywhere in the topology would be sure to obtain the modification.
Assured replication is a method of making regular replication work in a more synchronized manner. The topics in this section describe how assured replication works, from an architectural perspective. For information about configuring assured replication, see Section 32.5.9, "Configuring Assured Replication."
The following sections describe the implementation of assured replication:
7.7.1 Assured Replication Modes
The directory server currently supports the following assured replication modes, depending on the level of synchronization that is required, the goal of the replicated topology, and the acceptable performance impact.
7.7.1.1 Safe Data Mode
In safe data mode, any change is propagated to a specified number of servers in the topology before the LDAP client call returns. If the LDAP server on which the change was made fails, it is guaranteed that the change has already been propagated to at least the specified number of servers.
This specified number of servers (N) defines the safe data level. The safe data level is based on acknowledgments from the replication servers only. In other words, an update message that is sent from an LDAP server must be acknowledged by at least N (N>=1) replication servers before the LDAP client call that initiated the update returns.
The higher the safe data level, the greater the number of machines that are assured to have the update and, consequently, the more reliable the data. However, as the safe data level increases, the overall performance decreases because additional acknowledgments are required before the LDAP client call returns.
The safe data level functions in best effort mode. That is, if the safe data level is set to 3 and there are temporarily only two replication servers available in the topology, an acknowledgment from the third (unavailable) replication server will not be expected until this server is available again.
Safe data mode is affected by the use of replication groups. Because assured replication does not cross group boundaries, a replication server with a group ID of 1 waits for an acknowledgment from other replication servers with the same group ID but not for acknowledgments from replication servers with a different group ID. For more information, see Section 7.6, "Replication Groups."
Note:
In the current replication implementation, thesetup and dsreplication commands support only a scenario in which the main replication server is physically located in the same host as the LDAP server (that is, on the same machine). However, the fundamental replication design is to support deployments where the replication servers run on separate machines, to increase reliability.
Such deployments can currently be configured only by using the dsconfig command and are not supported by the setup and dsreplication commands. However, these deployments provide better failover and availability. In such deployments, if the safe data level is set to 1 (acknowledgment of only one replication server is expected), this replication server must run on a separate machine to the LDAP server.
Example 7-1 Safe Data Level = 1
Setting the safe data level to 1 ensures that the first replication server returns an acknowledgment to the directory server immediately after receiving the update. The replication server does not wait for acknowledgments from other replication servers in the topology. The modification is guaranteed to exist on one additional server (other than the directory server on which the change was made).
This example can only be configured with dsconfig and is not yet supported by the setup or dsreplication commands.
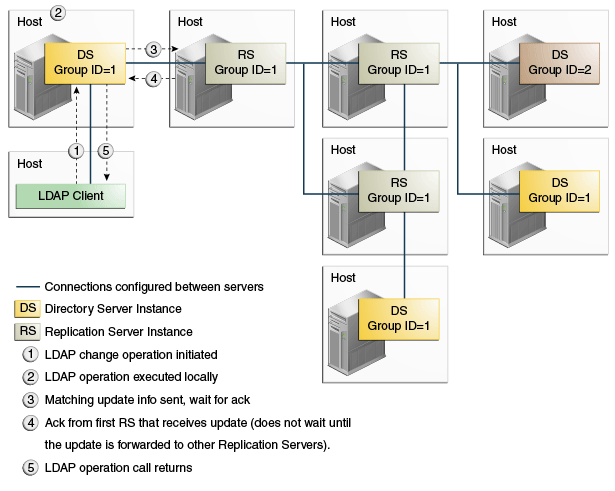
Description of the illustration ''safedatalevel1.gif''
Example 7-2 Safe Data Level = 2 (RS and DS on Different Hosts)
Setting the safe data level to 2 ensures that the first replication server will wait for an acknowledgment from one peer replication server before returning an acknowledgment to the directory server. The modification is guaranteed to exist on two additional servers (other than the directory server on which the change was made).
This example can only be configured with dsconfig and is not yet supported by the setup or dsreplication commands.
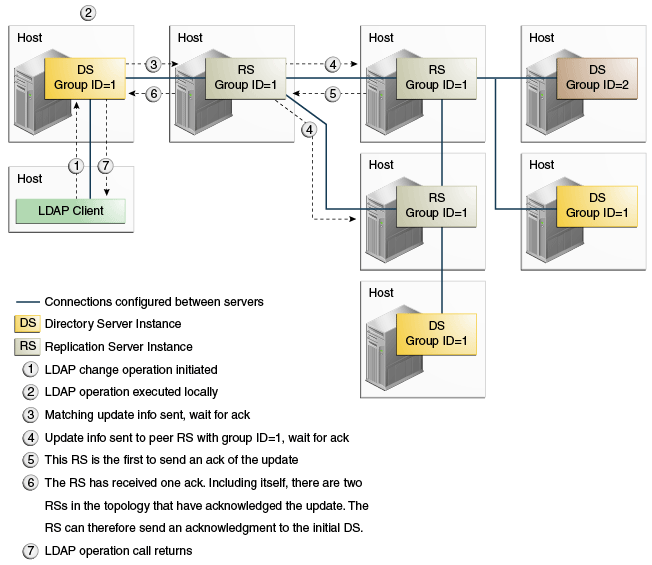
Description of the illustration ''safedatalevel2diffhosts.gif''
Example 7-3 Safe Data Level = 2 (RS and DS on Same Host)
In the current replication implementation, the setup and dsreplication commands only support configurations in which the replication is on the same machine as the directory server. With this implementation, if you want to ensure that a change is sent to at least one additional host, then you must set the safe data level to 2.
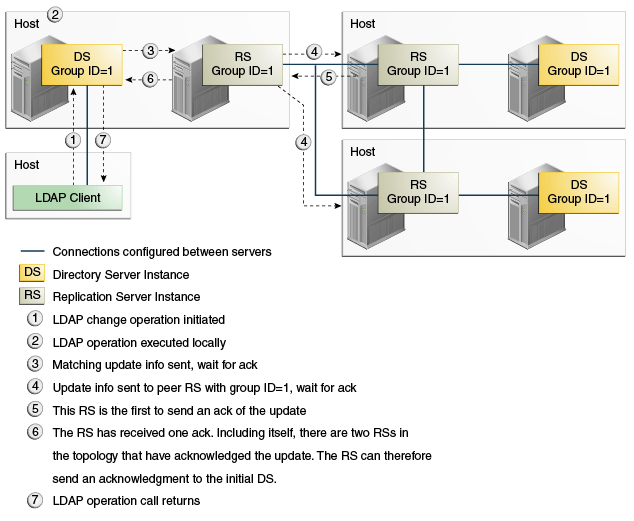
Description of the illustration ''safedatalevel2samehosts.gif''
7.7.1.2 Safe Read Mode
Safe read mode ensures that any modification made on a specific directory server has been replayed to all other directory servers within the topology before the LDAP call returns. In this mode, if another LDAP client performs a read operation on another directory server in the topology, that client is assured of reading the modification that has just been performed. Safe read mode is the most synchronized manner in which you can configure replication. However, this mode also has the biggest performance impact in terms of write time.
Safe read mode is based on acknowledgments from the LDAP servers rather than the replication servers in a topology. When a modification is made on a directory server, the update is sent to the corresponding replication server. The replication server then forwards the update to the other replication servers in the topology. These replication servers wait for acknowledgment of the modification being replayed on all the directory servers to which the modification is forwarded. When the modification has been replayed on all directory servers in the topology, the replication servers send their acknowledgment back to the first replication server, which in turn sends an acknowledgment to the original directory server.
The first replication server also waits for an acknowledgment from any other directory servers that are directly connected to it before sending the acknowledgment to the original directory server. Only when the original directory server has received an acknowledgment from its replication server does it finally return the end of the operation call to the LDAP client.
At this point, all directory servers in the topology contain the modification. If an LDAP client reads the data from any directory server, it is therefore certain of obtaining the modification.
7.7.1.3 Safe Read Mode and Replication Groups
Replication groups support multi-data center replication and high availability. For more information about replication groups, see Section 7.6, "Replication Groups." In the context of assured replication, replication groups enable a set of directory servers to work together in safe read mode. All directory servers that work together in a synchronized manner require the same group ID. This group ID should also be assigned to all the replication servers working in the synchronized topology. Assured replication does not cross group boundaries.
When a change occurs on a directory server with certain group ID (N), the LDAP call is not returned before every other directory server with group ID N has returned an acknowledgment of the change.
The use of replication groups provides more flexibility in a replicated topology that uses safe read mode.
-
In a single data center deployment, you can define a subset of the directory servers that should be fully synchronized. Only the directory servers with the same group ID will wait for an acknowledgment from their peers with the same group ID. All the replication servers will have the same group ID.
-
In a multi-data center deployment, you can specify that all the directory servers within a single data center are fully synchronized. A directory servers will wait for acknowledgment only from its peers located in the same data center before returning an LDAP call. Acknowledgment is expected only if the directory server is connected to a replication server with the same group ID.
Example 7-4 Safe Read Mode in a Single Data Center With One Group
The following illustration shows a deployment in which all nodes are in the same data center and are part of the same replication group. Each directory server and replication server has the same group ID. Any modification must be replayed on every directory server in the topology before an LDAP client call returns. Any subsequent LDAP read operation on any directory server in the topology is assured of reading the modification.
Such a scenario might be convenient, for example, if there is an LDAP load balancer in front of the replicated directory server pool. Because it is impossible to determine the directory server to which the load balancer will redirect an LDAP modification, a subsequent read operation is not necessarily routed to the directory server on which the modification was made. In this case, it is imperative that the change is made on all servers in the topology before the LDAP client call is returned.
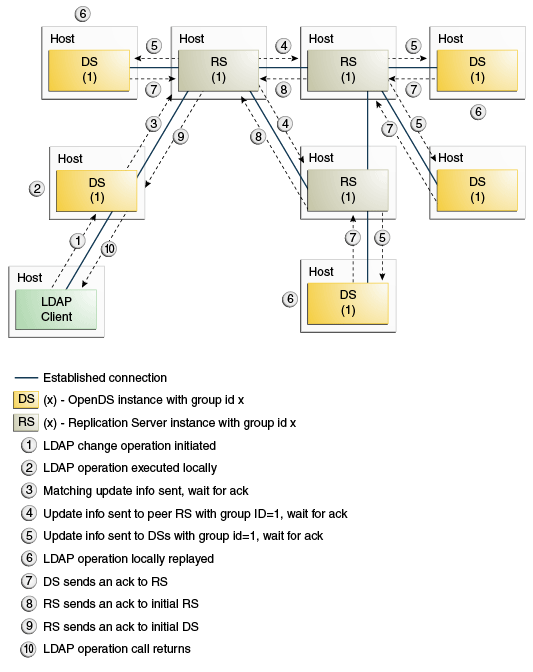
Description of the illustration ''safereadonegrp.gif''
Example 7-5 Safe Read Mode in a Single Data Center With More Than One Group
The following illustration shows a deployment in which all nodes are in the same data center but in which assured replication is configured on only a subset of the directory servers. This subset of servers constitutes a replication group, and each server is assigned the same group ID (1). When a change is made on one of the directory servers in the replication group, an acknowledgment must be received from all the directory servers in the group before the initial LDAP call is returned to the client. The remaining directory servers in the topology will still replay the change, but their acknowledgment is not required before the LDAP call is returned. If a change made on one of the servers outside of the group, no acknowledgment from other directory servers is required before the LDAP call is returned to the client.
In this example, the replication server that is connected to directory servers outside of the replication group is still assigned a group ID of 1. This configuration ensures failover if another replication server is offline. In this case, if a directory server within the replication group connects to this particular replication server, assured replication must still work. For the purpose of failover, any replication server must be assigned the same group ID if there is a chance that a directory server within the group might connect to it at some stage.
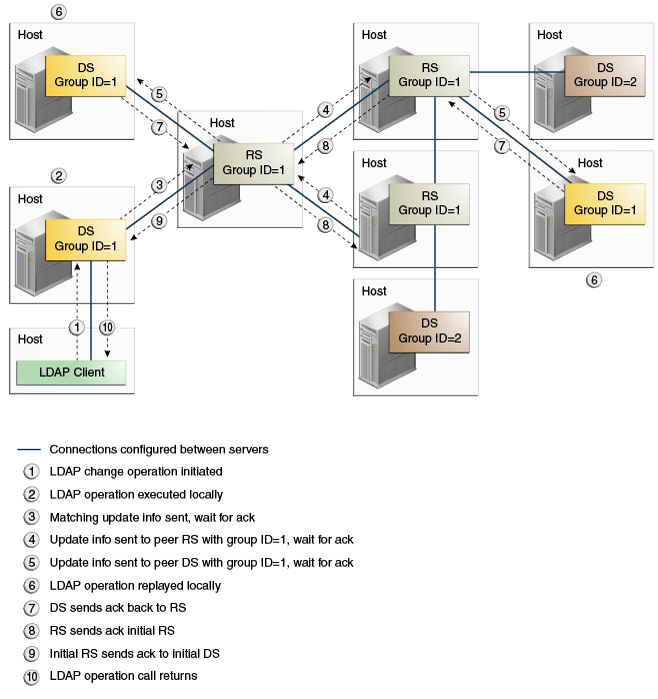
Description of the illustration ''safe_subset.gif''
Example 7-6 Safe Read Mode in a Multi-Data Center Deployment
The following illustration shows a deployment with two data centers (in different geographical locations). Each data center has safe read mode configured locally within the data center. All of the directory servers and the replication servers within the same data center are assigned the same group ID (1 for the first data center and 2 for the second data center). The directory servers within the same data center operate in a more tightly consistent synchronized manner. Any change made on a directory server must be replayed and acknowledged from all directory servers within that data center before the LDAP client call returns.
In this example, data is synchronized between the two data centers, but any change made on a specific directory server is immediately visible on all other directory servers within the same data center. This scenario is convenient if there is an LDAP load balancer in front of the directory servers of a data center. The performance impact in terms of writes is not too great because no acknowledgments are requested from the servers of the remote data center.
Description of the illustration ''safe_subset.gif''
The group ID of the replication server is important in this scenario. If a change arrives from a directory server with group ID N, the replication server compares N with its own group ID and takes the following action:
-
If the replication server has the same group ID (N), it forwards the change to all the replication servers and directory servers to which it is directly connected. However, it waits for an acknowledgment only from the servers with the same group ID (N) before sending its own acknowledgment back to the original directory server.
-
If the replication server has a different group ID, it forwards the change to all the replication servers and directory servers but does not wait for any acknowledgment.
7.7.2 Assured Replication Connection Algorithm
In implementing the scenarios described in the previous sections, a directory server in a topology uses the following algorithm to select the replication server to which that directory server should connect:
-
Connect to each replication server in the list of configured replication servers and obtain its server state and group ID.
-
From the list of replication servers that are up to date with the changes on the directory server, and that have same group ID as the directory server, select the one that has the most updates from other directory servers in the topology. If no replication server exists with the same group ID as the directory server, select the replication server that is most up to date.
This algorithm ensures that a higher priority is given to replication servers with the same group ID as the directory server's group ID. A directory server will therefore favor a replication server located in its own data center.
Connecting to a replication server with the same group ID (in the same data center) provides the safe read mode functionality. Connecting to a replication server with a different group ID provides failover to another data center (if all the replication servers in the local data center fail). In this case, safe read mode is disabled as no acknowledgment is requested when sending update messages to replication servers with a different group ID. Replication continues, but in degraded mode (that is, the safe read mode requested at configuration time is not applied.)
To return replication to normal, a directory server periodically polls the configuration list for the arrival of replication servers with the same group ID as its own. If the directory server detects that a replication server with its own group ID is available, it disconnects from the current replication server (with a different group ID), and reconnects to the recovered replication server with the same group ID. Safe read mode is thus reenabled and replication returns to the mode in which it was configured.
7.7.3 Assured Replication and Replication Status
When a replication server detects that a directory server is out of sync regarding the overall updates made in the topology, that directory server is said to have a degraded status. A directory server that is out of sync is unlikely to be able to send the expected acknowledgments in time for the replication server to avoid a time-out situation. The server therefore has a degraded status until it has an acceptable level of updates. With a degraded status, a directory server is no longer expected to send acknowledgments to the replication server, until it returns to having a normal status.
Because a directory server with a degraded status cannot send acknowledgments, the synchronization of an LDAP operation in safe read mode cannot be assured. In other words, data read from this directory server might not contain the modifications made on another directory server in the topology.
For more information, see Section 7.5.1, "Replication Status Definitions."
7.7.4 Assured Replication Monitoring
The assured replication mechanism includes several attributes defined to monitor how well the mechanism is working. The following tables list the monitoring attributes defined on the directory servers and on the replication servers in a topology.
On a directory server, the attributes are located under the monitor entry for that replicated DN. For example, monitoring information related to the replicated domain dc=example,dc=com is located under the monitoring entry cn=Replication Domain,dc=example,dc=com,server-id,cn=monitor.
On a replication server, the monitoring information related to assured replication is on a per connection basis. Monitoring attributes are found in the monitoring entry of a directory server or replication server that is connected to the current replication server. For example, on a particular replication server, the monitoring information related to a connected directory server would be under the monitoring entry cn=Directory Server dc=example,dc=com ds-host,server-id,cn=monitor. The monitoring information related to a connected replication server would be under the monitoring entry cn=Remote Replication Server dc=example,dc=com repl-server-host:repl-port,server-id,cn=monitor.
Table 7-1 Monitoring Attributes on the Directory Server
| Attribute Name | Attribute Type | Purpose |
|---|---|---|
|
|
Integer (0..N) |
Number of updates sent in assured replication, safe read mode |
|
|
Integer (0..N) |
Number of updates sent in assured replication, safe read mode, that have been successfully acknowledged |
|
|
Integer (0..N) |
Number of updates sent in assured replication, safe read mode, that have not been successfully acknowledged (either because of timeout, wrong status, or error at replay) |
|
|
Integer (0..N) |
Number of updates sent in assured replication, safe read mode, that have not been successfully acknowledged because of timeout |
|
|
Integer (0..N) |
Number of updates sent in assured replication, safe read mode, that have not been successfully acknowledged because of wrong status |
|
|
Integer (0..N) |
Number of updates sent in assured replication, safe read mode, that have not been successfully acknowledged because of replay error |
|
|
String |
Multiple values allowed: number of updates sent in assured replication, safe read mode, that have not been successfully acknowledged (either because of timeout, wrong status or error at replay) for a particular server (directory server or replication server). String format: server id:number of failed updates |
|
|
Integer (0..N) |
Number of updates received in assured replication, safe read mode |
|
|
Integer (0..N) |
Number of updates received in assured replication, safe read mode that have been acknowledged without errors |
|
|
Integer (0..N) |
Number of updates received in assured replication, safe read mode, that have been acknowledged with errors |
|
|
Integer (0..N) |
Number of updates sent in assured replication, safe data mode |
|
|
Integer (0..N) |
Number of updates sent in assured replication, safe data mode, that have been successfully acknowledged |
|
|
Integer (0..N) |
Number of updates sent in assured replication, safe data mode, that have not been successfully acknowledged because of timeout |
|
|
String |
Multiple values allowed: number of updates sent in assured replication, safe data mode, that have not been successfully acknowledged (because of timeout) for a particular RS. String format: server id:number of failed updates |
Table 7-2 Monitoring Attributes on the Replication Server
| Attribute Name | Attribute Type | Purpose |
|---|---|---|
|
|
Integer (0..N) |
Number of updates received from the remote server in assured replication, safe read mode |
|
|
Integer (0..N) |
Number of updates received from the remote server in assure replication, safe read mode, that timed out when forwarding them |
|
|
Integer (0..N) |
Number of updates sent to the remote server in assured replication, safe read mode |
|
|
Integer (0..N) |
Number of updates sent to the remote server in assured replication, safe read mode, that timed out |
|
|
Integer (0..N) |
Number of updates received from the remote server in Assured Replication, Safe Data |
|
|
Integer (0..N) |
Number of updates received from the remote server in assured replication, safe date mode, that timed out when forwarding them. This attribute is meaningless if the remote server is a replication server. |
|
|
Integer (0..N) |
Number of updates sent to the remote server in assured replication, safe data mode. This attribute is meaningless if the remote server is a directory server. |
|
|
Integer (0..N) |
Number of updates sent to the remote server in assured replication, safe data mode, that timed out. This attribute is meaningless if the remote server is a directory server. |
7.8 Fractional Replication
The fractional replication feature enables you to restrict certain attributes from being included when modify operations are replayed on specific servers in a topology. For information about configuring fractional replication, see Section 32.5.10, "Configuring Fractional Replication."
This section describes the architecture of the fractional replication mechanism and covers the following topics:
7.8.1 Fractional Data Set Identification
A fractional data set is identified by the following operational attributes that are stored in the root entry of the replicated domain:
-
ds-sync-fractional-exclude -
ds-sync-fractional-include
The syntax and meaning of these attributes is identical to their corresponding configuration attributes, described in Section 32.5.10, "Configuring Fractional Replication." The role of these operational attributes is to tag a data set as fractional: their presence in a domain implies "this data set is a fractional domain and does not contain the following specific attributes...".
The fractional configuration stored in the root entry of the domain, combined with the generation ID (ds-sync-generation-id) and the replication state (ds-sync-state), can be seen as the fractional signature of the data set.
When a domain is enabled (for example, after its fractional configuration is modified), the server compares the fractional configuration of the domain (under cn=config) with the fractional configuration attributes in the root entry of the domain. If both configurations match, the domain assumes a normal status and LDAP operations can be accepted. If the configurations do not match, the domain assumes a bad generation ID status and the data set must be synchronized (by importing a data set) before LDAP operations can be accepted.
The data set that is imported must either:
-
have the same fractional configuration in its root entry as the local domain has under
cn=config. In this case, the data set is imported as is. -
have no fractional configuration in its root entry. In this case, the data set is imported and filtered according to the attribute filtering rules defined in the fractional configuration of the local domain (under
cn=config). Theds-sync-fractional-excludeords-sync-fractional-includeattributes are then created in the root entry of the imported data, by copying the fractional configuration of the local domain.
7.8.2 Fractional Replication Filtering
When a domain is configured as fractional, all ADD, MODIFY, and MODIFYDN operations that arrive from the network to be replayed are filtered. These operations can end up being abandoned if all of the attributes in the operation are filtered attributes according to the fractional configuration.
7.8.3 Fractional Replication and Local Operations
If an LDAP client performs an operation directly on a fractional replica and the operation does not match the fractional configuration, the operation is forbidden and the server returns an "unwilling to perform" error.
For example, if a fractional replica is configured with fractional-exclude: *:jpegPhoto and an LDAP client attempts to add a new entry that contains a jpegPhoto attribute, the operation is rejected with an "unwilling to perform" error. This behavior ensures that the domain remains consistent with its fractional configuration definition, which implies that no jpegPhoto attribute can exist on the domain.