| Oracle® Clinical Administrator's Guide Release 5.1 E53556-02 |
|
|
PDF · Mobi · ePub |
| Oracle® Clinical Administrator's Guide Release 5.1 E53556-02 |
|
|
PDF · Mobi · ePub |
This section includes:
This does not replace the Oracle technical documentation regarding partitioning or indexes. Oracle strongly recommends that the DBA in charge of the Oracle Clinical database be familiar with partitioning before attempting to convert an existing Oracle Clinical database to a partitioned Responses table.
For detailed information on partitioning and on maintaining partitioned tables, see the Oracle database documentation.
There are two basic sets of decisions you must make to plan the upgrade:
Whether and when to convert to a partitioned Responses table
If you are not partitioning, when and how to upgrade the index structure of the Responses table
These two decisions are inter-related — the conversion to partitioning subsumes the index upgrade. If you decide that you will be partitioning shortly after upgrading, you might want to skip the separate index upgrade. Conversely, if you are postponing partitioning you might want to do the separate index conversion soon after upgrade. If you are not converting to partitioning, you need to consider the path to index upgrade (see ).
If you have a fresh installation of Oracle Clinical, you do not need the index upgrade. You do need to decide about partitioning.
The index upgrade and partitioning both require impact analysis in advance and both can take a significant amount of time to implement. Assuming that the impact analysis is done prior to upgrading and the upgrade path chosen, the primary consideration for when to upgrade is the elapsed time needed to perform the actual upgrades. While either could be done at the same time as the upgrade, deferring the index or partition upgrade to a separate time might reduce the risk and time pressure. The index upgrade is the least time-consuming and is easily performed overnight even on a large database. Partitioning is more time-consuming and, while it can easily be accomplished over a weekend on even the largest Oracle Clinical database, it needs more careful advanced planning.
If you decide to defer both partitioning and the index upgrade, you can force Oracle Clinical to continue to create validation and derivation procedures and data extract views that are optimized for the pre-4.0-style index structure (see "Enforcing Pre-Version 4.0 Optimization").
The upgrade for Responsest should be done at the same time as either partitioning or the Responses table index upgrade.
See "Upgrading Indexes" for more information. This upgrade can be done at any time that is convenient.
Figure 9-1 Partitioning and Indexing Decision Paths
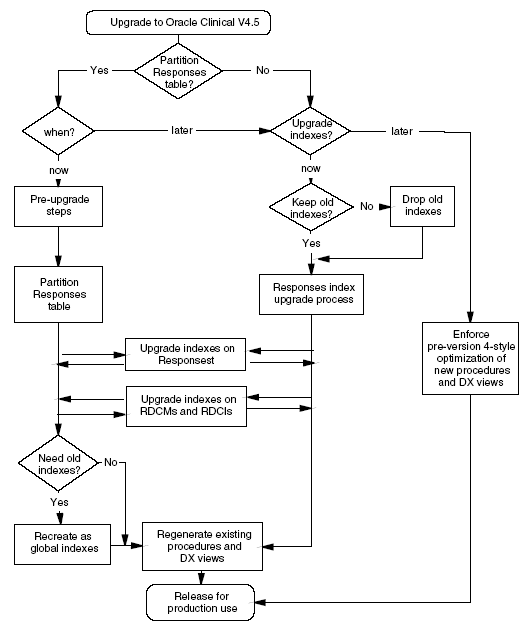
If you decide to postpone both the partitioning and indexing upgrades, you can force Oracle Clinical to continue to create validation and derivation procedures and data extract views that are optimized for the pre-4.0-style index structure.
You do this by inserting a record in the local OCL_STATE reference codelist with the short value of USE RESP_DCMQG and a long value of YES.
Later, when you are ready to convert to the new index scheme or partitioning, change the long value to NO before you regenerate views and procedures. The absence of an entry is equivalent to NO.
Partitioning is an Oracle database capability that allows you to divide a single Oracle table into separate physical partitions, each with its own storage characteristics. The indexes on a table can be partitioned as well. When a table is partitioned, each partition functions physically like a separate table while the table, as a whole, can still be treated as a single table for purposes of data access through SQL. Partitions can be managed like independent tables. They can be reorganized, imported, exported, taken off line and even dropped.
This section provides an overview of partitioning as it has been used for the Responses table in Oracle Clinical. For complete information on partitioning, see the Oracle Database documentation.
The response table is range partitioned on clinical_study_id. This means that the data is placed into partitions based upon ranges of the internal clinical_study_id identifier. The two indexes on the Responses table are equipartitioned with the Responses table on clinical_study_id. This means they share the same partitioning scheme as defined for the Responses table. This equipartitioning guarantees partition independence, that is, operations on one partition or its indexes do not affect any other partition or its indexes. Equipartitioning also means that the index partitions are automatically maintained during most partition maintenance operations on the Response table partitions. It is important to note that the Response table partitions and the index partitions have separate storage specifications, so it is still possible to place the index partitions on separate tablespace/physical devices from the table partitions.
In Oracle Clinical Version 3.1, the Responses table together with its indexes is 20 times larger than the next largest table, Received DCMs. Partitioning the Responses table and reorganizing the indexes accomplish a number of goals:
Partitioning improves database and system management in several ways. First, by dividing the Responses table into many physical segments, you can manage the physical growth and structure of the table at a finer level of granularity. Individual partition segments can be rebuilt independently to consolidate space and improve performance. Partition segments can be placed on separate tablespaces on separate physical devices to improve performance; for example, by moving studies that will be used for intensive reporting onto separate disks from studies with active entry. Studies that are no longer active can be periodically moved to a read-only tablespace on a physical device that need only be backed up after the periodic maintenance and not as part of nightly backups. Similarly, if table export is used as a backup mechanism, only active partitions need to be exported.
Prior to partitioning, a single bad index block would require rebuilding the entire index and a bad data block might require rebuilding the entire responses table. Since all of the partitioned indexes are local indexes, with partitioning, a bad index only affects the particular partition and a bad data block only requires the rebuild of that particular partition; the remaining partitions can remain in use while the one with problems is restored.
Both transactional and retrieval performance are improved by partitioning. Transactional performance is improved in two ways: by reducing contention for the data associated with a particular study and reducing transaction overhead. Contention is reduced by distributing inserts, updates, and deletes over different data blocks for each study and by allowing data blocks that are actively being accessed for reporting to be separated from those that are actively being modified by data entry.
Retrieval performance is improved in two ways as well: by physically grouping study data and by allowing physical reorganization on a study basis. By allowing data for each study to be stored their own data and index blocks instead of interspersed with data from many other studies, retrieval by study performs significantly less disk I/O and, in fact, a study can usually be buffered entirely in the SGA. This can produce dramatically improved extract view performance. In addition, when a study is about to be heavily accessed for reporting, the particular partition can be reorganized to consolidate space used by the index and data blocks, thus reducing I/O, and even to place the partition on a separate, perhaps faster, physical device to optimize access.
The most dramatic reduction in space requirements comes from the re-optimization of Oracle Clinical to do away with the need for three of the indexes on the Responses table. Combined with the Oracle database leading key compression on one of the remaining indexes, this drops the space required by the Responses table and its indexes by over 50%. This benefit can be realized whether or not you partition the Responses table. In addition, the ability to rebuild partitions individually means that space can be recovered from partitions that are no longer being modified by rebuilding them with reduced free space. Since freshly rebuilt indexes are frequently two-thirds the size of an actively growing index, and the free space requirement can be reduced by 10%, the net improvement over time could be an additional 30-40% reduction in space requirements.
Before partitioning the Responses table you must decide how you want to partition it, both initially and on an ongoing basis. To do this, you need to understand how the partitioning is implemented and how this impacts your partition strategy.
Oracle recommends that you place all but the smallest active studies in separate partitions. Small studies that happen to have contiguous clinical_study_ids can share a single partition without impacting performance significantly. Inactive studies with contiguous clinical_study_ids can be merged into a single partition (see "Using Read-Only Partitions to Minimize Backup").
Other partitioning schemes are possible and give differing degrees of performance and problem isolation benefits. One alternate approach is to segment the table into larger partitions that loosely correspond to time-slices based upon sequential clinical_study_id allocation. This approach minimizes partition maintenance and gives some problem isolation benefit, but is not likely to give much performance benefit because active studies will tend to share the same partitions.
To assist in the planning process, Oracle Clinical includes several listings and utilities to create the initial partitioning structure. A forms-based user interface is used to perform the actual partition definition prior to generating the partitioned Response table creation script.
The following SQL statement provides a listing of all studies with data, the number of responses per study, the most recent response creation in the study, and the flag that indicates whether the study is frozen:
SELECT /*+ ordered */ cs.study, cs.clinical_study_id, css.frozen_flag,
a.resp_count, a.max_date
FROM
(SELECT count(*) resp_count, clinical_study_id,
to_char(max(response_entry_ts), 'DD-MON-YYYY') max_date
FROM responses
GROUP BY clinical_study_id ORDER BY clinical_study_id) a,
clinical_studies cs,
clinical_study_states css
WHERE a.clinical_study_id = cs.clinical_study_id
AND cs.clinical_study_id = css.clinical_study_id
AND css.current_flag = 'Y'
ORDER BY clinical_study_id
Analyze the resulting list to determine which ranges of clinical_study_id can be combined into single partitions and which should be in their own partition. Among the issues to consider are:
Identify studies that will never have changes to their data and that are unlikely to have intensive reporting requirements in the future (see "Using Read-Only Partitions to Minimize Backup").
Action: Consolidate as much as possible and locate in read-only tablespace (see "Using Read-Only Partitions to Minimize Backup").
Identify studies that are complete, but may have continued reporting requirements.
Action: Keep in separate partitions, as appropriate by size, but allocate minimal free space. Consider placing tablespace on fast storage devices.
Identify contiguous ranges of small studies that will not grow to be large studies.
Action: Consider consolidating into single partitions. This is especially relevant if there are studies that were created but will never contain data.
Once you are prepared to define the initial partition structure, you use the following script to populate the actual table:
SQL> @populate_part_map_table.sql log_file_name.log
This script populates the mapping table with one row per study with storage clauses based upon the number of responses. The storage clauses are designed to result in a range of 1 to 15 extents for a given table size.
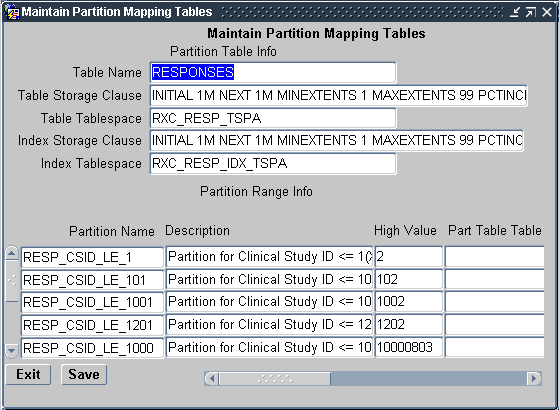
Once you have executed the script, you can use the Maintain Partition Mapping Tables form, shown in (navigate to Admin, then Partition Admin), to implement the partitioning scheme determined above.
Note:
You always specify the maximum clinical_study_id included in a partition. The minimum is implicitly one more than the maximum of the previous partition.You can delete rows to merge partitions. You can edit the storage clauses to reflect consolidation or to adjust the storage because you are aware of factors that affect the size, such as planned rapid growth of a partition. Bear in mind that you can always rebuild a partition later, independent of the upgrade process.
Figure 9-2 Maintain Partition Mapping Tables Window
Once you have completed modifying the partition mapping, you use the script:
SQL> @gen_create_part_table.sql part_table_ddl.sql
to generate the partitioned table creation script and:
SQL> @gen_create_part_index.sql part_index_ddl.sql
to generate a creation script for both partitioned indexes (see Example 9-2, "Sample Responses Primary Key Index Creation Script" and Example 9-3, "Sample Responses Foreign Key Index Creation Statement"). Note that the CREATE statement for RESPONSE_RDCM_NFK_ID uses the index tablespace but the table storage clause (see "Sample Responses Foreign Key Index Creation Statement"), because this large concatenated index is approximately 70-80% as large as the data segment while RESPONSE_PK_IDX is 40-50% as large.
Example 9-1 Sample Responses Table Creation Statement
CREATE TABLE RESPONSES ( RESPONSE_ID NUMBER(10,0) NOT NULL , RESPONSE_ENTRY_TS DATE NOT NULL , ENTERED_BY VARCHAR2(30) NOT NULL , RECEIVED_DCM_ID NUMBER(10,0) NOT NULL , DCM_QUESTION_ID NUMBER(10,0) NOT NULL , DCM_QUESTION_GROUP_ID NUMBER(10,0) NOT NULL , CLINICAL_STUDY_ID NUMBER(10,0) NOT NULL , REPEAT_SN NUMBER(3,0) NOT NULL , END_TS DATE NOT NULL , VALIDATION_STATUS VARCHAR2(3) DEFAULT 'NNN' NOT NULL , SECOND_PASS_INDICATOR VARCHAR2(1) NULL , VALUE_TEXT VARCHAR2(200) NULL , DISCREPANCY_INDICATOR VARCHAR2(1) NULL , DATA_CHANGE_REASON_TYPE_CODE VARCHAR2(15) NULL , DATA_COMMENT_TEXT VARCHAR2(200) NULL , AUDIT_COMMENT_TEXT VARCHAR2(200) NULL , EXCEPTION_VALUE_TEXT VARCHAR2(200) NULL) TABLESPACE RXC_RESP_TSPA STORAGE (INITIAL 1M NEXT 1M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) PARTITION BY RANGE (CLINICAL_STUDY_ID) ( PARTITION RESP_CSID_LE_1 VALUES LESS THAN (2) STORAGE (INITIAL 512K NEXT 512K MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_101 VALUES LESS THAN (102) STORAGE (INITIAL 1M NEXT 1M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_1001 VALUES LESS THAN (1002) STORAGE (INITIAL 1M NEXT 1M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_1201 VALUES LESS THAN (1202) STORAGE (INITIAL 4M NEXT 4M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_10000802 VALUES LESS THAN (10000803) STORAGE (INITIAL 16M NEXT 16M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_10001202 VALUES LESS THAN (10001203) …. …. , PARTITION RESP_CSID_LE_10242201 VALUES LESS THAN (10242202) STORAGE (INITIAL 256K NEXT 256K MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_9999999998 VALUES LESS THAN (9999999999) STORAGE (INITIAL 1M NEXT 1M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) ) ENABLE ROW MOVEMENT;
Example 9-2 Sample Responses Primary Key Index Creation Script
CREATE UNIQUE INDEX RESPONSE_PK_IDX ON RESPONSES ( RESPONSE_ID, RESPONSE_ENTRY_TS,CLINICAL_STUDY_ID) TABLESPACE RXC_RESP_IDX_TSPA COMPUTE STATISTICS NOLOGGING STORAGE (INITIAL 1M NEXT 1M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) LOCAL ( PARTITION RESP_CSID_LE_1 STORAGE (INITIAL 256K NEXT 256K MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_101 STORAGE (INITIAL 512K NEXT 512K MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_1001 STORAGE (INITIAL 512K NEXT 512K MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_1201 STORAGE (INITIAL 2M NEXT 2M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) … … , PARTITION RESP_CSID_LE_10242201 STORAGE (INITIAL 128K NEXT 128K MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_9999999998 STORAGE (INITIAL 512K NEXT 512K MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) ) ;
Once these scripts are generated you should review them and manually make any changes that can not be made through the Maintain Partition Mapping Table form. For instance, to modify the percent free default, for the table as a whole or for particular partitions, you must currently do this by editing the generated creation script. The script generation currently ignores the partition-specific tablespace specification, so you must manually amend the scripts to add this after the partition name and before the storage clause to place a partition in a tablespace other than the one specified for the table or index as a whole.
In addition, you should amend the index creation scripts to add the clauses COMPUTE STATISTICS and NOLOGGING at the position indicated in bold in Examples (UNKNOWN STEP NUMBER) and (UNKNOWN STEP NUMBER) . COMPUTE STATISTICS allows the cost-based statistics to be computed as the new indexes are created and avoids the time-consuming extra step of separately computing the statistics. NOLOGGING avoids the overhead of writing to the Oracle redo log file, which is unnecessary since the database will be backed up after the upgrade (see "Step 6. Create Indexes on Partitioned Responses Table" and "Maintenance of Cost-Based Statistics").
Example 9-3 Sample Responses Foreign Key Index Creation Statement
CREATE INDEX RESPONSE_RDCM_NFK_IDX ON RESPONSES ( CLINICAL_STUDY_ID, RECEIVED_DCM_ID, DCM_QUESTION_GROUP_ID, DCM_QUESTION_ID, END_TS, RESPONSE_ENTRY_TS, REPEAT_SN, RESPONSE_ID, VALUE_TEXT, VALIDATION_STATUS, EXCEPTION_VALUE_TEXT, DATA_COMMENT_TEXT) TABLESPACE RXC_RESP_IDX_TSPA COMPUTE STATISTICS NOLOGGING STORAGE (INITIAL 1M NEXT 1M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) COMPRESS 6 LOCAL ( PARTITION RESP_CSID_LE_1 STORAGE (INITIAL 512K NEXT 512K MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_101 STORAGE (INITIAL 1M NEXT 1M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_1001 STORAGE (INITIAL 1M NEXT 1M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_1201 STORAGE (INITIAL 4M NEXT 4M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_10000802 STORAGE (INITIAL 16M NEXT 16M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) … … , PARTITION RESP_CSID_LE_10242201 STORAGE (INITIAL 256K NEXT 256K MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) , PARTITION RESP_CSID_LE_9999999998 STORAGE (INITIAL 1M NEXT 1M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) ) ;
Once you have prepared the partition table and index creation scripts, you are ready to perform the partition upgrade. The upgrade consists of the following steps:
Back Up the Database (can be deferred to after Step 8).
Back Up the Database. (Optional, can be deferred to normal backup schedule.)
Note:
Conduct all SQL activities while connected to the RXC account, from the tools directory for Oracle Clinical, unless otherwise specified.Since the upgrade process involves dropping and recreating the Responses table and since there is a finite chance that the export of the Responses table could be corrupted, Oracle highly recommends that you perform a full database backup before you start the upgrade.
The migration of data from the non-partitioned Responses table to a partitioned Responses table is done through the exporting of data into a dump file using the Oracle Export utility and then importing the data into the partitioned table using the Oracle Import utility. During this migration process the Responses table is not available to users.
The Export utility reads the data blocks or rows from non-partitioned Responses table and writes into a dump file (or files). It uses a parameter file exp_resp_param.dat which is shipped with Oracle Clinical and located in the tools directory. The DBA in charge of migration at your location should review and make any changes to the parameters they feel are required.
Note that by default the export includes grants on the Responses table and that the import restores these grants. The upgrade process relies upon this to restore the grants on the newly reconstructed Responses table, so you should not modify the export or import to exclude grants.
exp rxc/password parfile=exp_resp_param.dat
The exp_resp_param.dat file contains the following information:
FILE=responses1.dmp,responses2.dmp,responses3.dmp,responses4.dmp FILESIZE=1G DIRECT=Y TABLES=(RXC.RESPONSES) COMPRESS=y CONSTRAINTS=N INDEXES=N LOG=exp_resp.log #RECORDLENGTH=64K STATISTICS=none
FILE The names of the files to create. Use multiple files, as shown, but extend or shorten this list to handle the maximum estimated size of your exported database.
FILESIZE As a rough guideline, test exports of a multi-gigabyte Responses table resulted in a total export size approximately 130% of the size of the unpartitioned Responses table's data segment.
For full information on Export and its parameters, see the Oracle Utilities manual.
Prior to creating the new Responses table, you should consider restarting the database specifying NOARCHIVELOG. Since you will back up the database at the completion of the upgrade and it is easier to restart a failed upgrade than to attempt to recover it from redo logs, there is no reason to pay the overhead of archiving the redo logs.
Drop the existing, unpartitioned Responses table and its indexes:
SQL> drop table responses;
If you are changing the use of tablespaces, for instance, to allocate different partitions to different tablespaces, you might want to drop the existing RXC_RESP_TSPA and RXC_RESP_IDX_TSPA and associated database files and recreate the new tablespace structure for the partitioned response table and indexes. This is not required, however.
Create an empty partitioned Responses table by executing the table creation script generated earlier (see Example 9-1, "Sample Responses Table Creation Statement"). Do not create the indexes.
SQL> @part_table_ddl.sql
The Import utility reads the dump file (or files) created by the export step and populates the partitioned Responses table. It uses a parameter file imp_resp_param.dat which is shipped with Oracle Clinical and located in the tools directory. The DBA in charge of migration at your location should review and make any changes to the parameters which they feel are required.
imp rxc/password PARFILE=imp_resp_param.dat
The imp_resp_param.dat file contains the following information:
FILE=responses1.dmp,responses2.dmp,responses3.dmp FILESIZE=1G IGNORE=Y ANALYZE=N #BUFFER COMMIT=Y TABLES=RESPONSES INDEXES=N LOG=imp_resp.log #RECORDLENGTH ANALYZE=N
FILE The names of the files to create. Make sure you edit this list to match the files created by the Export.
For full information on Import and its parameters, see the Oracle Utilities manual.
Once the import completes successfully, you should compute the statistics that are used by the cost-based optimizer by executing the ANALYZE command:
SQL> analyze table responses compute statistics;
While you can perform the analyze step with a small sample size, as illustrated below, the time saved here is relatively small. Because the indexes do not yet exist, the entire ANALYZE is performed by full scans of each partition, which are very efficient.
SQL> analyze table responses estimate statistics sample 5 percent;
See "Strategy for Ongoing Partition Maintenance" for a discussion of the ongoing maintenance of cost-based statistics.
Before creating the indexes on the Responses table, amend the index creation script to add the clauses COMPUTE STATISTICS and NOLOGGING, as shown in Examples (UNKNOWN STEP NUMBER) and (UNKNOWN STEP NUMBER) , above.
Create the indexes by executing the index creation scripts generated and edited earlier (see "Generating Table and Index Creation SQL").
SQL> @part_index_ddl.sql
These scripts take significant time to execute, proportionate to the size of the Responses table. You can monitor progress by querying the USER_SEGMENTS dictionary view from the RXC account because each index partition is committed separately.
Dropping and recreating Responses invalidates some packages and views. Execute the script compile_all_invalid.sql to compile all invalid objects in the database.
To run the compile_all_invalid.sql script:
Set up the environment to point to the correct database and code environment.
cd $RXC_INSTALL
Open a SQL*Plus session as system.
Run compile_all_invalid.sql:
SQL> start compile_all_invalid.sql
If you use pre-version 3.1 procedures and replicate study data using a database trigger on the Responses table to ensure that certain data changes occurring during batch validation are replicated, then execute the script resptrig.sql in the install directory.
SQL> @resptrig.sql
After the upgrade is complete, perform your normal full database backup. Re-enable redo log archiving before releasing Oracle Clinical for production use. This backup is mandatory because logging was disabled during the index rebuild and archive logging disabled during the import. You can wait until after Step 8, if you do that immediately after Step 6 and before production use of the database.
Once the Response table is partitioned, you must regenerate all procedures and data extract views for active studies. If you have disabled the generation of Version 4-style procedure and view optimization (see "Enforcing Pre-Version 4.0 Optimization"), you must enable it before regenerating procedures and views.
To regenerate procedures and views, follow the instructions in Chapter 10, "Utilities." For procedure regeneration you should select the parameters FULL, GENERATE and ALL. Note that in Releases 4.0 and above, procedure regeneration with GENERATE no longer causes discrepancies to be closed and reopened.
This section includes:
Ensure that distributed studies do not intersperse clinical_study_ids arbitrarily.
If you intend to collapse studies into single partitions or to consolidate dormant studies into read-only partitions, you must ensure that new studies do not get created whose clinical_study_ids lie between existing studies. This can occur in distributed installations of Oracle Clinical when studies are created at multiple locations using database seeds that differ only in their trailing digits. To address this you should either share clinical_study_id sequence across locations by replicating OCL_STUDIES and creating studies centrally or, alternatively, you should ensure that sequences do not overlap by seeding at non-overlapping starting seed values, not just separate trailing digits. For instance, start location 1 at ID 101 and location 2 at ID 1000102 rather than 102.
Preallocate planned studies to achieve grouping of small studies.
To consolidate small studies in single partitions, you should make sure that they have contiguous ranges. For instance, for a new project, create placeholder planned studies for all phase 1 and phase 2 studies so that they have contiguous IDs. This allows them to be grouped into a single partition.
There are three types of partition maintenance activities:
Activities that rebuild partitions
Activities that split or merge partitions
Activities that change ongoing characteristics of partitions
Activities that rebuild partitions must be performed manually. These include rebuilding the indexes on a partition, moving the data in a partition to a different tablespace, and restructuring the data in a partition to reduce the number of extents or change the PCTFREE storage parameter. See the Oracle documentation for instructions on how to carry out these activities.
Oracle Clinical includes the partition mapping form (see "Maintain Partition Mapping Tables Window") and a utility script generator that support SPLIT and MERGE operations and changes to ongoing storage characteristics.
Note that all SQL activities are carried out while connected to the RXC account.
Periodically, at weekly or monthly intervals depending on growth rate, review the current partition growth by querying the USER_SEGMENTS view:
SQL> select segment_name, partition_name, extents SQL> from user_segments SQL> where extents > 20 SQL> and segment_name like 'RESPONSE%';
This shows you any partitions that might need to be rebuilt.
In addition, you might want to initiate a manual process for identifying studies that are about to enter periods of intense reporting. The partitions for these studies could then be rebuilt, both to coalesce index space by rebuilding the indexes and, perhaps, to decrease the PCTFREE storage parameter if data is no longer changing.
See Example 9-6 for instructions on rebuilding partition indexes.
Unless there is a study that will grow extremely rapidly, for instance, due to batch loading, there is no need to anticipate the creation of studies and preallocate their partitions. Since new studies are created with incrementally higher clinical_study_ids, they are automatically added to the maximum partition. As long as this partition has a storage clause with large enough space allocations, these studies can start there without significant performance impact. At planned intervals you should review this partition to determine how these studies should be partitioned and use the partition maintenance script ("Instructions for Partition Maintenance") to split out the new partitions.
Use the script list_study_resp_cnt_part.sql to obtain a count by study of studies in a particular partition:
list_study_resp_cnt_part.sql partition_name spool_file_name
The following example lists the studies in the last partition, that is, the new ones:
SQL>@list_study_resp_cnt_part.sql RESP_CSID_LE_9999999998 new_studies.lis
As with new studies, existing partitions that contain multiple studies should be periodically reviewed and split as needed.
You may also want to merge partitions for studies that become inactive or that did not grow as planned. In particular, you might want to use the approach of using read-only tablespaces for inactive studies discussed in "Using Read-Only Partitions to Minimize Backup".
Whenever a partition is merged or split, or when the data volume in a partition has changed significantly, the cost-based statistics for that partition need to be refreshed. The command to refresh the statistics for a partition is:
ANALYZE TABLE Responses PARTITION (partition_name) COMPUTE STATISTICS;
If the partition is large, you can use the statistics estimation with a small sample size. However, since you do not need to analyze the whole table, but just partitions with changes, this may no longer be necessary:
SQL> analyze table responses partition (partition_name)
SQL> estimate statistics sample 5 percent;
One approach to maintaining the statistics is to use a table to hold the partition statistics from the previous partition maintenance and then drive the creation of the analyze statements from that table and the current statistics. The code fragment in illustrates this approach. It triggers the ANALYZE when the data volume in a partition increases by more than 50%.
Example 9-4 Using a Table to Compute Statistics
CREATE TABLE resp_part AS
SELECT partition_name, bytes
FROM user_segments
WHERE segment_name = 'RESPONSES';
spool analyze_responses.sql
SELECT 'ANALYZE TABLE RESPONSES PARTITION ('||
u.partition_name||') COMPUTE STATISTICS'
FROM resp_part r, user_segments u
WHERE u.segment_name = 'RESPONSES'
AND u.partition_name = r.partition_name
AND u.bytes/1.5 > r.bytes
UNION ALL
SELECT 'ANALYZE TABLE RESPONSES PARTITION ('||
u.partition_name||') COMPUTE STATISTICS'
FROM user_segments u
WHERE u.segment_name = 'RESPONSES'
AND not exists (select null from resp_part r
where r.partition_name = u.partition_name)
When you determine that you need to merge or split partitions, first use the Maintain Partition Mapping form (see ). Insert records for partitions that are to be split or delete records for partitions that are to be merged. You can also alter the storage clauses for partitions, although this affects only new storage allocations — it does not rebuild the existing partition space.
You then use the utility script gen_alter_partition.sql to generate the SQL partition maintenance commands.
gen_alter_partition output_file.sql
For example:
SQL> @gen_alter_partition.sql alter.sql
The generation script compares the partition definition in the Oracle Clinical Partition Mapping table with the actual partition structure in the database. It then generates the SQL DDL statements to merge or split the partitions and to alter the storage clauses (see ).
You should review the generated script and make any necessary modifications before you run it.
Example 9-5 Sample Output from the Partition Maintenance Script
REM Split case 4: Split RESP_CSID_LE_10002201 into RESP_CSID_LE_10001901 at 10001902 ALTER TABLE responses SPLIT PARTITION RESP_CSID_LE_10002201 AT (10001902) INTO (PARTITION RESP_CSID_LE_10001901 , PARTITION RESP_CSID_LE_10002201 STORAGE (INITIAL 4M NEXT 4M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) ); ALTER INDEX RESPONSE_PK_IDX MODIFY PARTITION RESP_CSID_LE_10001901 STORAGE (NEXT 2M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) ; ALTER INDEX RESPONSE_RDCM_NFK_IDX MODIFY PARTITION RESP_CSID_LE_10001901 STORAGE (NEXT 4M MINEXTENTS 1 MAXEXTENTS 99 PCTINCREASE 0) ; REM Merge case 2: Merge RESP_CSID_LE_10001102 into RESP_CSID_LE_10001202 ALTER TABLE responses MERGE PARTITIONS RESP_CSID_LE_10001102, RESP_CSID_LE_10001202 INTO PARTITION RESP_CSID_LE_10001202; REM Merge case 2: Merge RESP_CSID_LE_10001101 into RESP_CSID_LE_10001202 ALTER TABLE responses MERGE PARTITIONS RESP_CSID_LE_10001101, RESP_CSID_LE_10001202 INTO PARTITION RESP_CSID_LE_10001202;
After you run the partition maintenance script (see Example 9-5), some of the associated index partitions may be unusable. Use the SQL code shown in Example 9-6 to detect the affected partitions. It generates a script (rebuild.sql) that you run to rebuild the index partitions.
Example 9-6 SQL Code for Rebuilding Index Partitions
set pagesize 1000
set verify off
set feedback off
set heading off
spool rebuild.sql
select distinct 'ALTER TABLE RESPONSES MODIFY PARTITION '|| partition_name||'
REBUILD UNUSABLE LOCAL INDEXES
/'
from all_ind_partitions
where index_name in ('RESPONSE_PK_IDX', 'RESPONSE_RDCM_NFK_IDX')
and status = 'UNUSABLE'
/
spool off
set verify on
set feedback on
set heading on
Oracle enables you to designate tablespaces as read-only. If a tablespace is designated read-only, any attempt to modify data in that tablespace causes an Oracle error. Since the tablespace can not be modified, it can be created using data files on a separate physical device that only needs to be backed-up after maintenance activity during which the tablespace is modifiable. Over time, a significant portion of the Responses table data volume could be migrated to such read-only tablespaces, dramatically reducing the data volume that needs to be backed up by nightly backups.
To implement this strategy, you would set up the tablespace using data files on a separate physical device. A manual process of identifying studies that will no longer have modifications must be implemented. At periodic intervals, quarterly or semi-annually, you would perform partition maintenance to rebuild the partitions for those studies. During the maintenance, you alter the tablespace to make it writable. You move the data by exporting the partition, dropping the partition, and recreating the partition using the new tablespace. Once all studies have been moved, you alter the tablespace to be read-only once again and perform a backup of the device.
Oracle Clinical was retuned to require only two indexes on the Responses table:
RESPONSE_PK_IDX – primary key index on RESPONSE_ID and RESPONSE_ENTRY_TS
RESPONSE_RDCM_NFK_IDX – an expanded, concatenated index on RECEIVED_DCM_ID
The following indexes are no longer required:
RESPONSE_CS_NFK_IDX – on CLINICAL_STUDY_ID
RESPONSE_DCMQG_NFK_IDX – on DCM_QUESTION_GROUP_ID
RESPONSE_UK_IDX – on DCM_QUESTION_ID
This, combined with the use of Oracle database leading key compression, results in up to 50% savings in space allocated to the Responses table and its indexes, and a significant reduction in runtime overhead to maintain the indexes. These savings occur whether you partition or not.
To upgrade the indexes you must modify and execute the script rebuild_resp_index_non_part.sql in the install directory while connected to the RXC account. You should modify the script to provide storage parameters appropriate for the size of your Responses table. The foreign key index is approximately 70% the size of the Responses table when created and the primary key index is approximately 40%. In addition, if you are dropping the obsolete indexes, you should un-comment the drop index statements and move them to before the index creation statements to ensure that their space is freed before the new indexes are created.
SQL> @rebuild_resp_index_non_part.sql
If you have other applications that directly access the Responses table, these may need to be retuned before you perform the index upgrade (due to the new leading CLINICAL_STUDY_ID key on the RESPONSE_RDCM_NFK_IDX) or before you drop the optional indexes (see "Query Tuning Guidelines"). If you are not partitioning you can retain one or more of these indexes until your other applications are retuned.
Note:
If you are partitioning, the new index structure is automatically created as part of the partitioning upgrade, so you should not do the upgrade described in this section.If you are partitioning and want to retain one or more of the old indexes, you have to manually recreate them as non-partitioned global indexes after the partitioning upgrade.
Before upgrading the indexes, you must analyze your disk space requirements if you are preserving the existing indexes. Due to leading key compression the new, concatenated RESPONSE_RDCM_NFK_IDX index is significantly smaller than the version 3.1 concatenated RESPONSE_DCMQG_NFK_IDX it functionally replaces. However, if you are preserving all pre-existing indexes, there is a small (20-30%) net increase in the size of the pre-existing RESPONSE_RDCM_NFK_IDX. Dropping any of the pre-existing indexes, including the largely superfluous RESPONSE_CS_NFK_IDX, releases at least that amount of space.
Even if you are not preserving existing indexes, since you will be dropping and recreating all of the indexes, the index upgrade is a good time to replan the use of physical storage for the Response table indexes. Placing the indexes on a tablespace on a separate physical device from the Responses table is a good practice.
Once the Response table indexes are rebuilt, you must regenerate all procedures and data extract views for active studies. If you have disabled the generation of Version 4-style procedure and view optimization (see "Enforcing Pre-Version 4.0 Optimization"), you must enable it before regenerating procedures and views.
To regenerate procedures and views, follow the instructions for using the procedure and view regeneration utilities documented in Chapter 10, "Utilities." For procedure regeneration you should select the parameters FULL, GENERATE and ALL.
A script, rebuild_respt_index.sql in the install directory, rebuilds the indexes on the Responsest, or test database Responses table. This script should be run whether or not you are partitioning the Responses table. The upgrade for Responsest should be done at the same time as either partitioning or the Responses table index upgrade.
To take advantage of the Oracle index compression feature, you can optionally rebuild selected indexes on the RECEIVED_DCMs and RECEIVED_DCIs tables. Since these can be large tables, this script is not automatically run as part of the upgrade to Oracle Clinical V4. The upgrade of the RECEIVED_DCMs and RECEIVED_DCIs indexes can be done at any time that is convenient, independently of either partitioning or Responses table index upgrade. This change reduces the size of these indexes and, therefore, improves performance due to fewer disk accesses.
To rebuild the indexes on the RECEIVED_DCMs and RECEIVED_DCIs tables, execute the script oclupg32to40opt5.sql in the install directory:
SQL> @oclupg32to40opt5.sql
For both partitioning and index upgrade, Oracle Clinical has been retuned to use only the primary key index RESPONSES_PK_IDX with the Response ID leading key or the concatenated RESPONSES_RDCM_NFK_IDX with the clinical_study_id and RECEIVED_DCM_ID leading keys. You should review any applications that directly access the Responses table to ensure that they are correctly optimized for the new index structure.
The basic guidelines for re-optimization are:
Include clinical_study_id in all access to the Responses table.
There are two reasons for this. Primarily, because Responses are in a partition based on clinical_study_id, the query optimizer can restrict its search to the proper partition if the query contains clinical_study_id. This is called 'Partition Pruning'. In order of preference this reference to clinical_study_id can be a constant, a bind variable in an equi-join, or a join from another table.
Secondly, the concatenated index is prefixed with clinical_study_id to force Responses from different studies in the same partition to be physically grouped together and to optimize certain partition accesses.
Redirect all previous queries on DCM_QUESTION_ID or DCM_QUESTION_GROUP_ID to use a join through RECEIVED_DCMs so that they can use the concatenated index.
Since there are no longer indexes with DCM_QUESTION_ID or DCM_QUESTION_GROUP_ID as leading keys, these are no longer efficient access paths. Much of the access involving these keys is already done in the context of a RECEIVED_DCM, so the query tuning is usually minimal. In some cases, it might be necessary to add joins to DCM_QUESTIONS or DCM_QUESTION_GROUPS, then through RECEIVED_DCMs via DCM_ID. For instance, the query shown in Examples (UNKNOWN STEP NUMBER) and (UNKNOWN STEP NUMBER) selects responses to a particular Question where the patient position is owned locally.
Example 9-7 Query Before Redirection
SELECT response_id, to_char(response_entry_ts, 'DD-MON-YYYY HH24:MI:SS'),
received_dcm_id
FROM responses r
WHERE r.dcm_question_id = :dcm_question_id
AND EXISTS
(SELECT NULL FROM received_dcms rd, patient_positions papo
WHERE rd.patient_position_id = papo.patient_position_id
AND papo.owning_location = :current_location
AND rd.received_dcm_id = r.received_dcm_id)
Example 9-8 Query After Redirection
SELECT response_id, to_char(response_entry_ts, 'DD-MON-YYYY HH24:MI:SS'),
received_dcm_id
FROM responses r
WHERE r.dcm_question_id = :dcm_question_id
AND
(clinical_study_id, received_dcm_id, dcm_question_group_id) IN
(SELECT rd.clinical_study_id, rd.received_dcm_id, dq.dcm_question_group_id
FROM received_dcms rd, patient_positions papo, dcm_questions dq
WHERE dq.dcm_question_id = :dcm_question_id
AND dq.dcm_que_dcm_subset_sn = 1
AND dq.dcm_que_dcm_layout_sn = 1
AND rd.dcm_id = dq.dcm_id
AND rd.patient_position_id = papo.patient_position_id
AND papo.owning_location = :current_location)
|
Copyright © 1996, 2015, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|