| Oracle® Big Data Applianceソフトウェア・ユーザーズ・ガイド リリース2 (2.5) E53260-01 |
|


 前 |
 次 |
この章では、Perfect Balanceを使用して一部のMapReduceジョブの実行時間を短縮する方法について説明します。この章の内容は次のとおりです。
Oracle Big Data ApplianceのPerfect Balance機能は、MapReduceアプリケーションのリデューサ・ロードを分散して、各リデュース・タスクで実行される処理がほぼ同じ量になるようにします。リデュース・ロードを分散するためのデフォルトのHadoopメソッドは、多くのジョブに対して適切ですが、データ・スキューが大きい場合にはジョブのロードを均等に分散できません。
データ・スキューとは、複数のリデュース・タスクに対する不均等なロード割当てのことです。ロードとは、次の要因がもたらす作用のことです。
1つのリデューサに割り当てられたキーの数。
キー当たりの値に含まれるレコード数とバイト数。
ジョブの総実行時間は、最大ロードのリデューサの所要時間に応じて長くなります。ジョブのロードが不均衡な場合、リデューサによってジョブの所要時間にばらつきが生じます。Perfect Balanceを使用すると、ロードが均等に分散され、すべてのリデューサがほぼ同じ時間で処理を完了できるようになるため、総実行時間を大幅に短縮できます。
MapReduceジョブはmapredかmapreduceのいずれかのAPIを使用して記述されますが、Perfect Balanceはこれら両方をサポートしています。
Perfect Balanceは、Oracle Big Data Appliance上のデフォルトのインストールである、MapReduce 1 (MRv1) CDHクラスタ上でテストされています。
典型的なHadoopジョブには、マップ・タスクとリデュース・タスクがあります。Hadoopは、マッパーのワークロードをHadoop Distributed File System (HDFS)全体と各マップ・タスク間にわたって均一に分散しながら、データのローカル性も維持します。これにより、マッパー間のスキューが減ります。
Hadoopはまた、マップ出力キーをすべてのリデューサに均一にハッシュします。この手法は、リデューサの数よりもキーの数のほうがかなり多く、各キーがワークロードのごく一部しか占めていない場合に効果的です。ただし、マッパー出力が少数のキーに集中している場合には効果的ではありません。これらのキーをハッシュするとスキューが発生し、並べ替えなど、レンジ・パーティショニングを必要とするアプリケーションではうまく機能しません。
Perfect Balanceは、最初にデータをサンプリングし、サイズの大きなキーを必要に応じて2つ以上のキーに分割し、ロード認識型のパーティショニング手法を使用してリデューサ・タスクにキーを割り当てることで、ロードを各リデューサに均等に分配します。
Perfect Balance機能の実行方法は次の2つの中から選択できます。
Perfect Balance: Perfect Balanceを適切に構成すると、アプリケーション・コードを変更することなくジョブを実行できます。これは、推奨される方法であり、ほとんどのジョブに適しています。
この方法は、「Perfect Balanceを使用したBalanced MapReduceジョブの実行」に説明されており、この章の主な目的です。
Perfect Balance API: Perfect Balanceを実行するためのコードをアプリケーション・コードに追加できます。Perfect Balanceを使用する前にアプリケーション設定コードを実行する必要がある場合、この方法を使用します。それ以外の場合は、前述の方法(コードの変更は不要)を使用します。
この方法は、「Perfect Balance APIの使用」に説明されています。
Perfect Balanceには次のコンポーネントがあります。
Job Analyzer: Perfect Balanceを使用するかどうかの判断材料として、MapReduceジョブに関する統計情報を収集し、レポートします。
Counting Reducer: Perfect Balanceの効果を測定するための、追加の統計情報をJob Analyzerに提供します。
Load Balancer: MapReduceジョブの前に実行して、静的パーティション・プランを生成し、プランを使用するジョブを再構成します。バランサには、良好なパーティショニング・プランが生成されしだいデータのサンプリングを停止する、ユーザー構成可能なプログレッシブ・サンプラが含まれます。
Driver: Perfect Balanceをhadoopコマンド内で実行できます。
Perfect Balanceを正常に使用するには、アプリケーションが次の要件を満たしている必要があります。
ジョブは分散型で、リデュース・キーに関連付けられたレコードのグループを分割してもアプリケーションの不正確な結果が生成されることはありません。
ロードを均衡化するために、Perfect Balanceは大きいリデュース・キーの値をサブパーティション化し、各サブパーティションを別のリデューサに送信します。この分散は、1つのリデュース・キーのすべての値を同じリデューサに送信する標準のHadoopとは対照的です。アプリケーションは、不正確な結果を生成しないように、完全に集計されていないリデューサからの出力を処理できる必要があります。
この値のパーティショニングは分割と呼ばれます。分割をサポートするアプリケーションには分散リデュース機能があります。「分割について」を参照してください。
アプリケーションが分散型でない場合でも、キー分割機能を無効にした後であればPerfect Balanceを実行できます。その場合、Perfect Balanceのメリットは一応は発揮されますが、キー分割が有効な場合ほどにはロードは均等に分散されません。キー分割を無効にするには、oracle.hadoop.balancer.keyLoad.minChopBytes構成プロパティを参照してください。
今リリースでは、コンバイナはサポートされません。Perfect Balanceはコンバイナの存在を検出し、コンバイナが存在する場合にはバランシングを行いません。
Perfect Balanceは、次の手順に従って使用します。
アプリケーションが「アプリケーション要件」にリストされている要件を満たしていることを確認してください。
ジョブを発行するサーバーにログインします。
Perfect Balanceに付属している例を実行することにより、本製品について理解できます。この章で示しているすべての例は付属の例を基にしており、同じデータ・セットを使用します。「Perfect Balanceの例について」を参照してください。
Bash exportコマンドを使用して次の変数を設定します。
BALANCER_HOME: Perfect Balanceのインストール・ディレクトリ(Oracle Big Data Applianceの/opt/oracle/orabalancer-1.1.1-h2)に設定します(オプション)。この章の例ではこの変数を使用しますが、変数を自分で定義することもできます。Perfect BalanceではBALANCER_HOMEは不要です。
HADOOP_CLASSPATH: ${BALANCER_HOME}/jlib/orabalancer-1.1.1.jarと${BALANCER_HOME}/jlib/commons-math-2.2.jarを既存の値に追加します。アプリケーションのJARファイルも追加します。
Perfect Balanceを有効にするには、${BALANCER_HOME}/jlib/orabalancerclient-1.1.1.jarを追加します(APIモードではこのJARファイルを使用しません)。
HADOOP_USER_CLASSPATH_FIRST: commons-math.jarのPerfect Balanceバージョンを使用する場合は、trueに設定します。
Perfect Balanceを使用していないかぎり、これらの変数を設定する必要はありません。
バランサを使用せずにJob Analyzerを実行し、生成されたレポートを使用して、ジョブがPerfect Balanceの使用に適した候補であるかどうかを判断します。
「ジョブ・リデューサ・ロードの分析」を参照してください。
設定する構成プロパティを決定します。構成ファイルを作成するか、hadoopコマンドで設定を個別に入力します。
「Perfect Balanceの構成について」を参照してください。
Perfect Balanceを使用してジョブを実行します。
Job Analyzerレポートを使用して、Perfect Balanceを使用する効果を評価します。「Job Analyzerレポートの分析」を参照してください。
Perfect Balanceを使用してジョブを再実行する前に、必要に応じてジョブ構成プロパティを変更します。「Perfect Balanceの構成について」を参照してください。
Job Analyzerは、ロードの不均衡を特定するとともに、実際のジョブの実行時にPerfect Balanceによっていかに効果的に不均衡を解消できるかを評価するための、Perfect Balanceの1コンポーネントです。この項の内容は次のとおりです。
Job Analyzerを使用すると、あるジョブがPerfect Balanceによるロード・バランシングの候補かどうかを判定できます。Job Analyzerは、MapReduceジョブの出力ログを使用して、各リデュース・タスクの経過時間やロードなどの統計情報を含んだシンプルなレポートを生成します。デフォルトでは、JobTrackerのユーザー・インタフェースによって表示される標準のHadoopカウンタが使用されますが、リデュース・タスクの相対パフォーマンスとロードを強調するためにデータが整理されるので、結果をより簡単に把握できます。
レポートで、データに不均衡がある(リデューサの処理するロードや実行時間に大きな差が見られる)場合、そのアプリケーションはPerfect Balanceの使用対象として適していると言えます。
Job Analyzerの実行方法は次の2つの中から選択できます。
スタンドアロン・ユーティリティとして実行する: この場合、Job Analyzerは既存のジョブ出力ログに対して実行されます。この実行方法は、Perfect Balanceを使用せずに実行しているアプリケーションがOracle Big Data Appliance上にすでに存在する場合に適しています。
Perfect Balanceを使用中に実行する: この場合Job Analyzerは、Perfect Balanceで実行されている現在のジョブの出力ログに対して実行されます。これは、Oracle Big Data Applianceで初めてアプリケーションを実行するときに適しています。スタンドアロンのJob Analyzerユーティリティを使用して分析する既存のジョブ出力ログがないからです。
Job Analyzerをスタンドアロン・ユーティリティとして実行すると、以前に実行されたジョブのリデュース・ロードをすばやく分析できます。
Job Analyzerをスタンドアロン・ユーティリティとして実行するには、次の手順に従います。
Job Analyzerを実行するサーバーにログインします。
分析するジョブからの出力ファイルを探します。mapred.output.dirをこのディレクトリに設定します。
「Job Analyzerユーティリティの構文」の説明に従って、Job Analyzerを実行します。
Job Analyzerレポートをブラウザで参照します。
例4-1では、必要な変数を設定し、jdoe_nobal_outdirに保存されたMapReduceジョブのログを使用して、デフォルトの場所にレポートを作成するスクリプトが実行されます。その後、HTMLバージョンのレポートがHDFSから/home/jdoeローカル・ディレクトリにコピーされ、ブラウザでレポートが開かれます。
この例を実行する場合は、jdoe_nobal_outdirを、前のジョブ実行の出力ログへのHDFSパスに置き換えます。InvertedIndex例を実行したときの出力ログを使用できます。デフォルトのHDFS出力ディレクトリはinvindx/outputにあります。「Perfect Balanceの例について」を参照してください。
例4-1 Job Analyzerユーティリティの実行
$ cat runja.sh BALANCER_HOME=/opt/oracle/orabalancer-1.1.1-h2 export HADOOP_CLASSPATH=${BALANCER_HOME}/jlib/orabalancer-1.1.1.jar:${BALANCER_HOME}/jlib/commons-math-2.2.jar:$HADOOP_CLASSPATH export HADOOP_USER_CLASSPATH_FIRST=true hadoop jar ${BALANCER_HOME}/jlib/orabalancer-1.1.1.jar oracle.hadoop.balancer.tools.JobAnalyzer \ -D mapred.output.dir=jdoe_nobal_outdir $ sh ./runja.sh $ $ hadoop fs -get jdoe_nobal_outdir/_balancer/jobanalyzer-report.html /home/jdoe $ cd /home/jdoe $ firefox jobanalyzer-report.html
Job Analyzerユーティリティを実行するための構文を次に示します。
bin/hadoop jar ${BALANCER_HOME}/jlib/orabalancer-1.1.1 oracle.hadoop.balancer.tools.JobAnalyzer \
-D mapred.output.dir=job_output_dir \
[ja_report_path]
以前のアプリケーション実行時にジョブ・ファイルが保存されたHDFSディレクトリ。
Job Analyzerが自身のレポートを作成するHDFSディレクトリ(オプション)。デフォルトのディレクトリは、job_output_dir/_balancerです。
Perfect Balanceを使用してジョブを実行するとき、Job Analyzerが自動的に実行されるように構成できます。この項の内容は次のとおりです。
Perfect Balanceを使用してJob Analyzerを実行するには、次の手順に従います。
Perfect Balanceを使用するジョブを発行するサーバーにログインします。
「Perfect Balanceの概要」の手順を実行し、Perfect Balanceを設定します。
Job Analyzerを有効にするには、oracle.hadoop.balancer.autoAnalyze構成プロパティを次のいずれかの値に設定します。
BASIC_REPORT: Job Analyzerを有効にします。oracle.hadoop.balancer.autoBalanceをtrueに設定した場合、Perfect Balanceはoracle.hadoop.balancer.autoAnalyzeを自動的にBASIC_REPORTに設定します。
REDUCER_REPORT: 追加のロード統計を収集するようにJob Analyzerを構成します。「追加メトリックの収集」を参照してください。
設定する追加構成プロパティを決定します(必要な場合)。
「Perfect Balance構成プロパティ・リファレンス」を参照してください。
ジョブを実行します。
例4-2では、必要な変数を設定するスクリプトを実行し、ロード・バランシングを行わずにPerfect Balanceを使用してJob Analyzerでジョブを実行し、デフォルトの場所にレポートを作成します。その後、HTMLバージョンのレポートがHDFSから/home/jdoeローカル・ディレクトリにコピーされ、ブラウザでレポートが開かれます。出力には警告が含まれますが、これは無視できます。
例4-2 Perfect Balanceを使用したJob Analyzerの実行
$ cat ja_nobalance.sh # set up perfect balance BALANCER_HOME=/opt/oracle/orabalancer-1.1.1-h2 export HADOOP_CLASSPATH=${BALANCER_HOME}/jlib/orabalancerclient-1.1.1.jar:${BALANCER_HOME}/jlib/orabalancer-1.1.jar:${BALANCER_HOME}/jlib/commons-math-2.2.jar:${HADOOP_CLASSPATH} export HADOOP_USER_CLASSPATH_FIRST=true # run the job hadoop jar application_jarfile.jar ApplicationClass \ -D application_config_property \ -D mapred.input.dir=jdoe_application/input \ -D mapred.output.dir=jdoe_nobal_outdir \ -D mapred.job.name=nobal \ -D mapred.reduce.tasks=10 \ -D oracle.hadoop.balancer.autoBalance=false \ -D oracle.hadoop.balancer.autoAnalyze=REDUCER_REPORT \ -conf application_config_file.xml $ sh ja_nobalance.sh 13/10/23 17:35:09 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 13/10/23 17:35:10 INFO input.FileInputFormat: Total input paths to process : 5 13/10/23 17:35:10 INFO mapred.JobClient: Running job: job_201310212138_0169 13/10/23 17:35:11 INFO mapred.JobClient: map 0% reduce 0% 13/10/23 17:35:24 INFO mapred.JobClient: map 31% reduce 0% . . . 13/10/23 17:36:04 INFO mapred.JobClient: Reduce input records=20000000 13/10/23 17:36:04 INFO mapred.JobClient: Reduce output records=13871794 13/10/23 17:36:04 INFO mapred.JobClient: Spilled Records=60000000 13/10/23 17:36:04 INFO mapred.JobClient: CPU time spent (ms)=268450 13/10/23 17:36:04 INFO mapred.JobClient: Physical memory (bytes) snapshot=10195607552 13/10/23 17:36:04 INFO mapred.JobClient: Virtual memory (bytes) snapshot=34434174976 13/10/23 17:36:04 INFO mapred.JobClient: Total committed heap usage (bytes)=16998989824 $ hadoop fs -get jdoe_nobal_outdir/_balancer/jobanalyzer-report.html /home/jdoe $ cd /home/jdoe $ firefox jobanalyzer-report.html
oracle.hadoop.balancer.autoAnalyzeプロパティをREDUCER_REPORTに設定した場合、Job Analyzerレポートには各キーのロード・メトリックが含まれます。この追加情報を使用すると、標準のHadoopカウンタでは使用できないメトリックを使用して、各リデューサのロードを詳細に把握できます。
Job Analyzerレポートは、予測ロードと実際のロードとの比較も行います。これらの値の違いに基づいて、Perfect Balanceがジョブの均衡化にどれほど効果を発揮しているか測定できます。
Job Analyzerでは、ジョブのロードの分析に基づいてPerfect Balanceキー・ロード・モデルのキー・ロード係数を推奨する場合があります。Perfect Balanceを使用してジョブを実行するときにこれらの推奨係数を使用するには、oracle.hadoop.balancer.linearKeyLoad.feedbackDirプロパティを、以前に分析したジョブの実行のJob Analyzerレポートを含むディレクトリに設定します。レポートに推奨係数が含まれる場合、Perfect Balanceは自動的にその係数を使用します。
Perfect Balanceを使用して初めてジョブを実行する場合など、ジョブのロード・モデル係数の値がわからない場合は、feedbackDirプロパティを使用します。推奨値はジョブのロードの分析に基づいているため、推奨値は通常、Perfect Balanceのデフォルト値よりも優れた結果になります。
ジョブのロード・モデル係数の適切な値がわかっている場合は、ロード・モデル・プロパティを設定することもできます。
ジョブを再度実行すると、これらの係数によってジョブがさらに均衡化されます。
Job Analyzerは、レポートの内容を2つの形式で記述します。HTML (ユーザー用)とXML (Perfect Balance用)です。例4-2に示すように、HDFSからローカル・ファイル・システムにHTMLバージョンをコピーし、ブラウザで開きます。
Job Analyzerレポートの内容を調べる際には、次のようなスキューの指標を探します。
一部のリデューサの実行時間が他のものよりも長い。
一部のリデューサが他のリデューサよりも多くのレコードやバイトを処理している。
一部のマップ出力キーのレコード数が他のものよりも多い。
一部のマップ出力レコードのバイト数が他のものよりも多い。
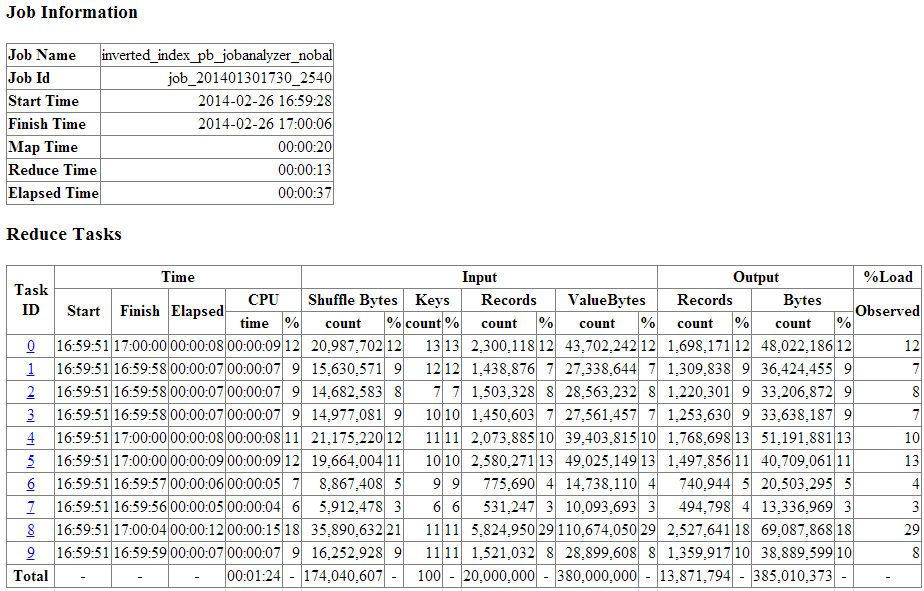
図4-1に、転置インデックス(invindx)の例に対するアナライザ・レポートの冒頭を示します。このジョブは適切な構成設定を使用して実行されたため、図にはキー・ロード係数の推奨値が表示されています。「追加メトリックの収集」を参照してください。
タスクIDは、特定のタスクの分析結果を示すテーブルへのリンクです。これにより、最初のサマリー・テーブルからより詳細なデータへとドリルダウンできます。
この例では極端に小さなデータ・セットが使用されていますが、タスク7と8の間の差に注目してください。入力レコードの差が3%と18%で大きく開いており、対応する経過時間の差も6秒と20秒で大きく開いています。この開きはスキューの発生を示しています。
Perfect Balanceでは、コマンドラインでの構成プロパティの指定に、標準のHadoopメソッドが使用されます。ユーザーは、-confオプションを使用して構成ファイルを特定できます。または、-Dオプションを使用して個別のプロパティを指定できます。Perfect Balanceのすべての構成プロパティにはデフォルト値があるため、各プロパティの設定は任意です。
『Perfect Balance構成プロパティ・リファレンス』には、構成プロパティがアルファベット順でリストされており、それらの詳しい説明が記載されています。次に示すのは、プロパティの機能グループです。
Perfect Balance基本プロパティ
Job Analyzerプロパティ
キー分割プロパティ
ロード・バランシング・プロパティ
ロード・モデル・プロパティ
MapReduce関連プロパティ
パーティション・レポート・プロパティ
サンプラ・プロパティ
Perfect Balanceでは、アプリケーション・コードの変更は不要です。実行するジョブをHadoopに発行すると、そのジョブに対してPerfect Balanceが自動的に実行されます。
Perfect Balanceを使用してジョブを実行するには、次の手順を実行します。
ジョブを発行するサーバーにログインします。
「Perfect Balanceの概要」の手順を実行し、Perfect Balanceを設定します。
Perfect Balanceの次のプロパティを設定してジョブを構成します。
バランシングを有効にするには、oracle.hadoop.balancer.autoBalanceをtrueに設定します。この設定で、Job Analyzerも実行されます。ロード・バランシングは、デフォルトで有効ではありません。
Job Analyzerで追加のメトリックを収集できるようにするには、oracle.hadoop.balancer.autoAnalyzeをREDUCER_REPORTに設定します。
「追加メトリックの収集」を参照してください。
設定する追加構成プロパティを決定します(必要な場合)。
「Perfect Balanceの構成について」を参照してください。
次の構文で、通常どおりにジョブを実行します。
bin/hadoop jar application_jarfile.jar ApplicationClass\ -D application_config_property \ -D oracle.hadoop.balancer.autoBalance=true \ -D other_perfect_balance_config_property \ -conf application_config_file.xml \ -conf perfect_balance_config_file.xml
アプリケーションのコードを変更する必要はありません。Perfect Balanceの構成プロパティは、コマンドラインと構成ファイルのどちらでも指定できます。Perfect BalanceのプロパティとMapReduceのプロパティは同じ構成ファイル内で組み合せて使用することもできます。「Perfect Balanceの構成について」
例4-3では、pb_balance.shというスクリプトを実行しています。これは、ジョブに対するPerfect Balanceを設定し、続いてそのジョブを実行します。キー・ロード・メトリック・プロパティは、図4-1で示したJob Analyzerレポートの推奨値に設定されます。
例4-3 Perfect Balanceを使用したジョブの実行
$ cat pb_balance.sh #setup perfect balance as described in Getting Started with Perfect Balance BALANCER_HOME=/opt/oracle/orabalancer-1.10.0-h2 export HADOOP_CLASSPATH=${BALANCER_HOME}/jlib/orabalancerclient-1.1.1.jar: ${BALANCER_HOME}/jlib/orabalancer.jar:${BALANCER_HOME}/jlib/commons-math-2.2.jar:$HADOOP_CLASSPATH export HADOOP_USER_CLASSPATH_FIRST=true # setup optional properties like java heap size and garbage collector export HADOOP_CLIENT_OPTS="-XX:+UseConcMarkSweepGC –Xmx512M ${HADOOP_CLIENT_OPTS}" # run the job with balancing and job analyzer enabled hadoop jar application_jarfile.jarApplicationClass -D application_config_property \ -D mapred.input.dir=jdoe_application/input \ -D mapred.output.dir=jdoe_outdir \ -D mapred.job.name="autoinvoke" \ -D mapred.reduce.tasks=10 \ -D oracle.hadoop.balancer.autoBalance=true \ -D oracle.hadoop.balancer.autoAnalyze=REDUCER_REPORT \ -D oracle.hadoop.balancer.linearKeyLoad.keyWeight=93.98 \ -D oracle.hadoop.balancer.linearKeyLoad.rowWeight=0.001126 \ -D oracle.hadoop.balancer.linearKeyLoad.byteWeight=0.0 \ -conf application_config_file.xml $ sh ./pb_balance.sh 13/10/23 17:47:48 INFO balancer.Balancer: Starting Balancer 13/10/23 17:47:49 INFO input.FileInputFormat: Total input paths to process : 5 13/10/23 17:47:54 INFO balancer.Balancer: Balancer completed 13/10/23 17:47:54 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 13/10/23 17:47:54 INFO input.FileInputFormat: Total input paths to process : 5 13/10/23 17:47:54 INFO mapred.JobClient: Running job: job_201310212138_0170 13/10/23 17:47:55 INFO mapred.JobClient: map 0% reduce 0% 13/10/23 17:48:09 INFO mapred.JobClient: map 18% reduce 0% 13/10/23 17:48:10 INFO mapred.JobClient: map 31% reduce 0% . . . 13/10/23 17:48:45 INFO mapred.JobClient: Reduce input records=20000000 13/10/23 17:48:45 INFO mapred.JobClient: Reduce output records=13871794 13/10/23 17:48:45 INFO mapred.JobClient: Spilled Records=60000000 13/10/23 17:48:45 INFO mapred.JobClient: CPU time spent (ms)=275560 13/10/23 17:48:45 INFO mapred.JobClient: Physical memory (bytes) snapshot=10480836608 13/10/23 17:48:45 INFO mapred.JobClient: Virtual memory (bytes) snapshot=34511245312 13/10/23 17:48:45 INFO mapred.JobClient: Total committed heap usage (bytes)=17533239296
Perfect Balanceは、ジョブの実行時に次のレポートを生成します。
Job Analyzerレポート: ジョブ内のロードの分散に関する様々な指標を含みます。このレポートは、ユーザー用のHTML形式と、Perfect Balanceで使用するためのXML形式で保存されます。このレポートには常に、jobanalyzer-report.htmlおよび-.xmlという名前が付けられます。「Job Analyzerレポートの分析」を参照してください。
パーティション・レポート: 様々なマッパーに割り当てられたキーを識別します。このレポートは、Perfect Balanceで使用するためのXML形式で保存されます。ユーザーが使用するための情報は含まれません。このレポートには、${mapred_output_dir}/_balancer/orabalancer_report.xmlという名前が付けられます。均衡化されたジョブのためにのみ生成されます。
リデュース・キー・メトリック・レポート: 適切な構成プロパティが設定されている場合、Perfect Balanceは各ファイル・パーティションに対してレポートを生成します。これらのレポートは、Perfect Balanceで使用するためのXML形式で保存されます。ユーザーが使用するための情報は含まれません。これらのレポートには、${mapred_output_dir}/_balancer/ReduceKeyMetricList-attempt_jobid_taskid_task_attemptid.xmlという名前が付けられます。これらのレポートは、カウンティング・リデューサを使用する場合のみ生成されます(つまり、Perfect Balanceを使用する場合はoracle.hadoop.balancer.autoAnalyze=REDUCER_REPORT、またはAPIを使用する場合はBalancer.configureCountingReducerメソッドの呼出し)。
「追加メトリックの収集」を参照してください。
これらのレポートは、デフォルトではジョブの出力ディレクトリ(${mapred.output.dir})に保存されます。次に示すのは、このディレクトリの構造です。
job_output_directory
/_SUCCESS
/_balancer
ReduceKeyMetricList-attempt_201305031125_0016_r_000000_0.xml
ReduceKeyMetricList-attempt_201305031125_0016_r_000001_0.xml
.
.
.
jobanalyzer-report.html
jobanalyzer-report.xml
orabalancer_report.xml
/_logs
/history
job_201305031125_0016_1372277234720_jdoe_invindx_nobal
localhost.localdomain_1367594758596_job_201305031125_0016_conf.xml
/part-r-00000
/part-r-00001
.
.
.
ロードを均衡化するために、Perfect Balanceは単一のリデュース・キーの値をサブパーティション化し、各サブパーティションを別のリデューサに送信する場合があります。この値のパーティショニングは分割と呼ばれます。
oracle.hadoop.balancer.enableSorting構成パラメータを設定することで、Perfect Balanceが値を分割する方法を構成できます。
ハッシュ・パーティショニングによる分割: ソートが不要な場合、enableSorting=falseを設定します。これはデフォルトの分割方法です。
ソートによる分割: 各サブパーティションの値をソートするようにenableSorting=trueを設定し、すべてのサブパーティションの値を並べ替えます。パラレル・ソート・ジョブでは、各タスクはタスク内の行をソートします。ジョブは、リデュース・タスク2の値がリデュース・タスク1の値より大きく、リデュース・タスク3の値がリデュース・タスク2の値より大きい(以下同様)ことを確認する必要があります。ジョブは、ソートされたデータを含む1つの大きいファイルではなく、ソート順のデータを含む複数のファイルを生成します。
たとえば、キーが3つのサブパーティションに分割され、サブパーティションがリデューサ5、8および9に送信される場合、リデューサ9のそのキーの値はリデューサ8のそのキーのすべての値より大きく、リデューサ8のそのキーの値はリデューサ5のそのキーのすべての値よりも大きくなります。enableSorting=trueの場合、Perfect Balanceはこの順序がリデュース・タスク全体に及ぶことを確認します。
アプリケーションでファイル全体のデータを集計する必要がある場合、oracle.hadoop.balancer.keyLoad.minChopBytes=-1を設定することで分割を無効にできます。Perfect Balanceでは、ビン・パッキングと呼ばれる小さいリデュース・キーを結合することで引き続きパフォーマンスが向上するようにします。
MapReduceがリデュース・キーでデータを集計する場合、各リデュース・タスクはそのタスク内のキーごとに値を集計します。ただし、Perfect Balanceで分割が有効になっている場合、リデュース・キーに関連付けられた行は異なるリデュース・タスクに存在し、部分集計になる可能性があります。つまり、リデュース・キーの値は、リデュース・タスク全体ではなく1つのリデュース・タスク内で集計されます。(「分割方法の選択」に説明されているように、リデュース・タスク全体のリデュース・キーの値をソートできます)。
完全な集計が必要な場合、分割を無効にできます。MapReduceジョブの出力を使用するアプリケーションを調べることもできます。アプリケーションは部分集計に適している場合があります。
たとえば、検索エンジンは転置インデックスを作成するMapReduceジョブから出力をパラレルに読み取る場合があります。リデュース・タスクの出力は単語のリストであり、単語ごとに、その単語が発生するドキュメントのリストです。単語はキーであり、ドキュメントのリストは値です。部分集計を使用すると、一部の単語には集計されたリストではなく複数のドキュメント・リストが含まれます。複数のリストは、検索エンジンがパラレルに使用するのに役立ちます。パラレル検索エンジンでは、1つのリストに集計するのではなくドキュメント・リストを分割する必要がある場合もあります。ドキュメント・コレクションから転置インデックスを作成するHadoopジョブについては、「Perfect Balanceの例について」を参照してください。
別の例として、Oracle Loader for Hadoopはデータを複数のファイルからターゲット表の正しいパーティションにロードします。リデュース・キーの複数のファイルがある場合、ロード・ステップは高速になります。これは、リデュース・キーの1つのファイルからロードする場合よりもより高度な並列化が可能になるためです。
Perfect Balanceで実行されているジョブのトラブルシューティングでは、次の点を確認してください。
Perfect Balanceでジョブを実行中にクライアント・ノードでJavaの「GC overhead limit exceeded」エラーが発生した場合には、そのジョブのクライアントJVMガベージ・コレクタを変更してください。
Java JVMの-XX:+UseConcMarkSweepGCオプションを設定します。HADOOP_CLIENT_OPTS変数を設定すれば、Hadoopジョブを実行する前にクライアントJVMのオプションを指定できます。
export HADOOP_CLIENT_OPTS="-XX:+UseConcMarkSweepGC $HADOOP_CLIENT_OPTS"
HADOOP_CLIENT_OPTSを設定しても、変更されるのはクライアント・ノード上のJVMオプションのみです。マップおよびリデュース・タスクでのJVMオプションは変更されません。この変数の設定例は、invindxスクリプトを参照してください。
クライアントJVMのヒープ・サイズを増やすこともできます。「Javaの「Out of Heap Space」エラー」を参照してください。
Perfect Balanceでジョブを実行中にクライアント・ノードでJavaの「out of heap space」エラーが発生した場合には、そのジョブのクライアントJVMのヒープ・サイズを増やしてください。
Java JVMの-Xmxオプションを使用します。HADOOP_CLIENT_OPTS変数を設定すれば、Hadoopジョブを実行する前にクライアントJVMのオプションを指定できます。
$ export HADOOP_CLIENT_OPTS="-Xmx512M $HADOOP_CLIENT_OPTS"
HADOOP_CLIENT_OPTSを設定しても、変更されるのはクライアント・ノード上のJVMオプションのみです。マップおよびリデュース・タスクでのJVMオプションは変更されません。この変数の設定例は、invindxスクリプトを参照してください。
oracle.hadoop.balancer.Balancerクラスには、パーティショニング・プランを作成したり、プランをファイルに保存したり、プランを使用してMapReduceジョブを実行したりするためのメソッドが含まれています。アプリケーションのジョブ・ドライバJavaクラスにコードを追加するのみで、アプリケーションの再設計は必要ありません。シェル・スクリプトを実行してアプリケーションを実行する際には、Perfect Balanceの構成設定を含めることができます。
Perfect Balanceのインストール・ディレクトリには、Perfect Balance APIを使用するJava MapReduceプログラムの完全な例(入力データを含む)が含まれています。
転置インデックスの例と実行方法については、orabalancer-1.1.1-h2/examples/invindx/README.txtを参照してください。
変更されたJavaコードを探すには、orabalancer-1.1.1-h2/examples/jsrc/oracle/hadoop/balancer/examples/invindx/InvertedIndexMapred.javaまたはInvertedIndexMapreduce.javaを参照してください。
Perfect Balanceを実行するための変更には、次のものが含まれます。
createBalancerメソッドは、構成プロパティを検証し、Balancerインスタンスを返します。
waitForCompletionメソッドは、データをサンプリングし、パーティショニング・プランを作成します。
addBalancingPlanメソッドは、パーティショニング・プランをジョブ構成設定に追加します。
configureCountingReducerメソッドは、追加のロード統計を収集します。
saveメソッドは、パーティショニング・レポートを保存し、Job Analyzerレポートを生成します。
例4-4は、転置インデックスのJavaコードの一部を示したものです。
例4-4 MapReduceジョブでのPerfect Balanceの実行
.
.
.
import oracle.hadoop.balancer.Balancer;
.
.
.
///// BEGIN: CODE TO INVOKE BALANCER (PART-1, before job submission) //////
Configuration conf = job.getConfiguration();
Balancer balancer = null;
boolean useBalancer =
conf.getBoolean("oracle.hadoop.balancer.driver.balance", true);
if(useBalancer)
{
balancer = Balancer.createBalancer(conf);
balancer.waitForCompletion();
balancer.addBalancingPlan(conf);
}
if(conf.getBoolean("oracle.hadoop.balancer.tools.useCountingReducer", true))
{
Balancer.configureCountingReducer(conf);
}
////////////// END: CODE TO INVOKE BALANCER (PART-1) //////////////////////
boolean isSuccess = job.waitForCompletion(true);
///////////////////////////////////////////////////////////////////////////
// BEGIN: CODE TO INVOKE BALANCER (PART-2, after job completion, optional)
// If balancer ran, this saves the partition file report into the _balancer
// sub-directory of the job output directory. It also writes a JobAnalyzer
// report.
Balancer.save(job);
////////////// END: CODE TO INVOKE BALANCER (PART-2) //////////////////////
.
.
.
}
|
関連項目: Oracle Big Data Appliance Perfect Balance Java APIリファレンス |
変更したJavaコードを実行する際には、標準のhadoopコマンド構文を使用してPerfect Balanceプロパティを設定できます。
bin/hadoop jar application_jarfile.jar ApplicationClass \ -conf application_config.xml \ -conf perfect_balance_config.xml \ -D application_config_property \ -D perfect_balance_config_property \ -libjars /opt/oracle/orabalancer-1.1.1-h2/jlib/commons-math-2.2.jar,/opt/oracle/orabalancer-1.1.1-h2/jlib/orabalancer-1.1.1.jar,application_jar_path.jar...
例4-5では、pb_balanceapi.shというスクリプトが実行されます。このスクリプトは、Perfect Balance JARファイルにパッケージされたInvertedIndexMapreduceクラスの例を実行します。キー・ロード・メトリック・プロパティは、図4-1で示したJob Analyzerレポートの推奨値に設定されます。
InvertedIndexMapreduceクラスの例を実行するには、「Perfect Balanceの例について」を参照してください。
例4-5 InvertedIndexMapreduceクラスの実行
$ cat pb_balanceapi.sh BALANCER_HOME=/opt/oracle/orabalancer-1.1.1-h2 APP_JAR_FILE=/opt/oracle/orabalancer-1.1.1-h2/jlib/orabalancer-1.1.1.jar export HADOOP_CLASSPATH=${BALANCER_HOME}/jlib/orabalancer-1.1.1.jar:${BALANCER_HOME}/jlib/commons-math-2.2.jar:$HADOOP_CLASSPATH export HADOOP_USER_CLASSPATH_FIRST=true hadoop jar ${APP_JAR_FILE} oracle.hadoop.balancer.examples.invindx.InvertedIndexMapreduce \ -D mapred.input.dir=invindx/input \ -D mapred.output.dir=jdoe_outdir_api \ -D mapred.job.name=jdoe_invindx_api \ -D mapred.reduce.tasks=10 \ -D oracle.hadoop.balancer.autoAnalyze=true \ -D oracle.hadoop.balancer.linearKeyLoad.keyWeight=93.981394 \ -D oracle.hadoop.balancer.linearKeyLoad.rowWeight=0.001126 \ -D oracle.hadoop.balancer.linearKeyLoad.byteWeight=0.0 \ -libjars ${BALANCER_HOME}/jlib/commons-math-2.2.jar,${BALANCER_HOME}/jlib/orabalancer-1.1.1.jar $ sh ./balanceapi.sh 13/06/24 17:21:47 INFO balancer.Balancer: Creating balancer 13/06/24 17:21:48 INFO input.FileInputFormat: Total input paths to process : 5 13/06/24 17:21:48 INFO balancer.Balancer: Starting Balancer 13/06/24 17:21:54 INFO balancer.Balancer: Balancer completed . . .
Perfect Balanceインストール・ファイルには、すぐに実行できる例の一式が含まれています。InvertedIndex例は、入力した一連のテキスト・ファイルについて転置インデックスを作成するMapReduceアプリケーションです。転置インデックスは、語をテキスト・ファイル内のその語の場所にマップします。入力データは含まれています。
InvertedIndex例は、この章のすべての例の基礎を提供します。これらは同じデータ・セットを使用して同じMapReduceアプリケーションを実行します。InvertedIndex例の変更は、自分のアプリケーションをPerfect Balanceで実行するときに行う必要があるステップをハイライトしているにすぎません。
この章の例を実行する場合、あるいはこれらの例を自分のジョブを実行する際の基礎として使用する場合は、次の変更を行ってください。
自分のアプリケーションを実行するために例を変更している場合は、アプリケーションJARファイルをHADOOP_CLASSPATHおよび-libjarsに追加してください。
mapred.input.dirの値がデータの場所を示していることを確認してください。
invindx/inputディレクトリには、InvertedIndex例のサンプル・データが含まれています。このデータを使用するには、最初に設定してください。「例データ・セットの抽出」を参照してください。
jdoeをHadoopユーザー名に置き換えます。
-confオプションを、既存の構成ファイルに設定します。
jdoe_conf_invindx.xmlファイルは、InvertedIndex例の構成ファイルを変更したものです。変更したファイルには、パフォーマンス最適化設定がありません。例構成ファイルはそのまま使用することも、変更することもできます。/opt/oracle/orabalancer-1.1.1-h2/examples/invindx/conf_mapreduce.xml (またはconf_mapred.xml)を参照してください。
ファイル内とシェル・スクリプト内の構成設定を見直して、これらがジョブに適切であることを確認してください。
ブラウザをノートパソコンから実行することも、あるいはグラフィカル・インタフェースをサポートするクライアント(VNCなど)を使用してOracle Big Data Applianceに接続することもできます。
InvertedIndex例を実行したりこの章のいずれかの例を実行するには、最初にデータ・ファイルを設定する必要があります。
InvertedIndexデータ・ファイルを抽出するには、次の手順を実行します。
Perfect Balanceがインストールされているサーバーにログインします。
ディレクトリをexamples/invindxサブディレクトリに移動します。
cd /opt/oracle/orabalancer-1.1.1-h2/examples/invindx
データを解凍して、HDFS invindx/inputディレクトリにコピーします。
./invindx -setup
InvertedIndex例を実行する手順の詳細は、/opt/oracle/orabalancer-1.1.1-h2/examples/invindx/README.txtを参照してください。
このセクションでは、Perfect Balanceの構成プロパティと、Perfect Balanceがジョブ構成から読み取るいくつかの汎用Hadoop MapReduceプロパティについて説明します。
機能カテゴリにまとめられるプロパティのリストについては、「Perfect Balanceの構成について」を参照してください。
MapReduce構成プロパティ
型: String
デフォルト値: 定義されていません。
説明: コンマで区切られた、入力ディレクトリのリスト。
型: String
デフォルト値: org.apache.hadoop.mapred.TextInputFormat
説明: InputFormatクラスのフル・ネーム。
型: String
デフォルト値: org.apache.hadoop.mapred.lib.IdentityMapper
説明: マッパー・クラスのフル・ネーム。
型: String
デフォルト値: 定義されていません。
説明: ジョブの出力ディレクトリ。
型: String
デフォルト値: org.apache.hadoop.mapred.lib.HashPartitioner
説明: パーティショナ・クラスのフル・ネーム。
型: String
デフォルト値: org.apache.hadoop.mapred.lib.IdentityReducer
説明: リデューサ・クラスのフル・ネーム。
型: String
デフォルト値: org.apache.hadoop.mapreduce.lib.input.TextInputFormat
説明: InputFormatクラスのフル・ネーム。
型: String
デフォルト値: org.apache.hadoop.mapreduce.Mapper
説明: マッパー・クラスのフル・ネーム。
型: String
デフォルト値: org.apache.hadoop.mapreduce.lib.partition.HashPartitioner
説明: パーティショナ・クラスのフル・ネーム。
型: String
デフォルト値: org.apache.hadoop.mapreduce.Reducer
説明: リデューサ・クラスのフル・ネーム。
Perfect Balance構成プロパティ
タイプ: 列挙
デフォルト値: oracle.hadoop.balancer.autoBalanceがtrueの場合はBASIC_REPORT、それ以外の場合はNONE
説明: Perfect Balanceを使用してJob Analyzerを呼び出すときのJob Analyzerの動作を制御します。次の値が有効です。
NONE: Job Analyzerを無効にします。
BASIC_REPORT: Job Analyzerを有効にします。
REDUCER_REPORT: ジョブの各リデュース・タスクに関する追加のロード統計を収集するようにJob Analyzerを有効にします。「追加メトリックの収集」を参照してください。
Perfect Balanceは次のプロパティを使用し、Perfect Balance APIは使用しません。
型: Boolean
デフォルト値: false
説明: ロード・バランシング機能が有効かどうかを制御します。falseに設定すると、バランシングがオフになります。Perfect Balanceは次のプロパティを使用し、Perfect Balance APIは使用しません。
型: Float
デフォルト値: 0.95
説明: oracle.hadoop.balancer.maxLoadFactorプロパティによって指定された負荷係数に対する統計的信頼指標。
このプロパティは、0.5以上、1.0未満(0.5 <= 値 < 1.0)の値を受け入れます。値が0.5未満の場合、プロパティがデフォルト値に再設定されます。0.9以上の値をお薦めします。典型的な値は、0.95と0.99です。
型: Boolean
デフォルト値: false
説明: マップ出力キーをチョップ(分割)するかどうかを制御します。
false: ハッシュ関数を使用します。
true: マップ出力キーのソーティング・コンパレータをトータルオーダー・パーティショニング関数として使用します。バランサは、分割されたキーの値に対するトータル・オーダーを保存します。
ジョブで2番目のソートが構成されていない場合、Perfect Balanceが次のプロパティをfalseに設定します。
型: Integer
デフォルト値: 100
説明: 入力形式のgetSplitsを呼び出す直前に、Hadoopのmapred.map.tasksプロパティをサンプリングの継続時間用に設定します。実際のジョブのmapred.map.tasksは変更しません。最適なマップ・タスク数は、良好なサンプルの取得(より大きい数)と限定されたメモリー・リソース(より小さい数)との間のトレードオフになります。
このプロパティは1以上の値に設定してください。1未満の値に設定すると、プロパティが無効になります。
一部の入力形式(DBInputFormatなど)では、このプロパティはgetSplitsによって返される分割数を決定するためのヒントとして使用されます。値が高いほど、より大きなデータ・チャンクがランダムにサンプリングされ、サンプルが改善されます。
値を高くすると、より大きいデータ・セットを取得できます(たとえば、行当たり約100バイトで数百行を取得するなど)。ただし、極端に大きな値を設定すると、入力形式のgetSplitsメソッドから返される分割が増えすぎて、メモリーが不足する可能性があります。
型: Long
デフォルト値: 1048576 (1 MB)
説明: 入力形式のgetSplitsを呼び出す直前に、Hadoopのmapred.max.split.sizeプロパティをサンプリングの継続時間用に設定します。実際のジョブのmapred.max.split.sizeは変更しません。
このプロパティは1以上の値に設定してください。1未満の値に設定すると、プロパティが無効になります。最適な分割サイズは、良好なサンプルの取得(より少ない分割数)と効率的なI/Oパフォーマンス(より多い分割数)との間のトレードオフになります。
一部の入力形式(FileInputFormatなど)では、最大分割サイズはgetSplitsによって返される分割数を決定するためのヒントとして使用されます。分割サイズが小さいほど、より大きなデータ・チャンクがランダムにサンプリングされ、サンプルが改善されます。良好なパフォーマンスでサンプリングできるよう、なるべく小さい値を設定しますが、あまり小さくしすぎないようにしてください。極端に小さな値を設定すると、I/Oパフォーマンスが非効率になり、サンプルが改善されません。
大きなデータ・セット(数十TB)を取得しようとして値を高くすると、入力形式のgetSplitsメソッドからメモリー不足エラーがスローされる場合があります。分割が大きいと、I/Oパフォーマンスは高まりますが、サンプリング品質は低下します。
型: Long
デフォルト値: 0
説明: Perfect Balanceでマップ出力キーを中間キーに分割するかどうかを制御します。
-1: Perfect Balanceは大きなマップ出力キーを分割しません。
0: Perfect Balanceは大きなマップ出力キーを分割し、各中間キーの最適なサイズを決定します。
正の整数: Perfect Balanceは大きなマップ出力キーを指定された整数以上のサイズで中間キーに分割します。
型: Float
デフォルト値: 0.05
説明: oracle.hadoop.balancer.KeyLoadLinearクラスによって指定された線形キー・ロード・モデル内の、キー当たりのバイト数を決定します。
型: String
デフォルト値: 定義されていません。
説明: 以前に分析したジョブのJob Analyzerレポートを含むディレクトリへのパス。サンプラはフィードバックのためにこのレポートを分析し、現在のバランシング・プランを最適化します。その後、フィードバックを直接適用できるように、このプロパティを、現在のジョブと同一または類似するジョブのJob Analyzerレポート・ディレクトリに設定できます。
フィードバック・ディレクトリにPerfect Balance線形キー・ロード・モデル係数の推奨値を含むJob Analyzerレポートが含まれている場合、Perfect Balanceはその係数を自動的に読み取って使用します。推奨値は、これらの構成パラメータでユーザーが指定した値よりも優先されます。
Job Analyzerはこれらの係数に適切な値の推奨を試行します。ただし、Perfect Balanceはこのような状況では構成プロパティの以前のリストからロード・モデル係数を読み込みます。
このプロパティ設定されていません。
このプロパティは設定されていますが、指定したディレクトリのJob Analyzerレポートにはロード・モデル係数の適切な推奨値が含まれていません。
型: Float
デフォルト値: 50.0
説明: oracle.hadoop.balancer.KeyLoadLinearクラスによって指定された線形キー・ロード・モデル内の、大きなキー当たりの中間キー数を決定します。
型: Float
デフォルト値: 0.05
説明: oracle.hadoop.balancer.KeyLoadLinearクラスによって指定された線形キー・ロード・モデル内のキー当たりの行数を決定します。
型: Float
デフォルト値: 0.05
説明: バランサのパーティション・プランで達成するターゲット・リデューサ負荷係数。
負荷係数とは、見積り値からの相対偏差です。たとえば、maxLoadFactor=0.05かつconfidence=0.95の場合、信頼度が95%より高ければ、ジョブのリデューサ・ロードはパーティション・プランの値よりも(最大で)5%大きくなります。
これら2つのプロパティの値により、サンプラの停止条件が決定されます。バランサは、指定された負荷係数を指定された信頼度で保証するプランを生成できるかぎり、サンプリングを継続します。この保証では、他の停止条件(サンプル数がoracle.hadoop.balancer.maxSamplesPctを超えるなど)によってサンプラが早期に停止するケースは対象外とされる場合があります。停止条件はパーティション・レポートに記録されます。
oracle.hadoop.balancer.confidenceを参照してください。
型: Float
デフォルト値: 0.01 (1%)
説明: Perfect Balanceが収集できるサンプル数を、総入力レコードのごく一部に制限します。ゼロより小さい値を設定すると、プロパティは無効(無制限)になります。
リデューサ・パーティションがきわめて不均一な場合や、マップ出力キーが高密度でクラスタ化されている場合には、Hadoopアプリケーションの値を高くすることが必要になることがあります。これらの場合、サンプラは良好なパーティショニング・プランを達成するためにより多くのデータをサンプリングする必要があります。
oracle.hadoop.balancer.useClusterStatsを参照してください。
型: Integer
デフォルト値: 5
説明: サンプラが読み取る最小分割数を設定します。総分割数がこの値よりも少ない場合、サンプラはすべての分割を読み取ります。このプロパティは、1以上の値に設定してください。正の数以外を指定すると、プロパティは1に設定されます。
型: Integer
デフォルト値: 5
説明: サンプラ・スレッドの数。この値は、ジョブが開始されるノードで使用可能なプロセッサとメモリー・リソースに基づいて設定します。サンプラ・スレッドの数を増やすほど、より多くのサンプリングが並行処理されます。このプロパティを(1)に設定すると、サンプラでのマルチスレッディングは無効になります。
型: Boolean
デフォルト値: false
説明: Perfect Balanceがoracle.hadoop.balancer.reportPathプロパティによって指定された場所のファイルを上書きするかどうかを制御します。デフォルトでは、Perfect Balanceはファイルを上書きしません(例外をスローします)。このプロパティをtrueに設定すると、パーティション・レポートの上書きが許可されます。
型: String
デフォルト値: directory/orabalancer_report-random_unique_string.xml (HDFS用のディレクトリは、ジョブを送信するユーザーのホーム・ディレクトリ)。ローカル・ファイル・システム用のディレクトリは、ジョブが送信されるディレクトリです。
説明: Hadoopジョブ出力ディレクトリが使用可能になる前(つまり、MapReduceジョブが実行を完了する前)に、Perfect Balanceがパーティション・レポートを書き込む場所のパス。ジョブの最後に、Perfect Balanceはファイルをjob_output_dir/_balancer/orabalancer_report.xmlに移動します。APIでは、saveメソッドがこのタスクを実行します。
型: String
デフォルト値: local
説明: Perfect Balanceサンプラの実行方法を指定します。次の値が有効です。
local: サンプラはジョブが発行されたクライアント・ノード上で実行されます。
distributed: サンプラはHadoopジョブとして実行されます。ジョブがDistributedCache symlinksを使用する場合、Perfect Balanceはこのプロパティを自動的にdistributedに設定します。
このプロパティを無効な文字列に設定すると、Perfect Balanceによってlocalにリセットされます。
型: String
デフォルト値: /tmp/orabalancer-user_name
説明: ジョブ出力ディレクトリ(HDFSまたはローカル)のファイル・システム内にあるステージング・ディレクトリへのパス。Perfect Balanceは、ディレクトリが存在していなければディレクトリを作成し、パーティション・レポートをそこにコピーして、Hadoop分散キャッシュにロードできるようにします。
型: String
デフォルト値: ${mapred.output.dir}/_logs/history
説明: Hadoopジョブ構成ファイルへのパス。Job Analyzerは、この設定を使用してファイル場所を特定します。
型: String
デフォルト値: ${mapred.output.dir}/_logs/history
説明: Hadoopジョブ履歴ファイルへのパス。Job Analyzerは、この設定を使用してファイル場所を特定します。
型: Boolean
デフォルト値: false
説明: カウンティング・リデューサがJob Analyzer用のリデュース・キーのバイト表現を収集するかどうかを制御します。このプロパティをtrueに設定すると、レポート内で一意のキー値がBase64エンコーディングで表現されます。レポート内には、キーの文字列表現(key.toStringを使用して作成されたもの)も記載されます。この文字列値は各キーに対して一意でない場合があります。
型: Boolean
デフォルト値: true
説明: サンプラがクラスタ・サンプリング統計情報を使用できるようにします。これらの統計情報は、マップ出力キーがすべての入力分割に対して個別に分散されているのではなく、各入力分割に対してクラスタ内で分散されている場合に、サンプリングされた見積り値(マップ出力キー内のレコード数など)の精度を改善します。
このプロパティは、マップ出力キーがクラスタ化されていないことが確実にわかっている場合にのみ、falseに設定してください。この設定は、クラスタリングが一切存在しない場合にのみ、サンプラの見積りを改善します。マップ出力キーの分散は通常確認されないので、このプロパティはtrueのままにしておくことをお薦めします。
型: Boolean
デフォルト値: true
説明: Hadoopジョブで使用されるMapReduce APIを識別します。
true: ジョブはmapreduce APIを使用します。
false: ジョブはmapred APIを使用します。