| Oracle® Big Data Connectorsユーザーズ・ガイド リリース2 (2.5) E53261-01 |
|


 前 |
 次 |
この章では、Oracle Loader for Hadoopを使用してApache HadoopからOracle Databaseの表にデータをコピーする方法について説明します。内容は次のとおりです。
Oracle Loader for Hadoopは、HadoopクラスタからOracle Databaseの表にデータをすばやく移動するための効率的でパフォーマンスのよいローダーです。これは、必要に応じてデータを事前にパーティション化し、そのデータをデータベース対応形式に変換します。また、データのロードや出力ファイルの作成の前に主キーまたはユーザー指定の列でレコードをソートすることもできます。Oracle Loader for Hadoopは、他のローダーでは一般にデータベース・サーバーでロード処理の一部として行うこれらの事前処理を、Hadoopの並列処理フレームワークを利用して行います。これらの操作をHadoopにオフロードすることによってデータベース・サーバーに必要なCPUの量を削減し、他のデータベース・タスクのパフォーマンスに与える影響を軽減します。
Oracle Loader for Hadoopは、リデューサ間のデータのバランスを調整してパフォーマンスを向上させるJava MapReduceアプリケーションです。このアプリケーションは様々な入力データ形式を扱い、フィールドを集めたレコード形式でデータを表します。レコード形式のデータが存在するソース(AvroファイルやApache Hive表など)からデータを読み取ったり、テキスト・ファイルの行をフィールドに分割できます。
Oracle Loader for Hadoopを実行するには、hadoopコマンドライン・ユーティリティを使用します。コマンドラインで、ジョブの詳細を構成設定します。通常、これらの設定はジョブ構成ファイルに指定します。
Javaプログラミングのスキルがあれば、カスタム入力形式を定義して、ローダーで処理できるデータ・タイプを拡張できます。Oracle Loader for Hadoopは、そのカスタム・コードを使用してフィールドとレコードを抽出します。
Oracle Loader for Hadoopには次の2つの動作モードがあります。
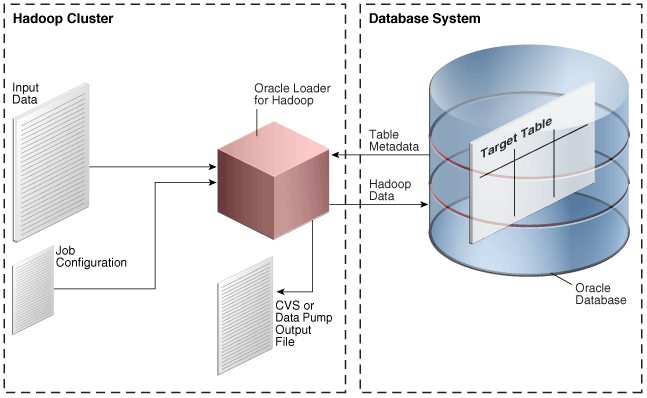
オンライン・データベース・モードでは、Oracle Loader for Hadoopはジョブ構成ファイルまたはOracle Walletに格納されている資格証明を使用してターゲット・データベースに接続します。ローダーはこのデータベースから表のメタデータを取得します。新規レコードは、直接ターゲット表に挿入することも、Hadoopクラスタ内のファイルに書き込むこともできます。データベースのデータが必要なとき、またはデータベース・システムが比較的空いているときには、レコードを出力ファイルからロードできます。
図3-1は、オンライン・データベース・モードの要素間の関係を示しています。
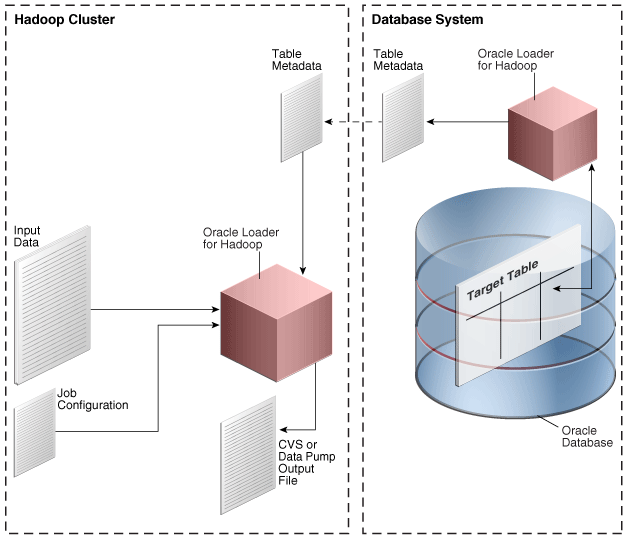
オフライン・データベース・モードでは、Oracle DatabaseシステムがHadoopクラスタと異なるネットワークにあるなどの事情によってデータベースにアクセスできない場合に、Oracle Loader for Hadoopを使用できます。このモードでは、Oracle Loader for Hadoopは表のメタデータ・ファイルに指定された情報を使用します。このメタデータ・ファイルは、ユーザーが別のユーティリティで生成します。ローダーのジョブによって、出力データがHadoopクラスタ上のバイナリまたはテキスト形式の出力ファイルに保存されます。Oracle Databaseにデータをロードする手順は、Oracle SQL Connector for Hadoop Distributed File System (HDFS)やSQL*Loaderなど、別のユーティリティを使用して別途実行します。
図3-2は、オフライン・データベース・モードの要素間の関係を示しています。この図には、データをターゲット表にロードする別途の手順は示されていません。
Oracle Loader for Hadoopを使用する場合は、次の基本的な手順に従います。
初めてOracle Loader for Hadoopを使用する場合は、ソフトウェアがインストールおよび構成されていることを確認します。
「Oracle Loader for Hadoopの設定」を参照してください。
Oracle Databaseに接続してターゲット表を作成します。
「ターゲット表の作成」を参照してください。
オフライン・データベース・モードを使用する場合、表のメタデータを生成します。
「ターゲット表メタデータの生成(オフライン・データベース・モードの場合)」を参照してください。
HadoopクラスタのノードまたはクラスタのHadoopクライアントとして設定されているシステムにログインします。
オフライン・データベース・モードを使用する場合、ログインしたHadoopシステムに表のメタデータをコピーします。
構成ファイルを作成します。このファイルは、ターゲット表のメタデータへのアクセス、データの入力形式、出力形式などの構成情報を示すXMLドキュメントです。
「ジョブ構成ファイルの作成」を参照してください。
入力フィールドをOracleデータベース表の列にマップするXMLドキュメントを作成します。オプション。
「ターゲット表列への入力フィールドのマッピング」を参照してください。
Oracle Loader for Hadoopのジョブを実行するシェル・スクリプトを作成します。
「ローダー・ジョブの実行」を参照してください。
セキュアなクラスタに接続する場合は、自分自身を認証するためにkinitを実行します。
シェル・スクリプトを実行します。
ジョブが失敗した場合、出力の診断メッセージを使用してエラーを特定し、修正します。
「ジョブのレポート作成」を参照してください。
ジョブが成功したら、コマンド出力を参照し、拒否されたレコード数を確認します。拒否されたレコードが多すぎる場合は、入力形式のプロパティの変更が必要になることがあります。
テキスト・ファイルまたはデータ・ポンプ形式ファイルを生成した場合は、次のいずれかの方法でOracle Databaseにデータをロードします。
Oracle SQL Connector for HDFSを使用して外部表を作成します(オンライン・データベース・モードの場合のみ)。
第2章を参照してください。
ファイルをOracle Databaseシステムにコピーし、SQL*Loaderまたは外部表を使用してターゲット・データベース表にデータをロードします。Oracle Loader for Hadoopで、この方法に使用できるスクリプトが生成されます。
「DelimitedTextOutputFormatの概要」または「DataPumpOutputFormatの概要」を参照してください。
ターゲット表の所有者としてOracle Databaseに接続します。この表に問い合せて、データが適切にロードされたことを確認します。適切にロードされなかった場合は、必要に応じて入力形式または出力形式のプロパティを変更し、問題を修正してください。
OraLoaderジョブを本番環境で実行する前に、次の最適化を行います。
Oracle Loader for Hadoopはデータを1つのターゲット表にロードします。この表はOracleデータベース内に存在する必要があります。表は、空でも、データが格納されていてもかまいません。Oracle Loader for Hadoopは既存のデータを上書きしません。
表は、他の用途に使用する場合も同じ方法で作成します。その際は、次の制限に従う必要があります。
BINARY_DOUBLE
BINARY_FLOAT
CHAR
DATE
FLOAT
INTERVAL DAY TO SECOND
INTERVAL YEAR TO MONTH
NCHAR
NUMBER
NVARCHAR2
RAW
TIMESTAMP
TIMESTAMP WITH LOCAL TIME ZONE
TIMESTAMP WITH TIME ZONE
VARCHAR2
ターゲット表には、サポートされていないデータ型の列が含まれていてもかまいませんが、これらの列はnull値可能である必要があります。そうでない場合、値を設定します。
パーティション化は、非常に大規模な表の管理および効率的な問合せを行うためのデータベースの機能です。アプリケーションに対して完全に透過的な方法で、大規模な表をパーティションと呼ばれる小規模でより管理し易いサイズに分割する方法を提供します。
ターゲット表の定義には、次のシングルレベルおよびコンポジットレベルのパーティション化方式を使用できます。
ハッシュ
ハッシュ-ハッシュ
ハッシュ-リスト
ハッシュ-レンジ
時間隔
時間隔-ハッシュ
時間隔-リスト
時間隔-レンジ
リスト
リスト-ハッシュ
リスト-リスト
リスト-レンジ
レンジ
レンジ-ハッシュ
レンジ-リスト
レンジ-レンジ
Oracle Loader for Hadoopでは、参照パーティション化または仮想列ベースのパーティション化はサポートされません。
|
関連項目: 『Oracle Database VLDBおよびパーティショニング・ガイド』 |
構成ファイルは、HadoopがMapReduceジョブを実行するために必要なすべての情報を格納しているXMLドキュメントです。このファイルには、Oracle Loader for Hadoopに必要なすべての情報も指定できます。「Oracle Loader for Hadoop構成プロパティ・リファレンス」を参照してください。
構成プロパティは、Oracle Loader for Hadoopのすべてのジョブに必要な次の情報を示します。
ターゲット表のメタデータの取得方法
「ターゲット表のメタデータの概要」を参照してください。
入力データの形式
「入力形式の概要」を参照してください。
出力データの形式
「出力形式の概要」を参照してください。
OraLoaderは、org.apache.hadoop.util.Toolインタフェースを実装し、MapReduceアプリケーションを構築する標準的なHadoopの方法に従います。これらの構成プロパティは、以下に示すようなファイルまたはhadoopのコマンドラインで指定できます。「ローダー・ジョブの実行」を参照してください。
ファイルの作成には任意のテキスト・エディタまたはXMLエディタを使用できます。例3-1に、ジョブ構成ファイルの例を示します。
例3-1 ジョブ構成ファイル
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<!-- Input settings -->
<property>
<name>mapreduce.inputformat.class</name>
<value>oracle.hadoop.loader.lib.input.DelimitedTextInputFormat</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/oracle/moviedemo/session/*00000</value>
</property>
<property>
<name>oracle.hadoop.loader.input.fieldTerminator</name>
<value>\u0009</value>
</property>
<!-- Output settings -->
<property>
<name>mapreduce.outputformat.class</name>
<value>oracle.hadoop.loader.lib.output.OCIOutputFormat</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>temp_out_session</value>
</property>
<!-- Table information -->
<property>
<name>oracle.hadoop.loader.loaderMapFile</name>
<value>file:///home/oracle/movie/moviedemo/olh/loaderMap_moviesession.xml</value>
</property>
<!-- Connection information -->
<property>
<name>oracle.hadoop.loader.connection.url</name>
<value>jdbc:oracle:thin:@${HOST}:${TCPPORT}/${SERVICE_NAME}</value>
</property>
<property>
<name>TCPPORT</name>
<value>1521</value>
</property>
<property>
<name>HOST</name>
<value>myoraclehost.example.com</value>
</property>
<property>
<name>SERVICE_NAME</name>
<value>orcl</value>
</property>
<property>
<name>oracle.hadoop.loader.connection.user</name>
<value>MOVIEDEMO</value>
</property>
<property>
<name>oracle.hadoop.loader.connection.password</name>
<value>oracle</value>
<description> A password in clear text is NOT RECOMMENDED. Use an Oracle wallet instead.</description>
</property>
</configuration>
ターゲット表に関する情報をOracle Loader for Hadoopに指定する必要があります。この情報の指定方法は、Oracle Loader for Hadoopをオンライン・データベース・モードまたはオフライン・データベース・モードのどちらで実行するかによって異なります。「操作モードの概要」を参照してください。
Oracle Loader for HadoopはOracleデータベースの表のメタデータを使用して列名、データ型、パーティションなどを識別します。JDBC接続が確立可能な場合、ローダーでメタデータを自動的にフェッチします。
資格証明にはウォレットを使用することをお薦めします。Oracleウォレットを使用するには、次のプロパティをジョブ構成ファイルに入力します。
パスワードは、クリア・テキストには保存しないで、ウォレットを使用して資格証明を保護することをお薦めします。Oracle Walletを使用しない場合は、次のプロパティを入力します。
ローダー・ジョブでデータベースにアクセスできない場合があります。たとえば、HadoopクラスタがOracle Databaseとは別のネットワークにある場合などです。この場合、OraLoaderMetadataユーティリティを使用して、ターゲット表のメタデータをファイルに抽出し、保存します。
オフライン・データベース・モードでターゲット表のメタデータを指定するには、次の手順を実行します。
Oracle Databaseシステムにログインします。
初めてオフライン・データベース・モードを使用する場合は、データベース・システムがインストールおよび構成されていることを確認します。
「オフライン・データベース・モードのサポート」を参照してください。
OraLoaderMetadataユーティリティ・プログラムを実行して、表のメタデータをエクスポートします。「OraLoaderMetadataユーティリティ」を参照してください。
表のメタデータが格納されている生成済XMLファイルをHadoopクラスタにコピーします。
ジョブ構成ファイルのoracle.hadoop.loader.tableMetadataFileプロパティを使用して、Hadoopクラスタ上のXMLメタデータの場所を指定します。
ローダー・ジョブの実行時、このXMLドキュメントがアクセスされ、ターゲット表のメタデータが検出されます。
Oracle Databaseシステムで、次の構文を使用してOraLoaderMetadataユーティリティを実行します。javaコマンドは1行で入力する必要がありますが、以下では見やすくするために複数行に分けて示しています。
java oracle.hadoop.loader.metadata.OraLoaderMetadata -user userName -connection_url connection [-schema schemaName] -table tableName -output fileName.xml
OraLoaderMetadataのヘルプ・ファイルを表示するには、このコマンドをオプションなしで使用します。
オプション
ターゲット表を所有するOracle Databaseユーザー。ユーザーは、パスワードを要求されます。
次のようなThinスタイル・サービス名形式のデータベース接続文字列。
jdbc:oracle:thin:@//hostName:port/serviceName
サービス名が不明な場合は、特権ユーザーとして次のSQLコマンドを入力します。
SQL> show parameter service
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
service_names string orcl
ターゲット表を含むスキーマの名前。引用符で囲まれていない値は大文字に変換され、引用符で囲まれていない値は入力したとおりに使用されます。このオプションを省略した場合、-userオプションで指定したスキーマ内のターゲット表が検索されます。
ターゲット表の名前。引用符で囲まれていない値は大文字に変換され、引用符で囲まれていない値は入力したとおりに使用されます。
メタデータ・ドキュメントの格納に使用される出力ファイルの名前。
例3-2に、ターゲット表のメタデータをXMLファイルに保存する方法を示します。
例3-2 表のメタデータの生成
OraLoaderMetadataユーティリティを実行します。
$ java -cp '/tmp/oraloader-2.3.0-h1/jlib/*' oracle.hadoop.loader.metadata.OraLoaderMetadata -user HR -connection_url jdbc:oracle:thin://@localhost:1521/orcl.example.com -table EMPLOYEES -output employee_metadata.xml
OraLoaderMetadataユーティリティを実行すると、データベース・パスワードを要求されます。
Oracle Loader for Hadoop Release 2.3.0 - Production
Copyright (c) 2011, 2013, Oracle and/or its affiliates. All rights reserved.
[Enter Database Password:] password
XMLファイルがスクリプトと同じディレクトリに作成されます。
$ more employee_metadata.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
Oracle Loader for Hadoop Release 2.3.0 - Production
Copyright (c) 2011, 2013, Oracle and/or its affiliates. All rights reserved.
-->
<DATABASE>
<ROWSET><ROW>
<TABLE_T>
<VERS_MAJOR>2</VERS_MAJOR>
<VERS_MINOR>5 </VERS_MINOR>
<OBJ_NUM>78610</OBJ_NUM>
<SCHEMA_OBJ>
<OBJ_NUM>78610</OBJ_NUM>
<DATAOBJ_NUM>78610</DATAOBJ_NUM>
<OWNER_NUM>87</OWNER_NUM>
<OWNER_NAME>HR</OWNER_NAME>
<NAME>EMPLOYEES</NAME>
.
.
.
入力形式は、Hadoopに保存されている特殊な種類のデータを読み取る場合に使用します。次に示す様々な入力形式を使用して、Hadoopで一般的に利用されるデータ形式を読み取ることができます。
固有のカスタム入力形式を使用することもできます。組込み形式の説明に、カスタムInputFormatクラスの開発に役立つ情報を記入します。「カスタム入力形式」を参照してください。
データベース表にロードするデータの特定の入力形式を指定するには、ジョブ構成ファイルのmapreduce.inputformat.class構成プロパティを使用します。
圧縮データは、Oracle Loader for Hadoopによる読取り時に自動的に解凍されます。
|
注意: 組込みテキスト形式では、引用符で囲んだ値に埋め込まれたヘッダー行や改行文字(\n)は処理されません。 |
デリミタ付きテキスト・ファイルからデータをロードするには、mapreduce.inputformat.classを次のように設定します。
oracle.hadoop.loader.lib.input.DelimitedTextInputFormat
入力ファイルは次の要件に従う必要があります。
レコードは改行文字で区切る。
フィールドは、カンマやタブなどの1文字のマーカーで区切る。
空の文字列のトークンは囲まれていても囲まれていなくても、nullで置き換えられます。
DelimitedTextInputFormatは、SQL*Loaderのトークン化方式をエミュレートします。つまり、各データはtで終了し、オプションでieまたはieとteで囲みます。DelimitedTextInputFormatは次の構文規則に従います。tはフィールドの終端文字、ieは開始フィールド囲み文字、teは終了フィールド囲み文字、cは1文字です。
Line = Token t Line | Token\n
Token = EnclosedToken | UnenclosedToken
EnclosedToken = (white-space)* ie [(non-te)* te te]* (non-te)* te (white-space)*
UnenclosedToken = (white-space)* (non-t)*
white-space = {c | Character.isWhitespace(c) and c!=t}
囲まれたトークン(データ値)の前後の空白は破棄されます。囲まれていないトークンの場合、先頭の空白は破棄されますが、末尾の空白(ある場合)は破棄されません。
この実装では、カスタム囲み文字と終端文字は許可されますが、レコード終端文字は改行、空白はJavaのCharacter.isWhitespaceにハードコードされます。空白はフィールドの終端文字として定義できますが、その文字は、あいまいになるのを防ぐために空白文字のクラスから削除されます。
圧縮デリミタ付きテキスト・ファイルは、読取り時にHadoopによって自動的に解凍されます。
DelimitedTextInputFormatで処理するには複雑すぎるテキスト・ファイルからデータをロードするには、mapreduce.inputformat.classを次のように設定します。
oracle.hadoop.loader.lib.input.RegexInputFormat
たとえば、Webログのあるフィールドが引用符で区切られ、別のフィールドが角カッコで区切られている場合があります。
RegexInputFormatを使用する場合、レコードは改行文字で区切る必要があります。各テキスト行のフィールドは、正規表現のマッチングによって識別されます。
正規表現はテキスト行全体が一致する必要があります。
フィールドの識別には正規表現のキャプチャ・グループが使用されます。
RegexInputFormatはjava.util.regexの正規表現ベースのパターン・マッチング・エンジンを使用します。圧縮正規表現ファイルは、読取り時にHadoopによって自動的に解凍されます。
|
関連項目: java.util.regexの詳細は、次のサイトにあるJava Platform Standard Edition 6 Javaリファレンスを参照してください。
|
Hive表からデータをロードするには、mapreduce.inputformat.classを次のように設定します。
oracle.hadoop.loader.lib.input.HiveToAvroInputFormat
HiveToAvroInputFormatは、表全体(Hive表のディレクトリ内の全ファイル、またはパーティション表の場合は各パーティション・ディレクトリ内の全ファイル)をインポートします。
Oracle Loader for Hadoopは、複合(非プリミティブの)列に値があるすべての行を拒否します。プリミティブ値に解決するUNIONTYPEフィールドがサポートされています。「拒否されたレコードの処理」を参照してください。
HiveToAvroInputFormatは、Hive表の行をAvroレコードに変換し、Hive表の列名を大文字に変換して、フィールド名を生成します。この自動大文字変換により、フィールド名がターゲット表の列名と一致する確率が高くなります。「ターゲット表列への入力フィールドのマッピング」を参照してください。
Hive表は、読取り時に自動的に解凍されます。
標準的なAvro形式のレコードが格納されているバイナリAvroデータ・ファイルからデータをロードするには、mapreduce.inputformat.classを次のように設定します。
oracle.hadoop.loader.lib.input.AvroInputFormat
拡張子が.avroのファイルのみを処理するには、mapred.input.dir構成プロパティにリストされているディレクトリに*.avroを追加します。
圧縮Avroファイルは、Avroリーダーによって自動的に解凍されます。
Oracle NoSQL Databaseからデータをロードするには、mapreduce.inputformat.classを次のように設定します。
oracle.kv.hadoop.KVAvroInputFormat
この入力形式はOracle NoSQL Database 11g、リリース2以降で定義されています。
Oracle Loader for Hadoopでは、KVAvroInputFormatを使用してOracle NoSQL Databaseから直接データを読み取ります。
KVAvroInputFormatは、Oracle NoSQL Databaseのキーと値のペアからキーではなく値を渡します。Oracle NoSQL DatabaseのキーにAvroデータ値としてアクセスする必要がある場合(ターゲット表に格納する場合など)、oracle.kv.hadoop.AvroFormatterを実装するJavaのInputFormatクラスを作成する必要があります。その後で、Oracle Loader for Hadoop構成ファイルのoracle.kv.formatterClassプロパティを指定できます。
KVAvroInputFormatクラスはorg.apache.hadoop.mapreduce.InputFormat<oracle.kv.Key, org.apache.avro.generic.IndexedRecord>のサブクラスです。
次の構成プロパティを使用して、キーと値のストアの名前と場所を指定する必要があります。
「Oracle NoSQL Databaseの構成プロパティ」を参照してください。
組込み入力形式では不十分な場合は、カスタム入力形式のJavaクラスを作成できます。以下では、Oracle Loader for Hadoopで使用できる入力形式のフレームワークについて説明します。
Oracle Loader for Hadoopは、org.apache.hadoop.mapreduce.InputFormatを拡張するクラスから入力を取得します。このクラスの名前をmapreduce.inputformat.class構成プロパティに指定する必要があります。
この入力形式では、getCurrentValueメソッドからAvroのIndexedRecord入力オブジェクトを返すRecordReaderインスタンスを作成する必要があります。次のメソッド・シグネチャを使用します。
public org.apache.avro.generic.IndexedRecord getCurrentValue() throws IOException, InterruptedException;
Oracle Loader for Hadoopでは、IndexedRecord入力オブジェクトのスキーマを使用して入力フィールドの名前を検出し、ターゲット表の列にマップします。
IndexedRecordの値の処理でエラーが発生した場合、Oracle Loader for HadoopはRecordReaderのgetCurrentKeyメソッドで返されるオブジェクトを使用してフィードバックを提供します。また、キーのtoStringメソッドを呼び出し、結果をエラー・メッセージで書式設定します。InputFormatの開発者は、次のいずれかの情報を返すことにより、拒否されたレコードの識別でユーザーを支援できます。
データ・ファイルのURI
InputSplit情報
データ・ファイル名とそのファイルのレコードのオフセット
機密情報が含まれる可能性があるため、レコードをクリア・テキスト形式で返すことはお薦めできません。返された値はクラスタ全体のHadoopのログに出力できます。「拒否されたレコードの不正なファイルへのロギング」を参照してください。
レコードが失敗すると、キーがnullの場合、ローダーは識別情報を生成しません。
Oracle Loader for Hadoopは、サンプラを使用してMapReduceジョブのパフォーマンスを向上させます。サンプラはマルチスレッド化され、各サンプラ・スレッドは、指定されたInputFormatクラスのコピーをインスタンス化します。新しいInputFormatを実装する場合は、スレッドセーフであることを確認します。「パーティション化表にデータをロードする場合のロード・バランシング」を参照してください。
Oracle Loader for HadoopにはInputFormatのサンプル・ソース・コードが用意されており、このソース・コードはexamples/jsrc/ディレクトリにあります。
サンプルの形式では、データを単純なカンマ区切り値(CSV)ファイルからロードします。この入力形式を使用するには、oracle.hadoop.loader.examples.CSVInputFormatをジョブ構成ファイルのmapreduce.inputformat.classの値として指定します。
この入力形式では、F0、F1、F2といったフィールド名が自動的に割り当てられます。構成プロパティはありません。
マッピングは、入力フィールドをターゲット表のどの列にロードするかを示します。自動マッピング機能を使用することも、常に手動で入力フィールドをターゲット列にマップすることもできます。
Oracle Loader for Hadoopでは、入力データが次の要件に従っていれば、フィールドを適切な列に自動的にマップできます。
ターゲット表のすべての列をロードする。
DATE列にマップされるすべての入力フィールドを、同じJava日付形式を使用して解析できる。
自動マッピングの場合は、次の構成プロパティを使用します。
oracle.hadoop.loader.loaderMap.targetTable: ターゲット表を識別します。
oracle.hadoop.loader.defaultDateFormat: すべてのDATEフィールドに適用するデフォルトの日付形式を指定します。
自動マッピングの要件に準拠していないロードの場合は、追加のプロパティを定義する必要があります。これらのプロパティでは、次のことが可能です。
データをターゲット表の列のサブセットにロードする。
入力フィールド名がデータベースの列名とまったく同じではない場合に、明示的なマッピングを作成する。
入力フィールドごとに異なる日付形式を指定する。
手動マッピングの場合は、次のプロパティを使用します。
oracle.hadoop.loader.loaderMap.targetTable構成プロパティは、ターゲット表を識別します。必須。
oracle.hadoop.loader.loaderMap.columnNames: ロード対象の列をリストします。
oracle.hadoop.loader.defaultDateFormat: すべてのDATEフィールドに適用するデフォルトの日付形式を指定します。
oracle.hadoop.loader.loaderMap.column_name.format: 特定の列に対して日付形式を指定します。
oracle.hadoop.loader.loaderMap.column_name.field: 特定の列にマップされるAvroレコード・フィールドの名前を識別します。
次のユーティリティは、以前のリリースのローダー・マップ・ファイルを構成ファイルに変換します。
hadoop oracle.hadoop.loader.metadata.LoaderMap -convert map_file conf_file
オプション
ローカル・ファイル・システム(HDFSではなく)にある入力のローダー・マップ・ファイルの名前。
ローカル・ファイル・システム(HDFSではなく)にある出力の構成ファイルの名前。
例3-3に、サンプルの変換を示します。
例3-3 ローダー・ファイルから構成プロパティへの変換
$ HADOOP_CLASSPATH="$HADOOP_CLASSPATH:$OLH_HOME/jlib/*" $ hadoop oracle.hadoop.loader.metadata.LoaderMap -convert loadermap.xml conf.xml Oracle Loader for Hadoop Release 2.3.0 - Production Copyright (c) 2011, 2013, Oracle and/or its affiliates. All rights reserved.
入力のローダー・マップ・ファイルのloadermap.xml
<?xml version="1.0" encoding="UTF-8"?> <LOADER_MAP> <SCHEMA>HR</SCHEMA> <TABLE>EMPLOYEES</TABLE> <COLUMN field="F0">EMPLOYEE_ID</COLUMN> <COLUMN field="F1">LAST_NAME</COLUMN> <COLUMN field="F2">EMAIL</COLUMN> <COLUMN field="F3" format="MM-dd-yyyy">HIRE_DATE</COLUMN> <COLUMN field="F4">JOB_ID</COLUMN> </LOADER_MAP>
出力の構成ファイルのconf.xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<configuration>
<property>
<name>oracle.hadoop.loader.loaderMap.targetTable</name>
<value>HR.EMPLOYEES</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.columnNames</name>
<value>EMPLOYEE_ID,LAST_NAME,EMAIL,HIRE_DATE,JOB_ID</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.EMPLOYEE_ID.field</name>
<value>F0</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.EMPLOYEE_ID.format</name>
<value></value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.LAST_NAME.field</name>
<value>F1</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.LAST_NAME.format</name>
<value></value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.EMAIL.field</name>
<value>F2</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.EMAIL.format</name>
<value></value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.HIRE_DATE.field</name>
<value>F3</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.HIRE_DATE.format</name>
<value>MM-dd-yyyy</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.JOB_ID.field</name>
<value>F4</value>
</property>
<property>
<name>oracle.hadoop.loader.loaderMap.JOB_ID.format</name>
<value></value>
</property>
</configuration>
オンライン・データベース・モードでは、データを直接Oracleデータベース表にロードするか、ファイルに保存するかを選択できます。オフライン・データベース・モードでは、出力データの保存先はファイルに制限され、このファイルをターゲット表に個別のプロシージャとしてロードできます。ジョブ構成ファイルに出力形式を指定するには、mapreduce.outputformat.classプロパティを使用します。
次の出力形式から選択します。
JDBC出力形式: データをターゲット表に直接ロードします。
Oracle OCIダイレクト・パス出力形式: データをターゲット表に直接ロードします。
デリミタ付きテキスト出力形式: データをローカル・ファイルに保存します。
Oracle Data Pump出力形式: データをローカル・ファイルに保存します。
HadoopシステムとOracle Databaseとの間のJDBC接続を利用してデータをロードできます。ローダー・ジョブの出力レコードは、タスクをオンライン・データベース・モードのOraLoaderプロセスの一部としてマップまたはリデュースすると、ターゲット表に直接ロードされます。データをロードするための追加手順は不要です。
ジョブの実行中は、HadoopクラスタとOracle Databaseシステムとの間のJDBC接続をオープンしている必要があります。
この出力形式を使用するには、mapreduce.outputformat.classを次のように設定します。
oracle.hadoop.loader.lib.output.JDBCOutputFormat
JDBCOutputFormatでは、標準のJDBCバッチを使用してパフォーマンスと効率を最適化します。バッチの実行中に制約違反などのエラーが発生した場合、JDBCドライバはただちに実行を停止します。つまり、バッチに100行あり、10行目でエラーが発生した場合、9行は挿入され、91行は挿入されません。
JDBCドライバではエラーが発生した行が特定されないため、Oracle Loader for Hadoopでは、バッチ内の各行の挿入ステータスは把握されません。バッチ内のエラーが発生したすべての行に問題があるとみなされ、行はターゲット表に挿入される場合もあれば、挿入されない場合もあります。次のバッチのロードが続けられます。バッチ・エラーの数と問題のある行の数を示すロード・レポートがジョブの最後に生成されます。
この問題に対処する方法の1つは、ターゲット表に対して一意キーを定義することです。たとえば、HR.EMPLOYEES表にEMPLOYEE_IDという名前の主キーがあるとします。この場合、データをHR.EMPLOYEESにロードした後、EMPLOYEE_IDで問合せを行って欠落している従業員IDを検出します。欠落している従業員IDが入力データに見つかったら、ロードに失敗した原因を特定し、再度ロードを試行できます。
Oracle Call Interface (OCI)のダイレクト・パス・インタフェースを使用して、データをターゲット表にロードします。オンライン・データベース・モードでは、各リデューサが異なるデータベース・パーティションにロードするため、並列ロードのパフォーマンス向上が可能になります。データをロードするための追加手順は不要です。
ジョブの実行中は、HadoopクラスタとOracle Databaseシステムとの間のOCI接続をオープンしている必要があります。
この出力形式を使用するには、mapreduce.outputformat.classを次のように設定します。
oracle.hadoop.loader.lib.output.OCIOutputFormat
OCIOutputFormatには、次の制限があります。
Linux x86.64プラットフォームでのみ使用できます。
MapReduceジョブで1つ以上のリデューサを作成する必要があります。
ターゲット表は、パーティション化されている必要があります。
Oracle Database 11g (11.2.0.3)では、ターゲット表が、サブパーティション・キーにCHAR、VARCHAR2、NCHARまたはNVARCHAR2列が含まれるコンポジット時間隔パーティション化表の場合、Oracle Bug#13498646を適用します。後続バージョンのOracle Databaseでは、このパッチは必要ありません。
Hadoopクラスタでデリミタ付きテキスト出力ファイルを作成できます。マップまたはリデュース・タスクは、ジョブ構成ファイルに指定されたフィールド・デリミタと囲み文字を使用して、デリミタ付きテキスト・ファイルを生成します。後で、このデータを個別のプロシージャとしてOracleデータベースにロードできます。「DelimitedTextOutputFormatの概要」を参照してください。
この出力形式では、オンライン・データベース・モードの場合には、Oracle Databaseシステムへのオープン状態の接続で表のメタデータを取得し、オフライン・データベース・モードの場合には、OraloaderMetadataユーティリティによって生成された表のメタデータ・ファイルを使用できます。
この出力形式を使用するには、mapreduce.outputformat.classを次のように設定します。
oracle.hadoop.loader.lib.output.DelimitedTextOutputFormat
出力タスクによって、デリミタ付きテキスト形式ファイル、1つ以上の対応するSQL*Loader制御ファイルおよび外部表を使用してロードするためのSQLスクリプトが生成されます。
ターゲット表がパーティション化されていない場合、またはoracle.hadoop.loader.loadByPartitionがfalseの場合には、DelimitedTextOutputFormatによって次のファイルが生成されます。
データ・ファイル: oraloader-taskId-csv-0.dat
ジョブ全体のSQL*Loader制御ファイル: oraloader-csv.ctl
デリミタ付きテキスト・ファイルをターゲット表にロードするSQLスクリプト: oraloader-csv.sql
パーティション化された表の場合、複数の出力ファイルが作成されます。各ファイルの名前は次のとおりです。
データ・ファイル: oraloader-taskId-csv-partitionId.dat
SQL*Loader制御ファイル: oraloader-taskId-csv-partitionId.ctl
SQLスクリプト: oraloader-csv.sql
生成されたファイル名のtaskIdはマッパー(リデューサ)識別子を表し、partitionIdはパーティション識別子を表します。
HadoopクラスタがOracle Databaseシステムに接続している場合、Oracle SQL Connector for HDFSを使用してデリミタ付きテキスト・データをOracleデータベースにロードできます。第2章を参照してください。
または、デリミタ付きテキスト・ファイルをデータベース・システムにコピーして、次のいずれかの方法でデータをターゲット表にロードすることもできます。
このファイルは${map.output.dir}/_olhディレクトリにあります。
出力ファイル内のレコードとフィールドの形式は、次のプロパティによって制御されます。
例3-4に、出力タスクで生成されるサンプルSQL*Loader制御ファイルを示します。
例3-4 サンプルSQL*Loader制御ファイル
LOAD DATA CHARACTERSET AL32UTF8 INFILE 'oraloader-csv-1-0.dat' BADFILE 'oraloader-csv-1-0.bad' DISCARDFILE 'oraloader-csv-1-0.dsc' INTO TABLE "SCOTT"."CSV_PART" PARTITION(10) APPEND FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ( "ID" DECIMAL EXTERNAL, "NAME" CHAR, "DOB" DATE 'SYYYY-MM-DD HH24:MI:SS' )
Hadoopクラスタでデータ・ポンプ形式ファイルを作成できます。データ・ポンプ・ファイルは、マップまたはリデュース・タスクによって生成されます。後で、このデータを個別のプロシージャとしてOracleデータベースにロードできます。「DataPumpOutputFormatの概要」を参照してください。
この出力形式では、オンライン・データベース・モードの場合には、Oracle Databaseシステムへのオープン状態の接続を使用し、オフライン・データベース・モードの場合には、OraloaderMetadataユーティリティによって生成された表のメタデータ・ファイルを使用できます。
この出力形式を使用するには、mapreduce.outputformat.classを次のように設定します。
oracle.hadoop.loader.lib.output.DataPumpOutputFormat
DataPumpOutputFormatは、データ・ファイルを生成し、次の形式でファイル名を付けます。
oraloader-taskId-dp-partitionId.dat
生成されたファイル名のtaskIdはマッパー(リデューサ)識別子を表し、partitionIdはパーティション識別子を表します。
HadoopクラスタがOracle Databaseシステムに接続している場合、Oracle SQL Connector for HDFSを使用してデータ・ポンプ・ファイルをOracleデータベースにロードできます。第2章を参照してください。
または、データ・ポンプ・ファイルをデータベース・システムにコピーし、Oracle Loader for Hadoopによって生成されたSQLスクリプトを使用してロードすることもできます。このスクリプトは次のタスクを実行します。
ORACLE_DATAPUMPアクセス・ドライバを使用する外部表定義を作成します。バイナリ形式のOracle Data Pump出力ファイルは、外部表のLOCATION句にリストされます。
外部表によって使用されるディレクトリ・オブジェクトを作成します。スクリプトを実行する前に、このコマンドのコメントを解除する必要があります。スクリプトで使用するディレクトリ名を指定するには、ジョブ構成ファイルにoracle.hadoop.loader.extTabDirectoryNameプロパティを設定します。
外部表からターゲット表に行を挿入します。スクリプトを実行する前に、このコマンドのコメントを解除する必要があります。
このSQLスクリプトは${map.output.dir}/_olhディレクトリにあります。
Oracle Loader for Hadoopでジョブを実行するには、hadoopコマンドのOraLoaderユーティリティを使用します。
基本的な構文は次のとおりです。
hadoop jar $OLH_HOME/jlib/oraloader.jar oracle.hadoop.loader.OraLoader \ -conf job_config.xml \ -libjars input_file_format1.jar[,input_file_format2.jar...]
任意の汎用的なhadoopコマンドライン・オプションを指定できます。OraLoaderは、org.apache.hadoop.util.Toolインタフェースを実装し、MapReduceアプリケーションを構築する標準的なHadoopの方法に従います。
基本オプション
ジョブ構成ファイルを識別します。「ジョブ構成ファイルの作成」を参照してください。
入力形式としてJARファイルを識別します。
サンプル入力形式を使用する場合は、$OLH_HOME/jlib/oraloader-examples.jarを指定します。
HiveまたはOracle NoSQL Databaseの入力形式を使用する場合は、この項で後述する追加JARファイルを指定する必要があります。
カスタム入力形式を使用する場合は、JARを指定します(HADOOP_CLASSPATHにも忘れずに追加してください)。
複数のファイル名をカンマで区切り、各ファイル名を明示的にリストします。ワイルドカード文字および空白は使用できません。
Oracle Loader for Hadoopは、MapReduceタスク用に内部構成情報を準備します。また、表のメタデータ情報と従属するJavaライブラリを分散キャッシュに格納して、クラスタ全体でMapReduceタスクに使用できるようにします。
OraLoaderの起動例
次の例では、組込み入力形式を使用し、ジョブ構成ファイルの名前をMyConf.xmlとしています。
HADOOP_CLASSPATH="$HADOOP_CLASSPATH:$OLH_HOME/jlib/*" hadoop jar $OLH_HOME/jlib/oraloader.jar oracle.hadoop.loader.OraLoader \ -conf MyConf.xml -libjars $OLH_HOME/jlib/oraloader-examples.jar
|
関連項目:
|
HiveToAvroInputFormatを使用する場合は、Hive構成ディレクトリをHADOOP_CLASSPATH環境変数に追加する必要があります。
HADOOP_CLASSPATH="$HADOOP_CLASSPATH:$OLH_HOME/jlib/*:hive_home/lib/*:hive_conf_dir"
次のHive JARファイルを、カンマ区切りリスト形式で、hadoopコマンドの-libjarsオプションに追加する必要もあります。アスタリスク(*)を完全なファイル名に置き換えます。
hive-exec-*.jar
hive-metastore-*.jar
libfb303*.jar
次の例は、Cloudera's Distribution including Apache Hadoop (CDH) 4.4の完全なファイル名を示しています。
# hadoop jar $OLH_HOME/jlib/oraloader.jar oracle.hadoop.loader.OraLoader \
-conf MyConf.xml \
-libjars hive-exec-0.10.0-cdh4.4.0.jar,hive-metastore-0.10.0-cdh4.4.0.jar,libfb303-0.9.0.jar
Oracle NoSQL Database 11gリリース2のKVAvroInputFormatを使用する場合、HADOOP_CLASSPATHに$KVHOME/lib/kvstore.jarを含め、hadoopコマンドに-libjarsオプションを含める必要があります。
hadoop jar $OLH_HOME/jlib/oraloader.jar oracle.hadoop.loader.OraLoader \ -conf MyConf.xml \ -libjars $KVHOME/lib/kvstore.jar
Oracle Loader for Hadoopは、個々のタスクからのレポート情報をまとめて${map.output.dir}/_olh/oraloader-report.txtファイルを作成します。このレポートには、その他の統計とともに、各マッパーおよびリデューサのタイプとタスク別に分類されたエラーの数が表示されます。
Oracle Loader for Hadoopは、次のような様々な理由で入力レコードを拒否します。
マッピング・プロパティのエラー
入力データ内の欠落フィールド
無効な表パーティションにマップされたレコード
不正な書式のレコード(たとえば、日付が日付形式に一致しない場合や、レコードが正規表現パターンに一致しない場合)
デフォルトでは、Oracle Loader for Hadoopは、拒否されたレコードをHadoopログに記録せず、拒否されたレコードの識別方法のみを記録します。これにより、クラスタ全体に存在するHadoopログにユーザーの機密情報が格納されることを防ぎます。
拒否されたレコードを記録するようにOracle Loader for Hadoopを管理するには、構成プロパティoracle.hadoop.loader.logBadRecordsをtrueに設定します。Oracle Loader for Hadoopは、ジョブの出力ディレクトリ内にある_olh/ディレクトリの1つ以上の「不正な」ファイルに不正なレコードを記録します。
一部の問題により、Oracle Loader for Hadoopが入力のすべてのレコードを拒否することがあります。このような問題による時間とリソースの無駄を軽減するため、Oracle Loader for Hadoopは、1000レコードが拒否されると、ジョブを中止します。
拒否されるレコードの最大許可数を変更するには、構成プロパティoracle.hadoop.loader.rejectLimitを設定します。負の値を設定すると、拒否制限が無効になり、拒否されるレコードの数に関係なくジョブの実行が完了します。
ロード・バランシングの目標は、すべてのリデューサにほぼ同量の処理を割り当てるMapReduceパーティション化スキームを生成することです。
Oracle Loader for Hadoopのサンプリング機能を使用すると、パーティション化されたデータベース表にデータをロードするときにリデューサ間で負荷を分散できます。このサンプリング機能では、データベース・パーティションをリデューサに割り当てる効率的なMapReduceパーティション化スキームが生成されます。
リデューサの実行時間は、通常、処理するレコードの数に比例します。レコードが多いほど、実行時間は長くなります。サンプリング機能が無効の場合、特定のデータベース・パーティションのすべてのレコードが1つのリデューサに送られます。データベース・パーティションによってレコードの数が異なることがあるため、これによってリデューサの負荷は不均等になります。Hadoopジョブの実行時間は、通常、最も遅いリデューサの実行時間によって決まるため、リデューサの負荷が不均等な場合、ジョブ全体のパフォーマンスが低下します。
サンプリング機能の有効/無効を切り替えるには、構成プロパティoracle.hadoop.loader.sampler.enableSamplingを設定します。サンプリング機能はデフォルトで有効になっています。
次のジョブ構成プロパティによってロード・バランシング機能の質を制御します。
サンプラは、所定のリデューサ負荷係数を使用してパーティション化スキームの質を評価します。負荷係数は、(assigned_load - ideal_load)/ideal_loadの計算で求められる各リデューサの相対的な過負荷を表します。このメトリックは、リデューサの負荷が、完全に分散されたリデューサの負荷とどの程度違っているかを示します。負荷係数1.0は、完全に分散された負荷(過負荷ではない)を表します。
負荷係数が小さい場合、負荷分散が適切であることを表します。maxLoadFactorのデフォルト0.05は、5%以上の過負荷状態になるリデューサがないことを表します。サンプラでは、loadCIの値で決まる統計的信頼度でこのmaxLoadFactorが保証されます。loadCIのデフォルト値は0.95で、maxLoadFactorを超えるリデューサの負荷係数は5%のみであることを表します。
サンプラの実行時間と負荷分散の質の間にはトレードオフがあります。maxLoadFactorの値を低くしてloadCIの値を高くすると、リデューサの負荷はより均等化されますが、サンプリング時間は長くなります。maxLoadFactor=0.05およびloadCI=0.95というデフォルト値では、負荷分散の質と実行時間の兼合いが適切にとられます。
デフォルトでは、サンプラは、maxLoadFactorとloadCIの基準を満たすパーティション化スキームを生成するのに十分なサンプルを収集するまで実行されます。
ただし、サンプリングする最大レコード数を指定するoracle.hadoop.loader.sampler.maxSamplesPctプロパティを設定すると、サンプラの実行時間を制限できます。
Oracle Loader for Hadoopでは、サンプリングが成功の場合にのみ、生成されたパーティション化スキームを使用します。統計的信頼度loadCIで保証される最大リデューサ負荷係数(1+ maxLoadFactor)のパーティション化スキームが生成される場合、サンプリングは成功です。
デフォルト値maxLoadFactor、loadCIおよびmaxSamplesPctにより、サンプラは、様々な入力データ分布に対する質の高いパーティション化スキームを正常に生成できます。ただし、制約が厳しすぎる場合や、必要なサンプルの数が、ユーザーが指定した最大数であるmaxSamplesPctを超えている場合などには、サンプラがカスタム・プロパティ値を使用したパーティション化スキームの生成に失敗することがあります。このような場合、Oracle Loader for Hadoopは、問題を特定するログ・メッセージを生成し、データベースのパーティション化スキームを使用してレコードの分割を行い、負荷分散は保証されません。
代替策は、構成プロパティの値を緩和することです。これは、maxSamplesPctを大きくするか、maxLoadFactorまたはloadCI、あるいはその両方を小さくすることによって行えます。
カスタム入力形式では、メモリーに収まらない入力分割が返されることがあります。このような場合、サンプラは、ローダー・ジョブが発行されるクライアント・ノードでメモリー不足エラーを返します。
この問題の解決策は、次のとおりです。
ジョブが発行されるJVMのヒープ・サイズを大きくします。
次のプロパティを調整します。
カスタム入力形式を開発する場合は、「カスタム入力形式」を参照してください。
Oracle Loader for Hadoopを使用してデータをOracle Big Data ApplianceからOracle Exadata Database Machineにロードする場合、InfiniBandプライベート・ネットワーク上でSockets Direct Protocol (SDP)を使用するようにシステムを構成することによって、スループットを向上させることができます。この設定は、データのロードのみを目的としてOracle Databaseに接続するための追加接続属性を指定します。
SDPプロトコルを指定するには、次のようにします。
HADOOP_OPTS環境変数にJVMオプションを追加して、JDBC SDPエクスポートを有効にします。
HADOOP_OPTS="-Doracle.net.SDP=true -Djava.net.preferIPv4Stack=true"
標準のイーサネット通信を構成します。ジョブ構成ファイルで、次の構文に従ってoracle.hadoop.loader.connection.urlを設定します。
jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=TCP)(HOST=hostName)(PORT=portNumber)))
(CONNECT_DATA=(SERVICE_NAME=serviceName)))
ExadataでOracleリスナーを、SDPプロトコルをサポートするように構成し、特定のポート・アドレス(1522など)にバインドします。ジョブ構成ファイルで、次の構文に従ってoracle.hadoop.loader.connection.oci_urlの値としてリスナー・アドレスを指定します。
(DESCRIPTION=(ADDRESS=(PROTOCOL=SDP)
(HOST=hostName) (PORT=portNumber))
(CONNECT_DATA=(SERVICE_NAME=serviceName)))
hostName、portNumberおよびserviceNameは、Oracle Exadata Database Machine上のSDPリスナーを識別するための適切な値に置き換えます。
|
関連項目: InfiniBandによる通信の構成の詳細は、『Oracle Big Data Applianceソフトウェア・ユーザーズ・ガイド』を参照してください。 |
OraLoaderは、構成プロパティの指定にhadoopコマンドの標準的なメソッドを使用します。構成ファイルを指定する場合は-confオプションを使用し、個別のプロパティを指定する場合は-Dオプションを使用します。「ローダー・ジョブの実行」を参照してください。
この項では、一般にOraLoaderジョブに設定する必要があるOraLoader構成プロパティ、Oracle NoSQL Database構成プロパティ、そしていくつかの汎用的なHadoop MapReduceプロパティについて説明します。
すべてのOraLoaderプロパティを示す構成ファイルは、$OLH_HOME/doc/oraloader-conf.xmlにあります。
MapReduce構成プロパティ
型: String
デフォルト値: OraLoader
説明: Hadoopのジョブ名。一意の名前を付けることで、Hadoop JobTracker WebインタフェースやCloudera Managerなどのツールを使用してジョブを監視できます。
型: String
デフォルト値: 定義されていません。
説明: 入力ディレクトリの名前のカンマ区切りリスト。
型: String
デフォルト値: 定義されていません。
説明: 入力データの形式を識別します。次のいずれかの組込み入力形式またはカスタムInputFormatクラスの名前を入力できます。
oracle.hadoop.loader.lib.input.AvroInputFormat
oracle.hadoop.loader.lib.input.DelimitedTextInputFormat
oracle.hadoop.loader.lib.input.HiveToAvroInputFormat
oracle.hadoop.loader.lib.input.RegexInputFormat
oracle.kv.hadoop.KVAvroInputFormat
組込み入力形式の詳細は、「入力形式の概要」を参照してください。
型: String
デフォルト値: 定義されていません。
説明: 出力ディレクトリのカンマ区切りリスト。ジョブを実行する前には存在しません。必須。
型: String
デフォルト値: 定義されていません。
説明: 出力タイプを指定します。値は次のとおりです。
oracle.hadoop.loader.lib.output.DataPumpOutputFormat
外部表を使用してターゲット表にロードされるバイナリ形式ファイルにデータ・レコードを書き込みます。
oracle.hadoop.loader.lib.output.JDBCOutputFormat
JDBC接続を使用して行をターゲット表に挿入します。
oracle.hadoop.loader.lib.output.OCIOutputFormat
「出力形式の概要」を参照してください。
OraLoaderの構成プロパティ
型: Integer
デフォルト値: 500
説明: ログ・ファイルをフラッシュするまでにタスクの試行を記録できる最大レコード数を設定します。この設定により、レコードの拒否が制限(oracle.hadoop.loader.rejectLimit)に達し、ジョブの実行が停止した場合に失われる可能性があるレコード数が制限されます。
フラッシュ間隔を有効にするには、oracle.hadoop.loader.logBadRecordsプロパティをtrueに設定する必要があります。
型: 小数
デフォルト値: BASIC=5.0,OLTP=5.0,QUERY_LOW=10.0,QUERY_HIGH=10.0,ARCHIVE_LOW=10.0,ARCHIVE_HIGH=10.0
説明: 1つのパーティションへの並列ダイレクト・パス・ロード時に、各種圧縮についてOracle Databaseの圧縮係数を定義します。値は名前=値のペアのカンマ区切りリストです。名前には、次のいずれかのキーワードを指定できます。
ARCHIVE_HIGH ARCHIVE_LOW BASIC OLTP QUERY_HIGH QUERY_LOW
型: Integer
デフォルト値: 100
説明: データベースへのトリップごとに挿入されるレコード数。JDBCOutputFormatおよびOCIOutputFormatにのみ適用されます。
1以上の値を指定します。最大値の制限はありませんが、パフォーマンスはあまり向上せずにメモリー・フットプリントが大きくなるため、非常に大きいバッチ・サイズを使用することは推奨されません。
値が1未満の場合は、デフォルト値が設定されます。
型: String
デフォルト値: oracle.hadoop.loader.connection.urlの値
説明: OCIOutputFormatで使用されるデータベース接続文字列。このプロパティを指定することによって、JDBC接続URLとは異なる接続パラメータを使用してOCIクライアントからデータベースに接続できます。
次の例では、OCI接続にソケット・ダイレクト・プロトコル(SDP)を指定しています。
(DESCRIPTION=(ADDRESS_LIST= (ADDRESS=(PROTOCOL=SDP)(HOST=myhost)(PORT=1521))) (CONNECT_DATA=(SERVICE_NAME=my_db_service_name)))
この接続文字列に接頭辞"jdbc:oracle:thin:@"は不要です。最初のアット記号(@)までのすべての文字が削除されます。
型: String
デフォルト値: 定義されていません。
説明: 接続するユーザーのパスワード。パスワードの保存にはクリア・テキストを使用しないことをお薦めします。かわりにOracle Walletを使用してください。
型: String
デフォルト値: LOCAL
説明: データベース接続のセッション・タイムゾーンを変更します。有効な値は、次のとおりです。
[+|-]hh:mm: 協定世界時(UTC)との差分を表す時間数と分数(例: 東部標準時の場合は-5:00)
LOCAL: JVMのデフォルト・タイムゾーン
time_zone_region: 有効なJVMタイムゾーン・リージョン(東部標準時を表すESTやAmerica/New_Yorkなど)
このプロパティは、TIMESTAMP WITH TIME ZONEおよびTIMESTAMP WITH LOCAL TIME ZONEのデータベース列タイプにロードされる入力データに使用されるデフォルト・タイムゾーンも決定します。
型: String
デフォルト値: 定義されていません。
説明: Hadoopクラスタの各ノードにある、sqlnet.oraやtnsnames.oraなどのSQL*Net構成ファイルが含まれるディレクトリへのファイル・パス。データベース接続文字列でTNSエントリ名を使用できるようにこのプロパティを設定します。
Oracle Walletを外部パスワード・ストアとして使用する場合、このプロパティを設定する必要があります。「oracle.hadoop.loader.connection.wallet_location」を参照してください。
型: String
デフォルト値: 定義されていません。
説明: tnsnames.oraファイルに定義されたTNSエントリ名。このプロパティは、oracle.hadoop.loader.connection.tns_adminとともに使用します。
型: String
デフォルト値: 定義されていません。
説明: データベース接続のURL。このプロパティは、他のすべての接続プロパティより優先されます。
Oracle Walletが外部パスワード・ストアとして構成されている場合、プロパティ値は、ドライバ接頭辞jdbc:oracle:thin:@で始まる必要があり、データベース接続文字列は、ウォレットに格納されている資格証明と完全に一致する必要があります。「oracle.hadoop.loader.connection.wallet_location」を参照してください。
次の例に、接続URLの有効な値を示します。
Oracle Net形式:
jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS_LIST=
(ADDRESS=(PROTOCOL=TCP)(HOST=myhost)(PORT=1521)))
(CONNECT_DATA=(SERVICE_NAME=example_service_name)))
TNSエントリ形式:
jdbc:oracle:thin:@myTNSEntryName
Thinスタイル:
jdbc:oracle:thin:@//myhost:1521/my_db_service_name jdbc:oracle:thin:user/password@//myhost:1521/my_db_service_name
型: String
デフォルト値: 定義されていません。
説明: データベース・ユーザー名。オンライン・データベース・モードを使用する場合は、このプロパティまたはoracle.hadoop.loader.connection.wallet_locationを設定する必要があります。
型: String
デフォルト値: 定義されていません。
説明: Hadoopクラスタの各ノードにある、接続資格証明が格納されているOracle Walletディレクトリへのファイル・パス。
Oracle Walletを使用する場合、次のプロパティも設定する必要があります。
型: String
デフォルト値: yyyy-MM-dd HH:mm:ss
説明: java.text.SimpleDateformatパターンとデフォルトのロケールを使用して、入力フィールドをDATE列に解析します。入力ファイルのフィールドごとに異なるパターンが必要な場合は、手動マッピング・プロパティを使用します。「手動マッピング」を参照してください。
型: Boolean
デフォルト値: true
説明: 各リデューサ・グループ内の出力レコードをソートするかどうかを制御します。ターゲット表のソート・キーとなる列を指定するには、oracle.hadoop.loader.sortKeyプロパティを使用します。このプロパティを指定しなければ、レコードは主キーでソートされます。
型: String
デフォルト値: OLH_EXTTAB_DIR
説明: 外部表のLOCATIONデータ・ファイルのデータベース・ディレクトリ・オブジェクトの名前。Oracle Loader for Hadoopがこのディレクトリにデータ・ファイルをコピーするのではなく、外部表のDDLを格納しているSQLファイルがファイル出力形式によって生成され、このファイルにディレクトリ名が記録されます。
このプロパティはDelimitedTextOutputFormatおよびDataPumpOutputFormatのみに適用されます。
型: String
デフォルト値: F0,F1,F2,...
説明: 入力フィールドの名前のカンマ区切りリスト。
組込み入力形式の場合は、目的のフィールドだけではなく、データ内のすべてのフィールドの名前を指定します。入力行のフィールド数がこのプロパティに指定されたフィールド名の数より多い場合、余分なフィールドは破棄されます。行のフィールド数がこのプロパティに指定されたフィールド名の数より少ない場合、余分なフィールドにはnullが設定されます。選択したフィールドのみをロードする場合は、「ターゲット表列への入力フィールドのマッピング」を参照してください。
名前は、レコードのAvroスキーマの作成に使用されるため、有効なJSON名文字列である必要があります。
型: String
デフォルト値: , (カンマ)
説明: DelimitedTextInputFormatの入力フィールドの終了を示す文字。値には、1文字または\uHHHH (HHHHは文字のUTF-16エンコーディング)を指定できます。
型: String
デフォルト値: 定義されていません。
説明: 入力表が格納されているHiveデータベースの名前。
型: String
デフォルト値: 定義されていません。
説明: 入力データが格納されているHive表の名前。
型: String
デフォルト値: 定義されていません。
説明: フィールドの開始を示す文字。値には、1文字または\uHHHH (HHHHは文字のUTF-16エンコーディング)を指定できます。デフォルト設定(囲み文字なし)に戻すには、長さが0の値を入力します。フィールドの囲み文字には、入力形式に定義された終端文字および空白文字とは異なる文字を使用する必要があります。
このプロパティが設定されている場合、パーサーは、各フィールドを囲まれていないトークン(値)として読み取る前にまず、囲まれたトークンとして読み取ります。フィールド囲み文字が設定されていない場合、パーサーは各フィールドを囲まれていないトークンとして読み取ります。
このプロパティを設定し、oracle.hadoop.loader.input.trailingFieldEncloserを設定していない場合は、両方のプロパティに同じ値が使用されます。
型: Boolean
デフォルト値: false
説明: パターンの照合時に大文字と小文字を区別するかどうかを制御します。trueに設定すると、大文字と小文字の違いは無視され、"string"は"String"、"STRING"、"string"、"StRiNg"などと一致します。デフォルトでは、"string"は"string"のみと一致します。
このプロパティはorg.apache.hadoop.hive.contrib.serde2.RegexSerDeのinput.regex.case.insensitiveプロパティと同じです。
型: テキスト
デフォルト値: 定義されていません。
説明: 正規表現のパターン文字列
正規表現はテキスト行全体が一致する必要があります。たとえば、入力行"a,b,c,"の正しい正規表現パターンは"([^,]*),([^,]*),([^,]*),"ですが、"([^,]*),"は無効です。その理由は、この表現は入力テキストの行に反復して適用されていないためです。
RegexInputFormatでは、正規表現の一致による取得グループをフィールドとして使用します。特殊なグループのゼロは、入力行全体を表すため無視されます。
このプロパティはorg.apache.hadoop.hive.contrib.serde2.RegexSerDeのinput.regexプロパティと同じです。
|
関連項目: 正規表現と取得グループの詳細は、次のサイトにあるJava Platform Standard Edition 6 API仕様のjava.util.regexのエントリを参照してください。
|
型: String
デフォルト値: oracle.hadoop.loader.input.initialFieldEncloserの値
説明: フィールドの終了を示す文字を表します。値には、1文字または\uHHHH (HHHHは文字のUTF-16エンコーディング)を指定できます。終了囲み文字がない場合は、長さが0の値を入力します。
フィールドの囲み文字には、入力形式に定義された終端文字および空白文字とは異なる文字を使用する必要があります。
終了フィールド囲み文字が入力フィールドに組み込まれている場合、リテラル・テキストとして解析されるようにするには、二重にする必要があります。たとえば、'(1つの単一引用符)をロードするには、入力フィールドに''(2つの単一引用符)を指定する必要があります。
このプロパティを設定する場合、oracle.hadoop.loader.input.initialFieldEncloserも設定する必要があります。
型: Boolean
デフォルト値: true
説明: パーティションを認識するロードを指定します。Oracle Loader for Hadoopは、Hadoopクラスタ上のすべての出力形式の出力をパーティション別に整理します。このタスクはデータベース・システムのリソースには影響しません。
DelimitedTextOutputFormatおよびDataPumpOutputFormatでは複数のファイルが生成され、各ファイルに1つのパーティションのレコードが格納されます。DelimitedTextOutputFormatでは、このプロパティによって、SQL*Loader用に生成された制御ファイルにPARTITIONキーワードを含めるかどうかも制御されます。
OCIOutputFormatにはパーティション化表が必要です。このプロパティをfalseに設定すると、OCIOutputFormatが有効になります。その他の出力形式では、loadByPartitionをfalseに設定すると、Oracle Loader for Hadoopでパーティション化表がパーティション化されていない表と同様に処理されます。
型: String
デフォルト値: 定義されていません。
説明: ターゲット表の列名を任意の順序で示したカンマ区切りリスト。名前は引用符で囲むか囲まないかのいずれかです。引用符で囲む名前には二重引用符(")を最初と最後に付けることで、入力したとおりに使用されます。引用符で囲まれていない名前は大文字に変換されます。
このプロパティは、oracle.hadoop.loader.loaderMap.targetTableを設定しないと無視されます。必要に応じて、oracle.hadoop.loader.loaderMap.column_name.fieldおよびoracle.hadoop.loader.loaderMap.column_name.formatを設定できます。
型: String
デフォルト値: 正規化された列名
説明: Avroレコードを含むフィールドの名前で、このプロパティ名で識別される列にマップされます。列名は引用符で囲むか囲まないかのいずれかです。引用符で囲む名前には二重引用符(")を最初と最後に付けることで、入力したとおりに使用されます。引用符で囲まれていない名前は大文字に変換されます。オプション。
このプロパティは、oracle.hadoop.loader.loaderMap.columnNamesを設定しないと無視されます。
型: String
デフォルト値: 定義されていません。
説明: このプロパティ名で識別される列にロードするデータのデータ形式を指定します。日付形式にはjava.text.SimpleDateformatパターンを、テキストには正規表現パターンを使用します。オプション。
このプロパティは、oracle.hadoop.loader.loaderMap.columnNamesを設定しないと無視されます。
型: String
デフォルト値: 定義されていません。
説明: ロード先の表のスキーマで修飾された名前。このプロパティは、oracle.hadoop.loader.loaderMapFileよりも優先されます。
列のサブセットをロードするには、oracle.hadoop.loader.loaderMap.columnNamesプロパティを設定します。columnNamesに関しては、必要に応じて、oracle.hadoop.loader.loaderMap.column_name.fieldを設定して列にマップするフィールドの名前を指定したり、oracle.hadoop.loader.loaderMap.column_name.formatを設定してそれらのフィールドのデータの形式を指定できます。表のすべての列をロードし、入力フィールド名がデータベース列名と一致している場合、columnNamesを設定する必要はありません。
ローダー・マップは、リリース2.3で非推奨になりました。ローダー・マップ・ファイルは、oracle.hadoop.loader.loaderMap.*構成プロパティに置き換えられています。「手動マッピング」を参照してください。
型: Boolean
デフォルト値: false
説明: Oracle Loader for Hadoopが不正なレコードをファイルにログ記録するかどうかを制御します。
このプロパティは、入力形式とマッパーで拒否されるレコードのみに適用されます。出力形式またはサンプリング機能で発生したエラーには適用されません。
型: String
デフォルト値: log4j.logger.oracle.hadoop.loader
説明: 構成ファイルからロードされたApache log4jプロパティで使用する接頭辞を識別します。
Oracle Loader for Hadoopでlog4jのプロパティを指定するには、hadoopコマンドに-confオプションおよび-Dオプションを使用します。次に例を示します。
-D log4j.logger.oracle.hadoop.loader.OraLoader=DEBUG -D log4j.logger.oracle.hadoop.loader.metadata=INFO
この接頭辞で始まるすべての構成プロパティがlog4jにロードされます。これらのプロパティは、log4jに${log4j.configuration}からロードされたものと同じプロパティの設定をオーバーライドします。このオーバーライドは、Oracle Loader for Hadoopのジョブ・ドライバおよびそのマップとリデュースのタスクに適用されます。
構成プロパティはRAW値とともにlog4jにコピーされます。変数の拡張はすべてlog4jに対して実行されます。拡張に使用する構成変数もこの接頭辞で始まる必要があります。
型: String
デフォルト値: OLH_HOME環境変数の値
説明: OraLoaderジョブを開始するノード上のOracle Loader for Hadoopのホーム・ディレクトリのパス。このパスは、必要なライブラリの場所を示します。
型: String
デフォルト値: ${mapred.output.dir}/../olhcache
説明: Oracle Loader for HadoopがMapReduceの分散キャッシュにロードするファイルを作成できるHDFSディレクトリのフル・パスを識別します。
この分散キャッシュは、大規模なアプリケーション固有ファイルをキャッシュし、クラスタ内のノード間に効率的に分散する機能です。
型: Integer
デフォルト値: 131072 (128KB)
説明: OCIOutputFormatのダイレクト・パス・ストリーム・バッファのサイズをバイト単位で設定します。値は8KBの倍数に切り上げられます。
型: Boolean
デフォルト値: false
説明: 埋込みの終了囲み文字をリテラル・テキストとして処理するかどうか(つまり、エスケープするかどうか)を制御します。このプロパティをtrueに設定すると、フィールドにデータ値の一部として終了囲み文字を含めることができます。「oracle.hadoop.loader.output.trailingFieldEncloser」を参照してください。
型: String
デフォルト値: , (カンマ)
説明: DelimitedTextInputFormatの出力フィールドの終了を示す文字。値には、1文字または\uHHHH (HHHHは文字のUTF-16エンコーディング)を指定できます。
型: Integer
デフォルト値: 10240000
説明: 生成されたデータ・ポンプ・ファイルのグラニュル・サイズ(バイト)。
グラニュルは、ORACLE_DATAPUMPアクセス・ドライバを使用してファイルをロードする場合の並列処理(PQスレーブ)の作業負荷を決定します。
|
関連項目: ORACLE_DATAPUMPアクセス・ドライバの詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
型: String
デフォルト値: 定義されていません。
説明: 出力で生成される、フィールドの開始を示す文字。値には、1文字または\uHHHH (HHHHは文字のUTF-16エンコーディング)を指定する必要があります。長さが0の値は、出力で囲み文字が生成されないことを表します(デフォルト値)。
フィールドにoracle.hadoop.loader.output.fieldTerminatorの値を含める場合は、このプロパティを使用します。フィールドにoracle.hadoop.loader.output.trailingFieldEncloserの値も含めることができるようにするには、oracle.hadoop.loader.output.escapeEnclosersをtrueに設定します。
このプロパティを設定する場合、oracle.hadoop.loader.output.trailingFieldEncloserも設定する必要があります。
型: String
デフォルト値: oracle.hadoop.loader.output.initialFieldEncloserの値
説明: 出力で生成される、フィールドの終了を示す文字。値には、1文字または\uHHHH (HHHHは文字のUTF-16エンコーディング)を指定する必要があります。ゼロ長値は囲み文字がないことを表します(デフォルト値)。
フィールドにoracle.hadoop.loader.output.fieldTerminatorの値を含める場合は、このプロパティを使用します。フィールドにoracle.hadoop.loader.output.trailingFieldEncloserの値も含めることができるようにするには、oracle.hadoop.loader.output.escapeEnclosersをtrueに設定します。
このプロパティを設定する場合、oracle.hadoop.loader.output.initialFieldEncloserも設定する必要があります。
型: Integer
デフォルト値: 1000
説明: ジョブの実行が停止するまでに拒否またはスキップできるレコードの最大数。負の値を設定すると、拒否制限が無効になり、ジョブの実行が完了します。
mapred.map.tasks.speculative.executionがtrueの場合(デフォルト)、拒否されるレコードの数が一時的に増加して、ジョブが未完了の状態で停止することがあります。
入力形式のエラーは、修復不可能でマップ・タスクが中止になるため、拒否制限に反映されません。サンプリング機能またはオンライン出力形式で発生したエラーも拒否制限に反映されません。
型: Boolean
デフォルト値: true
説明: サンプリング機能が有効かどうかを制御します。サンプリングを無効にするには、このプロパティをfalseに設定します。
enableSamplingプロパティがtrueに設定されている場合でも、サンプリングが不要な場合、または適切なサンプルを作成できないとローダーが判断した場合、ローダーによってサンプリングが自動的に無効になります。たとえば、表がパーティション化されていない場合、リデューサ・タスクの数が2未満の場合、または入力データが少なすぎて適切なロード・バランシングの計算ができない場合、サンプリングは無効になります。このような場合、ローダーは情報メッセージを返します。
型: Integer
デフォルト値: 1048576 (1MB)
説明: サンプリング・プロセスにHadoopのmapred.max.split.sizeプロパティを設定します。ジョブ構成のmapred.max.split.sizeの値は変わりません。1未満の値は無視されます。
一部の入力形式(FileInputFormatなど)では、getSplitsによって返される分割の数を判断するヒントとしてこのプロパティを使用します。値が小さいほど、ランダムにサンプリングされるデータ・チャンクが多いことを意味し、サンプリング性能が高くなります。
データセットのデータ量が数十TB単位に上る場合や、入力形式のgetSplitsメソッドからメモリー不足エラーが返される場合には、この値を増やします。
分割サイズが大きいほど、I/Oパフォーマンスは高くなりますが、サンプリング性能は必ずしも高くなりません。この値を、適切なサンプリング性能を得られるような小さい値(ただし、小さすぎない値)に設定します。極度に小さい値を設定すると、I/Oパフォーマンスが非効率になり、返される分割数が多すぎてgetSplitsでメモリー不足が発生する可能性があります。
org.apache.hadoop.mapreduce.lib.input.FileInputFormatメソッドでは、このプロパティの値に関係なく、常に最小分割サイズの設定以上の大きさの分割が返されます。
型: Integer
デフォルト値: 100
説明: サンプリング・プロセスにHadoopのmapred.map.tasks構成プロパティを設定します。ジョブ構成のmapred.map.tasksの値は変わりません。1未満の値は無視されます。
一部の入力形式(DBInputFormatなど)では、getSplitsメソッドによって返される分割の数を判断するヒントとしてこのプロパティを使用します。値が高いほど、ランダムにサンプリングされるデータ・チャンクが多いことを意味し、サンプリング性能が高くなります。
データセットに対して、この値を100万行より大きい値に増やします。ただし、極度に大きい値を設定すると、返される分割数が多すぎてgetSplitsでメモリー不足が発生する可能性があります。
型: 小数
デフォルト値: 0.95
説明: リデューサの最大負荷係数に対する統計的信頼性インジケータ。
このプロパティは0.5以上1未満の値(0.5 <= 値 < 1)を受け入れます。値が0.5未満の場合、プロパティはデフォルト値にリセットされます。一般的な値は0.90、0.95および0.99です。
型: Integer
デフォルト値: -1
説明: サンプラが使用可能なメモリーの最大容量をバイト単位で指定します。
次のいずれかの条件が真になった場合、サンプリングは中止されます。
サンプラがロード・バランシングに必要な最低数のサンプルを収集した。
サンプリングされたデータの割合(パーセント)がoracle.hadoop.loader.sampler.maxSamplesPctの値を超えている。
サンプリングされたバイト数がoracle.hadoop.loader.sampler.maxHeapBytesの値を超えている。プロパティに負の値が設定されている場合、この条件は適用されません。
型: Float
デフォルト値: 0.05 (5%)
説明: リデューサに対する最大許容負荷係数。値が0.05の場合、リデューサは最適な負荷より最大5%多くのデータを割当て可能であることを表します。
このプロパティは0より大きい値を受け入れます。値が0以下の場合、プロパティはデフォルト値にリセットされます。一般的な値は0.05および0.1です。
負荷が完全に分散された状態では、各リデューサに均等な作業量(負荷)が割り当てられています。負荷係数は、(assigned_load - ideal_load)/ideal_loadの計算で求められる各リデューサの相対的な過負荷を表します。ロード・バランシングが成功した場合、ジョブは指定した信頼度の最大負荷係数の範囲内で実行されます。
「oracle.hadoop.loader.sampler.loadCI」を参照してください。
型: Float
デフォルト値: 0.01 (1%)
説明: 最大サンプル・サイズ(入力データ内のレコード数の割合)を設定します。値0.05は、サンプラがサンプリングするのはレコードの総数の5%以下であることを示します。
このプロパティは0~1の範囲の値(0~100%)を受け入れます。負の値を設定すると、このプロパティは無効になります。
次のいずれかの条件が真になった場合、サンプリングは中止されます。
サンプラがロード・バランシングに必要な最低数のサンプルを収集した。このサンプル数は、このプロパティで設定した値より小さい場合があります。
サンプリングされたデータの割合(パーセント)がoracle.hadoop.loader.sampler.maxSamplesPctの値を超えている。
サンプリングされたバイト数がoracle.hadoop.loader.sampler.maxHeapBytesの値を超えている。プロパティに負の値が設定されている場合、この条件は適用されません。
型: Integer
デフォルト値: 5
説明: サンプラが中止条件を評価するまでに読み取る入力分割の最小数。入力分割の合計数がminSplitsより少ない場合、サンプラはすべての入力分割から読み取ります。
0以下の数値は1として扱われます。
型: Integer
デフォルト値: 5
説明: サンプラのスレッド数。スレッド数が多いほど、サンプリングの同時実行性が高くなります。値が1の場合、サンプラのマルチスレッドが無効になります。
Oracle Loader for Hadoopのジョブを開始するノード上のプロセッサおよびメモリー・リソースに基づいて値を設定します。
型: String
デフォルト値: 定義されていません。
説明: リデューサ・グループ内の出力レコードのソート・キーを構成する列名のカンマ区切りリスト。
引用符で囲まれている識別子または引用符で囲まれていない識別子を列名にすることができます。
引用符で囲まれている識別子の開始と終了には二重引用符(")を使用します。
引用符で囲まれていない識別子は、使用する前に大文字に変換されます。
型: String
デフォルト値: 定義されていません。
説明: ターゲット表のメタデータ・ファイルへのパス。このプロパティは、オフライン・データベース・モードで実行する場合に設定します。
ローカル・ファイルを指定するには、次の例のようにfile://の構文を使用します。
file:///home/jdoe/metadata.xml
表のメタデータ・ファイルを作成するには、OraLoaderMetadataユーティリティを実行します。「OraLoaderMetadataユーティリティ」を参照してください。
非推奨。oracle.hadoop.loader.loaderMap.targetTableを使用します。
Oracle NoSQL Databaseの構成プロパティ
型: String
デフォルト値: 定義されていません。
説明: ソース・データがあるKVストアの名前。
型: String
デフォルト値: 定義されていません。
説明: ソース・データがあるKVストア内のホストを識別する、1つ以上のhostname:portペアの配列。複数のペアはカンマで区切ります。
型: Key
デフォルト値: 定義されていません。
説明: 各ネットワーク・ラウンドトリップ中、KVAvroInputFormatがフェッチに必要とするキー数。ゼロ(0)値は、プロパティをデフォルト値に設定します。
型: String
デフォルト値: 定義されていません。
説明: 返される値を、指定されたキーの子のキーと値のペアのみに制限します。メジャー・キー・パスを部分パスとし、マイナー・キー・パスを空にする必要があります。null値(デフォルト)は出力を制限しないため、KVAvroInputFormatがストア内のすべてのキーを返します。
型: KeyRange
デフォルト値: 定義されていません。
説明: 返される値を、oracle.kv.parentKeyにより指定された親キーの下の特定の子へ、さらに制限します。
型: Depth
デフォルト値: PARENT_AND_DESCENDENTS
説明: 返される値を、oracle.kv.parentKeyの値の下の、特定の階層の深さに制限します。次のキーワードは有効な値です。
CHILDREN_ONLY: 子を返します。指定された親は返しません。
DESCENDANTS_ONLY: すべての子孫を返します。指定された親は返しません。
PARENT_AND_CHILDREN: 子および親を返します。
PARENT_AND_DESCENDANTS: すべての子孫と親を返します。
型: Consistency
デフォルト値: NONE_REQUIRED
説明: 子のキーと値のペアを読み取る際の一貫性保証です。次のキーワードは有効な値です。
ABSOLUTE: 一貫性が絶対的となるよう、マスターがトランザクションを提供する必要があります。
NONE_REQUIRED: レプリカが、マスターと比較したレプリカの状態に関係なく、トランザクションを提供することが可能です。
型: Long
デフォルト値:
説明: 選択したキーと値のペアを取得する場合の最大時間間隔(ミリ秒)を設定します。ゼロ(0)値は、プロパティをデフォルト値に設定します。
型: String
デフォルト値: 定義されていません。
説明: KeyValueVersionインスタンスをAvro IndexedRecord文字列に書式設定するAvroFormatterインタフェースを実装するクラスの名前を指定します。
Oracle NoSQL DatabaseのAvroレコードは直接Oracle Loader for Hadoopに移るため、NoSQLキーはターゲットのOracle Database表へのマッピングに使用できません。しかし、フォーマッタ・クラスはNoSQLのキーと値の両方を受け取るので、値とキーの両方を含む新しいAvroレコードを作成して返すことができ、これをOracle Loader for Hadoopに渡すことが可能になります。
Oracle Loader for Hadoopは、次のサードパーティ製品をインストールします。
Apache Avro
Apache Commons Mathematics Library
Jackson JSON Processor
Oracle Loader for Hadoopには、Oracle 11gリリース2 (11.2)クライアント・ライブラリが含まれます。Oracle Database 11gリリース2 (11.2)に含まれるサードパーティ製品の詳細は、『Oracle Databaseライセンス情報』を参照してください。
特に断りがないかぎり、あるいは、サードパーティ・ライセンス(LGPLなど)の条項で求められている場合、Apache Licensed Codeに関連するすべてのステートメントを含めた、この項のライセンスとステートメントは、告知のみを目的とするものです。
The following is included as a notice in compliance with the terms of the Apache 2.0 License, and applies to all programs licensed under the Apache 2.0 license:
You may not use the identified files except in compliance with the Apache License, Version 2.0 (the "License.")
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
A copy of the license is also reproduced below.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and limitations under the License.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
Definitions
"License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity.For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
"Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship.For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner.For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
Grant of Copyright License.Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
Grant of Patent License.Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted.If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
Redistribution.You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that you meet the following conditions:
You must give any other recipients of the Work or Derivative Works a copy of this License; and
You must cause any modified files to carry prominent notices stating that You changed the files; and
You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and
If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear.The contents of the NOTICE file are for informational purposes only and do not modify the License.You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
Submission of Contributions.Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions.Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
Trademarks.This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
Disclaimer of Warranty.Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE.You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
Limitation of Liability.In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
Accepting Warranty or Additional Liability.While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License.However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information.(Do not include the brackets!)The text should be enclosed in the appropriate comment syntax for the file format.We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License.You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions and limitations under the License.
This product includes software developed by The Apache Software Foundation (http://www.apache.org/) (listed below):
Licensed under the Apache License, Version 2.0 (the "License"); you may not use Apache Avro except in compliance with the License.You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions and limitations under the License.
Copyright 2001-2011 The Apache Software Foundation
Licensed under the Apache License, Version 2.0 (the "License"); you may not use the Apache Commons Mathematics library except in compliance with the License.You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions and limitations under the License.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this library except in compliance with the License.You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions and limitations under the License.