| Oracle® Fusion Middleware Oracle Coherenceでのアプリケーションの開発 12c (12.1.3) E56206-04 |
|


 前 |
 次 |
この章では、Coherenceで提供される基本的なキャッシュのタイプの概要を説明し、それぞれのタイプを比較します。
この章には次の項が含まれます:
分散キャッシュ(パーティション・キャッシュ)は、線形スケーラビリティを持つクラスタ化されたフォルト・トレラント・キャッシュです。データは、クラスタのすべての記憶域メンバー間でパーティション化されます。フォルト・トレランスを実現するため、パーティション・キャッシュでは、各データをクラスタ内の1つ以上の個別コンピュータに保持するように構成できます。分散キャッシュはCoherenceで最もよく使用されるキャッシュです。
Coherenceでは、分散キャッシュは、複数のクラスタ・ノードに分散されたデータのコレクションとして定義されるため、クラスタ内の1つのノードがキャッシュ内の各データに対応し、その対応がクラスタ・ノード間で分散(ロード・バランシング)されます。
分散キャッシュには、いくつかの重要な留意事項があります。
パーティション化: 分散キャッシュ内のデータは、同じデータが2つのサーバーで保持されることがないようにすべてのサーバーに分配されます。キャッシュのサイズ、およびキャッシュの管理に関連する処理能力は、クラスタのサイズとともに線形に拡大します。また、キャッシュ内のデータに対する読取り操作を単一ホップ(他のサーバーを多くても1つしか必要としない)で実行できることになります。書込み操作は、バックアップが構成されていない場合に単一ホップで実行できます。
ロード・バランシング: データがサーバー間に均等に分配されるため、データを管理する役割はクラスタ全体を通して自動的にロード・バランシングされます。
位置の透過性: データはクラスタ・ノード全体に分配されますが、データのアクセスにはまったく同じAPIが使用され、各APIメソッドからも同じ動作が実行されます。これを位置の透過性と呼びます。ローカルのJCache、レプリケートされたキャッシュ、または分散キャッシュではAPIおよびAPIの動作が同じになるため、開発者はキャッシュのトポロジに基づいてコードを記述する必要がありません。
フェイルオーバー: Coherenceのすべてのサービスは、データ損失のないフェイルオーバーおよびフェイルバックを実行しますが、分散キャッシュ・サービスも例外ではありません。分散キャッシュ・サービスではバックアップの回数を設定できます。バックアップ回数を1以上に設定すれば、いずれかのクラスタ・ノードに障害が発生しても、データを失うことはありません。
分散キャッシュにアクセスするには、ネットワークを介して別のクラスタ・ノードに接続する必要があります。他の条件がすべて同じであるとして、n個のクラスタ・ノードがある場合は、(n-1)/nの操作がネットワークを経由することになります。
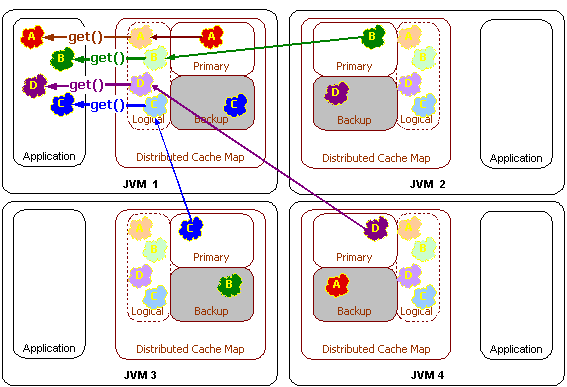
図12-1は、分散キャッシュのget操作の際の概念図です。
各データは1つのクラスタ・ノードのみで管理されるため、ネットワーク経由の読取り操作は単一ホップ操作になります。このタイプのアクセスは、Point-to-Point通信を使用できるためスイッチド・ネットワークを最大限に活用できます。そのため、スケーラビリティに非常に優れています。
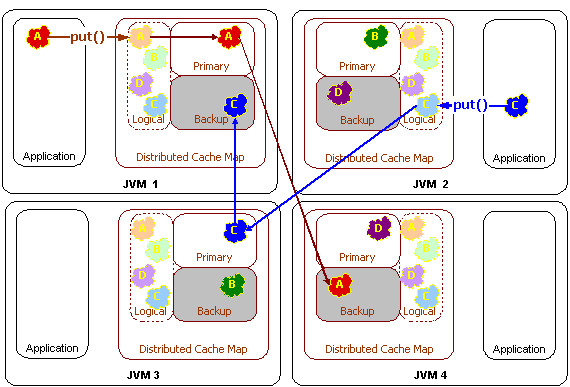
図12-2は、分散キャッシュのput操作の際の概念図です。
上の図では、データはプライマリ・クラスタ・ノードとバックアップ・クラスタ・ノードに送信されています。これはフェイルオーバーを目的としたものであり、この場合のバックアップ回数は1になります。(デフォルトのバックアップ回数の設定は1です。)キャッシュのデータがクリティカルでない(ディスクから再ロードできる)場合は、バックアップ回数をゼロに設定できますが、クラスタ・ノードに障害が発生したときに分散キャッシュ・データの一部が失われる可能性があります。キャッシュがきわめてクリティカルな場合は、バックアップ回数を2などの高い値に設定します。バックアップ回数は、キャッシュ・エントリの追加、変更、削除などによるキャッシュの変更パフォーマンスにのみ影響します。
キャッシュに対する変更は、すべてのバックアップが変更を受信したことを認識するまで完了したとは見なされません。分散キャッシュのバックアップを使用する場合は、キャッシュの変更パフォーマンスが若干低下します。しかし、クラスタ・ノードに予期しない障害が発生しても、データの整合性が維持されることが保証され、データが損失することはありません。
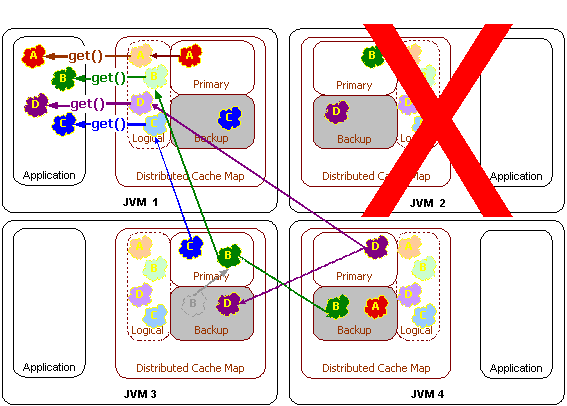
分散キャッシュのフェイルオーバーでは、バックアップ・データがプライマリ記憶域に昇格されます。あるクラスタ・ノードに障害が発生すると、残りのすべてのクラスタ・ノードは、障害が発生したクラスタ・ノードがプライマリ記憶域で停止時に管理していたデータを各自のバックアップ記憶域から判別します。これらのデータの管理は、それをバックアップ記憶域に保持していたクラスタ・ノードに引き継がれます。
図12-3は、分散キャッシュのフェイルオーバーの際の概念図です。
バックアップに複数のレベルがある場合は、最初のバックアップでデータがバックアップされ、2番目以降のバックアップでは前のバックアップがバックアップされるようになります。レプリケート・キャッシュ・サービスとまったく同じように、サーバーの障害時にはロック情報も維持されます。ただし、唯一の例外として、障害が発生したクラスタ・ノードのロックは自動的に解除されます。
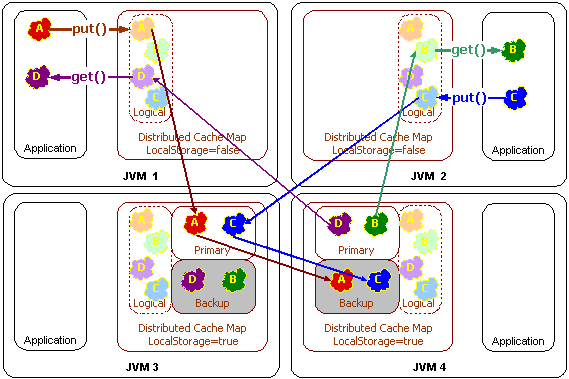
分散キャッシュ・サービスでは、データを格納するクラスタ・ノードと格納しないクラスタ・ノードを構成できます。この設定はローカル記憶域の有効化と呼ばれています。ローカル記憶域を有効化するオプションで構成されたクラスタ・ノードは、分散キャッシュのキャッシュ記憶域とバックアップ記憶域を提供します。この設定にかかわらず、位置の透過性により、データはすべてのクラスタ・ノードでまったく同じように表示できます。
図12-4は、分散キャッシュのgetおよびput操作の際のローカル記憶域の概念図です。
「ローカル記憶域有効」オプションには、次のような利点があります。
クラスタ・ノードの「ローカル記憶域有効」を選択しない場合、データが他のクラスタ・ノードにキャッシュされるため、このノードのJavaヒープ・サイズはキャッシュ内のデータ量に影響されません。この機能は、大きなJavaヒープを持つ古いバージョンのJVMでアプリケーション・サーバー・プロセスを実行している場合に特に有用です。これらのプロセスは、ヒープ・サイズとともに急激に増加するガベージ・コレクションの一時停止に妨げられることが多いためです。
Coherenceでは、クラスタ・ノードごとに、サポートされている任意のJVMバージョンを実行できます。したがって、「ローカル記憶域有効」を有効にしたクラスタ・ノードでは、大きいヒープ・サイズ、またはエラスティック・データを使用するCoherenceのヒープ外記憶域をサポートする、新しいJVMバージョンを実行できます。記憶域が有効なノードと記憶域が無効なノードの間では、それぞれ異なるJVMバージョンを使用できますが、記憶域が有効なノード間では、すべて同じJVMバージョンを使用する必要があります。
「ローカル記憶域有効」オプションを使用すると、一部のクラスタ・ノードをキャッシュ・データの格納目的にのみ使用できます。このようなクラスタ・ノードをCoherenceキャッシュ・サーバーと呼びます。キャッシュ・サーバーは、主にCoherenceの分散問合せ機能の拡張に使用されます。
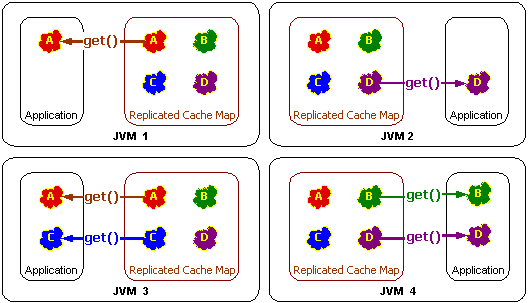
レプリケート・キャッシュはクラスタ化されたフォルト・トレラントなキャッシュで、そこではデータがクラスタ内のすべてのメンバーに完全にレプリケートされます。このキャッシュは、読取りに対して線形パフォーマンスのスケーラビリティで最速の読取りパフォーマンスを示しますが、書込みのスケーラビリティは優れていません(クラスタ内のすべてのメンバーに書込み処理が必要なため)。データがすべてのサーバーにレプリケートされるので、サーバーを追加した場合でもキャッシュの合計容量は増加しません。レプリケート・キャッシュは、一般的に読取り専用の小さなデータ・セットで使用されます。
|
注意: 分散キャッシュとは異なり、レプリケート・キャッシュでは、記憶域が有効なクラスタ・メンバーと記憶域が無効なクラスタ・メンバーが区別されません。 |
自身のメモリ内でデータにアクセスできる各クラスタ・ノード(JVM)にデータがレプリケートされているため、レプリケート・キャッシュには大変高速にアクセスできます。このタイプのアクセスはゼロ待機時間アクセスと呼ばれることが多く、アプリケーションに最高速のデータ・アクセスが要求される状況においては、まさに理想的な機能です。ただし、ゼロ待機時間アクセスはデータが最初にアクセスされた後にのみ発生することに注意してください。レプリケート・キャッシュでは、アクセスがあるまでデータはシリアライズされた形式で格納され、アクセスされた際にデシリアライズされます。データへのアクセスが発生する各クラスタ・ノードで、(データが最初に作成されたノードの場合でも)最初のデシリアライズ・ステップを実行する必要があります。レプリケート・キャッシュを使用する場合は、デシリアライズ・ステップにはパフォーマンス・コストがかかることを考慮する必要があります。
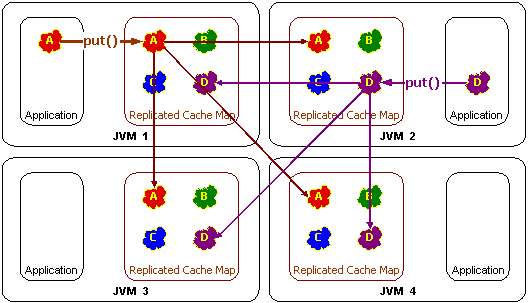
信頼性のあるレプリケート・キャッシュを構築するには、いくつかの課題があります。その1つは、どのような方法で高いスケーラビリティとパフォーマンスを得るかということです。キャッシュに対する更新はすべてのクラスタ・ノードに送信する必要があり、たとえ同じデータへの更新が同時に複数行われても、最終的にはすべてのクラスタ・ノードのデータが一致している必要があります。また、あるクラスタ・ノードがロックをリクエストしても、すべてのクラスタ・ノードがそれに従う必要はありません。そうしないと、スケーラビリティがきわめて低くなります。さらに、クラスタ・ノードに障害が発生した場合は、すべてのデータおよびロック情報が安全に維持される必要があります。Coherenceは、このようなシナリオをすべて透過的に処理し、スケーラブルで可用性の高いレプリケート・キャッシュの実装を実現します。
図12-5は、レプリケート・キャッシュのget操作の際の概念図です。
put操作では、レプリケートされたキャッシュの更新には、他のすべてのクラスタ・ノードに新しいバージョンのデータをプッシュすることが要求されます。図12-6は、レプリケート・キャッシュのput操作の際の概念図です。
Coherenceにおけるレプリケート・キャッシュ・サービスの実装は、読取り専用操作をすべてローカルで実行する、並行処理制御操作に使用する他のクラスタ・ノードは最大1つとする、他のすべてのクラスタ・ノードとの通信が要求される操作を更新にのみ制限する、という方法で行われます。これにより、スケーラビリティに優れたパフォーマンスが実現し、すべてのCoherenceサービスと同様に、レプリケート・キャッシュ・サービスからも透過的で完全なフェイルオーバーおよびフェイルバックが提供されます。
次のレプリケート・キャッシュ・サービスの制限事項にも十分な留意が必要です。
データは、サービスに参加しているすべてのクラスタ・ノード上でレプリケート・キャッシュ・サービスによって管理されます。したがって、メモリー使用量(Javaヒープ・サイズ)はクラスタ・ノードごとに増加し、パフォーマンスに影響する可能性があります。
更新頻度の高いレプリケート・キャッシュは、クラスタの拡大に比例して変化しません。クラスタ・ノードが追加されるに従って、クラスタでは返されるデータが減少します。
レプリケート・キャッシュでは、エントリごとの期限切れはサポートされていません。期限はキャッシュ・レベルで設定する必要があります。バッキング・マップによって、失効およびエビクションがローカルで強制されるため、データは各ノードで失効する可能性があります。エントリは多少異なる時間に失効する可能性があり、別のノードでは多少長く使用可能である可能性があります。失効およびエビクションを使用する場合、アプリケーションは部分的なデータ・セットに対応するように設計されている必要があります。記録システム(データベースなど)が使用されている場合、項目が失効または削除されているどうかはアプリケーションとは無関係である必要があります。
オプティミスティック・キャッシュは、レプリケート・キャッシュと同様のクラスタ化されたキャッシュの実装になりますが、並行処理制御は行われません。この実装では、レプリケート・キャッシュより、書込みのスループットが高くなります。また、MRU/MFUベースのキャッシュなどのキャッシュ・データの格納に、代替の基礎となるストアを使用できます。ただし、2つのクラスタ・メンバーが基礎となるローカル・ストアの削除やパージを個別に実行すると、それぞれのメンバーが保持している格納済の内容が異なる可能性があります。
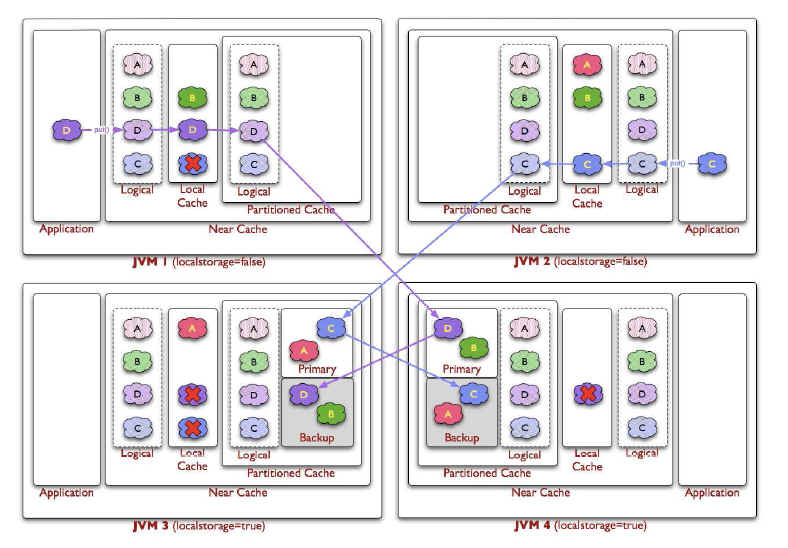
ニア・キャッシュはハイブリッドなキャッシュであり、一般に分散キャッシュまたはリモート・キャッシュとローカル・キャッシュを組み合せた役割を果たします。ニア・キャッシュでは、構成済の無効化戦略を使用してフロント・キャッシュ・エントリを無効にし、優れたパフォーマンスおよび同期化を実現します。パーティション・キャッシュによってバッキングされたニア・キャッシュでは、反復的なデータ・アクセスにおいて0ミリ秒のローカル・アクセスが可能になります。同時実行性が可能になり、整合性およびフェイルオーバーが保証されるのみでなく、レプリケート・キャッシュとパーティション・キャッシュの長所が効率的に結合されます。
ニア・キャッシュの目的は、最後に使用した(MRU: Most Recently Used)データと最も頻繁に使用する(MFU: Most Frequently Used)データの読取りアクセスの速度を上げて、レプリケーション・キャッシュの長所である最大のパフォーマンスと分散キャッシュの長所である最大のスケーラビリティの両方を最大限に実現することです。そのため、ニア・キャッシュの実装にはフロント・キャッシュとバック・キャッシュの2つのキャッシュが含まれています。これらはリードスルー/ライトスルー方式を使用することにより、互いに自動的および透過的に通信します。
フロント・キャッシュは、ローカル・キャッシュ・アクセスを提供します。高速でサイズも限られていることから、低コストといえます。バック・キャッシュは、ローカル・キャッシュが使用不能な場合に必要に応じてロードできる、集中型のキャッシュまたは複数層構成のキャッシュにすることができます。バック・キャッシュは、非常に容量が大きいという点で完璧かつ適切ですが、アクセス速度の点では割高といえます。
この設計により、ニア・キャッシュでは、最も基本的な有効期間ベースのキャッシュや無効化ベースのキャッシュから、データのバージョニングおよび整合性の保証が可能な高度なキャッシュまでの、キャッシュの整合性を様々に構成できます。その結果、ローカル・メモリー・リソースを維持するという点と、真のローカル・キャッシュのパフォーマンス上の利点を活用するという点のバランスを調整できます。
一般的なデプロイメントでは、フロント・キャッシュにローカル・キャッシュが使用されます。ローカル・キャッシュは、スレッド・セーフである、並行性が高い、サイズ制限がある、自動的に失効する、データがオブジェクト形式で保存される、などの点から妥当な選択といえます。バック・キャッシュには、パーティション・キャッシュが使用されます。
次の図は、ニア・キャッシュのデータ・フローを示しています。クライアントがオブジェクトDをグリッドに書き込むと、このオブジェクトは、ローカルJVM内のローカル・キャッシュ、およびそれをバックアップする(バックアップ・コピーを含む)パーティション・キャッシュに配置されます。クライアントがオブジェクトをリクエストすると、オブジェクトはローカル、すなわちフロント・キャッシュからオブジェクト形式で待機することなく取得されます。
|
注意: ニア・キャッシュのフロント層ではエントリがオブジェクト形式で格納されているため、同じJVM内における複数のスレッドのアクセスの同期化はアプリケーションが担当する必要があります。たとえば、あるスレッドがニア・キャッシュのフロント層から取得したエントリを変更した場合は、同じJVM内の他のスレッドもその変更をすぐに参照できる必要があります。 |
図12-7は、ニア・キャッシュのput操作の際の概念図です。
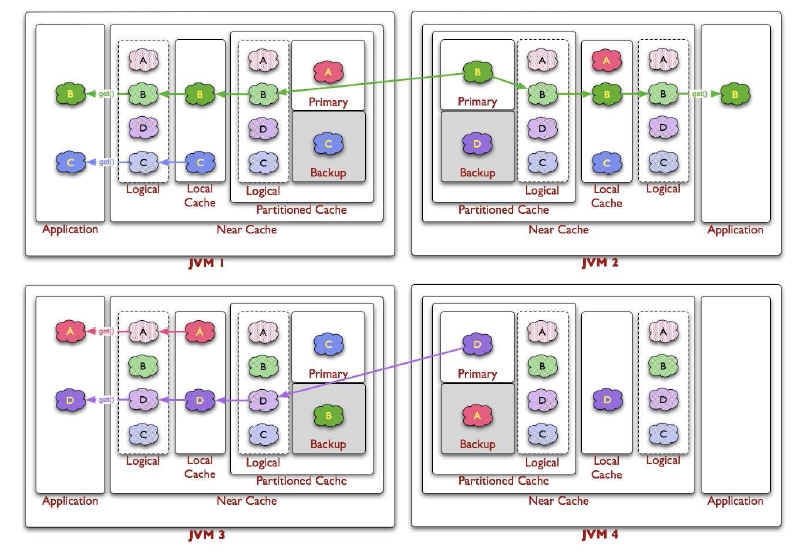
フロント・キャッシュで失効しているオブジェクトまたは無効化されているオブジェクトがクライアントからリクエストされた場合、Coherenceは自動的にパーティション・キャッシュからそのオブジェクトを取得します。フロント・キャッシュは、クライアントに配信される前にオブジェクトが保存される場所です。
図12-8は、ニア・キャッシュのget操作の際の概念図です。
クラスタ化サービスではありませんが、ローカル・キャッシュ実装は、各種クラスタ化キャッシュ・サービスと組み合せてニア・キャッシュの一部として使用されることがよくあります。
|
注意: ニア・キャッシュの一部としてローカル・キャッシュを使用するアプリケーションでは、キーが不変である必要があります。可変であるキーが原因で、スレッドがハングしたり、デッドロックが発生する可能性があります。特に、ニア・キャッシュの実装ではキー・オブジェクトを使用してローカル・キャッシュ(フロント・マップ)の同期化を行うため、キーが内部マップにキャッシュされることもあります。そのため、 |
ローカル・キャッシュは、特定のクラスタ・ノード内に完全に含まれます。ローカル・キャッシュの特に興味深い属性について、次に示します。
ローカル・キャッシュはクラスタ化キャッシュと同じ標準のコレクション・インタフェースを実装します。つまり、ローカル・キャッシュを使用することとクラスタ化キャッシュを使用することにプログラミング上の違いはありません。クラスタ化キャッシュ同様、ローカル・キャッシュではJCache APIまで追跡しています。このAPI自体は、ローカル・キャッシュがベースとする同じ標準のコレクションAPIをベースとしています。
ローカル・キャッシュのサイズは制限できます。ローカル・キャッシュでは、キャッシュするエントリ数を制限し、キャッシュが一杯になったらエントリを自動的に削除できます。さらに、エントリのサイジングとエビクション・ポリシーの両方のカスタマイズが可能です。たとえば、キャッシュされたエントリで使用されるメモリー量を基準にしてキャッシュのサイズを制限できます。デフォルトのエビクション・ポリシーでは、対数曲線で測定された、最も頻繁に使用する(MFU)情報と最後に使用した(MRU)情報の組合せを使用して削除するキャッシュ項目が決定されます。このアルゴリズムは、短期キャッシュと長期キャッシュの両方に対して十分に機能し、頻度と新しさのバランスをとってキャッシュ・スラッシングを回避するため、最適な汎用エビクション・アルゴリズムであるといえます。また、ピュアLRUアルゴリズムおよびピュアLFUアルゴリズムがサポートされ、カスタム・エビクション・ポリシーのプラグイン機能もサポートされています。
ローカル・キャッシュはキャッシュ・エントリの自動失効をサポートしています。つまり、キャッシュ内の各キャッシュ・エントリに有効時間を割り当てることができます。
ローカル・キャッシュはスレッド・セーフで並行性が高いため、数多くのスレッドがローカル・キャッシュの複数のエントリに同時にアクセスしたり、エントリを更新したりできます。
ローカル・キャッシュはキャッシュ通知をサポートしています。キャッシュ通知は、追加(クライアントによって追加されたりキャッシュへ自動的にロードされたエントリ)、変更(クライアントによって追加されたり自動的にリロードされたエントリ)、および削除(クライアントによって削除されたり、自動的に失効、フラッシュ、または削除されたエントリ)を処理するために送信されます。これらは、クラスタ化キャッシュでサポートされているキャッシュ・イベントと同じです。
ローカル・キャッシュには、キャッシュ・ヒットおよびキャッシュ・ミスの統計情報が保持されます。これらの実行時統計を使用すれば、キャッシュの有効性を正確に推定できるため、キャッシュ実行時にサイズ制限や自動失効の設定を適宜調整できます。
Coherenceのニア・キャッシュ・テクノロジの一部として機能したり、モジュールで構成されたバッキング・マップ・アーキテクチャで使用されるなど、ローカル・キャッシュはクラスタ化キャッシュ・サービスにおいて重要な役割を果たします。
リモート・キャッシュは、Coherence*Extendクライアントによりアクセスされるアウトオブプロセス・キャッシュを表します。キャッシュ・リクエストはすべてCoherenceプロキシに送られ、そこでキャッシュ(レプリケート、オプティミスティック、パーティション)に委任されます。リモート・キャッシュの使用方法の詳細は、『Oracle Coherenceリモート・クライアントの開発』を参照してください。
数値に関する用語
JVMs = JVMの数
DataSize = キャッシュ・データの合計サイズ(冗長性を除く)
Redundancy = 保持されているデータのコピー数
LocalCache = ローカル・キャッシュ・サイズ(ニア・キャッシュの場合)
表12-1 キャッシュのタイプと特性のサマリー
| レプリケート・キャッシュ | オプティミスティック・キャッシュ | パーティション・キャッシュ | ニア・キャッシュ(パーティション・キャッシュによるバッキング) | ローカル・キャッシュ(非クラスタ) | |
|---|---|---|---|---|---|
|
トポロジ |
レプリケート |
レプリケート |
パーティション・キャッシュ |
ローカル・キャッシュ+パーティション・キャッシュ |
ローカル・キャッシュ |
|
読取りパフォーマンス |
即時5 |
即時5 |
ローカル・キャッシュ: 即時5 リモート: ネットワーク速度 1 |
ローカル・キャッシュ: 即時5 リモート: ネットワーク速度 1 |
即時5 |
|
フォルト・トレランス性 |
非常に高い |
非常に高い |
構成可能 4 (0から非常に高い) |
構成可能 4 (0から非常に高い) |
0 |
|
書込みパフォーマンス |
高速 2 |
高速 2 |
非常に高速 3 |
非常に高速 3 |
即時5 |
|
メモリー使用量(JVM別) |
DataSize |
DataSize |
DataSize/JVMs x Redundancy |
LocalCache + [DataSize / JVMs] |
DataSize |
|
整合性 |
完全な整合性あり |
完全な整合性あり |
完全な整合性あり |
完全な整合性あり6 |
N/A |
|
メモリー使用量(合計) |
JVMs x DataSize |
JVMs x DataSize |
Redundancy x DataSize |
[Redundancy x DataSize] + [JVMs x LocalCache] |
N/A |
|
ロック機能 |
完全に機能 |
なし |
完全に機能 |
完全に機能 |
完全に機能 |
|
一般的な用途 |
メタデータ |
N/A(ニア・キャッシュを参照) |
読取り/書込みキャッシュ |
アクセス・アフィニティのある読取り頻度の高いキャッシュ |
ローカル・データ |
注意:
概算では、100Mbイーサネットの場合、ネットワークで100KBのオブジェクトを1つ読み取るのに最大20ミリ秒を通常必要とします。ギガビット・イーサネットでは一般に、1KBの複数オブジェクトのネットワークでの読取りが1ミリ秒未満になります。
JVMの数に応じて、UDPマルチキャスト操作、またはいくつかのUDPユニキャスト操作が必要です。
冗長性のレベルに応じて、いくつかのUDPユニキャスト操作が必要です。
パーティション・キャッシュでは、バックアップのレベルを必要な数だけ構成することも、まったく構成しないこともできます。ほとんどのインストールでは、バックアップ・コピーを1つ使用します(合計で2コピー)。
ごくわずかな処理を必要とする(一般にはミリ秒未満のパフォーマンス)、ローカルのCPUまたはメモリーのパフォーマンスによって制限されます。
リスナーベースのニア・キャッシュには整合性が確保されています。失効ベースのニア・キャッシュでは、非トランザクション読取りについては部分的な整合性が確保され、トランザクション・アクセスについては整合性が確保されています。