9 Built-In Aggregate Functions
This chapter provides a reference to built-in aggregate functions included in Oracle Continuous Query Language (Oracle CQL). Built-in aggregate functions perform a summary operation on all the values that a query returns.
For more information, see .
This chapter includes the following section:
9.1 Introduction to Oracle CQL Built-In Aggregate Functions
Table 9-1 lists the built-in aggregate functions that Oracle CQL provides:
Table 9-1 Oracle CQL Built-in Aggregate Functions
| Type | Function |
|---|---|
|
Aggregate |
|
|
Aggregate (incremental computation) |
|
|
Extended aggregate |
Specify distinct if you want Oracle Event Processing to return only one copy of each set of duplicate tuples selected. Duplicate tuples are those with matching values for each expression in the select list. For more information, see .
Oracle Event Processing does not support nested aggregations.
Note:
Built-in function names are case sensitive and you must use them in the case shown (in lower case).Note:
In stream input examples, lines beginning withh (such as h 3800) are heartbeat input tuples. These inform Oracle Event Processing that no further input will have a timestamp lesser than the heartbeat value.For more information, see:
9.1.1 Built-In Aggregate Functions and the Where, Group By, and Having Clauses
In Oracle CQL, the where clause is applied before the group by and having clauses. This means the Oracle CQL statement is invalid:
<query id="q1"><![CDATA[ select * from InputChanel[rows 4 slide 4] as ic where count(*) = 4 ]]></query>
Instead, you must use the Oracle CQL statement:
<query id="q1"><![CDATA[ select * from InputChanel[rows 4 slide 4] as ic, count(*) as myCount having myCount = 4 ]]></query>
avg
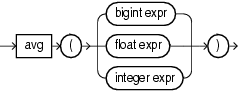
avg returns average value of expr.
This function takes as an argument any bigint, float, or int data type. The function returns a float regardless of the numeric data type of the argument.
Consider the query float_avg and the data stream S3. Stream S3 has schema (c1 float). The query returns the relation. Note that the avg function returns a result of NaN if the average value is not a number. For more information, see .
<query id="float_avg"><![CDATA[ select avg(c1) from S3[range 5] ]]></query>
Timestamp Tuple 1000 2000 5.5 8000 4.4 9000 15000 44.2 h 200000000
Timestamp Tuple Kind Tuple 1000: - 1000: + 0.0 2000: - 0.0 2000: + 5.5 6000: - 5.5 6000: + 5.5 7000: - 5.5 7000: + 8000: - 8000: + 4.4 9000: - 4.4 9000: + 4.4 13000: - 4.4 13000: + NaN 14000: - NaN 14000: + 15000: - 15000: + 44.2 20000: - 44.2 20000: +
count
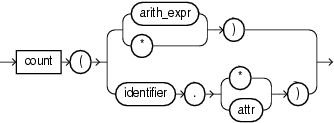
count returns the number of tuples returned by the query as an int value.
The return value depends on the argument as Table 9-2 shows.
Table 9-2 Return Values for COUNT Aggregate Function
| Input Argument | Return Value |
|---|---|
|
|
The number of tuples where |
|
|
The number of all tuples, including duplicates and nulls. |
|
|
The number of all tuples that match the correlation variable |
|
|
The number of tuples that match correlation variable |
count never returns null.
Consider the query q2 and the data stream S2. Stream S2 has schema (c1 integer, c2 integer). The query returns the relation.
<query id="q2"><![CDATA[ SELECT COUNT(c2), COUNT(*) FROM S [RANGE 10] ]]></query>
Timestamp Tuple 1000 1,2 2000 1, 3000 1,4 6000 1,6
Timestamp Tuple Kind Tuple -9223372036854775808: + 0,0 1000: - 0,0 1000: + 1,1 2000: - 1,1 2000: + 1,2 3000: - 1,2 3000: + 2,3 6000: - 2,3
For more information, see:
first
first returns the value of the specified stream element the first time the specified pattern is matched.
The type of the specified stream element may be any of:
-
bigint -
integer -
byte -
char -
float -
interval -
timestamp
The return type of this function depends on the type of the specified stream element.
This function takes a single argument made up of the following period-separated values:
-
identifier1: the name of a pattern as specified in aDEFINEclause. -
identifier2: the name of a stream element as specified in aCREATE STREAMstatement.
See Also:
Consider the query q9 and the data stream S0. Stream S0 has schema (c1 integer, c2 float). This example defines pattern C as C.c1 = 7. It defines firstc as first(C.c2). In other words, firstc will equal the value of c2 the first time c1 = 7. The query returns the relation.
<query id="q9"><![CDATA[ select T.firstc, T.lastc, T.Ac1, T.Bc1, T.avgCc1, T.Dc1 from S0 MATCH_RECOGNIZE ( MEASURES first(C.c2) as firstc, last(C.c2) as lastc, avg(C.c1) as avgCc1, A.c1 as Ac1, B.c1 as Bc1, D.c1 as Dc1 PATTERN(A B C* D) DEFINE A as A.c1 = 30, B as B.c2 = 10.0, C as C.c1 = 7, D as D.c1 = 40 ) as T ]]></query>
Timestamp Tuple 1000 33,0.9 3000 44,0.4 4000 30,0.3 5000 10,10.0 6000 7,0.9 7000 7,2.3 9000 7,8.7 11000 40,6.6 15000 19,8.8 17000 30,5.5 20000 5,10.0 23000 40,6.6 25000 3,5.5 30000 30,2.2 35000 2,10.0 40000 7,5.5 44000 40,8.9
Timestamp Tuple Kind Tuple 11000: + 0.9,8.7,30,10,7.0,40 23000: + ,,30,5,,40 44000: + 5.5,5.5,30,2,7.0,40
last
last returns the value of the specified stream element the last time the specified pattern is matched.
The type of the specified stream element may be any of:
-
bigint -
integer -
byte -
char -
float -
interval -
timestamp
The return type of this function depends on the type of the specified stream element.
This function takes a single argument made up of the following period-separated values:
-
identifier1: the name of a pattern as specified in aDEFINEclause. -
identifier2: the name of a stream element as specified in aCREATE STREAMstatement.
See Also:
Consider the query q9 and the data stream S0. Stream S1 has schema (c1 integer, c2 float). This example defines pattern C as C.c1 = 7. It defines lastc as last(C.c2). In other words, lastc will equal the value of c2 the last time c1 = 7. The query returns the relation.
<query id="q9"><![CDATA[ select T.firstc, T.lastc, T.Ac1, T.Bc1, T.avgCc1, T.Dc1 from S0 MATCH_RECOGNIZE ( MEASURES first(C.c2) as firstc, last(C.c2) as lastc, avg(C.c1) as avgCc1, A.c1 as Ac1, B.c1 as Bc1, D.c1 as Dc1 PATTERN(A B C* D) DEFINE A as A.c1 = 30, B as B.c2 = 10.0, C as C.c1 = 7, D as D.c1 = 40 ) as T ]]></query>
Timestamp Tuple 1000 33,0.9 3000 44,0.4 4000 30,0.3 5000 10,10.0 6000 7,0.9 7000 7,2.3 9000 7,8.7 11000 40,6.6 15000 19,8.8 17000 30,5.5 20000 5,10.0 23000 40,6.6 25000 3,5.5 30000 30,2.2 35000 2,10.0 40000 7,5.5 44000 40,8.9
Timestamp Tuple Kind Tuple 11000: + 0.9,8.7,30,10,7.0,40 23000: + ,,30,5,,40 44000: + 5.5,5.5,30,2,7.0,40
listagg
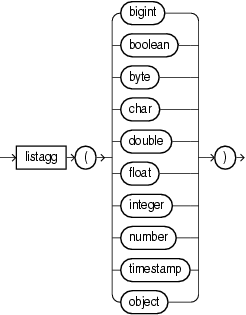
listagg returns a java.util.List containing the Java equivalent of the function's argument.
Note that when a user-defined class is used as the function argument, the class must implement the equals method.
<view id="v1"><![CDATA[ ISTREAM(select c1, listAgg(c3) as l1, java.util.LinkedHashSet(listAgg(c3)) as set1 from S1 group by c1) ]]></view> <query id="q1"><![CDATA[ select v1.l1.size(), v1.set1.size() from v1 ]]></query>
Timestamp Tuple 1000 rcl, 1, 15, 400 1000 msft, 1, 15, 400 2000 orcl, 2, 20, 300 2000 msft, 2, 20, 300 5000 orcl, 4, 5, 200 5000 msft, 4, 5, 200 7000 orcl, 3, 10, 100 7000 msft, 3, 20, 100 h 20000000
Timestamp Tuple Kind Tuple 1000: + 1,1 1000: + 1,1 2000: + 2,2 2000: + 2,2 5000: + 3,3 5000: + 3,3 7000: + 4,4 7000: + 4,3
max
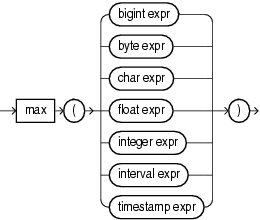
Consider the query test_max_timestampand the data stream S15 . Stream S15 has schema (c1 int, c2 timestamp). The query returns the relation.
<query id="test_max_timestamp"><![CDATA[ select max(c2) from S15[range 2] ]]></query>
Timestamp Tuple 10 1,"08/07/2004 11:13:48" 2000 ,"08/07/2005 11:13:48" 3400 3,"08/07/2006 11:13:48" 4700 ,"08/07/2007 11:13:48" h 8000 h 200000000
Timestamp Tuple Kind Tuple 0: + 10: - 10: + 08/07/2004 11:13:48 2000: - 08/07/2004 11:13:48 2000: + 08/07/2005 11:13:48 2010: - 08/07/2005 11:13:48 2010: + 08/07/2005 11:13:48 3400: - 08/07/2005 11:13:48 3400: + 08/07/2006 11:13:48 4000: - 08/07/2006 11:13:48 4000: + 08/07/2006 11:13:48 4700: - 08/07/2006 11:13:48 4700: + 08/07/2007 11:13:48 5400: - 08/07/2007 11:13:48 5400: + 08/07/2007 11:13:48 6700: - 08/07/2007 11:13:48 6700: +
min
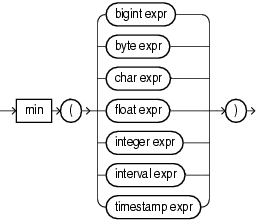
Consider the query test_min_timestamp and the data stream S15. Stream S15 has schema (c1 int, c2 timestamp). The query returns the relation.
<query id="test_min_timestamp"><![CDATA[ select min(c2) from S15[range 2] ]]></query>
Timestamp Tuple 10 1,"08/07/2004 11:13:48" 2000 ,"08/07/2005 11:13:48" 3400 3,"08/07/2006 11:13:48" 4700 ,"08/07/2007 11:13:48" h 8000 h 200000000
Timestamp Tuple Kind Tuple 0: + 10: - 10: + 08/07/2004 11:13:48 2000: - 08/07/2004 11:13:48 2000: + 08/07/2004 11:13:48 2010: - 08/07/2004 11:13:48 2010: + 08/07/2005 11:13:48 3400: - 08/07/2005 11:13:48 3400: + 08/07/2005 11:13:48 4000: - 08/07/2005 11:13:48 4000: + 08/07/2006 11:13:48 4700: - 08/07/2006 11:13:48 4700: + 08/07/2006 11:13:48 5400: - 08/07/2006 11:13:48 5400: + 08/07/2007 11:13:48 6700: - 08/07/2007 11:13:48 6700: +
sum
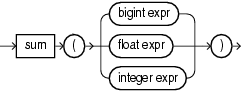
sum returns the sum of values of expr. This function takes as an argument any bigint, float, or integer expression. The function returns the same data type as the numeric data type of the argument.
Consider the query q3 and the data stream S1. Stream S1 has schema (c1 integer, c2 bigint). The query returns the relation. For more information on range, see .
<query id="q3"><![CDATA[ select sum(c2) from S1[range 5] ]]></query>
Timestamp Tuple 1000 5, 1000 10,5 2000 ,4 3000 30,6 5000 45,44 7000 55,3 h 200000000
Timestamp Tuple Kind Tuple 1000: - 1000: + 5 2000: - 5 2000: + 9 3000: - 9 3000: + 15 5000: - 15 5000: + 59 6000: - 59 6000: + 54 7000: - 54 7000: + 53 8000: - 53 8000: + 47 10000: - 47 10000: + 3 12000: - 3 12000: +
xmlagg
xmlagg returns a collection of XML fragments as an aggregated XML document. Arguments that return null are dropped from the result.
You can control the order of fragments using an ORDER BY clause.
This section describes the following xmlagg examples:
xmlagg Function and the xmlelement Function
Consider the query tkdata67_q1 and the input relation. Stream tkdata67_S0 has schema (c1 integer, c2 float). This query uses xmlelement to create XML fragments from stream elements and then uses xmlagg to aggregate these XML fragments into an XML document. The query returns the relation.
<query id="tkdata67_q1"><![CDATA[ select c1, xmlagg(xmlelement("c2",c2)) from tkdata67_S0[rows 10] group by c1 ]]></query>
Timestamp Tuple 1000 15, 0.1 1000 20, 0.14 1000 15, 0.2 4000 20, 0.3 10000 15, 0.04 h 12000
Timestamp Tuple Kind Tuple 1000: + 15,<c2>0.1</c2> <c2>0.2</c2> 1000: + 20,<c2>0.14</c2> 4000: - 20,<c2>0.14</c2> 4000: + 20,<c2>0.14</c2> <c2>0.3</c2> 10000: - 15,<c2>0.1</c2> <c2>0.2</c2> 10000: + 15,<c2>0.1</c2> <c2>0.2</c2> <c2>0.04</c2>
xmlagg Function and the ORDER BY Clause
Consider the query tkxmlAgg_q5 and the input relation. Stream tkxmlAgg_S1 has schema (c1 int, c2 xmltype). These query selects xmltype stream elements and uses XMLAGG to aggregate them into an XML document. This query uses an ORDER BY clause to order XML fragments. The query returns the relation.
<query id="tkxmlAgg_q5"><![CDATA[ select xmlagg(c2), xmlagg(c2 order by c1) from tkxmlAgg_S1[range 2] ]]></query>
Timestamp Tuple 1000 1, "<a>hello</a>" 2000 10, "<b>hello1</b>" 3000 15, "<PDRecord><PDName>hello</PDName></PDRecord>" 4000 5, "<PDRecord><PDName>hello</PDName><PDName>hello1</PDName></PDRecord>" 5000 51, "<PDRecord><PDId>6</PDId><PDName>hello1</PDName></PDRecord>" 6000 15, "<PDRecord><PDId>46</PDId><PDName>hello2</PDName></PDRecord>" 7000 55, "<PDRecord><PDId>6</PDId><PDName>hello2</PDName><PDName>hello3</PDName></PDRecord>"
Timestamp Tuple Kind Tuple 0: + 1000: - 1000: + <a>hello</a> ,<a>hello</a> 2000: - <a>hello</a> ,<a>hello</a> 2000: + <a>hello</a> <b>hello1</b> ,<a>hello</a> <b>hello1</b> 3000: - <a>hello</a> <b>hello1</b> ,<a>hello</a> <b>hello1</b> 3000: + <b>hello1</b> <PDRecord> <PDName>hello</PDName> </PDRecord> ,<b>hello1</b> <PDRecord> <PDName>hello</PDName> </PDRecord> 4000: - <b>hello1</b> <PDRecord> <PDName>hello</PDName> </PDRecord> ,<b>hello1</b> <PDRecord> <PDName>hello</PDName> </PDRecord> 4000: + <PDRecord> <PDName>hello</PDName> </PDRecord> <PDRecord> <PDName>hello</PDName> <PDName>hello1</PDName> </PDRecord> ,<PDRecord> <PDName>hello</PDName> <PDName>hello1</PDName> </PDRecord> <PDRecord> <PDName>hello</PDName> </PDRecord> 5000: - <PDRecord> <PDName>hello</PDName> </PDRecord> <PDRecord> <PDName>hello</PDName> <PDName>hello1</PDName> </PDRecord> ,<PDRecord> <PDName>hello</PDName> <PDName>hello1</PDName> </PDRecord> <PDRecord> <PDName>hello</PDName> </PDRecord> 5000: + <PDRecord> <PDName>hello</PDName> <PDName>hello1</PDName> </PDRecord> <PDRecord> <PDId>6</PDId> <PDName>hello1</PDName> </PDRecord> ,<PDRecord> <PDName>hello</PDName> <PDName>hello1</PDName> </PDRecord> <PDRecord> <PDId>6</PDId> <PDName>hello1</PDName> </PDRecord> 6000: - <PDRecord> <PDName>hello</PDName> <PDName>hello1</PDName> </PDRecord> <PDRecord> <PDId>6</PDId> <PDName>hello1</PDName> </PDRecord> ,<PDRecord> <PDName>hello</PDName> <PDName>hello1</PDName> </PDRecord> <PDRecord> <PDId>6</PDId> <PDName>hello1</PDName> </PDRecord> 6000: + <PDRecord> <PDId>6</PDId> <PDName>hello1</PDName> </PDRecord> <PDRecord> <PDId>46</PDId> <PDName>hello2</PDName> </PDRecord> ,<PDRecord> <PDId>46</PDId> <PDName>hello2</PDName> </PDRecord> <PDRecord> <PDId>6</PDId> <PDName>hello1</PDName> </PDRecord> 7000: - <PDRecord> <PDId>6</PDId> <PDName>hello1</PDName> </PDRecord> <PDRecord> <PDId>46</PDId> <PDName>hello2</PDName> </PDRecord> ,<PDRecord> <PDId>46</PDId> <PDName>hello2</PDName> </PDRecord> <PDRecord> <PDId>6</PDId> <PDName>hello1</PDName> </PDRecord>