| Oracle® Databaseオブジェクト・リレーショナル開発者ガイド 12cリリース1 (12.1) B72963-02 |
|


 前 |
 次 |
この章では、Oracleのオブジェクト・リレーショナル・モデルの実装およびパフォーマンス特性について説明します。ここで説明する内容は、論理データ・モデルをOracleの物理的な実装にマップしたり、オブジェクト指向機能を使用するアプリケーションを開発する場合に役立ちます。
内容は次のとおりです。
この項では、様々なオブジェクト型の記憶域に関する一般的な考慮点を説明します。
この項の内容は次のとおりです。
オブジェクトは、列オブジェクトとしてリレーショナル表に格納するか、または行オブジェクトとしてオブジェクト表に格納できます。包含しているリレーショナル・データベースの外で意味を持つオブジェクトは、オブジェクト表内で行オブジェクトとして参照できるようにする必要があります。そうしない場合、それらのオブジェクトはリレーショナル表に列オブジェクトとして格納する必要があります。
表記憶域の概要は、「オブジェクトを表に格納する方法」を参照してください。
この項の内容は次のとおりです。
列オブジェクトの記憶域は、1つの集合としてオブジェクトを形成する、同等のスカラー列集合の記憶域と似ています。違いは、非コレクション列オブジェクトのアトミックNULL値およびその埋込みオブジェクト属性をメンテナンスするオーバーヘッドが加わることです。これらの値はNULLインジケータと呼ばれ(NULLイメージと呼ばれることもあります)、それぞれの列オブジェクトがNULLかどうか、およびその埋込みオブジェクト属性それぞれがNULLかどうかを指定します。
NULLインジケータは、列オブジェクトのスカラー属性がNULLかどうかは指定しませんので注意してください。Oracleでは、別の方法でスカラー属性がNULLかどうかを判断します。
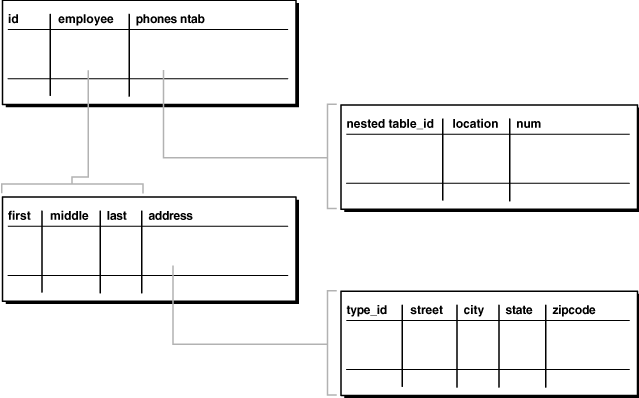
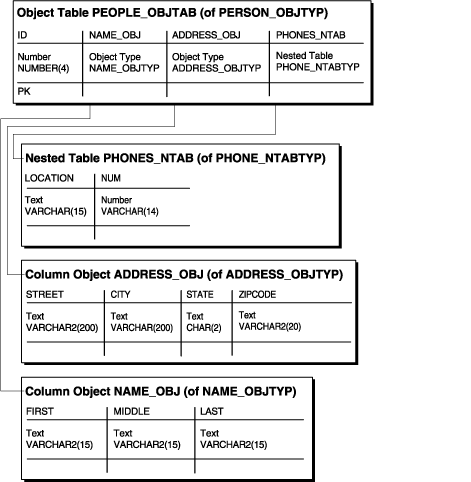
ある組織の構成員の識別番号、名前、住所および電話番号を持つ表を考えてみます。名前、住所および電話番号を保持するための3種類のオブジェクト型と、名前オブジェクトと住所オブジェクトが含まれるオブジェクトemployee_objtypを作成できます。各人が複数の電話番号を持つ場合があるため、電話番号オブジェクト型に基づいてネストした表型を作成する必要があります。
まず、例9-1のSQL文を入力して、電話番号オブジェクトに対して4つのオブジェクト型と1つの表を作成します。
例9-1 リレーショナル表の列のオブジェクト型の作成
CREATE TYPE name_objtyp AS OBJECT ( first VARCHAR2(15), middle VARCHAR2(15), last VARCHAR2(15)); / CREATE TYPE address_objtyp AS OBJECT ( street VARCHAR2(200), city VARCHAR2(200), state VARCHAR2(2), zipcode VARCHAR2(20)); NOT FINAL; / CREATE TYPE phone_objtyp AS OBJECT ( location VARCHAR2(15), num VARCHAR2(14)); / CREATE TYPE employee_objtyp AS OBJECT ( name name_objtyp; address address_objtyp; / CREATE TYPE phone_ntabtyp AS TABLE OF phone_objtyp; /
次に、例9-2のSQL文を使用して、組織の構成員の情報を保持する表を作成します。この文により、組織の構成員のIDも作成されます。
例9-2 列オブジェクトを含む表の作成
CREATE TABLE people_reltab ( id NUMBER(4) CONSTRAINT pk_people_reltab PRIMARY KEY, employee employee_objtyp phones_ntab phone_ntabtyp) NESTED TABLE phones_ntab STORE AS phone_store_ntab;
people_reltab表には、employeeおよびphones_ntabの2つの列オブジェクトがあります。phones_ntab列オブジェクトは、ネストした表(列オブジェクトのコレクション型)です。
people_reltab表の各オブジェクトの記憶域は、オブジェクトの属性の記憶域にNULLインジケータのオーバーヘッドを加えたものです。
オブジェクトおよびその埋込みオブジェクト属性のNULLインジケータは、それぞれ1ビットずつ占有します。したがって、(すべてのネスト・レベルのオブジェクトを含めて)n個の埋込みオブジェクト属性を持つオブジェクトには、記憶域のオーバーヘッドがCEIL(n/8)バイトあります。非コレクション列オブジェクト(name_objおよびaddress_obj)にはそれぞれNULLインジケータ列が1つずつあります。1ビットがオブジェクトそのものを表し、それがCEIL(1/8)または1と解釈されるため、NULLインジケータ列の長さは1バイトです。
NULLインジケータのサイズが1バイトなので、people_reltab表の各行のNULL情報のオーバーヘッドは2バイト(オブジェクト列ごとに1バイトずつ)になります。
非コレクション・オブジェクトはいずれも、FINALであるかどうかにかかわらず、NULLインジケータ列を持ちます。これらの例では、列はFINALです。
|
関連項目: CEILの詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
行オブジェクトは、オブジェクト表に格納されます。オブジェクト表は、オブジェクトを格納し、このオブジェクト属性に対してリレーショナル表と同様にアクセスできるリレーショナル・ビューを提供する特殊な表です。オブジェクト表は、オブジェクト表に格納された、オブジェクトの最上位の属性に対応するデータ型の列を持つリレーショナル表と、論理的、物理的に類似しています。主な違いは、オブジェクト表には、追加のオブジェクト識別子(OID)の列および索引をオプションで含めることができることです。
この項では、オブジェクト表の行オブジェクトの2種類のオブジェクト識別子を示し、それらがどのように格納および参照されるかを説明します。
オブジェクト識別子(OID)を利用することで、対応する行オブジェクトを、他のオブジェクトまたはリレーショナル表間で参照できます。このような参照は、REFと呼ばれる組込みデータ型によって表されます。REFは、オブジェクト識別子(OID)を使用して行オブジェクトを指します。
システムによって生成されるOIDまたは主キー・ベースのOIDのどちらかを使用できます。
システム生成のOIDは、オブジェクト表の行オブジェクトのデフォルトです。
システム生成の一意のOID (16バイト長)が、各行オブジェクトに割り当てられ、このOIDは、効率的なOIDベースの検索ができるように自動的に索引付けされます。OID列は、16バイトの主キー列を別に持つのと同じ効果があります。分散環境では、システム生成の一意の識別子によって、オブジェクトが明確に識別されます。
オブジェクト識別子列は、Oracleが行オブジェクトの参照を構成するために使用する非表示の列です。Oracleでは、オブジェクト識別子の内部構造へのアクセスは提供されていません。この構造は随時変更される可能性があります。アプリケーションが関連するのは、オブジェクトのフェッチおよびナビゲートにオブジェクト参照を使用する場合のみです。
Oracleでは、主キー列が存在する場合、行オブジェクトの主キー値をそのオブジェクト識別子として指定するというオプションを使用できます。
システム生成のOIDを使用せず、CREATE TABLE文をこの句(OBJECT IDENTIFIER IS PRIMARY KEY)とともに使用します。これにより、システムで主キー列を表のオブジェクトのOIDとして使用することを指定します。この方法で、既存の列をオブジェクトのOIDとして使用することも、Oracleによって生成されたグローバルに一意な16バイトのOIDよりも小さい、アプリケーションによって生成されたOIDを使用することもできます。
|
関連項目: OBJECT IDENTIFER構文の詳細は、 『Oracle Database SQL言語リファレンス』を参照してください。 |
リレーショナル表の外部キーと同様の方法で、これらの行オブジェクトの参照を格納する列に対して、参照整合性を確保できます。
|
注意: 主キー・ベースの各OIDは、ローカルに一意です(グローバルに一意である必要はありません)。グローバルに一意の識別子が必要な場合は、主キーがグローバルに一意であることを保証するか、またはシステムによって生成されるOIDを使用する必要があります。 |
主キー・ベースの識別子を利用することで、オブジェクト表へのデータのロードを高速かつ容易に行うことができます。それに対して、システム生成のオブジェクト識別子は、それらの参照も格納される場合は特に、ユーザーが指定したキーを使用して再度マップする必要があります。オブジェクト表に対して、システムが生成するOIDを使用する場合、OracleがこれらのOIDを格納する列の索引をメンテナンスします。システム生成のOIDには、この索引用の追加の記憶域と、行オブジェクト1つにつき16バイトの追加の記憶域が必要です。
ただし、各主キーのサイズが16バイトを超え、数多くのREFがある場合は、各REFのサイズは主キーと同じであるため、主キー・ベースのOIDを使用すると、システムによって生成されるOIDより多くの領域が必要になる場合があります。
オブジェクトを比較するには、マップ・メソッドまたはオーダー・メソッドを起動します。マップ・メソッドは、オブジェクトの順序付けを行う際にオブジェクトをスカラー値に変換します。マップ・メソッドを使用するとオブジェクトの順序付けが効率的に行われるため、マップ・メソッドの使用をお薦めします。
|
注意: どのオブジェクト型でも、マップ・メソッドまたはオーダー・メソッドのどちらか一方を実装できますが、両方は実装できません。どちらも必須ではありません。 |
ORDER BYまたはGROUP BYプロセスを使用してオブジェクトをソートするとき、オブジェクトのマップ方法がパフォーマンスに大きく影響します。オブジェクトを他のオブジェクトに何度も比較する必要がある場合があり、オブジェクトを最初にスカラー値にマップできると(マップ・メソッド)、効率が大幅に向上します。比較セマンティクスが非常に複雑な場合、またはオブジェクトを比較用のスカラー値にマップできない場合、指定された2つのオブジェクトに対して、オブジェクト作成者によって決定された順序を戻すオーダー・メソッドを定義できます。オーダー・メソッドは、マップ・メソッドほど効率的でないため、オーダー・メソッドを使用するとパフォーマンスが低下する場合があります。
4つの文字属性、street、city、stateおよびzipcodeで構成されるオブジェクト型addressについて考えてみます。この場合は、各オブジェクトは簡単にスカラー値に変換できるため、最も効率的な比較メソッドはマップ・メソッドです。たとえば、州によってすべてのオブジェクトを順序付けるマップ・メソッドを定義できます。
一方、イメージなどのバイナリ・オブジェクトを比較する場合を考えてみます。この場合、比較セマンティクスが複雑すぎてマップ・メソッドは使用できない可能性があります。その場合は、オーダー・メソッドを使用して比較を実行できます。たとえば、各イメージの明度またはピクセル数によってイメージを比較するオーダー・メソッドを作成できます。
マップ・メソッドもオーダー・メソッドもないオブジェクト型のオブジェクトに対しては、等価比較のみが可能です。この場合、Oracleでは、対応するオブジェクト属性のフィールド同士が定義順に比較されます。いずれかのフィールドの比較結果が不一致となると、その時点で、FALSE値が戻されます。すべてのフィールドの比較において一致が確認されると、TRUE値が戻されます。ただし、オブジェクトがLOB属性またはANYDATA属性を持つ場合、フィールド・ベースのオブジェクトの比較は行われません。このようなオブジェクトの比較を実行するためにはマップ・メソッドまたはオーダー・メソッドが必要です。
この項では、REFを使用した作業での考慮点を説明します。
REFには、次の3つの論理コンポーネントが含まれています。
参照されるオブジェクトのOID。システムによって生成されるOIDの長さは16バイトです。主キー・ベースのOIDのサイズは、主キー列のサイズによって決まります。
参照されるオブジェクトが含まれている表またはビューのOID。この長さは16バイトです。
ROWIDヒント。この長さは10バイトです。
REF列に対する参照整合性制約によって、そのREFに対応する行オブジェクトが存在することが保証されます。REFに対する参照整合性制約によって、リレーショナル・データに対して主キー/外部キー関連を指定した場合と同じ関連が生成されます。参照整合性制約は、REFに対応する行オブジェクトが存在することを保証する唯一の方法であるため、通常はできるだけ参照整合性制約を使用してください。ただし、ネストした表にあるREFに対しては、参照整合性制約を指定できません。
有効範囲付きREFには、指定したオブジェクト表の参照のみを含む、という制約があります。有効範囲付きREFは、REFとなる列型、コレクション要素、またはオブジェクト型属性を宣言するときに指定できます。
有効範囲付きREFの方が格納する際に効率的なため、通常は、有効範囲なしのREFではなく、有効範囲付きREFを使用してください。有効範囲なしのREFを格納するには、36バイト以上(ROWIDを使用する場合はさらに多く)必要ですが、有効範囲付きREFの格納には、ターゲット・オブジェクトのOIDと同じだけの領域のみを必要とするため、参照されるOIDがシステムによって生成されたOIDか、主キー・ベースのOIDかによって、16バイト未満で格納できる場合もあります。システムによって生成されたOIDの場合は、16バイト必要です。主キー・ベース(PKベース)のOIDの場合は、主キー値を格納できるだけの領域が必要ですが、これは16バイト未満の場合もあります。ただし、PKベースのOIDに対するREFは、選択時に動的な構成が必要なので、システムによって生成されたOIDに対するREFの場合と比較して、多くのメモリー領域が必要となる場合があります。
有効範囲付きREFは記憶域が少なくてすむうえに、オプティマイザによって、有効範囲付きREFを参照解除する問合せを最適化して、さらに効率的な結合にすることができます。有効範囲なしのREFに対しては、問合せの最適化時に、有効範囲なしのREFをどの表に含めるべきか、オプティマイザによる判断が不可能なため、この最適化はできません。
参照整合性制約とは異なり、有効範囲付きREFによっては、参照される行オブジェクトの存在は保証されません。保証されるのは、参照されるオブジェクト表の存在のみです。したがって、行オブジェクトに対して有効範囲付きREFを指定した後でその行オブジェクトを削除すると、参照対象となるオブジェクトがなくなるため、その有効範囲付きREFは、参照先がないREFになります。
|
注意: 参照整合性制約には、暗黙的に有効範囲が付きます。 |
アプリケーション設計上、参照されるオブジェクトが複数の表に分散している場合は、有効範囲なしのREFが便利です。ROWIDヒントは有効範囲付きREFに対しては無視されるため、「WITH ROWIDオプションを使用したオブジェクト・アクセスの高速化」で説明するとおり、ROWIDヒントによるパフォーマンスの向上の方が、有効範囲付きREFを使用した場合の記憶域の節約および問合せの最適化よりも重要である場合は、有効範囲なしのREFを使用してください。
CREATE INDEXコマンドを使用して、有効範囲付きREF列に対する索引を作成できます。作成した索引を使用して、有効範囲付きREFを参照解除する問合せを効率的に評価できます。このような問合せは暗黙的に結合に変換されます。Oracleでは、ある種の問合せに対しては、有効範囲付きREF列の索引を使用して結合を効率的に評価できます。
たとえば、オブジェクト型address_objtypを使用してaddress_objtabという名前のオブジェクト表を作成するとします。
CREATE TABLE address_objtab OF address_objtyp ;
住所に対してREFが使用されること以外は、例9-2に示したpeople_reltab表と同じ定義を持つpeople_reltab2表を作成できます。次に、address_ref列に対して索引を作成できます。
例9-3 有効範囲付きREF列に対する索引の作成
CREATE TABLE people_reltab2 ( id NUMBER(4) CONSTRAINT pk_people_reltab2 PRIMARY KEY, name_obj name_objtyp, address_ref REF address_objtyp SCOPE IS address_objtab, phones_ntab phone_ntabtyp) NESTED TABLE phones_ntab STORE AS phone_store_ntab2 ; CREATE INDEX address_ref_idx ON people_reltab2 (address_ref) ;
次の問合せでaddress_refが参照解除されます。
SELECT id FROM people_reltab2 p WHERE p.address_ref.state = 'CA' ;
この問合せの実行時には、効率的に評価を行うためにaddress_ref_idx索引が使用されます。ここで、address_refは、address_objtabオブジェクト表に格納される住所の参照を格納した有効範囲付きREF列です。前述の問合せは、結合を持つ問合せに暗黙的に変換されます。
SELECT p.id FROM people_reltab2 p, address_objtab a WHERE p.address_ref = REF(a) AND a.state = 'CA' ;
Oracle問合せオプティマイザによって、address_objtabを外部表としてネステッド・ループ結合を実行し、有効範囲付きREF列address_refの索引を使用して、一致する住所を検索する計画が作成される場合があります。
REF列に対してWITH ROWIDオプションが指定されていると、REFで参照されるオブジェクトのROWIDがメンテナンスされます。こうしておくと、REFに含まれているROWIDを直接使用して参照されるオブジェクトの検索が実行できるため、OID索引からROWIDをフェッチする手間が省けます。したがって、ROWIDヒントを指定するには、WITH ROWIDオプションを使用してください。ROWIDを含めることによって、REFの記憶域要件が10バイト増加するため、これをメンテナンスするにはそれだけ多くの記憶域が必要です。
OID索引検索を迂回すると、アプリケーションでのREFを使用した操作(ナビゲーショナル・アクセス)のパフォーマンスが向上します。実際のパフォーマンス向上率は、次の要因によって、アプリケーションごとに異なります。
OID索引の大きさ
OID索引がバッファ・キャッシュにキャッシュされているかどうか
アプリケーションが実行するREFを使用した操作数
WITH ROWIDオプションを使用する場合、REF内のOIDで行オブジェクトのOIDがチェックされるため、このオプションは単なるヒントとなります。2つのOIDが一致しない場合は、OID索引がかわりに使用されます。ROWIDヒントは、有効範囲付きREF、参照整合性制約付きREFおよび主キー・ベースのREFに対しては利用できません。
この項では、コレクションを使用した作業での考慮点を説明します。
コレクションに対してネストを解除する問合せを実行することで、データをフラットな(リレーショナルな)形式で表示できます。ネストを解除する問合せは、ネストした表およびVARRAYのいずれについても、シングルレベル・コレクションおよびマルチレベル・コレクションで実行できます。この項では、ネストを解除する問合せの例を示します。
ネストした表は、次の例のように、TABLE構文を使用して問合せに対してネストを解除できます。
例9-4 TABLEファンクションによるネストした表のネスト解除
SELECT p.name_obj, n.num FROM people_reltab p, TABLE(p.phones_ntab) n ;
ここで、phones_ntabは、ネストした表phones_ntabの属性を指定します。子である行(この例では電話番号)を持たない親である行も確実に取り出されるようにするには、+を使用して外部結合構文を使用します。次に例を示します。
SELECT p.name_obj, n.num FROM people_reltab p, TABLE(p.phones_ntab) (+) n ;
問合せのSELECT構文のリストが、親表のネストした表の列以外の列を参照しない場合は、ネストした表の記憶表に対してのみ実行されるように、問合せの最適化が実行されます。
ネストを解除する問合せの構文は、VARRAYおよびネストした表のどちらの場合も同じです。たとえば、ネストした表phones_ntabではなく、phones_varという名前のVARRAYの場合を考えてみます。次の例は、TABLE構文を使用してVARRAYを問い合せます。
SELECT p.name_obj, v.num FROM people_reltab p, TABLE(p.phones_var) v;
ネストを解除する問合せを実行するためのプロシージャおよびファンクションを作成できます。たとえば、locationがhomeである電話番号のみを戻す、home_phones()というファンクションを作成できます。home_phones()ファンクションを作成するには、次の例のようなコードを入力します。
例9-5 home_phonesファンクションの作成
CREATE OR REPLACE FUNCTION home_phones(allphones IN phone_ntabtyp)
RETURN phone_ntabtyp IS
homephones phone_ntabtyp := phone_ntabtyp();
indx1 number;
indx2 number := 0;
BEGIN
FOR indx1 IN 1..allphones.count LOOP
IF
allphones(indx1).location = 'home'
THEN
homephones.extend; -- extend the local collection
indx2 := indx2 + 1;
homephones(indx2) := allphones(indx1);
END IF;
END LOOP;
RETURN homephones;
END;
/
ここで、人のリストおよびその自宅の電話番号を問い合せるには、次のように入力します。
例9-6 TABLEファンクションを使用した問合せのネスト解除
SELECT p.name_obj, n.num
FROM people_reltab p, TABLE(
CAST(home_phones(p.phones_ntab) AS phone_ntabtyp)) n ;
自宅の電話番号がリストされていない人も含めて、人のリストおよびその自宅の電話番号を問い合せるには、次のように入力します。
SELECT p.name_obj, n.num
FROM people_reltab p,
TABLE(CAST(home_phones(p.phones_ntab) AS phone_ntabtyp))(+) n ;
|
関連項目: TABLEファンクションの詳細は、『Oracle Database SQL言語リファレンス』および『Oracle Databaseデータ・カートリッジ開発者ガイド』を参照してください。 |
格納されるVARRAYのサイズは、VARRAY内の現行の要素数にのみ依存し、保持できる最大要素数には関係しません。VARRAYの記憶域には、NULL情報など、わずかなオーバーヘッドがかかるため、格納されるVARRAYのサイズは、(要素のサイズ)×(要素数)より少し大きくなります。
VARRAYは、列値またはLOBとして格納されます。VARRAYの定義時に、宣言されたVARRAYのLIMIT(要素の上限値)を使用して計算されるVARRAYの最大許容サイズに基づいて、VARRAYの格納方法が決定されます。サイズが約4000バイトを超える場合、VARRAYはLOBに格納されます。その他の場合は、その列自体に列値として格納されます。さらに、インラインLOBがサポートされており、(LOBロケータ用に何バイトか予約された)大きなVARRAYの最初の4000バイトに相当する要素は、その行自体の列に格納されます。『Oracle Database SecureFilesおよびラージ・オブジェクト開発者ガイド』も参照してください。
VARRAY型のサイズを変更する際、依存型については新しい型バージョンが生成されます。VARRAY列がLOBとして明示的に格納されておらず、元の最大サイズが4000バイト未満の場合、このことに注意する必要があります。増加後のサイズが4000バイト以上になる場合、VARRAY列をLOBとして格納する必要があります。この場合、LOBセグメントおよびLOB索引を含めた必須LOBメタデータ情報を設定する必要があるため、VARRAY列のメタデータをアップグレードするという追加操作が必要になります。
ALTER TYPE文のCASCADEオプションを使用すると、VARRAYのサイズ変更が、依存型および依存表に伝播されます。有効な各依存型に対して新しいバージョンが生成され、前述の様々な異なる場面に基づいて、依存表メタデータが更新されます。VARRAY列がクラスタ表内に存在する場合、クラスタ表はLOBをサポートしていないため、ALTER TYPE文のCASCADEオプションの実行は失敗します。
ALTER TYPE文のCASCADEオプションでは、[NOT] INCLUDING TABLE DATAオプションも用意されています。NOT INCLUDING TABLE DATAオプションを使用すると、表のメタデータは更新されますが、データ・イメージは変換されません。VARRAYのイメージを最新バージョンの形式に変換するには、ALTER TYPE CASCADE文でINCLUDING TABLE DATAを明示的に指定するか、またはALTER TABLE UPGRADE文を発行します。
アプリケーションでコレクション全体が1つの単位として操作される場合、VARRAYはネストした表よりも高速に処理されます。VARRAYはまとまって格納され、ネストした表とは異なり、データを取り出すための結合は必要ありません。
ネストを解除する構文を、ネストした表へのアクセスの場合と同様の方法で、VARRAY列へのアクセスにも使用できます。詳細は、「ネストを解除する問合せを使用したリレーショナル形式でのオブジェクト・データの表示」を参照してください。
VARRAYの要素単位の更新は、サポートされていません。このため、VARRAYが更新される場合、古いコレクション全体が新しいコレクションで置き換えられます。
次の項では、ネストした表を使用するための設計上の考慮点について説明します。
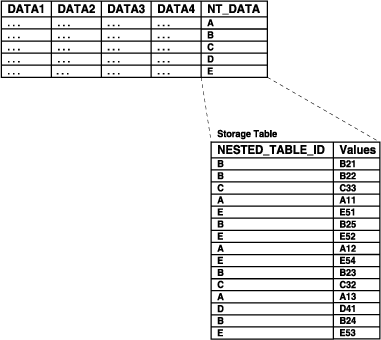
Oracleでは、ネストした表の行は別の記憶表に格納されます。システムが生成するNESTED_TABLE_ID(長さ16バイト)によって、親である行およびそれに対応する記憶表の行が関連付けられます。
図9-2に、記憶表の動作を示します。記憶表には、ネストした表列内のネストした表ごとの値が含まれています。この個々の値が、記憶表の1行に相当します。記憶表は、NESTED_TABLE_IDを使用して、個々の値に対するネストした表を追跡します。したがって、図9-2では、ネストした表Aに属するすべての値が識別され、それに続いてネストした表Bに属するすべての値も同様に識別されます。
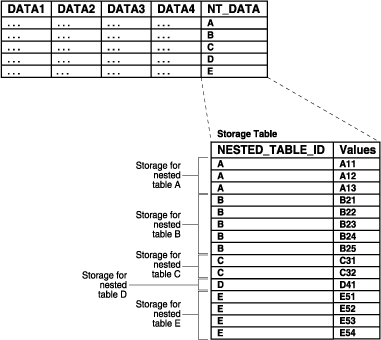
ネストした表が主キーを持つ場合、この表をIOTとして構成できます。NESTED_TABLE_ID列が、指定された親である行に対する主キーの第一要素(プレフィックス)である場合、その子である行は物理的に1つにクラスタ化されます。このため、親である行がアクセスされるときに、そのすべての子である行を効率的に取り出せます。親である行のみがアクセスされる場合も、子である行が親である行に混入することはないため、同等の効率が維持されます。
図9-3に、ネストした表がIOTである場合の記憶表の動作を示します。記憶表では、ネストした表列内のネストした表ごとの値は、NESTED_TABLE_ID別にグループ化されます。図9-3では、記憶表のデータは、親表のNT_DATA列にあるネストした表ごとにグループ化されています。つまり、ネストした表Aのすべての値がグループ化され、ネストした表Bのすべての値も同様にグループ化され、というようにグループ化されています。
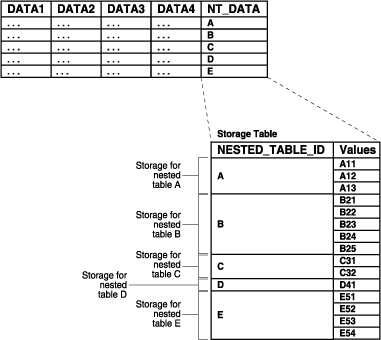
さらに、COMPRESS句によって、IOT列に対してプレフィックスを圧縮することが可能です。この圧縮では、それぞれの子である行にある親のキーの重複部分を取り除きます。つまり、親キーが個々の子である行で繰り返されることがないため、記憶域を大幅に節約できます。
つまり、COMPRESS句を使用してネストした表の圧縮を指定すると、同じグループの各値に対して同一のNESTED_TABLE_IDが繰り返されないため、記憶表に必要な領域容量が削減されます。かわりに、図9-4に示すように、NESTED_TABLE_IDはグループにつき1回のみ格納されます。
通常は、NESTED_TABLE_ID列を主キーのプレフィックスとして使用して、ネストした表をIOTに格納することをお薦めします。さらに、IOTでプレフィックス圧縮を有効にする必要があります。ただし、通常の業務としてはネストした表を1つの単位として取り出すことがなく、子である行をクラスタ化することもない場合は、ネストした表をIOTに格納したり、圧縮を指定したりしないでください。
(IOTでない)ヒープ表に格納されたネストした表を作成する場合、記憶表のNESTED_TABLE_ID列および親表の対応するID列に索引が自動的に作成されます。データベースでは、NESTED_TABLE_ID列を使用して、親表とネストした表の結合を実行する必要があるため、NESTED_TABLE_ID列に索引を作成することによって、ネストした表の子である行にさらに効率的にアクセスできるようになります。
大規模な子集団の場合は、必要に応じて子である行にアクセスできるように、親である行、および子集団に対するロケータを戻せます。子集団のフィルタもできます。ネストした表のロケータを使用すると、各親に対して子である行が不必要に転送されることを回避できます。
次のいずれかのアクションを実行して、ネストした表のロケータを使用して子である行にアクセスできます。
OCIコレクション関数をコールします。このアクションは、OCIColl*関数などのクライアント側コードでコレクション要素にアクセスするときに暗黙的に発生します。最初のアクセスで、コレクション全体が暗黙的に取り出されます。
|
関連項目: OCIコレクション関数の詳細は、『Oracle Call Interfaceプログラマーズ・ガイド』を参照してください。 |
SQLを使用して、ネストした表に対応する行を取り出します。
マルチレベル・コレクションでは、任意のネスト・レベルで指定されたコレクションを持つロケータを使用できます。
次の内容では、コレクションをロケータとして取り出すことができる方法を指定します。
コレクション型が列型として使用されていて、NESTED TABLE記憶域句が使用されている場合は、RETURN AS LOCATOR句を使用して、特定のコレクションをロケータとして取り出すように指定できます。
たとえば、inner_tableが3つのレベルのネストした表で構成されたコレクション型だとします。次の例では、RETURN AS LOCATOR句によって、常に第3レベルのネストした表がロケータとして取り出されることが指定されています。
例9-7 RETURN AS LOCATOR句の使用
CREATE TYPE inner_table AS TABLE OF NUMBER;/
CREATE TYPE middle_table AS TABLE OF inner_table;/
CREATE TYPE outer_table AS TABLE OF middle_table;/
CREATE TABLE tab1 (
col1 NUMBER,
col2 outer_table)
NESTED TABLE col2 STORE AS col2_ntab
(NESTED TABLE COLUMN_VALUE STORE AS cval1_ntab
(NESTED TABLE COLUMN_VALUE STORE AS cval2_ntab RETURN AS LOCATOR) );
ネストした表にある特定の項目を検索する場合、セット・メンバーシップ問合せが役立ちます。たとえば、次の問合せでは、homeというロケーションが、子集団のメンバーシップ、具体的には、ネストした表phones_ntab(親表people_reltabにあります)にあるかどうかをテストします。
SELECT * FROM people_reltab p WHERE 'home' IN (SELECT location FROM TABLE(p.phones_ntab)) ;
Oracleでは、子集団のメンバーシップを内部的にセミ結合に変換することによって、そのメンバーシップをテストする問合せをより効率的に実行しています。ただし、この最適化は、ALWAYS_SEMI_JOIN初期化パラメータが設定されている場合にのみ実行されます。セミ結合を実行する場合、このパラメータの有効な値はMERGEおよびHASHです。これらのパラメータ値によって、使用すべき結合メソッドが示されます。
|
注意: 前述の例では、homeおよびlocationは子集団要素です。子集団要素がオブジェクト型である場合は、セット・メンバーシップ問合せを実行するマップ・メソッドまたはオーダー・メソッドが必要です。 |
第5章「コレクション・データ型のサポート」では、コレクション型をネストして、真のマルチレベル・コレクション(たとえばネストした表のネストした表、VARRAYのネストした表、ネストした表のVARRAY、コレクション型の属性を持つオブジェクト型のVARRAYまたはネストした表など)を作成する方法について説明しています。
REFを使用して間接的にコレクションをネストすることもできます。たとえば、ネストした表属性またはVARRAYの属性を持つオブジェクトを参照する属性を持つオブジェクト型のネストした表を作成できます。実際にはマルチレベル・コレクションのすべての要素にアクセスする必要はない、という場合、ロードする必要があるのは、要素そのものではなくREFのみなので、REFを使用してコレクションをネストすると、パフォーマンスが向上する可能性があります。
真のマルチレベル・コレクション(具体的にはマルチレベルのネストした表)を使用すると、コレクションの個々の要素にアクセスする問合せのパフォーマンスが向上します。すべての要素にアクセスする必要はない場合、ネストした表ロケータを使用すると、プログラムで規定されたアクセスのパフォーマンスが向上する可能性があります。
REFを使用して別のコレクションをネストする例として、例9-1に示したname_objtyp、address_objtypおよびphone_ntabtypの各オブジェクト型を使用して、person_objtypと呼ばれる新しいオブジェクト型を作成するとします。1人が複数の電話番号を持つことがあるため、phone_ntabtypオブジェクト型がネストした表になっていることに注意してください。
person_objtypオブジェクト型およびpeople_objtabオブジェクト型のpeople_objtabというオブジェクト表を作成するには、次のSQL文を発行します。
例9-8 マルチレベル・コレクションを含むオブジェクト表の作成
CREATE TYPE person_objtyp AS OBJECT ( id NUMBER(4), name_obj name_objtyp, address_obj address_objtyp, phones_ntab phone_ntabtyp); /
CREATE TABLE people_objtab OF person_objtyp (id PRIMARY KEY) NESTED TABLE phones_ntab STORE AS phones_store_ntab ;
people_objtab表は、people_reltab表と同じ属性を持ちます。違いは、people_objtabは行オブジェクトを持つオブジェクト表であり、people_reltab表は列オブジェクトを持つリレーショナル表であるという点です。
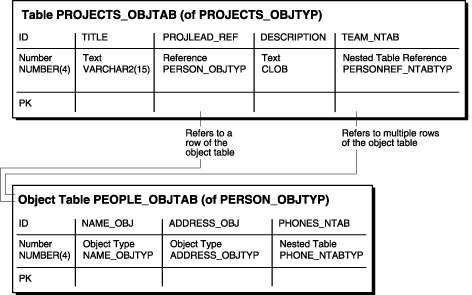
ここで、people_objtabオブジェクト表にある行オブジェクトを他の表から参照できます。たとえば、次の項目が含まれるprojects_objtab表を作成するとします。
各プロジェクトのプロジェクト識別番号
各プロジェクトのタイトル
各プロジェクトのプロジェクト・リード
各プロジェクトの説明
各プロジェクトに割り当てられたチームのメンバーを格納するネストした表コレクション
プロジェクト・リードに対してはpeople_objtabにREFを使用でき、チームに対してはREFのネストした表コレクションを使用できます。まず、person_objtypオブジェクト型に基づいて、personref_ntabtypというネストした表オブジェクト型を作成します。
CREATE TYPE personref_ntabtyp AS TABLE OF REF person_objtyp; /
これで、オブジェクト表projects_objtabを作成する準備ができました。例9-9に示すように、まずオブジェクト型projects_objtypを作成してから、projects_objtypに基づいてオブジェクト表projects_objtabを作成します。
例9-9 REFを使用したオブジェクト表の作成
CREATE TYPE projects_objtyp AS OBJECT ( id NUMBER(4), title VARCHAR2(15), projlead_ref REF person_objtyp, description CLOB, team_ntab personref_ntabtyp); / CREATE TABLE projects_objtab OF projects_objtyp (id PRIMARY KEY) NESTED TABLE team_ntab STORE AS team_store_ntab ;
people_objtabオブジェクト表およびprojects_objtabオブジェクト表が作成されると、間接的にネストしたコレクションを持つことになります。つまり、projects_objtab表には、people_objtab表にある人物を指すREFのネストした表コレクションが含まれ、people_objtab表にある人物には電話番号のネストした表コレクションがあります。
例9-10のように、people_objtab表に値を挿入できます。
例9-10 people_objtabオブジェクト表への値の挿入
INSERT INTO people_objtab VALUES (
0001,
name_objtyp('JOHN', 'JACOB', 'SCHMIDT'),
address_objtyp('1252 Maple Road', 'Fairfax', 'VA', '22033'),
phone_ntabtyp(
phone_objtyp('home', '650.555.0141'),
phone_objtyp('work', '510.555.0122'))) ;
INSERT INTO people_objtab VALUES (
0002,
name_objtyp('MARY', 'ELLEN', 'MILLER'),
address_objtyp('33 Spruce Street', 'McKees Rocks', 'PA', '15136'),
phone_ntabtyp(
phone_objtyp('home', '415.555.0143'),
phone_objtyp('work', '650.555.0192'))) ;
INSERT INTO people_objtab VALUES (
0003,
name_objtyp('SARAH', 'MARIE', 'SINGER'),
address_objtyp('525 Pine Avenue', 'San Mateo', 'CA', '94403'),
phone_ntabtyp(
phone_objtyp('home', '510.555.0101'),
phone_objtyp('work', '650.555.0178'),
phone_objtyp('cell', '650.555.0143'))) ;
さらに、例9-11のように、REF演算子を使用してpeople_objtabオブジェクト表から選択することによって、projects_objtabリレーショナル表に挿入できます。
例9-11 projects_objtabオブジェクト表への値の挿入
INSERT INTO projects_objtab VALUES (
1101,
'Demo Product',
(SELECT REF(p) FROM people_objtab p WHERE id = 0001),
'Demo the product, show all the great features.',
personref_ntabtyp(
(SELECT REF(p) FROM people_objtab p WHERE id = 0001),
(SELECT REF(p) FROM people_objtab p WHERE id = 0002),
(SELECT REF(p) FROM people_objtab p WHERE id = 0003))) ;
INSERT INTO projects_objtab VALUES (
1102,
'Create PRODDB',
(SELECT REF(p) FROM people_objtab p WHERE id = 0002),
'Create a database of our products.',
personref_ntabtyp(
(SELECT REF(p) FROM people_objtab p WHERE id = 0002),
(SELECT REF(p) FROM people_objtab p WHERE id = 0003))) ;
|
注意: この例では、REFを格納するためにネストした表を使用していますが、REFをVARRAYに格納することもできます。つまり、REFのVARRAYを作成できます。 |
この項では、メソッドを使用した作業での考慮点を説明します。
メソッド・ファンクションは、Oracleでサポートされる任意の言語(PL/SQL、Java、Cなど)で実装できます。特定のアプリケーション用に言語を選択する場合は、次の要因を考慮してください。
使用しやすさ
SQLコール
実行速度
同一/異なるアドレス空間
一般に、アプリケーションで主に計算を実行する場合には、Cが適していますが、比較的多くのデータベース・コールを実行する場合は、PL/SQLまたはJavaが適しています。
Cで実装されるメソッドは、外部プロシージャを使用して、サーバーとは別のプロセスで実行されます。それに対して、JavaまたはPL/SQLで実装されるメソッドは、サーバーと同じプロセスで実行されます。
メソッドの実装例
この項で説明する例では、異なる言語で実装されたメソッドを持つオブジェクト型が関係しています。この例では、オブジェクト型ImageTypeは、ID属性(一意に識別されるNUMBER)およびIMG属性(イメージを格納するBLOB)を持ちます。オブジェクト型ImageTypeは、次のメソッドを持ちます。
get_nameメソッド。データベース内でイメージの名前を検索してフェッチします。このメソッドは、PL/SQLで実装されています。
rotateメソッド。イメージを回転します。このメソッドは、Cで実装されています。
clearメソッド。指定された色の新しいイメージを戻します。このメソッドは、Javaで実装されています。
Cでメソッドを実装する場合は、外部Cルーチンが含まれるライブラリを指す、LIBRARYオブジェクトを定義する必要があります。Javaでメソッドを実装する場合を想定して、この例では、メソッドを持つJavaクラスがコンパイルされ、Oracleにアップロードされていると仮定しています。
例9-12に、オブジェクト型の定義およびそのメソッドを示します。
例9-12 様々な言語で実装されたメソッドを持つオブジェクト型の作成
CREATE LIBRARY myCfuncs TRUSTED AS STATIC
/
CREATE TYPE ImageType AS OBJECT (
id NUMBER,
img BLOB,
MEMBER FUNCTION get_name return VARCHAR2,
MEMBER FUNCTION rotate return BLOB,
STATIC FUNCTION clear(color NUMBER) return BLOB);/
CREATE TYPE BODY ImageType AS
MEMBER FUNCTION get_name RETURN VARCHAR2
IS
imgname VARCHAR2(100);
sqlstmt VARCHAR2(200);
BEGIN
sqlstmt := 'SELECT name INTO imgname FROM imgtab WHERE imgid = id';
EXECUTE IMMEDIATE sqlstmt;
RETURN imgname;
END;
MEMBER FUNCTION rotate RETURN BLOB
AS LANGUAGE C
NAME "Crotate"
LIBRARY myCfuncs;
STATIC FUNCTION clear(color NUMBER) RETURN BLOB
AS LANGUAGE JAVA
NAME 'myJavaClass.clear(oracle.sql.NUMBER) return oracle.sql.BLOB';
END;
/
|
制限事項: タイプ・メソッドは、Javaの静的メソッドのみにマップできます。 |
静的メソッドは、SELF値が第1パラメータとして渡されない点で、メンバー・メソッドと異なります。SELFの値が問題ではないメソッドは、静的メソッドとして実装する必要があります。静的メソッドは、ユーザー定義コンストラクタに使用できます。
例9-13では、コンストラクタに類似したメソッドで、明示的な入力パラメータに基づいてその型のインスタンスを作成し、指定された表にそのインスタンスを挿入します。
例9-13 静的メソッドを持つオブジェクト型の作成
CREATE TYPE atype AS OBJECT(
a1 NUMBER,
STATIC PROCEDURE newa (
p1 NUMBER,
tabname VARCHAR2,
schname VARCHAR2));
/
CREATE TYPE BODY atype AS
STATIC PROCEDURE newa (p1 NUMBER, tabname VARCHAR2, schname VARCHAR2)
IS
sqlstmt VARCHAR2(100);
BEGIN
sqlstmt := 'INSERT INTO '||schname||'.'||tabname|| ' VALUES (atype(:1))';
EXECUTE IMMEDIATE sqlstmt USING p1;
END;
END;
/
CREATE TABLE atab OF atype;
BEGIN
atype.newa(1, 'atab', 'HR');
END;
/
メンバー・プロシージャにSELFが宣言されていない場合、そのパラメータ・モードはデフォルトでIN OUTに設定されます。ただし、デフォルトの動作には、NOCOPYコンパイラ・ヒントは含まれません。「メンバー・メソッド」を参照してください。
IN OUT実パラメータの値が対応する仮パラメータにコピーされるため、パラメータがラージ・オブジェクト型のインスタンスなどの大きなデータ構造を保持している場合、コピーによって実行速度が遅くなります。
パフォーマンスを改善するために、パラメータとしてラージ・オブジェクト型を渡す場合、SELF IN OUT NOCOPYを含められます。次に例を示します。
MEMBER PROCEDURE my_proc (SELF IN OUT NOCOPY my_LOB)
|
関連項目:
|
ファンクション索引は、式またはファンクションの戻り値に基づいた索引です。このファンクションは、オブジェクト型のメソッド・ファンクションの場合もあります。
メソッド・ファンクションに基づくファンクション索引は、索引付けの対象となっている列または表の各オブジェクト・インスタンスに対するファンクションの戻り値をあらかじめ計算しておいて、それらの値を索引に格納します。この索引では、ファンクションを評価しなおすことなく列や表が参照されます。
ファンクション索引は、WHERE句にファンクションを含む問合せのパフォーマンスを向上させる場合に役立ちます。たとえば、次のコードにはオブジェクト表empsの問合せが含まれています。
CREATE TYPE emp_t AS OBJECT( name VARCHAR2(36), salary NUMBER, MEMBER FUNCTION bonus RETURN NUMBER DETERMINISTIC); / CREATE TYPE BODY emp_t IS MEMBER FUNCTION bonus RETURN NUMBER DETERMINISTIC IS BEGIN RETURN self.salary * .1; END; END; / CREATE TABLE emps OF emp_t ; SELECT e.name FROM emps e WHERE e.bonus() > 2000;
この問合せを評価するためには、この表の各行オブジェクトに対するbonus()を評価する必要があります。bonus()の戻り値に対してファンクション索引がある場合は、この評価の作業はすでに実行済なので、Oracleの動作としては、索引内にある問合せ結果を検索するのみですみます。これによって、Oracleが問合せを実行した結果を戻す速度が向上します。
ファンクションの戻り値の索引付けが効果的に実行できるのは、戻り値が一定である場合、つまり、ファンクションが各オブジェクト・インスタンスに対して常に同じ値を戻す場合のみです。このため、ファンクション索引でユーザー定義ファンクションを使用する場合は、前述の例のように、DETERMINISTICキーワードを使用してそのファンクションを宣言しておく必要があります。このキーワードによって、各オブジェクト・インスタンスの入力引数値の集合に対して、このファンクションから常に一定の値が戻されることが保証されます。
次の例では、表empsのメソッドbonus()に対するファンクション索引を作成します。
|
関連項目: ファンクション索引の詳細は、『Oracle Database概要』および『Oracle Database SQL言語リファレンス』を参照してください。 |
任意のスキーマで使用できる汎用オブジェクト型を作成するには、CREATE OR REPLACE TYPEのAUTHID CURRENT_USERオプションを介して、実行者権限を使用する型を定義する必要があります。
|
注意: 実行者権限の制御の詳細は、『Oracle Databaseセキュリティ・ガイド』を参照してください。 |
一般に、次の条件がいずれも真である場合に実行者権限を使用します。
データにアクセスし操作するタイプ・メソッドがある。
これらのタイプ・メソッドを定義していないユーザーによって使用される必要がある。
たとえば、HRによって「静的メソッド」で作成されたatype型に対する実行権限を、ユーザーOEに付与し、その後この型に基づいて表atabを作成できます。
GRANT EXECUTE ON atype TO oe;
CONNECT oe;
Enter password: password
CREATE TABLE atab OF HR.atype ;
ここで、ユーザーOEが、次の文でatypeを使用するとします。
BEGIN -- follwing call raises an error, insufficient privileges HR.atype.newa(1, 'atab', 'OE'); END; /
型定義者(HR)には、newaプロシージャで挿入を実行するために必要な権限がないため、この文を実行するとエラーが戻されます。このエラーは、実行者権限を使用してatypeを定義することによって回避できます。ここで、まず両方のスキーマのatab表を削除し、実行者権限を使用してatypeを再作成します。
DROP TABLE atab;
CONNECT hr;
Enter password: password
DROP TABLE atab;
DROP TYPE atype FORCE;
COMMIT;
CREATE TYPE atype AUTHID CURRENT_USER AS OBJECT(
a1 NUMBER,
STATIC PROCEDURE newa(p1 NUMBER, tabname VARCHAR2, schname VARCHAR2));
/
CREATE TYPE BODY atype AS
STATIC PROCEDURE newa(p1 NUMBER, tabname VARCHAR2, schname VARCHAR2)
IS
sqlstmt VARCHAR2(100);
BEGIN
sqlstmt := 'INSERT INTO '||schname||'.'||tabname|| '
VALUES (HR.atype(:1))';
EXECUTE IMMEDIATE sqlstmt USING p1;
END;
END;
/
これで、ユーザーOEが再度atypeを使用しようとした場合、文は正常に実行されます。
GRANT EXECUTE ON atype TO oe; CONNECT oe; Enter password: password CREATE TABLE atab OF HR.atype; BEGIN HR.atype.newa(1, 'atab', 'OE'); END; / DROP TABLE atab; CONNECT hr; Enter password: password DROP TYPE atype FORCE;
このとき文が正常に実行されるのは、プロシージャは定義者(HR)権限でなく実行者(OE)権限で実行されるためです。
型階層内では、サブタイプには、そのすぐ上のスーパータイプと同じ権限モデルが存在します。つまり、サブタイプはスーパータイプの権限を暗黙的に継承するため、明示的な権限の指定はできません。さらに、スーパータイプが定義者権限によって宣言された場合は、サブタイプはスーパータイプと同じスキーマ内に配置されている必要があります。これらの規則によって、実行者権限型の階層がスキーマを超えて展開されることになります。ただし、定義者権限モデルを使用する型の階層は、単一のスキーマ内に存在する必要があります。次に例を示します。
CREATE TYPE deftype1 AS OBJECT (...); --Definer-rights type CREATE TYPE subtype1 UNDER deftype1 (...); --subtype in same schema as supertype CREATE TYPE schema2.subtype2 UNDER deftype1 (...); --ERROR CREATE TYPE invtype1 AUTHID CURRENT_USER AS OBJECT (...); --Invoker-rights type CREATE TYPE schema2.subtype2 UNDER invtype1 (...); --LEGAL
サブプログラムでのロールの使用は、定義者権限で実行するか、実行者権限で実行するかによって異なります。定義者権限のサブプログラム内では、ロールはすべて無効です。ロールは権限チェックに使用されないため、設定できません。
実行者権限のサブプログラム内では、ロールは有効です(サブプログラムが直接または間接的に、定義者権限サブプログラムにコールされた場合は無効です)。ロールは権限チェックに使用され、固有の動的SQLを使用してセッションに設定できます。ただし、ロールはコンパイル時ではなく実行時に適用されるため、ロールを使用してテンプレート・オブジェクトに権限を付与することはできません。
Oracle Databaseリリース12cリリース12.1以降、伝播にXMLを使用して、次の内容がサポートされます。
型の進化および継承を含むオブジェクト・レプリケーション
VARRAY
ANYDATAデータ型
オブジェクトには、ロジカル・スタンバイのデータ型がサポートされます。
レプリケーションは、ネストした表、VARRAY、REF、または埋込みLOBのピース単位の更新にサポートされません。
|
関連項目: SQL Apply(ロジカル・スタンバイ)でサポートされるデータ型の詳細は、『Oracle Data Guard概要および管理』を参照してください。 |
オブジェクト表およびオブジェクト・ビューは、マテリアライズド・ビューとしてレプリケートできます。また、あるオブジェクト型、コレクション型またはREF型の列を含むリレーショナル表もレプリケートできます。このようなマテリアライズド・ビューは、オブジェクト・リレーショナル・マテリアライズド・ビューと呼ばれます。
オブジェクト・リレーショナル・マテリアライズト・ビューが必要とするすべてのユーザー定義型は、マスター・サイトおよびマテリアライズド・ビュー・サイトに存在する必要があります。そのようなユーザー定義型のIDおよびバージョンは両方のサイトで一致している必要があります。
この項の内容は次のとおりです。
更新可能とするには、オブジェクト列を含む表に基づくマテリアライズド・ビューでは、そのビューを定義する問合せにある列をオブジェクトとして選択する必要があります。問合せが、その列のオブジェクト型の一定の属性のみを選択する場合は、マテリアライズド・ビューは読取り専用となります。
ビュー定義問合せは、コレクション型またはREF型の列も選択できます。REFは、主キー・ベースのキーか、システム生成のキーのいずれかで、有効範囲付きまたは有効範囲なしの場合があります。有効範囲付きREFの列は、元のリモート表ではなくマテリアライズド・ビュー・サイトの別の表(たとえば、マスター表のローカル・マテリアライズド・ビューなど)に、有効範囲を付けなおすことができます。
オブジェクト表に基づくマテリアライズド・ビューはオブジェクト・マテリアライズド・ビューと呼ばれます。このようなマテリアライズド・ビューは、それ自体がオブジェクト表です。オブジェクト・マテリアライズド・ビューは、OF typeのキーワードをCREATE MATERIALIZED VIEW文に追加することによって作成されます。次に例を示します。
CREATE MATERIALIZED VIEW customer OF cust_objtyp AS SELECT * FROM HR.Customer_objtab@dbs1;通常のオブジェクト表の場合と同様、オブジェクト・マテリアライズド・ビューの各行もオブジェクト・インスタンスです。したがって、マテリアライズド・ビューを作成するビュー定義問合せは、マスター表にあるオブジェクト全体を選択する必要があります。この問合せは、オブジェクト型属性のサブセットのみの選択はできません。たとえば、次のようなマテリアライズド・ビューは使用できません。
CREATE MATERIALIZED VIEW customer OF cust_objtyp AS SELECT * FROM HR.Customer_objtab@dbs1;OF typeのキーワードを省略することによってオブジェクト表からオブジェクト・リレーショナル・マテリアライズド・ビューを作成できますが、そのようなビューは読取り専用です。オブジェクト表から、更新可能なオブジェクト・リレーショナル・マテリアライズド・ビューを作成できます。
たとえば、次のCREATE MATERIALIZED VIEW文は、オブジェクト表の読取り専用オブジェクト・リレーショナル・マテリアライズド・ビューを作成します。ビュー定義問合せは、そのオブジェクト型のすべての列および属性を選択しますが、オブジェクトの属性として選択するわけではないので、作成されたビューは、オブジェクト・リレーショナル・ビューで、読取り専用です。
CREATE MATERIALIZED VIEW customer AS SELECT * FROM HR.Customer_objtab@dbs1;オブジェクト表に基づいたオブジェクト・リレーショナル・ビューとマテリアライズド・ビューのいずれの場合も、マスターのオブジェクト表の型がFINALでない場合は、マテリアライズド・ビューの定義問合せにあるFROM句に、ONLYキーワードが含まれている必要があります。次に例を示します。
CREATE MATERIALIZED VIEW customer OF cust_objtyp AS SELECT CustNo FROM ONLY HR.Customer_objtab@dbs1;そうでない場合は、FROM句からONLYキーワードを省略してください。
|
関連項目: オブジェクト表とオブジェクト列のレプリケーションの詳細は、『Oracle Databaseアドバンスト・レプリケーション』を参照してください。 |
Oracleでは、型指定内での制約およびデフォルトはサポートされません。ただし、表を作成するときに、制約およびデフォルトを指定できます。
例9-15 表作成時のオブジェクト型に対する制約の指定
CREATE TYPE customer_typ AS OBJECT( cust_id INTEGER); / CREATE TYPE department_typ AS OBJECT( deptno INTEGER); / CREATE TABLE customer_tab OF customer_typ ( cust_id default 1 NOT NULL); CREATE TABLE department_tab OF department_typ ( deptno PRIMARY KEY); CREATE TABLE customer_tab1 ( cust customer_typ DEFAULT customer_typ(1) CHECK (cust.cust_id IS NOT NULL), some_other_column VARCHAR2(32));
次の項では、型進化に関連する設計上の考慮点について説明します。
この項の内容は次のとおりです。
ある型がサーバー側で進化すると、この型を使用するすべてのクライアント・アプリケーションで、この型に対応付けられている構造体の変更が必要になります。この変更は、OTTまたはJPublisherを使用して実行できます。また、構造体の変更に伴ってプログラムの変更が必要な場合もあります。このような変更を行った後、アプリケーションをコンパイルしなおし、再リンクする必要があります。
サード・パーティ・アプリケーションのリリース間で型が変更される場合があります。サード・パーティ・アプリケーションの最新リリースとの互換性を確立するために再コンパイルする必要があることをクライアント・アプリケーションに通知するには、リリース指向互換性初期化ファンクションをクライアントからコールします。このファンクションは、クライアント・アプリケーションのどのリリースを使用しているかを示す文字列を入力として受け取ることができます。リリース文字列が最新バージョンと一致しない場合は、エラーが発生します。その場合、クライアント・アプリケーションは、最新リリースとの互換性を確立するための変更の一環として、リリース文字列を変更します。
次に例を示します。
FUNCTION compatibility_init( rel IN VARCHAR2, errmsg OUT VARCHAR2)RETURN NUMBER;ここで
relは、その製品、たとえば、リリース10.1によって選択されたリリース文字列です。
errmsgは、戻す必要のある任意のエラー・メッセージです。
このファンクションは、成功すると0(ゼロ)を戻し、エラーの場合は0(ゼロ)以外の値を戻します。
型が変更されると、新しく追加された属性をパラメータ・リストに含めるためなどに、デフォルトでシステム定義されたコンストラクタを変更する必要があります。デフォルトのコンストラクタを使用している場合は、コールをコンパイルするためにプログラム内の起動を変更する必要があります。
システム定義されたデフォルトのコンストラクタではなく、独自でコンストラクタ・ファンクションを定義して使用する場合は、コンストラクタのコールを変更する必要はありません。「ユーザー定義コンストラクタの利点」を参照してください。
型T1を、FINALからNOT FINALに変更した場合、クライアント・プログラムにある型T1の属性はすべて、インライン構造体からT1へのポインタに変更されます。したがって、この属性がアクセスされた場合に参照解除を使用できるようにするには、プログラムを変更する必要があります。
逆に、ある型を、NOT FINALからFINALに変更するには、その型の属性をポインタからインライン構造体に変更する必要があります。
たとえば、型T1(a int)とT2(b T1)があるとします(ここで、T1のプロパティはFINALです)。T2に対応するC/JAVA構造体はT2(T1 b)です。ところが、T1のプロパティをNOT FINALに変更すると、T2の構造体はT2(T1 *b)になります。
Oracleでは、オブジェクト、およびビューから合成されたオブジェクトを使用して、パラレル問合せを実行できます。ただし、次の制限があります。
(ORDER BY、GROUP BYおよびSET操作を使用して)結合およびソートをパラレルに実行する問合せを行うには、MAPファンクションが必要です。MAPファンクションがない場合、問合せは自動的にシリアルになります。
ネストした表でのパラレル問合せはサポートされません。表に対するパラレル・ヒントまたはパラレル属性がある場合でも、問合せはシリアルになります。
パラレルDMLおよびパラレルDDLは、オブジェクトではサポートされません。DMLおよびDDLは、常にシリアルに実行されます。
パラレルDMLは、INSTEAD OFトリガーを持つビューではサポートされません。ただし、トリガー内の個々の文は、パラレル化できます。
次の項では、Oracleのオブジェクト型を使用した作業の様々な側面に関するヒントを示します。
この項の内容は次のとおりです。
アプリケーションがライフ・サイクルを終了するまでには、既存のオブジェクト型を変更するか、それとも、新しい要件を満たす特化されたサブタイプを作成するか、という問題が頻繁に発生します。その答えは、新しい要件の性質およびアプリケーションのセマンティクス全体でのコンテキストによって異なります。次に2つの例をあげて説明します。
広範囲に使用されているベース型の変更
属性Street、State、ZIPを持つオブジェクト型addressがあるとします。
CREATE TYPE address AS OBJECT ( Street VARCHAR2(80), State VARCHAR2(20), ZIP VARCHAR2(10)); /
後になって、世界各地の住所をサポートするためには、Country属性を追加してaddress型を拡張する必要性に気がつきます。addressのサブタイプの作成とaddress型自体の進化とでは、どちらが得策でしょうか。
アプリケーション全体にわたって広範囲に使用されている一般的なベース型の場合は、型進化を通じて変更を実行することをお薦めします。
特化の追加
図形型(たとえば、曲線、円、正方形、テキスト)の既存の型階層に、追加のバリエーション、具体的にはベジエ曲線を格納する必要があるとします。ベース型の不足を反映しないこのような新しい特化をサポートするために、継承を使用して、Curve型の下に、新しいサブタイプBezierCurveを作成する必要があります。
つまり、必要とされる変更のセマンティクスによって、型進化を使用すべきか、それとも継承を使用すべきかが決まります。より全般的な変更で、ベース型に影響が及ぶ場合は、型進化を使用してください。より特化された変更に対しては、継承を使用して変更を実行してください。
ANYDATAはOracleによって提供される型で、任意のOracleデータ型のインスタンスを、組込み型かユーザー定義かにかかわらず保持できます。ANYDATAは自己記述的な型で、インスタンスの形式を決定するために使用できるリフレクションに類似したAPIです。
代入性機能を通して、継承およびANYDATAは、ともにプレースホルダ内に考えられるインスタンスの任意の集合を格納するポリモフィックな能力を備えていますが、この2つのモデルがその機能を提供する形式は異なります。
継承モデルの場合は、考えられるインスタンスのポリモフィックな集合は、単一の型の階層の一構成部分である必要があります。変数には、定義された型またはそのサブタイプのインスタンスのみを保持する潜在的な能力があります。スーパータイプの属性にアクセスして、そのサブタイプで定義されている(またサブタイプによってオーバーライドされる可能性のある)メソッドをコールできます。IS OF演算子およびTREAT演算子を使用して、あるインスタンスの具体的な型をテストすることもできます。
ただし、ANYDATA変数は、異質なインスタンスを格納する可能性があります。インスタンスを抽出してしまわないかぎり、ANYDATA変数に格納されている実際のインスタンスの属性にアクセスすることも、メソッドをコールすることもできません。該当するインスタンスの型を抽出するには、ANYDATAメソッドを使用します。ANYDATAは、ファンクション/プロシージャがパラメータの具体的な型には関心がない場合にパラメータの受渡しを行う場合に便利です。
継承は優れたモデリング、厳密な型指定、特化などを提供します。共通するものがあるとはかぎらない、任意の数の考えられるインスタンスのうちの1つを保持するのみの場合は、ANYDATAを使用してください。
第6章「オブジェクト・モデルのリレーショナル・データへの適用」では、それぞれが単一の型のオブジェクトを含んでいるオブジェクト・ビューの集合からビュー階層を構築する方法について説明しました。このようなビュー階層では、その階層内のビューに対する問合せによる、ビューまたはそのサブビューによって格納されたオブジェクトのポリモフィックな集合の参照が可能です。
このようなポリモフィックな問合せをサポートする代入の方法として、オブジェクトのポリモフィックな集合を戻す問合せに基づいてオブジェクト・ビューを定義できます。このアプローチは、あるビューを既存の表またはビューの集合にまたがって定義するときに特に便利です。
たとえば、Person_tのオブジェクト・ビューを、Employee_tインスタンスも含めたPerson_tインスタンスを戻す問合せに対して定義できます。次の文からは、persons表から個人を、employees表から従業員を選択する問合せに基づいてビューが作成されます。
CREATE VIEW Persons_view OF Person_t AS SELECT Person_t(...) FROM persons UNION ALL SELECT TREAT(Employee_t(...) AS Person_t) FROM employees;このビューに対して定義されているINSTEAD OFトリガーのかわりに、VALUEファンクションを使用して、現在のオブジェクトにアクセスでき、また、オブジェクトの最も具体的な型に基づいて適切なアクションをとることができます。
ポリモフィック・ビューとオブジェクト・ビュー階層には、次のような重要な相違点があります。
アドレス指定可能度: ビュー階層では、各サブビューは、問合せおよびDML文の中で別々に参照できます。したがって、特定の型のオブジェクトの各集合には、論理名があります。一方、ポリモフィック・ビューは単一のビューなので、特定の型のオブジェクトの集合を取得するには、述語を使用する必要があります。
進化: 新しいサブタイプを追加する場合は、既存のビュー定義を変更することなくビュー階層にサブビューを追加できます。ポリモフィック・ビューの場合は、別のUNIONブランチを追加することによって、単一のビュー定義を変更する必要があります。
DML文: ビュー階層では、各サブビューは、本質的に更新可能であるか、INSTEAD OFトリガーを持っているかのいずれかです。ポリモフィック・ビューの場合は、ビュー上の与えられた操作に対してINSTEAD OFトリガーを1つのみ定義できます。
この項では、SQLJオブジェクト型について説明します。
『Information Technology - SQLJ - Part 2』ドキュメント(SQLJ規格)によると、SQLJオブジェクト型は、Java用に設計されたデータベース・オブジェクト型です。SQLJオブジェクト型はJavaクラスにマップされます。マッピングが拡張SQLのCREATE TYPEコマンド(DDL文)によって登録されると、JavaアプリケーションでOracle JDBCドライバを通じて、Javaオブジェクトを直接またはデータベースから、挿入または選択できるようになります。したがって、ユーザーは、同じクラスを、クライアントではJDBCを使用して、サーバーではSQLメソッドのディスパッチによって、デプロイできます。
拡張SQLのCREATE TYPEコマンドは、次のことを行います。
データベース・カタログに属性、ファンクションおよびJavaクラスの外部名を移入します。また、Javaクラスとそれに対応するSQLJオブジェクト型間の依存関係は維持されます。
Javaクラスが存在することを検証し、また、それによってUSING句の値に対応するインタフェースが実装されることも検証します。
Javaフィールドが(EXTERNAL NAME句で指定されているとおりに)存在すること、また、これらのフィールドが対応するSQL属性に対する互換性を検証します。
コンストラクタ、外部変数名、結果としてselfを返す外部ファンクションをサポートする内部クラスを生成します。
SQLJオブジェクト型は、SQLオブジェクト型の特殊なケースで、すべてのメソッドがJavaクラスで実装されています。Javaクラスと対応するSQL型間のマッピングは、SQLJオブジェクト型仕様によって管理されます。つまり、SQLJオブジェクト型仕様には、対応する型本体の仕様はありません。
また、SQLJオブジェクト型間の継承ルールによって、Javaクラス階層と対応するSQLJオブジェクト型階層の正しいマッピングが指定されます。これらのルールによって、SQLJ型階層に有効なマッピングが含まれていることが保証されます。したがって、SQLJオブジェクト型のスーパータイプまたはサブタイプは別のSQLJオブジェクト型である必要があります。
カスタム・オブジェクト型は、SQLオブジェクト型にアクセスするためのJavaインタフェースです。SQLオブジェクト型には、PL/SQL、Java、Cなどの言語で実装されたメソッドが含まれている場合があります。与えられたSQLオブジェクト型内のJavaで実装されたメソッドは、関連のない様々なクラスに属することができます。つまり、SQLオブジェクト型は特定のJavaクラスにマップされるわけではありません。
クライアントがこれらのオブジェクトにアクセスできるようにするため、JPublisherを使用して対応するJavaクラスを生成できます。さらに、ユーザーは、生成されたクラスを、対応するメソッドのコードで補強する必要があります。別の方法として、SQLオブジェクト型に対応するクラスを作成する方法もあります。
JDBCユーザーは、マップ内のSQL型名とそれに対応するJavaクラス間の対応関係を実行時に登録する必要があります。
次の表は、SQLJオブジェクト型とカスタム・オブジェクト型の相違点の要約です。
表9-1 SQLJオブジェクト型とカスタム・オブジェクト型の相違点
この項では、Oracleオブジェクトの設計に関するその他のヒントを説明します。
属性データを格納するため、列または表が型Tである場合は、Oracleによって、Tの各属性に対して、列または表が置換え可能な場合は、Tの各サブタイプの各属性に対して、非表示列が追加されます。同様に、行の中のオブジェクト・インスタンスの型を追跡するため、非表示のtypeid列も追加されます。
1つの表内の列の数は、1,000に制限されています。属性の合計数が1,000に迫っている型階層では、その階層内の型の置換え可能な列を使用しているときにこの制限を超えてしまうというリスクがあります。この結果発生する問題を回避するため、属性の合計数が大きい階層については、次のオプションのいずれかを検討してください。
ビューの使用
REFの使用
階層の分割