| Oracle® Application Expressエンド・ユーザー・ガイド リリース4.2 for Oracle Database 12c B71355-01 |
|


 前 |
 次 |
この項では、既存のアプリケーションのデータのロード・ウィザードを使用して、Oracle Application Expressアプリケーションにデータをインポートする方法を説明します。
|
ヒント: この項で説明する機能を使用するには、アプリケーションにデータ・アップロード機能が組み込まれている必要があります。詳細は、『Oracle Application Expressアプリケーション・ビルダー・ユーザーズ・ガイド』のデータのロード機能を使用したアプリケーションの作成に関する説明を参照してください。 |
内容は次のとおりです。
データのロード機能を持つアプリケーションでは、エンド・ユーザーは、アクセスできる任意のスキーマ内にある表にデータを動的にインポートできます。エンド・ユーザーは、データ・ロード・ウィザードを実行して、ファイルからデータをアップロードするか、エンド・ユーザーがウィザードに直接入力したデータをコピー・アンド・ペーストします。
アプリケーションのデータのロード・ウィザードに、データのアップロード時に表参照およびトランスフォーメーション・ルールを適用する機能が組み込まれている場合があります。データを実際にデータベースにインポートする前に、ユーザーにはすべての参照およびトランスフォーメーション・ルールが適用されたデータを確認する機会が与えられます。
表参照: これらのルールは、インポート・ファイル内のデータを自動的にマップしたり、別の表に含まれるデータにフィールドをコピー・アンド・ペーストします。たとえば、インポート・ファイルにはDEPTNO列に部門名が含まれているが、アップロード表ではその列に数値が必要な場合、表参照ルールを使用して、別の表でその部門名に対応する部門番号を探します。
データ・トランスフォーメーション・ルール: このルールでは、インポート・データを大文字や小文字に変更するなどといったフォーマットの自動変換を行います。たとえば、インポート・ファイルの列データで大文字と小文字の両方が使用され、インポート先の表ではすべて大文字である必要がある合、データ・トランスフォーメーション・ルールにより、その列にはデータのアップロード時に自動的に大文字のみが挿入されるようにします。
アプリケーションにデータをアップロードするには、アプリケーションにデータ・アップロード機能が組み込まれ、ファイルが正しくフォーマットされている必要があります。
次の項では、データ・ロード・ウィザードを使用してテキスト・ファイルからデータをインポートするアップロード手順を、サンプル・パッケージ・アプリケーションであるサンプル・データベース・アプリケーションの例を使用して説明します。
|
関連項目: 『Oracle Application Expressアプリケーション・ビルダー・ユーザーズ・ガイド』のパッケージ・アプリケーションの使用に関する説明およびサンプル・データベース・アプリケーションに関する説明 |
ファイルからサンプル・パッケージ・アプリケーションであるサンプル・データベース・アプリケーションにデータをインポートするには、次のステップを実行します。
サンプル・パッケージ・アプリケーションであるサンプル・データベース・アプリケーションにログインします。
「顧客」ページで「データをアップロード」をクリックし、データ・ロード・ウィザードを起動します。
データ・ロード・ウィザードが表示されます。
「データ・ロード・ソース」で次のステップを実行します。
インポート元: 「ファイルをアップロード(カンマ区切り(*.csv)またはタブ区切り)」を選択します。
「データ・ロード・ソース」ページにデータ・ファイルからロードする際のオプションが表示されます。
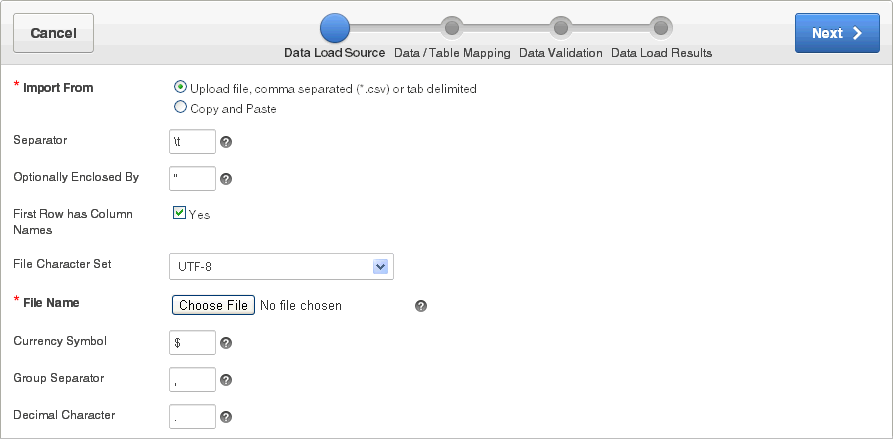
セパレータ: 列セパレータ文字を入力します。タブ区切りには\tを使用します。
囲み文字(オプション): データ値の開始および終了の範囲を区切るデリミタ文字を入力します。
1行目に列名がある: 次のオプションがあります。
はい: 列名には、アップロードされたデータ・ファイルの最初の行の列名が使用されます。
いいえ: 列名には、アップロードされたデータ・ファイルの列名が使用されません。
ファイルのキャラクタ・セット: アップロードするファイルに関連付けられているファイル・キャラクタ・セットを選択します。
ファイル名: アップロードするデータを含むファイル名を参照します。
次に、customer.txtデータ・ロード・ファイルの例を示します。

通貨記号: データに国際通貨記号が含まれている場合は、それをここに入力します。たとえば、データが$1,234.56または¥1,234.56の場合、$または¥を入力します。このようにしないと、データが正しくロードされない場合があります。
グループ・セパレータ: データにグループ・セパレータが含まれる場合、ここに入力します。グループ・セパレータとは、たとえば、千や100万などを示すために整数グループを区切る文字です。
グループ・セパレータには任意の文字を使用できます。指定した文字はシングルバイトで、グループ・セパレータは他の小数点文字とは異なる必要があります。これらの文字には、スペースは使用できますが、数字、プラス記号(+)、ハイフン(-)または小なり記号(<>)、大なり記号(>)は使用できません。
小数点文字: データに小数点文字が含まれる場合、ここに入力します。小数点文字は、数値の整数部と小数部を区切ります。少数点文字には任意の文字を使用できます。指定した文字はシングルバイトで、小数点文字は他の小数点文字とは異なる必要があります。これらの文字には、スペースは使用できますが、数字、プラス記号(+)、ハイフン(-)または小なり記号(<>)、大なり記号(>)は使用できません。
「次へ」をクリックします。
「データと表のマッピング」ページが表示されます。
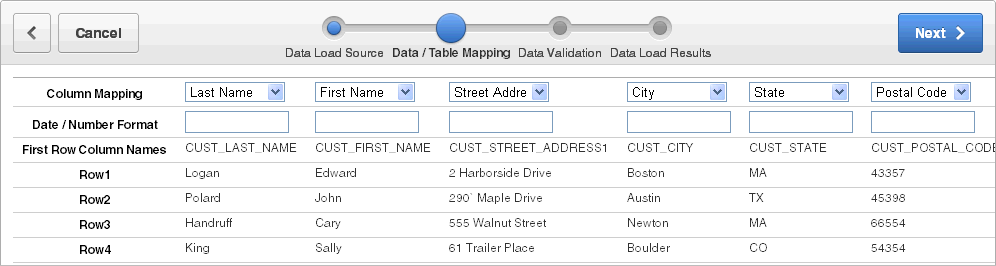
「データと表のマッピング」では、次のステップを実行します。
列のマッピング: 宛先の列名が示されます。列名を変更するには、リストから新しい列名を選択します。列を非表示にするには、「ロードしない」を選択します。
日付/数値書式: 多くの標準化されている日付および数値書式は、自動解析され、データベースに渡されます。独自の書式を定義したい場合や、自動的に解析されない書式の場合、このフィールドを使用し独自のものを定義します。「自動的にサポートされている日付、タイムスタンプおよび数値書式」を参照してください。
「次へ」をクリックします。
すべての表参照およびトランスフォーメーション・ルールの適用後、挿入または更新されるデータを示す「データ検証」ページが表示されます。表参照およびトランスフォーメーション・ルールの詳細は、「データ・ロード・ウィザードの使用」を参照してください。
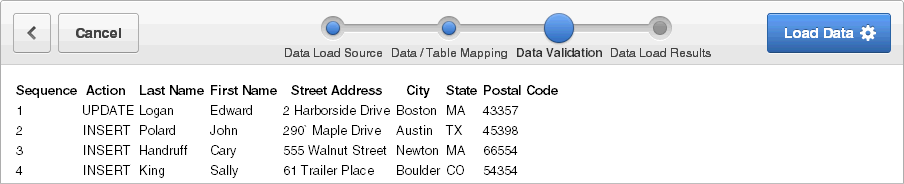
アップロードするデータを確認して、「データのロード」をクリックします。
「データ・ロード結果」ページが表示されます。
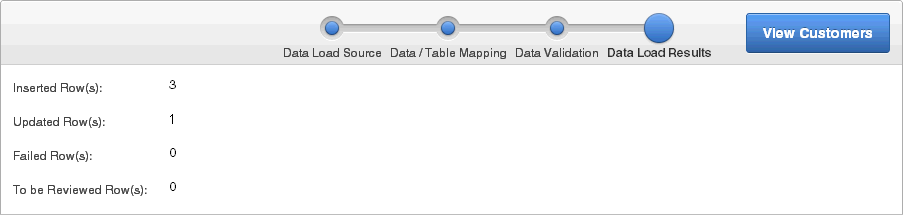
「データ・ロード結果」ページには、次が表示されます。
挿入された行: 表にアップロードされた新しい行です。
更新された行: 新しい情報で更新された表内の行数です。
失敗した行: 追加または更新されていないアップロード・ファイルからの行数です。
レビューの必要な行: レビューが必要な行数です。
「顧客」ページに戻るには、顧客の表示をクリックします。
アプリケーションにデータをアップロードするには、アプリケーションにデータ・アップロード機能が組み込まれ、ペーストしたデータが正しくフォーマットされている必要があります。
次の項では、データ・ロード・ウィザードを使用してテキスト・ファイルからのデータをコピー・アンド・ペーストするアップロード手順を、サンプル・パッケージ・アプリケーションであるサンプル・データベース・アプリケーションの例を使用して説明します。
アプリケーションにデータをコピー・アンド・ペーストするには、次のステップを実行します。
サンプル・パッケージ・アプリケーションであるサンプル・データベース・アプリケーションにログインします。
「顧客」ページで「データをアップロード」をクリックし、データ・ロード・ウィザードを起動します。
データ・ロード・ウィザードの最初のページが表示されます。
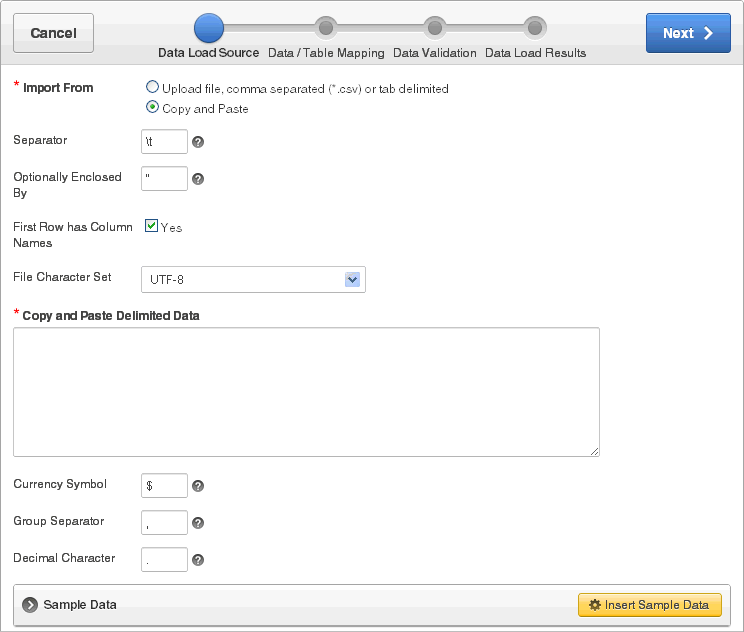
「データ・ロード・ソース」で次のステップを実行します。
インポート元: 「コピー・アンド・ペースト」を選択します。
セパレータ: 列セパレータ文字を入力します。タブ区切りには\tを使用します。
囲み文字(オプション): データ値の開始および終了の範囲を区切るデリミタ文字を入力します。
1行目に列名がある: 次のオプションがあります。
はい: 列名には、アップロードされたデータ・ファイルの最初の行の列名を使用します。
いいえ: 列名には、アップロードされたデータ・ファイルの列名は使用しません。
ファイルのキャラクタ・セット: コピーするデータに関連付けられているファイル・キャラクタ・セットを選択します。
区切りデータをコピー・アンド・ペースト: ページ下部の「サンプル・データを挿入」ボタンをクリックします。
「区切りデータをコピー・アンド・ペースト」フィールドに、サンプル・データが表示されます。
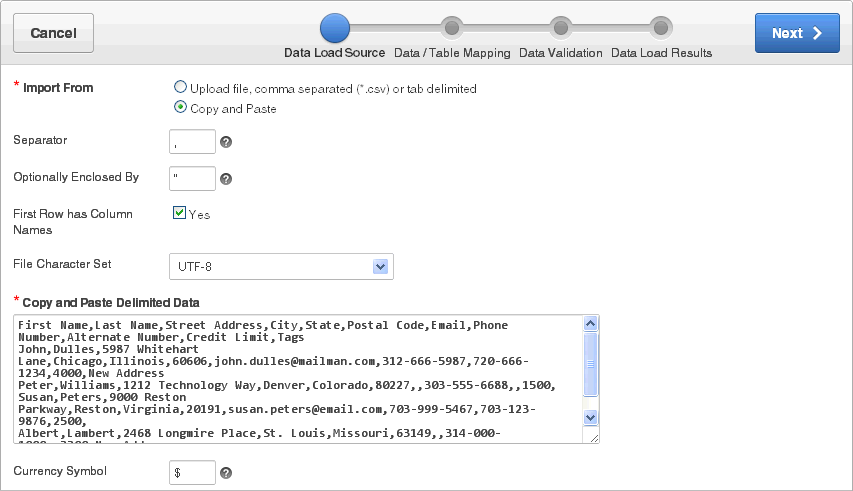
通貨記号: データに国際通貨記号が含まれている場合は、それをここに入力します。たとえば、データが$1,234.56または¥1,234.56の場合、$または¥を入力します。このようにしないと、データは正しくロードされない場合があります。
グループ・セパレータ: データにグループ・セパレータが含まれる場合、ここに入力します。グループ・セパレータとは、たとえば、千や100万などを示すために整数グループを区切る文字です。
グループ・セパレータには任意の文字を使用できます。指定した文字はシングルバイトで、グループ・セパレータは他の小数点文字とは異なる必要があります。これらの文字には、スペースは使用できますが、数字、プラス記号(+)、ハイフン(-)または小なり記号(<>)、大なり記号(>)は使用できません。
小数点文字: データに小数点文字が含まれる場合、ここに入力します。小数点文字は、数値の整数部と小数部を区切ります。少数点文字には任意の文字を使用できます。指定した文字はシングルバイトで、小数点文字は他の小数点文字とは異なる必要があります。これらの文字には、スペースは使用できますが、数字、プラス記号(+)、ハイフン(-)または小なり記号(<>)、大なり記号(>)は使用できません。
「次へ」をクリックします。
「データと表のマッピング」ページが表示されます。
「データと表のマッピング」では、次のステップを実行します。
列のマッピング: 宛先の列名が示されます。列名を変更するには、リストから新しい列名を選択します。列を非表示にするには、「ロードしない」を選択します。
日付/数値書式: 多くの標準化されている日付および数値書式は、自動解析され、データベースに渡されます。独自の書式を定義したい場合や、自動的に解析されない書式の場合、このフィールドを使用し独自のものを定義します。「自動的にサポートされている日付、タイムスタンプおよび数値書式」を参照してください。
「次へ」をクリックします。
「次へ」をクリックします。
すべての表参照およびトランスフォーメーション・ルールの適用後、挿入または更新されるデータを示す「データ検証」ページが表示されます。表参照およびトランスフォーメーション・ルールの詳細は、「データ・ロード・ウィザードの使用」を参照してください。
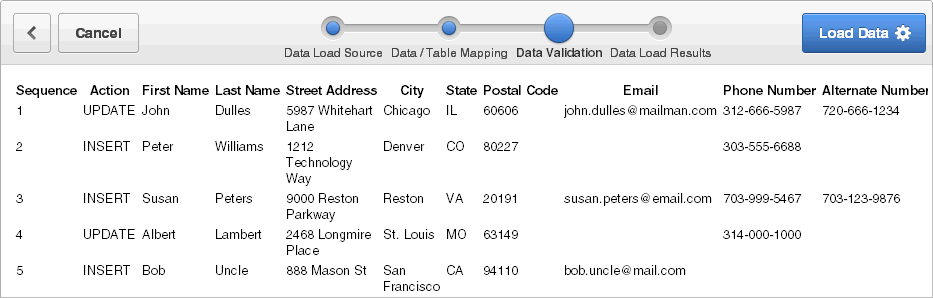
アップロードするデータを確認してデータ検証を行い、「データのロード」をクリックします。
「データ・ロード結果」ページが表示されます。
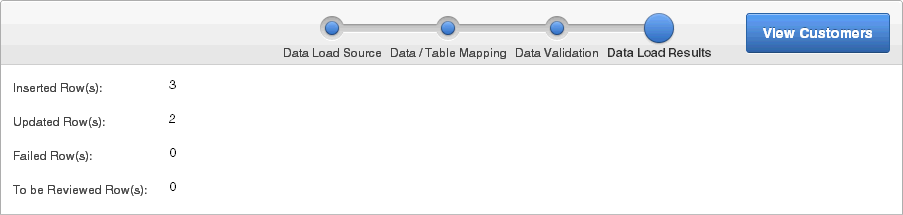
「データ・ロード結果」ページには、次が表示されます。
挿入された行: 表にアップロードされた新しい行です。
更新された行: 新しい情報で更新された表内の行数です。
失敗した行: 追加または更新されていないアップロード・ファイルからの行数です。
レビューの必要な行: レビューが必要な行数です。
「顧客」ページに戻るには、顧客の表示をクリックします。
データのアップロード時、次の日付、タイムスタンプおよび数値書式が自動解析され、データベースに渡されます。
自動的にサポートされている日付書式マスク
'MM/DD/RRRR'
'DD/MM/RRRR'
'DD/MM/RR'
'fmMM/DD/RRRR'
'fmDD/fmMM/RRRR'
'RRRR.MM.DD.'
'DD-MM-RR'
'DD.MM.RRRR'
'DD/MON/RR'
'RRRR-MM-DD'
'DD-MM-RRRR'
'fmDD/MM/RRRR'
'RRRR/MM/DD'
'DD.MM.RR'
'fmRRRR/MM/DD'
'fmDD.MM.RRRR'
'MM/DD/RRRR'
'RRRR.MM.DD'
'fmDD-MM-RRRR'
'RRRR-MM-DD"T"hh24:mi:ss'
自動的にサポートされているタイムスタンプ書式マスク
'DD/MM/RR HH24.MI.SSXFF'
'DD.MM.RR HH:MI:SSXFF PM'
'DD/MM/RR HH:MI:SSXFF PM'
'DD-MON-YYYY HH24:MI'
'DD-MON-YYYY HH24.MI.SSXFF'
'DD-MON-YYYY HH:MI:SSXFF PM'
'DD-MON-YYYY HH24:MI TZR'
'DD-MON-YYYY HH24.MI.SSXFF TZR'
'DD-MON-YYYY HH.MI.SSXFF PM TZR'
自動的にサポートされている数値書式マスク
'FML999G999G999G999G990D00'
'999G999G999G999G990D00'
'999G999G999G999G990D0000'
'999G999G999G999G999G999G990'
'999G999G999G999G990D00MI'
'S999G999G999G999G990D00'
'999G999G999G999G990D00PR'
