| Oracle® Database SQL言語リファレンス 12cリリース1 (12.1) B71278-13 |
|


 前 |
 次 |
構文
feature_value::=

分析の構文
feature_value_analytic::=

mining_attribute_clause:=
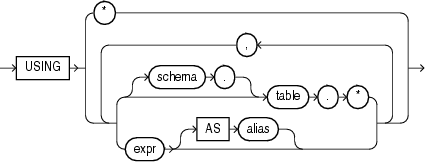
mining_analytic_clause::=

用途
FEATURE_VALUEは、選択内に含まれる各行の特徴の値を返します。この値は、最も値が大きい特徴または指定されたfeature_idを参照します。特徴の値は、BINARY_DOUBLEとして返されます。
構文の選択
FEATURE_VALUEは、2つの方法のどちらかでデータにスコアを付けます。1つの方法では、データにマイニング・モデル・オブジェクトを適用します。もう1つの方法では、1つ以上の一時マイニング・モデルを作成して適用する分析句を実行して動的にデータをマイニングします。構文または分析構文を選択します。
構文 — 事前に定義されたモデルでデータにスコアを付ける場合は、最初の構文を使用します。特徴抽出モデルの名前を指定します。
分析構文 — 事前定義されたモデルなしで、データにスコアを付ける場合は、分析構文を使用します。INTO n (nは、抽出する特徴の数)と、mining_analytic_clause (複数のモデル構築のためにデータをパーティション化する必要がある場合に指定します)を含めます。mining_analytic_clauseは、query_partition_clauseと、order_by_clauseをサポートします。("analytic_clause::="を参照。)
mining_attribute_clause
mining_attribute_clauseは、スコアの予測子として使用する列の属性を特定します。分析構文でファンクションが起動されると、このデータは一時モデルの構築にも使用されます。mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。("mining_attribute_clause::="を参照。)
|
関連項目:
|
|
例について: 次に示す例は、Data Miningのサンプル・プログラムからの抜粋です。サンプル・プログラムの詳細は、Oracle Data Miningユーザーズ・ガイドの「付録A」を参照してください。 |
例
次の例では、特徴3に対応する顧客を、一致する品質の順序で示します。
SELECT *
FROM (SELECT cust_id, FEATURE_VALUE(nmf_sh_sample, 3 USING *) match_quality
FROM nmf_sh_sample_apply_prepared
ORDER BY match_quality DESC)
WHERE ROWNUM < 11;
CUST_ID MATCH_QUALITY
---------- -------------
100210 19.4101627
100962 15.2482251
101151 14.5685197
101499 14.4186292
100363 14.4037396
100372 14.3335148
100982 14.1716545
101039 14.1079914
100759 14.0913761
100953 14.0799737
