| Oracle® Database SQL言語リファレンス 12cリリース1 (12.1) B71278-13 |
|


 前 |
 次 |
構文
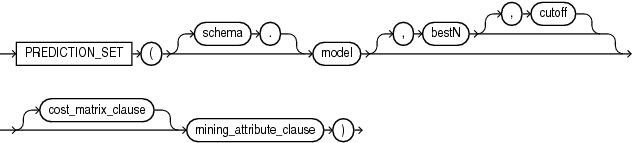
prediction_set::=
分析の構文
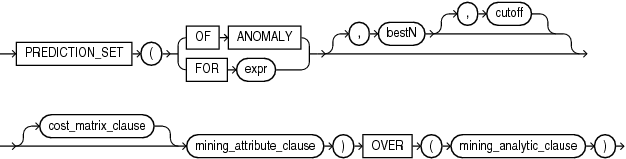
prediction_set_analytic::=
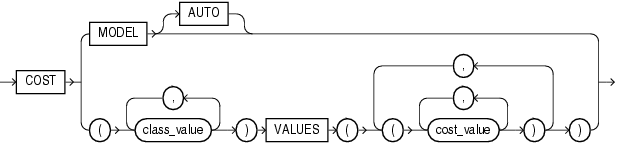
cost_matrix_clause::=
mining_attribute_clause::=
mining_analytic_clause::-

用途
PREDICTION_SETは、選択内に含まれる各行の確率またはコストとともに一連の予測を戻します。戻り値は、フィールド名がPREDICTION_IDおよびPROBABILITYまたはCOSTのオブジェクトのVARRAYです。予測識別子(ID)は、OracleのNUMBERです。確率とコストのフィールドは、BINARY_DOUBLEです。
PREDICTION_SETでは、分類または異常検出を実行できます。分類の場合、戻り値は予測されたターゲット・クラスを参照します。異常検出の場合、戻り値は分類1(通常の行)または0(異常な行)を参照します。
bestNおよびcutoff
bestNとcutoffを指定すると、このファンクションから返される予測の数を制限できます。デフォルトでは、bestNおよびcutoffがnullであり、すべての予測が戻されます。
bestNは、最も確率が高いか、コストが低いN個の予測です。N番目の確率またはコストを持つ予測が複数ある場合でも、ファンクションが選択するのはそのうち1つのみです。
cutoffは、値のしきい値です。cutoff以上の確率か、cutoff以下のコストの予測のみが返されます。cutoffのみでフィルタ処理するには、bestNにNULLを指定します。問合せに使用するcost_matrix_clauseにCOST MODEL AUTOを指定すると、cutoffは無視されます。
cutoffとともにbestNを指定して、cutoff以上の最も確率が高い最大N個の予測を戻すことができます。コストが使用される場合、cutoffとともにbestNを指定して、cutoff以下の最もコストが低い最大N個の予測を戻します。
cost_matrix_clause
最も悪影響を及ぼす誤分類を最小限に抑えるために、cost_matrix_clauseをバイアス係数として指定できます。cost_matrix_clauseは、「PREDICTION_COST」で説明されているように動作します。
構文の選択
PREDICTION_SETは、2つの方法のどちらかでデータにスコアを付けます。1つの方法では、データにマイニング・モデル・オブジェクトを適用します。もう1つの方法では、1つ以上の一時マイニング・モデルを作成して適用する分析句を実行して動的にデータをマイニングします。構文または分析構文を選択します。
構文 — 事前に定義されたモデルでデータにスコアを付ける場合は、最初の構文を使用します。分類または異常検出を実行するモデルの名前を指定します。
分析構文 — 事前定義されたモデルなしで、データにスコアを付ける場合は、分析構文を使用します。分析構文は、mining_analytic_clauseを使用します。これは、複数のモデル構築のためにデータをパーティション化する必要がある場合に指定します。mining_analytic_clauseは、query_partition_clauseとorder_by_clauseをサポートします。("analytic_clause::="を参照。)
分類の場合は、FOR exprを指定します。exprは、文字データ型のターゲット列を特定する式です。
異常検出の場合は、キーワードOF ANOMALYを指定します。
mining_attribute_clause
mining_attribute_clauseは、スコアの予測子として使用する列の属性を特定します。このファンクションが分析構文で起動された場合は、これらの予測子が一時モデルの構築にも使用されます。mining_attribute_clauseは、PREDICTIONファンクションと同様に動作します。("mining_attribute_clause::="を参照。)
|
関連項目:
|
|
例について: 次に示す例は、Data Miningのサンプル・プログラムからの抜粋です。サンプル・プログラムの詳細は、Oracle Data Miningユーザーズ・ガイドの「付録A」を参照してください。 |
例
この例では、100006より小さいIDを持つ顧客が提携カードを使用する予測とコストを示します。この例のターゲットはバイナリですが、このような問合せは低、中、高などの複数クラスの分類にも有効です。
SELECT T.cust_id, S.prediction, S.probability, S.cost
FROM (SELECT cust_id,
PREDICTION_SET(dt_sh_clas_sample COST MODEL USING *) pset
FROM mining_data_apply_v
WHERE cust_id < 100006) T,
TABLE(T.pset) S
ORDER BY cust_id, S.prediction;
CUST_ID PREDICTION PROBABILITY COST
---------- ---------- ------------ ------------
100001 0 .966183575 .270531401
100001 1 .033816425 .966183575
100002 0 .740384615 2.076923077
100002 1 .259615385 .740384615
100003 0 .909090909 .727272727
100003 1 .090909091 .909090909
100004 0 .909090909 .727272727
100004 1 .090909091 .909090909
100005 0 .272357724 5.821138211
100005 1 .727642276 .272357724
