| Oracle® Streams拡張例 12c リリース1 (12.1) B71330-02 |
|


 前 |
 次 |
この章では、Oracle Streamsを使用して構成できる簡単な単一ソース・レプリケーション環境の例を説明します。
この章の内容は次のとおりです。
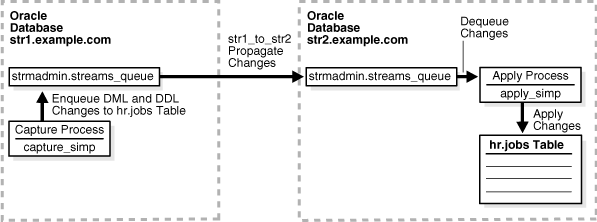
この章の例では、Oracle Streamsを使用して2つのデータベース間の1つの表でデータをレプリケートする方法を示します。取得プロセスによって、str1.example.com Oracle Databaseでhrスキーマ内のjobs表に対して行われたデータ操作言語(DML)変更およびデータ定義言語(DDL)変更が取得され、これらの変更が伝播によってstr2.example.com Oracle Databaseへ伝播されます。次に、適用プロセスによってこれらの変更がstr2.example.comデータベースで適用されます。この例では、hr.jobs表がstr2.example.comデータベースで読取り専用であることを想定しています。
図1-1に、この環境の概要を示します。
この章の例を開始する前に、前提条件となる次の作業を完了する必要があります。
GLOBAL_NAMES: Oracle Streams環境の各データベースで、このパラメータをTRUEに設定する必要があります。
COMPATIBLE: Oracle Streams環境の各データベースで、このパラメータを10.2.0以上に設定する必要があります。
STREAMS_POOL_SIZE: オプションで、このパラメータを環境内の各データベースの適切な値に設定します。このパラメータでは、Oracle Streamsプールのサイズを指定します。Oracle Streamsプールは、バッファ・キューにメッセージを格納し、パラレル取得およびパラレル適用中の内部通信に使用されます。MEMORY_TARGET、MEMORY_MAX_TARGETまたはSGA_TARGET初期化パラメータを0 (ゼロ)以外の値に設定した場合、Oracle Streamsプールのサイズは自動的に管理されます。
|
関連項目: Oracle Streams環境で重要なその他の初期化パラメータについては、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
取得される変更を生成するデータベースは、ARCHIVELOGモードで実行している必要があります。この例では、str1.example.comで変更が生成されるため、str1.example.comはARCHIVELOGモードで実行する必要があります。
|
関連項目: ARCHIVELOGモードでデータベースを実行する方法の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
ネットワークとOracle Netを、str1.example.comデータベースがstr2.example.comデータベースと通信できるように構成します。
|
関連項目: 『Oracle Database Net Services管理者ガイド』 |
レプリケーション環境の各データベースでOracle Streams管理者を作成します。この例では、データベースstr1.example.comおよびstr2.example.comで作成します。この例では、Oracle Streams管理者のユーザー名がstrmadminであると想定しています。
|
関連項目: Oracle Streams管理者を作成する方法は、『Oracle Streamsレプリケーション管理者ガイド』を参照してください。 |
次の手順を実行して、2つのOracle Databaseを含むOracle Streamsレプリケーション環境にキューおよびデータベース・リンクを作成します。
|
注意: このマニュアルをオンラインで参照している場合、この注意の後にある「BEGINNING OF SCRIPT」の行から次の「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーし、テキストを編集してご使用の環境用のスクリプトを作成できます。環境内のすべてのデータベースに接続可能なコンピュータで、SQL*Plusを使用してスクリプトを実行します。 |
/************************* BEGINNING OF SCRIPT ******************************
SET ECHO ONを実行し、スクリプトのスプール・ファイルを指定します。このスクリプトの実行後に、スプール・ファイルにエラーがないかをチェックします。
*/ SET ECHO ON SPOOL streams_setup_simple.out /*
変更を取得するデータベースにOracle Streams管理者として接続します。この例では、データベースstr1.example.comに接続します。
*/ CONNECT strmadmin@str1.example.com /*
SET_UP_QUEUEプロシージャを実行して、str1.example.comでstreams_queueというキューを作成します。このキューはANYDATAキューとして動作し、他のデータベースに伝播される取得された変更を保持します。
SET_UP_QUEUEプロシージャを実行すると、次のアクションが実行されます。
streams_queue_tableというキュー表の作成。このキュー表は、Oracle Streams管理者(strmadmin)が所有し、このユーザーのデフォルトの記憶域を使用します。
Oracle Streams管理者(strmadmin)が所有するstreams_queueというキューの作成。
キューの起動。
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
変更が取得されるデータベースから変更が伝播されるデータベースにデータベース・リンクを作成します。この例では、変更が取得されるデータベースはstr1.example.comで、これらの変更はstr2.example.comに伝播されます。
*/ ACCEPT password PROMPT 'Enter password for user: ' HIDE CREATE DATABASE LINK str2.example.com CONNECT TO strmadmin IDENTIFIED BY &password USING 'str2.example.com'; /*
Oracle Streams管理者としてstr2.example.comに接続します。
*/ CONNECT strmadmin@str2.example.com /*
SET_UP_QUEUEプロシージャを実行して、str2.example.comでstreams_queueというキューを作成します。このキューはANYDATAキューとして動作し、このデータベースに適用される変更を保持します。
SET_UP_QUEUEプロシージャを実行すると、次のアクションが実行されます。
streams_queue_tableというキュー表の作成。このキュー表は、Oracle Streams管理者(strmadmin)が所有し、このユーザーのデフォルトの記憶域を使用します。
Oracle Streams管理者(strmadmin)が所有するstreams_queueというキューの作成。
キューの起動。
*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
streams_setup_simple.outスプール・ファイルをチェックして、このスクリプトの完了後にすべてのアクションが正常に終了していることを確認します。
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
次の手順を実行して、DBMS_STEAMS_ADMパッケージを使用したhr.jobs表の取得、伝播および適用の定義を指定します。
|
注意: このマニュアルをオンラインで参照している場合、この注意の後にある「BEGINNING OF SCRIPT」の行から次の「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーし、テキストを編集してご使用の環境用のスクリプトを作成できます。環境内のすべてのデータベースに接続可能なコンピュータで、SQL*Plusを使用してスクリプトを実行します。 |
/************************* BEGINNING OF SCRIPT ******************************
SET ECHO ONを実行し、スクリプトのスプール・ファイルを指定します。このスクリプトの実行後に、スプール・ファイルにエラーがないかをチェックします。
*/ SET ECHO ON SPOOL streams_share_jobs.out /*
strmadminユーザーとしてstr1.example.comに接続します。
*/ CONNECT strmadmin@str1.example.com /*
str1.example.comのキューからstr2.example.comのキューへのhr.jobs表に対するDML変更およびDDL変更の伝播を構成およびスケジュールします。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES(
table_name => 'hr.jobs',
streams_name => 'str1_to_str2',
source_queue_name => 'strmadmin.streams_queue',
destination_queue_name => 'strmadmin.streams_queue@str2.example.com',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'str1.example.com',
inclusion_rule => TRUE,
queue_to_queue => TRUE);
END;
/
/*
str1.example.comでhr.jobs表に対する変更を取得するように取得プロセスを構成します。この手順では、この表に対する変更が取得プロセスによって取得され、指定したキューにエンキューされるように指定します。
また、この手順では、hr.jobs表をインスタンス化のために準備し、この表のすべての主キー列、一意キー列、ビットマップ索引列および外部キー列のサプリメンタル・ロギングを有効にします。サプリメンタル・ロギングによって、表に対する変更の追加の情報がREDOログに記録されます。適用プロセスでは、一意の行の識別や競合解消など、一部の操作を実行するために、この追加情報が必要です。この環境では、str1.example.comでのみ変更が取得されるため、hr.jobs表に対してサプリメンタル・ロギングを有効化する必要があるのはこのデータベースのみです。
|
関連項目: 『Oracle Streamsレプリケーション管理者ガイド』 |
*/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.jobs',
streams_type => 'capture',
streams_name => 'capture_simp',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
inclusion_rule => TRUE);
END;
/
/*
この例では、hr.jobs表がstr1.example.comデータベースとstr2.example.comデータベースの両方に存在し、この表がこれらのデータベースで同期化されると想定しています。hr.jobs表はstr2.example.comにすでに存在するため、この例ではstr1.example.comでDBMS_FLASHBACKパッケージのGET_SYSTEM_CHANGE_NUMBERファンクションを使用して、ソース・データベースの現行のSCNを取得します。このSCNは、str2.example.comでDBMS_APPLY_ADMパッケージのSET_TABLE_INSTANTIATION_SCNプロシージャを実行するために使用されます。このプロシージャを実行して、str2.example.comのhr.jobs表にインスタンス化SCNを設定します。
SET_TABLE_INSTANTIATION_SCNプロシージャを使用すると、適用プロセスで無視される表のLCRと、適用プロセスで適用される表のLCRを制御できます。ソース・データベースからの表に関するLCRのコミットSCNが、接続先データベースでその表のインスタンス化SCN以下であれば、接続先データベースの適用プロセスではLCRが廃棄されます。それ以外の場合は、適用プロセスによってLCRが適用されます。
この例では、str2.example.comの適用プロセスはいずれも、この手順で取得したSCNの後にコミットされたSCNを持つhr.jobs表にトランザクションを適用します。
|
注意: この例では、str1.example.comとstr2.example.comのhr.jobs表の内容は、この手順の実行時に一貫性があると想定しています。インスタンス化SCNの設定中に、この表でのアクティビティがないことを確認します。一貫性を確保するために、この手順の実行中に各データベースの表をロックすることをお薦めします。接続先データベースに表が存在しない場合は、エクスポート/インポートを使用してインスタンス化できます。 |
*/
DECLARE
iscn NUMBER; -- Variable to hold instantiation SCN value
BEGIN
iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER();
DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@STR2.EXAMPLE.COM(
source_object_name => 'hr.jobs',
source_database_name => 'str1.example.com',
instantiation_scn => iscn);
END;
/
/*
strmadminユーザーとしてstr2.example.comに接続します。
*/ CONNECT strmadmin@str2.example.com /*
hr.jobs表に変更を適用するようにstr2.example.comを構成します。
*/
BEGIN
DBMS_STREAMS_ADM.ADD_TABLE_RULES(
table_name => 'hr.jobs',
streams_type => 'apply',
streams_name => 'apply_simp',
queue_name => 'strmadmin.streams_queue',
include_dml => TRUE,
include_ddl => TRUE,
source_database => 'str1.example.com',
inclusion_rule => TRUE);
END;
/
/*
エラーが発生した場合に適用プロセスが無効化されないように、disable_on_errorパラメータをnに設定して、str2.example.comで適用プロセスを起動します。
*/
BEGIN
DBMS_APPLY_ADM.SET_PARAMETER(
apply_name => 'apply_simp',
parameter => 'disable_on_error',
value => 'N');
END;
/
BEGIN
DBMS_APPLY_ADM.START_APPLY(
apply_name => 'apply_simp');
END;
/
/*
strmadminユーザーとしてstr1.example.comに接続します。
*/ CONNECT strmadmin@str1.example.com /*
str1.example.comで取得プロセスを起動します。
*/
BEGIN
DBMS_CAPTURE_ADM.START_CAPTURE(
capture_name => 'capture_simp');
END;
/
/*
streams_share_jobs.outスプール・ファイルをチェックして、このスクリプトの完了後にすべてのアクションが正常に終了していることを確認します。
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
次の手順を実行して、str1.example.comのhr.jobs表にDML変更およびDDL変更を行い、str1.example.comでそれらの変更が取得され、str1.example.comからstr2.example.comに伝播され、str2.example.comのhr.jobs表に適用されることを確認します。
hr.jobs表に次の変更を行います。
CONNECT hr@str1.example.com
Enter password: password
UPDATE hr.jobs SET max_salary=9545 WHERE job_id='PR_REP';
COMMIT;
ALTER TABLE hr.jobs ADD(duties VARCHAR2(4000));
前述の手順で行った変更が取得、伝播および適用されてから、次の問合せを実行して、UPDATE変更が伝播されstr2.example.comで適用されていることを確認します。
CONNECT hr@str2.example.com
Enter password: password
SELECT * FROM hr.jobs WHERE job_id='PR_REP';
max_salary列の値が9545であるはずです。
次に、hr.jobs表の定義を表示して、ALTER TABLE変更が伝播されstr2.example.comで適用されていることを確認します。
DESC hr.jobs
duties列が最終列であるはずです。