This diagram illustrates a cluster of Big Data Discovery nodes deployed on top of an existing CDH cluster.
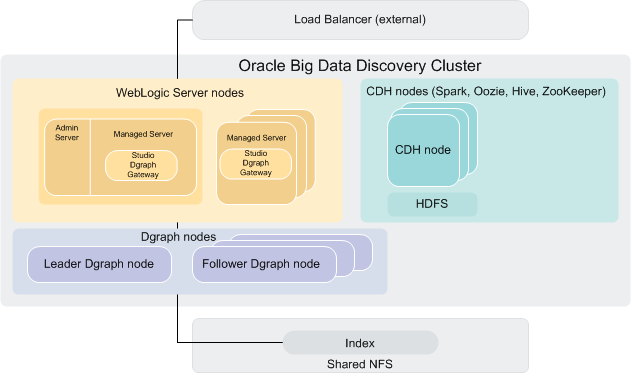
This diagram depicts a suggested deployment topology for production, although many configurations are possible. For information on staging and learning, demo and production-level deployment topology, see the Installation and Deployment Guide.
In this diagram,
starting from the top, the following components of the Big Data Discovery
cluster deployment are included:
- An optional external load
balancer serves as the single point of entry to the Big Data Discovery cluster.
All browser requests are routed through this load balancer to Studio nodes.
Note: Although it is recommended to use an external load balancer in your deployment, it is optional. For information, see Load balancing and routing of requests.
- The Big Data Discovery
cluster comprises three categories of nodes:
- Nodes that host WebLogic Server with Studio and Dgraph Gateway.
- CDH only nodes. These nodes do not host WebLogic Server or Dgraph instances. They run Data Processing jobs, within a Big Data Discovery deployment.
- Dgraph nodes. These nodes are solely dedicated to hosting Dgraph instances.
- WebLogic Server nodes. These nodes represent machines on which WebLogic Server is deployed that is hosting two Java applications — Studio and Dgraph Gateway. Note that WebLogic Server nodes and Dgraph nodes can be stopped and started independently of each other, although in practice both must be running in order to service requests.
- CDH nodes. Big Data Discovery is deployed on top of an existing CDH (or Hadoop) cluster. This diagram shows only those CDH nodes on which BDD is deployed. These CDH nodes represent a subset of the entire pre-existing CDH cluster, onto which BDD is deployed. These nodes have both CDH and BDD installation on them and share access to HDFS. Optimally, three CDH nodes are required for hosting ZooKeeper instances. ZooKeeper maintains a cluster state for all participating members of the Big Data Discovery cluster, in particular, it ensures automatic Dgraph leader node election, in case the leader Dgraph node fails.
- Dgraph nodes. These nodes form a Dgraph cluster that is part of the larger BDD cluster deployment. One node serves as the leader Dgraph node, and the remaining nodes are follower Dgraph nodes. All nodes in the Dgraph cluster have write access to a shared file system (NFS) on which the index is stored. Only the leader Dgraph node writes to the index located on the file system. Follower Dgraph nodes can only read from the index. The index includes internal indexes for each of the data sets in BDD.
- Enterprise Manager for Big Data Discovery is not shown on this diagram. It can be optionally used with any Big Data Discovery deployment. When used, Enterprise Manager is installed on a separate WebLogic Server. For more information, see Using the Enterprise Manager for Big Data Discovery.
