Data Processing collectively refers to a set of processes and jobs, all launched by Big Data Discovery once it is deployed. Many of these processes run in Hadoop and perform discovery, sampling, profiling, and enrichment of source data.
Data Processing Workflow
- Discovery of source data in Hive tables
- Loading and creating a sample of a data set
- Running a select set of enrichments on this data set
- Profiling the data
- Transforming the data set
- Exporting data from Big Data Discovery into Hadoop
More information on some of these topics is found below.
You launch the data processing workflow either from Studio (by creating a Hive table), or by running the Data Processing CLI (Command Line Interface) utility. As a Hadoop system administrator, you can control some parts of the data processing workflow.
The following diagram illustrates how the data processing workflow fits within the larger picture of Big Data Discovery:
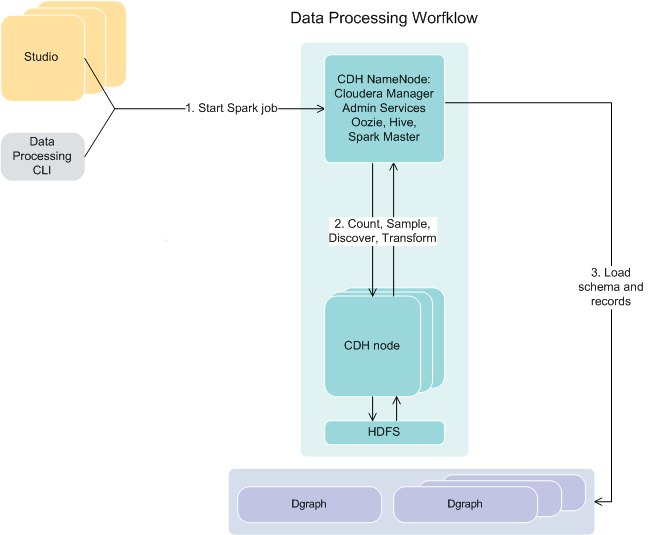
- The data processing workflow starts either from Studio (automatically), or when you run the Data Processing CLI.
- The Spark job is launched on those CDH NameNodes on which Big Data Discovery is installed.
- The counting, sampling, discovery and transformations take place and are processed on CDH nodes. The information is written to HDFS and sent back.
- Next, the data processing workflow launches the process of loading the records and their schema into the Dgraph, for each discovered source data set.
Sampling of a data set
During data processing, Big Data Discovery discovers data in Hive tables, and performs data set sampling and initial data profiling using enrichments.
Working with data at very large scales causes latency and reduces the interactivity of data analysis. To avoid these issues in Big Data Discovery, you work with a sampled subset of the records from large tables discovered in HDFS. Using sample data as a proxy for the full tables, you can analyze the data as if using the full set.
During data processing, a random sample of the data is taken. The default sample size is 1 million records. Administrators can adjust the sample size.
- Every element has the same probability of being chosen, and
- Each subset of the same size has an equal probability of being chosen.
These requirements, combined with the large absolute size of the data sample, mean that samples taken by Big Data Discovery allow for making reliable generalizations to the entire corpus of data.
Profiling of a data set
Profiling is a process that determines the characteristics (columns) in the Hive tables, for each source Hive table discovered by Big Data Discovery during data processing.
- Attribute value distributions
- Attribute type
- Topics
- Classification
Using Explore in Studio, you can then look deeper into the distribution of attribute values or types. Later, using Transform, you can change some of these metadata. For example, you can replace null attribute values with actual values, or fix other inconsistencies.
Enrichments
Enrichments are derived from a data set's additional information such as terms, locations, the language used, sentiment, and views. Big Data Discovery determines which enrichments are useful for each discovered data set, and automatically runs them on samples of the data. As a result of automatically applied enrichments, additional derived metadata (columns) are added to the data set, such as geographic data, a suggestion of the detected language, or positive or negative sentiment.
The data sets with this additional information appear in Catalog in Studio. This provides initial insight into each discovered data set, and lets you decide if the data set is a useful candidate for further exploration and analysis.
In addition to automatically-applied enrichments, you can also apply enrichments using Transform in Studio, for a project data set. From Transform, you can configure parameters for each type of enrichment. In this case, an enrichment is simply another type of available transformation.
Some enrichments allow you to add additional derived meaning to your data sets, while others allow you to address invalid or inconsistent values.
Transformations
- Changing data types
- Changing capitalization of values
- Removing attributes or records
- Splitting columns
- Grouping or binning values
- Extracting information from values
Transformations can be thought of as a substitute for an ETL process of cleaning your data before or during the data loading process. Transformations can be used to overwrite an existing attribute, or create new attributes.
Most transformations are available directly as specific options in Transform in Studio. Some transformations are enrichments.
The custom transformation option lets you use the Groovy scripting language and a list of custom, predefined Groovy functions available in Big Data Discovery, to create a transformation formula.
Exporting data from Big Data Discovery into HDFS
You can export the results of your analysis from Big Data Discovery into HDFS/Hive, this is known as exporting to HDFS.
From the perspective of Big Data Discovery, the process is about exporting the files from Big Data Discovery into HDFS/Hive. From the perspective of HDFS, you are importing the results of your work from Big Data Discovery into HDFS. In Big Data Discovery, the Dgraph HDFS Agent is responsible for exporting to HDFS and importing from it.
