| Oracle® Big Data Applianceソフトウェア・ユーザーズ・ガイド リリース4 (4.0) E57728-01 |
|


 前 |
 次 |
この章では、Oracle Big Data Appliance上でMapReduceジョブを実行、またはOracle Big Data Connectorsを使用しているユーザーをサポートする方法について説明します。次の項について説明します。
Apache Hadoopは、本質的に安全なシステムではありません。ネットワーク・セキュリティによってのみ保護されています。接続が確立されると、クライアントはシステムに対して完全なアクセス権限を取得します。
こうしたオープンな環境に対処するために、Oracle Big Data Applianceは、ソフトウェア・インストールのオプションとしてKerberosセキュリティをサポートしています。Kerberosは、悪質な偽装の防止に効果的なネットワーク認証プロトコルです。
Kerberosを使用するように構成された場合、CDHは次のセキュリティを提供します。
CDHマスター・ノード、NameNodeおよびJournalNodeでグループ名を解決し、ユーザーがグループのメンバーシップを操作できないようにします。
マップ・タスクはジョブを発行したユーザーのアイデンティティの下で実行されます。
Oracle Big Data ApplianceクラスタをKerberosで保護する場合には、この章で説明するように、CDHクライアントと個々のユーザーを認証するための追加の手順が必要です。ユーザーは、Kerberosユーザー名、パスワードおよびレルムを把握している必要があります。
表3-1では、よく使用されるKerberosのコマンドについて説明します。詳細は、MITのKerberosに関するドキュメントを参照してください。
表3-1 Kerberosのユーザー・コマンド
| コマンド | 説明 |
|---|---|
|
|
Kerberosチケットを取得します。 |
|
|
すでにチケットがある場合に、Kerberosチケットをリストします。 |
|
|
有効期限が切れる前にチケットを無効にします。 |
|
|
パスワードを変更します。 |
|
関連項目:
|
Oracle Big Data Applianceでは、Cloudera's Distribution including Apache Hadoop (CDH)のすべてのコマンドおよびユーティリティに対する完全なローカル・アクセスをサポートしています。
Oracle Big Data Applianceのクライアント・ネットワークにアクセスできる任意のコンピュータ上でブラウザを使用すれば、Cloudera Manager、Hadoop Map/Reduce Administration、Hadoop Task TrackerインタフェースなどのブラウザベースのHadoopツールにアクセスできます。
ただし、リモートでHadoopコマンドを発行するには、CDHクライアントとして構成され、Oracle Big Data Applianceクライアント・ネットワークへのアクセス権を持つシステムから接続する必要があります。この項では、HDFSにアクセスしてOracle Big Data Appliance上でMapReduceジョブを発行できるよう、コンピュータを設定する方法について説明します。
|
関連項目: My Oracle Support ID 1506203.1 |
次の前提条件を満たしていることを確認します。
次のアクセス権限を持っている必要があります。
クライアント・システムへのsudoアクセス権
Cloudera Managerへのログイン・アクセス権
これらの権限がない場合は、社内のシステム管理者にお問い合せください。
クライアント・システムが、ClouderaでCDH5用にサポートされているオペレーティング・システムを実行している必要があります。次の場所にある『Cloudera CDH5 Installation Guide』を参照してください。
クライアント・システムが、Oracle JDK 1.7.0_25以上を実行している必要があります。
バージョンを確認するには、次のコマンドを使用します。
$ java -version
java version "1.7.0_25"
Java(TM) SE Runtime Environment (build 1.7.0_25-b15)
Java HotSpot(TM) 64-Bit Server VM (build 23.25-b01, mixed mode)
どちらのエンジニアド・システムでも同じオペレーティング・システム(Linux 5.xまたは6.x)が使用される場合には、Oracle Exadata Database Machineをクライアントとして使用するときにOracle Big Data Appliance上のRPMファイルを使用できます。ローカル・ネットワーク内でファイルをコピーするほうが、Cloudera Webサイトからダウンロードするよりも高速です。
|
注意: 以下のステップでは、version_numberを、ファイル名の欠けた部分(cdh5.0.0+28-1.cdh5.0.0.p0.36.el6など)と置き換えてください。 |
Oracle Exadata Database Machine上にCDHクライアントをインストールするには、次の手順に従います。
Exadataデータベース・サーバーにログインします。
ExadataシステムにHadoopがインストールされていないことを確認します。
rpm -qa | grep hadoop
rpmコマンドが値を返した場合は、次のように既存のHadoopソフトウェアを削除します。
rpm -e hadoop_rpm
次のLinux RPMを、Oracle Big Data Applianceの第1サーバーからデータベース・サーバーにコピーします。RPMは、/opt/oracle/BDAMammoth/bdarepo/RPMS/x86_64ディレクトリに置かれています。
ed-version_number.x86_64.rpm
m4-version_number.x86_64.rpm
nc-version_number.x86_64.rpm
redhat-lsb-version_number.x86_64.rpm
ステップ4でコピーしたOracle Linux RPMを、すべてのデータベース・ノードにインストールします。次に例を示します。
sudo yum --nogpgcheck localinstall ed-1.1-3.3.el6.x86_64.rpm sudo yum --nogpgcheck localinstall m4-1.4.13-5.el6.x86_64.rpm sudo yum --nogpgcheck localinstall nc-1.84-22.el6.x86_64.rpm sudo yum --nogpgcheck localinstall redhat-lsb-4.0-7.0.1.el6.x86_64.rpm
CDH RPMをインストールする前に、必ずOracle Linux RPMをインストールしてください。
次のCDH RPMを、/opt/oracle/BDAMammoth/bdarepo/RPMS/noarchディレクトリからコピーします。
bigtop-utils-version_number.noarch.rpm
次のCDH RPMを、/opt/oracle/BDAMammoth/bdarepo/RPMS/x86_64ディレクトリからコピーします。
zookeeper-version_number.noarch.rpm
hadoop-version_number.x86_64.rpm
bigtop-jsvc-version_number.x86_64.rpm
hadoop-hdfs-version_number.x86_64.rpm
hadoop-0.20-mapreduce-version_number.x86_64.rpm
hadoop-yarn-version_number.x86_64.rpm
hadoop-mapreduce-version_number.x86_64.rpm
hadoop-client-version_number.x86_64.rpm
CDH RPMを、ステップ6と7で示したのとまったく同じ順序で、すべてのサーバーにインストールします。次に例を示します。
rpm -ihv bigtop-utils-0.7.0+cdh5.0.0+0-1.cdh5.0.0.p0.36.el6.noarch.rpm rpm -ihv zookeeper-3.4.5+cdh5.0.0+28-1.cdh5.0.0.p0.36.el6.x86_64.rpm rpm -ihv hadoop-2.3.0+cdh5.0.0+548-1.cdh5.0.0.p0.69.el6.x86_64.rpm rpm -ihv bigtop-jsvc-0.6.0+cdh5.0.0+427-1.cdh5.0.0.p0.34.el6.x86_64.rpm rpm -ihv hadoop-hdfs-2.3.0+cdh5.0.0+548-1.cdh5.0.0.p0.69.el6.x86_64.rpm rpm -ihv hadoop-0.20-mapreduce-2.3.0+cdh5.0.0+548-1.cdh5.0.0.p0.69.el6.x86_64.rpm rpm -ihv hadoop-yarn-2.3.0+cdh5.0.0+548-1.cdh5.0.0.p0.69.el6.x86_64.rpm rpm -ihv hadoop-mapreduce-2.3.0+cdh5.0.0+548-1.cdh5.0.0.p0.69.el6.x86_64.rpm rpm -ihv hadoop-client-2.3.0+cdh5.0.0+548-1.cdh5.0.0.p0.69.el6.x86_64.rpm
CDHクライアントを構成します。「保護されていないクラスタ用のCDHクライアントの構成」を参照してください。
CDHクライアントを、Clouderaでのサポート対象として識別されたすべてのオペレーティング・システムにインストールするには、次の指示に従います。
CDHクライアント・ソフトウェアをインストールするには、次の手順を実行します。
クライアント・システムにログインします。
以前のバージョンのHadoopがすでにインストールされている場合には、削除します。
CDH4の削除については、次の場所にあるClouderaのドキュメントを参照してください。
ClouderaのWebサイトからCDH5ソフトウェアをダウンロードします。
$ wget http://archive-primary.cloudera.com/cdh5/cdh/5/hadoop-2.3.0-cdh5.0.0.tar.gz
ファイルを常設の場所に解凍します。これがHadoopのホーム・ディレクトリになります。次のコマンドは、現在のディレクトリでhadoop-2.3.0-cdh5.0.0にファイルを解凍します。
tar -xvzf hadoop-2.3.0-cdh5.0.0.tar.gz
CDHクライアントを構成します。「保護されていないクラスタ用のCDHクライアントの構成」を参照してください。
CDHをインストールしたら、Oracle Big Data Applianceを操作できるように構成する必要があります。
Hadoopクライアントを構成するには、次の手順を実行します。
クライアント・システムにログインし、Cloudera ManagerからMapReduceクライアント構成をダウンロードします。次の例では、Cloudera Managerがbda01node03.example.comのポート7180 (デフォルト)でリスニングしており、構成yarn-conf.zipというファイルに格納されています。
$ wget -O yarn-conf.zip http://bda01node03.example.com:7180/cmf/services/3/client-config
mapreduce-config.zipをクライアント・システム上の常設の場所に解凍します。
$ unzip yarn-config.zip
Archive: yarn-config.zip
inflating: yarn-conf/hadoop-env.sh
inflating: yarn-conf/hdfs-site.xml
inflating: yarn-conf/core-site.xml
inflating: yarn-conf/mapred-site.xml
inflating: yarn-conf/log4j.properties
inflating: yarn-conf/yarn-site.xml
すべてのファイルは、yarn-configという名前のサブディレクトリに格納されます。
hadoop-env.shをテキスト・エディタで開き、環境変数をシステム上の実際のパスに設定します。
export HADOOP_HOME=hadoop-home-dir/share/hadoop/mapreduce1 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=yarn-conf-dir export JAVA_HOME=/usr/java/version ln -s $HADOOP_HOME/../../../bin-mapreduce1 $HADOOP_HOME/bin ln -s $HADOOP_HOME/../../../etc/hadoop-mapreduce1 $HADOOP_HOME/conf rm -f $HADOOP_HOME/lib/slf4j-log4j*jar alias hadoop=$HADOOP_HOME/bin/hadoop alias hdfs=$HADOOP_HOME/../../../bin/hdfs
Hadoop構成ファイルのバックアップ・コピーを作成します。
# cp /full_path/yarn-conf /full_path/yarn-conf-bak
ステップ2でダウンロードした構成ファイルで既存の構成ファイルを上書きします。
# cd /full_path/yarn-conf
# cp * /usr/lib/hadoop/conf
CDHクライアントをセキュアなCDHクラスタで動作できるようにするには、次の手順に従います。
Kerberos用にCDHクライアントを構成するには、次の手順を実行します。
CDHクライアントを作成するシステムにログインします。
Java Cryptography Extension Unlimited Strength Jurisdiction Policy Filesをインストールします。
使用しているJavaのバージョン用のファイルをダウンロードします。
Java 6: http://www.oracle.com/technetwork/java/javase/downloads/jce-6-download-429243.html
Java 7: http://www.oracle.com/technetwork/java/javase/downloads/jce-7-download-432124.html
ダウンロードしたファイルを解凍します。この例では、JCE-7を解凍しています。
$ unzip UnlimitedJCEPolicyJDK7.zip
Archive: UnlimitedJCEPolicyJDK7.zip
creating: UnlimitedJCEPolicy/
inflating: UnlimitedJCEPolicy/US_export_policy.jar
inflating: UnlimitedJCEPolicy/local_policy.jar
inflating: UnlimitedJCEPolicy/README.txt
|
注意: JCE-6ファイルが、UnlimitedJCEPolicyではなくjceという名前のディレクトリに解凍されます。 |
解凍されたファイルをJavaのセキュリティ・ディレクトリにコピーします。次に例を示します。
$ cp UnlimitedJCEPolicy/* /usr/java/latest/jre/lib/security/
保護されていないクライアントを構成する手順に従います。
「保護されていないクラスタ用のCDHクライアントの構成」を参照してください。
Kerberosレルムに追加されているCDHクラスタのユーザーIDがあることを確認します。
「Hadoopクラスタ・ユーザーの作成」を参照してください。
CDHクライアント・システムで、$HADOOP_CONF_DIRディレクトリにkrb5.confという名前のファイルを作成します。インストール環境に応じ、サーバー名、ドメインおよびレルムに適した値を使用して次のように構成設定を入力します。
[libdefaults]
default_realm = EXAMPLE.COM
dns_lookup_realm = false
dns_lookup_kdc = false
clockskew = 3600
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
[realms]
EXAMPLE.COM = {
kdc = bda01node01.example:88
admin_server = bda01node07:749
default_domain = example.com
}
[domain_realm]
.com = EXAMPLE.COM
新しい構成ファイルを有効にします。
export KRB5_CONFIG=$HADOOP_CONF_DIR/krb5.conf export HADOOP_OPTS="-Djava.security.krb5.conf=$HADOOP_CONF_DIR/krb5.conf" export KRB5CCNAME=$HADOOP_CONF_DIR/krb5cc_$USER
Oracle Big Data Applianceクラスタへのアクセス権があることを確認します。
「CDHクライアントからクラスタへのアクセス権の確認」を参照してください。
Oracle Big Data Applianceクラスタへのアクセス権があることを確認するには、次の手順に従います。
クラスタのアクセス権を確認するには、次の手順を実行します。
Kerberosで保護されたCDHクラスタにアクセスするには、まずチケット発行チケット(TGT)を取得します。
$ kinit userid@realm
次のような簡単なHadoopファイル・システム・コマンドを入力して、クライアントからOracle Big Data ApplianceのHDFSにアクセスできることを確認します。
$ hadoop fs -ls /user
Found 6 items
drwxr-xr-x - jdoe hadoop 0 2014-04-03 00:08 /user/jdoe
drwxrwxrwx - mapred hadoop 0 2014-04-02 23:25 /user/history
drwxr-xr-x - hive supergroup 0 2014-04-02 23:27 /user/hive
drwxrwxr-x - impala impala 0 2014-04-03 10:45 /user/impala
drwxr-xr-x - oozie hadoop 0 2014-04-02 23:27 /user/oozie
drwxr-xr-x - oracle hadoop 0 2014-04-03 11:49 /user/oracle
クライアント・システムではなく、Oracle Big Data Applianceで定義されているHDFSユーザーに対する出力を確認します。Oracle Big Data Appliance上で直接コマンドを入力した場合と同じ結果が表示されます。
MapReduceジョブを発行します。Oracle Big Data Appliance上のHDFSユーザー名と同じユーザー名でクライアント・システムにログインする必要があります。
次の例では、piの値を算出します。
$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples-2.3.0-cdh5.0.0.jar pi 10 1000000
Number of Maps = 10
Samples per Map = 1000000
Wrote input for Map #0
Wrote input for Map #1
.
.
.
Job Finished in 12.403 seconds
Estimated value of Pi is 3.14158440000000000000
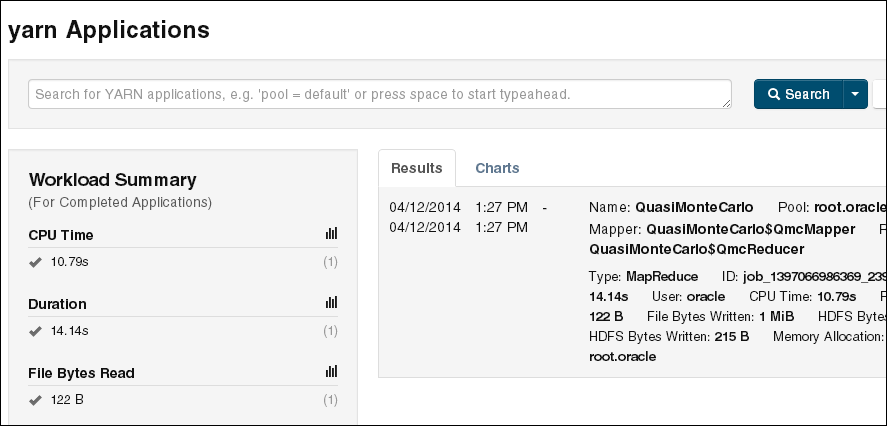
Cloudera Managerを使用して、ローカル・システムではなくOracle Big Data Applianceでジョブが実行されたことを確認します。「Activities」メニューから「mapreduce Jobs」を選択してジョブのリストを表示します。
図3-1に、前述の例で作成されたジョブを示します。
Hiveへのリモート・クライアント・アクセス権を提供するには、次の手順に従います。
Hiveクライアントを設定するには、次の手順を実行します。
CDHクライアントを設定します。「CDHへのリモート・クライアント・アクセスの提供」を参照してください。
クライアント・システムにログインし、Cloudera ManagerからHiveクライアント構成をダウンロードします。次の例では、Cloudera Managerがbda01node03.example.comのポート7180 (デフォルト)でリスニングしており、構成はhive-conf.zipというファイルに格納されています。
$ wget -O hive-conf.zip http://bda01node03.example.com:7180/cmf/services/5/client-config
Length: 1283 (1.3K) [application/zip]
Saving to: 'hive-conf.zip'
100%[======================================>] 1,283 --.-K/s in 0.001s
2014-05-15 08:19:06 (2.17 MB/s) - `hive-conf.zip' saved [1283/1283]
ファイルを常設のインストール・ディレクトリに解凍します。これがHive構成ディレクトリになります。
$ unzip hive-conf.zip
Archive: hive-conf.zip
inflating: hive-conf/hive-env.sh
inflating: hive-conf/hive-site.xml
ClouderaのWebサイトからHiveソフトウェアをダウンロードします。
$ wget http://archive.cloudera.com/cdh5/cdh/5/hive-0.12.0-cdh5.0.0.tar.gz
Length: 49637596 (47M) [application/x-gzip]
Saving to: 'hive-0.12.0-cdh5.0.0.tar.gz'
100%[======================================>] 49,637,596 839K/s in 47s
2014-05-15 08:22:18 (1.02 MB/s) - `hive-0.12.0-cdh5.0.0.tar.gz' saved [49637596/49637596]
ファイルを常設のインストール・ディレクトリに解凍します。これがHiveのホーム・ディレクトリになります。次のコマンドは、現在のディレクトリでhive-0.12.0-cdh5.0.0という名前のサブディレクトリにファイルを解凍します。
$ tar -xvzf hive-0.12.0-cdh5.0.0.tar.gz
hive-0.12.0-cdh5.0.0/
hive-0.12.0-cdh5.0.0/examples/
.
.
.
hive-home-dirとhive-conf-dirを、ステップ3と5で作成したディレクトリに置き換えて、次の変数を設定します。
export HIVE_HOME=hive-home-dir export HIVE_CONF_DIR=hive-conf-dir alias hive=$HIVE_HOME/bin/hive
次の手順は、Hiveクライアントが正常に設定されたかどうかをテストします。
Hiveのアクセス権を確認するには、次の手順を実行します。
Kerberosで保護されたCDHクラスタにアクセスするには、まずチケット発行チケット(TGT)を取得します。
$ kinit userid@realm
Hiveコンソールを開きます。
$ hive
Logging initialized using configuration in jar:file:/usr/lib/hive/lib/hive-common-0.12.0-cdh5.0.0.jar!/hive-log4j.properties
Hive history file=/tmp/oracle/hive_job_log_e10527ee-9637-4c08-9559-a2e5cea6cef1_831268640.txt
hive>
すべての表をリストします。
hive> show tables;
OK
src
このセクションでは、HDFS、MapReduceおよびHiveにアクセスできるユーザーの作成方法を説明します。この項の内容は次のとおりです。
ユーザー・アカウントを作成する場合は、次のように定義してください。
MapReduceジョブを実行するには、ユーザーはhadoopグループに属しているか、または同等の権限を付与されている必要があります。
Hive内に表を作成または変更するには、ユーザーはhiveグループに属しているか、または同等の権限を付与されている必要があります。
Hueユーザーを作成するには、ブラウザでHueを開き、「User Admin」アイコンをクリックします。詳細は、「Cloudera Hueを使用したHadoopの操作」を参照してください。
保護されていないHadoopクラスタ上でユーザーを作成するには、次の手順を実行します。
rootユーザーとして、非クリティカル・ノード(node04からnode18)へのssh接続を開きます。
ユーザーのホーム・ディレクトリを作成します。
# sudo -u hdfs hadoop fs -mkdir /user/user_name
HDFSスーパー・ユーザーはhdfsである(rootではない)ため、sudoを使用します。
ディレクトリの所有者を変更します。
# sudo -u hdfs hadoop fs -chown user_name:hadoop /user/user_name
ディレクトリが正しく設定されていることを確認します。
# hadoop fs -ls /user
クラスタ内のすべてのノードに対してオペレーティング・システム・ユーザーを作成します。
# dcli useradd -G hadoop,hive[,group_name...] -m user_name
この構文では、group_nameを既存のグループ名、user_nameを新しいユーザー名でそれぞれ置換します。
オペレーティング・システム・ユーザーが正しいグループに属していることを確認します。
# dcli id user_name
ユーザーのホーム・ディレクトリがすべてのノードに作成されたことを確認します。
# dcli ls /home | grep user_name
例3-1では、hadoopをプライマリ・グループとし、hiveを追加グループとしてjdoeという名前のユーザーを作成します。
例3-1 Hadoopユーザーの作成
# sudo -u hdfs hadoop fs -mkdir /user/jdoe # sudo -u hdfs hadoop fs -chown jdoe:hadoop /user/jdoe # hadoop fs -ls /user Found 5 items drwx------ - hdfs supergroup 0 2013-01-16 13:50 /user/hdfs drwxr-xr-x - hive supergroup 0 2013-01-16 12:58 /user/hive drwxr-xr-x - jdoe jdoe 0 2013-01-18 14:04 /user/jdoe drwxr-xr-x - oozie hadoop 0 2013-01-16 13:01 /user/oozie drwxr-xr-x - oracle hadoop 0 2013-01-16 13:01 /user/oracle # dcli useradd -G hadoop,hive -m jdoe # dcli id jdoe bda1node01: uid=1001(jdoe) gid=1003(jdoe) groups=1003(jdoe),127(hive),123(hadoop) bda1node02: uid=1001(jdoe) gid=1003(jdoe) groups=1003(jdoe),123(hadoop),127(hive) bda1node03: uid=1001(jdoe) gid=1003(jdoe) groups=1003(jdoe),123(hadoop),127(hive) . . . # dcli ls /home | grep jdoe bda1node01: jdoe bda1node02: jdoe bda1node03: jdoe
Kerberosで保護されたクラスタ上でユーザーを作成するには、次の手順を実行します。
HDFSプリンシパルとしてKerberosに接続し、jdoeを実際のユーザー名に置き換えて次のコマンドを実行します。
hdfs dfs -mkdir /user/jdoe hdfs dfs -chown jdoe /user/jdoe dcli -C useradd -G hadoop,hive -m jdoe hash=$(echo "hadoop" | openssl passwd -1 -stdin) dcli -C "usermod --pass='$hash' jdoe"
キー配布センター(KDC)にログインし、ユーザーのプリンシパルを追加します。次の例で、jdoe、bda01node01およびexample.comを正しいユーザー名、サーバー名、ドメインおよびレルムで置き換えます。
ssh -l root bda01node01.example.com kadmin.local
add_principal user_name@EXAMPLE.COM
リモート・クライアントからMapReduceジョブを実行する場合、Oracle Big Data Applianceでログイン権限は必要ありません。ただし、Oracle Big Data Applianceにログインする場合、パスワードを設定する必要があります。パスワードの設定とリセットは同じ方法で行えます。
すべてのOracle Big Data Applianceサーバーに対するユーザー・パスワードを設定するには、次の手順を実行します。
「Hadoopクラスタ・ユーザーの作成」の説明に従って、Hadoopクラスタ・ユーザーを作成します。
ユーザーにパスワードがないことを確認します。
# dcli passwd -S user_name bda1node01.example.com: jdoe NP 2013-01-22 0 99999 7 -1 (Empty password.) bda1node02.example.com: jdoe NP 2013-01-22 0 99999 7 -1 (Empty password.) bda1node03.example.com: jdoe NP 2013-01-22 0 99999 7 -1 (Empty password.)
出力に「Empty password」または「Password locked」と表示された場合は、パスワードを設定する必要があります。
パスワードを設定します。
hash=$(echo 'password' | openssl passwd -1 -stdin); dcli "usermod --pass='$hash' user_name"
すべてのサーバーに対してパスワードが設定されていることを確認します。
# dcli passwd -S user_name bda1node01.example.com: jdoe PS 2013-01-24 0 99999 7 -1 (Password set, MD5 crypt.) bda1node02.example.com: jdoe PS 2013-01-24 0 99999 7 -1 (Password set, MD5 crypt.) bda1node03.example.com: jdoe PS 2013-01-24 0 99999 7 -1 (Password set, MD5 crypt.)
|
関連項目:
|
CDHはオプションのごみ箱機能を備えているので、削除されたファイルまたはディレクトリをただちにシステムから削除せずに、指定した期間trashディレクトリに移動できます。デフォルトで、ごみ箱機能はHDFSおよびすべてのHDFSクライアントで有効です。
ごみ箱機能が有効になっている場合は、削除してしまったファイルを簡単にリストアできます。
trashディレクトリからファイルをリストアするには、次の手順を実行します。
削除されたファイルがごみ箱にあることを確認します。次の例では、oracleユーザーによって削除されたファイルを確認します。
$ hadoop fs -ls .Trash/Current/user/oracle
Found 1 items
-rw-r--r-- 3 oracle hadoop 242510990 2012-08-31 11:20 /user/oracle/.Trash/Current/user/oracle/ontime_s.dat
以前の場所にファイルを移動またはコピーします。次の例では、ontime_s.datをごみ箱からHDFSの/user/oracleディレクトリに移動します。
$ hadoop fs -mv .Trash/Current/user/oracle/ontime_s.dat /user/oracle/ontime_s.dat
ごみ箱を空にする間隔とは、ファイルがシステムから永久に削除されるまで、trashディレクトリに保持される時間の最小値です。デフォルト値は、1日(24時間)です。
ごみ箱を空にする間隔を変更するには、次の手順を実行します。
Cloudera Managerを開きます。詳細は、「Cloudera Managerを使用した操作の管理」を参照してください。
「Home」ページの「Status」で、hdfsをクリックします。
hdfsページで、「Configuration」サブタブをクリックし、「View and Edit」を選択します。
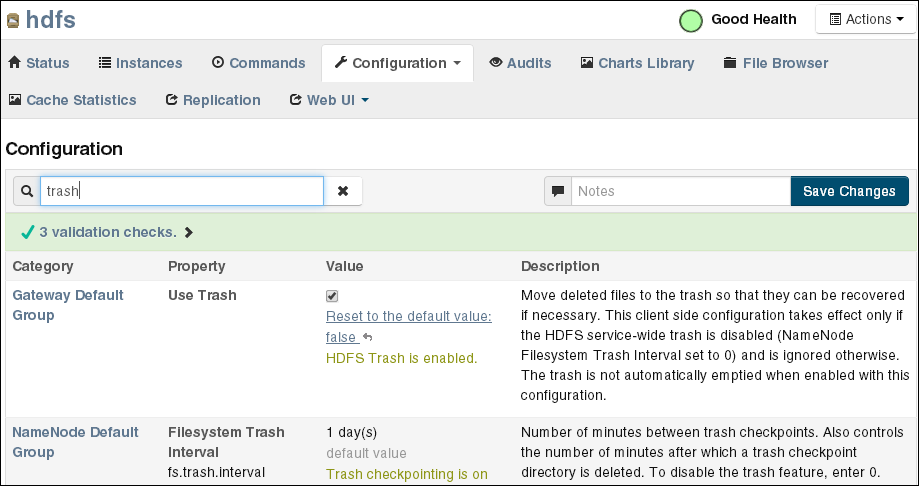
「NameNode Default Group」の下にある「Filesystem Trash Interval」プロパティを検索するか、下方向にスクロールして探します。図3-2を参照してください。
現在の値をクリックして、ポップアップ・フォームに新しい値を入力します。
「Save Changes」をクリックします。
ページ上部の「Actions」メニューを展開して、「Restart」を選択します。
rootとして、クラスタ内のノードへの接続を開きます。
新しい構成をデプロイします。
dcli -C bdagetclientconfig
図3-2は、Cloudera ManagerにFilesystem Trash Intervalプロパティが表示されているところを示しています。
Oracle Big Data Applianceでは、デフォルトでごみ箱機能が有効になっています。この構成はクラスタに対して無効にできます。ごみ箱機能を無効化すると、削除されたファイルおよびディレクトリはごみ箱に移動しません。リカバリできなくなります。
次の手順を実行すると、HDFSのごみ箱機能は無効化されます。ごみ箱機能が完全に無効化されても、クライアント構成には影響しません。
Cloudera Managerを開きます。詳細は、「Cloudera Managerを使用した操作の管理」を参照してください。
「Home」ページの「Status」で、hdfsをクリックします。
hdfsページで、「Configuration」サブタブをクリックし、「View and Edit」を選択します。
「NameNode Default Group」の下にある「Filesystem Trash Interval」プロパティを検索するか、下方向にスクロールして探します。図3-2を参照してください。
現在の値をクリックして、ポップアップ・フォームに値0 (ゼロ)と入力します。
「Save Changes」をクリックします。
ページ上部の「Actions」メニューを展開して、「Restart」を選択します。
Oracle Big Data ApplianceにインストールされているすべてのHDFSクライアントは、ごみ箱機能を使用するように構成されています。HDFSクライアントとは、HDFSに接続して、HDFSファイルの一覧表示、HDFSとの間のファイルのコピー、ディレクトリの作成といった操作を実行する任意のアプリケーションです。
Cloudera Managerを使用すると、ローカルのクライアント構成設定を変更できますが、ごみ箱機能は有効なままです。
ローカルのHDFSクライアントのごみ箱機能を無効化するには、次の手順を実行します。
Cloudera Managerを開きます。詳細は、「Cloudera Managerを使用した操作の管理」を参照してください。
「Home」ページの「Status」で、hdfsをクリックします。
hdfsページで、「Configuration」サブタブをクリックし、「View and Edit」を選択します。
「Gateway Default Group」の下にある「Filesystem Trash Interval」プロパティを検索するか、下方向にスクロールして探します。図3-2を参照してください。
「Client Settings」の下にある「Use Trash」プロパティを検索するか、下方向にスクロールして探します。図3-2を参照してください。
「Use Trash」チェック・ボックスの選択を解除します。
「Save Changes」をクリックします。この設定は、Oracle Big Data Applianceに新たにダウンロードされるすべてのHDFSクライアントの構成に使用されます。
rootとして、クラスタ内のノードへの接続を開きます。
新しい構成をデプロイします。
dcli -C bdagetclientconfig
リモートのHDFSクライアントは、通常、CDHクライアントをダウンロードおよびインストールすると構成されます(「CDHへのリモート・クライアント・アクセスの提供」を参照)。Oracle SQL Connector for HDFSやOracle R Advanced Analytics for Hadoopなどがリモート・クライアントです。
リモートのHDFSクライアントのごみ箱機能を無効化するには、次の手順を実行します。
CDHクライアントがインストールされているシステムへの接続を開きます。
テキスト・エディタで/etc/hadoop/conf/hdfs-site.xmlを開きます。
ごみ箱を空にする間隔をゼロに設定します。
<property>
<name>fs.trash.interval</name>
<value>0</value>
</property>
ファイルを保存します。