始める前に
目的
このチュートリアルでは、Big Data Cloud Service - Compute Edition (BDCS-CE)クラスタでノートを作成および実行する方法を説明します。
所要時間
約20分
背景
Seattle Traffic Flow Countsデータセットには、現地調査に基づいたシアトルの幹線道路における交通量に関する情報が含まれます。BDCS-CEにノートを作成し、このデータセットを使用して、2009年に交通量が多い上位10本の通りを導出します。データセットには、次の列があります。
DOWNTOWN: これはブール値のフィールドで、通りが中心街にあるかどうかを示します。
STNAME: このフィールドには、通りの名前が含まれます。
YEAR: このフィールドには、情報が記録された年が含まれます。
AAWDT: AAWDTの数は季節ごとに調整された、すべてのレーンの平日の日次平均交通量の合計です。つまり、平日(月曜日から金曜日)の24時間における両方向の平均交通量の合計です。
必要なもの
実行中のBDCS-CEクラスタ。
BDCS-CEアカウント資格証明またはBig Data Cluster ConsoleのダイレクトURL (例: https://xxx.xxx.xxx.xxx:1080/)。
BDCS-CEクラスタ・ログイン資格証明。
「Seattle Traffic Flow Counts」データセットが含まれるCSVファイルへのURLです。
Big Data Cluster Console - 「Notebook」ページへのナビゲート
BDCS-CEアカウントにログインします。
注意: Big Data Cluster ConsoleにアクセスするためのダイレクトURLがわかっている場合、直接リンクにナビゲートして手順3から続行できます。
「Services」ページで、ノートを作成するクラスタの「Manage this Service」アイコン
 をクリックしてから、「Big Data Cluster Console」をクリックします。
をクリックしてから、「Big Data Cluster Console」をクリックします。
このイメージの説明 「Authentication Required」という名前のウィンドウが表示されます。BDCS-CEクラスタのユーザー名およびパスワードを入力し、「Log In」をクリックします。
このイメージの説明 「Big Data Cloud - Compute Edition Console」で、「Notebook」をクリックします。

このイメージの説明
ノートの作成

段落の作成
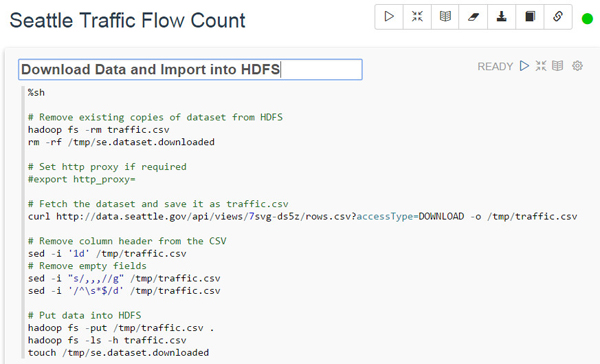
段落1: 「Download Data and Import into HDFS」
次のシェル・スクリプトをコピーして空の段落に貼り付けます。
%sh # Remove existing copies of dataset from HDFS hadoop fs -rm traffic.csv rm -rf /tmp/se.dataset.downloaded # Set http proxy if required #export http_proxy= # Fetch the dataset and save it as traffic.csv curl http://data.seattle.gov/api/views/7svg-ds5z/rows.csv?accessType=DOWNLOAD -o /tmp/traffic.csv # Remove column header from the CSV sed -i '1d' /tmp/traffic.csv # Remove empty fields sed -i "s/,,,//g" /tmp/traffic.csv sed -i '/^\s*$/d' /tmp/traffic.csv # Put data into HDFS hadoop fs -put /tmp/traffic.csv . hadoop fs -ls -h traffic.csv touch /tmp/se.dataset.downloaded「Settings」アイコン
 をクリックして、「Show title」を選択します。
をクリックして、「Show title」を選択します。
このイメージの説明 段落のタイトルをクリックして、「Download Data and Import into HDFS」に設定します。
このイメージの説明
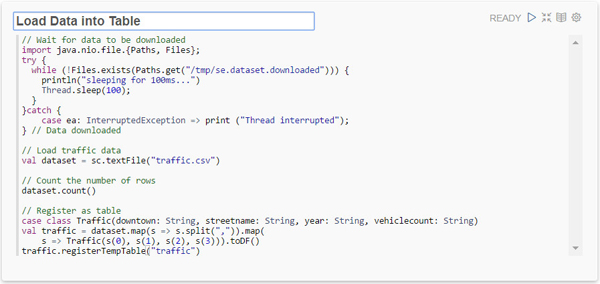
段落2: 「Load Data into Table」
段落の下にある+アイコンをクリックします。
次のSparkスクリプトをコピーして、空の段落に貼り付けます。
// Wait for data to be downloaded import java.nio.file.{Paths, Files}; try { while (!Files.exists(Paths.get("/tmp/se.dataset.downloaded"))) { println("sleeping for 100ms...") Thread.sleep(100); } }catch { case ea: InterruptedException => print ("Thread interrupted"); } // Data downloaded // Load traffic data val dataset = sc.textFile("traffic.csv") // Count the number of rows dataset.count() // Register as table case class Traffic(downtown: String, streetname: String, year: String, vehiclecount: String) val traffic = dataset.map(s => s.split(",")).map( s => Traffic(s(0), s(1), s(2), s(3))).toDF() traffic.registerTempTable("traffic")「Settings」アイコン
をクリックして、「Show title」を選択します。 このイメージの説明 段落のタイトルをクリックして、「Load Data into Table」に設定します。
このイメージの説明
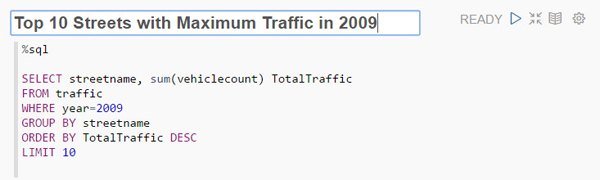
段落3: 「Top 10 Streets with Maximum Traffic in 2009」
再度、段落の下にある+アイコンをクリックします。
次のSQL文をコピーして、空の段落に貼り付けます。
%sql SELECT streetname, sum(vehiclecount) TotalTraffic FROM traffic WHERE year=2009 GROUP BY streetname ORDER BY TotalTraffic DESC LIMIT 10「Settings」アイコン
をクリックして、「Show title」を選択します。 このイメージの説明 段落のタイトルをクリックして、「Top 10 Streets with Maximum Traffic in 2009」に設定します。
このイメージの説明
段落の実行および出力の表示
「Run all」アイコン![]() をクリックして、すべての段落を一度に実行するか、1つずつ実行することもできます。この例では、段落を1つずつ実行します。
をクリックして、すべての段落を一度に実行するか、1つずつ実行することもできます。この例では、段落を1つずつ実行します。
「Run this paragraph」アイコン
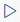 をクリックして、最初の段落を実行します。
をクリックして、最初の段落を実行します。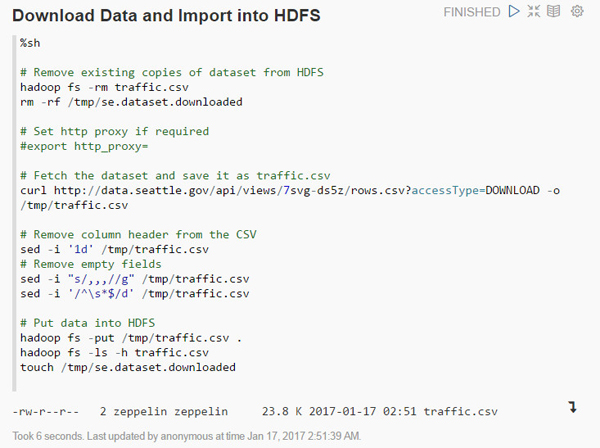
このイメージの説明 出力にダウンロードされたファイルのプロパティが表示されることに注意してください。
「Run this paragraph」アイコン
をクリックして、2番目の段落を実行します。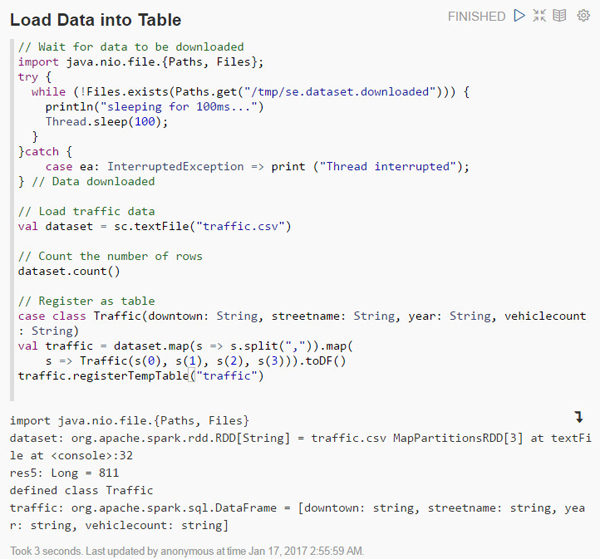
このイメージの説明 データが表にロードされたことに注意してください。
次に、「Run this paragraph」アイコン
をクリックして、3番目の段落を実行します。
このイメージの説明 出力には、2009年の交通量の多い上位10本の通りが交通量の降順にソートされて表示されます。
様々なタイプのグラフでデータを表示できます。棒グラフの形式でデータを表示するには、「Bar Graph」アイコン
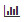 をクリックします。
をクリックします。
このイメージの説明