始める前に
目的
このチュートリアルでは、Big Data Cloud Service - Compute Edition (BDCS-CE)クラスタで単純なバッチ・スパーク・ジョブを実行する方法を説明します。
所要時間
約20分。
背景
New York City (NYC) Taxi & Limousine Commission - 移動記録データがこのチュートリアルで分析されます。このタスクのために、2つのジョブが作成されます。
-
TripParserJob: このジョブでは、Oracle Storage Cloud Containerに格納されているNYC Taxiのログを読み取り、Hadoop分散ファイル・システム(HDFS)にカンマ区切りの値(CSV)のファイルで格納します。
-
TripProcessorJob: このジョブでは、TripParserJobによって生成された出力を読み取り、1日の時間ごとに平均料金を計算します。結果はキーと値のペアで、キーは1日の時間で、値は最初の入力ファイルによって表される指定された期間の任意の日、月、年のその時間にお客様によって支払われた平均料金です。出力は、BDCS-CEクラスタに関連付けられているOracle Storage Cloud Containerのテキスト・ファイルとして格納されます。
必要なもの
実行中のBDCS-CEクラスタ。
BDCS-CEアカウント資格証明またはBig Data Cluster ConsoleのダイレクトURL (例: https://xxx.xxx.xxx.xxx:1080/)。
BDCS-CEクラスタ・ログイン資格証明。
Oracle Storage Cloud資格証明、テナント名およびコンテナ名。
BDCS-CEクラスタにリンク付けされているOracle Storage Cloud ContainerにアップロードされているsmallTrip.csvファイル。
Oracle Storage Cloud Serviceでオブジェクトをアップロード/作成する手順は、「単一オブジェクトの作成」を参照してください。
Big Data Cluster Console - 「Jobs」ページへのナビゲート
-
BDCS-CEアカウントにログインします。
注意: Big Data Cluster ConsoleにアクセスするためのダイレクトURLがわかっている場合、直接リンクにナビゲートして手順3から続行できます。
-
「Services」ページで、ジョブを作成するクラスタの「Manage this Service」
 アイコンをクリックしてから、「Big Data Cluster Console」をクリックします。
アイコンをクリックしてから、「Big Data Cluster Console」をクリックします。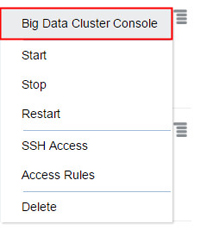
このイメージの説明 -
「Authentication Required」という名前のウィンドウが表示されます。BDCS-CEクラスタのユーザー名およびパスワードを入力し、「Log In」をクリックします。

このイメージの説明 -
「Big Data Cloud - Compute Edition Console」で、「Jobs」をクリックします。

このイメージの説明
ジョブの作成
TripParserJobの作成
-
「Big Data Cloud - Compute Edition Console Jobs」ページで、「New Job」をクリックします。

このイメージの説明 -
TripParserJobの「Name」および「Description」を入力し、「Next」をクリックします。
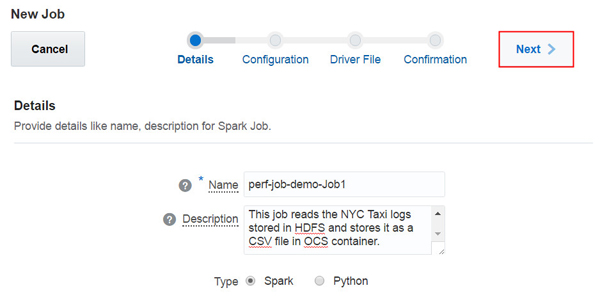
このイメージの説明 -
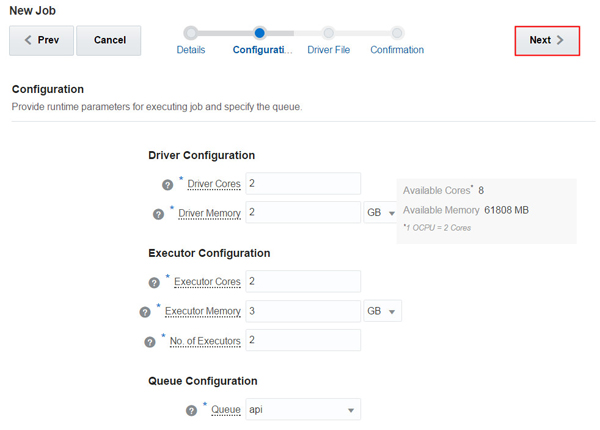
ジョブを実行するための構成パラメータを指定し、「Next」をクリックします。この例では、次のパラメータが使用されます。
ドライバ・コア: 2
ドライバ・メモリー: 2 GB
エグゼキュータ・コア: 2
エグゼキュータ・メモリー: 3 GB
エグゼキュータ数: 2
キュー: api
このイメージの説明 ファイル・パス、メイン・クラス、引数、追加Jars、追加サポート・ファイルなどのドライバ・ファイル情報を指定し、「Next」をクリックします。この例では、次の情報が入力されます。
ファイル・パス: hdfs:///spark/examples/perf-jobs-apache-openstack-1.1.0-20160628.173357-1.jar
メイン・クラス: com.oracle.spoccs.jobs.TripParserJob
引数:
inDS=swift://storageContainerName.main/smallTrip.csv outDS=hdfs:///user/oracle/data/parsedTrip fs.swift.SERVICE_NAME=main fs.swift.CONTAINER_NAME=storageContainerName fs.swift.service.main.auth.url=https://storage-ucf2.oraclecorp.com/auth/v2.0/tokens fs.swift.service.main.tenant=Storage-TenantName fs.swift.service.main.username=Storageadmin fs.swift.service.main.password=StoragePassword fs.swift.service.main.public=true fs.swift.service.http.location-aware=false構成ごとに
CONTAINER_NAME、tenant、usernameおよびpasswordの値を変更します。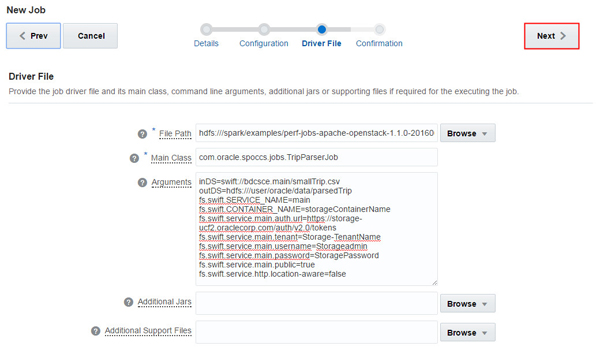
このイメージの説明
確認ページで、レスポンスを確認して「Create」をクリックします。
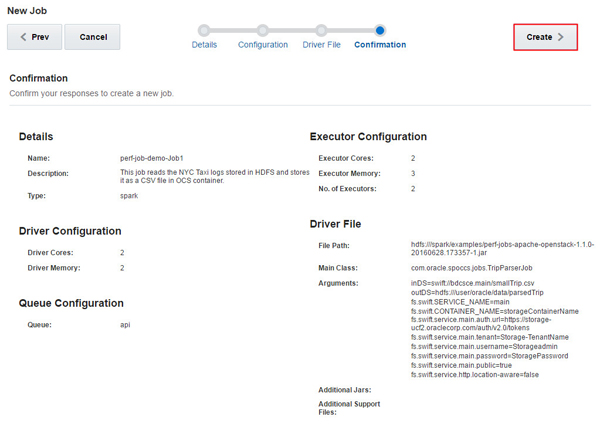
このイメージの説明 ジョブが正常に完了したら、TripProcessorJobを作成します。

このイメージの説明
TripProcessorJobの作成
-
「Big Data Cloud - Compute Edition Console Jobs」ページで、「New Job」をクリックします。
このイメージの説明 -
TripProcessorJobの「Name」および「Description」を入力し、「Next」をクリックします。
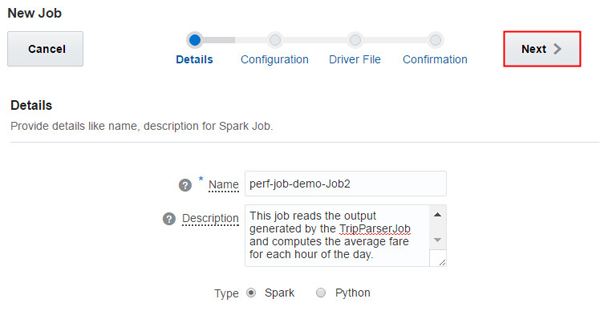
このイメージの説明 -
ジョブを実行するための構成パラメータを指定し、「Next」をクリックします。この例では、次のパラメータが使用されます。
ドライバ・コア: 2
ドライバ・メモリー: 2 GB
エグゼキュータ・コア: 2
エグゼキュータ・メモリー: 3 GB
エグゼキュータ数: 2
キュー: api
このイメージの説明 -
ファイル・パス、メイン・クラス、引数、追加Jars、追加サポート・ファイルなどのドライバ・ファイル情報を指定し、「Next」をクリックします。この例では、次の情報が入力されます。
ファイル・パス: hdfs:///spark/examples/perf-jobs-apache-openstack-1.1.0-20160628.173357-1.jar
メイン・クラス: com.oracle.spoccs.jobs.TripProcessorJob
引数:
inDS=hdfs:///user/oracle/data/parsedTrip outDS=swift://storageContainerName.main/processedJob fs.swift.SERVICE_NAME=main fs.swift.CONTAINER_NAME=storageContainerName fs.swift.service.main.auth.url=https://storage-ucf2.oraclecorp.com/auth/v2.0/tokens fs.swift.service.main.tenant=Storage-TenantName fs.swift.service.main.username=Storageadmin fs.swift.service.main.password=StoragePassword fs.swift.service.main.public=true fs.swift.service.http.location-aware=false
構成ごとに
CONTAINER_NAME、tenant、usernameおよびpasswordの値を変更します。
この図の説明 注意:
TripParserJobで生成された出力ファイルは、ここで入力ファイルとして使用されます。 確認ページで、レスポンスを確認して「Create」をクリックします。

このイメージの説明 ジョブが正常に完了したら、出力の表示に進みます。

このイメージの説明
出力の表示
-
「Big Data Cloud - Compute Edition Console」で、「Data Stores」をクリックします。

このイメージの説明 TripProcessorJobの最終出力がOracle Storage Cloud Containerに格納されたら、「Cloud Storage」をクリックします。
このイメージの説明 「Filter by Prefix」フィールドにTripProcessorJob引数の
outDS値(この場合、processedJob)を入力し、[Enter]を押します。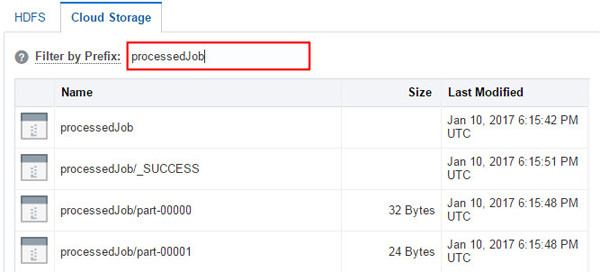
このイメージの説明 出力ファイルがOracle Storage Cloud Containerに作成されていることに注意してください。
Oracle Storage Cloud Containerから出力ファイル/出力オブジェクトをダウンロードする手順は、「オブジェクトのダウンロード」を参照してください。