| Oracle® Big Data Connectorsユーザーズ・ガイド リリース4 (4.1) E60568-01 |
|


 前 |
 次 |
この章では、Oracle Big Data Connectorsについて説明し、インストール手順を示します。
この章は次の項で構成されています:
Oracle Big Data Connectorsを使用すると、Apache Hadoopクラスタに格納されているデータへのアクセスが簡単になります。Oracle Big Data Applianceまたはコモディティ・ハードウェア上で稼働するHadoopクラスタでの使用に対してライセンス供与されます。
次のコネクタがあります。
Oracle SQL Connector for Hadoop Distributed File System (旧Oracle Direct Connector for HDFS): Oracle外部表は、Hadoop Distributed File System (HDFS)ファイルまたはApache Hiveの表に格納されているデータにアクセスできます。データをHDFSまたはHive表に保持することも、Oracle Databaseにロードすることもできます。
Oracle Loader for Hadoop: HadoopクラスタからOracle Databaseの表にデータをすばやく移動するための効率的でパフォーマンスのよいローダーを提供します。Oracle Loader for Hadoopは、必要に応じてデータを事前にパーティション化し、そのデータをデータベース対応形式に変換します。また、データのロードや出力ファイルの作成の前に主キーまたはユーザー定義の列でレコードを任意にソートします。
Oracle Data Integrator Application Adapter for Hadoop: グラフィカル・ユーザー・インタフェースを使用して定義されたとおりに、HadoopクラスタからOracle Databaseの表にデータを抽出、変換およびロードします。
Oracle XQuery for Hadoop: XQuery言語で表された変換を一連のMapReduceジョブに解釈して実行します(これらのジョブはHadoopクラスタ上で並列で実行されます)。入力データは、Hadoop Distributed File System (HDFS)など、Hadoopのファイル・システムAPIを介してアクセス可能なファイル・システムに配置するか、Oracle NoSQL Databaseに格納できます。Oracle XQuery for Hadoopでは、変換結果をHDFS、Oracle NoSQL Database、Apache SolrまたはOracle Databaseに書き込むことができます。追加のXML処理機能は、XML Extensions for Hiveを通じて提供されます。
Oracle R Advanced Analytics for Hadoop: 汎用計算フレームワークを提供します。このフレームワークでは、R言語を使用してカスタム・ロジックをマッパーまたはレデューサとして作成できます。Rパッケージのコレクションにより、MapReduceジョブとして実行される予測分析法が提供されます。コードは、Hadoopクラスタで使用可能な計算リソースとストレージ・リソースを使用する分散並列方式で実行されます。Oracle R Advanced Analytics for Hadoopには、Apache Hive表、Apache Hadoop計算インフラストラクチャ、ローカルR環境およびOracleデータベース表を操作するインタフェースが組み込まれています。
それぞれのコネクタでは、Oracle Databaseと、Hadoopクラスタまたはクラスタに対してHadoopクライアントとして設定した外部システムにソフトウェア・コンポーネントをインストールする必要があります。Oracle Databaseでの追加のアクセス権限が必要な場合もあります。
|
関連項目: My Oracle Support情報センター: Big Data Connectors (ID 1487399.2)およびその関連情報センター |
エンタープライズでは、複数のソースから生じる大量のデータを参照します。分析した場合にエンタープライズにとってきわめて大きな価値となる膨大な量のデータのほんの一例として、Webログのクリックストリーム・データ、GPS追跡情報、小売事業のデータ、センサー・データおよびマルチメディア・ストリームなどがあります。生のデータ・フィードから取得する非構造化および半構造化情報は、それ自体ほとんど価値はありません。実際に価値のある情報を抽出するには、データを処理する必要があります。処理されたデータは、その後データベースに格納して管理できます。このデータをデータベースの構造化データと一緒に分析することで、新たな理解が得られ、実質的なビジネス利益につながります。
MapReduceは、分散システムでデータを処理するための並列プログラミング・モデルです。大量のデータを迅速に処理し、線形的に拡張できます。特に、非構造化データおよび半構造化データのバッチ処理のメカニズムとして効果的です。MapReduceは、比較的下位の操作を一連のキーと値を通じて計算に抽象化します。
MapReduceジョブを簡単に定義すると、2つのフェーズ(マップ・フェーズとリデュース・フェーズ)が連続的に交代する操作になります。各マップ・フェーズは、入力データの各レコードに変換機能を適用して、キーと値のペアで表現される一連のレコードを作成します。マップ・フェーズからの出力は、リデュース・フェーズへの入力になります。リデュース・フェーズでは、マップ出力レコードはキーと値のセットにソートされるため、セット内のすべてのレコードのキーの値が同じになります。リデューサ関数がセット内のすべてのレコードに適用され、一連の出力レコードがキーと値のペアで作成されます。マップ・フェーズは、各レコードに対して論理的に並列で実行され、リデュース・フェーズは、すべてのキーの値に対して並列で実行されます。
|
注意: Oracle Big Data Connectors 3.0以降は、MapReduceのYet Another Resource Negotiator (YARN)実装をサポートしています。 |
Apache Hadoopは、MapReduceプログラミング・モデルに基づく、データ処理ジョブの開発およびデプロイ用ソフトウェア・フレームワークです。中核機能として、Hadoopは、信頼できる共有ストレージおよび分析システム脚注 1 を提供します。分析はMapReduceによって行われます。ストレージは、MapReduceジョブ向けに設計された共有ストレージ・システムであるHadoop Distributed File System (HDFS)によって行われます。
Hadoopエコシステムには、その他にApache Avro (Oracle Loader for Hadoopで使用されるデータ・シリアライズ・システム)などのプロジェクトが複数含まれています。
Cloudera's Distribution including Apache Hadoop (CDH)は、Oracle Big Data Applianceにインストールされます。この章の設定手順で説明されているように、CDHまたは同等のApache Hadoopコンポーネントが稼働するHadoopクラスタでOracle Big Data Connectorsを使用できます。
|
関連項目:
|
Oracle Big Data Connectorsは、Oracle Technology NetworkまたはOracle Software Delivery Cloudからダウンロードできます。
Oracle Technology Networkからダウンロードするには、次の手順を実行します。
ブラウザを使用して次のWebサイトにアクセスします。
http://www.oracle.com/technetwork/bdc/big-data-connectors/downloads/index.html
各コネクタの名前をクリックして、インストール・ファイルを含むzipファイルをダウンロードします。
Oracle Software Delivery Cloudからダウンロードするには、次の手順を実行します。
ブラウザを使用して次のWebサイトにアクセスします。
条件と制限事項を受け入れて、「メディア・パック検索」ページを表示します。
検索条件を次のように選択します。
製品パックを選択: Oracle Database
プラットフォーム: Linux x86-64
「実行」をクリックして製品パックの一覧を表示します。
Oracle Big Data Connectors Media Pack for Linux x86-64 (B65965-0x)を選択して、「続行」をクリックします。
各コネクタの「ダウンロード」をクリックして、インストール・ファイルを含むzipファイルをダウンロードします。
Oracle SQL Connector for Hadoop Distributed File System (HDFS)は、Oracle Databaseが稼働するシステムにインストールして構成します。Hive表がデータソースとして使用される場合、ユーザーがHiveにアクセスするHadoopクライアントにOracle SQL Connector for HDFSもインストールして実行する必要があります。
Oracle SQL Connector for HDFSは、Oracle Big Data Connectors用に構成されている場合には、Oracle Big Data Applianceにインストール済です。このインストールでサポートされるのは、Oracle Big Data Applianceに直接接続して各自のジョブを実行するユーザーです。
この項の内容は次のとおりです。
Oracle SQL Connector for HDFSには、次のソフトウェアが必要です。
Hadoopクラスタの場合:
Cloudera's Distribution including Apache Hadoopバージョン4 (CDH4)またはバージョン5 (CDH5)、あるいはApache Hadoop 2.2.0
Java Development Kit (JDK) 1.6_08以上。推奨バージョンについては、Hadoopソフトウェアの代理店(ClouderaまたはApache)に確認してください。
Hive 0.8.1、0.9.0、0.10.0または0.12.0 (Hive表にアクセスする場合は必須、それ以外はオプション)
このソフトウェアは、Oracle Big Data Applianceにすでにインストールされています。
Oracle DatabaseシステムおよびHadoopクライアント・システムの場合:
Oracle Database 12c、Oracle Database 11gリリース 2 (11.2.0.2以上)またはOracle Database 10gリリース2 (10.2.0.5) for Linux。
Oracle Databaseリリース11.2.0.2または11.2.0.3でOracle Data Pumpファイル形式をサポートするための、Oracle Databaseの個別パッチ。このパッチをダウンロードするには、http://support.oracle.comにアクセスしてOracle Bug#14557588を検索します。
リリース11.2.0.4以降では、このパッチは不要です。
Hadoopクラスタと同じバージョンのHadoop: CDH4、CDH5、Apache Hadoop 1.0またはApache Hadoop 1.1.1。
Kerberosを使用してセキュアなHadoopクラスタを構成している場合は、データベース・システムのHadoopクライアントを、セキュアなクラスタにアクセスするように設定する必要があります。「セキュアなHadoopクラスタでのOracle SQL Connector for HDFSの使用」を参照してください。
Hadoopクラスタと同じバージョンのJDK。
Oracle SQL Connector for HDFSは、Hadoopクライアントとして機能します。Oracle DatabaseシステムにHadoopをインストールして、Hadoopクライアントを使用する場合にかぎり、最小限の構成を行う必要があります。Oracle SQL Connector for HDFSのMapReduceジョブを実行するために、Oracle DatabaseシステムでHadoopを完全に構成する必要はありません。
Oracle Exadata Database Machineが含まれるOracle RACシステムの場合は、Oracleインスタンスを実行しているすべてのシステムで同一パスを使用して、Oracle SQL Connector for HDFSをインストールして構成する必要があります。
必要に応じて次の手順に従うことで、追加のHadoopクライアント・システムを設定できます。
Oracle DatabaseシステムをHadoopクライアントとして構成するには、次の手順を実行します。
Hadoopクラスタと同じバージョンのCDHまたはApache HadoopをOracle Databaseシステムにインストールして構成します。Oracle Big Data Applianceを使用する場合、『Oracle Big Data Applianceソフトウェア・ユーザーズ・ガイド』のリモート・クライアント・アクセスを提供するための手順を完了します。それ以外の場合は、代理店(ClouderaまたはApache)が提供するインストール手順に従います。
|
注意: Oracle DatabaseシステムでHadoopを起動しないでください。Hadoopが実行されていると、Oracle SQL Connector for HDFSではHadoopクラスタではなく、そのHadoopの使用が試行されます。Oracle SQL Connector for HDFSは、Oracle DatabaseシステムのHadoopクラスタにあるHadoopのJARファイルおよび構成ファイルを使用します。 |
クラスタがKerberosで保護されている場合は、Kerberos認証を許可するようにOracleシステムを構成する必要があります。「セキュアなHadoopクラスタでのOracle SQL Connector for HDFSの使用」を参照してください。
Oracle DatabaseからHDFSにアクセスできることを確認します。
Oracle Databaseアカウントを使用して、Oracle Databaseが稼働しているシステムにログインします。
Bashシェルを開き、次のコマンドを入力します。
hdfs dfs -ls /user
場合によっては、Hadoopの実行可能ファイルが格納されているディレクトリをPATH環境変数に追加する必要があります。CDHのデフォルト・パスは/usr/binです。
Hadoopクラスタ上で直接hdfs dfsコマンドを実行する場合と同じディレクトリ・リストが表示されます。表示されない場合、最初にHadoopクラスタが稼働していることを確認します。問題が続く場合、Oracle DatabaseからHadoopクラスタ・ファイル・システムにアクセスできるようにHadoopクライアント構成を修正する必要があります。
Oracle RACシステムの場合、各Oracleインスタンスに対してこの手順を繰り返します。
これで、Hadoopクライアントは使用できる状態です。Hadoopの他の構成手順は必要ありません。
Oracle DatabaseシステムにOracle SQL Connector for HDFSをインストールするには、次の手順を実行します。さらに、Oracle SQL Connector for HDFSはHadoopクライアントとして構成されたどのシステムにもインストールできます。
Oracle SQL Connector for HDFSをインストールするには、次の手順を実行します。
Oracle Databaseが稼働するシステムのディレクトリにzipファイルをダウンロードします。
$ unzip oraosch-3.2.0zip
Archive: oraosch-3.2.0.zip
extracting: orahdfs-3.2.0.zip
inflating: README.txt
orahdfs-version.zipを永続ディレクトリに解凍します。
$ unzip orahdfs-3.2.0.zip
unzip orahdfs-3.2.0.zip
Archive: orahdfs-3.2.0.zip
creating: orahdfs-3.2.0/
creating: orahdfs-3.2.0/log/
creating: orahdfs-3.2.0/examples/
creating: orahdfs-3.2.0/examples/sql/
inflating: orahdfs-3.2.0/examples/sql/mkhive_unionall_view.sql
creating: orahdfs-3.2.0/doc/
inflating: orahdfs-3.2.0/doc/README.txt
creating: orahdfs-3.2.0/jlib/
inflating: orahdfs-3.2.0/jlib/osdt_cert.jar
inflating: orahdfs-3.2.0/jlib/oraclepki.jar
inflating: orahdfs-3.2.0/jlib/osdt_core.jar
inflating: orahdfs-3.2.0/jlib/ojdbc6.jar
inflating: orahdfs-3.2.0/jlib/orahdfs.jar
inflating: orahdfs-3.2.0/jlib/ora-hadoop-common.jar
creating: orahdfs-3.2.0/bin/
inflating: orahdfs-3.2.0/bin/hdfs_stream
解凍したファイルの構造は、例1-1のようになります。
必要に応じて、orahdfs-3.2.0/bin/hdfs_stream Bashシェル・スクリプトをテキスト・エディタで開き、スクリプトのコメントで示されている変更を行います。
hdfs_streamスクリプトには環境変数の設定は継承されないため、Oracle SQL Connector for HDFSで環境変数が必要な場合はこのスクリプトに設定します。
PATH: hadoopスクリプトが/usr/bin:bin (hdfs_streamに初期設定されているパス)に存在しない場合、Hadoopのbinディレクトリ(/usr/lib/hadoop/binなど)を追加します。
JAVA_HOME: HadoopによってJavaが検出されない場合、この変数をJavaのインストール・ディレクトリに設定します(/usr/bin/javaなど)。
各環境変数の詳細は、スクリプトのコメントを参照してください。
hdfs_streamスクリプトは、Oracle SQL Connector for HDFSで作成されたOracle Database外部表のプリプロセッサです。
Kerberosを使用してクラスタを保護している場合は、Kerberosチケットを取得します。
> kinit
> password
HDFSの/binディレクトリの場合は、Oracle SQL Connectorからhdfs_streamを実行します。次の使用方法の情報が表示されます。
$ ./hdfs_stream
Usage: hdfs_stream locationFile
使用方法の情報が表示されない場合、Oracle Databaseを実行しているオペレーティング・システム・ユーザー(oracleなど)に次の権限があることを確認します。
hdfs_streamスクリプトに対する読取り権限と実行権限。
$ ls -l OSCH_HOME/bin/hdfs_stream -rwxr-xr-x 1 oracle oinstall Nov 27 15:51 hdfs_stream
orahdfs.jarに対する読取り権限。
$ ls -l OSCH_HOME/jlib/orahdfs.jar -rwxr-xr-x 1 oracle oinstall Nov 27 15:51 orahdfs.jar
これらの権限が表示されない場合、chmodコマンドを入力して権限を修正します。たとえば、次のように入力します。
$ chmod 755 OSCH_HOME/bin/hdfs_stream
前述のコマンドでは、OSCH_HOMEは、Oracle SQL Connector for HDFSホーム・ディレクトリを表します。
Oracle RACシステムの場合、同じパスの場所を使用し、各Oracleインスタンスに対して前述の手順を繰り返します。
Oracle Databaseにログインし、hdfs_streamが格納されているorahdfs-version/binディレクトリのデータベース・ディレクトリを作成します。Oracle RACシステムの場合、このディレクトリは、すべてのOracleインスタンスでアクセスできる共有ディスク上に存在する必要があります。
次の例では、Oracle SQL Connector for HDFSは/etcにインストールされます。
SQL> CREATE OR REPLACE DIRECTORY osch_bin_path AS '/etc/orahdfs-3.2.0/bin';
Hive表へのアクセスをサポートするには、次の手順を実行します。
システムがHiveクライアントして構成されていることを確認します。
HiveのJARファイルとconfディレクトリをHADOOP_CLASSPATH環境変数に追加します。各種のHadoop製品間でJARが競合しないようにするため、HADOOP_CLASSPATHは、グローバルに変更するのではなく、ローカル・シェル初期化スクリプトに設定することをお薦めします。
解凍したファイルの構造は、例1-1のようになります。
例1-1 orahdfsディレクトリの構造
orahdfs-version
bin/
hdfs_stream
doc/
README.txt
examples/
sql/
mkhive_unionall_view.sql
jlib/
ojdbc6.jar
ora-hadoop-common.jar
oraclepki.jar
orahdfs.jar
osdt_cert.jar
osdt_core.jar
log/
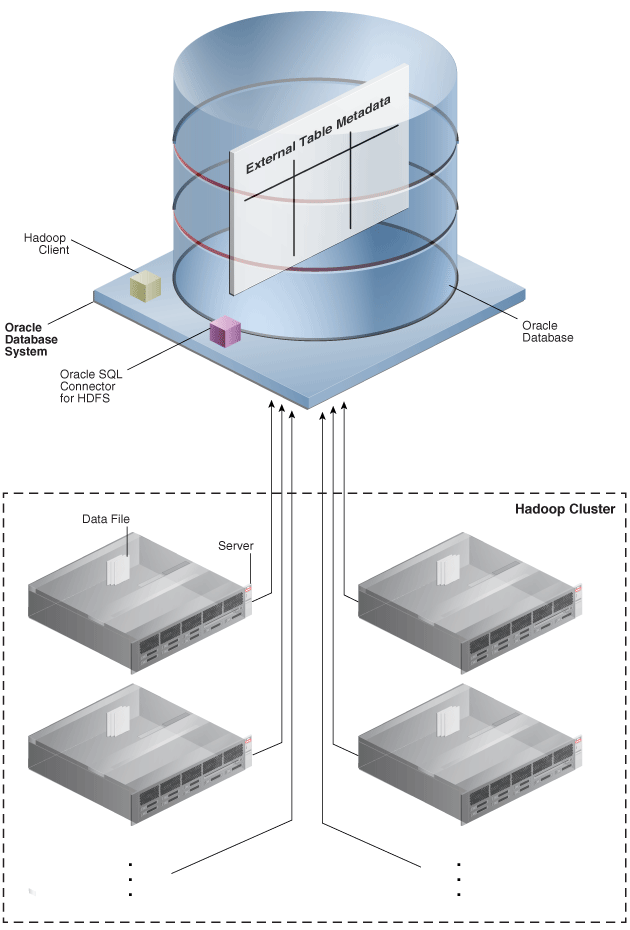
図1-1に、データの流れとコンポーネントの場所を示します。
図1-1 HDFSおよびデータ・ポンプ・ファイルをサポートするOracle SQL Connector for HDFSのインストール
Oracle DatabaseユーザーがOracle SQL Connector for HDFSを使用して外部表を作成するには、次の権限が必要です。
CREATE VIEW
UTL_FILE PL/SQLパッケージに対するEXECUTE
Oracle SQL Connector for HDFSのインストール時に作成されるOSCH_BIN_PATHディレクトリに対するREADおよびEXECUTE。書込みアクセス権は誰にも付与しないでください。Oracle SQL Connector for HDFSを使用する予定のユーザーにのみEXECUTEを付与します。
外部表を格納するデータベース・ディレクトリに対するREADとWRITE、またはCREATE ANY DIRECTORYシステム権限。Oracle RACシステムの場合、このディレクトリは、すべてのOracleインスタンスでアクセスできる共有ディスク上に存在する必要があります。
データをOracleデータベースにコピーする表領域と割当て。オプション。
例1-2に、これらの権限をHDFSUSERに付与するSQLコマンドを示します。
例1-2 Oracle SQL Connector for HDFSに対するユーザー・アクセス権の付与
CONNECT / AS sysdba;
CREATE USER hdfsuser IDENTIFIED BY password
DEFAULT TABLESPACE hdfsdata
QUOTA UNLIMITED ON hdfsdata;
GRANT CREATE SESSION, CREATE TABLE, CREATE VIEW TO hdfsuser;
GRANT EXECUTE ON sys.utl_file TO hdfsuser;
GRANT READ, EXECUTE ON DIRECTORY osch_bin_path TO hdfsuser;
GRANT READ, WRITE ON DIRECTORY external_table_dir TO hdfsuser;
|
注意: Oracle SQL Connector for HDFSを使用する外部表を問い合せる場合にユーザーに必要な権限は、対象の表に対するSELECT権限のみです。 |
HDFSおよびデータ・ポンプ形式ファイルの外部表を作成する場合、ユーザーは、Oracle DatabaseシステムまたはHadoopクライアントとして設定された別のシステムにログインできます。
これらのシステムのアカウントは、他のオペレーティング・システム・ユーザーの場合と同様に設定できます。HADOOP_CLASSPATHにpath/orahdfs-3.2.0/jlib/*を含める必要があります。この設定は、このインストール手順の一部としてシェルのプロファイルに追加することも、ユーザーが設定することもできます。次の例では、BashシェルのHADOOP_CLASSPATHを変更します。ここでは、Oracle SQL Connector for HDFSは/usr/binにインストールされています。
export HADOOP_CLASSPATH="$HADOOP_CLASSPATH:/usr/bin/orahdfs-3.2.0/jlib/*"
ユーザーが、Oracle SQL Connector for HDFSを使用して作成された外部表にアクセスする場合、外部表は、Oracleデータベースが稼働しているシステムで実行されているHadoopクライアントのように動作します。また、Oracleのインストール先のオペレーティング・システム・ユーザーのIDが使用されます。
セキュアなHadoopクラスタでは、Kerberosがインストール済で、クライアント・アクティビティを認証するように構成されています。Oracle SQL Connector for HDFSをKerberosで保護されたHadoopクラスタとともに使用するように構成する必要があります。
kinitを使用してユーザーを認証する場合:
Hadoop管理者は、クラスタに対するKey Distribution Center (KDC)にオペレーティング・システム・ユーザー(oracleなど)およびパスワードを登録する必要があります。
Oracle Databaseシステムのシステム管理者は、/etc/krb5.confを構成して、セキュアなクラスタによって管理されているKDCを参照するドメイン定義を追加します。
これらの手順を使用すると、オペレーティング・システム・ユーザーは、kinitユーティリティで認証されてから、Oracle SQL Connector for HDFSジョブを発行できます。kinitユーティリティは通常、認証用のKerberosキータブ・ファイルを使用し、パスワードに対話型プロンプトを使用しません。
システムではkinitをKerberosチケットの失効前に定期的に実行して、Oracle SQL Connector for HDFSによる透過的な認証を可能にする必要があります。cronまたは類似ユーティリティを使用して、kinitを実行します。たとえば、Kerberosチケットが2週間ごとに期限が切れる場合は、チケットの期限を1週間ごとに延長するようにcronジョブを設定します。
Oracle SQL Connector for HDFSがアクティブに使用されなくなったら実行されるように、cronジョブがスケジュールされていることを確認してください。
Oracle SQL Connector for HDFSプリプロセッサ・スクリプト(hdfs_stream)内のkinitは、kinitに対する大量の同時呼出しがトリガーされて、内部Kerberosキャッシュ・エラーが作成される可能性があるため、呼び出さないでください。
|
注意: Oracle Big Data Applianceでは、Kerberosセキュリティが構成オプションとして自動的に構成されます。セキュアなOracle Big Data Applianceクラスタに対するクライアント・システムの設定の詳細は、『Oracle Big Data Applianceソフトウェア・ユーザーズ・ガイド』を参照してください。 |
Oracle Loader for Hadoopを設定するには、次の各項の手順に従います。
Oracle Loader for Hadoopには、次のソフトウェアが必要です。
次のいずれかが稼働しているターゲット・データベース・システム
Oracle Database 12c
Oracle Database 11gリリース2 (11.2.0.4)
Oracle Database 11gリリース2 (11.2.0.3)
必要なパッチを含むOracle Database 11gリリース2 (11.2.0.2)
Oracle Database 10gリリース2 (10.2.0.5)
|
注意: Oracle Database 11gリリース2 (11.2.0.2)でOracle Loader for Hadoopを使用するには、Oracle Bug#11897896に対処する個別パッチを最初に適用する必要があります。このパッチを入手するには、http://support.oracle.comにアクセスしてバグ番号を検索します。 |
Cloudera's Distribution including Apache Hadoopバージョン4 (CDH4)またはバージョン5 (CDH5)、あるいはApache Hadoop 2.2.0。
Hive表からデータをロードする場合はApache Hive 0.8.1、0.9.0、0.10.0、0.12.0または0.13.0。
Oracle Loader for Hadoopは、Oracle Database 11gリリース2クライアント・ライブラリおよびOracle Database 11.2.0.2または11.2.0.3に接続するためのOracle Instant Clientライブラリに同梱されています。
|
注意: Oracle Loader for Hadoopをインストールするシステムには、Oracle Clientが必要とするリソースと同じリソースが必要です。Oracle Database 12c リリース1 (12.1)におけるOracle Clientの要件に関する詳細は、『Oracle Database Client インストレーション・ガイド for Linux』を参照してください。 |
Oracle Loader for Hadoopをインストールするには、次の手順を実行します。
oraloader-version.x86_64.zipの内容をHadoopクラスタまたはHadoopクライアントとして構成したシステムのディレクトリに解凍します。
oraloader-version-h2.x86_64.zipをHadoopクラスタのディレクトリに解凍します。
oraloader-version-h2というディレクトリが次のサブディレクトリとともに作成されます。
doc jlib lib examples
HADOOP_CLASSPATH変数に次のパスを追加します。
すべてインストールする場合:
$OLH_HOME/jlib/*
Hive表からのデータのロードをサポートする場合:
/usr/lib/hive/lib/* /etc/hive/conf
「Hive入力形式のJARファイルの指定」を参照してください。
Oracle NoSQL Databaseリリース2からデータを読み取る場合:
$KVHOME/lib/kvstore.jar
一般的なインストールでは、Oracle Loader for HadoopはHadoopクラスタまたはHadoopクライアントからOracle Databaseシステムに接続できます。接続できない場合(複数のシステムが異なるネットワーク上にある場合など)は、Oracle Loader for Hadoopをオフライン・データベース・モードで使用できます。「操作モードの概要」を参照してください。
オフライン・データベース・モードをサポートするには、2つのシステムにOracle Loader for Hadoopをインストールする必要があります。
HadoopクラスタまたはHadoopクライアントとして設定されているシステム(「Oracle Loader for Hadoopのインストール」を参照)。
Oracle DatabaseシステムまたはOracle Databaseへのネットワーク・アクセスを備えたシステム(次の手順を参照)。
Oracle Loader for Hadoopをオフライン・データベース・モードでサポートするには、次の手順を実行します。
oraloader-version.zipの内容をOracle DatabaseシステムまたはOracle Databaseへのネットワーク・アクセスを備えたシステムに解凍します。
CDH4またはCDH5のいずれかに対して、Hadoopクラスタにインストールしたソフトウェアのoraloader-version-h2.x86_64.zipバージョンを解凍します。
OLH_HOMEという変数を作成し、その変数をインストール・ディレクトリに設定します。次の例では、Bashシェル構文を使用しています。
$ export OLH_HOME="/usr/bin/oraloader-version-h2/"
Oracle Loader for HadoopのJARファイルをCLASSPATH環境変数に追加します。次の例では、Bashシェル構文を使用しています。
$ export CLASSPATH=$CLASSPATH:$OLH_HOME/jlib/*
セキュアなHadoopクラスタでは、Kerberosがインストール済で、クライアント・アクティビティを認証するように構成されています。オペレーティング・システム・ユーザーは認証されてから、Oracle Loader for Hadoopジョブを開始してセキュアなHadoopクラスタで実行する必要があります。認証の場合、ユーザーは、ジョブを発行するオペレーティング・システムにログインして、標準のKerberosのkinitユーティリティを使用する必要があります。
kinitを使用してユーザーを認証する場合:
Hadoop管理者は、クラスタに対するKey Distribution Center (KDC)にオペレーティング・システム・ユーザーおよびパスワードを登録する必要があります。
オペレーティング・システム・ユーザーがOracle Loader for Hadoopジョブを開始するクライアント・システムのシステム管理者は、/etc/krb5.confを構成して、セキュアなクラスタによって管理されているKDCを参照するドメイン定義を追加する必要があります。
通常、kinitユーティリティでは、数日間有効の認証チケットを取得します。後続のOracle Loader for Hadoopジョブは、失効していないチケットを使用して透過的に認証されます。
|
注意: Oracle Big Data Applianceでは、Kerberosセキュリティが構成オプションとして自動的に構成されます。セキュアなOracle Big Data Applianceクラスタに対するクライアント・システムの設定の詳細は、『Oracle Big Data Applianceソフトウェア・ユーザーズ・ガイド』を参照してください。 |
Oracle XQuery for HadoopをHadoopクラスタにインストールして構成します。Oracle Big Data Applianceを使用している場合、このソフトウェアはすでにインストールされています。
次のトピックでは、このソフトウェアのインストールについて説明します。
Oracle Big Data Appliance 3.1は、次のソフトウェア要件を満たしています。ただし、サードパーティのクラスタにOracle XQuery for Hadoopをインストールしている場合は、これらのコンポーネントがインストールされていることを確認する必要があります。
Java 7.xまたは6.x
Cloudera's Distribution including Apache Hadoopバージョン5 (CDH 5.0)以降
Oracle NoSQL Databaseに対する読取りおよび書込みをサポートするOracle NoSQL Database 3.xまたは2.x
Oracleデータベースへの表の書込みをサポートするOracle Loader for Hadoop 3.1
次の手順に従って、Oracle XQuery for Hadoopをインストールします。
Oracle XQuery for Hadoopをインストールするには、次の手順を実行します。
oxh-version.zipの内容をインストール・ディレクトリに解凍します。
$ unzip oxh-4.1.0-cdh-5.0.0.zip
Archive: oxh-4.1.0-cdh-5.0.0.zip
creating: oxh-4.1.0-cdh5.0.0/
creating: oxh-4.1.0-cdh5.0.0/lib/
creating: oxh-4.1.0-cdh5.0.0/oozie/
creating: oxh-4.1.0-cdh5.0.0/oozie/lib/
inflating: oxh-4.1.0-cdh5.0.0/lib/ant-launcher.jar
inflating: oxh-4.1.0-cdh5.0.0/lib/ant.jar
.
.
.
これで、Oracle XQuery for Hadoopを実行できます。
実行時間を最速にするには、ライブラリをHadoop分散キャッシュにコピーします。
Oracle XQuery for HadoopおよびサードパーティのすべてのライブラリをHDFSディレクトリにコピーします。ファイルのコピーに-exportliboozieオプションを使用する場合は、「Oracle XQuery for Hadoopのオプション」を参照してください。あるいは、HDFSコマンドライン・インタフェースを使用してライブラリを手動でコピーすることもできます。
Oozieを使用する場合は、すべてのファイルで同じフォルダを使用します。「Oracle XQuery for HadoopアクションのOozieの構成」を参照してください。
oracle.hadoop.xquery.lib.shareプロパティを設定するか、コマンドラインで-sharelibオプションを使用して、Hadoop分散キャッシュのディレクトリを指定します。
Oracle Databaseへのデータのロードをサポートするには、次のようにOracle Loader for Hadoopをインストールします。
oraloader-version.x86_64.zipの内容をHadoopクラスタまたはHadoopクライアントとして構成したシステムのディレクトリに解凍します。このアーカイブには、アーカイブとREADMEファイルが含まれています。
Hadoopクラスタのディレクトリにアーカイブを解凍します。
unzip oraloader-version-h2.x86_64.zip
oraloader-version-h2というディレクトリが次のサブディレクトリとともに作成されます。
doc jlib lib examples
OLH_HOMEという環境変数を作成して、インストール・ディレクトリに設定します。HADOOP_CLASSPATHは設定しないでください。
Oracle NoSQL Databaseへのデータのロードをサポートするには、インストール後、KVHOMEという環境変数をOracle NoSQL Databaseのインストール・ディレクトリに設定します。
Apache Solrによる索引をサポートするには、次のようにします。
HadoopクラスタにSolrがインストールされ、構成されていることを確認します。SolrはCloudera Searchに含まれており、Oracle Big Data Appliance上に自動的にインストールされます。
ドキュメントのロード先となるインストールしたSolrにコレクションを作成します。コレクションを作成するにはsolrctlユーティリティを使用します。
|
関連項目: solrctlユーティリティに関しては、次のサイトのCloudera Searchユーザー・ガイドを参照してください。
|
OXH_SOLR_MR_HOME環境変数をsearch-mr-version.jarおよびsearch-mr-version-job.jarを含むローカル・ディレクトリに設定し、インストールしたSolrを使用するようにOracle XQuery for Hadoopを構成します。次に例を示します。
$ export OXH_SOLR_MR_HOME="/usr/lib/solr/contrib/mr"
|
注意: また、Apache Tikaアダプタを使用する前に、Oracle XQuery for Hadoopを構成し、OXH_SOLR_MR_HOME環境変数をローカル・ディレクトリに設定してください。 |
Oracle XQuery for Hadoopで問合せの実行時に独自のライブラリまたはサードパーティのライブラリの検出に失敗した場合は、「Oracle XQuery for Hadoopのインストール」で説明されているように、環境変数が設定されていることを最初に確認してください。
正しく設定されている場合は、lib/oxh-lib.xmlの編集が必要な可能性があります。このファイルは、Oracle XQuery for HadoopシステムのJARファイルと、Avro、Oracle Loader for HadoopやOracle NoSQL Databaseなどのその他のライブラリの場所を識別します。
必要に応じて、このファイルの環境変数は、${env.variable} (${env.OLH_HOME}など)で参照できます。Hadoopプロパティも${property}(${mapred.output.dir}など)で参照できます。
「Apache Oozieからの問合せの実行」で説明しているように、Apache Oozieワークフローを使用して問合せを実行できます。ソフトウェアは、Oracle Big Data Applianceにすでにインストールおよび構成されています。
その他のHadoopクラスタの場合は、まずOracle XQuery for Hadoopアクションを使用するようにOozieを構成する必要があります。これらは、Oracle XQuery for Hadoopアクションをインストールする一般的な手順です。
Oozie構成を変更します。CDHをサードパーティ・ハードウェアで実行する場合、Cloudera Managerを使用してOozieサーバー構成を変更します。それ以外のHadoopのインストールの場合は、oozie-site.htmを編集します。
oracle.hadoop.xquery.oozie.OXHActionExecutorをoozie.service.ActionService.executor.ext.classesプロパティの値に追加します。
oxh-action-v1.xsdをoozie.service.SchemaService.wf.ext.schemasプロパティの値に追加します。
oxh-oozie.jarをOozieサーバーのクラス・パスに追加します。たとえば、CDH5のインストールではoxh-oozie.jarをサーバーの/var/lib/oozieにコピーします。
Oracle XQuery for Hadoopのすべての依存関係を、oxhサブディレクトリのOozie共有ライブラリに追加します。CLI -exportliboozieオプションを使用できます。「Oracle XQuery for Hadoopのオプション」を参照してください。
変更を反映するためにOozieを再起動します。
具体的な手順は、Oozieがすでにインストールされているか、どのバージョンを使用しているかなどOozieのインストールによって決まります。
Oracle R Advanced Analytics for Hadoopでは、Hadoop側とクライアントLinuxシステムへのソフトウェア環境のインストールが必要です。次のトピックでは、インストールについて説明します。
|
関連項目: Oracle R Advanced Analytics for Hadoopリリース・ノートは次のサイトを参照してください。
|
Oracle Big Data Applianceでは、追加ソフトウェアのインストールや構成なしにOracle R Advanced Analytics for Hadoopがサポートされます。ただし、サードパーティのHadoopクラスタでOracle R Advanced Analytics for Hadoopを使用するには、必要な環境を作成する必要があります。
Oracle R Advanced Analytics for HadoopをサポートするサードパーティHadoopクラスタにいくつかのソフトウェア・コンポーネントをインストールする必要があります。
次のコンポーネントをサードパーティ・サーバーにインストールします。
Cloudera's Distribution including Apache Hadoopバージョン4 (CDH5)またはApache Hadoop 0.20.2+923.479以上。
代理店で提供される手順を完了します。
Apache Hive 0.10.0+67以上
「サードパーティHadoopクラスタへのHiveのインストール」を参照してください。
Oracle Databaseに接続する関数を実行するためのSqoop 1.3.0+5.95以上。Oracle R Advanced Analytics for Hadoopでは、Sqoopをインストールまたはロードする必要はありません。
「サードパーティHadoopクラスタへのSqoopのインストール」を参照してください。
Mahout (orch_lmf_mahout_als.Rを実行する場合)。
Java Virtual Machine (JVM)、できればJava HotSpot Virtual Machine 6。
http://www.oracle.com/technetwork/java/javase/downloads/index.html
HadoopクラスタのすべてのノードにOracle R Distribution 3.0.1とすべてのベース・ライブラリ。
「サードパーティHadoopクラスタへのRのインストール」を参照してください。
各RエンジンのORCHパッケージ。Hadoopクラスタの各ノードに必要です。
「サードパーティHadoopクラスタへのORCHパッケージのインストール」を参照してください。
OLHドライバ(オプション)をサポートするOracle Loader for Hadoop。
「Oracle Loader for Hadoopの設定」を参照してください。
|
注意: HadoopクラスタにHADOOP_HOMEを設定しないでください。CDH5はその設定を必要とせず、設定するとOracle R Advanced Analytics for Hadoopに支障をきたします。他のアプリケーションでHADOOP_HOMEを設定する必要がある場合は、/etc/bashrcファイルにHADOOP_LIBEXEC_DIRも設定してください。次に例を示します。
export HADOOP_LIBEXEC_DIR=/usr/lib/hadoop/libexec |
Sqoopには、Hadoopに対するSQLライクなインタフェースがあり、これはJavaベース環境になります。Oracle R Advanced Analytics for Hadoopでは、Oracle DatabaseへのアクセスにSqoopを使用します。
|
注意: Oracle DatabaseへのデータのロードにOracle Loader for Hadoopをドライバとして使用する場合もSqoopが必要です。Sqoopは、データベースからHDFSへのデータのコピーや自由形式の問合せのデータベースへの送信などの関数を実行します。このドライバでは、Oracle Loader for Hadoopがサポートしない操作の実行にもSqoopが使用されます。 |
Oracle Databaseで使用するためにSqoopをインストールして構成するには、次の手順を実行します。
Sqoopがサーバーにインストールされていない場合はインストールします。
Cloudera's Distribution including Apache Hadoopについては、次のサイトの『CDH Installation Guide』のSqoopインストール手順を参照してください
Oracle Databaseに適したJava Database Connectivity (JDBC)ドライバを次のOracle Technology Networkからダウンロードします
http://www.oracle.com/technetwork/database/features/jdbc/index-091264.html
ドライバのJARファイルを$SQOOP_HOME/libにコピーします。これは、/usr/lib/sqoop/libなどのディレクトリです。
SqoopにOracle Databaseへの接続文字列を指定します。
$ sqoop import --connect jdbc_connection_string
sqoop import --connect jdbc:oracle:thin@myhost:1521/orclのようになります。
Hiveは、HiveQLと呼ばれる問合せ言語によって、代替のストレージおよび取得メカニズムをHDFSファイルに提供します。Oracle R Advanced Analytics for HadoopではHiveQLのデータ準備と分析機能が使用されますが、R言語構文も使用できます。
Hiveをインストールするには、次の手順を実行します。
代理店(ClouderaまたはApache)で提供されるHiveインストール手順に従います。
インストールが適切に機能することを確認します。
$ hive -H
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
.
.
.
コマンドが失敗したり、出力に警告が表示される場合、Hiveインストールを修正します。
次のWebサイトからOracle R Distribution 3.0.1をダウンロードして、インストール手順を入手できます。
http://www.oracle.com/technetwork/database/database-technologies/r/r-distribution/downloads/index.html
ORCHは、Oracle R Advanced Analytics for Hadoopパッケージの名前です。
ORCHパッケージをインストールするには、次の手順を実行します。
クラスタの第1ノードにrootとしてログインします。
サポートするソフトウェアの環境変数を設定します。
$ export JAVA_HOME="/usr/lib/jdk7" $ export R_HOME="/usr/lib64/R" $ export SQOOP_HOME "/usr/lib/sqoop"
ダウンロードしたファイルを解凍します。
$ unzip orch-version.zip $ unzip orch-linux-x86_64-2.4.0.zip Archive: orch-linux-x86_64-2.4.0.zip creating: ORCH2.4.0/ extracting: ORCH2.4.0/ORCH_2.4.0_R_x86_64-unknown-linux-gnu.tar.gz inflating: ORCH2.4.0/ORCHcore_2.4.0_R_x86_64-unknown-linux-gnu.tar.gz . . .
新しいディレクトリに変更します。
$ cd ORCH2.4.0
次の順序でパッケージをインストールします。
R --vanilla CMD INSTALL OREbase_1.4_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL OREstats_1.4_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL OREmodels_1.4_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL OREserver_1.4_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL ORCHcore_2.4.0_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL ORCHstats_2.4.0_R_x86_64-unknown-linux-gnu.tar.gz R --vanilla CMD INSTALL ORCH_2.4.0_R_x86_64-unknown-linux-gnu.tar.gz
次のパッケージは、クラスタのその他すべてのノードにもインストールする必要があります。
OREbase
OREmodels
OREserver
OREstats
次の例では、dcliユーティリティ(Oracle Big Data Applianceでは使用可能で、サードパーティ・クラスタでは使用不可)を使用して、OREserverパッケージをコピーおよびインストールします。
$ dcli -C -f OREserver_1.4_R_x86_64-unknown-linux-gnu.tar.gz -d /tmp/ OREserver_1.4_R_x86_64-unknown-linux-gnu.tar.gz $ dcli -C " R --vanilla CMD INSTALL /tmp/OREserver_1.4_R_x86_64-unknown-linux-gnu.tar.gz"
Hadoopクラスタでは、すべてのノードにlibpng-develがインストールされている必要があります。コモディティ・ハードウェア上で稼働するクラスタを使用する場合も基本手順は同じです。ただし、dcliユーティリティを使用してコマンドをすべてのノード間に複製することはできません。dcliユーティリティの構文は、『Oracle Big Data Applianceオーナーズ・ガイド』を参照してください。
libpng-develのインストール手順:
Hadoopクラスタの任意のノードにrootとしてログインします。
libpng-develがすでにインストールされているかどうかを確認します。
# dcli rpm -qi libpng-devel
bda1node01: package libpng-devel is not installed
bda1node02: package libpng-devel is not installed
.
.
.
すべてのサーバーにパッケージがインストール済の場合、この手順は省略できます。
ファイアウォールの外側にプロキシ・サーバー経由で接続する必要がある場合は、HTTP_PROXY環境変数を設定します。この例では、dcliを使用します。これは、Oracle Big Data Applianceでのみ使用可能です。
# dcli export HTTP_PROXY="http://proxy.example.com"
yumディレクトリに移動します。
# cd /etc/yum.repos.d
使用するLinuxのバージョンに適した構成ファイルをダウンロードして構成します。
Enterprise Linux 5 (EL5)の場合:
yum構成ファイルをダウンロードします。
# wget http://public-yum.oracle.com/public-yum-el5.repo
テキスト・エディタでpublic-yum-el5.repoを開き、次のように変更します。
el5_latestの下で、enabled=1と設定します。
el5_addonsの下で、enabled=1と設定します。
変更を保存し、終了します。
他のOracle Big Data Applianceサーバーにファイルをコピーします。
# dcli -d /etc/yum.repos.d -f public-yum-el5.repo
Oracle Linux 6 (OL6)の場合:
yum構成ファイルをダウンロードします。
# wget http://public-yum.oracle.com/public-yum-ol6.repo
テキスト・エディタでpublic-yum-ol6.repoを開き、次のように変更します。
ol6_latestの下で、enabled=1と設定します。
ol6_addonsの下で、enabled=1と設定します。
変更を保存し、終了します。
他のOracle Big Data Applianceサーバーにファイルをコピーします。
# dcli -d /etc/yum.repos.d -f public-yum-ol6.repo
すべてのサーバーにパッケージをインストールします。
# dcli yum -y install libpng-devel
bda1node01: Loaded plugins: rhnplugin, security
bda1node01: Repository 'bda' is missing name in configuration, using id
bda1node01: This system is not registered with ULN.
bda1node01: ULN support will be disabled.
bda1node01: http://bda1node01-master.abcd.com/bda/repodata/repomd.xml:
bda1node01: [Errno 14] HTTP Error 502: notresolvable
bda1node01: Trying other mirror.
.
.
.
bda1node01: Running Transaction
bda1node01: Installing : libpng-devel 1/2
bda1node01: Installing : libpng-devel 2/2
bda1node01: Installed:
bda1node01: libpng-devel.i386 2:1.2.10-17.el5_8 ibpng-devel.x86_64 2:1.2.10-17.el5_8
bda1node01: Complete!
bda1node02: Loaded plugins: rhnplugin, security
.
.
.
すべてのサーバーでインストールが正常に終了したことを確認します。
# dcli rpm -qi libpng-devel
bda1node01: Name : libpng-devel Relocations: (not relocatable)
bda1node01: Version : 1.2.10 Vendor: Oracle America
bda1node01: Release : 17.el5_8 Build Date: Wed 25 Apr 2012 06:51:15 AM PDT
bda1node01: Install Date: Tue 05 Feb 2013 11:41:14 AM PST Build Host: ca-build56.abcd.com
bda1node01: Group : Development/Libraries Source RPM: libpng-1.2.10-17.el5_8.src.rpm
bda1node01: Size : 482483 License: zlib
bda1node01: Signature : DSA/SHA1, Wed 25 Apr 2012 06:51:41 AM PDT, Key ID 66ced3de1e5e0159
bda1node01: URL : http://www.libpng.org/pub/png/
bda1node01: Summary : Development tools for programs to manipulate PNG image format files.
bda1node01: Description :
bda1node01: The libpng-devel package contains the header files and static
bda1node01: libraries necessary for developing programs using the PNG (Portable
bda1node01: Network Graphics) library.
.
.
.
Rユーザーは、Hadoopクラスタで自身のプログラムをMapReduceジョブとして実行しますが、通常、そのプラットフォームでの個別アカウントは保有していません。かわりに、外部Linuxサーバーでリモート・アクセスが提供されます。
HadoopクラスタへのアクセスをRユーザーに提供するには、次のコンポーネントをLinuxサーバーにインストールします。
Hadoopクラスタと同じバージョンのHadoop。インストールされていない場合、予想外の問題や障害が生じることがあります。
Hadoopクラスタと同じバージョンのSqoop。Oracle Database内外でのデータのコピーをサポートする場合にのみ必要です。
Mahout。Mahout ALS-WSアルゴリズムでorch.ls関数を使用する場合にのみ必要です。
Hadoopクラスタと同じバージョンのJava Development Kit (JDK)。
ORCH Rパッケージ。
データベース・オブジェクトにアクセスできるようにするには、Oracle DatabaseへのOracle Advanced Analyticsオプションが必要です。その後、Hadoopクライアントにこの追加コンポーネントをインストールできます。
Oracle R Enterpriseクライアントのパッケージ。
クライアントにHadoopをインストールし、HDFSクライアントを使用する場合はHadoopの最小限の構成を行う必要があります。
クライアント・システムにHadoopをインストールして構成するには、次の手順を実行します。
クライアント・システムにCDH5またはApache Hadoop 0.20.2をインストールして構成します。このシステムがOracle Databaseのホストになります。Oracle Big Data Applianceを使用する場合、『Oracle Big Data Applianceソフトウェア・ユーザーズ・ガイド』のリモート・クライアント・アクセスを提供するための手順を完了します。それ以外の場合は、代理店(ClouderaまたはApache)が提供するインストール手順に従います。
Rユーザーでクライアント・システムにログインします。
Bashシェルを開き、次のHadoopファイル・システム・コマンドを入力します。
$HADOOP_HOME/bin/hdfs dfs -ls /user
ファイルのリストが表示されたら終了です。表示されない場合、Hadoopクラスタが稼働していることを確認します。それでも問題が修正されない場合は、クライアントHadoopのインストールをデバッグする必要があります。
Sqoopをインストールして構成する場合、「サードパーティHadoopクラスタへのSqoopのインストール」で説明する手順と同じ手順をクライアント・システムで完了します。
Oracle R Distributionの次のWebサイトからR 2.13.2をダウンロードして、インストール手順を入手できます。
終了したら、Linuxサーバーへの接続とRの実行に必要な権限がユーザーにあることを確認します。
また、Rユーザーによるアクセスが簡単になるようにRStudioサーバーもインストールできます。RStudioの次のWebサイトを参照してください。
ORCHをHadoopクライアント・システムにインストールするには、次の手順を実行します。
ORCHパッケージをダウンロードし、クライアント・システムに解凍します。
インストール・ディレクトリに移動します。
次のようにクライアント・スクリプトを実行します。
# ./install-client.sh
Rを使用したOracle Databaseへの完全なアクセスをサポートするには、Oracle R Enterpriseリリース1.4のクライアントのパッケージをインストールします。このパッケージがない場合、Oracle R Advanced Analytics for Hadoopでは、Oracle R Enterpriseで提供される高度な統計アルゴリズムを利用できません。
|
関連項目: RおよびOracle R Enterpriseのインストールの詳細は、Oracle R Enterpriseユーザーズ・ガイド |
脚注の説明
脚注 1: 『Hadoop: The Definitive Guide, Third Edition』Tom White著(O'Reilly Media Inc., 2012, 978-1449311520)