11 Using Derived Associations
Effective management of IT infrastructure requires knowledge of the relationships between IT entities. Best practices such as those described by ITIL (Information Technology Infrastructure Library) rely on capturing and using such relationships.Enterprise Manager Cloud Control 12c extends the kinds of relationships being supported and adds a declarative mechanism by which these relationships can be maintained. It also determines the membership of entities in a system based on relationships. Based on accurate relationships, various Enterprise Manager applications and components can support customer uses such as:
-
Dependency analysis.
For instance, to understand the impact (to applications and infrastructure) of shutting down a host.
-
Topology viewer.
-
Change management.
For instance, tracking the source of cloned databases.
-
End-to-end performance analysis, in which interdependencies between application components must be known in order to analyze and isolate issues.
-
Change tracking of relationships, such as changes in the way VM resources are allocated.
This chapter covers the following:
11.1 Introduction to Derived Associations
As an plug-in developer, you are responsible for defining those association types that apply to your managed entity types and for verifying that the correct associations (association instances) are present.
A manageable entity is an entity that Enterprise Manager is capable of managing. This implies that the entity is exposed in some form to end users in the Cloud Control application, and has well-defined attributes and semantics.
As a plug-in developer, you are responsible for the following steps with regard to derived associations:
-
Identify all associations that need to be represented for any managed entities (MEs) that you own.
This generally includes any containment or dependency associations between an ME you own and any other MEs. For each kind of association identified, you may need to coordinate with the owner of the related ME type to determine who should be responsible for assuring that association instances of that type are kept up to date. Some associations (in particular,
hosted_byandmanaged_by) are automatically maintained by Enterprise Manager, so association derivation rules should not be used for these. -
Understand the set of out-of-box association types that are shipped with Enterprise Manager and ensure the use of the most appropriate type.
For more information, see Section 11.2.1, "About Out-of-Box Association Types".
-
Ensure that association derivation rules are used to (declaratively) describe the associations that are to exist based on configuration data that resides in the repository.
Rules are triggered by configuration collections (where target property changes are also treated as a configuration collection).
For more information, see Section 11.3.1, "Using Association Derivation Rules Syntax and Semantics".
-
You need to coordinate with the owners of other ME's regarding association maintenance, as associations with your ME types often involve other plug-in's ME types.
Decide which plug-in will package the rules. The plug-in that owns the rule must ensure that it specifies all other needed plug-ins as prerequisites to ensure that all target types and their ECM metadata is present prior to rule installation.
Advanced activation expressions, as described in Section 11.3.10, "Understanding Activation Expressions" can be used if it is not possible to assure all needed target types are present. Rule triggers should reside in plug-ins that define target types specified by the triggers. However, if target types are known to exist before the plug-in installation, the triggers can reside along with the rule.
11.1.1 Assumptions and Prerequisites
This chapter assumes you are familiar with the following:
-
Association types in general, association type hierarchy, concepts of allowed pairs of manageable entity types for association types, forward and concrete (versus abstract) association type, and the semantics of the Enterprise Manager out-of-box association types.
-
Target model, target properties, and target components.
-
Enterprise Configuration Management configuration collections, including treatment of target properties as configuration data.
-
Plug-in development overview, including how to package a plug-in and its XML files.
-
Topology viewer (to view your associations).
11.2 Understanding Enterprise Manager Association Concepts
In Enterprise Manager, the concept of a relationship is internally referred to as an association. An association (association instance) represents a relationship between two managed entities and specifies three values, namely, source, destination, and association type. For instance, in ”database1 exposed_by listener1”, database1 is the source, listener1 is the destination, and ”exposed_by” is the association type.
This section describes association derivation rules, which provide a concise declarative means of defining association types. Association derivation (so called because the existence of associations is derived from collected data) provides a mechanism by which developers can cause association instances to be created and removed based on data collected from a target.
The association derivations are based on the data collected using configuration collections and present in the Enterprise Manager repository. The association derivation mechanism allows you to keep the association consistent with the collected configuration data and to determine associations centrally based on all known data (instead of being done by agent logic, which has access to less data).
11.2.1 About Out-of-Box Association Types
Enterprise Manager provides a common set of association types that should meet the needs of most plug-in developers and you are encouraged to become familiar with these association types and use them if applicable.
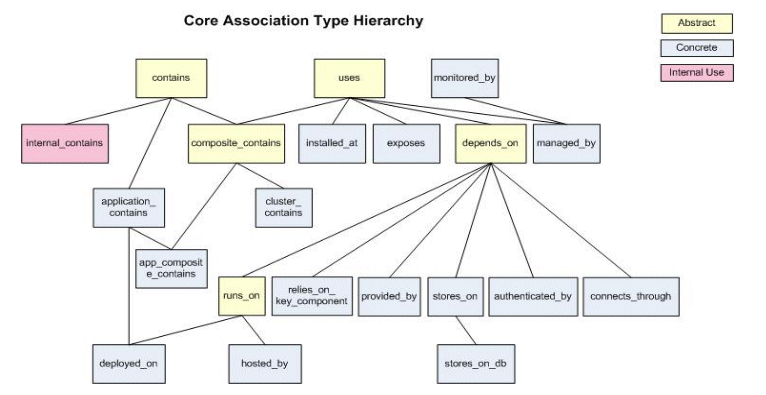
The cardinality specifies the cardinality for the overall association type. An allowed_pairs (constraint) should not specify conflict cardinality, but may specify more specific cardinality. An abstract association type can not have association instance created for it.
The following diagram shows the core association type hierarchy. For more information on out-of-box association types, see Appendix A, "Out-of-Box Associations"
11.2.2 Using Association Derivation
To use association derivation, complete the following:
-
Specify the logic to run after the collection of target configuration.
The logic derives a set of association instances in the form of triples that specify the source managed entity GUID, association type, and destination managed entity GUID. For instance, the association derivation logic for targets of type oracle_listener could return triples that represent associations between the listener and each database for which it listens.
-
Create and run a SELECT statement that contains the logic used to derive the triples.
Each returned row contains association type, source, and destination columns and represents an association that should exist.
-
Register the derivation logic against an Enterprise Configuration Management snapshot type.
After every snapshot collection, the registered logic is invoked. Input to the logic is the GUID of the target for which the data was collected.
When the association derivation logic for snapshot S of target T is executed, the derived associations replace the previously derived associations for snapshot S of target T. For example, if associations A1 and A2 were collected yesterday and only A1 is collected today, then A2 is effectively deleted.
11.2.3 About Automated Discovery and Promotion of Associations
One option for adding associations to Enterprise Manager is to provide a discovery script which discovers targets and the associations between them, and the discovery script is then scheduled to run on a selected set of agents by the end-user. The targets and associations discovered by this type of script are automatically promoted, that is they are automatically added to Enterprise Manager. This approach is useful for associations that are between targets that are managed by your plug-in and therefore the specific target identification is known (that is you create the targets on both ends of the association). If these associations are to other targets not included in your plug-in, then typically a derived association rule is used to specify how to locate the "external" target.
A guided discovery process may be used if some interaction with the end-user or administrator is necessary to filter the information discovered by the script, or if some amount of post-processing is necessary to compare it to other information already known to Enterprise Manager.
11.2.4 Understanding Association Creation During Guided Discovery
This approach is similar to the automated discovery approach described in the previous section in that you provide a discovery script that can be run by an Enterprise Manager agent. That discovery script may return any number of related targets and the associations between them. The difference is that in the guided discovery case, you provide a user interface that the end-user interacts with to drive the execution of the discovery script and then process the results returned from it. This processing takes the output from the discovery script and may further filter it or present it to the end-user to allow them to add important information to it.
Guided discovery may also interact with the Enterprise Manager system using target services to obtain information about targets already known to Enterprise Manager to perform incremental updates to the topology of targets discovered. This approach is also used for cases where the associations to be created are between targets that are managed by your plug-in and therefore the specific target identification is known. That is you create the targets on both ends of the association, but some additional intervention is needed before those associations are added to Enterprise Manager.
11.2.5 Using Associations Derived from a System Stencil
This approach is used solely for creating system membership associations between a system target and its members. The system target and its members are typically all part of a single plug-in, as you must have knowledge of the types of associations that exist between the system target and its members in order to form the system topology.
The system stencil defines the set of association paths that should be considered when forming the system membership. In this way, the plug-in can traverse complex association paths to locate targets that should be treated as members of the system. This is important in cases where a system member is not directly associated with the system target by some other "native" association.
If the plug-in does not include a target type that you wish to be treated as a system, then this approach can be ignored.
11.2.6 Associations Derived from Rule
This approach for creating associations is particularly suited to cases where the destination target of the association is not part of the plug-in but is known to be managed by Enterprise Manager. For example, assume that the configuration of your target included a connection to an Oracle database that was used to store information related to your target operation (such as an application store). The configuration of your target knows something about the database that it uses, likely some connection related details such as host-port-sid or host-service.
You would like to represent this association between your target and the database in Enterprise Manager so that if Enterprise Manager is managing the database, the end-user can see this relationship and traverse it to obtain other information about that database and manage it (if appropriate and allowed).
Because you do not know if Enterprise Manager is managing the database and the identifying information you have is not the Enterprise Manager database target name, but instead the connect information, you can construct a derivation rule that maps the connection information in your target's configuration to that of a database in Enterprise Manager.
This approach is very useful for cases where you wish to construct this type of association between a target that is part of your plug-in and some external target, particularly some Enterprise Manager stack component like Oracle Fusion Middleware or the Oracle Database.
11.3 About Association Derivation Rules Management
Enterprise Manager Cloud Control 12c extends the use of associations by Enterprise Manager components and enhances the overall association framework. It introduces new consumers of associations, including the topology viewer.
Association framework enhancements include the treatment of associations as configuration data. Enterprise Configuration Management features such as change tracking and saved snapshots now apply to associations as well as to traditional configuration data. Associations can now specify source and destination target components, as well as target GUIDs.
The following sections provide detailed instructions on the use and management of derivation rules:
11.3.1 Using Association Derivation Rules Syntax and Semantics
The following sections describe the contents of a rule, including name, query, triggers, and database objects that can be referenced by rule queries.
A rule is identified by a unique rule name that must be unique across all plug-ins. Oracle recommends that you use a suitable prefix to avoid name conflicts. For example, a company symbol or name followed by the plug-in name.
The primary component of a rule is the rule query, which identifies a set of associations. Each row returned by the query represents an association. The SQL must return four columns whose names and types must be:
-
assoc_type(VARCHAR2(64)): the association type
-
source_me_guid(RAW(16)): a managed entity GUID
-
dest_me_guid(RAW(16)): a managed entity GUID
-
derivation_target_guid, derivation_target_guid2, derivation_target_guid3(RAW(16))
Often unnecessary, these are one or more optional target GUID columns that identify targets involved in deriving the association (other than the source or destination).
-
These cannot be a target component ID, but must be a target GUID.
-
Columns should be used in order.
This means that queries returning
derivation_target_guid2must also returnderivation_target_guid. Queries returningderivation_target_guid3must also returnderivation_target_guidandderivation_target_guid2columns.
The need in some cases for a derivation target guid is illustrated by the case in which the collection for a target determines associations between two other targets. For instance, the collection for a Siebel Enterprise System determines associations between its member targets.
In this case, the derivation target GUID is the target GUID of the Siebel Enterprise System target, but the source and destination are other targets. Similar cases exist for Oracle E-Business Suite and Oracle WebLogic Server, where configuration information is collected from a single source, such as the Oracle WebLogic Server domain admin server, and used to derive associations between the domain members.
-
Each row returned by the query must specify a valid association instance and must use a concrete (not abstract) forward (not inverse) association type. Valid association instances must specify managed entities that are valid for the specified association type. For example, a hosted_by association must specify a destination that is a host target. Inverse association types must not be returned. For example, do not use host_for, which is the inverse of hosted_by and would be logged as an error.
Note that the rule query returns a repository-wide set of associations, but associations are populated incrementally on behalf of one target at a time. When the rule is evaluated, it is from the perspective of a single target. At evaluation time, the framework wraps the query with an outer query. For example:
"SELECT … FROM <query> WHERE derivation_target_guid = <initiatingTarget> AND …"
Note:
You do not need to specify a DISTINCT keyword (at the outmost level) in your rule query as the framework will eliminate the duplicates by itself when it wraps your query with its own query.Query size should not exceed 2000 characters. (It is planned to extend this to 4000 characters in a future release).
DB Objects Referenced by Rule Queries
For security reasons, the SYSMAN_RO user will execute your rule query. Therefore, only objects accessible by this user are allowed to be referenced. For objects created outside of your plug-in you can reference views exposed by the Extensibility Development Kit (EDK) at your plug-in level, including those prefixed with MGMT$.
For objects created in your plug-in, you can reference CM$ views auto-generated by the Enterprise Configuration Management framework for your target type collections. You can also reference views prefixed with a DA_ prefix and packages with invokers rights with a DA_ prefix.
Your query should not rely on associations unless you ensure that they are present by the time the query is executed (for example, when corresponding triggers fire – see below). For derived associations, the order of executions is not deterministic because the order in which configurations arrive and then corresponding associations are derived is arbitrary. An example of an association that can be used is a hosted_by association, which appears during target discovery and is not a derived association.
Triggers are usually provided in addition to the rule query. A trigger specifies a table that, when changed, may impact the associations returned by the rule query. Generally there are multiple triggers because the rule query often refers to data from multiple tables and because changes to either target's data can affect the association rows returned by the query.
Two triggers may not always be needed as it may be the case that the data for one of the two targets does not change. For instance, an association rule that determines its destination based on (immutable) identity properties of one of the targets is only affected by changes to the source target's configuration. Even in that case, it may still be desirable to specify two triggers. If the destination target can appear after the source and this appearance causes the immediate creation of a new association, the trigger is needed.
A trigger specifies the following:
-
A snapshot table
A change to the table (due to upload of new data) will fire the trigger. You should only include tables that affect the set of associations because needless firing of triggers impacts performance. A table is identified by target type, snapshot type, and table name.
-
Column ID flag
This indicates whether the source, destination, or a derivation target guid should be used to identify associations affected by the newly uploaded configuration data. In other words, depending on this column value, associations for the source, destination, or a derivation target will be replaced with a new set of associations computed for that target when the trigger table data changes. Possible values include
source,destination,derivationTarget,derivationTarget2, orderivationTarget3.
When the trigger fires, the association derivation framework will effectively replace all currently existing associations where the given target is a source, destination, or derivation (depending on the flag) with newly computed associations. To compute the new set of associations, the rule query is executed with the corresponding column bound to the target id. This simplified explanation assumes that associations only exist because of this single rule and it would be slightly changed for a target components case.
For example, a rule query accesses data from a listener configuration table and a database configuration table and returns associations of the form <database> exposed by <listener>. One trigger specifies the database configuration table and a column id flag of source, because a change to the configuration table for a database may affect rows where the database is the source of the association. Similarly, a second trigger specifies the listener configuration table and a column id flag of the destination, because a change to the configuration table for a listener may affect rows where the listener is the destination of the association.
If multiple rules can be triggered for a snapshot table, then the order in which the triggers execute is non-deterministic. This means that the developer cannot make any assumptions about the order.
The table name (TN) specified in a trigger can actually be the name of a base table, view, or synonym. In all cases, the underlying tables of TN are identified. A trigger is created for each such table that is an Enterprise Configuration Management table.
11.3.2 Understanding XML Metadata File Syntax and Semantics
To create or update a rule, you edit an XML metadata file that defines the rule (or set of rules) and then import it into the repository. The metadata import is done when a repository is created or upgraded. It is also done when a plug-in is added, upgraded, or removed.
Schematically, you specify the following information for each rule in the file:
-
Name
-
Query
-
0 to n triggers with
-
Fully qualified snapshot type (which includes target type).
-
Metric table of that snapshot (view or synonym that refers to such a table)
Normally, this view is used by the rule query.
-
Column flag (source, destination, derivationTarget, derivationTarget2, or derivationTarget3).
-
Optional details (used to specify target property names for triggers based on target properties).
-
The XML semantics are designed to describe the latest state of a rule and its triggers, no matter what the prior state was. So you only need the latest XML specification of a given rule to know how the rule and its triggers are specified for a plug-in. Moreover, one plugin will not be able to directly affect triggers of another plug-in. However, if a rule is removed, triggers referencing the rule from the other plug-ins will not be useful.
The following outlines the rule query specification semantics:
-
A non-empty query implies that you need to add or, if needed, overwrite a prior rule query for a rule that had been registered by the same plug-in.
-
Specifying no query implies removing the rule, if the rule query had been registered by the same plugin, and no change otherwise.
Once a rule R with its query is located in a file F within a plug-in P, its corresponding XML Rule element can never be removed from that file or from that plug-in (although its attributes and subelements can be modified). Rule R will always be owned by plug-in P. If the rule does need to be removed, a Rule element with no query sub-element must remain in file F indicating that rule R had been removed. If it is important to move rule R to another file or plug-in, you must rename the rule (to R2 for example), remove rule R using the above syntax in file F, and add R2 in the new location. This will effectively remove R and create a new rule R2.
Plug-in P that owns a rule R should be chosen carefully to ensure that all target types needed by the rule query are present by the time plug-in P is installed. Rule R should rely only on targets of types that are always present in Enterprise Manager (for example, host), targets of types defined by plug-in P, or targets of types defined in plug-ins that are prerequisites of plug-in P. If it is impossible to chose such a plug-in, consider using the advanced feature of activation expressions discussed later.
Trigger Specification Semantics
In terms of trigger specification semantics, you should replace triggers in the same plug-in with a new specified set of triggers. Alternatively, you can just remove any pre-existing triggers if the newly specified set is empty.
Normally triggers are defined as part of the rule definition in the same plug-in. This way, when the rule changes, corresponding triggers can also change if needed. However, in some cases it is preferable or only possible to place triggers in plug-ins defining the target types of the triggers. For example, a rule that computes association between targets and their corresponding Oracle Home targets cannot list all possible target types and corresponding triggers.
Instead, plug-ins owning target types that want to use the rule specify the triggers for the relevant target types. Therefore, a plug-in that owns an oracle_ias target type will have a trigger for this rule with oracle_ias listed as the target type in the trigger. Such triggers are changed or removed along with the corresponding plugin.
Once the rule's XML is listed in some file F in the plug-in that owns oracle_ias, it cannot move to another file (even if it specifies only triggers for the rule). Note that in our example, the rule query itself is not target type specific, as it only depends on the Oracle Home target type and not other specific target types. Therefore, the rule is defined in the plug-in P that is installed prior to the plug-ins (such as oracle_ias plugin). This way, when the trigger is imported into Enterprise Manager, it finds the rule already present.
The following points should also be taken into consideration:
-
You should always have a rule and its triggers specified in at most one file for a given plug-in.
For example, if some of the triggers for a rule (defined in a different plug-in P1) are specified in two files for plug-in P2, an import of the second file would overwrite the triggers that were specified in the first file. The order of import of the two files is not guaranteed.
-
An error will result if a query is specified for a rule that has been registered by a different plug-in.
In other words, plug-ins that have not specified a rule query can only specify a new set of triggers in their context, but cannot overwrite the query. Only one plug-in effectively owns the rule query.
-
An error will result if there is a trigger specification for a rule that does not exist or is being removed (by not specifying the rule query).
-
To effectively disable all triggers in all plug-ins for a given rule, the plug-in author can just remove the rule, using the syntax mentioned previously. If needed, the author can also create a rule with a different name as a replacement.
-
To replace triggers, but not the rule query, in the plug-in that had specified the rule query in a prior release, specify the same query again and a set of new triggers in the next plug-in version.
Note:
In terms of performance, specifying textually the same query will result in the best upgrade performance, since the framework will not need to recompute all associations for the query.The syntax for rule definitions is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" attributeFormDefault="unqualified"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xs:simpleType name="YesNo">
<xs:annotation><xs:documentation>
Type definition for the Yes/No atribute value.
</xs:documentation></xs:annotation>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="Y"/>
<xs:enumeration value="N"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NameDef">
<xs:restriction base="xs:string">
<xs:pattern value="[A-Za-z][A-Za-z0-9_]*"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="TriggerKind">
<xs:restriction base="xs:string">
<xs:enumeration value="C"/>
<xs:enumeration value="H"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="ColumnID">
<xs:restriction base="xs:string">
<xs:enumeration value="source"/>
<xs:enumeration value="destination"/>
<xs:enumeration value="derivationTarget"/>
<xs:enumeration value="derivationTarget2"/>
<xs:enumeration value="derivationTarget3"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RuleContentWFlags">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="source_comp" type="YesNo" use="optional">
<xs:annotation> <xs:documentation>
Can source entity be a target component? Default: No
</xs:documentation> </xs:annotation>
</xs:attribute>
<xs:attribute name="dest_comp" type="YesNo" use="optional">
<xs:annotation> <xs:documentation>
Can destination entity be a target component? Default: No
</xs:documentation> </xs:annotation>
</xs:attribute>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="RuleType">
<xs:annotation> <xs:documentation>
Rule definition.
</xs:documentation> </xs:annotation>
<xs:sequence minOccurs="0">
<xs:choice>
<xs:element name="query" type="RuleContentWFlags" minOccurs="0"
maxOccurs="1">
<xs:annotation> <xs:documentation>
Query that returns 1 row per association. Must return
columns named ASSOC_TYPE, SOURCE_ME_GUID, DEST_ME_GUID, and
optionally, one or more of DERIVATION_TARGET_GUID,
DERIVATION_TARGET_GUID2, DERIVATION_TARGET_GUID3.
Returning DERIVATION_TARGET_GUID[N] column
implies the query also returns DERIVATION_TARGET_GUID and all
DERIVATION_TARGET_GUID[K] for all K between 2 and N.
</xs:documentation> </xs:annotation>
</xs:element>
</xs:choice>
<xs:element name="trigger" minOccurs="0" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="targetType" type="xs:string" minOccurs="1"
maxOccurs="1"/>
<xs:element name="snapshotType" type="xs:string" minOccurs="0"
maxOccurs="1"/>
<xs:element name="table" type="xs:string" minOccurs="0"
maxOccurs="1">
<xs:annotation> <xs:documentation>
Name of an ECM table or more likely a view whose query
relies on ECM snapshot table(s). The table(s), when
uploaded,
should trigger evaluation of the rule. (The fully
qualified name includes target type and snapshot
type.)
</xs:documentation> </xs:annotation>
</xs:element>
<xs:element name="idColumn" type="ColumnID" minOccurs="1"
maxOccurs="1">
<xs:annotation> <xs:documentation>
Indicates whether source, destination, or a derivation
target
should be used to identify associations affected by the
newly
uploaded configuration data. In other words, depending on
this
column value, associations for the source, destination, or
a derivation target will be replaced with new set of
associations computed for that target, when the trigger
table data changes.
ColumnID type definition contains allowed values.
</xs:documentation> </xs:annotation>
</xs:element>
<xs:element name="details" type="xs:string" minOccurs="0"
maxOccurs="1">
<xs:annotation> <xs:documentation>
Additional details for the trigger. Currently used for
target properties table, in which case, it contains comma
separated list of property names that should fire the
trigger. Absence
of property names indicates that any property change would
fire the trigger (for the given target type).
Note: white space is ignored.
</xs:documentation> </xs:annotation>
</xs:element>
</xs:sequence>
<xs:attribute name="kind" type="TriggerKind" use="optional">
<xs:annotation> <xs:documentation>
Kind of the trigger. "C" (configuration load trigger) by
default.
Other allowed value: "H" (host change trigger)
</xs:documentation> </xs:annotation>
</xs:attribute>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="name" type="NameDef" use="required">
<xs:annotation> <xs:documentation>
Name of rule, which must be unique. Recommendation: Use a
prefix that identifies your plugin.
</xs:documentation> </xs:annotation>
</xs:attribute>
<xs:attribute name="activation_expr" type="xs:string" use="optional">
<xs:annotation> <xs:documentation>
Optional activation expression. If not present or empty, implies
that the rule is always active. Else, the value is a Boolean
activation expression which must produce true if and only if
the rule should be active.
The expression can use (case insensitive) "AND", "OR", and
parenthesis. Operands of the expression are target types.
Each occurrence of a target type evaluates to "true" if
and only if the target type is present in EM.
Note that a number of target types do not need to be listed in
the expression because they are always going to be present
whenever the rule is installed and present in EM installation.
These include:
- target types installed with the plugin where the rule resides
(i.e. target types in the plugin which owns the rule)
- target types in other plugins on which the plugin owning
the rule depends
- target types always installed with EM (like host)
Thus, in many cases, if this option is used, a single target
type, as in example 1 below, may suffice.
Examples:
(1) "oracle_ovm"
This simple expression implies that the rule should be
active only if oracle_ovm target type is installed at EM
(in addition to any other target types that are already known
to be present when this rule is installed).
(2) "oracle_ovm and (oracle_oam_cluster or oracle_oim_cluster)"
This expression implies that the rule should be active only if
oracle_ovm target type is present and either oracle_oam_cluster or
oracle_oim_cluster is also present.
</xs:documentation> </xs:annotation>
</xs:attribute>
</xs:complexType>
<xs:element name="Rules">
<xs:complexType>
<xs:sequence minOccurs="1" maxOccurs="unbounded">
<xs:element name="Rule" type="RuleType"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
<?xml version="1.0" encoding="UTF-8"?>
<Rules xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Rule name="ora_listensFor">
<query>
SELECT ...
fill in query
</query>
<trigger>
<targetType>oracle_database</targetType>
<snapshotType>db_config</snapshotType>
<table>CM$DB_CONFIG_TABLE</table>
<idColumn>destination</idColumn>
</trigger>
</Rule>
</Rules>
11.3.3 Using Rule Semantics
The following algorithm depicts a simplified form of the semantics for rule R, where the trigger specifies a query Q and a flag FC that corresponds to a column name of either source, destination, or derivation target GUID.
When updates to a snapshot table are uploaded for some target t with a GUID of t_guid, for each trigger that specifies the modified table, execute these statements:
DELETE FROM MGMT_ASSOC_INSTANCES WHERE <FC> = t_guid AND RULE_ID = R INSERT INTO MGMT_ASSOC_INSTANCES (SELECT a.*, R FROM (<Q>) a WHERE <FC> = t_guid )
The actual implementation differs from the above example for the following reasons:
-
The actual implementation will not delete and then add the same association as this would be inefficient.
Rather it will compare the current and new set, making changes only where needed. Moreover, an actual delete statement also deletes any associations that specify a target component of the target.
-
It is possible that an association may be asserted by more than one origin
This is managed using an origins table, whose contents are rolled up into the
MGMT_ASSOC_INSTANCEStable. -
Validity testing is performed at various points.
For example, to test that the association type is valid for the provided source and destination MEs.
11.3.4 Maintaining Performance
Because the evaluation of derivation rules may be frequent, any poor performance of the rule queries can be problematic. Rule authors must ensure that any needed indexes are present and that they test query performance based on the specific queries that are generated for each trigger.
In particular, testing of the rule query must be done for each trigger because each trigger causes the execution of a different query. Note how rule query return values are bound to a given target globally unique identifier (GUID) depending on your triggers.
You must have indexes that will make use of these bindings. Furthermore, queries should be written in such a way that they would not prevent the push of bindings from outside into your queries.
11.3.5 About Regular Query and Trigger Patterns
The following sections outline the regular patterns you would normally see in queries and triggers. You should check whether your queries and triggers adhere to these patterns and if not, document the reasons why (since such cases normally represent the exceptions from the rules of thumb).
The following outline common query patterns:
-
The derivation target should be non-null when the ECM configuration of such target is used to derive associations between two other entities.
One known case for the use of derivation targets is associations with a database system. The database instance target provides configuration, while associations are made with the corresponding database system target. In such cases, the database instance must act as a derivation target for the associations to the corresponding database system target.
-
The query must only access objects such as
CM$, other views that access Enterprise Configuration Management data, or views that access target information, such asMGMT_TARGETS.For more information on the objects that can be accessed, see Section 11.3.1, "Using Association Derivation Rules Syntax and Semantics".
-
Association types must be forward and concrete.
The following outline common trigger patterns:
-
The number of triggers will often be equal to the number of non-target-entity views in the FROM clause. In other words if the
mgmt_targets,mgmt_target_properties,mgmt$target,mgmt$target_properties, and other such views are disregarded.Each Enterprise Configuration Management view will correspond to one trigger. One exception is when a table may be triggered from more than one target type (for example,
oracle_databaseandrac_database). In this case, multiple triggers for the same Enterprise Configuration Management view could be supplied. -
The table name of the trigger must be based on Enterprise Configuration Management metadata tables for the snapshot specified by the trigger's target type and snapshot type.
Normally, it should be one of the objects in the rule query FROM clause (for example, a
CM$view). -
A view specified in the trigger is joined (perhaps indirectly) in the query with a target (or target component) entity.
The entity id will be returned as source, destination, or derivation target in the select clause. The idColumn will match this.
For example, association between targets A and B is dependent on a join between the
cm$Aconfigandcm$Bconfigtables, where data from thecm$Aconfigtable comes from target A and data from thecm$Bconfigtable comes from target B. The trigger for thecm$Aconfigtable will have an idColumn matching target A (for example, source) and the trigger for thecm$Bconfigtable will have an idColumn that matches where target B GUID is returned (for example, destination). -
The trigger target type must match the target type of the target returned by the query in the column specified by idColumn.
More generally, the target type of the target returned by the rule query could be a subtype or a target component of the trigger target type.
-
If trigger relies on target properties, specific property names should be identified in the details tag.
11.3.6 Diagnosing Issues
To help diagnose issues and understand how associations were derived, the framework records information about how associations were derived when in debug mode. For more information on debug, see Section 11.3.11, "Troubleshooting and Debugging". It also includes additional sanity (error) checking. For instance, one test checks that the derivation target GUID is that of a real and current target.
11.3.7 Useful Examples
While the following examples include the use of target properties to illustrate their proper employment, Oracle does not recommend relying on target properties. Instead, configuration data should be properly modeled using ECM tables. For more information, see Section 11.7.2, "Are there guidelines for when to use target properties?".
When reviewing these examples, it is helpful to remember the following concepts:
-
Every target type has an Enterprise Configuration Management snapshot type called
orcl_tp_config.It includes a snapshot table referenced by the
GC$TARGET_PROPERTIESview, which if needed should be used by the triggers. Current data for target properties can be accessed through theMGMT_TARGET_PROPERTIESandMGMT$TARGET_PROPERTIESEDK objects. -
Every Enterprise Configuration Management snapshot table will by default have a view for accessing the current configuration data.
Its name will be that of the table, with the prefix
CM$. Most rule queries will refer to configuration tables through theirCM$views.
11.3.7.1 Host on a Virtual Machine
A ’deployed_on' association type is used to represent the fact that a host target is deployed on a virtual machine target.
The Query below returns all associations between a host and associated virtual machines based on matching their MAC addresses. Triggers are defined so that they trigger the rule whenever the corresponding configuration view (that includes the MAC address) changes. The rule described below would reside in the plug-in defining virtual machine (host target type is guaranteed to be present on any EM installation). Both triggers can be included in the rule and would belong to the plug-in defining virtual machine.
<Rule name="...">
<query>
select 'deployed_on' as assoc_type,
host.target_guid as source_me_guid,
guest.cm_target_guid as dest_me_guid
from mgmt$hw_nic host,
cm$vt_vm_vnic guest
where guest.mac_address = host.mac_address_std
</query>
<trigger>
<targetType>host</targetType>
<snapshotType>ll_host_config</snapshotType>
<table>MGMT$HW_NIC</table>
<idColumn>source</idColumn>
</trigger>
<trigger>
<targetType>oracle_vm_guest</targetType>
<snapshotType>ovm_guest_config</snapshotType>
<table>CM$VT_VM_VNIC</table>
<idColumn>destination</idColumn>
</trigger>
</Rule>
11.3.7.2 Target installed_at Oracle Home
The Oracle Home target type includes the INSTALL_LOCATION target property that contains the name of the directory in which the Oracle Home resides. For all target types that are installed in Oracle homes, there is an OracleHome target property that specifies the same value as INSTALL_LOCATION. Whenever a target's OracleHome value matches the INSTALL_LOCATION value and both targets reside on the same host, an installed_at association exists.
Both a target's OracleHome and a home's INSTALL_LOCATION are subject to change. It is also possible for a target or home to be created that in turn matches up with a home or target. However, the value of a target's host is immutable.
Returns all associations between Oracle Home targets and the targets that are installed in them.
<Rule name="...">
<query>
select 'installed_at' as assoc_type,
t.target_guid as source_me_guid,
o.target_guid as dest_me_guid
from mgmt_targets t,
mgmt_targets o,
mgmt_target_properties tp,
mgmt_target_properties op
where o.target_type = 'oracle_home' and
t.host_name = o.host_name and
tp.target_guid = t.target_guid and
tp.property_name = 'OracleHome' and
op.target_guid = o.target_guid and
op.property_name = 'INSTALL_LOCATION' and
tp.property_value = op.property_value
</query>
<trigger>
<targetType>oracle_home</targetType>
<snapshotType>orcl_tp_config</snapshotType>
<table>GC$TARGET_PROPERTIES</table>
<idColumn>destination</idColumn>
<details>INSTALL_LOCATION</details>
</trigger>
</Rule>
The following trigger for the same rule would reside in the plug-in that defines oracle_database target type:
<Rule name="...">
<trigger>
<targetType>oracle_database</targetType>
<snapshotType>orcl_tp_config</snapshotType>
<table>GC$TARGET_PROPERTIES</table>
<idColumn>source</idColumn>
<details>OracleHome</details>
</trigger>
</Rule>
This is the same as trigger 2 only with another target type that has an OracleHome property. These triggers would reside with plug-ins that define corresponding target types. This trigger has the same characteristics as trigger 2, except it uses a different target type that has an Oracle_Home property.
11.3.7.3 Listener and Database
An exposed_by association type is used to represent the fact that a database is exposed by a listener to applications. One way that this association can be created is based on the ports for which the listener is configured.
Returns all associations between a database and listener on the same machine such that the ports match. Both triggers can reside with the rule in the plug-in that defines Oracle database and Oracle listener target types.
<Rule name="...">
<query>
select 'exposed_by' AS assoc_type,
oradb.target_guid AS source_me_guid,
oralsnr_ports.cm_target_guid AS dest_me_guid
from mgmt_targets oradb,
mgmt_target_properties oradbprops1,
mgmt_target_properties oradbprops2,
cm$listener_ports oralsnr_ports
where oradb.target_type = 'oracle_database'
and oradb.target_guid = oradbprops1.target_guid
and oradbprops1.property_name = 'MachineName'
and oradbprops1.property_value = oralsnr_ports.machine_name
and oradbprops1.target_guid = oradbprops2.target_guid
and oradbprops2.property_name = 'Port'
and oradbprops2.property_value = oralsnr_ports.listener_port
</query>
<trigger>
<targetType>oracle_database</targetType>
<snapshotType>orcl_tp_config</snapshotType>
<table>GC$TARGET_PROPERTIES</table>
<idColumn>source</idColumn>
<details>MachineName</details>
</trigger>
<trigger>
<targetType>oracle_listener</targetType>
<snapshotType>listener_config</snapshotType>
<table>CM$LISTENER_PORTS</table>
<idColumn>destination</idColumn>
</trigger>
</Rule>
11.3.8 Applying the Mechanical Steps of Integration
After you decide on the ME/association model and write the rules, proceed with the implementation as follows:
-
If your rules need Enterprise Configuration Management configuration data not yet present, add new Enterprise Configuration Management metrics or extend the existing ones.
If needed, you should add new Enterprise Configuration Management tables or columns. You must also make sure that the default collection schedule specifies
<Schedule OFFSET_TYPE="INCREMENTAL">. Failure to do so will delay the loading of the configuration such that, for instance, newly discovered targets may not get associations for thirty minutes or more. -
The Association types framework has the concept of allowed pairs indicating which target types are allowed to be associated by a given association type. If you are creating associations between ME types that are not listed as allowed pairs for the respective association type, add the needed pairs.
-
Create one or more files to define the association derivation rules. Syntax errors, such as failing to conform to the XSD, are passed through as Java exceptions. You may want to use JDeveloper or another tool to confirm that you have created a valid document.
-
Test the rule files by importing them using the following command:
emctl register oms metadata -sysman_pwd sysman -pluginId <your.plugin.id> -service derivedAssocs -file <fileName>
Validity testing is performed, so diagnostics may result.
-
Package the files into your plug-in.
Place them so that they are imported at repository creation or upgrade time in accordance with the conventions defined by the metadata framework. If part of a plug-in, place the files in a location similar to:
<stage_dir/plugin_dist>/oms/metadata/derivedAssoc
-
Test the derivation rules with cases that exercise every rule trigger that you specified.
One option is to initiate the upload of the Enterprise Configuration Management configuration data and check that the associations are properly established. Alternatively, you can directly call the PL/SQL procedure that will trigger the rules:
DECLARE temp GC$DERIV_ASSOC_CHANGE_LIST := GC$DERIV_ASSOC_CHANGE_LIST(); BEGIN GC$ECM_CONFIG.run_assoc_deriv_rule( p_target_guid => hextoraw('CC70BC294B82E7E9A95DFC257CFA6459'), -- Updated target/ME guid p_rule_name => '...', -- your rule name p_column_flag => 'D', -- column flag specifying the perspective from which to fire the rule. Possible values: S|D|T|U|V (implying source,destination, derivation target, derivation target 2, or derivation target 3, respectively) p_change_list => temp); COMMIT; -- examine p_change_list if needed END;Note:
Test the performance of your queries for each trigger after the corresponding output of the query has been bound, as described in Section 11.4, "Ensuring Performance".Use the import utility to make rule changes and try again.
11.3.9 Special Triggers: Host Name Change Triggers
With this release, a new kind of trigger is supported for when the host name of a target changes. If your query relies on the host_name column of the mgmt_targets table, this trigger can be useful as it will fire when the host_name column changes, for example, upon relocation of the target.
The trigger syntax specifies a ”kind” attribute of the ”trigger” element with a value of ”H” (which stands for ”Host change” trigger). Trigger sub-elements will specify target type, which the trigger applies, and idColumn, which identifies the perspective from which to evaluate the rule. Possible values for idColumn are the same as those for regular triggers.
For example:
<trigger kind="H"> <targetType>oracle_database</targetType> <idColumn>source</idColumn> </trigger>
This specifies that the rule (which the trigger is part of) has to be reevaluated from the source perspective whenever oracle_database target's host_name column changes.
In general, the same rules apply to host change triggers as to regular triggers, including applicable trigger patterns (such as trigger pattern 4, which indicates that the column returned by the query corresponding to idColumn should be type or subtype of the targetType element). The rules related to trigger lifecycle and regular trigger placements in files and plug-ins also apply to host name change triggers.
11.3.10 Understanding Activation Expressions
As described previously, rules are normally owned by the plug-ins that require all target types needed by the rule query to be present by the time the rule is installed. However, on rare occasions you may encounter a case where two or more plug-ins needed by a rule query are independent and any one of the plug-ins may exist without the presence of the other. In other words, it may not be possible to specify that one plug-in is a prerequisite of another for a given rule query that relies on configuration tables and data from target types of both plug-ins.
For such cases, you can specify an activation expression in a rule that will indicate when the rule should be active. Note that the rule is still owned by (at most) a single plug-in and the rule query can only be specified in one plug-in that will in the future be responsible for changing or removing the rule. However, the rule could be inactive for as long as not all needed target types are present on the system.
In terms of syntax, you specify activation expression using an attribute in the Rule element where the rule's query is specified:
<Rule name="..." activation_expr="..."> ...
Normally, when the activation_expr attribute is not present, it implies that the rule should always be active. If it is present, its value is a Boolean expression which must produce true if and only if the rule should be active. The expression can use (case insensitive) "AND", "OR", and parenthesis. Operands of the expression are target types. Each occurrence of a target type evaluates to "true" if and only if the target type is present in Enterprise Manager.
Note that a number of target types do not need to be listed in the expression because they are always going to be present whenever the rule is installed and present in Enterprise Manager installation. These include:
-
target types installed with the plug-in where the rule resides (target types in the plug-in that owns the rule).
-
target types in other plug-ins on which the plug-in owning the rule depends.
-
target types always installed with Enterprise Manager (like host).
Therefore, in many cases when activation expression is used, a single target type as described in Example 1 below may suffice:
-
Example 1: oracle_ovm
This simple expression implies that the rule should be active only if oracle_ovm target type is installed in Enterprise Manager (in addition to any other target types that are already known to be present when this rule is installed).
This kind of activation expression could be expected in a rule with a query that relies on configuration tables of oracle_ovm and oracle_xyz (for example) target types. Assuming these target types belong to different and independent plug-ins, if the rule is placed in a plug-in owning oracle_xyz target type, its activation expression would be oracle_ovm.
-
Example 2: oracle_ovm and (oracle_oam_cluster or oracle_oim_cluster)
This expression implies that the rule should be active only if the oracle_ovm target type is present and either oracle_oam_cluster or oracle_oim_cluster is also present.
Please note that activation expressions should be used very carefully and rarely, since their usages are error prone due to lack of checks prior to rule activation. For example, any typo in a target type or any logical expression error may result in the rule never being activated or not being activated in correct cases. Enterprise Manager cannot check for validity of target types because it will assume unknown target types in the expression may get installed in the future.
The following describes how the activation expression feature interacts with other derived association features:
-
During a new release of a rule XML, if rule query is unchanged but the activation expression is changed, the activation expression is updated and the rule is activated or deactivated if needed. If the rule is activated or deactivated, the rule's association instances are reevaluated or removed, respectively.
-
Whenever Enterprise Manager adds or removes a target type (due to installation or deinstallation of a plugin for example), Oracle will reevaluate relevant activation expressions and activate or deactivate corresponding rules accordingly.
Note that target type addition is performed before any corresponding targets and their associations or data are added. Target type deletion is done after target instances and their associations are removed. Therefore, we do not reevaluate corresponding association instances for the affected rules. By the time the rule is activated due to the addition of a target type, no associations should exist for such a rule.
Similarly, when the rule is deactivated due to the removal of a target type, the associations are also removed because all targets of that target type are removed. This logic applies to all known cases, including when the target types in the expression are those of source, destination, or one of the derivation targets. Thus, there is no reevaluation of the rule upon target type addition or removal.
-
Note that there is a difference between the quarantine feature and the activation expressions. The quarantine feature is controlled by the end-users or administrators to decide which rule evaluations to turn off. On the other hand, activation expressions are controlled by the rule authors and a given Enterprise Manager setup (for example, the presence or absence of involved target types).
Rules that were never activated cannot be quarantined. Otherwise, all other combinations are supported. For example, if a quarantined rule is deactivated and then activated again using an activation expression, it stays quarantined.
Similarly, if an active rule gets quarantined by an administrator and later becomes deactivated due to a target type removal, administrators can still unquaratine it so that if it ever gets activated, it will start computing associations.
-
When a rule is being removed, rules activation expression and its activation status are ignored. In other words, a rule can be removed even if it is inactive.
In general, there are four kinds of version specifications that are supported:
-
"target_type[version], e.g. "oracle_ovm[3.7]"
Indicates that this part of the expression is true only if the specified version of the target type is present. In above example, if oracle_ovm target type version 3.7 is not installed, the expression will evaluate to false even if other versions of oracle_ovm are present.
-
"target_type[version1-version2], e.g. "oracle_ovm[3.7-5.2]"
Indicates that this part of the expression is true only if a version of the target type is present that is between the indicated versions, including the two specified versions. Thus, in above example, the expression would be true if oracle_ovm target type of version 3.7, 3.8, 4.5, 5.0, or 5.2 is present.
If, on the other hand, none of the installed versions of oracle_ovm target type fall into the range between 3.7 and 5.2, "oracle_ovm[3.7-5.2]" would evaluate to false.
-
"target_type[version-], e.g. "oracle_ovm[3.7-]"
Indicates that this part of the expression is true only if a version of the target type is present that is the same as the specified version or greater than the specified version. This is the most commonly used variation and the specified version would normally be the one where a table used by the rule query is introduced into a target type collection. In above example, the expression will evaluate to true if and only if a version of 3.7 or higher for target type "oracle_ovm" is installed at Enterprise Manager.
-
"target_type[-version], e.g. "oracle_ovm[-5.2]"
Indicates that this part of the expression is true only if a version of the target type is present that is the same as the specified version or less than the specified version. Thus, in above example, the expression will evaluate to true if and only if a version of 5.2 or less for target type "oracle_ovm" is installed on Enterprise Manager.
Note:
"There are no spaces between target type and the opening square bracket.Version specification is optional. You can use just target type specification implying that any version of the target type would satisfy that part of the expression.
For example:
"oracle_ovm[3.7-] and (oracle_oam_cluster or oracle_oim_cluster[-2.5] or oracle_oim_cluster[2.8-])"
This expression implies that the rule should be active only if oracle_ovm target type of version 3.7 or higher is present, and either oracle_oam_cluster (of any version) or oracle_oim_cluster of versions 2.5 and below or 2.8 and above is also present.
11.3.11 Troubleshooting and Debugging
You can begin debugging by initiating the configuration collections used to fire your triggers. These collections occur when a target is used for the first time or whenever you make changes to the configuration data contained in the tables or views specified in your triggers. You can restart the Management Agent to recollect the data. Make sure that the data in your configuration tables changes as expected before checking whether the triggers fired.
Check that your rule query produces all the required associations across your development Enterprise Manager repository.
Finally, you can manually run the GC$ECM_CONFIG.RUN_ASSOC_DERIV_RULE PL/SQL API to manually create the required associations as if the rule did fire during the configuration change.
If the associations you expect are not created, then:
-
Make sure your query produces the required association when run manually and binding a source or destination GUID to the correct target.
-
Check for errors in relevant error tables mentioned in this section.
If this does not help, then you must figure out where the process is failing. This can be any of the following:
-
The configuration collection is not collected
-
The configuration collection is not changing in the place specified by the trigger
-
The trigger firing resulted in an error
-
The trigger that did fire is not producing the required association
-
The trigger firing action did not get processed yet because of a queue backlog
The following list provides tips about how to investigate your issue with associations not being created:
-
Make sure that the rule is active and not quarantined in your environment:
select r.rule_name, q.column_flag, r.is_active, case when q.quarantined_time is null then 'No' else 'Yes' end as is_quarantined from mgmt_deriv_rules r, mgmt_deriv_rule_queries q where r.rule_id = q.rule_id and r.rule_name = your_rule_name; -
Check for derived association-related errors in the Management Repository:
select * from mgmt_system_error_log where module_name = 'EM.deriv' order by occur_date desc
Optionally, you can add an "and error_msg like '%<your rule name>%'" condition or use other substrings related to your association to limit the results, if there are too many that seem unrelated.
For example, if you see a message containing "ORA-20624: Specified assoc does not match any constraint assoc type", this implies that the allowed type pair for this association type and source/destination target types was not registered in the repository.
-
If you can reproduce the issue, turn on additional logging and call one of the following:
EMDW_LOG.SET_TRACE_LEVEL('EM.deriv', EMDW_LOG.LINFO); COMMIT; EMDW_LOG.SET_TRACE_LEVEL('EM.deriv', EMDW_LOG.LDEBUG); COMMIT;DEBUG is very verbose and includes the queries used.
Note:
- The module name is
EM.deriv. -
New sessions get a new level. Existing sessions, such as long-running sessions, are not affected by the change as implemented in EMDW_LOG.
-
You can turn logging off using the constant
EMDW_LOG.LOFF.
- The module name is
-
View the log.
Logging is performed on the
EMDW_TRACE_DATAtable. Use this query to view the log:SELECT log_timestamp, TRIM(log_message) FROM emdw_trace_data WHERE module = 'EM.deriv' ORDER BY log_timestamp ASC
Note:
Adding conditions such as "log_message like" and "log_message like '%<your rule name>%'" condition can reduce your results. -
Check the log to confirm that the correct rules are getting triggered.
Look for the line "Resulting action list:" followed by a line for each action that specifies the rule and column flag S|D|T|U|V.
-
Determine which trigger should have fired and for which target your required association should have been created. For example, check the saved_timestamp in the MGMT$ECM_CURRENT_SNAPSHOTS view for your snapshots that trigger one of your triggers to see which one changed and was last saved.
Next, check if the trigger did not fire because of a queue backlog. This applies to larger sites that are more likely to have backlogs in execution queues.
-
Check the derived association queue for retry actions:
select * from em_deriv_retry_actions where is_pending = 'T' and rule_id = (select rule_id from mgmt_deriv_rules where rule_name = <'<your rule name>') and target_guid in (list of hextoraw(<target_guid on both ends of your missing associations - or just the target you found should have triggered the evaluation>);If this statement returns rows, then evaluation of the trigger is still pending due to the backlog.
-
If you have a trigger that relies on target properties, then check the target properties queue to see if the system has processed all the follow-up actions for a given target property update:
select * from EM_TPROPS_PENDING
where target_guid = hextoraw(<target guid of the target with changed target property>);This query returns all the yet-unprocessed target properties in the queue for which the trigger would not have fired yet.
-
-
Test your rule query (if debugging is turned on as described in a previous bullet point).
In the emdw_trace_data table, find the variant of the query executed immediately after the line that reads
After query:Try to execute it, replacing:xwithHEXTORAW(target guid). The GUID can be found earlier in the log on thevvvvvvvvvvv RUN_SNAPSHOT_RULESline.It should return a row for each association that should exist based on the specified rule and the collection for your target. If not, check that you did not enter an incorrect query or specify the wrong flag on the trigger.
You can try variants on the last line. For example:
WHERE source_me_guid = :y WHERE dest_me_guid = :y WHERE derivation_target_guid[N] = :y
-
After you have logged the rule query, the log reflects the rows in the
MGMT_ASSOC_INST_ORIGINStable that need to be changed, followed by the actual association rows inMGMT_ASSOC_INSTANCES. -
Check that the association instances are present in
MGMT_ASSOC_INST_ORIGINS.If so, the derived association rule listed in column
DERIVATION_RULE_IDhas correctly asserted the existence of that association. Something is preventing the association from being created. Is the association type correct, and are the allowed type pairs registered with the association framework? Were any exceptions thrown?
11.4 Ensuring Performance
The rules you provide may be fired frequently, depending on the triggers you define and the change frequency for the corresponding configuration tables. Poor performance of frequently triggered rules can adversely affect overall OMS operation.
A rule query is mapped to more specific queries. The query that gets executed depends on the column flag of the trigger (source, destination, or derivationTarget[N] column). As noted previously, the rule query <Q> is mapped to a query of this form:
SELECT a.*, FROM (<Q>) a WHERE <FC> = ?
where the parameter is the GUID of the target for which the Enterprise Configuration Management collection fired the trigger and <FC> is the source/destination/derivationTarget[N] column of your query specified by the trigger.
As you can see, the overall query (<Q>) will be filtered based on one of the target GUIDs that it returns. This means that query plans will generally start with data for that target and perform joins from there. Your query plans must push the ”<FC> = ?” predicate all the way down and start evaluation with this predicate. Normally, they contain many nested loops that on the deepest level perform above binding and then get to the rest of the data starting from there via indexed lookups. Normally, there should be no full table scans of potentially large data tables (or hash joins).
Consider the example in Section 11.3.7.3, "Listener and Database". When the first trigger fires, the query will bind a database target and look for associated listener targets. The only way the Enterprise Manager repository can find the other end of the association (for example, the listener targets) is via ”cm$listener_ports oralsnr_ports” joins on the machine_name and listener_port columns. If the table under view cm$listener_ports can be large, rule author should ensure an index exists starting with these two columns to quickly locate the listener targets instead of performing a full table scan on the table.
For each trigger, you must ensure that supporting indexes are present and that you test the performance of your queries after surrounding them in the query, as described earlier. However, if for example you have multiple triggers for the source column flag, you may have to test the performance only once as the generated query will be the same for both queries.
11.4.1 Using Custom Configuration Specifications for Data Collection
Skip this note if you are not familiar with Custom Configuration Specifications (CCS). CCS tables are generic so that they can accommodate a variety of data and so tend not to perform well for querying. However, properly modeled ECM tables are specific to the data being collected and can perform well for critical code paths, like derived associations computation code. Therefore, you should not use CCS collected data for derived association rules. Instead, collect the data required for derived associations separately using standard ECM collections.
11.5 Using Overlapping Associations
It is possible for more than one rule to derive the same association, although usually you should avoid creating such overlapping rules. This section describes what happens when an association is derived by multiple rules and includes suggestions on when to avoid this and how.
11.5.1 Overlap Between Associations Derived by Rules
When more than one rule derives the same association, that association continues to exist until each rule no longer derives it.
Sometimes, this is what you want. For instance, suppose each of two application target types has knowledge of both the Oracle WebLogic Server on which it runs and the database it accesses. Based on that knowledge, each has a way to derive an association between the Oracle WebLogic Server and the database. If either rule derives the association, that association is real and should exist. Only when both rules no longer derive the association can you be sure that the association no longer exists.
The "exists when any rule derives it" semantics may not be what you intend. Consider two rules that could be defined for the installed_on association between the database and Oracle home. Both access the same data, but one is triggered by a property change to the Oracle home and the other by a change to the database. As soon as either rule determines the relationship is gone, the association should be deleted. In such a case, you should use a single rule with two triggers.
Suppose you did not take care to write only one rule in such cases. You may think that this mistake is not serious as, after all, the association will soon be deleted. But this is not so, and the bogus association may exist indefinitely. If in the example described above the association was derived using two rules, then the database is upgraded and its OracleHome property gets changed. The association with the old home should be removed, but this will not happen until the other rule is fired. However, nothing about the Oracle Home target has changed, so its rule is not triggered and the association remains. Indeed, it is often the case that only one target is changed and the other remains unchanged for a long period of time.
As a general rule of thumb, associations based on data from a specific set of tables should be derived using a single rule with multiple triggers.
Unless there are different reasons for asserting an association exists, you should only use one rule. In such cases, the associations returned by derivation rules should be disjoint. Another way to state this is that for those associations, the set of all rows returned by all rule queries must specify no duplications. An association is identified by source, destination, and association type. So this means that the combination of these three values should be unique.
11.6 Creating Associations for Composite and System Target Types
There are several types of associations that must be considered when constructing either a composite target or a system target, and there are several ways in which these associations can be added to Enterprise Manager. The following describes each of these types of associations, how they are used by the Enterprise Manager framework and the typical approach to how they are created.
11.6.1 Composite Membership and the Containment Association
The first important association type is the "contains" association. This association type is typically added between a composite target and each of its members. The presence of this association is necessary in order to populate the target navigator (tree) for a composite target. The set of targets that are members of a composite (associated with it through a "contains" association) can be retrieved using the getCompositeMembers() method of the Target class.
These containment associations are most often created during discovery, using either a fully automated approach or through the guided discovery process. In either case, the discovery scripts provided with the plug-in are used to identify the set of containment associations between the composite and its members. Other non-containment associations may also be discovered; however, they will not affect the membership of the composite and will not affect the contents of the target navigator.
If the composite target is also to be treated as a system, it is strongly recommended that the system stencil include rule paths that represent the type of containment associations created in this way. This ensures that the target navigator and system membership display member targets consistently.
11.6.2 Other Non-Composite Associations (Composite Topology)
In addition to the discovery of containment associations, you may wish to represent other types of associations between the members of your composite topology. These associations may have meaning only to your target administrators and may be used by your plug-in code to perform other operations.
These associations are typically created using a discovery script, either as part of fully automated discovery or through the guided discovery process.
11.6.3 System Membership Associations
System membership is constructed by the Enterprise Manager framework based on the system stencil. This stencil defines the set of native associations that should be considered when identifying the system members. These native associations are typically either containment or other non-composite associations.
If these associations are found during the evaluation of the system stencil, the destination targets are added as system members.
11.6.4 Associations to External Targets
Up to this point all of the associations discussed have been between targets that are assumed to be part of the same plug-in, and therefore your plug-in code including discovery and UI has intimate direct knowledge of the configuration and topology of these targets.
However, in some cases your target configuration may include associations to other targets not included in your plug-in, such as an Oracle Database used as an application or backing store for your targets. The configuration of your target knows something about the database that it uses, likely some connection related details such as host-port-sid or host-service.
You would like to represent this association between your target and the database in Enterprise Manager so that if Enterprise Manager is managing the database, the end-user can see this relationship and traverse it to obtain other information about that database and manage it (if appropriate and allowed).
Because you do not know if Enterprise Manager is managing the database and the identifying information you have is not the Enterprise Manager database target name, but instead the connect information, you can construct a derivation rule that maps the connection information in your target's configuration to that of a database in Enterprise Manager.
11.6.5 Regarding the Timing of Association Creation
Because the creation and deletion of targets and associations can be initiated from various sources (such as automated discovery, guided discovery, derived association rules, and system stencil rules), there are cases where the topology of a composite entity in Enterprise Manager may not appear in sync with the reality of that entity. As a plug-in developer, it is important that you are aware of this and account for it in information you present to end-users whenever possible.
One typical situation that may occur is that the discovery of targets occurs, configuration information is collected, and this is followed by the modification of associations as derivation rules are processed by the Enterprise Manager association framework. In this scenario, the user will first see the topology of the entity, including any association added during discovery. However, the additional associations created by derivation rules will not appear until sometime later.
11.7 Frequently Asked Questions
This section addresses three of the most frequently asked questions:
11.7.1 Which tables can I reference in a rule query?
In most cases, your query will just reference configuration (Enterprise Configuration Management) tables using the CM$ views, and so will your triggers. For a more complete list of objects that can be referenced, see Section 11.3.1, "Using Association Derivation Rules Syntax and Semantics".If you refer to other tables and if that data may change independently of Enterprise Configuration Management table changes, then the associations may not be updated when needed. If you have a use case in which a non Enterprise Configuration Management table is referenced where changes to that table must trigger rule evaluation, contact your Oracle representative.Another consideration is the component in which the table is located. If the table your rule references is not part of the Enterprise Manager core EDK, your plug-in must account for the dependency on that table's plug-in. For example, you must ensure that any object that you reference already exists in the repository using a plug-in dependency mechanism.
11.7.2 Are there guidelines for when to use target properties?
Target properties are being treated as configuration data and there is an Enterprise Configuration Management snapshot table that is populated for each target type. Some care should be taken in using data from this table:
-
Many target properties are set at discovery time and never modified.
-
Querying name/value pair data can be awkward and take longer than queries on other tables where the data is more structured.
-
If the data is available from both the target properties table and an Enterprise Configuration Management snapshot table, you should use the latter.
-
If you need to add collection of configuration data, you should do so in an Enterprise Configuration Management table, not as a new row in the target properties table.
-
In general, the use of target properties should be avoided and data should be collected and modelled using standard ECM mechanisms.
However, a rule may need to refer to target properties if, for example, the target has no Enterprise Configuration Management collections that can be added. If an association to such a target is to be created, there must be some way to identify it (for example, the rule must refer to its target properties).
If you must use target properties, you should reference MGMT_TARGET_PROPERTIES in your rule query. You can also reference MGMT$TARGET_PROPERTIES in the rule query if the view already performs the join you need to do. However, in triggers you must use the GC$TARGET_PROPERTIES view for the orcl_tp_config snapshot type.
MGMT_TARGET_PROPERTIES should be used in queries because it is more efficient, but may include some properties not available in the GC$ view. Triggering is only available based on property changes in the GC$ view. For example, the GC$ view only includes those properties that are properly registered with Enterprise Manager.
11.7.3 What is the relationship between discovered and derived associations?
This is another example of overlapping associations (for more information, see Section 11.5, "Using Overlapping Associations"). For instance, you may have discovery logic that discovers an association between targets T1 and T2, plus a rule that derives the same association. Oracle recommends that you do not write two sets of logic to create the same association. In this case it is suggested that:
-
If a derivation rule is needed because the association may change, you should just write the derivation rule.
-
If the association that is discovered will not change until the source or destination is removed, then discovering the association is fine and may be simpler or more efficient.
If you do write two sets of logic to create the same association (discovery logic and derivation rule), then the discovered association will remain and the derivation logic will also assert the existence of that association. If the rule evaluation later determines that the association should no longer exist, the rule's assertion will be removed, but the association will continue to exist unless you manually delete the discovered association.