F Working with XPath Queries
This appendix provides detailed information about the support available within RUEI for the use of XPath queries. These can be used as part of content message, client identification, custom dimension, page and service identification definitions.
F.1 Introduction to XPath
XPath (XML Path Language) is a query language that can be used to select nodes and compute values from XML documents. Within RUEI, XPath version 1.0 support is based on the libxml2 library. Further information about it is available from the following location:
http://xmlsoft.org/
A complete specification of the XPath language is available at the following location:
http://www.w3.org/TR/xpath
RUEI supports XPath on XML, HTML, or JSON content. JSON content is internally transformed to XML before XPath queries are applied.
RUEI applies XPath matching to all traffic content, regardless of whether or not it is actually in XML format. Therefore, in order to obtain accurate results, it is strongly recommended that you ensure that all XPath expressions are executed against well-formed XHTML code, and review the information in Section F.5, "Optimizing XPath Scanning". In addition, note that XPath expressions are case sensitive.
F.2 Namespace Support
XML namespaces are used for providing uniquely named elements and attributes in an XML document. An XML instance may contain element or attribute names from more than one XML vocabulary. If each vocabulary is assigned a namespace, then the ambiguity between identically named elements or attributes can be resolved.
Within RUEI, all namespaces used in your XPath queries must be explicitly defined. If a namespace is used in a query, but is not defined, it will not work. To define a namespace, do the following:
-
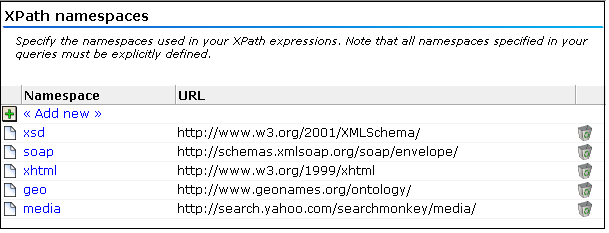
Select Configuration, then General, Advanced settings, and then XPath namespaces. The window shown in Figure F-1 appears.
Note that this window can also be reached by clicking the Namespaces tab when specifying an XPath-based content message, custom dimension, user identification, and page and service identification definition.
-
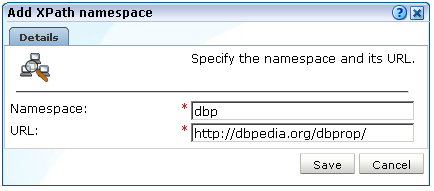
Click Add new to define a new namespace, or click an existing definition to modify it. The dialog shown in Figure F-2 appears.
-
Specify the namespace prefix used within monitored XML document, and its corresponding base URL. The name must be unique. See Section F.3, "Understanding Namespaces Prefixes and URLs" for important information on the use of namespaces and prefixes. Note that the namespace definitions are global and are applied to all monitored traffic.
When ready, click Save. Any new definition, or modification to an existing definition, takes effect within a 5-minute period.
Note:
When removing a defined namespace, it is recommended that you verify that it is no longer required in traffic monitoring.F.3 Understanding Namespaces Prefixes and URLs
A namespace consists of a prefix (which can be considered as a form of local binding), and a URL. This specifies the location of a document that defines the actual namespace. For example, my_ns1=http://www.w3.org/1999/xhtml.
It is important to understand that a namespace is defined by its URL (or the contents of document at that location). The prefix merely represents a reference to the namespace URL within XML nodes and elements. Hence, you can bind the same namespace to multiple prefixes, and mix these prefixes in a document. The result is that all elements will be in the same namespace because all prefixes point to the same URL.
The same prefix may be bound to a different namespace in different documents. Moreover, XML allows you to bind the same prefix to different URLs in the same document.
Different Namespaces, Same Prefix
Consider the following example:
<parent xmlns:ns1="foo">
<child xmlns:ns2="bar">
<ns2:some_element>
</child>
<child xmlns:ns2="baz">
<ns2:some_element>
</child>
</parent>
Here, the two children nodes use two different namespaces (bar and baz), but use the same prefix to bind it locally. Hence, the <some_element> node has a different meaning in each of the two children.
Imagine that you want to select the second <some_element> node. You might consider using the XPath expression //ns2:some_element. However, this will not work, because RUEI cannot determine if the ns2 prefix refers to the first definition (bar) or the second (baz).
Now imagine that you want to match both of these nodes. One possible solution is to ignore the namespace definition altogether, and use a wildcard expression. For example:
//*[local-name()='some_element']
However, this expression would find all <some_element> nodes, even ones bound to namespaces in which you are not interested. It is important to understand that the actual prefix name is irrelevant. Because the prefix is local to the part of the document where it is defined, it does not matter which prefix you use in your XPath expression as long as it is a prefix bound to the namespace that is valid at that location. Hence, the following XPath expression
//ns2:some_element
where ns2 specifies baz would match the second <some_element> node. However, because the actual prefix specified in the XPath expression does not have to match the prefix used in the document, you could also use the following XPath expression:
//boo:some_element
where boo specifies bar. In this case, the XPath expression is used to find a node that is locally bound to the namespace baz, and boo is used to refer to that namespace in the XPath expression. When RUEI loads this expression, it will reference the namespace that is pointed to by boo (which in this case is baz), and record that it has to find a node called <some_element> inside the namespace baz. At that point, the prefix is no longer required. When RUEI scans a document, each time it finds a <some_element> element, it retrieves the current namespace through the locally defined prefix, and compares that to the namespace defined in the XPath expression. If they are both baz, then a match is found.
In the light of the above, RUEI can be configured to extract both nodes by using the following XPath expressions:
//boo:some_element where boo=bar//hoo:some_element where hoo=baz
Additional Example
Consider the following XML document:
<parent xmlns:ns2="foo">
<child xmlns:ns2="bar">
<ns2:some_element>
</child>
</parent>
In this case, both the parent and the child node use different namespaces, but both are bound to the same prefix (ns2). This is legal because namespaces definitions are local. To find the content of the <some_element> node, you could use the following XPath expression:
/p_parent:parent/p_child:child/p_child:some_element
where p_parent is foo and p_child is bar (or whatever local prefix strings you want).
F.4 Using Third-Party XPath Tools
For convenience, you can use third-party XPath tools, such as the XPather extension for Mozilla Firefox, to create XPath expressions for use within RUEI. The XPather extension is available at the following location:
http://xpath.alephzarro.com/index
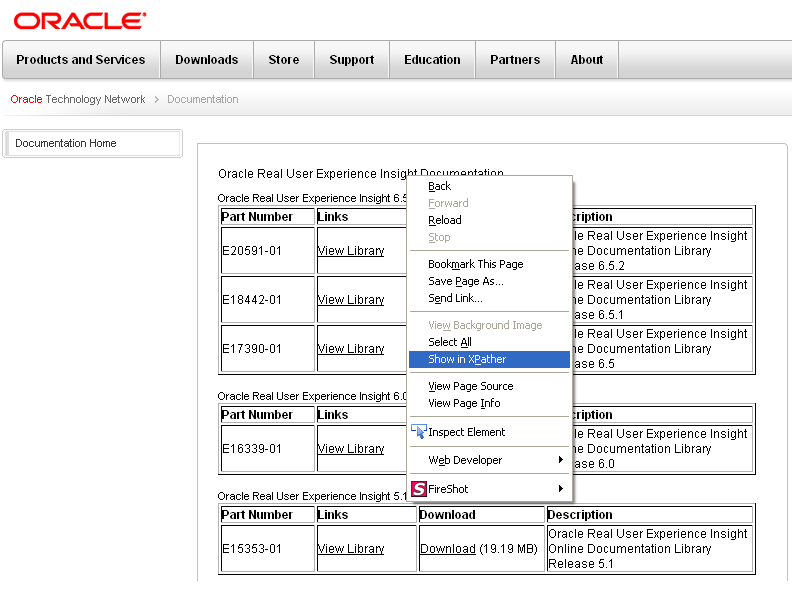
When installed, you can right-click within a page, and select the Show in XPather option. An example is shown in Figure F-3.
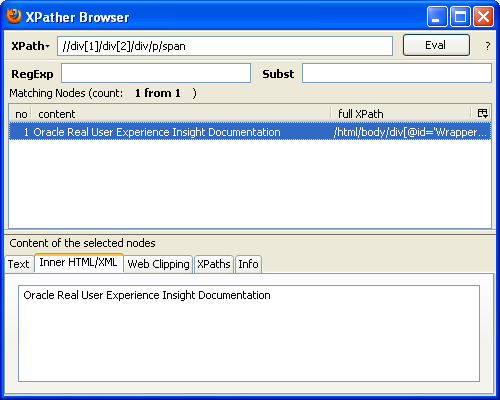
You can then copy the XPath expression within the XPather browser (shown in Figure F-4) and use it the basis for your XPath query with RUEI. Be aware that you should review the generated XPath expression to ensure that it confirms to the restrictions described above.
Note:
If the underlying XHTML code within the page is not well-formed, the XPath expression generated by XPather may not function correctly within RUEI.F.5 Optimizing XPath Scanning
This section describes how you can optimize XML scanning, and prevent the unnecessary scanning of large numbers of documents which can lead to excessive memory and CPU usage on a Collector system.
Which documents are scanned for defined XPath definitions is determined in the following way:
-
If a document is a forced object, it is not scanned. See Section 12.16, "Controlling the Reporting of Objects as Pages" for information about the file extensions regarded as forced objects, and how this can be configured.
-
Otherwise, if the document's Content-Type header specifies HTML or XML, it is scanned as either an HTML or XML file.
-
If the document's Content-Type is something other than
htmlorxml, or the document does not contain a Content-Type header, the start of its message content is compared to predefined content strings and, if a match is found, the document will be scanned for HTML or XML content. -
Finally, if the predefined content strings do not generate a match, but a default content type (HTML or XML) has been configured, then the document is scanned as though it is the specified default type.
When the Content-Type header is missing from a document, or specifies something other than HTML or XML, the start of its message content is compared to predefined strings and, if a match is found, it is scanned as though it was an HTML or XML document. The default content strings are shown in Table F-1.
Note that XML content strings are case sensitive, while HTML strings are not.
Additional content strings can be defined by issuing the following command as the RUEI_USER user on the Collector system:
execsql config_set_prj_value xpath-options type add "content-string"
where:
-
typespecifies whether the document should be scanned as HTML (html-magic) or XML (xml-magic). -
content-stringspecifies the string against which the start of documents should be compared.
For example:
execsql config_set_prj_value xpath-options xml-magic add "<soap:"
If the defined content strings do not generate a match, a default content type can be assigned to these documents to ensure that they are scanned. To do so, issue the following command as the RUEI_USER user on the Collector system:
execsql config_set_prj_value xpath-options default-content-type replace "type"
where type is xml or html.
F.6 XPath on JSON Content
JSON documents are internally converted to an XML structure, where each value in the JSON document is transformed into a XML tag. Values in an object have string keys, and the XML tag is named after the string key in the object. Values in an array will get XML keys with incrementing sequence numbers. The root value of the JSON document is transformed into an XML tag with the name json.
For example, a JSON document can have the following content:
{"name":"juices","value":["apple","orange","carrot"]}
This is transformed into the following XML document:
<?xml version="1.0" encoding="UTF-8"?>
<json>
<name>juices</name>
<value>
<0>apple</0>
<1>orange</1>
<2>carrot</2>
</value>
</json>
The following examples show XPath queries and results based on the JSON document above:
/json/name => juices count(/json/value/*) => 3 /json/value/1 => orange
F.7 Testing XPath Expressions Using xpathtester Utility
To provide a method to easily test XPath expressions, the xpathtester utility is included with RUEI. The following shows the basic usage syntax:
xpathtester filename xpath-expr
where filename is the name of the XML HTML file you want to use and xpath-expr is the XPath expression you want to test. For example:
xpathtester boe.html //body -->> Input file is "boe.html" -->> Parsing document in XML mode...done, parse time: 0000.000164 -->> Evaluating expression: "//body" -->> Eval time: 0000.000037 -->> Found the following object(s) Node 0 (0x12b4c00), type element: name: body (ns="") value: " Hoi " where: line=5-7, file offset=46-59 match: " Hoi "
The following shows the advanced usage syntax:
xpathtester [options] filename xpath-expr1 [xpath-expr2 xpath-expr3 ..]
where the options are described in Table F-2.
Table F-2 xpathtester Utility Options
| Option | Description |
|---|---|
|
|
HTML mode, uses the HTML parser instead of the XML parser. This parser is more forgiving than the XML parser and should be used for HTML files. |
|
-c namespace_file |
Loads namespaces from the specified file. Each line of the file must use the following format: namespace1=http:/the/namespace/url for example soap12=http://www.w3.org/2003/05/soap-envelope |
|
-d dump_file |
Dumps (formatted) XML content to the specified file. This is useful for soap services that send a document as a single line. |
|
-e encoding |
Uses the specified coding in HTML mode. If the document uses an encoding which cannot be determined automatically by the parser, then you can set the encoding to use with this argument. Use the standard IANA naming here, for example, UTF-8 or ISO-LATIN-2. |
|
-h |
display help for the xpathtester utility |
|
-m |
Masks the selection matched by the XPath expression. This is useful to verify which part of the document will be masked by XPath masking. |
|
-v[vvv] |
Set verbosity level ( |