9 Configuring Messaging Server for High Availability
This chapter describes how to configure Oracle Communications Messaging Server for high availability.
Designing for Service Availability
Once you have decided on your Messaging Server logical architecture, the next step is deciding what level of service availability is right for your site. The level of service availability you can expect is related to hardware chosen as well as the software infrastructure and maintenance practices you use. The following information discusses several choices, their value, and their costs.
High Availability Solutions Overview
Messaging Server supports three different high availability solutions, Oracle Solaris Cluster, Veritas Cluster Server (VCS), and Oracle Clusterware. Messaging Server provides agents for each of these solutions.
Messaging Server supports different cluster topologies. Refer to the appropriate cluster product documentation for more information. In addition, you can build in availability to your Messaging Server deployment by making infrastructure components, such as Directory Server, highly available.The following topics in this section explain the options available for each component.
Automatic System Reconfiguration (ASR)
In addition to evaluating a purely highly available (HA) solution, you should consider deploying hardware that is capable of ASR.
ASR is a process by which hardware failure related downtime can be minimized. If a server is capable of ASR, it is possible that individual component failures in the hardware result in only minimal downtime. ASR enables the server to reboot itself and configure the failed components out of operation until they can be replaced. The downside is that a failed component that is taken out of service could result in a less performing system. For example, a CPU failure could result in a machine rebooting with fewer CPUs available. A system I/O board or chip failure could result in system with diminished or alternative I/O paths in use.
Different SPARC systems support very different levels of ASR. Some systems support no ASR, while others support very high levels. As a general rule, the more ASR capabilities a server has, the more it costs. In the absence of high availability software, choose machines with a significant amount of hardware redundancy and ASR capability for your data stores, assuming that it is not cost prohibitive.
Directory Server and High Availability
From a Messaging Server standpoint, the most important factor in planning your directory service is availability. As an infrastructure service, the directory must provide as near-continuous service as possible to the higher-level applications for authorization, access, email routing, and so forth.
A key feature of Directory Server that provides for high availability is replication. Replication is the mechanism that automatically copies directory data from one Directory Server to another. Replication enables you to provide a highly available directory service, and to geographically distribute your data. In practical terms, replication brings the following benefits:
-
Failover
-
Load balancing
-
Higher performance and reduced response times
-
Local data management
Table 9-1 shows how you can design your directory for availability.
Table 9-1 Designing Directory Server for High Availability
| Method | Description |
|---|---|
|
Single-master replication |
A server acting as a supplier copies a master replica directly to one or more consumer servers. In this configuration, all directory modifications are made to the master replica stored on the supplier, and the consumers contain read-only copies of the data. |
|
Two-way, multi-master replication |
In a multi-master environment between two suppliers that share responsibility for the same data, you create two replication agreements. Supplier A and Supplier B each hold a master replica of the same data and there are two replication agreements governing the replication flow of this multi-master configuration. |
|
Four-way multi-master |
Provides a pair of Directory Server masters, usually in two separate data centers. This configuration uses four-way MultiMaster Replication (MMR) for replication. Thanks to its four-way master failover configuration, this fully-connected topology provides a highly-available solution that guarantees data integrity. When used with hubs in the replication topology, load distribution is facilitated, and the four consumers in each data center allow this topology to scale for read (lookup) operations. |
|
Oracle Solaris Cluster Agent for Directory Server |
Using Oracle Solaris Cluster software provides the highest level of availability for your directory implementation. In the case of failure of an active Directory Server node, Oracle Solaris Cluster provides for transparent failover of services to a backup node. However, the administrative (and hardware) costs of installing, configuring, and maintaining a cluster are typically higher than the Directory Server replication methods. |
See the Directory Server Documentation for more information.
Messaging Server and High Availability
You can configure Messaging Server to be highly available by using clustering software. Messaging Server supports Oracle Solaris Cluster, Veritas Cluster Server, and Oracle Clusterware software.
In a tiered Messaging Server architecture, where front-end and back-end components are distributed onto separate machines, you would want to make the back-end components highly available through cluster technology as the back ends are the ”stores” maintaining persistent data. Cluster technology is not typically warranted on the Messaging Server front ends as they do not hold persistent data. Typically, you would want to make the Messaging Server MTA and MMP, and Webmail Server front ends highly available through redundancy, that is, by deploying multiple front-end hosts. You could also add high availability to the MTA by protecting its disk subsystems through RAID technology.
For more information on Oracle Solaris Cluster topologies, see the discussion on key concepts for hardware service providers in the Oracle Solaris Cluster Concepts Guide for Solaris OS.
Using Enabling Techniques and Technologies
In addition to the high availability solutions discussed in the above section, you can use enabling techniques and technologies to improve both availability and performance. These techniques and technologies include load balancers, Directory Proxy Server, and replica role promotion.
Using Load Balancers
You can use load balancers to ensure the functional availability of each tier in your architecture, providing high availability of the entire end-to-end system. Load balancers can be either a dedicated hardware appliance or a strictly software solution.
Load balancing is the best way to avoid a single application instance, server, or network as a single point of failure while at the same time improving the performance of the service. One of the primary goals of load balancing is to increase horizontal capacity of a service. For example, with a directory service, load balancers increase the aggregate number of simultaneous LDAP connections and LDAP operations per second that the directory service can handle.
Using Directory Proxy Server
Directory Proxy Server provides many proxy type features. One of these features is LDAP load balancing. Though Directory Proxy Server might not perform as well as dedicated load balancers, consider using it for failover, referral following, security, and mapping features.
See the Directory Proxy Server documentation for more information.
Using Replica Role Promotion
Directory Server includes a way of promoting and demoting the replica role of a directory instance. This feature enables you to promote a replica hub to a multi-master supplier or vice versa. You can also promote a consumer to the role of replica hub and vice versa. However, you cannot promote a consumer directly to a multi-master supplier or vice versa. In this case, the consumer must first become a replica hub and then it can be promoted from a hub to a multi-master replica. The same is true in the reverse direction.
Replica role promotion is useful in distributed deployments. Consider the case when you have six geographically dispersed sites. You would like to have a multi-master supplier at each site but are limited to only one per site for up to four sites. If you put at least one hub at each of the other two sites, you could promote them if one of the other multi-master suppliers is taken offline or decommissioned for some reason.
See the Directory Server documentation for more information.
Locating High Availability Product Reference Information
For more information on high availability models, see the following product documentation:
Oracle Solaris Cluster
-
Oracle Solaris Cluster Concepts Guide for Oracle Solaris OS
-
Oracle Solaris Cluster Data Services Developer's Guide for Solaris OS
-
Oracle Solaris Cluster Overview for Solaris OS
-
Oracle Solaris Cluster System Administration Guide for Solaris OS
Veritas Cluster Server
-
Veritas Cluster Server User's Guide
Oracle Clusterware
-
Oracle Clusterware Administration and Deployment Guide
Understanding Remote Site Failover
Remote site failover is the ability to bring up a service at a site that is WAN connected to the primary site in the event of a catastrophic failure to the primary site. There are several forms of remote site failover and they come at different costs.
For all cases of remote site failover, you need additional servers and storage capable of running all or part of the users' load for the service installed and configured at the remote site. By all or part, this means that some customers might have priority users and non-priority users. Such a situation exists for both ISPs and enterprises. ISPs might have premium subscribers, who pay more for this feature. Enterprises might have divisions that provide email to all of their employees but deem this level of support too expensive for some portion of those users. For example, an enterprise might choose to have remote site failover for mail for those users that are directly involved in customer support but not provide remote site failover for people who work the manufacturing line. Thus, the remote hardware must be capable of handling the load of the users that are allowed to access remote failover mail servers.
While restricting the usage to only a portion of the user base reduces the amount of redundant server and storage hardware needed, it also complicates configuration and management of fail back. Such a policy can also have other unexpected impacts on users in the long term. For instance, if a domain mail router is unavailable for 48 hours, the other MTA routers on the Internet will hold the mail destined for that domain. At some point, the mail will be delivered when the server comes back online. Further, if you do not configure all users in a failover remote site, then the MTA will be up and give permanent failures (bounces) for the users not configured. Lastly, if you configure mail for all users to be accepted, then you have to fail back all users or set up the MTA router to hold mail for the nonfunctional accounts while the failover is active and stream it back out once a failback has occurred.
Potential remote site failover solutions include:
-
Simple, less expensive scenario. The remote site is not connected by large network bandwidth. Sufficient hardware is setup but not necessarily running. In fact, it might be used for some other purpose in the meantime. Backups from the primary site are shipped regularly to the remote site, but not necessarily restored. The expectation is that there will be some significant data loss and possibly a significant delay in getting old data back online. In the event of a failure at the primary site, the network change is manually started. Services are started, followed by beginning the imsrestore process. Lastly, the file system restore is started, after which services are brought up.
-
More complicated, more expensive solution. Both Veritas and Oracle sell software solutions that cause all writes occurring on local (primary) volumes to also be written to remote sites. In normal production, the remote site is in lock step or near lock step with the primary site. Upon primary site failure, the secondary site can reset the network configurations and bring up services with very little to no data loss. In this scenario, there is no reason to do restores from tape. Any data that does not make the transition prior to the primary failure is lost, at least until failback or manual intervention occurs in the case of the MTA queued data. Veritas Site HA software is often used to detect the primary failure and reset the network and service bring up, but this is not required to get the higher level of data preservation. This solution requires a significant increase in the quantity of hardware at the primary site as there is a substantial impact in workload and latency on the servers to run the data copy.
-
Most available solution. This solution is essentially the same as the software real time data copy solution except the data copy is not happening on the Message Store server. If the Message Store servers are connected to storage arrays supporting remote replication, then the data copy to the remote site can be handled by the storage array controller itself. Storage arrays that offer a remote replication feature tend to be large, so the base cost of obtaining this solution is higher than using lower-end storage products.
There are a variety of costs to these solutions, from hardware and software, to administrative, power, heat, and networking costs. These are all fairly straightforward to account for and calculate. Nevertheless, it is difficult to account for some costs: the cost of mistakes when putting a rarely practiced set of procedures in place, the inherent cost of downtime, the cost of data loss, and so forth. There are no fixed answers to these types of costs. For some customers, downtime and data loss are extremely expensive or totally unacceptable. For others, it is probably no more than an annoyance.
In doing remote site failover, you also need to ensure that the remote directory is at least as up to date as the messaging data you are planning to recover. If you are using a restore method for the remote site, the directory restore needs to be completed before beginning the message restore. Also, it is imperative that when users are removed from the system that they are only tagged as disabled in the directory. Do not remove users from the directory for at least as long as the messaging backup tapes that will be used might contain those users' data.
Questions for Remote Site Failover
Use the following questions to assist you in planning for remote site failover:
-
What level of responsiveness does your site need?
For some organizations, it is sufficient to use a scripted set of manual procedures in the event of a primary site failure. Others need the remote site to be active in rather short periods of time (minutes). For these organizations, the need for Veritas remote site failover software or some equivalent is overriding.
Note:
Do not use both Oracle Solaris Cluster for local HA and Veritas software for remote site failover. Oracle Solaris Cluster does not support remote site failover at this time.Also, do not allow the software to automatically failover from the primary site to the backup site. The possibility for false positive detection of failure of the primary site from the secondary site is too high. Instead, configure the software to monitor the primary site and alert you when it detects a failure. Then, confirm that the failure has happened before beginning the automated process of failing over to the backup site.
-
How much data must be preserved and how quickly must it be made available?
Although this seems like a simple question, the ramifications of the answer are large. Variations in scenarios, from the simple to the most complete, introduce quite a difference in terms of the costs for hardware, network data infrastructure, and maintenance.
New Recipe for Unified Configuration
Wherever you see references to the ha_ip_config script, in Unified Configuration, use the HAConfig.rcp recipe. (Recipes are installed in the MessagingServer_home/lib/recipes directory.) To run a recipe, use the msconfig runrecipe command. For example, to run the HAConfig.rcp recipe, type:
/opt/sun/comms/messaging64/bin/msconfig run HAConfig.rcp
Respond to the prompts according. The recipe configures the logical IP and sets the following options:
base.listenaddr job_controller.listenaddr dispatcher.service:SMTP_SUBMIT.listenaddr dispatcher.service:SMTP.listenaddr http.smtphost metermaid.listenaddr metermaid_client.server_host
The recipe verifies that the watcher is enabled, and if not, enables it; and also enables autorestart if not already enabled.
Supported Versions of High-Availability Software in Messaging Server
For the latest supported versions and platforms, see "Supported High Availability Software."
Installation Methods for Messaging Server
A cluster agent is a Messaging Server program that runs under the cluster framework.
The Oracle Solaris Cluster Messaging Server agent is installed when you select Messaging Server Oracle Solaris Cluster HA Agent through the Messaging Server Installer.
-
Run the Messaging Server Installer command:
commpkg install
When prompted, select the Messaging Server Oracle Solaris Cluster HA Agent software.
-
Run the Oracle Solaris Cluster HA Agent pre-configuration command:
cd MessagingServer_hahome/bin/ init-config
Messaging Server Oracle Solaris Cluster HA Agent Initial Configuration
After installing the Messaging Server Oracle Solaris Cluster HA Agent software, you need to perform an initial configuration by running the following command:
MessagingServer_hahome/bin/init-config
This command registers the HA agent with the Oracle Solaris Cluster HA software. You must have the Oracle Solaris Cluster HA software installed prior to issuing this command.
Installing Messaging Server Oracle Solaris Cluster HA Agent in Solaris Zones
Oracle Solaris Cluster has added support for Oracle Solaris Zones. In this scenario, the Messaging Server Oracle Solaris Cluster HA agent should be installed in the global zone (and automatically installed in non-global zones). The Comms Installer will do this for you as long as you do the install in the global zone.
Take the following steps to install the Messaging Server Oracle Solaris Cluster HA agent in non-global zones:
-
Run the Messaging Server Installer command in the global zone only:
commpkg install
When prompted, select the Messaging Server Oracle Solaris Cluster HA Agent software. This command installs the Messaging Server Oracle Solaris Cluster HA Agent package on global zone and all non-global zones.
-
Run the Oracle Solaris Cluster HA Agent pre-configuration command in the global zone only:
cd MessagingServer_hahome/bin/ init-config
About High Availability Models
Messaging Server supports the following HA models:
Consult your HA documentation to determine which models your HA product supports.
Table 9-2 summarizes the advantages and disadvantages of each high availability model. Use this information to help you determine which model is right for your deployment.
Table 9-2 HA Model Summary and Recommendation
| Model | Advantages | Disadvantages | Recommended Users |
|---|---|---|---|
|
Asymmetric |
Simple Configuration Backup node is 100 percent reserved |
Machine resources are not fully utilized |
A small service provider with plans to expand in the future |
|
Symmetric |
Better use of system resources Higher availability |
Resource contention on the backup node HA requires fully redundant disks |
A small corporate deployment that can accept performance penalties in the event of a single server failure |
|
N + 1 |
Load distribution Easy expansion |
Management and configuration complexity |
A large service provider who requires distribution with no resource constraints |
Table 9-3 illustrates the probability that on any given day the messaging service will be unavailable due to system failure. These calculations assume that on average, each server goes down for one day every three months due to either a system crash or server hang, and that each storage device goes down one day every 12 months. These calculations also ignore the small probability of both nodes being down simultaneously.
Table 9-3 System Downtime Calculation
| Model | Downtime Probability |
|---|---|
|
Single server (no HA) |
Pr(down) = (4 days of system down + 1 day of storage down)/365 = 1.37% |
|
Asymmetric |
Pr(down) = (0 days of system down + 1 day of storage down)/365 = 0.27% |
|
Symmetric |
Pr(down) = (0 days of system down + 0 days of storage down)/365 = (near 0) |
|
N + 1 |
Pr(down) = (5 hours of system down + 1 day of storage down)/(365xN) = 0.27%/N |
Asymmetric
The basic asymmetric or hot standby high availability model consists of two clustered host machines or nodes. A logical IP address and associated host name are designated to both nodes.
In this model, only one node is active at any given time; the backup or hot standby node remains idle most of the time. A single shared disk array between both nodes is configured and is mastered by the active or primary node. The message store partitions and MTA queues reside on this shared volume.
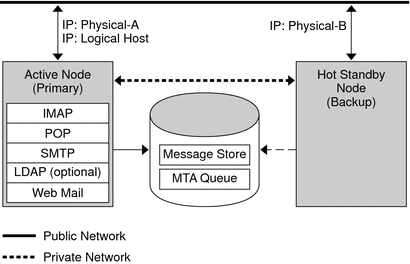
Figure 9-1 shows two physical nodes, Physical-A and Physical-B. Before failover, the active node is Physical-A. Upon failover, Physical-B becomes the active node and the shared volume is switched so that it is mastered by Physical-B. All services are stopped on Physical-A and started on Physical-B.
The advantage of this model is that the backup node is dedicated and completely reserved for the primary node. Additionally, there is no resource contention on the backup node when a failover occurs. However, this model also means that the backup node stays idle most of the time and this resource is therefore under utilized.
Symmetric
The basic symmetric or "dual services" high availability model consists of two hosting machines, each with its own logical IP address. Each logical node is associated with one physical node, and each physical node controls one disk array with two storage volumes. One volume is used for its local message store partitions and MTA queues, and the other is a mirror image of its partner's message store partitions and MTA queues.
Figure 9-2 shows the symmetric high availability mode. Both nodes are active concurrently, and each node serves as a backup node for the other. Under normal conditions, each node runs only one instance of Messaging Server.
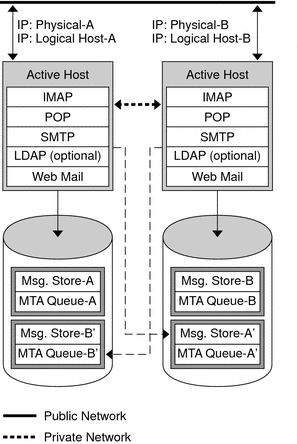
Upon failover, the services on the failing node are shut down and restarted on the backup node. At this point, the backup node is running Messaging Server for both nodes and is managing two separate volumes.
The advantage of this model is that both nodes are active simultaneously, thus fully utilizing machine resources. However, during a failure, the backup node will have more resource contention as it runs services for Messaging Server from both nodes. Therefore, you should repair the failed node as quickly as possible and switch the servers back to their dual services state.
This model also provides a backup storage array. In the event of a disk array failure, its redundant image can be picked up by the service on its backup node.
To configure a symmetric model, you need to install shared binaries on your shared disk. Note that doing so might prevent you from performing rolling upgrades, a feature that enables you to update your system during Messaging Server patch releases.
N+1 (N Over 1)
The N + 1 or "N over 1" model operates in a multi-node asymmetrical configuration. N logical host names and N shared disk arrays are required. A single backup node is reserved as a hot standby for all the other nodes. The backup node is capable of concurrently running Messaging Server from the N nodes.
Figure 9-3 illustrates the basic N + 1 high availability model.
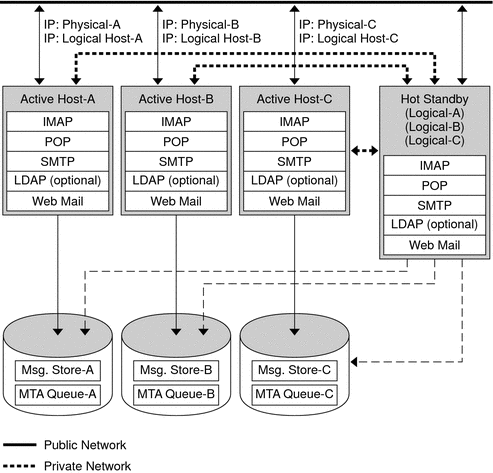
Upon failover of one or more active nodes, the backup node picks up the failing node's responsibilities.
The advantages of the N + 1 model are that the server load can be distributed to multiple nodes and that only one backup node is necessary to sustain all the possible node failures. Thus, the machine idle ratio is 1/N as opposed to 1/1, as is the case in a single asymmetric model.
To configure an N+1 model, you need to install binaries only on the local disks (that is, not shared disks as with the symmetric model). The current Messaging Server installation and setup process forces you to put the binaries on the shared disk for any symmetric, 1+1, or N+1 asymmetrical or symmetrical HA solution.
Configuring Messaging Server Oracle Solaris Cluster HA Agent
To configure the Solaris Cluster HA agent:
-
On each node in the cluster create the Messaging Server runtime user and group under which the Messaging Server will run.
The user ID and group ID numbers must be the same on all nodes in the cluster. The runtime user ID is the user name under which Messaging Server runs. This name should not be root. The default is mailsrv. The runtime Group ID is the group under which Messaging Server runs. The default is mail. Although the configure utility can create these names for you, you can also create them before running configure as part of the preparation of each node as described in this chapter. The runtime user and group ID names must be in the following files:
-
mailsrv, or the name you select, must in /etc/passwd on all nodes in the cluster
-
mail, or the name you select, must be in /etc/group on all nodes in the cluster
-
-
Add required resource types to Oracle Solaris Cluster.
Configure Oracle Solaris Cluster to know about the resources types we will be using.
To register Messaging Server as your resource use the following command:
# scrgadm -a -t SUNW.ims
To register HAStoragePlus as a resource type, use this command:
# scrgadm -a -t SUNW.HAStoragePlus
To do the same with HAStorage as a resource type, use this command:
# scrgadm -a -t SUNW.HAStorage
-
Create a failover resource group for the Messaging Server.
If you have not done so already, create a resource group and make it visible on the cluster nodes which will run the Messaging Server. The following command creates a resource group named MAIL-RG, making it visible on the cluster nodes mars and venus:
# scrgadm -a -g MAIL-RG -h mars,venus
You may, of course, use whatever name you wish for the resource group.
-
Create an HA logical host name resource and bring it on-line.
If you have not done so, create and enable a resource for the HA logical host name placing that resource in the resource group. The following command does so using the logical host name meadow. Since the -j switch is omitted, the name of the resource created will also be meadow. meadow is the logical host name by which clients communicate with the services in the resource group.
# scrgadm -a -L -g MAIL-RG -l meadow # scswitch -Z -g MAIL-RG
-
Create an HAStorage or HAStoragePlus resource.
Next, you need to create an HA Storage or HAStoragePlus resource type for the file systems on which Messaging Server is dependent. The following command creates an HAStoragePlus resource named disk-rs, and the file system disk_sys_mount_point is placed under its control:
# scrgadm -a -j disk-rs -g MAIL-RG \-t SUNW.HAStoragePlus \-x FilesystemMountPoints=disk_sys_mount_point-1, disk_sys_mount_point-2 -x AffinityOn=True
SUNW.HAStoragePlus represents the device groups, cluster and local file systems which are to be used by one or more data service resources. One adds a resource of type SUNW.HAStoragePlus to a resource group and sets up dependencies between other resources and the SUNW.HAStoragePlus resource. These dependencies ensure that the data service resources are brought online after:
-
All specified device services are available (and collocated if necessary)
-
All specified file systems are mounted following their checks
The FilesystemMountPoints extension property allows for the specification of either global or local file systems. That is, file systems that are either accessible from all nodes of a cluster or from a single cluster node. Local file systems managed by a SUNW.HAStoragePlus resource are mounted on a single cluster node and require the underlying devices to be Oracle Solaris Cluster global devices. SUNW.HAStoragePlus resources specifying local file systems can only belong in a failover resource group with affinity switch overs enabled. These local file systems can therefore be termed failover file systems. Both local and global file system mount points can be specified together.
A file system whose mount point is present in the FilesystemMountPoints extension property is assumed to be local if its /etc/vfstab entry satisfies both of the following conditions:
-
Non-global mount option
-
Mount at boot flag is set to no
Note:
Instances of the SUNW.HAStoragePlus resource type ignore the mount at boot flag for global file systems.For the HAStoragePlus resource, the comma-separated list of FilesystemMountPoints are the mount points of the Cluster File Systems (CFS) or Failover File Systems (FFS) on which Messaging Server is dependent. In the above example, only two mount points, disk_sys_mount_point-1 and disk_sys_mount_point-2, are specified. If one of the servers has additional file systems on which it is dependent, then you can create an additional HA storage resource and indicate this additional dependency in Step 15.
For HAStorage use the following:
# scrgadm -a -j disk-rs -g MAIL-RG \-t SUNW.HAStorage-x ServicePaths=disk_sys_mount_point-1, disk_sys_mount_point-2 -x AffinityOn=True
For the HAStorage resource, the comma-separated list of ServicePaths are the mount points of the cluster file systems on which Messaging Server is dependent. In the above example, only two mount points, disk_sys_mount_point-1 and disk_sys_mount_point-2, are specified. If one of the servers has additional file systems on which it is dependent, then you can create an additional HA storage resource and indicate this additional dependency in Step 15.
-
-
Install the required Messaging Server packages on the primary node. Choose the Configure Later option.
Use the Communications Suite installer to install the Messaging Server packages.
For symmetric deployments: Install Messaging Server binaries and configuration data on files systems mounted on a shared disk of the Oracle Solaris Cluster. For example, for Messaging Server binaries could be under /disk_sys_mount_point-1/SUNWmsgsr and the configuration data could be under /disk_sys_mount_point-2/config.
For asymmetric deployments: Install Messaging Server binaries on local file systems on each node of the Oracle Solaris Cluster. Install configuration data on a shared disk. For example, the configuration data could be under /disk_sys_mount_point-2/config.
-
Configure the Messaging Server. See "Running the Messaging Server Initial Configuration Script."
In the initial runtime configuration, you are asked for the Fully Qualified Host Name. You must use the HA logical hostname instead of the physical hostname.Be sure to use the shared disk directory path of your HAStorage or HAStoragePlus resource.
-
Run the ha_ip_config script to set service.listenaddr and service.http.smtphost to configure the dispatcher.cnf and job_controller.cnf files for high availability.
The script ensures that the logical IP address is set for these parameters and files, rather than the physical IP address. It also enables the watcher process (sets local.watcher.enable to 1), and auto restart process (local.autorestart to 1).
The ha_ip_config script should only be run once on the primary node.
-
Fail the resource group from the primary to the secondary cluster node in order to ensure that the failover works properly.
Manually fail the resource group over to another cluster node. (Be sure you have superuser privileges on the node to which you failover.)
Use the scstat command to see what node the resource group is currently running on ("online" on). For instance, if it is online on mars, then fail it over to venus with the command:
# scswitch -z -g MAIL-RG -h venus
If you are upgrading your first node, use the Messaging Server Installer and then configure Messaging Server. You will then failover to the second node where you will install the Messaging Server package through the Communications Suite Installer, but you will not have to run the Initial Runtime Configuration Program again. Instead, you can use the useconfig utility.
-
Install the required Messaging Server packages on the secondary node. Choose the Configure Later option.
After failing over to the second node, install the Messaging Server packages using the Communications Suite Installer.
For symmetric deployments: Do not install Messaging Server.
For asymmetric deployments: Install Messaging Server binaries on local file systems on the local file system.
-
Run useconfig on the second node of the cluster.
The useconfig utility allows you to share a single configuration between multiple nodes in an HA environment. You don't need to run the initial runtime configure program. Instead use the useconfig utility.
See "Using the useconfig Utility"for more information
-
Create an HA Messaging Server resource.
It is now time to create the HA Messaging Server resource and add it to the resource group. This resource is dependent upon the HA logical host name and HA disk resource.
In creating the HA Messaging Server resource, we need to indicate the path to the Messaging Server top-level directory: the msg-svr-base path. These are done with the IMS_serverroot extension properties as shown in the following command.
# scrgadm -a -j mail-rs -t SUNW.ims -g MAIL-RG \ -x IMS_serverroot=msg-svr-base \ -y Resource_dependencies=disk-rs,meadowThe above command, creates an HA Messaging Server resource named mail-rs for the Messaging Server, which is installed on IMS_serverroot in the msg-svr-base directory. The HA Messaging Server resource is dependent upon the HA disk resource disk-rs as well as the HA logical host name meadow.
If the Messaging Server has additional file system dependencies, then you can create an additional HA storage resource for those file systems. Be sure to include that additional HA storage resource name in the Resource_dependencies option of the above command.
-
Enable the Messaging Server resource.
It is now time to activate the HA Messaging Server resource, thereby bringing the messaging server online. To do this, use the command
# scswitch -e -j mail-rs
The above command enables the mail-rs resource of the MAIL-RG resource group. Since the MAIL-RG resource was previously brought online, the above command also brings mail-rs online.
-
Verify that things are working.
Use the scstat -pvv command to see if the MAIL-RG resource group is online.
Unconfiguring Messaging Server HA Support
This section describes the high-level steps to unconfigure a simple HA configuration for Oracle Solaris Cluster. The exact procedure may differ for your deployment, but follows the same logical order described below.
-
Become the superuser.
All of the following Oracle Solaris Cluster commands require that you be running as user superuser.
-
Bring the resource group offline.
To shut down all of the resources in the resource group, issue the command
# scswitch -F -g MAIL-RG
This shuts down all resources within the resource group (for example, the Messaging Server and the HA logical host name).
-
Disable the individual resources.
Next, remove the resources one-by-one from the resource group with the commands:
# scswitch -n -j mail-rs # scswitch -n -j disk-rs # scswitch -n -j budgie
-
Remove the individual resources from the resource group.
Once the resources have been disabled, you may remove them one-by-one from the resource group with the commands:
# scrgadm -r -j mail-rs # scrgadm -r -j disk-rs # scrgadm -r -j budgie
-
Remove the resource group.
Once the all the resources have been removed from the resource group, the resource group itself may be removed with the command:
# scrgadm -r -g MAIL-RG
-
(Optional) Remove the resource types.
Should you need to remove the resource types from the cluster, issue the commands:
# scrgadm -r -t SUNW.ims # scrgadm -r -t SUNW.HAStoragePlus
Veritas Cluster Server Agent Installation
Messaging Server can be configured with Veritas Cluster Server 3.5, 4.0, 4.1, 5.0, and 6.0.2. Be sure to review the Veritas Cluster Server documentation prior to following these procedures. Veritas cluster Server agent for Messaging Server is part of the Messaging Server core package and is installed during Messaging Server installation only.
This topic contains the following sections:
Veritas Cluster Server Requirements
Veritas Cluster software is already installed and configured as described in the following instructions along with the Messaging Server software on both nodes.
VCS Installation and Configuration Notes
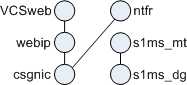
The following instructions describe how to configure Messaging Server as an HA service, by using Veritas Cluster Server. The default main.cf configuration file sets up a resource group called ClusterService that launches the VCSweb application. This group includes network logical host IP resources like csgnic and webip. In addition, the ntfr resource is created for event notification.
To Configure Messaging Server as an HA Service by Using Veritas Cluster Server
These Veritas Cluster Server instructions assume you are using the graphical user interface to configure Messaging Server as an HA service.
-
Launch Cluster Explorer from one of the nodes.
To launch Cluster Explorer, run the following command:
/opt/VRTSvcs/bin/hagui
The VRTScscm package must be installed to use the GUI.
-
Using the Cluster Explorer, add a service group called MAIL-RG.
-
Add s1ms_dg disk group resource of type DiskGroup to the service group MAIL-RG and enable it.
-
Add s1ms_mt mount resource of type Mount to the service group MAIL-RG.
Click the Link button to enable linking resources, if they are not already enabled.
-
Create a link between s1ms_mt and s1ms_dg.
-
Enable the resource s1ms_mt.
Figure 9-4 depicts the dependency tree:
-
Run the Messaging Server Installer to install the Messaging Server software.
-
Run the Messaging Server Initial Runtime Configuration (configure) from the primary node (for example, Node_A) to configure Messaging Server. The initial runtime configuration program asks for the Fully Qualified Host Name. Enter the logical hostname. The program also asks to specify a configuration directory. Enter mount point of the file system related to shared disk.
-
Messaging Server running on a server requires that the correct IP address binds it. This is required for proper configuration of Messaging in an HA environment. Execute ha_ip_config command to bind to correct IP address.
MessagingServer_home/bin/ha_ip_config
The ha_ip_config program asks for the Logical IP address and Messaging Server Base (MessagingServer_home).
-
During Messaging Server installation, VCS agent related directory vcsha is created under the Messaging Server base directory, which will have VCS HA agent related files. Run config-vcsha to copy agent files to VCS configuration.
MessagingServer_home/bin/config-vcsha
Messaging Server and the Veritas agent are available on Node_A.
-
-
Switch to the backup node (for example, Node_B).
-
Run the Messaging Server Installer to install Messaging Server software on the backup node (Node_B).
-
After installing Messaging Server, use the useconfig utility to obviate the need for creating an additional initial runtime configuration on the backup node (Node_B).
The useconfig utility enables you to share a single configuration between multiple nodes in an HA environment. This utility is not meant to upgrade or update an existing configuration. To enable the utility, run useconfig to point to your previous Messaging Server configuration:
MessagingServer_home/bin/useconfig MessagingServer_home/config
-
As VCS HA agent is part of Messaging Server installation, run config-vcsha to copy agent files to VCS configuration.
MessagingServer_home/bin/config-vcsha
The Veritas agent is also now installed on Node_B.
-
From the Veritas Cluster Server Cluster Manager, select ImportTypes from the File menu, which will display a file selection box.
-
Import the MsgSrvTypes.cf file from the /etc/VRTSvcs/conf/config directory.
-
Import this type file.
You need to be on a cluster node to find this file.
-
Create a resource of type MsgSrv (for example, Mail).
This resource requires the logical host name property to be set.
-
The Mail resource depends on s1ms_mt and webip. Create links between the resources as shown in the following dependency tree:
Figure 9-5 Veritas Cluster Dependencies (s1ms_mt and webip)
Description of ''Figure 9-5 Veritas Cluster Dependencies (s1ms_mt and webip)''
-
Enable all resources and bring Mail online
-
All servers should be started. Switch over to Node_A and check if the High Availability configuration is working.
-
MsgSrv Attributes and Arguments
This section describes MsgSvr additional attributes and arguments that govern the behavior of the mail resource.
Table 9-4 Veritas Server Attributes
| Attribute | Description |
|---|---|
|
FaultOnMonitorTimeouts |
If unset (=0), monitor (probe) time outs are not treated as resource fault. Recommend setting this to 2. If the monitor times out twice, the resource will be restarted or failed over. |
|
ConfInterval |
Time interval over which faults/restarts are counted. Previous history is erased if the service remains online for this duration. Suggest 600 seconds. |
|
ToleranceLimit |
Number of times the monitor should return OFFLINE for declaring the resource FAULTED. Recommend leaving this value at 0 (default). |
| Option | Description |
|---|---|
|
State |
Indicates if the service is online or not in this system. This value is not changeable by the user. |
|
LogHostName |
The logical host name that is associated with this instance. |
|
PrtStatus |
If set to TRUE, the online status is printed to the Veritas Cluster Server log file. |
|
DebugMode |
If set to TRUE, the debugging information is sent to the Veritas Cluster Server log file. |
To obtain the current values of following debug options:
pwd /opt/VRTSvcs/bin hares -value ms-srvr DebugMode hares -value ms-srvr PrtStatus
To set the following debug options:
pwd /opt/VRTSvcs/bin hares -modify ms-srvr PrtStatus true hares -modify ms-srvr DebugMode true
Unconfiguring High Availability
This section describes how to unconfigure high availability. To uninstall high availability, follow the instructions in your Veritas or Oracle Solaris Cluster documentation. The High Availability unconfiguration instructions differ depending on whether you are removing Veritas Cluster Server or Oracle Solaris Cluster.
To Unconfigure the Veritas Cluster Server
This section describes how to unconfigure the high availability components for Veritas Cluster Server.
-
Bring the MAIL-RG service group offline and disable its resources.
-
Remove the dependencies between the mail resource, the logical_IP resource, and the mountshared resource.
-
Bring the MAIL-RG service group back online so the sharedg resource is available.
-
Delete all of the Veritas Cluster Server resources created during installation.
-
Stop the Veritas Cluster Server and remove following files on both nodes:
/etc/VRTSvcs/conf/config/MsgSrvTypes.cf /opt/VRTSvcs/bin/MsgSrv/online /opt/VRTSvcs/bin/MsgSrv/offline /opt/VRTSvcs/bin/MsgSrv/clean /opt/VRTSvcs/bin/MsgSrv/monitor /opt/VRTSvcs/bin/MsgSrv/sub.pl
-
Remove the Messaging Server entries from the /etc/VRTSvcs/conf/config/main.cf file on both nodes.
-
Remove the /opt/VRTSvcs/bin/MsgSrv/ directory from both nodes.
Oracle Clusterware Installation and Configuration
Messaging Server can be configured with Oracle Clusterware. Be sure to review the Oracle Clusterware documentation prior to following these procedures.
This topic contains the following sections:
To Install Oracle Clusterware
For information about installing Oracle Clusterware, see the overview of installing Oracle Clusterware in the Oracle Clusterware Administration and Deployment Guide.
To Configure Messaging Server to Use with Oracle Clusterware
After Oracle Clusterware is installed:
-
On each node in the cluster, including the NFS server (if used), create the Messaging Server runtime user and group under which the Messaging Server will run.
The user ID and group ID numbers must be the same on all nodes in the cluster. The run time user ID is the user name under which Messaging Server runs. This name should not be root. The default is mailsrv. The runtime Group ID is the group under which Messaging Server runs. The default is mail. Although the configure utility can create these names for you, you can also create them before running configure as part of the preparation of each node as described in this chapter. The runtime user and group ID names must be in the following files:
-
mailsrv, or the name you select, must in /etc/passwd on all nodes in the cluster
-
mail, or the name you select, must be in /etc/group on all nodes in the cluster
-
-
Configure NFS shares with proper options on the NFS server machine and export them to the NFS clients (all Cluster nodes). Also make sure that NFS shares are on highly available storage. To use file systems other then NFS, like Failover File system or Clustered File systems created on shared storage, refer to Oracle Clusterware documentation.
For NFS, mount all the NFS shares on all cluster nodes. These NFS mounts will be used for installing Messaging Server binaries, keeping configuration and runtime data.
If a two-node symmetric cluster setup used, then two NFS mounts are needed on both nodes for Messaging Server instance 1 on node1 and Messaging Server instance 2 on node 2. Here is an example of the NFS share details from /etc/exportfs file on Linux.
Node 1 : /export/msg1 <NFS Client1 IP > (rw,nohide,insecure,no_subtree_check,async,no_root_squash) Node 2: /export/msg2 <NFS Client2 IP > (rw,nohide,insecure,no_subtree_check,async,no_root_squash) - (in case of Symmetric HA)
On all cluster nodes, mount the NFS shares with following options. To make the mount points persistent across the boots, keep mount details in the /etc/fstab file.
Node 1:/export/msg1 /export/msg1 nfs rw,bg,hard,intr,rsize=32768,wsize=32768,tcp,noac,vers=3,timeo=600 Node 2:/export/msg2 /export/msg2 nfs rw,bg,hard,intr,rsize=32768,wsize=32768,tcp,noac,vers=3,timeo=600 (In case of symmetric HA)
-
Create an HA logical host name resource and bring it on-line.
/u01/app/12.1.0/grid/bin $ ./appvipcfg create -network=1 -ip=<logical IP> -vipname=<Logical IP Resource Name> -user=root
For example:
/u01/app/12.1.0/grid/bin $ ./appvipcfg create -network=1 -ip=10.0.0.3 -vipname=msg1 -user=root
-
Install the required Messaging Server packages on the primary node. Use the Messaging Server installer to install the Messaging Server packages.
For asymmetric deployments: For NFS, install Messaging Server binaries on local file systems OR NFS mounts on each node of Oracle Clusterware. Install configuration data and run time data only on NFS mounted directory. For example, on /export/msg1.
For symmetric deployments: For NFS, install Messaging Server binaries and configuration data on NFS mounts on node of Oracle Clusterware. For example, for Messaging Server instance 1 binaries and the configuration data on /export/msg1 and Messaging Server instance 2 binaries and the configuration data on /export/msg2.
-
Configure the Messaging Server.
In the initial runtime configuration, you are asked for the Fully Qualified Host Name. You must use the HA logical hostname instead of the physical hostname.
-
For legacy configuration, run the ha_ip_config script to set service.listenaddr and to configure the dispatcher.cnf and job_controller.cnf for high availability.
The script ensures that the logical IP address is set for these parameters and files, rather than the physical IP address. It also enables the watcher process (sets local.watcher.enable to 1), and the auto restart process (local.autorestart to 1).
The ha_ip_config script should only be run once on the primary node. ha_ip_configis for legacy configuration. The corresponding Unified Configuration recipe is msconfig run HAConfig.rcp
-
Create an HA Messaging Server resource and start the resource.
It is now time to create the HA Messaging Server resource. This resource is dependent upon the HA logical host name and HA disk resource if NFS mounts are not used (Eg. Cluster File system).
~ $ /u01/app/12.1.0/grid/bin/crsctl add type ocucs.ms.type -basetype cluster_resource -attr "ATTRIBUTE=INSTANCE_PATH,TYPE=string,FLAGS=READONLY|REQUIRED" ~ $ /u01/app/12.1.0/grid/bin/crsctl add resource ocucs.ms.msg1 -type ocucs.ms.type -attr " INSTANCE_PATH=<instance_path>/messaging64, AGENT_FILENAME='%CRS_HOME%/bin/scriptagent', ACTION_SCRIPT='<instance_path>/messaging64/cwha/bin/ms_actionscript.pl', ENABLED=1, AUTO_START=restore, UPTIME_THRESHOLD=10m, CHECK_INTERVAL=10, SCRIPT_TIMEOUT=300, RESTART_ATTEMPTS=2, OFFLINE_CHECK_INTERVAL=0, START_DEPENDENCIES='hard(msg1) pullup(msg1)', STOP_DEPENDENCIES='hard(intermediate:msg1)',CARDINALITY=1, FAILURE_INTERVAL=0, FAILURE_THRESHOLD=0, SERVER_POOLS=*,PLACEMENT=favored" /u01/app/12.1.0/grid/bin $ /u01/app/12.1.0/grid/bin/crsctl stop resource msg1 /u01/app/12.1.0/grid/bin $ /u01/app/12.1.0/grid/bin/crsctl start resource ocucs.ms.msg1 -n cl1
Where ocucs.ms.type is the Messaging Server resource type, ocucs.ms.msg1 is the Messaging Server resource name, and cl1 is the primary node.
For a Symmetric HA setup, you should create another Messaging Server resource on the primary node for the second Messaging Server installation.
To Unconfigure Oracle Clusterware
To unconfigure the high availability components for Oracle Clusterware.
-
Stop the Messaging server resource ocucs.ms.msg1.
/u01/app/12.1.0/grid/bin/crsctl stop resource ocucs.ms.msg1
-
Remove the Messaging Server resource ocucs.ms.msg1.
/u01/app/12.1.0/grid/bin/crsctl delete resource ocucs.ms.msg1
-
Stop the HA logical IP resource msg1.
/u01/app/12.1.0/grid/bin/crsctl stop resource msg1
-
Remove the HA logical IP resource msg1.
/u01/app/12.1.0/grid/bin/crsctl delete resource msg1
-
Remove the Messaging server resource type ocucs.ms.type.
/u01/app/12.1.0/grid/bin/crsctl delete type ocucs.ms.type
-
Uninstall the Messaging Server.
-
Repeat the steps above for each instance in the Cluster setup if more then one instance is present.
Using the useconfig Utility
The useconfig utility allows you to share a single configuration between multiple nodes in an HA environment. This utility is not meant to upgrade or update an existing configuration. Note that only useconfig command usage has been changed in this release. All the MS HA info from the previous release is still valid.
For example, if you are upgrading your first node, you will install with the Installer and then configure Messaging Server. You will then failover to the second node where you will install the Messaging Server package with the Installer, but you will not have to run the Initial Runtime Configuration Program (configure) again. Instead, you can use the useconfig utility. To enable the utility, run useconfig to point to your previous Messaging Server configuration:
MessagingServer_home/sbin/useconfig MessagingServer_home/config