3 The File Parser Processor
This chapter provides information about the Oracle Communications Network Integrity file parser processor.
About the File Parser Processor
The file parser processor is code-generated and can parse XML and structured ASCII files into Java representations, which can then be processed by other processors. For information about the ASCII reference cartridge, see "The ASCII Reference Cartridge". For information about the XML reference cartridge, see "The XML Reference Cartridge".
File parser processors can be used within discovery, import, and assimilation actions.
The file parser processor receives a collection of files as its input. The input context parameter is of type java.util.Collection<java.io.File>. The input context parameter typically comes from a file transfer processor, but it can come from any processor that outputs the proper type. A processor with a custom implementation, which outputs a java.util.Collection<java.io.File> context parameter, can supply input to the file transfer processor as well.
The file parser processor returns an iterator output context parameter. For XML files, the iterator is of type DocumentWrappers. For ASCII files, the iterator is of type RecordWrappers. The iterator is typically used as an input parameter to a For Each processor. The For Each processor returns individual document or record wrappers on each iteration of the For Each loop.
Note:
The names of the DocumentWrapper and RecordWrapper classes are derived from the name of the processor. For example, if the name of a processor that is used to parse XML documents is "XML File Parser," the name of the DocumentWrapper class is "XMLFileParserDocument." If the name of a processor that is used to parse ASCII files is "ASCII File Parser," the name of the RecordWrapper class is "ASCIIFileParserWrapper."The file parser processor uses the iterator pattern to help reduce resource usage. It ensures that only one file is open at a time, and it also helps to reduce memory usage. When parsing ASCII files, only a single record is loaded into memory at a time. When parsing XML files, only a single document is loaded into memory at a time. However, for large XML files, the memory use might still be significant.
Note:
For very large XML files, consider using a processor with a custom implementation that uses a SAX-style parser.If a processor throws an exception while using the iterator, the exception is caught by the action controller class. The action controller class calls the close method with a wasError parameter value of true, which causes the file parser processor to rename the current file to the same name but with a ".error" extension. This allows the file to be analyzed. A log file is also produced if this event occurs.
About the XML API
When configured to parse XML files, one of the main configuration parameters of the file parser processor is the name of an XML schema file that describes the documents to be parsed. From the schema file, the file parser processor generates an API to allow the interrogation and manipulation of the data in the XML files. The XML API consists of:
-
A document wrapper class, which wraps an XMLBeans document and provides:
-
A method for checking if the document is valid. When a document is parsed, it is automatically validated against the schema. The isValid method determines if the document is a valid document.
-
If the document is not valid, it might have failed to be parsed. This usually means that the XML is not well formed. The method getParseException retrieves the exception that was thrown by the XMLBeans parser, which can sometimes be useful in diagnosing the reason for the parsing failure.
-
Schemas that have multiple top-level elements defined support different document types. The getDocumentType method determines the type of the document. The method returns a DocumentType enumeration value.
-
Methods for getting the wrapped XMLBeans document. There is a getter method for each document type, supported by the schema. If the user calls the wrong document getter method, null is returned.
-
The getFile method returns the file associated with the XML wrapper document.
-
A constructor that takes a java.io.File. The constructor is used by the iterator. It is not normally used by clients of the document wrapper class.
-
-
The XMLBeans classes are the second and main part of the XML API. The schema is automatically compiled into XMLBeans. The XMLBeans provide the remainder of the XML API. XMLBeans is an open source technology. Documentation on XMLBeans and its APIs can be found at:
Example 3-1 shows sample code that demonstrates the use of the XML API generated by the file parser. This code is located in the modeler processor implementation class, as seen in the code below. This code is supplied by the cartridge developer.
Example 3-1 File Parser-generated XML API
package com.oracle.integrity.xmlexamplecartridge.discoveryprocessors.xmlmodeller;
import java.util.logging.Level;
import java.util.logging.Logger;
import
com.oracle.integrity.xmlexamplecartridge.fileparserprocessors.examplexmlparserprocessor.ExampleXMLParserProcessorDocument;
import oracle.communications.integrity.scanCartridges.sdk.ProcessorException;
import oracle.communications.integrity.scanCartridges.sdk.context.DiscoveryProcessorContext;
public class XMLModellerProcessorImpl implements XMLModellerProcessorInterface {
private static Logger logger = Logger
.getLogger(XMLModellerProcessorImpl.class.getName());
@Override
public void invoke(DiscoveryProcessorContext context,
XMLModellerProcessorRequest request) throws ProcessorException {
logger.log(Level.FINE, "Entering XMLModellerProcessorImpl");
ExampleXMLParserProcessorDocument documentWrapper = request
.getXmlDocument();
if (!documentWrapper.isValid()) {
logger.log(Level.WARNING, "Document for file '"
+ documentWrapper.getFile()
+ "' is invalid. Parse exception: "
+ documentWrapper.getParseException());
} else if (!(documentWrapper.getDocumentType() ==
ExampleXMLParserProcessorDocument.DocumentType. BulkCmConfigDataFileDocument)) {
logger.log(Level.WARNING, "Document for file '"
+ documentWrapper.getFile()
+ "' is invalid. Parse exception: "
+ documentWrapper.getParseException());
} else {
// Get the XMLBeans document class
BulkCmConfigDataFileDocument bulkCmConfigDataFileDocument = documentWrapper
.getBulkCmConfigDataFileDocument();
/*
* Additional code, not shown here, would use the XMLBeans API to
* access the information in the document.
*/
}
logger.log(Level.FINE, "Leaving XMLModellerProcessorImpl");
}
}
About ASCII Record API
When configured for structured ASCII files, the cartridge developer supplies the rules for parsing the ASCII file. Included are the rules for parsing the header, body, and trailer records, and their fields. The header and trailer rules are optional, because, in some cases, they might not be required. From the rules, the file parser processor generates a Java API, which allows easy access to the information in the ASCII files. The RecordWrapper class is that API.
The RecordWrapper class provides the following:
-
The getRecordType method returns the type of the wrapped record: Body, Header, and Trailer, for valid records, and Unknown for a record that fails to parse correctly. If a header record is not configured, the header value is not included in the RecordWrapper API. The same is true for trailer records.
-
The methods getBodyRecord, getHeaderRecord, and getTrailerRecord return the wrapped BodyRecord, HeaderRecord, and TrailerRecoder classes. The BodyRecord, HeaderRecord, and TrailerRecord classes provide getter methods for retrieving each of the included fields of the record. If a record is configured to be ignored, its corresponding getter method is not available in the RecordWrapper API. Also, if the wrong get record method is called, the method returns null. (For example, if the RecordWrapper wraps a HeaderRecord, the getBodyRecord returns null.)
-
The method getFile returns the file associated with the record.
-
The method getRecordPosition returns, the character offset of the record within its file.
The sample code in Example 3-2 demonstrates the use of the ASCII API generated by the file parser processor. This code is located in the modeler processor implementation class. This code is supplied by the cartridge developer.
Example 3-2 File Parser-generated ASCII API
package com.oracle.integrity.asciicarparser.discoveryprocessors.asciimodeller;
import java.util.logging.Level;
import java.util.logging.Logger;
import com.oracle.integrity.asciicarparser.fileparserprocessors.parseasciicars.ParseASCIICarsWrapper;
import com.oracle.integrity.asciicarparser.fileparserprocessors.parseasciicars.ParseASCIICarsWrapper.BodyRecord;
import com.oracle.integrity.asciicarparser.fileparserprocessors.parseasciicars.ParseASCIICarsWrapper.HeaderRecord;
import com.oracle.integrity.asciicarparser.fileparserprocessors.parseasciicars.ParseASCIICarsWrapper.TrailerRecord;
import oracle.communications.integrity.scanCartridges.sdk.ProcessorException;
import oracle.communications.integrity.scanCartridges.sdk.context.DiscoveryProcessorContext;
public class ASCIIModellerProcessorImpl implements
ASCIIModellerProcessorInterface {
private static Logger logger = Logger
.getLogger(ASCIIModellerProcessorImpl.class.getName());
@Override
public void invoke(DiscoveryProcessorContext context,
ASCIIModellerProcessorRequest request) throws ProcessorException {
logger.log(Level.FINE, "Entering ASCIIModellerProcessorImpl");
ParseASCIICarsWrapper carWrapper = request.getCarRecord();
if (carWrapper.getRecordType() == ParseASCIICarsWrapper.RecordType.Header) {
// For this example, our columns are "Make", "Model" and "Year".
// Here we are verify that the header of the file is correct.
if ((!headerRecord.getMakeColumn().equals("Make"))
|| (!headerRecord.getModelColumn().equals("Model"))
|| (!headerRecord.getYearColumn().equals("Year"))) {
throw new ProcessorException("Error in header columns");
}
} else if (carWrapper.getRecordType() == ParseASCIICarsWrapper.RecordType.Body) {
BodyRecord bodyRecord = carWrapper.getBodyRecord();
logger.log(Level.FINE, "Car body record: " + bodyRecord.getMake()
+ " " + bodyRecord.getModel() + " " + bodyRecord.getYear());
} else if (carWrapper.getRecordType() == ParseASCIICarsWrapper.RecordType.Trailer) {
TrailerRecord trailerRecord = carWrapper.getTrailerRecord();
// For this example, the trailer record configuration has a single
// field defined called "All" with Aggregate Extra Fields option
// selected. This returns the full record as a single field.
logger.log(Level.FINE, "Car trailer record: "
+ trailerRecord.getAll());
} else {
throw new ProcessorException("Error parsing: "
+ carWrapper.getFile());
}
logger.log(Level.FINE, "Entering ASCIIModellerProcessorImpl");
}
}
ASCII Parsing Examples
The ASCII parsing examples in this section show how the files might be configured and how the information is then displayed in the file parser processor user interface.
Example: CSV File with Header, Body, and Trailer Records
Example 3-3 shows a CSV file with header, body, and trailer records.
Example 3-3 CSV File with Header, Body, and Trailer Records
Make,Model,Year
Lamborghini,Murcielago,2003
Lamborghini,Gallardo,2007
Lamborghini,LP 640,2007
===========================
Figure 3-1 shows how the header record definition might be configured. With this definition, the API would include getMakeColumn, getModelColumn, and getYearColumn methods on the HeaderRecord, which could be used to validate that the correct type of file is being read.
Note:
Using the Aggregate Extra Fields option causes the full line of data to be returned by the getAll method.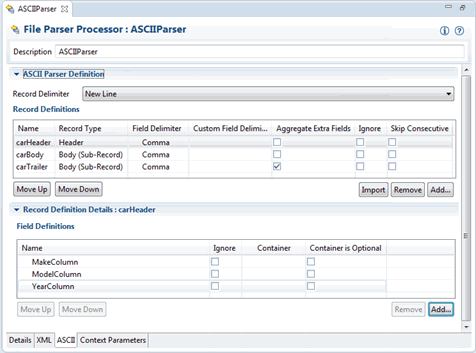
Figure 3-2 shows how the body record definition might be configured. With this definition, the API would include getMake, getModel, and getYear methods on the BodyRecord, which could be used to field values from the body record.
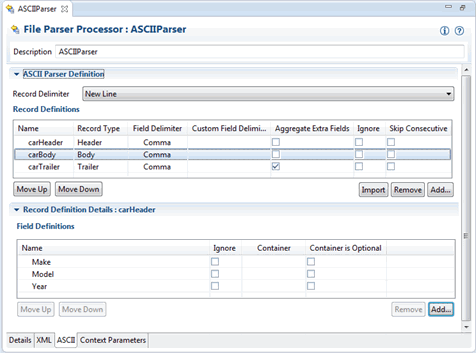
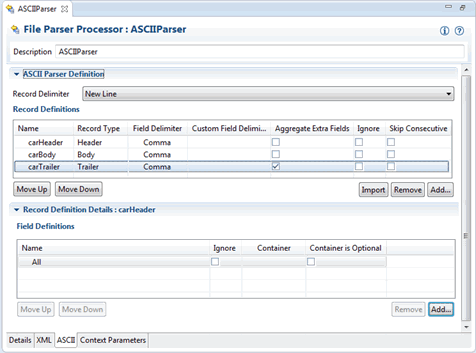
Figure 3-3 shows how the trailer record might be configured. With this definition, the API would include a getAll method on the TrailerRecord.
Example: ASCII File with Multi-line Records
Example 3-4 shows an ASCII file that has multi-line records.
Example 3-4 ASCII File with Multi-line Records
1, John
Doe,8000
2,Dave
Smith,8001
3,Jim
Yong,8002
4,Kate
May,8003
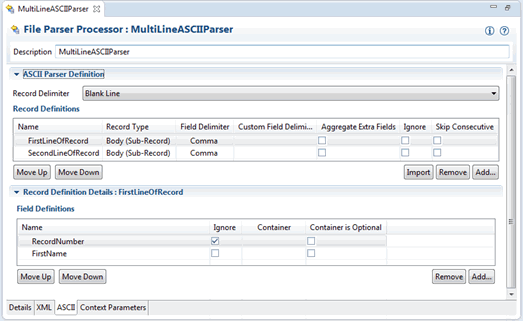
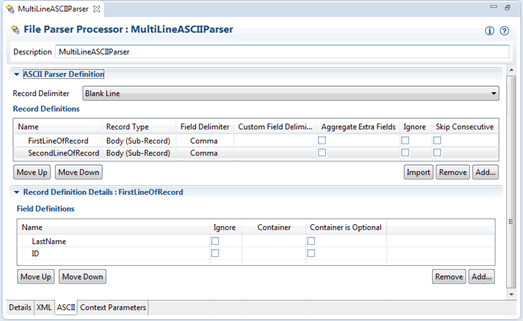
Figure 3-4 and Figure 3-5 show how the body record definitions can be configured for this record structure. In this example, the record delimiter is a blank line. The Ignore option is set on the RecordNumber field. With this definition, the API would include getFirstName, getLastName, and getID methods on the BodyRecord.