| Oracle® Big Data Applianceソフトウェア・ユーザーズ・ガイド リリース4 (4.2) E64887-02 |
|


 前 |
 次 |
この章では、Oracle Big Data SQLについて説明します。この項の内容は次のとおりです。
Oracle Big Data SQLは、Apache Hive、HDFS、Oracle NoSQL Database、Apache HBaseなどの複数のデータ・ソースに格納された大量のビッグ・データに対する問合せをサポートしています。様々なデータ・ストアのすべてのデータを、Oracleデータベースに格納されているかのようにまとめて表示および分析できます。
Oracle Big Data SQLを使用すると、完全なSQL構文を使用してHadoopクラスタに格納されたデータを問い合せることができます。手動で、または既存のアプリケーションを使用して、Hadoop内のデータに対して最も複雑なSQL SELECT文を実行し、最も重要な洞察を引き出すことができます。たとえば、Oracle Advanced Analyticsデータベース・オプションのユーザーは、Oracle Databaseに存在するデータ・マイニング・モデルをOracle Big Data Applianceに存在するデータに適用できます。
次の項に詳細を示します。
Oracle Big Data SQLは、外部表で次世代のパフォーマンス向上を実現します。外部表は、データベース外のデータの場所を識別および記述するOracle Databaseオブジェクトです。他のデータベース表に使用するのと同じSQL SELECT構文を使用して、外部表を問い合せることができます。
外部表はアクセス・ドライバを使用して、データベース外のデータを解析します。外部データのタイプごとに一意のアクセス・ドライバが必要です。Oracle Big Data SQLのこのリリースには、ビッグ・データ用の2つのアクセス・ドライバが含まれています。Apache Hiveに格納されているデータにアクセスするためのドライバ、およびHadoop Distributed File System (HDFS)ファイルに格納されているデータにアクセスするためのドライバです。
外部表への問合せによって、データがOracleデータベースの表に格納されている場合と同様に、HDFSやHive表に格納されているデータにアクセスできます。Oracle Databaseは、外部表の作成時に指定されたメタデータを使用してデータにアクセスします。
Oracle Database 12.1.0.2は、Oracle Big Data SQL用の新しい2つのアクセス・ドライバをサポートしています。
ORACLE_HIVE: Apache Hiveデータ・ソースに対するOracle外部表を作成できます。HDFSデータ・ソースに対してHive表がすでに定義されている場合、このアクセス・ドライバを使用します。ORACLE_HIVEは、Hive表が定義されている他の場所(HBaseなど)に格納されているデータにもアクセスできます。
ORACLE_HDFS: HDFSに格納されているファイルに対するOracle外部表を直接作成できます。このアクセス・ドライバはHive構文を使用してデータ・ソースを記述し、COL_1、COL_2などのデフォルトの列名を割り当てます。個別の手順としてHive表を手動で作成する必要はありません。
ORACLE_HIVEと同じ方法でHiveメタデータ・ストアからメタデータを取得するのではなく、ORACLE_HDFSアクセス・ドライバは必要な情報をすべてアクセス・パラメータから取得します。メタデータを指定するにはORACLE_HDFSアクセス・パラメータが必要です。このパラメータは、Oracle Database内の外部表定義の一部として格納されます。
Oracle Big Data SQLは、これらのアクセス・ドライバを使用して問合せのパフォーマンスを最適化します。
通常、外部表に対する問合せには全表スキャンが必要なため、外部表には従来の索引はありません。ただし、Oracle Big Data SQLはOracle Big Data Appliance上にExadataストレージ・サーバー・ソフトウェアをインストールすることで、SmartScan機能(フィルタ述語オフロードなど)をOracle外部表に拡張します。このテクノロジを使用すると、Oracle Big Data Applianceは大部分(合計で最大99パーセント)の無関係なデータを破棄し、より小さい結果セットをOracle Exadata Database Machineに返すことができます。エンド・ユーザーが問合せの結果を得るまでの時間は大幅に短縮されます。これは、Oracle Databaseに対する負荷、およびネットワーク上のトラフィックが軽減されたことの直接的な結果です。
|
関連項目: 外部表の概要、およびOracle Databaseドキュメント・ライブラリ内の詳細情報への手引きについては、『Oracle Database概要』を参照してください。 |
Oracle Big Data SQLでは、ストレージ索引が自動的に管理され、Oracle Databaseに対して透過的です。ストレージ索引には、HDFに格納されているデータに関するハード・ディスク上のデータ分散のサマリーが含まれています。ストレージ索引により、I/O操作とフラット・ファイルからOracle Databaseブロックにデータを変換するCPUコストを減らすことができます。
ストレージ索引は、HDFSに基づいた外部表またはORACLE_HDFSドライバとORACLE_HIVEドライバのいずれかを使用して作成された外部表に対してのみ使用できます。ストレージ索引は、Apache、HBase、Oracle NoSQLなどのストレージ・ハンドラを使用する外部表に対して使用することはできません。
ストレージ索引はインメモリー領域索引を収集したもので、各領域索引には最大32列のサマリーが格納されています。各分割に領域索引が1つあります。1つの領域索引に格納されているコンテンツは、その他の領域索引とは無関係です。これにより拡張性が高まり、ラッチ競合を回避できます。
各領域索引では、ストレージ索引が領域の列の最小値と最大値を管理します。最小値および最大値は、不要なI/Oの回避に使用されます。これは、I/Oフィルタリングとも呼ばれます。V$SYSSTATビューにあるストレージ索引統計別に保存されたセルのXTグラニュルI/Oバイト数は、ストレージ索引を使用して保存されたI/Oのバイト数を示したものです。
|
関連項目: "V$SYSSTAT"ビューの詳細は、『Oracle® Databaseリファレンス』を参照してください |
次の比較を使用する問合せはストレージ索引によって改善されます。
等価(=)
不等価(<、!=または>)
以下(<=)
以上(>=)
IS NULL
IS NOT NULL
Oracle Big Data SQLサービスでは、領域内の列の最大値より大きいか、最小値より小さいという比較述語が指定された問合せを受け取った後に、ストレージ索引は自動的に作成されます。
|
注意:
|
例6-1 ストレージ索引を使用したディスクI/Oの回避
次の図に、表および領域索引を示します。表内の値の範囲は1から8です。一方の領域索引には最小値として1、最大値として5が格納されています。もう一方の領域索引には、最小値として3、最大値として8が格納されています。
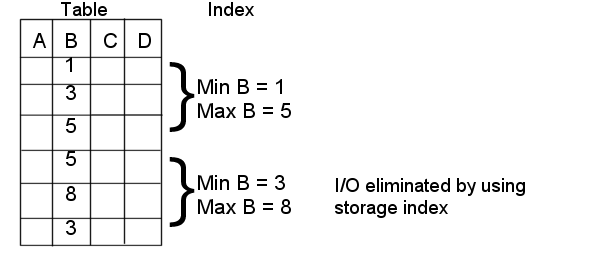
SELECT * FROM TABLE WHERE B < 2などの問合せの場合、最初の行セットのみが一致します。2番目の行セットの最小値と最大値は問合せのWHERE句と一致しないため、ディスクI/Oが回避されます。
例6-2 ストレージ索引による結合パフォーマンスの向上
ストレージ索引を使用すると、表の結合で不要なI/O操作をスキップできます。たとえば、次の問合せでは、I/O操作を実行し、ファクト表の最初のブロックにのみブルーム・フィルタを適用しています。
SELECT count(*) from fact, dim where fact.m=dim.m and dim.name="Hard drive"
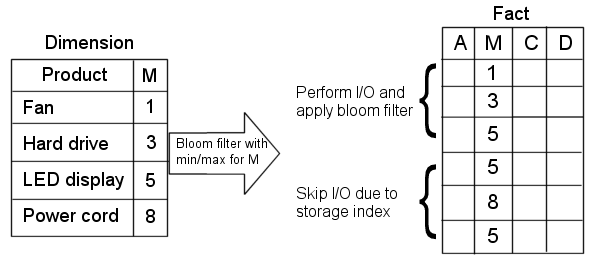
ファクト表の2番目のブロックに対するI/Oは、最小値/最大値の範囲(5,8)がブルーム・フィルタに存在しないため、ストレージ索引によって完全に回避されます。
Oracle Big Data Applianceには、Oracle Big Data Appliance上のCDHクラスタに格納されているデータを保護するための多数のセキュリティ機能がすでに用意されています。
Kerberos認証: ユーザーおよびクライアント・ソフトウェアは、クラスタにアクセスする前に資格証明を提供する必要があります。
Apacheセキュリティ認証: データおよびメタデータにファイングレインのロールベース認証を提供します。
オンディスク暗号化: ディスクにあるデータを保護します。通常のユーザー・アクセスでは、データは自動的に復号化されます。
Oracle Audit Vault and Database Firewall監視: Oracle Big Data Appliance上のAudit Vaultプラグインは、MapReduce、HDFSおよびOozieサービスから監査およびロギング・データを収集します。そうすると、Audit Vault Serverを使用してOracle Big Data Appliance上でこれらのサービスを監視できるようになります。
Oracle Big Data SQLは、このリストに様々なOracle Databaseセキュリティ機能を追加します。リレーショナル・データに適用するHadoopデータに同じセキュリティ・ポリシーおよびルールを適用できます。
Oracle Big Data SQLは、Oracle Big Data Applianceに接続されたOracle Exadata Database Machineでのみ使用できます。Oracle Big Data SQLソフトウェアを両方のシステムにインストールする必要があります。
次のトピックでは、Oracle Big Data SQLをインストールする方法について説明します。
Oracle Exadata Database Machineは次の要件に準拠している必要があります。
計算サーバーでは、Oracle DatabaseおよびOracle Enterprise Manager Grid Control 12.1.0.2.1以降を実行しています。
ストレージ・サーバーでは、Exadataストレージ・サーバー・ソフトウェア12.1.1.1または12.1.1.0を実行しています。
Oracle Exadata Database Machineは、Oracle Big Data Applianceと同じインフィニバンド・サブネットで構成されています。
Oracle Exadata Database Machineは、インフィニバンド・ネットワークによってOracle Big Data Applianceに接続されています。
Oracle Big Data ApplianceとOracle Exadata Database MachineにOracle Big Data SQLソフトウェアをインストールするには、次の手順を実行します。
12.1.0.2.1のOracle Databaseの個別パッチをダウンロードします。
|
注意: Bundle Patch 6以上を使用している場合、追加のOracle Databaseの個別パッチは必要ありません。 |
すべてのOracle Exadata Database Machine計算サーバーで、パッチをインストールします。
グリッド・インフラストラクチャ・ホーム
Oracle Databaseホーム
Bundle PatchのDatapatch部分を忘れずに実行してください。パッチをインストールする順を追った手順は、パッチのREADMEを参照してください。
Oracle Big Data Applianceで、ソフトウェアをインストールするか、最新のバージョンにアップグレードします。詳細は、『Oracle Big Data Applianceオーナーズ・ガイド』を参照してください。
Oracle Big Data Appliance構成生成ユーティリティを使用する場合、インストール・オプションとしてOracle Big Data SQLを選択できます。詳細は、『Oracle Big Data Applianceオーナーズ・ガイド』を参照してください。
Oracle Big Data SQLがインストール中に有効でない場合、bdacliユーティリティを使用します。
# bdacli enable big_data_sql
詳細は、『Oracle Big Data Applianceオーナーズ・ガイド』を参照してください。
Oracle Exadata Database Machineで、インストール後スクリプトを実行します。
「Oracle Big Data SQLのインストール後スクリプトの実行」を参照してください。
Cloudera Managerを使用すると、Oracle Big Data SQLが稼働していることを確認できます。「Oracle Big Data SQLの管理」を参照してください。
Oracle Big Data SQLのインストール後スクリプトを実行するには、次の手順を実行します。
bds-exa-install.shインストール・スクリプトを、MammothがインストールされているOracle Big Data Applianceノードからコピーします。一般に、Oracle Exadataに対するクラスタの最初のノードです。任意の場所にコピーできます。wget、curlなどのコマンドを使用できます。この例では、bda1node07からスクリプトをコピーします。
wget http://bda1node07/bda/bds-exa-install.sh
Oracleインストールの所有者の名前を確認し、Oracleユーザーとして実行可能ファイルを設定します。通常は、oracleユーザーがインストールを所有します。次のコマンドを使用します。
$ ls -l bds-exa-install.sh $ chown oracle:oinstall bds-exa-install.sh $ chmod +x bds-exa-install.sh
次の環境変数を適切に設定します。
$ORACLE_HOME to <database home> $ORACLE_SID to <correct db SID> $GI_HOME to <correct grid home>
|
注意: この手順で説明するように、$GI_HOMEを設定するかわりに、手順5で説明するように、グリッド・ホームとインストール・スクリプトを設定できます。 |
TNS_ADMINが、直接listener.oraが実行されている場所を指していることを確認します。リスナーがデフォルトの場所のTNS_ADMIN、$ORACLE HOME/network/adminにある場合、TNS_ADMINを定義する必要はありません。リスナーがデフォルトの場所にない場合は、コマンドを使用して、正しくTNS_ADMINがこれを指すように設定する必要があります。
export TNS_ADMIN=<path to listener.ora>
ORACLE_SIDが大文字の場合、この手順のみを実行します。それ以外の場合は、次の手順に進みます。これは、小文字の場合にのみ、インストール・スクリプトがCRSデータベース・リソースをORACLE_SIDから取得するためです。大文字の場合、次の手順を実行してSIDをスクリプトに手動で渡します。
次のコマンドを実行して、すべてのリソースをリストします。
$ crsctl stat res -t
出力ノートから、ora.<dbresource>.dbリソース名を選択します。
次のコマンドを実行して、正しいora.<dbresource>.dbリソース名が返されているかどうか確認します。
$ ./crsctl stat res ora.<dbresource>.db
出力には、次のようにリソース名が表示されます。
NAME=ora.<dbresource>.db TYPE=ora.database.type TARGET=ONLINE , ONLINE STATE=ONLINE on <name01>, ONLINE on <name02>
次のようにして、--db-name=<dbresource>をインストール・スクリプトへの追加引数として指定します。
./bds-exa-install.sh --db-name=<dbresource>
また、手順3で説明するように、次のようにして上記のコマンドを使用して$GI_HOMEを設定するかわりにグリッド・ホームを設定することができます。
./bds-exa-install.sh --db-name=<dbresource> --grid-home=<grid home>
|
注意: この手順を実行済の場合、次の手順をスキップできます。 |
oracleとしてスクリプトを実行します。
./bds-exa-install.sh
スクリプトからoracleユーザーとして次に進むように求められた場合、別のセッションではスクリプトをbds-rootとして実行する必要があります。たとえば、次のように実行します。
$ ./bda-exa-install.sh: bds-exa-install: root shell script : /u01/app/oracle/product/12.1.0.2/dbhome_1/install/bds-root-<cluster-name>-setup.sh please run as root: /u01/app/oracle/product/12.1.0.2/dbhome_1/install/bds-root-<rack-name>-clu-setup.sh
出力例を次に示します。
bds-exa-install: setup script started at: Mon May 4 16:56:48 PDT 2015 bds-exa-install: version : 1.1.09 bds-exa-install: bda cluster name : <cluster-name> bds-exa-install: bda web server : bdanode01.example.com bds-exa-install: cloudera manager url : bdanode03.example.com:7180 bds-exa-install: hive version : hive-0.13.1-cdh5.3.0 bds-exa-install: hadoop versi : hadoop-2.5.0-cdh5.3.0 bds-exa-install: bds ve : Bds 1.1 bds-exa-install: bds install date : 05/04/2015 16:34 PDT bds-exa-install: bd_cell version : bd_cell-12.1.2.0.100_LINUX.X64_150225.1100-1.x86_64 bds-exa-install: action : setup bds-exa-install: crs : useCrs bds-exa-install: db resource : <db_resource> bds-exa-install: database type : RAC bds-exa-install: cardinality : 8 ************************ README--README--README--README--README--README--README--README--README--README ************************ Detected a multi instance database (<db_resource>). Run this script on all instances. Please read all option of this program (bds-exa-install --help) This script does extra work on the last instance. The last instance is determined as the instance with the largest instance_id number. press <return> bds-exa-install: root shell script : /u01/app/oracle/product/12.1.0.2/dbhome_1/install/bds-root-<cluster-name>-setup.sh please run as root: /u01/app/oracle/product/12.1.0.2/dbhome_1/install/bds-root-<cluster-name>-setup.sh waiting for root script to complete, press <enter> to continue checking.. q<enter> to quit bds-exa-install: root script seem to have succeeded, continuing with setup bds mkdir: created directory `/u01/app/oracle/product/12.1.0.2/dbhome_1/bigdatasql' mkdir: created directory `default_dir' mkdir: created directory `bigdata_config' mkdir: created directory `log' mkdir: created directory `jlib' bds-exa-install: working directory : /u01/app/oracle/product/12.1.0.2/dbhome_1/bigdatasql/jlib bds-exa-install: removing old oracle bds jars if any bds-exa-install: downloading oracle bds jars bds-exa-install: installing oracle bds jars bds-exa-install: working directory : /u01/app/oracle/product/12.1.0.2/dbhome_1/bigdatasql bds-exa-install: downloading : hadoop-2.5.0-cdh5.3.0.tar.gz ... bds-exa-install: creating bds property files bds-exa-install: working directory : /u01/app/oracle/product/12.1.0.2/dbhome_1/bigdatasql/bigdata_config bds-exa-install: created bigdata.properties bds-exa-install: created bigdata-log4j.properties ... catcon: See /u01/app/oracle/product/12.1.0.2/dbhome_1/install/bdscatcon*.log files for output generated by scripts catcon: See /u01/app/oracle/product/12.1.0.2/dbhome_1/install/bdscatcon_*.lst files for spool files, if any catcon.pl: completed successfully bds-exa-install: granted default and cluster directories to public! bds-exa-install: no mta will be setup, dropping db links for bda01clu ... catcon: See bdscatcon-<##>_*.lst files for spool files, if any catcon.pl: completed successfully bds-exa-install: setup script completed all steps
詳細は、「bds-exa-installスクリプトの実行」を参照してください。
複数のインスタンス・データベースを使用している場合、データベース・インスタンスごとに手順6を繰り返します。
スクリプトが終了すると、Oracle Big Data SQLを含む次の項目が使用できるようになり、データベース・インスタンス上で実行されます。ただし、イベントによってOracle Big Data SQLエージェントが停止した場合、再起動する必要があります。「Big Data SQLエージェントの起動および停止」を参照してください。
Oracle Big Data SQLのjarのディレクトリおよび構成、環境ファイルおよびプロパティ・ファイル。
Database dba_directories。
Database dblinks。
Databaseビッグ・ファイルspfileパラメータ。
たとえば、次のようにして、dba_directoriesをSQLプロンプトから確認できます。
SQL> select * from dba_directories where directory_name like '%BIGDATA%';
bds-exa-installスクリプトは、Oracleホーム・ディレクトリの所有者によって実行されるカスタム・インストール・スクリプトを生成します。そのセカンダリ・スクリプトは、Oracle Big Data SQLで必要なすべてのファイルを$ORACLE_HOME/bigdatasqlディレクトリにインストールします。Oracle NoSQL Databaseのサポートには、クライアント・ライブラリ(kvclient.jar)をインストールします。また、データベース・ディレクトリ・オブジェクト、およびマルチスレッドのOracle Big Data SQLエージェントのデータベース・リンクも作成します。
--generate-onlyオプションを使用してセカンダリ・スクリプトを作成し、$ORACLE_HOMEの所有者として実行することもできます。
次にbds-exa-installの構文を示します。
./bds-exa-install.sh [option]
オプション名の前には2つのハイフン(--)が付いています。
セカンダリ・スクリプトを生成するだけで実行しない場合は、trueに設定します。1つのステップでスクリプトを生成して実行する場合は、falseに設定します(デフォルト)。
Exadataでインストール・スクリプトを実行する場合に問題が発生したら、次の手順を実行してOracleサポートでSRを開き詳細を確認します。
次のようにして、デバッグ内のスクリプトを実行してデバッグ出力を収集します。
$ ./bds-exa-install.sh --db-name=<dbresource> --grid-home=<grid home> --root-script=false --debug OR $ ./bds-exa-install.sh --root-script=false --debug
次のようにして、Oracle Databaseバージョンを収集します。
RDBMS-RAC Homeからopatch lsinventoryの結果を収集します。
Grid Homeからopatch lsinventoryの結果を収集します
次のSQL文の結果により、Datapatchが設定されていることを確認します。
SQL> select patch_id, patch_uid, version, bundle_series, bundle_id, action, status from dba_registry_sqlpatch;
次の環境変数から、情報を収集します。
$ORACLE_HOME
$ORACLE_SID
$GI_HOME
$TNS_ADMIN
lsnrctl statusコマンドを実行します。
Apache Hive内のデータのOracle外部表を簡単に作成できます。Oracle Databaseはメタデータを使用できるため、Hive表に関する情報をデータ・ディクショナリに問い合せることができます。次に、PL/SQL関数を使用して、基本的なSQL CREATE TABLE EXTERNAL ORGANIZATION文を生成できます。実行前に文を変更して、外部表をカスタマイズできます。
DBMS_HADOOP PL/SQLパッケージには、CREATE_EXTDDL_FOR_HIVEという名前の関数が含まれています。データ・ディクショナリ言語(DDL)を返して、Hive表にアクセスするための外部表を作成します。この関数では、Hive表に関する基本情報を指定する必要があります。
Hadoopクラスタの名前
Hiveデータベースの名前
Hive表の名前
Hive表がパーティション化されているかどうか
ALL_HIVE_TABLESデータ・ディクショナリ・ビューを問い合せることで、この情報を取得できます。Oracle DatabaseからアクセスできるすべてのHive表に関する情報が表示されます。
この例では、現在のユーザーにデフォルト・データベース内のRATINGS_HIVE_TABLEという名前のパーティション化されていないHive表へのアクセス権があることを示します。JDOEという名前のユーザーは所有者です。
SQL> SELECT cluster_id, database_name, owner, table_name, partitioned FROM all_hive_tables; CLUSTER_ID DATABASE_NAME OWNER TABLE_NAME PARTITIONED ------------ -------------- -------- ------------------ -------------- hadoop1 default jdoe ratings_hive_table UN-PARTITIONED
データ・ディクショナリからの情報とともに、DBMS_HADOOPのCREATE_EXTDDL_FOR_HIVE関数を使用できます。この例では、現在のスキーマ内のRATINGS_DB_TABLEのデータベース表名を指定します。関数は、DDLoutという名前のローカル変数でCREATE TABLEコマンドのテキストを返しますが、実行はしません。
DECLARE
DDLout VARCHAR2(4000);
BEGIN
dbms_hadoop.create_extddl_for_hive(
CLUSTER_ID=>'hadoop1',
DB_NAME=>'default',
HIVE_TABLE_NAME=>'ratings_hive_table',
HIVE_PARTITION=>FALSE,
TABLE_NAME=>'ratings_db_table',
PERFORM_DDL=>FALSE,
TEXT_OF_DDL=>DDLout
);
dbms_output.put_line(DDLout);
END;
/
このプロシージャを実行すると、PUT_LINE関数はCREATE TABLEコマンドを表示します。
CREATE TABLE ratings_db_table (
c0 VARCHAR2(4000),
c1 VARCHAR2(4000),
c2 VARCHAR2(4000),
c3 VARCHAR2(4000),
c4 VARCHAR2(4000),
c5 VARCHAR2(4000),
c6 VARCHAR2(4000),
c7 VARCHAR2(4000))
ORGANIZATION EXTERNAL
(TYPE ORACLE_HIVE DEFAULT DIRECTORY DEFAULT_DIR
ACCESS PARAMETERS
(
com.oracle.bigdata.cluster=hadoop1
com.oracle.bigdata.tablename=default.ratings_hive_table
)
) PARALLEL 2 REJECT LIMIT UNLIMITED
この情報をSQLスクリプトで取得し、アクセス・パラメータを使用して、実行前に必要に応じてOracle表名、列名およびデータ型を変更できます。アクセス・パラメータを使用して日付書式マスクを指定することもできます。
ALL_HIVE_COLUMNSビューには、デフォルトの列名およびデータ型の導出方法が表示されます。この例では、Hive列の名前がC0からC7であり、Hive STRINGデータ型がVARCHAR2(4000)にマップされることを示します。
SQL> SELECT table_name, column_name, hive_column_type, oracle_column_type FROM all_hive_columns; TABLE_NAME COLUMN_NAME HIVE_COLUMN_TYPE ORACLE_COLUMN_TYPE --------------------- ------------ ---------------- ------------------ ratings_hive_table c0 string VARCHAR2(4000) ratings_hive_table c1 string VARCHAR2(4000) ratings_hive_table c2 string VARCHAR2(4000) ratings_hive_table c3 string VARCHAR2(4000) ratings_hive_table c4 string VARCHAR2(4000) ratings_hive_table c5 string VARCHAR2(4000) ratings_hive_table c6 string VARCHAR2(4000) ratings_hive_table c7 string VARCHAR2(4000) 8 rows selected.
DBMS_HADOOPを使用するか、CREATE TABLE文を最初から作成するかを選択できます。どちらの場合にも、ORACLE_HIVEのデフォルトの動作を変更するように一部のアクセス・パラメータを設定する必要があります。
次の文は、HiveデータにアクセスするためにORDERという名前の外部表を作成します。
CREATE TABLE order (cust_num VARCHAR2(10),
order_num VARCHAR2(20),
description VARCHAR2(100),
order_total NUMBER (8,2))
ORGANIZATION EXTERNAL (TYPE oracle_hive);
この文ではアクセス・パラメータが設定されていないため、ORACLE_HIVEアクセス・ドライバはデフォルト設定を使用して次の処理を実行します。
デフォルトのHadoopクラスタに接続します。
orderという名前のHive表を使用します。Hive表にCUST_NUM、ORDER_NUM、DESCRIPTIONおよびORDER_TOTALという名前のフィールドがない場合、エラーが発生します。
CUST_NUM値が10バイトを超えるなど、変換エラーが発生した場合は、フィールドの値をNULLに設定します。
外部表の句のACCESS PARAMETERS句でプロパティを設定できます。これにより、アクセス・ドライバのデフォルトの動作が上書きされます。次の句には、com.oracle.bigdata.overflowアクセス・パラメータが含まれています。前述の例でこの句を使用する場合、エラーをスローするのではなく、100文字を超えるDESCRIPTION列のデータが切り捨てられます。
(TYPE oracle_hive
ACCESS PARAMETERS (
com.oracle.bigdata.overflow={"action:"truncate", "col":"DESCRIPTION""} ))
次の例では、ORACLE_HIVEの使用可能なパラメータの大部分を設定します。
CREATE TABLE order (cust_num VARCHAR2(10),
order_num VARCHAR2(20),
order_date DATE,
item_cnt NUMBER,
description VARCHAR2(100),
order_total (NUMBER(8,2)) ORGANIZATION EXTERNAL
(TYPE oracle_hive
ACCESS PARAMETERS (
com.oracle.bigdata.tablename: order_db.order_summary
com.oracle.bigdata.colmap: {"col":"ITEM_CNT", \
"field":"order_line_item_count"}
com.oracle.bigdata.overflow: {"action":"TRUNCATE", \
"col":"DESCRIPTION"}
com.oracle.bigdata.erroropt: [{"action":"replace", \
"value":"INVALID_NUM" , \
"col":["CUST_NUM","ORDER_NUM"]} ,\
{"action":"reject", \
"col":"ORDER_TOTAL}
))
これらのパラメータは、ORACLE_HIVEアクセス・ドライバがデータを特定してエラー条件を処理する方法で、次の変更を行います。
com.oracle.bigdata.tablename: 表名の違いを処理します。ORACLE_HIVEは、ORDER.DBデータベース内のORDER_SUMMARYという名前のHive表を調べます。
com.oracle.bigdata.colmap: 列名の違いを処理します。HiveのORDER_LINE_ITEM_COUNTフィールドはOracleのITEM_CNT列にマップされます。
com.oracle.bigdata.overflow: 文字列データを切り捨てます。DESCRIPTION列の100文字を超える値は切り捨てられます。
com.oracle.bigdata.erroropt: 不正なデータを置換します。CUST_NUMまたはORDER_NUMのデータのエラーにより、値がINVALID_NUMに設定されます。
ORACLE_HIVEアクセス・ドライバを使用して、Oracle NoSQL Databaseに格納されているデータにアクセスできます。ただし、KVStoreにアクセスするHive外部表を最初に作成する必要があります。次に、「HiveデータのOracle外部表の作成」に示されているプロセスのように、それに対してOracle Databaseの外部表を作成できます。
この項の内容は次のとおりです。
Oracle NoSQL Databaseのデータにアクセス可能にするには、Oracle NoSQL表に対してHive外部表を作成します。Oracle Big Data SQLは、HiveによるOracle NoSQL Database表形式の読取りが可能なoracle.kv.hadoop.hive.table.TableStorageHandlerという名前のストレージ・ハンドラを提供します。
Oracle NoSQL表に対するHive外部表のHive CREATE TABLE文の基本的な構文は次のとおりです。
CREATE EXTERNAL TABLE tablename colname coltype[, colname coltype,...] STORED BY 'oracle.kv.hadoop.hive.table.TableStorageHandler' TBLPROPERTIES ( "oracle.kv.kvstore" = "database", "oracle.kv.hosts" = "nosql_node1:port[, nosql_node2:port...]", "oracle.kv.hadoop.hosts" = "hadoop_node1[,hadoop_node2...]", "oracle.kv.tableName" = "table_name");
Hive CREATE TABLEパラメータ
作成されるHive外部表の名前。
この表名はOracle Databaseで発行されるSQL問合せで使用されるため、ユーザーに適した名前を選択してください。Oracle Databaseで作成する外部表の名前は、このHive表の名前と同じである必要があります。
表、列およびフィールド名は、Oracle NoSQL Database、Apache HiveおよびOracle Databaseで大文字と小文字を区別しません。
Hive外部表の列の名前およびデータ型。Oracle NoSQL DatabaseとHive間のデータ型マッピングは、表6-1を参照してください。
Hive CREATE TABLE TBLPROPERTIES句
KVStoreの名前。大文字、小文字および数字のみが名前で有効です。
Oracle NoSQL Databaseクラスタのホスト名およびポート番号のカンマ区切りリスト。各文字列では形式hostname:portを使用します。ホストで障害が発生した場合の冗長性を提供するには、複数の名前を入力します。
Oracle Big Data SQLが有効であるOracle Big Data ApplianceのCDHクラスタのすべてのホスト名のカンマ区切りリスト。
このHive外部表のデータを格納するOracle NoSQL Databaseの表の名前。
|
関連項目: 次のApache Hive LanguageManual DDL
|
次の構文を使用して、Hive外部表を介してOracle NoSQLデータにアクセスできるOracle Databaseの外部表を作成します。
CREATE TABLE tablename(colname colType[,colname colType...]) ORGANIZATION EXTERNAL (TYPE ORACLE_HIVE DEFAULT DIRECTORY directory ACCESS PARAMETERS (access parameters) ) REJECT LIMIT UNLIMITED;
この構文では、列名およびデータ型を識別します。この構文の詳細は、「SQL CREATE TABLE文について」を参照してください。
Oracle Big Data SQLがOracle NoSQL Databaseからデータを取得する場合、データが次の別のデータ型に2回変換されます。
データがHive外部表の列に読み込まれる場合にHiveデータ型。
データがOracle Database外部表の列に読み込まれる場合にOracleデータ型。
表6-1に、サポートされているOracle NoSQLデータ型およびHiveとOracle Databaseデータ型のマッピングを示します。Oracle Big Data SQLは、Oracle NoSQL複合データ型の配列、マップおよびレコードをサポートしません。
表6-1 Oracle NoSQL Databaseのデータ型マッピング
| Oracle NoSQL Databaseデータ型 | Apache Hiveデータ型 | Oracle Databaseデータ型 |
|---|---|---|
|
文字列 |
STRING |
VARCHAR2 |
|
Boolean |
BOOLEAN |
NUMBER脚注1 |
|
Integer |
INT |
NUMBER |
|
Long |
INT |
NUMBER |
|
Double |
DOUBLE |
NUMBER(p,s) |
|
Float |
FLOAT |
NUMBER(p,s) |
脚注1 0はfalse、1はtrueです
この例は、Oracle NoSQL Databaseソフトウェアで用意されているサンプル・データを使用します。
次のファイルがexamples/hadoop/tableディレクトリにあることを確認します。
create_vehicle_table.kvs CountTableRows.java LoadVehicleTable.java
この例は、bda1node07という名前のOracle Big Data Applianceサーバーで実行され、BDAKVという名前のKVStoreを使用します。
Oracle NoSQL Databaseのサンプルの表を作成して移入するには、次の手順を実行します。
Oracle Big Data ApplianceのOracle NoSQL Databaseノードの接続を開きます。
vehicleTableという名前の表を作成します。次の例は、loadコマンドを使用して、create_vehicle_table.kvsのコマンドを実行します。
$ cd NOSQL_HOME
$ java -jar lib/kvcli.jar -host bda1node07 -port 5000 \
load -file examples/hadoop/table/create_vehicle_table.kvs
LoadVehicleTable.javaをコンパイルします。
$ javac -cp examples:lib/kvclient.jar examples/hadoop/table/LoadVehicleTable.java
LoadVehicleTableクラスを実行して、表に移入します。
$ java -cp examples:lib/kvclient.jar hadoop.table.LoadVehicleTable -host bda1node07 -port 5000 -store BDAKV
{"type":"auto","make":"Chrysler","model":"PTCruiser","class":"4WheelDrive","colo
r":"white","price":20743.240234375,"count":30}
{"type":"suv","make":"Ford","model":"Escape","class":"FrontWheelDrive","color":"
.
.
.
10 new records added
vehicleTable表には、次のフィールドが含まれています。
| フィールド名 | データ型 |
|---|---|
| type | STRING |
| Make | STRING |
| model | STRING |
| クラス | STRING |
| color | STRING |
| price | DOUBLE |
| count | INTEGER |
次の例では、BDAKV KVStoreのvehicleTableにアクセスするVEHICLESという名前のHive表を作成します。Oracle Big Data Applianceは、最初の6つのサーバー(bda1node01からbda1node06)のCDHクラスタと次の3つのサーバー(bda1node07からbda1node09)のOracle NoSQL Databaseクラスタで構成されます。
CREATE EXTERNAL TABLE IF NOT EXISTS vehicles
(type STRING,
make STRING,
model STRING,
class STRING,
color STRING,
price DOUBLE,
count INT)
COMMENT 'Accesses data in vehicleTable in the BDAKV KVStore'
STORED BY 'oracle.kv.hadoop.hive.table.TableStorageHandler'
TBLPROPERTIES
("oracle.kv.kvstore" = "BDAKV",
"oracle.kv.hosts" = "bda1node07.example.com:5000,bda1node08.example.com:5000",
"oracle.kv.hadoop.hosts" = "bda1node01.example.com,bda1node02.example.com,bda1node03.example.com,bda1node04.example.com,bda1node05.example.com,bda1node06.example.com",
"oracle.kv.tableName" = "vehicleTable");
DESCRIBEコマンドは、VEHICLES表の列をリストします。
hive> DESCRIBE vehicles;
OK
type string from deserializer
make string from deserializer
model string from deserializer
class string from deserializer
color string from deserializer
price double from deserializer
count int from deserializer
Hive VEHICLES表に対する問合せは、Oracle NoSQL vehicleTable表のデータを返します。
hive> SELECT make, model, class FROM vehicletable WHERE type='truck' AND color='red' ORDER BY make, model; Total MapReduce jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 . . . Chrysler Ram1500 RearWheelDrive Chrysler Ram2500 FrontWheelDrive Ford F150 FrontWheelDrive Ford F250 RearWheelDrive Ford F250 AllWheelDrive Ford F350 RearWheelDrive GM Sierra AllWheelDrive GM Silverado1500 RearWheelDrive GM Silverado1500 AllWheelDrive
Hive表を作成した後、メタデータをOracle Database静的データ・ディクショナリ・ビューで使用できます。次のSQL SELECT文は、前のトピックで作成されたHive表の情報を返します。
SQL> SELECT table_name, column_name, hive_column_type FROM all_hive_columns WHERE table_name='vehicles'; TABLE_NAME COLUMN_NAME HIVE_COLUMN_TYPE --------------- ------------ ---------------- vehicles type string vehicles make string vehicles model string vehicles class string vehicles color string vehicles price double vehicles count int
次のSQL CREATE TABLE文は、ORACLE_HIVEアクセス・ドライバを使用して、Hive VEHICLES表に対するVEHICLESという名前の外部表を生成します。Oracle Databaseの表の名前は、Hiveの表の名前と同じである必要があります。ただし、Oracle NoSQL DatabaseおよびOracle Databaseは、大文字と小文字を区別しません。
CREATE TABLE vehicles
(type VARCHAR2(10), make VARCHAR2(12), model VARCHAR2(20),
class VARCHAR2(40), color VARCHAR2(20), price NUMBER(8,2),
count NUMBER)
ORGANIZATION EXTERNAL
(TYPE ORACLE_HIVE DEFAULT DIRECTORY DEFAULT_DIR
ACCESS PARAMETERS
(com.oracle.bigdata.debug=true com.oracle.bigdata.log.opt=normal))
REJECT LIMIT UNLIMITED;
このSQL SELECT文は、Oracle NoSQL DatabaseのvehicleTableから赤いトラックのすべての行を取得します。
SQL> SELECT make, model, class FROM vehicles WHERE type='truck' AND color='red' ORDER BY make, model; MAKE MODEL CLASS ------------ -------------------- --------------------- Chrysler Ram1500 RearWheelDrive Chrysler Ram2500 FrontWheelDrive Ford F150 FrontWheelDrive Ford F250 AllWheelDrive Ford F250 RearWheelDrive Ford F350 RearWheelDrive GM Sierra AllWheelDrive GM Silverado1500 RearWheelDrive GM Silverado1500 4WheelDrive GM Silverado1500 AllWheelDrive
ORACLE_HIVEアクセス・ドライバを使用して、Apache HBaseに格納されているデータにアクセスすることもできます。ただし、最初にHBase表にアクセスするHive外部表を作成する必要があります。次に、それに対してOracle Databaseの外部表を作成できます。基本的な手順は、「Oracle NoSQL DatabaseのOracle外部表の作成」に示されている手順と同じです。
HBase表のデータにアクセス可能にするには、それに対してHive外部表を作成します。Apacheは、ストレージ・ハンドラおよびHiveによるHBase表形式の読取りが可能なSerDeを提供します。
HBase表に対する外部表のHive CREATE TABLE文の基本的な構文は、次のとおりです。
CREATE EXTERNAL TABLE tablename colname coltype[, colname coltype,...] ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe' STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ( 'serialization.format'='1', 'hbase.columns.mapping'=':key,value:key,value:
|
関連項目:
|
次の構文を使用して、Hive外部表を介してHBaseデータにアクセスできるOracle Databaseの外部表を作成します。
CREATE TABLE tablename(colname colType[,colname colType...]) ORGANIZATION EXTERNAL (TYPE ORACLE_HIVE DEFAULT DIRECTORY DEFAULT_DIR ACCESS PARAMETERS (access parameters) ) REJECT LIMIT UNLIMITED;
この構文では、列名およびデータ型を識別します。アクセス・パラメータを指定するには、「SQL CREATE TABLE文について」を参照してください。
ORACLE_HDFSアクセス・ドライバを使用すると、HDFSに格納されている様々なタイプのデータにアクセスできますが、HDFSにはHiveメタデータはありません。テキスト・データのレコード形式を定義することも、特定のデータ形式のSerDeを指定することもできます。
HDFSファイルの外部表を手動で作成し、データを特定するためにアクセス・ドライバが必要とするすべての情報を提供して、レコードおよびフィールドを解析する必要があります。CREATE TABLE ORGANIZATION EXTERNAL文のいくつかの例を次に示します。
次の文は、ORDERという名前の文を作成して、HDFSの/usr/cust/summaryディレクトリに格納されているすべてのファイル内のデータにアクセスします。
CREATE TABLE ORDER (cust_num VARCHAR2(10),
order_num VARCHAR2(20),
order_total (NUMBER 8,2))
ORGANIZATION EXTERNAL (TYPE oracle_hdfs)
LOCATION ("hdfs:/usr/cust/summary/*");
この文ではアクセス・パラメータが設定されていないため、ORACLE_HDFSアクセス・ドライバはデフォルト設定を使用して次の処理を実行します。
デフォルトのHadoopクラスタに接続します。
ファイルをデリミタ付きテキスト、フィールドをSTRINGタイプとして読み取ります。
HDFSファイル内のフィールドの数は、列の数と一致すると仮定します(この例では3)。
CUST_NUMデータが第1フィールド、ORDER_NUMデータが第2フィールド、ORDER_TOTALデータが第3フィールドになるように、フィールドは列と同じ順序であることを前提とします。
値によってデータ変換エラーが発生するレコードを拒否します。CUST_NUMの値が10文字を超える場合、ORDER_NUMの値が20文字を超える場合、またはORDER_TOTALの値がNUMBERに変換できない場合です。
ORACLE_HDFSでも、ORACLE_HIVEと同じアクセス・パラメータの多くを使用できます。
次の例は、「ORACLE_HIVEのデフォルト設定の上書き」に示した例に相当します。外部表は、HDFSに格納されているデリミタ付きテキスト・ファイルにアクセスします。
CREATE TABLE order (cust_num VARCHAR2(10),
order_num VARCHAR2(20),
order_date DATE,
item_cnt NUMBER,
description VARCHAR2(100),
order_total (NUMBER8,2)) ORGANIZATION EXTERNAL
(TYPE oracle_hdfs
ACCESS PARAMETERS (
com.oracle.bigdata.colmap: {"col":"item_cnt", \
"field":"order_line_item_count"}
com.oracle.bigdata.overflow: {"action":"TRUNCATE", \
"col":"DESCRIPTION"}
com.oracle.bigdata.erroropt: [{"action":"replace", \
"value":"INVALID NUM", \
"col":["CUST_NUM","ORDER_NUM"]} , \
{"action":"reject", \
"col":"ORDER_TOTAL}]
)
LOCATION ("hdfs:/usr/cust/summary/*"));
これらのパラメータは、ORACLE_HDFSアクセス・ドライバがデータを特定してエラー条件を処理する方法で、次の変更を行います。
com.oracle.bigdata.colmap: 列名の違いを処理します。HDFSファイル内のORDER_LINE_ITEM_COUNTは、外部表のITEM_CNT列と一致します。
com.oracle.bigdata.overflow: 文字列データを切り捨てます。DESCRIPTION列の100文字を超える値は切り捨てられます。
com.oracle.bigdata.erroropt: 不正なデータを置換します。CUST_NUMまたはORDER_NUMのデータのエラーにより、値がINVALID_NUMに設定されます。
次の例では、SerDeを使用してAvroコンテナ・ファイルにアクセスします。
CREATE TABLE order (cust_num VARCHAR2(10),
order_num VARCHAR2(20),
order_date DATE,
item_cnt NUMBER,
description VARCHAR2(100),
order_total (NUMBER8,2)) ORGANIZATION EXTERNAL
(TYPE oracle_hdfs
ACCESS PARAMETERS (
com.oracle.bigdata.rowformat: \
SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
com.oracle.bigdata.fileformat: \
INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'\
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
com.oracle.bigdata.colmap: { "col":"item_cnt", \
"field":"order_line_item_count"}
com.oracle.bigdata.overflow: {"action":"TRUNCATE", \
"col":"DESCRIPTION"}
LOCATION ("hdfs:/usr/cust/summary/*"));
アクセス・パラメータは、次の情報をORACLE_HDFSアクセス・ドライバうに提供します。
com.oracle.bigdata.rowformat: アクセス・ドライバがレコードおよびフィールドを解析するために使用する必要があるSerDeを識別します。ファイルはデリミタ付きテキスト形式ではありません。
com.oracle.bigdata.fileformat: レコードを抽出し、それらを目的の形式で出力できるJavaクラスを識別します。
com.oracle.bigdata.colmap: 列名の違いを処理します。ORACLE_HDFSは、外部表のITEM_CNT列を持つHDFSファイル内のORDER_LINE_ITEM_COUNTと一致します。
com.oracle.bigdata.overflow: 文字列データを切り捨てます。DESCRIPTION列の100文字を超える値は切り捨てられます。
SQLのCREATE TABLE文には、外部表の作成に特化した句があります。この句に指定する情報により、アクセス・ドライバは外部ソースからデータを読み取り、そのデータを外部表用に準備できます。
次に外部表のCREATE TABLE文の基本的な構文を示します。
CREATE TABLE table_name (column_name datatype, column_name datatype[,...]) ORGANIZATION EXTERNAL (external_table_clause);
他の表と同様に、列名およびデータ型を指定します。ORGANIZATION EXTERNALは、表を外部表として識別します。
external_table_clauseはアクセス・ドライバを識別し、データのロードに必要な情報を提供します。「外部表の句について」を参照してください。
CREATE TABLE ORGANIZATION EXTERNALは、引数としてexternal_table_clauseを取ります。次の従属句があります。
|
関連項目: external_table_clauseの詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
TYPE句はアクセス・ドライバを識別します。アクセス・ドライバのタイプによって、外部表定義の他の部分がどのように解釈されるかが決まります。
Oracle Big Data SQLに次の値のいずれかを指定します。
ORACLE_HDFS: HDFSディレクトリ内のファイルにアクセスします。
ORACLE_HIVE: Hive表にアクセスします。
|
注意: ORACLE_DATAPUMPおよびORACLE_LOADERアクセス・ドライバは、Oracle Big Data SQLには関連付けられません。 |
DEFAULT DIRECTORY句はOracle Databaseディレクトリ・オブジェクトを識別します。ディレクトリ・オブジェクトは、外部表が読取りおよび書込みを行うファイルを含むオペレーティング・システム・ディレクトリを識別します。
ORACLE_HDFSおよびORACLE_HIVEはデフォルト・ディレクトリのみを使用して、Oracle Databaseシステムにログ・ファイルを書き込みます。
ORACLE_HDFSのLOCATION句には、ファイルの場所のコンマ区切りのリストが含まれます。ファイルは、デフォルト・クラスタ上のHDFSファイル・システムに存在する必要があります。
場所は次のいずれかになります。
完全修飾HDFS名(/user/hive/warehouse/hive_seed/hive_typesなど)。ORACLE_HDFSはディレクトリ内のすべてのファイルを使用します。
完全修飾HDFSファイル名(/user/hive/warehouse/hive_seed/hive_types/hive_types.csvなど)。
HDFSファイルまたはファイルのセットのURL (hdfs:/user/hive/warehouse/hive_seed/hive_types/*など)。ディレクトリ名のみは無効です。
ファイル名には、表6-2に説明されているパターン一致文字を含めることができます。
表6-2 パターン一致文字
| 文字 | 説明 |
|---|---|
|
? |
任意の1文字に一致します。 |
|
* |
0文字以上の文字に一致します。 |
|
[abc] |
セット{a, b, c}内の1文字に一致します。 |
|
[a-b] |
範囲{a...b}内の1文字に一致します。文字は、b以下である必要があります。 |
|
[^a] |
文字セットまたは範囲{a}外の1文字に一致します。カレット(^)は、左カッコの直後に付ける必要があります(スペースなし)。 |
|
\c |
cの特別な意味を無効にします。バックスラッシュ(\)は、エスケープ文字です。 |
|
{ab\,cd} |
セット{ab, cd}内の文字列に一致します。エスケープ文字(\)は、パス区切りとしてのコンマの意味を無効にします。 |
|
{ab\,c{de\,fh} |
セット{ab, cde, cfh}内の文字列に一致します。エスケープ文字(\)は、パス区切りとしてのコンマの意味を無効にします。 |
ORACLE_HIVEにLOCATION句を指定しないでください。指定すると、エラーが発生します。データはHiveに格納され、アクセス・パラメータおよびメタデータ・ストアは必要な情報を提供します。
Oracle Databaseが問合せを停止し、エラーを返すまで、外部表の問合せ中に許可される変換エラーの数を制限します。
行が拒否される処理エラーは、制限に対してカウントされます。拒否制限は、各並列問合せ(PQ)プロセスに個別に適用されます。すべてのPQプロセスについて、拒否されたすべての行の合計ではありません。
ACCESS PARAMETERS句は、アクセス・ドライバがデータを外部表に正しくロードするために必要な情報を提供します。「CREATE TABLE ACCESS PARAMETERS句」を参照してください。
アクセス・ドライバは、データを外部表にロードする際に、Hiveデータをターゲット列のデータ型に変換できることを確認します。互換性がない場合、アクセス・ドライバはエラーを返します。それ以外の場合は、適切なデータ変換を行います。
通常、Hiveは他の場所(HDFSファイル内など)に格納されているデータに表抽象化レイヤーを提供します。Hiveはシリアライザ/デシリアライザ(SerDe)を使用して、必要に応じてデータを格納されている形式からHiveデータ型に変換します。その後、アクセス・ドライバはHiveデータ型からOracleデータ型にデータを変換します。たとえば、テキスト・ファイルに対するHive表にBIGINT列がある場合、SerDeはデータをテキストからBIGINTに変換します。その後、アクセス・ドライバはデータをBIGINT (Hiveデータ型)からNUMBER (Oracleデータ型)に変換します。
2つではなく1つのデータ型変換を実行する場合、パフォーマンスが向上します。したがって、HDFSファイル内のフィールドのデータ型は、ディスク上に実際に格納されているデータを示す必要があります。たとえば、JSONはクリア・テキスト形式であるため、JSONファイル内のデータはすべてテキストです。フィールドのHiveタイプがDATEの場合、SerDeはデータを文字列(データ・ファイル内)からHive日付に変換します。その後、アクセス・ドライバはデータをHive日付からOracle日付に変換します。ただし、フィールドのHiveタイプが文字列の場合、SerDeは変換を実行せず、アクセス・ドライバはデータを文字列からOracle日付に変換します。2番目の例では、外部表に対する問合せはより速くなります。これは、アクセス・ドライバがデータ変換のみを実行するためです。
表6-3は、データを外部表にロードするときにORACLE_HIVEが実行できるデータ型変換を示します。
表6-3 サポートされているHiveデータ型からOracleデータ型への変換
| Hiveデータ型 | VARCHAR2、CHAR、NCHAR2、NCHAR、CLOB | NUMBER、FLOAT、BINARY_NUMBER、BINARY_FLOAT | BLOB | RAW | DATE、TIMESTAMP、TIMESTAMP WITH TZ、TIMESTAMP WITH LOCAL TZ | INTERVAL YEAR TO MONTH、INTERVAL DAY TO SECOND |
|---|---|---|---|---|---|---|
|
INT SMALLINT TINYINT BIGINT |
はい |
はい |
はい |
はい |
いいえ |
いいえ |
|
DOUBLE FLOAT |
はい |
はい |
はい |
はい |
いいえ |
いいえ |
|
DECIMAL |
はい |
はい |
いいえ |
いいえ |
いいえ |
いいえ |
|
BOOLEAN |
はい脚注 1 |
はい脚注 2 |
はい脚注 2 |
はい |
いいえ |
いいえ |
|
BINARY |
はい |
いいえ |
はい |
はい |
いいえ |
いいえ |
|
STRING |
はい |
はい |
はい |
はい |
はい |
はい |
|
TIMESTAMP |
はい |
いいえ |
いいえ |
いいえ |
はい |
いいえ |
|
STRUCT ARRAY UNIONTYPE MAP |
はい |
いいえ |
いいえ |
いいえ |
いいえ |
いいえ |
脚注 1 FALSEは文字列FALSEにマップされ、TRUEは文字列TRUEにマップされます。
脚注 2 FALSEは0にマップされ、TRUEは1にマップされます。
ユーザーは、他の表を問い合せる場合と同じように、SQL SELECT文を使用して外部表を問い合せることができます。
Hadoopクラスタ上のデータを問い合せるユーザーには、外部表、およびクラスタ・ディレクトリを指すデータベース・ディレクトリ・オブジェクトへのOracle Database内のREADアクセス権が必要です。「クラスタ・ディレクトリについて」を参照してください。
デフォルトでは、列の値を計算しているときにエラーが発生した場合、問合せはデータを返しません。ほとんどのエラー(特に、列の値を計算中にスローされたエラー)の後も処理は続行します。
エラーの処理方法を決定するには、com.oracle.bigdata.erroroptパラメータを使用します。
Oracle Big Data SQLは、Oracle Exadata Database Machineに接続されたOracle Big Data Applianceがあるシステム上で排他的に実行されます。Oracle Exadata Storage Server Softwareは、構成可能な数のOracle Big Data Applianceサーバー上にデプロイされます。これらのサーバーは、CDHノードとOracle Exadata Storage Serverの機能を結合します。
Mammothユーティリティは、Oracle Big Data ApplianceとOracle Exadata Database Machineの両方にBig Data SQLソフトウェアをインストールします。この項の情報では、MammothがOracle Databaseシステムに対して行う変更について説明します。
この項の内容は次のとおりです。
|
注意: Oracle SQL Connector for HDFSは、Oracle Exadata Database Machineに接続されていないラックを含む、すべてのOracle Big Data ApplianceラックにHadoopデータへのアクセスを提供します。ただし、Oracle Big Data SQLのパフォーマンス上の利点はなく、Oracle Big Data Applianceライセンスにも含まれません。『Oracle Big Data Connectorsユーザーズ・ガイド』を参照してください。 |
データベース上のBig Data SQLエージェントはクラスタウェアにより管理されます。Big Data SQLのインストール中にエージェントがクラスタウェアに登録され、データベースを自動的に開始および停止します。ステータスを確認するには、GridホームまたはClusterwareホームから実行します。
mtactl check bds_databasename_clustername
共通ディレクトリには、すべてのHadoopクラスタに共通の構成情報が含まれています。このディレクトリは、Oracle DatabaseシステムのOracleホーム・ディレクトリの下にあります。oracleファイル・システムのユーザー(またはOracle Databaseインスタンスを所有するユーザー)は、共通ディレクトリを所有します。ORACLE_BIGDATA_CONFIGという名前のデータベース・ディレクトリは共通ディレクトリを指します。
Mammothインストール・プロセスでは、次のファイルが作成され、共通ディレクトリに格納されます。
Oracle DBAは、必要に応じてこれらの構成ファイルを編集できます。
共通ディレクトリ内のbigdata.propertiesファイルには、HDFS内のデータにアクセスするために必要なJavaクラス・パスおよびネイティブ・ライブラリ・パスを定義するプロパティ/値のペアが含まれています。
次のプロパティを設定する必要があります。
次のリストで、bigdata.propertiesで許可されているすべてのプロパティを説明します。
bigdata.properties
デフォルトのHadoopクラスタの名前。アクセス・パラメータがクラスタを指定しない場合、アクセス・ドライバはこの名前を使用します。必須。
デフォルトのクラスタ名を変更すると、明示的なクラスタ名なしで以前に作成された外部表が使用できなくなる可能性があります。
Hadoopクラスタ名のコンマ区切りのリスト。オプション。
Hadoopクラス・パス。必須。
Hiveクラス・パス。必須。
Oracle JXAD Java JARファイルへのパス。必須。
ユーザーJARファイルへのパス。オプション。
JVM共有ライブラリ(libjvm.soなど)への完全なファイル・パス。必須。
JVMに渡されるオプションのコンマ区切りのリスト。オプション。
この例では、最大ヒープ・サイズを2GBに設定し、Java Native Interface (JNI)呼出しの詳細なロギングを設定します。
Xmx2048m,-verbose=jni
Hadoopネイティブ・ライブラリを検索するためのディレクトリ・パスのコロン区切りの(:)リスト。推奨。
このオプションを設定した場合は、java.optionsでjava.libraryパスを設定しないでください。
例6-3は、サンプルのbigdata.propertiesファイルを示します。
例6-3 サンプルのbigdata.propertiesファイル
# bigdata.properties # # Copyright (c) 2014, Oracle and/or its affiliates. All rights reserved. # # NAME # bigdata.properties - Big Data Properties File # # DESCRIPTION # Properties file containing parameters for allowing access to Big Data # Fixed value properties can be added here # java.libjvm.file=$ORACLE_HOME/jdk/jre/lib/amd64/server/libjvm.so java.classpath.oracle=$ORACLE_HOME/hadoopcore/jlib/*:$ORACLE_HOME/hadoop/jlib/hver-2/*:$ORACLE_HOME/dbjava/lib/* java.classpath.hadoop=$HADOOP_HOME/*:$HADOOP_HOME/lib/* java.classpath.hive=$HIVE_HOME/lib/* LD_LIBRARY_PATH=$ORACLE_HOME/jdk/jre/lib bigdata.cluster.default=hadoop_cl_1
共通ディレクトリのbigdata-log4j.propertiesファイルは、外部表に対する問合せのロギング動作をJavaコードで定義します。このファイルでは、すべてのlog4jプロパティを使用できます。
例6-4は、サンプルのbigdata-log4j.propertiesファイルと関連するlog4jプロパティを示します。
例6-4 サンプルのbigdata-log4j.propertiesファイル
# bigdata-log4j.properties
#
# Copyright (c) 2014, Oracle and/or its affiliates. All rights reserved.
#
# NAME
# bigdata-log4j.properties - Big Data Logging Properties File
#
# DESCRIPTION
# Properties file containing logging parameters for Big Data
# Fixed value properties can be added here
bigsql.rootlogger=INFO,console
log4j.rootlogger=DEBUG, file
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
log4j.logger.oracle.hadoop.sql=ALL, file
bigsql.log.dir=.
bigsql.log.file=bigsql.log
log4j.appender.file.File=$ORACLE_HOME/bigdatalogs/bigdata-log4j.log
クラスタ・ディレクトリには、CDHクラスタの構成情報が含まれています。Oracle DatabaseがOracle Big Data SQLを使用してアクセスする各クラスタにクラスタ・ディレクトリがあります。このディレクトリは、Oracle Databaseシステムの共通ディレクトリの下にあります。たとえば、bda1_cl_1という名前のクラスタには、共通ディレクトリに同じ名前(bda1_cl_1)のディレクトリがあります。
クラスタ・ディレクトリには、次のようなクラスタにアクセスするためのCDHクライアント構成ファイルが含まれています。
core-site.xml
hdfs-site.xml
hive-site.xml
mapred-site.xml (オプション)
log4jプロパティ・ファイル(hive-log4j.propertiesなど)
データベース・ディレクトリ・オブジェクトはクラスタ・ディレクトリを指します。クラスタ内のデータにアクセスするユーザーには、ディレクトリ・オブジェクトの読取りアクセス権が必要です。
oracleオペレーティング・システム・ユーザー(またはOracle Databaseインストール・ディレクトリを所有するユーザー)には次の設定が必要です。
ログ・ディレクトリを指すデータベース・ディレクトリへのREAD/WRITEアクセス権。これらの権限を使用すると、アクセス・ドライバはログ・ファイルを作成し、ユーザーはそれを読み取ることができます。
Oracle Big Data Applianceで定義されている、該当するoracleオペレーティング・システム・ユーザー。ソース・データが格納されているHDFSディレクトリへのオペレーティング・システム内のREADアクセス権を持ちます。
