| Oracle® Fusion Middleware Oracle Unified Directoryの管理 11g リリース2 (11.1.2.3) E61945-07 |
|

 前 |
 次 |
この章では、様々なタイプのデプロイメントにプロキシ・サーバーを使用できるOracle Unified Directoryの機能の概念的な概要について説明します。
この機能には、構成可能なワークフロー要素および拡張可能なプラグインAPIが含まれており、リモートおよび分散されたデータ・ソースまたはサーバーにあるデータの処理に使用できます。
この章には次のセクションが含まれます:
|
注意: この章をお読みになる前に、第1章「Oracle Unified Directoryの概要」および第3章「プロキシ・サーバーを使用するデプロイメントの例」を確認しておくと、ここで説明する概念をより理解しやすくなります。この章で説明する機能の構成の詳細は、第IV部「プロキシ、分散および仮想化機能の構成」の該当する章を参照してください。 |
この項では、Oracle DatabaseまたはリモートLDAPディレクトリ・サーバーなど、リレーショナル・データベース管理システム(RDBMS)のリモート・データにアクセスする方法について説明します。
この項の内容は次のとおりです。
構成の詳細は、第20章「リモート・データ・ソースへのアクセスの構成」を参照してください。
RDBMSワークフロー要素は、LDAPプロトコルを使用して、LDAPクライアントからリレーショナル・データベース管理システム(RDBMS)に格納されているアイデンティティ・データへのアクセスを有効にします。
この項の内容は次のとおりです。
RDBMSワークフロー要素とそのサポートしているコンポーネントの構成の詳細は、第20.1項「RDBMSに格納されているアイデンティティ・データへのアクセスの構成」を参照してください。
RDBMSワークフロー要素を使用すると、Oracle Unified Directory LDAPクライアントとRDBMS (Oracle Databaseなど)の間のブリッジを作成できます。デプロイメントでは、次の要件を満たすRDBMSワークフロー要素の実装を使用できます。
デプロイメントにより、一部のアイデンティティ・データはLDAPディレクトリ・サーバーに格納され、他のデータはRDBMSに格納されます。LDAPクライアントが両方のソースのデータを集約仮想ビューに統合します。
LDAPクライアントがLDAPプロトコルを使用して、LDAPディレクトリ・サーバーとRDBMSの両方に格納されているアイデンティティ・データの読取りと書込みを行います。これらのクライアントでは、RDBMSデータへのアクセスにSQL問合せおよびコマンドを使用しません。
RDBMSワークフロー要素の実装では、次の機能をサポートしています。
JDBCをサポートするほとんどのRDBMSデータベースへの接続を構成できます。サポートされているデータベースのリストは、Oracle Unified Directory 11g リリース2 (11.1.2.3)動作保証マトリックスを確認してください。
LDAPオブジェクト・クラスおよび属性をRDBMSのSQL表および列にマップし、RDBMSデータの仮想ビューを作成できます。RDBMSに変更を加える必要はありません。
次のLDAP操作を使用できます。これらの操作は、RDBMSに格納されているデータにアクセスするために同等のSQL問合せに変換されます。
BIND
ADD
DELETE
MODIFY
MODIFYDN
SEARCH
|
注意: 現在のリリースでは、エントリが複数のSQL表から作成されている場合、RDBMSワークフロー要素でLDAP書込み操作(追加、変更または削除)はサポートされません。 |
アクセス制御グループおよびLDAPクライアント・アイデンティティに基づいた仮想ACIを使用して、RDBMSデータの仮想ビューへのアクセスを制御できます。
RDBMSワークフロー要素は、RDBMSからすでにアクセスされたデータを含むインメモリー・キャッシュを維持します。デフォルトでは、このキャッシュは有効になっています。
デフォルト(および推奨)のcaching-schemeはsoft-weakです。このスキームは、メモリーが少ないときにJVMによるオブジェクトのガベージ・コレクションを許可する一方で、データベース・エントリへのソフト参照を保持し、オブジェクトの最適なキャッシュを可能にします。また、このスキームはオブジェクトへのソフト参照を含む、最も頻繁に使用されるサブキャッシュを維持します。これにより、最近使用された一定数のオブジェクトを除いて、オブジェクトのガベージ・コレクションを実行できます。
RDBMSワークフロー要素に別のキャッシュ・スキームを指定するには、dsconfigを使用します。例:
$ dsconfig set-workflow-element \ --element-name ORCL1 \ --set caching-scheme:full
プロキシでターゲットとされるデータ・エントリが外部手段(SQL文を使用してアプリケーションまたはユーザーがデータベースに直接アクセスするなど)で変更された場合、この変更はRDBMSワークフロー要素に反映されない可能性があります。厳密なデータの一貫性が必要な場合、RDBMSワークフロー要素にcaching-schemeプロパティを設定することによりキャッシュ・スキームを変更するか、キャッシュを完全に無効にできます。
たとえば、キャッシンクを無効化するには、caching-schemeプロパティをnoneに設定します。
$ dsconfig set-workflow-element \ --element-name ORCL1 \ --set caching-scheme:none
RDBMSワークフロー要素のキャッシュ・プロパティ(構成可能なキャッシュ・スキームを含む)の詳細は、Oracle Fusion Middleware Oracle Unified Directory構成リファレンスを参照してください。
RDBMSワークフロー要素を実装するには、次のコンポーネントを構成します。
コンポーネントの構成の詳細は、第20.1項「RDBMSに格納されているアイデンティティ・データへのアクセスの構成」を参照してください。
RDBMSワークフロー要素には、LDAPクライアントとRDBMSの間のインタフェースとしてOracle Unified Directoryプロキシ・サーバーが必要です。プロキシ・サーバーは、次の要素を使用してRDBMSと通信します。
RDBMS拡張は、リモート・ピアからのレスポンスを定期的に確認し、接続プールで保持されている有効な接続を提供することによって、JDBCを使用したリモート・サーバーとの接続性を管理します。
RDBMSワークフロー要素は、RDBMS拡張要素から接続を取得し、LDAPエントリとSQL表とのマッピングを実行し、LDAPクライアントから受け取った操作を実行します。
プロキシ・サーバーを作成するには、oud-proxy-setupスクリプトまたはoud-proxy-setup.batスクリプトを実行します。これらのスクリプトには、サポートされているJavaのインストールが必要です(JRE 7またはJDK 7)。JAVA_HOME環境変数でこのインストールを指定する必要があります。
RDBMSワークフロー要素の実装はRDBMSと通信するJDBC標準に依存するため、使用しているRDBMSに対応するJDBCドライバのJARファイルをインストールする必要があります。
RDBMSとの通信には、RDBMSワークフロー要素とそのコンポーネントが必要です。これらのコンポーネントを作成および構成するには、次のタスクを実行します。
RDBMS拡張、RDBMSワークフロー要素、およびRDBMSワークフロー要素に関連付けられるワークフローを作成します。
RDBMSワークフロー要素に関連付けられるワークフローをネットワーク・グループに割り当てます。
RDBMS内のアクセスするSQL表および列に対応するLDAP属性とオブジェクト・クラスに対してLDAP-SQLマッピングを構成します。
RDBMSの仮想データに対するアクセス制御は、LDAPクライアント・アイデンティティに基づいた仮想ACIを持つアクセス制御グループを使用して構成されます。仮想ACIが作成されると、Oracle Unified Directoryプロキシ・インスタンスに格納されます。
仮想データに対するアクセス制御を構成するには、次のタスクを実行します。
RDBMSワークフロー要素に関連付けられるワークフローに対してアクセス制御グループを作成します。
LDAPクライアント・アイデンティティに基づいた仮想ACIを作成し、これらの仮想ACIをステップ1で作成したアクセス制御グループに追加します。
|
注意: RDBMSの仮想データに対するアクセス制御方法は、コーポレート・ポリシーによって異なるため、これらのポリシーに準拠した仮想ACIを作成する必要があります。 |
詳細は、第9章「Oracle Unified Directoryのアクセス制御モデルの理解」の第9.7項「仮想ACIの理解」を参照してください。
次の要素を使用して、プロキシ・インスタンスとリモートLDAPサーバーとの通信を有効にできます。
LDAPサーバー拡張: この要素では、リモート・ピアからのレスポンスを定期的に確認し、接続プールで保持されている有効な接続を提供することによって、リモート・サーバーとの接続性が管理されます。
プロキシLDAPワークフロー要素: この要素では、LDAPサーバー拡張要素から接続が取得され、構成されているモードで定義されているとおりにユーザーから受け取った操作が実行されます。
|
注意:
|
プロキシを使用して、複数のデータ・ソースまたはレプリケートされたLDAPサーバー間でリクエストをロード・バランシングすることができます。
ロード・バランシング・デプロイメントでは、リクエストは、設定されているロード・バランシング・アルゴリズムに基づいて、データ・ソースの1つにルーティングされます。次のいずれかのロード・バランシング・アルゴリズムを選択できます:
フェイルオーバー。複数のリモートLDAPサーバーが、特定の操作タイプに対して、サーバー上で構成されている優先度に基づいてリクエストを処理します。エラーが発生すると、その操作タイプに対して次に優先度が高いサーバーに、リクエストが送信されます。
詳細は、第12.2.1項「フェイルオーバー・ロード・バランシング」を参照してください。
最適。複数のリモートLDAPサーバー間に優先度が設けられません。飽和レベルが最も低いLDAPサーバーが、リクエストを処理するサーバーになります。最適なルートが選択されるように、リモートLDAPサーバーの飽和レベルは定期的に再評価されます。
詳細は、第12.2.2項「最適ロード・バランシング」を参照してください。
比例。すべてのリモートLDAPサーバーが、設定された比率(重み)に基づいてリクエストを処理します。
詳細は、第12.2.3項「比例ロード・バランシング」を参照してください。
飽和。飽和制限に達するまで、1つのメインLDAPサーバーがすべてのリクエストを処理します。
詳細は、第12.2.4項「飽和ロード・バランシング」を参照してください。
検索フィルタ。複数のLDAPサーバーがデプロイされ、リクエスト検索フィルタの特定の属性に基づいてリクエストを処理します。
詳細は、第12.2.5項「検索フィルタ・ロード・バランシング」を参照してください。
フェイルオーバー・アルゴリズムを使用したロード・バランシングでは、プロキシが、特定の操作タイプ(追加操作など)に対して優先度が一番高いリモートLDAPサーバーまたはデータ・センターにリクエストをルーティングします。リモートLDAPサーバーが停止するまで、プロキシは優先度ルートにリクエストを送信し続けます。これは、ネットワークの切断、ハードウェアの障害、ソフトウェアの障害などの問題が原因になります。フェイルオーバーにより、プロキシは、特定の操作タイプに対する2番目の優先度のサーバーに着信リクエストをルーティングします。
図12-1は、フェイルオーバー・ロード・バランシングの構成を示しています。この例では、3つのルートがあり、それぞれ、操作タイプごとに一意の優先度が設定されています。追加操作はすべて、最高優先度(priority=1)が設定されているサーバー1によって処理され、バインド操作はサーバー2によって処理されます。サーバー1が停止すると、追加リクエストは、2番目の優先度が設定されているサーバー2に送信されます。
デフォルトでは、停止したサーバーが再度実行しても、プロキシはそのサーバーへのリクエストの再ルーティングをすぐには行いません。たとえば、サーバー1が停止すると、追加リクエストはサーバー2に送信されます。サーバー1が再起動しても、着信した追加リクエストは、サーバー2が処理し続けます。ただし、サーバー2が停止して、サーバー1が再起動している場合、サーバー1が着信リクエストを再び受信するようになります。このデフォルト動作は、switch-backフラグで変更できます。switch-backフラグの構成については、第21.1.4.2項「switch-backフラグの設定」を参照してください。
フェイルオーバーを効果的に実行するには、ビジネス・ニーズに合った間隔内でフェイルオーバーが発生するようにモニタリング・チェック間隔を低く設定する必要があります。モニタリング・チェックの間隔の設定の詳細は、第20.2.1.7項「LDAPデータ・ソースの接続モニタリング・プロパティの変更」を参照してください。
最適ロード・バランシング・アルゴリズムでは、プロキシは、最低飽和レベルのルートにリクエストを送信します。ルート上のリモートLDAPサーバーの飽和レベルが、そのデプロイメントでの他のリモートLDAPサーバーの飽和レベルを超えるまで、プロキシはリクエストをこのルートに送信し続けます。飽和レベルは割合で表されます。
ルートの飽和レベルが変わると、ロード・バランシング・アルゴリズムが最適なルートを再評価し、必要に応じて別のルートを選択します。最低飽和レベルのルートが、常に最適ルートとして選択されます。図12-5の構成では、最低飽和レベルのサーバーはサーバー1であり、この飽和レベルが他のサーバーの飽和レベルを超えるまで、サーバー1がすべてのリクエストを処理します。サーバーの1つが停止すると、その飽和レベルは100%になります。
飽和精度を構成して、ルートが最低飽和レベルのサーバーに切り替わる前の2つのサーバー間の飽和レベルの差を設定できます。デフォルトでは、飽和精度は5に設定されています。ただし、アルゴリズムがサーバー間で頻繁に切り替わっている場合は、飽和精度を10に設定できます。飽和精度はLDAPサーバーの拡張で設定します。詳細は、第21.1.4.3項「最適アルゴリズムまたは飽和アルゴリズムでの飽和精度の設定」を参照してください。
飽和レベルは、接続プール内の使用中の接続数と、その構成済の最大サイズとの割合を示します。接続プールの最大サイズは、LDAPサーバー拡張オブジェクトの拡張パラメータの1つです。
使用中の接続数が、最大プール・サイズの2で割った数より小さい場合、飽和は0になります。これは、プールが飽和していないことを意味します。
接続の半分以上が使用中である場合、次のように飽和レベルが計算されます:
100 * (1 - 使用可能な接続数/(最大プール・サイズ/2))
この計算により、すべての接続が使用中であるとき、飽和レベルが100になります。
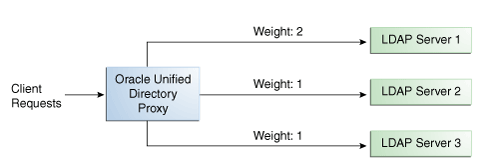
比例ロード・バランシング・アルゴリズムでは、プロキシは、複数のルート間において、設定されている比率に基づいて、リモートLDAPサーバーまたはデータ・ソースにリクエストを転送します。ルートによって処理されるリクエストの比率は、構成内の各ルートに対して設定した重みによって識別されます。重みは整数値で表されます。
ロード・バランシングを構成する際に、各LDAPサーバーが処理するリクエスト比率を示す必要があります。図12-3の例では、2:1という重みが設定されているため、サーバー1は、サーバー2の2倍の数の接続を処理します。サーバー2とサーバー3は、同じリクエスト量を処理します(1:1)。
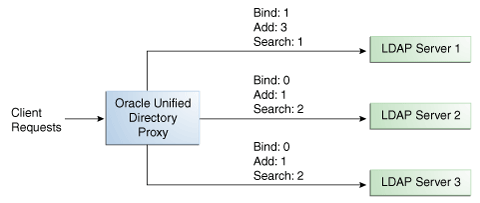
図12-4に示されているように、クライアント操作の各タイプに対して重みを構成できます。たとえば、サーバー1で全バインド操作を処理するように設定できます。そのためには、バインドの重みをサーバー1は1 (以上)に設定し、サーバー2とサーバー3は0に設定します。
図12-4の例では、サーバー1は、サーバー2とサーバー3の3倍の追加リクエストを処理します。ただし、サーバー1が処理する検索リクエストは、サーバー2とサーバー3が処理する半分になります。サーバー2とサーバー3は、追加リクエストと検索リクエストについて同じ量を処理しますが、バインド・リクエストは処理しません。
図12-4のように、バインド、追加および検索以外の操作の重みを変更しなければ、サーバーは他のすべての操作(削除など)については、同じロードを共有します。
比例ロード・バランシングにおけるルートの重みの構成の詳細は、第21.1.4項「ロード・バランシングのプロパティの変更」を参照してください。
飽和ロード・バランシング・アルゴリズムでは、プロキシは、選択された優先度のルートにリクエストを送信します。そのルートのリモートLDAPサーバーが、設定されている飽和しきい値を超えるまで、プロキシは、その優先度のルートにリクエストを送信し続けます。飽和しきい値は割合で表されます。
たとえば、1つのリモートLDAPサーバーですべての着信リクエストを管理する必要がある場合、このサーバーに優先度1を設定します。飽和索引が70%に達するとリクエストの処理を停止するように同じリモートLDAPサーバーを設定するには、図12-5のように、飽和しきい値を70%に設定します。このようにすると、サーバーは飽和レベルが70%に達するまで、全着信リクエストを処理します。そして、プロキシは、次に優先度の高いサーバー2に、リモートLDAPサーバーへの新しいリクエストをすべて送信します。サーバー2は、サーバー2の飽和しきい値に達するまで、またはサーバー1の飽和レベルが再び低くなるまで、リクエストを処理し続けます。
つまり、サーバー1の飽和レベルが70%に達すると、プロキシはサーバー2にリクエストを送信し始めます。サーバー1が70%のままで、サーバー2が60%に達すると、プロキシは、新しいリクエストをサーバー3に送信します。
ただし、サーバー2がリクエストを処理しているときに、サーバー1の飽和レベルが55%まで落ちると、サーバー2が飽和しきい値に達していない場合でも、プロキシはサーバー1に新しい全リクエストを送信し始めます。
すべてのルートが飽和しきい値に達する場合、プロキシは、飽和レベルが最低のルートを選択します。
サーバーが飽和レベルに達したときに警告を発するように、飽和しきい値アラートを設定することができます。たとえば、飽和しきい値アラートを60%に設定した場合、サーバーがこの値に達すると通知が届き、サーバーのパフォーマンスが低下しすぎないうちに対応策をとることができます。
飽和レベルの決定方法の詳細は、第12.2.2.1項「飽和レベルの決定」を参照してください。
検索フィルタ・ロード・バランシング・アルゴリズムでは、プロキシは、リクエスト検索フィルタで定義されている特定属性に基づいてLDAPサーバーに検索リクエストをルーティングします。
トポロジは、プロキシ経由でアクセス可能な複数のLDAPサーバーで構成されます。すべてのLDAPサーバーには似たデータが含まれますが、各サーバーが、より高いパフォーマンスを提供するように検索フィルタで定義された属性に基づいて最適化されます。各ルートを、許可属性リストと禁止属性リストで構成できます。リクエストの検索フィルタに少なくとも1つの許可属性が含まれ、禁止属性が含まれていない場合に、検索リクエストはルートと一致します。
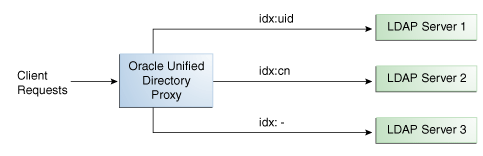
図12-6は、検索フィルタ・ロード・バランシング・アルゴリズムを示しています。この例では、3つのLDAPサーバーがあり、3つの個別ルートが設定されています。LDAPサーバー1は索引としてuid属性を持ち、LDAPサーバー2は索引としてcn属性を持ち、3つ目のLDAPサーバーはパススルー・ルートです。
プロキシが、検索フィルタにuid属性を含む検索リクエストを受信すると、検索リクエストは、より高いパフォーマンスのためLDAPサーバー1にルーティングされます。同様に、検索フィルタにcn属性が含まれている場合、検索リクエストはLDAPサーバー2にルーティングされます。他のすべての検索リクエストは、パススルーLDAPサーバー3にルーティングされます。
追加、削除、変更などのその他すべてのリクエストは、優先度ベースでLDAPサーバーにルーティングできます。各検索フィルタ・ルートに優先度が設定されます。この優先度によってルートの評価順序が決まります。検索フィルタに一致し、優先度が一番高いルート・フィルタが、リクエスト処理用に選択されます。すべての検索フィルタ・ルートの優先度が同じ場合、どのルートでもリクエストを処理できます。
Oracle Unified Directoryの分散機能は、水平スケーラビリティなど、全エントリを単一のデータ・ソースまたはLDAPサーバーに格納できない大規模デプロイメントに対応できる機能です。また、分散を使用して、1秒当たりの更新回数を調整することができます。
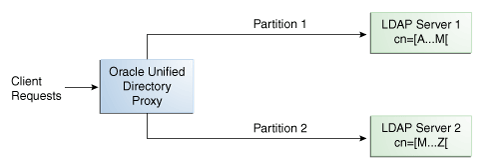
分散デプロイメントでは、まずデータを小さなチャンクに分割する必要があります。データを分割するには、split-ldifコマンドを使用します。このようなデータ・チャンクをパーティションと呼びます。通常、各パーティションは別々のサーバー上に格納されます。
データの分割は、次の分散アルゴリズムのいずれかに基づきます:
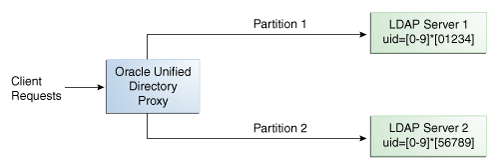
数値。エントリを、命名属性(たとえばuid)の数値に基づいて、パーティションに分割し、分散します。詳細は、第12.3.1項「数値分散」を参照してください。
辞書編集。エントリを、命名属性(たとえばcn)のアルファベット値に基づいて、パーティションに分割し、分散します。詳細は、第12.3.2項「辞書編集分散」を参照してください。
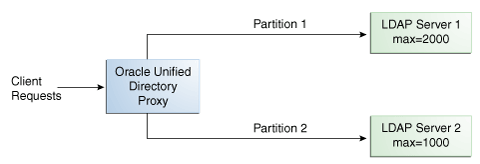
容量。エントリは、各パーティションの容量に基づいてパーティションに追加されます。このアルゴリズムは、追加リクエストにのみ使用されます。他のすべてのリクエストは、グローバル索引カタログまたはブロードキャストによって分散されます。詳細は、第12.3.3項「容量分散」を参照してください。
DNパターン。エントリを、エントリDNのパターン(値)に基づいて、パーティションに分割し、分散します。詳細は、第12.3.4項「DNパターン分散」を参照してください。
選択するデータ分散タイプは、ディレクトリ・サービス内のデータの編成方法によります。数値分散と辞書編集分散は、特別な分散形式を持ちます。DNパターンは、既存のデータ分散モデルと一致させるのに使用できます。
クライアント・リクエスト(追加以外)が、分散パーティションの1つとリンクできない場合、グローバル索引カタログが構成されていないかぎり、プロキシは、着信リクエストをすべてのパーティションにブロードキャストします。
ただし、リクエストが分散範囲外であることが明確な場合は、このリクエストは、エントリが存在しないことを示すエラーとともに返されます。たとえば、分散パーティションにuidが1-100 (partition1)と100-200 (partition2)が含まれている状態で、ベースDNがuid=222,ou=people,dc=example,dc=comの検索を実行すると、プロキシは、このエントリが存在しないことを示します。
さらに、数値アルゴリズムと辞書編集アルゴリズムの場合、分散ベースDNの直下の最初のRDNが、リクエストの処理用に使用されます。たとえば、次の検索はエラーを返します。uidが分散ベースDN (たとえばou=people,dc=example,dc=com)の直下の最初のRDNでないためです。
$ ldapsearch -b "uid=1010,o=admin,ou=people,dc=example,dc=com" "objectclass=*"
パーティション数は慎重に決めてください。デプロイメントのパーティション数を定義する際、後でデータを分割し、新しいパーティションに再分散する場合、ダウンタイムが必要になることを念頭に置いておく必要があります。ただし、初期パーティション外のエントリを持つデータで、新しいパーティションを追加することはできます。
たとえば、初期パーティションが、uidが1-100のデータ(partition1)と100-200のデータ(partition2)で構成されている場合に、後で、200-300のuidを含むpartition3を追加することはできます。ただし、partition1とpartition2を分割して、たとえばpartition1に1-150のuidを含め、partition2に150-300のuidを含めることは簡単ではありません。パーティションの分割は、新しい分散デプロイメントを再構成するのと実質同じです。
数値アルゴリズムを使用する分散では、プロキシは、リクエスト内の分散ベースDNの直下の最初のRDNの数値に基づいて、リクエストをパーティションの1つに転送します。数値アルゴリズムの分散を設定する場合、選択した属性の数値に基づいてデータベース上のデータをパーティションに分割します。このとき、選択する属性が数値文字列を表すものである必要があります。プロキシは、同じ数値アルゴリズムを使用して、適切なパーティションにすべてのクライアント・リクエストを転送します。
たとえば、図12-7に示されているように、エントリのuidに基づいて、2つのパーティションにデータを分割できます。
この例では、uidが1111のエントリの検索はパーティション1に送信され、uidが2345のエントリの検索はパーティション2に送信されます。定義されているパーティション範囲外のuidのエントリに対するリクエストについては、そのエントリが存在していないことが示されます。
|
注意: 分散アルゴリズムの上限は含まれません。つまり、この例においては、uidが3000の検索では、このエントリが存在していないことを示すエラーが返されます。 |
例12-1 数値分散アルゴリズムを使用した検索例
次の検索は成功します:
$ ldapsearch -b "uid=1010,ou=people,cn=example,cn=com" "cn=Ben"
ただし、次の検索では、エントリが存在しないことが示されます(結果コード32):
$ ldapsearch -b "uid=1010,o=admin,ou=people,cn=example,cn=com" "objectclass=*" $ ldapsearch -b "uid=99,ou=people,cn=example,cn=com" "objectclass=*"
プロキシが、上記定義されている分散アルゴリズムでエントリの所属するパーティションを判断できないため、次の検索はブロードキャストされます:
$ ldapsearch -b "ou=people,cn=example,cn=com" "uid=*"
辞書編集アルゴリズムを使用する分散では、プロキシは、リクエスト内の分散ベースDN直下の最初のRDNのアルファベット値に基づいて、リクエストをパーティションの1つに転送します。辞書編集アルゴリズムの分散を設定する場合、選択した属性のアルファベット値に基づいてデータベース上のデータをパーティションに分割します。プロキシは、同じアルゴリズムを使用して、適切なパーティションにすべてのクライアント・リクエストを転送します。
たとえば、図12-8に示されているように、エントリのcnに基づいて、2つのパーティションにデータを分割できます。
この例では、cnがBenなど、Bで始まるエントリに対するリクエストはパーティション1に送信され、cnがM-Yのエントリに対するリクエストはパーティション2に送信されます。
|
注意: 分散アルゴリズムの上限は含まれません。つまり、この例において、cn=Zacharyの検索については、このエントリが存在していないことが示されます。検索範囲にZで始まるエントリを含める場合、unlimitedキーワードを使用します。たとえば、cn=[M..unlimited[を使用すると、M以降のすべてのエントリが含まれます。 |
例12-2 辞書編集分散アルゴリズムを使用した検索例
次の検索は成功します:
$ ldapsearch -b "cn=Ben,ou=people,cn=example,cn=com" "objectclass=*"
次の検索も、cn=Benが最初のRDNになるので、成功します。
$ ldapsearch -b "uid=1010,cn=Ben,ou=people,cn=example,cn=com" "objectclass=*"
ただし、次の検索では、エントリが存在しないことが示されます(結果コード32):
$ ldapsearch -b "cn=Ben,o=admin,ou=people,cn=example,cn=com" "objectclass=*" $ ldapsearch -b "cn=Zach,ou=people,cn=example,cn=com" "objectclass=*"
次の検索は、所属するパーティションを判断できないので、ブロードキャストされます:
$ ldapsearch -b "ou=people,cn=example,cn=com" "cn=*"
容量ベースの分散では、プロキシは、各パーティションの容量に基づいて追加リクエストを送信します。これは、パーティションに含めることができるエントリの最大数により判断されます。他のすべてのリクエストは、グローバル索引カタログまたはブロードキャストによって分散されます。
データは完全無作為にパーティションに分散されるため、特定のデータ・エントリが所属するパーティションを識別する最も簡単な方法はグローバル索引を使用する方法です。容量分散を使用する場合は、グローバル索引は必須です。グローバル索引がセットアップされていない場合、追加以外のすべてのリクエストはブロードキャストされます。グローバル索引の詳細は、第12.6項「グローバル索引カタログの理解」および第23.7項「コマンド行を使用したグローバル索引の構成」を参照してください。
図12-9の例では、パーティション1は、パーティション2の2倍の容量があるので、パーティション1は、パーティション2より2倍の追加リクエストを受信します。この場合、両方のパーティションが同時に一杯になります。すべてのパーティションが一杯になったら、各サイクルで各パーティションに1つのリクエストが送信されます。
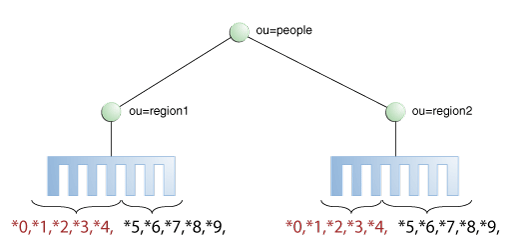
DNパターン・アルゴリズムを使用する分散では、プロキシは、リクエスト・ベースDNと文字列パターンとの照合に基づいて、リクエストをパーティションの1つに転送します。照合は、リクエスト・ベースDNの相対部分、つまり、分散ベースDN以下の部分についてのみ行われます。たとえば、図12-10に示されているように、エントリのuid内のDNパターンに基づいて、2つのパーティションにデータを分割できます。
DNパターンを使用する分散は、数値アルゴリズムまたは辞書編集アルゴリズムを使用する分散より面倒です。できるかぎり、別の分散アルゴリズムを使用するようにしてください。
この例では、0、1、2、3または4で終わるuidのすべてのデータ・エントリがパーティション1に送信されます。5、6、7、8または9で終わるuidのデータ・エントリはパーティション2に送信されます。
この分散は、数値を使用していますが、数値分散とはまったく異なります。数値分散では、データは数値の範囲に基づいて分割されますが、DNパターン分散は、データ文字列のパターンに基づきます。
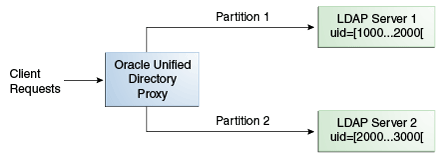
DNパターン・アルゴリズムを使用する分散は、通常、分散パーティションが分散ベースDNに正確に対応していない場合に使用します。たとえば、データが図12-11で示されているように分散されている場合、パーティション1とパーティション2のデータは、ベースDN ou=people,ou=region1とou=people,ou=region2の両方に該当します。データを簡単に分散するには、DNパターンを使用する以外方法がありません。
例12-3 地域別分割DNパターン・アルゴリズムの例
情報のデプロイメントが2つの地域で行われている場合、データの分散にはDNパターン分散を使用するのが簡単です。たとえば、従業員番号が4桁コードで、最初の桁が地域を示している場合、次のようになります:
| 地域1 | 地域2 |
|---|---|
| 1000 | 2000 |
| 1001 | 2001 |
| 1002 | 2002 |
| 1003 | 2003 |
| 1004 | 2004 |
| 1005 | 2005 |
| 1006 | 2006 |
| 1007 | 2007 |
| 1008 | 2008 |
| 1009 | 2009 |
| 1010 | 2010 |
| ... | ... |
データのロードを分散するには各場所のエントリを2つのサーバーに分割します。このとき、サーバー1には、0、1、2、3および4で終わるすべてのエントリが含まれ、サーバー2には、5、6、7、8および9で終わるすべてのエントリが含まれます(図12-10を参照)。
したがって、DNパターン1222の検索はパーティション1に送信され、2222も同様です。
この項では、様々なソース(データベースおよびディレクトリ)からデータを取得して統合し、そのデータの統合ビューの表示に使用できる様々な方法について説明します。
この項の内容は次のとおりです。
複数値属性のコンテンツの取得で、多数の値が返されることになる場合があります。Microsoft Active Directoryサーバーでは、1回の問合せで取得できる属性値の最大数が制限されます。
Microsoft Active Directoryでは、複数値属性のすべての値を取得できる範囲取得メカニズムを使用できます。このメカニズムでは、検索リクエストで、値のクライアント指定のサブセットを取得できます。複数の検索リクエストを実行し、各リクエストで個別のサブセットを取得することによって、属性の完全な値セットを取得できます。
Oracle Unified Directoryは、Microsoft Active Directoryページングのサポートを提供することによって、Active Directoryの範囲取得に対応します。Microsoft Active Directoryページングの主な目的は、返された属性のオプションの中に範囲オプションがあるかどうかを検出すること、およびMicrosoft Active Directoryサーバーから完全な範囲の属性値を取得することです。この完全な属性値セットが返されると、クライアント・アプリケーションでは範囲オプションを処理する必要がなくなります。
Microsoft Active Directoryページングは、ワークフロー要素チェーンのリーフがActive Directoryサーバーに接続されている場合にのみ関連するワークフロー要素として実装されます。Active Directoryページング・ワークフロー要素の次のプロパティを構成できます:
チェーン内の次のワークフロー要素(このワークフロー要素はリーフ・ワークフロー要素ではないため)
範囲オプションを検出するための属性のスキャン処理を軽減できるオプションの属性リスト
追加の同期なしで、Oracle Unified Directoryおよびエンタープライズ・ユーザー・セキュリティを統合して、LDAP準拠ディレクトリ・サービスに格納されているユーザーIDを利用できます。
エンタープライズ・ユーザー・セキュリティと統合した場合、Oracle Unified Directoryで次のものがサポートされます。
Microsoft Active Directory
Novell eDirectory
Oracle Unified Directory
Oracle Directory Server Enterprise Edition
Oracle Enterprise User Securityの詳細は、『Oracle Databaseエンタープライズ・ユーザー・セキュリティ管理者ガイド』を参照してください。Oracle Unified Directoryおよびエンタープライズ・ユーザー・セキュリティが連携して動作するように構成する手順の詳細は、第31章「Oracle Enterprise User SecurityへのOracle Unified Directoryの統合」を参照してください。
ADパスワード・ワークフロー要素により、Oracle Unified Directory LDAPクライアント・アプリケーションでは、LDAPプロトコルを使用してMicrosoft Active DirectoryおよびActive Directoryライトウェイト・ディレクトリ・サービス(AD LDS)に保存されているユーザー・パスワードを更新できるようになります。
このセクションには次のトピックが含まれます:
Adパスワード・ワークフロー要素を構成するには、第23.3項「Active Directoryに保存されているユーザー・パスワードの更新」を参照してください。
Microsoft Active DirectoryおよびAD LDSには、Oracle Unified Directory LDAPクライアントが標準LDAP操作を使用して処理できない特性や要件があります。
たとえば、クライアントが標準LDAP変更操作を使用してユーザー・パスワード(userPassword属性)を更新した場合、ほとんどのLDAPサーバーで更新は正常に行われます。Active Directoryはこの変更操作を受け入れますが、次の要件により、ユーザー・パスワードは更新されません。
Active Directoryでは、userPassword属性ではなく、ユーザー・オブジェクトのunicodePwd属性にユーザー・パスワードが格納されます。
unicodePwd属性の構文は、二重引用符(")で囲まれたUNICODE文字列を含むオクテット文字列です。
unicodePwd属性はユーザー・オブジェクトの作成時には追加できません。unicodePwd属性を持たないユーザー・オブジェクトを作成してから、変更操作で新規オブジェクトに属性を追加する必要があります。
以前のパスワードがわからなくても、ユーザー・パスワードをリセットできるのは管理者のみです。
Active Directoryユーザー・パスワードはSSL接続経由でのみ更新できます。
Adパスワード・ワークフロー要素では、これらの特定の要件を処理できます。これにより、既存のクライアント・アプリケーションをリコードしなくても、標準LDAP操作を使用してActive DirectoryまたはAD LDSに格納されているユーザー・パスワードを更新できます。
サポートされているActive DirectoryおよびAD LDSのバージョンは、Oracle Unified Directory 11g リリース2 (11.1.2.3)動作保証マトリックスを確認してください。
Adパスワード・ワークフロー要素では、処理中の次のLDAP操作に応じて特定の機能を実行します。
セキュアなプロキシLDAPワークフロー要素が構成されている場合、Adパスワード・ワークフロー要素では、次のようにuserPassword属性を含めるADD操作を処理します。
userPassword属性をunicodePwd属性にマップします(map-userpasswordプロパティはtrueに設定されます)。
userPassword属性を含めるADD操作を次の順序で処理します。
unicodePwd属性、useraccountcontrol属性およびmsds-useraccountdisabled属性を持たないActive Directoryユーザー・オブジェクトでADD操作を実行します。この操作は、Adパスワード・ワークフロー要素のnext-workflow-elementプロパティで定義されたワークフロー要素によって処理されます。
ユーザー・オブジェクトでMODIFY操作を実行し、unicodePwd属性を作成します。この操作は、Adパスワード・ワークフロー要素のsecure-proxy-workflow-elementプロパティで定義されたワークフロー要素によって処理されます。
元のADD操作にuseraccountcontrol属性またはmsds-useraccountdisabled属性が含まれていた場合は、ユーザー・オブジェクトでMODIFY操作を実行します。この操作は、Adパスワード・ワークフロー要素のnext-workflow-elementプロパティで定義されたワークフロー要素によって処理されます。
ステップ2のunicodePwd属性が作成される前に、useraccountcontrol属性およびmsds-useraccountdisabled属性を設定することはできません。
バインド操作またはMOD操作のいずれかでステップ2またはステップ3に失敗した場合、ADD操作はロールバックされます(つまり、エントリが削除されます)。
セキュアなプロキシLDAPワークフロー要素が構成されていない場合、Adパスワード・ワークフロー要素では、次のようにuserPassword属性を含めるADD操作を処理します。
必要に応じて、userPasswordをunicodePwdにマップします(map-userpasswordプロパティはtrueに設定されます)。
Adパスワード・ワークフロー要素のnext-workflow-elementプロパティで定義されたワークフロー要素によってADD操作を処理します。next-workflow-elementでSSLを使用していない場合、Active Directoryでこの操作が拒否される可能性があります。
セキュアなプロキシLDAPワークフロー要素が構成されている場合、Adパスワード・ワークフロー要素では、次のようにuserPassword属性を含めるMODIFY操作を処理します。
ユーザー・オブジェクトでMODIFY操作を実行し、ユーザー・パスワードを変更します。この操作は、Adパスワード・ワークフロー要素のsecure-proxy-workflow-elementプロパティで定義されたワークフロー要素によって処理されます。
バインド操作またはMOD操作のいずれかでこのステップに失敗した場合、Oracle Unified Directoryではステップ2を試行せずにMOD結果コードをクライアントに返します。
オブジェクトでMODIFY操作を実行します。この操作は、Adパスワード・ワークフロー要素のnext-workflow-elementプロパティで定義されたワークフロー要素によって処理されます。
セキュアなプロキシLDAPワークフロー要素が構成されていない場合、Adパスワード・ワークフロー要素では、次のようにユーザー・パスワードを含めるMODIFY操作を処理します。
必要に応じて、userPasswordをunicodePwdにマップします(map-userpasswordプロパティはtrueに設定されます)。
オブジェクトでMODIFY操作を実行します。この操作は、Adパスワード・ワークフロー要素のnext-workflow-elementプロパティで定義されたワークフロー要素によって処理されます。
SSLが必要な場合、Adパスワード・ワークフロー要素では、SSL接続がリモートのActive DirectoryまたはAD LDSサーバーに対して構成されていることを確認します。
secure-proxy-workflow-elementが構成されている場合、Oracle Unified Directoryでは、このワークフロー要素が、常にSSLを使用するように構成された(remote-ldap-server-ssl-policyプロパティがalwaysに設定されている)LDAPサーバー拡張を使用しているプロキシLDAPワークフロー要素であることを確認します。
secure-proxy-workflow-elementが構成されていない場合、next-workflow-elementは、常にSSLを使用するように構成されたLDAPサーバー拡張を使用する必要があります。
構成が正しくないためにユーザー・パスワードに対する操作が失敗した場合、Adパスワード・ワークフロー要素はリモートのActive DirectoryまたはAD LDSサーバーから受け取ったエラー・コードを返します。
Adパスワード・ワークフロー要素を作成および構成する前に、次のユースケースを使用してデプロイメントのセキュリティおよびパフォーマンス要件を検討します。
|
関連項目:
|
このユースケースでは、クライアントとActive DirectoryまたはAD LDSサーバーの間のすべてのLDAP操作をSSL接続を使用して実行します。
このユースケースの利点は、クライアントとプロキシ・サーバーの接続方法に関係なく、常にすべてのLDAP操作が完全にセキュアなSSL接続を使用して実行されることです。短所は、SSL接続を使用して実行される一部のLDAP操作により、デプロイメントのパフォーマンスが低下する可能性があることです。
構成要件
このユースケースには、次のコンポーネントが必要です。
alwaysに設定されたremote-ldap-server-ssl-policyプロパティで構成されたLDAPサーバー拡張。
前の項目で説明したとおりLDAPサーバー拡張を指定するセキュアなプロキシLDAPワークフロー要素(つまり、remote-ldap-server-ssl-policyオプションがalwaysに設定された構成)。
セキュアなプロキシLDAPワークフロー要素を指定するnext-workflow-elementプロパティで構成されたAdパスワード・ワークフロー要素。
このユースケースでは、パスワード変更に関連する操作をActive DirectoryまたはAD LDSサーバーへのSSL接続を使用して実行します。他のLDAP操作は、next-workflow-elementで使用されるLDAPサーバー拡張のremote-ldap-server-ssl-policy構成プロパティに応じて、SSL接続または非SSL接続で実行されます。
このユースケースの利点は、SSL接続を使用してパスワード変更が実行され、リモート・サーバーへのすべての通信にSSLを使用する必要がないことです。他の通信は、SSLを使用しない、またはクライアント接続がSSLを使用している場合のみSSLを使用できます。
構成要件
このユースケースには、次のコンポーネントが必要です。
リモートのActive DirectoryまたはAD LDSサーバーと通信するための2つのLDAPサーバー拡張。
SSL接続のためのLDAPサーバー拡張。remote-ldap-server-ssl-policyプロパティをalwaysに設定する必要があります。
パスワード変更に関連しない操作のための別のLDAPサーバー拡張。remote-ldap-server-ssl-policyプロパティをneverまたはuserのいずれかに設定します(または省略します)。
リモートのActive DirectoryまたはAD LDSサーバーと通信するための2つのプロキシLDAPワークフロー要素。
SSL接続のためのセキュアなプロキシLDAPワークフロー要素。
パスワードに関連しない操作のための別のプロキシLDAPワークフロー要素。
secure-proxy-workflow-elementプロパティおよびnext-workflow-elementプロパティの両方で構成されたAdパスワード・ワークフロー要素。
ユーザー・パスワードを変更するLDAP操作は、secure-proxy-workflow-elementプロパティで指定されたワークフロー要素で処理され、SSL接続を使用して実行されます。
パスワード変更に関連しない他のLDAP操作は、next-workflow-elementで指定されたワークフロー要素で処理されます。
Active DirectoryおよびAD LDSは、userPassword属性をunicodePwd属性にマップしなくても、特定の構成を使用してuserPassword属性での変更を処理できます。
このActive DirectoryまたはAD LDSには次の構成が必要です。
ドメイン・コントローラ(DC)がActive DirectoryまたはAD LDSとして実行中であり、ドメイン機能レベルがWindows 2003以降である必要があります。
fUserPwdSupport文字をdSHeuristics属性でtrueに設定する必要があります。
この特定の構成の詳細は、次のMicrosoftのドキュメントを参照してください。
http://msdn.microsoft.com/en-us/library/cc223249.aspx
この構成では、ユーザー・パスワード属性のマッピングは必要ありません。このマッピングを制御するには、Adパスワード・ワークフロー要素でmap-userpasswordプロパティを指定します。
true (デフォルト)の場合、マッピングが有効です。userPassword属性は自動的にunicodePwdにマップされます。LDAPのADD操作およびMODIFY操作は、userPasswordではなくunicodePwdで実行されます。
falseの場合、マッピングは無効です。LDAPのADD操作およびMODIFY操作は、userPasswordで実行されます。
パススルー認証(PTA)は、あるディレクトリ・サーバーが別のディレクトリ・サーバーにバインド・リクエストの認証を求めるメカニズムです。パススルー認証の一般的なシナリオは、Oracle Unified Directoryからのユーザーについての認証をActive Directoryに渡すなどです。
この項では、パススルー認証の使用と操作について説明します。内容は次のとおりです。
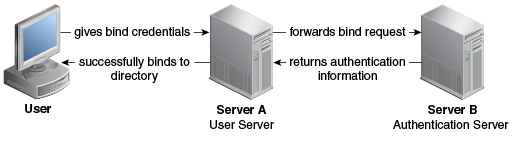
クライアントがディレクトリ・サーバーへのバインドを試行するとき、認証用のユーザー資格証明がローカルで格納されておらず、認証(Auth)サーバーと呼ばれるリモートの別のディレクトリ・サーバーに格納されている場合、パススルー認証メカニズムが使用されます。ディレクトリ・サーバーは、次に資格証明を検証するために認証サーバーへバインドの操作をリダイレクトします。ここでの資格証明は、userpassword属性を指します。ユーザー資格証明が格納されたAuthサーバーには、Oracle Unified Directory、Microsoft Active DirectoryまたはLDAP V3互換ディレクトリ・サーバーを使用できます。
Oracle Unified Directoryがバインドをリダイレクトする方法は、ユーザー・サーバーのユーザー・エントリが認証サーバーの対応するユーザー・エントリにマップされている方法に完全に依存します。Oracle Unified Directoryでは、ユーザー・エントリと認証エントリ間の1対1のマッピングがサポートされます。
パススルー認証メカニズムについて詳しく理解するために、図12-12に示す例について考えます。
2つのサーバーについて検討します。サーバーAとサーバーBがあり、ユーザー・エントリcn=myuserがサーバーBに保存されているとします。ユーザーがサーバーAにアクセスして操作を実行するように試みる場合、先に認証用の資格証明を使用してサーバーAにバインドする必要があります。ただし、資格証明がサーバーAに存在しないため、通常はサーバーAへのバインドは失敗します。ただし、パススルー認証メカニズムを使用すれば、サーバーAでバインド・リクエストをサーバーBに誘導することで、資格証明を検証できます。サーバーBを使用して資格証明が検証され、バインドに成功すると、サーバーAはバインド操作の成功を返します。
この例のサーバーAは、ユーザー・ディレクトリ・サーバーまたはパススルー認証ディレクトリ・サーバーとして動作します。これは、このサーバーがバインド・リクエストを他のディレクトリ・サーバーに渡すためです。認証ディレクトリ・サーバーBは、認証ディレクトリとして動作し、エントリを格納しており、リクエストしているクライアントのバインド資格証明を検証します。
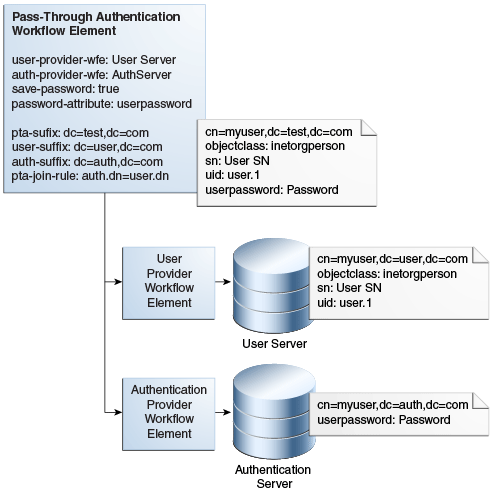
Oracle Unified Directoryは、パススルー認証ワークフロー要素を使用してパススルー認証を実装します。これにより、異なるディレクトリ・サーバーのインスタンスにあるユーザーおよび認証ディレクトリの管理が可能になります。
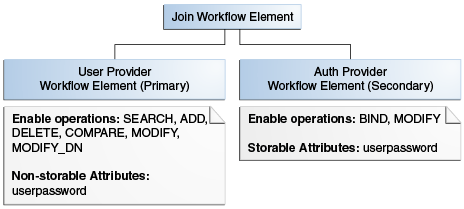
ユーザー・プロバイダは、ユーザー・エントリを含んだワークフロー要素であり、これはつまりユーザーのパスワードを除くすべての属性を含みます。一方、認証プロバイダは、ユーザー・パスワードを含んだワークフロー要素です。
|
注意: Oracle Unified Directoryは、ユーザー・プロバイダ・ワークフロー要素および認証プロバイダ・ワークフロー要素の両方のローカル・バックエンドまたはプロキシをサポートします。ただし、Kerberosは認証プロバイダ・ワークフロー要素のみでサポートされます。 |
図12-13は、パススルー認証構成モデルを示しています。
表12-1は、第12.4.4.2項「パススルー認証の構成モデル」で説明されているパススルー認証構成モデルで使用される構成パラメータについて説明しています。
dsconfigコマンドを使用したパススルー認証の構成の詳細は、第23.4項「パススルー認証の構成」を参照してください。
ODSMを使用したパススルー認証の構成の詳細は、第17.3.4.1項「ワークフロー要素の作成」を参照してください。
表12-1 パススルー認証プロセスで使用されるパラメータの構成
| パラメータ | 説明 |
|---|---|
|
|
ユーザー・プロバイダ・ワークフロー要素 このパラメータは、ユーザー・エントリを含むワークフロー要素を定義します。このワークフロー要素は、BIND以外のすべての操作に使用します。 これは必須パラメータです。 |
|
|
認証プロバイダ・ワークフロー要素 このパラメータは、認証エントリを格納し、リクエストしているクライアントのバインド資格証明を検証するワークフロー要素を定義します。このワークフロー要素は、 これは必須パラメータです。 |
|
|
このパラメータによって、パスワードコピー機能を有効化または無効化できます。このパラメータが これはオプションのパラメータです。デフォルト値は |
|
|
このパラメータは、パスワードコピー機能が有効なときに、ユーザー・エントリでコピーされるパスワード値の属性を定義します。パスワードの保存後、 これはオプションのパラメータです。デフォルト値は |
|
|
このパラメータは、パススルー認証ワークフロー要素によって公開される仮想DNを定義します。 これはオプションのパラメータです。デフォルトでは、このパラメータは設定されず、DNマッピングがないことを意味します。 |
|
|
このパラメータは、ユーザー・プロバイダ・ワークフロー要素のユーザー・エントリを含む実際の接尾辞を定義します。 これはオプションのパラメータです。デフォルトでは、このパラメータは設定されず、DNは |
|
|
このパラメータは、認証プロバイダ・ワークフロー要素の認証エントリを含む実際の接尾辞を定義します。 これはオプションのパラメータです。デフォルトでは、このパラメータは設定されず、DNは |
|
|
このパラメータは、認証エントリとユーザー・エントリ間のマッピングを定義します。 これはオプションのパラメータです。デフォルトでは、このパラメータは設定されず、ルールが |
ユーザー・エントリがKerberosサーバーに格納されている場合、Kerberosワークフロー要素を構成する必要があります。詳細は、第23.4.3.1項「異なるサーバーに対するパススルー認証の構成」を参照してください。
次に、パススルー認証ワークフロー要素のいくつかの機能を示します。
リクエスト・タイプに応じて、リクエストを特定のワークフロー要素へルーティングできます。たとえば、バインド・リクエストが認証ワークフロー要素へルーティングされます。userpasswordを除く任意の属性にMODIFYを適用する場合は、ユーザー・ワークフロー要素にルーティングされます。userpassword属性へのMODIFYの適用は、認証ワークフロー要素にルーティングされます(さらにパスワードコピーが有効な場合にはユーザー・ワークフロー要素にもルーティングされます)。ADD、DELETE、RENAME、COMPAREおよびSEARCHなどのその他の要素はすべて、ユーザー・ワークフロー要素にルーティングされます。
Kerberosワークフロー要素を認証ワークフロー要素としてサポートします。認証ワークフロー要素がKerberosワークフロー要素の場合、Oracle Unified Directoryが認証リクエストをKerberosサーバーに転送し、認証がLDAPバインドのかわりにKerberosプロトコルを使用して実行されます。
ユーザー資格証明を含んだ外部LDAPサーバーからOracle Unified Directoryへの移行を単純化します。移行フェーズの間に、正常なバインドが行われると、パススルー認証ワークフロー要素がユーザー・パスワードを外部LDAPサーバーからOracle Unified Directoryにコピーします。この機能は、パスワードコピーと呼ばれます。たとえば、ユーザーが正常に認証されると、外部LDAPサーバーの認証ワークフロー要素にバインドがルーティングされます。次に、パススルー認証ワークフロー要素は、ユーザー・ワークフロー要素でこのバインド操作に使用するパスワードを保存します。この移行フェーズでは、移行フェーズの間にアクセスを開始したすべてのユーザーのユーザー・パスワード属性が移入されます。
認証ワークフロー要素のエントリを結合ルールと認証サフィックスによってユーザー・ワークフロー要素のエントリにリンクする方法がサポートされます。この結合ルールは、DN=DNマッピングか、次の形式による単純な結合ルールで指定できます。
auth.<Attribute1>=user.<Attribute2>
結合ルールの詳細は、第12.5.1.3項「結合ルールの理解」を参照してください。
ユーザー・エントリと認証エントリ間のマッピングは、1対1のマッピングになる必要があります。これは、ユーザー・プロバイダの各エントリが認証プロバイダの1つのエントリに対応することを意味します。
DNマッピングのサポートにより、たとえばユーザー・ワークフロー要素の接尾辞がdc=user,dc=comである一方で、dc=pta,dc=comの配下にエントリを発行できます。
パスワード変更をサポートします。
ユーザー・ワークフロー要素に対して、ローカルやリモートなど、すべての種類のワークフロー要素をサポートします。
パススルー認証ワークフロー要素を使用する際には、次の点に留意する必要があります。
認証ワークフロー要素はバインド・リクエストのみを処理します。
ユーザー・ワークフロー要素は、ADD、DELETE、RENAME、COMPAREおよびSEARCHなどのその他のすべての操作に使用されます。
MODIFY操作は、save-password-on-successful-bindパラメータに依存します。このパラメータは、パススルー認証ワークフロー要素が認証ワークフロー要素へと正常にバインドしたとき、ユーザー・ワークフロー要素で要求されるとパスワードを保存します。
save-password-on-successful-bindを有効にした場合、両方の参加要素でuserpasswordパラメータが変更されます。
save-password-on-successful-bindを無効にした場合、userpasswordは、認証参加要素のみで変更されます。
user-suffixまたはauth-suffixパラメータを定義する場合、pta-suffixを定義する必要があります。両方のパラメータが、ユーザー認証参加要素とパススルー認証参加要素間のDNリネームに適用されます。
結合ルールを定義するときに、認証およびユーザー・エントリが同じDNを持つ必要がない場合、auth-suffixを定義する必要があります。
user-suffixが定義されていない場合、ワークフロー要素はuser-suffix=pta-suffixを仮定します。auth-suffixが定義されていない場合も同様です。この場合も、ワークフロー要素はauth-suffix=pta-suffixを仮定します。
Oracle Unified Directoryでは、パススルー認証ワークフロー要素を使用した次のLDAPの操作をサポートしています。
| 操作 | 説明 |
|---|---|
| ADD | パススルー認証ワークフロー要素によって処理されるADD操作はすべて、ユーザー・プロバイダ・ワークフロー要素に送信されます。
|
| BIND | BIND操作は、認証プロバイダ・ワークフロー要素にルーティングされます。
|
| COMPARE | COMPARE操作は、ユーザー・プロバイダ・ワークフロー要素にルーティングされます。userpassword属性に適用されるCOMPARE操作は、ユーザー・プロバイダ・ワークフロー要素にルーティングされます。save-password-on-successful-bindパラメータが有効化されていない場合、この要素には、この属性が含まれていない可能性があります。 |
| DELETE | DELETE操作は、ユーザー・プロバイダ・ワークフロー要素のみにルーティングされます。認証サーバーのエントリは削除されません。 |
| MODIFY | userpasswordを除くすべての属性に対して、ユーザー・プロバイダ・ワークフロー要素で変更が実行されます。userpassword属性の場合:
|
| MODIFY_DN | パススルー認証ワークフロー要素は、MODIFY_DNをユーザー・プロバイダ・ワークフロー要素のみで処理し、認証プロバイダ・ワークフロー要素のエントリは変更しません。 |
| SEARCH | SEARCH操作は、ユーザー・プロバイダ・ワークフロー要素のみにルーティングされます。これは、userpassword属性に対するリクエストを送信するSEARCH操作は、ユーザー・プロバイダ・ワークフロー要素にコピーがない場合は値を返さない可能性があることを意味します。 |
ユーザー・エントリがKerberosサーバーに格納されている場合、Kerberosワークフロー要素を構成する必要があります。詳細は、第23.4.3.2項「Kerberosサーバーに対するパススルー認証の構成」を参照してください。
Oracle Unified Directoryでは、既存のディレクトリ・サーバー機能を拡張できるプラグインAPIを提供しています。プラグインはワークフロー要素に類似しており、Oracle Unified Directoryワークフロー要素ツリーにプラグインを挿入できます。
特定のディレクトリ・サーバー要件があり、Oracle Unified Directoryにその要件に対応するための必要な機能がない場合、独自のプラグインの開発が必要になる場合があります。
Oracle Unified Directoryプラグインの詳細は、『Oracle Fusion Middleware Oracle Unified Directoryのためのプラグインの開発』のOracle Unified Directoryプラグインの基本コンセプトの理解に関する項を参照してください。
この項では、Oracle Unified Directoryの様々な機能を使用して、仮想ディレクトリおよびデータ・ソースのデータを表示および取得する方法について説明します。
この項の内容は次のとおりです。
この項では、結合ワークフロー要素について説明します。結合ワークフロー要素では、リポジトリの仮想ディレクトリ・ビューの表示や、これらのリポジトリ間でのデータのルーティングを行います。
この項の内容は次のとおりです。
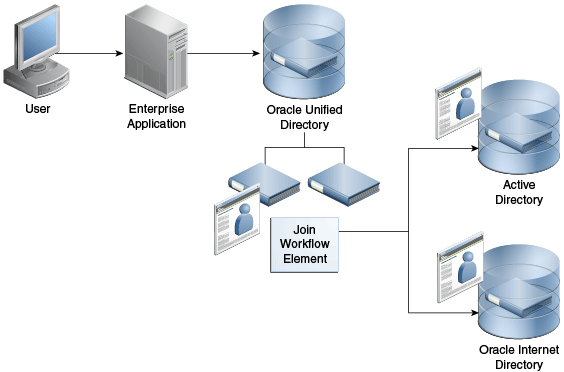
多くの企業では、1つのエントリのユーザー・プロファイル、アクセス・データおよび認証データなどのユーザー・アイデンティティ情報が、複数の場所の異種データ・ソースに散在しています。たとえば、従業員情報はHR (人事管理)データベースやMicrosoft Active Directoryに保存され、顧客およびパートナ・データはCRM (顧客管理)データベースやその他のLDAPディレクトリに保存されています。企業は、様々なデータ・ソースからリアルタイムでユーザー・データを集計する必要があります。その結果、アイデンティティ・データのコピーや同期を実行するアプリケーション専用のディレクトリが急激に増加し、これが高い管理コストやアイデンティティ・データの不整合およびコンプライアンスの問題を引き起こしています。
Oracle Unified Directoryには、これらの課題に対応するディレクトリ・サービス・ソリューションが用意されています。Oracle Unified Directoryでは結合ワークフロー要素がサポートされ、リポジトリの仮想ディレクトリ・ビューを表示したり、リポジトリ間でデータをルーティングすることができます。
Oracle Unified Directoryでは、基盤となるデータ・リポジトリに接続する、プロキシLDAPワークフロー要素などのワークフロー要素を定義できます。結合ワークフロー要素を使用して、必要に応じて別のワークフロー要素のデータを結合し、カスタマイズしたディレクトリ・ツリーを表示できます。
結合ワークフロー要素は動的で、データ・ソース間の同期を必要としません。識別データを元の場所から移動することなく編成し、コピーすることなく識別データを再使用します。これらの機能により、デプロイメントが簡単になり、コストが削減され、アイデンティティ・インフラストラクチャが単純になり、さらにアイデンティティ・ストアの変更に常にアプリケーションをあわせる必要がなくなるため投資回収率が向上します。
|
注意: ディレクトリの仮想化では、仮想化環境でディレクトリ・サーバーが実行されない点に注意してください。 |
1つのエントリに対応するデータが複数のデータ・ソースに分散されている場合、このワークフロー要素はこれらの異なるデータ・ソースを1つの統合LDAPビューに結合します。これは、リレーショナル・データベースの表結合に類似しています。結合ワークフロー要素は、基盤となるデータ・リポジトリには接続しません。かわりに、1つ以上のプロキシ・ソースまたはローカル・バックエンドに基づき、必要に応じてデータを構成します。結合ワークフロー要素は、ワークフロー要素間の結合関係(ジョイナとも呼ばれます)を定義することにより複数のデータ・リポジトリを結合するものと考えることができます。ワークフロー要素は必要な数だけ構成できます。
|
注意: 結合と分散を混同しないでください。
分散ワークフロー要素の詳細は、第22.1項「 |
結合ワークフロー要素の主な機能は次のとおりです。
任意の2つの参加要素間における関係を定義できます。1つのプライマリ参加要素と任意の数のセカンダリ参加要素をサポートします。詳細は、第12.5.1.2項「結合参加要素の理解」を参照してください。
複雑な結合ルールによる、結合参加要素間の洗練された関係ツリーをサポートします。詳細は、第12.5.1.3項「結合ルールの理解」を参照してください。
結合されたエントリを構成するために、プライマリ参加要素から取得された各エントリに、すべての関連付けられているセカンダリ参加要素を問い合せます。詳細は、第12.5.1.3項「結合ルールの理解」を参照してください。
1つの参加要素から取得された各エントリに、joinedentrydn属性値を追加します。これは、統合されたエントリの構成にセカンダリ参加要素のどのエントリが使用されたかを示します。詳細は、第12.5.1.3項「結合ルールの理解」を参照してください。
様々な結合シナリオに対応する1対1、多対1、シャドウなどの異なるジョイナ・タイプがサポートされます。詳細は、第12.5.1.5項「結合タイプの理解」を参照してください。
複数の参加要素の属性およびオブジェクトクラスを集計し、新しい仮想エントリを構成できます。詳細は、第12.5.1.7項「仮想属性の作成」を参照してください。
参加データ・ソースから取得する属性と、格納する属性を指定できます。詳細は、第12.5.1.8項「属性フロー設定の理解」を参照してください。
バインドのフォールスルー機能をサポートします。詳細は、第12.5.1.9項「バインド操作の処理」を参照してください。
各リポジトリ接尾辞から一般的な結合ワークフロー要素の接尾辞まで、DN構文属性値の翻訳をサポートします。詳細は、第12.5.1.10項「DN属性の翻訳の処理」を参照してください。
結合参加要素のクリティカル度を構成できます。詳細は、第12.5.1.11項「結合参加要素のクリティカル度の構成」を参照してください。
有効に設定された操作をサポートします。詳細は、第12.5.1.12項「有効化された操作の管理」を参照してください。
書込み操作をカスケードできます。詳細は、第12.5.1.13項「セカンダリ参加要素への書き込み処理のカスケードの処理」を参照してください。
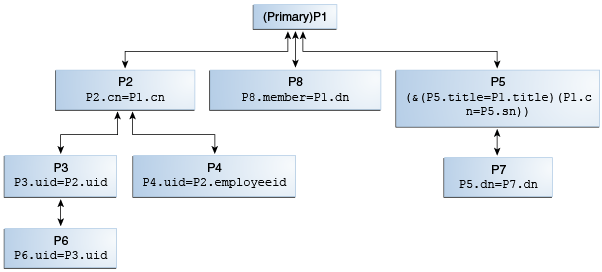
図12-14は、結合ワークフロー要素と結合ルールを使用する結合参加要素の構成モデルを示しています。
参加要素は、統合済の結合エントリを構成する結合ワークフロー要素に情報を提供するワークフロー要素です。結合ルールは、ある参加要素が他の参加要素とどのように関係するかを決定します。
Oracle Unified Directoryでは、すべての参加要素は同等に扱われますが、1つの参加要素をプライマリとして構成する必要があります。プライマリ参加要素に結合ルールを定義する必要はありません。この図のP1はプライマリ参加要素、他のすべての参加要素P2からP8はセカンダリ参加要素になります。
セカンダリ参加要素にはそれぞれ、他の参加要素との関係を定義する結合ルールとジョイナ・タイプがあります。たとえば、P2の場合、P2.cn=P1.cnの結合ルールがP1との関係を定義し、P2で構成されたジョイナ・タイプが多対1の場合、P1からP2への関係は1対多であることを意味します。
参加要素P2、P8およびP5はプライマリ参加要素P1と直接関係し、その他のセカンダリ参加要素はプライマリ参加要素と間接的に関係しています。
|
注意: 参加要素、結合ルールおよびジョイナ・タイプの詳細は、次の項を参照してください。 |
結合参加要素は、統合済の結合エントリを構成する結合ワークフロー要素にいくつかの情報を提供するワークフロー要素です。
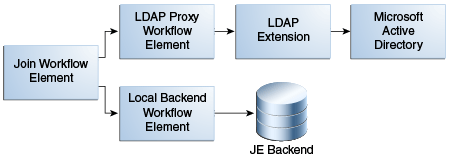
結合ワークフロー要素には、1つ以上の参加データ・ソースがあり、それぞれがワークフロー要素を通じて公開されます。参加しているワークフロー要素は次のとおりです。
分散ワークフロー要素
プロキシLDAPワークフロー要素
ローカル・バックエンド・ワークフロー要素
ロード・バランシング・ワークフロー要素
別の結合ワークフロー要素
たとえば、ディレクトリごとに、そのディレクトリから情報を取得するために、ディレクトリに関連付けられるプロキシLDAPワークフロー要素を作成する必要があります。次に、これらのワークフロー要素を結合ワークフロー要素の参加要素として編成する必要があります。
図12-15は、結合ワークフロー要素と参加しているワークフロー要素との関係を示しています。
結合ワークフロー要素にあるのは1つのプライマリ参加要素のみで、1つ以上のセカンダリ参加要素を含めることができます(このディレクトリ情報ツリー(DIT)構造はデフォルトで公開されています)。どの参加要素がプライマリであるかを決定します。
プライマリ参加要素を使用して、ディレクトリ・ツリー・エントリを作成および検索します。エントリは、結合ワークフロー要素から返されるために、プライマリ参加要素内に存在する必要があります。
結合ワークフロー要素は、プライマリ参加要素内の各エントリを取得し、定義された結合ルールに基づいて別の参加要素のエントリと結合します。プライマリ参加要素のエントリおよびセカンダリ参加要素にのみ存在するエントリを公開するように結合ワークフロー要素を構成することもできます。結合ルールの詳細は、第12.5.1.3項「結合ルールの理解」を参照してください。
結合ワークフロー要素および各参加要素には関連付けられた接尾辞(DN)を含める必要があります。
結合ワークフロー要素のDNは仮想DNであり、その結合ワークフロー要素に関連付けられたワークフローによって公開されます。表示をクライアントに関係のあるディレクトリ情報ツリーのみに制限するように結合ワークフロー要素を構成できます。
参加要素DNが、参加しているワークフロー要素またはワークフロー要素の子のDNによって公開されるバックエンド・ネーミング・コンテキストであることが理想的です。
結合ルールは、ある参加要素が他の参加要素とどのように関係するかを決定します。結合ルールを定義すると、LDAP操作時に結合ワークフロー要素がセカンダリ参加要素を問い合せることができます。
|
注意:
|
結合ワークフロー要素は、セカンダリ参加要素に定義された結合ルールに基づいて、各セカンダリ参加要素を検索する検索フィルタを構成します。
結合ワークフロー要素を構成する場合、ある参加要素のエントリと他の参加要素のエントリ間の関係を指定する結合ルールをセカンダリ参加要素ごとに構成する必要があります。また、結合ワークフロー要素が、関係ツリー全体の走査をプライマリ参加要素から開始できるように、少なくとも1つのセカンダリ参加要素に指定された結合ルールがプライマリ参加要素と関係する必要があります。
結合ルールは、他の参加要素を検索して一致したエントリを取得するために、1つの参加要素のエントリの属性に特定します。次に、この一致したエントリが、結合エントリを構成するために、元のエントリと結合されます。一致した値が対象となるビューで検出されると、2つのエントリ間に結合が作成されます。
結合ワークフロー要素は、参加している要素から取得された各エントリに属性値joinedentrydnを追加します。この値は、統合されたエントリの構成にセカンダリ参加要素のどのエントリが使用されたかを示します。この属性を移入するように、結合ワークフロー要素を構成するかどうかを判断できます。これは、結合の問題のトラブルシューティングに役立つ場合があります。
Oracle Unified Directoryでは次の結合ルール・タイプをサポートしています。
LDAPフィルタ結合ルール
DN結合ルール
結合ルールはLDAPフィルタ構文に従うため、ANDおよびORを使用する複雑な結合ルールを作成できます。例:
(&(P1.userId = P2.uid)(|(P1.deptNumber = P2.department)(P1.empNum = P2.empId)))
|
注意: Shadow結合関係では、結合ルールは、プライマリおよびシャドウ参加要素の両方で同じ属性を使用する必要があります。たとえば、p1.cn = p2.cnのように指定します。
詳細は、第12.5.1.5.4項「Shadowジョイナ・タイプ」を参照してください。 |
次に有効な結合ルールの例を示します。
p3.uid=p2.uid
(&(P5.title=Primary.title)(Primary.cn=P5.sn))
P5.dn = P7.dn
P8.member = Primary.dn
Primary.dn = P2.uniquemember
|
注意: 結合ルールを定義する順序は関係ありません。たとえば、P1.cn=P2.commonnameは、P2.commonname=P1.cnと同じです。 |
次の項では、2つの結合ルールについて簡単に説明します。
属性ベースの結合ルールは、2つの参加要素の一致するエントリにある共通の属性値を基に、2つの参加要素間の結合関係を定義します。
たとえば、p1.uid=p2.usernameという結合ルールについて検討します。ここでp1とp2は2つの結合参加要素です。この結合ルールは、p1内のエントリについて、p1のエントリのuid属性値がp2のエントリのusername属性値と一致する場合、p2の対応する一致エントリが取得され、p1のエントリと結合されることを示します。uidが、p1の複数値属性の場合、p2の対応するエントリは少なくともp1の1つの値と一致する必要があります。たとえば、p1のエントリにuid=user.12およびuid=user.34が含まれる場合、p2のエントリにはuid=user.12またはuid=user.34のいずれかが含まれている必要があります。
状況によっては、参加しているデータ・ソースに、エントリDN以外に共通の属性値がないことがあります。このような場合、エントリDNに関連する結合ルールを構成できます。
DN結合ルールではDN構文を使用し、次のいずれかの形式を使用することができます。
ある参加要素のエントリDNが、他の参加要素の属性から構成される。DNにセカンダリ参加要素のベースDNを含めることはできないため、相対DNにします。たとえば、次のDN結合ルールを構成できます。これにより、参加要素P2のエントリDNに参加要素P1のcnと接尾辞ou=peopleを含める必要があることを規定します。
P2.dn = "cn={P1.cn},ou=people"
ある参加要素のエントリDNが、他の参加要素の属性と一致する。たとえば、このルールは次の構文を使用して構成できます。
P8.member = P7.dn
このDN結合ルールは、P8のメンバー属性値が、P7の一致するエントリの検出に使用される必要があることを要求します。
ある参加要素のエントリDNが、他の参加要素のエントリDNと同じである。たとえば、このルールは次の構文を使用して構成できます。
P2.dn = P3.dn
この結合ルールはP2のエントリDNが、結合エントリを構成するためにP3のエントリDNと一致する必要があることを規定します。この場合、結合ルールは、完全DNが異なっても、参加要素の接尾辞より下位のDNの部分に一致するエントリを検索します。たとえば、参加要素P2にdc=primary接尾辞があり、参加要素P3にdc=secondary接尾辞がある場合、結合ルールは、接尾辞より下位のツリーは同一で、"uid=user.1,cn=users,dc=secondary"エントリを"uid=user.1,cn=users,dc=primary"に関連付けることを意味しています。
|
注意: Oracle Unified Directory 11.1.2.3は標準の結合機能のみをサポートします。そのため、第12.5.1.4項「結合ポリシーの理解」に記載されている左の外部結合および完全外部結合ポリシーは、このリリースで使用できないために、設定することはできません。 |
この項では、プライマリ参加要素とセカンダリ参加要素の結合を制御する様々な結合ポリシーについて説明します。特に、これらのポリシーでは、プライマリ参加要素のみのエントリ、セカンダリ参加要素のみのエントリまたはプライマリ参加要素とセカンダリ参加要素の両方のエントリなど、どのエントリを返すかを決定します。
Oracle Unified Directoryでは次の結合ポリシー・タイプをサポートしています。
標準結合。
左の外部結合。
完全外部結合。
|
注意: 特定の結合タイプを指定しない場合、Oracle Unified Directoryはデフォルトで標準結合を実行します。 |
標準結合ポリシー・タイプを指定した場合、Oracle Unified Directoryは、セカンダリ参加要素の対応するエントリを結合した後に検索フィルタを満たす、プライマリ参加要素のすべてのエントリを返します。
左の外部結合ポリシー・タイプを指定した場合、Oracle Unified Directoryは、セカンダリ参加要素の対応するエントリと結合した後にプライマリ参加要素のすべてのエントリを返し(標準結合を使用)、さらに、結合条件を満たし、かつプライマリ参加要素に対応する一致がある、セカンダリ参加要素のエントリを返します。このプロセスは、データベース用語の左の外部結合と同等です。
セカンダリ参加要素からプライマリ参加要素にエントリを結合している場合、結合関係は逆になります。たとえば、プライマリ参加要素からセカンダリ参加要素への1対多結合は多対1結合になります。これは、セカンダリ参加要素からプライマリ参加要素への1対1結合と同じです。同様に、プライマリからセカンダリへの多対1結合は、セカンダリからプライマリへの1対多結合になります。
完全外部結合ポリシー・タイプを指定した場合、Oracle Unified Directoryは、セカンダリ参加要素の対応するエントリと結合した後にプライマリ参加要素のすべてのエントリを返し(標準結合を使用)、さらに、結合条件を満たし、かつプライマリ参加要素に対応する一致がある、セカンダリ参加要素のエントリを返し(左の外部結合を使用)、さらに、検索フィルタを満たすが、プライマリ参加要素に一致するエントリがないセカンダリ参加要素のエントリを返します。このプロセスは、データベース用語の左の外部結合+右の外部結合と同等です。
セカンダリ参加要素からプライマリ参加要素にエントリを結合している場合、結合関係は逆になります。たとえば、プライマリ参加要素からセカンダリ参加要素への1対多結合は多対1結合になります。これは、セカンダリ参加要素からプライマリ参加要素への1対1結合と同じです。同様に、プライマリからセカンダリへの多対1結合は、セカンダリからプライマリへの1対多結合になります。完全外部結合の場合、逆の結合条件を計算できないため、セカンダリ参加要素のエントリの結合条件は無視されます。
次の表に、それぞれの結合ポリシーがどのように機能するかを示します。この例では、プライマリ参加要素およびセカンダリ参加要素に次のデータがあることを前提としています。
プライマリ参加要素のネームスペースはdc=internal, dc=comです。
セカンダリ参加要素のネームスペースはdc=external, dc=comです。
結合ワークフロー要素の接尾辞はdc=example,dc=comです。
表12-2 結合ポリシーの機能の説明
| プライマリ参加要素のデータ | セカンダリ参加要素のデータ |
|---|---|
dn: cn=Ronald, dc=internal,dc=com objectclass: inetorgperson cn: Ronald sn: Anne givenname: Anne Ronald telephonenumber: 54300 |
dn: cn=Ronald, dc=external,dc=com objectclass: inetorgperson cn: Ronald sn: Anne title: Manager |
dn: cn=Sam, dc=internal,dc=com objectclass: inetorgperson cn: Sam sn: Ketty manager: cn=Ronald, dc=internal,dc=com telephonenumber: 54301 |
dn: cn=Sam, dc=external,dc=com objectclass: inetorgperson cn: Sam sn: Ketty title: SMTS |
dn: cn=Richard,dc=internal,dc=com objectclass: inetorgperson cn: Richard sn: Rod title: Trainee manager: cn=Ronald, dc=external,dc=com telephonenumber: 54303 description: Trainee for dept 543 departmentNumber: 543 |
dn: cn=Richard,dc=external,dc=com objectclass: inetorgperson cn: Richard sn: Rod title: Trainee |
dn: cn=William,dc=internal,dc=com objectclass: inetorgperson cn: William sn: Tent description: User with no title |
dn: cn=Mike,dc=external,dc=com objectclass: inetorgperson cn: Mike sn: Ret title: MTS - dept_sec |
ジョイナ・タイプは2つの参加要素間の結合関係を定義します。結合関係は2つの結合参加要素の接続方法を定義します。さらに、2つの結合参加要素の結合関係は、接続元の参加要素から接続先の参加要素へ導き、その接続方法を定義します。これらのジョイナ・タイプは、定義済、複雑または単純などのあらゆる結合ルールで機能します。
|
注意: P1からP2への結合関係が多対1のジョイナ・タイプで構成された場合、結合ワークフロー要素はP2からP1への逆の関係を1対多のジョイナ・タイプで内部で暗黙的に作成します。また、この逆の場合も同様です。1対1のジョイナとShadowジョイナの場合、逆の関係にも元の関係で構成されたジョイナ・タイプと同じものが含まれています。 |
次の各項で、サポートされているジョイナ・タイプについて説明します。
1対1のジョイナ(単純な結合)は、2つの参加要素のエントリ間での1対1の関係を定義します。1対1のジョイナ・タイプでは、接続元の参加要素の各エントリが、この関係の接続先の参加要素にある1つのエントリと対応します。接続先の参加要素に複数の一致するエントリが存在する場合、結合ワークフロー要素は、接続先の参加要素から結合のために最初に返されたエントリを使用します。
結合の基準には、LDAPフィルタ構文を使用し、ANDおよびOR条件を組み合せて、より複雑な結合基準を指定できます。例:
( & (P1.userId = P2.uid) ( | (P1.deptNumber = P2.department) (P1.empNum = P2.empId) ) )
このシナリオでは、複雑な結合基準の構成を基にした、セカンダリ参加要素に使用される検索フィルタが含まれています。プライマリ参加要素のエントリに、結合ルールに指定されたプライマリ属性のいずれかがない場合、結合は構成されません。
図12-16に、認証に使用される1対1のジョイナの高度な例を示します。
1対多のジョイナ・タイプは、2つの参加要素間に1対多の関係を定義します。1対1の結合関係と同様に、1対多のジョイナでは、属性を比較することにより接続先の参加要素にエントリを配置します。ただし、接続元の参加要素のエントリが、接続先の参加要素の複数のエントリと対応する場合、このジョイナ・タイプでは、すべての一致するエントリを1つの仮想結合エントリに統合します。
1対多の結合は、複数のロール・オブジェクトまたはIDを1つの仮想エントリに統合するときに役立ちます。
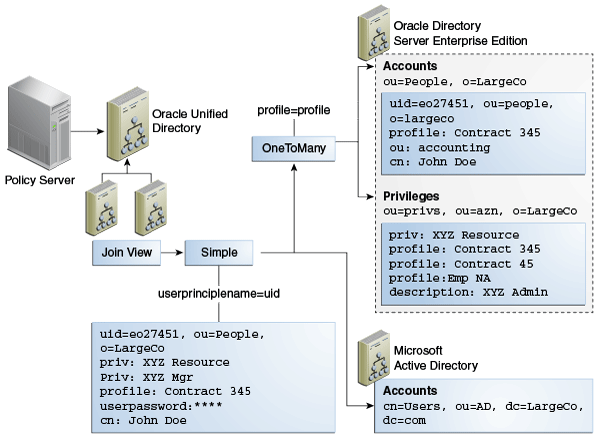
図12-17は、ポリシー・サーバーが、ある人のポリシーを決定するシナリオを表しています。統合を目的とする場合、ポリシー・サーバーは、権限属性として公開されているユーザーの権限が含まれる1つのエントリを認識することが望ましいとされます。これにより、ポリシー・サーバーは次の問合せで権限のアサーションをテストできます。
ldapsearch -b "uid=e027451,ou=People,o=LargeCo" -s base "(priv=XYZ Mgr)"
1対多ジョイナは、メインのou=Peopleエントリのプロファイル属性に基づいて、1つ以上の権限を1人のユーザーと一致させるために使用されます。1対多ジョイナは、エントリと同じプロファイル値を持つすべての権限を検索して、それらをエントリとマージします。第2段階では、1対1の結合が使用され、Oracle Directory Server Enterprise Edition (ODSEE)の統合されたプロファイルがユーザーのActive Directory資格証明に使用されます。
多対1の結合関係は、2つの参加要素間に多対1の関係を定義します。これは、接続元の参加要素の複数エントリに、接続先の参加要素の対応するエントリが1つ存在します。これは、1対多のジョイナ・タイプの逆です。
たとえば、プライマリ参加要素に従業員情報のリストがあり、セカンダリ参加要素に部門情報のリストがあるとします。1つの部門に複数の従業員が所属している場合、セカンダリ参加要素の1つの部門番号がプライマリ参加要素の複数の従業員に適用される可能性があります。
ただし、プライマリ参加要素からある従業員が削除された場合に、セカンダリ参加要素からその従業員の部門番号を削除する必要はありません。セカンダリ参加要素に多対1の関係を構成することで、このカスケード削除を回避できます。この関係は、プライマリ参加要素のエントリを削除しても、セカンダリ参加要素の共有エントリが削除されることはないことを意味します。
LDAPストアやデータベース・ストアなど、スキーマ拡張機能を必要とするが、ビジネスまたは技術的な理由によりスキーマ拡張ができないソースにエントリを格納する必要がある場合があります。Shadowジョイナでは、ローカル・バックエンド・ワークフロー要素など、別のストアの拡張属性を格納できます。
Shadow結合関係は、プライマリ参加要素のエントリと同じ構造を維持しますが、別のソースを使用してシャドウ・エントリを作成することで追加の属性を保持します。Shadow結合関係を使用すると、アプリケーションで企業ディレクトリを使用し、アプリケーション固有の属性をローカル・バックエンド・ワークフロー要素などのシャドウ・ディレクトリに格納できます。アプリケーションは、すべての属性を格納するディレクトリと通信していると認識しますが、アプリケーション固有のデータは、Oracle Unified Directoryにより別のシャドウ・ディレクトリに暗黙的に格納されています。
Shadowジョイナは、すべてのプライマリ参加要素のDNをハッシュにエンコードします。ハッシュはシャドウ参加要素の一致するエントリを検出するために使用されます。結合ワークフロー要素は、対応するレコードをシャドウ参加要素で見つけられないと、自動的に新しいレコードを作成し、指定の属性をシャドウ参加要素に格納します。Shadowジョイナ・タイプはアプリケーションに透過的に機能し、プライマリ・ワークフロー要素のエントリと同期してエントリの作成や名前の変更を処理します。
Shadowジョイナでは、すべてのLDAP操作がサポートされています。LDAP変更操作が行われると、Shadow結合はシャドウ参加要素の格納可能な属性によって示されたパラメータを調査し、これらの属性のいずれかをセカンダリ参加要素に格納する必要があるかどうかを確認します。これらの属性のいずれかが存在する場合、Shadow結合は、プライマリ・エントリのハッシュを使用して、ローカル・エントリの特定を試行します。
Shadow結合がローカル・エントリを特定した場合、そのエントリで適切なLDAP変更操作が実行されます。
Shadow結合がローカル・エントリを検出できない場合、セカンダリ検索が試行されます。Shadow結合は、プライマリDNが変更されている場合に備えて、主キーを使用して検索します。
ローカル・エントリが検出されない場合、Shadow結合は新しいエントリを自動的に作成します。
|
注意: Shadowジョイナの場合、結合ルールは、プライマリおよびシャドウ参加要素の両方に同じ属性を含める必要があります。たとえば、 p1.cn = p2.cnのように指定します。 |
高可用性を実現するには、シャドウ・バックエンドにレプリケーションを構成する必要があります。
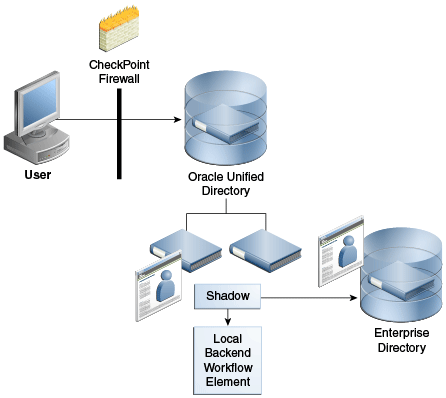
図12-18は、Oracle Unified Directoryへ接続するように構成された、CheckPointなどのファイアウォールを示しています。Oracle Unified Directoryは、ファイアウォール・スキーマを管理するためにローカル・バックエンド・データベースを使用します。これにより、企業ディレクトリ・スキーマをアプリケーション固有データで拡張することなく、企業エンタープライズ・ディレクトリへのファイアウォールの統合が可能になります。かわりに、Oracle Unified Directoryローカル・バックエンド・データベースにそれを格納することにより、ファイアウォール管理を担当するチームがアプリケーション固有データを管理できます。
図12-18 アプリケーション固有データをローカルに格納するために使用されるShadow結合の例
Oracle Unified Directoryでは、結合ルールのフィルタ条件を定義できます。指定された条件を満たすエントリのみが結合対象とみなされます。条件を満たさないエントリはすべて結合されずそのまま返されます。
この章で説明したジョイナ・タイプのいずれかを使用して結合フィルタ条件を構成できます。それぞれのジョイナ・タイプの詳細は、第12.5.1.5項「ジョイナ・タイプの理解」を参照してください。
Oracle Unified Directoryでは、結合条件が定義されている参加要素に対して常に結合条件を評価します。多くの場合、この結合条件の定義はプライマリ参加要素内でのみ役に立ち、他の参加要素内では役に立ちません。
LDAPフィルタ構文で結合条件を指定すると、ORおよびANDを使用する複雑なフィルタで結合条件を定義できます。例:
(&(employeenumber=101)(sn=Smith))
Oracle Unified Directoryでは、結合条件が定義されている参加要素に基づいて、常に結合条件を評価します。次の例では、Oracle Unified Directoryで、snがSmithおよびdepartmentNumberが101であるP2のユーザーのみをUserPrincipleName属性に基づいてP3に結合することを検討します。つまり、P2に対してこの構成を定義した場合、参加要素P2に関連付けられます。
ds-cfg-join-criteria: P2.uid = P3.UserPrincipleName ds-cfg-join-condition: (&(departmentNumber=101)(sn=Smith))
仮想属性は、結合ワークフロー要素の複数の参加要素に格納されている物理属性に基づいて作成できます。複数の参加要素から属性を取得できるため、属性の内容を定義する変数は完全修飾する必要があります。つまり、ソースの属性値には、その属性の取得元である参加要素の名前が含まれている必要があります。
たとえば、次のパラメータはP1およびP2の既存の属性からmail属性を作成します。このmail属性は、結合ワークフロー要素のds-cfg-create-virtual-attribute構成パラメータで指定されます。
ds-cfg-create-virtual-attribute: mail =
{P1.firstName}.{P2.lastName}@{P1.domainName}
この場合、firstName属性およびdomainName属性はP1参加要素から取得され、lastName属性はP2から取得されます。
結合ワークフロー要素は、各参加要素の個々の属性値に基づいた仮想属性の作成をサポートしています。また、単純な連結またはリテラル/属性値割当てもサポートしています。
department = "ST"
empid = P4.uid
memberof = P8.dn
mail = P3.CN + "." + P2.sn + "@oracle.com";
参加している各データ・ソースには、そこから取得できる属性と、格納できる属性を指定するための権限があります。参加しているワークフロー要素ごとに次の属性フロー設定を指定することにより、この権限を構成できます。
retrievable-attributeおよびnon-retrievable-attribute
storable-attributeおよびnon-storable-attribute
特に、これらの設定は結合参加要素に対する属性の移入方法および移出方法を制御します。また、認証されていないクライアントからの情報のリクエストや、そのようなクライアントに情報が返されるのを防ぐことによりセキュリティを強化できます。さらに、結合ワークフロー要素の場合、複数の結合参加要素が同じ仮想結合エントリに寄与できるため、属性フロー設定によってどの属性がどの参加要素に流れるかを制御します。
|
注意: アクセス制御とは異なり、属性フロー設定は通知のない適用を行います。つまり、クライアントにエラーを返すことなく、リクエストをフィルタ処理します。セキュリティ性の高い環境では、この通知のない適用により、クライアント側では、特定の属性の表示が許可されているかどうかさえ知ることができません。 |
次の各項では、それぞれの属性フロー設定について詳しく説明します。
この項では、retrievable-attributeおよびnon-retrievable-attributeの設定により、結合参加要素がターゲット・ディレクトリから取得できる属性を制御する方法について説明します。
結合参加要素を構成した場合、デフォルトではretrievable-attributeおよびnon-retrievable-attributeのリストは両方とも空です。つまり、すべての属性を取得できます。ただし、次のように、結合参加要素が取得できるまたは取得できない属性のリストを指定できます。
retrievable-attribute設定を使用して、結合参加要素がターゲット・ディレクトリから取得できる属性のリストを指定します。
この設定により、SEARCH操作およびCOMPARE操作中に、プロキシ設定されたサーバーから指定された属性のみを取得できるため、サーバーのパフォーマンスや、場合によってはセキュリティが向上します。
さらに、結合ワークフロー要素の使用時に、retrievable-attribute設定を使用して属性フローを制御できます。結合ワークフロー要素は複数の参加要素のエントリを結合するため、結合ワークフロー要素の参加要素ごとに、結合ビューの参加要素からの属性のフローを制限するようにretrievable-attribute設定を構成する必要があります。
non-retrievable-attribute設定を使用して、結合参加要素がターゲット・ディレクトリから取得できない属性のリストを指定します。
取得可能な属性のリストを指定するということは、特定の属性のみがプロキシ設定されたディレクトリからリクエストされることを意味します。retrievable-attributeのリストが空の場合は、non-retrievable attributeのリストが指定されないかぎり、すべての属性が取得可能であることを意味します。
たとえば、次の場合は属性A1を取得できます。
retrievable-attributeおよびnon-retrievable-attributeのリストが両方とも空の場合。
retrievable-attributeのリストが空で、non-retrievable-attributeのリストにA1が含まれていない場合。
retrievable-attributeのリストにA1が含まれ、non-retrievable-attributeのリストにA1が含まれていない場合。
この項では、storable-attributeおよびnon-storable-attributeの設定により、結合参加要素がターゲット・ディレクトリに格納できる属性を制御する方法について説明します。
結合参加要素を構成した場合、デフォルトではstorable-attributeおよびnon-storable-attributeのリストは両方とも空です。つまり、すべての属性を格納できます。ただし、次のように、結合参加要素が格納できるまたは格納できない属性のリストを指定できます。
storable-attribute設定を使用して、結合参加要素がターゲット・ディレクトリに格納できる属性のリストを指定します。
この設定により、ADD操作およびMODIFY操作では、指定された属性とその値のみがプロキシ設定されたサーバーに送信されるため、サーバーのパフォーマンスや、場合によってはセキュリティが向上します。
さらに、結合ワークフロー要素の使用時に、storable-attribute設定を使用して属性フローを制御できます。結合ワークフロー要素は複数の参加要素のエントリを結合するため、結合ビューの参加要素ごとに、結合ビューの参加要素からの属性のフローを制限するようにstorable-attribute設定を構成する必要があります。
non-storable-attribute設定を使用して、結合参加要素がターゲット・ディレクトリに格納できない属性のリストを指定します。
属性のリストを指定するということは、特定の属性のみが、参加しているワークフロー要素に移動できることを意味します。storable-attributeのリストが空の場合は、non-storable-attributeのリストが指定されないかぎり、すべての属性が格納可能であることを意味します。
たとえば、次の場合は属性を格納できます。
storable-attributeおよびnon-storable-attributeのリストが両方とも空の場合。
storable-attributeのリストは空であるが、non-storable-attributeのリストに該当する属性が含まれていない場合。
storable-attributeのリストに属性が含まれているが、non-storable-attributeのリストに該当する属性が含まれていない場合。
結合ワークフロー要素は、すべての参加要素に対してユーザー認証をサポートします。結合ワークフロー要素では、複数のデータ・ソースに対してパスワード検証を試行できるバインドのフォールスルー機能を提供しています。ユーザーの識別情報が複数のディレクトリに存在し、パスワードが任意のデータ・ソースに格納されている可能性があるため、複数のデータ・ソースに対してユーザーを認証する必要があります。
バインド機能を使用するには、バインドを該当する参加要素での有効な操作として構成する必要があります。--set participant-bind-priority構成パラメータを使用して、結合ワークフロー要素の各参加要素にバインドの優先度を割り当てます。これにより、バインドの処理時の参加要素の優先度が決まります。
各参加要素には、バインドの優先度が割り当てられ、バインドが成功するまですべてのバインド参加要素は指定された順序でフォールスルーされます。バインドのエラーは、すべてのバインド参加要素がユーザーの認証に失敗した場合にのみ返されます。
バインドの優先度は、ゼロ以上の任意の正の整数を指定できます。優先度は0から高い整数値になるにつれて低くなります。つまり、最小の値を指定された参加要素はバインドの優先度が最も高く、次に小さな値を指定された参加要素はバインドの優先度が次に高く、それ以降も同様です。最も高い優先度はゼロです。
DN属性は、member、uniquemember、managerなど、ネームスペース変換が必要なDNとして処理される属性のリストです。たとえば、これらの属性がDN属性リストにある場合、プロキシ・ディレクトリからグループ・エントリを読み取る際には、結合ワークフロー要素でuniquemember属性またはmember属性だけでなく、グループ・エントリのDNが変換されます。
|
注意: クライアント・アプリケーションで必要とされる属性のみを変換します。すべての有効なDN属性を入力することが、アプリケーションで必要になる場合はないはずです。 |
criticality構成パラメータは、ホスト・エラーによって参加要素に対して実行される検索が失敗したときの結合ワークフロー要素の動作を指定します。クリティカル度は検索リクエストにのみ適用されます。
WRITE操作は、すべての参加要素で常にクリティカルです。
BIND操作およびCOMPARE操作は、すべての参加要素で常に非クリティカルであるため、成功が検出されるまで、すべての適用可能な参加要素をフォールスルーできます。
結合参加要素のクリティカル度を構成するには、dsconfig set-join-participant-propサブコマンドを使用して、次のクリティカル度フラグ値のいずれかを設定します。
true (デフォルト設定)
この設定は、対象の参加要素がクリティカルであることを示します。参加要素が操作エラーによって結果を返すことに失敗した場合、結合ワークフロー要素によって検索操作全体が失敗し、データが他の参加要素で検出されたかどうかにかかわらずDSA Unavailableエラーがクライアントに返されます。
false
この設定は、参加要素での操作実行の失敗は全体的な結果にとってクリティカルではないことを結合ワークフロー要素に伝えます。非クリティカルな参加要素で操作エラーが発生した場合、LDAP検索の全体的な結果からその結果が除外されます。結合ワークフロー要素は、他の参加要素から結果の一部を返し、エラーを通知しません。
partial
この設定は、対象の参加要素が部分的にクリティカルであることを示します。結果の一部が取得されたことをアプリケーションからユーザーに通知できることを意味します。部分的にクリティカルな参加要素が、操作エラーによって結果を返すことに失敗した場合、結合ワークフロー要素は部分的な結果だけでなくAdmin Limit Exceededエラーも返します。これは、実際の内容とは異なるエラーですが、この設定の目的は、クライアント・アプリケーションのロジックによって、表示されている結果が全体の一部にすぎないことが示されることです。
たとえば、次のコマンドでは、joinparticipant-1という名前の参加要素のクリティカル度がtrueに設定されます。
dsconfig -h localhost -p 4444 -D "cn=Directory Manager" -j pwd-file \ set-join-participant-prop --element-name we-join \ --participant-name joinparticipant-1 \ --set participant-criticality:true
結合参加要素で実行するLDAP操作をds-cfg-enabled-operationパラメータを使用して構成できます。次の操作が対象となります。
ADD
BIND
COMPARE
DELETE
MODIFY
MODIFYDN
SEARCH
参加要素は、このパラメータで指定された操作にのみ参加できます。
COMPARE、DELETE、MODIFYおよびSEARCHの操作はデフォルトで有効になっています。
参加要素がバインド操作に参加できるように、BINDを有効な操作として構成する必要があります。BIND操作を有効にした場合、構成されたバインドの優先度によって、バインドの処理時の参加要素の優先度が決定されます。
ADDおよびMODIFYDNの操作はデフォルトでは有効ではありません。
結合がShadow結合の場合、プライマリ参加要素およびセカンダリ参加要素でADDおよびMODIFYDNを有効にできます。
結合がShadow結合ではない場合、プライマリ参加要素でADDおよびMODIFYDNのみ有効にできます。
セカンダリ参加要素にDELETEおよびMODIFYなどの書込み操作をカスケードできます。つまり、エントリがプライマリ参加要素から削除された場合、すべてのセカンダリ参加要素の関係するエントリも削除されます。ただし、このカスケード操作は、関連付けられたセカンダリ参加要素でDELETE操作が有効な操作として構成されており、さらに元の参加要素とto-be-cascaded-delete参加要素の関係が多対1ではない場合にのみ適用可能です。
MODIFY変更も、有効な操作の構成と、格納可能な属性の構成を基に、すべての適用可能なセカンダリ参加要素にカスケードされます。ADDおよびMODIFYDN変更も、セカンダリ参加要素での格納可能属性の構成を基に、シャドウセカンダリ参加要素にのみカスケードされます。
結合ワークフロー要素では、図12-19に示すとおり、バインド・リクエストを認証(Auth)プロバイダ・ワークフロー要素に委譲し、非バインド・リクエストをユーザー・プロバイダ・ワークフロー要素に委譲するように構成できます。また、この構成では、Authプロバイダ・ワークフロー要素へのMODIFY PASSWORDリクエストの委譲と、ユーザー・プロバイダ・ワークフロー要素へのその他のMODIFY操作の委譲も処理します。
パススルー認証ワークフロー要素では満たすことができない特別な要件がある場合のみ、結合ワークフロー要素を使用してパススルー認証を構成します。たとえば、パススルー認証ワークフロー要素がバインド・リクエストをユーザー・プロバイダ・ワークフロー要素にルーティングせず、ユーザー・パスワードが認証プロバイダ・ワークフロー要素にのみ格納される場合です。ユーザー・パスワードを認証プロバイダ・ワークフロー要素とユーザー・プロバイダ・ワークフロー要素の両方に格納する、異なるデプロイメントのシナリオが必要な場合は、結合ワークフロー要素を使用して、バインド・リクエストを処理するように両方のプロバイダを構成できます。
ある属性がプライマリ参加要素およびセカンダリ参加要素の両方に存在する場合、結合ワークフロー要素では属性値をマージします。読取り操作の場合、これは、すべての参加要素の値を持つ複数値属性が返されることを意味します。書込み操作の場合、プロキシが、すべての参加要素に問い合わせて、結合参加要素のそれぞれで構成されている格納可能属性を基に、どこに値を書込むかを決定します。
結合ワークフロー要素を構成する場合、次の点に留意する必要があります。
複数のデータ・ソースの複数の属性が同じ名前の場合(2つの異なるプロキシLDAPワークフロー要素の2つのuid属性など)、結合ワークフロー要素により表示されるのは1つの値のみです。
ただし、特定の参加要素の属性値を取得するように結合ワークフロー要素を構成できます。これを実行するには、属性を表示しない参加要素の「取得可能な属性」フィールドから属性を削除します。
結合ワークフロー要素のエントリおよび属性に、適切にアクセス権の付与または拒否を行うように仮想ACIを構成する必要があります。
プロキシLDAPワークフロー要素が結合参加要素として使用されている場合、各参加要素で操作の実行に使用される資格証明は、次のように重要な役割を果たします。
プロキシLDAPワークフロー要素でuse-specific-identityバインド・モードが構成されている場合、すべての非バインド操作に特定のIDのみが使用されます。
プロキシLDAPワークフロー要素でuse-client identityバインド・モードが構成されている場合、userDNがプロキシLDAPワークフロー要素のinclude-listで構成されている任意のDNの子の場合に、実際のクライアント資格証明が使用されます。そうでない場合、Oracle Unified Directoryでは、プロキシLDAPワークフロー要素で操作を実行するために、特定のIDが使用されます。
すべてのプロキシLDAPワークフロー要素が、それぞれのユーザー・コンテナDNにinclude-listを設定し、バインドがクライアントDNまたは特定のIDのいずれかによって正しく発生するようにする必要があります。この構成では、各参加要素のユーザー・コンテナが一意であることも必要です。そうでない場合、バインドは失敗します。
プロキシLDAPワークフロー要素では、一部の内部操作でプロキシおよびルート資格証明が使用されるため、これらの資格証明を常に構成する必要があります。これらの資格証明は、プロキシLDAPワークフロー要素でinclude-listを構成する場合にも必要です。
表12-3では、結合ワークフロー要素が各LDAP操作を処理する方法について説明します。
表12-3 結合ワークフロー要素がLDAP操作を処理する方法
| LDAP操作 | 処理の説明 |
|---|---|
|
|
|
|
|
バインドの優先度を基に各バインド参加要素で処理されます。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
先に、プライマリ参加要素で処理されます。次に、結合条件を満たすプライマリ参加要素から返されたエントリごとに、該当するすべてのセカンダリ参加要素とエントリが結合されます。 |
|
注意: たとえば2つの異なるプロキシLDAPワークフロー要素にある2つのuid属性など、複数のデータ・ソースの複数の属性が同じ名前の場合、結合ワークフロー要素は1つの値のみを表示します。ただし、特定の参加要素の属性値のみを取得するように結合ワークフロー要素を構成できます。特定の参加要素の属性のみを表示するには、属性を表示しない参加要素の「取得可能な属性」フィールドに、その属性がリストされていないことを確認する必要があります。 |
Oracle Unified Directoryでは、検索結果を自動的に絞り込む2つのワークフロー要素が提供されており、仮想データ・ソースのデータを効率的に表示または取得するのに役立ちます。これらのワークフロー要素を、検索結果を返すワークフローに挿入できます。
GetRidofDuplicateワークフロー要素は、現在の検索操作の検索結果から、クライアント・アプリケーションにDNがすでに返されたすべてのエントリを削除します。これは、ワークフロー要素が、DNが同じ複数(数百の場合もある)のエントリを返す可能性がある場合に有用です。
HideByFilterワークフロー要素では、検索操作によってエントリが返される詳細を制御できます。たとえば、Oracle Unified Directoryをアドレス帳ディレクトリとして使用する場合、カスタマ・サービス担当者のエントリのみを表示できます。まず、カスタマ・サービス担当者にCSRなどのou値を付与します。そうすると、hideByFilterがou=CSRに設定されたHideByFilterワークフロー要素を使用できます。ディレクトリが検索されると、カスタマ・サービス担当者のエントリのみが返されます。
GetRidOfDuplicatesおよびHideByFilterワークフロー要素の構成の詳細は、第24.2項「仮想ディレクトリからの検索結果の最適化」を参照してください。
personエントリへのmemberofユーザー属性の追加memberofユーザー属性をpersonエントリに追加するように、VirtualMemberofワークフロー要素を構成できます。これは、アプリケーションでグループ・メンバーシップを確認する必要があるが、これらのグループに対するセカンダリ検索の実行を必要としない場合に役立ちます。
memberof属性の値は、personエントリが属するすべてのグループのDNです。
|
注意: VirtualMemberOfワークフロー要素のみがSEARCH操作に影響を与えます。
VirtualMemberofワークフロー要素の作成および構成の詳細は、第24.3項「 |
memberof属性の使用検索フィルタでmemberof属性を使用できます(例: MemberOf=group1)。ただし、memberofは次の組合せをサポートしていません。
memberofに対するPRESENT、SUBSTRING、GREATER_OR_EQUAL、LESS_OR_EQUAL
ORフィルタと内部memberofコンポーネント
NOTフィルタと内部memberofコンポーネント
これらの制限に基づいて、内部memberofコンポーネントはANDフィルタでのみサポートされます。
検索フィルタでmemberof属性を使用する場合、Oracle Unified Directoryではobjectclass=personのエントリのみ返します。VirtualMemberofワークフロー要素は、非personエントリでのmemberof属性の使用をサポートしていません。
ディレクトリの各エントリは、DNおよび属性と属性値のセットにより識別されます。クライアント側で定義されたDNおよび属性は、サーバー側で定義されたDNおよび属性にマップされない場合があります。たとえば、サンプルAという組織ではdc=parentcompany, dc=comというエントリを使用しているとします。ここに、サンプルBという別の組織が加わりました。このサンプルBは、dc=newcompany, dc=comというエントリを使用しています。つまり、既存のクライアント・アプリケーションを正しく動かすには、dc=newcompany, dc=comをdc=parentcompany, dc=comにリネームする必要があります。
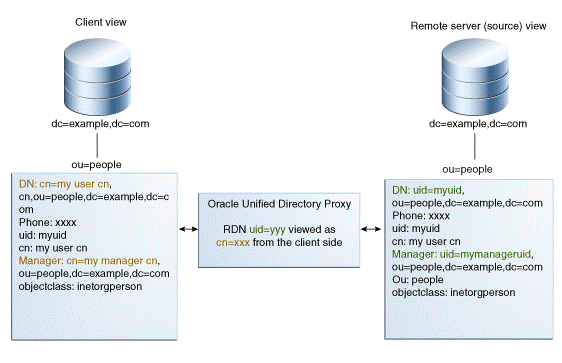
DNリネーム・ワークフロー要素を定義して、DNをサーバー側と一致する値にリネームできます。クライアントがリクエストを行うと、DNと属性の名前がサーバー側と一致するように変更されます。結果がクライアントに返されるときには、DNと属性はクライアント側と一致するよう元に戻されます。
Oracle Unified Directoryでは、ディレクトリ情報ツリー(DIT)のコンテンツを、異なるベースDNの別のDITに変換できるDNリネーム・ワークフロー要素が用意されています。ある操作(追加、バインド、削除、変更など)がDNリネーム・ワークフロー要素を通ることにより、DNリネーム構成に従ってパラメータが変換され、仮想エントリから実際のエントリへの変換が行われます。
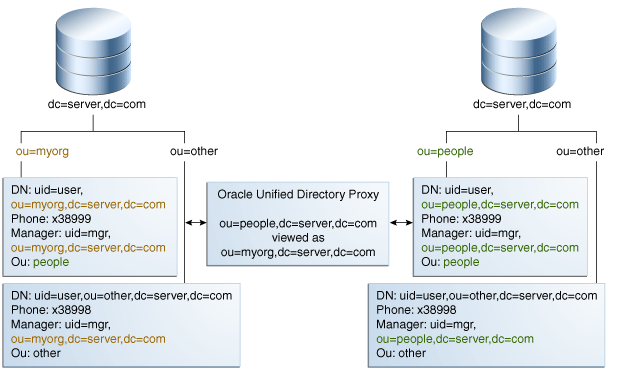
図12-20は、プロキシを使用したDNリネームの動作を示しています。
クライアントはou=myorg, dc=server, dc=comエントリを待機します。しかし、LDAPサーバー上のエントリはou=people, dc=server, dc=comです。プロキシは、DNリネーム・ワークフロー要素を使用してDNのリネームを行います。
この例では、実際のエントリou=people, dc=server, dc=comを、クライアントからはou=myorg, dc=server, dc=comエントリに見えるようにします。
DNリネーム変換は、次のオブジェクトに対して適用可能です:
エントリのDN
たとえば、LDAPサーバー上の実際のエントリであるdn:uid=user, ou=people, dc=server, dc=comが、クライアントの仮想エントリdn:uid=user, ou=myorg, dc=server, dc=comに変換されます。
DNまたは名前とオプションUID構文のいずれかを含むエントリの属性。
たとえば、オブジェクトクラスinetorgpersonのエントリのmanager属性のサーバー側の値は、DN構文: manager: uid=mgr,ou=people,dc=server,dc=comを持ち、クライアント側の値であるmanager: uid=mgr,ou=myorg,dc=server,dc=comに変換されます。
別の例では、uniquemember属性のサーバー側の値は、名前とオプションUID構文(RFC 4517で定義)をuniquemember: uid=member,ou=people,dc=server,dc=com#'0111'Bとして持ち、クライアント側で値uniquemember: uid=member,ou=myorg,dc=server,dc=com#'0111'Bに変換されます。
|
注意: 変換は、エントリのすべてのユーザー属性に適用できます。このとき、該当する属性リストを定義したり、該当しない属性リストを定義することもできます。 |
Oracle Unified Directoryでは、RDNChanging構成を使用して、ソース・ディレクトリからOracle Unified Directoryに対して、RDN値をリネームまたは置換することが可能です。
図12-21は、プロキシを使用したRDN変更の動作を示しています。
|
注意: 相対識別名(RDN)は、エントリDNの左端の要素です。たとえば、uid=Marcia Garza,ou=People,dc=example,dc=comのRDNは、uid=Marcia Garzaです。変更できるのは、エントリDNの一番左の要素のみです。 |
RDNChanging構成には、次のパラメータがあります:
RDNの名前変更を実行するオブジェクト・クラスのタイプを指定します。デフォルト設定はpersonです。
TrueまたはFalse: クライアント・ビュー内の元のRDN値(source-rdnパラメータで指定)を新しいRDN値(client-rdnパラメータで指定)に置き換えるかどうかを指定します。デフォルトの設定はtrueです。
|
注意: この値がtrueに設定されており、エントリの新しいRDN属性に複数の値がある場合、Oracle Unified DirectoryではRDNの最初の値が使用されます。 |
Oracle Unified Directoryで置換または変更される、ソース・ディレクトリの元のRDN属性名を指定します。
Oracle Unified Directoryで使用される新しいRDN属性名を指定し、source-rdn構成パラメータで指定されている属性名と置き換えます。
RDNの名前変更を実行するDNを持つ属性のリスト。属性のデフォルト・リストはmember、managerおよびownerです。
分散デプロイメントでグローバル索引カタログを使用できます。容量ベース分散を構成する場合、DNを索引とするグローバル索引カタログをセットアップする必要があります。グローバル索引カタログは、エントリと、そのデータを格納する分散パーティションとをマップします。プロキシはクライアントからリクエストを受信すると、分散が、グローバル索引カタログで属性エントリを検索して、クライアント・リクエストを正しいパーティションに転送します。これにより、ブロードキャストの手間を省くことができます。さらに、DN変更リクエストが行われる場合、グローバル索引カタログにより、そのエントリが確実に存在することを確認することができます。
グローバル索引カタログは、従業員番号や電話番号など、特定の属性に基づいてエントリをマップします。索引とする属性値は、全エントリにおいて一意である必要があります。たとえば、一意でない国などに基づいて、グローバル索引を使用してエントリをマップすることはできません。
値が一意でない属性を索引とした場合、プロキシ・サーバーが、リクエストされるすべてのエントリを返せないことがあります。たとえば、必ずしも一意とはかぎらないmail属性を索引にしたとします。そして、次の2つのエントリを連続で追加します:
uid=user.1およびmail=joe.smith@example.comの属性を持つエントリ1はパーティション1に送信されます。
uid=user.2およびmail=joe.smith@example.comの属性を持つエントリ2はパーティション2に送信されます。
この状況では、グローバル索引mailは、2つ目のエントリへの参照のみを保持します。この場合、フィルタ(mail=joe.smith@example.com)の検索を実行すると、2つ目のエントリuid=user.2のみが返されることになります。
グローバル索引カタログには、複数のグローバル索引を含めることができます。各グローバル索引でそれぞれ異なる属性のマッピングを行います。たとえば、電話番号をベースにしたエントリのマッピングを行うグローバル索引と、従業員番号をベースにしたエントリのマッピングを行うグローバル索引を含むGI-catalogというグローバル索引カタログをセットアップできます。この場合、電話番号または従業員番号のいずれかを使用して、正しいパーティションにクライアント・リクエストを転送できます。
グローバル索引カタログとグローバル索引は、gicadmコマンドを使用して作成および構成されます。
グローバル索引には、LDIFファイルからデータを移入できます。1つのLDIFファイルのデータは、split-ldifコマンドを使用してパーティションに分割できます。詳細は、付録A「split-ldif」を参照してください。
シングル・ポイント障害を回避するために、グローバル索引カタログはレプリケートする必要があります。グローバル索引カタログのレプリケートの詳細は、第23.7.2項「グローバル索引カタログのレプリケーション」を参照してください。
例12-4 電話番号のグローバル索引カタログの使用
グローバル索引の作成に使用できる一意の属性の一般的な例は、電話番号です。この属性値は一意になるので、その電話番号を持っている人物(従業員など)は1人のみです。
次の例では、データベース内のエントリは電話番号に基づいて分割されています。グローバル索引には、次の情報が含まれています:
| 値 | パーティションID |
|---|---|
| 4011233 | 1 |
| 4011234 | 1 |
| 7054477 | 2 |
グローバル索引には、従業員名、場所または電話番号に関連付けることのできるその他の属性値は格納されません。属性の索引とパーティションとのマッピングのみが行われます。索引値(ここでは電話番号)に関連付けられているデータは、リモートLDAPサーバー上に置かれています。
1人の従業員が複数の電話番号を持っている場合、複数値エントリとしての扱いになります。この場合、グローバル索引が電話番号に基づいて作成される際、たとえばBen Brownという1人の従業員を検出するグローバル索引エントリが2つできるということになります。
前述の例では、従業員Ben Brownには、4011233と7054477の両方の電話番号が割り当てられています。この場合、Ben Brownの1つの電話番号を検索すれば、Ben Brownに2つの電話番号が割り当てられていることとは関係なく、正しいパーティションと、その電話番号に関連付けられている、Ben Brownという名前を含むすべての情報が返されます。
Oracle Unified Directoryは、ワークフロー要素の定義を介したデータ変換をサポートしています。ワークフロー要素のインスタンスを作成することにより、物理データを異なる方法で表示できます。
この章では、Oracle Unified Directoryで変換がどのように発生するのかについて説明します。この章の内容は次のとおりです:
LDAPクライアント・アプリケーションのデータ構造が、LDAPリポジトリのデータ構造と異なる場合があります。スキーマが異なる場合もあれば(エントリ内の属性タイプが異なる)、値が異なる場合もあります(属性名は同じでも値のセマンティクスが異なる)。これが、変換が必要な対象となります。
1つの変換は、特定の方向における特定のアクションを実行します。必要な変換を指定し、既存のワークフロー要素に対する変換を定義します。
この項の内容は次のとおりです。
変換の方向(つまり、変換がリクエスト中に適用されるのか、応答中に適用されるのか、または両方に適用されるのか)により、変換モデルが決まります。
変換は次のタイプに分類できます:
読取り変換(アウトバウンド変換): 詳細は、第12.7.1.1.1項「読取り変換」を参照してください。
書込み変換(インバウンド変換): 詳細は、第12.7.1.1.2項「書込み変換」を参照してください。
マッピング変換(双方向変換): 詳細は、第12.7.1.1.3項「マッピング変換」を参照してください。
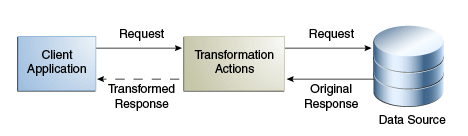
読取り変換は、一般的に使用される変換です。読取り変換は、リクエストへの応答中にのみ発生します。リクエスト中には変換は行われず、物理データの変更はありません。
図12-22は、読取り変換の概念を示しています。
組織に、personエントリを表示するレガシー・アプリケーションがあるとします。このアプリケーションは、email属性を含まないエントリをサポートしません。物理データ・ソースはアップグレードされており、email属性はpersonエントリから削除されています。
そこで、検索応答中にemail属性を追加するという変換を適用する必要があります。この変換は、データ・ソースから読み取られるエントリを変更し、email属性を追加します。このとき、この属性値はfirstname.surname@mycompany.comになります。元に戻す変換は必要ないので、物理データは変更されません。
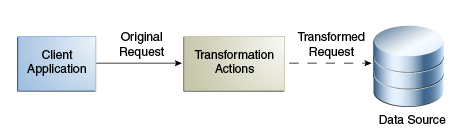
書込み変換は、応答中ではなく、リクエスト中に適用される変換です。書込み変換は、バックエンドに格納する前に、クライアントによって提供されたデータを変更します。
図12-23は、書込み変換の概念を示しています。
組織に、personエントリをデータ・ソースに追加するレガシー・アプリケーションがあるとします。このアプリケーションは、email属性なしでエントリを追加します。物理データ・ソースはアップグレードされており、email属性はpersonエントリの必須属性となっています。そこで、追加リクエスト中にemail属性を追加するという変換を適用する必要があります。この変換は、データベースに書き込むエントリを変更します。逆の変換は必要ありません。
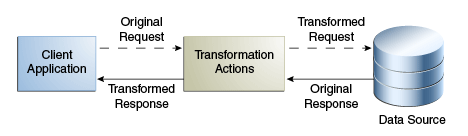
マッピング変換は、一般的に使用される変換です。これは、まず変換がリクエスト中に適用され、逆の変換が応答中に適用されるという双方向の変換です。このような変換は、物理データ・ビュー内の属性またはエントリが、仮想データ・ビュー内の属性またはエントリにマップされるため、マッピング変換と呼ばれます。マッピング変換では、既存値を、DNコンポーネント、属性タイプまたは値、またはオブジェクト・クラスに割り当てる前に、処理することができます。
図12-24は、マッピング変換の概念を示しています。
組織に、surnameおよびfirstnameの属性を持つエントリが格納される物理データ・ソースがあるとします。この組織には、firstname surnameという形式のcn (共通名)属性を持つエントリを要求するクライアント・アプリケーションがあります。
このクライアント・アプリケーションは、cn=Joe Smithという形式のエントリの検索リクエストを送信します。変換は、このリクエスト中に名(firstname)と姓(surname)を抽出し、このリクエストをsurname=Smith, firstname=Joeという形式に変換するように定義されています。対応するエントリは、データ・ソース内にあります。このエントリをクライアント・アプリケーションに戻す前に、逆の変換が実行されます。クライアント・アプリケーションは、認識できるcn=Joe Smithというエントリを受信します。
このリクエストは、surname=Smith, firstname=Joeという形式に変換されます。
Oracle Unified Directoryは、プロキシ・サーバーでの変換をサポートするLDAPサーバーです。
変換を実装するには、次の処理が必要です。
変換タイプのワークフロー要素のインスタンスを作成します。
目的のワークフロー要素リストに変換ワークフロー要素を挿入します。
|
注意:
|
変換ワークフロー要素インスタンスは、特定の変換アクションが定義されているデータ・ビューのことです。
この項では、変換のワークフロー要素を構成するためのコンポーネントについて説明します。
この項の内容は次のとおりです。
変換タイプのワークフロー要素は、次の変換セットで構成できます:
|
注意: 説明:
|
この項の内容は次のとおりです。
addOutboundAttribute変換タイプこの変換は、検索操作中、リクエスト内の属性リストが未定義(つまり、すべて該当)な場合、またはその属性が含まれている場合に、クライアントに返されるエントリに、仮想属性または値を追加します。
エントリに仮想属性がすでに含まれているかどうか判断できない場合、conflict-behaviorパラメータが、次のポリシーのどれを適用するかを決定します:
仮想値を追加しない
仮想値を追加して、既存値とマージする
既存値を仮想値に置き換える
仮想属性をソース・リポジトリで検索できる場合(ソース・リポジトリ内のエントリの一部に仮想属性が含まれており、この属性について検索が最適化されている)、およびフラグvirtual-in-sourceが設定されている場合、変換プロセスは、SEARCH REQUESTフィルタで仮想属性をソース・リポジトリに転送します。通常、仮想属性はソース・リポジトリに転送されません。このパラメータがFALSEに設定されている場合、検索リクエストは一般用に最適化されているということです。つまり、仮想属性はソース・リポジトリには存在していないことを意味します。
|
注意: 追加リクエストまたは変更リクエストに仮想属性を含めることが必要とされる場合は、ソース・スキーマ・チェックが適用されます。したがって、仮想属性を受け入れるようにソースのスキーマを構成することをお薦めします。それ以外の場合は、スキーマ・チェックを無効にしてください。 |
表12-4は、addOutboundAttribute変換タイプのパラメータを説明しています。
表12-4 addOutboundAttribute変換タイプのパラメータ
| パラメータ | dsconfig CLI | 複数(M)/単一(S)値 | オプション(O)/必須(M) | 値 |
|---|---|---|---|---|
|
クライアント仮想属性の名前とクライアント仮想属性の値定義 |
|
S |
M |
文字列 詳細は、第12.7.2.3項「変換のための属性値の定義」を参照してください。 たとえば、 |
|
競合動作ポリシー |
|
S |
O [デフォルト= |
|
|
ソース内の仮想ポリシー |
|
S |
O |
|
|
エントリが一致する必要があるフィルタベースの条件 |
|
S |
O |
LDAPフィルタ |
|
祖先である必要があるDNベースの条件 |
|
M |
O |
DN |
|
処理する操作から操作を除外する条件 |
|
M |
O |
列挙(ADD、MODIFY...) |
filterOutboundAttribute変換タイプこの変換では、ソースから受信したエントリをクライアントに送信する前に、ここから属性または値を削除します。
表12-5は、filterOutboundAttribute変換タイプのパラメータを説明しています。
表12-5 filterOutboundAttribute変換タイプのパラメータ
| パラメータ | dsconfig CLI | 複数(M)/単一(S)値 | オプション(O)/必須(M) | 値 |
|---|---|---|---|---|
|
ソース属性の名前とソース属性の値定義 |
|
S |
M |
文字列 詳細は、第12.7.2.3項「変換のための属性値の定義」を参照してください。 たとえば、 |
|
エントリが一致する必要があるフィルタベースの条件 |
|
S |
O [デフォルト = ワークフロー要素によって処理されるすべてのエントリに適用] |
LDAPフィルタ |
|
祖先である必要があるDNベースの条件 |
|
M |
O [デフォルト = ワークフロー要素によって処理されるすべてのリクエストに適用] |
DN |
|
処理する操作から操作を除外する条件 |
|
M |
O [デフォルト = すべてのLDAP操作に適用] |
列挙(ADD、MODIFY...) |
addInboundAttribute変換タイプこの変換は、追加操作の実行中、データをソースに転送する前に、クライアントから受信したエントリに仮想属性または値を追加します。
エントリに仮想属性がすでに含まれているかどうか判断できない場合、conflict-behaviorパラメータが、次のポリシーのどれを適用するかを決定します:
仮想値を追加しない
仮想値を追加して、既存値とマージする
既存値を仮想値に置き換える
表12-6は、addInboundAttribute変換タイプのパラメータを説明しています。
表12-6 addInboundAttribute変換タイプのパラメータ
| パラメータ | dsconfig CLI | 複数(M)/単一(S)値 | オプション(O)/必須(M) | 値 |
|---|---|---|---|---|
|
ソース仮想属性の名前とソース仮想属性の値定義 |
|
S |
M |
文字列 詳細は、第12.7.2.3項「変換のための属性値の定義」を参照してください。 たとえば、 |
|
競合動作ポリシー |
|
S |
O [デフォルト= |
|
|
エントリが一致する必要があるフィルタベースの条件 |
|
S |
O [デフォルト = ワークフロー要素によって処理されるすべてのエントリに適用] |
LDAPフィルタ |
|
祖先である必要があるDNベースの条件 |
|
M |
O [デフォルト = ワークフロー要素によって処理されるすべてのリクエストに適用] |
DN |
|
処理する操作から操作を除外する条件 |
|
M |
O [デフォルト = すべてのLDAP操作に適用] |
列挙(ADD、MODIFY) |
filterInboundAttribute変換タイプこの変換では、追加(および変更)時に、クライアントから受信したエントリ(および変更)をソースに送信する前に、ここから属性または値を削除します。
表12-7は、filterInboundAttribute変換タイプのパラメータを説明しています。
表12-7 filterInboundAttribute変換タイプのパラメータ
| パラメータ | dsconfig CLI | 複数(M)/単一(S)値 | オプション(O)/ 必須(M) |
値 |
|---|---|---|---|---|
|
クライアント仮想属性の名前とクライアント仮想属性の値定義 |
|
S |
M |
文字列 詳細は、第12.7.2.3項「変換のための属性値の定義」を参照してください。 たとえば、 同様に、 |
|
エントリが一致する必要があるフィルタベースの条件 |
|
S |
O [デフォルト = ワークフロー要素によって処理されるすべてのエントリに適用] |
LDAPフィルタ |
|
祖先である必要があるDNベースの条件 |
|
M |
O [デフォルト = ワークフロー要素によって処理されるすべてのリクエストに適用] |
DN |
|
処理する操作から操作を除外する条件 |
|
M |
O [デフォルト = すべてのLDAP操作に適用] |
列挙(ADD、MODIFY...) |
mapAttribute変換タイプこの変換では、両方向において、クライアント属性を1つのソース属性にリネームしたり、値の変換を行うことができます。
表12-8は、mapAttribute変換タイプのパラメータを説明しています。
表12-8 mapAttribute変換タイプのパラメータ
| パラメータ | dsconfig CLI | 複数(M)/単一(S)値 | オプション(O)/必須(M) | 値 |
|---|---|---|---|---|
|
クライアント属性の名前とクライアント仮想属性からソース仮想属性へのマッピングの値定義 |
|
S |
M |
文字列 詳細は、第12.7.2.3項「変換のための属性値の定義」を参照してください。 たとえば、 |
|
ソース内の仮想ポリシー |
|
S |
O [デフォルト = |
|
|
競合動作ポリシー |
|
S |
O [デフォルト= |
|
|
エントリが一致する必要があるフィルタベースの条件 |
|
S |
O [デフォルト = ワークフロー要素によって処理されるすべてのエントリに適用] |
LDAPフィルタ |
|
祖先である必要があるDNベースの条件 |
|
M |
O [デフォルト = ワークフロー要素によって処理されるすべてのリクエストに適用] |
DN |
|
処理する操作から操作を除外する条件 |
|
M |
O [デフォルト = すべてのLDAP操作に適用] |
列挙(ADD、MODIFY...) |
条件付きで変換ワークフロー要素を構成できます。条件は、transformations-workflow-elementまたは個々のtransformationに対して設定できるプロパティ(属性)です。変換は、LDAPリクエストがすべての条件およびワークフロー要素レベルで設定されているすべての条件を満たしている場合のみ、実行されます。
変換の実装には、次の条件を使用できます:
変換を実施するかどうかを決定するルールに対して条件を構成できます。
transformations-workflow-elementに対して条件を設定できます。この場合、そのworkflow-elementに設定されているすべての変換に対して条件が照合され、各変換が実際に処理される前に評価されます。
個々の各変換に対して条件を設定でき、この変換の実際の処理前に評価されます。
条件は、広い意味で次のカテゴリに分類されます:
この条件は、指定されている1つの親接頭辞の下にある名前のエントリをターゲットとするLDAP操作のみに適用される変換に対して使用されます。
このタイプの条件が構成されていない場合、処理されるすべてのエントリに対して変換が適用されます。
この条件は、指定フィルタと一致するエントリに対するLDAP操作にのみ適用される変換に対して使用されます。
このタイプの条件が構成されていない場合、処理されるすべてのエントリに対して変換が適用されます。
この条件は、複数値属性のリストを指定し、各属性が、変換によって影響を受けてはならないLDAP操作を示します。各LDAPプロトコル・メッセージに対する変換(ある場合)のアクションを無効にできます。
このタイプの条件が構成されていない場合、このタイプの変換が通常影響するすべてのLDAP操作に対して変換が実行されます。
属性値により、変換中における仮想属性の値を定義できます。この値は、デフォルト値のままにすることもできますし、他の属性値から値を作成するルールにすることもできます。
addInboundAttribute、addOutboundAttributeおよびmapAttributeでは、追加する仮想属性の値を構成する必要があります。filterInboundAttributeおよびfilterOutboundAttributeでは、フィルタリングする値を構成することもできます。
属性は、次から値を導出できます:
静的なデフォルト値の属性を生成したり、属性の静的な値でフィルタリングする場合に使用します。
たとえば、プロパティsource-attribute:mycompany=Acmeは、デフォルトの会社名を指定する際に使用します。
dsconfig create-transformation \ --type add-inbound-attribute \ --set source-attribute:mycompany=Acme \ --transformation-name virtDeptName \
%inputAttrName%構文を使用して、処理対象のエントリ内の既存の属性から新しい属性を作成したり、別の属性から取得する値をフィルタリングできます。
たとえば、プロパティsource-attribute:displayName=%cn%は、cn属性の値から新しい属性値を取得する必要があることを示します。
dsconfig create-transformation \ --type add-inbound-attribute \ --set source-attribute:displayName=%cn% \ --transformation-name virtDeptName \
|
注意: 同じtransformations-workflow-elementで生成される別の仮想属性は参照しないでください。評価順序が保証されません。 |
{expression}構文を使用して、既存の属性値を操作することにより、属性値を作成したり、属性値をフィルタリングできます。
たとえば、プロパティclient-attribute:mail={%cn%.%sn%@mycompany.com}は、既存の属性の値を組み合せて属性を導出するための正規表現です。
dsconfig create-transformation \
--type add-outbound-attribute \
--set client-attribute:mail={%cn%.%sn%@mycompany.com} \
--transformation-name virtDeptName \
virtAttrName=%refAttrName%(virtValue1,refValue1)(virtValue2,refValue2)構文を使用して、別の属性の値のマッピングとして仮想値を定義します。
virtAttrNameパラメータに対して、変換が、refAttrNameから抽出された値を追加またはフィルタリングします。refAttrNameがrefValue1と一致すれば、変換は、virtValue1に対する追加またはフィルタリングを行います。指定する値内の文字(、)、,および\は\文字でエスケープ処理する必要があります。
たとえば、複数の部署を持つ組織があり、取得される部署IDにより、部署名が、Department:1–Marketing、2–Sales、3–Financeなどのように返されます。ただし、deptIdが1の場合、deptNameに対して返される値はMarketingです。deptIdが2の場合は、deptName値はSalesです。同様に、deptIdが3の場合は、deptNameに対して返される値はFinanceです。
dsconfig create-transformation \ --type add-outbound-attribute \ --set client-attribute:deptName=%deptId%(Marketing,1)(Sales,2)(Finance,3) \ --transformation-name virtDeptName
virtAttrName=virtAttrValue1=virtAttrValue2=構文を使用して、複数値仮想属性を指定します。
dsconfig create-transformation \ --type add-outbound-attribute \ --set client-attribute:countriesResp=France=Germany=Italy \ --transformation-name virtCountriesRep
次の各項では、変換の実際の使用について説明し、構成例を示します。
この構成は、アプリケーションに独自のユーザー・アクティブ化属性および値があるが、バックエンドのユーザー・アクティブ化属性および値とは異なるため、読取り操作および書込み操作用にマッピングが必要な場合に役立ちます。
次の例では、値activatedとdeactivatedを持つ属性myuseraccountcontrolが、値falseとtrueを持つDSEE (SunONE)バックエンドのバックエンド属性nsAccountLockに変換されます。
$ ./dsconfig -X -n -Q -p 1444 -D cn=directory manager -j pwdfile create-transformation --transformation-name mapactivate --type map-attribute --set client-attribute:myuseraccountcontrol="%nsAccountLock%(activated,false) (deactivated,true)"
次の例では、値activatedとinactivatedを持つ属性myuseraccountcontrolが、値544と546を持つActive Directoryバックエンドのバックエンド属性userAccountControlに変換されます。
$ ./dsconfig -X -n -Q -p 1444 -D cn=directory\ manager -j pwdfile create-transformation --transformation-name mapactivate --type map-attribute --set client-attribute:myuseraccountcontrol="%userAccountControl% (activated,544)(deactivated,546)"
この構成は、バックエンド・サーバーにあるオブジェクト・クラスと同じ意味を持つオブジェクト・クラスがアプリケーションにあるが、この2つのオブジェクト・クラスの名前が異なる場合に役立ちます。読取り操作および書込み操作でオブジェクト・クラス名に対するマッピングが必要です。
次の例では、フィルタobjectClass=Userを持つクライアントで検索が行われ、そのフィルタをobjectClass=inetOrgUserに変換します。クライアントにエントリが返されるときに、objectClass=inetOrgUserのエントリが格納されている場合、このエントリはオブジェクト・クラスUserにマップされます。
$ ./dsconfig -X -n -Q -p 1444 -D cn=directory manager -j pwdfile create-transformation --transformation-name mapoc --type map-attribute --set client-attribute:objectClass="%objectClass%(User,inetOrgUser)" $ ./dsconfig -X -n -Q -p 1444 -D cn=directory manager -j pwdfile create-workflow-element --type transformations --element-name trsfwfe --set enabled:true --set next-workflow-element:userRoot --set transformation:mapoc $ ./dsconfig -X -n -Q -p 1444 -D cn=directory manager -j pwdfile set-workflow-prop --workflow-name userRoot0 --set workflow-element:trsfwfe