7 ACSLS HA 8.4 설치 및 시작
SUNWscacsls 패키지에는 Oracle Solaris Cluster와 통신하는 ACSLS 에이전트 소프트웨어가 포함됩니다. 여기에는 ACSLS와 Solaris Cluster 사이의 적절한 작업을 보장하는 특수 구성 파일 및 패치가 포함됩니다.
기본 설치 절차
-
다운로드한
SUNWscacsls.zip파일을 /opt에 압축을 풉니다.# cd /opt # unzip SUNWscacsls.zip
-
SUNWscacsls패키지를 설치합니다.# pkgadd -d .
-
인접한 노드에서 1~2단계를 반복합니다.
-
두 노드 중 하나에
acslspool이 마운트된 상태인지 확인합니다.# zpool status acslspool
acslspool이 마운트되지 않았으면 다른 노드를 선택합니다.acslspool이 어느 노드에도 마운트되지 않았으면 다음과 같이 현재 노드에 가져옵니다.# zpool import -f acslspool
zpool status를 사용하여 확인합니다. -
acslspool을 소유하는 노드의/opt/ACSLSHA/util디렉토리로 이동하고copyUtils.sh스크립트를 실행합니다. 이 작업을 수행하면 필수 파일이 업데이트되거나 두 노드의 적합한 위치로 복사됩니다. 인접한 노드에서는 이 작업을 반복할 필요가 없습니다.# cd /opt/ACSLSHA/util # ./copyUtils.sh
-
acslspool이 활성 상태인 노드에서 사용자acsss로 ACSLS 응용 프로그램을 시작(acsssenable)하고 작동 중임을 확인합니다. 발생한 모든 문제를 해결합니다. 주요 문제는 노드에서 STKacsls 패키지를 제거하고 다시 설치하여 해결할 수 있습니다.STKacsls 패키지를 다시 설치해야 하는 경우 패키지를 설치한 후
/opt/ACSLSHA/util/copyUtils.sh스크립트를 실행합니다. -
acsls를 종료합니다.# su - acsss $ acsss shutdown $ exit #
-
활성 노드에서
acslspool을 내보냅니다.# zpool export acslspool
주:
사용자acsss가 로그인되어 있거나, 사용자 셸이acslspool의 모든 위치에서 활성 상태이거나acsss서비스가 사용으로 설정된 상태로 있는 경우 이 작업이 실패합니다. -
인접한 노드에서
acslspool을 가져옵니다.# zpool import acslspool
-
이 노드에서 ACSLS 응용 프로그램을 시작하고 라이브러리 작업이 성공적인지 확인합니다. 발생한 모든 문제를 해결합니다. 주요 문제는 노드에서 STKacsls 패키지를 제거하고 다시 설치하여 해결할 수 있습니다.
STKacsls 패키지를 다시 설치해야 하는 경우 패키지를 설치한 후
/opt/ACSLSHA/util/copyUtils.sh스크립트를 실행합니다.
ACSLS HA 구성
이 단계는 Solaris Cluster에서 관리 및 제어하는 ACSLS 리소스를 만듭니다.
-
acsls-rs는 ACSLS 응용 프로그램 자체입니다. -
acsls-storage는 ACSLS가 상주하는 ZFS 파일 시스템입니다. -
<logical host>는 가상 IP(두 노드에 공통적인 네트워크 ID)입니다. /etc/hosts 구성을 참조하십시오.
이 리소스 핸들이 생성되면 이름 acsls-rg 아래에 공통 리소스 그룹이 지정됩니다.
이 리소스를 구성하려면 acslspool이 마운트되었는지 먼저 확인하고(zpool list) /opt/ACSLSHA/util 디렉토리로 이동하여 acsAgt configure를 실행합니다.
# cd /opt/ACSLSHA/util # ./acsAgt configure
이 유틸리티는 논리 호스트 이름을 묻는 프롬프트를 표시합니다. 논리 호스트가 /etc/hosts 파일에 정의되어 있고 해당 IP 주소가 Solaris 시스템의 ACSLS HA 구성 장에서 정의된 ipmp 그룹으로 매핑되는지 확인합니다. 또한 acsAgt configure를 실행하기 전에 zpool list를 사용하여 acslspool이 현재 서버 노드에 마운트되었는지 확인합니다.
이 구성 단계를 완료하는 데 약간의 시간이 걸릴 수 있습니다. 리소스 핸들이 생성되면 작업에서 ACSLS 응용 프로그램을 시작하려고 시도합니다.
ACSLS 클러스터 작업 모니터링
ACSLS 클러스터 작업을 확인할 수 있는 여러 우세 지점이 있습니다. Solaris Cluster가 1분마다 ACSLS 응용 프로그램을 프로브하는 경우 프로브 결과가 발생할 때마다 이 결과를 확인하는 것이 좋습니다. 프로브가 노드 스위치 오버 이벤트를 트리거하도록 상태를 반환하는 경우 한 노드의 종료 작업과 인접 노드의 시작 작업을 확인하는 것이 좋습니다. 일반적으로 시간에 따른 ACSLS 응용 프로그램의 작업 상태를 확인하는 것이 좋습니다.
ACSLS 관점의 기본 작동 우세 지점입니다. acsss_event.log의 끝 부분에는 경우에 따라 전체 시스템 상태의 중요한 부분이 나와 있을 수 있습니다.
/opt/ACSLSHA/util/ 디렉토리의 event_tail.sh 도구는 두 노드 중 하나의 acsss_event.log에 대한 직접 액세스를 제공합니다. 이 도구에서 제공한 보기는 한 노드에서 다른 노드로 제어가 전환되는 경우에도 활성 상태로 유지됩니다. 이 도구는 일반 ACSLS 작업 이외에도 ACSLS 클러스터 리소스 그룹(acsls-rg)의 각 상태 변경을 동적으로 추적하여 한 노드가 오프라인으로 전환되고 다른 노드가 온라인으로 전환되는 경우 실시간으로 볼 수 있습니다. 다음과 같이 셸에서 이 도구를 명제화합니다.
# /opt/ACSLSHA/util/event_tail.sh
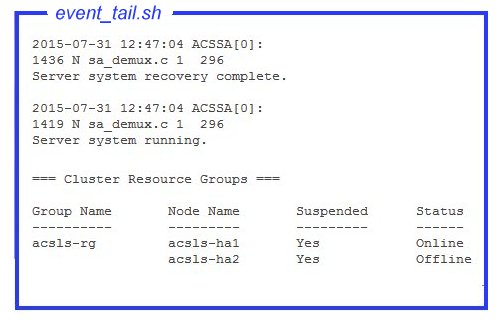
단일 노드 관점에서 시작 및 중지 작업을 보려면 다음과 같이 해당 노드에서 start_stop_log를 확인합니다.
# tail -f /opt/ACSLSHA/log/start_stop_log
작업 노드에서 각각의 주기적인 프로브 결과를 확인하려면 다음을 수행합니다.
# tail -f /opt/ACSLSHA/log/probe_log
Solaris Cluster 및 ACSLS 클러스터 에이전트가 중요 이벤트의 세부정보를 Solaris 시스템 로그(var/adm/messages)로 전송합니다. 제공된 노드에서 시스템 로그를 보기 위해 /opt/ACSLSHA/log 디렉토리에 링크가 제공됩니다.
# tail -f /opt/ACSLSHA/log/messages
ha_console.sh 유틸리티
클러스터화된 구성의 여러 우세 지점 및 시간에 따른 노드 간 클러스터 제어 마이그레이션을 사용하는 경우 단일 관점에서 특정 시간 동안의 시스템 작동 작업을 쫓아가기 어려울 수 있습니다. ha_console.sh 유틸리티는 광범위한 보기를 더욱 쉽게 제공할 수 있게 해줍니다.
원격 데스크탑에서 ACSLS HA 시스템의 노드 중 하나에 로그인하고
ha_console.shDISPLAY를 보낼 위치를 결정하기 위해 로그인 ID(who am i)를 확인합니다. 로컬 콘솔 또는 데스크탑 시스템에서 HA 노드로 직접 로그인하여 표시 내용을 확인합니다. 문제가 발생하는 경우 /opt/ACSLSHA/log 디렉토리의 gnome-terminal.log에서 메시지를 찾아봅니다.
# /opt/ACSLSHA/util/ha_console.sh
이 유틸리티는 이 섹션에 설명한 두 노드의 모든 로그를 모니터합니다. 로컬 콘솔 화면의 gnome 단말기 창 7개를 실행합니다. 다음 방식으로 화면에서 창을 구성하는 데 도움이 될 수 있습니다.

단일 단말기 화면에서 전체 ACSLS 클러스터 컴플렉스의 광범위한 보기가 표시됩니다.
원격 시스템이 로컬 화면으로 표시 데이터를 전송하므로 yopen X-11은 로컬 시스템에 액세스합니다. UNIX 시스템에서 이를 수행하기 위한 명령은 xhost +입니다. Windows 시스템에 xming 또는 exceed와 같은 X-11 클라이언트 소프트웨어가 설치되어 있어야 합니다.
ha_console.sh를 사용하는 데 어려움이 있는 경우 로컬 시스템에서 각 노드까지 다중 로그인 세션을 열어 이 절에서 설명한 다양한 로그를 확인합니다.
클러스터 작업 확인
-
acslsha가 시작되고 Solaris Cluster에 등록되었으면 클러스터 명령을 사용해서 ACSLS 리소스 그룹 및 연관된 리소스의 상태를 확인합니다.# clrg status === Cluster Resource Groups === Group Name Node Name Suspended Status ---------- --------- --------- ------ acsls-rg node1 No Online node2 No Offline # clrs status === Cluster Resources === Resource Name Node Name State Status Message ------------- --------- ----- -------------- acsls-rs node1 Online Online node2 Offline Offline acsls-storage node1 Online Online node2 Offline Offline <logical host> node1 Online Online node2 Offline Offline -
초기 테스트를 시작하기 위해 클러스터 페일오버 준비를 일시적으로 중단합니다.
# clrg suspend acsls-rg # clrg status
-
활성 노드에서 대기 노드로 클러스터 전환 작업을 테스트합니다.
# cd /opt/ACSLSHA/util # ./acsAgt nodeSwitch
스위치 오버 작업은 이전 절에서 설명한 절차를 사용하여 다양한 측면에서 모니터할 수 있습니다.
-
ACSLS 서버의 논리 호스트 이름을 사용해서 ACSLS 클라이언트 시스템에서 네트워크 연결을 확인합니다.
# ping acsls_logical_host # ssh root@acsls_logical_host hostname passwd:
이 작업은 활성 노드의 호스트 이름을 반환합니다.
-
ACSLS 작업을 확인합니다.
# su acsss $ acsss status
-
반대 노드에서 3~5단계를 반복합니다.
-
클러스터 페일오버 준비를 재개합니다.
# clrg resume acsls-rg # clrg status
-
다음 테스트는 노드 페일오버 동작 확인과 관련됩니다.
다중 페일오버 시나리오를 차례대로 수행하려면 기본 pingpong 간격을 20분에서 5분으로 줄입니다. 자세한 내용은 ACSLS HA 세부 조정 장을 참조하십시오. 테스트용인 경우 기본 설정을 낮추는 것이 좋습니다.
pingpong 간격을 변경하려면
/opt/ACSLSHA/util디렉토리로 이동하고acsAgt pingpong을 실행합니다.# ./acsAgt pingpong Pingpong_interval current value: 1200 seconds. desired value: [1200] 300 Pingpong_interval : 300 seconds
-
활성 노드를 재부트하고 ACSLS 클러스터 작업 모니터링에서 제안된 관점에 따라 두 시스템 콘솔에서 작업을 모니터합니다. 대기 노드에 대한 자동 페일오버 작업을 확인합니다.
-
4단계에서 제안된 클러스터 시스템에서 논리 호스트에 대한 네트워크 액세스를 확인합니다.
-
ACSLS 작업이 새 노드에서 활성 상태이면 이 노드를 재부트하고 반대 노드에 대한 페일오버 작업을 확인합니다.
ha_console.sh를 사용하여 작업을 모니터하는 경우 재부트 노드와 연관된 창이 사라진 것으로 보일 수 있습니다. 노드가 다시 작동되면 한 노드에서ha_console.sh명령을 다시 한 번 실행하여 새로 재부트된 노드의 창을 복원합니다. -
4단계에서 제안된 네트워크 확인을 반복합니다.
ACSLS 클러스터 작업에는 페일오버 시나리오의 전체 세트가 나와 있습니다. ACSLS HA 시스템을 운용 환경에 배치하기 전에 여러 시나리오를 테스트할 수 있습니다. 시스템을 운용 환경으로 되돌리기 전에 권장되는 pingpoing 간격 설정을 복원하여 지속적으로 페일오버가 반복되지 않게 합니다.