9 Configuring ECE for Disaster Recovery
This chapter provides an overview of the Oracle Communications Billing and Revenue Management Elastic Charging Engine (ECE) disaster recovery architecture. In addition, it describes how to configure ECE for disaster recovery and how the ECE system handles failover.
For information about the standard ECE system architecture, see the discussion about ECE system architecture in BRM Elastic Charging Engine Concepts.
About Disaster Recovery
Disaster recovery is a backup and recovery process that provides continuity in realtime processing of prepaid services in case of system failure. Implementing disaster recovery involves configuring multiple ECE systems that run at geographically remote locations. Typically, you configure a production system and one or more remote backup systems that take over when the production system fails. However, you can also configure duplicate remote production systems.
An ECE backup system at a remote location is called a backup site and an active ECE production system is called a production site.
When configuring ECE for disaster recovery, consider the following objectives:
-
Recovery time objective (RTO). Specifies the time within which the services must be resumed after a system failure.
-
Recovery point objective (RPO). Specifies the time within which the ECE data must be recovered from the production site before the quantity of data lost during the recovery period exceeds the maximum allowable threshold.
ECE supports the following types of disaster recovery systems:
-
Active-cold standby. A disaster recovery system that consists of an active production site and one or more idle backup sites. This system requires starting the backup site manually when the production site goes down. This might cause a delay in bringing up the backup site to full operational capability. As a result, RTO and RPO are relatively high in an active-cold standby system.
-
Active-hot standby. A disaster recovery system that consists of an active production site and one or more active backup sites. The ECE data is asynchronously replicated from the production site to the backup sites. When the production site goes down, the ECE requests are diverted from the production site to the backup sites. The RTO and RPO for an active-hot standby system are less than the active-cold standby system.
-
Segmented active-active. A disaster recovery system that consists of two or more active production sites at remote locations (one primary production site and one or more remote production sites), which concurrently processes ECE requests for a different set of customers. The pricing, customer, and ECE cache data are asynchronously replicated from the primary production site to remote production sites. When one of the production sites goes down, the requests from that site are diverted to the other sites. The RTO and RPO for a segmented active-active system are less than active-cold standby and active-hot standby systems. ECE requests are routed across the production sites based on your load balancing configuration. See "About Load Balancing in a Segmented Active-Active System" for more information.
Overview of Disaster Recovery Architecture
A disaster recovery system contains a primary production site and one or more backup sites or remote production sites.
In an active-cold standby system, each site contains Oracle Communications Billing and Revenue Management (BRM), Pricing Design Center (PDC), and ECE with the following core components:
-
ECE Charging Server
-
Customer Updater
-
Pricing Updater
-
BRM Gateway
-
External Manager (EM) Gateway
-
Rated Event Formatter
-
Rated Event Publisher
-
Diameter Gateway
-
RADIUS Gateway
In an active-hot standby system or a segmented active-active system, each site contains BRM, PDC, and ECE. However, Customer Updater, Pricing Updater, and EM Gateway are configured only in the primary production site.
For more information about these components, see the discussion about ECE system architecture in BRM Elastic Charging Engine Concepts.
Figure 9-1 shows a basic architecture of an ECE disaster recovery system.
Figure 9-1 Basic Architecture of Disaster Recovery System
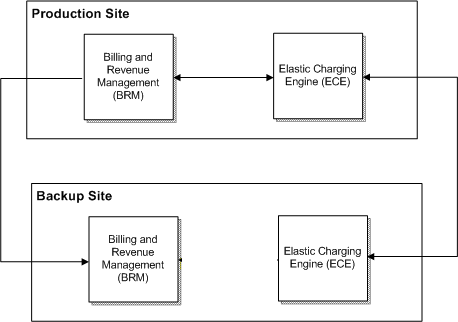
Description of ''Figure 9-1 Basic Architecture of Disaster Recovery System''
Figure 9-1 contains a production site and a backup site. Table 9-1 describes the status of each site depending on the type of disaster recovery system.
Table 9-1 Status of Disaster Recovery Systems
| Disaster Recovery System | Production Site | Backup Site |
|---|---|---|
|
Active-cold standby |
Active |
Idle standby |
|
Active-hot standby |
Active |
Active standby |
|
Segmented active-active |
Active |
Active |
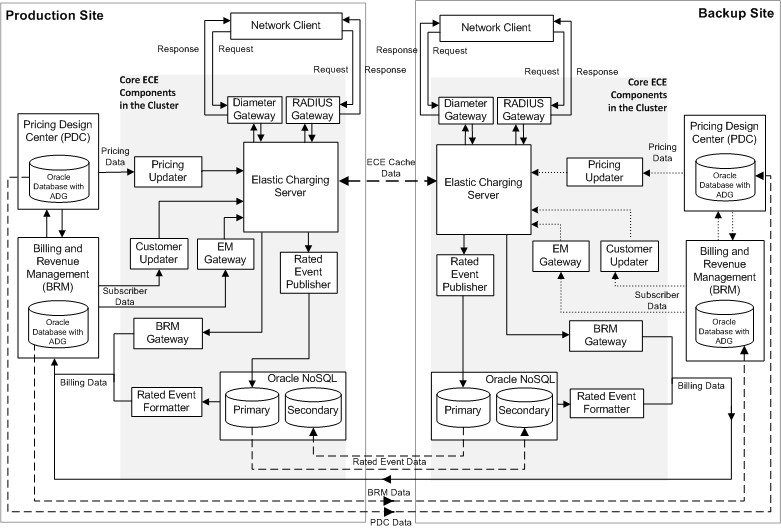
Figure 9-3 shows the architecture of an active-hot standby system. The solid line depicts the data flow, the dashed line depicts the data replication flow, and the dotted line depicts the components that are available but are not configured to load data.
Note:
For simplicity, Figure 9-3 shows the architecture of an active-hot standby system with one production site and one active backup site. In general, an active-hot standby system can contain more than one active backup site to allow failover.Figure 9-2 Architecture of an Active-Hot Standby Disaster Recovery System
Description of ''Figure 9-2 Architecture of an Active-Hot Standby Disaster Recovery System''
Some of the key aspects of the architecture shown in Figure 9-3 are:
-
The architecture has an active production site and an active backup site.
-
ECE components are deployed and are active in both sites, but only the production site is processing requests.
-
PDC and BRM databases are available in both sites, but they are active only in the production site. The PDC and BRM data are replicated from the PDC and BRM databases in the production site to the PDC and BRM databases in the backup site asynchronously using Oracle Active Data Guard.
-
The ECE data in the Oracle NoSQL database data store is replicated from the production site to the backup site asynchronously using primary and secondary Oracle NoSQL database data store nodes.
-
The ECE cache data is replicated from the production site to the backup site asynchronously using the Oracle Coherence federated caching feature.
-
ECE requests are routed only to the production site. When the production site fails, the backup site takes over the role of the production site, and the ECE requests are diverted to the backup site.
About Replicating Data in a Disaster Recovery System
You replicate the following data from the production site to the backup or remote production sites:
-
Data in the BRM and PDC databases. You use Oracle Active Data Guard to replicate data from the BRM and PDC databases in the production site to the BRM and PDC databases in the backup or remote production sites asynchronously. When the BRM and PDC databases in the production site fail, manual or automatic failover is performed to switch the BRM and PDC databases in the backup or remote production sites into the primary role based on your Oracle Active Data Guard configuration. For more information about configuring Oracle Active Data Guard and performing a manual or automatic failover, see the discussion about data guards in the Oracle Database documentation.
-
Data in the ECE cache. In an active-hot standby system or a segmented active-active system, you use the Oracle Coherence federated caching feature to synchronize the ECE data grid and replicate the ECE cache data between participant sites (primary production site and backup sites or remote production sites) asynchronously. For more information about federated caching, see the Oracle Coherence documentation. You use the gridSync utility to start the federation service to replicate data to the participant sites asynchronously and also replicate all the existing ECE cache data to the participant sites. See "Replicating ECE Cache Data" for more information.
-
Data in the Oracle NoSQL database data store. In an active-hot standby system or a segmented active-active system, you use the primary and secondary storage nodes of the Oracle NoSQL database data store to replicate the rated event data between participant sites. You configure the primary and secondary nodes in all the participant sites to replicate the data. See "About Configuring Oracle NoSQL Database Data Store Nodes" for more information.
-
Call detail records (CDRs) generated by Rated Event Formatter. You use the Secure Shell (SSH) File Transfer Protocol (SFTP) utility to replicate CDR files generated by Rated Event Formatter between participant sites.
About Configuring Oracle NoSQL Database Data Store Nodes
In an active-hot standby system or a segmented active-active system, you configure primary and secondary storage nodes in the Oracle NoSQL database data store for each participant site to store and replicate the rated event data. The secondary storage nodes in one site act as a backup for the primary storage nodes of the other site. For example, when rated events are stored in the primary storage nodes of the production site, the information is replicated in the secondary storage nodes of the backup site. Similarly, the information that is stored in the primary storage nodes of the backup site is replicated in the secondary storage nodes of the production site.
Figure 9-3 shows the primary and secondary Oracle NoSQL database storage nodes configured in a disaster recovery system.
Figure 9-3 Primary and Secondary Oracle NoSQL Database Storage Nodes
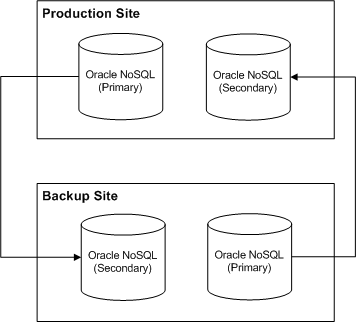
Description of ''Figure 9-3 Primary and Secondary Oracle NoSQL Database Storage Nodes''
Oracle recommends that you configure a minimum of three storage nodes in each site: two storage nodes to store rated events and one storage node to allow for failover. You can add additional storage nodes as needed to handle the expected throughput for your system. For information about adding and configuring storage nodes in the Oracle NoSQL database data store, see the Oracle NoSQL Database documentation.
About Load Balancing in a Segmented Active-Active System
In a segmented active-active system, ECE requests are routed across the production sites based on your load balancing configuration. To ensure proper load balancing on your system, you can use a combination of global and local load balancers. The local load balancer routes the connection requests across the full range of available Diameter Gateway and RADIUS Gateway nodes. The global load balancer routes the connection requests to the Diameter Gateway and RADIUS Gateway nodes in only one site unless it detects that site is busy or if the local load balancer signals that it cannot reach ECE. You can set up your own load balancing configuration based on your requirements.
Configuring a Disaster Recovery System
This section describes how to configure a disaster recovery system.
Configuring an Active-Cold Standby System
To configure an active-cold standby system:
-
In the production site and backup sites, do the following:
-
Install ECE and other components required for the ECE integrated system.
See the discussion about installing all ECE components in BRM Elastic Charging Engine Installation Guide for instructions.
-
Ensure that any customizations to configuration files and extension implementation files in your production site are reapplied to the corresponding default files in the backup sites.
-
-
In the production site, start ECE. See "About Starting and Stopping ECE" for more information.
Configuring an Active-Hot Standby System or a Segmented Active-Active System
To configure an active-hot standby system or a segmented active-active system:
-
In the primary production site and backup or remote production sites, install ECE and other components required for the ECE integrated system.
See the discussion about installing all ECE components in BRM Elastic Charging Engine Installation Guide for instructions.
-
In the primary production site, do the following:
-
Configure primary and secondary Oracle NoSQL database data store nodes. See "About Configuring Oracle NoSQL Database Data Store Nodes".
-
On the machine on which the Oracle WebLogic server is installed, verify that the Java Message Service (JMS) queues have been created for loading pricing data and for sending event notification and that JMS credentials have been configured correctly.
See the discussion about creating JMS queues and configuring credentials in BRM Elastic Charging Engine Installation Guide for more information.
-
Ensure that the connection details for all the instances of the following ECE core components are available in the ECE_home/oceceserver/config/management/charging-settings.xml file, where ECE_home is the directory in which ECE is installed:
Customer Updater
BRM Gateway
EM Gateway
Rated Event Formatter
Rated Event Publisher
Diameter Gateway
RADIUS Gateway
Important:
If you are configuring a segmented active-active system, ensure the following:-
The name of Diameter Gateway, RADIUS Gateway, Rated Event Formatter, and Rated Event Publisher for each site is unique.
-
A minimum of two instances of Rated Event Formatter are configured to allow for failover.
For information on the configuration parameters for Customer Updater, Rated Event Formatter, Rated Event Publisher, BRM Gateway, and EM Gateway, see the discussion about implementing ECE with BRM in BRM Elastic Charging Engine Implementation Guide.
For information on the configuration parameters for Diameter Gateway, see Table 4-4, "Diameter Gateway Node Configuration Parameters".
For information on the configuration parameters for RADIUS Gateway, see Table 4-5, "RADIUS Gateway Node Base Configuration Attributes" and Table 4-6, "RADIUS Gateway Node Instance Configuration Attributes".
-
-
Verify that the JMS queues' details for Pricing Updater are specified in the PdcEceQueue and PDCResultQueue sections of the ECE_home/config/management/migration-configuration.xml file.
See the discussion about configuring the Pricing Updater in BRM Elastic Charging Engine Implementation Guide for more information.
-
Add all the participant sites' details in the federation-config section of the ECE Coherence override file (for example, ECE_home/oceceserver/config/charging-coherence-override-prod.xml).
To confirm which ECE Coherence override file is used, see the tangosol.coherence.override value in the ECE_ home/oceceserver/config/ece.properties file.
Table 9-2 provides the federation configuration parameter descriptions and default values.
Table 9-2 Federation Configuration Parameters
Name Description name
The name of the participant site.
Note: The name of the participant site must match the name of the cluster in the participant site.
address
The IP address of the participant site.
port
The port number assigned to the Coherence clusterport of the participant site.
initial-action
Specifies whether the federation service has to be started for replicating data to the participant sites.
Valid values are:
-
start. Specifies that the federation service has to be started and the data must be automatically replicated to the participant sites.
-
stop. Specifies that the federation service has to be stopped and the data must not be automatically replicated to the participant sites.
Note: Ensure that this parameter is set to stop for all the participant sites except for the current site. For example, if you are adding the backup or remote production sites details in the primary production site, this parameter must be set to stop for all the backup or remote production sites.
-
-
Start ECE. See "About Starting and Stopping ECE" for more information.
-
Start the following ECE processes and gateways:
start emGateway start ratedEventFormatter start diameterGateway start radiusGatewayECE in the primary production site is now in a usage-processing state to process requests sent from the network.
-
-
In the backup or remote production sites, do the following:
-
Configure primary and secondary Oracle NoSQL database data store nodes. See "About Configuring Oracle NoSQL Database Data Store Nodes" for more information.
-
On the machine on which the Oracle WebLogic server is installed, verify that the JMS queues have been created for event notification and the JMS credentials have been configured correctly. See the discussion about creating JMS queues and configuring credentials in BRM Elastic Charging Engine Installation Guide for more information.
-
Set the following parameter in the ECE_home/oceceserver/config/ece.properties file to false:
loadConfigSettings = falseThe application-configuration data is not loaded into memory when you start the charging server nodes.
-
Add all the participant sites details in the federation-config section of the ECE Coherence override file (for example, ECE_home/oceceserver/config/charging-coherence-override-prod.xml).
To confirm which ECE Coherence override file is used, see the tangosol.coherence.override value in the ECE_ Home/oceceserver/config/ece.properties file. Table 9-2 provides the federation configuration parameter descriptions and default values.
-
Go to the ECE_home/oceceserver/bin directory.
-
Start Elastic Charging Controller (ECC):
./ecc -
Start the charging server nodes:
start server
-
-
In the primary production site, run the following commands:
gridSync start gridSync replicate
The federation service is started and all the existing data is replicated to the backup or remote production sites.
-
In the backup or remote production sites, do the following:
-
Verify that the same number of entries as in the primary production site are available in the customer, balance, configuration, and pricing caches in the backup or remote production sites by using the query.sh utility.
See the discussion about using the query.sh in BRM Elastic Charging Engine Implementation Guide for more information.
-
Verify that the charging server nodes in the backup or remote production sites are in the same state as the charging server nodes in the primary production site.
-
Configure the following ECE core components and the Oracle NoSQL database connection details by using a JMX editor:
Rated Event Formatter
Rated Event Publisher
Diameter Gateway
RADIUS Gateway
Important:
If you are configuring a segmented active-active system, ensure the following:-
The name of Diameter Gateway, RADIUS Gateway, Rated Event Formatter, and Rated Event Publisher for each site is unique.
-
Minimum two instances of Rated Event Formatter are configured to allow for failover.
See the discussion about implementing ECE with BRM in BRM Elastic Charging Engine Implementation Guide for information on configuring Rated Event Formatter and Rated Event Publisher by using a JMX editor.
See "Specifying Diameter Gateway Node Properties" and "Configuring RADIUS Gateway Nodes" for information on configuring Diameter Gateway and RADIUS Gateway by using a JMX editor.
-
-
If you are configuring a segmented active-active system, start the following ECE processes and gateways:
start brmGateway start ratedEventFormatter start diameterGateway start radiusGateway
The remote production sites are up and running with all required data.
-
If you are configuring a segmented active-active system, run the following command:
gridSync startThe federation service is started to replicate the data from the backup or remote production sites to the primary production site.
After starting Rated Event Formatter in the remote production sites, ensure that you copy the CDR files generated by Rated Event Formatter from the remote production sites to the primary production site by using the SFTP utility.
-
Replicating ECE Cache Data
To replicate the ECE cache data:
-
Go to the ECE_home/oceceserver/bin directory.
-
Start ECC:
./ecc -
Do one of the following:
-
To start replicating data to a specific participant site asynchronously and also replicate all the existing ECE cache data to a specific participant site, run the following commands:
gridSync start [remoteClusterName] gridSync replicate [remoteClusterName]
where remoteClusterName is the name of the cluster in a participant site.
-
To start replicating data to all the participant sites asynchronously and also replicate all the existing ECE cache data to all the participant sites, run the following commands:
gridSync start gridSync replicate
-
See "gridSync" for more information on the gridSync utility.
About Disaster Recovery Operations
When the production site fails, perform the following disaster recovery operations:
-
Switchover. In an active-cold standby system, enable a backup site to take over the role of the production site. See "Switching Over to a BackUp Site" for more information.
-
Failover. In an active-hot standby system or a segmented active-active system, enable a backup or remote production site to take over the role of the primary production site. See "Failing Over to a Backup Site or a Remote Production Site" for more information.
-
Switchback. After the original production site is fixed, you can return the sites to their original state by switching the workload back to the original production site. See "Switching Back to the Original Production Site" for more information.
Switching Over to a BackUp Site
To switch over to a backup site:
-
In the backup site, start ECE. See "About Starting and Stopping ECE" for more information.
-
Verify that ECE is connected to BRM and PDC in the backup site by doing the following:
Important:
If only ECE in the production site failed and BRM and PDC in the production site are still running, you must change the BRM, PDC, and Customer Updater connection details in the backup site to connect to BRM and PDC in the production site.See the discussions about configuring BRM Gateway and Pricing Updater in BRM Elastic Charging Engine Implementation Guide for information on changing the connection details by using a JMX editor.
-
Verify that the JMS queues' details for Pricing Updater in the backup site are specified in the PdcEceQueue and PDCResultQueue sections of the ECE_home/config/management/migration-configuration.xml file.
-
Verify that the connection details of BRM in the backup site are provided in the oracle.communication.brm.charging.appconfiguration.beans.connection.BRMConnectionConfiguration section of the ECE_home/oceceserver/config/management/charging-settings.xml file.
-
-
Load the pricing and customer data into ECE. See the discussions about loading pricing data and customer data into ECE in BRM Elastic Charging Engine Implementation Guide.
-
Ensure that the network clients route all requests to the backup site.
Important:
Information such as the balance, configuration, and rated event data that was still in the ECE cache when the production site failed is lost.The former backup site is now the new production site. When you recover the original production site, after performing the planned tasks in the original production site, you can use it again as either the production or backup site. See "Switching Back to the Original Production Site" for more information.
Failing Over to a Backup Site or a Remote Production Site
To fail over to a backup site or a remote production site:
-
In a backup or remote production site, stop replicating the ECE cache data to the primary production site by running the following command:
gridSync stop [PrimaryProductionClusterName]
where PrimaryProductionClusterName is the name of the cluster in the primary production site.
-
In a backup or remote production site, do the following:
-
In a backup or remote production site, change the BRM, PDC, and Customer Updater connection details to connect to BRM and PDC in the backup or remote production site by using a JMX editor.
Important:
If only ECE in the primary production site failed and BRM and PDC in the primary production site are still running, you need not change the BRM and PDC connection details in the backup or remote production site.See the discussions about configuring BRM Gateway and Pricing Updater in BRM Elastic Charging Engine Implementation Guide for information on changing the connection details by using a JMX editor.
-
Start BRM and PDC.
See the discussion about starting and stopping the BRM system in BRM System Administrator's Guide and the discussion about starting and stopping PDC in PDC Installation and System Administration Guide for more information.
-
-
Recover the data in the Oracle NoSQL database data store of the primary production site by doing the following:
-
Convert the secondary Oracle NoSQL database data store node of the primary production site to the primary Oracle NoSQL database data store node by performing a failover operation in the Oracle NoSQL database data store.
See the discussion about performing a failover in the Oracle NoSQL Database documentation for more information.
The secondary Oracle NoSQL database data store node of the primary production site is now the primary Oracle NoSQL database data store node of the primary production site.
-
In a backup or remote production site, convert the rated events from the Oracle NoSQL database data store node that you converted into the primary node in step 3a into CDR files by starting Rated Event Formatter.
See "Starting and Stopping Rated Event Formatter" for more information.
-
In a backup or remote production site, load the CDR files that you generated in step 3b into BRM by using Rated Event (RE) Loader.
See the discussion about setting up RE Loader for ECE in BRM Elastic Charging Engine Implementation Guide for more information.
-
Shut down the Oracle NoSQL database data store node that you converted into the primary node in step 3a.
See the discussion about shutting down an Oracle NoSQL data store node in the Oracle NoSQL Database documentation for more information.
-
Stop Rated Event Formatter that you started in step 3b.
See "Starting and Stopping Rated Event Formatter" for more information.
-
-
In a backup or remote production site, start Pricing Updater, Customer Updater, and EM Gateway by running the following commands:
start pricingUpdater start customerUpdater start emGateway
All the pricing and customer data is now back into the ECE grid in the backup or remote production site.
-
Stop and restart BRM Gateway. See "Starting and Stopping BRM Gateway" for more information.
-
Migrate internal BRM notifications from the primary production site to a backup or remote production site. See "Migrating ECE Notifications" for more information.
Important:
If the expiry duration is configured for these notifications, ensure that you migrate the notifications before they expire. For the expiry duration, see the expiry-delay entry for the ServiceContext module in the ECE_home/oceceserver/config/charging-cache-config.xml file. -
Ensure that the network clients route all requests to the backup or remote production site.
The former backup site or one of the remote production sites is now the new primary production site. You can now recover the original production site and use it again as either the production or backup site.
Switching Back to the Original Production Site
When the original production site is recovered, you can switch back the new production site and original production site to the roles they had prior to the failover operation.
Important:
If you switch back to the original production site in an active-cold standby system, any data in memory will be lost. Oracle does not recommend switching back to the original production site in an active-cold standby system.In an active-hot standby or a segmented active-active system, before you switch back to the original primary production site, you must restart the original primary production site.
To restart the original primary production site:
-
Install ECE and other required components in the original primary production site.
Important:
If only ECE in the original primary production site failed and BRM and PDC in the original primary production site are still running, install only ECE and provide the connection details of BRM and PDC in the original primary production site during ECE installation.See the discussion about installing all ECE components in BRM Elastic Charging Engine Installation Guide for instructions on ECE integrated installation.
-
Configure primary and secondary Oracle NoSQL data store nodes. See "About Configuring Oracle NoSQL Database Data Store Nodes" for more information.
-
On the machine on which the Oracle WebLogic server is installed, verify that the JMS queues have been created for loading pricing data and for sending event notification and that JMS credentials have been configured correctly.
See the discussion about creating JMS queues and configuring credentials in BRM Elastic Charging Engine Installation Guide for more information.
-
Set the following parameter in the ECE_home/oceceserver/config/ece.properties file to false:
loadConfigSettings = falseThe configuration data is not loaded into memory.
-
Add all the participant sites details in the federation-config section of the ECE Coherence override file (for example, ECE_home/oceceserver/config/charging-coherence-override-prod.xml).
To confirm which ECE Coherence override file is used, see the tangosol.coherence.override value in the ECE_ home/oceceserver/config/ece.properties file. Table 9-2 provides the federation configuration parameter descriptions and default values.
-
Go to the ECE_home/oceceserver/bin directory.
-
Start ECC:
./ecc -
Start the charging server nodes:
start server -
Replicate the ECE cache data to the original production site by using the gridSync utility. For more information, see "Replicating ECE Cache Data".
-
Start the following ECE processes and gateways:
start brmGateway start ratedEventFormatter start diameterGateway start radiusGateway
To switch back to the original primary production site in an active-hot standby or a segmented active-active system:
-
Verify that the same number of entries as in the new production site are available in the customer, balance, configuration, and pricing caches in the original production site by using the query.sh utility.
See the discussion about using the query.sh in BRM Elastic Charging Engine Implementation Guide for more information.
-
Stop Pricing Updater, Customer Updater, and EM Gateway in the new primary production site and then start them in the original primary production site.
-
Migrate internal BRM notifications from the new primary production site to the original primary production site. See "Migrating ECE Notifications" for more information.
-
If you are switching back to BRM and PDC in the original primary production site, do the following:
-
In the new primary production site, change BRM Gateway, Customer Updater, and Pricing Updater connection details to connect to BRM and PDC in the original primary production site by using a JMX editor.
See the discussions about configuring BRM Gateway and Pricing Updater in BRM Elastic Charging Engine Implementation Guide for information on changing the connection details by using a JMX editor.
-
Stop RE Loader in the new primary production site and then start it in the original primary production site.
See the discussion about setting up RE Loader for ECE in BRM Elastic Charging Engine Implementation Guide for more information.
-
Stop and restart BRM Gateway in both the new primary production site and the original primary production site. See "Starting and Stopping BRM Gateway" for more information.
-
The roles of the sites are now reversed to the original roles.
Migrating ECE Notifications
To migrate ECE notifications:
-
Access the ECE MBeans:
-
Do one of the following:
If you are migrating notifications from the primary production site to a backup or remote production site, log on to the driver machine in the backup or remote production site.
If you are migrating notifications from the new primary production site to the original primary production site, log on to the driver machine in the original primary production site.
-
Start the ECE charging servers (if they are not started).
-
Start a JMX editor, such as JConsole, that enables you to edit MBean attributes.
-
Connect to the ECE charging server node set to start CohMgt = true in the ECE_home/oceceserver/config/eceTopology.conf file.
The eceTopology.conf file also contains the host name and port number for the node.
-
In the editor's MBean hierarchy, expand the ECE Configuration node.
-
-
Expand systemAdmin.
-
Expand Operations.
-
Select triggerFailedClusterServiceContextEventMigration.
-
In the failedClusterName parameter, enter the name of the failed site's cluster.
-
Click the triggerFailedClusterServiceContextEventMigration button.
All the internal BRM notifications are migrated to the destination site.