| Oracle® Health Sciences Translational Research Center User's Guide Release 3.1.0.3 E66623-05 |
|
|
PDF · Mobi · ePub |
| Oracle® Health Sciences Translational Research Center User's Guide Release 3.1.0.3 E66623-05 |
|
|
PDF · Mobi · ePub |
This section contains the following topics:
Oracle Health Sciences Translational Research Center (TRC) suite comprises of Oracle Health Sciences Cohort Explorer (CE) 3.1 and Oracle Health Sciences Omics Data Bank (ODB) 3.1. TRC enables storing, integrating, controlling, and providing means to analyze clinical and omics data required to support the complete biomarker lifecycle. This includes the data acquisition, discovery, and research as well as clinical use of patient and specimen information.
Translational Research Center v3.1 features the following:
Cohort-driven built-in reports:
Demographic statistics reports including age, gender, ethnicity
Clinical statistics reports
Genomic reports including mutations, copy number variation, drill-into single and dual channel gene expression
Genomic reports also include mutation reports as gene vs sample matrix and also specific variants vs sample matrix
Structural Variation histograms based on occurrence frequency in genes and (or) gene pairs
Genomic report to view the percentage of patients or subjects in a cohort containing genomic data
Web infrastructure to support collaboration
UIs and workflows to enable sharing cohort queries and lists
User group creation and maintenance through custom-built UIs
Usability enhancements
Autocomplete and type-in enabled for all searchable concepts
Improvements to layouts and interface flexibility
Workflow improvements to simplify user experience
New icons, images and so on to improve the look and feel
More than twofold increase in the Cohort Data Model schema
Subject study tables and unidirectional link between subject and patient
Attributes have been added across multiple concept areas including Observation, Clinical Encounter, Patient and Subject Family, Allergy and so on Histories, Familial Relationship
Personally Identifiable attributes such as First Name, Last Name, Contact Information are now supported in the schema with obfuscation governed by individual customer's requirements
RNA-sequence based querying for cohorts
Genome Viewers for Variants and Copy Number Variation
Drill in hierarchy viewer for Diagnosis and Anatomical Site
Job Scheduling
Clinical concepts for search: Encounters, Observation types, Sources of data, Coding systems, Familial History and so on
Gene Set generation through cut-and-paste or import from files
Genomic assembly version selection for searching reference and result data with the option to select preferred ensembl annotation for the selected assembly version. Supports multiple assembly version selection for most usecases.
Genomic Data export now has the option to export data from the last-loaded VCF files, when there is duplicate data loaded for a specimen.
Single patient viewer now supports Dalliance genomic browser from gene and variant
Variant search can now accept a list of variant IDs as input for a search in various screens
Whole genome and whole chromosome VCF export is much faster
Search medication codes using hierarchical drill down
Define observation query using result reference range
Context-based values in Result String and Result UoM search popups in the test and observation search
Enhancement in Cohort timelines with single line mode option to display same events on the same line with visual separation, and a table to display additional information on the selected event.
Single patient or subject viewer now has the ability to navigate in cohort through Previous or Next buttons.
TRC consists of the following three tiers:
Database tier that includes tables and views (to simplify creating certain patterns of queries), indexes, sequences, and PL/SQL packages. PL/SQL packages are of two types:
Utility: For example, supporting integration between Cohort Data Mart (CDM) and ODB.
Data Movement: Processes data loaded into staging tables.
Client tier comprising of the following functions:
Middle tier consists of a set of ADF-based UIs deployed into WebLogic Server.
CDM consists of the following two tiers:
Database tier that includes tables, views (to simplify creation of certain patterns of queries), indexes, sequences and PL/SQL packages
Middle tier consist of set of ADF-based User Interfaces deployed into WebLogic Server. It also contains ETL that brings data from Oracle Healthcare Data Warehouse Foundation (HDWF) into CDM.
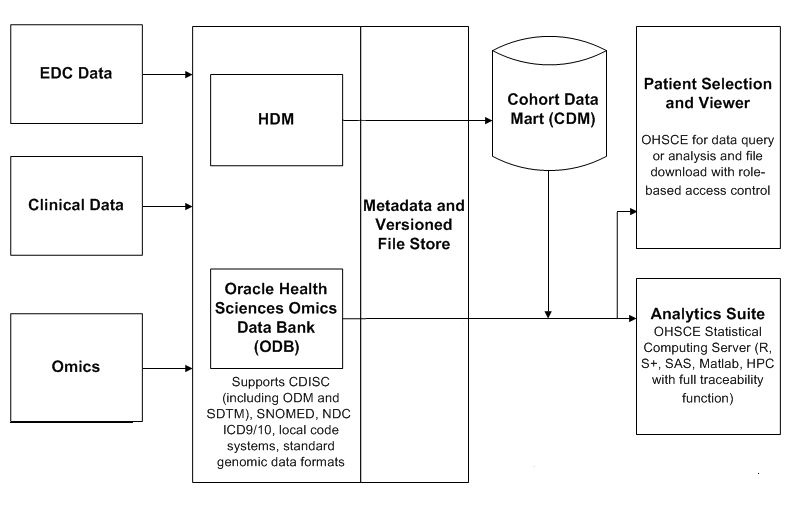
Figure 1-1 illustrates the overall data flow in TRC.
The TRC suite of products enables the following functions:
querying for patient count based on a combination of genomics and clinical attributes. The clinical attributes are available through querying clinical data model, namely CDM as part of OHSCE. The omics attributes are available through the same interface yet the data will come from Omics Data Bank model, namely ODB
listing the actual patients that correspond to the obtained count and their clinical profiles
looking at the timeline view of the clinical history of such patients
comprehensive reporting on the cohort including cohorts demographics, clinical, genomic features and further drilling into the details on the statistics
looking at the individual patient's clinical and genomic data together. Also, integration of such APIs as Visquick enables display of omics data in a user-friendly way for bioinformaticians
exporting selected ODB omics data for patient cohort into standard file formats such as VCF, SEG, RES, which can then be loaded into genome viewers that support such data formats
downloading genomic files to the desktop through links on the application. This is available only for selected user groups
searching for genes and variants using a simple search interface that lets the end user perform live queries to find any genomic results that are present in Omics Data Bank model.
loading data into the Omics Data Bank model from several public reference sources using provided autoloader scripts
loading your own result data into the ODB using provided autoloader scripts
Cohort Explorer is developed with HIPAA regulations in mind. The software enables the customer to easily implement obfuscation rules to protect any patient identifiable medical information. Cohort Explorer development also follows the software development guidelines and requirements for FDA 21 CFR Part 11 compliant software.
The origin of any data stored in CDM must be traceable to its source, and all transformations applied to the data must be accessible. Data sourced from HDWF is traced by the following criteria:
ETL Load: When data was loaded from HDWF into CDM.
ODI Interfaces: The version of ODI interface used to transform the data from HDWF to CDM, and when the data was executed.
Informatica Interfaces: The version of Informatica interface used to transform the data from HDWF to CDM, and when the data was executed.
Configuration Seed Data: There are two tables which contain seed data. Based on these tables, data is loaded in CDM and another configuration table, which is automatically seeded during ETL load.
Data in Oracle HDWF also keeps audit trails of all modifications.
You can use a third-party versioning tool or the in-built functionality of ODI and Informatica versioning to manage ETL versions. Currently, all ODI and Informatica objects are in the default version.
If you change the context from patient to subject when no patient ID is present, the demographic text is struck out. You must delete the criteria and add it again.
When searching for genes in the gene search popup, if no value is provided for a search, no results are displayed.
When patients (or subjects) are marked as deleted, the function indexes in ODB have to be recreated. When specimens are marked as deleted, the downstream linked tables have to be marked as deleted.
When you search for a gene (hugo_name), you may also see results for a different hugo_name. This is because of synonyms or aliases present in the gene cross-reference in the ODB data model.
In the variant search tab, when the context is changed from patient to subject or vice versa, the DNA reference version stays blank and is not loaded with default.
Specimen Number value (obfuscated and non-obfuscated) is not consistent.
Description column length in UI for Single Patient page is restricted to 2000 characters.
Export functionality of Cohort List shows incorrect Start Date and End date.
The existing query cannot handle genes that have multiple identifiers of the same type.
The current ETL package does not include ETL for populating the table W_EHA_STUDY_PATIENT_H, which stores the association of Patients and Studies.To associate Patients to Studies, you can develop custom code to populate the above table. Any existing data in W_EHA_STUDY_PATIENT_H is unaffected during an upgrade.
The drop-down DNA Reference Version is blank or empty while switching context or navigating to Genomic query with Variant Search from other tabs or pages. You can reset the value by changing, or selecting All, from the Assembly version.
When you search for a gene, pathway or geneset, which does not exist in the database, the message "<name> is not found." is displayed. Immediately after, if you search for a gene, pathway, or geneset which is present in database, the earlier message does not disappear. Ignore the message and proceed with you search, it will not affect your search.
When you add multiple codes in a single item in Cohort Query (for example, Diagnosis) you may see following error while saving the query:
"An error has occurred. Please contact support with reference 'LOG-1082033954.'"
There is an extra empty column in Genomic Query > Variant Search report in Google Chrome v 50.0.2661.94 m (64 bit).
Searching for a whole chromosome (for example, chr1) in Genomic Query can take more than 5min in some cases. Use a specific region for your search (for example, chr1:1-100000) to get a faster response.
Oracle makes no express or implied warranty, including but not limited to warranties regarding the accuracy, completeness, merchantability, or fitness for a particular purpose, with respect to third party data loaded into this application or the results of any functions of the application using such data. It may be used for information purposes only, and no medical, clinical or other health related decisions may be based upon such results. You are solely responsible for your use of the third party data, including your right to use the data for your purposes.
Copyright © 2010, Institute for Systems Biology. All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
Neither the name of the Institute for Systems Biology nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Copyright © 2010, Stanford Visualization Group
All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
Neither the name of Stanford University nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Copyright © 2006-2014, Thomas Down and others.
All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
Copyright © 2013, 2016, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|