This diagram illustrates a cluster of Big Data Discovery nodes deployed on top of an existing Hadoop cluster.
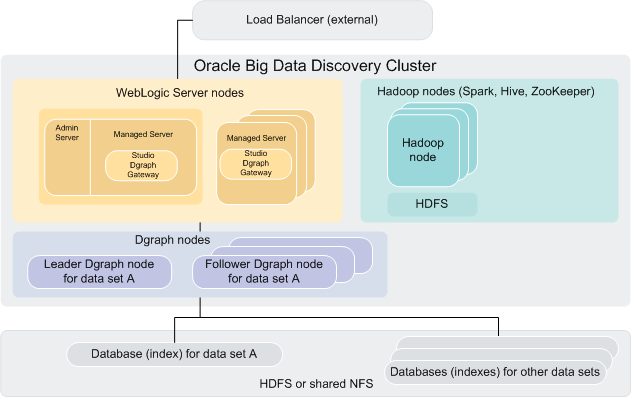
Note that this is just one supported deployment scenario; many other configurations are possible. For information on staging and learning, demo and production-level deployment topology, see the Installation Guide.
- An optional external load
balancer serves as the single point of entry to the Big Data Discovery cluster.
All browser requests are routed through this load balancer to Studio nodes.
Note: Although it is recommended to use an external load balancer in your deployment, it is optional. For information, see Load balancing and routing requests.
- WebLogic Server nodes, which host Studio and the Dgraph Gateway. Note that one node functions as both the Admin Server and a Managed Server.
- Data Processing nodes, which run data processing jobs. Data Processing is automatically installed on Hadoop nodes running Spark on YARN, YARN, and HDFS. These nodes represent a subset of the Hadoop cluster BDD is installed on.
- Dgraph nodes, which
host the Dgraph. These are the main computational modules in BDD, providing
search, refinement computation, Guided Navigation, and other features used in
Studio.
The specific nodes the Dgraph is installed on depend on where your Dgraph databases are located. If they're in HDFS, the Dgraph is installed on HDFS DataNodes. If the indexes are on a shared NFS, the Dgraph can be installed on standalone (non-HDFS) nodes.
In the diagram, notice that there is a leader Dgraph node for a data set A, and a set of follower Dgraph nodes for this same data set.
At the same time, the directory holding Dgraph databases may include databases for other data sets. For each of these data sets, at different points in time, a leader Dgraph and follower Dgraph instances may be elected. The other data sets are shown in the diagram, but their leader and follower Dgraph nodes are not shown, for simplicity.
A single Dgraph instance can serve as the leader node for one Dgraph database and a follower for others. Note that there can never be two leader Dgraphs for a single Dgraph database.
ZooKeeper maintains a cluster state for all participating members of the BDD cluster; in particular, it ensures automatic Dgraph leader election for each of the Dgraph databases, in case a leader Dgraph instance fails. Optimally, three Hadoop nodes are required for hosting ZooKeeper instances.
- Additional Hadoop nodes, which are also not shown in the diagram. These run other Hadoop components required by BDD, such as Cloudera Manager/Ambari and ZooKeeper.
