| Oracle® Fusion Middleware Oracle Data Integratorでのナレッジ・モジュールの開発 12c (12.2.1) E69913-01 |
|


 前 |
 次 |
| Oracle® Fusion Middleware Oracle Data Integratorでのナレッジ・モジュールの開発 12c (12.2.1) E69913-01 |
|
前 |
次 |
この章では、ナレッジ・モジュール(KM)の概要を示します。ナレッジ・モジュールの内容を説明し、そして様々なタイプのKMについて記載します。
この章では、次の項目について説明します。
ナレッジ・モジュール(KM)はコード・テンプレートです。それぞれのKMは、データ統合プロセス全体の中の、独立した1つのタスクに対応しています。KMのコードの表示は、実行される形式とほとんど同じですが、Oracle Data Integrator (ODI)の置換メソッドが含まれている点で異なるため、一般的に多様な統合ジョブで使用できます。生成および実行されるコードは、ODIのデザイナ・モジュールで定義された宣言規則およびメタデータから導出されます。
KMは、複数のマッピングまたはモデルの間で再使用されます。ハンドコードされたスクリプトおよびプロシージャを使用する数百ものジョブの動作を変更するには、開発者がそれぞれのスクリプトまたはプロシージャを変更する必要があります。これに対して、ナレッジ・モジュールの利点は、1回の変更が即座に数百の変換に伝播されることです。KMは、実行される論理タスクに基づきます。物理オブジェクト(データストア、属性、物理パスなど)への参照は含まれません。
KMは、影響分析のために分析可能です。
KMはスタンドアロンでは実行できません。マッピング、データストアおよびモデルからのメタデータが必要です。
KMは、6つの異なるカテゴリに分類されます。その要約を次の表に示します。
| ナレッジ・モジュール | 説明 | 使用方法 |
|---|---|---|
| リバースエンジニアリングKM | Oracle Data Integrator の作業リポジトリに格納するメタデータを取得します | カスタマイズされたリバースエンジニアリングを実行するモデル |
| チェックKM | 制約と照合してデータの一貫性をチェックします |
|
| ロードKM | 異機種間データをステージング領域にロードします | 異機種間ソースを使用するマッピング |
| 統合KM | ステージング領域からターゲットにデータを統合します | マッピングでの使用 |
| ジャーナル化KM | ソース・ステージング領域に、チェンジ・データ・キャプチャ・フレームワーク・オブジェクトを作成します | モデル、サブモデルおよびデータストア(ジャーナルの作成、開始、停止、およびサブスクライバの登録のため) |
| サービスKM | データ操作Web サービスを生成します | モデルおよびデータストア |
KMにはテンプレートスタイルとコンポーネントスタイルの2種類の実装スタイルがあります。テンプレートスタイルのKMはユーザー自身で作成して編集できます。コンポーネントスタイルのKMはビルトインのKMであり、オプションによる構成は可能ですが、ユーザー自身で作成して編集することはできません。現在使用可能なコンポーネントスタイルのKMは、ロードKMと統合KMです。KMのスタイルはマッピング・エディタの物理ビュー・プロパティで確認できます。
次の各項では、それぞれのタイプのナレッジ・モジュールについて説明します。
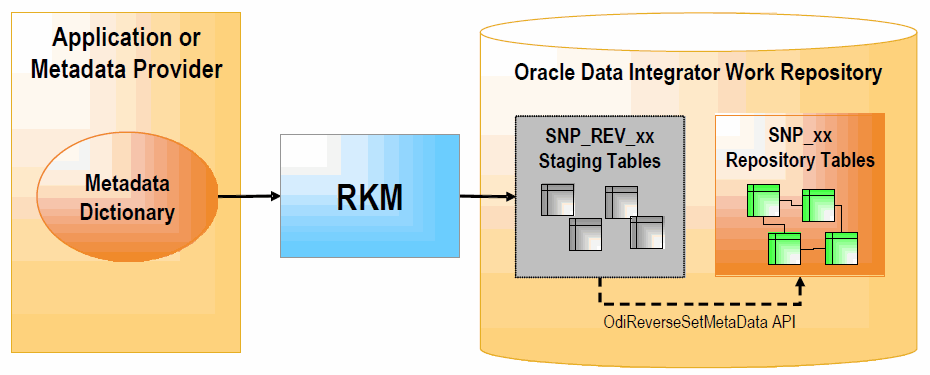
RKMの役割は、モデルのカスタマイズ済リバースエンジニアリングを実行することです。RKMは、アプリケーションまたはメタデータ・プロバイダに接続し、作成されたメタデータを変換してOracle Data Integratorのリポジトリに書き込みます。メタデータは、一時的にSNP_REV_xx表に書き込まれます。その後、RKMによってOracle Data Integrator APIがコールされ、これらの表からデータが読み取られ、Oracle Data Integratorの作業リポジトリのメタデータ表に、増分更新モードで書き込まれます。図に示すと次のようになります。
通常のRKMは、次の手順に従います。
前の実行で取得されたSNP_REV_xx表を、OdiReverseResetTableツールを使用してクリーンアップします。
メタデータ・プロバイダからサブモデル、データストア、属性、一意キー、外部キー、条件を取得し、SNP_REV_SUB_MODEL、SNP_REV_TABLE、SNP_REV_COL、SNP_REV_KEY、SNP_REV_KEY_COL、SNP_REV_JOIN、SNP_REV_JOIN_COL、SNP_REV_CONDの各表に書き込みます。
OdiReverseSetMetaDataツールをコールして、作業リポジトリ内のモデルを更新します。
CKMは、データセットのレコードが定義済の制約と一致することをチェックします。CKMは、データの整合性を保持するために使用され、全体的なデータ品質の決定に関与します。CKMは、次の2つの方法で使用できます。
既存データの一貫性チェック。これは、STATIC_CONTROLオプションを「Yes」に設定して、任意のデータストアまたはマッピング内で実行できます。1つ目のケースでは、現在データストアにあるデータがチェックされます。2つ目のケースでは、ターゲット・データストアのデータがロード後にチェックされます。
ターゲット・データストアにレコードをロードする前の、受け取ったデータの一貫性チェック。これは、FLOW_CONTROLオプションを使用して実行します。このケースでは、作成されたフローのターゲット・データストアの制約が、ターゲットに書き込まれる前に、CKMによってシミュレートされます。
要約すると: CKMは、既存の表またはIKMによって作成された一時表「I$」をチェックできます。
CKMは、一連の制約とチェック対象の表名を受け入れます。また、拒否されたすべてのレコードを書き込むエラー表「E$」を作成します。さらに、チェックした結果セットからエラーのあるレコードを削除することもできます。
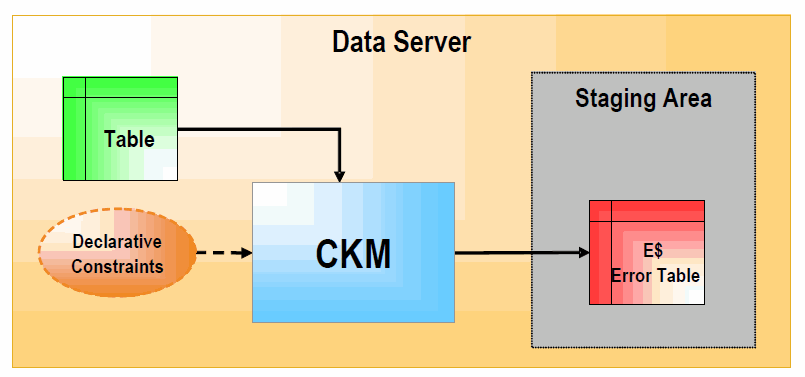
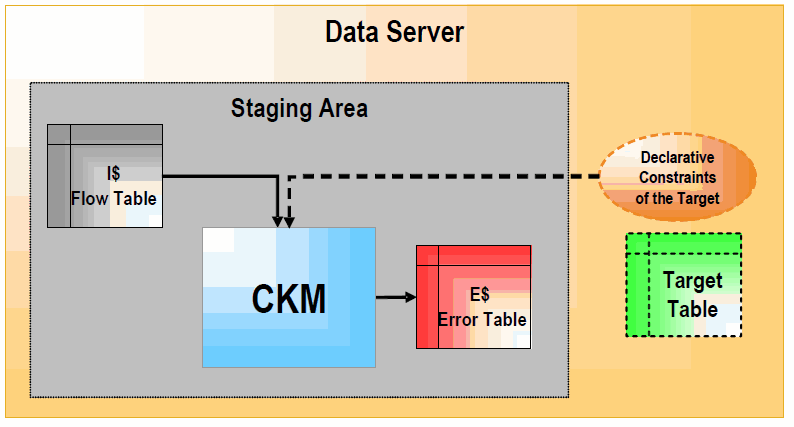
次の図は、STATIC_CONTROLモードおよびFLOW_CONTROLモードの両方で、CKMがどのように動作するかを示しています。
STATIC_CONTROLモードの場合、CKMは表の制約を読取り、表のデータと照合してチェックします。制約と一致しないレコードは、ステージング領域の「E$」エラー表に書き込まれます。
FLOW_CONTROLモードでは、CKMがマッピングのターゲット表の制約を読み取ります。これらの制約を、ステージング領域の「I$」フロー表に含まれるデータと照合してチェックします。これらの制約に違反するレコードは、ステージング領域の「E$」表に書き込まれます。
いずれの場合も、通常、CKMは次のタスクを実行します。
ステージング領域に「E$」エラー表を作成します。エラー表には、データストア内の属性と同じ列に加えて、エラー・メッセージのトレース、エラー元のチェックおよび日付のチェックを行うための追加の列が必要です。
チェックする必要がある主キー、代替キー、外部キー、条件、必須列ごとに、エラーのあるレコードを「E$」表に隔離します。
必要に応じて、チェックした表からエラーのあるレコードを削除します。
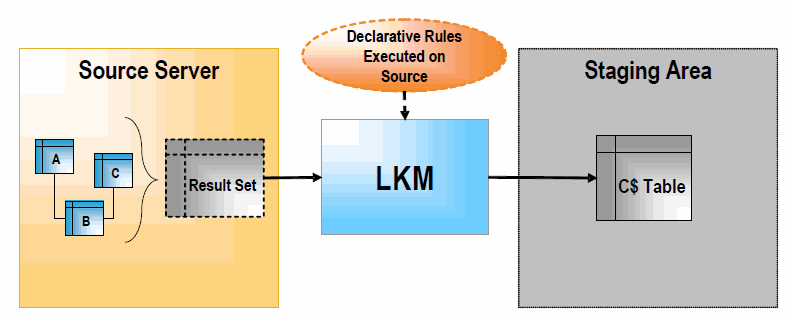
LKMは、ソース・データをリモート・サーバーからステージング領域へロードします。ソース・データストアがステージング領域と同じデータ・サーバー上にない場合に、マッピングによって使用されます。次の図に示すように、LKMは、ソース・サーバーで実行する必要がある宣言規則を実装し、単一の結果セットを取得して、ステージング領域の「C$」表に格納します。
LKMは、ステージング領域に一時表「C$」を作成します。この表には、ソース・サーバーからロードされたレコードが保持されます。
LKMは、ソース上で適切な変換を実行することで、ソース・サーバーから一連の事前変換済レコードを取得します。ソース・サーバーがRDBMSの場合は通常、単一のSQL SELECT問合せを使用して実行されます。ソースにSQLの機能がない場合(フラット・ファイルまたはアプリケーションなど)、LKMは、単純に適切な方法(ファイルの読取りまたはAPIの実行)でソース・データを読み取ります。
LKMは、ステージング領域の「C$」表にレコードをロードします。
マッピングでは、異なるソースからデータストアを使用する際にいくつかのLKMが必要になる場合があります。すべてのソース・データストアがステージング領域と同じデータ・サーバー上にある場合は、LKMは不要です。
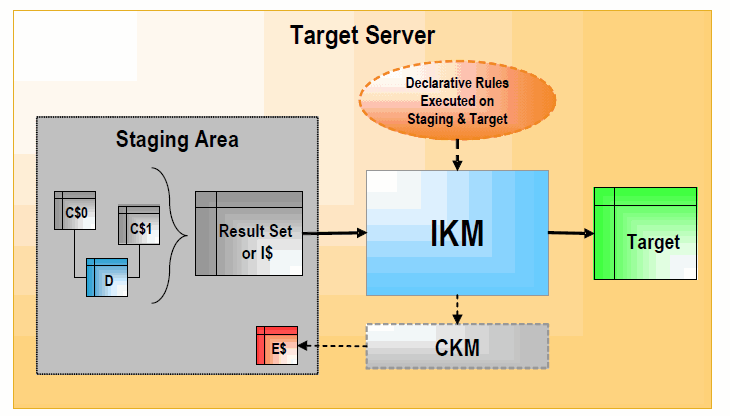
IKMは、変換された最終データをターゲット表に書き込みます。それぞれのマッピングでは、単一のIKMが使用されます。IKMの起動時には、リモート・サーバーの全ロード・フェーズのタスクは完了済であるとみなされます。つまり、すべてのリモート・ソース・データセットがLKMによってステージング領域の一時表「C$」にロードされている、もしくはソース・データストアがステージング領域と同じデータ・サーバー上にあるとみなされます。そのため、IKMによって実行されるのは、「C$」表およびステージング領域と同じデータ・サーバー上にある表に対するステージングおよびターゲットの変換、結合およびフィルタ処理のみです。通常、作成されるセットはIKMによって処理され、ターゲットにロードされる前に一時表「I$」に書き込まれます。これらの変換済最終レコードは、マッピングで選択されたIKMに応じて複数の方法で書き込むことができます。ターゲットに単純に追加するか、増分更新または緩やかに変化するディメンションのために比較することが可能です。IKMには、ステージング領域がターゲット・データストアと同じサーバー上にあることを前提条件とするIKM、およびこの条件に当てはまらない場合に使用できるIKMの2種類があります。これらを次の図に示します。
ステージング領域がターゲット・サーバー上にある場合は、通常、IKMは次の手順で行われます。
セット指向の単一のSELECT文を実行し、すべての「C$」表およびローカル表(図のDのような)のステージング領域およびターゲットの宣言規則を実行します。これにより、結果セットが生成されます。
単純な追加IKMでは、この結果セットがターゲット表に直接書き込まれます。より複雑なIKMでは、この結果セットを格納する「I$」表が作成されます
ターゲットの制約と照合してデータ・フローをチェックする必要がある場合は、CKMをコールしてエラーのあるレコードを隔離し、「I$」表をクレンジングします。
定義された戦略(増分更新、緩やかに変化するディメンションなど)に従って、「I$」表からターゲットにレコードを書き込みます。
一時表「I$」を削除します。
必要に応じて、CKM を再びコールしてターゲット・データストアの一貫性をチェックします。
この種類のKMは、ターゲット・サーバー外部のデータを操作しません。大量のジョブを実行する場合は、最大限の効率を得るために、データ処理はセット指向で行われます。
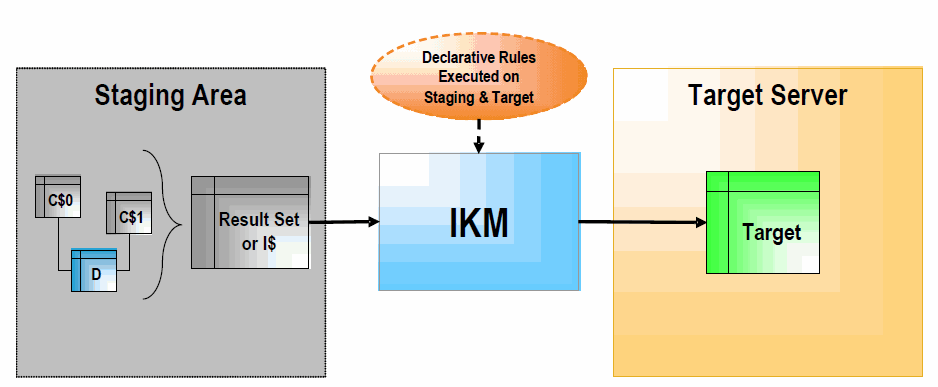
図1-6に示すように、ステージング領域がターゲット・サーバーと異なる場合は、通常、IKMは次の手順で行われます。
セット指向の単一のSELECT文を実行し、すべての「C$」表およびステージング領域の表(図のDのような)に対して宣言規則を実行します。これにより、結果セットが生成されます。
定義された戦略(追加または増分更新)に従って、この結果セットをターゲット・データストアにロードします。
このアーキテクチャには、次のような一定の制限があります。
CKMを使用して、処理対象のデータにデータ整合性監査を実行することはできません。
データは、ターゲットにロードする前にステージング領域から抽出する必要があります。これによってパフォーマンスの問題が発生する場合があります。
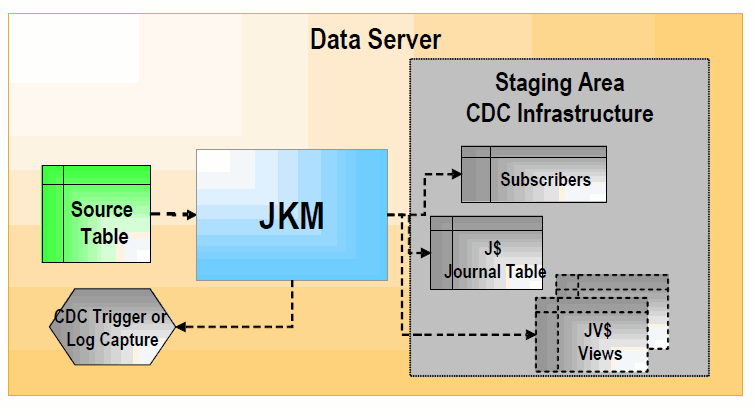
JKMは、モデル、サブモデルまたはデータストア上に、チェンジ・データ・キャプチャのインフラストラクチャを作成します。JKMは、CDCインフラストラクチャの初期化方法を定義するために、マッピングではなくモデル内で使用されます。次の図に示すように、このインフラストラクチャは、サブスクライバ表、変更の表、この表のビューおよび1つ以上のトリガーまたはログ取得プログラムで構成されます。
SKMは、データ操作Webサービスを作成して、サービス指向アーキテクチャ(SOA)インフラストラクチャにデプロイします。SKMはモデル上で設定されます。それらは、各データストアのWebサービスに対して生成される、様々な操作を定義します。他のKMとは異なり、実行可能コードを生成しません。かわりにWebサービス・デプロイメントのアーカイブ・ファイルを生成します。SKMは、Oracle Data IntegratorのWebサービス用フレームワークを使用して、Javaコードを生成するように設計されています。生成されたコードは後でコンパイルされ、最終的にアプリケーション・サーバーのコンテナにデプロイされます。
独自のKMを開発する場合の第一のガイドラインは、決してゼロから始めないことです。
Oracle Data Integratorには、すぐに使用できる多数のナレッジ・モジュールが用意されています。まずは既存のKMを確認することから開始し、自分のユースケースに近い既存のKMを出発点とすることをお薦めします。そのKMを複製し、コードを編集してカスタマイズします。
独自のKMを開発する際には、そのKMが統合プロセスの特定の段階を対象とすることに留意してください。その他の留意事項は次のとおりです。
LKMは、リモート・ソース・データセットをステージング領域のロード表(「C$」)にロードするように設計されています。
IKMは、ステージング領域のソース・フローをターゲットに適用します。まず、ロード表を変換および結合して単一の統合表(「I$」)を作成し、CKMをコールしてこの統合表のデータ品質チェックを実行して、最後にフロー・データをターゲットに書き込みます。
CKMは制約として表されるデータ品質規則と照合して、データストアまたは統合表(「I$」)でデータ品質をチェックします。拒否されたレコードはエラー表(「E$」)に格納されます。
RKMは、SNP_REV_xx一時表を使用して、メタデータ・プロバイダからOracle Data Integratorのリポジトリへメタデータを抽出します。
JKMは、チェンジ・データ・キャプチャ・インフラストラクチャを作成および管理します。
次に示す一般的な過ちに注意してください。
KMの多用: 通常のプロジェクトで必要なKMの数は5未満です。KMとプロシージャを混同しないでください。KMを特定のユースケースごとに作成しないでください。似たKMは1つのKMにまとめて、オプションを使用してパラメータ化できます。
KMでのハードコードされた値(カタログまたはスキーマ名を含む)の使用: かわりにgetTable()、getTargetTable()、getObjectName()、ナレッジ・モジュール・オプションなどの適切な置換メソッドを使用してください。
KMでの変数の使用: かわりに、オプションまたはフレックス・フィールドを使用して設計者から情報を収集してください。
KM全体のJython、GroovyまたはJavaでの記述: それが適切なソリューションである場合にのみ使用してください(たとえば、Java APIのみを持つテクノロジからソースを取得する場合)。Java、Groovy、またはJythonコードよりもSQLの方が読取りおよびメンテナンスを簡単に行えます。
コード生成の条件の作成にチェック・ボックス・オプションのかわりに<%if%>文を使用。
KMに適用されるその他の一般的なコード記述の推奨事項:
コードは正しくインデントしてください。
生成されるコードも、読み取れるようにインデントしてください。
selectやinsertなどのSQLキーワードは、読み取りやすくするために小文字で記述してください。