| Oracle® Fusion Middleware Oracle Data Integratorでの統合プロジェクトの開発 12c (12.2.1) E72513-01 |
|

 前 |
 次 |
この章では、マッピングを作成および使用する方法について説明します。
この章には次の項が含まれます:
マッピングは、データソース、データ・ターゲット、およびソースからターゲットにデータが流れる変換の論理および物理編成です。ODI 12cの新機能であるマッピング・エディタを使用してマッピングを作成および管理します。
マッピングを開くと、常にマッピング・エディタが開きます。マッピングは、デザイナ・ナビゲータの「プロジェクト」の下にあり、個々のプロジェクトの下のフォルダに編成されます。
マッピングは、次の部分で構成および定義されています。
データストア
ソース・データストアのデータはマッピングによって抽出され、ロード・プロセス中にフィルタ処理できます。ターゲット・データストアは、マッピングによってロードされる要素です。データストアはプロジェクタ・コンポーネントとして機能します。
ロード・プロセスのソースおよびターゲットとして使用されるデータストアをマッピングで使用するには、データストアがデータ・モデル内に存在している必要があります。詳細は、第3章「データ・モデルおよびデータストアの作成および使用」を参照してください。
データセット
オプションで、データセットをマッピング内でソースとして使用できます。データセットとは、マッピングの他の場所で使用されているフロー・メカニズムではなく結合およびフィルタとして宣言されたエンティティ関係によってデータを編成する論理コンテナです。データセットは、ODI 11gインタフェースと同様に動作し、11gインタフェースをODI 12cにインポートした場合、ODIでは、インタフェース論理に基づいて自動的にデータセットが作成されます。データセットはセレクタ・コンポーネントとして機能します。
再使用可能マッピング
再使用可能マッピングはモジュラで、保存および再利用可能な、カプセル化されたコンポーネント・フローです。再使用可能マッピングは、別のマッピング内や別の再使用可能マッピング内に配置できます(つまり、再使用可能マッピングはネスト化が可能)。再使用可能マッピングには、他のマッピング・コンポーネントと同様にソースおよびターゲット自体としてデータストアを含めることも可能です。再使用可能マッピングはプロジェクタ・コンポーネントとして機能します。
その他のコンポーネント
ODIには、ソースとターゲット間でデータを操作するために使用される追加のコンポーネントがあります。これらのコンポーネントは、マッピング・ダイアグラムのコンポーネント・パレットで使用できます。
コンポーネント・パレットでデフォルトで使用可能なコンポーネントは次のとおりです。
式
集計
個別
集合
フィルタ
結合
ルックアップ
ピボット
ソート
分割
副問合せフィルタ
テーブル・ファンクション
アンピボット
コネクタ
コネクタは、マッピング・コンポーネント間のデータのフローを作成します。ほとんどのコンポーネントに入力と出力の両方のコネクタを設定できます。出力コネクタのみがあるデータストアはソースとみなされ、入力コネクタのみがあるデータストアはターゲットとみなされます。複数の入力コネクタまたは出力コネクタをサポートできるコンポーネントもあります。たとえば、分割コンポーネントは、2つ以上の出力コネクタをサポートしているため、データを複数のダウンストリーム・フローに分割できます。
コネクタ・ポイントは、マッピング内のコンポーネント間の接続を定義します。コネクタ・ポイントは、コンポーネントの入力または出力の単一経路です。
コネクタ・ポートは、マッピング・ダイアグラムに表示されるコンポーネントの左側や右側にある小さな円です。
マッピング・ダイアグラムで、コネクタ・ポート間が1本の可視線で接続された2つのコンポーネントに1つ以上のコネクタ・ポイントが存在することがあります。このダイアグラムには、2つのコンポーネント間のすべての接続を表す1本の線のみが示されています。プロパティ・インスペクタでその線を選択すると、接続の詳細が表示されます。
ステージング・スキーマ
オプションで、マッピングのステージング領域や、マッピングの特定の物理マッピング設計のステージング領域を指定できます。ソース・データストアまたはターゲット・データストアとは異なるステージング領域を定義する場合は、マッピングを作成する前に、マッピングの実行コンテキストで正しい物理スキーマと論理スキーマを定義する必要があります。詳細は、第2章「Oracle Data Integratorトポロジの概要」を参照してください。
ナレッジ・モジュール
ナレッジ・モジュールでは、データがデータ・サーバー間で転送され、データ・ターゲットにロードされる方法を定義します。フローで選択されるナレッジ・モジュール(IKM、LKM、EKMおよびCKM)は、プロジェクトにインポートされているか、グローバル・ナレッジ・モジュールとして使用できる必要があります。
IKMでは、実際の変換およびロードが実行される方法を定義(または指定)できます。
LKMを使用すると、あるデータ・サーバーから別のデータ・サーバーへのデータ転送の実行方法を指定できます。
CKMは、フロー制御として使用される場合、ターゲット・データストアへのレコードのロード時にデータ・フローでのエラーをチェックできます。CKMは、静的制御として使用する場合、表内のエラーをチェックするために使用できます。データが制約を満たしているかどうかを確認するために、モデルに対していつでも静的制御を起動できます。
適切なKMを選択することで、これらのタスクを実行するための戦略を選択できます。たとえば、2つのデータベース間のデータ転送にJDBCを使用するか、または2つのOracleデータベース間の転送である場合にOracleデータベース・リンクを使用するかを決定できます。
詳細は、第6章「統合プロジェクトの作成」を参照してください。
変数、順序およびユーザー関数
マッピング内の式で使用する変数、順序およびユーザー関数を、プロジェクトに作成する必要があります。詳細は、第10章「プロシージャ、変数、順序およびユーザー関数の作成および使用」を参照してください。
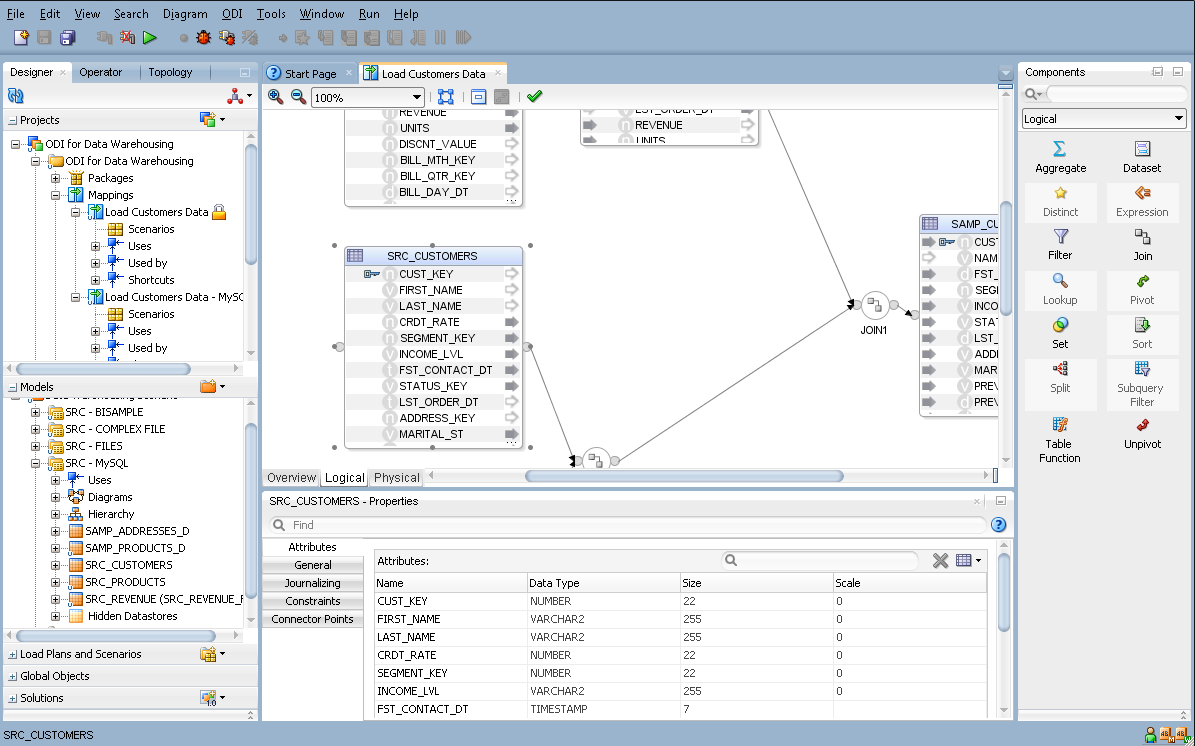
マッピング・エディタには、マッピングを設計および編集するための単一の環境が用意されています。
マッピングは、デザイナ・ナビゲータのプロジェクトのフォルダ内に編成されます。各フォルダにはマッピング・ノードがあり、その中にすべてのマッピングがリストされています。
マッピング・エディタを開くには、既存のマッピングを右クリックして「開く」を選択するか、マッピングをダブルクリックします。新しいマッピングを作成するには、マッピング・ノードを右クリックして「新規マッピング」を選択します。ODI Studioのメイン・ペインのタブとしてマッピングが開きます。マッピングに対応するタブを選択して、マッピング・エディタを表示します。
マッピング・エディタは、表8-1に説明するセクションで構成されています。
表8-1 マッピング・エディタの各セクション
| セクション | 図8-1での位置 | 説明 |
|---|---|---|
|
マッピング・ダイアグラム |
中央 |
マッピング・ダイアグラムには、マッピングの編集可能な論理ビューまたは物理ビューが表示されます。これらのビューは、論理ダイアグラムまたは物理ダイアグラムと呼ばれる場合があります。 「モデル」ツリーからデータストアをダイアグラムにドラッグし、「グローバル・オブジェクト」または「プロジェクト」ツリーから再使用可能マッピングをマッピング・ダイアグラムにドラッグします。コンポーネント・パレットからコンポーネントをドラッグして、様々なデータ操作を定義することもできます。 |
|
マッピング・エディタのタブ |
マッピング・ダイアグラムの下部中央 |
マッピング・エディタのタブは、マッピング作成プロセスの順序に従って表示されています。次のタブがあります。
|
|
プロパティ・インスペクタ |
下部 |
選択したオブジェクトのプロパティが表示されます。 プロパティ・インスペクタが表示されない場合は、「ウィンドウ」メニューから「プロパティ」を選択します。 |
|
コンポーネント・パレット |
右 |
マッピングの作成に使用できるマッピング・コンポーネントが表示されます。コンポーネント・パレットから論理マッピング・ダイアグラムにコンポーネントをドラッグ・アンド・ドロップできます。 コンポーネント・パレットが表示されない場合は、「ウィンドウ」メニューから「コンポーネント」を選択します。 |
|
構造パネル |
表示されていない |
タブおよび矢印キーを使用してナビゲートできる、マッピングのテキストベースの階層ツリー・ビューが表示されます。 構造パネルは、デフォルトでは表示されません。開くには、「ウィンドウ」メニューから「構造」を選択します。 |
|
サムネイル・パネル |
表示されていない |
マッピングの縮小グラフィックが長方形で表示されます。長方形は、マッピング・ダイアグラムで現在表示している部分を示します。このパネルは、非常に大きなマッピングまたは複雑なマッピングをナビゲートする場合に役立ちます。 サムネイル・パネルは、デフォルトでは表示されません。開くには、「ウィンドウ」メニューから「サムネイル」を選択します。 |
マッピングは標準プロセスに従って作成しますが、ユース・ケースによって異なる場合があります。
マッピング・エディタの論理ダイアグラムを使用すると、ダイアグラムへのコンポーネントのドラッグ、コンポーネント間での接続のドラッグ、これらの接続をまたいだ属性のドラッグ、およびプロパティ・インスペクタを使用したコンポーネントのプロパティを変更して、マッピングを構成できます。論理ダイアグラムが完了したら、物理ダイアグラムを使用して、物理インフラストラクチャ上で統合プロセスを実行する場所および方法を定義できます。マッピングの論理および物理設計が完了したら、それを実行できます。
通常は、次の手順に従ってマッピングを作成します。また、この手順は、最初のマッピングを設計する際のガイドラインとしても使用できます。
|
注意: プロパティ・インスペクタおよび構造パネルを使用して、ステップ2から5を実行することもできます。詳細は、「プロパティ・インスペクタおよび構造パネルを使用したマッピングの編集」を参照してください。 |
新しいマッピングを作成するには:
デザイナ・ナビゲータで、マッピングを作成するプロジェクトのフォルダ内にあるマッピング・ノードを選択します。
右クリックして「新規マッピング」を選択します。「新規マッピング」ダイアログが表示されます。
「新規マッピング」ダイアログで、マッピングの名前を入力します。必要に応じて、「説明」を入力します。新しいマッピングに新しい空のデータセットを含める場合は、空のデータセットの作成を選択します。「OK」をクリックします。
|
注意: マッピングの作成後、データセット(空のデータセットを含む)を追加または削除できます。データセットは完全にオプションであり、データセットのすべての動作は、マッピング・エディタで他のコンポーネントを使用して作成できます。ODI 12cでは、データセットには、前のバージョンのODIのユーザーが使い慣れているエンティティ関係方法を使用してデータ・フローを作成するオプションが用意されています。場合によっては、エンティティ関係ダイアグラムを作成するほうがフロー・ダイアグラムを作成するよりも時間がかからなかったり、あるいあ簡単かつ高速に変更を導入できます。 データセットを含む論理ダイアグラムに基づいて物理ダイアグラムを計算する場合、データセット内のエンティティ関係はODIで自動的にフロー・ダイアグラムに変換され、周囲のフローとマージされます。フローがどのように接続されているかを意識する必要はありません。 |
新しいマッピングは、ODI Studioのメイン・ペインの新しいタブに開きます。
|
ヒント: 「マッピング」タブで使用されるデータストア、再使用可能マッピングまたはデータセットのエディタを表示するには、オブジェクトを右クリックして「開く」を選択します。 |
コンポーネント・パレットからコンポーネントをドラッグして、論理ダイアグラムにコンポーネントを追加します。デザイナ・ナビゲータからデータストアおよび再使用可能マッピングをドラッグします。
コンポーネントを選択して[Delete]キーを押すか、右クリック・コンテキスト・メニューを使用して「削除」を選択して、コンポーネントをマッピングから削除します。確認ダイアログが表示されます。
ソース・データストアとターゲット・データストアは、マッピングによって抽出およびロードされる要素です。
ソース・データストアとターゲット・データストア間で、マッピングのその他すべてのコンポーネントが調整されます。マッピングが実行されると、データはソース・データストアから、定義したコンポーネントを介して、ターゲット・データストアに流れます。
ダウンストリーム式の保持および削除
該当する場合は、コンポーネントを削除するときに、確認ダイアログのチェック・ボックスを使用して、ダウンストリーム式を保持または削除できます(このような式はコンポーネントの接続時または変更時に作成された可能性があります)。デフォルトでは、ODIはこれらの式を保持します。
この機能を使用すると、すでに完了した作業を破棄することなく、マッピングに対する変更を行うことができます。たとえば、ソース・データストアがターゲット・データストアにマップされると、属性はすべてマップされます。その後、ソース・データをフィルタ処理する必要があることに気付きます。フィルタを追加する場合、1つのオプションとして、2つのデータストア間の接続を削除するが、ターゲット・データストアで設定されている式は維持し、中間にフィルタを接続します。いずれのマッピング式も失われません。
元のコネクタ・ポートから宛先のコネクタ・ポートにドラッグして、コンポーネント間にコネクタを作成します。コンポーネント間で属性をドラッグし、暗黙的にコネクタを作成することもできます。2つのポート間にコネクタを作成する際に、名前や位置に基づいて自動的に属性をマップするための属性照合ダイアログが表示されることがあります。
「属性照合」ダイアログは、マッピング・エディタでコネクタをプロジェクタ・コンポーネント(「プロジェクタ・コンポーネント」を参照)にドラッグする際に表示されます。「属性照合」ダイアログには、照合メカニズムに基づいて、ソースからターゲット・コンポーネントに属性をマップするための式を自動的に作成するオプションがあります。また、ソースに基づいてターゲットに新しい属性を作成するオプション、またはターゲットに基づいてソースに新しい属性を作成するオプションもあります。
この機能を使用すると、コンポーネント内に別のコンポーネントから導出された一連の属性を簡単に定義できます。たとえば、空の新しいセット・コンポーネントから接続をダウンストリーム・ターゲット・データストアにドラッグできます。「属性照合」ダイアログの「ソースでの属性の作成」オプションを選択したままでいると、セット・コンポーネントにはターゲット・データストアのすべての属性が移入されます。セット・コンポーネントをアップストリーム・コンポーネントに接続すると、アップストリーム属性にマップできるターゲット属性がすでに存在します。
ODIコネクタの用語の概要は、「コネクタ」を参照してください。
1つのコンポーネント上のコネクタ・ポートをクリックし、別のコンポーネントのコネクタ・ポートに線をドラッグして、接続を定義できます。接続が許可される場合、ODIは、各コンポーネントで使用されていない既存のコネクタ・ポイントを使用するか、または必要に応じて追加のコネクタ・ポイントを作成します。接続がマッピング・ダイアグラムに表示され、接続された2つのコンポーネントのコネクタ・ポートをつなぐ線が示されます。2つのコンポーネント間に複数の接続があっても、1本の線しか表示されません。
ほとんどのコンポーネントは、マッピング・ダイアグラムでコンポーネントの横に小さい円として表示される、他のコンポーネントへの入力コネクタと出力コネクタの両方を使用できます。使用できる各タイプのコネクタ数が制限されるコンポーネント・タイプや、入力接続か出力接続のどちらか一方しか設定できないコンポーネントもあります。
プロパティ・インスペクタを使用して、コネクタ・ポイントを追加または削除できるコンポーネントもあります。
たとえば、結合コンポーネントにはデフォルトで2つの入力コネクタ・ポイントと、1つの出力コネクタ・ポイントがあります。ただし、複数の入力が許可されます。3つ目の接続を結合コンポーネントの入力コネクタ・ポートにドラッグすると、ODIは3つ目の入力コネクタ・ポイントを作成します。また、結合コンポーネントを選択し、プロパティ・インスペクタの「コネクタ・ポイント」セクションで緑色のプラス・アイコンをクリックして、追加の入力コネクタ・ポイントを追加することもできます。
|
注意: すでに接続が最大数になっている入力ポートとの間で接続をドラッグすることはできません。たとえば、ターゲット・データストアで1つの入力コネクタ・ポイントしか許可されない場合、新たな接続を入力コネクタ・ポートにドラッグしようとしても接続は作成されません。 |
コネクタを削除するには、2つのコネクタ・ポイントの間の線を右クリックして「削除」を選択するか、線を選択して[Delete]キーを押します。
コンポーネントをマッピングに追加する場合、データをソースから中間コンポーネントを介してターゲットに流すために、コンポーネントに属性を作成する必要がある場合があります。通常、新しい属性を定義して、データの変換を実行します。
次の方法を使用して、新しい属性を定義します。
「属性照合」ダイアログ: このダイアログは、あるコンポーネントのコネクタ・ポートから別のコンポーネントのコネクタ・ポートに接続をドラッグする際、少なくとも1つのコンポーネントがプロジェクタ・コンポーネントである場合に表示されます。
「属性照合」ダイアログには、ターゲットに属性を作成するオプションが含まれます。ターゲットに一致する名前の属性がすでにある場合、ODIはこれらの属性を自動的にマップします。「位置別」を選択した場合、ODIは最初の属性をターゲット内の既存の属性にマップし、残り(複数存在する場合)をその下に追加します。たとえば、ターゲット・コンポーネントに3つの属性があり、ソースに12の属性がある場合、最初の3つの属性が既存の属性にマップされ、残りの9つは既存のラベルを使用してコピーされます。
属性のドラッグ・アンド・ドロップ: 単一(または複数選択した)属性を1つのコンポーネントから別のコンポーネント(の既存の属性の上にではなく、コンポーネント・グラフィックの空白領域)にドラッグ・アンド・ドロップします。ODIは、接続を作成し(まだ存在しない場合)、属性も作成します。
|
ヒント: コンポーネントのグラフィックに空白がない場合は、属性上にマウスを置くと、右側にスクロール・バーが表示されます。下部にスクロールし、空白行を表示します。これで、属性を空白領域にドラッグできます。属性を別の属性にドラッグすると、ODIは、名前が一致しない場合でもその属性を別の属性にマップします。ターゲット・コンポーネントに新しい属性は作成されません。 |
プロパティ・インスペクタでの新しい属性の追加: プロパティ・インスペクタの「属性」タブで、緑のプラス・アイコンを使用して、新しい属性を作成します。「属性」表で、新しい属性の名前、データ型およびその他のプロパティを選択または入力できます。次に、他のコンポーネントの属性を新しい属性にドラッグして、新しい属性にマップできます。
|
注意: ODIでは、無効なデータ型接続の作成が許可されます。したがって、新しい属性を作成するときは、適切なデータ型を必ず設定する必要があります。たとえば、DATEデータ型の属性を新しい属性にマップする場合、新しい属性もDATE型になるようにする必要があります。実行中、タイプ不一致エラーがSQLエラーとして捕捉されます。 |
式と条件を使用して、個々の属性をコンポーネントからコンポーネントにマップします。コンポーネント・タイプによって、デフォルトの式と条件が決まり、これらがマッピングの基礎となるコードに変換されます。
たとえば、すべてのターゲット・コンポーネントは属性ごとに1つの式を持ちます。フィルタ、結合またはルックアップ・コンポーネントは、(SQLなどの)コードを使用して、コンポーネント・タイプに適した式を作成します。
|
ヒント: ターゲットで式が設定されると、その式により参照されるソース属性が、アップストリーム・ソースでマゼンタとして強調表示されます。たとえば、tgt_empno (をクリックして)選択し、ターゲット列tgt_empnoの式emp.empnoを選択した場合、ソース・データストアempの属性empnoが強調表示されます。
この強調表示機能により、目的の各ターゲット属性に有効な相互参照を含む式があることをすばやく確認できます。式を誤って手動で編集した場合(ソース属性のスペルを間違えた場合など)、相互参照は無効になり、ターゲット属性をクリックしてもソース属性は強調表示されません。 |
様々なプロパティ・フィールドに表示されるコードを変更して、コンポーネントの式と条件を変更できます。
|
注意: 通常は手動で式を編集せずに、式エディタを使用することをお薦めします。式エディタからソース属性を選択すると、必ずその式に有効な相互参照が付与されるため、編集エラーを最小限に抑えることができます。詳細は、「式エディタ」を参照してください。 |
式にはVARCHARやNUMERICなどの戻り型があります。条件の結果の型はブールであるため、条件の結果は常にTRUEまたはFALSEに評価される必要があります。条件は、フィルタ、結合およびルックアップ(セレクタ)の各コンポーネントに必要です。一方、式は、一部の変換の実行や、属性レベルのマッピングの作成のために、データストア、集計および個別(プロジェクタ)の各コンポーネントで使用されます。
各プロジェクタ・コンポーネントには、その属性に対する式を含めることができます。(ほとんどのプロジェクタ・コンポーネントでは1つの属性に1つの式のみ含まれますが、セット・コンポーネントの属性には複数の式を含めることができます。)属性の式を変更した場合は、小さな「f」アイコンが論理ダイアグラムの属性に表示されます。このアイコンは、関数がそこに配置されていることを示す視覚的キューとなります。
ターゲット属性のマッピングを定義するには:
マッピング・エディタで、属性のプロパティをプロパティ・インスペクタに表示する属性を選択します。
「ターゲット」タブ(式の場合)または「条件」タブ(条件の場合)で、「式」フィールドまたは「条件」フィールドを変更して、必要な論理を作成します。
|
ヒント: ダイアグラム内のコンポーネントの属性を式フィールドにドラッグ・アンド・ドロップすると、完全修飾属性名がコードに自動的に追加されます。 |
オプションで、式が含まれるフィールドをプロパティ・インスペクタで選択するか、フィールド上にマウスを置いてから、フィールドの右に表示される歯車アイコンをクリックすると、高度な「式エディタ」が開きます。
左側の属性は、スコープ内にある(すでに接続されている)属性のみです。このため、属性を持つコンポーネントへのアップストリーム接続またはダウンストリーム接続がないコンポーネントを作成した場合、属性はリストされません。
オプションで、式または条件の変更後に、SQLコードのエラーをチェックするためにマッピングを検証することを検討します。論理ダイアグラムの上部にある緑のチェック・マーク・アイコンをクリックします。検証エラーがある場合は、パネルに表示されます。
マッピング・エディタの「物理」タブで、マップされたデータのロード戦略と統合戦略を定義します。Oracle Data Integratorでは、マッピングの論理ダイアグラムの構成に応じてフローが自動的に計算されます。データ・フローに対するデフォルトのナレッジ・モジュール(KM)が提案されます。「物理」タブでは、データ・フローを表示し、データのロードおよび統合に使用するKMを選択できます。
物理設計の詳細は、「物理設計」を参照してください。
マッピングが作成されると、そのマッピングを実行できます。この項では、マッピングの実行プロセスの要約を示します。統合プロセスの実行の詳細は、『Oracle Data Integratorの管理』の統合プロセスの実行に関する項を参照してください。
マッピングを実行するには:
デザイナ・ナビゲータの「プロジェクト」メニューで、マッピングを右クリックして「実行」を選択します。
または、マッピング・エディタでマッピングを開いて、ツールバーの「実行」アイコンをクリックします。または、「実行」メニューから「実行」を選択します。
「実行」ダイアログで、次の実行パラメータを選択します:
マッピングが実行されるコンテキストを選択します。コンテキストの詳細は、「コンテキスト」を参照してください。
実行する「物理マッピング設計」を選択します。「物理マッピング設計の作成および管理」を参照してください。
マッピングを実行する論理エージェントを選択します。「ローカル(エージェントなし)」を選択することで、Oracle Data Integrator Studioに組み込まれているエージェントを使用して、オブジェクトを実行することもできます。論理エージェントの詳細は、「エージェント」を参照してください。
「ログ・レベル」を選択して、マッピングの実行時にバリデータに表示されるメッセージの詳細を制御します。ロギングの詳細は、『Oracle Data Integratorの管理』のログの管理に関する項を参照してください。
コードを実際に実行せずにプレビューする場合は、「シミュレーション」ボックスを選択します。この場合、ソース・データストアまたはターゲット・データストア上のデータは変更されません。詳細は、『Oracle Data Integratorの管理』の実行のシミュレーションに関する項を参照してください。
「OK」をクリックします。
「情報」ダイアログが表示されます。セッションが正常に開始されると、「セッションを開始しました」というメッセージが表示されます。
「OK」をクリックします。
|
注意:
|
マッピング・エディタの論理ビューで、データストアを他のコンポーネントと結合して、マッピングを設計します。マッピング・ダイアグラムを使用して、データセット、フィルタ、ソートなどのコンポーネントを調整および接続できます。データストアとコンポーネント間に接続を形成するには、これらのオブジェクトに表示されるコネクタ・ポート間で線をドラッグします。
マッピング・コンポーネントは、マッピングでの使用方法を示す2つのカテゴリ(プロジェクタ・コンポーネントとセレクタ・コンポーネント)に分けられます。
プロジェクタ・コンポーネント
プロジェクタは、マッピング内を流れるデータに存在する属性に影響するコンポーネントです。プロジェクタ・コンポーネントでは独自の属性を定義し、式を使用して、前のコンポーネントの属性をプロジェクタの属性にマップします。プロジェクタでは前のコンポーネントから発生した属性は表示されないため、後続のすべてのコンポーネントで使用できるのは、そのプロジェクタの属性のみです。
様々なプロジェクタ・コンポーネントの使用方法を理解するために、次の項を確認してください。
セレクタ・コンポーネント
セレクタ・コンポーネントは、前のコンポーネントの属性を再使用します。結合セレクタおよびルックアップ・セレクタは、前のコンポーネントの属性を結合します。たとえば、データストア・コンポーネントの後に続くフィルタ・コンポーネントでは、そのデータストア・コンポーネントのすべての属性が再使用されます。そのため、セレクタ・コンポーネントでは、独自の属性がダイアグラムやプロパティの一部として表示されず、丸い形で表示されます。(式コンポーネントはこのルールの例外です。)
セレクタ・コンポーネントの属性をマッピング内の別のコンポーネントにマッピングする場合は、属性を選択し、その属性をソースから、一連の接続済セレクタ・コンポーネントを通って、ターゲット・データストアまたは次のプロジェクタ・コンポーネントまでドラッグできます。ODIは、その属性が中間セレクタ・コンポーネントを通って移動するために必要な問合せを自動的に作成します。
次の項では、様々なセレクタ・コンポーネントの使用方法を説明します。
マッピングで使用するほとんどのコンポーネントは、実際は、データがソースからターゲット・データストアに流れるときにデータに作用する、コード内の式の表現です。これらのコンポーネントを作成または変更する場合は、プロパティ・インスペクタで直接式のコードを編集できます。
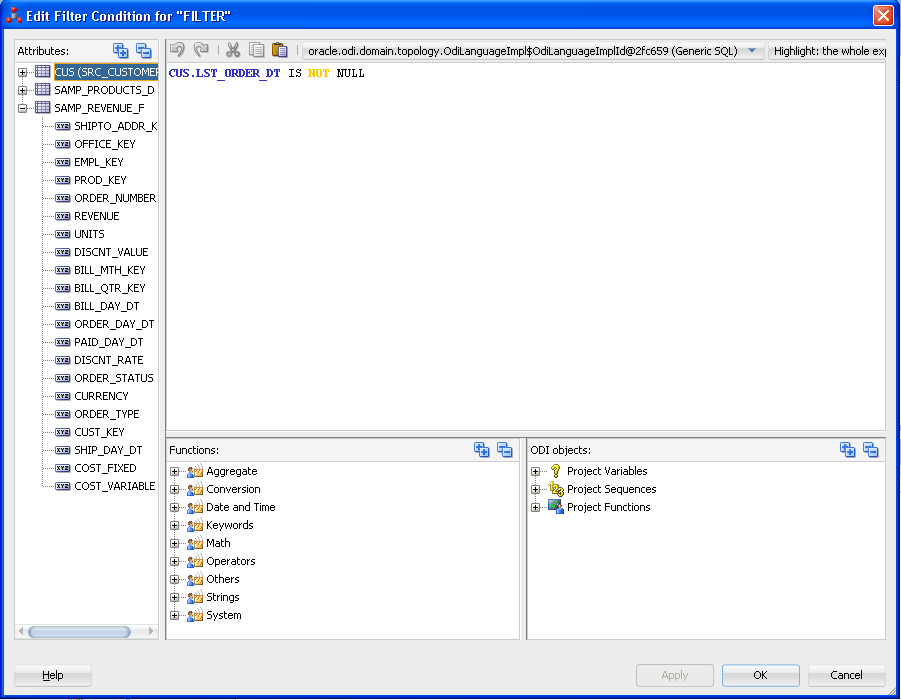
より複雑な式で支援が必要な場合は、式エディタと呼ばれる拡張エディタを開くこともできます。(場合によっては、エディタにコンポーネントのタイプに応じたラベルが付いていることがあります。たとえば、フィルタ・コンポーネントでは、エディタはフィルタ条件拡張エディタと呼ばれます。ただし、提供される機能は同じです。)
式エディタにアクセスするには、コンポーネントを選択し、プロパティ・インスペクタでコードが含まれるフィールドを選択するか、フィールド上にマウス・ポインタを置きます。フィールドの右側に歯車アイコンが表示されます。歯車アイコンをクリックして、式エディタを開きます。
たとえば、フィルタ・コンポーネントで歯車アイコンを表示するには、「条件」タブの「フィルタ条件」フィールドを選択するか、フィールド上にマウスを置きます。データストア・コンポーネントで歯車アイコンを表示するには、「ジャーナル化」タブの「ジャーナル化されたデータ・フィルタ」フィールドを選択するか、フィールド上にマウスを置きます。
式エディタの一般的なビュー例を図8-2に示します。
「式」エディタは、次のパネルで構成されています。
属性: このパネルは、式エディタの左に表示されます。マッピングの式を編集する場合、このパネルにはスコープ内の属性の名前が含まれます。つまり、現在表示されている属性は、コンポーネントの式で参照できることを意味します。たとえば、コンポーネントがソース・データストアに接続されている場合、そのデータストアのすべての属性がリストされます。
式: このパネルは、「式」エディタの中央に表示されます。式の現在のコードが表示されます。ここに直接コードを入力したり、他のパネルから要素をドラッグ・アンド・ドロップできます。
テクノロジ関数: このパネルは、式の下に表示されます。設定されているテクノロジで対応している言語要素および関数をリストします。
変数、順序、ユーザー関数およびodiRef API: このパネルは、テクノロジ関数の右に表示され、次のものが含まれます。
プロジェクトおよびグローバル変数。
プロジェクトおよびグローバル順序
プロジェクトおよびグローバル・ユーザー定義関数
OdiRef置換メソッド
ツールバーのボタンを使用して、標準的な編集機能(切取り、コピー、貼付け、元に戻す、やりなおし)を使用できます。
マッピングにソースまたはターゲット・データストアを挿入するには:
デザイナ・ナビゲータで、「モデル」ツリーを展開し、ソースまたはターゲットとして挿入するデータストアを含むモデルまたはサブモデルを展開します。
このデータストアを選択してマッピング・パネルにドラッグします。データストアが表示されます。
データストアをソースにするには、データストアの出力(右)コネクタから1つ以上のコンポーネントにリンクをドラッグします。データストアは、少なくとも1つの発信接続を持たないとソースになりません。
データストアをターゲットにするには、コンポーネントからデータストアの入力(左)コネクタにリンクをドラッグします。データストアは、着信接続があるまではターゲットになりません。
データストアを定義した後は、そのデータを表示できます。
データストアのデータをマッピングに表示するには:
マッピング・ダイアグラムでデータストアのタイトルを右クリックします。
「データ」を選択します。
データ・エディタが開きます。
Oracle Data Integrator 12cで、マッピングに複数のターゲットを作成することは簡単です。論理ダイアグラムで入力はあるが出力がないデータストア・コンポーネントはすべて、ターゲットとみなされます。
ODIでは、マッピングの任意のポイントでコンポーネント出力を複数のフローに分割できます。また、複数の独立フローを持つ単一マッピングを作成でき、これにより、複数マッピングを調整するためのパッケージが不要になります。
多数のコンポーネントの出力ポートを複数のダウンストリーム・コンポーネントに接続できます。これにより、コンポーネントのすべての行が各ダウンストリーム・フローで処理される結果となります。行をルーティングするか、ダウンストリーム・フローで条件付きで処理する必要がある場合は、分割コンポーネントを使用して分割条件を定義することを考慮してください。
複数のターゲットを持つマッピングは、デフォルトで、ターゲットへの定義済データ・ロード順序に従います。「ターゲット・ロード順序」プロパティを使用して、部分的または完全な順序を定義できます。順序を明示的に割り当てていないターゲットは、ODIによって任意の順序でロードされます。
|
注意: ターゲット・ロード順序は、再使用可能マッピングにも適用されます。再使用可能マッピングにソース・データストアまたはターゲット・データストアが含まれている場合は、親マッピングのターゲット・ロード順序プロパティに再使用可能マッピング・コンポーネントを含めることができます。 |
複数のターゲットの処理順序は、マッピングの「ターゲット・ロード順序」プロパティで設定できます。
論理ダイアグラムのバックグラウンドをクリックして、マッピングのオブジェクトの選択を解除します。プロパティ・インスペクタにマッピングのプロパティが表示されます。
プロパティ・インスペクタで、デフォルトのターゲット・ロード順序を受け入れるか、「ターゲット・ロード順序」フィールドに新しいターゲット・ロード順序を入力します。
|
注意: デフォルトのロード順序は、マッピングのターゲット・データストアの主キー/外部キーの関係に基づいて自動的に計算されます。このデフォルトは、変更の必要があれば、それによってロード順序が主キー/外部キーの関係と競合する場合でも変更できます。この場合、マッピングを検証すると、警告が表示されます。 |
「ターゲット・ロード順序」フィールドを選択するか、フィールドにマウスを置き、歯車アイコンをクリックして、「ターゲット・ロード順序」を開きます。このダイアログには、ターゲットにすることができる、使用可能なすべてのデータストア(およびデータストアを含む再使用可能マッピング)が表示され、1つ以上を「順序付きターゲット」フィールドに移動できます。「順序付きターゲット」フィールドで、右側のアイコンを使用して、処理順序を再調整します。
|
ヒント: ターゲット順序は、マッピングに複数のターゲットがあり、ターゲット間に外部キー(FK)関係がある場合に有効です。たとえば、マッピングにEMPおよびDEPTという2つのターゲットがあり、EMP.DEPTNOはDEPT.DEPTNOのFKです。ソース・データに従業員と部門に関する情報があり、従業員に関する行(EMP)をロードする前に、まず部門に関する情報(DEPT)をロードする必要があります。これが確実に行われるようにするには、ターゲット・ロード順序がDEPT, EMPに設定されている必要があります。 |
再使用可能マッピングは、プロジェクトのフォルダ内に格納したり、デザイナ・ナビゲータの「グローバル・オブジェクト」ツリー内のグローバル・オブジェクトとして格納できます。
再使用可能マッピングをマッピングに追加するには:
現在のプロジェクト内に格納された再使用可能マッピングを追加するには:
デザイナ・ナビゲータで、「プロジェクト」ツリーを展開し、作業しているプロジェクトのツリーを展開します。再使用可能マッピング・ノードを展開して、このプロジェクト内に格納されているすべての再使用可能マッピングをリストします。
グローバル再使用可能マッピングを追加するには:
デザイナ・ナビゲータで、グローバル・オブジェクト・ノードを展開し、再使用可能マッピング・ノードを展開して、すべてのグローバル再使用可能マッピングをリストします。
再使用可能マッピングを選択し、それをマッピング・ダイアグラムにドラッグします。再使用可能マッピング・コンポーネントが、基礎となる再使用可能マッピングへのインタフェースとしてダイアグラムに追加されます。
集計コンポーネントは、平均、カウント、最大、合計などの集計関数を使用して属性をグループ化および結合するプロジェクタ・コンポーネントです(「プロジェクタ・コンポーネント」を参照)。ODIは、GROUP BY属性として使用される集計関数なしで属性を自動的に選択します。これは、「グループ化基準」プロパティや、「手動のGROUP BY句」プロパティを使用してオーバーライドできます。
集計コンポーネントを作成するには:
コンポーネント・パレットから論理ダイアグラムに集計コンポーネントをドラッグ・アンド・ドロップします。
属性がソース・コンポーネントと異なる場合は、集計の属性を定義します。これを行うには、プロパティ・インスペクタの「属性」タブを選択し、緑のプラス・アイコンをクリックして、属性を追加します。「ターゲット」列に新しい属性名を入力し、それらに適切な値を割り当てます。
集計コンポーネントの属性がソース・コンポーネントの属性と同じである場合は、属性照合を使用します(ステップ4を参照)。
ソースのコネクタ・ポートから集計コンポーネントのコネクタ・ポートに線をドラッグして、ソース・コンポーネントからの接続を作成します。
「属性照合」ダイアログが表示されます。集計コンポーネントの属性がソース・コンポーネントの属性と同じである場合は、「ターゲットでの属性の作成」ボックスを選択します(「属性照合」を参照)。
必要に応じて、ソースのすべての属性を、属性照合によりマップされていないターゲットにマップし、必要に応じて変換式を作成します(「式および条件の定義」を参照)。
プロパティ・インスペクタで、属性が「属性」タブの表にリストされます。必要に応じて、各属性に集計関数を指定します。デフォルトでは、集計関数(合計、カウント、平均、最大、最小など)を使用してマップされないすべての属性は、GROUP BYとして使用されます。
属性をクリックして、集計式を変更できます。たとえば、部門ごとの平均給与を計算する場合は、2つの属性があります。最初の属性はAVG_SALと呼ばれ、式AVG(EMP.SAL)を提供します。2つ目の属性はDEPTNOと呼ばれ、式はありません。グループ化基準がAutoに設定されている場合、生成されたコードのGROUP BY句にDEPTNOが自動的に含まれます。
このデフォルトをオーバーライドするには、指定の属性でプロパティ「グループ化基準」をAutoからYesまたはNoに変更するか、表のセルをダブルクリックし、ドロップダウン・リストから目的のオプションを選択します。
集計コンポーネント全体に対してデフォルト以外のGROUP BY句を設定できます。プロパティ・インスペクタの「一般」タブを選択し、「手動のGROUP BY句」を設定します。たとえば、「手動のGROUP BY句」をYEAR(customer.birthdate)に設定し、誕生年別にグループ化します。
オプションで、集計コンポーネントのHAVINGプロパティを設定して、HAVING句を追加します。たとえば、SUM(order.amount) > 1000となります。
個別は、フローに存在する属性のサブセットを予測するプロジェクタ・コンポーネント(「プロジェクタ・コンポーネント」を参照)です。各行の値は一意であることが必要で、動作はSQL DISTINCT句のルールに従います。
ソース・データストアから個別の行を選択するには:
コンポーネント・パレットから論理ダイアグラムに個別コンポーネントをドラッグ・アンド・ドロップします。
前のコンポーネントから個別コンポーネントに線をドラッグして、前のコンポーネントを個別コンポーネントに接続します。
「属性マッピング」ダイアログが表示されます。「ターゲットでの属性の作成」を選択して、個別コンポーネントのすべての属性を作成します。または、必要に応じて、プロパティ・インスペクタの「属性」タブを使用して、属性を手動でマップできます。
個別コンポーネントは、予測されたすべての属性一致を持つ行をすべてフィルタ処理するようになります。
式は、フロー内の前のコンポーネントから属性を継承し、追加の再使用可能な属性を追加するセレクタ・コンポーネント(「セレクタ・コンポーネント」を参照)です。式を使用して、1つのマッピング内に再使用可能な多数の式を定義できます。SQL式を使用して、ソース属性から、属性の名前を変更したり、変換したりできます。動作は、SQL SELECT句のルールに従います。
式コンポーネントの最適な用途は、中間変換が複数回使用される場合です。たとえば、複数のターゲットで使用されるフィールドを事前計算する場合です。
変換が1度だけ使用される場合は、ターゲット・データベースまたは他のコンポーネントで変換を実行することを検討します。
|
ヒント: 複数のマッピングにわたって式を再使用する場合は、複雑度に応じて、再使用可能マッピングまたはユーザー関数の使用を検討します。「再使用可能マッピング」および「ユーザー関数の使用」を参照してください。 |
式コンポーネントを作成するには:
コンポーネント・パレットから論理ダイアグラムに式コンポーネントをドラッグ・アンド・ドロップします。
前のコンポーネントから式コンポーネントに線をドラッグして、前のコンポーネントを式コンポーネントに接続します。
「属性マッピング」ダイアログが表示されます。「ターゲットでの属性の作成」を選択して、式コンポーネントのすべての属性を作成します。
場合によっては、式コンポーネントがダウンストリーム・コンポーネントの属性と一致する必要がある場合があります。この場合は、最初に式コンポーネントをダウンストリーム・コンポーネントと接続し、「ソースでの属性の作成」を選択して、式コンポーネントにターゲットの属性を移入します。
必要に応じて、プロパティ・インスペクタの「属性」タブを使用して、式コンポーネントに属性を追加します。ダウンストリーム・コンポーネントの複数の式で使用される事前計算済フィールドに属性を追加すると便利な場合があります。
必要に応じて個々の属性の式を編集します(「式および条件の定義」を参照)。
フィルタは、フィルタ条件に基づいてデータのサブセットを選択できるセレクタ・コンポーネント(「セレクタ・コンポーネント」を参照)です。動作は、SQL WHERE句のルールに従います。
フィルタは、データセットに配置しても、マッピングにフロー・コンポーネントとして直接配置してもかまいません。
データセットで使用する際、フィルタは1つのデータストアまたは再使用可能マッピングに接続され、データセットからこのコンポーネントのすべてのプロジェクションをフィルタします。詳細は、「データセットを使用したマッピングの作成」を参照してください。
マッピングにフィルタを定義するには:
コンポーネント・パレットから論理ダイアグラムにフィルタ・コンポーネントをドラッグ・アンド・ドロップします。
前のコンポーネントからフィルタ・コンポーネントに属性をドラッグします。コネクタは、前のコンポーネントからフィルタにドラッグされ、属性はフィルタ条件で参照されます。
プロパティ・インスペクタの「条件」タブで、フィルタ条件を編集し、式を完了します。たとえば、CUSTOMER表(別名がCUSTOMERのソース・データストア)からNAMEがnullでない顧客を選択する場合、式はCUSTOMER.NAME IS NOT NULLとなります。
|
ヒント: 「フィルタ条件」フィールドの右にある歯車アイコンをクリックして、フィルタ条件拡張エディタを開きます。歯車アイコンは、「フィルタ条件」フィールドを選択するか、またはフィールド上にマウス・ポインタを置く場合にのみ表示されます。フィルタ条件拡張エディタの詳細は、「式エディタ」を参照してください。 |
オプションで、プロパティ・インスペクタの「一般」タブで、「名前」フィールドに新しい名前を入力します。マッピングに複数のフィルタがある場合は、一意の名前を使用すると役立ちます。
オプションで、優先する実行場所を示すように「実行ヒント」を設定します(ヒントなし、ソース、ステージングまたはターゲット)。物理ダイアグラムでは、可能な場合、ヒントに応じたフィルタの実行が特定されます。詳細は、「実行場所の構成」を参照してください。
この項には次のトピックが含まれます:
結合について
結合は、複数のフロー間に結合を作成するセレクタ・コンポーネント(「セレクタ・コンポーネント」を参照)です。アップストリーム・コンポーネントの属性は、結合コンポーネントの属性として結合されます。
結合は、データセットに配置しても、マッピングにフロー・コンポーネントとして直接配置してもかまいません。結合は、2つ以上のデータ・フロー(データストア、データセット、再使用可能マッピング、または様々なコンポーネントの組合せ)のデータを結合します。
データセットで使用すると、結合は、選択された結合タイプを使用しているデータストアのデータを結合します。詳細は、「データセットを使用したマッピングの作成」を参照してください。
フロー・コンポーネントとして使用される結合では、データストアやその他のアップストリーム・コンポーネントなど、2つ以上のソースの属性を結合できます。結合条件は、マッピング・ダイアグラム内で、2つ以上のコンポーネントから結合コンポーネントに連続して属性をドラッグすることで形成できます。デフォルトでは、結合条件は、2つの属性間の等結合になります。
ルックアップについて
ルックアップは、駆動フローの値を指定されたルックアップ・フローからデータを戻すセレクタ・コンポーネント(「セレクタ・コンポーネント」を参照)です。結合コンポーネントと同様に、両方のフローの属性が結合されます。
ルックアップは、データセットに配置しても、マッピングにフロー・コンポーネントとして直接配置してもかまいません。
データセットで使用すると、ルックアップは、選択された結合タイプを使用してデータストアのデータを結合している、2つのデータストアまたは再使用可能マッピングに接続されます。詳細は、「データセットを使用したマッピングの作成」を参照してください。
フロー・コンポーネントとして使用される(つまり、データセット内にない)ルックアップは、2つのフローを結合できます。ルックアップ条件は、駆動フロー、ルックアップ・フローの順で属性をルックアップ・コンポーネントにドラッグして作成できます。ルックアップ条件は、2つの属性間の等結合になります。
「複数の一致行」プロパティは、ルックアップによって複数の結果が戻された場合に、ルックアップ結果のどの行をルックアップ結果として選択するかを定義します。指定されたルックアップ条件が複数のレコードに一致した場合、複数の行が戻されます。
次のオプションのいずれかを選択して、ルックアップ操作によって複数の行が戻された場合に実行するアクションを指定できます。
エラー: 複数行により、マッピングが失敗します。
このオプションは、ルックアップ操作によって複数の行が戻された場合にマッピングの実行が失敗することを示します。
|
注意: ODI 12.1.3では、「非推奨 - エラー: 複数行により、マッピングが失敗します。」オプションでEXPRESSION_IN_SELECTオプション値を使用することは推奨されなくなりました。これは、ODI 12.1.2の特定のパッチ適用バージョンとの下位互換性のために用意されています。
このオプションは、「エラー: 複数行により、マッピングが失敗します。」の |
すべての行(結果行の数が入力行の数と異なる可能性があります)
このオプションは、ルックアップ操作によって複数の行が戻された場合に、すべての行がルックアップ結果として戻されることを示します。
|
注意: ODI 12.1.3では、「非推奨 - すべての行(結果行の数が入力行の数と異なる可能性があります)。」オプションでLEFT_OUTERオプション値を使用することは推奨されなくなりました。これは、ODI 12.1.2の特定のパッチ適用バージョンとの下位互換性のために用意されています。
このオプションは、「すべての行(結果行の数が入力行の数と異なる可能性があります)。」の |
任意の単一行を選択する
このオプションは、ルックアップ操作によって複数の行が戻された場合に、戻された行から任意の1行がルックアップ結果として選択されることを示します。
最初の単一行を選択する
このオプションは、ルックアップ操作によって複数の行が戻された場合に、戻された行から最初の1行がルックアップ結果として選択されることを示します。
n番目の単一行を選択する
このオプションは、ルックアップ操作によって複数の行が戻された場合に、結果行からn番目の行がルックアップ結果として選択されることを示します。このオプションを選択すると「n番目の行番号」フィールドが表示され、ここでnの値を指定できます。
最後の単一行を選択してください。
このオプションは、ルックアップ操作によって複数の行が戻された場合に、戻された行から最後の1行がルックアップ結果として選択されることを示します。
「参照属性のデフォルト値および順序基準」表を使用して、複数の行を含む結果セットを順序付けする方法と、ルックアップで入力属性にルックアップ条件に一致するものが見つからなかった場合のデフォルト値を指定します。結果セットの順序と同じ順序で(上から下に)属性が表示されていることを確認します。たとえば、ORDER BY attr2、attr3、attr1のように順序付けを実行する場合、属性は同じ順序でリストされている必要があります。矢印ボタンを使用して属性の位置を変更し、順序を指定できます。
「一致行なし」プロパティは、ルックアップ条件を満たす行がない場合に実行されるアクションを示します。ルックアップ操作によって行が戻されなかった場合に実行するオプションを次のうちから選択できます。
戻り行なし
このオプションでは、ルックアップ結果にルックアップ条件を満たす行がない場合、行を戻しません。
行を次のデフォルト値とともに戻します
このオプションでは、ルックアップ結果にルックアップ条件を満たす行がない場合に、デフォルト値を含む行を戻します。このオプションの下の「参照属性のデフォルト値および順序基準」表を使用して、各ルックアップ属性のデフォルト値を指定します。
結合またはルックアップの作成
2つのアップストリーム・コンポーネント間に結合またはルックアップを作成するには:
コンポーネント・パレットから論理ダイアグラムに結合またはルックアップをドラッグします。
結合に存在する属性またはルックアップ条件を、前のコンポーネントから結合またはルックアップ・コンポーネントにドラッグします。たとえば、ソース・データストアCUSTOMERの属性ID、およびソース・データストアORDERのCUSTIDが結合にドラッグされると、結合条件CUSTOMER.ID = ORDER.CUSTIDが作成されます。
|
注意: 3つ以上の属性が結合またはルックアップにドラッグされると、ODIは属性を比較し、AND演算子を使用して結合します。たとえば、ソースAおよびBから結合コンポーネントに属性を次の順序でドラッグした場合:A.FIRSTNAME B.FIRSTNAME A.LASTNAME B.LASTNAME 次の結合条件が作成されます。 A.FIRSTNAME=B.FIRSTNAME AND A.LASTNAME=B.LASTNAME 追加の属性ペアを使用して同様に続行できます。 必要に応じて、条件を作成した後に編集できます。 |
プロパティ・インスペクタの「条件」タブで、結合条件またはルックアップ条件を編集し、式を完了します。
|
ヒント: 「結合条件」または「ルックアップ条件」フィールドの右にある歯車アイコンをクリックして、式エディタを開きます。歯車アイコンは、条件フィールドを選択するか、または条件フィールド上にマウス・ポインタを置く場合にのみ表示されます。式エディタの詳細は、「式エディタ」を参照してください。 |
オプションで、優先する実行場所を示すように「実行ヒント」を設定します(ヒントなし、ソース、ステージングまたはターゲット)。物理ダイアグラムでは、可能な場合、ヒントに応じたフィルタの実行が特定されます。
結合の場合:
各種ボックス(「相互」、「自然」、「左外部」、「右外部」、「完全外部」(左側のボックスと右側のボックスの両方をチェック)または「内部結合」(すべてのボックスを空のままにする))をチェックして、「結合タイプ」を選択します。結合によって取得される行の説明テキストが更新されます。
ルックアップの場合:
ドロップ・ダウン・リストからオプションを選択して、「複数の一致行」を選択します。「技術的な説明」フィールドは、完全修飾属性名を使用して、ルックアップを表すSQLコードで更新されます。
該当する場合、「参照属性のデフォルト値および順序基準」表を使用して、複数の行が含まれる結果セットを順序付けする方法を指定します。
「一致行なし」プロパティの値を選択して、ルックアップ条件を満たす行がない場合に実行されるアクションを指定します。
結合の場合、オプションで、この結合に順序付き結合構文を使用する場合は、「ANSI構文の生成」ボックスを選択します。
「ANSI構文の生成」を有効化すると「結合順序」ボックスが選択され、結合に順序番号が自動的に割り当てられます。
データセット内部の結合の場合、結合順序を定義します。「結合順序」チェック・ボックスを選択し、「ユーザー定義」フィールドに整数を入力します。結合コンポーネントの結合順序番号がより小さい場合は、特定の結合が他の結合の中で最初に処理されることを意味します。結合順序番号により、FROM句での結合の順序が決定します。結合の結合順序番号がより小さい場合は、他の結合よりも早く実行されることを意味します。これは、データセット内に外部結合がある場合に重要となります。
例: マッピングには2つの結合、JOIN1およびJOIN2があります。JOIN1はAおよびBを接続し、その結合タイプはLEFT OUTER JOINです。JOIN2はBとCを接続し、その結合タイプはRIGHT OUTER JOINです。
(A LEFT OUTER JOIN B) RIGHT OUTER JOIN Cを生成するには、結合順序10をJOIN1に割り当て、20をJOIN2に割り当てます。
A LEFT OUTER JOIN (B RIGHT OUTER JOIN C)を生成するには、結合順序20をJOIN1に割り当て、10をJOIN2に割り当てます。
ピボット・コンポーネントは、複数の入力行に格納されているデータを単一の出力行に変換するプロジェクタ・コンポーネント(「プロジェクタ・コンポーネント」を参照)です。ピボット・コンポーネントを使用すると、ソースからデータを1回抽出し、ソース・データ内で属性別にグループ化されているソース行セットから1行を生成できます。ピボット・コンポーネントは、マッピングのデータ・フローの任意の場所で使用できます。
表8-2に、SALESリレーショナル表のサンプル・データを示します。QUARTER属性がとることのできる文字値は4種類あり、それぞれが各四半期に対応しています。すべての売上データは、SALESという1つの属性に含まれます。
表8-2 SALES
| YEAR | QUARTER | SALES |
|---|---|---|
|
2010 |
Q1 |
10.5 |
|
2010 |
Q2 |
11.4 |
|
2010 |
Q3 |
9.5 |
|
2010 |
Q4 |
8.7 |
|
2011 |
Q1 |
9.5 |
|
2011 |
Q2 |
10.5 |
|
2011 |
Q3 |
10.3 |
|
2011 |
Q4 |
7.6 |
表8-3に、表がピボットされた後のリレーショナル表SALESのデータを示します。それまでQUARTER属性(Q1、Q2、Q3およびQ4)に格納されていたデータは個別の4つの属性(Q1_Sales、Q2_Sales、Q3_SalesおよびQ4_Sales)に対応します。前にSALES属性に含まれていた売上データは、各四半期を表す4つの属性間に分散されます。
ピボット・コンポーネントを使用すると、行ロケータに基づいて複数の入力行が1行に変換されます。行ロケータは、定義した一連の出力属性に対応するようにソースから選択する必要のある属性です。ピボット操作を実行するには、行ロケータを指定する必要があります。
この例では、行ロケータはSALES表の属性QUARTERで、ピボットされた出力データの属性Q1_Sales、Q2_Sales、Q3_SalesおよびQ4_Salesに対応します。
マッピングでピボット・コンポーネントを使用するには:
ソース・データストアを論理ダイアグラムにドラッグ・アンド・ドロップします。
コンポーネント・パレットから論理ダイアグラムにピボット・コンポーネントをドラッグ・アンド・ドロップします。
ソース・データストアから適切な属性をピボット・コンポーネントにドラッグ・アンド・ドロップします。この例では、YEAR属性です。
|
注意: 行ロケータ属性または出力属性に対応するデータ値が含まれる属性をドラッグしないでください。この例では、QUARTERが行ロケータ属性で、SALESがQ1_Sales、Q2_Sales、Q3_SalesおよびQ4_Sales出力属性に対応するデータ値(売上高)が格納される属性です。 |
ピボット・コンポーネントを選択します。ピボット・コンポーネントのプロパティは、プロパティ・インスペクタに表示されます。
ピボット・コンポーネントの名前および説明を入力します。
必要に応じて、ピボット・コンポーネントの集計関数を変更します。デフォルトはMINです。
式を入力するか式エディタを使用して行ロケータを指定します。この例では、SALES表のQUARTER属性が行ロケータであるため、式はSALES.QUARTERとなります。
「行ロケータ値」の下で「+」記号をクリックして行ロケータ値を追加します。この例では、行ロケータ属性QUARTERに指定可能な値はQ1、Q2、Q3およびQ4です。
「属性」の下で、各入力行に対応する出力属性を追加します。必要に応じて、新規属性を追加したり、リストされている属性の名前を変更できます。
この例では、4つの入力行Q1、Q2、Q3およびQ4にそれぞれ対応する4つの新規属性Q1_Sales、Q2_Sales、Q3_SalesおよびQ4_Salesを追加します。
必要に応じて、ソースから売上高を取得する各属性の式を変更し、各属性に一致する行を選択します。
この例では、各属性に対する式をSALES.SALESに設定し、それぞれ一致する行をQ1、Q2、Q3およびQ4に設定します。
ターゲット・データストアを論理ダイアグラムにドラッグ・アンド・ドロップします。
ピボット・コンポーネントの出力(右)コネクタからターゲット・データストアの入力(左)コネクタへとリンクをドラッグし、ピボット・コンポーネントをターゲット・データストアに接続します。
ピボット・コンポーネントの適切な属性をターゲット・データストアにドラッグ・アンド・ドロップします。この例では、YEAR、Q1_Sales、Q2_Sales、Q3_SalesおよびQ4_Salesです。
必要に応じて、物理ダイアグラムに移動して新しいKMを割り当てます。
マッピングを保存および実行してピボット操作を実行します。
セット・コンポーネントは、UNION、INTERSECT、EXCEPT、MINUSなどのセット操作を使用して、複数の入力フローを1つに結合するプロジェクタ・コンポーネント(「プロジェクタ・コンポーネント」を参照)です。動作は、SQL演算子を反映します。
|
注意: PigSetCmdでは、EXCEPTセット操作はサポートされません。 |
追加の入力フローをセット・コンポーネントに追加するには、新しいフローを接続します。入力フローの数は、「演算子」タブの「入力コネクタ・ポイント」のリストに表示されます。入力フローを削除する場合は、入力コネクタ・ポイントも削除する必要があります。
2つ以上のソースから1つのセットを作成するには:
コンポーネント・パレットから論理ダイアグラムにセット・コンポーネントをドラッグ・アンド・ドロップします。
属性がソース・コンポーネントと異なる場合は、セットの属性を定義します。これを行うには、プロパティ・インスペクタの「属性」タブを選択し、緑のプラス・アイコンをクリックして、属性を追加します。「ターゲット」列で新しい属性名を選択し、それらに適切な値を割り当てます。
属性がソース・コンポーネントの属性と同じである場合は、属性照合を使用します(ステップ4を参照)。
ソースのコネクタ・ポートからセット・コンポーネントのコネクタ・ポートに線をドラッグして、最初のソースからの接続を作成します。
「属性照合」ダイアログが表示されます。セットの属性がソース・コンポーネントの属性と同じである必要がある場合は、「ターゲットでの属性の作成」ボックスを選択します(「属性照合」を参照)。
必要に応じて、ソースのすべての属性を、属性照合によりマップされていないターゲットにマップし、必要に応じて変換式を作成します(「式および条件の定義」を参照)。
マップされたすべての属性が、論理ダイアグラムで黄色の矢印でマークされます。これにより、この属性についてすべてのソースがマップされているわけではないことが示されます。セットに少なくとも2つのソースがあります。
このセット・コンポーネントに接続するすべてのソースに対して接続および属性マッピングのステップを繰り返します。完了すると、黄色の矢印がなくなります。
プロパティ・インスペクタで、「演算子」タブを選択し、「演算子」列のセルを選択し、適切な集合演算子(UNION、EXCEPT、INTERSECTなど)を選択します。デフォルトでは、UNIONが選択されます。接続されたソースの順番を変更して、セット動作を変更することもできます。
|
注意: セット・コンポーネントの属性に「実行ヒント」を設定できますが、セット・コンポーネント自体にも「実行ヒント」プロパティがあります。コンポーネントのヒントは、実際のセット操作(UNION、EXCEPTなど)が実行される優先場所を示し、一方、属性のヒントは、式が実行される優先場所を示します。
一般的なユース・ケースは、セット操作がステージング実行ユニットに対して実行されるが、その式の一部はソース実行ユニットに対して実行できることです。実行ユニットの詳細は、「実行場所の構成」を参照してください。 |
ソートは、SQL ORDER BY文を使用して、ソート順序を処理済データセットの行に適用するプロジェクタ・コンポーネントです(「プロジェクタ・コンポーネント」を参照)。
ソース・データストアでソートを作成するには:
コンポーネント・パレットから論理ダイアグラムにソート・コンポーネントをドラッグ・アンド・ドロップします。
ソートする属性を前のコンポーネントからソート・コンポーネントにドラッグします。複数の属性に基づいて行をソートする必要がある場合は、目的の順序で属性をソート・コンポーネントにドラッグできます。
ソート・コンポーネントを選択し、プロパティ・インスペクタで「条件」タブを選択します。「ソーター条件」フィールドは、基礎となるデータベースのSQL ORDER BY文の構文に従います。複数のフィールドは、カンマで区切ってリストでき、ASCまたはDESCを各フィールドの後に追加して、ソートが昇順または降順であるかを定義できます。
分割は、指定した条件に基づいて、1つのフローを2つ以上のフローに分割するセレクタ・コンポーネント(「セレクタ・コンポーネント」を参照)です。分割条件は、必ずしも相互排他である必要はありません。ソース行は、すべての分割条件に照らして評価され、複数の出力フローで有効な可能性があります。
フローが無条件で複数のフローに分割される場合、分割コンポーネントは不要です。複数のダウンストリーム・コンポーネントを、前のコンポーネントの単一発信コネクタ・ポートに接続でき、前のコンポーネントのデータ出力はすべてのダウンストリーム・コンポーネントにルーティングされます。
分割コンポーネントを使用して、前の複数のフローおよびターゲットに行を条件付きでルーティングできます。
マッピングの複数ターゲットに分割を作成するには:
コンポーネント・パレットから論理ダイアグラムに分割コンポーネントをドラッグ・アンド・ドロップします。
前のコンポーネントから分割コンポーネントに線をドラッグして、分割コンポーネントを前のコンポーネントに接続します。
分割コンポーネントを各後続コンポーネントに接続します。アップストリーム・コンポーネントまたはダウンストリーム・コンポーネントのいずれかに属性が含まれている場合は、「属性マッピング」ダイアログが表示されます。ダイアログの「接続パス」セクションでは、マップされていない最初のコネクタ・ポイントにデフォルト設定され、必要に応じてコネクタ・ポイントが追加されます。特定のコネクタ・ポイントを使用する必要がある場合は、この選択を変更します。
プロパティ・インスペクタで、「分割条件」タブを開きます。「出力コネクタ・ポイント」表で、各ターゲットの行を選択する式を入力します。式を空のままにすると、すべての行が、選択したターゲットにマップされます。「残り」ボックスを選択して、他のいずれのターゲットでも選択されなかったすべての行をマップします。
副問合せフィルタ・コンポーネントは、副問合せの結果に基づいて行をフィルタするプロジェクタ・コンポーネント(「プロジェクタ・コンポーネント」を参照)です。行のフィルタに使用できる条件は、EXISTS、NOT EXISTS、INおよびNOT INです。
たとえば、EMPデータストアに従業員データが格納されており、DEPTデータストアに部門データが格納されているとします。副問合せを使用してDEPTデータストアからレコードのセットをフェッチし、その後、いずれかの副問合せ条件を使用してEMPデータストアの行をフィルタできます。
副問合せフィルタ・コンポーネントには2つの入力コネクタ・ポイントと、1つの出力コネクタ・ポイントがあります。この2つの入力コネクタ・ポイントは、ドライバ入力コネクタ・ポイントと副問合せフィルタ入力コネクタ・ポイントです。ドライバ入力コネクタ・ポイントではメイン・データストアが設定され、これを基に全体問合せが実行されます。副問合せフィルタ入力コネクタ・ポイントでは、副問合せで使用されるデータストアが設定されます。この例では、EMPがドライバ入力コネクタ・ポイントで、DEPTが副問合せフィルタ入力コネクタ・ポイントです。
副問合せフィルタ・フィルタ・コンポーネントを使用して行をフィルタするには:
コンポーネント・パレットから論理ダイアグラムに副問合せフィルタ・コンポーネントをドラッグ・アンド・ドロップします。
副問合せフィルタ・コンポーネントをソース・データストアおよびターゲット・データストアに接続します。
ソース・データストアから入力属性を副問合せフィルタ・コンポーネントにドラッグ・アンド・ドロップします。
副問合せフィルタ・コンポーネントの出力属性をターゲット・データストアにドラッグ・アンド・ドロップします。
「コネクタ・ポイント」タブに移動し、ドライバ入力コネクタ・ポイントおよび副問合せフィルタ入力コネクタ・ポイントの入力データストアを選択します。
副問合せフィルタ・コンポーネントをクリックします。副問合せフィルタ・コンポーネントのプロパティは、プロパティ・インスペクタに表示されます。
「Attributes」タブに移動します。出力コネクタ・ポイント属性がリストされます。ドライバ入力コネクタ・ポイントおよび副問合せフィルタ・コネクタ・ポイントの式を設定します。
|
注意: 副問合せフィルタ入力ロールが次のいずれかに設定されている場合のみ、副問合せフィルタ入力コネクタ・ポイントの式を設定する必要があります。IN、NOT IN、=、>、<、>=、<=、!=、<>、^= |
「条件」タブに移動します。
「副問合せフィルタ条件」フィールドに式を入力します。副問合せフィルタ入力ロールが「EXISTS」または「NOT EXISTS」に設定されている場合、副問合せフィルタ条件を指定する必要があります。
副問合せフィルタ入力ロールを「副問合せフィルタ入力ロール」ドロップダウン・リストから選択します。
グループ比較条件を「グループ比較条件」ドロップダウン・リストから選択します。グループ比較条件は、次の副問合せ入力ロールでのみ使用できます。
=、>、<、>=、<=、!=、<>、^=
マッピングを保存し、実行します。
テーブル・ファンクション・コンポーネントは、マッピングのテーブル・ファンクションを表すプロジェクタ・コンポーネント(「プロジェクタ・コンポーネント」を参照)です。テーブル・ファンクション・コンポーネントを使用すると、入力行セットを操作し、同一または異なるカーディナリティを持つ別の出力行セットを戻すことができます。出力行セットは物理表のように問合せ可能です。テーブル・ファンクション・コンポーネントは、ソース、ターゲットまたはデータ・フロー・コンポーネントとして、マッピングのどこにでも配置できます。
テーブル・ファンクション・コンポーネントには、複数の入力コネクタ・ポイントと、1つの出力コネクタ・ポイントを設定できます。入力コネクタ・ポイント属性はテーブル・ファンクションの入力パラメータとして動作し、出力コネクタ・ポイント属性は戻り値を格納するのに使用されます。
各入力コネクタに対し、入力コネクタ・ポイントに設定される属性タイプに応じてパラメータ・タイプREF_CURSORまたはSCALARを定義できます。
マッピングでテーブル・ファンクション・コンポーネントを使用するには:
データベースにテーブル・ファンクションが存在しない場合は作成します。
「マッピング」ノードを右クリックし、「新規マッピング」を選択します。
ソース・データストアを論理ダイアグラムにドラッグ・アンド・ドロップします。
コンポーネント・パレットから論理ダイアグラムにテーブル・ファンクション・コンポーネントをドラッグ・アンド・ドロップします。入力コネクタ・ポイントがなく、デフォルト出力コネクタ・ポイントが1つ設定されたテーブル・ファンクション・コンポーネントが作成されます。
テーブル・ファンクション・コンポーネントをクリックします。テーブル・ファンクション・コンポーネントのプロパティは、プロパティ・インスペクタに表示されます。
プロパティ・インスペクタで「属性」タブに移動します。
「名前」フィールドにテーブル・ファンクションの名前を入力します。テーブル・ファンクションが別のスキーマにある場合は、ファンクション名をSCHEMA_NAME.FUNCTION_NAMEのように入力します。
「コネクタ・ポイント」タブに移動し、「+」記号をクリックして新しい入力コネクタ・ポイントを追加します。各入力コネクタに対して適切なパラメータ・タイプを設定するのを忘れないでください。
|
注意: REF_CURSOR属性はそれぞれ、パラメータ・タイプがREF_CURSORに設定された別個の入力コネクタ・ポイントに設定する必要があります。SCALAR属性は、パラメータ・タイプがSCALARに設定された単一の入力コネクタ・ポイントに複数設定できます。 |
「属性」タブに移動し、(前のステップで作成した)入力コネクタ・ポイントおよび出力コネクタ・ポイントに対して属性を追加します。入力コネクタ・ポイント属性はテーブル・ファンクションの入力パラメータとして動作し、出力コネクタ・ポイント属性は戻り値を格納するのに使用されます。
ソース・データストアの必要な属性を、テーブル・ファンクション・コンポーネントの入力コネクタ・ポイントの適切な属性にドラッグ・アンド・ドロップします。ソース・データストアとテーブル・ファンクション・コンポーネント間の接続が作成されます。
ターゲット・データストアを論理ダイアグラムにドラッグ・アンド・ドロップします。
テーブル・ファンクション・コンポーネントの出力属性をターゲット・データストアの属性にドラッグ・アンド・ドロップします。
マッピングの物理ダイアグラムに移動し、テーブル・ファンクション・コンポーネントが正しい実行ユニット内にあることを確認します。そうでない場合は、テーブル・ファンクションを正しい実行ユニットに移動します。
必要な場合は、新しいKMを割り当てます。
マッピングを保存し、実行します。
アンピボット・コンポーネントは、属性にまたがって格納されているデータを複数の行に変換するプロジェクタ・コンポーネント(「プロジェクタ・コンポーネント」を参照)です。
アンピボット・コンポーネントは、ピボット・コンポーネントと逆の処理を実行します。ピボット・コンポーネントと同様に、アンピボット・コンポーネントはマッピングのフローの任意の場所で使用できます。
アンピボット・コンポーネントは、フラット・ファイルなど、行ではなく属性にまたがってデータが格納されている非リレーショナル・データ・ソースからデータを抽出する場合に特に役立ちます。
表8-4に示す外部表QUARTERLY_SALES_DATAには、フラット・ファイルのデータが含まれています。1行に各年と、各四半期の売上を示す個別の属性が格納されています。
表8-4 QUARTERLY_SALES_DATA
| 年 | Q1_Sales | Q2_Sales | Q3_Sales | Q4_Sales |
|---|---|---|---|---|
|
2010 |
10.5 |
11.4 |
9.5 |
8.7 |
|
2011 |
9.5 |
10.5 |
10.3 |
7.6 |
表8-5に、アンピボット操作が実行された後のデータのサンプルを示します。それまで複数の属性(Q1_Sales、Q2_Sales、Q3_SalesおよびQ4_Sales)にわたって格納されていたデータが単一の属性(SALES)に格納されています。アンピボット・コンポーネントは単一の属性(Q1_Sales)のデータを2つの属性(QUARTERおよびSALES)に分割します。QUARTERLY_SALES_DATAの1つの行はアンピボット・データの4行(各四半期の売上に対して1行)に対応します。
行ロケータはソースからの反復データ・セットに対応する出力属性です。アンピボット・コンポーネントでは1つの入力属性が複数行に変換され、行ロケータの値が生成されます。ソースからのデータに対応する他の属性は値ロケータとして参照されます。この例では、属性QUARTERが行ロケータで、属性SALESは値ロケータです。
|
注意: アンピボット・コンポーネントを使用するには、アンピボット・コンポーネントの行ロケータ属性および値ロケータ属性を作成する必要があります。「アンピボット変換」表の値ロケータ・フィールドには、任意の式を移入できます。例: UNPIVOT_EMP_SALES.Q1_SALES + 100 |
マッピングでアンピボット・コンポーネントを使用するには:
ソース・データストアを論理ダイアグラムにドラッグ・アンド・ドロップします。
コンポーネント・パレットから論理ダイアグラムにアンピボット・コンポーネントをドラッグ・アンド・ドロップします。
ソース・データストアから適切な属性をアンピボット・コンポーネントにドラッグ・アンド・ドロップします。この例では、YEAR属性です。
|
注意: 値ロケータに対応するデータが格納されている属性をドラッグしないでください。この例では、Q1_Sales、Q2_Sales、Q3_SalesおよびQ4_Salesです。 |
アンピボット・コンポーネントを選択します。アンピボット・コンポーネントのプロパティは、プロパティ・インスペクタに表示されます。
アンピボット・コンポーネントの名前および説明を入力します。
属性エディタを使用して行ロケータ属性および値ロケータ属性を作成します。この例では、QUARTERおよびSALESという名前の2つの属性を作成する必要があります。
|
注意: 属性に対して適切なデータ・タイプおよび制約(必要な場合)を定義するのを忘れないでください。 |
プロパティ・インスペクタの「UNPIVOT」の下で、「行ロケータ」ドロップダウン・リストから行ロケータ属性を選択します。この例では、QUARTERです。
行ロケータを選択したため、他の属性は値ロケータとして動作できます。この例では、SALESです。
「UNPIVOT TRANSFORMS」の下で、「+」をクリックして各出力属性の変換ルールを追加します。変換ルールのデフォルト値を編集し、適切な式を指定して必要な論理を作成します。
この例では、各四半期に対して1つ、合わせて4つの変換ルールを追加する必要があります。変換ルールでは、行ロケータ属性QUARTERおよび値ロケータ属性SALESに移入される値が定義されます。QUARTER属性には定数値(Q1、Q2、Q3およびQ4)を移入する必要があり、SALES属性にはソース・データストア属性(Q1_Sales、Q2_Sales、Q3_SalesおよびQ4_Sales)からの値を移入する必要があります。
NULLとして定義されている属性に対してデータがない行を生成するには、「INCLUDE NULLS」チェック・ボックスを選択したままにしておきます。
ターゲット・データストアを論理ダイアグラムにドラッグ・アンド・ドロップします。
アンピボット・コンポーネントの出力(右)コネクタからターゲット・データストアの入力(左)コネクタへとリンクをドラッグし、アンピボット・コンポーネントをターゲット・データストアに接続します。
アンピボット・コンポーネントの適切な属性をターゲット・データストアにドラッグ・アンド・ドロップします。この例では、YEAR、QUARTERおよびSALESです。
必要に応じて、物理ダイアグラムに移動して新しいKMを割り当てます。
「保存」をクリックし、それからマッピングを実行してアンピボット操作を実行します。
フラット化コンポーネントは、複雑な構造を持つ入力データを処理し、標準データ型を使用して同じデータのフラット化表現を生成するプロジェクタ・コンポーネントです(「プロジェクタ・コンポーネント」を参照)。
「フラット化」では、ネストした構造の各行が結果で新しい行を生成するように、囲み構造でネストされた構造の外積を生成します。
フラット化コンポーネントには、1つの入力コネクタ・ポイントと、1つの出力コネクタ・ポイントがあります。
例: フラット化した複合データ
表8-6に、複合タイプの属性ratingsを持つデータストアmovie_ratingsの例を示します。複合タイプ属性ratingsは反復し、子属性ratingを持ちます。
表8-7に、フラット化した後のレコードを示します。
マッピングでフラット化コンポーネントを使用するには:
ソース・データストアを論理ダイアグラムにドラッグ・アンド・ドロップします。
コンポーネント・パレットから論理ダイアグラムにフラット化コンポーネントをドラッグ・アンド・ドロップします。
フラット化するソース・コンポーネントから属性を1つ選択し、「フラット化」コンポーネントのプロパティ「複合タイプ属性」にそれを入力します。この属性は、ソース・データの複合タイプである必要があります。
複合タイプのすべての属性を、「フラット化」コンポーネントの「属性」プロパティに手動で入力します。これらの属性に、式はありません。
他のソース属性を「フラット化」コンポーネントにマップします。
複合タイプ属性をNULLまたは空文字列にできる場合は、プロパティ「NULLを含む」をチェックします。
「フラット化」コンポーネントを、ターゲット・データストアまたは他のダウンストリーム・コンポーネントに接続します。
必要に応じて、物理ダイアグラムに移動して新しいKMを割り当てます。
「保存」をクリックし、それからマッピングを実行してフラット化操作を実行します。
ソースがJSONデータの場合に「フラット化」コンポーネントを使用するときは、次の点を考慮する必要があります。
フラット化は、JSONファイル内で複数の子オブジェクトとネストしたオブジェクトをサポートしません。次の例に示すように、ソースのJSONデータは、プレーンである必要があります。
例: {"POSTAL_AREA":1, "POSTAL_AREA_DETAIL":[{"STATE":"CA","POSTAL_CODE":"200001"}]}
Pigをステージング領域としてマッピングにJSONファイルとフラット化したコンポーネントを使用する場合、ストレージ機能オプションと、複合フィールドのスキーマ・オプションをPigのLKMファイルに設定する必要があります。
これらのオプションを、次の例に示すように設定する必要があります。
ストレージ機能: JsonLoader
複雑なフィールドのスキーマ: POSTAL_AREA_DETAIL:{(STATE:chararray,POSTAL_CODE:chararray)}
不規則コンポーネントは、メタ・ピボットを使用して非構造化データを処理するプロジェクタ・コンポーネントです。不規則コンポーネントを使用して、データをデータベース表にロード可能な構造化エンティティに変換できます。
不規則データ・コンポーネントには、コンポーネントの構成に基づいて1つの入力グループと複数の出力グループがあります。
入力グループには、受信データ・セットの名前の部分と値の部分の2つの必須属性があります。3つ目のオプションの属性は、行識別子順序が行セットを説明するために使用されます。
マッピングで不規則コンポーネントを使用するには:
ソース・データストアを論理ダイアグラムにドラッグ・アンド・ドロップします。
コンポーネント・パレットから論理ダイアグラムに不規則コンポーネントをドラッグ・アンド・ドロップします。
不規則入力グループには、名前と値の2つの属性レベル・マッピングが必要です。
1つ以上の出力グループをダウンストリーム・コンポーネントにマップします。
|
注意: 場合によっては、デフォルト・グループ以外の追加の属性であるその他は、必要ない可能性があります。 |
必要に応じて、物理ダイアグラムに移動して新しいKMを割り当てます。
「保存」をクリックし、それからマッピングを実行してフラット化操作を実行します。
データセット・コンポーネントはコンテナ・コンポーネントで、複数のデータソースをグループ化し、関係結合を使用してそれらを結合できます。データセットには次のコンポーネントが含まれます。
データストア
結合
ルックアップ
フィルタ
再使用可能マッピング: 使用できるのは、入力シグネチャがなく、出力シグネチャが1つの再使用可能マッピングのみです。
データセット内で、あるデータストアから別のデータストアへ属性をドラッグすることで、結合およびルックアップを作成します。関係を結合にするかルックアップにするかを選択するダイアログが表示されます。
|
注意: 駆動表にはルックアップするためのキーがあり、ルックアップ表には結果を追加するための追加情報があります。データセットでは、駆動表から属性をルックアップ表にドラッグします。矢印は、ダイアグラムの駆動表からルックアップ表をポイントします。 これに対し、フローベース・ルックアップ(データセット内にないマッピングでのルックアップ)では、駆動およびルックアップ・ソースは、接続が作成される順番で決まります。最初の接続は |
データストアまたは再使用可能マッピングの属性を、データセットのバックグラウンドにドラッグして、フィルタを作成します。結合、ルックアップおよびフィルタをコンポーネント・パレットからデータセットにドラッグすることはできません。
この項には次のトピックが含まれます:
データセットは、フィルタおよび結合を使用して関連付けられる1つ以上のソース・データストアを含むコンテナ・コンポーネントです。マッピング内のその他のコンポーネントにとって、データセットは、他のプロジェクタ・コンポーネント(データストアなど)と区別できません。データセット内のフィルタと結合の結果はその出力ポートで表されます。
データセット内では、データソースはフローではなく関係を使用して関連付けられます。これは、エンティティ関係ダイアグラムを使用して表示されます。マッピング・エディタの「物理」タブに切り替えると、データセットは表示されなくなります。ODIは、データの物理フローを、フロー・ダイアグラムがマッピング・エディタの「論理」タブで定義されているとおり厳密にモデル化します。
データセットは、ODI 12cマッピングで使用されるフロー・メタファとは対照的に、ODI 11gのデータソース編成方法を模倣します。プロジェクトをODI 11gからインポートすると、マッピングに変換されるインタフェースには、ソース・データストアを含むデータセットが含まれます。
新しい空のマッピングを作成すると、空のデータセットを含めるかどうかを尋ねられます。この空のデータセットを削除しても問題が発生することはなく、空のデータセットを任意のマッピングにいつでも追加できます。空のデータセットを含めるオプションは、単に便宜を図るために用意されています。
データセットは、マッピングまたは再使用可能マッピング内にのみ存在し、独立したオブジェクトとして個別に設計することはできません。
マッピングにデータセットを作成するには、コンポーネント・パレットから論理ダイアグラムにデータセットをドラッグします。次に、デザイナ・ナビゲータの「モデル」セクションからデータストアをデータセットにドラッグできます。データセット内の異なるデータストア間で属性をドラッグして、結合およびルックアップ関係を定義します。
データセットの出力コネクタ・ポイントから、マッピング内の他のコンポーネントの入力コネクタ・ポイントに接続をドラッグして、データ・フローに統合します。
データセットを、親マッピング・フロー・ダイアグラムとマージされるフローベース・マッピング・ダイアグラムに個別に変換できます。
データセットをフローに変換すると、データセットはエンティティ関係設計とともに永久に削除されます。これは、対応するフローベース設計に置き換えられます。変換の結果は元に戻せません。
データセットをフローベース・マッピングに変換する手順は、次のとおりです。
マッピング・ダイアグラム内のデータセットを選択します。
タイトルを右クリックし、コンテキスト・メニューから「フローへの変換」を選択します。
警告および確認のダイアログが表示されます。変換を実行する場合は「はい」をクリックし、変換を取り消す場合は「いいえ」をクリックします。
データセットがフローベース・マッピング・コンポーネントに変換されます。
「物理」タブには、物理サーバーを表す様々な実行ユニット間の実行の配布が表示されます。ODIは、実行ユニットおよび実行グループを含むデフォルトの物理マッピング設計を、論理設計、これらのアイテムのトポロジ、および定義したルールに基づいて計算します。
物理ダイアグラムを使用して、この設計をカスタマイズすることもできます。ダイアグラムを使用して、実行ユニット間でのコンポーネントの移動や、別の実行ユニットを作成するダイアグラムのバックグラウンドへのコンポーネントの移動を行うことができます。複数の実行ユニットを実行グループにグループ化すると、含まれる実行ユニットのパラレル実行が可能になります。
マッピングには複数の物理マッピング設計を含めることができ、それらはダイアグラムの下のタブにリストされます。複数の物理マッピング設計を含めると、同じマッピングに異なる実行計画を作成できます。
新しい物理マッピング・タブを作成するには、新規作成タブをクリックします。
物理マッピング設計を削除するには、削除する物理マッピング設計タブを右クリックし、コンテキスト・メニューから「削除」を選択します。
物理コンポーネントは、ランタイムにマッピングを実行する方法を定義するもので、論理コンポーネントの物理表現です。論理コンポーネントによって、物理コンポーネントに含まれるプロパティのセットは異なります。
この項には次のトピックが含まれます:
物理ダイアグラムには、次のアイテムが表示されます。
物理マッピング設計: 物理ダイアグラム全体が1つの物理マッピング設計を表します。バックグラウンドをクリックするか、物理マッピング設計ラベルが付いた白いタブを選択して、物理マッピング・プロパティを表示します。デフォルトでは、ステージング場所はターゲットでコロケートされますが、異なるステージング場所を明示的に選択して、ODIがステージングを異なるホストに自動的に移動するようにできます。
物理ダイアグラム下部の現在の物理マッピング設計タブの横にある小さなタブをクリックして、追加の物理マッピング設計を定義できます。新しい物理マッピング設計がマッピングの論理設計から自動的に作成されます。
実行グループ: 黄色いボックスに、同じ実行グループ内でパラレルに実行される、実行ユニットと呼ばれるオブジェクトのグループが表示されます。これらは、通常ソース・グループとターゲット・グループです。
ソース実行グループ: 同じデータセット内にある、または同じ物理データ・サーバー上に存在するソース・データストアは、物理ダイアグラムで単一のソース実行グループにグループ化されます。ソース実行グループは、同時に抽出できるデータストアのグループを表します。
ターゲット実行グループ: 同じ物理データ・サーバー上に存在するターゲット・データストアは、物理ダイアグラムで単一のターゲット実行グループにグループ化されます。ターゲット実行グループは、同時書込みが可能なデータストアのグループを表します。
実行ユニット: 黄色い実行グループ内にある青いボックスは実行ユニットと呼ばれます。単一の実行グループ内の実行ユニットは、同じ物理サーバー上にありますが、構造は異なる場合があります。
アクセス・ポイント: ターゲット実行グループでは、データが実行ユニットから別の実行ユニットに流れるときはいつでもアクセス・ポイントがあります(丸いアイコンで表示されます)。ロード・ナレッジ・モジュール(LKM)は、実行ユニットから別の実行ユニットにデータがどのように転送されるかを制御します。
アクセス・ポイントは、データがソース側からターゲット側に移動するときに、(論理ダイアグラムで「実行ヒント」を使用して異なる実行場所を示す場合を除いて)実行ユニット・ペアのターゲット側で作成されます。アクセス・ポイント・ノードをソース側に移動することはできません。ただし、アクセス・ポイント・ノードを空のダイアグラム領域にドラッグすることは可能で、ダイアグラムの元のソースとターゲット実行ユニット間に新しい実行ユニットが作成されます。
コンポーネント: 結合、フィルタなどのマッピング・コンポーネントも物理ダイアグラムに表示されます。
「物理」タブで次のナレッジ・モジュール(KM)を使用します。
ロード・ナレッジ・モジュール(LKM): LKMはデータの移動方法を定義します。データをソースからステージング領域に移動するためのLKMをアクセス・ポイントごとに1つ選択します。ステージング領域に対して単一のテクノロジIKMが選択されている場合は、ターゲット実行ユニット内にないステージング領域からターゲットにデータを移動するためにLKMを選択することもできます。アクセス・ポイントを選択して、そのLKMをプロパティ・インスペクタで定義または変更します。
統合ナレッジ・モジュール(IKM)およびチェック・ナレッジ・モジュール(CKM): IKMおよびCKMは、データがターゲットに統合される方法を定義します。通常は、1つのIKMと1つのCKMがターゲット・データストアで選択されます。ステージング領域がターゲットと異なる場合は、ステージング領域からターゲットにデータを移動して統合する複数テクノロジIKMを選択できます。ターゲット・データストアを選択して、そのIKMおよびCKMをプロパティ・インスペクタで定義または変更します。
|
注意:
|
論理ダイアグラムを作成する際、ODIにより物理ダイアグラムのナレッジ・モジュールが自動的に選択されます。
|
注意: ターゲット・データストアの「統合タイプ」プロパティ(有効な値は制御追加、増分更新または緩やかに変化するディメンション)は、KMを選択する際にODIによって参照されます。このプロパティは、表示されるIKM選択を制限するためにも使用されるため、適用可能なIKMのみがリストされます。 |
物理ダイアグラムを使用して、使用中のKMを変更できます。
使用中のLKMを変更するには:
物理ダイアグラムで、アクセス・ポイントを選択します。このオブジェクトのプロパティ・インスペクタが開きます。
「ロード・ナレッジ・モジュール」タブを選択し、「ロード・ナレッジ・モジュール」リストから異なるLKMを選択します。
KMには、ほとんどのユース・ケースで機能するデフォルト・オプションが設定されています。KMオプションは、必要に応じて変更できます。
|
注意: 同一名のオプションが存在する場合は、あるKMから別のKMに切り替えると、前のKMのオプションが保持されます。ただし、新しいKMに複製されていないオプションは失われます。 |
使用中のIKMを変更するには:
|
注意: ターゲット・ノードで複数接続IKMを使用するには、その実行ユニットのアクセス・ポイントに「LKM SQL複数接続」または「LKMなし」を選択します。別のLKMを選択すると、単一接続IKMのみが選択可能になります。 |
物理ダイアグラムで、ターゲット・データストアのタイトルをクリックして選択します。このオブジェクトのプロパティ・インスペクタが開きます。
プロパティ・インスペクタで、「統合ナレッジ・モジュール」タブを選択し、「統合ナレッジ・モジュール」リストからIKMを選択します。
KMには、ほとんどのユース・ケースで機能するデフォルト・オプションが設定されています。KMオプションは、必要に応じて変更できます。
|
注意: 同一名のオプションが存在する場合は、あるKMから別のKMに切り替えると、前のKMのオプションが保持されます。ただし、新しいKMに複製されていないオプションは失われます。 |
使用中のCKMを変更するには:
物理ダイアグラムで、ターゲット・データストアのタイトルをクリックして選択します。このオブジェクトのプロパティ・インスペクタが開きます。
プロパティ・インスペクタで、「チェック・ナレッジ・モジュール」タブを選択し、「チェック・ナレッジ・モジュール」リストからCKMを選択します。
KMには、ほとんどのユース・ケースで機能するデフォルト・オプションが設定されています。KMオプションは、必要に応じて変更できます。
|
注意: 同一名のオプションが存在する場合は、あるKMから別のKMに切り替えると、前のKMのオプションが保持されます。ただし、新しいKMに複製されていないオプションは失われます。 |
マッピング・エディタの「物理」タブで、ステージング領域を変更し、コンポーネントが実行される場所を決定できます。論理ダイアグラムでコンポーネントを使用してマッピングを設計した場合、「実行ヒント」プロパティを使用して優先する実行場所をオプションで設定します。物理ダイアグラムで、ODIは、可能な場合はこれらのヒントに従おうとします。
「物理」タブで実行場所をさらに操作できます。詳細は、次の各項を参照してください。
物理ノードの実行場所を移動できます。ノードを選択し、それをある実行グループから別の実行グループにドラッグします。または、それを物理ダイアグラムの空白領域にドラッグすると、ODIでは、コンポーネントの新しい実行グループが自動的に作成されます。
実行順序を変更できるのは、一部のコンポーネントのみです。物理ダイアグラムでは、次のコンポーネントの順序を変更できます。
式
フィルタ
結合
ルックアップ
物理ダイアグラム内の式を移動できます。実行ユニットを選択し、プロパティ・インスペクタで、「式」タブを選択します。式の実行場所が「実行」プロパティに表示されます。プロパティをダブルクリックして、実行場所を変更します。
コンポーネントをその現在の実行ユニットから物理ダイアグラムの空白領域にドラッグして、新しい実行ユニットを定義できます。新しい実行ユニットおよび実行グループが作成されます。実行ユニットを選択し、プロパティ・インスペクタを使用してそのプロパティを変更します。
ODIでは、マッピングの前後に実行されるコマンドを追加できます。これらのコマンドは、ODIでサポートされる言語(SQL、Jython、Groovyなど)です。SQL言語では、マッピング開始コマンドとマッピング終了コマンドはマッピングと同じトランザクションで実行されます。マッピングの物理設計には、この動作を制御する次のプロパティがあります。
| プロパティ | 説明 |
|---|---|
| マッピング開始コマンド | マッピングの開始時に実行されるコマンド。 |
| マッピング開始コマンドのテクノロジ | このコマンドの実行で使用されるテクノロジ。 |
| マッピング開始コマンドの場所 | このコマンドの実行で使用される論理スキーマ。 |
| マッピング終了コマンド | マッピングの終了時に実行されるコマンド。 |
| マッピング終了コマンドのテクノロジ | このコマンドの実行で使用されるテクノロジ。 |
| マッピング終了コマンドの場所 | このコマンドの実行で使用される論理スキーマ。 |
これらのプロパティを表示および設定するには、プロパティ・インスペクタから物理マッピング設計を選択します。
ODIエージェントは、指定のホスト上でODIマッピング・ジョブ全体を実行するスケジューラです。2つ以上のロードがある場合、それらを1つずつ実行するか(逐次実行)、同時に実行します(個別のプロセッサ・スレッドを使用した並列実行)。
同じ実行グループ内の実行ユニットは、並列化されます。実行ユニットをそのユニット自身のグループに移動すると、他の実行ユニットと並列実行されなくなり、逐次実行されるようになります。個別の実行グループが実行される順序が選択されます。
システムによる瞬間的リソース使用率を減らすためにロードの逐次実行を選択する一方で、システムによるリソース使用が長引くのを防ぐためにロードの並列実行を選択する場合もあります。
物理マッピング設計では、ターゲット表のパラレル・ロードを有効にできます。(物理ダイアグラムの下部にあるタブをクリックするか、ダイアグラムの空白領域をクリックして)物理マッピング設計を選択し、プロパティ・インスペクタで「一意の一時オブジェクト名を使用」プロパティのボックスを選択します。
このオプションを使用すると、同じマッピングの複数のインスタンスを同時に実行できます。ソースからステージング領域にデータをロードするために、C$表がステージング・データベースに作成されています。
|
注意: ODI 11gでは、C$表の名前は、インタフェースのターゲット表から導出されていました。そのため、同じマッピングの複数インスタンスが同時に実行された場合、様々なセッションのデータが同じC$表にロードされ、競合が発生することがありました。
ODI 12cでは、オプション「一意の一時オブジェクト名を使用」がtrueに設定されている場合、各マッピング実行でグローバルに一意の名前が |
フィルタ、結合またはデータストアの実行を最適化するためにODIで一時索引を自動的に生成する場合は、物理ダイアグラムでノードを選択します。プロパティ・インスペクタで、「一時索引」タブを選択します。「索引タイプ」フィールドをダブルクリックして、一時索引タイプを選択します。
|
注意: 一時索引の作成は、フロー全体では時間を要する操作です。実行統計を検討して、索引を使用して短縮できる実行時間と、一時索引の作成に要する時間を比較することをお薦めします。 |
ジャーナル化されたデータのみを使用するように物理ダイアグラムでソース・データストアを構成できます。これは、ソース・データストアの「一般」プロパティの「ジャーナル化されたデータのみ」を有効化することで実行されます。チェック・ボックスは、参照データストアがモデル・ナビゲータでCDCに追加されている場合にのみ使用可能です。
ジャーナル化を有効にできるのは、マッピングごとに1つのデータストアのみです。
ジャーナル化の詳細は、第4章「ジャーナル化の使用」を参照してください。
物理ダイアグラムの各コンポーネント(アクセス・ポイントとターゲット・データストアは除く)には、プロパティ・インスペクタに抽出オプション・タブがあります。抽出オプションは、指定のコンポーネントに対するSQLの生成方法に影響を与えます。ほとんどのコンポーネントには抽出オプションの空のリストがあり、SQL生成のこれ以上の構成はサポートされていません。
抽出オプションは、抽出オプション・タブの「拡張」サブタブで選択されている抽出ナレッジ・モジュール(XKM)によって決定されます。XKMはODIの一部であり、ユーザーが作成または変更することはできません。
物理ダイアグラム全体が1つの物理マッピング設計を表します。バックグラウンドをクリックするか、物理マッピング設計ラベルが付いた白いタブを選択して、表示された物理マッピング設計の物理マッピング・プロパティを表示します。
物理ダイアグラム下部の現在の物理マッピング設計タブの横にある小さなタブをクリックして、追加の物理マッピング設計を定義できます。新しい物理マッピング設計が自動的に作成され、マッピングの論理設計から生成されます。この物理マッピング設計を変更して、マッピングの一部として保存できます。
たとえば、初期ロードに対してある物理マッピング設計を使用し、チェンジ・データ・キャプチャ(CDC)を使用する増分ロードに対して別の物理マッピング設計を使用できます。この2つの物理マッピング設計は、異なるジャーナル化設定やナレッジ・モジュール設定を持つことができます。
また、物理マッピング設計ごとに異なる最適化コンテキストを使用することもできます。各最適化コンテキストは、多少異なるユーザーのトポロジを表します。ある最適化コンテキストは開発環境を表し、別のコンテキストはテスト環境を表すことができます。これら2つの異なるトポロジに対して適切なKMをそれぞれ選択できます。
再使用可能マッピングを使用すると、複数ステップによる統合(または統合の一部)を単一コンポーネントにカプセル化できます。これを保存し、他のコンポーネントと同様にマッピング内で使用できます。再使用可能マッピングは、マッピングで何度も使用するデータ操作の類似サブルーチンや同一サブルーチンを作成する作業を回避する場合に便利な方法です。
たとえば、結合コンポーネントの2つの表からデータをロードし、それをフィルタ・コンポーネントおよび個別コンポーネントの順に経由して渡し、ターゲット・データストアに出力できます。このプロシージャを再使用可能マッピングとして保存し、作成または変更する今後のマッピングに配置できます。
再使用可能マッピング・コンポーネントをマッピングに配置した後に、それを選択し、現在のマッピングのみに影響する変更を加えることができます。
再使用可能マッピングは、次のもので構成されています。
入力シグネチャおよび出力シグネチャ・コンポーネント: これらのコンポーネントは、再使用可能マッピングへのマップ、または再使用可能マッピングからのマップに使用される属性について説明します。再使用可能マッピングがマッピングで使用される場合、これらは、他のマッピング・コンポーネントで照合できる属性です。
標準のマッピング・コンポーネント: 再使用可能マッピングには、データストア、プロジェクタ・コンポーネントおよびセレクタ・コンポーネントを含む、標準のマッピング・コンポーネントをすべて含めることができます。これらを標準マッピングでの場合とまったく同様に使用して、論理フローを作成できます。
標準のマッピング・コンポーネントをシグネチャ・コンポーネントと結合して、データソース、データ・ターゲット、またはマッピング・フローでの中間ステップとしての役割を果たすための再使用可能マッピングを作成できます。標準マッピングで作業する場合、再使用可能マッピングを単一コンポーネントであるかのように使用できます。
再使用可能マッピングをプロジェクト内で作成したり、グローバル・オブジェクトとして作成できます。再使用可能マッピングを作成するには、次の手順を実行します。
デザイナ・ナビゲータ:
プロジェクトを開き、「再使用可能マッピング」を右クリックし、「再使用可能な新しいマッピング」を選択します。
または、「グローバル・オブジェクト」ツリーを展開し、「グローバル再使用可能マッピング」を右クリックして、「再使用可能な新しいマッピング」を選択します。
名前を入力し、オプションで、再使用可能な新しいマッピングに関する説明を入力します。オプションで、デフォルト入力シグネチャの作成またはデフォルト出力シグネチャの作成、あるいはその両方を選択します。これらのオプションにより、空の入力および出力シグネチャが再使用可能マッピングに追加されます。再使用可能マッピングの編集時に、入力および出力シグネチャを後で追加または削除できます。
|
注意: これらのシグネチャを使用するためには、それらを再使用可能マッピング・フローに接続する必要があります。 |
コンポーネント・パレットから再使用可能マッピング・ダイアグラムにコンポーネントをドラッグし、デザイナ・ナビゲータからデータストアおよび他の再使用可能マッピングをドラッグして、再使用可能マッピング論理を構築します。標準マッピングを作成する場合と同じすべてのプロセスに従います。
|
注意: 再使用可能マッピングを編集のために開いている場合、コンポーネント・パレットには、標準のマッピング・コンポーネントに加えて、入力シグネチャ・コンポーネントと出力シグネチャ・コンポーネントが含まれます。 |
「マッピングの検証」ボタン(緑のチェック・マーク・アイコン)をクリックして、再使用可能マッピングを検証します。エラーが新しいエラー・ペインに表示されます。
再使用可能マッピングの作成が完了したら、「ファイル」をクリックして「保存」を選択するか、または「保存」ボタンをクリックして、再使用可能マッピングを保存します。これで、再使用可能マッピングをマッピング・プロジェクトで使用できるようになります。
プロパティ・インスペクタを構造パネルとともに使用して、マッピング・エディタの論理ダイアグラムと物理ダイアグラムでのアクションと同じアクションを、グラフィカルでない形式で実行できます。
構造パネルの使用
論理ダイアグラムおよび物理ダイアグラムを使用せずにマッピングを作成および編集する場合は、構造パネルを開く必要があります。構造パネルでは、マッピングの展開可能ツリー・ビューが提供されます。このビューでは、[Tab]キーを使用して移動して、マッピングのコンポーネントを選択できます。構造パネルでコンポーネントまたは属性を選択すると、論理または物理ダイアグラムでコンポーネントを選択した場合と同様に、そのプロパティがプロパティ・インスペクタに表示されます。
構造パネルは、スクリーン・リーダーを使用する場合など、アクセシビリティ要件がある場合に有用です。
構造パネルを開くには、メイン・メニューから「ウィンドウ」を選択し、「構造」をクリックします。ホットキー[Ctrl]+[Shift]+[S]を使用して構造パネルを開くこともできます。
この項には次のトピックが含まれます:
プロパティ・インスペクタ、コンポーネント・パレットおよび構造パネルを使用して、マッピングのコンポーネントを追加または削除できます。
コンポーネント・パレットおよび構造パネルを使用してコンポーネントをマッピングに追加する手順は、次のとおりです。
マッピングをマッピング・エディタで開いた状態で、コンポーネント・パレットを開きます。
[Tab]キーを使用して目的のコンポーネントを選択し、[Enter]を押して、選択したコンポーネントをマッピング・ダイアグラムおよび構造パネルに追加します。
構造パネルを使用してマッピングにコンポーネントを削除するには:
構造パネルで、削除するコンポーネントを選択します。
[Ctrl]+[Shift]を押しながら[Tab]を押して、ポップアップ・ダイアログを開きます。[Ctrl]+[Shift]を押したまま、矢印キーを使用して、左の列にナビゲートし、マッピングを選択します。次に、右矢印キーを使用して論理または物理ダイアグラムを選択します。論理ダイアグラムを選択したら、[Ctrl]+[Shift]キーを離します。
または、メイン・メニュー・バーから「ウィンドウ」→「ドキュメント」を選択します。ドキュメント・ウィンドウのリストからマッピングを選択し、ドキュメントに切替えをクリックします。
ステップ1で構造パネル内で選択したコンポーネントが、マッピング・ダイアグラムで強調表示されます。[Delete]を押して、コンポーネントを削除します。ダイアログ・ボックスで削除が確認されます。
構造パネルおよびプロパティ・インスペクタを使用してマッピングのコンポーネントを編集するには:
構造パネルで、コンポーネントを選択します。コンポーネントのプロパティがプロパティ・インスペクタに表示されます。
プロパティ・インスペクタで、必要に応じてプロパティを変更します。「属性」タブを使用して、属性を追加または削除します。「コネクタ・ポイント」タブを使用して、マッピングの他のコンポーネントへの接続を追加します。
構造パネルで任意のコンポーネントを展開して、個々の属性をリストします。次に、個々の属性を選択して、それらのプロパティをプロパティ・インスペクタで表示します。
プロパティ・インスペクタで表をカスタマイズして表示される列を決定する方法は、2つあります。いずれの場合も、構造パネルを開き、プロパティ・インスペクタでプロパティを表示するコンポーネントを選択します。次に、表を含むタブを選択し、次のいずれかの方法を使用します。
表のツールバーから「列の選択」アイコン(表の右上隅)をクリックし、次に、ドロップダウン・メニューから、表に表示する列を選択します。現在表示されている列にはチェック・マークが付いています。
「表のカスタマイズ」ダイアログを使用します。
表のツールバーから「列の選択」をクリックします。
ドロップダウン・メニューから「列の選択」を選択します。
「表のカスタマイズ」ダイアログで、表に表示する列を選択します。
「OK」をクリックします。
この項では、プロパティ・インスペクタで使用するキーボード・ナビゲーションについて説明します。
表8-8に、プロパティ・インスペクタで使用する共通タスクおよびキーボード・ナビゲーションを示します。
表8-8 共通タスクでのキーボード・ナビゲーション
| ナビゲーション | タスク |
|---|---|
|
矢印キー |
ナビゲート: 1つのセルを上、下、左または右に移動します。 |
|
[Tab] |
次のセルに移動します。 |
|
[Shift]+[Tab] |
前のセルに移動します。 |
|
[Space] |
テキストの編集の開始、リストの項目の表示、またはチェック・ボックスの値の変更を行います。 |
|
[Ctrl]+[C] |
選択内容をコピーします。 |
|
[Ctrl]+[V] |
選択内容を貼り付けます。 |
|
[Esc] |
セルへの入力を取り消します。 |
|
[Enter] |
セルへの入力を完了して次のセルに移動するか、ボタンをアクティブ化します。 |
|
[Delete] |
選択した内容をクリアします(テキスト・フィールドのみ)。 |
|
[Back Space] |
アクティブなセル内で、選択した内容を削除するか、前の文字を削除します(テキスト・フィールドのみ)。 |
|
[Home] |
行の最初のセルに移動します。 |
|
[End] |
行の最後のセルに移動します。 |
|
[Page Up] |
列の最初のセルに移動します。 |
|
[Page Down] |
列の最後のセルに移動します。 |
マッピングでは、2つの制御ポイントを設定できます。フロー制御では、データがターゲットに統合される前に、着信フローでのデータがチェックされます。静的制御では、統合後にターゲット・データストアに対する制約がチェックされます。
IKMには、FLOW_CONTROLを実行するオプションおよびSTATIC_CONTROLを実行するオプションを含めることができます。これらのいずれかを有効化する場合は、ターゲット・データストアに設定されたプロパティである、IKMでのオプションを設定する必要があります。物理ダイアグラムで、データストアを選択し、プロパティ・インスペクタで「統合ナレッジ・モジュール」タブを選択します。フロー制御オプションは、使用可能な場合、「オプション」表にリストされます。オプションをダブルクリックして、変更します。
|
注意:
|
この項には次のトピックが含まれます:
フロー制御戦略では、データがターゲット・データストアに統合される前に、このデータストアに定義された制約に対してデータをチェックする方法を定義します。これは、チェック・ナレッジ・モジュール(CKM)で定義されます。CKMは、ターゲット・データストアの物理ノードで選択できます。CKMによってチェックされる制約は、「論理」タブのデータストア・コンポーネントのプロパティで指定されます。
マッピングで使用されるCKMを定義するには、「LKM、IKMおよびCKMの選択」を参照してください。
統合後制御戦略では、ターゲット・データストアに定義された制約に対してデータをチェックする方法を定義します。このチェックは、データがターゲット・データストアに統合された後に実行されます。これは、CKMで定義されます。統合後制御を実行するには、IKMのSTATIC_CONTROLオプションをtrueに設定する必要があります。統合後制御では、マッピングのターゲット・データストアのデータ・モデルに主キーが定義されている必要があります。
「許容されているエラーの最大数」および「統合エラーのパーセント」設定は、ターゲット・データストア・コンポーネントに設定できます。論理ダイアグラムでデータストアを選択し、プロパティ・インスペクタで「ターゲット」タブを選択します。
統合後制御では、フロー制御と同じCKMを使用します。
マッピングで更新機能またはフロー制御機能を使用する場合は、ターゲット・データストアに更新キーを定義する必要があります。
ターゲット・データストア・コンポーネントの更新キーには1つ以上の属性が含まれています。バインドされているデータストアの一意キー、またはキー属性としてマークされている属性のグループである場合があります。更新キーによって、ターゲットへの挿入前に、更新またはチェック対象になる各レコードが識別されます。
一意キーから更新キーを定義するには:
マッピング・ダイアグラムで、ターゲット・データストア・コンポーネントのヘッダーを選択します。コンポーネントのプロパティが、プロパティ・インスペクタに表示されます。
「ターゲット」プロパティで、ドロップダウン・リストから「更新キー」を選択します。
|
注意:
|
次の場合は、属性から更新キーを定義することもできます。
データストアに一意キーがない場合。
すでに定義したキーに関係なく、キーを指定する場合。
属性から更新キーを定義する場合は、更新キーを構成する各属性を手動で選択します。
属性から更新キーを定義するには:
更新キーが選択されている場合は、選択を解除します。
「ターゲット・データストア」パネルで、更新キーを構成する属性を1つ選択して、プロパティ・インスペクタを表示します。
プロパティ・インスペクタの「ターゲット」プロパティで、「キー」ボックスを選択します。キー記号が、マッピング・エディタの論理ダイアグラムに表示されるデータストア・コンポーネントのキー属性の前に表示されます。
更新キーを構成する属性ごとにこの操作を繰り返します。
|
関連項目: E-LTおよびETLの定義と説明は、『Oracle Data Integratorの理解』のE-LTの概要に関する項を参照してください。 |
E-LTスタイル統合マッピングでは、ターゲット上に存在するステージング領域のデータが、ODIで処理されます。ステージング領域とターゲットは同じRDBMSに配置されます。データはソースからターゲットにロードされます。E-LTスタイル統合マッピングを作成するには、「マッピングの作成」で説明している標準の手順に従ってください。
ETLスタイル・マッピングでは、ターゲットと異なるステージング領域内のデータが、ODIで処理されます。データは最初にソースから抽出され、次にステージング領域にロードされます。ステージング領域でデータ変換が実行され、中間結果がステージング領域の一時表に保存されます。データのロードと変換は標準のELT KMを使用して実行されます。
Oracle Data Integratorには、データをステージング領域からターゲットにロードする方法が2通り用意されています。
使用するKM戦略に応じて フローおよび静的制御がサポートされます。詳細は、『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』の、ETLスタイル・マッピングの設計に関する項を参照してください。
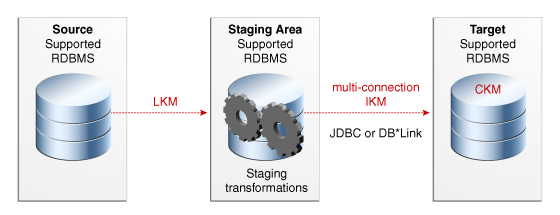
複数接続IKMの使用
複数接続IKMを使用すると、ステージング領域とソースが異なるデータ・サーバーにある場合にターゲットを更新できます。図8-3は、複数接続IKMを使用してターゲット・データを更新する統合マッピングの構成を示しています。
複数接続IKMを使用する場合の詳細は、『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』で、使用しているステージング領域のテクノロジに対応する章を参照してください。
ETLスタイル・マッピングで複数接続IKMを使用するには:
「マッピングの作成」で説明している標準の手順を使用して、マッピングを作成します。ここでは、ETLスタイルに固有の手順のみ説明します。
マッピング・エディタの「物理」タブで、目的の物理マッピング設計タブをクリックし、ダイアグラムのバックグラウンドをクリックして、物理マッピング設計を選択します。プロパティ・インスペクタのフィールド「ステージング場所のプリセット」で、ステージング場所を定義します。空のエントリは、ターゲット・スキーマをステージング場所として定義します。ターゲット以外の他のスキーマをステージング場所として選択します。
物理スキーマでアクセス・ポイント・コンポーネントを選択し、プロパティ・インスペクタに移動します。アクセス・ポイントの詳細は、「物理マッピング・ダイアグラムについて」を参照してください。
「LKMセレクタ」リストで、データをソースからステージング領域にロードするLKMを選択します。使用できるLKMを確認するには、『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』で、使用しているステージング領域のテクノロジに対応する章を参照してください。
オプションで、KMのオプションを変更します。
物理ダイアグラムで、ターゲット・データストアを選択します。このターゲット・オブジェクトのプロパティ・インスペクタが開きます。
プロパティ・インスペクタの「IKMセレクタ」リストで、データをステージング領域からターゲットにロードするETL複数接続IKMを選択します。使用できるIKMを確認するには、『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』で、使用しているステージング領域のテクノロジに対応する章を参照してください。
オプションで、KMのオプションを変更します。
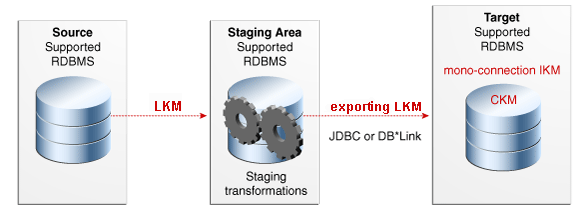
LKMと単一接続IKMの使用
専用の複数接続IKMがない場合は、標準のエクスポートLKMを標準の単一接続IKMと組み合せて使用します。図8-4は、エクスポートLKMと単一接続IKMを使用してターゲット・データを更新する統合マッピングの構成を示しています。エクスポートLKMは、フロー表をステージング領域からターゲットにロードするために使用します。単一接続IKMは、データ・フローをターゲット表に統合するために使用します。
この構成(LKM + エクスポートLKM + 単一接続IKM)には、次の制限があります:
ソースがステージング領域と同じデータ・サーバーにある場合(マッピング・エディタで明示的に選択)、簡易CDCも一貫性CDCもサポートされません
一時索引はサポートされません
標準のLKMを単一接続IKMと組み合せて使用する場合の詳細は、『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』で、使用しているステージング領域のテクノロジに対応する章を参照してください。
ETLスタイル・マッピングでLKMおよび単一接続IKMを使用するには:
「マッピングの作成」で説明している標準の手順を使用して、マッピングを作成します。ここでは、ETLスタイルに固有の手順のみ説明します。
マッピング・エディタの「物理」タブで、目的の物理マッピング設計タブをクリックし、ダイアグラムのバックグラウンドをクリックして、物理マッピング設計を選択します。プロパティ・インスペクタのフィールド「ステージング場所のプリセット」で、ステージング場所を定義します。空のエントリは、ターゲット・スキーマをステージング場所として定義します。ターゲット以外の他のスキーマをステージング場所として選択します。
物理スキーマでアクセス・ポイント・コンポーネントを選択し、プロパティ・インスペクタに移動します。アクセス・ポイントの詳細は、「物理マッピング・ダイアグラムについて」を参照してください。
プロパティ・インスペクタの「ロード・ナレッジ・モジュール」タブで、「ロード・ナレッジ・モジュール」ドロップダウン・リストからLKMを選択し、ソースからステージング領域にロードします。使用できるLKMを確認するには、『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』で、使用しているステージング領域のテクノロジに対応する章を参照してください。
オプションで、KMのオプションを変更します。オプション表の「値」列のセルをダブルクリックして、値を変更します。
ターゲット実行ユニットのアクセス・ポイント・ノードを選択します。プロパティ・インスペクタの「ロード・ナレッジ・モジュール」タブで、「ロード・ナレッジ・モジュール」ドロップダウン・リストからLKMを選択し、ステージング領域からソースにロードします。使用できるLKMを確認するには、『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』で、使用しているステージング領域のテクノロジに対応する章を参照してください。
オプションで、オプションを変更します。
ターゲットのタイトルをクリックして選択します。このオブジェクトのプロパティ・インスペクタが開きます。
プロパティ・インスペクタの「統合ナレッジ・モジュール」タブで、「統合ナレッジ・モジュール」ドロップダウン・リストから標準の単一接続IKMを選択し、ターゲットを更新します。使用できるIKMを確認するには、『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』で、使用しているステージング領域のテクノロジに対応する章を参照してください。
オプションで、KMのオプションを変更します。