After you add a data set to a project, you can choose to load the full data set into the project. This is useful for comprehensive data analysis and building a BDD application. Remember that without this full data load, Studio displays a sampled data set of approximately 1 million records if the full data set is larger than 1 million records.
- It loads all records stored in the Hive table for a data set. This includes any table updates performed by a system administrator. The full data load happens during the initial full data load only. After the first full data load, the action changes to Reload Data Set and you can reload the data set any number of times.
- It increases a sampled data set up to the full size of the data set.
- If the project contains a transformation script that you have committed, then Studio runs that script against the full data set. This way, all transformations apply to the full data set in the project.
The following diagram shows the workflow of loading a full data set into a project:
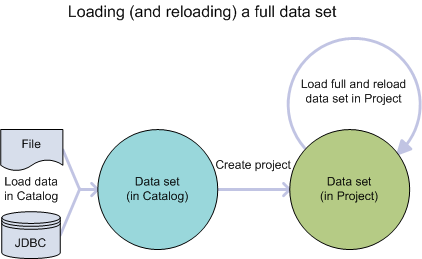
- You load a data set from a file or JDBC data source. This is the initial load of the data set into the Catalog.
- You can then explore the data and add it to a project to use Transform and Discover.
- You load the full data set and reload the data set as necessary.
Notice that loading the full data set affects only the data set in a specific project: it does not affect the data set as it displays in the Catalog.
To check if a data set has already been fully loaded into a project, go to the Data Set Manager page and see if the Record Data Volume property indicates Full data set is loaded.
To load the full data set in a project:
- From the Configuration Options menu, select Project Settings.
- Select Data Set Manager and expand the options next to the data set name.
- Select Load Full Data Set.
- In the confirmation dialog, select Load Full Data Set again.
- Return to Explore or Transform to monitor the progress of the load operation.
