The diagram in this topic shows data sets loaded in Studio by uploading a personal file or importing data from a JDBC source. It illustrates how you can reload this data set in Studio. Also, you can update the data set with DP CLI, and increase its size from sample to full.
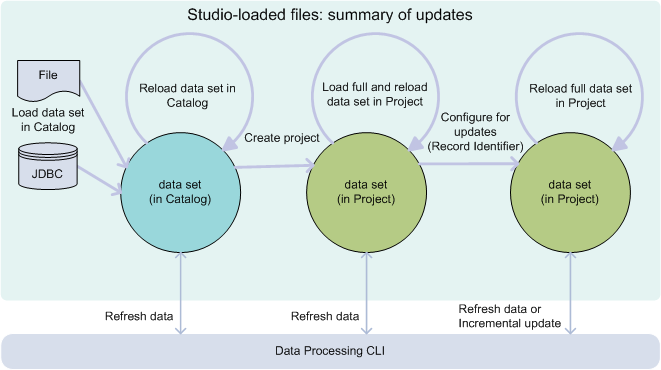
In this diagram, the following
actions take place, from left to right:
- You load data with the Studio's Add data set action. This lets you load a personal file, or data from a JDBC data source. Once loaded, the data sets appear in Catalog. BDD creates a Hive table for each data set. This Hive table is associated with the data set in Catalog.
- If you later have a newer version of these files, you can reload them with Reload data set action, found in data set's details, in Catalog.
- Next, if you'd like to transform, or to use Discover area to create visualizations, you should create a project. This is shown in the diagram in the middle circle. Notice that in this circle, the data set is now in your project and is no longer in Catalog. This data set can still be shown in Catalog, for others to use, if they have permissions to see it. However, now you have your own "version" of this data set, inside your project.
- Next, you can choose to load full data into this data set with Load full data, found in Data Set Manager. This replaces the data set sample with a fully loaded data set within your project. Or, if the data set was already fully loaded, you can reload the full data set in your project, by using this option again. This is shown as a circular arrow above the middle circle.
- Alternatively, you can use the options from Data Processing CLI to run scripted updates. There are two types of scripted updates: Refresh Data and Incremental update.
- To run Refresh Data with DP CLI, identify the data set's logical name in the properties for this data set in Studio. You must use that data set's logical name as a parameter for the data refresh command in DP CLI.
- To run Incremental update with DP CLI, you must specify a primary key (also known as record identifier in Studio). To add a primary key in Studio, go to Control Panel, then Data Set Manager, then Configure for Updates. You also need the data set's logical name for the incremental update.
- Be careful to use the correct data set logical name. Notice that a data set in Catalog differs from the data set in a project.
- Notice that you can run
Reload data set in Catalog only for data sets in
Catalog. If you want to update a data set that is already added to a project,
you need to use one of the scripted updates from DP CLI.
If you reload a data set in Catalog that has a private copy in a project, Studio alerts you to this when you open the project, and gives you a chance to accept these updates. If any transformations were made to the data set in the project, you can apply them to the data set in Catalog.
Note the following about this diagram:
- You can Refresh Data with DP CLI for data sets in Catalog and in projects. Typically, you use DP CLI Refresh Data for data sets in a project.
- You can run an Incremental Update with DP CLI after you specify a record identifier. For this, you must move the data set into a project in Studio.
- Once you load full data, this does not change the data set that appears in Catalog. Moving a data set to a project is similar to creating your personal version of the data set. Next, you can load full data and write scripted updates to this data set using DP CLI commands Refresh data and Incremental update. You can run these updates periodically, as cron jobs. The updates will run on your personal version of this data set in this project. This way, your version of this data set is independent of the data set's version that appears in Catalog.
