Oracle Tuxedo Advanced Performance Packの使用
このドキュメントでは、Oracle Tuxedo Advanced Performance Packのすべての機能を紹介します。このドキュメントで、これらの新機能の構成方法および既存のアプリケーションでの利用方法について学習できます。
Oracle Tuxedo Advanced Performance Packについて
Oracle Tuxedo Advanced Performance Packは、Oracle Tuxedo 12
cリリース2 (12.1.3)の新しい製品オプションです。このパックを使用すると、Oracle Tuxedoアプリケーションのパフォーマンスが大幅に向上し、アプリケーションの可用性が増します。特に、Oracle Database/RACと連携している場合は顕著です。このパックの機能は、Microsoft Windowsプラットフォーム上のOracle Tuxedo 32ビットを除く、Oracle Tuxedoでサポートされるすべてのプラットフォームで実行できます。
Oracle Tuxedo Advanced Performance Packの機能
Oracle Tuxedo Advanced Performance Packには、次の機能が備わっています。
表1
Oracle Tuxedo Advanced Performance Packの機能
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
この機能を使用すると、CPUサイクルを最大限に活用できるように
SPINCOUNTの値を動的に調整できます。
Tuxedoの掲示板(BB)は、すべてのアプリケーション構成情報および動的処理情報が実行時に格納されるメモリー・セグメントです。Tuxedoシステムの一部の操作(サービス名のルックアップやトランザクションなど)では、掲示板をロックし、掲示板へのアクセスを1つのプロセスのみに制限する場合があります。プロセスまたはスレッドにより、掲示板が別のプロセスまたはスレッドでロックされていることが検出されると、再試行するか、ロック・スピンを
SPINCOUNT回数行ってから(スピンを介したユーザー・レベル・メソッド)、この操作をやめて、待機キューでスリープ状態に入ります(システム・セマフォを介したシステム・レベル・メソッド)。スリープ状態はリソースを消費するため、一定のロック・スピンを行ってからスリープ状態になるように設定しておく方が効率的です。
SPINCOUNTパラメータの値は、アプリケーションおよびシステムによって異なるため、管理者は異なる
SPINCOUNT値の下でアプリケーション・スループットを確認して、
SPINCOUTが適切な値になるように手動で調整する必要があります。
自動チューニング・ロック・メカニズムにより、ジョブのチューニングを自動的に行います。
SPINCOUNT値が適切な値になるように設計されているため、掲示板をロックするほとんどのリクエストが、待機キューでスリープ状態になるのではなく、ロック・スピンを行うことによって完了します。
Oracle Tuxedo 12
cリリース2 (12.1.3)では、同一のTuxedoノードにおけるプロセス間通信でIPCメッセージ・キューのかわりに共有メモリー・キューを用いることで、Tuxedoアプリケーションのパフォーマンスが大幅に改善されます。共有メモリー・キューを使用すると、送信側と受信側のプロセスが割当て前のメッセージを共有メモリー内で交換することができ、本来の宛先にメッセージが届くまでに何回もコピーする必要がなくなるため、スループットが大幅に向上し、待機時間が短縮されます。
異なるドメインでは異なるグローバル・トランザクション識別子(GTRID)が使用されるため、トランザクションのブランチが同じデータベース上で実行される場合でも、ドメインをまたがるトランザクションは疎結合されます。Oracle Tuxedo Advanced Performance Packのこの機能を使用すると、共通GTRIDがデフォルトで導入され、ドメインをまたがるグローバル・トランザクション内のブランチで共通GTRIDが使用されます。ブランチが同一データベースで実行される場合、ブランチは密結合されます(データベースが許可している場合)。
Oracle Tuxedoでは、グローバル・トランザクション表(GTT)と呼ばれるOracle Tuxedo掲示板にアクティブなグローバル・トランザクションとそのパーティシパントの表を保持することでグローバル・トランザクションを管理します。この表は複数の同時プロセスによってアクセスされるため、セマフォを使用して保護する必要があります。通常のOracle Tuxedoの場合、掲示板のロックを使用してこの表へのアクセスはシリアライズされます。ただし、トランザクションの負荷が高い場合、このロックの競合が激しくなり、人為的なパフォーマンス・ボトルネックとなる場合があります。
Oracle Tuxedo Advanced Performance Packでは、XAトランザクションを使用して同時実効性を向上させ、ボトルネックを解消してTuxedoアプリケーションのパフォーマンスを改善します。
この機能では、XAのリソース・マネージャの読取り専用最適化を利用します。2フェーズ・コミットのシナリオを例にします。Tuxedoが1つのトランザクション・ブランチを保留し、他のすべてのブランチを同時に準備します。他のすべてのトランザクション・ブランチが読取り専用の場合、Tuxedoは保留したブランチについて準備リクエストの送信および
TLOGの書込みを行わずに直接1フェーズ・コミットを行います。それ以外の場合、Tuxedoは保留したブランチについて2フェーズ・コミットを行います。
TuxedoドメインおよびWTCを介したWLS間のグローバル・トランザクションを含む、ドメイン内またはドメイン間のいずれのトランザクションもサポートされます(WLS 12.1.1の場合、WLSのパッチ、または以降のリリースについて、Oracleサポートにお問い合せください)。
以前のリリースでは、同一の参加グループのサーバーはグローバル・トランザクション内の同一トランザクション・ブランチを使用しています。これらのサーバーが同一RACの異なるインスタンスに接続する場合は、トランザクション・ブランチは失敗し、XAエラー
XAER_AFFINITYが報告されます。これは、1つのブランチでは複数のインスタンスを通過できないことを示しています。このような理由から、Tuxedoグループで使用できるのは、シングルトンRACサービスのみです。DTPサービス(DTPオプションである
srvctl内の
-xが指定されている場合)または1つのインスタンスのみで提供されるサービスを、シングルトンRACサービスに指定できます。
このリリースでは、この機能により、サーバー・グループ内の複数サーバーが同一のグローバル・トランザクションに参加している場合の、シングルトンRACサービスの使用が不要になります。同一サーバー・グループおよび同一グローバル・トランザクションのサーバーが異なるRACインスタンスに接続している場合は、別のトランザクション・ブランチが使用されます。これにより、このようなアプリケーションは、使用可能なRACインスタンス間でロード・バランシングを実行できるようになります。
|
注意:
|
1つのグループに16を超えるインスタンスが含まれる場合、トランザクションは依然として失敗します。 |
グローバル・トランザクションでは、参加している各グループにはそれぞれのトランザクション・ブランチがあり、特別なトランザクション・ブランチ識別子(XID)で各ブランチが識別されます。グローバル・トランザクションに複数のグループが含まれる場合、Tuxedoでは各ブランチで2フェーズ・コミットを採用し、最初に参加しているグループをコーディネータとみなします。
Oracle Tuxedo Advanced Performance Packの共通XID (トランザクション・ブランチ識別子)機能を使用して、Tuxedoは同一グローバル・トランザクション内の他のすべてのグループとコーディネータ・グループのXIDを共有します。以前のリリースでは、複数グループが参加している場合は、各グループが自身のXIDを持つために2フェーズ・コミットを必要としましたが、これとは対照的です。
共通XIDは、コーディネータ・ブランチを直接使用するため、同一のサービスを介して同一のOracle RACインスタンスに接続するグループに対するXAコミット操作が不要です。
グローバル・トランザクションのすべてのグループがコーディネータ・ブランチを直接使用する場合、(2フェーズ・コミット・プロトコルではなく)1フェーズ・コミット・プロトコルが使用されるため、
TLOGの書込みは行われません。
XAトランザクション・アフィニティは、可能な場合に、1つのグローバル・トランザクション内のすべてのOracle Databaseリクエストを同一のOracle RACインスタンスにルーティングする機能を提供します。そのリクエストがOracle Tuxedoアプリケーション・サーバーからのものか、Oracle WebLogic Serverからのものかは関係ありません。この機能により、データベース要求を新しいOracle RACインスタンスにリダイレクトするコストを削減できるため、アプリケーション・パフォーマンス全体が向上します。
データベース・インスタンス間のフェイルオーバー/フェイルバック
高速アプリケーション通知(FAN)は、データベース・クライアントがデータベースの状態の変化を知ることができる、Oracle Databaseによって提供される機能です。これらの通知によって、アプリケーションはRACノードの計画停止やデータベースの負荷の不均衡などのイベントに対してプロアクティブに対応できます。Tuxedoは、新しいシステム・サーバー
TMFANによってFAN通知のサポートを提供します。このシステム・サーバーでOracle RACインスタンスをモニターし、データベース・インスタンスの起動または停止の場合にTuxedoアプリケーション・サーバーに通知して新規データベース接続を確立できます。
FAN通知に基づいてTuxedo
TMFANサーバーは、各RACインスタンスの負荷情報を含むロード・バランシング・アドバイザリを受信できます。指摘された負荷の変化が
TMFANコマンド行スイッチで指定されたしきい値を超えた場合、Tuxedoリクエストはデータベースの負荷の低いTuxedoアプリケーション・サーバーに転送されます。
Oracle Tuxedo Advanced Performance Packの構成
この項では、Oracle Tuxedo Advanced Performance Packの各種機能の構成方法について説明します。
UBBCONFIGの
RESOURESの
OPTIONSパラメータが
XPPに設定されている場合、この製品のすべての機能が有効です。Oracle ExalogicおよびOracle SPARC SuperClusterプラットフォームでは、
OPTIONSパラメータは
EECSに設定される必要があります。
一部の機能には追加構成が必要です。このような各機能の構成について以降で説明します。これらの各機能は、必要に応じて個々に無効にできます。機能を個々に無効にする方法についてもこの項で説明します。
2つのオプション属性が
UBBCONFIG *MACHINESセクションでサポートされます。
オプション
SPINTUNING_FACTORは、チューニング対象を制御します。デフォルト値は100で、ほとんどのシナリオでは十分な値です。必要に応じて、1から10000まで変更できます。100という値は、ロック試行回数が1/100未満である結果、システム・レベル・メソッドでBBロックを取得し、十分なアイドルCPUがあるかぎり、
SPINCOUNTがチューニングを停止することを示します。システム・レベル・メソッドのロック試行回数が1を超え、十分なアイドルCPU時間がある場合には、
SPINCOUNTが増加します。
SPINTUNING_MINIDLECPU: CPUアイドル時間を指定します。
ユーザー・レベル・メソッドの悪影響は、余分なCPU処理が行われる点です。ユーザー・レベル・メソッドの試行回数が多すぎると、多くのCPU時間がかかります。このオプションを使用すると、ユーザー・レベル・メソッドで使用されるCPUを制限できます。自動チューニング・ロック・メカニズムは、チューニング対象が満たされない場合にも
SPINTUNING_MINIDLECPUの制限に達すると、
SPINCOUNTを増加しません。それとは反対に、チューニング対象が満たされるかどうかにかかわらず、
SPINTUNING_MINIDLECPUの制限が解除される場合は、
SPINCOUNTは減少します。たとえば、20の値が指定される場合、自動チューニング・ロック・メカニズムは、調整中に20%以上のアイドルCPU時間を制御します。デフォルト値は20です。
|
•
|
指定しないと、これらの属性にはデフォルト値が使用されます。 |
|
•
|
自動チューニング・ロック・メカニズムは、スキャン単位ごとに SPINCOUNTを調整できますが、対象を満たすために何度か調整する必要がある場合があります。 |
TM_MIBを介しても構成を設定できます。詳細は、
『ファイル形式、データ記述、MIBおよびシステム・プロセス・リファレンス』の
TM_MIB(5)に関する項を参照してください。
リスト1は、自動チューニング・ロック・メカニズムを有効化する
UBBCONFIGサンプル・ファイルです。
リスト1
自動チューニング・ロック・メカニズムを有効化するUBBCONFIGサンプル・ファイル
この機能は、
UBBCONFIGファイルでオプション
NO_SPINTUNINGを指定して無効にできます。
リスト2は、自動チューニング・ロック・メカニズムを無効化する
UBBCONFIGサンプル・ファイルです。
リスト2
自動チューニング・ロック・メカニズムを無効化するUBBCONFIGサンプル・ファイル
OPTIONS XPP,NO_SPINTUNING
*RESOURCESセクションでは、さらに別のオプション属性が用意されています
メッセージ・バッファに使用される最大共有メモリー・サイズ(MB)を指定します。
UNIX 32ビット・プラットフォームおよびWindowsプラットフォームの場合、
numeric_valueの範囲は1から2000 (1と2000を含む)です。その他のプラットフォームの場合、
numeric_valueの範囲は1から96000 (1と96000を含む)です。
SHMQMAXMEMが指定されていない場合、推奨最小値が使用されます。この値はほとんどすべてのシナリオで十分な値です。
推奨最小値を取得するには、
tmloadcf – cを実行します。詳細は、
『Oracle Tuxedoコマンド・リファレンス』の
tmloadcf(1)に関する項を参照してください。
|
注意:
|
IBM AIX 32ビット・プロセスでは、必要なメモリーが256MBより大きい場合、大規模または非常に大規模なアドレス空間モデルを有効にする必要があります。通常、環境変数 LDR_CNTRLを使用してモデルを有効にできます。詳細は、IBMナレッジ・センターで大規模および非常に大規模なアドレス空間モデルを参照してください。 |
リスト3に、共有メモリー・プロセス間通信を有効にする
UBBCONFIGファイルの例を示します。
リスト3
共有メモリー・プロセス間通信を有効にするUBBCONFIGファイルの例
この機能は、
UBBCONFIGファイルでオプション
NO_SHMQを指定して無効にできます。
リスト4に、共有メモリー・プロセス間通信を無効にする
UBBCONFIGファイルの例を示します。
リスト4
共有メモリー・プロセス間通信を無効にするUBBCONFIGファイルの例
Oracle Tuxedo Advanced Performance Packを使用する場合、この機能はデフォルトで有効で、無効にできません。
Oracle Tuxedo Advanced Performance Packを使用する場合、この機能はデフォルトで有効で、無効にできません。
リスト5
デフォルトで同時グローバル・トランザクション表ロックを有効化する構成例
リスト6に、RACの部分的1フェーズ読取り専用最適化を有効にする
UBBCONFIGファイルの例を示します。
リスト6
RACの部分的1フェーズ読取り専用最適化を有効にするUBBCONFIGファイルの例
この機能は、
UBBCONFIGファイルでオプション
NO_RDONLYを指定して無効にできます。
リスト7に、RACの部分的1フェーズ読取り専用最適化を無効にする
UBBCONFIGファイルの例を示します。
リスト7
RACの部分的1フェーズ読取り専用最適化を無効にするUBBCONFIGファイルの例
TM_MIBを介しても構成を取得/変更できます。詳細は、
『ファイル形式、データ記述、MIBおよびシステム・プロセス・リファレンス』の
TM_MIB(5)に関する項を参照してください。
リスト8に、SGMBを有効にする
UBBCONFIGファイルの例を示します。
この機能は、
UBBCONFIGファイルでオプション
RMOPTIONSの
SINGLETONを指定して無効にできます。
RMOPTIONS {[...|SINGLETON],*}
|
注意:
|
このオプションは、ドメインで使用されるすべてのRACサービスがシングルトンであることを示します。 |
リスト9に、SGMBを無効にする
UBBCONFIGファイルの例を示します。
Tuxedoアプリケーションがアクティブでない場合は、
TM_MIBの
T_DOMAINクラスを介して、このフラグを設定することもできます。詳細は、
『ファイル形式、データ記述、MIBおよびシステム・プロセス・リファレンス』の
TM_MIB(5)に関する項を参照してください。
リスト10に、共通XIDを有効にする
UBBCONFIGファイルの例を示します。
リスト10
デフォルトで共通XIDを有効化する構成例
この機能は、
UBBCONFIGファイルでオプション
RMOPTIONSの
NO_COMMONXIDを指定して無効にできます。
RMOPTIONS {[...|NO_COMMONXID],*}
リスト11に、共通XIDを無効にする
UBBCONFIGファイルの例を示します。
Tuxedoアプリケーションがアクティブでない場合は、
TM_MIBの
T_DOMAINクラスを介して、このフラグを設定することもできます。詳細は、
『ファイル形式、データ記述、MIBおよびシステム・プロセス・リファレンス』の
TM_MIB(5)に関する項を参照してください。
リスト12に、XAトランザクション・アフィニティを有効にする
UBBCONFIGファイルの例を示します。
リスト12
デフォルトでXAトランザクション・アフィニティを有効化する構成例
この機能は、
UBBCONFIGファイルでオプション
RMOPTIONSの
NO_XAAFFINITYを指定して無効にできます。
RMOPTIONS {[...|NO_XAAFFINITY],*}
リスト13に、XAトランザクション・アフィニティを無効にする
UBBCONFIGファイルの例を示します。
リスト13
XAトランザクション・アフィニティを明示的に無効化する構成例
Tuxedoアプリケーションがアクティブでない場合は、
TM_MIBの
T_DOMAINクラスを介して、このフラグを設定することもできます。詳細は、
『ファイル形式、データ記述、MIBおよびシステム・プロセス・リファレンス』の
TM_MIB(5)に関する項を参照してください。
データベース・インスタンス間のフェイルオーバー/フェイルバック
この機能は、FANテクノロジを使用して実装されます。このテクノロジを有効にするには、
「FAN統合」を参照してください。
この機能は、FANテクノロジを使用して実装されます。このテクノロジを有効にするには、
「FAN統合」を参照してください。
リスト14に、FAN統合を有効にする
UBBCONFIGファイルの例を示します。
この機能は、
UBBCONFIGファイルでオプション
RMOPTIONSの
NO_FANを指定して無効にできます。
RMOPTIONS {[...|NO_FAN],*}
リスト15に、FAN統合を無効にする
UBBCONFIGファイルの例を示します。
Tuxedoアプリケーションがアクティブでない場合は、
TM_MIBの
T_DOMAINクラスを介して、このフラグを設定することもできます。詳細は、
『ファイル形式、データ記述、MIBおよびシステム・プロセス・リファレンス』の
TM_MIB(5)に関する項を参照してください。
FANイベントをモニターするために、
SERVERSセクションでTuxedoシステム・サーバー
TMFANを指定します。詳細は、
『ファイル形式、データ記述、MIBおよびシステム・プロセス・リファレンス』の
TMFAN(5)に関する項を参照してください。
Tuxedo XAサーバーのOracle TAF(透過アプリケーション・フェイルオーバー)をサポートするために、
threads=tが
UBBCONFIGの
*GROUPSセクションの
OPENINFOに含まれている必要があります。
パフォーマンスを最適化するためのベスト・プラクティス
適切な
SPINCOUNTは、サーバーがほとんどの時間でユーザー・レベル・メソッドを介してBBロックを保持できることを示しています。BBロックの競合が大きいシナリオで、パフォーマンスを著しく向上させることができます。通常のシナリオは、Tuxedo XAメカニズムを使用したトランザクション・アプリケーションです。したがって、CPUが十分でない場合を除き、Tuxedoアプリケーションのこの機能がOracle Exalogic上でデフォルトで有効になっていることがお薦めされます。
プロセスまたはスレッドは、ユーザー・レベル・メソッドまたはシステム・レベル・メソッドを介して掲示板をロックします。システム・レベル・メソッドはコストのかかる操作であるため、適切なロック・スピン数を設定して、ほとんどのロック試行をユーザー・レベル・メソッドを介して実行することが効果的です。
ユニプロセッサ・システム上のプロセスは、ロック・スピンができません。ユニプロセッサの場合、
SPINCOUNTの適切な値は1です。マルチプロセッサでは、
SPINCOUNTパラメータの値は、アプリケーションおよびシステムによって異なります。自動チューニング・ロック・メカニズムでは、適切な
SPINCOUNTを自動的に算出できます。
SHMQを使用することにより、不要なメッセージ・コピーを削減して、ネイティブTuxedoアプリケーションでより高いパフォーマンスを得ることができます。次のリストの1つ以上のケースが満たされる場合は、この機能を有効にすることを検討できます。
サービス・ルーチン自体が多くの時間を消費しすぎない場合に、メッセージ・コピーを削減することによって、この機能でパフォーマンスを向上させます。
この機能が有効な場合、共有メモリーが多くなるばかりでなく、余分なセマフォも必要になります。この機能を使用する前に、
tmloacf -cを介して最小IPCリソースを確認することをお薦めします。
デフォルト値は、ほとんどすべてのシナリオで十分な値です。ただし、メッセージ・サイズが32KBを超える場合は、
UBBCONFIGの
SHMQMAXMEMの値を調整する必要があります。詳細は次のとおりです。
|
•
|
SHMQMAXMEM = (Recommend_value * Message_size) / 32
|
|
•
|
Recommend_value: tmloadcf -cによって返される値
|
|
•
|
Message_size: 1つのメッセージのバッファ・サイズ(単位はKB)。
|
SHMQで使用される特定の共有メモリーがある場合、Tuxedoではそれを様々なサイズに設定されたバッファ用にいくつかの部分に分けます。一般的に、バッファ・サイズが大きくなればなるほど、この種のバッファの総エントリ数は少なくなります。一部のサイズ設定されたバッファが大きすぎる場合、SHMQの共有メモリー全体がフルでなくても、Tuxedoでローカル・メモリーを使用するために変換されます。
このリリースでは、2つの新しいMIBフィールド、
TA_SHMQSTATおよび
TA_MSG_SHMQNUMがあり、共有メモリー使用量に関する詳細情報を取得するために使用されます。
TA_SHMQSTATおよび
TA_MSG_SHMQNUMの詳細は、
『ファイル形式、データ記述、MIBおよびシステム・プロセス・リファレンス』の
TM_MIB(5)に関する項を参照してください。
SHMQメッセージを使用するための
tpcall()における
TPNOCOPYの新しいフラグです。ゼロコピー・メッセージングの一般的なTuxedoユーザー・ケース:
|
1.
|
クライアントは、 tpalloc()でリクエスト SHMMSGバッファを取得する |
|
2.
|
クライアントは、サーバーのリクエストSHMQに呼応して tpcall()でリクエストを送信し、応答を待機する |
|
3.
|
サーバーはリクエストをそのリクエストSHMQから受信し、リクエストを処理する |
|
4.
|
サーバーは、応答に同じ SHMMSGバッファを使用する |
|
5.
|
サーバーは、クライアントの応答SHMQに tpreturn()で応答を送信する |
ゼロコピー・メッセージングは、送信者と受信者が同時に共有バッファにアクセスできないという前提条件のある、理想的な状況です。現実の世界では、安全なメモリー・アクセスを保証するために、送信者は1つのコピーを実行し、元の
SHMMSGのかわりにそのコピーを送信する必要があります。ただし、優れたパフォーマンスを得るために、新しいフラグ
TPNOCOPYがコピー・コストを回避するために
tpcall()に提供されます。アプリケーションでこのフラグの使用を選択した場合、
tpcall()の失敗後は、
tpfree()以外が
SHMMSGバッファにアクセスしていないことを確認する必要があります。
TPNOCOPYが
tpcall()フラグに対して設定されていて、送信バッファがSHMMSGバッファである場合、メッセージの送信中に安全なコピーは行われません。
tpcall()の成功後は通常どおり、送信者アプリケーションが、送信バッファに対する完全なアクセス権を持ちます。ただし、
tpcall()がなんらかの状況で失敗した場合、送信者アプリケーションは送信バッファにアクセスできなくなります。この場合の推奨アクションは、バッファで
tpfree()を実行することです。これがバッファにおける唯一の安全な操作です。
TPNOCOPYが
tpacall()に対して設定できないか、または
tperrnoが
TPEINVALに設定されて
tpacall()が失敗します。
一般に、tuxedoネイティブ・リクエスト/応答メッセージは、機能が利用可能な場合は、共有メモリー・キュー(SHMQ)を使用して転送されます。ただし、次の場合には、かわりにIPCキューが使用されます。
|
•
|
デジタル署名および暗号化に関連付けられたTuxedoメッセージ |
たとえば、
tpseal()または
tpsign()では、暗号化またはデジタル署名用にTuxedoメッセージをマーク付けします。
|
•
|
BUFTYPECONVで指定されたサーバーからのTuxedoメッセージ
|
|
•
|
フィールド型ポインタ付きTuxedo FML32型メッセージ |
|
•
|
フィールド型埋込みFML32付きTuxedo FML32型メッセージ |
一般に、Tuxedoはグローバル・トランザクションの唯一の参加グループの場合は1フェーズ・コミットを実行し、複数のグループの場合は2フェーズ・コミットを実行します。2フェーズ・コミットは、Tuxedoがグローバル・トランザクションの各ブランチに1つの準備リクエストを送信した後に、すべての準備リクエストが成功したら、各ブランチに1つのコミット・リクエストを送信することを示します。
読取り専用の最適化が使用可能な場合、Tuxedoは2フェーズ・コミットのかわりに、予約されたブランチ上で1フェーズ・コミットを呼び出して、1つの準備リクエストと密結合されたグローバル・トランザクション用のTLOG書込みを削減します。
tuxedoアプリケーションが、Oracle Databaseなどの、読取り専用最適化をサポートするデータベース上で実行されており、アプリケーションに複数のグループが関係する場合、この機能を利用できます。また、
OPENINFOのデフォルト・プロパティであるOracle Databaseに対してブランチが密結合される必要があります。
通常のシナリオは、参加グループが異なるRACインスタンスに接続されるか、異なるデータベース・サービスを使用するシナリオです。通常のUBBの構成は次のとおりです。
GRP1 LMID=L1 GRPNO=10 TMSNAME="TMSORA1"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux1+ACC= P/scott/tiger +SesTM=120"
GRP2 LMID=L1 GRPNO=20 TMSNAME="TMSORA2"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux2+ACC= P/scott/tiger +SesTM=120"
server1 SRVGRP=GRP1 SRVID=10 MIN=2
server2 SRVGRP=GRP2 SRVID=10 MIN=2
GRP1はネット・サービス
orcl.tux1を使用してリソース・マネージャに接続します。
orcl.tux1は、RAC instance1でサポートされているデータベース・サービスtux1に構成されます。
GRP2はネット・サービス
orcl.tux2を使用してリソース・マネージャに接続します。
orcl.tux2は、RAC instance2でサポートされているデータベース・サービス
tux2に構成されます。
server1は、Tuxedoサービス
svc1を提供します。
server2は、Tuxedoサービス
svc2を提供します。トランザクション・ビジネスAは
svc1および
svc2に依存するため、このビジネスには
server1と
server2が含まれます。
読取り専用最適化が有効になっていることにより、1つの準備リクエストが省略され、TLOG書込みが無視されます。1フェーズ・コミットが実行されます。
参加グループが同一のデータベース・サービスを介して同一のOracleインスタンスに接続される場合、グローバル・トランザクションを1フェーズ・コミットに導く共通XID機能を有効にすることをお薦めします。共通XID機能は、すべての準備リクエストおよびTLOG書込みを無視できるため、読取り専用最適化よりもパフォーマンスが向上します。
トランザクション・ビジネスで読取り専用最適化を呼び出さないことが明確な場合は、パフォーマンス上に負の影響が生じないように、読取り専用最適化を有効にしないでください。通常のシナリオは、複数のリソース・マネージャがビジネスで使用されるというシナリオです。
TuxedoアプリケーションがOracle RAC上で実行されている場合、ロード・バランス、サービス・フェイルオーバーなどの非シングルトン・データベース・サービスを利用することが望ましい場合があります。Tuxedoグループは、この機能を有効にすることにより、RAC非シングルトン・サービスを使用できます。ビジネスには複数のグループが含まれる場合があるため、良好なパフォーマンスが得られるように、共通XIDとXAトランザクション・アフィニティも有効にすることをお薦めします。
GRP1 LMID=L1 GRPNO=10 TMSNAME="TMSORA1"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux3+ACC= P/scott/tiger +SesTM=120"
GRP2 LMID=L1 GRPNO=20 TMSNAME="TMSORA2"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux3+ACC= P/scott/tiger +SesTM=120"
server1 SRVGRP=GRP1 SRVID=10 MIN=4
server2 SRVGRP=GRP2 SRVID=10 MIN=4
GRP1と
GRP2は同一のネット・サービス
orcl.tux3を使用して、リソース・マネージャに接続します。
orcl.tux3はデータベース・サービス
tux3に対して構成されており、RAC instance1とinstance2の両方でサポートされます。
Server1は、Tuxedoサービス
svc1を提供し、
server2はTuxedoサービス
svc2を提供します。トランザクション・ビジネスAは
svc1を、次に
svc2をコールします。これにより、
server1と
server2が含められます。
orcl.tux3は非シングルトン・データベース・サービスであるため、
server1のコピーがinstance1またはinstance2のいずれかと関連付けられ、
server2のコピーでも同様の処理が行われます。
SGMBでは、ビジネスが良好に機能し、ビジネスAのトランザクションがinstance1およびinstanc2で均等に分散されていることを確認できます。
共通XIDおよびXAトランザクション・アフィニティが両方とも有効になっている場合、ビジネスAのすべてのトランザクションは、1フェーズ・コミットとなります。
|
•
|
複数のリソース・マネージャを使用するグループはサポートされません。 |
|
•
|
1つのグループに16を超えるインスタンスが含まれる場合、トランザクションは失敗します。 |
|
•
|
優先予約グループがマルチブランチ・グループの場合、RACの部分的1フェーズ読取り専用最適化はトランザクションで機能しません。GWTDOMAINがコーディネータでない場合は、優先予約グループがコーディネータ・グループです。それ以外の場合、優先予約グループは、コーディネータ・ドメイン内で次に登場する参加グループです。 |
|
•
|
マルチスレッド・サーバーは、MIBを介してインスタンス情報を提供しません。しかし、SGMBは、サーバーによってディスパッチされたスレッドではそのまま適切に機能します。 |
共通XIDは、コーディネータのインスタンス情報とブランチ(共通XID)をすべての参加グループと共有します。参加グループのサーバーは、コーディネータと同じインスタンス情報を持つ場合には共通XIDを再使用します。この機能は、グローバル・トランザクションが複数のグループを含み、特にすべての参加グループが同一データベース・サービスを介して同一データベース・インスタンスを関連付ける場合には、パフォーマンスにおける著しい向上をもたらします。
Tuxedoアプリケーションでは、1つのOracle Databaseインスタンスのみが使用されます。標準のUBB構成は次のとおりです。
GRP1 LMID=L1 GRPNO=10 TMSNAME="TMSORA1"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux1+ACC= P/scott/tiger +SesTM=120"
GRP2 LMID=L1 GRPNO=20 TMSNAME="TMSORA2"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux1+ACC= P/scott/tiger +SesTM=120"
server1 SRVGRP=GRP1 SRVID=10 MIN=2
server2 SRVGRP=GRP2 SRVID=10 MIN=2
前述の構成では、
GRP1および
GRP2が同一のネット・サービス(
orcl.tux1、Oracle Databaseに対して構成)を使用してリソース・マネージャに接続します。
Server1は、Tuxedoサービス
svc1を提供し、
server2はTuxedoサービス
svc2を提供します。トランザクション・ビジネスAは
svc1を、次に
svc2をコールします。これにより、
server1と
server2が含められます。共通XIDが有効になると、ビジネスAのすべてのトランザクションは1フェーズ・コミットになります。
TuxedoアプリケーションがOracle RAC上で実行されている場合は、すべての参加グループが同一データベース・サービスを介して同一データベース・インスタンスを関連付けます。
標準のUBBサンプルは
リスト18と同じですが、ネット・サービス
orcl.tux1は、データベース・サービス
tux1を介してOracle RAC instance1に対して構成されます。共通XIDが有効になると、ビジネスAのすべてのトランザクションは1フェーズ・コミットになります。
冗長サーバーまたはグループは、異なるOracle RACインスタンス上で実行されている場合に構成されます。このシナリオの場合、XAトランザクション・アフィニティ機能も有効である必要があります。ビジネスで同一データベースを介して同一のデータベース・インスタンスをコーディネータと関連付けるサービス/グループを含むことができます。
GRP1 LMID=L1 GRPNO=10 TMSNAME="TMSORA1"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux1+ACC= P/scott/tiger +SesTM=120"
GRP2 LMID=L1 GRPNO=20 TMSNAME="TMSORA2"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux1+ACC= P/scott/tiger +SesTM=120"
GRP3 LMID=L1 GRPNO=30 TMSNAME="TMSORA3"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux2+ACC= P/scott/tiger +SesTM=120"
server1 SRVGRP=GRP1 SRVID=10 MIN=2
server2 SRVGRP=GRP2 SRVID=10 MIN=2
server3 SRVGRP=GRP3 SRVID=10 MIN=2
GRP1と
GRP2は同一のネット・サービス
orcl.tux1を使用して、リソース・マネージャに接続します。
orcl.tux1はデータベース・サービス
tux1に対して構成されており、RAC instance1でサポートされます。
GRP3はネット・サービス
orcl.tux2を使用して、リソース・マネージャに接続します。
orcl.tux2はデータベース・サービス
tux2に対して構成されており、RAC instance2でサポートされます。
server1は、Tuxedoサービス
svc1を提供し、
server2および
server3はTuxedoサービス
svc2を提供します。トランザクション・ビジネスAは
svc1をコールし、その後
svc2をコールします。
一般に、ビジネスAはTuxedoのロード・バランスのため、
server1および
server2または
server1および
server3を含む場合があります。共通XIDが有効な場合は、
server1および
server2を含むトランザクションは1フェーズ・コミットになります。XAトランザクション・アフィニティが有効になっている場合、ビジネスAは常に
server1および
server2を含むため、ビジネスAのすべてのトランザクションは、1フェーズ・コミットとなります。
参加グループの一部は、同一データベース・サービスを介した同一インスタンスをコーディネータと関連付けます。このシナリオでは、共通XIDおよび読取り専用最適化機能の両方を有効にすることをお薦めします。
GRP1 LMID=L1 GRPNO=10 TMSNAME="TMSORA1"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux1+ACC= P/scott/tiger +SesTM=120"
GRP2 LMID=L1 GRPNO=20 TMSNAME="TMSORA2"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux1+ACC= P/scott/tiger +SesTM=120"
GRP3 LMID=L1 GRPNO=30 TMSNAME="TMSORA3"
OPENINFO="Oracle_XA:ORACLE_XA+SqlNet=orcl.tux2+ACC= P/scott/tiger +SesTM=120"
server1 SRVGRP=GRP1 SRVID=10 MIN=2
server2 SRVGRP=GRP2 SRVID=10 MIN=2
server3 SRVGRP=GRP3 SRVID=10 MIN=2
GRP1と
GRP2は同一のネット・サービス
orcl.tux1を使用して、リソース・マネージャに接続します。
orcl.tux1はデータベース・サービス
tux1に対して構成されており、RAC instance1でサポートされます。
GRP3はネット・サービス
orcl.tux2を使用して、リソース・マネージャに接続します。
orcl.tux2はデータベース・サービス
tux2に対して構成されており、RAC instance2でサポートされます。
server1は、Tuxedoサービス
svc1を、
server2はTuxedoサービス
svc2を、
server3はTuxedoサービス
svc3を提供します。トランザクション・ビジネスBは
svc1をコールし、次に
svc2、最後に
svc3をコールします。
ビジネスBは
server1/GRP1、
server2/GRP2および
server3/GRP3を含みます。共通XIDが有効な場合は、
GRP2に対する準備リクエストが省略されます。読取り専用最適化も有効である場合は、
GRP1に対する準備リクエストも省略され、
GRP1で1フェーズ・コミットが実行され、TLOG書込みが回避されます。
|
•
|
複数のリソース・マネージャを使用するグループはサポートされません。 |
|
•
|
マルチスレッド・サーバーは、 MIBを介してインスタンス情報を提供しません。しかし、共通XIDは、サーバーによってディスパッチされたスレッドではそのまま適切に機能します。 |
|
•
|
2フェーズ・コミットのシナリオでは、 GWTDOMAINが準備やコミットの実行に常に関与しています。 |
|
•
|
GWTDOMAINが配置されているグループがコーディネータ・グループの場合、共通XIDは機能しません。
|
Tuxedoサーバーが同一のOracle Databaseサービスを介して異なるOracle RACインスタンス上で実行される複数のインスタンスを持つ場合に、この機能を有効にすることをお薦めします。
XAトランザクション・アフィニティが有効であるかぎり、環境変数
TUXRACGROUPSで指定されるOracle RACルーティングのルールを使用する必要はなく、このルールは無効になります。
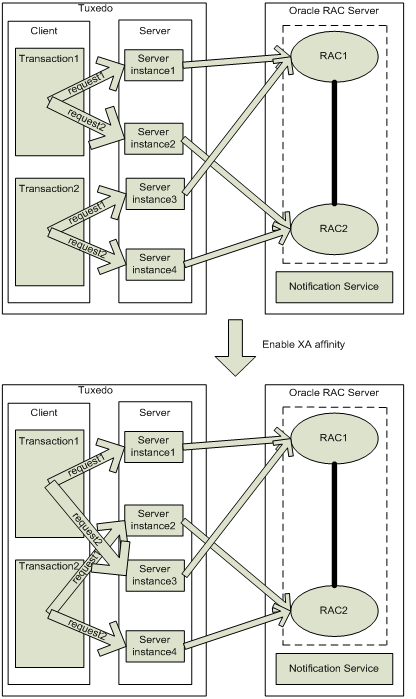
次の図は、XAトランザクション・アフィニティが有効な場合に行われる変更事項を示しています。
|
•
|
複数のリソース・マネージャを使用するグループはサポートされません。 |
|
•
|
1つのトランザクション内でのアフィニティ・コンテキスト(データベース名+インスタンス名+サービス名)の最大数は16です。 |
|
•
|
XAトランザクション・アフィニティでは、複数サーバー単一キュー、マルチスレッド・サーバー、ドメイン間サービスはサポートされません。 |
データベース・インスタンス間のフェイルオーバー/フェイルバック
Oracle FAN (高速アプリケーション通知)から利点を享受するには、TuxedoがOracle RACとともに使用される場合は常にこの機能を有効にすることをお薦めします。
UBBCONFIGのほかに、次の構成の場合には、Oracleデータベースを適切に設定してください。
|
•
|
ONS (Oracle Notification System) |
この機能は、FANイベントにアクセスするためにONS (Oracle Notification System)に依存します。TuxedoがネイティブONSクライアントである場合、ONSデーモンは、Oracle Databaseのサーバー側とクライアント側で有効である必要があります。Tuxedoをリモート・モードで機能させることをお薦めします。
ONSデーモン構成ファイルは、
$ORACLE_HOME/opmn/conf/ons.configにあります。このファイルは、ONSデーモンにその動作方法を示します。
ons.config内の構成情報は、単純な名前と値のペアで定義されます。
ONSの構成後、
onsctlコマンドで開始できます。ONSデーモンが常に実行されていることを確認してください。
|
注意:
|
Oracle Databaseクライアント側で、Oracleバージョンが12.1.0.1.0より下のバージョンの場合、ONSデーモンが有効になっている必要があります。 |
|
•
|
TAF (透過的アプリケーション・フェイルオーバー) |
Oracle Tuxedo非XAサーバーでOracle RAC高速アプリケーション通知(FAN)を利用する場合、TAFをお薦めします。
TAF(透過的アプリケーション・フェイルオーバー)は、データベース・インスタンスに障害が発生した場合に、クライアントが、存続するデータベース・インスタンスに自動的に再接続可能なOracle Databaseのクライアント側の機能です。
|
•
|
TAFが構成されている場合、OracleクライアントがOracle TuxedoからOracle Databaseサーバーへの新規接続の再確立を行います。 |
|
•
|
TAFが構成されていない場合、Oracle Tuxedo非XAサーバーは再確立を行わないため、この機能は無効です。 |
特定のXA以外のアプリケーション・サーバーに関連付けられたインスタンスに対してFANイベントをモニターするには、
$TUXDIR/lib/tuxociucb.so.1.0が
$ORACLE_HOME/libでデプロイされ、このバイナリの名前が
ORA_OCI_UCBPKG環境変数で指定されている必要があります。
TAFをサポートするには、次のルールに従ってください。
|
•
|
OCIアプリケーションの場合は、 OCI_THREADEDモードでOCI環境を作成します。 |
|
•
|
Pro*Cアプリケーションの場合、 threads=yesを使用して事前コンパイルを実行して、最初に実行可能な埋込みSQL文を作成する前に EXEC SQL ENABLE THREADSを使用してください。 |
servoptsの-Lオプションは、サーバーが Oracle Databaseに接続されることを示すために、XA以外のサーバーに対して使用される必要があります。
-Lを指定するとECIDが有効になるため、ECIDをクローズする新しいオプション
-Fが
servoptsに導入されています。使用法は
-F noECIDです。次に例を示します。
SRVGRP=GRP1 SRVID=1 ClOPT="-L libclntsh.so -F noECID"
|
•
|
複数のリソース・マネージャを使用するグループはサポートされません。 |
|
•
|
カスタマイズされたサーバーがOCIを使用してOracle Databaseに接続する場合、 OCI_NO_UCBはOCI初期化時に設定できません。 |
Oracle FAN (高速アプリケーション通知)から利点を享受するには、TuxedoがOracle RACとともに使用される場合は常にこの機能を有効にすることをお薦めします。
|
•
|
LBA (Load Balance Advisory) |
Oracle Databaseロード・バランシング・アドバイザに基づいて、Tuxedoは同一Oracle Databaseサービスに接続されるTuxedoアプリケーション・サーバー間でサービス・リクエストを分散できます。LBAおよびFANロード・バランシング・イベントのパブリッシュを有効にするには、実行時接続ロード・バランシングのサービスレベルの目標がOracle Databaseサービス定義で指定されている必要があります。サービスの作成時または変更時に、
-Bオプションを使用して(
srvctlを介して)目標を指定できます。
|
•
|
複数のリソース・マネージャを使用するグループはサポートされません。 |
|
•
|
カスタマイズされたサーバーがOCIを使用してOracle Databaseに接続する場合、 OCI_NO_UCBはOCI初期化時に設定できません。 |
|
•
|
Oracle RAC LBAに基づいたロード・バランスでは、複数サーバー単一キュー、マルチスレッド・サーバー、ドメイン間サービスはサポートされません。 |
Oracle Tuxedo Advanced Performance Packの機能を使用するには、次のソフトウェア要件を満たす必要があります。
Oracle Tuxedo 12
cリリース2 (12.1.3)ローリング・パッチ040以上が必要です。
|
•
|
「データベース・インスタンス間のフェイルオーバー/フェイルバック」および「RACインスタンス間のロード・バランシング」機能には、Oracle Database 12.1.0.2 Patch for bug 21462577以上のクライアントが必要です。 |
|
•
|
その他の各機能には、Oracle Database 11.2.0.2.0以上が必要です。 |