3 Advanced Features
This chapter provides an introduction to the Advanced Features of EDQ.
This chapter includes the following sections:
3.1 Matching Concept Guide
The need to match and reconcile information from one or more business applications can arise in numerous ways. For example:
-
Reconciliation of data held in multiple systems
-
Mergers or acquisitions resulting in duplicate systems and information
-
Migration of data to new systems with a desire to eliminate duplicates
-
An identified need to improve the quality of system information by matching against a trusted reference set
Defining whether records should match each other is not always simple. Consider the following two records:

They are different in every database field, but on inspection there are clearly similarities between the records. For example:
-
They share a common surname
-
The address could be the same if the second is simply missing its house number
Making a decision as to whether we should treat these as "the same" depends on factors such as:
-
What is the information being used for?
-
Do we have any other information that will help us make a decision?
Effective matching requires tools that are much more sophisticated than traditional data analysis techniques that assume a high degree of completeness and correctness in the source data. It also demands that the business context of how the information is to be used is included in the decision-making process. For example, should related individuals at the same address be considered as one customer, or two?
EDQ provides a set of matching processors that are suited to the most common business problems that require matching. The matching processors use a number of logical stages and simple concepts that correspond with the way users think about matching:
Rather than forcing users to express matching rules at the field by field level, EDQ's matching processors exploit the powerful concept of Identifiers.
Identifiers allow the user to map related fields into real world entities and deliver a range of key benefits:
-
Where similar information is stored in different applications or databases, any naming differences between fields can be overcome by mapping identifiers. This is illustrated below:
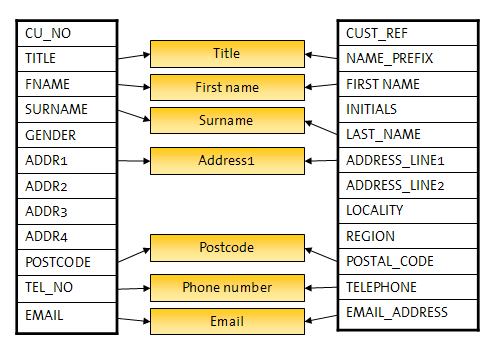
-
For specific types of identifier, such as a person's name, EDQ's extensibility also allows the introduction of new identifier types, and associated comparisons. These new identifier types allow many fields to be mapped to a single identifier, allowing structural differences to be dealt with once and then ignored. In this case, matching rules can be simple but powerful as they are working at the entity level, rather than the field level. As a result, the configuration is quicker to define and easier to understand. This is illustrated below:
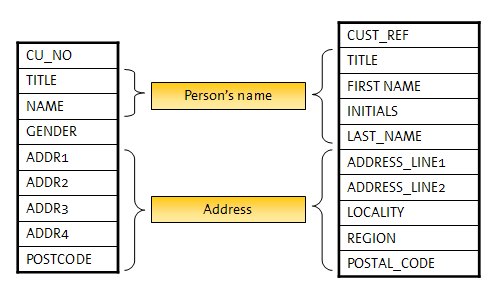
Clustering is a necessary part of matching, used to divide up data sets into clusters, so that a match processor does not attempt to compare every record with every other record.
In EDQ, you can configure many clusters, using many identifiers, in the same match processor, so that you are not reliant on the data having pre-formed cluster keys.
To read more about clustering, see the Clustering Concept Guide.
Comparisons are replaceable algorithms that compare identifier values with each other and deliver comparison results. The nature of result delivered is dependent on the comparison. For example, a comparison result could be simply True (match), or False (no match), or may be a percentage value indicating match strength:
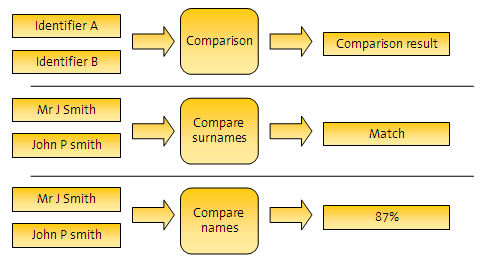
Match rules offer a way to interpret comparison results according to their business significance. Any number of ordered rules can be configured in order to interpret the comparison results. Each rule can result in one of three decisions:
-
Match
-
No match
-
Review – manual review required to confirm or deny the match
The use of match rules form a rule table across all comparisons to determine the decision of the match operation, for example:
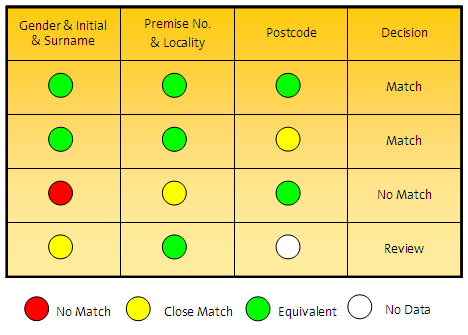
Using pre-constructed match processes
EDQ is designed to allow you to construct new matching processes quickly and easily rather than depending on pre-configured matching processes that are not optimized for your data and specific matching requirements, and which will be more difficult to modify.
However, in some cases, a matching template can be used to learn how matching in EDQ works, and in order to provide very fast initial results to give an indication of the level of duplication in your data.
Configurability and Extensibility
EDQ comes with a highly configurable and tuneable library of matching algorithms, allowing users to refine their matching process to achieve the best possible results with their data.
In addition, EDQ provides the ability to define new matching algorithms and approaches. The ”best” matching functions depend entirely on the problem being addressed and the nature of the data being matched. All key elements of the matching process can use extended components. For example:
-
What we use to identify the records
-
How we compare the records
-
How we transform and manipulate the data to improve the quality of comparisons
The combination of configurability and extensibility ensures that the optimal solution can be deployed in the shortest possible time.
See the "Extending EDQ" topic in the Enterprise Data Quality Online Help for more information about adding matching extensions into the application.
Key features of matching in EDQ include:
-
Matching for any type of data
-
Guidance through the configuration of the matching process
-
User-definable data identification, comparison and match rules
-
Business rule-based matching
-
Multi-user manual review facility for both match and merge decisions
-
Remembers manual decisions when new data is presented
-
Automates the production of output from the matching process
-
Configurable matching library provides flexible matching functionality for the majority of needs
-
Extensible matching library ensures the optimal matching algorithms can be deployed
-
Allows import and export of match decisions
-
Provides a complete audit trail of review activity (decisions and review comments)
3.2 Clustering Concept Guide
Clustering is a necessary aspect of matching, required to produce fast match results by creating intelligent 'first cuts' through data sets, in order that the matching processors do not attempt to compare every single record in a table with every single other record - a process that would not be feasible in terms of system performance.
Clustering is also vital to Real time matching, to allow new records to be matched against existing records in a system, without the need for EDQ to hold a synchronized copy of all the records in that system.
Rather than attempt to compare all records with each other, matching in EDQ takes place within Clusters, which are created by a clustering process.
Clustering does not attempt to compare any records in a data set. Rather, it creates clusters for a data set by manipulating one or more of the identifier values used for matching on a record-by-record basis. Records with a common manipulated value (cluster key) fall within the same cluster, and will be compared with each other in matching. Records that are in different clusters will not be compared together, and clusters containing a single record will not be used in matching.
This is illustrated below, for a single cluster on a Name column, using a Make Array from String transformation to cluster all values from the Name identifier that are separated by a space:
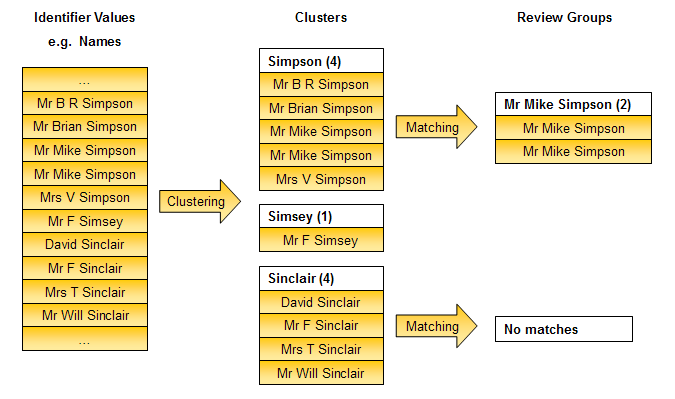
The clustering process is therefore crucial to the performance and functionality of the matching process. If the clusters created are too large, matching may have too many comparisons to make, and run slowly. If on the other hand the clusters are too small, some possible matching records may have been missed by failing to cluster similar values identically.
Depending on the matching required, clustering must be capable of producing common cluster keys for records that are slightly different. For example, it is desirable for records containing identifier values such as 'Oracle' and 'Oracle Ltd' to fall within the same cluster, and therefore be compared against each other.
EDQ supports the use of multiple clusters. On a given data set, clustering on a single identifier value is often insufficient, as matches may exist where the identifier value is slightly different. For instance, a Surname cluster with no transformations will be unreliable if some of the data in the Surname field is known to be misspelt, and adding a soundex or metaphone transformation may make the clusters too large. In this case, an additional cluster may be required. If an additional cluster is configured on another identifier, EDQ will create entirely new clusters, and perform the same matching process on them. For example, you could choose to cluster on the first three digits of a post code, such that all records with a post code of CB4 will be in a single cluster for matching purposes.
It is also possible to cluster the same identifier twice, using different clustering configurations with different transformations. To do this, create two clusters on the same identifier, and configure different transformations to work on the identifier values.
The more clusters there are, the more likely matching is to detect matches. However, clusters should still be used sparingly to ensure that matching performance does not suffer. The more clusters that exist, the more records matching has to compare.
Composite clusters allow a more sensitive and efficient way of dividing up data sets into clusters, using multiple identifiers. In this case, different parts of each identifier are combined to create a single cluster key that is used to group records for matching. For example, when matching customers, the following cluster might be configured using a combination of Surname and Postcode identifiers:
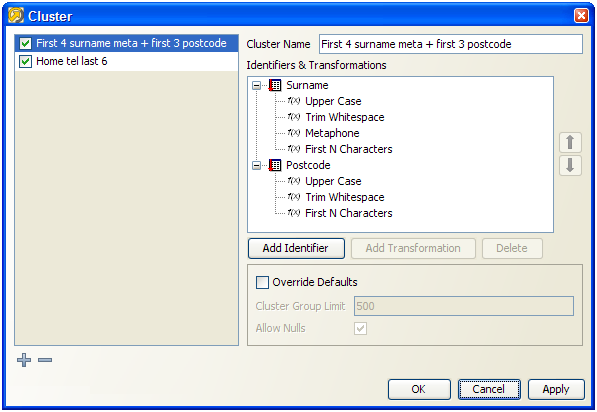
For each record in the matching process, therefore, the value for the Surname identifier will be transformed (converted to upper case, all whitespace removed, a metaphone value generated, and trimmed to the first 4 characters), and then concatenated with the transformed value from the Postcode identifier (converted to upper case, all whitespace removed, and trimmed to the first 3 characters).
Note that the concatenation of the identifier values after transformation is not configured, and occurs automatically.
So, using the above cluster configuration, cluster keys will be generated as follows:
| Surname | Postcode | Cluster Key |
|---|---|---|
| Matthews | CB13 7AG | M0SCB1 |
| Foster | CB4 1YG | FSTRCB4 |
| JONES | SW11 3QB | JNSSW1 |
| Jones | sw11 3qb | JNSSW1 |
This means that the last two records would be in the same cluster, and would be compared with each other for a possible match, but would not be compared with the other two records.
Transformations in clustering allow you to normalize space, case, spelling and other differences between values that are essentially the same, enabling the creation of clusters for records that are only similar, rather than identical, in their identifier values.
For example, a Name identifier may use either a Metaphone or a Soundex transformation during clustering, such that similar-sounding names are included in the same cluster. This allows matching to work where data may have been misspelt. For example, with a Soundex transformation on a Surname identifier, the surnames 'Fairgrieve' and 'Fairgreive' would be in the same cluster, so that matching will compare the records for possible duplicates.
The valid transformations for an identifier vary depending on the Identifier Type (for example, there are different transformations for Strings as for Numbers).
For example, the following are some of the transformations available for String identifiers:
-
Make Array from String (splits up values into each separate word, using a delimiter, and groups by each word value. For example, 'JOHN' and 'SMITH' will be split from the value 'JOHN SMITH' if a space delimiter is used).
-
First N Characters (selects the first few characters of a value. For example, 'MATT' from 'MATTHEWS').
-
Generate Initials (generates initials from an identifier value. For example, 'IBM' from 'Internal Business Machines').
EDQ comes with a library of transformations to cover the majority of needs. It is also possible to add custom transformations to the system.
The options of a transformation allow you to vary the way the identifier value is transformed. The available options are different for each transformation.
For example, the following options may be configured for the First N Characters transformation:
-
Number of characters (the number of characters to select)
-
Characters to ignore (the number of characters to skip over before selection)
The 'best' clustering configuration will depend upon the data used in matching, and the requirements of the matching process.
Where many identifiers are used for a given entity, it may be optimal to use clusters on only one or two of the identifiers, for example to cluster people into groups by Surname and approximate Date of Birth (for example, Year of Birth), but without creating clusters on First Name or Post Code, though all these attributes are used in the matching process.
Again, this depends on the source data, and in particular on the quality and completeness of the data in each of the attributes. For accurate matching results, the attributes used by cluster functions require a high degree of quality. In particular the data needs to be complete and correct. Audit and transformation processors may be used prior to matching in order to ensure that attributes that are desirable for clustering are populated with high quality data.
Note that it is common to start with quite a simple clustering configuration (for example, when matching people, group records using the first 5 letters of a Surname attribute, converted to upper case), that yields fairly large clusters (with hundreds of records in many of the groups). After the match process has been further developed, and perhaps applied to the full data sets rather than samples, it is possible to improve performance by making the clustering configuration more sensitive (for example, by grouping records using the first 5 letters of a Surname attribute followed by the first 4 characters of a Postcode attribute). This will have the effect of making the clusters smaller, and reducing the total number of comparisons that need to be performed.
When matching on a number of identifiers, where some of the key identifiers contain blanks and nulls, It is generally better to use multiple clusters rather than a single cluster with large groups.
Note:
All No Data (whitespace) characters are always stripped from cluster keys after all user-specified clustering transformations are applied, and before the clustering engine finishes. For example, if you use the Make Array from String transformation, and split data on spaces, the values "Jim<space><carriage return>Jones" and "Jim<space>Jones" would both create the cluster values "Jim" and "Jones". The former would not create the cluster value "<carriage return>Jones". This is in order that the user does not always have to consider how to cope with different forms of whitespace in the data when clustering.Reviewing the clustering process
In EDQ, the clusters used in matching can be reviewed in order to ensure they are created to the required level of granularity.
This is possible using the views of clusters created when the match processor has been run with an clustering configuration. The Results Browser displays a view of the clusters generated, with their cluster keys:
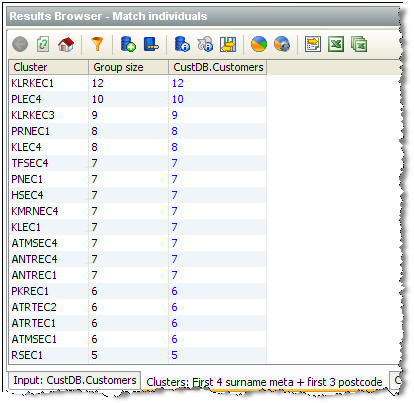
The list of clusters can be sorted by the cluster key value in order to see similar groups that possibly ought not be distinct.
By drilling down, it is possible to see the constituent records within each cluster from each input data set. For example the 9 records from the Customers data set with a cluster key of 'KLRKEC3' above are:
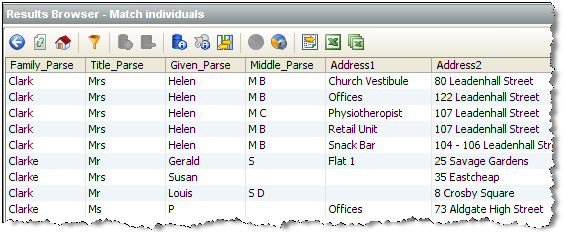
In this way, an expert user can inspect and tune the clustering process to produce the optimal results in the quickest time. For example, if the clusters are too big, and matching performance is suffering, extra clusters could be created, or a cluster configuration may be made tighter. If, on the other hand, the user can see that some possible matches are in different clusters, the clustering options may need to be changed to widen the clusters.
Note:
With some clustering strategies, large clusters are created. This is often the case, for example, if there are a large number of null values for an identifier, creating a large cluster with a NULL cluster key. If a cluster contains more than a configurable number of records, or will lead to a large number of comparisons being performed, it can be skipped to save the performance of the matching engine. The default maximum size of a cluster is 500 records, and it is also possible to limit the maximum number of comparisons that should be performed for each cluster. To change these options, see the "Advanced options for match processors" topic in Enterprise Data Quality Online Help.3.3 Real-Time Matching
EDQ provides two different types of real time matching:
-
Real-time duplication prevention for matching against dynamically changing data (for example, working data in an application).
-
Real-time reference matching for matching against slowly changing data (for example, reference lists).
This topic provides a general guide to how real time matching works in EDQ.
Note:
If you want to use EDQ for real-time duplicate prevention and/or data cleansing with Oracle Siebel UCM or CRM, Oracle provides a standard connector for this purpose.Real time duplicate prevention
EDQ's real-time duplicate prevention capability assumes that the data being matched is dynamic, and therefore changes regularly (for example, customer data in a widely-used CRM system). For this reason, EDQ does not copy the working data. Instead, the data is indexed on the source system using key values generated using an EDQ cluster generation process.
Real-time duplicate prevention occurs in two stages - Clustering, and Matching.
Clustering
In the Clustering stage, EDQ receives a new record on its real-time interface and assigns it cluster keys using a process that has been enabled for real-time execution. It returns the cluster keys for the record using a Writer. The source system then receives this message, selects candidate records using a pre-keyed table, and feeds back to EDQ a set of all the records that have share one of the cluster keys with the driving record.
Normally, it is advisable to generate many key values per record, as is also the case for batch matching.
Matching
In the Matching stage, EDQ receives the message containing the records that share a cluster key with the input record. It then uses a match processor, with all records presented as working records on a single input, to select the definite and possible matches to the new record from these candidate match records, and assign them a score that can be used to sort the matches. The matching results are then returned on a real-time interface, and this response is handled externally to determine how to update the system. Possible responses include declining the new (duplicate) record, merging the new record with its duplicate record(s), or adding the new record, but including a link to the duplicate record or records.
The following is an example of a real-time matching process:
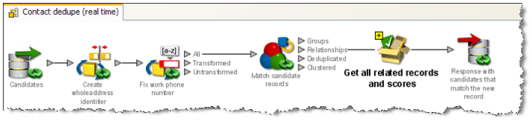
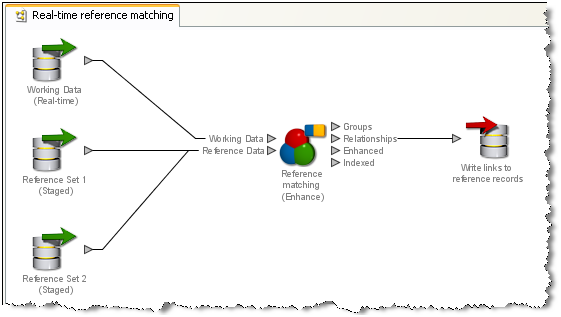
EDQ's real-time reference matching implementation matches new records against one or many reference sets. The data in the reference sets is assumed to be non-dynamic. That is, they are updated on a regular basis, but not constantly accessed and updated by multiple users (for example watch lists, rather than CRM data). Reference matching is a single stage process. Incoming records from a working real-time source are matched against snapshots of reference records from one or more staged sources. A writer on the process then returns the output of the match processor back to the calling system. Note that the output returned may be any of the forms of output from the match processor. If you want only to link the new records to the reference sets, you can write back the Relationships output. If you want to enhance the new records by merging in data from the matching reference records, you can use the merge rules in a match processor, and write back the Merged (or Enhanced) data output.
Note:
The Reference Data in a real-time matching process can be cached and interrogated in memory on the EDQ server if required. See the "Cache reference records for real-time processes" topic in Enterprise Data Quality Online Help, for further information.In the following example, the links to reference records are written:
Preparing a process for real-time reference matching
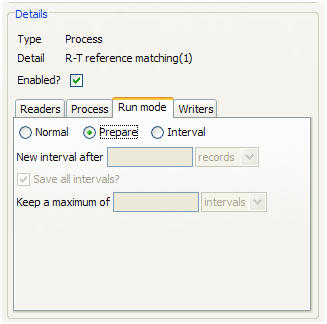
For a real-time reference matching process to perform correctly, it must first be run in Prepare mode. This allows it to compare the inbound records quickly against the reference sets and issue a response. Running a process in Prepare mode will ensure that all the cluster keys for the reference data sets have been produced.
To run a process in Prepare mode, set up a job and add the relevant process as a task. Click on the process to set the configuration details. Click on the Run Mode tab, and select Prepare:
Re-preparing reference data
Real-time matching uses a cached and prepared copy of the reference data. This means that when updates are made to reference data, the snapshot must be re-run and the data re-prepared before the updates can be propagated to the matching process.
Re-preparing reference data involves:
-
Stopping the real-time match process.
-
Refreshing the snapshot of the reference data.
-
Running the real-time match process in prepare mode.
-
Re-starting the real-time process.
Triggers, which can start and stop other jobs, can be used to create a job which includes all the above phases. A Stop, re-prepare and restart job would appear as follows:
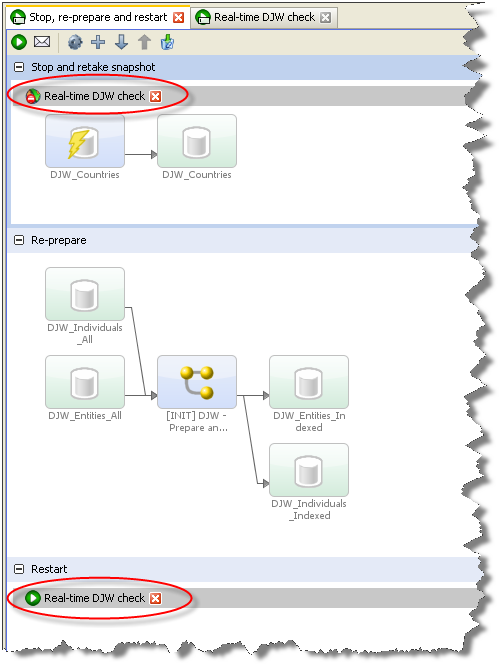
This job consists of three phases. The first stops the real-time match process and re-runs the reference data snapshot. The second runs the match process in Prepare mode. The third re-starts the real-time match process in Interval mode.
Triggers are configured to run either at the beginning of a phase or at the end, so it would be possible to include the restart trigger at the end of the second phase, just as the stop trigger is placed at the beginning of the first phase. However, placing the restart trigger in its own phase means you can configure the restart phase to run only if the re-prepare phase is successful; see the "Using Job Triggers" topic in Administering Enterprise Data Quality for further information.
In order to enable real time matching, you must configure a process containing a match processor, and use a single working input (to the match processor) only.
Real time processes may be run in Interval mode. In Interval mode, the processes run on a continuous basis, and write their results to the results database at regular intervals. See "Execution Options".
A real-time process can be run in Normal mode, but in this case:
-
The process will only write results when the process is cancelled (with the option to keep results ticked).
Note:
In many cases, there is no requirement to write results since all results may be persisted externally, for example in a log file. -
If the process needs to be prepared this will always happen first; meaning the process will not be able to respond to requests until this is complete.
Real time consumer and provider interfaces must also be configured to communicate with an external system, using either JMS or Web Services.
Note:
For real-time reference matching via a Web Service, you can use EDQ's Web Service capability to generate the real-time consumer and provider interfaces automatically. If you are using the EDQ Customer Data Services Pack, pre-configured Web Services are provided.3.4 Parsing Concept Guide
An important aspect of data being fit for purpose is the structure it is found in. Often, the structure itself is not suitable for the needs of the data. For example:
-
The data capture system does not have fields for each distinct piece of information with a distinct use, leading to user workarounds, such as entering many distinct pieces of information into a single free text field, or using the wrong fields for information which has no obvious place (for example, placing company information in individual contact fields).
-
The data needs to be moved to a new system, with a different data structure.
-
Duplicates need to be removed from the data, and it is difficult to identify and remove duplicates due to the data structure (for example, key address identifiers such as the Premise Number are not separated from the remainder of the address).
Alternatively, the structure of the data may be sound, but the use of it insufficiently controlled, or subject to error. For example:
-
Users are not trained to gather all the required information, causing issues such as entering contacts with ’data cheats' rather than real names in the name fields.
-
The application displays fields in an illogical order, leading to users entering data in the wrong fields
-
Users enter duplicate records in ways that are hard to detect, such as entering inaccurate data in multiple records representing the same entity, or entering the accurate data, but in the wrong fields.
These issues all lead to poor data quality, which may in many cases be costly to the business. It is therefore important for businesses to be able to analyze data for these problems, and to resolve them where necessary.
The EDQ Parse processor is designed to be used by developers of data quality processes to create packaged parsers for the understanding and transformation of specific types of data - for example Names data, Address data, or Product Descriptions. However, it is a generic parser that has no default rules that are specific to any type of data. Data-specific rules can be created by analyzing the data itself, and setting the Parse configuration.
Parsing is a frequently used term both in the realm of data quality, and in computing in general. It can mean anything from simply 'breaking up data' to full Natural Language Parsing (NLP), which uses sophisticated artificial intelligence to allow computers to 'understand' human language. A number of other terms are also frequently used related to parsing. Again, these can have slightly different meanings in different contexts. It is therefore important to define what we mean by parsing, and its associated terms, in EDQ.
Please note the following terms and definitions:
| Term | Definition |
|---|---|
| Parsing | In EDQ, Parsing is defined as the application of user-specified business rules and artificial intelligence in order to understand and validate any type of data en masse, and, if required, improve its structure in order to make it fit for purpose. |
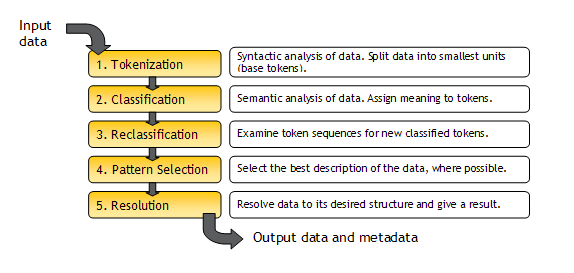
| Token | A token is a piece of data that is recognized as a unit by the Parse processor using rules. A given data value may consist of one or many tokens.
A token may be recognized using either syntactic or semantic analysis of the data. |
| Tokenization | The initial syntactic analysis of data, in order to split it into its smallest units (base tokens) using rules. Each base token is given a tag, such as <A>, which is used to represent unbroken sequences of alphabetic characters. |
| Base Token | An initial token, as recognized by Tokenization. A sequence of Base Tokens may later be combined to form a new Token, in Classification or Reclassification. |
| Classification | Semantic analysis of data, in order to assign meaning to base tokens, or sequences of base tokens. Each classification has a tag, such as 'Building', and a classification level (Valid or Possible) that is used when selecting the best understanding of ambiguous data. |
| Token Check | A set of classification rules that is applied against an attribute in order to check for a specific type of token. |
| Reclassification | An optional additional classification step which allows sequences of classified tokens and unclassified (base) tokens to be reclassified as a single new token. |
| Token Pattern | An explanation of a String of data using a pattern of token tags, either in a single attribute, or across a number of attributes.
A String of data may be represented using a number of different token patterns. |
| Selection | The process by which the Parse processor attempts to select the 'best' explanation of the data using a tuneable algorithm, where a record has many possible explanations (or token patterns). |
| Resolution | The categorization of records with a given selected explanation (token pattern) with a Result (Pass, Review or Fail), and an optional Comment. Resolution may also resolve records into a new output structure using rules based on the selected token pattern. |
Summary of the EDQ Parse Processor
The following diagram shows a summary of the way the EDQ Parse processor works:
See the help pages for the "EDQ Parse Processor" in Enterprise Data Quality Online Help for full instructions on how to configure it.