| Oracle® Retail Bulk Data Integration Implementation Guide Release 16.0.023 E89306-01 |
|

 Previous |
 Next |
| Oracle® Retail Bulk Data Integration Implementation Guide Release 16.0.023 E89306-01 |
|
Previous |
Next |
BDI Job Admin is a web application that provides the runtime and GUI for managing batch jobs. It provides the following high level functionality.
RESTful service to start/restart, check status and so on of a job.
RESTful service to stream data from source system to destination system.
The Infrastructure for various bulk data integration jobs. This includes the database for keeping track of data and the batch database for holding information about jobs.
The User Interface provides ability to:
Start/restart, and track status of jobs
Trace data
View Diagnostic Errors
Manage options at job and system level
View the logs
BDI uses instances of Job Admin to run the downloader and uploader jobs. For example; RMS uses an instance of Job Admin to run extractor jobs whereas RXM uses an instance of Job Admin to run importer jobs.
The BDI Job Admin contains the batch jobs for moving bulk data from source (senders) systems (for example RMS) to destination (receiver) systems (for example SIM, RXM and so on). A bulk integration flow moves data for one family from source to destination application(s).
An Integration Flow is made up of the multiple activities: Extractor, Downloader, Transporter, Uploader, and Importer. These activities are implemented as batch jobs.
An Extractor Job extracts data for a Family from a source system and moves data to the outbound Interface Tables.
Outbound Interface Tables typically exist in the integration database schema and the schema resides in the source system database.
The Extractor Job uses a Batchlet and PL/SQL stored procedures to move data from transactional tables of source system (for example RMS) to outbound tables. A PL/SQL stored procedure calls BDI PL/SQL stored procedure to insert data set information in the outbound data control tables. Extractor jobs are currently implemented to provide full data (not delta) for an interface.
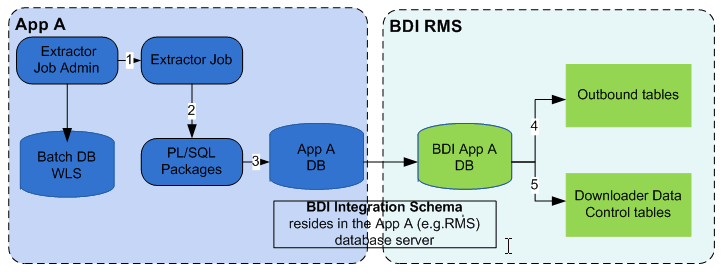
BDI Extractor (PL/SQL Application)
The Extractor job is run from App A (for example RMS) Extractor Job Admin application through REST or UI.
The Extractor job invokes PL/SQL stored procedure in App A database.
A PL/SQL stored procedure is run in the App A database.
The PL/SQL stored procedure moves data from transactional tables to the outbound tables in the BDI schema.
The PL/SQL stored procedure inserts entries in downloader data control tables to indicate the data set is ready for download.
|
Note: Review Appendix E.Sample Extractor – PL/SQL application code that calls procedures in PL/SQL package. |
The Downloader Data Control Tables act as a handshake between the Extractor and the Downloader. There are two Outbound Data Control Tables:
BDI_DWNLDR_IFACE_MOD_DATA_CTL
BDI_DWNLDR_IFACE_DATA_CTL
The Extractor job inserts entries in the downloader data control tables to indicate that data is ready to be downloaded after it completes moving data to outbound interface tables.
A Downloader-Transporter job downloads the data set from outbound interface tables for an Interface Module (family) and streams data to a BDI destination application using the Receiver Service.
If there are multiple Interfaces for an Interface Module, data for all interfaces for that interface module are downloaded and streamed concurrently to the Receiver Service of BDI destination application.
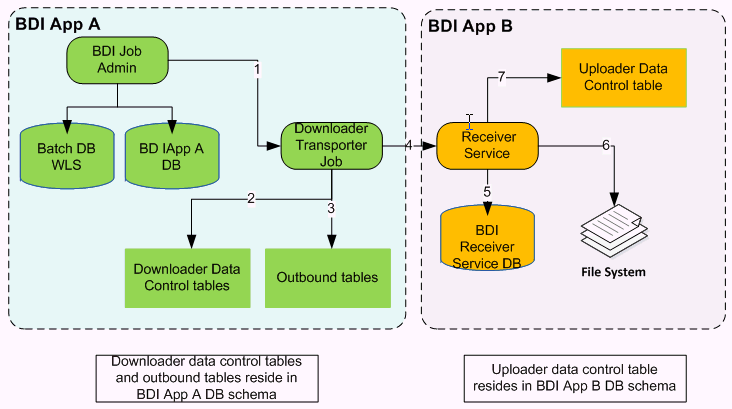
BDI Downloader Transporter
The Downloader Transporter job is run from the BDI App A Job Admin application through REST or UI.
The Downloader Transporter job checks for new data sets in Downloader Data Control Tables.
If a Data Set is available for download, the Downloader Transporter job downloads a block of data from the outbound table.
The Downloader Transporter job streams downloaded blocks to Receiver Service.
The Receiver Service stores meta data in Receiver Service database.
The Receiver Service creates a file for every block that it receives. Steps 3, 4, 5, and 6 repeat until there is no more data to download.
The Receiver Service inserts an entry in the uploader data control table indicating that the data set is ready for upload.
Rules for processing a data set by Downloader Job
A full data set is available for download, if it is not processed by a downloader job yet and if a newer full data set is not processed successfully.
If data set id is passed through job parameters (for example jobParameters=dataSetId=1) to downloader job, it will use the data set if it is available as per the above rule. Otherwise job will fail.
If the data set id is not passed through job parameters to downloader job, it will identify the next available data set if there is one. Otherwise job completes without processing any data set.
If the downloader-transporter job fails for whatever reason, the data set that it tried to download can only be downloaded by restarting the job after fixing the issues.
If the downloader-transporter job is started instead of a restart, it will either pick up a new data set or none.
Downloader Data Sets
A Data Set consists of rows between a begin and end sequence number (bdi_seq_id column) in the Outbound Interface Table. The BDI_SEQ_ID column is automatically incremented when data is inserted into the outbound table.
The Downloader-Transporter job downloads a single data set that is not downloaded yet from the outbound interface tables.
If a data set id is passed as job parameter (for example jobParameters=dataSetId=1) to Downloader-Transporter job, it will use that data set if it is available for download. Job Parameters as a query parameter. Job Parameters is a comma separated list of name value pairs. This parameter is optional.
If there are multiple data sets in the outbound tables that are available for download, then the Downloader-Transporter job picks up the oldest data set.
If there is no data set available in the outbound tables, the Downloader-Transporter job completes without downloading any data.
If a newer data set is processed by the Downloader-Transporter job, then older data set cannot be processed.
A data set is divided into Logical Partitions and data in each partition is downloaded by a separate thread. The Downloader-Transporter job tries to allocate data equally between partitions. Data in each partition is divided into blocks based on the ”item-count” value in the job and each block is retrieved from an outbound table and streams it to the destination application using the Receiver Service.
A data set is divided into logical partitions based on the number of partitions specified in the BDI_DWNLDR_TRNSMITTR_OPTIONS table and the number of rows in the data set.
The number of rows is calculated by subtracting the begin sequence number from the end sequence number provided in the BDI_DWNLDR_IFACE_DATA_CTL table. The number of rows may be approximate as there can be gaps in sequence numbers.
The number of rows allocated to each logical partition is calculated by dividing the approximate row count with the number of partitions.
Example 1:
Begin Sequence number = 1
End Sequence number = 100
Number of partitions = 2
Approximate row count = 100 - 1 + 1
Items for partition = 100/2 = 50
Data assigned to partition 1
Begin Sequence number = 1
End Sequence number = 1 + 50 - 1 = 50
Data assigned to partition 2
Begin Sequence number = 51
End Sequence number = 51 + 50 - 1 = 100
Example 2:
Begin Sequence number = 1
End Sequence number = 75
Number of partitions = 2
Approximate row count = 75 - 1 + 1
Items for partition = 75/2 = 37
Extra items = 75 % 2 = 1
Data assigned to partition 1
Begin Sequence number = 1
End Sequence number = 1 + 37 - 1 = 37
Data assigned to partition 2
Begin Sequence number = 38
End Sequence number = 38 + 37 + 1 - 1 = 75
The Downloader-Transporter job deletes data from outbound tables after the successful completion of the job if AUTO_PURGE_DATA flag in BDI_DWNLDR_TRNSMITTR_OPTIONS table is set to TRUE. The default value for this flag is TRUE. If sender side split topology is used, this flag needs to be changed to FALSE. Otherwise all destination applications may not get the data.
When a Downloader-Transporter job fails, the error information such as stack trace gets stored in BDI_JOB_ERROR and BDI_DOWNLOADER_JOB_ERROR tables. Errors are displayed in the ”Diagnostics” tab of the Job Admin GUI. The error information can be used to fix the issues before restarting the failed job. Note that if there are exceptions in Batch runtime, then those exceptions won't show up in the Job Error tables and so in the Diagnostics tab of the Job Admin GUI.
Downloader-Transporter Job Configuration
Seed data for the Downloader-Transporter jobs is loaded to the database during the deployment of Job Admin. Some of the seed data can be changed from the Job Admin GUI.
BDI_SYSTEM_OPTIONS
During the installation of Job Admin, the following information is provided by the user and that information is loaded into the BDI_SYSTEM_OPTIONS table.
Table 2-1 System Options
| Column | Type | Comments |
|---|---|---|
|
VARIABLE_NAME |
VARCHAR2(255) |
Name of the system variable |
|
APP_TAG |
VARCHAR2(255) |
The application name |
|
VARIABLE_VALUE |
VARCHAR2(255) |
Value of the variable |
<app>JobAdminBaseUrl - Base URL for Job Admin of destination applications such as sim/rxm
<app>JobAdminBaseUrlUserAlias - User alias for Job Admin of destination applications such as sim/rxm
<app> - Destination application name (for example sim or rxm)
Example:
MERGE INTO BDI_SYSTEM_OPTIONS USING DUAL ON (VARIABLE_NAME='rxmJobAdminBaseUrl' and APP_TAG='bdi-rms-batch-job-admin.war') WHEN MATCHED THEN UPDATE SET VARIABLE_VALUE='http://rxmhost:7001/bdi-rxm-batch-job-admin', UPDATE_TIME=SYSDATE WHEN NOT MATCHED THEN INSERT (VARIABLE_NAME, APP_TAG, VARIABLE_VALUE, CREATE_TIME) VALUES('rxmJobAdminBaseUrl', 'bdi-rms-batch-job-admin.war', 'http://rxmhost:7001/bdi-rxm-batch-job-admin', SYSDATE)
BDI_INTERFACE_CONTROL
During the design time, seed data for the BDI_INTERFACE_CONTROL table is generated for all interface modules (aka families) for a job type (DOWNLOADER, UPLOADER) so that interface modules are active.
Table 2-2 Interface Control
| Column | Type | Comments |
|---|---|---|
| ID | NUMBER | Primary Key |
| INTERFACE_CONTROL_COMMAND | VARCHAR2(255) | ACTIVE or IN_ACTIVE |
| INTERFACE_MODULE | VARCHAR2(255) | Name of interface module |
| SYSTEM_COMPONENT_TYPE | VARCHAR2(255) | DOWNLOADER or UPLOADER |
Example: insert into BDI_INTERFACE_CONTROL (ID, INTERFACE_CONTROL_COMMAND, INTERFACE_MODULE, SYSTEM_COMPONENT_TYPE) values (1, 'ACTIVE', 'Diff_Fnd', 'DOWNLOADER')
BDI_DWNLDR_TRNSMITTR_OPTIONS
Seed data for BDI_DWNLDR_TRNSMITTR_OPTIONS specifies various configuration options for the Downloader-Transmitter job. Seed data is generated during design time and executed during deployment.
Table 2-3 Transmitter Options
| Column | Type | Comments |
|---|---|---|
| ID | NUMBER | Primary Key |
| INTERFACE_MODULE | VARCHAR2(255) | Name of interface module |
| INTERFACE_SHORT_NAME | VARCHAR2(255) | Name of the interface |
| RECVR_END_POINT_URL | VARCHAR2(255) | Name of the URL variable in BDI_SYSTEM_OPTIONS table |
| RECVR_END_POINT_URL_ALIAS | VARCHAR2(255) | Name of the URL alias variable in BDI_SYSTEM_OPTIONS table |
| PARTITION . | NUMBER | Number of partitions used by Downloader-Transporter job. Default value is 10. This value can be changed through Job Admin GUI |
| THREAD | NUMBER | Number of threads used by Downloader-Transporter job. Default value is 10. This value can be changed through Job Admin GUI. |
| QUERY_TEMPLATE | VARCHAR2(255) | Query to be run by downloader job |
| AUTO_PURGE_DATA | VARCHAR2(255) | This flag indicates Downloader-Transporter job whether to clean data set in the outbound table after the job successfully downloads the data set. Default value is set to True. This value need to be changed based on the deployment topology used for bulk data integration. |
Example: MERGE INTO BDI_DWNLDR_TRNSMITTR_OPTIONS USING DUAL ON (ID=1) WHEN MATCHED THEN UPDATE SET INTERFACE_MODULE='Diff_Fnd', INTERFACE_SHORT_NAME='Diff', RECVR_END_POINT_URL='rxmJobAdminBaseUrl', RECVR_END_POINT_URL_ALIAS='rxmJobAdminBaseUrlUserAlias', PARTITION=10, THREAD=10, QUERY_TEMPLATE='select * from InterfaceShortName where (bdi_seq_id between ? and ?) QueryFilter order by bdi_seq_id', AUTO_PURGE_DATA='TRUE' WHEN NOT MATCHED THEN INSERT (ID, INTERFACE_MODULE, INTERFACE_SHORT_NAME, RECVR_END_POINT_URL, RECVR_END_POINT_URL_ALIAS, PARTITION, THREAD, QUERY_TEMPLATE, AUTO_PURGE_DATA) values (1, 'Diff_Fnd', 'Diff', 'rxmJobAdminBaseUrl', 'rxmJobAdminBaseUrlUserAlias', 10, 10, 'select * from InterfaceShortName where (bdi_seq_id between ? and ?) QueryFilter order by bdi_seq_id', 'TRUE') MERGE INTO BDI_DWNLDR_TRNSMITTR_OPTIONS USING DUAL ON (ID=1) WHEN MATCHED THEN UPDATE SET INTERFACE_MODULE='Diff_Fnd', INTERFACE_SHORT_NAME='Diff', RECVR_END_POINT_URL='rxmJobAdminBaseUrl', RECVR_END_POINT_URL_ALIAS='rxmJobAdminBaseUrlUserAlias', PARTITION=10, THREAD=10, QUERY_TEMPLATE='select * from InterfaceShortName where (bdi_seq_id between ? and ?) QueryFilter order by bdi_seq_id', AUTO_PURGE_DATA='TRUE' WHEN NOT MATCHED THEN INSERT (ID, INTERFACE_MODULE, INTERFACE_SHORT_NAME, RECVR_END_POINT_URL, RECVR_END_POINT_URL_ALIAS, PARTITION, THREAD, QUERY_TEMPLATE, AUTO_PURGE_DATA) values (2, 'Diff_Fnd', 'Diff', 'rxmJobAdminBaseUrl', 'rxmJobAdminBaseUrlUserAlias', 10, 10, 'select * from InterfaceShortName where (bdi_seq_id between ? and ?) QueryFilter order by bdi_seq_id', 'TRUE')
Downloader-Transporter Job Properties
The following job properties can be changed in the Downloader-Transporter jobs to tune the performance.
item-count
Item Count is an attribute of the ”chunk” element in the Downloader-Transporter job. The default value for ”item-count” is set to 1000. The Downloader job retrieves 1000 rows of data from the database before it sends data to the Receiver Service.
<chunk checkpoint-policy="item" item-count="1000">
This value can be changed to fine tune the performance of the Downloader-Transporter job. You need to manually change the value in the job xml files in bdi-<app>-home/setup-data/job/META-INF/batch-jobs folder and reinstall the app. Increasing the item count will increase memory utilization.
fetchSize
The Fetch Size is a property in the Downloader-Transporter job.
FetchSize property is used by JDBC to fetch n number of rows and cache them. The default value is set to 1000. Typically ”item-count” and ”fetchSize” values are identical to get better performance.
<property name="fetchSize" value="1000"/>
This value can be changed to fine tune the performance of the Downloader-Transporter job. You need to manually change the value in the job xml files.
Cleanup
The Downloader-Transporter job deletes data from outbound tables after the successful completion of the job if the AUTO_PURGE_DATA flag in BDI_DWNLDR_TRNSMITTR_OPTIONS table is set to TRUE. The default value for this flag is TRUE. If sender side split topology is used, this flag needs to be changed to FALSE. Otherwise all destination applications may not get the data.
Error Handling
When a Downloader-Transporter job fails, error information like the stack trace gets stored in the BDI_JOB_ERROR and BDI_DOWNLOADER_JOB_ERROR tables. Errors are displayed in the ”Diagnostics” tab of the Job Admin GUI. The error information can be used to fix the issues before restarting the failed job.
|
Note: If there are exceptions in Batch runtime, then those exceptions won't show up in Job Error tables and so in Diagnostics tab of Job Admin GUI. |
BDI_DOWNLOADER_JOB_ERROR
Table 2-4 Downloader Job Error
| Column | Type | Comments |
|---|---|---|
| DOWNLOADER_JOB_ERROR_ID | NUMBER | Primary key |
| PARTITION_INDEX | VARCHAR2(255) | Partition number of data set |
| BLOCK_NUMBER | NUMBER | Block number in the partition |
| BEGIN_SEQ_NUM_IN_BLOCK | NUMBER | Begin sequence number in the block |
| END_SEQ_NUM_IN_BLOCK | NUMBER | End sequence number in the block |
| JOB_ERROR_ID | NUMBER | Foreign key to JOB_ERROR table |
BDI_JOB_ERROR
Table 2-5 Job Error
| Column | Type | Comments |
|---|---|---|
| JOB_ERROR_ID | NUMBER | Primary key |
|
CREATE_TIME |
TIMESTAMP |
Time when error occurred |
| TRANSACTION_ID | VARCHAR2(255) | Transaction Id of the job |
| INTERFACE_MODULE | VARCHAR2(255) | Name of the interface module |
| INTERFACE_SHORT_NAME | VARCHAR2(255) | Name of the interface |
| DESCRIPTION | VARCHAR2(1000) | Error description |
| STACK_TRACE | VARCHAR2(4000) | Stack trace |
The Receiver Service is a RESTful service that provides various endpoints to send data transactionally.
The Receiver Service is part of Job Admin. It stores data as files and keeps track of metadata in the database. The Receiver Service also supports various merge strategies for merging files at the end.
The Receiver Service is used by the Downloader-Transporter job to transmit data from source to destination.
An Uploader Job uploads data from CSV files into Inbound Tables for an Interface Module. It divides files into logical partitions and each partition is processed concurrently. If a data set is already present in inbound tables, and the Uploader Job tries to upload the same data set, then it will overwrite the existing data set.
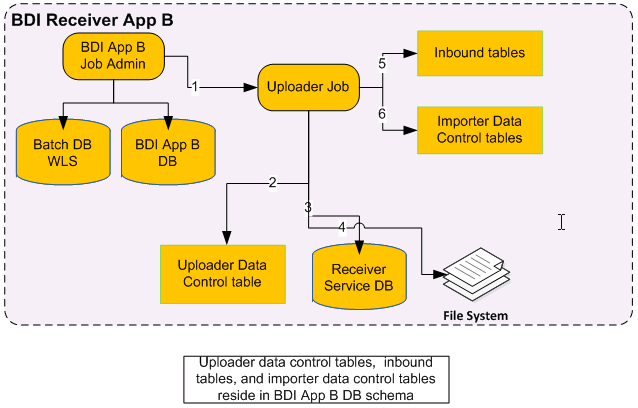
BDI Uploader
The Uploader job is run from the BDI App B Job Admin application through REST or UI.
The Uploader job checks for data sets in the uploader data control table.
If the data set is available for upload, the uploader job finds the location of the files from Receiver Service database.
The Uploader job retrieves a block of data from the file(s).
The Uploader job inserts/updates data in inbound tables.
The Uploader job inserts entries in importer data control tables to indicate that a data set is ready for import.
Steps 4, 5, and 6 are repeated until there is no more data to upload.
Rules for processing a data set by an Uploader Job
A data set is available for upload, if it is not processed by an uploader job yet and if a newer data set is not processed successfully.
If the data set id is passed through job parameters (for example jobParameters=dataSetId=1) to the uploader job, it will use the data set if it is available as per the above rule. Otherwise job will fail.
If the data set id is not passed through job parameters to the uploader job, it will identify the next available data set if there is one. Otherwise the job completes without processing any data set.
If an uploader job fails for whatever reason, the data set that it tried to upload can only be uploaded by restarting the job after fixing the issue. If uploader job is started instead of a restart, it will either pick up a new data set or none.
Uploader Data Set
A Data Set consists of files created by the Receiver Service.
The Uploader job uploads a single data set that is not uploaded to inbound tables yet. It uses BDI_UPLDER_IFACE_MOD_DATA_CTL and Receiver Service tables to identify the data set to be uploaded.
If source data set id is passed through the job parameters, then the Uploader job uses that data set if it is available for upload.
If there are multiple data sets available, then the Uploader job picks up the oldest data set available for upload.
If a newer data set is processed by the Uploader job, then the older data set cannot be processed.
If there is no data set available, the Uploader job completes without uploading any data.
The Uploader job tries to allocate files equally between different partitions. Data is read from files in each partition based on the ”item-count” value in the job and data is uploaded to inbound tables. The job continues to read data from files in a partition until there is no more data to be read.
A data set is divided into logical partitions based on the number of partitions specified in the BDI_UPLOADER_OPTIONS table and number of files in the data set. The number of files allocated to each logical partition is calculated by dividing file count with number of partitions.
Example 1:
Number of files = 100
Number of partitions = 2
Files for partition = 100/2 = 50
Files assigned to partition 1
Begin File index = 0
End File index = 49
Data assigned to partition 2
Begin File Index = 50
End File Index = 99
Example 2:
Number of files = 75
Number of partitions = 2
Files for partition = 75/2 = 37
Extra files = 75 % 2 = 1
Files assigned to partition 1
Begin File index = 0
End File index = 36
Files assigned to partition 2
Begin File index = 37
End File index = 37 +37 = 74
Uploader Cleanup Jobs
The Cleanup job cleans data set(s) for an interface module from outbound tables or receiver files. Cleanup jobs are generated during design time. They are included in the sender side or receiver side split flows.
There are two types of cleanup jobs - extractor and receiver cleanup jobs.
The Extractor cleanup job deletes data set(s) from outbound tables. It identifies data sets that have been successfully downloaded and transmitted to destination applications and deletes the identified data sets from outbound tables.
The Receiver cleanup job deletes CSV files from the receiver file system. It identifies the files that have been successfully uploaded to inbound tables and deletes the files from the file system.
BDI_INTERFACE_CONTROL
During the design time, seed data for the BDI_INTERFACE_CONTROL table is generated for all interface modules (aka families) for a job type of UPLOADER so that interface modules are active. DML runs during deployment.
Example:
MERGE INTO BDI_INTERFACE_CONTROL USING DUAL ON (ID=1) WHEN MATCHED THEN UPDATE SET INTERFACE_CONTROL_COMMAND='ACTIVE', INTERFACE_MODULE='Diff_Fnd', SYSTEM_COMPONENT_TYPE='UPLOADER' WHEN NOT MATCHED THEN INSERT (ID, INTERFACE_CONTROL_COMMAND, INTERFACE_MODULE, SYSTEM_COMPONENT_TYPE) VALUES(1, 'ACTIVE', 'Diff_Fnd', 'UPLOADER')
BDI_UPLOADER_OPTIONS
Seed data for BDI_UPLOADER_OPTIONS specifies various configuration options for uploader job. Seed data is generated during design time and executed during deployment.
Table 2-6 Uploader Options
| Column | Type | Comments |
|---|---|---|
| ID | NUMBER | Primary Key |
| INTERFACE_MODULE | VARCHAR2(255) | Name of interface module |
| INTERFACE_SHORT_NAME | VARCHAR2(255) | Name of the interface |
| PARTITION | NUMBER | Number of partitions used by Uploader job. Default value is 10. This value can be changed through Job Admin GUI. |
| THREAD | NUMBER | Number of threads used by Uploader job. Default value is 10. This value can be changed through Job Admin GUI. |
| MERGE_STRATEGY | VARCHAR2(255) | Merge strategy used by Receiver Service - NO_MERGE, MERGE_TO_PARTITION_LEVEL, MERGE_TO_INTERFACE_LEVEL |
| AUTO_PURGE_DATA | VARCHAR2(255) | This flag indicates Uploader job whether to clean the files after uploader job successfully uploads the data to inbound tables. Default value is True. This value needs to be changed based on the deployment topology used for bulk data integration. |
Example: MERGE INTO BDI_UPLOADER_OPTIONS USING DUAL ON (ID=1) WHEN MATCHED THEN UPDATE SET INTERFACE_MODULE='Diff_Fnd', INTERFACE_SHORT_NAME='Diff', MERGE_STRATEGY='NO_MERGE', PARTITION=10, THREAD=10, AUTO_PURGE_DATA='TRUE' WHEN NOT MATCHED THEN INSERT (ID, INTERFACE_MODULE, INTERFACE_SHORT_NAME, MERGE_STRATEGY, PARTITION, THREAD, AUTO_PURGE_DATA) values (1, 'Diff_Fnd', 'Diff', 'NO_MERGE', 10, 10, 'TRUE')
Uploader Job Properties
The following job property can be changed in uploader jobs to tune the performance.
item-count
Item Count is an attribute of ”chunk” element in the Uploader job. The default value for ”item-count” is set to 1000. Uploader job reads 1000 rows from the file(s) before it inserts/updates that data in the inbound tables.
<chunk checkpoint-policy="item" item-count="1000">
This value can be changed to fine tune the performance of an Uploader job. You need to manually change the value in the the job xml files in the bdi-<app>-home/setup-data/job/META-INF/batch-jobs folder and reinstall the app for changes to take place.
Cleanup
The Uploader job deletes CSV files from the receiver file system after the successful completion of the job if the AUTO_PURGE_DATA flag in BDI_UPLOADER_OPTIONS table is set to TRUE. The default value for this flag is TRUE. If receiver side split topology is used, this flag needs to be changed to FALSE. Otherwise all destination applications may not get the data in inbound tables.
Error Handling
When Uploader job fails, error information like stack trace gets stored in BDI_UPLOADER_JOB_ERROR table. Errors are displayed in the ”Diagnostics” tab of Job Admin GUI. The error information can be used to fix the issues before restarting the failed job.
|
Note: If there are exceptions in Batch runtime, then those exceptions won't show up in Job Error tables and so in Diagnostics tab of Job Admin GUI. |
BDI_UPLOADER_JOB_ERROR
Table 2-7 Uploader Job Error
| Column | Type | Comments |
|---|---|---|
| UPLOADER_JOB_ERROR_ID | NUMBER | Primary key |
| FILE_NAME | VARCHAR2(255) | File in which error occurred |
| BEGIN_ROW_NUMBER | NUMBER | Beginning row number in the file |
| END_ROW_NUMBER | NUMBER | Ending row number in the file |
| JOB_ERROR_ID | NUMBER | Foreign key to JOB_ERROR table |
The tables BDI_IMPRTR_IFACE_MOD_DATA_CTL and BDI_IMPORTER_IFACE_DATA_CTL act as a handshake between the uploader and importer jobs. When the Uploader Job completes processing a data set successfully, it creates an entry in these tables.
An entry in the table BDI_IMPRTR_IFACE_MOD_DATA_CTL indicates to the Importer Job that a data set is ready to be imported.
The Importer job imports a data set for an Interface Module from inbound tables into application specific transactional tables. Importer jobs are application (for example SIM/RXM) specific jobs. It uses the Importer Data Control Tables to identify whether a data set is ready for import or not.
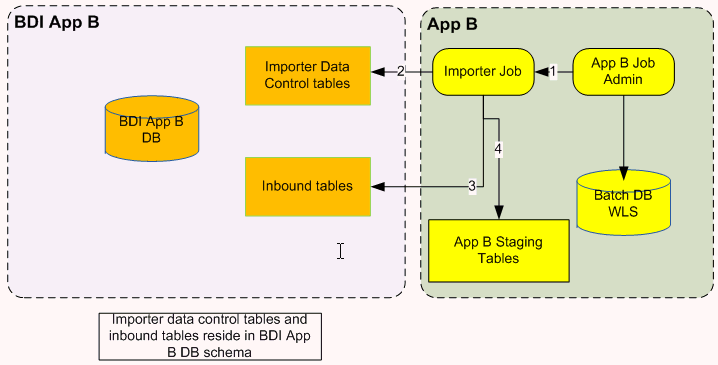
RXM Importer
Importer job is run from App B Job Admin application through REST or UI.
Importer job checks for data sets in importer data control tables.
If data set is available for import, importer job downloads data from inbound table.
Importer job loads data to App B staging tables.
BDI_IMPRTR_IFACE_MOD_DATA_CTL
Table 2-8 Importer Data
| Column | Type | Comments |
|---|---|---|
| IMPORTER_IFACE_MOD_DATACTL_ID | NUMBER | Primary key |
| INTERFACE_MODULE | VARCHAR2(255) | Name of the interface module |
| SOURCE_SYSTEM_NAME | NUMBER | Name of the source system |
| SOURCE_DATA_SET_ID | NUMBER | Source data set id |
| SRC_SYS_DATA_SET_READY_TIME | TIMESTAMP | Time when data set was ready in outbound tables |
| DATA_SET_TYPE | VARCHAR2(255) | Type of data set (FULL or PARTIAL) |
| DATA_SET_READY_TIME | TIMESTAMP | Time when data set was available in inbound tables |
| UPLOADER_TRANSACTION_ID | NUMBER | Transaction id of the uploader job |
BDI_IMPORTER_IFACE_DATA_CTL
Table 2-9 Importer Data
| Column | Type | Comments |
|---|---|---|
| IMPORTER_IFACE_DATA_CTL_ID | NUMBER | Primary key |
| INTERFACE_SHORT_NAME | VARCHAR2(255) | Name of the interface |
| INTERFACE_DATA_BEGIN_SEQ_NUM | NUMBER | Beginning sequence number of the data set in the inbound table |
| INTERFACE_DATA_END_SEQ_NUM | NUMBER | Ending sequence number of the data set in the inbound table |
| JIMPORTER_IFACE_MOD_DATACTL_ID | NUMBER | Foreign key to BDI_IMPRTR_IFACE_MOD_DATA_CTL table |
