BDDでは、多くの異なるクラスタ構成がサポートされています。インストールする前に、ニーズに最も適したものを決定する必要があります。
次の各項では、デモ環境、開発環境および本番環境に適した3つの構成、およびそれらの考えられるバリエーションを説明します。
単一ノードのデモ環境
BDDは、単一の物理または仮想マシンで稼働しているデモ環境にインストールできます。この構成は、処理できるデータの量にかぎりがあるため、製品の機能を少さいサンプル・データベースでデモンストレーションする場合にのみお薦めします。
単一ノード・デプロイメントでは、すべてのBDDおよびHadoopコンポーネントは同一ノードでホストされ、Dgraphデータベースはローカル・ファイルシステムに格納されます。

ノード2つのデプロイメント環境
BDDは、2つのノードで稼働している開発環境にインストールできます。この構成では、単一ノード・デプロイメントよりもやや大きいデータベースを処理できますが、処理容量はまだ制限されています。また、DgraphまたはStudioのための高可用性は提供されません。
ノード2つの構成では、Hadoopおよびデータ処理が1つのノードでホストされ、WebLogic Server (StudioとDgraph Gatewayを含む)およびDgraphが別のノードでホストされます。Dgraphデータベースはローカル・ファイルシステムに格納されます。

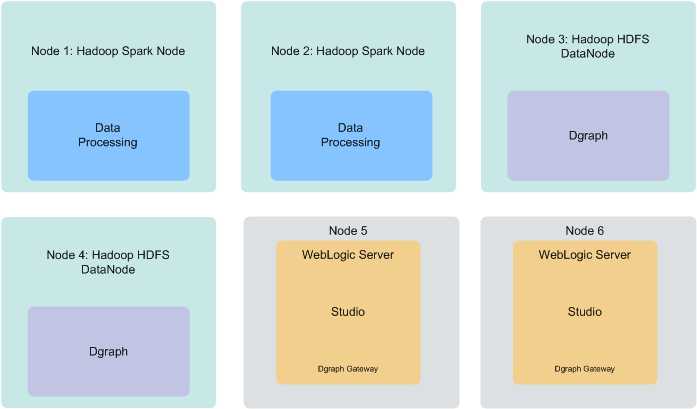
ノード6つの本番環境
本番環境は、スケールに必要なだけの任意の数のノードで構成されます。ただし、少なくとも4つのHadoopノードにBDDがデプロイされた6ノードのクラスタで最大限の可用性が保証されます。
- ノード1および2では、Spark on YARN (および他の関連サービス)とBDDデータ処理が実行されています。
- ノード3および4では、HDFS DataNodeサービスとDgraphが実行されており、DgraphデータベースはHDFSに格納されています。
この構成は、上で説明した2つとは異なることに注意してください。ここでは、DgraphはHadoopと分離されており、そのデータベースはローカル・ファイルシステムに格納されます。HDFSへのデータベースの格納は、Dgraphの高可用性オプションであり、大規模な本番環境の場合にお薦めします。
- ノード4および5では、WebLogic Server、StudioおよびDgraph Gatewayが実行されています。これらのノードのうち2つがあると、Studioインスタンスの冗長性が最小になります。
前述の構成に限定されるわけではないことを覚えておいてください。クラスタには、必要に応じて多数のデータ処理、WebLogic ServerおよびDgraphノードを含むことができます。また、WebLogic ServerとHadoopを同一ノードに併置するか、データベースを共有NFSでホストしてDgraphをその固有のノードで実行することができます。このような決定はクラスタの全体的なパフォーマンスに影響する可能性があり、サイトのリソースおよび要件に依存することに注意してください。
ノードの数について
このドキュメントにはサイズ設定要件は含まれていませんが、現場の固有要件に従って次のガイドラインを使用し、クラスタの適切なサイズを決定できます。必要な場合は、より多くのDgraphノードおよびデータ処理ノードを追加することもできます。詳細は、管理者ガイドを参照してください。
- データ処理ノード: BDDクラスタには、データ処理が実行されている1つ以上のHadoopノードを含める必要があります。高可用性を実現するために、3つ以上にすることをお薦めします。(注意: 既存のHadoopクラスタに4つ以上のノードが含まれているかもしれません。ここで説明しているHadoopノードは、BDDもインストールされているノードです)。BDDインストーラは、自動的にデータ処理をSpark on YARN、YARNおよびHDFSを実行するすべてのHadoopノードにインストールします。
- WebLogic Serverノード: BDDクラスタには、StudioおよびDgraph Gatewayが稼働しているWebLogic Serverノードを少なくとも1つ含める必要があります。Studioインスタンスの数については推奨はありませんが、同時に問合せを行うエンド・ユーザーの数が多くなることが予想される場合は、2つ必要になる可能性があります。
- Dgraphノード: デプロイメントには、少なくとも1つのDgraphインスタンスを含める必要があります。複数ある場合は、BDDクラスタ内のクラスタとして実行されます。問合せ処理の可用性が増すため、Dgraphsをクラスタにするのが望ましいです。DgraphデータベースがHDFS上にある場合はDgraphをHDFS DataNodeにインストールする必要があることに注意してください。
Hadoop、WebLogic ServerおよびDgraphの併置
クラスタを構成する1つの方法は、異なるコンポーネントを同じノードに併置することです。ノード全体を特定のBDDコンポーネント専用にする必要がないため、これは、より効率的なハードウェア使用方法となります。
ただし、併置されたコンポーネント間でメモリーが競合し、パフォーマンスに悪影響を及ぼす可能性があることに注意してください。異なるコンポーネントを同じノードでホストするかどうかは、現場の本番要件およびハードウェア能力によります。
HadoopおよびBDDコンポーネントの組合せは、3つすべてを一緒に含めて、単一ノードで実行できます。可能な組合せは次のとおりです。
- DgraphとHadoop。DgraphはHadoop DataNode上で実行できます。これは、データベースをHDFSに格納する場合に必要となり、また、それらをNFSに格納する場合はオプションとなります。
最善のパフォーマンスのためには、DgraphをSpark on YARNが実行されているノードでホストしないようにしてください。これは、両方のプロセスで大量のメモリーが必要になるためです。ただし、それらを併置する必要がある場合は、cgroupを使用して、Dgraphのためにリソースを分割できます。詳細は、cgroupの設定を参照してください。
- DgraphとWebLogic Server。DgraphとWebLogic Serverは同じノードでホストできます。これを使用する場合、消費するメモリーの量が限定されるようWebLogic Serverを構成し、Dgraphが問合せ処理に十分なリソースにアクセスできるようにします。
- WebLogic ServerとHadoop。WebLogic Serverは、どのHadoopノードでも実行できます。これを行う場合、消費するメモリーの量が限定されるようWebLogic Serverを構成し、Hadoopが処理に十分なリソースにアクセスできるようにします。
