| Oracle® Enterprise Data Quality状況依存ヘルプ 12c (12.2.1.2.0) E88273-01 |
|

 前 |
 次 |
次の項では、Oracle Enterprise Data Qualityのアプリケーションで使用できるヘルプについて説明します。
Oracle Enterprise Data Quality (EDQ)をご利用いただきありがとうございます。
EDQは、データ品質のプロファイリング、分析、解析、標準化、照合および結合を行うためのコラボレーティブな製品で、単一の統合環境から業務で使用する情報の品質を理解、改善、保護および制御できるように設計されています。
次のヘルプ・ページは、EDQをすぐに使い始められるように、および製品の使用時に便利なリファレンスとして利用できるように設計されています。
EDQアプリケーション
EDQの管理
EDQをインストールする必要があるのは、プロセスを実行するマシンのみです。クライアント・マシンでは、サーバー・インストールは不要です。サポートされるJava Runtime Environment (JRE)がインストールされているクライアントは、サポートされるWebブラウザを使用してEDQサーバーに接続できます。EDQでは、Java Web Startを使用して、クライアント・マシンにクライアント・アプリケーションをダウンロードして起動します。
EDQリリース12.2.1ドキュメント・ライブラリにあるOracle Enterprise Data Qualityのインストールと構成を参照してください。
EDQの主な機能を次に示します。
統合されたデータ・プロファイリング、監査、クレンジングおよび照合
ブラウザベースのクライアント・アクセス
すべてのタイプのデータを処理できる機能(たとえば、顧客、製品、資産、会計、操作)
Java Database Connectivity (JDBC)準拠データ・ソースおよびターゲットへの接続
マルチユーザーのプロジェクト・サポート(ロールベースのアクセス、問題追跡、プロセス注釈、およびバージョン制御)
サービス指向アーキテクチャ(SOA) - サービスとして外部アプリケーションに公開される可能性のあるプロセスの設計をサポート
大量のデータの処理用に設計
共有アクセスを使用した、収集された統計とプロジェクト追跡情報とともにデータを保持する単一リポジトリ
実情報の品質に関する問題を迅速に解決できるように設計された、直感的なグラフィカル・ユーザー・インタフェース
検証および変換ルールの、容易でデータ主導の作成および拡張
必要なカスタム処理を挿入できる、完全に拡張可能なアーキテクチャ
Oracle Technology Networkでは、Oracleソフトウェアに関するリソースを幅広く用意しています。
技術上の問題や解決策については、ディスカッション・フォーラムを参照してください。
実践的なステップ・バイ・ステップのチュートリアルについては、Oracle By Exampleを参照してください。
サンプル・コードをダウンロードできます。
すべてのOracle製品の最新のニュースおよび情報を入手できます。
無料のトレーニング・ビデオおよびリソースとしてOracle Learning Libraryにアクセスできます。
また、次の場所では、Oracleソフトウェアに関するより詳細なヘルプと情報を参照できます。
My Oracle Support (登録が必要)
Oracleサポート・サービス
すべてのEDQアプリケーションには、次のUI言語オプションが用意されています。
英語(米国)
フランス語
イタリア語
ドイツ語
スペイン語
中国語
日本語
韓国語
ポルトガル語(ブラジル)
EDQには全言語の翻訳が自動的にインストールされており、単一のサーバーで様々な言語のクライアントをサポートします。
注意:
EDQはUnicodeに完全対応しているため、あらゆる言語のデータを処理できます。これらの言語オプションは、UIテキストを制御するためだけのものです。
クライアントのロケール設定により、UI言語が設定されます。詳細は、次の「クライアント・ロケールの調整」を参照してください。
製品のオンライン・ヘルプおよび技術文書は、現在サポートされる言語すべてで提供されています。
構成オブジェクト(プロジェクト、プロセス、参照データなど)のユーザー指定名は、現在翻訳対象外です。つまり、事前パッケージ済の拡張機能(Customer Data Services PackやOracle Watchlist Screening)で使用されている構成オブジェクト名は英語(米国)のみです。
クライアント・マシンでは、EDQ UIはマシンの表示設定に基づいてロケール言語で表示されます。
UIの言語を変更するためにクライアントの言語を調整するには、次の手順を使用します。
選択した言語でEDQサーバーからWebページを表示するように、Webブラウザの言語表示オプションを設定します。
EDQ Java WebStart UIを選択した言語で表示するために、クライアント・マシンの地域設定を変更します。たとえば、Windowsマシンで、「システム ロケール」、「形式」および「表示言語」を変更します。
注意:
Java 7 Update 25により、Javaアプリケーションが表示される言語を変更するためには「表示言語」を調整しなければならなくなりました。以前のバージョンでは、「システム ロケール」と「形式」のみが使用されていました。Windowsを使用している場合、「表示言語」をインストールされた設定から変更するのに必要なMultilingual User Interface Packは、Windows EnterpriseとWindows Ultimateにのみ付属しています。
テスト目的で、すべてのクライアントのロケールを設定するサーバー・オプションを使用して、クライアント設定を上書きできます。それには、次の設定を[edq_local_home]/properties/clientstartup.propertiesに追加します: locale = [ISO 639-2 Language Code]。たとえば、クライアントの地域設定に関係なく、すべてのクライアントJava UIを日本語で表示するには、次の行を追加します: locale = ja
ダッシュボード管理でのロケールの設定
ダッシュボード管理でロケールを設定するには、クライアントで環境変数を追加する必要があります。ロケールを設定するには、次の手順を使用します。
「システムのプロパティ」→「詳細設定」→「環境変数」にナビゲートします。
「新しいユーザー変数」ダイアログで、「変数名」列にDASHBOARD_ADMIN_LOCALEと入力します。「変数値」列にde_DE (ドイツ語の場合)と入力します。
システムを再起動し、ダッシュボードにナビゲートします。「管理」をクリックすると、設定した言語で表示されます。
このソフトウェアおよび関連ドキュメントの使用と開示は、ライセンス契約の制約条件に従うものとし、知的財産に関する法律により保護されています。ライセンス契約で明示的に許諾されている場合もしくは法律によって認められている場合を除き、形式、手段に関係なく、いかなる部分も使用、複写、複製、翻訳、放送、修正、ライセンス供与、送信、配布、発表、実行、公開または表示することはできません。このソフトウェアのリバース・エンジニアリング、逆アセンブル、逆コンパイルは互換性のために法律によって規定されている場合を除き、禁止されています。
ここに記載された情報は予告なしに変更される場合があります。また、誤りが無いことの保証はいたしかねます。誤りを見つけた場合は、オラクル社までご連絡ください。
このソフトウェアまたは関連ドキュメントを、米国政府機関もしくは米国政府機関に代わってこのソフトウェアまたは関連ドキュメントをライセンスされた者に提供する場合は、次の通知が適用されます。
U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. Government.
このソフトウェアもしくはハードウェアは様々な情報管理アプリケーションでの一般的な使用のために開発されたものです。このソフトウェアもしくはハードウェアは、危険が伴うアプリケーション(人的傷害を発生させる可能性があるアプリケーションを含む)への用途を目的として開発されていません。このソフトウェアもしくはハードウェアを危険が伴うアプリケーションで使用する際、安全に使用するために、適切な安全装置、バックアップ、冗長性(redundancy)、その他の対策を講じることは使用者の責任となります。このソフトウェアもしくはハードウェアを危険が伴うアプリケーションで使用したことに起因して損害が発生しても、オラクル社およびその関連会社は一切の責任を負いかねます。
OracleおよびJavaはOracle およびその関連企業の登録商標です。その他の名称は、それぞれの所有者の商標または登録商標です。
Intel、Intel Xeonは、Intel Corporationの商標または登録商標です。すべてのSPARCの商標はライセンスをもとに使用し、SPARC International, Inc.の商標または登録商標です。AMD、Opteron、AMDロゴ、AMD Opteronロゴは、Advanced Micro Devices, Inc.の商標または登録商標です。UNIXは、The Open Groupの登録商標です。
このソフトウェアまたはハードウェア、そしてドキュメントは、第三者のコンテンツ、製品、サービスへのアクセス、あるいはそれらに関する情報を提供することがあります。適用されるお客様とOracle Corporationとの間の契約に別段の定めがある場合を除いて、Oracle Corporationおよびその関連会社は、第三者のコンテンツ、製品、サービスに関して一切の責任を負わず、いかなる保証もいたしません。適用されるお客様とOracle Corporationとの間の契約に定めがある場合を除いて、Oracle Corporationおよびその関連会社は、第三者のコンテンツ、製品、サービスへのアクセスまたは使用によって損失、費用、あるいは損害が発生しても一切の責任を負いかねます。
Oracle Enterprise Data Qualityスイートには、次のアプリケーションが含まれます。
ディレクタは、Oracle Enterprise Data Qualityスイートのコア・アプリケーションです。
ディレクタのユーザー・インタフェースには、次の画面上の要素があります。
ディレクタを開始するには、Oracle Fusion Middleware Oracle Enterprise Data Qualityの使用のスタート・ガイドを参照してください。
メニューには、次に示す4つのサブメニューがあります。
表1-1 「ファイル」メニュー
| 要素 | 説明 |
|---|---|
|
新規プロセス... |
新規プロセスを作成します([Ctrl]+[N])。 |
|
新規プロジェクト... |
新規プロジェクトを作成します。 |
|
新規サーバー... |
別のOEDQサーバーに接続します。 |
|
パッケージ・ファイルを開く |
パッケージ・ファイルを開きます。 |
|
閉じる |
現在選択しているプロセスを閉じます。 |
|
すべて閉じる |
開いているプロセスをすべて閉じます。 |
|
保存 |
現在選択しているプロセスを保存します([Ctrl]+[S])。 |
|
すべて保存 |
開いているプロセスをすべて保存します([Ctrl]+[Shift]+[S])。 |
|
印刷 |
現在のキャンバスを印刷します([Ctrl]+[P])。 |
|
終了 |
OEDQを終了します。 |
表1-2 「編集」メニュー
| 要素 | 説明 |
|---|---|
|
元に戻す |
キャンバスの最後のアクションを元に戻します([Ctrl]+[Z])。 |
|
やり直し |
キャンバスの最後のアクションを再実行します([Ctrl]+[Y])。 |
|
切取り |
選択したプロセッサを切り取ります([Ctrl]+[X])。 |
|
コピー |
選択したプロセッサをコピーします([Ctrl]+[C])。 |
|
貼付け |
選択したプロセッサを貼り付けます([Ctrl]+[V])。 |
|
削除 |
選択したプロセッサを削除します([Delete])。 |
|
名前変更 |
選択したオブジェクト名を変更します([F2])。 |
|
すべて選択 |
アクティブなペインのすべての項目を選択します([Ctrl]+[A])。 |
|
プリファレンス... |
プロセッサの進捗状況レポート、Excelへのエクスポート結果およびキャンバスのプリファレンスを設定します。 |
表1-3 「ビュー」メニュー
| 要素 | 説明 |
|---|---|
|
ズーム・イン |
キャンバス上でズーム・インします。 |
|
ズーム・アウト |
キャンバス上でズーム・アウトします。 |
|
プロジェクト・ブラウザ |
プロジェクト・ブラウザを表示または非表示にします。 |
|
ツール・パレット |
ツール・パレットを表示または非表示にします。 |
|
結果ブラウザ |
結果ブラウザを表示または非表示にします。 |
|
タスクの進捗 |
タスク・ウィンドウを表示または非表示にします。 |
|
キャンバスの概要 |
「キャンバスの概要」を表示または非表示にします。 |
|
サーバー・コンソール |
サーバー・コンソール・アプリケーションを開きます。 |
|
構成分析 |
構成分析アプリケーションを開きます。 |
|
Webサービス・テスター |
Webサービス・テスター・アプリケーションを開きます。 |
|
スケジュール済ジョブ |
サーバー上のスケジュール済ジョブを表示します。 |
|
イベント・ログ |
イベント・ログを表示します。 |
ツールバーを使用すると、EDQの複数の一般的な機能に簡単にアクセスできます。ツールバー上の各アイコンは、これらの一般的な機能を表します。次の図は、ディレクタのツールバーを示しています。

次の表に、ツールバーのアイコンの説明を示します。
表1-5 ツールバーのアイコン
| ツールバー・アイコン | 説明 |
|---|---|
 |
キャンバスで現在選択しているプロセスを保存します。 |
 |
キャンバスで開いているすべてのプロセスへの変更を保存します。 |
 |
現在のキャンバスを印刷します。 |
 |
キャンバスの最後のアクションを元に戻します。「元に戻す」ボタンを繰り返し使用して、多くのアクションを元に戻すことができます。 |
 |
キャンバスの最後のアクションをやり直します。「やり直し」ボタンを繰り返し使用して、多くのアクションをやり直すことができます。 |
|
|
異なるプロセスに貼り付けるために、キャンバスで選択した1つ以上のアイテムをクリップボードに切り取ります。 |
|
|
別の場所に貼り付けるために、選択した1つ以上のアイテムをクリップボードにコピーします。何が選択されているかに応じて、次の3つのコピー操作を使用できます。
|
|
|
現在選択されている1つ以上のアイテムを貼り付けます。クリップボードに何があるかに応じて、次の3つの貼付け操作を使用できます。
|
|
|
プロジェクト・ブラウザ、キャンバス、結果ブラウザおよびツール・パレットを含め、すべてのパネルをディレクタ・ユーザー・インタフェースに表示します。 |
|
|
キャンバスおよびツール・パレットのみを表示します。 |
|
|
接続されたサーバーで実行するようにスケジュールされているジョブのリストを示す、「スケジュール済ジョブ」ウィンドウを起動します。 |
|
|
接続されたサーバー上の完了したジョブ、タスクおよびシステム・タスクのリストを示す、「イベント・ログ」ウィンドウを起動します。 詳細は、「イベント・ログ」セクションを参照してください。 |
ツールバーのアイコンにカーソルを置くと使用できるツールチップにも、機能の簡単な説明が表示されます。
問題通知には、接続しているサーバーでユーザーに現在割り当てられている未解決の問題数が表示されます。
問題通知をクリックすると、問題マネージャが起動して、ユーザーに割り当てられている問題の詳細が表示されます。
プロジェクト・ブラウザを使用すると、EDQサーバーとその中に格納されているプロジェクトを参照できます。
プロジェクト
参照データ
データ・ストア
公開されたプロセッサ
イメージ
プロジェクト・ブラウザ内のほとんどの項目は、ドラッグ・アンド・ドロップするか、コピー([Ctrl]+[C])および貼付け([Ctrl]+[V])を使用して、新規プロジェクトまたは他のEDQサーバーにコピーできます。
新規EDQサーバーに接続したり、パッケージ・ファイルを開くには、プロジェクト・ブラウザの空白領域を右クリックします。
プロジェクト・ブラウザ・オブジェクトの状態
プロジェクト・ブラウザのオブジェクトには、その状態に基づいて異なるアイコンが重なって表示されます。緑色の再生アイコンはオブジェクトが実行中であることを示し、黄色の停止アイコンはオブジェクトの実行が取り消されたことを示し、赤色の警告アイコンはオブジェクトの実行の結果がエラーであったことを示します。
次の状態があります。
標準
実行中
取消済
エラー
ロックには、2つのタイプがあります。赤色の下向き三角形は、オブジェクトがロックされていて開くことができないことを示します(多くの場合、別のユーザーが編集のために開いているため)。青色の点は、オブジェクトが読取り専用であることを示します(多くの場合、現在ジョブで使用されていて、ジョブの論理を保存するために編集できないため)。
ロック状態を次に示します。
ロック(オブジェクトの表示不可)
読取り専用(オブジェクトは表示可能だが編集不可)
キャンバスは、プロセスを開く場所で、EDQを使用してデータ品質プロセスを設計する場所です。
複数のプロセスをキャンバスに同時に開くことができます。
個々のプロセスを閉じるには、右クリックして「閉じる」を選択するか、キャンバスの右上にある「閉じる」プロセス・アイコンをクリックします。
主要なツールバー機能のほとんどは、キャンバスでも使用できます。
キャンバス上のプロセスは、その状態に基づいて異なる表示になる場合があることに注意してください。「プロセスの状態」を参照してください。
プロセス内のプロセッサもその状態に基づいて表示が変化します。「プロセッサの状態」を参照してください。
実行するプロセスがキャンバスに開いている場合は、プロセス内の各プロセッサの進行状況を表示して、プロセスの進行状況全体を監視できます。それ以外の場合は、タスク・ウィンドウで進行状況を監視できます。
次の図に示すように、キャンバス・ツールバーはキャンバスの上部にあります。

次の表に、キャンバス・ツールバーのアイコンの説明を示します。
表1-6 キャンバス・ツールバーのアイコン
| アイコン | アイコン名 | 説明 |
|---|---|---|
|
|
実行 |
選択したプロセスを、その現在の実行プリファレンスを使用して実行します |
|
|
実行プリファレンス |
選択したプロセスの実行プリファレンスを設定します |
|
|
属性検索 |
属性の元プロセッサの検索を実行します |
|
|
クリア |
属性検索をクリアします |
|
|
グループ |
選択したプロセッサをグループ化します |
|
|
グループ解除 |
選択したグループをグループ解除します |
|
|
プロセッサの作成 |
選択したプロセッサを新しいプロセッサにします |
|
|
公開プロセッサ |
選択したプロセッサを公開します |
|
|
キャンバス・ノートの追加 |
キャンバスにノートを追加します |
|
|
外部化 |
実行時にEDQサーバー・コンソールのユーザー、またはEDQのコマンドライン・インタフェースを使用してEDQを呼び出す外部アプリケーションによって上書きされるような構成設定を公開することで、EDQプロセッサ、ジョブ、スナップショット、外部タスク、またはデータ・ストアのエクスポートの外部化を許可します。ジョブを外部化する方法の詳細は、「ジョブの外部化」を参照してください。 EDQを外部システムと統合する方法の詳細は、 Fusion Middleware Enterprise Data Qualityと外部システムの統合を参照してください。 |
|
|
公開された結果ビュー |
プロセスの公開された結果ビューのリストを表示し、関連するプロセッサにリンクすることもできます。 |
|
|
上揃え |
選択したプロセッサをキャンバスの上部に揃えます。 |
|
|
水平方向の中央揃え |
選択したプロセッサをキャンバスの中央に水平方向に揃えます。 |
|
|
下揃え |
選択したプロセッサをキャンバス下部に揃えます。 |
|
|
水平方向の間隔 |
選択したプロセッサを間に水平方向の間隔が生じるように配置します。 |
|
|
左揃え |
選択したプロセッサをキャンバスの左側に揃えます |
|
|
垂直方向の中央揃え |
選択したプロセッサをキャンバスの中央に垂直方向に揃えます。 |
|
|
右揃え |
選択したプロセッサをキャンバスの右側に揃えます |
|
|
垂直方向の間隔 |
選択したプロセッサを間に垂直方向の間隔が生じるように配置します。 |
|
|
ズーム・アウト |
選択されたプロセスをズーム・アウトします。 |
|
|
ズーム・イン |
選択されたプロセスをズーム・インします。 |
キャンバスを右クリックすると、キャンバス内で迅速にタスクを行うためのオプションがある、コンテキスト・メニューが表示されます。これらのオプションの一部は、キャンバス・ツールバーのオプションと重複しています。
次の表で、これらのメニュー・オプションについて説明します。
| メニュー・オプション | 説明 |
|---|---|
| 構成 | 選択したプロセッサの構成ダイアログ・ボックスを開きます |
| 開く | プロセス・キャンバスで、公開されたプロセッサを開くことができます。公開されたプロセッサが選択されている場合のみ有効です。
ジョブ・キャンバスで、プロセスを開くことができます。プロセス・タスクが選択されている場合のみ有効です。 |
| 名前変更 | キャンバス上で選択したプロセスまたはジョブの名前を変更します |
| グループ | 選択したプロセッサをグループ化します |
| グループ解除 | 選択したプロセッサをグループ解除します |
| 切取り | 選択したプロセッサを異なる場所または新しいプロセスに貼り付けるために切り取ります |
| コピー | 選択したプロセッサを異なる場所または新しいプロセスに貼り付けるためにコピーします |
| 貼付け | 選択したプロセッサを貼り付けます |
| 削除 | 選択したプロセッサを削除します |
| プロセッサの検索 | キャンバスのプロセッサを検索するために、キャンバス下部に検索バーを開きます |
| 無効なプロセッサの検索 | キャンバス上に多くのプロセッサがある場合、問題の検出をサポートします。このオプションは、そのキャンバスで1つ以上のプロセッサにエラーがある場合にのみ使用できます。 |
| 属性検索 | 属性の元プロセッサの検索を実行します |
| クリア | 属性検索をクリアします |
| キャンバス・ノートの追加 | キャンバスにノートを追加します |
| プロセッサの作成 | 選択したプロセッサを新しいプロセッサに作成します |
| 公開プロセッサ | 選択したプロセッサを公開します |
| 参照プロセッサへのリンクの削除 | 参照公開済プロセッサのインスタンスをその参照バージョンからデタッチします
詳細は、「参照公開済プロセッサ」を参照してください。 |
| 外部化 | 実行時にEDQサーバー・コンソールのユーザー、またはEDQのコマンドライン・インタフェースを使用してEDQを呼び出す外部アプリケーションによって上書きされるような構成設定を公開することで、EDQプロセッサ、ジョブ、スナップショット、外部タスク、またはデータ・ストアのエクスポートの外部化を許可します。ジョブを外部化する方法の詳細は、「ジョブの外部化」を参照してください
EDQを外部システムと統合する方法の詳細は、 Fusion Middleware Enterprise Data Qualityと外部システムの統合を参照してください。 |
| 公開された結果ビュー | プロセスの公開された結果ビューのリストを、関連プロセッサへのリンク機能とともに表示します |
| ヘルプの格納場所の設定 | これは、内部開発で使用されます。プロセッサは、サーバーにインストールされている追加のヘルプ・ページを持つことができます。指定されたパスは、EDQがインストールされているアプリケーション・サーバー上の場所への相対パスです。 |
| 左揃え | 選択したプロセッサをキャンバスの左側に揃えます |
| 垂直方向の中央揃え | 選択したプロセッサをキャンバスの中央に垂直方向に揃えます |
| 右揃え | 選択したプロセッサをキャンバスの右側に揃えます |
| 垂直方向の間隔 | 選択したプロセッサを間に垂直方向の間隔が生じるように配置します。 |
| 上揃え | 選択したプロセッサをキャンバスの上部に揃えます。 |
| 水平方向の中央揃え | 選択したプロセッサをキャンバスの中央に水平方向に揃えます |
| 下揃え | 選択したプロセッサをキャンバス下部に揃えます。 |
| 水平方向の間隔 | 選択したプロセッサを間に水平方向の間隔が生じるように配置します |
| ヘルプの添付 | プロセッサが公開されている場合、zipファイルをプロセッサに添付して含めることができます。プロセッサにヘルプが添付されています。公開されたプロセッサの詳細は、「公開されたプロセッサ」を参照してください。
プロセッサにヘルプが添付されている場合、ユーザーはプロセッサを選択して[F1]を押して、ヘルプにアクセスできます。公開されたプロセッサのヘルプ・ファイルは、製品に付属する標準のOEDQオンライン・ヘルプには統合されていないため、索引には表示されておらず、検索で見つけることはできません。 |
| 結果を新規ウィンドウで表示 | プロセッサを実行した後に表示される結果を新しいウィンドウで表示します |
ツール・パレットでは、EDQでのプロジェクトの作業時に使用できるすべてのプロセッサのリストが提供されます。
プロセッサは、プロセッサ・ファミリ別にリストされます。
プロセスの定義でプロセッサを使用するには、ツール・パレットから開いているプロセスにドラッグ・アンド・ドロップします。
次に、プロセッサの入力を接続して、そのプロセスで使用されるように構成できます。また、プロセッサを探すには、ツール・パレットの下部にある検索ボックスを使用して検索を実行します。これにより、入力したテキストを使用してプロセッサをすばやく検索できます。たとえば、名前に「length」という単語を含むすべてのプロセッサを探すには、検索ボックスに「length」と入力します。
「概要」ペインは、キャンバス上に全体を表示できない大規模プロセスのナビゲーションを支援します。
「概要」ペインには、プロセス全体のサムネイル・ビューが表示され、重なって表示される矩形によってキャンバス上に現在表示されている領域が示されます。
プロセス内をすばやく移動するには、調査する領域に矩形をドラッグします。キャンバスは囲まれている領域に自動的に移動します。
タスク・ウィンドウを使用すると、ジョブ、プロセスおよびスナップショットを含む、接続されているすべてのサーバー上で現在実行されているすべてのタスクの進行状況を表示できます。タスクはサーバー別にグループ化され、オーバーレイを使用してタスクの状態が示されます。
タスク・ウィンドウのジョブを展開すると、そのジョブに関連するフェーズおよびプロセスの詳細を表示できます。
タスクを右クリックすると、選択したタスクで使用可能なオプションを含むコンテキスト依存メニューが表示されます。
実行中のタスクを取り消すことができます。エラーがあるタスクを開いたり、編集することができます。エラーを表示したり、消去することができます。「すべてのエラーのクリア」オプションを選択すると、タスク・ウィンドウからすべてのエラー・タスクが削除されます。
結果ブラウザは、EDQによる処理結果を対話型の方法で参照できるようにすることで、ユーザーがデータを理解しやすいように設計されています。プロセス実行でリポジトリを使用している場合は、結果ブラウザで統計を有用なデータのビューまでドリルダウンでき、データを検証および変換するためのビジネス・ルールの形成を支援するように設計されています。
結果ブラウザには、使用可能な一般的な機能がいくつかあります。これらの機能には、結果ブラウザ・ウィンドウの上部にあるツールバーからアクセスします。
次のシステムレベル参照データのセットがEDQで提供されています。
|
注意: EDQに付属している参照データのリストおよびマップは、名前の前にアスタリスクが付けられており、ユーザーが作成する参照データと区別されます。 |
これらのリストおよびマップの多くは、デフォルトでプロセッサにより使用されます。これらは変更できますが(プロジェクトで使用して変更し、システム・ライブラリにコピーする)、EDQのアップグレード時に上書きされないように、独自の要求に合せて異なる名前で新しいリストおよびマップを作成することをお薦めします。
また、オラクル社は、個別のデータ・タイプ用および個別の問題解決用の参照データ・パック、たとえば既知の電話番号の接頭辞のリスト、名前と住所のリスト、およびURLなどの構造化データをチェックする正規表現も提供しています。これらのパックは、EDQの拡張パックとして提供されています。
| 参照データ名 | 目的 |
|---|---|
| *基本のトークン化マップ | 「解析」プロセッサ内のデータのトークン化に使用される参照データ・セットで、限定されたキャラクタ・セットのみをカバーします。下位互換性を目的として維持されています。 |
| *文字パターン・マップ | 「パターン」プロセッサ内のパターンの生成に使用される参照データ・セットで、限定されたキャラクタ・セットのみをカバーします。下位互換性を目的として維持されています。 |
| *日付書式 | 日付を認識するための標準書式のリストです。 |
| *区切り文字 | 一般的に使用される区切り文字のリストです。 |
| *電子メール正規表現 | 電子メール・アドレスの構文のチェックに使用されるデフォルトの正規表現です。 |
| 非データ処理 | 「データなし」文字の標準EDQセットです。 |
| *ノイズ文字 | 一般的なノイズ文字のリストです。 |
| *バンドの番号付け | 数値プロファイラのバンドの番号付けセットの例です。 |
| *数値書式 | 数値を認識するための標準書式のリストです。 |
| *アクセント記号付きの文字の標準化 | アクセント記号付きの文字をアクセント記号なしの同等の文字に標準化するために使用される文字マップです。 |
| *イギリスの郵便番号の正規表現 | イギリスの郵便番号の構文のチェックに使用されるデフォルトの正規表現です。 |
| *Unicodeベースのトークン化マップ | 「解析」プロセッサ内のデータのトークン化に使用されるデフォルト参照データ・セットで、Unicode範囲全体をカバーします。 |
| *Unicode文字パターン・マップ | パターン・プロセッサ内のパターンの生成に使用されるデフォルト参照データ・セットで、Unicode範囲全体をカバーします。 |
「プロファイルの実行」は、ジョブの実行時に、外部化されたオプション用の複数の上書き構成設定を指定するオプションのテンプレートです。個々の上書きを引数として個別に指定するのではなく、複数の構成上書きを保存し再使用する便利な方法を提供します。IEは外部化されたオプションに推奨されていないことに注意してください。
「プロファイルの実行」は、コマンドライン・インタフェースからrunopsjobを使用するか、サーバー・コンソールUIのいずれかでジョブを実行する際に使用できます。
「プロファイルの実行」は、任意のテキスト・エディタを使用して作成できます。これには、.properties接頭辞を付けて、EDQインストールのoedq_local_home/runprofilesフォルダに保存する必要があります。
通常、本番デプロイメントで構成を上書きする方法に関する知識のある上級ユーザーによって設定されます。これは、oedq_local_homeディレクトリへのアクセス権を持つユーザーが作成または編集を直接行うか、oedq_local_home/runprofilesディレクトリにFTPタスクによって転送される場合があります。Oracle Watchlist Screeningなど、EDQを使用して構築されたソリューションには、事前パッケージ済ジョブ内の外部化された構成オプションの上書きに適した事前定義済「プロファイルの実行」を複数含めることができます。
「プロファイルの実行」を作成するためのテンプレートは、template.propertiesと呼ばれ、[Installpath]/oedq_local_home/run profiles ディレクトリにあります。テンプレートには、各タイプの上書きの完全な手順および例が含まれます。
「プロファイルの実行」ファイルの例を次に示します。
######### Real-time Setup ########### # Globally turns on/off real-time screening phase.Start\ Real-time\ Screening.enabled = Y # Control single real-time screening types phase.Real-time\ Screening.process.Individual\ Real-time\ Screening.san_enabled = Y phase.Real-time\ Screening.process.Individual\ Real-time\ Screening.pep_enabled = Y phase.Real-time\ Screening.process.Individual\ Real-time\ Screening.edd_enabled = Y phase.Real-time\ Screening.process.Entity\ Real-time\ Screening.san_enabled = Y phase.Real-time\ Screening.process.Entity\ Real-time\ Screening.pep_enabled = Y phase.Real-time\ Screening.process.Entity\ Real-time\ Screening.edd_enabled = Y ########## Batch Setup ############## # Globally turns on/off batch screening phase.Start\ Batch\ Screening.enabled = Y # Control single batch screening types phase.Match\ Individuals\ Batch\ SAN.enabled = Y phase.Match\ Individuals\ Batch\ PEP.enabled = Y phase.Match\ Individuals\ Batch\ EDD.enabled = Y phase.Match\ Entities\ Batch\ SAN.enabled = Y phase.Match\ Entities\ Batch\ PEP.enabled = Y phase.Match\ Entities\ Batch\ EDD.enabled = Y ######## Screening Receipt ########## phase.Real-time\ Screening.process.Individual\ Real-time\ Screening.receipt_prefix = OWS phase.Real-time\ Screening.process.Individual\ Real-time\ Screening.receipt_suffix = IND phase.Real-time\ Screening.process.Entity\ Real-time\ Screening.receipt_prefix = OWS phase.Real-time\ Screening.process.Entity\ Real-time\ Screening.receipt_suffix = ENT
サーバー・コンソールは、組織の一般的な操作ユーザー(ディレクタUIのフル機能へのアクセス権が不要であるか、持つことができないユーザー)が使用するように設計されています。
アプリケーションは、1つ以上のEDQサーバーに接続できます。詳細は、「サーバー接続の管理」を参照してください。
機能領域
サーバー・コンソールは、次の機能領域に分かれています。
スケジューラ - プロンプトの指示に従って、またはスケジュールに応じて、実行するジョブを選択するために使用します。
現在のタスク - ディレクタUIで開始されたものを含め、選択したサーバーで現在実行されているすべてのタスクを表示します。
イベント・ログ - ディレクタUIで実行されたものを含め、サーバー上のすべてのイベント(タスクおよびジョブ)の履歴ビュー。
結果 - サーバー・コンソールUIから実行されたすべてのジョブのステージング済データおよびステージングの結果のビュー、および実行ラベル付きでコマンドラインから実行されたジョブの結果を表示します。
ユーザー・プロファイル
サーバー・コンソールのすべてのユーザーに、これらすべての機能領域へのアクセスが必要なわけではありません。一般的なプロファイルは次のとおりです。
ジョブ・ユーザー - ジョブのみを実行します。スケジューラおよび現在のタスクへのアクセスが必要です。
品質スーパーバイザ - ジョブの結果を確認し、問題を分析します。現在のタスク、イベント・ログおよび結果へのアクセスが必要です。
サーバー・コンソールの「サーバー」メニューで、サーバーへの接続を管理します。
起動時に、サーバー・コンソールは起動元のサーバーに接続されます。一度に複数のサーバーに接続でき、これらはサーバー・コンソール・ウィンドウの各タブに分けられます。
サーバーへの接続
サーバーに接続するには、次のようにします。
「サーバー」メニューで「接続」をクリックします。
「接続」をクリックします。「ログイン」ダイアログが表示されます。
ログイン資格証明を入力して、「OK」をクリックします。
サーバーからの切断
サーバーから切断するには、次のようにします。
現在適切なサーバーが表示されていることを確認します(関連するタブを選択)。
「サーバー」メニューで「切断」をクリックします。
「切断」ダイアログで「OK」をクリックします。
新しいサーバーの追加
新規サーバーを追加するには、次のようにします。
「サーバー」メニューで「新規サーバー」をクリックします。「サーバーの追加」ダイアログが表示されます。
次に示すように、フィールドに入力します。
「OK」をクリックしてサーバーを追加します。
サーバーの編集
追加したサーバーの詳細を編集できます。
|
注意: サーバー・コンソールの起動元のサーバーの詳細は編集できません。 |
サーバーを編集するには、次のようにします。
必要なサーバーを選択します。
サーバーを切断します(前述の「サーバーからの切断」を参照)。
「サーバー」メニューで「サーバーの編集」をクリックします。
「サーバーの編集」ダイアログで、必要に応じてサーバーの詳細を変更します。フィールドは、前述の「サーバーの追加」ダイアログのフィールドと同一です。
「OK」をクリックして変更を保存します。
サーバーの削除
サーバーを削除するには、次のようにします。
|
注意: サーバー・コンソールの起動元のサーバーの詳細は削除できません。 |
必要なサーバーを選択します。
「サーバー」メニューで「サーバーの削除」をクリックします。
「削除」ダイアログで「OK」をクリックします。
スケジューラ・ウィンドウを使用して、ジョブの1回かぎりのインスタンスを実行し、ジョブ・スケジュールを作成または編集します。
ウィンドウは3つの領域に分かれています。
ジョブ - ユーザーが実行およびスケジュールを許可されているジョブをリストします(複数ある場合はサーバー別に)。
ジョブ詳細 - 選択したジョブ(複数可)の詳細を表示します。
スケジュール - スケジュールされているジョブをリストします。
1回かぎりのジョブの実行
1回かぎりのジョブを実行するには:
「ジョブ」領域で、必要なジョブを見つけてダブルクリックします。
「ジョブ詳細」領域で「実行」ボタンをクリックします。「実行」ダイアログが表示されます。
使用可能な場合、必要な実行プロファイルを選択して、ジョブの外部化された構成オプションの設定を上書きします。
ジョブのステージング済データの結果を保存する実行ラベルを入力します。新しいラベルを入力するか、ドロップダウン・リストから選択します。注意: ドロップダウン・リストには、最後に使用した100の実行ラベルが含まれます。
「OK」をクリックしてジョブを実行します。
ジョブのスケジュール
「スケジュール」ダイアログを使用して、ジョブのスケジュールを作成および編集します。
新規スケジュールの作成
新規スケジュールを作成するには、次のようにします。
「ジョブ」領域で、必要なジョブを見つけてダブルクリックします。
「ジョブ詳細」領域で「スケジュール」ボタンをクリックします。「スケジュール」ダイアログが表示されます。
スケジュール・タイプを選択し、日時の詳細を入力します(次の「スケジュール・タイプ」を参照)。
必要に応じて、実行プロファイルを選択します。
新しい実行ラベルを入力するか、ドロップダウン・リストから選択します。
「OK」をクリックして保存します。
スケジュールの編集
スケジュールを編集するには:
「スケジュール」領域で、必要なジョブを見つけてダブルクリックします。
「ジョブ詳細」領域で「スケジュール」ボタンをクリックします。「スケジュール」ダイアログが表示されます。
スケジュール・タイプを選択し、日時の詳細を入力します(次の「スケジュール・タイプ」を参照)。
必要に応じて、実行プロファイルを選択します。
新しい実行ラベルを入力するか、ドロップダウン・リストから選択します。
「OK」をクリックして保存します。
スケジュールの削除
スケジュールを削除するには:
「スケジュール」領域で、必要なスケジュールを右クリックします。
「削除」を選択します。
「削除」ダイアログで、「はい」をクリックして削除するか、「いいえ」をクリックしてスケジュールを保持します。
スケジュール・タイプ
使用可能なスケジュール・タイプが5つあります。
1回
このオプションでは、指定した日時に1回のみジョブを実行するように設定します。
「スケジュール」ダイアログで「1回」を選択します。
必要な日時をこのジョブを次の日時に実行フィールドに入力します。次のいずれかです。
フィールドの右にある上下の矢印をクリックして、日付を変更します。
ウィンドウの右にあるカレンダを使用して、日、月または年を変更します。
次の形式で、フィールドを手動で編集します: dd-MMM-yyyy hh:mm。
日次
このオプションでは、毎日または特定日数の間隔で、1日に1回ジョブを実行するようにスケジュールします(例: 3日ごとにまたは10日ごとに)。
「スケジュール」ダイアログで「日」を選択します。
「間隔」フィールドに、スケジュールの頻度を入力します。たとえば、1ではジョブを毎日実行し、3では3日ごとにジョブを実行します。
「サーバー時間」フィールドに、ジョブを実行する時刻を24時間形式で入力します。
「開始日」フィールドに、スケジュールの最初の日の日付を入力します。それには、画面右にあるカレンダから必要な日付を選択するか、dd-MMM-yyyy形式で手動でフィールドを編集します。
週次
このオプションでは、週単位でジョブをスケジュールします。
「スケジュール」ダイアログで「週」を選択します。
「毎」領域で、ジョブを実行する各曜日を選択します。任意の数の曜日の組合せを選択できます。
「サーバー時間」フィールドで、ジョブを実行する時刻を24時間形式で選択します。
「開始日」フィールドに、スケジュールの最初の日の日付を入力します。それには、画面右にあるカレンダから必要な日付を選択するか、dd-MMM-yyyy形式で手動でフィールドを編集します。または、週の最初の指定曜日にジョブを実行するには、チェック・ボックスを選択解除して「開始日」フィールドを無効にします。
月次
このオプションでは、月の特定日にジョブをスケジュールします。
「スケジュール」ダイアログで「月」を選択します。
「日付」ドロップダウン・リストで月の日付を選択します。
「サーバー時間」フィールドで、ジョブを実行する時刻を24時間形式で選択します。
デフォルトでは、スケジュールに週末が含まれています。つまり、選択した日付が週末に当たる場合、ジョブはスケジュールどおりに実行されます。週末を除外するには、「週末を除外」フィールドを選択します。
「開始日」フィールドに、スケジュールの最初の日の日付を入力します。それには、画面右にあるカレンダから必要な日付を選択するか、dd-MMM-yyyy形式で手動でフィールドを編集します。または、月の最初の指定日にジョブを実行するには、チェック・ボックスを選択解除して「開始日」フィールドを無効にします。
起動
このオプションでは、サーバーの起動時に選択したジョブを実行するように設定します。
実行ラベルは、同じジョブが別のデータ・セットに対して、実行プロファイルを使用して別の構成オプションが指定されて、または単に別の時間に(たとえば、月次スケジュールで)複数回実行されている場合に、結果を別個に保存するために使用されます。
実行ラベルは、サーバー・コンソール・アプリケーションで使用されます。ジョブのステージング済データの結果は書き出されて実行ラベルによって保存され、サーバー・コンソールのユーザーは結果ウィンドウで結果の間を移動できます。
サーバー・コンソールUIでジョブを実行する際は、実行ラベルを指定する必要があります。前に使用した実行ラベルを同じジョブで再利用する場合、以前に書き出されたそのジョブの結果と実行ラベルの組合せは上書きされます。
ジョブをディレクタUIで対話形式で実行する場合、実行ラベルは使用されません。これらの対話形式で実行されるジョブは、本番ではなくプロジェクト設計中およびテスト中に実行されると推定されるため、結果はサーバー・コンソールUIでは表示されません。
これは、実行ラベルを使用しないでディレクタから実行した場合にジョブの結果ブックのエクスポートで期待した結果が得られたにもかかわらず、同じジョブを実行ラベルを使用して実行した場合、実行ラベルを使用すると結果ブック・データが生成されないため、結果がエクスポートされないということでもあります。実行ラベルを使用した場合の表示されない結果には、ドリルダウンや結果ブックなどが含まれています。
現在のタスク・ウィンドウには、ディレクタUIで開始されたものを含め、選択したサーバーで現在実行されているすべてのタスクが表示されます。
次の2つの領域に分かれています。
「現在のタスク」領域
タスク・フィルタ
「現在のタスク」領域
この領域には、進行中のタスクの詳細が表示されます。「+」ボタンを使用して各グループを展開することで、これらのタスクにドリルダウンしてステータスや進捗を確認できます。
タスク・フィルタ
この領域では、選択したサーバーで現在実行されているタスクの詳細をフィルタリングします。
この領域の要素は次のとおりです。
表1-8 「タスク・フィルタ」の要素
| 要素 | 説明 |
|---|---|
|
表示の分類 |
「現在のタスク」領域のコンテンツを、ジョブ(デフォルト・オプション)または実行ラベルでソートします。 |
|
自動拡張 |
「現在のタスク」領域にリストされている内容を自動的に拡張するには、このボックスを選択します。このボックスは、デフォルトでは選択解除されています。 |
|
プロジェクト |
実行されているタスクのプロジェクト。 |
|
ジョブ |
実行されているジョブの名前。 |
|
ラベル |
実行されているジョブのラベル。 |
現在のタスクのポップアップ
このダイアログ・ボックスを使用して、接続されているすべてのサーバーで現在実行されているタスクを表示します。
このポップアップを開くには、「ビュー」 > 「現在のタスクのポップアップ」をクリックします。
現在のタスク・ウィンドウには、ディレクタUIを使用して対話形式で実行されているタスクやジョブ、およびコマンドライン・インタフェースを使用して外部で開始されたジョブを含め、接続されているすべてのサーバーのすべてのアクティビティが表示されます。
イベント・ログは、EDQサーバーで実行したすべてのジョブおよびタスクの完全な履歴を提供します。
デフォルトでは、すべてのタイプの最近完了したイベントがログに表示されます。ただし、複数の基準を使用してイベントをフィルタリングし、確認する必要があるイベントを表示できます。最上位レベルのビューに表示される列を変更して、イベント・ログをカスタマイズすることもできます。イベントをダブルクリックすると、入手可能な詳細情報が表示されます。
表示されたイベントのビューは、必要に応じて任意の列でソートできます。ただし、デフォルトでは古いイベントは表示されないため、イベントが表示されるように、ソートする前にフィルタを適用する必要があります。
ログに記録されるイベント
ジョブ、タスクまたはシステム・タスクが開始または終了すると、イベント・ログにイベントが追加されます。
タスクは、ジョブの一部として、またはディレクタUIを使用して個別に開始されます。
次のタイプのタスクがログ記録されます。
プロセス
スナップショット
エクスポート
結果のエクスポート
外部タスク
ファイルのダウンロード
次のタイプのシステム・タスクがログ記録されます。
OFB - 参照用に最適化することを意味するシステム・タスクであり、データを索引付けしてデータをソートおよびフィルタリングできるようにすることで、書き出された結果を結果ブラウザで参照するために最適化します。OFBタスクは通常、スナップショットまたはプロセス・タスクが実行された直後に実行されますが、EDQクライアントを使用して手動で開始することもできます。それには、一連のステージング済データを右クリックして「ソート/フィルタの有効化」を選択するか、最適化されていない列でソートまたはフィルタリングを試みて、ただちに最適化を選択します。
DASHBOARD - 結果をダッシュボードに公開するシステム・タスク。これは、プロセス・タスクが実行された直後に、「ダッシュボードに公開」オプションをオンにして実行されます。
サーバーの選択
ディレクタUIが複数のサーバーに接続されている場合、左上の「サーバー」ドロップダウン・フィールドを使用してサーバー間を切り替えることができます。
サーバー・コンソールUIが複数のサーバーに接続されている場合、ウィンドウ上部のタブ・リストで必要なサーバーを選択します。
イベントのフィルタリング
次のフィルタリング・イベントを使用できます。
クイック・フィルタ
クイック・フィルタ・オプションは、「イベント・タイプ」、「ステータス」および「タスク・タイプ」でのフィルタリングに使用できます。イベントをフィルタリングするには、フィルタに含める値を選択し(複数の項目を選択するには、[Ctrl]キーを押しながら選択)、画面左下にある「フィルタの実行」ボタンをクリックします。
フリー・テキスト・フィルタ
詳細なフリー・テキスト・フィルタ・オプションは、「プロジェクト名」、「ジョブ名」、「タスク名」および「ユーザー名」でのフィルタリングに使用できます。これらはフリー・テキストであるため、フィールドに名前の一部を入力できます。これらの任意のフィールドに名前の一部を入力すると、オブジェクトにその名前の一部が含まれる場合は、そのオブジェクトが表示されます(一致では大文字と小文字が区別されます)。たとえば、ライブ・システムで稼働しているすべてのプロジェクトに「Live」という語を含む名前を指定する命名規則を使用する場合、ライブ・システムのすべてのイベントを表示できます。
|
注意: 「プロジェクト名」列は、デフォルトでは表示されません。表示されるようにビューを変更するには、左側にある「列の選択」ボタンをクリックして「プロジェクト名」ボックスを選択します。 |
日付/時間フィルタ
画面右側にあるフィルタの最終設定で、イベントのリストを日時でフィルタリングできます。特定の日付を簡単に指定できるように、日付ピッカーが用意されています。イベント・ログにアクセスしている際は、最新のイベントのみが表示されますが、必要に応じて、フィルタを適用して古いイベントを表示できます。
|
注意: イベントがEDQによって履歴から削除されることはありませんが、リポジトリに保存されているため、リポジトリ・データベースに構成されているカスタム・データベースレベルのアーカイブまたは削除ポリシーの影響を受けることがあります。 |
イベントは、開始時刻または終了時刻(あるいはその両方)でフィルタリングできます。たとえば、フィルタを適用して、2008年11月に完了したすべてのジョブおよびタスク(システム・タスクではない)を表示できます。
列の選択
イベント・ログに表示される列のセットを変更するには、「イベント・ログ」領域の左上にある「列選択」ボタンをクリックします。「列選択」ダイアログが表示されます。必要に応じて列を選択または選択解除し、「OK」をクリックして保存するか、「取消」をクリックして変更を破棄します。または、「デフォルト」をクリックしてデフォルト設定を復元します。
「重大度」はめったに使用されない列で、現在、正常に完了したタスクまたはジョブは50に設定され、エラーまたは警告が発生したタスクまたはジョブは100に設定されています。
イベントを開く
ダブルクリックしてイベントを開くと、入手可能な詳細が表示されます。
タスクを開くと、タスクの実行時に生成されたメッセージを示すタスク・ログが表示されます。
|
注意: メッセージはINFO、WARNINGまたはSEVEREに分類されます。INFOメッセージは情報提供を目的としており、問題を示すものではありません。WARNINGメッセージは、プロセス構成(またはデータ)で問題が発生していることを示すために生成されますが、これによってタスクがエラーになることはありません。SEVEREメッセージは、タスクのエラーに対して生成されます。 |
ジョブでは、ジョブに対して通知電子メールが構成されている場合、ジョブの完了イベントを開くと、Webブラウザに通知電子メールが表示されます。通知が設定されていないジョブには、詳細情報は保持されません。
イベント・ログからのデータのエクスポート
イベント・ログの表示可能データは、CSVファイルにエクスポートできます。これは、Oracleサポートに連絡した際に、サーバー上で何が実行されているかの詳細を要求された場合に便利です。
イベントの現在のビューをエクスポートするには、「CSVにエクスポート」をクリックします。これにより、CSVファイルを書き込むクライアントでブラウザが起動します。ファイルに名前を付けて「エクスポート」をクリックし、ファイルに書き込みます。
結果ウィンドウには、サーバー・コンソールUIから実行されたすべてのジョブのステージング済データおよびステージング結果のビュー、および実行ラベル付きでコマンドラインから実行されたジョブの結果が表示されます。
ウィンドウは「ジョブ履歴」領域と「結果ブラウザ」領域に分かれています。
ジョブ履歴
この領域には、ジョブ実行が日付順にリストされます。それぞれのプロジェクト、ジョブ、実行ラベルおよび終了時間が表示されます。
結果ブラウザ
この領域には、前述の「ジョブ履歴」領域で選択したジョブの詳細が表示されます。
結果ブラウザには、上部のボタンで使用できる各種の簡単なオプションがあります。ボタンの上にカーソルを置くと、機能が表示されます。
ただし、結果ブラウザには、あまり知られていない機能が他にもいくつかあります。
新規ウィンドウで開く
多くの場合、特定ジョブの結果を新しいウィンドウに開くと便利です。それには、「ジョブ履歴」領域でジョブを右クリックして「新規ウィンドウで開く」を選択します。
文字の表示
ときどき、結果ブラウザに見慣れない文字が表示されたり、全部表示するのが難しい非常に長いフィールドが出現することがあります。
たとえば、Unicode対応データストアからのデータを処理する場合、EDQクライアントにデータを画面上に正しく表示するための一部のフォントがインストールされていないことがあります(データはEDQサーバーによって正しく処理されます)。
この場合、文字または見慣れない文字を含む文字列を右クリックして「文字の表示」オプションを選択し、文字を調べられると便利です。たとえば、文字を正しく表示するために必要なフォントがクライアントにインストールされていない場合に、マルチバイト文字が選択されたUnicodeデータを文字プロファイラ・プロセッサが処理することがあります。このため、文字は2つの制御文字として表示されます。
文字を右クリックして「文字の表示」オプションを使用すると、Unicode仕様の文字の文字範囲が表示されます。
「文字の表示」オプションは、結果ブラウザに全部表示するのが難しい非常に長いフィールド(説明など)で作業する場合にも便利です。
完全列幅ボタンは、列の幅を広げて完全なデータを表示しますが、この場合、画面幅に表示するにはデータが多すぎます。詳細な説明フィールドを折り返されたテキストとして表示するには、表示する行を右クリックして「文字の表示」オプションを使用します。次に、画面右上の矢印をクリックして各値をテキスト領域に表示したり、画面下部の矢印を使用してレコードの間をスクロールできます。
列ヘッダーの選択
結果ブラウザで列ヘッダーをクリックすると、その列でデータがソートされます。ただし、列ヘッダーを[Ctrl]+クリック([Ctrl]キーを押しながらヘッダーをクリック)すると、結果ブラウザのその列に表示されている(ロードされた)データすべてを選択できます。これは、ロードされたすべての行をコピーしたり、それらを使用して右クリック・オプションで参照データを作成または追加する場合などに便利です。デフォルトでは、結果ブラウザでは100個のレコードしかロードされないため、列ヘッダーを選択する前に「データをすべてロード」ボタンを使用できます。
同じ方法で複数の列ヘッダーを選択できます。
結果のパージ
サーバー・コンソールで結果をパージするには、「ジョブ履歴」領域でレコードを右クリックします。
結果はプロジェクト、実行ラベルまたはジョブによってパージできます。
「結果パージ・ルール」ダイアログを使用して、サーバー・コンソールで特定の状況下で結果を自動的にパージするルールを設定できます。
このダイアログを開くには、「サーバー・コンソール」メニュー・バーで「ツール」 > 「パージ・ルール」を選択します。
ルールの追加
ルールを追加するには、次のようにします。
「結果パージ・ルール」ダイアログで「ルールの追加」ボタンをクリックします。「新規ルール」ダイアログが表示されます。
「有効」チェックボックスが、デフォルトで選択されています。作成した新規ルールをただちに有効にしない場合は、選択を解除します。
各フィールドに次の情報を入力します。
名前 - ルールの名前を入力します。このフィールドは必須です。
後で結果をパージします - 結果をパージするまでの時間数、日数、週数または月数を指定します。フリー・テキスト・フィールドに数値を入力し、ドロップダウン・リストから時間の単位を選択します。「なし」を選択して、ルール条件と一致する結果がパージされないようにすることもできます。このフィールドは必須です。
プロジェクト - 必要に応じて、ルールに特定のプロジェクトを選択します。
ジョブ - 必要に応じて、ルールに特定のジョブを選択します。
実行ラベル - 正確な実行ラベルを指定するか(入力するか、ドロップダウン・リストから選択して)、「Regex」フィールドに正規表現を入力して特定の語を含む実行ラベルを取得します。たとえば、正規表現.*test.*は、「test」という語を含むすべての実行ラベルを取得します。
「OK」をクリックして新規ルールを保存するか、「取消」をクリックして破棄します。
ルールの編集
ルールを編集するには:
ルールをダブルクリックするか、選択して「ルールの編集」ボタンをクリックします。ルールのすべての詳細を示すダイアログが表示されます。
必要に応じてフィールドを編集します。
「OK」をクリックして変更内容を保存するか、「取消」をクリックして破棄します。
ルールの有効化または無効化
ルールを有効または無効にするには、横にある「有効」チェック・ボックスを選択解除します。編集のためにルールが開かれているときにも、このチェック・ボックスを編集できます。
ルールの削除
ルールを削除するには、「結果パージ・ルール」で選択して「ルールの削除」ボタンをクリックします。
エラーが表示されてルールが削除された場合は、「OK」ではなく「取消」をクリックしてダイアログを閉じます。再び開くと、間違って削除されたルールが再び表示されます。
ルールの順序の設定
「結果パージ・ルール」ダイアログの右下に、ルールの順序を変更するための4つのボタンがあります。
ルールを移動するには、選択してから次を実行します。
ルールを一番上に移動ボタンをクリックして、リストの一番上に移動します。
「ルールを上に移動」ボタンをクリックして、リストの1つ上に移動します。
「ルールを下に移動」ボタンをクリックして、リストの1つ下に移動するか、
ルールを一番下に移動ボタンをクリックして、リストの一番下に移動します。
ダッシュボードには、結果の概要が指数、サマリーの形式で、またはルール別に表示されます。これらは、まとめて要素とも呼ばれます。詳細は、「ダッシュボード要素」のトピックを参照してください。
ダッシュボード管理を使用して、ダッシュボードへのユーザー・アクセスを制御し、指数、サマリーおよびルールを構成します。「マイ・ダッシュボード」ビューは、「指数」、「サマリー」、「ルール」の各領域に分かれています。
要素の名前をクリックして、「指数」や「サマリー」にドリルダウンできます。要素を選択して、グラフィカル・ビューの右にある「グラフ」アイコンをクリックすることもできます。
|
注意: ウィンドウのコンテンツは、表示しているユーザーの権限レベルによって異なります。各ルールの後に、そのルールが含まれるサマリーの名前が続きます。名前をクリックすると、そのサマリー内のすべてのルールが表示されます。 |
ビューのカスタマイズ
領域内で要素を移動するには、選択して、領域のツールバーで上矢印および下矢印をクリックします。
要素を削除するには、選択して、領域上部にあるバツ印をクリックします。
ビューへの指数またはサマリーの追加
まだ追加されていない指数またはサマリーがある場合、ウィンドウの左上に表示されたドロップダウン・ボックスで同じものを追加できます。
必要な指数またはサマリーを選択して、「追加」をクリックします。
ビューへのルールの追加
ビューにルールを追加するには:
サマリーをクリックします。サマリー内のルールの完全なリストが表示されます。
ルールを選択して、ピン・ボタンをクリックします。
必要に応じて、他のルールに対して繰り返します。
「マイ・ダッシュボード」ビューは要素で構成されており、各要素には要素の結果から導出されるステータスがあります。
ダッシュボード要素は、ユーザーがダッシュボードで監視できるデータ品質情報の明細項目です。ダッシュボード要素には、4つのタイプがあります。
指数 - 長期間追跡された、ルール結果の重み付けされたセットから導出された計算済の値。
サマリー - 多数のルール結果のステータスのサマリー
リアルタイム集計 - 指定した期間にわたるリアルタイム・ルール結果の集計
ルール結果 - EDQのプロセッサより公開された結果
指数、サマリーおよびリアルタイム集計は、ルール結果を集計するための3つの異なる方法であり、バッチまたはリアルタイムで生成されます。
索引
指数は、単一の数値を持つダッシュボード要素の1つのタイプであり、データ品質の多数の測定の集計結果を表します(ルール結果)。関連測定は、選択されたすべての測定で指数を形成するように重み付けされます。指数は、1つまたは複数のシステムで一定期間にわたってデータ品質を追跡するために、データ品質の傾向分析に使用されます。詳細は、「ダッシュボードの指数」のトピックを参照してください。
サマリー
サマリーはダッシュボード要素の1つのタイプであり、多数のルール結果を、各ステータス(赤、黄および緑)のルール数を示すサマリー・ビューに集計します。
サマリー・ダッシュボード要素は、EDQプロセスからルール結果が公開されるたびに直接作成されるか(この場合、サマリーはプロセスから公開されたすべてのルール結果を集計して作成されます)、ダッシュボード管理者が手動で構成できます。管理者によって構成される場合、サマリーでは、多数の異なるプロセス、および必要に応じて多数の異なるプロジェクトの結果を集計できます。
他のすべてのタイプのダッシュボード要素とは異なり、サマリーでは傾向分析はサポートされません。これは、サマリーを構成するルール結果が時の経過とともに変化し、様々な時期に公開されることがあるためです。
リアルタイム集計
リアルタイム集計はダッシュボード要素の1つのタイプであり、単一のリアルタイム・ルール結果というダッシュボード要素を、様々な(一般に長期の)期間の結果セットに集計します。リアルタイム・ルール結果は、間隔モードで実行されるプロセスによって公開されます(通常は継続的な実行プロセス)。間隔は定期的に書き込まれることがあるため、EDQユーザーは定期的に結果を確認できます(例: 毎時または100レコードごと)。ただし、エグゼクティブまたは他のユーザーが結果を監視するのは、日次または週次ベースの場合があります。この場合は、リアルタイム集計を構成して、基となるリアルタイム・ルール結果ではなく、この要素をユーザーが使用できるようにします。
ルール結果
ルール結果は、その結果をダッシュボードに公開するように構成されている、EDQプロセッサの結果を直接反映するダッシュボード要素です。このため、ルール結果は、最も詳細な(最下位レベル)タイプのダッシュボード要素です。
ルール結果は、定期的(バッチ・プロセスから公開)またはリアルタイム(間隔モードで実行されるリアルタイム・プロセスから公開)のいずれかです。ダッシュボード管理ウィンドウの「ダッシュボード要素」ペインに含まれる様々なタイプのルール結果は、次のとおりです。
定期的なルール結果
リアルタイム・ルール結果
ダッシュボード管理を使用すると、管理者は次を構成できます。
公開された結果にアクセスできるユーザー
公開された結果をサマリー、指数およびリアルタイム集計に集計する方法
ダッシュボードの各項目のステータスを計算する方法
ダッシュボードから項目を削除して、公開された項目の結果をパージすることもできます。
|
注意: ダッシュボードから項目を削除しても、以後、基となるプロセッサによる結果の公開が阻止されることはありません。「ダッシュボードに公開」を有効にして次回プロセスが実行されたときに、削除された項目はダッシュボードで再作成されます。 |
ダッシュボード管理で使用される用語および概念の詳細は、「ダッシュボード要素」を参照してください。
ダッシュボード管理へのアクセス
ダッシュボード管理にアクセスするには:
Launchpadから管理者としてログインするか、EDQでサーバーを右クリックして「ダッシュボードの表示」を選択して、ダッシュボードを開きます。
ダッシュボードのフロント・ページで「管理」ボタンをクリックします。
これにより、Java Webstartアプリケーションであるダッシュボード管理が起動します。
ダッシュボード管理のGUI
ダッシュボード管理のGUIでは、「ダッシュボード」と「デフォルトしきい値」の2つのビューを使用できます。これらは、左側の列に表示されます。
「ダッシュボード」ビューでは、公開されたすべての結果を管理できます。
「デフォルトしきい値」ビューでは、各タイプのダッシュボード要素のステータスを計算するデフォルトの方法を変更できます。必要に応じて、特定のダッシュボード要素のデフォルトしきい値を上書きできます。
「ダッシュボード管理」ダイアログの「ダッシュボード」ビューは、次の3つのペインに分かれています。
ダッシュボード要素 - 構成済集計など、その集計タイプごとに編成された、ダッシュボード要素の完全なリスト。
監査および指数 - 公開済ダッシュボード要素、および構成済指数のリスト。
ユーザー・グループ - 構成済ユーザー・グループ、およびそのユーザー・グループがアクセスできるダッシュボード要素のリスト。
ダッシュボード要素
「ダッシュボード要素」セクションには、すべてのダッシュボード要素がその集計ごとに編成されて表示されます。新しい結果は、それらが公開されたEDQプロセスに基づいてデフォルトのサマリーに集計されるため、すべての公開済結果が集計されます。これらのサマリーは、ユーザー・グループに関連付けられていないためにユーザーのダッシュボードには表示されない場合でも、常に「ダッシュボード要素」セクションに表示されます。同じルール結果が、複数の集計にリストされることがあります。
集計の3つのタイプは、索引、サマリーおよびリアルタイム集計です。
「ダッシュボード要素」ペインを使用して、次のように、結果の新しい集計を作成します。
索引の作成
新しい指数を作成するには、「ダッシュボード要素」ペイン下部の新規指数をクリックし、指数がユーザーのダッシュボードに表示される際の名前を付けます。たとえば、顧客データの品質を測定する索引には、「Customer DQ」という名前を付けます。
指数にルールの結果を追加するには、「ダッシュボード要素」ペインまたは監査および指数ペインからルール結果をドラッグ・アンド・ドロップします。サマリーを索引にドラッグすると、そのサマリーを構成するすべてのルール結果が索引に追加されます。
他の索引を索引に追加して、他の複数の索引の索引を作成することもできます。このことが指数計算に及ぼす影響は、「ダッシュボードの指数」を参照してください。
すべての関連ルールまたはその他の索引(あるいはその両方)を追加したら、索引の加重を構成できます。デフォルトでは、すべての関連ルール/指数が均等に加重されますが、指数を右クリックして「カスタム加重」を選択すると変更できます。
加重を変更するには、加重の数値を変更します。関連ルールまたは索引の加重率は自動的に計算されます。たとえば、6つの関連ルールがある索引を構成できます。アドレス移入ルールには、加重2が付与されています(つまり、他のルールの2倍重く加重されています)。
表1-9 カスタム加重
|
アドレス移入 |
2 |
28.57 |
|
連絡先番号移入 |
1 |
14.29 |
|
連絡先プリファレンス移入 |
1 |
14.29 |
|
電子メール・アドレス移入 |
1 |
14.29 |
|
携帯番号移入 |
1 |
14.29 |
|
名前移入 |
1 |
14.29 |
必要に応じて、索引のステータス(赤、黄または緑)の計算方法を変更することもできます。それ以外の場合、指数のステータスは「デフォルトしきい値」セクションに示されているルールを使用して計算されます。
この指数のステータスの計算方法のみを変更するには、指数を右クリックして「カスタムしきい値」を選択します。たとえば、800を下回ったときは赤(アラート)のステータスおよび700を下回ったときは黄のステータスになるように、特定の索引を構成できます。
索引の構成を終了したら、索引を監視できるようにするユーザー・グループを選択する必要があります。それには、「ユーザー・グループ」ペインのグループに索引をドラッグ・アンド・ドロップします。これらのグループのユーザーは、ダッシュボードで「カスタマイズ」リンクを使用して、新しい索引をダッシュボードに追加できるようになります。
サマリーの作成
新しいサマリーを作成するには、「ダッシュボード要素」ペイン下部にある「新規サマリー」ボタンをクリックし、サマリーがユーザーのダッシュボードに表示される際の名前を付けます。たとえば、すべての製品データ・ルールのサマリーを「製品データ」と呼ぶことができます。
サマリーにルール結果を追加するには、「ダッシュボード要素」ペインまたは監査および指数ペインからルール結果をドラッグ・アンド・ドロップします。別のサマリーを新しいサマリーにドラッグすると、ドラッグしたサマリーのすべての関連ルール結果が、新しいサマリーに追加されます。
必要に応じて、サマリーのステータス(赤、黄または緑)を計算する方法を変更することもできます。それ以外の場合、サマリーのステータスは「デフォルトしきい値」セクションに示されているルールを使用して計算されます。
このサマリーのステータスの計算方法のみを変更するには、サマリーを右クリックして「カスタムしきい値」を選択します。たとえば、5以上の関連ルールが赤または10以上の関連ルールが黄の場合は赤(アラート)のステータスになるように、および1以上の関連ルールが赤または5以上の関連ルールが黄の場合は黄(警告)のステータスになるように、特定のサマリーを構成できます。
サマリーの構成を終了したら、サマリーを監視できるようにするユーザー・グループを選択する必要があります。それには、「ユーザー・グループ」ペインのグループにサマリーをドラッグ・アンド・ドロップします。これらのグループのユーザーは、ダッシュボードで「カスタマイズ」リンクを使用して、新しいサマリーをダッシュボードに追加できるようになります。
リアルタイム集計の作成
新しいリアルタイム集計を作成するには、リアルタイム・ルール結果というダッシュボード要素を監査および指数ペインから「ダッシュボード要素」ペインのリアルタイム集計ノードにドラッグ・アンド・ドロップします。
リアルタイム・ルール結果は、地球アイコンで示されます。
リアルタイム集計の詳細を指定する前に、保存するよう求められます。たとえば、名前を検証するリアルタイム・ルールの日次集計を作成するために、次の詳細を指定するとします。
Name: Name Validation (Daily) Aggregation settings Start date: 23-Jan-2009 00:00 Results by: Aggregate by time period: 1 days.
期間が指定されている場合、リアルタイム集計には、指定された期間内の完了した各間隔のルール結果が含まれます。(通常は、日次集計の場合は午前0時、1時間ごとの集計の場合は1時間の開始時刻など、ちょうどの開始時間を使用することをお薦めします。)
間隔数が指定されている場合、リアルタイム集計には、指定された開始日時から開始する、指定された間隔数のルール結果が含まれます。
どちらの場合も、ルール結果はただ単に合計されるだけであるため、たとえば集計のアラート数は、対象となるすべての間隔で合計したアラート数になります。
必要に応じて、リアルタイム集計のステータス(赤、黄または緑)を計算する方法を変更することもできます。それ以外の場合、ステータスは「デフォルトしきい値」セクションに示されているルールを使用して計算されます。
このリアルタイム集計のステータスの計算方法のみを変更するには、集計を右クリックして「カスタムしきい値」を選択します。たとえば、実行されたチェックの10%以上がアラートの場合は赤(アラート)のステータスになるように、特定の集計を構成できます。
監査および指数
監査および指数ペインには、監査別に編成され、直接公開されたすべてのルール結果、つまりそれらが公開されたEDQプロセスおよび構成されているすべての指数が表示されます。
このペインから「ダッシュボード要素」ペインにルール結果をドラッグして、結果の新しい集計を作成します。
監査および索引のパージ
監査または指数からデータをパージするには、監査および指数ペインで要素を右クリックして「パージ」を選択します。
その要素に公開されたすべてのデータが、ダッシュボードからパージされます。EDQに保存された結果は影響を受けません。
ダッシュボード管理で保存するまで、変更内容は確定されません。
監査および索引の削除
監査および指数ペインでリストから要素を削除するには、監査および指数ペインで要素を右クリックして「削除」を選択します。
要素がダッシュボードおよびダッシュボード管理から削除されます。ダッシュボード管理で保存するまで、変更内容は確定されません。
|
注意: 削除された要素は、それらを公開したプロセスが「ダッシュボードに公開」オプションを有効にして再実行されると回復されます。ただし、カスタムしきい値など、ダッシュボード管理で行ったカスタマイズは再作成されません。 |
ユーザー・グループ
「ユーザー・グループ」ペインには、構成されているすべてのユーザー・グループ、およびそれらにアクセス権が付与されているダッシュボード要素が表示されます。ダッシュボード要素を表示するためのアクセス権をグループに付与するには、「ダッシュボード要素」ペインからグループ名にドラッグするだけです。
ユーザーのダッシュボードに表示される実際のダッシュボード要素は、ユーザー自身が構成可能です。ユーザーはログインして「カスタマイズ」リンクをクリックして、監視するダッシュボード要素を変更できます。
各タイプのダッシュボード要素のステータスを計算するデフォルトの方法を変更するには、「デフォルトしきい値」ビューを使用します。
ダッシュボード要素のタイプごとにタブがあります - 「ルール」、「サマリー」、指数および「リアルタイム・ルール」。
すべての場合において、指定されたいずれかのしきい値ルールに該当する場合を除き、ダッシュボード要素のステータスは緑になります。それ以外の場合、ルールはORベースで適用されます。つまり、画面の「赤」セクションに複数のルールがあり、それらのいずれかが適用される場合、ダッシュボード要素のステータスは赤になります。
「ダッシュボード要素」セクションでカスタムしきい値を構成することで、特定のダッシュボード要素のデフォルトのしきい値は上書きされることがあります。
指数ではルール結果が集計されますが、指数を階層的に集計して、複数の指数の指数を作成することもできます。たとえば、データ品質指数は、多数のソース・システム、または多数のデータ・タイプ(顧客、製品など)のそれぞれに対して作成できます。その後、これらの指数を集計して全体的なデータ品質指数を作成できます。
指数は常にダッシュボード管理で構成されます。
指数の計算
指数値は、単独ではほとんど意味がありません。ただし、スコアは1つまたは複数のプロセス(一定期間)の多数の実行の結果から計算されるため、ビジネス・ユーザーは傾向分析によって指数が上昇しているか下降しているかを監視できます。これは、FTSE100指数と類似しています。
より高い指数は、データ品質スコアが高いことを表します。デフォルトでは、最高DQ指数スコアは1000です。
ルール結果の指数
指数が多数のルール結果で構成される場合は、関連結果全体の加重平均として計算されます。
たとえば、顧客データDQ指数が次のルール結果および加重で構成されるとします。
この構成では、住所の検証と名前の検証ルールは、デフォルト加重の25% (4つのルール全体の加重の1/4)ですが、管理者は、他のルールには異なる加重を指定しており、電子メール・アドレスの検証ルールは重要度が低いと解釈され、敬称/性別の不一致は重要度が高いと解釈されています。
このため、実際の指数スコアは、各関連ルールに対して内部的に計算される指数スコア全体の加重平均として計算されます。
ルールごとに、1000 (または構成された基準最高点)に対する指数スコアが次のように計算され、ここで、合格に対しては10点、警告に対しては5点が与えられ、アラートに対しては点数は与えられません。
(((# of passes * 10) + (# of warnings * 5)) / (# of checks *10)) * 1000
たとえば、関連ルールの結果が次のとおりであるとします。
表1-11 関連ルールの結果
| ルール | チェック | 合格 | 警告 | アラート |
|---|---|---|---|---|
|
電子メール・アドレスの検証 |
1000 |
800 (80%) |
100 (10.0%) |
100 (10.0%) |
|
住所の検証 |
1000 |
800 (80%) |
0 (0%) |
200 (20.0%) |
|
敬称/性別の不一致 |
1000 |
800 (80%) |
0 (0%) |
200 (20.0%) |
|
名前の検証 |
1000 |
800 (80%) |
0 (0%) |
200 (20.0%) |
各関連ルールの指数スコアは、次のようになります。
表1-12 指数スコア
| ルール | 指数スコアの計算 | 指数スコア |
|---|---|---|
|
電子メール・アドレスの検証 |
800合格* 10点= 8000 + 100警告* 5点= 500 合計 = 8500 1000チェック* 10 = 10000 8500/10000 = 0.85 * 1000 = 850 |
850 |
|
住所の検証 |
800合格* 10点= 8000 + 0警告* 5点= 0 合計 = 8000 1000チェック* 10 = 10000 8000/10000 = 0.8 * 1000 = 800 |
800 |
|
敬称/性別の不一致 |
800合格* 10点= 8000 + 0警告* 5点= 0 合計 = 8000 1000チェック* 10 = 10000 8000/10000 = 0.8 * 1000 = 800 |
800 |
|
名前の検証 |
800合格* 10点= 8000 + 0警告* 5点= 0 合計 = 8000 1000チェック* 10 = 10000 8000/10000 = 0.8 * 1000 = 800 |
800 |
次に、全体指数スコアが、加重を使用して次のように計算されます。
Validate email address score (850) * Validate email address weight (0.125) = 106.25 + Validate address score (800) * Validate address weight (0.25) = 200 + Title/gender mismatch score (800) * Title/gender mismatch weight (0.375) = 300 + Validate name score (800) * Validate name weight (0.25) = 200
顧客データDQ指数スコアの合計は806.25で、表示目的で806.3に切り上げられます。
複数の指数の指数
他の複数の指数を集計するために1つの指数が作成される場合、その指数は、単に関連指数の加重平均として計算されます。たとえば、ユーザーが他の多数の指数全体の指数を次のように設定するとします。
各指数の指数値が次のとおりであるとします。
指数は次のように計算されます。
Customer data index (825) * Customer data index weight (0.50) = 412.5 + Contact data index (756.8) * Contact data index weight (0.25) = 189.2 + Order data index (928.2) * Order data index weight (0.25) = 232.5
全体のデータ品質指数の値は834.2です。
時間差のある監査結果の指数
指数では、多数のプロセスの結果が集計されることがあります。通常、この集計フォームは、プロセスが同じ間隔で実行される場合に使用されると想定しています。しかし、これは保証できません。指数に関連するプロセスが同期しない場合があります。たとえば、2つのデータ品質監査プロセスが実行されるとします。指数は両方のプロセスのルール結果を集計するように構成されており、指数履歴の結果が次のように公開されます。
表1-15 指数履歴の結果
| 日付 | 次の顧客監査プロセスの実行結果 | 次の担当者監査プロセスの実行結果 |
|---|---|---|
|
12/06/05 |
12/06/05 |
12/06/05 |
|
13/06/05 |
13/06/05 |
12/06/05 |
|
14/06/05 |
13/06/05 |
14/06/05 |
|
15/06/05 |
15/06/05 |
14/06/05 |
|
16/06/05 |
16/06/05 |
16/06/05 |
これは、指数に対する結果を、その関連プロセスの1つが実行されるたびに再計算することによって機能します。各プロセスの最終実行の結果が使用され、以前に計算された別の日付(日)に対する指数の結果が上書きされます。
一致レビューを使用して、ディレクタでバッチまたはリアルタイム照合プロセスによって識別された、可能性がある一致をレビューします。Enterprise Data Quality Launchpadを使用してアクセスします。
起動すると、一致レビュー・サマリー・ウィンドウが表示されます。ただし、ウィンドウ左側で「レビュー」領域の項目が選択されるまで、コンテンツは表示されません。
その後、サマリー・ウィンドウに選択したレビューの詳細が移入されます。詳細は、「一致レビュー・サマリー・ウィンドウ」のトピックを参照してください。
次に、ウィンドウの領域について説明します。
タイトル・バー
現在選択されているレビューの名前、割り当てられたレビュー・グループが完了している率を示すステータス・バー、およびレビュー・アプリケーションを起動するための直接リンクで構成されます。
レビュー
現在ユーザーに割り当てられているすべてのレビュー(全部または一部)が表示されます。
照合ステータス
この領域では、照合ステータス別にレコードを分類します。
自動照合
一致
一致なし
可能性がある一致
保留中
レビュー・ステータス
この領域には、レビュー・タイプ別にレコードが表示されます。
レビュー待ち
レビュー済ユーザー
レビューは不要
|
注意: 「レビューは不要」に表示された数は、常に「照合ステータス」領域の自動照合値と一致します。 |
ルール
この領域には、照合プロセス中にトリガーされた各ルール、および各ルールで識別された解決済の関係および未解決の関係の数が表示されます。
レビュー・アプリケーションは、次のいずれかをクリックして起動します。
タイトル・バーの「レビュー・アプリケーションの起動」、または
サマリー・ウィンドウの各領域のいずれかのリンク。
|
注意: ユーザーは通常、ルールによってレビューの一致を割り当てられるため、「ルール」領域で必要なルールをクリックします。可能性がある一致の数が比較的少ない場合は、「照合ステータス」領域で「可能性がある一致」をクリックして、すべてを表示することもできます。 |
このウィンドウは、次の領域に分かれています。
ツールバー
この表はツールバーの各項目を説明しています。
グループのフィルタ
この領域のフィールドでは、フィルタ基準を使用して特定のグループを検索します。詳細は、「グループのフィルタリング」を参照してください。
「レコード」および「関係」領域
「レコード」領域には、現在選択されているレビュー・グループ内のレコードが表示されます。一致するレコードは黄色で強調表示され、レビューのためにフラグが設定されたレコードは藤色で強調表示され、現在選択されているレコードは常に青色で強調表示されます。
「関係」領域には、グループ内の各レコードの関係が表示され、一致または可能性がある一致が存在する場合には示されます。
そのため、下の例では、R1、R2およびR3の3つのレコードがあります。「関係」領域には、R1が自動的にR2と照合され、R1とR3の間に可能性のある一致が存在することが示されています。
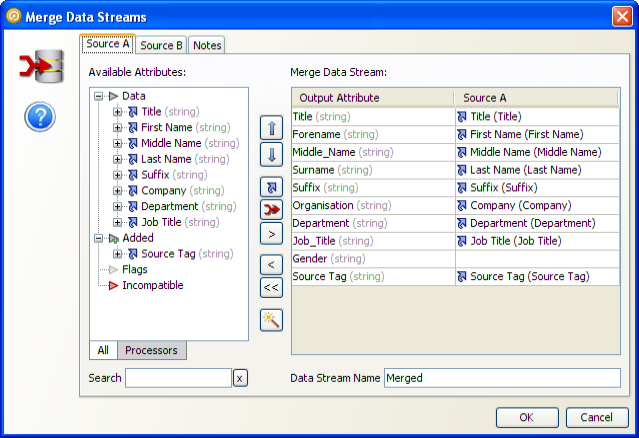
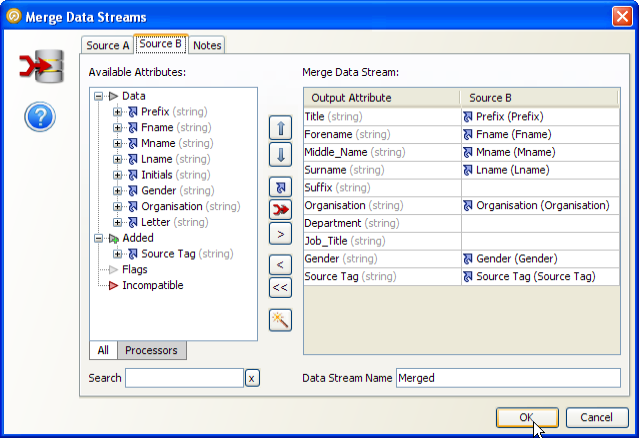
マージ済出力のレビュー
「マージ済出力のレビュー」タブは、次の2つの領域に分かれています。
レコード: 現在選択されているレビュー・グループで一致したレコード。
マージ済出力: マージした際にレコードを表示する方法。
「グループのフィルタ」領域は、表示するグループの絞込みに使用します。グループは次の方法でフィルタできます。
レコード属性のテキスト値の検索
個別のレビュー基準の検索
両方。
次の表では、この領域のユーザー・インタフェース要素について説明します。
| アイテム | タイプ | 説明 |
|---|---|---|
| 検索 | フリー・テキスト・フィールド | レコード属性内を検索するテキストを入力します。 |
| 検索先 | ドロップダウン・フィールド | 検索先のレコード属性を選択します。 |
| 関係の属性 | ドロップダウン・フィールド | 検索に使用する関係基準を選択します。 |
| 演算子 | ドロップダウン・フィールド | 必要な演算子を選択します。ほとんどの検索では、= (等号)または<> (不等号)が使用されます。 |
| 関係値 | 状況により異なる | 検索する関係値を選択します。選択した関係基準に応じて、ドロップダウン、日付選択またはフリー・テキスト・フィールドのいずれかになります。 |
| 検索 | ボタン | フィルタを実行します。 |
| クリア | ボタン | フィルタ・フィールドをすべてクリアします。 |
|
ORロジックを使用します |
チェックボックス | 選択した場合、レコードおよび関係フィールドのフィルタは、個別に実行されます。つまり、表示されるグループは、いずれかに指定された基準を満たしています。選択を解除した場合、フィルタ結果は、レコード・フィルタ・フィールドと関係フィルタ・フィールドの両方に指定されているすべての基準に一致します。このチェック・ボックスはデフォルトで選択されています。 |
|
大/小文字区別 |
チェックボックス | フリー・テキスト・フィールドに設定された値に基づく、大/小文字を区別したレコードのフィルタリングを有効にします。デフォルトでは選択されていません。 |
|
完全一致 |
チェックボックス | 選択した場合、指定されたすべてのフィルタ基準に完全に一致するレコードのみが返されます。デフォルトでは選択されていません。 |
フィルタリングの例
姓で個人を検索するには、次のようにします。
「検索」フィールドで、姓(例: Williams)を入力します。
「検索先」ドロップダウン・フィールドで姓を選択します。
完全に一致する名前を検索するか、大/小文字を区別して検索するかを決定し、それに応じて「大/小文字の区別」および「完全一致」のボックスを選択またはクリアします。
「検索」をクリックします。最初に見つかったグループが「レコード」および「関係」領域に表示されます。
個人の姓および「一致ルール」名で、グループを検索するには、次のようにします。
「検索」フィールドで、姓を入力します。
「検索先」ドロップダウン・フィールドで姓を選択します。
関係の属性フィールドで、「一致ルール名」を選択します。
演算子フィールドを=に設定されたままにします。
関係値フィールドで、ルール名(完全名、郵便番号など)を選択します。
「ORロジックを使用します」ボックスが選択されていることを確認し、「大/小文字の区別」および「完全一致」ボックスを必要に応じて選択またはクリアします。
「検索」をクリックします。最初に見つかったグループが「レコード」および「関係」領域に表示されます。
タスク・バーのグループ・ナビゲーションボタンを使用して、返されたグループ間を移動します。
レビュー対象のグループの選択
一致レビュー・アプリケーションを使用すると、特定のグループ・タイプを、ステータス、トリガーしたルール、または特定のフィルタ基準別にレビューできます。
一致レビュー・サマリー・ウィンドウで、次のいずれかを行います。
すべてのグループを表示するには、タイトル・バーの「レビュー・アプリケーションの起動」をクリックします。
選択したカテゴリに含まれるグループを表示するには、「照合ステータス」、「レビュー・ステータス」または「ルール」領域内のリンクをクリックします。
|
注意: ほとんどのユーザーは、すべての「可能性がある一致」(「照合ステータス」領域内のこのリンクをクリック)を表示、またはルール別に表示する必要があります。 |
または、グループ内のレコードまたはレコード間の関係に関連する特定の基準に該当するグループを検索できます。詳細は、「グループのフィルタ」のトピックを参照してください。
決定の適用
グループを表示する際、ユーザーは、レビュー・アプリケーションのツールバー内のグループ・ナビゲーション・ボタンを使用して、これらの間を移動できます。
決定を適用するには、次の手順を使用します。
「レコード」領域の情報をレビューします。必要に応じて、「違いの強調表示」をクリックして、レコード属性が異なる場所を表示します。
「関係」領域で、可能な各関係に対して、「決定」ドロップダウン・フィールドで必要な設定を選択します。オプションは次のとおりです。
可能性がある一致
一致
一致なし
保留中
オプションが選択されている場合は常に、決定を適用したユーザーの名前および決定が行われた時刻で関係が更新されます。
必要な場合、グループ・ナビゲーション・ボタンを使用して次のグループに進みます。
関係に関するコメント
関係に関して決定が行われているかどうかにかかわらず、関係に対してコメントを追加できます。作成されるのが最初のコメントかどうかによって、手順が異なります
関係に最初のコメントを追加するには、次のようにします。
関係の横にある最初のコメントの追加ボタン(  ) をクリックします。
) をクリックします。
「コメント」ダイアログで、必要なテキストを入力します。
「OK」をクリックし保存します(または「取消」をクリックして破棄します)。
「コメント」ダイアログが表示され、コメント、コメントを残したユーザー名およびコメントが作成された日付が示されます。
「OK」をクリックし、ダイアログを閉じます。または、コメントを選択し「削除」をクリックして削除するか、「追加」をクリックしてさらにコメントを追加します。
関係に追加コメントを追加するには、次のようにします。
関係の横にある追加コメントの追加ボタン(  ) をクリックします。
) をクリックします。
「コメント」ダイアログで「追加」をクリックします。
「コメント」ダイアログで、必要なテキストを入力します。
「OK」をクリックし保存します(または「取消」をクリックして破棄します)。
「コメント」ダイアログが表示され、コメント、コメントを残したユーザー名およびコメントが作成された日付が示されます。
「OK」をクリックし、ダイアログを閉じます。または、コメントを選択し「削除」をクリックして削除するか、「追加」をクリックしてさらにコメントを追加します。
列構成
列構成ウィンドウでは、列の詳細をカスタマイズできます。
「自動」チェック・ボックスでは、列のセルに存在する文字の数に基づいて列の幅が自動的に調整されます。
「日付フィールドに時刻を表示」では、日付の詳細が含まれるすべてのフィールドに時刻が表示されます。
ツリーの列は、複数選択が可能になり、選択した列は、パネルの横にある2つの新しいボタンを使用してオンとオフを切り替えることができます。ボタンの機能を説明するツールチップが表示されます。
グループ内のレコードが一致と識別されると、マージされます。その後、マージ結果をレビューでき、必要に応じて、マージ済出力レコードが生成される方法を上書きできます。
マージ済出力を上書きする手動で行われた決定は、一致グループのハッシュに対して格納され、一致グループ内のレコード・セットが同じである間は保持されます。一致グループが導出されたレビュー・グループが完全に解決されると(たとえば、すべてのレビュー関係が「一致」または「一致なし」とマークされるなど)、グループがUI内で「確認済」とマークされます。ソース・データまたは一致ルールが変更されないかぎり、マージ対象のレコード・セットは同じ状態のままとなり、手動の上書きが適用されます。
出力を上書きする際、グループ内の候補レコードの値(マージ対象のレコード・セット)を、値上で右クリックして、値を移入するマージ済出力フィールドを選択することで出力属性として選択できます。または、マージ済出力フィールドに値入力して、出力値を直接上書きできます。
自動マージ出力生成で発生したエラーは、UI内でユーザーに強調表示されます。エラーは、出力フィールドの手動決定が必要であることを示します。
|
注意: 決定が適用されると、個別のマージ結果をレビューできます。詳細は、後述の「個別のマージ済グループのレビュー」を参照してください。 |
マージ済グループのレビューを開始するには、次のようにします。
一致レビュー・アプリケーション・ウィンドウを開きます。
「マージ済出力のレビュー」タブを選択します。「レコード」および「マージ済出力」領域には、最初のマージ済グループの詳細が移入されます。
「レコード」領域には、一致と確認されたすべてのレコードがリストされます。「違いの強調表示」をクリックすると、レコードが互いに異なる箇所を表示できます。
「マージ済出力」領域には、一致の結果であるマージ済レコードが表示されます。
マージ済出力を手動で上書きするには、次のいずれかを行います。
「マージ済出力」領域から編集する属性をダブル・クリックし、正しいテキストを入力します。
|
ヒント: 属性を右クリックし、「クリア」を選択して値をクリアするか、「リセット」を選択して属性を自動出力値にリセットします。 |
ソース・データ属性値を右クリックして、この値を移入するマージ済出力フィールドを選択します。
|
ヒント: ソース・データ属性は、レコード表内で色付きの背景で識別でき、右にスクロールした所にあります。レコード表の左側に表示される識別子属性の背景は白であり、右クリックによるマージ済出力フィールドへの移入に使用することはできません。 |
コメントを追加でき、各マージ済レコードのコメント履歴を、「マージ済出力」領域の右側にある「最新コメント」領域を使用してレビューできます。「コメントの追加」ボタン()をクリックしてコメントを追加するか、コメント履歴ボタン( )をクリックして履歴を表示します。
)をクリックして履歴を表示します。
マージ済グループを必要に応じて編集し、ツールバーのグループ・ナビゲーション・ボタンを使用して次のグループに移動します。
個別のマージ済グループのレビュー
一致の確認の結果を即座にレビューする必要がある場合があります。個別のマージ済グループをレビューするには、次の手順を使用します。
一致レビュー・アプリケーション・ウィンドウの「レビュー」領域内のグループを表示します。
「アプリケーション」ウィンドウの右上にある「マージ済出力のレビュー」をクリックします。現在選択されているグループの詳細は、「マージ済出力のレビュー」タブに表示されます。
必要に応じてマージ済グループをレビューします。
ケース管理はOracle Enterprise Data Qualityユーザー・アプリケーションで、データ品質プロセスの結果の手動調査をサポートするように設計されています。また、バッチおよびリアルタイムの両方のスクリーニング結果に関して、Oracle Watchlist Screeningで主な調査アプリケーションとしても使用されます。
多くのユーザーは、ケース管理を使用することで、高度に構成可能なワークフローおよびすべての調査作業の包括的な監査履歴を使用して、一致結果を管理およびレビューできます。
この項では、ケース管理アプリケーションで使用する主な概念について説明します。ここで使用する用語は次のとおりです。
アラートは、ケース管理で使用するレビュー作業の最小単位です。通常、アラートは異なるデータ・ソースの2レコード間の一致候補を示します。アラートの内容は、アラート・キーによって定義されます。
アラートはケースを形成するためにグループ化されます。アラートには、現在の状態や権限を含め、値が時間によって変化する可能性のある、多数の属性が含まれています。システムで構成されている場合、アラートには拡張属性も含まれることがあります。
アラート・キーでは、ケース・ソースで定義され、アラートを形成する際に関係をグループ化する方法を指定します。アラートは、アラート・キー・フィールドに同じ値を持つ関係セットで構成されます。通常、ケース・ソースに含まれている各データ・ソースでは、そのデータ・ソースから行を一意に識別できるように、アラート・キーに十分なフィールドが提供されます。
属性は、すべてのケースおよびアラートに表示されるフィールドです。これには照合プロセスに送信されたデータを直接反映していないデータが含まれていますが、ここからデータを導出できます。受信ルールで実行された処理の一部として、属性値を設定できます。受信ルールでは、条件付き処理の一部として属性値を調査することもできます。
また、属性値は、遷移の結果として、または状態が期限切れになった場合に変更することもできます。
ケースは、関連アラートのグループです。ケースの内容は、ケース・キーによって定義されます。
ケース・キーは、ケース・ソースで定義され、アラートを形成する際にアラートをグループ化する方法を指定します。ケースは関連アラートのグループであるため、通常、ケース・キーはアラート・キーのフィールド・サブセットから形成されます。多くの場合、適切なケース・キーによって作業データの1つの行が特定されます。このような場合、ケースは単一の作業データ行に関連付けられ、その行と参照データ・ソースを照合することにより生成されたアラートがすべて含まれます。
ケース・ソースは、ケース管理を使用するすべての照合プロセッサに対して定義する必要があります。ケース・ソースは、照合プロセッサで生成された関係を使用してケースおよびアラートを作成する方法を制御します。
ケース・ソースで定義するものは、次のとおりです。
ケース識別子の一部として使用する接頭辞
オプションの権限設定
アラートの内部ワークフロー状態とカスタム・ワークフロー状態間のマッピング
アラート・キー、ケース・キーおよびフラグ・キーの定義を含むデータ・ソース
データ・ソースが照合プロセッサの入力データ・ストリームにマップする方法
ケース・ソースでは、アラートを収集してケースを形成する方法およびレビュー用にケース管理に送信するデータを定義します。1つのケース・ソースを複数の異なるスクリーニング処理で使用できますが、ケース管理の入力として使用するフィールドが定義されるため、そのソースのすべてのケースとアラートを同じように処理できます。
ケース・ソースでは、このプロセッサから生成されたケースとアラートに使用するワークフローも指定します。
ケース・ソースは、ケース管理を使用する照合プロセッサに対して「拡張オプション」ダイアログで定義されます。
注意: ケース管理では、配列識別子の使用はサポートされません。
データ・ソースは、ケース・ソースで必要な入力データ・ストリームのモデルです。データ・ソースは、ケース管理に対して内部にある実際の入力データのモデルとして使用します。これは、ケースとアラートの生成プロセスで認識されるモデルです。ケース・キー、アラート・キーおよびフラグ・キーは、実際の入力データ・ストリームのフィールドではなく、データ・ソースのフィールドに対して定義されます。
データ・ソースを使用すると、入力データ・ストリームのあいまいなフィールド名を、人間が認識できて一貫性のある名前として再度解釈することもできます。さらに、ケース・ソースですでに定義されたデータ・ソースに入力データ・ストリームをマップすると、ケース・ソースを他の照合プロセッサで再使用できるということでもあります。
導出状態は、ケースを形成するアラートの状態に基づいたステータスです。導出状態は、新規、処理中または完了のいずれかです。すべての問題のレビュー・ステータスがレビュー待ちの場合に、導出状態は新規になります。すべての問題がレビュー済になり、一致なし決定または一致決定にマップされるワークフロー状態にある場合に、導出状態は完了になります。1つ以上の問題がレビュー済であるが、すべての問題が解決されているわけではない場合に、導出状態は処理中になります。
拡張属性は、ケースおよびアラートに表示されるカスタム・フィールドです。属性と同様に移入および処理されますが、定義と格納方法は異なっています。
属性はケースおよびアラート構造の固有の部分ですが、拡張属性は構成ファイルflags.xmlで定義されます。このファイルは\oedq_local_home\casemanagementディレクトリにあります。
デフォルトのインストールでは、次の2つの拡張属性が定義されます。
Escalation - ブール属性。trueに設定されている場合、ケースまたはアラートはエスカレート済の状態であることを示します。
PriorityScore - 数値属性。照合プロセッサで生成されたとおり、アラートの優先度のスコアを保持するために使用されます。
フラグ・キーは、ケース・ソースで定義され、ケース・キーまたはアラート・キーに含まれないデータ・フィールドを指定しますが、内容は一致決定に影響を与える可能性があります。つまり、これらのフィールドの情報は、このアラートが一致であるかどうかについて、レビューアの決定に影響を与える可能性があります。したがって、この情報に対する変更をケース管理の受信ルールで使用すると、次に照合処理を実行したときに、アラートの再レビューをトリガーできます。
フラグ・キーに一致決定に関連しないフィールドが含まれている場合、実際にもうレビューの必要のないアラートが再生成され、レビューアの負担になります。一方で、フラグ・キーに含まれている必要のあるフラグがない場合、データに対する重要な変更が欠落する可能性があります。したがって、フラグ・キーの設計は、スクリーニング・ソリューションの継続的な正確性において重要になります。
パラメータは、ワークフローの一部として定義します。パラメータは照合プロセッサによって移入され、追加情報をケースとアラートの生成メカニズムに渡すために使用されます。ケース・ソースでは、ケースとアラートに対してパラメータ値の計算方法を指定します。
|
注意: パラメータ値は、ケースとアラートへのコピーを自動的には行いません。かわりに、ワークフローでも定義される受信ルールがパラメータ値の使用方法を指定します。 |
ケース管理の権限は、EDQユーザー権限の拡張機能です。これらは、どのユーザーがどのデータにアクセスできるかを制御するために使用します。
権限はケース管理の管理で定義され、ケース・ソース、状態および遷移に関連付けることができます。これらはEDQの他のセキュリティ設定と同様に、グループを介してユーザーに割り当てられます。
ユーザーは、自分の権限と互換性のある権限が設定されたデータのみ表示できます。ユーザーは適切な権限がある場合にのみ、遷移をケースまたはアラートに適用できます。ユーザー・グループからデータ・セット全体を非表示にするには、これらのユーザーに付与されていない権限設定をケース・ソースに割り当てます。
受信ルールを使用して、新規のケースまたはアラートがワークフローに最初に入ったときの処理方法を定義します。受信ルールは、受信イベントに対して適用するかどうかを検討する一連のアクションから構成されます。各アクションでは、ケースまたはアラートごとに評価する条件式を指定できます。式がtrueと評価した場合にのみ、アクションがアラートに適用されます。
アクションでは、属性および拡張属性に新しい値を指定できます。また、受信ケースまたはアラートに適用する遷移も指定できます。
状態は、遷移とともに、ワークフローを構成するブロックです。アラートまたはケースの状態は、ワークフローにおける位置を示します。各状態では、その状態からの有効な遷移を定義します。状態を構成して自動的に期限切れにすることもできます。これにより、新しい状態に遷移したり、属性または拡張属性の値に変更したりできます。
遷移では、ケースまたはアラートが新しい状態に入る方法を定義します。遷移では、ケースまたはアラートの新しい状態や、同時に発生する属性または拡張属性値への変更を指定します。遷移を状態に関連付けるということは、ケースまたはアラートがその状態から遷移で指定された状態に移動するということです。ケースまたはアラートが現在の状態から移動するには、その状態に割り当てた遷移のいずれかに従います。
遷移はケースまたはアラートに新しい状態しか指定しないため、ワークフローでは何度でもこれらを再使用できます。たとえば、toSecondLevelReviewと呼ばれる遷移では、ケースまたはアラートがSecondLevelReviewと呼ばれる状態に移動するということを指定します。この遷移はFirstLevelReviewと呼ばれる状態およびAwaitingMoreInformationと呼ばれる状態に関連付けられています。この関連付けにより、ケースと問題は他の2つの状態のいずれかからSecondLevelReview状態に移動できることが示されます。
|
注意: 遷移は一方向です。つまり、ケースまたはアラートが状態Aから状態Bに移動できるということは、状態Bから状態Aに移動できるということではありません。また、遷移はケースまたはアラートの開始のステータスを認識しません。ケースまたはアラートを状態Bに移動する遷移は、ワークフローの他の任意の状態から状態Bに移動できるということです。 |
遷移では、コメントを追加することが必要な場合もあります。頻繁に使用する理由やフレーズを反映するように、各遷移に対してコメント・テンプレートを定義できます。
ワークフローは、遷移とリンクしている一連の状態から構成されます。これらは、有効なケースまたはアラートのライフサイクルを示すネットワークを形成します。
ワークフローは、照合プロセッサから追加情報を渡すことができるパラメータも定義できます。また、最初の作成時に新しいケースまたはアラートで実行される処理を指定する受信ルールも定義できます。
ケース・ソースを構成して、2つのワークフロー(1つはアラート用で、もう1つはケース用)を使用します。
2つのデフォルトのワークフロー(1つはアラート用で、もう1つはケース用)は、ケース管理で提供されます。ケース管理の管理アプリケーションで、他のワークフローを定義できます。
ケース管理のユーザー・インタフェースは、使用しやすいように設計されています。ケース管理のすべての画面では、同一の基本レイアウトを使用しています。
画面の上部には、ナビゲーション・コントロールおよび一括編集コントロールを含むツールバーがあります。
画面の左側には、サマリー情報および編集コントロールがあります。
画面の他の領域には詳細情報が表示されます。これは、現在使用している画面によって異なります。
「詳細」領域の右下部にはステータス・バーがあり、現在接続しているサーバー、ログイン・ユーザー名および使用しているOracle Enterprise Data Qualityのバージョンが表示されます。
次の主な4つの画面があります。
「ブラウザ」画面。事前定義されたフィルタに従ってケースおよびアラートを参照できます。
「フィルタ」画面。「ブラウザ」画面で使用するためのフィルタを作成および編集できます。
「アラート」画面。単一のアラートの詳細を表示および変更できます。
「ケース」画面。単一のケースの詳細を表示および変更できます。
画面の正確な内容およびレイアウトは、ケース管理の構成方法および付与されているセキュリティ権限によって異なります。
「ブラウザ」画面を使用し、事前に定義したフィルタを選択することにより、ケースとアラートを見つけます。
画面上部のナビゲーション・バーでは、画面のリフレッシュ、ケースまたはアラートへの直接移動、または現在の結果セットに対する一括操作を行うことができます。
画面左側の「ブラウザ」ペインには、使用可能なフィルタがリストされます。
画面右側の「結果」ペインには、現在選択しているフィルタに関連付けられているケースまたはアラート、あるいはその両方が表示されます。
フィルタは「フィルタ」画面で定義され、この画面の「ブラウザ」ペインに表示されます。フィルタをクリックして選択します。選択したフィルタで返されるレコードは「結果」ペインに表示されます。
ナビゲーション・バー
次の表に示すように、ナビゲーション・バーにはいくつかの異なるコントロールが含まれています。
|
注意: 「割当て」、「一括更新」および「一括削除」ボタンは特権機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
表1-16 「ブラウザ」画面のナビゲーション・バーのコントロール
| 要素 | 説明 |
|---|---|
|
リフレッシュ |
このボタンを使用して、画面上の情報をリフレッシュし、最新の状態にします。 |
|
IDにジャンプ |
ケースまたはアラートのIDがわかっていて直接これに移動する場合に、このボタンを使用します。テキスト・ボックスにIDを入力して、矢印をクリックします。 |
|
割当て |
このボタンを使用して、「結果」ペインで選択したケースまたはアラート(あるいはその両方)を割り当てます。 |
|
一括更新 |
このボタンを使用して、「結果」ペインのケースまたはアラート(あるいはその両方)の詳細を変更します。 |
|
一括削除 |
このボタンを使用して、「結果」ペインのすべてのケースまたはアラート(あるいはその両方)を削除します。 |
|
Excelにエクスポート |
このボタンを使用して、「結果」ペインのケースまたはアラート(あるいはその両方)をExcelスプレッドシートにエクスポートします。 |
|
ヘルプ |
このボタンを使用して、ケース管理ユーザー・アプリケーションのオンライン・ヘルプを起動します。 |
「ブラウザ」ペイン
「ブラウザ」ペインでは、ケースおよびアラートの検索に使用できる、保存済フィルタがすべてリストされます。3つのフィルタ・リストがペインに表示されます。
「お気に入り」では、お気に入りとしてマークしたフィルタがすべてリストされます。ここでは自分のお気に入りのみ表示され、他のユーザーにはそのユーザーの「お気に入り」リストが表示されます。
「グローバル」では、定義済ですべてのユーザーと共有されているフィルタがすべてリストされます。
「ユーザー」では、ユーザーが自分用に定義したフィルタがすべてリストされます。
各リストは、折りたたんでその内容を非表示にしたり、展開したりできます。セクション名の横にある青い矢印は、リストが展開されているか(下向きの矢印)、または折りたたまれているか(横向きの矢印)を示します。矢印または矢印の横のリストの名前をクリックして、状態を切り替えます。
フィルタをクリックして選択します。選択したフィルタは太字で表示され、フィルタによって返されたケースまたはアラート(あるいはその両方)は「結果」ペインに表示されます。
お気に入りとしてフィルタをマークした場合、「お気に入り」リストに追加され、黄色の星でマークされます。元のリストも「お気に入り」リストも引き続き表示されます。
レポート・オプションが定義されているフィルタの場合、クリップボード・アイコンとともに表示されます。
ペインの下部には、「検索」ボックスがあります。ボックスに入力を開始するとすぐに、入力した文字を含むフィルタ名のみが含まれるように、リストがフィルタリングされます。検索をクリアするには、ボックスの横の「x」をクリックします。
「結果」ペイン
ケース管理を最初に開いたときは、「結果」ペインは空です。選択したフィルタによって返されたケースとアラートがすべて表示されます。
フィルタの構成方法によって、「結果」ペインに表示される列や表示順が異なることがあります。ペイン上部のタイトル・バーには、選択したフィルタ名、およびフィルタが返した項目(ケースとアラートの両方)の合計数が表示されます。
すべてのユーザーに最適なパフォーマンスを維持するために、フィルタを選択するたびに最大100項目が返されることに注意してください。
「ブラウザ」画面からの移動
「ブラウザ」画面から「フィルタ」画面、「アラート」画面または「ケース」画面に移動できます。
「フィルタ」画面に移動するには、画面の左下部にある「フィルタ」タブをクリックします。
「結果」ペインにアラートまたはケースが含まれている場合にのみ、「アラート」画面または「ケース」画面に移動できます。
「アラート」画面に移動するには、「結果」リストのアラートをダブルクリックします。
「ケース」画面に移動するには、「結果」リストのケースをダブルクリックします。
「フィルタ」画面を使用して、フィルタを作成および編集します。フィルタの作成および編集の詳細は、「フィルタの管理」を参照してください。
画面の上部にあるナビゲーション・バーを使用すると、画面をリフレッシュしてケースまたはアラートに直接ジャンプしたり、現在の結果セットで一括操作を実行することができます。
画面の左側にある「ブラウザ」ペインには、フィルタを作成および編集するためのコントロールがあります。
画面の右側にある「結果」ペインには、現在アクティブなフィルタに関連付けられているケースまたはアラート(あるいはその両方)が表示されます。
「フィルタ」画面への移動
「フィルタ」画面に移動するには、「ブラウザ」画面の左下部にある「フィルタ」タブをクリックします。「フィルタ」画面から直接「ケース」画面または「アラート」画面に移動した場合、「ケース」画面または「アラート」画面を閉じたときに「フィルタ」画面に戻ります。
ナビゲーション・バー
次の表に示すように、ナビゲーション・バーにはいくつかの異なるコントロールが含まれています。
|
注意: 「一括更新」、「一括削除」および「Excelにエクスポート」ボタンは特権機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
表1-17 「フィルタ」画面のナビゲーション・バーのコントロール
| 要素 | 説明 |
|---|---|
|
リフレッシュ |
このボタンを使用して、画面上の情報をリフレッシュし、最新の状態にします。 |
|
IDにジャンプ |
ケースまたはアラートのIDがわかっていて直接これに移動する場合に、このボタンを使用します。テキスト・ボックスにIDを入力して、矢印をクリックします。 |
|
割当て |
このボタンを使用して、「結果」ペインで選択したケースまたはアラート(あるいはその両方)を割り当てます。 |
|
一括更新 |
このボタンを使用して、「結果」ペインのケースまたはアラート(あるいはその両方)の詳細を変更します。 |
|
一括削除 |
このボタンを使用して、「結果」ペインのすべてのケースまたはアラート(あるいはその両方)を削除します。 |
|
Excelにエクスポート |
このボタンを使用して、「結果」ペインのケースまたはアラート(あるいはその両方)をExcelスプレッドシートにエクスポートします。 |
|
ヘルプ |
このボタンを使用して、ケース管理ユーザー・アプリケーションのオンライン・ヘルプを起動します。 |
「ブラウザ」ペイン
「ブラウザ」ペインでは、フィルタ・オプションがすべてリストされ、現在のフィルタ構成が表示されます。オプションは、次のセクションに分かれています。
「一般」セクションを使用して、テキスト検索の実行、ケース・ソースによるフィルタリングおよびケースまたはアラートのみの指定を行います。
「属性」セクションでは、ケースおよびアラートの標準属性別に結果をフィルタリングします。
「拡張属性」セクションでは、ケースおよびアラートの拡張属性別に結果をフィルタリングします。
「ソース属性」セクションでは、ケース・ソースを選択した場合に、ケース・ソースに関連付けられた属性別に結果をフィルタリングします。
「履歴」セクションでは、ケースに対してユーザーが行った属性またはコメント(あるいはその両方)への変更別に結果をフィルタリングします。
「許容されている遷移」セクションでは、ユーザーが許可されている遷移別に結果をフィルタリングします。
「レポート」セクションを使用して、グリッド形式で結果サマリーを作成します。グリッドの結果をドリルダウンして、各カテゴリをさらに調査できます。
各セクションは、折りたたんでその内容を非表示にしたり、展開したりできます。セクション名の横にある青い矢印は、セクションが展開されているか(下向きの矢印)、または折りたたまれているか(横向きの矢印)を示します。矢印または矢印の横のセクションの名前をクリックして、状態を切り替えます。
リストから要素を選択し適切な値を指定してフィルタを構成してから、緑色の矢印をクリックすると、右側の「結果」ペインに結果が表示されます。
ペインの下部にはいくつかのボタンと緑色の矢印が表示されます。
「結果」ペイン
ケース管理を最初に開いたときは、「結果」ペインは空です。緑色の矢印を押したときにフィルタによって返された関連付け済ケースとアラートがすべて表示されます。
構成方法によっては、「結果」ペインは異なるレイアウトになることがあります。ペイン上部のタイトル・バーには、選択したフィルタ名(変更した場合はアスタリスク*が付加)、およびフィルタが返した項目(ケースとアラートの両方)の合計数が表示されます。
「フィルタ」画面からの移動
「フィルタ」画面から「ブラウザ」画面、「アラート」画面または「ケース」画面に移動できます。
「ブラウザ」画面に移動するには、画面の左下部にある「ブラウザ」タブをクリックします。
「結果」ペインにアラートまたはケースが含まれている場合にのみ、「アラート」画面または「ケース」画面に移動できます。
「アラート」画面に移動するには、「結果」リストのアラートをダブルクリックします。
「ケース」画面に移動するには、「結果」リストのケースをダブルクリックします。
「アラート」画面を使用して、アラートの状態を表示、割当て、編集および変更します。この画面では、現在アクティブなアラートのリストから、一度に1つのアラートの詳細が表示されます。現在アクティブなアラートのリストには、「ブラウザ」画面または「フィルタ」画面で選択したフィルタによって返されたアラートがすべて含まれています。
画面上部のナビゲーション・バーでは、リスト内のアラート間を移動したり、アラートのリストに戻ったり、現在のアラートに関連付けられているケースに移動できます。
画面左側の「サマリー」ペインには、選択したアラートの概要が表示され、アラートを編集するためのコントロールがあります。
画面右側の「結果」ペインは、上の領域と下の領域に分かれています。上の領域にはアラートに関連付けられたアラートが表示され、下の領域にはアラートの履歴が表示されます。
「アラート」画面への移動
「アラート」画面に移動するには、次のようにします。
「ブラウザ」画面または「フィルタ」画面のいずれかの結果パネルのアラートをダブルクリックします。選択したアラートとしてダブルクリックしたアラートとともに、「アラート」画面が開きます。
関連付けられたアラートを「ケース」画面でダブルクリックします。選択したケースとしてダブルクリックしたケースとともに、「アラート」画面が開きます。
ナビゲーション・バー
次の表に示すように、ナビゲーション・バーにはいくつかの異なるコントロールが含まれています。
表1-18 「アラート」画面のナビゲーション・バーのコントロール
| 要素 | 説明 |
|---|---|
|
リストに戻る |
このボタンを使用して、「アラート」画面から移動し「フィルタ」画面または「ブラウザ」画面に戻ります。 |
|
{X}/{Y}を表示しています |
このコントロールを使用して、リスト内のアラート間を移動します。外側の2つのボタンを使用すると、それぞれリスト内の最初のアラートまたは最後のアラートに移動します。内側の2つのボタンを使用すると、リスト内の前のアラートまたは次のアラートに移動します。ボタン間のキャプションには、現在のケースおよびリスト内のアラート数が表示されます。 |
|
ケースに移動 |
このボタンを使用して、選択したアラートに関連付けられたケースに移動します。 |
|
ヘルプ |
このボタンを使用して、ケース管理ユーザー・アプリケーションのオンライン・ヘルプを起動します。 |
「サマリー」ペイン
「サマリー」ペインは次の3つのセクションに分かれています。
パネル上部の「現在の状態」セクションでは、アラートの現在の状態、アラートの状態を最後に変更したユーザー名および変更した日時が表示されます。
「使用可能なアクション」セクションには、アラートの編集用のコントロールが含まれています。使用可能なコントロールはアラートの状態およびセキュリティ権限によって異なるので、ここで表示されるコントロールと異なることがあります。
「サマリー」セクションには、ケースに関する追加情報が含まれています。最小限のサマリー情報を表示するか、拡張バージョンを表示するかを選択できます。
ペインには次の3つのボタンがあります。
|
注意: アラートの編集ボタンは特権機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
表1-19 「サマリー」ペインのボタン
| 要素 | 説明 |
|---|---|
|
アラートの編集 |
このボタンを使用して、アラートの詳細を編集します。 |
|
詳細の表示 |
このボタンは、最小限のサマリー情報が表示されている場合に表示されます。これを押すと、拡張サマリー情報が表示されます。 |
|
詳細を非表示 |
このボタンは、拡張サマリー情報が表示されている場合に表示されます。これを押すと、最小限のサマリー情報が表示されます。 |
「結果」ペイン
「結果」ペインは、上の領域と下の領域に分かれています。上の領域にはアラートに関連付けられたレコードと関係が表示され、下の領域にはアラートの監査証跡が表示されます。
構成方法によっては、「結果」ペインは異なるレイアウトになることがあります。
「監査ログ」ペインの下部にあるタブを使用すると、コメント、添付ファイルまたは状態の履歴のみが表示されるように情報をフィルタリングできます。
「アラート」画面からの移動
「アラート」画面から「ケース」画面に移動して、アラートに関連付けられたケースを表示したり、「フィルタ」または「ブラウザ」画面に戻ることができます。
「ケース」画面に戻るには、ツールバーの「ケースに移動」をクリックします。
「ブラウザ」または「フィルタ」画面に戻るには、「リストに戻る」をクリックします。「ケース」または「アラート」画面に移動するために使用した画面に戻ります。
「ケース」画面を使用して、ケースの状態を表示、割当て、編集および変更します。この画面では、現在アクティブなケースのリストから、一度に1つのケースの詳細が表示されます。現在アクティブなケースのリストには、「ブラウザ」画面または「フィルタ」画面で選択したフィルタによって返されたケースがすべて含まれています。
画面上部のナビゲーション・バーでは、リスト内のケース間を移動したり、ケースのリストに戻ることができます。
画面左側の「サマリー」ペインには、選択したケースの概要が表示され、ケースを編集するためのコントロールがあります。
画面右側の「結果」ペインは、上の領域と下の領域に分かれています。上の領域にはケースに関連付けられたアラートが表示され、下の領域にはケースの履歴が表示されます。
「ケース」画面への移動
「ケース」画面に移動するには、次のようにします。
「ブラウザ」画面または「フィルタ」画面のいずれかの結果パネルのケースをダブルクリックします。選択したケースとしてダブルクリックしたケースとともに、「ケース」画面が開きます。
「アラート」画面で「ケースに移動」をクリックします。
ナビゲーション・バー
次の表に示すように、ナビゲーション・バーにはいくつかの異なるコントロールが含まれています。
表1-20 「ケース」画面のナビゲーション・バーのコントロール
| 要素 | 説明 |
|---|---|
|
リストに戻る |
このボタンを使用して、「ケース」画面から移動し「フィルタ」画面または「ブラウザ」画面に戻ります。 |
|
{X}/{Y}を表示しています |
このコントロールを使用して、ケース間を移動します。外側の2つのボタンを使用すると、それぞれリスト内の最初のケースまたは最後のケースに移動します。内側の2つのボタンを使用すると、リスト内の前のケースまたは次のケースに移動します。ボタン間のキャプションには、現在のケースおよびリスト内のケース数が表示されます。 |
|
ヘルプ |
このボタンを使用して、ケース管理ユーザー・アプリケーションのオンライン・ヘルプを起動します。 |
「サマリー」ペイン
「サマリー」ペインは次の3つのセクションに分かれています。
パネル上部の「現在の状態」セクションでは、ケースの現在の状態と導出状態、ケースの状態を最後に変更したユーザー名および変更した日時が表示されます。
「使用可能なアクション」セクションには、ケースの編集用のコントロールが含まれています。使用可能なコントロールはケースの状態およびセキュリティ権限によって異なるので、ここで表示されるコントロールと異なることがあります。
「サマリー」セクションには、ケースに関する追加情報が含まれています。最小限のサマリー情報を表示するか、拡張バージョンを表示するかを選択できます。
ペインの下部には次の3つのボタンがあります。
|
注意: 「ケースの編集」ボタンは特権機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
表1-21 「サマリー」ペインのボタン
| 要素 | 説明 |
|---|---|
|
ケースの編集 |
このボタンを使用して、ケースの詳細を編集します。 |
|
詳細の表示 |
このボタンは、最小限のサマリー情報が表示されている場合に表示されます。これを押すと、拡張サマリー情報が表示されます。 |
|
詳細を非表示 |
このボタンは、拡張サマリー情報が表示されている場合に表示されます。これを押すと、最小限のサマリー情報が表示されます。 |
「結果」ペイン
「結果」ペインは、上の領域と下の領域に分かれています。上の領域にはケースに関連付けられたアラートが表示され、下の領域にはケースの監査証跡が表示されます。
構成方法によっては、「結果」ペインは異なるレイアウトになることがあります。
「監査ログ」ペインの下部にあるタブを使用すると、コメント、添付ファイルまたは状態の履歴のみが表示されるように情報をフィルタリングできます。監査証跡の状態の変更は編集できませんが、コメントと添付ファイルはこの画面から編集または削除(あるいはその両方)を行うことができます。
「ケース」画面からの移動
「ケース」画面から「アラート」画面に移動したり、「フィルタ」または「ブラウザ」画面に戻ることができます。
「アラート」画面に移動するには、ケースに関連付けられたアラートのいずれかをダブルクリックします。
「ブラウザ」または「フィルタ」画面に戻るには、「リストに戻る」ボタンをクリックします。「ケース」または「アラート」画面に移動するために使用した画面に戻ります。
通常、ケースとアラートは作業データと参照データを照合して作成されます。両方のタイプのデータの情報はケースとアラートにコピーでき、手動決定を実行する際に使用できます。
作業データと参照データの両方は時間によって変化する可能性があります。このような場合、関連アラートは新しいデータで更新されます。ただし、決定を行ったときのままの状態でデータを表示できることは重要です。
これを可能にするために、ケース管理では状態を変更するたびにアラートのデータをアーカイブします。今後、変更がデータに対して行われると、古いデータを使用して行った変更に対して、監査ログでは履歴データ・アイコンが表示されます。
|
注意: フラグ・キー・データへの変更だけでなく、ケース管理を介して渡されたすべてのデータの変更は、履歴データのアーカイブをトリガーできます。 |
状態変更の横の履歴データ・アイコンをクリックすると、別のタブが監査ログの上にある詳細領域で開き、状態変更時のデータを表示します。
この項では、ケース管理で実行される主な操作について説明します。次の3つの主要な項に分かれています。
ケースおよびアラートは、「ケース」または「アラート」画面からそれぞれ編集します。ケースおよびアラートに行える変更は、ケースとアラートの状態、およびユーザーのセキュリティ設定の両方によって異なります。一般的に、ユーザーにアクションを実行するためのセキュリティが正しく設定されていない場合、そのアクションのコントロールはそのユーザーに表示されません。つまり、ここに示されている画面と異なる画面が表示される場合があります。
次のアクションは、これらのヘルプの項で説明します。
ケースまたはアラートの状態を変更するには、「ケース」または「アラート」画面のサマリー・ペイン内の「状態の変更」リンクをクリックします。これにより、「状態の変更」ダイアログが起動されます。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
「状態の変更」ダイアログ
ケースまたはアラートの新規状態を指定するには、次のようにします。
ドロップダウン・リストから、「遷移」を選択します。このリストには、ケースまたはアラートの現在の状態に対して有効な遷移がすべて含まれます。選択した遷移により、ケースまたはアラートの新しい状態が決定されます。
(オプション)状態の変更の理由を示すコメントを追加します。
(オプション)この遷移に適用する1つ以上のテンプレート・コメントを選択します。テンプレート・コメントを使用すると、標準または頻繁に使用するコメントまたは遷移の理由を定義し、同じ詳細を繰返し入力する手間を省けます。テンプレート・コメントを使用するには、ドロップダウン・リストから選択し、プラス・ボタンをクリックしてコメント・ブロックに追加します。テンプレート・コメントは必要な数だけ追加できます。
(オプション)「このコメントを制限します」リストから権限レベルを選択します。権限をコメントに適用すると、この権限を持つユーザーのみにこれが表示されます。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
遷移およびコメントを指定したら、「OK」ボタンをクリックして変更を適用します。状態の変更情報の保存に加えて、ケース管理では、決定の実行時にアラート・データの永続レコードも保存されます。詳細は、「アラート・データのアーカイブ」のトピックを参照してください。
ケースおよびアラートは、リストからの複数選択(「複数選択によるアラートの割当て」を参照)によって、または一括でユーザーに個別に(「単一のアラートまたはケースの割当て」を参照)割り当てることができます。この項では、1つずつ割り当てる、または複数選択によって割り当てる方法について説明します。ケースまたはアラートの一括割当ての詳細は、「一括割当て変更の実行」を参照してください。
|
注意: ユーザーは、ケースまたはアラートが自分に割り当てられていない場合でも、そのケースおよびアラートを編集できます。割当てはケース管理で必須ではありませんが、特に電子メール通知と組み合せて使用すると、業務区分を明確にできます。 |
単一のアラートまたはケースの割当て
単一のアラートまたはケースを割り当てるまたは再度割り当てるには、まず、ケースまたはアラートを開く必要があります。その後、ケースまたはアラートを別のユーザーに割り当てるか、自分に割り当てることができます。
別のユーザーへの割当て
ケースまたはアラートを別のユーザーに割り当てるには、「ケース」または「アラート」画面のサマリー・ペイン内の「割当ての変更」リンクをクリックします。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
これにより、「割当ての変更」ダイアログが起動されます。
「割当ての変更」ダイアログには、割当てを受けることができるユーザーのリストが含まれます。ケースまたはアラートを表示する権限を持たないユーザーは、リストから除外されることに注意してください。ケースまたはアラートをユーザーに割り当てるには、リストからユーザーを選択し、「OK」をクリックします。
ダイアログには、「検索」ボックスも含まれます。リストに多数のユーザーが含まれる場合、検索ボックスに入力してリストをフィルタリングできます。リストは、入力した文字が含まれるユーザー名のみを含むように自動的に更新されます。
自分への割当て
ケースまたはアラートを自分に割り当てるには、「自分の割当て」オプションをクリックします。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
ケースまたはアラートは即座に再割当てされます。
複数選択によるアラートの割当て
ケースまたはアラートのリストを表示する際、リストから多くの項目を選択し、1回のアクションですべてを割当て(または再割当て)できます。
多くのアラートまたはケースをリスト・ビューから割り当てるには、次のようにします。
[Ctrl]または[Shift]を使用して、リスト内の複数の項目を選択します。
上部にあるナビゲーション・バー内の「割当て」ボタンをクリックします。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
これにより、個別のアラートまたはケースの場合と同じように、「割当ての変更」ダイアログが起動されます。アラートの割当て(または再割当て)先のユーザーを選択します。
ケースまたはアラートにコメントを追加するには、「ケース」または「アラート」画面のサマリー・ペイン内の「コメントの追加」リンクをクリックします。これにより、「コメントの追加」ダイアログが起動されます。
「コメントの追加」ダイアログ
ケースまたはアラートにコメントを追加するには、次のようにします。
コメント・ボックスにコメントを入力します。
[オプション]権限レベルを「権限」リストから選択します。権限をコメントに適用すると、この権限を持つユーザーのみにこれが表示されます。
コメントおよびオプションの権限を指定したら、「OK」ボタンをクリックして変更を適用します。
コメントにURL(http://www.example.comまたは単純にwww.example.comなど)が含まれる場合、URLはコメントの表示時に自動的に有効になります。
コメントは、「ケース」または「アラート」画面の「監査ログ」ペインから編集または削除できます。
コメントの削除
コメントを削除するには、コメントのヘッダーにある「削除」ボタンをクリックします。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
コメントを削除してよいかを確認するメッセージ・ボックスが表示されます。続行するには、「OK」を押します。
コメントは削除され、削除は監査ログに記録されます。
コメントの編集
コメントを編集するには、コメントのヘッダーにある「編集」ボタンをクリックします。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
「コメントの編集」ダイアログが表示されます。このダイアログのレイアウトおよびコントロールは、「コメントの追加」ダイアログと同じです。
必要な編集をコメントに行い、「OK」を押して保存します。
|
注意: 編集に関する監査履歴は入力されません。コメントおよび監査証跡はコメントがもともと入力されていたかのように表示されます(コメントは、変更が含まれた状態で表示されるためです)。 |
ケースまたはアラートに添付ファイルを追加するには、「ケース」または「アラート」画面のサマリー・ペイン内の「添付ファイルの追加」リンクをクリックします。これにより、「添付ファイルの追加」ダイアログが起動されます。
「添付ファイルの追加」ダイアログ
ケースまたはアラートに添付ファイルを追加するには、次のいずれかを行います。
「参照」 ボタンをクリックして、添付するファイルを参照します。
添付するファイルを「ファイルをここにドロップします」ラベルにドラッグアンドドロップします。
必要な場合、「説明」ボックスでファイルに関する追加情報を追加し、「権限」リストから権限レベルを選択します。権限を添付ファイルに適用すると、この権限を持つユーザーのみにこれが表示されます。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
ファイルを添付したら、「OK」をクリックして保存します。
添付ファイルは、「ケース」画面および「アラート」画面の「監査ログ」ペインからダウンロード、編集または削除できます。
添付ファイルのダウンロード
添付ファイルをダウンロードするには、ファイル・アイコンまたは名前をクリックします。添付ファイル・ダイアログが起動され、現在の添付ファイルのダウンロードおよび以前に保存されたダウンロードが表示されます。
「ダウンロード時に開く」オプションを選択した場合、ダウンロードが完了すると即座に添付ファイルが自動的に開きます。このオプションを選択しない場合、または保存されている添付ファイルを開く場合、添付ファイルの横にあるファイルを開くアイコンをクリックします。
指定した場所への添付ファイルのコピーの保存
添付ファイル・ダイアログを使用するのではなく、添付ファイルを右クリックして、コンテキスト依存メニューから「別名保存」をクリックして、指定した場所に添付ファイルのコピーを保存できます。
これにより、標準のファイル保存ダイアログが表示され、添付ファイルを保存する場所を選択できます。
添付ファイルの削除
添付ファイルを削除するには、添付ファイルのヘッダーにある「削除」ボタンをクリックします。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
添付ファイルを削除してよいかを確認するメッセージ・ボックスが表示されます。続行するには、「OK」を押します。
添付ファイルは削除され、削除は監査ログに記録されます。
添付ファイルの編集
添付ファイルを編集するには、添付ファイルのヘッダーにある「編集」ボタンをクリックします。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
「添付ファイルの編集」ダイアログが表示されます。このダイアログのレイアウトおよびコントロールは、「添付ファイルの追加」ダイアログと同じです。
必要な編集を添付ファイルに行い、「OK」を押して保存します。
|
注意: 編集に関する監査履歴は入力されません。添付ファイルおよび監査証跡は、添付ファイルが最初から現在表示されているものと同じように作成されていたかのように、変更が含まれた状態で表示されます。 |
ケースまたはアラートの詳細を編集するには、「アラート」画面のサマリー・ペインの下部にある「アラートの編集」リンクをクリックするか、「ケース」画面のサマリー・ペインの下部にある「ケースの編集」リンクを必要に応じてクリックします。これにより、「編集」ダイアログが起動されます。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
「編集」ダイアログ
「編集」ダイアログでは、次のことを行えます。
ケースまたはアラートの説明の編集
ケースまたはアラートの優先順位の設定
ケースまたはアラートのレビュー・フラグの設定
ケースまたはアラートの権限の設定
インストール用に定義されている書込み可能な拡張属性の値の設定。
新しい詳細を指定したら、「OK」ボタンをクリックして変更を適用します。
フィルタはケース管理で使用され、操作しているケースまたはアラート(あるいはその両方)のセットをどの時点でも制御できます。フィルタは「フィルタ」画面で作成、テストおよび削除され、「ブラウザ」画面に公開されます。「ブラウザ」画面で、フィルタをお気に入りとしてマークし、権限がある場合、定義したフィルタを他のユーザーと共有できます。詳細は、次の項を参照してください。
フィルタは、「フィルタ」画面で作成および変更されます。新しいフィルタを最初から作成することも、既存のフィルタを変更して新しい名前で保存することもできます(「フィルタの保存」を参照)。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
フィルタを他の場所で使用した後に「フィルタ」画面に移動する場合、そのフィルタの編集するものと自動的にみなされます。バナーが、「ブラウザ」パネルの上部に表示され、どのフィルタを編集しているかが示されます。
「ブラウザ」パネルから必要な属性および値を選択してアドホック・フィルタを作成し、緑色の矢印を使用して「結果」パネル内でフィルタの結果を表示できます。
フィルタで使用できる属性は、次のセクションに分けられます。
否定またはNullフィルタリング
一部のフィルタ・オプションでは、選択したパラメータ以外のすべての検索、またはパラメータ内のnull値の検索(あるいはその両方)のいずれを行うかを指定できます。これらのオプションは、それぞれ「否定」および「Null」です。
使用可能な場合、これらのオプションへは、パラメータ設定の下の「拡張オプション」 ボタンをクリックしてアクセスできます。
たとえば、「属性」セクションの「状態変更日」パラメータにはこれらの両方のオプションがあります。次の例では、26-Jan-2013から27-Jun-2013までの日付範囲が指定されています。
State Changed On Range From: 26-Jan-2013 11:26 To: 27-Jun-2013 11:26
「状態変更日」の値が指定された日付範囲外であるケースまたはアラートを検索するには、「否定」フィールドをチェックします。
「状態変更日」の値がnullのケースまたはアラートを検索するには、「Null」フィールドをチェックします。Nullオプションは以前に選択した基準をオーバーライドすることに注意してください。
一般
「一般」セクションでは、テキスト検索の実行、ケース・ソースによるフィルタリングおよびケースまたはアラートのみの指定を行えます。3つのサブセクションがあります。
クイック検索(テキストの検索が可能)
タイプ(ケースまたはアラートのいずれか、あるいはその両方を検索するかを指定可能)
ソース(特定のケース・ソースのケースまたはアラート(あるいはその両方)を検索可能)。
クイック検索
クイック検索 では、ケースまたはアラート(あるいはその両方)に関連付けられているテキストを検索できます。説明内のテキスト、コメント、またはケースおよびアラートのキーを検索できます。「検索問合せ」ボックスに検索するテキストを入力し、検索対象フィールドの横にあるボックスを選択します。
「クイック検索」オプションをクリアするには、「クイック検索」サブヘディングの横にある戻り矢印をクリックします。
このフィールドでは、Lucene問合せ構文を使用できます。詳細は、Apache Lucene - Query Parser Syntaxドキュメントを参照してください。
タイプ
タイプでは、ケースまたはアラートのいずれかに検索を制限できます。検索するタイプをクリックします。いずれのタイプも選択されていない場合、ケースとアラートの両方がフィルタによって返されます。
「タイプ」オプションをクリアするには、「タイプ」サブヘディングの横にある戻り矢印をクリックします。
ソース
ソースでは、特定のケース・ソースまたはソースに公開されているケースまたはアラートに検索を制限できます。
検索する結果のケース・ソースをクリックします。ケース・ソース名を選択する際に[Ctrl]ボタンを押したままにすることで、複数のケース・ソースを指定できます。単一のソースを選択することで、ワークフロー状態についてレポートし、ソース属性を検索できます。
「ソース」オプションをクリアするには、「ソース」サブヘディングの横にある戻り矢印をクリックします。
属性
「属性」セクションでは、ケースおよびアラートの標準属性をフィルタリングできます。「属性」セクションは、新規フィルタに対して初期状態では空です。セクション・ヘディングの「属性の追加」ボタンをクリックして、属性セクションにエントリを追加します。使用可能な属性のドロップダウン・リストが表示されます。
|
注意: 同じ属性に対して複数回フィルタリングすることはできません。「属性」セクションに「割当先」エントリがすでに含まれている場合、「割当先」オプションは、ドロップダウン・リストで無効になります。 |
リストで属性を選択すると、それに対するサブセクションが「属性」セクションで作成されます。使用可能なコントロールおよび値は、選択した属性によって異なります。
属性フィルタに使用する値を指定します。
属性に選択した値をクリアするには、サブセクション・ヘディング内の戻り矢印をクリックします。
特定の属性についてのフィルタリングを停止するには、サブセクション・ヘディング内のマイナス記号をクリックします。
データ属性についてのフィルタリング
「日付」属性のフィルタ(「作成日」または「状態変更日」など)は、次のような多くの関数のいずれかを指定して構成します。
次以内 - タイムスタンプが対象となるには、指定した間隔より最近である必要があります。たとえば、現在11:45 amで、フィルタが1時間以内と設定されている場合、10:45 amより後のタイムスタンプのみがフィルタをパスします。
次より古い - タイム・スタンプが対象となるには、指定した間隔より古い必要があります。たとえば、現在11:45 amで、フィルタが1時間より古いと設定されている場合、10:45 amより前のタイムスタンプのみがフィルタをパスします。
日付範囲 - フィルタをパスするには、タイムスタンプは指定した範囲内である必要があります。
今日 - 現在の日付の午前0時以降のタイムスタンプのみが、フィルタをパスします。
|
注意: すべての時刻は、ローカル時刻で表示されます。すべてのフィルタは、時刻がローカル時刻に変換された後に、タイムスタンプに適用されます。サーバーに格納される時刻(および日付)は、異なる場合があります。たとえば、月曜日の23:00GMTは、GMT+4タイムゾーンでは火曜日の03:00です。ケースが、GMTタイムゾーンのサーバーでその時刻で更新された場合、タイムスタンプは月曜日の23:00で格納されます。ただし、火曜日の13:00に今日更新されたケースを検索する、GMT+4タイムゾーン内のユーザーには、そのケースが今日更新されたように表示されます。 |
拡張属性
「拡張属性」セクションでは、ケースおよびアラートの拡張属性をフィルタリングできます。「拡張属性」セクションは、新規フィルタに対して初期状態では空です。セクション・ヘディング内のプラス・ボタンをクリックして、「拡張属性」セクションにエントリを追加します。使用可能な拡張属性のドロップダウン・リストが表示されます。
|
注意: 同じ拡張属性に対して複数回フィルタリングすることはできません。「拡張属性」セクションにエスカレーション・エントリがすでに含まれている場合、エスカレーション・オプションは、ドロップ・ダウン・リストで無効になります。 |
リストで拡張属性を選択すると、それに対するサブセクションが「拡張属性」セクションで作成されます。使用可能なコントロールおよび値は、選択した拡張属性によって異なります。
拡張属性フィルタに使用する値を指定します。
|
注意: 文字列型の拡張属性に対してフィルタリングする場合、完全一致検索のみを実行できます。つまり、拡張属性が値"Test String"に設定されている場合、"Test String"を検索するフィルタによってのみ照合されます。部分文字列を検索することはできず(つまり、"Test"を検索するフィルタでは検出されません)、論理演算子を使用できません(つまり、"Test String OR Help"の検索では、属性が"Test String OR Help"に正確に設定されているレコードのみが返されます)。 |
拡張属性に選択した値をクリアするには、サブセクション・ヘディング内の戻り矢印をクリックします。
特定の拡張属性についてのフィルタリングを停止するには、サブセクション・ヘディング内のマイナス記号をクリックします。
ソース属性
「ソース属性」セクションでは、ケース・ソース内のデータ・ソースの属性に対してフィルタリングできます。
「ソース属性」セクションは、新規フィルタに対して初期状態では空です。セクション・ヘディング内でクリックして、「ソース属性」セクションにエントリを追加します。ケース・ソースに関連付けられているデータ・ソースのディレクトリ・ツリー表示を含む複数選択ボックスが表示されます。
必要に応じて、データ・ソースを選択します。「検索」フィールドを使用して、特定のデータ・ソースを検索することもできます。
このフィールドでは、Lucene問合せ構文を使用できます。詳細は、Apache Lucene - Query Parser Syntaxドキュメントを参照してください。
|
注意: 同じソース属性に対して複数回フィルタリングすることはできません。 |
リストでソース属性を選択すると、それに対するサブセクションが「ソース属性」セクションで作成されます。使用可能なコントロールおよび値は、選択したソース属性によって異なります。
ソース属性フィルタに使用する値を指定します。
ソース属性に選択した値をクリアするには、サブセクション・ヘディング内の戻り矢印をクリックします。
特定のソース属性についてのフィルタリングを停止するには、サブセクション・ヘディング内のマイナス記号をクリックします。
履歴
「履歴」セクションは、ユーザーによってケースに作成された属性またはコメント(あるいはその両方)への変更に基づいてフィルタリングします。
フィールドを使用して、フィルタ条件となるパラメータを選択します。フィールドについては、次の表で説明します。
表1-22 「属性変更履歴」のフィールド
| フィールド | タイプ | 説明 |
|---|---|---|
|
属性 |
単一の選択、検索オプションを含みます。 |
フィルタ条件となる属性のリストです。 |
|
ユーザー |
単一選択。 |
フィルタ条件となるユーザーを指定します。 |
|
アクション日付/時間 |
単一選択のドロップダウンであり、ブランク値がデフォルトです。 |
このフィールドには、デフォルト・ブランク選択を除いて、4つの可能な値があります。
「今日」以外の各オプションを使用すると、ユーザーは期間を指定してその範囲内の属性変更に対して検索できます。たとえば、「次以内」と5日を選択すると、直近の5日間に変更された属性に対してフィルタします。 |
表1-23 「コメント日付」のフィールド
| フィールド | タイプ | 説明 |
|---|---|---|
|
ユーザー |
単一選択。デフォルトは空白値です。 |
フィルタ条件となるユーザーを指定します。 |
|
コメント日付/時間 |
単一選択のドロップダウンであり、ブランク値がデフォルトです。 |
このフィールドには、デフォルト・ブランク選択を除いて、4つの可能な値があります。
「今日」以外の各オプションを使用すると、ユーザーは期間を指定してその範囲内の属性変更に対して検索できます。たとえば、「次以内」と5日を選択すると、直近の5日間に変更された属性に対してフィルタします。 |
許容されている遷移
「許容されている遷移」セクションでは、ユーザーが許可されている遷移別に結果をフィルタリングします。
表1-24 「許容されている遷移」セクション
| フィールド | タイプ | 説明 |
|---|---|---|
|
ユーザー |
単一選択。デフォルトは空白値です。 |
フィルタ条件となるユーザーを指定します。 |
|
遷移 |
単一の選択、検索オプションを含みます。 |
フィルタ条件の遷移を選択してください。 |
たとえば、ユーザーが、"現在のユーザー"と"[分析の]作業の開始"を選択した場合、その遷移を実行できるケースまたはアラート(あるいはその両方)が返されます。
レポート
「レポート」セクションは、フィルタによって返される結果を実際には変更しないため、他のセクションとは異なります。かわりに、「結果」ペインでの結果の表示方法を変更できます。レポーティングの設定が指定されていない場合、結果は簡易リストで表示されます。レポーティングでは、1つ以上の属性の値に従って結果をグループ化できるため、グリッド形式の最初に表示されます。
このレポートには、現在未割当ての3つのケース、ディレクタ管理者ユーザーに割当て済の5つのケース、現在未割当ての11のアラート、およびディレクタ管理者ユーザーに割当て済の7つのアラートが含まれます。
該当のセル内の数値をクリックし、各カテゴリの詳細を調査するためにグリッド結果をドリルダウンできます。
レポーティング・セクションでは、レポートの各軸に対して、1つ以上の属性を選択できます。
たとえば、グリッドの最初(横)の軸に「割当先」を選択し、2番目(縦)の軸に「タイプ」を選択できます。
属性名をクリックする際に[Ctrl]キーを押したままにすることで、各軸に複数の属性を指定できます。
結果は、縦軸の状態およびタイプ別にグループ化されます。
レポート日付
横軸または縦軸に割当て可能ないくつかの日付属性があります。
作成日時
割当日時
変更日時
状態変更日時
フラグ更新日時
状態失効
|
注意: 軸に日付属性を選択した場合、他の属性を選択できません。たとえば、レポートのX軸を作成日時に設定でき、他の必要な属性(タイプ、ソース名など)はY軸に指定する必要があります。 |
日付属性を選択した場合、「集計」 ボタンがアクティブ化されます。このボタンをクリックすると、「集計構成」ダイアログが開き、これは日付範囲の粒度およびオフセットの指定に使用されます。
表1-26 「集計構成」ダイアログ
| フィールド | タイプ | 説明 |
|---|---|---|
|
有効 |
チェック・ボックス(デフォルトでは選択されています) |
このオプションによって、集計を有効または無効にすることができます。範囲ではなく、個別の値でのレポートが必要な場合に、無効にします。 |
|
粒度 |
ドロップダウン・リスト(デフォルト選択は「日」)。 |
このフィールドは、列の計算方法を指定します。たとえば、「日」値は、日付範囲の各日の列を含むレポートを生成します。粒度は、1秒から1年まで設定できます。 |
|
オフセット |
月、日、時間の選択。 |
たとえば、各月の15日から始まる列を含むレポートの生成が必要な場合があります。これらのフィールドは、このようなオフセットの指定に使用されます。 |
|
空白行の非表示 |
チェック・ボックス(デフォルトではクリアされています)。 |
このフィールドは、データを返さない列を非表示にする場合に使用します。 |
フィルタの保存
「保存」ボタンをクリックすると、フィルタ構成が保存されます。既存のフィルタを変更する場合、既存のフィルタ定義を上書きするか、新規フィルタを作成するかを尋ねられます。
「いいえ」を選択すると、新規フィルタ名およびオプションの説明の指定を求められます。
この項では、「ブラウザ」画面からアクセスできる次のフィルタ管理オプションについて説明します。
フィルタの編集
フィルタを編集するには、ブラウザ・リストでフィルタを右クリックします。表示されるオプションから「編集」を選択します。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
これにより、選択したフィルタが編集用に開かれた状態で「フィルタ」画面が開きます。フィルタの定義時に使用可能なオプションの詳細は、「フィルタの作成」を参照してください。
フィルタ名の変更
フィルタ名を変更するには、ブラウザ・リストでフィルタを右クリックします。表示されるオプションから「名前変更」を選択します。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
これにより、フィルタの名前または説明(あるいはその両方)を入力できるダイアログ・ボックスが開きます。
フィルタ名を変更し、「OK」を押します。
フィルタの削除
フィルタを削除するには、ブラウザ・リストでフィルタを右クリックします。表示されるオプションから「削除」を選択します。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
これにより、フィルタを本当に削除するかを確認するメッセージ・ボックスが開きます。
フィルタを削除するには「はい」を押し、フィルタ・リストに戻るには「いいえ」を押します。
お気に入りフィルタの管理
フィルタをお気に入りとしてマークするには、ブラウザ・リストでフィルタを右クリックします。表示されるオプションから「お気に入りに追加」を選択します。
フィルタは黄色の星とともに表示され、お気に入りリストで使用可能になります。
お気に入りからフィルタを削除するには、これを再度右クリックします。今回は、「お気に入りから削除」を選択します。
デフォルト・フィルタの管理
フィルタをデフォルト・フィルタとして設定するには、ブラウザ・リストでフィルタを右クリックします。表示されるオプションから「デフォルト・フィルタとして設定」を選択します。
フィルタは青色の星とともに表示され、ケース管理にログイン後、即座に選択および表示されます。
デフォルト・フィルタを削除するには、フィルタを再度右クリックし、今回はメニューから「デフォルト・フィルタとしての設定解除」を選択します。
フィルタでのケースまたはアラートの一括更新
フィルタ基準を満たすすべてのケースおよびアラートについて、一括更新操作を直接実行できます(たとえば、1つのフィルタでケースおよびアラートを複数のユーザーに割り当てるなど)。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
フィルタで一括更新を実行するには、ブラウザ・リストでフィルタを右クリックします。表示されるオプションから「一括更新」を選択します。
「一括更新」ダイアログが表示されます。使用可能なオプションの詳細は、「一括編集の実行」を参照してください。
フィルタでのケースまたはアラートの一括削除
フィルタ基準を満たすすべてのケースおよびアラートを一括削除できます。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
フィルタですべてのケースおよびアラートを一括削除するには、ブラウザ・リストでフィルタを右クリックします。表示されるオプションから「一括削除」を選択します。
他のユーザーとのフィルタの共有
作成済のフィルタはユーザー・リストに表示されます。自分のフィルタのいずれかを他のユーザーと共有する場合、適切なセキュリティ権限を持っていれば、フィルタをグローバル・リストに移動できます。グローバル・リスト内のフィルタは、ケース管理のすべてのユーザーに表示されます。
|
注意: フィルタがその条件の一部としてケース・ソースを指定している場合、フィルタがグローバルとして作成されていても、そのソースへの権限を持つユーザーのみがこれを表示できます。つまり、フィルタの結果だけではなくフィルタ自体も、セキュリティ設定によって非表示になります。 |
フィルタを共有するには、ユーザー・リストでフィルタを右クリックします。表示されるオプションから「グローバル・フィルタへの移動」を選択します。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
フィルタは、ユーザー・リストからグローバル・リストに移動されます。フィルタがデフォルトとしてマークされているかどうかにかかわらず、他の設定はこの変更によって影響を受けません。
フィルタを「グローバル」リストから削除するには、適切なセキュリティ権限を持っていれば、フィルタを再度クリックして「ローカル・フィルタへの移動」を選択するとこれを行えます。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
フィルタは、グローバル・リストからユーザー・リストに移動されます。他のフィルタ設定はすべて、この変更の影響を受けません。
権限によるフィルタ・アクセスの制限
グローバル・フィルタは権限に関連付けることができます。適切な権限が付与されている場合のみ、フィルタが表示されます。
権限をフィルタに割り当てるには、フィルタを右クリックして、「権限の変更」を選択します。
ドロップ・ダウン・ボックスから適切な権限を選択し、「OK」を押します。
フィルタのインポートおよびエクスポート
フィルタは、環境間で移動するために、ファイルに対してエクスポートおよびインポートできます。
ケース管理フィルタのファイル拡張子は.dflであることに注意してください。
ユーザー・フィルタは、ユーザー・アカウントを使用して格納されます。したがって、同じユーザー・アカウントを使用して異なるマシンにログオンする場合、これらをエクスポートおよびインポートする必要はありません。フィルタのエクスポートおよびインポートの主な目的は、ケース管理をホスティングする新規サーバーに、構成済のグローバル・フィルタを移動することです。
フィルタのインポート
有効なケース管理フィルタ・ファイルからフィルタをインポートするには、グローバル・ノード(フィルタをインポートし他のユーザーと共有する場合)またはユーザー・ノード(自分のためにのみフィルタをインポートする場合)を選択し、「フィルタのインポート」を選択します。
「インポート」ダイアログが表示されます。「参照」を使用して有効なフィルタ・ファイルを参照し、インポートするフィルタのファイルを選択して、「選択」をクリックします。フィルタ・ファイルで使用可能なフィルタのリストを示すダイアログが表示されます。インポートする対象を選択して、「OK」をクリックします。
インポートするフィルタに既存のフィルタと同じ名前のものがある場合、赤色で表示されます。その場合、インポートの取消し、インポートするフィルタの名前変更、またはインポート・ファイル内のフィルタによる既存フィルタの上書きのいずれかを行うことができます。インポートするフィルタ名を変更するには、ダイアログで新しい名前を直接指定します。
「名前が重複しています」のエラーは、フィルタに競合する名前がなくなると表示されなくなります。
または、同じ名前で既存のフィルタを上書きする場合、単純に「上書き」ボックスを選択し、「OK」をクリックします。
フィルタのエクスポート
フィルタ・ファイルへの単一のフィルタのエクスポート、またはグローバル・レベルまたはユーザー・レベルでのすべてのフィルタのエクスポートを行うことができます。
単一のフィルタをエクスポートするには、フィルタを右クリックして、「フィルタのエクスポート」を選択します。
「フィルタのエクスポート」ダイアログが表示されます。エクスポート・ファイルの書込み先を選択するには、「参照」ボタンをクリックします。ファイル名を入力し、「選択」を選択して、フィルタをエクスポートします。
多くのフィルタを単一のファイルにエクスポートするには、グローバル・ノードまたはユーザー・ノードのいずれかを右クリックして、「フィルタのエクスポート」を選択し、前述のプロセスに従います。
「Excelにエクスポート」オプションは、現在のフィルタの結果のエクスポートに使用できます。エクスポート・ファイルの形式は、使用中のフィルタのタイプに依存します。通常のフィルタが選択されている場合、フィルタによって返されるケースまたはアラート(あるいはその両方)のすべての詳細は、Microsoft Excelや他のスプレッドシート・プログラムと互換性のあるカンマ区切り(.csv)形式でエクスポートされます。現在のフィルタが、レポート・グリッドを作成するように構成されている場合、エクスポートはExcel (.xls)ファイルの形式になります。
ケースまたはアラート(あるいはその両方)をエクスポートするには、「ブラウザ」画面または「フィルタ」画面で、「Excelにエクスポート」ボタンを押します。これにより、ファイル・エクスポート・ダイアログが起動されます。
エクスポート・ファイルを格納するディレクトリを参照し、エクスポート・ファイル名を入力します。「OK」をクリックします。選択したケースまたはアラート(あるいはその両方)の詳細は、指定した名前のファイルに、.csv拡張子または.xls拡張子で保存されます。.csvファイル拡張子は、ケースまたはアラートのリストに使用されます。.xls拡張子は、レポートに使用されます。
「一括更新」ダイアログを使用すると、結果ペインに現在表示されているすべてのケースまたはアラート(あるいはその両方)に変更を適用できます。「一括更新」ダイアログでは、次のことを行えます。
グループまたは個人へのすべてのケースまたはアラート(あるいはその両方)の割当て
すべてのケースまたはアラート(あるいはその両方)のエスカレーション、レビュー・フラグ、説明、優先度または権限の編集
ケースまたはアラート(あるいはその両方)のすべてまたは一部の状態の変更。
「一括更新」ダイアログの入力
「一括更新」ダイアログにアクセスするには、「ブラウザ」画面または「フィルタ」画面で、「一括更新」をクリックします。
|
注意: これは権限が必要な機能です。適切なセキュリティ設定がない場合、このコントロールを表示できません。 |
一括割当て変更の実行
「一括更新」ダイアログを使用すると、現在のフィルタによって返されているすべてのケースまたはアラート(あるいはその両方)を1人のユーザーまたはユーザー・グループに割当てできます。また、ケースまたはアラート(あるいはその両方)の割当て解除(つまり、誰にも割り当てない)にも使用できます。
|
注意: 複数のユーザーまたはユーザー・グループに変更セットを割り当てる際、ケースまたはアラート(あるいはその両方)のセットは、指定したすべての個人間で分割されます。各ケースまたはアラートは、単一の特定のユーザーに割り当てられ、共有割当てという概念はありません。 |
ケースまたはアラート(あるいはその両方)の割当てを変更するには、ダイアログの「一括変更の割当て」領域内の必要なユーザーまたはグループ(あるいはその両方)の名前をクリックして選択します。複数のアイテムを選択するには、[Ctrl]キーを押しながら選択します。ケースまたはアラート(あるいはその両方)は、選択したエンティティ間で均等に分割されます。
誰にも割り当てられていないように、ケースまたはアラート(あるいはその両方)を更新するには、「未割当」を選択します。
|
注意: ケースまたはアラートを一括割当てする際、ユーザーおよびグループのリストのフィルタリングは解除されます。ユーザーまたはユーザー・グループは、割り当てているケースまたはアラートの一部またはすべてへの表示権限のないユーザーとして表示される場合があります。ケース管理では、ケースまたはアラートは、表示権限を持たないユーザーに割り当てられませんが、すべてのケースまたはアラートの割当てが試みられます。たとえば、2人のユーザーを選択し、そのうち1人にしかケースまたはアラートの表示権限がない場合、ケースまたはアラートは権限を持つユーザーに常に割り当てられます。一括更新において、いずれのユーザーにもケースまたはアラートの表示権限がない場合、再割当てされません。 |
ケース別のグループ割当て
ケースまたはアラート(あるいはその両方)のセットを複数のユーザーに割り当てる場合、単一のケース内のすべてのアラートおよびケース自体が同じユーザーに割り当てられるようにする場合があります。これを行うには、割当て先の下にある「ケース別のグループ割当て」をチェックします。
ユーザーおよびグループのリストのフィルタリング
「一括変更の割当て」領域の下部には検索ボックスが含まれており、これを使用すると、割当てに使用可能なユーザーおよびグループのリストをフィルタリングできます。ボックスへの入力を開始するとすぐに、入力した文字を含む名前のみが表示されるようにリストがフィルタリングされます。検索ボックスからすべてのコンテンツを削除するか、検索ボックスの横に表示される「x」をクリックすることで、フィルタを削除できます。
一括属性変更の実行
「一括更新」ダイアログでは、現在のフィルタによって返されたケースまたはアラート(あるいはその両方)すべての次の様々な属性値を変更できます。
エスカレーション;
レビュー・フラグ
説明;
優先度;
権限。
これらの属性の新しい値は、「一括更新」ダイアログの右側上部にある「一括編集」領域で設定されます。
属性のいずれかに新しい値を追加するには、ボックスの下にある「+」ボタンをクリックして、リストから属性を選択します。これにより、選択した属性に新規値を指定できるダイアログが起動されます。属性値を入力したら、「OK」をクリックします。このプロセスを繰り返して、必要な数の属性に対して新しい値を設定できます。属性およびその新しい値は、「一括編集」ボックスに表示されます。
一括編集設定を削除するには、リスト内で設定をクリックして「一括編集」ボックスの下にある「-」ボタンを押します。
必要な変更をすべて行ったら、ここおよび画面内の他の領域で「OK」をクリックします。
一括状態変更の実行
「一括更新」ダイアログを使用すると、アクティブ・フィルタによって返されたケースまたはアラートの一部またはすべての状態を変更できます。「一括変更の状態」リストにエントリを追加することで、状態変更を行えます。
一括状態変更は、ケースまたはアラートの開始状態に依存するため、他の一括編集とは異なります。一括状態変更は、ケース・ソースのワークフローに定義されている有効な状態遷移を順守する必要があります。このため、次のようになります。
一括状態変更は、ケース・ソースを指定するフィルタによって返されたケースまたはアラートにのみ実行できます。
一括状態変更は、ケースとアラートの両方ではなく、そのいずれかを返すフィルタにのみ実行できます。
一括状態変更は、開始状態に基づいて定義されます。現在2つの状態「クローズ済 - 一致なし」および「クローズ済 - 一致確認」のいずれかであるケースのセットを編集していると仮定します。自分のすべてのケースの状態を「再レビュー要」に変更する場合、2つの一括状態変更(「クローズ済 - 一致なし」状態のケース用および「クローズ済 - 一致確認」状態のケース用)を定義する必要があります。
リストにエントリを追加するには、その下にある「+」ボタンを押します。これにより、「一括更新」ダイアログが表示され、ここでは、このエントリによって影響を受けるケースまたはアラートの開始状態およびこれらに適用される遷移を指定できます。最初に開始状態を選択し、次に「新規状態」をクリックして、「状態の変更」ダイアログを起動します。
現在開始状態であるすべてのケースまたはアラートに適用する遷移を選択します。また、当初の状態変更に行った方法と同じ方法でコメントを追加することもできます。適用する遷移およびコメントを選択したら、「OK」をクリックします。次に、「OK」を再度クリックして、「一括更新」ダイアログを終了します。定義した一括状態変更がリストに表示されます。リストから変更を削除するには、変更の横にある「-」ボタンを押します。必要な変更をすべて行ったら、ここおよび画面内の他の領域で「OK」をクリックします。
「一括更新」ダイアログを使用すると、現在のフィルタに一致するすべてのケースまたはアラート(あるいはその両方)を削除できます。
すべてのケースまたはアラート(あるいはその両方)を削除するには、「ブラウザ」画面または「フィルタ」画面で、「一括削除」ボタンを押します。
警告メッセージが表示されます。
This will delete all items that match the currently configured filter. Warning: If other bulk updates or deletes are occuring this action will not take place until after these and therefore the results of the filter may be different.
削除を続行するには、「OK」をクリックします。これを行わない場合は、「取消」をクリックします。
ケース管理の管理アプリケーションは、EDQスイートのアプリケーションの一部です。「ケース管理の管理」で提供される機能の3つの主要領域は、次のとおりです。
「ケース管理の管理」の「ワークフロー管理」セクションでは、ワークフローを作成、編集、コピー、インポート、エクスポートおよび削除できます。
ワークフロー管理へのアクセス
「ワークフロー管理」ダイアログを開くには、「ケース管理の管理」のメイン画面にある「ワークフロー管理」オプションをダブルクリックします。
「ワークフロー管理」ダイアログには、定義済ワークフローのリストが表示されます。
この画面では、次の操作ができます。
ワークフローの作成、
ワークフローの編集、
ワークフローのコピー、
ワークフローのエクスポート、
ワークフローのインポートおよび
ワークフローの削除。
ワークフローの作成
新しいワークフローを作成するには、「新規」をクリックします。ワークフロー・エディタが開きます。
ワークフローの編集
既存のワークフローを編集するには、ワークフローのリストで編集するワークフローをクリックして選択し、「編集」をクリックします。ワークフロー・エディタが開きます。
ワークフローのコピー
既存のワークフローをコピーするには、「複製」をクリックします。ワークフロー・エディタが開きます。
ワークフローの新しいコピーに名前を指定する必要があります。同時に、ワークフローに必要な変更を指定することもできます。
ワークフローのエクスポート
ワークフロー定義をエクスポートするには、ワークフローの名前をクリックして「エクスポート」をクリックします。
エクスポートをEDQランディング領域に保存する場合は、ファイル名の指定のみが必要ですが、選択した場所に保存する場合は、適切な場所を参照してファイル名を指定する必要があります。
選択に対応するラジオ・ボタンをクリックします。
クライアント・ファイルに保存する場合は、省略記号(「...」)ボタンを使用して適切な場所を参照します。
エクスポート・ファイルのファイル名を指定します。ターゲット・ファイルがすでに存在する場合(クライアント・ファイルを保存する場合)はターゲット・ファイルをクリックし、またはファイル名領域にファイル名を入力して、ファイル名を指定できます。エクスポート処理によって、適切な拡張子(.dxic)が自動的に指定されます。
「OK」をクリックします。
ワークフローがエクスポートされます。ワークフローで動的権限が使用される場合は、ワークフローとともにそれらもエクスポートされます。
ワークフローのインポート
ワークフローをインポートするには、「インポート」をクリックします。
EDQランディング領域からインポートする場合は、ファイル名の指定のみが必要ですが、選択した場所からインポートする場合は、適切な場所を参照してファイル名を指定する必要があります。
選択に対応するラジオ・ボタンをクリックします。
クライアント・ファイルからインポートする場合は、省略記号(「...」)ボタンを使用して適切な場所を参照します。
インポート・ファイルのファイル名を選択または指定します。ファイル名をクリックするか(クライアント・ファイルからインポートする場合)、ファイル名領域にファイル名を入力して、ファイル名を指定できます。
「OK」をクリックします。
ワークフローがインポートされます。インポート・ファイルに動的権限が含まれている場合は、ワークフローとともにそれらもインポートされます。
インポート・ファイルで指定したワークフローの名前がすでに存在するワークフローと同じ場合は、上書きするかどうかを尋ねられます。インポート・ファイルに含まれる1つ以上の権限のキーがすでに存在する権限のキーと同じ場合、既存の権限は上書きされません。
|
注意: ワークフローを正常にインポートできるのは、インポートに使用しているのと同じバージョンのEDQからワークフローがエクスポートされた場合のみです。 |
ワークフローの削除
ワークフローを削除するには、ワークフローの名前をクリックし、「削除」ボタンを押します。ワークフローが削除される前に、処理の確認を求められます。
|
注意: 使用中のワークフローを削除できます。 |
ワークフロー・エディタを使用して、ケースおよびアラートのワークフローを定義および編集します。ユーザーは次のことができます。
ワークフローの状態および遷移の定義。
ワークフローの受信ルールの定義。
ワークフローのパラメータの定義。
現在のワークフローを保存して、ケース管理の管理に戻らずに、ワークフロー・エディタ内から他のワークフローを開いて編集し、新しいワークフローを作成することもできます。
ナビゲーション
ワークフロー・エディタのトップ・レベルには、エディタから移動せずに複数のワークフローを続けて編集できる機能がいくつかあります。
「新規ワークフロー」ボタン(または「ファイル」|「新規」メニュー項目)を使用して、新しいワークフローの作成を開始します。
「開く」ボタン(または「ファイル」|「開く」メニュー項目)を使用して、既存のワークフローを開きます。
「保存」ボタン(または「ファイル」|「保存」メニュー項目)を使用して、エディタから移動する前に、現在編集しているワークフローへの変更を保存します。
ワークフロー・エディタには、現在編集しているワークフローの名前と説明も表示されます。
「状態」タブ
ワークフロー・エディタの「状態」および「遷移」タブには、ワークフローに定義されている状態と遷移が表示されます。「状態」リストの各状態には、割り当てられている遷移と自動失効時間(構成されている場合)のリストも表示されます。すべてのワークフロー・エディタ画面と同様に、ダイアログの上部にはワークフローの名前と説明が表示されます。
たとえば、「Case Generator Default」ワークフローを編集するとします。このワークフローには、5つの状態と4つの遷移が定義されています。現在選択されている「Open」と呼ばれる状態には、「toInProgress」と「toResolved」という2つの関連する遷移があります。各遷移には、その名前およびターゲットの状態(大カッコ内)の両方が表示されます。また、「Open」状態には、4時間後に自動的に失効することを示すマーカーが付けられています。
状態は、この画面から追加、編集または削除できます。
状態を追加するには、「状態」リストの下にある「追加」ボタンを押します。
状態を編集するには、「状態」リストで選択して「編集」ボタンを押します。
状態を削除するには、「状態」リストで選択して「削除」ボタンを押します。処理を進める前に、削除の確認を求められます。状態を削除すると、その状態への遷移もすべて削除されます。
既存の状態の編集または新規状態の作成の詳細は、「状態の定義」のトピックを参照してください。
遷移は、この画面から追加、編集または削除できます。
遷移を追加するには、「状態」リストの下にある「追加」ボタンを押します。
遷移を編集するには、「状態」リストで選択して「編集」ボタンを押します。
遷移を削除するには、「状態」リストで選択して「削除」ボタンを押します。処理を進める前に、削除の確認を求められます。
既存の遷移の編集または新規遷移の作成の詳細は、「遷移の定義」のトピックを参照してください。
デフォルトの状態
ワークフローでは、ケースまたはアラートの作成時にそれらに割り当てるデフォルトの状態も定義する必要があります。ワークフローにデフォルトの状態を設定したり、ワークフローのデフォルトの状態を変更するには、「状態」リストで目的のデフォルトの状態をクリックし、「デフォルトとして設定」ボタンを押します。
「受信」タブ
受信ルールでは、ケースおよびアラートが最初に作成されたとき、またはこれらに添付したデータ(ケース・ソースの一部である属性の値)が更新されたときに、ワークフローでケースおよびアラートが処理される方法を指定します。
「受信」タブには、各ケースまたはアラートに適用可能なアクションと、そのアクションで使用するように定義されている遷移がリストされます。「受信」タブで構成されている遷移は、ワークフロー自体で構成されている遷移とは異なります。受信の遷移は、ディレクタ・ジョブによってケース管理で作成または更新されるケースまたはアラートの自動受信ルールで使用されます。
たとえば、「Match Default」ワークフローを編集するとします。このワークフローには、3つのアクションと1つの遷移が定義されています。現在選択されている「New case」と呼ばれるアクションには、「initial」という関連する遷移があります。各遷移には、その名前およびターゲットの状態(大カッコ内)の両方が表示されます。
アクションは、この画面から追加、編集または削除できます。
アクションを追加するには、「アクション」リストの下にある「追加」ボタンを押します。
アクションを編集するには、「アクション」リストで選択して「編集」ボタンを押します
アクションを削除するには、「アクション」リストで選択して「削除」ボタンを押します。処理を進める前に、削除の確認を求められます。
既存のアクションの編集または新規アクションの作成の詳細は、「アクションの定義」のトピックを参照してください。
遷移は、この画面から追加、編集、複製または削除できます。
遷移を追加するには、「状態」リストの下にある「追加」ボタンを押します。
遷移を編集するには、「状態」リストで選択して「編集」ボタンを押します。
遷移を複製するには、「状態」リストで選択して「複製」ボタンを押します。
遷移を削除するには、「状態」リストで選択して「削除」ボタンを押します。処理を進める前に、削除の確認を求められます。
既存の遷移の編集または新規遷移の作成の詳細は、「遷移の定義」のトピックを参照してください。
「パラメータ」タブ
パラメータは、ワークフローの一部として定義されます。照合プロセッサの追加情報を、その照合プロセッサから生成されたケースおよびアラートに渡すために使用されます。ワークフローを使用する各照合プロセッサでは、パラメータ値の移入方法を定義できます。次に、ワークフローでそれらのパラメータの使用方法を定義します。
ワークフローでは、パラメータ値を使用して、ケースおよびアラートの属性および拡張属性を移入します。パラメータ値が検査および使用されるのは、次の場合です。
遷移が発生した場合
状態が失効した場合
|
注意: 照合プロセッサによるパラメータの移入方法とケースまたはアラート・ワークフローでの値の使用方法の両方を構成する必要があります。属性および拡張属性にパラメータ値が自動的に移入されることはありません。 |
「パラメータ」タブには、現在のワークフローに定義されているパラメータ、および存在するグローバル・パラメータがリストされます。
パラメータは、このタブから作成、編集および削除できます。
パラメータを追加するには、「パラメータ」リストの下にある「+」ボタンを押します。
パラメータを編集するには、「パラメータ」リストでパラメータをダブルクリックします。
パラメータを削除するには、「パラメータ」リストでこれを選択して「-」ボタンを押します。
既存のパラメータの編集または新規パラメータの作成の詳細は、「パラメータの定義」のトピックを参照してください。
グローバル・パラメータ
グローバル・パラメータは、「パラメータ」リストで「グローバル」ラベルでマークされます。グローバル・パラメータはすべてのワークフローで使用できますが、ユーザーが構成することはできません。
matchPriorityScoreパラメータ
matchPriorityScoreパラメータは、パラメータは自動的に移入されないというルールの例外です。照合プロセッサは、matchPriorityScoreと呼ばれるパラメータを自動的に認識して移入します。matchPriorityScoreパラメータには、アラート内のレコード間の関係を識別するために使用された一致ルールの優先度スコアが移入されます。アラートに複数の関係が含まれる場合は、アラート内で最も高い優先度スコアがパラメータの移入に使用されます。
matchPriorityScoreに意味のある値を持たせるには、照合プロセッサを構成する際に注意が必要です。具体的には、次のとおりです。
一致ルールには、一致の強度を反映する優先度スコアを割り当てる必要があります。
一致ルールの順序は、同じペアのレコードが2つのルール両方を満たす場合、リスト内で強度が高いルールが低いルールよりも前に表示されるように順序付けする必要があります。一致ルールはリストされている順序で適用され、特定のペアのレコードが満たした最初のルールがレコード間の関係を作成するために使用されます。つまり、高い一致を表すルールが低い一致を表すルールよりもリストの下にある場合は、関係には低い一致のみが表され、見かけのmatchPriorityScoreはそれに応じて低くなります。
|
注意: EDQは、本質的にはスコアベースの一致システムではありませんが、スコアベースと同様に動作するように構成できます。一致ルールが正確に構成されている場合は、matchPriorityScoreパラメータを使用して、アラートによって表される一致の相対的な信頼度を示すことができます。 |
ケース管理の管理の「ケース・ソース管理」セクションでは、ケース・ソース定義をインポート、エクスポートおよび削除できます。
|
注意: ケース・ソースはケース管理の管理では定義されません。ケース・ソースは、EDQ内でケース管理を使用するように照合プロセッサを構成する際に定義します。ケース・ソースの作成の詳細は、「ケース・ソースの構成」を、ケース管理を使用する照合プロセッサの構成の詳細は、「ケース管理を使用する照合プロセッサの構成」を参照してください。 |
ケース・ソース管理へのアクセス
「ケース・ソース管理」をダブルクリックします。「ケース・ソース管理」ダイアログに、定義されているケース・ソースのリストが表示されます。この画面では、次の操作ができます。
ケース・ソース定義のエクスポート
ケース・ソース定義のインポート
ケース・ソース定義の複製および
ケース・ソース定義の削除。
ケース・ソース定義のエクスポート
ケース・ソース定義をエクスポートするには、次のようにします。
ケース・ソースを選択して、「エクスポート」をクリックします。
次のいずれかです。
ファイルをカスタム・ファイル名で特定の場所に保存するか、
ファイルをデフォルトのファイル名でランディング領域に保存します。
「OK」をクリックします。ケース・ソースがエクスポートされます。
|
注意: ケース・ソースで動的権限が使用される場合は、ケース・ソースとともにそれらもエクスポートされます。ケース・ソースのエクスポートには、flags.xmlも含まれます。これは、ケース管理インスタンスで使用される拡張属性のセットを定義するファイルです。これらの属性をカスタマイズするには、oedq_local_home/casemanagementディレクトリでflags.xmlファイルのバージョンを編集します。 |
ケース・ソース定義のインポート
ケース・ソース定義をインポートするには、「インポート」ボタンを押します。
EDQランディング領域からインポートする場合は、ファイル名の指定のみが必要ですが、選択した場所からインポートする場合は、適切な場所を参照してファイル名を指定する必要があります。
必要なラジオ・ボタンをクリックします。
クライアント・ファイルからインポートする場合は、「参照」(「...」)を使用して適切な場所を参照します。
インポート・ファイルのファイル名を選択または指定します。ファイル名をクリックするか(クライアント・ファイルからインポートする場合)、ファイル名領域にファイル名を入力して、ファイル名を指定できます。
「OK」をクリックします。
ケース・ソース定義がインポートされます。インポート・ファイルに動的権限が含まれる場合は、ケース・ソースとともにそれらもインポートされます。
|
注意: サーバーのflags.xmlファイルも、ケース・ソースでエクスポートされたバージョンで上書きされます。このため、保持するflags.xmlに変更が加えられた場合、ケース・ソースをインポートする前にサーバー上で既存のflags.xmlのコピーをとって、ケース・ソースのインポート後に変更内容(ケース・ソースがエクスポートされたシステムに存在しなかったその他の拡張属性など)を再適用できるようにすることが必要な場合があります。 |
インポート・ファイルで指定したケース・ソースの名前がすでに存在するケース・ソースと同じ場合は、上書きするかどうかを尋ねられます。インポート・ファイルに含まれる1つ以上の権限のキーがすでに存在する権限のキーと同じ場合、既存の権限は上書きされません。
|
注意: ケース・ソースを正常にインポートできるのは、インポートに使用しているのと同じバージョンのEDQからケース・ソースがエクスポートされた場合のみです。 |
ケース・ソース定義の複製
ケース・ソース定義を複製するには、次のようにします。
ケース・ソースを選択して、「複製」をクリックします。「複製」ダイアログが表示されます。
必要に応じてフィールドを編集します。同じ名前のケース・ソースを2つ持つことはできないため、「ソース名」フィールドを編集する必要があります。
「OK」をクリックします。ケース・ソースが複製されます。
ケース・ソース定義の複製
ケース・ソース定義を削除するには、ケース・ソースの名前をクリックして「削除」をクリックします。ケース・ソースが削除される前に、処理の確認を求められます。
使用中のケース・ソースは削除できません。
権限は、ケース管理の管理の「権限」セクションで定義して管理します。「権限管理」ダイアログを開くには、ケース管理の管理のメイン画面にある「権限管理」オプションをクリックします。
「権限管理」ダイアログには、定義済権限のリストが表示されます。
この画面では、次の操作ができます。
権限の作成、
権限の編集、および
権限の削除。
|
注意: 権限は、ケース・ソースやワークフローと同じ方法ではエクスポートまたはインポートされません。かわりに、権限はケース・ソースやワークフローに関連付けられて、それらとともにエクスポートおよびインポートされます。 |
権限の作成
権限を作成するには、「新規」をクリックします。
「権限の追加」ダイアログでは、新しい権限のキーおよび名称を入力する必要があります。オプションで、権限の詳細な説明を追加することもできます。
キーは一意で、権限の内部識別子です。多くの場合、キーには名前と同じ値を設定できます。
名前は、判読可能な権限の名前です。名前に指定する値は、EDQおよびケース管理の他の領域で権限を識別するために使用されます。
説明はオプションのテキスト・ブロックで、権限に関連付ける追加情報(権限の使用目的など)を指定するために使用できます。
必要な情報を指定したら、「OK」をクリックします。
権限の編集
権限を編集するには、「編集」ボタンを押します。編集対象として選択した権限の現在の情報が移入された、権限ダイアログが表示されます。
このダイアログで、権限の名前または説明(あるいはその両方)を編集できます。
|
注意: 権限の作成後はキーを編集できません。 |
選択に対応するラジオ・ボタンをクリックします。
クライアント・ファイルからインポートする場合は、省略記号(「...」)ボタンを使用して適切な場所を参照します。
インポート・ファイルのファイル名を選択または指定します。ファイル名をクリックするか(クライアント・ファイルからインポートする場合)、ファイル名領域にファイル名を入力して、ファイル名を指定できます。
権限の適切な詳細を入力した後、「OK」をクリックします。
権限の削除
権限を削除するには、権限の名前をクリックし、「削除」ボタンを押します。権限が削除される前に、処理の確認を求められます。
|
注意: 使用中の権限を削除できます。 |
状態は「状態」ダイアログで定義しますが、これは、「ケース管理の管理」内の「ワークフロー・エディタ」にある「状態」タブからアクセスできます。新しい状態を作成する場合は「状態」リストの下にある「追加」ボタンを押し、状態を編集する場合は既存の状態をダブルクリックして、ダイアログを開きます。
「状態」ダイアログは、2つのメイン領域で構成されています。
画面の上部は、遷移の基本属性を設定するために使用します。
画面の下部には2つのタブがあります。状態に遷移を割り当てるための「遷移」タブと、状態に自動失効設定を定義するための「状態失効」タブです。
これらの各セクションの詳細は、後述の説明を参照してください。状態の属性をすべて定義した後は、「OK」ボタンを押して変更内容を保存します。
基本構成
画面のこの部分では、状態の名前と説明を定義します。
名前は必須で、ユーザー・インタフェースの他の部分でこの状態を識別するために使用されます。記憶しやすい意味のある値を指定する必要があります。
説明はオプションです。このフィールドを使用して、状態の使用に関する詳細を示す長い情報を入力できます。
「遷移」タブ
このタブは、状態に遷移を割り当てるために使用します。状態に割り当てる遷移では、ケースまたはアラートがその状態から移動できる有効な方法と、状態が変更されたときにケースまたはアラートの属性設定に対して行う変更を定義します。
「使用可能」リストには、現在のワークフローに定義されていて別の状態に遷移しているか、状態に現在割り当てられていない遷移がすべて表示されます。
「選択済」リストには、状態に現在割り当てられているすべての遷移が表示されます。
遷移をリスト間で移動するには、次のいずれかの方法を使用します。
遷移をダブルクリックして、リスト間で移動します。
1つ以上の遷移をクリックして選択し、矢印ボタンを使用してリスト間で移動します。リストで複数の項目を選択するには、それらをクリックするときにキーボードの[Ctrl]キーを押します。
二重矢印ボタンを使用して、リスト内のすべての項目をリスト間で移動します。
「状態失効」タブ
このタブは、状態の失効設定を構成するために使用します。失効設定はオプションで、状態の失効時に実行するアクションを指定します。アクションには、ケースまたはアラートに遷移を適用すること、またはいずれかの属性または拡張属性の値を変更することなどがあります。
状態の失効は自動化でき、その場合、デフォルトでは指定した間隔の後に状態が自動的に失効します。ケース管理で個々のケースまたはアラートに失効間隔を手動で設定することもできます。ケースまたはアラートの状態で状態失効が有効になっていないかぎり、ケースまたはアラートに失効間隔を設定できません。
「有効」チェック・ボックスでは、この状態に対して状態失効をアクティブにするかどうかを指定します。このボックスが選択されていない場合、この状態に対して失効設定を指定できません。この状態のケースまたはアラートは自動的に失効せず、失効時間を手動で入力することもできません。
「遷移」ドロップダウン・ボックスでは、状態の失効時にケースまたはアラートに適用する遷移を指定できます。これにより、特定の期間後に、ケースまたはアラートがある状態から別の状態に自動的に移動するようにワークフローを構成できます。遷移を状態失効の一部として指定するのはオプションです。
「自動失効」チェック・ボックスでは、特定の時間間隔後に状態が自動的に失効するかどうかを指定できます。選択されていない場合、時間間隔を指定できません。状態に対して失効を有効にしていても、自動失効の時間間隔を指定しない場合、この状態のケースまたはアラートは自動的に失効されませんが、ケース管理で自動的に失効できます。
「時間間隔」フィールドでは、状態の失効時間を分単位で指定できます。ここで値を指定できるのは、自動失効が有効化されている場合のみです。
ケース属性リストおよび拡張属性リストには、状態の失効時にケースまたはアラートの属性および拡張属性に対して行われる変更が表示されます。上のボックスには、ケースまたはアラートの属性に対する変更が表示され、下のボックスには、拡張属性に対する変更が表示されます。
前述のダイアログに表示された状態の失効設定は、次のことを示しています。
240分後に自動的に失効します。
状態の失効時に適用する遷移は指定されていません。
状態の失効時にいずれのケース属性も変更されません。
状態が失効したときに、「エスカレーション」フラグの値が「true」に設定されます。
属性アクションおよび拡張属性アクションの定義
属性リストおよび拡張属性リストには、状態の失効時に属性および拡張属性に対して行われる変更が表示されます。
いずれかのリストにアクションを追加するには、リストの下にある「+」ボタンをクリックします。既存のアクションを編集するには、ダブルクリックします。アクションを削除するには、リストでクリックし、リストの下にある「-」ボタンを押します。
いずれかの種類のアクションを追加または編集するダイアログで必要なのは、属性または拡張属性とその新しい値の指定のみです。属性の新しい値の入力に使用されるコントロールは、属性のタイプに応じて変化します。
属性と必要な値を設定した後に、「OK」をクリックします。
遷移は「遷移」ダイアログで定義しますが、これは、「ケース管理の管理」内の「ワークフロー・エディタ」にある「状態」タブまたは「受信」タブからアクセスできます。「遷移」リストの下にある「追加」をクリックして新しい遷移を作成するか、既存の遷移をダブルクリックして編集します。
ダイアログの上部には、2つのフィールドがあります。遷移の名前を入力する「名前」(必須)と「説明」(オプション)です。
残りの「遷移」ダイアログは、2つのタブに分かれています。
遷移詳細 - 遷移自体の詳細、つまり基本構成の詳細、遷移の制限、属性および拡張属性です。
コメント - 遷移の行われるときに追加されるコメントの構成。
これらの各セクションについては、後述の説明を参照してください。
遷移の属性をすべて定義した後は、「OK」ボタンを押して変更内容を保存します。
基本構成
画面のこの部分では、遷移の名前と説明、およびターゲットの状態と権限を定義します。
表1-27 基本構成のフィールド
| フィールド | タイプ | デフォルト | 説明 |
|---|---|---|---|
|
有効 |
チェックボックス |
選択済 |
遷移を有効または無効にするために使用します。 |
|
終了状態 |
ドロップダウン |
空 |
ケースまたはアラートの変更先の状態。必須。 |
|
権限 |
ドロップダウン |
<未選択> |
権限が設定されている場合、この権限が付与されているユーザーのみ遷移を使用できます。オプション。 |
|
条件 |
フリー・テキスト・フィールド(Javascript形式) |
空 |
オプション・フィールドで、ユーザーが遷移を使用できる条件を指定します。詳細は、「条件の定義」を参照してください。 |
遷移制限
この領域は、2つのフィールドで構成されます。
遷移のブロック中 - このフィールドにリストされた遷移のいずれかを以前に実行した場合、その遷移はブロックされます。
遷移のブロックのクリア - 遷移が実行されると、このフィールドにリストされた遷移のブロックはクリアされます。
属性および拡張属性
タブのこの部分には、遷移の使用時に、遷移によってケースまたはアラートの属性および拡張属性に行われる変更が表示されます。上は属性のフィールド、下は拡張属性のフィールドです。
いずれかのリストにアクションを追加するには、リストの下にある「+」を押します。既存のアクションを編集するには、ダブルクリックします。アクションを削除するには、選択して、リストの下にある「-」をクリックします。
「名前」および「値」フィールドで必要な値を選択し、「OK」をクリックして保存します。
コメント
遷移は、ケースまたはアラートに適用されるときにコメントの入力を必須とするように構成できます。遷移が使用される最も一般的なシナリオに対応するデフォルト・コメント、および他の一般的なシナリオのための1つ以上のテンプレート・コメントを定義することもできます。
表1-28 「コメント」のフィールド
| フィールド | タイプ | デフォルト | 説明 |
|---|---|---|---|
|
必須? |
チェックボックス |
未選択 |
この遷移をケースまたはアラートに適用する際に、コメントを入力する必要があるかどうかを決定します。選択した場合、コメントは必須です。 |
|
デフォルト |
フリー・テキスト |
空 |
この遷移の使用時に表示される、デフォルト・コメントのテキストを記録するために使用します。 |
|
テンプレート |
リスト・ボックス |
空 |
この遷移に定義されているテンプレート・コメントが表示されます。 テンプレートを追加するには、リストの下にある「+」を押します。 テンプレートを編集するには、ダブルクリックします。 テンプレートを削除するには、選択して、リストの下にある「-」を押します。 |
「テンプレートの追加」および「テンプレートの編集」ポップアップ・ダイアログは、フリー・テキスト・フィールドです。必要に応じてテキストを入力/編集して、「OK」をクリックします。
アクションは「アクション」ダイアログで定義しますが、これは、「ケース管理の管理」内の「ワークフロー・エディタ」rにある「受信」タブからアクセスできます。新しいアクションを作成する場合は「アクション」リストの下にある「追加...」ボタンをクリックし、アクションを編集する場合は既存のアクションをクリックして「編集」ボタンをクリックします。
「アクション」ダイアログには次のフィールドがあります。
名前は必須で、ユーザー・インタフェースの他の部分でこのアクションを識別するために使用されます。記憶しやすい意味のある値を指定する必要があります。
説明はオプションです。このフィールドを使用して、アクションの使用に関する詳細を示す長い情報を入力できます。
条件はJavaScript式で指定され、受信ルールで評価するすべてのケースまたはアラートを評価します。アクションは、ケースまたはアラートについて条件がtrueと評価された場合に、そのケースまたはアラートにのみ適用されます。条件の指定はオプションで、条件が指定されていない場合、アクションはすべての新しいケースおよびアラート、および添付データ(ケース・ソースに含まれる任意の属性の)が変更されたすべてのケースまたはアラートに適用されます。条件の定義の詳細は、「条件の定義」のトピックを参照してください。
「遷移」フィールドでは、アクションの一部として遷移をケースまたはアラートに適用するように指定できます。遷移の指定はオプションです。
ケースの属性リストおよび拡張属性リストには、このアクションの適用時にケースまたはアラートの属性および拡張属性に対して行われる変更が表示されます。上のボックスには、ケースまたはアラートの属性に対する変更が表示され、下のボックスには、拡張属性に対する変更が表示されます。
属性アクションおよび拡張属性アクションの定義
属性リストおよび拡張属性リストには、アクションの適用時に属性および拡張属性の値に対して行われる変更が表示されます。
いずれかのリストにアクションを追加するには、リストの下にある「+」ボタンを押します。既存のアクションを編集するには、ダブルクリックします。アクションを削除するには、リストでクリックし、リストの下にある「-」ボタンを押します。
いずれかの種類のアクションを追加または編集するダイアログで必要なのは、属性または拡張属性とその新しい値の指定のみです。属性の新しい値の入力に使用されるコントロールは、属性のタイプに応じて変化します。
属性と必要な値を設定した後に、「OK」を押します。
例 - プロパティの設定
最も高い一致を最初に処理する必要があるというビジネス要件があるとします。一致優先度スコアが85以上のアラートは高優先度として処理する必要があり、エスカレーション・フラグも設定します。一致優先度スコアが75から84の間のアラートは、中優先度です。
たとえば、matchPriorityScoreの値が85以上の場合は、新しいケースに対して優先度を「高」に設定し、エスカレーション・フラグを「true」に設定する受信ルールを構成するとします。
matchPriorityScoreが75から84の間の一致候補の優先度は「中」に設定し、エスカレーションは不要です。
例 - 自動状態遷移
次のアクションでは、条件をトリガーする項目に自動凍結アカウント遷移を適用します。この条件はアラートのみに固有で、すでに状態がクローズ・アカウント必須であり、更新キーで変更が発生しているアラートを検出します。
名前: 凍結アカウント
説明: 凍結アカウント
条件(JavaScript):
caseData.caseType=='issue' && updateKeyChanged=='true' && caseData.currentState=='Close Account Required'
遷移: 凍結アカウント必須[凍結アカウント承認]
パラメータは「パラメータ」ダイアログで定義しますが、これは、「ケース管理の管理」内の「ワークフロー・エディタ」にある「パラメータ」タブからアクセスできます。新しいパラメータを作成する場合は「+」ボタンを押し、パラメータを編集する場合は既存のパラメータをダブルクリックして、ダイアログを開きます。
「パラメータ」ダイアログは、3つのフィールドのみで構成されています。
「名前」は必須です。「名前」で指定する値は、EDQの照合プロセッサにより移入されるパラメータの選択時、および遷移と状態の失効でのパラメータ値の使用方法の指定時に使用されます。よって、今後の使用のために、認識可能で記憶しやすい意味のある値を指定する必要があります。
説明はオプションです。このフィールドを使用して、パラメータの使用に関する詳細を示す長い情報を入力できます。
「有効」チェック・ボックスは、パラメータを他のシステムで使用可能にするかどうかを制御します。有効でないパラメータ(チェック・ボックスの選択が解除されている)は、EDQまたは他の場所で使用できません。デフォルトでは、パラメータは有効です。
必要な値を指定して「OK」をクリックするか、「取消」をクリックして変更内容を破棄します。
条件は、受信ルール・タブで定義されたアクションに適用されるJavaScript式です。この項は、受信ルールで使用する条件を記述するための一般的なガイドです。JavaScriptの基本知識と一般的なコーティング原理についても説明しています。特に、次について説明します。
条件で使用可能なケース属性。
条件を記述する際に最もよく使用するJavaScript演算子の概要。
条件で使用する属性
条件は、受信ケースの様々な特性をテストして、そのケースに特定のアクションを適用するかどうかを決定するために使用するように設計されています。
条件を定義する際、3つのタイプの属性を使用できます。
標準のケース処理パラメータ
ワークフロー定義パラメータ
ケース・データ・プロパティ
標準のケース処理パラメータ
標準のケース処理パラメータは、すべてのケース(およびアラート)で共通です。受信に表示される前にケースの変更内容に関する情報が提供されます。これらは次のとおりです。
表1-29 標準のケース処理パラメータ
| 名前 | 値と意味 |
|---|---|
|
|
|
|
|
注意: 照合プロセスの場合、更新キーには、ケース・ソースにマップされたすべての属性が含まれます。 |
|
|
|
|
|
|
ワークフロー定義パラメータ
ワークフロー定義パラメータは、ワークフロー・エディタの「パラメータ」タブで定義され、ケース・ソースで構成された選択機能を使用して移入されます。そのため、これはケースのワークフローおよびケース・ソースに固有です。
MatchPriorityScoreという暗黙的なワークフロー・パラメータが1つあります。ワークフローでmatchPriorityScoreという名前のパラメータを定義すると、そのパラメータはケース作成プロセスで自動的に移入されます。
ケース・データ・プロパティ
ケース・データ・プロパティは、ケースを表すJava Beanオブジェクトで使用可能なパブリック・プロパティです。ケース・データ・プロパティには、JavaScriptから次の構文を使用してアクセスします。
caseData.<property name>
たとえば、currentStateプロパティは、caseData.currentStateでアクセスします。
使用可能なケース・データ・プロパティは次のとおりです。
表1-30 ケース・データ・プロパティ
| 名前 | タイプ | 説明 |
|---|---|---|
|
|
整数 |
ケースの内部識別子。 |
|
|
文字列 |
このプロパティは常に、照合プロセッサから生成されたケースを表す「一致」に設定されます。その他の値は、今後、代替ケース生成メカニズムが導入されたときに使用されます。 |
|
|
文字列 |
このプロパティには、次の値を指定できます。
|
|
|
文字列 |
ケースの外部識別子。これは、ケース・ソースで定義された接頭辞と連番で構成されます。たとえば、接頭辞がDSANのケース・ソースの場合は、DSAN-1123になります。 |
|
|
文字列 |
自然順にソート可能なバージョンの |
|
|
文字列 |
ケース・キー。 |
|
|
文字列 |
判読可能なバージョンの |
|
|
整数 |
親ケースの内部識別子。ルート・ケースの場合は、-1に設定されます。 |
|
|
文字列 |
このキーは、 |
|
|
文字列 |
将来の使用のために予約されています。 |
|
|
文字列 |
このキーは、 |
|
|
文字列 |
ケースの説明。 |
|
|
整数 |
このケースを作成したユーザーのユーザーID。 |
|
|
日付 |
このケースが作成された時間のタイムスタンプ。 |
|
|
文字列 |
このケースを最後に変更したユーザーのユーザーID。 |
|
|
日付 |
このケースが最後に変更された時間のタイムスタンプ。 |
|
|
整数 |
このケースが現在割り当てられているユーザーのユーザーID。このケースが現在未割当ての場合、このプロパティは-1に設定されます。 |
|
|
整数 |
このケースを最後に割り当てたユーザーのユーザーID。このケースが現在未割当ての場合、このプロパティは-1に設定されます。 |
|
|
日付 |
このケースが最後に割り当てられた時間のタイムスタンプ。 |
|
|
整数 |
ケース優先度を表す数値。有効な値は、次のとおりです。 0 = なし 250 =低 500 =中 750 =高 |
|
|
文字列 |
このケースを表示するために必要な権限。権限が必要ない場合、このプロパティはnullになります。 |
|
|
文字列 |
ワークフローに定義されている現在の状態の名前。 |
|
|
文字列 |
ケースの場合は、「新規」、「処理中」または「完了」のいずれかに設定されます。アラートの場合は、nullに設定されます。 |
|
|
日付 |
現在の状態が自動的に失効する時間。 |
|
|
整数 |
このケースの状態を最後に変更したユーザーのユーザーID。 |
|
|
日付 |
状態が最後に変更された時間。 |
|
|
文字列 |
ケースの作成元を一意に識別するために、ケース・ジェネレータによって作成される文字列値。たとえば、照合プロセッサは、<process id>_<processor num>で表されます。 |
|
|
文字列 |
このケースの作成に使用したソースの名前。 |
|
|
整数 |
このプロパティは、フラグがケースに次のように設定されているかどうかを示します。 0 - ケースにフラグは設定されていません 1 - ケースにフラグが設定されています |
|
|
整数 |
ケース・マーカーを最後に設定したユーザーのユーザーID。 |
|
|
日付 |
ケース・マーカーが最後に設定された時間。 |
|
|
文字列 |
すべてのケースまたは同じ祖先に属する子ケース(あるいはその両方)の識別に使用できるソート可能な列。 |
|
|
整数 |
グループ内の子ケースのレベル。 |
|
|
文字列 |
ExtendedAttribute1の値。 |
|
|
整数 |
拡張属性の値を最後に変更したユーザーのユーザーID。 |
|
|
日付 |
拡張属性値が最後に変更された時間。 |
JavaScript演算子
条件は、ブール式のtrueまたはfalseに評価される必要があります。そのため、「より小さい」や「以上」などの概念をテストする条件演算子や、AND、ORおよびNOTなどの論理演算を表す論理演算子の使用頻度が高くなります。次の各表は、JavasScriptの条件演算子と論理演算子に関するクイック・リファレンス・ガイドです。
条件演算子
次の表では、JavaScript条件演算子の概要、および変数がxで、xが5に設定されている文の各評価方法の例を示します。
表1-31 条件演算子
| 演算子 | 説明 | 例 |
|---|---|---|
|
== |
次と等しい |
x==8はfalseと評価されます |
|
=== |
値と型の両方の構成で正確に等しい |
x===5はtrueと評価されます x==="5"はfalseと評価されます |
|
!= |
次と等しくない |
x!=8はtrueと評価されます |
|
> |
次より大きい |
x>5はfalseと評価されます |
|
< |
次より小さい |
x<8はtrueと評価されます |
|
>= |
次以上 |
x>=5はtrueと評価されます |
|
<= |
次以下 |
x<=8はtrueと評価されます |
論理演算子
次の表では、JavaScript条件演算子の概要、および変数がxとyの2つで、xが6、yが3に設定されている文の各評価方法の例を示します。
次のワークフローは、遷移と条件をどのように使用して厳しいレビュー階層を設けているかの例を示しています。最終決定が行われる前に、少なくとも2人の異なる個人がアラートをレビューする必要があります。次のダイアグラムはこのことを示しています。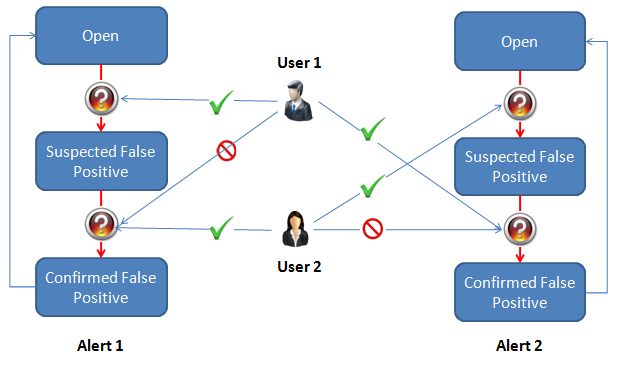
図「case_man_admin_4eyeprocess.png」の説明
前述のように、ユーザー1は、アラート1を疑わしい誤検出としてマークでき、確認済誤検出としてマークできません。別のユーザー(この場合はユーザー2)のみが、これを行えます。
同様に、ユーザー2がアラート2を疑わしい誤検出としてエスカレーションした場合、ユーザー1のみが確認済誤検出としてマークできます。
次のスクリーンショットは、単純な2段階ワークフローがワークフロー・エディタでどのように表示されるかを示しています。3つの可能な状態(オープン、疑わしい誤検出、確認済誤検出)および遷移(誤検出を疑う、誤検出の確認および再オープン)がそれぞれのリストに表示されます。
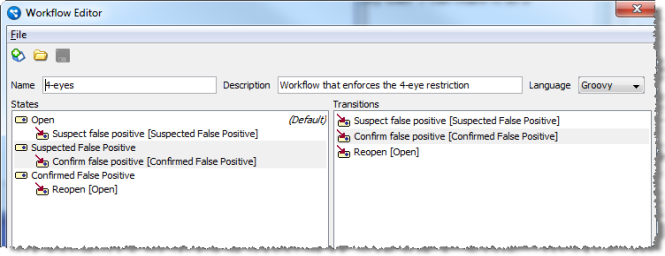
2段階ルールを実施するには、遷移を次のように構成する必要があります。
「誤検出を疑う」遷移には制限は必要ありません。
誤検出の確認 - 「誤検出を疑う」遷移を「遷移のブロック中」フィールドに追加します。これにより、「誤検出を疑う」遷移が作成されている場合に、ユーザーは「誤検出の確認」遷移を適用できなくなります。
再オープン - 「誤検出の確認」遷移を「遷移のブロックのクリア」フィールドに追加します。これにより、アラートに適用されている「誤検出の確認」への制限が、すべてのユーザーに対してクリアされます。
構成分析は、EDQスイートのアプリケーションの一部です。構成分析は、ディレクタ内のプロジェクトの構成、またはプロジェクトを構成するジョブ、プロセス、結果ブックなどのコンポーネントをレポートするために使用できます。
構成分析を使用すると、コンポーネント(またはコンポーネントのセット)の構成をレポートしたり、2つのコンポーネント(またはコンポーネントのセット)を比較して、それらの差異をレポートできます。
構成分析には、次のユーザー・インタフェースがあります。
画面上部に、メニューおよびツールバーのセットがあります。
画面左側に2つの選択ペインがあり、分析するコンポーネントを選択する際に使用します。
画面の残りの部分を占める結果領域は、分析の結果を表示するために使用されます。
メニューとツールバー
メニューおよびメインのツールバーには、構成分析を使用する際の主要なコントロールがあります。すべてのコントロールは、ツールバーと、「ファイル」または「分析」メニューにあります。「ヘルプ」メニューを使用すると、構成分析のオンライン・ヘルプおよびアプリケーションの「バージョン情報」ダイアログにアクセスできます。
ツールバーおよび対応するメニューを使用すると、次のことができます。
構成比較の開始。
構成レポートの開始。
比較またはレポートの取消し。
比較設定の構成。
レポート設定の構成。
HTML形式での結果の保存。
選択ペイン
選択ペインは、分析対象のコンポーネントを指定するために使用します。いずれかのペインでのみコンポーネントを選択すると、そのコンポーネントの構成レポートを実行できます。
各ペインで1つずつコンポーネントを選択すると、2つのコンポーネントの構成を相互に比較できます。
比較が実行されると、ペインAで選択したコンポーネントに関する変更が示されます。たとえば、2つのプロセスを比較したとします。レポートでプロセッサが追加されたことが示された場合、そのプロセッサはペインAで選択したプロセスには存在せず、ペインBで選択したプロセスに存在します。
「結果」ペイン
「結果」ペインには、最新の比較レポートまたは構成レポートの結果が表示されます。結果領域は、さらに複数のパネルに分割されており、そのレイアウトは分析するコンポーネントの複雑さによって異なります。
「結果」ペインには常に、分析に含まれる最上位レベルのコンポーネントを示すコンポーネント・リストと、現在選択されているコンポーネントに関するレポートの詳細を含む詳細ペインが含まれます。
コンポーネント・リストでプロセスを選択すると、詳細ペインにプロセッサ・リストが追加されます。これには、選択したプロセスのすべてのプロセッサのリストが含まれます。
コンポーネント・リスト
コンポーネント・リストでは、分析の対象になったすべてのコンポーネントのリストが保持されます。プロセスや参照データのセットなどの単一コンポーネントの分析が実行された場合、このリストには単一のエントリのみが表示されます。分析の対象になったコンポーネントが複数の場合、このリストには複数のエントリが表示されます。
結果領域に表示される情報は、比較結果を参照しているか構成レポート結果を参照しているかによって異なります。レポート結果の場合、各行には、コンポーネント名とコンポーネントのタイプ(ジョブ、プロセス、スナップショットなど)を示すアイコンのみが含まれます。
比較結果の場合、各行には、比較の両側に表示されるコンポーネント名と比較の結果が含まれます。比較フィルタを使用すると、比較の結果に基づいてリスト内の項目をフィルタできます(詳細は、「比較結果のフィルタリング」を参照)。
詳細は、「比較結果」および「レポート結果」の項をそれぞれ参照してください。
「詳細」ペイン
「詳細」ペインには、選択したコンポーネントの様々な構成可能属性とその値のリストが含まれます。2つのコンポーネントを比較する場合は、該当する行の構成の差異が色付きの背景を使用して強調表示されます。
「詳細」ペインのナビゲート
実行するのが比較でも構成レポートでも、提供される結果には、簡単にナビゲートできるようにハイパーリンクが自動的に挿入されます。青色で下線テキスト付きのハイパーリンクがレンダリングされ、これを使用して、コンポーネントのデータの各セクション間またはコンポーネント間を移動できます。
「オプション」セクションなどの各セクションの前には、レポートの現在のページの上部に戻るリンクが表示されます。サブセクションの前には、ページの上部に戻るリンクとセクションの上部に戻るリンクが表示されます。
プロセス内の前後のプロセッサへのリンクも提供されます。
レポート内のハイパーリンクをクリックすると、レポート内の移動パスに基づいて参照履歴が構築されます。これにより、詳細ペインの上部にあるナビゲーション・ボタンがアクティブ化され、これを使用して、必要に応じてレポート内の移動パスを再トレースできます。
プロセッサ・リスト
プロセッサ・リストは、コンポーネント・リストでプロセスを選択した場合にのみ表示されます。プロセッサ・リストには、選択したプロセスのすべてのプロセッサのリストが含まれます。比較が実行される場合、各行には、プロセスの各バージョンに表示されるプロセッサと、2つのプロセッサの比較結果が表示されます。
各プロセッサの名前とタイプが(該当する場合は、比較の両側に)表示されます。必要に応じて、結果をプロセッサ名およびプロセッサ・タイプでフィルタできます(詳細は、「比較結果のフィルタリング」および「レポート結果のフィルタリング」を参照)。また、プロセスにグループ化されたプロセッサが含まれている場合は、「親」列が表示されます。この列には、プロセッサが属するグループが表示されます。
プロセッサからキャンバスへのナビゲート
ディレクタ内から構成分析を起動すると、アプリケーション間のリンクが作成されます。このリンクを使用すると、分析結果にリストされているプロセッサからキャンバス上のそれらのプロセッサの位置にナビゲートできます。
結果からキャンバスにナビゲートするには、調査するプロセッサに対応する結果行を右クリックします。
表示されるオプションは、実行した分析のタイプ、比較の場合は、選択したプロセッサに関連付けられた結果によって異なります。
構成レポートの場合は、常に「実行中のプロセッサAの表示」が表示されます。このオプションを選択すると、キャンバス上にプロセスが開き、選択したプロセッサが強調表示されます。「実行中のプロセッサBの表示」は無効になります。
構成比較でプロセッサがプロセスの両バージョンに存在する場合は、「実行中のプロセッサAの表示」および「実行中のプロセッサBの表示」の両方が有効になります。「実行中のプロセッサAの表示」を選択すると、選択ペインAで選択したプロセスが開いて選択したプロセッサが強調表示されます。「実行中のプロセッサBの表示」を選択すると、選択ペインBで選択したプロセスが開いて選択したプロセッサが強調表示されます。
構成比較でプロセッサが追加されている場合(つまり、選択ペインBで選択したプロセスにはこのプロセッサが存在するが、選択ペインAのプロセスにはない場合)は、「実行中のプロセッサAの表示」が無効になります。「実行中のプロセッサBの表示」を選択すると、選択ペインBで選択したプロセスが開いて選択したプロセッサが強調表示されます。
構成比較でプロセッサが削除されている場合(つまり、選択ペインAで選択したプロセスにはこのプロセッサが存在するが、選択ペインBのプロセスにはない場合)は、「実行中のプロセッサBの表示」が無効になります。「実行中のプロセッサAの表示」を選択すると、選択ペインAで選択したプロセスが開いて選択したプロセッサが強調表示されます。
問題マネージャ・アプリケーションは、問題を表示、評価および管理するために使用します。
問題マネージャは、EDQ Launchpadから、問題通知メールから、またはディレクタのツールバーで「問題がn個あります」をクリックして起動します。
問題マネージャが起動されると、デフォルトでは、ログオン・ユーザーに割り当てられているすべてのオープン状態の問題が表示されます。
表示された問題は、「サーバー」、「プロジェクト」および「表示」の各ドロップダウン・フィールドおよび「表示」チェック・ボックスを使用してフィルタ処理できます。「フィルタ」メニュー・バー・ボタンで、フィルタ・オプションの表示/非表示を切り替えます。
問題をオープン状態にするには、右クリックして「オープン状態の問題」を選択するか、ダブルクリックします。問題が、別個のダイアログ・ボックスに開きます。
このダイアログで、問題を別のユーザーに再割当てするか、「ステータス」フィールドで「新規」、「処理中」または「完了」とマークできます。「関連プロセス」リンクをクリックして、問題が発生したプロセスを開くこともできます。
|
注意: 問題が発生したプロジェクトを表示する権限を持たないユーザーに、問題を割り当てることはできません。 |
Webサービス・テスターを使用して、統合作業を実行する前に、実行中のWebサービスをテストします。
Webサービス・テスターを開くには、Launchpadの「Webサービス」ドロップダウン・メニューからWebサービス・テスターを選択します。選択すると、サービスが自動的にロードされます。
Webサービス・アプリケーションから起動した場合、選択したWebサービスがデフォルトで表示されます。そうでない場合、Webサービスは選択されていません。
Webサービスをテストするには、次のようにします。
「設定」領域でプロジェクトとWebサービスを選択します。
「サービスの取得」をクリックして、WSDLファイルの最新バージョンを取得します。「イン」領域に、Webサービス入力がリストされます。
フィールドに使用可能な詳細を入力して、「送信」をクリックします。Webサービスが実行中の場合、「アウト」領域に結果が戻されます。
タイミング・テストを実行するには:
「タイミング・テスト」をクリックします。「タイミング・テスト」ダイアログが表示されます。
「リクエストの数」フィールドに、テストを実行する回数を入力します。
必要に応じて、間隔(ミリ秒)フィールドにテスト間の遅延をミリ秒で入力します。
「実行」をクリックします。「ステータス」領域に、テストの進捗状況、および完了時には結果が表示されます。
必要に応じて、「チャートの表示」をクリックします。「タイミング・チャート」ダイアログが表示されます。
EDQの特定の主要タスクの実行方法の詳細を示した手順トピックについては、『Oracle Fusion Middleware Oracle Enterprise Data Qualityの使用』の手順に関する項(http://docs.oracle.com/middleware/12211/edq/user/howto.htm#DQUSG257)を参照してください。
Oracle Enterprise Data Qualityで使用可能なプロセッサ。
拡張プロセッサを使用すると、スクリプトや式を使用したカスタム処理の定義やデータ処理からの警告の生成など、EDQの拡張機能を実行できます。拡張プロセッサはエキスパート・ユーザーが使用するためのものです。
自分専用のプロセッサを作成してEDQパレットに追加することもできます。「EDQの拡張」を参照してください。
「メッセージIDの追加」プロセッサでは、数値識別子を含むフィールドをプロセスに追加します。メッセージIDは、EDQプロセスを通過するデータのパケット(メッセージと呼ばれます)を識別します。
「メッセージIDの追加」は、数値識別子をレコードに追加するために使用します。メッセージIDは、バッチ・プロセス内のレコード、およびリアルタイム・プロセスによって単一のレコード入力を使用して作成されたレコードに対して、データ・ストリーム内で一意です。
特定のデータ・ストリームの場合、この識別子は次の状況では一意ではないことに注意してください。
メッセージIDは、複数レコード入力があるリアルタイム・プロセスまたはWebサービスから発生したレコードに対しては一意ではありません。この場合、メッセージIDは単一の要求から発生したすべてのレコードに対して同じです。
メッセージIDは、ストリーム内のレコードがプロセスによって分割される場合は、一意ではありません。この場合、メッセージIDは、単一の発生元レコードから導出されるすべてのレコードに対して同じです。
「メッセージIDの追加」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、追加された出力属性が表示されます。
例
この例では、メッセージIDはバッチ・プロセス内のレコードのセットに追加されています。プロセスはバッチ・モードで実行され、レコードは分割されないため、この場合のメッセージIDはすべて一意です。
「ユーザー詳細の追加」プロセッサでは、プロセスが使用されているWebサービスまたはジョブを呼び出す認証済EDQユーザーの詳細をプロセスに追加します。
「ユーザー詳細の追加」は通常、データ検証、クレンジングまたは照合処理にEDQ Webサービスを使用するアプリケーションで使用されます。EDQプロセスにおける認証済ユーザーの詳細の取得は、2つの理由で役立ちます。
レコードを入力/更新したユーザーの詳細など、処理されたすべてのレコードの完全な監査証跡を保持できます
この結果、データ処理の結果を含む電子メールを認証済ユーザーのアドレスに送信するなど、プロセスでユーザー詳細を使用できます
たとえば、EDQを使用してウォッチリストに対して個人をスクリーニングしている場合、個々のスクリーニング・サービスの認証済ユーザーに対して、そのユーザー用にEDQに格納されている(ユーザー構成で管理者が設定したとおりの)電子メール・アドレスを使用して、照合プロセスの結果を含む電子メールを送信できます。組織や電話番号などの追加のユーザー詳細を監査証跡に追加できるため、レコードを発行したユーザーに関する完全な情報が保持されます。
「式」プロセッサを使用すると、簡潔な式言語を使用して、他の多数のEDQプロセッサおよび関数のロジックを包含できる式を作成できます。
「式」は、複数のプロセッサを構成するのではなく、式を作成することによってプロセッサの必要ロジックを最も論理的かつ簡潔に表すことができる場合に便利です。一般的に、数学演算を実行する場合などがあります。
入力
「式」プロセッサは、任意の数、任意のタイプの入力を取得できますが、正式な日付属性は例外です。
オプション
| オプション | タイプ | 目的 | デフォルト値 |
|---|---|---|---|
| 評価する式 | 式 | EDQの式言語における必要なプロセッサ・ロジックです。次の注意を参照してください。 | なし |
EDQの式言語の注意の詳細は、「式の注意」を参照してください。
出力
データ属性
| データ属性 | タイプ | 目的 | 値 |
|---|---|---|---|
| ExpressionResult | 追加 | 式の結果を格納します | 式の結果を含む属性。属性タイプは式に依存します。前述の注意を参照してください。 |
フラグ
なし
実行
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム監視 | はい |
| リアルタイム・レスポンス | はい |
結果の表示
「式」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、各入力属性とともに、右側にExpressionResult属性が表示されます。
出力フィルタ
なし
「式フィルタ」プロセッサを使用すると、EDQの式言語を使用して式を作成できます。この式は、レコードの合否を判定して、レコードを別々の出力フィルタに分けるために使用されます。
「式フィルタ」プロセッサは実際には、式を構成するGUIを提供する「論理チェック」プロセッサの拡張形式です。「論理チェック」のGUIでは構成時に式が表示されるため、「論理チェック」を使用して有効な式の構成方法を習得できます。
「式フィルタ」は、すべての入力レコードに対して簡単なテストを適用し、テストに合格したレコードを失敗したレコードと分ける場合に有効です。
入力
「式フィルタ」プロセッサは、任意の数、任意のタイプの入力を取得できますが、正式な日付属性は例外です。
オプション
| オプション | タイプ | 目的 | デフォルト値 |
|---|---|---|---|
| 論理式 | 式 | EDQの式言語における必要なフィルタ・ロジックです。次の注意を参照してください。 | なし |
EDQの式言語の注意の詳細は、「式の注意」を参照してください。
出力
データ属性
なし
フラグ
| フラグ | 目的 | 使用可能な値 |
|---|---|---|
| ExpressionFilter | 式フィルタ・テストの結果を格納します | Y - テストにパスした場合
N - テストに失敗した場合 |
実行
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム監視 | はい |
| リアルタイム・レスポンス | はい |
出力フィルタ
「式フィルタ」プロセッサからは、次の出力フィルタが使用可能です。
True - 式フィルタ・テストにパスしたレコード
False - 式フィルタ・テストに失敗したレコード
「警告の生成」プロセッサは、(構成可能なしきい値を超えた)一定数のレコードを処理する場合に、警告を生成またはプロセス失敗をトリガー(あるいはその両方を実行)するように設計されています。
「警告の生成」プロセッサは、プロセスの実行時に警告を通知する場合に、ジョブの通知機能とともに使用します。たとえば、監査プロセッサを使用してデータ妥当性をチェックし、nを超える数のレコードがチェックに失敗した場合に警告を生成する場合があります。さらに、どのような場合でもプロセスの残りの部分を再実行する必要があることがわかっている場合は、実行を続行しないようにプロセスを失敗させる場合があります。
したがって、「警告の生成」プロセッサを使用すると、イベント・ログおよび通知電子メールに表示するデータ・エラーを生成する内容について独自の定義を設定できます。
警告の生成およびインテリジェント実行
設計中に同じプロセスを繰返し実行する際に不要な警告が生成されないように、「警告の生成」プロセッサでは、その再実行マーカーが設定されている場合、あるいはインテリジェント実行がオフの状態でプロセスまたはジョブで実行された場合にのみ、新しい警告が生成されます。
再実行マーカーは、データの新規セットがプロセスに入力された場合、またはプロセッサの構成が変更された場合に必ず設定されます。
「メッセージ処理スクリプト」プロセッサを使用すると、JavaScriptまたはGroovyを使用して、プロセッサに対するオプションとして入力される独自のプロセッサ・ロジックを指定できます。
「メッセージ処理スクリプト」プロセッサは「スクリプト」プロセッサと密接に関連しています。このプロセッサと「スクリプト」プロセッサの主な相違点は、「メッセージ処理スクリプト」プロセッサは、多数のレコードを含む可能性があるメッセージを処理するように設計されていることです。「メッセージ処理スクリプト」プロセッサは、メッセージ内の全レコードにわたって操作を実行でき、メッセージIDなどのメッセージ・レベルの属性にアクセスできます。
「メッセージ処理スクリプト」プロセッサを使用して、メッセージ内の全レコードにわたって機能する、またはメッセージ内の最初のレコードでのみ選択的に機能する処理ロジックを定義できます。
「メッセージ処理スクリプト」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、各入力属性とともに、右側に出力属性が表示されます。
スクリプト
「メッセージ処理スクリプト」プロセッサに対するスクリプトの作成時に、次の注意事項を考慮することが重要です。
「メッセージ処理スクリプト」プロセッサでは、作業単位としてメッセージが取得されます。メッセージは複数のレコードで構成される場合があり、レコードは、「メッセージ処理スクリプト」プロセッサ内でrecordsという配列としてモデル化されます。配列内の各レコードには、標準の「スクリプト」プロセッサのinput1およびoutput1属性に対応する、独自の入力属性のセットと独自の出力属性があります。
さらに、事前定義の変数であるmessageidに一意のメッセージIDが含まれ、変数tagsにはメッセージ・レベルのタグが含まれます。
各レコードに、プロセス内のレコードの処理の続行を抑制するcancel()関数もあります。
|
注意: 各レコードに対して呼び出される関数を指定し(スプリプト全体の毎回実行ではなく)、スクリプトの言語を変更できます。 |
次の行を含む関数を設定します。
#! function : doit
スクリプトの上部に前述の行を挿入します。doitは関数名で、使用する関数名にこれを変更します。
スクリプトの言語をJavascriptではなくGroovyに変更するには、次の行を追加します。
#! language : groovy
例
次のスクリプトはメッセージ内の全レコードにわたって繰り返され、各レコードに対する最初の入力属性(数値と想定されています)の値の合計が計算されます。次に、レコード全体で再度繰り返され、各レコードの出力属性の値に、最初のステップで計算された合計が設定されます。
var sum = 0;
for (var i = 0; i < records.length; i++)
{
sum += records[i].input1[0];
}
for (var i = 0; i < records.length; i++)
{
records[i].output1 = sum;
}
次のスクリプトでは、前述と同様に合計が計算されますが、最初のレコード以外の全レコードがcancel()関数を使用して抑制されます。この結果、全レコードにわたる最初の入力属性の合計がその出力属性として設定された、単一のレコード(最初のレコード)がメッセージごとに出力されます。
var sum = 0;
for (var i = 0; i < records.length; i++)
{
sum += records[i].input1[0];
}
for (var i = 0; i < records.length; i++)
{
if (i == 0)
{
records[i].output1 = sum;
}
else
{
records[i].cancel();
}
}
「スクリプト」プロセッサを使用すると、JavaScriptまたはGroovyを使用して単純なプロセッサに対する独自のプロセッサ・ロジックを指定できます。スクリプトは、「スクリプト」プロセッサのオプションとして入力されます。
EDQで作成されるプロセッサ内でスクリプトを使用できるため、そのスクリプトには、プロセッサのエンド・ユーザーは簡単にアクセスできないことに注意してください。また、プロセッサ・ライブラリに追加する新規プロセッサの作成時にスクリプトを使用できるため、スクリプトの大幅な複雑化が可能であり、たとえば、複数の入出力、参照データを使用するオプションおよび結果ビューを使用可能にできます。
「スクリプト」プロセッサは、提供されているいずれのプロセッサを使用しても簡単に実行できない、いくつかの単純な処理ロジックを定義するために使用します。
入力
あらゆるタイプの任意の数の属性を「スクリプト」プロセッサに入力できます。選択した入力属性は、input1という名前のJavaScript配列にマップされます。
オプション
| オプション | タイプ | 目的 | デフォルト値 |
|---|---|---|---|
| 結果タイプ | 選択(文字列/数値/日付/文字配列/番号配列/日付配列) | スクリプトの出力結果のタイプを決定します。
注意:「配列」タイプを選択する場合、スクリプト内の配列をインスタンス化する必要があります。 |
文字列 |
| スクリプト | スクリプト | プロセッサ・ロジックを定義するスクリプト。関数の使用およびスクリプト言語の変更については、次の注意を参照してください。 | なし |
|
注意: 各レコードに対して呼び出される関数を指定し(スクリプト全体の毎回実行ではなく)、スクリプトの言語を変更できます |
次の行を含む関数を設定します。
#! function : doit
スクリプトの上部に前述の行を挿入します。doitは関数名で、使用する関数名にこれを変更します。
スクリプトの言語をJavascriptではなくGroovyに変更するには、次の行を追加します。
#! language : groovy
出力
「スクリプト」プロセッサは、単一の出力データ属性のみをサポートします。この属性のタイプは、「結果」タイプ・オプションを設定することで決定されます。
単一の出力は、スクリプト名output1に割り当てられる必要があります。
|
注意: 結果タイプに対して「配列」タイプを選択すると、配列は自動的にインスタンス化されません。単純なデータ・タイプと配列タイプ間の違いのために、配列は、スクリプトによってインスタンス化される必要があります。これに失敗すると、プロセッサの実行時にスクリプト実行エラーが発生します。詳細は、例1-3を参照してください。 |
データ属性
| データ属性 | タイプ | 目的 | 値 |
|---|---|---|---|
| ScriptResult | 追加 | スクリプトの結果を含む属性。 | この値はスクリプトによって設定されます。 |
フラグ
なし
実行
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム監視 | はい |
| リアルタイム・レスポンス | はい |
|
注意: 新規プロセッサ(スクリプトの使用が含まれる)を記述する場合、完了まで実行する必要があるプロセッサとしてプロセッサにフラグを付けることで(たとえば、処理されるすべてのレコード全体での計算完了率に基づきレコードをフィルタリングするプロセッサなど)、プロセッサをリアルタイム・レスポンス実行と互換性を持たないように指定できます。 |
結果の表示
「スクリプト」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、各入力属性とともに、右側に出力属性が表示されます。
出力フィルタ
なし
例
例1-1 一意の識別子を出力するためのスクリプト
次の例のスクリプトでは、基礎となるJava関数を使用して一意のIDを生成しています。
output1 = java.util.UUID.randomUUID().toString()
この場合、入力属性はスクリプトによって実際には使用されていませんが、ダミー属性を「スクリプト」プロセッサが実行可能となるようにこれに入力する必要があります。
結果
| ScriptResult |
|---|
| 4d8ed32a-4175-409a-a752-3619cf9fbd5a |
| 8818e732-f56d-4658-bfd9-93ef7ee639bd |
| 4e957a42-6b6c-4669-a7fe-d5c17f1e734f |
| 49a658c1-20db-4d3c-81d8-8cc4aa91016b |
| 1dc94a3c-ec7c-4191-a199-ce1aa4316404 |
| 11d3c22f-77cf-4ccc-bbcf-e78ac2ebd227 |
| dd698c8d-9bfb-40b5-a5bd-2660787233ec |
| b624911b-9d16-4377-8520-4ab546132dfc |
| 7859603f-3348-4bae-ba62-e24daa11c1cd |
| 065fcae7-3a71-4683-931a-cd16c8d45d91 |
| ecdad97d-6dd2-4556-9f47-76cc9a4d74e9 |
| b22b386f-c655-4497-9ee4-a379381201dc |
| 7e7b817d-a752-4b9c-98ca-bfd2c85136fa |
例1-2 連結
次の例のスクリプトでは、すべての入力属性が単一の出力値に連結されており、各属性値は||によって区切られています。
var res = '';
for (var i = 0; i < input1.length; i++)
{ if (i > 0) res += '||';
res += input1[i];
}
output1 = res;
結果
| 敬称 | 名 | 姓 | 名前 |
|---|---|---|---|
| KAREN LOUSE | MILLER | ||KAREN LOUISE||MILLER | |
| MR | BRIAN MICHAEL | MILES | ||BRIAN MICHAEL||MILES |
| FREDRIK | MISTANDER | ||FREDRIK||MISTANDER | |
| MR | KENNETH | MIDDLEMASS | ||KENNETH||MIDDLEMASS |
| NEIL ALASTAIR | MITCHELL | ||NEIL ALASTAIR||MITCHELL | |
| KOKILA RAMESH | MISTRY | ||KOKILA RAMESH||MISTRY | |
| ANDREW SIMON | MICKLEBURGH | ||ANDREW SIMON||MICKLEBURGH |
例1-3 配列結果タイプの使用方法
単純なデータ型と異なり、配列変数は、値が書込み可能となるために必ずインスタンス化する必要があります。これに失敗すると、次のようなエラー・メッセージが表示されます。
Script execution failed: TypeError: Cannot set property '0.0' of null to '<value>' ([script]#2)
出力配列をインスタンス化するには、次に示すように、スクリプトで新規コマンドを使用して、配列にメモリーを割り当てる必要があります。
var output1 = new Array();
この文の後、配列はインスタンス化され、書込みが可能になります。
監査プロセッサまたは監査チェックでは、ビジネス・ルールを使用して入力データをチェックし、ビジネスの目的に合っているかどうかを評価します。
データのチェックに使用する監査プロセッサおよび監査プロセッサが使用するルールは、プロファイリングの結果から決定されます。
監査プロセッサは、チェックに従って、各入力レコードが有効か無効かについて分類します。無効なレコードは、出力フィルタにより後続の処理で有効なレコードと別に処理できます。たとえば、チェックに合格しなかったレコードのクリアを試行するだけです。リスト・チェックなどの一部の監査プロセッサには、3つの出力フィルタ(有効(チェックに合格したレコード)、無効(最終的に失敗として識別されたレコード)および不明(最終的に有効とも無効とも認識されなかったレコード))があります。
監査プロセッサでは、指定されたデータ属性をプロファイリング時に適用するビジネス・ルールが暗黙的に使用されます。適用できるビジネス・ルールの各タイプの監査プロセッサについては、次の表を参照してください。
| ルールのタイプ | ビジネス・ルールの例 | 監査プロセッサ |
|---|---|---|
| 属性にnull値を含めることが許可されているかどうか | CU_NO属性はnullにできません | データなしチェック |
| 許可または予期されている属性内のデータ長 | CU_ACCOUNT属性は10文字から-11文字の長さで指定する必要があり、空白を含めることはできません | 長さチェック |
| 属性内のデータ・タイプの一貫性 | NAME属性には数値を含められません | データ型チェック |
| 属性内の値の妥当性 | TITLE属性内の値は、有効タイトルのリストと一致する必要があります | リスト・チェック |
| 標準の文字パターンの順守 | TEL_NO属性内の値は、標準パターンを順守する必要があります | パターン・チェック |
| 標準パターンの順守(正規表現による) | イギリス国民保険番号は、標準の正規表現に一致している必要があります | 正規表現チェック |
| 属性内の特定の文字の妥当性 | NAME属性の値には、#~@;:/?.>,<%$£!^* などの文字を含めることができません | 無効な文字のチェック |
| 属性内の値の重複 | CU_NO値の重複は許可されません | 重複チェック |
| 属性に、必須フィールドに対する共通のユーザー・エントリ回避策が含まれているかどうか | FORENAME属性にaaaなどの値を含められません | サスペクト・データ・チェック |
| ある属性の値の別の属性の値に対するチェック | DATE_OF_BIRTH属性は、DATE_OF_DEATH属性より前である必要があります | 属性のクロス・チェック |
| 参照表における関連データの有無のチェック | 顧客のアクティブな連絡先レコードが少なくとも1つ存在する必要があります | ルックアップ・チェック |
| 論理式をパスしたデータの有無のチェック | 有効なDATE_OF_BIRTH属性、有効な郵便番号および有効な電子メール・アドレスがあります | 論理チェック |
| データに特定の値または値範囲があることのチェック | すべての男性顧客は、性別の値が'M'である必要があります | 値のチェック |
| データがEDQとは独立して定義されているビジネス・ルール・セットに適合していることのチェック。 | 顧客がイギリスを拠点にしている場合、郵便番号が存在しており、かつ有効な形式である必要があります。 | ビジネス・ルール・チェック |
EDQには、前述の汎用の監査プロセッサに加えて、電子メール・チェックなどの多数の特定の属性チェックが用意されています。
|
注意: 提供されている汎用のプロセッサを使用して専用のチェックを作成できない場合、JavaScriptを使用して専用のチェックを作成するか、EDQを拡張して新しいプロセッサを追加するように選択できます。詳細は、「EDQの拡張」を参照してください。 |
ビジネス・ルール・チェック・プロセッサを使用すると、EDQの外で定義および保持できる一連のビジネス・ルールに対してデータを照合してチェックできます。チェックされた各レコードについて検証エラーを出力できます。
ビジネス・ルール・チェック・プロセッサは、単一のプロセッサで潜在的に複雑な検証ルールをデータに適用するために使用します。ビジネス・ルールは参照データまたは外部ファイルに定義できるため、ルールをEDQの外で保持できます。
次の各表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | このプロセッサは、次のものを受け入れます。
ビジネス・ルールの定義方法の詳細は、「ビジネス・ルールの定義」を参照してください。 |
| オプション | 次のオプションを指定します。
|
ビジネス・ルールの定義にExcelファイルを使用する場合は、[Install Path]/oedq_local_home/businessrulesディレクトリ([Install Path]はEDQがインストールされたルートを示します)に配置する必要があり、そのExcelファイルは「ビジネス・ルールの定義」のトピックで指定されている書式に準拠している必要があります。
識別子の指定
識別子は、ビジネス・ルール・チェック・プロセッサの入力属性をビジネス・ルール・ドキュメントで参照される属性タグにマップするために使用します。識別子と属性の間のマッピングは、ビジネス・ルール・チェック・プロセッサのダイアログの「識別」タブで定義します。
各識別子に対して、右側のドロップダウンから適切な入力属性を選択します。
入力属性がマップされていない識別子がルール内で使用されている場合、そのルールは無視されます。
入力属性がマップされていない識別子が条件内で使用されている場合、その条件はTRUEとして評価されるものとみなされます。
|
注意: マップされていない識別子は、ビジネス・ルール・チェック・プロセッサによって内容に応じて別の方法で処理されます。 |
| 構成 | 説明 |
|---|---|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
次のフラグが出力されます。
|
このプロセッサでは常に再実行マーカーが表示されていますが、このマーカーは、構成が変更されたかどうかに関係なくプロセスが実行されるたびに完全に再実行されることを示します。これは、このプロセッサの後続のプロセッサも再実行が必要であることを意味します。これは、EDQアプリケーションの外で変更が行われ、その変更に伴って後続の実行の結果が異なる可能性があるためです。
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 成功 | 論理チェックに合格したレコードの数。 |
| 失敗 | 論理チェックに失敗したレコードの数。 |
出力フィルタ
論理チェックからは、次の出力フィルタを使用できます。
ビジネス・ルール・チェックに合格したレコード
ビジネス・ルール・チェックに失敗したレコード
例
この例では、contactDetailsCheck.xlsというExcelファイルを使用して、顧客データの連絡先詳細の一部を検証しています。このファイルには、次のことをチェックするルールが含まれています。
姓のフィールドにデータが含まれていること。
姓に文字のみが含まれていること。
住所内に都市および郡が少なくとも1つは指定されていること。
郵便番号が有効であること。
電話番号が有効であること。
サマリー・データは次のとおりです。
| 成功 | 失敗 |
|---|---|
| 11211 | 1045 |
チェックに失敗したレコードをドリルダウンすると、それらのレコードがどのようにルールに違反しているかが示され、ビジネス・ルール構成の一部として定義されたエラー・コード、重大度およびエラー・メッセージが表示されます。
「ビジネス・ルール・チェック」プロセッサを使用すると、一連のビジネス・ルールをEDQの外で定義および保持することができ、単一のプロセッサを使用して適用できます。ルールは、属性の観点で定義され、データ構造とは無関係です。属性には、a1、a2、a3などのタグがあり、ビジネス・ルール・チェック・プロセッサが構成されている場合、入力データ内の適切なフィールドにマップする必要があります(「ビジネス・ルール・チェック」のトピックを参照)。
ビジネス・ルールは、次の方法で定義できます。
Excelファイル(「Excelスプレッドシートでのビジネス・ルールの定義」を参照)
参照データ(「参照データでのビジネス・ルールの定義」を参照)。
ビジネス・ルール構造
ビジネス・ルールは、次の3つのコンポーネント・タイプで構成されます。
チェックは、再使用可能な小さいロジックです。ユーザー定義名、実行するチェックのタイプ、および意味がタイプに応じて異なるいくつかのオプションがゼロまたは複数含まれます。チェックは、より複雑な条件を作成するために構築したり、ルール内で直接使用できます。「チェックの定義」を参照してください。
条件は、より複雑なロジックであり、チェックを属性に適用しますが、完全なルールではありません。ビジネス・ルール構成での条件の使用はオプションであり、必ずしも必要ではありません。条件は、ルールへのゲートウェイとして機能できます。ルールに条件が割り当てられている場合、条件にパスした場合のみルールの残りが評価されます。条件は、チェックまたは他の条件を使用して構築でき、複雑な論理構造を持つことができます。「条件の定義」を参照してください。
ルールは、どのチェックをどの属性に適用するかを指定します。ルールには、参照しやすいようにIDおよびラベルがあり、ルール違反があった場合のエラー・コード、エラー・メッセージおよびエラーの重大度が指定されます。「ルールの定義」を参照してください。
チェックの定義
チェックには、次のような特徴があります。
名前: ユーザーが定義し、他の場所からチェックを参照できるようにします。
チェック・タイプ: チェックが実行する操作を定義します。
最大3つのオプション: チェック操作が機能するために必要な追加情報を提供します。
チェックでは、処理の対象となる属性は指定されません。
次の表はサポートされているチェック・タイプを示しています。
| 名前 | 説明 | オプション |
|---|---|---|
| データなしチェック | フィールドがブランクであることのチェックに使用します。フィールドにデータが含まれていると、このチェックは失敗します。 | なし |
| 移入のチェック | フィールドがブランクでないことのチェックに使用します。フィールドにデータが含まれていないと、このチェックは失敗します。 | なし |
| 文字のチェック | フィールド内のデータに、指定したリストからの文字のみが含まれていることのチェックに使用します。 | オプション1 = 許可されている文字のリスト(後述の注意を参照)
オプション2 = 許可されている文字を含むワークシートの名前(Excelベースのルールでのみ使用) オプション3 = 許可されている文字を含む参照データの名前 |
| 無効な文字のチェック | フィールド内のデータに、指定したリストからの文字が含まれていないことのチェックに使用します。 | オプション1 = 無効な文字のリスト(後述の注意を参照)
オプション2 = 無効な文字を含むワークシートの名前(Excelベースのルールでのみ使用) オプション3 = 無効な文字を含む参照データの名前 |
| 最小長のチェック | フィールド内の文字列データの最小長の指定に使用します | オプション1 = データ・フィールドの最小長 |
| 最大長のチェック | フィールド内の文字列データの最大長の指定に使用します | オプション1 = データ・フィールドの最大長 |
| リスト・チェック | フィールド内のデータに、指定したリストからの値のみが含まれていることのチェックに使用します。 | オプション1 = 許可されている単一の値
オプション2 = 許可されている値を含むワークシートの名前(Excelベースのルールでのみ使用) オプション3 = 許可されている値を含む参照データの名前 |
| 無効なリストのチェック | フィールド内のデータに、指定したリストからの値が含まれていないことのチェックに使用します。 | オプション1 = 無効な単一の値
オプション2 = 無効な値を含むワークシートの名前(Excelベースのルールでのみ使用) オプション3 = 無効な値を含む参照データの名前 |
| 正規表現チェック | フィールド内のデータが正規表現を順守していることのチェックに使用します。 | オプション1 = 正規表現
オプション2 = 正規表現を含むワークシートの名前(Excelベースのルールでのみ使用) オプション3 = 正規表現を含む参照データの名前 |
| 無効な正規表現のチェック | フィールド内のデータが正規表現を順守していないことのチェックに使用します。 | オプション1 = 無効な正規表現
オプション2 = 無効な正規表現を含むワークシートの名前(Excelベースのルールでのみ使用) オプション3 = 無効な正規表現を含む参照データの名前 |
| スクリプト | データに対する処理を実行する外部スクリプトの指定に使用します。 | オプション1 = 実行するスクリプトのスクリプト・コードまたは名前
オプション2 = スクリプト言語。有効な値は、javascriptまたはgroovyです。オプションが指定されていない場合、言語はjavascriptにデフォルト設定されます。 |
| 失敗 | 常に失敗するチェックの指定に使用します。 | なし |
|
注意: 有効または無効の文字のリストでは、大/小文字が区別され、すべての文字(英数字、空白文字および特殊文字)を含むことができます。リストがチェック内で直接指定される場合、区切り文字または空白文字なしで単一の文字列として入力する必要があります(これらは、それ自体がリストの一部として解釈されるためです)。 |
条件の定義
条件は、チェックを属性と関連付けます。条件は、単一のチェックを単一の属性に関連付けるだけでなく、2つのチェックを単一の属性に適用したり、単一のチェックを2つの属性に適用できます。また、他の条件を統合し、より複雑な条件を作成するためにも使用できます。条件には、次の属性があります。
名前: ユーザーが定義し、他の場所から条件を参照できるようにします。
「タイプ」フィールド: 条件フィールド内のエントリのタイプ(チェック、属性、条件)を指定します。
少なくとも1つの「条件」フィールド。「条件」フィールドには、「タイプ」で指定されているように、チェック、属性または条件を含めることができます。
「属性」または「チェック」'フィールド: 内容は「タイプ」の値に依存します。タイプが「チェック」の場合、このフィールドには、チェックが適用される属性が含まれます。タイプが「属性」の場合、このフィールドには、属性に適用されるチェックが含まれます。タイプが「条件」の場合、このフィールドは使用されません。
演算子フィールド: 論理演算子AND、ORおよびNOTのいずれかを含むことができます。このフィールドが「AND」に設定されていて、値が複数の「条件」フィールドで設定されている場合、両方の条件は、条件が全体としてtrueを返すためにはtrueに評価される必要があります。「OR」に設定されている場合、条件全体がtrueに評価されるようにするには、セットの1つの条件のみがtrueを返す必要があります。「NOT」に設定されている場合、最初の「条件」フィールドに指定されている式の反対に条件が評価される必要があります。このフィールドがNULLの場合、その意味はANDとみなされます。演算子ANDおよびORは、2つ以上の条件フィールドが設定されていない場合は意味がありません。
次の表は、2つの条件フィールド(Condition1およびCondition2)が使用されている場合の動作をまとめたものです。
| タイプの設定 | Condition1およびCondition2の内容... | 属性またはチェックの内容... | Condition1およびCondition2が設定されている場合... | AND演算子の場合、条件が返す値 | OR演算子の場合、条件が返す値 |
|---|---|---|---|---|---|
| チェック | チェック(複数可) | 属性 | 2つのチェックは両方とも属性に適用されます。 | 両方の条件が属性に対してTRUEを返す場合のみTRUE | いずれかの条件が属性に対してTRUEを返す場合はTRUE |
| 属性 |
属性(複数も可) |
チェック |
チェックは両方の属性に適用されます。 | 条件が両方の属性に対してTRUEを返す場合のみTRUE | 条件が属性のいずれかに対してTRUEを返す場合はTRUE |
| 条件 |
条件 |
なし |
両方の条件が評価されます。 | 両方の条件がTRUEを返す場合のみTRUE | いずれかの条件がTRUEを返す場合はTRUE |
チェックを様々な属性および演算子と組み合せ、結果である条件をまとめてより複雑な条件を形成することで、複雑な論理チェックを構築できることがわかります。
ルールの定義
ルールは、ビジネス・ルール・チェック内の最上位のエンティティです。ルールは、チェックと条件をまとめ、チェックが適用される属性を指定し、ルールの違反時に発生させるエラー・コードおよびエラー・メッセージを指定します。さらに、エラーの重大度をこのレベルで指定できます。
ルールには、次のフィールドがあります。
「ルールID」はルールの数値識別子です。
ルール・ラベルはルールの判読可能な名前です。
「無効化」フィールドは「はい」に設定すると、削除せずに処理からルールを除外できます。
「属性に適用」フィールドは、チェックが適用される属性を示します。
「条件」フィールドは、ルールを適用するまえに評価する必要がある条件を示します。条件を満たさない場合、ルールは適用されません。
エラー・コードは、ルールに違反があった場合に返されるエラー・コードを示します。エラー・コードは、完全にユーザーの裁量で定義され、任意の書式で指定できます。
エラー・メッセージは、ルールに違反があった場合に返されるユーザー定義メッセージです。
エラー重大度は、ルール違反の重大度の表示を示します。エラー重大度は、完全にユーザーの裁量で定義され、任意の書式で指定できます。
チェック1は、属性に適用される最初のチェックを指定します。
チェック2 は、属性に適用される2番目のチェックを示します。
2つのチェックが指定されている場合、属性が両方のチェックをパスした場合のみルールはパスしたことになります。つまり、結果は、両方のチェックの論理ANDです。
|
注意: 複雑な条件セットがtrueではないようにするために、条件をルールに適用できます。無効な構成を記述するロジックは、条件を使用して指定されます。次に、条件によって制御され、チェック1が「失敗」に設定される非常に単純なルールを作成できます。ルールがこのように構成された場合、条件は分析済の各行に対して評価され、条件を満たす場合ルールは常に失敗します。 |
Excelスプレッドシートでのビジネス・ルールの定義
Excelスプレッドシートを使用してビジネス・ルールを定義する場合、次のルールを順守する必要があります。
[Install Path]/oedq_local_home/businessrulesディレクトリに配置され、この場合の[Install Path]はEDQインストールのルートを表します。
ルール、条件およびチェックは、3つの異なるワークシート、名前付きルール、条件およびチェックでそれぞれ定義する必要があります。
同じExcelファイル内の追加のワークシートで、リスト・チェックなどで使用するための追加データを含むように指定できます。
ルール・ワークシートは、次のような名前の列を含む必要があります。
ルールID
ルール・ラベル
無効化
適用先属性
条件
エラー・コード
エラー重大度
エラー・メッセージ
チェック1
チェック2
条件ワークシートは、次のような名前の列を含む必要があります。
条件名
属性またはチェック
タイプ
演算子
Condition1
条件2...条件N
チェック・ワークシートは、次のような名前の列を含む必要があります。
チェック名
チェック・タイプ
オプション1
オプション2
オプション 3
参照データでのビジネス・ルールの定義
参照データを使用してビジネス・ルールを含める場合、次のルールを順守する必要があります。
ルール、条件およびチェックをそれぞれ指定する、参照データの3つの異なるセット(または条件を使用しない場合は2つのセット)が使用可能である必要があります。
参照データの構造は、前述のExcelスプレッドシートで説明されている構造と同じである必要があります。
属性のクロス・チェック・プロセッサを使用すると、ビジネス・ルール適用の一貫性をチェックするために、2つの属性の値を比較できます。
比較できるのは同じデータ型の属性のみです。つまり、文字列属性は別の文字列属性と、日付は別の日付と、数値は別の数値と比較する必要があります。
属性のクロス・チェック・プロセッサは、2つの関連属性のデータが正しいことをチェックするために使用します。たとえば、Date_Of_Deathの値がDate_Of_Birthの値より後の日付であることを確認する場合などです。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 比較する2つの属性を指定します。指定する属性は同じデータ型である必要があります。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 比較に成功したレコード | 比較に成功したレコードの数。 |
| 比較に失敗したレコード | 比較に失敗したレコードの数。 |
| レコード(null値あり) | 比較する値の一方または両方がnullだったレコードの数。 |
出力フィルタ
属性のクロス・チェックからは、次の出力フィルタを使用できます。
成功: 比較に成功したレコード
失敗: 比較に失敗したレコード
Nullの比較: チェックした属性の一方または両方にnull値があるレコード
例
この例では、2つの属性DT_ACC_OPENとDT_PURCHASEDが比較され、データの繰返し数を調べています。
| 比較に成功したレコード | 比較に失敗したレコード | レコード(null値あり) |
|---|---|---|
| 996 | 3 | 1 |
比較に成功したレコードをドリルダウンできます。
| DT_ACC_OPEN | DT_PURCHASED | CrossAttributeCheck |
|---|---|---|
| 03/01/2000 | 03/01/2000 | Y |
| 06/01/2000 | 06/01/2000 | Y |
| 10/01/2000 | 10/01/2000 | Y |
| 14/01/2000 | 14/01/2000 | Y |
データ型チェック・プロセッサは、文字列属性または文字配列属性の値が一貫性のあるデータ型に準拠しているかどうかチェックし、想定したデータ型以外の値を持つレコードを無効として分類します。
数値属性と日付属性のデータ型は定義上100%一貫しているため、チェックできません。
データ型チェックは、ユーザー・アプリケーションで誤ったフィールドに入力された値(通常は、テキスト値のみが想定されるフィールドに入力された数値または日付)をすばやく検出するのに便利な手段です。
文字列属性に日付または数値を想定して、想定した型以外の値を無効として分類できることに注意してください。この機能が提供されているのは、日付と数値はデータ・ソースのスキーマから読み取れる制御されたデータ型の属性に必ずしも格納されていないためです。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | データ型の一貫性をチェックする1つ以上の文字列属性または文字配列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | なし。 |
| フラグ | 属性入力ごとに、新しい属性が次の形式で作成されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
データ型チェックで使用する日付書式参照データは、標準のJava 1.6.0以降のSimpleDateFormat APIに準拠している必要があります。
| 統計 | 説明 |
|---|---|
| 有効 | 入力属性に対して想定されたデータ型のデータが格納されているレコード。 |
| 無効 | 入力属性に対して想定されていないデータ型のデータが格納されているレコード。 |
「追加情報」ボタンをクリックすると、前述の統計が、分析対象レコードの総数に対するパーセンテージとして表示されます。
出力フィルタ
データ型チェックでは、次の出力フィルタが生成されます。
有効レコード
無効レコード
例
この例では、NAME属性のすべての値がテキスト書式である場合に、データ型チェックを使用します。この場合、null値は無効として処理されます。
| 入力属性 | 有効/無効 |
|---|---|
| Michael | 有効 |
| John Smith | 有効 |
| <Null> | 無効 |
| 19-Aug-2012 | 無効 |
重複チェック・プロセッサを使用すると、1つまたは複数の属性間で重複値を簡単にチェックできます。
重複チェックは、データ移行の際に問題を引き起こす可能性がある重複値(キー属性の値など)を識別するために使用したり、データ内の重複レコードを検出する初期チェックとして使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 重複チェックで考慮する属性をすべて指定します。レコードは、すべての入力属性において同一である場合に重複として識別されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
重複チェックでは、レコードのバッチについて重複を評価します。したがって、処理が完了するまで結果が生成されないため、これはリアルタイム・レスポンスが必要なプロセスには適していません。
リアルタイム・データ・ソースからのトランザクションのバッチに対して実行した場合、リーダー・プロセッサで構成されたコミット・ポイント(トランザクションまたは制限時間)に到達すると処理が終了します。返される統計は、トランザクションのバッチ内でのみの重複数を示します。
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 重複 | 入力属性に重複があったレコード。ドリルダウンすると、すべての固有値とそれぞれの発生回数が表示されます。再度ドリルダウンすると、レコードが表示されます。 |
| 重複なし | 入力属性に重複がなかったレコード。 |
出力フィルタ
重複チェックからは、次の出力フィルタを使用できます。
重複レコード
重複なしのレコード
例
この例では、重複チェック・プロセッサを使用して、BUSINESS属性内の重複する会社名を検索します。
| 重複 | 重複なし |
|---|---|
| 41 | 1970 |
重複値をドリルダウンできます。
| ビジネス | カウント |
|---|---|
| テスト | 3 |
| Zircom | 2 |
| Darwins | 2 |
| Tamlite Group | 2 |
| BSA Guns (UK) Limited | 2 |
| Permanent Pest Control | 2 |
| Gemini Visuals | 2 |
| Northern Water Utilities | 2 |
| Attitude Flooring | 2 |
| N S News & Confectionery | 2 |
| Send Group | 2 |
| Press Patterns | 2 |
「電子メール・チェック」プロセッサは、属性内の電子メール・アドレスをチェックし、その構文を検証します。つまり、アドレスが電子メール・アドレスの正しいパターンに準拠しているかどうかチェックします。
電子メール・チェックでは、電子メール・アドレスが有効かどうかをチェックするために正規表現の参照リストが使用されることに注意してください。チェックに使用される正規表現のリストを変更することにより、電子メール・チェックで使用するルールを変更できます。
「電子メール・チェック」プロセッサは、電子メール・アドレスが正しく入力されていることを検証するために使用します。
|
注意: 電子メール・アドレスの検証に使用される正規表現は万能ではありません。@記号の直後にピリオド(.)がある電子メール・アドレスが有効と判定されてしまいます。このような誤った書式の電子メール・アドレスなどをチェックするために、このプロセッサによる有効な出力に対して追加のチェックを実行することをお薦めします。 |
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 電子メール・アドレスが有効かどうかをチェックする単一の属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 有効レコード | チェックした属性に有効なパターンの電子メール・アドレスがあるレコード。 |
| 無効レコード | チェックした属性のデータが有効な電子メール・アドレス・パターンではなかったレコード。 |
出力フィルタ
電子メール・チェックからは、次の出力フィルタを使用できます。
有効レコード
無効レコード
例
この例では、電子メール・チェックを使用してEMAIL属性内のデータをチェックしています。
| 有効レコード | 無効レコード |
|---|---|
| 1978 | 2 |
有効値または無効値をドリルダウンできます。
無効な値:
| 電子メール |
|---|
| elizabeth.reynolds@broomfield-lodge-nursing-home.com |
| shirley.bayer@angela's.com |
「無効な文字のチェック」プロセッサを使用すると、異常な文字を含む値をすばやく簡単に検出できます。
無効な文字のチェックは、異常な文字をチェックするために使用します。これは、データを入力するユーザーが#などのダミー文字を入力することで必須フィールドの入力を回避したために不正なデータが含まれている可能性がある、フリー・テキスト・フィールドを分析するときに特に有効です。無効な文字のチェックは、入力ミスの検出にも有効です。
無効な文字が何も影響を与えない場合は、ノイズ削除プロセッサを追加することで、その文字を単に削除できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 無効な文字を分析の対象にする単一の属性または配列を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
属性入力ごとに、新しい属性が次の形式で作成されます。
単一のサマリー・フラグも出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 有効レコード | 無効な文字のチェックで有効と分類されたレコード。 |
| 無効レコード | 無効な文字のチェックで無効と分類されたレコード。 |
出力フィルタ
無効な文字のチェックからは、次の出力フィルタを使用できます。
有効レコード
無効レコード
例
この例では、NAME属性で()#%^*$£"!'などの無効な文字をチェックしています。#の文字を含むいくつかのレコードと'の文字を含むレコードが1つ検出されています。
| 有効 | 無効 |
|---|---|
| 1988 | 14 |
無効な値をドリルダウンできます。
| 名前 |
|---|
| # MCAULEY |
| # RAE |
| # WILLIAM |
| # SWAN |
| # HAWKES |
| # BARKER |
| # PALMER |
| # SNOWDON |
| # DOONAN |
| # MCCLEMENTS |
| # SHIELDS |
| # SEADEN |
| {O'CONNAL} |
「長さチェック」プロセッサを使用すると、属性の値が適切な長さであるかをすばやく簡単にチェックできます。この入力属性は、単一の文字列属性、複数の文字列入力、文字配列属性のいずれかになります。
長さチェックでは、次のいずれかまたは両方をチェックできます。
文字の合計長(空白文字および制御文字を含む)
単語数
長さチェックのオプションを使用して、単語がカウントされる方法を選択できます。デフォルトでは、単語はスペースで区切られます。たとえば、「Oracle Limited」の単語数は2です。
長さチェックは、属性内のデータが技術上またはビジネス上の目的を満たすようにするために使用します。たとえば、属性のデータをターゲット・システムのより短い属性に移行する場合は、データを切り詰めて、移行前にターゲット・フィールドの文字長制限に準拠していることをチェックできます。あるいは、値が設定文字数または単語数を超えないようにする必要があるビジネス上の理由が存在する場合もあります。たとえば、Surname属性で、長さが2単語を超えるすべての値をチェックする場合があります。これは、属性の誤った使用、たとえば会社名の値が格納されていることを示している可能性があるためです。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 短すぎるか長すぎる値をチェックする、単一、複数または文字列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが入力ごとに出力されます。
また、単一のサマリー出力もあります。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 両方の数 - 正しい | 文字数と単語数が有効なレコードの数。 |
| 不正文字数、正しい単語数 | 文字数は無効であるが、単語数は有効なレコードの数。 |
| 正しい文字数、不正単語数 | 文字数は有効であるが、単語数は無効なレコードの数。 |
| 両方の数 - 不正 | 文字数と単語数が無効なレコードの数。 |
「追加データ」ボタンをクリックすると、前述の統計が、分析対象レコード数に対するパーセンテージとして表示されます。
出力フィルタ
長さチェックからは、次の出力フィルタを使用できます。
有効(両方の数が有効だったレコード)
無効(両方の数が無効だったレコード)
無効な文字数(文字数は無効であるが、単語数は有効なレコード)
無効な単語数(単語数は無効であるが、文字数は有効なレコード)
例
この例では、長さチェックを使用して、アカウント番号属性(CU_ACCOUNT)の長さについて、文字数が10から11の範囲外で、1つの単語で構成されていない値がないかチェックしています。
| 両方の数 - 正しい | 不正文字数、正しい単語数 | 正しい文字数、不正単語数 | 両方の数 - 不正 |
|---|---|---|---|
| 2002 | 4 | 0 | 4 |
不正文字長、正しい単語長の件数をドリルダウンできます。
前述のレコードのCU_ACCOUNT属性が短かすぎることがわかります。
| CU_ACCOUNT | CU_NUMBER |
|---|---|
| 97-19601- | 10944 |
| 02-999-ZZ | 99999 |
| 00-000-ZZ | |
| 00-0-XX | 0 |
リスト・チェック・プロセッサは、属性内のデータをその属性の有効値および無効値の参照リストと照合してチェックします。
プロセッサでは、大/小文字を区別する照合または大/小文字を区別しない照合を実行でき、様々な方法で参照リストと照合できます。
次を含む(値が照合リストのエントリを含んでいる必要があります)
全体の値(値がリストと正確に一致する必要があります)
次で始まる(値が照合リストのエントリで始まる必要があります)
後方から一致する(値が照合リストのエントリで終わる必要があります)
区切り文字の一致(指定した区切り文字を使用して照合前にデータが区切られます)
|
注意: リスト・チェック・プロセッサでは、有効値または無効値の外部参照データの使用はサポートされていません。これを行おうとすると、処理時にエラー・メッセージが表示されます。 |
リスト・チェック・プロセッサは重要なプロセッサであり、データ属性内の有効値および無効値を検出するために監査で使用されます。頻度プロファイラまたはフレーズ・プロファイラを使用して有効値と無効値のリストを作成し、それらをリスト・チェックで使用して、リストに基づいてデータを継続的に監査します。
リスト・チェックでは、参照リストを2つまで(属性の有効値のリストと無効値のリスト)使用できます。
この2つのリストのうち1つのみを使用することもできます。たとえば、プロファイリングによって1つの属性に多くの異なる有効値があることがわかった場合は、属性の無効値のみをチェックし、一致しない値を有効または不明とみなすことができます。たとえば、Surname属性で単に「Test」などの疑わしい単語を検索するという方法がとれます。
ただし、属性の有効値の数が少ない場合は、単にデータを有効値のリストと照合してチェックし、一致しない値を無効または不明とみなすことができます。たとえば、Titleの値を有効な敬称の小規模なセットと照合してチェックできます。
最後に、両方のリストを使用して、有効値と無効値の両方を認識し、いずれのリストとも一致しない値を不明に分類できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 有効または無効な値(あるいはその両方)のリストに基づいてチェックする任意のタイプ(文字列、日付、数値、文字配列、日付配列、番号配列)の1つ以上の属性を指定します。 |
| オプション | 有効値に対してチェックするための次のオプションを指定します。
無効値に対してチェックするための次のオプションを指定します。
次の照合オプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 有効レコード | リスト・チェックで有効と分類されたレコード。 |
| 不明レコード | リスト・チェックで不明と分類されたレコード。 |
| 無効レコード | リスト・チェックで無効と分類されたレコード。 |
結果をドリルダウンすると、レコード自体を表示できます。
出力フィルタ
リスト・チェックからは、次の出力フィルタを使用できます。
有効レコード
不明レコード
無効レコード
例
この例では、リスト・チェックを使用して、頻度プロファイリングから生成されたBusiness属性の有効値と無効値のリストを使用して、Business属性内の値をチェックしています。
いずれのリストとも一致しない値は不明と分類されることに注意してください。
サマリー・ビュー:
| 有効レコード | 不明レコード | 無効レコード |
|---|---|---|
| 1665 | 332 | 4 |
不明レコードのドリルダウン:
| 値 | カウント | % |
|---|---|---|
| 331 | 16.5 | |
| フィールド | 1 | <0.1 |
無効レコードのドリルダウン:
| 値 | カウント | % |
|---|---|---|
| テスト | 3 | 0.1 |
| Test Ltd | 1 | <0.1 |
論理チェック・プロセッサでは、複数の基準を使用して、レコードをルーティングまたはフィルタ処理するための論理チェックを実行できます。
論理チェック・プロセッサは通常、レコードをフィルタ処理して必要なセットに編成する手段として使用します。たとえば、すべてのレコードを複数のチェックにかける場合、その最後に論理チェックを付け加えれば、他の監査プロセッサによって追加されたフラグ属性を使用して、全体として合格または失敗とみなされるレコードを選択できます。
論理チェックは、レコードをフィルタ処理して、データが複数の属性で複数の基準と一致するセットに編成するためにも使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 任意の数の任意のタイプの属性を指定します。 |
| オプション | 次の有効値オプションを指定します。
指定したオプションに基づいて、レコードのフィルタ処理に使用される式の構成が決定されます。また、式の作成方法を習得している場合は、式を直接編集することもできます。式は、式フィルタ・カスタム・プロセッサでも使用できます。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| チェックに成功したレコード | 論理チェックに合格したレコードの数 |
| チェックに失敗したレコード | 論理チェックに失敗したレコードの数 |
出力フィルタ
論理チェックからは、次の出力フィルタを使用できます。
チェックされた属性にデータがあるレコード
チェックされた属性にデータがないレコード
例
たとえば、NAME、ADDRESS1、POSTCODE、EMAILの各属性すべてにデータがあるレコードを、フィルタ処理によって選び出すことができます。これらの属性は、Populatedフラグを生成するために、最初にクイック統計プロファイラでプロファイリングされます。
サマリー・ビュー:
| チェックに成功したレコード | チェックに失敗したレコード |
|---|---|
| 859 | 141 |
チェックに合格したレコードまたは失敗したレコードをドリルダウンできます。
ルックアップ・チェック・プロセッサを使用すると、現在処理中のレコードと関連付けられた参照データのセット内のレコードをチェックできます。たとえば、リレーショナル・データベース内の別の表のデータや別のシステム内の関連データをチェックできます。
ルックアップ・チェックでは、1つ以上のキー属性を使用した完全一致に基づいて、参照データ内のレコードを照合します。
ルックアップ・チェックは、各作業レコードの関連レコードが参照データ表内にいくつあるかをチェックするために使用します。構成可能なオプションを使用して、関連レコードが多すぎる場合や少なすぎる場合に、そのレコードのチェックは失敗ということにできます。
たとえば、各顧客レコードに住所レコードが少なくとも1つあることをチェックできます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 参照データに対するルックアップに使用する属性を指定します。これらは、参照データのルックアップ列を構成する属性と対応している必要があります。 |
| オプション | 次の有効値オプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
外部データ(ステージングされていないデータ)をルックアップする場合、ルックアップのパフォーマンスの適切なレベルは、選択した参照データのルックアップ列に適切な索引があるかどうかによって決まります。また、外部参照データをルックアップする場合は、ルックアップ・チェック・プロセッサに常に再実行マーカーが表示され、実際のプロセッサの構成が変更されたかどうかに関係なく、プロセスが実行のたびに完全に再実行されることを示します。このことは、ルックアップ・チェック・プロセッサの後続のプロセッサも再実行が必要であることを意味します。これは、EDQでは外部参照データが変更されたかどうかを検出できないため、変更があったとみなし(外部参照は一般的に、動的変更参照データに使用されるため)、ルックアップを再実行して依存する結果の一貫性を確保する必要があるためです。
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 有効レコード | 構成されたオプションに基づいて、作業データからのレコードのうち、参照データ内の関連レコードの数が許容範囲内であるレコードの数。 |
| 無効レコード | 構成されたオプションに基づいて、作業データからのレコードのうち、参照データ内の関連レコードの数が許容範囲外であるレコードの数。 |
出力フィルタ
次の出力フィルタを使用できます。
有効レコード
無効レコード
例
この例では、ルックアップ・チェックを実行して、各顧客レコードに対応する受注(Workorder表のレコード)が少なくとも1つ存在していることをチェックしています。その結果に基づいて、受注なしの顧客はすべて見込み客としてタグ付けされ、アクティブな顧客統計に組み込まれません。
サマリー・ビュー:
| 有効レコード | 無効レコード |
|---|---|
| 1718 | 292 |
無効レコードのドリルダウン:
| CU_NO | CU_NO.count.1 |
|---|---|
| 13810 | 0 |
| 13833 | 0 |
| 13840 | 0 |
| 13841 | 0 |
| 13865 | 0 |
| 13877 | 0 |
| 13938 | 0 |
| 13950 | 0 |
| 13952 | 0 |
| 13966 | 0 |
| 13971 | 0 |
| 13977 | 0 |
| 14001 | 0 |
「データなしチェック」プロセッサを使用すると、1つの属性または複数の属性に意味のあるデータが存在するかどうかを簡単にチェックできます。入力として配列も使用します。
データなしチェックでは、null値のみでなく、空の文字列や、スペースまたは印刷不可能な文字のみで構成されている値もチェックします。ただし、データがすでにスナップショットの非データ処理を完了している場合、存在するのはnull値のみです。
レコード内の分析対象属性のいずれかに空白文字以外のデータがある場合は、データが含まれていると分類されます。それ以外の場合、分析したすべての属性に含まれているのが非データである場合は、データが含まれていないと分類されます。
「データなしチェック」プロセッサは、1つの属性または複数の属性において、完全な値および不完全な値をチェックするために使用します。たとえば、性別の値がないレコードをすべてのチェックし、可能な場合は使用できるデータを使用して(おそらく敬称属性からマップすることによって)値を追加できます。あるいは、名前や住所のフィールドにデータがまったくないレコードをすべて分離できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 完全性チェックの対象にする任意の数の属性または配列入力を指定します。 |
| オプション | 次の有効値オプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| データなし | チェックした属性にデータがないレコードの数。 |
| データあり | チェックした属性にデータがあるレコードの数。 |
出力フィルタ
次の出力フィルタを使用できます。
チェックされた属性にデータがあるレコード
チェックされた属性にデータがないレコード
例
この例では、データなしチェックを使用して電子メール・アドレス(EMAIL属性)のないレコードを検出しています。
サマリー・ビュー:
| データなし | データあり |
|---|---|
| 91 | 1919 |
データなしのレコードのドリルダウン:
| 電子メール | CU_NO |
|---|---|
| 14057 | |
| 14072 | |
| 14307 | |
| 14515 | |
| 99999 | |
| 14978 | |
| 12586 | |
| 10087 | |
| 10090 | |
| 13899 | |
| 10187 | |
| 15164 |
「パターン・チェック」プロセッサは、属性内のデータのパターンを有効パターンおよび無効パターンの参照リストと照合してチェックします。複数の単一入力または配列入力を使用します。
「パターン・チェック」プロセッサは、ある属性のデータがその属性の有効パターンの1つに準拠していることを保証するために使用します。技術上またはビジネス上の理由で、データが有効パターンのセットに準拠する必要がある場合があります。たとえば、データの移行時に、ターゲット・システムで特定の属性のデータがすべて数字のみで構成されている必要があり、さらに最小長と最大長の制限が設けられている場合があります。あるいは、ビジネス上の理由で、不正なデータや属性にあわないデータ(たとえば名前のフィールドに入っている数値や無効な製品コードなど)が含まれているレコードを、無効なレコードとしてタグ付けする場合があります。
有効パターンと無効パターンのリストは、パターン・プロファイラを使用してデータ自体から作成できます。
パターン・チェックでは、参照リストを2つまで(属性の有効パターンのリストと無効パターンのリスト)使用できます。
この2つのリストのうち1つのみを使用することもできます。たとえば、プロファイリングによって、ある属性に対して多数の様々な有効パターンが存在することがわかった場合は、その属性の無効パターンのみをチェックし、一致しない値を有効または不明とみなすことができます。
ただし、属性の有効パターンの数が少ない場合は、単にデータを有効パターンのリストと照合してチェックし、一致しない値を無効または不明とみなすことができます。
最後に、両方のリストを使用して、有効パターンと無効パターンの両方を認識し、いずれのリストとも一致しない値を不明に分類できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 有効パターンまたは無効パターン(あるいはその両方)をチェックする単一または配列属性を1つ以上指定します。 |
| オプション | 次の有効値オプションを指定します。
次の有効パターン・オプションを指定します。
次の無効パターン・オプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
レコード全体に対して単一のサマリー・フラグも出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 有効レコード | パターン・チェックで有効と分類されたレコード。 |
| 不明レコード | パターン・チェックで不明と分類されたレコード。 |
| 無効レコード | パターン・チェックで無効と分類されたレコード。 |
前述のいずれかの統計値をドリルダウンすると、有効、不明または無効と判明したパターンの数がそれぞれ表示されます。その後再びドリルダウンすると、レコード自体を表示できます。
出力フィルタ
次の出力フィルタを使用できます。
有効レコード
不明レコード
無効レコード
例
この例では、パターン・プロファイリングから生成された有効パターンおよび無効パターンのリストを使用してパターン・チェックを実行し、アカウント番号属性(CU_ACCOUNT)の値を検証しています。
いずれのパターン・リストとも一致しなかった値は不明に分類されています。
サマリー・ビュー:
| 有効レコード | 不明レコード | 無効レコード |
|---|---|---|
| 1991 | 1 | 9 |
無効レコードのドリルダウン:
| 値 | カウント | % |
|---|---|---|
| aa-NNNNN-aa | 4 | 0.2 |
| NN-NNN-aa | 2 | <0.1 |
| NN-NNNNN-Na | 1 | <0.1 |
| NN-NNNNN- | 1 | <0.1 |
| NN-N-aa | 1 | <0.1 |
正規表現チェック・プロセッサは、属性内のデータをその属性の有効および無効な正規表現の参照リストと照合してチェックします。入力として文字列、複数の文字列、または文字配列を使用します。
チェックでの大/小文字の区別と照合方法(全体の値/次を含む/次で始まる/次で終わる)を制御できます。
正規表現プロセッサは強力なツールであり、データの位置、部分値と全体値、およびワイルドカードを使用して、その正確な内容に基づいてデータを検証できます。
正規表現チェックは、英国の国民保険番号などのように一貫した構成に準拠する必要があるデータをチェックする場合に役立ちます。
正規表現
正規表現は、パターンを表現し、文字列を操作するための標準の手法であり、一度習得すると非常に有用です。
正規表現に関するチュートリアルや参考資料はインターネットで入手できます。また、Jeffrey E. F. Friedl著、O'Reilly UK発行の『Mastering Regular Expressions』(ISBN: 0-596-00289-0)などの書籍も参考になります。
また、正規表現の習得に役立つソフトウェア・パッケージ(RegExBuddyなど)や、有益な正規表現のオンライン・ライブラリ(RegExLibなど)も使用できます。
データのチェックに使用される正規表現の例を次に示します。
| 正規表現 | パターンの意味 |
|---|---|
| ^\d{5}$ | 5桁の整数で表される米国の郵便番号。 |
| ([A-Z]{1,2}[0-9]{1,2}|[A-Z]{3}|[A-Z]{1,2}[0-9][A-Z])( |-)[0-9][A-Z]{2} | 有効な英国の郵便番号。 |
| ^[A-CEGHJ-PR-TW-Z]{1}[A-CEGHJ-NPR-TW-Z]{1}[0-9]{6}[A-DFM]{0,1}$ | 有効な英国の国民保険番号。 |
| ^([a-zA-Z0-9_\-\.]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$ | 有効な電子メール・アドレス。 |
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 有効または無効な正規表現(あるいはその両方)のリストに基づいてチェックする単一、複数または配列属性を指定します。 |
| オプション | 次の有効パターン・オプションを指定します。
次の無効パターン・オプションを指定します。
次の照合オプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
単一のサマリー・フラグも出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 有効レコード | 正規表現チェックで有効と分類されたレコード。 |
| 不明レコード | 正規表現チェックで不明と分類されたレコード。 |
| 無効レコード | 正規表現チェックで無効と分類されたレコード。 |
前述のいずれかの統計値をドリルダウンすると、有効、不明または無効と判明したパターンの数がそれぞれ表示されます。その後再びドリルダウンすると、レコード自体を表示できます。
出力フィルタ
次の出力フィルタを使用できます。
有効レコード
不明レコード
無効レコード
例
この例では、「正規表現チェック」を使用して、次の正規表現との「全体の値」一致を使用してアカウント番号属性(CU_ACCOUNT)の形式をチェックします。
^([0-9]{2})(-)([0-9]{4,5})(-)([a-zA-Z]{2})
この正規表現は、値が正確に2桁の数字で始まり、その後にハイフン、4桁または5桁の数字、別のハイフン、2文字の順に続く必要があることを示します。
サマリー・ビュー:
| 有効レコード | 不明レコード | 無効レコード |
|---|---|---|
| 1997 | 0 | 14 |
無効レコードのドリルダウン:
| 値 | カウント | % |
|---|---|---|
| 4 | 0.2 | |
| OO-24077-SH | 1 | <0.1 |
| OO-24282-LR | 1 | <0.1 |
| OO-24276-LR | 1 | <0.1 |
| 0975t3487263 | 1 | <0.1 |
| OI-25057-JD | 1 | <0.1 |
| 97-19671-5H | 1 | <0.1 |
| 97-19601- | 1 | <0.1 |
| 02-999-ZZ | 1 | <0.1 |
| 00-0-XX | 1 | <0.1 |
「サスペクト・データ・チェック」プロセッサでは、属性値のよくある様々な不正データ入力(名前フィールドに「aaa」と入力するなど)をチェックします。
具体的には、次のいずれかまたはすべてをチェックできます。
英字の繰返し(例: aaa)
数字の繰返し(例: 111)
英数字以外の文字の繰返し(例: >>>)
パターンの繰返し(例: abcabc)
最小文字長(例: xなどの短い値)
「サスペクト・データ・チェック」は、必須列のサスペクト・データとなる、よくあるユーザーの不正をチェックするために使用します。
データ入力時に空の値を入力できない場合、ユーザーはそこを通過するために単一の文字(スペース、ピリオド、ランダムな1文字など)を入力する場合があります。
あるいは、単一文字の繰返し(例: 9999)や、文字のパターンの繰返し(例: asdasd)を入力する場合もあります。
これは、ユーザーの誤りではなく、ビジネス・プロセスまたはサポート・アプリケーションのフォルトである可能性もあります。ユーザーは、データ入力アプリケーションが要求している完全なデータ・セットがわかっていない場合やそれを使用できない場合でも、システムにデータを入力する必要があります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | サスペクト・データ入力をチェックする単一の属性を指定します。 |
| オプション | 次の「英字の繰返し」オプションを指定します。
次の「数字の繰返し」オプションを指定します。
次の「英字以外の繰返し」オプションを指定します。
次の「パターンの繰返し」オプションを指定します。
次の「最小長」オプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | なし。 |
| フラグ | 次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| サスペクト・レコード | チェックした属性にサスペクト値があると特定されたレコード。
ドリルダウンすると、サスペクトを特定したチェックによるサスペクトの内訳が表示されます。再度ドリルダウンすると、レコードが表示されます。 |
| 有効レコード | チェックした属性にサスペクト値がなかったレコード。 |
| Nullレコード | チェックした属性にnull値のあるレコード。 |
出力フィルタ
次の出力フィルタを使用できます。
有効レコード
サスペクト・レコード
チェックした属性にnullがあったレコード
例
この例では、「サスペクト・データ・チェック」を使用して名前属性のサスペクト・データ入力をチェックします。
サマリー・ビュー:
| 英字の繰返し | 数字の繰返し | 英字以外の繰返し | パターンの繰返し | 短い値 |
|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 |
「英字の繰返し」のドリルダウン:
| NAME | CU_NUM |
|---|---|
| aaaaaaaaa | 87581 |
「値のチェック」プロセッサは、属性内のデータを単一の値と比較します。
比較を実行するためのオプションが複数あります。
等しい
以上
より大きい
以下
より小さい
「値のチェック」を使用すると、単一の属性の値に応じてレコードを簡単にフィルタ処理できます。これは、関心のある領域に分析を集中したり、値をしきい値と照合してチェックする目的で行います。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 1つ以上の属性(任意のタイプ)を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | なし。 |
| フラグ | 次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 有効レコード | 値チェックに合格したレコード。 |
| 無効レコード | 値チェックに合格しなかったレコード。 |
| Nullレコード | Nullレコード(これらを別々に分類するオプションを使用した場合)。 |
出力フィルタ
次の出力フィルタを使用できます。
有効レコード
無効レコード
Nullレコード
例
この例では、'is equal to M'という値チェックを使用して、レコードを性別属性によりフィルタ処理します。
サマリー・ビュー:
| 有効レコード | 無効レコード | Nullレコード |
|---|---|---|
| 819 | 1034 | 148 |
レコードのドリルダウン:
| GENDER | 妥当性 |
|---|---|
| M | 有効 |
| F | 無効 |
| <Null> | Null |
GNR (Global Name Recognition)は、IBM社が製造したAPIスイートです。
オラクル社では、これらの多数のAPIを統合して、言語の氏名バリアントに関するGNRの拡張ディクショナリに基づいて氏名を分析、パースおよび照合できるようにしました。
EDQ内でGNRを使用するには、次のことが必要です。
GNR APIを使用するための有効なライセンスをIBM社から購入する必要があります。
EDQは、Oracle Fusion Middleware Enterprise Data Qualityと外部システムの統合の IBMグローバル名認識との統合手順に従い、GNR APIと統合されている必要があります。
「GNR最適カルチャの取得」プロセッサでは、GNRの分類APIを使用して、そのAPIに基づいた姓名に対する単一の最適なカルチャを返します。
「GNR最適カルチャの取得」は、「グローバル名認識」を使用して氏名のカルチャを導出し、言語ルールを使用して、カルチャの違いによって変化する場合がある氏名を正確に照合できます。
「GNR検索」プロセッサが照合時に氏名カルチャの適切な比較パラメータ(comp_parms)を関連付けることができるように、作業データと検索で照合する参照データの両方について、「名」のカルチャ値と「姓」のカルチャ値が必要です。
「GNRカルチャの取得」プロセッサでは、GNRの分類APIを使用して、氏名について可能性のあるすべてのカルチャを返します。
「GNRカルチャの取得」は、1つ以上のデータ・セット内の氏名のプロファイリング時に使用して、氏名のカルチャのグループ化および氏名カルチャの派生のあいまいさを把握することを目的としていますが、特に氏名カルチャの派生のあいまいさは、「GNR検索」での氏名の照合方法に影響を与える場合があります。
「GNRカルチャの取得」は、「GNR最適カルチャの取得」を使用した氏名に対する「最適な」カルチャの選択を検証する際にも使用できます。
「GNR解析」プロセッサでは、GNRの解析APIを使用して、構造化されていない氏名(「氏名」フィールド)を読み取り、その氏名の構成部分を最もよく把握できるように解析します。
「GNR解析」は、既知の名と姓の構造を持たないグローバル氏名データで使用します。
氏名の解析は通常、名と姓の氏名構造が必要な「GNR検索」を使用する前に実行します。
「GNR検索」プロセッサは最も重要なGNRプロセッサで、問合せデータ(顧客名など)を参照データ(ウォッチリストの個人名など)と照合するために使用します。「GNR検索」プロセッサには、NameHunterパッケージの様々なGNR APIが含まれています。
「GNR検索」は、カルチャに依存する言語ルールを使用して、データ・セット間で氏名を照合します。「GNR検索」では、元のカルチャが広範囲な氏名のバリアントに関する大規模ディクショナリにアクセスできます。「GNR検索」には、異なる文字で表現されている氏名間で照合できるように、ロシア、ギリシャおよびアラビアの変換ルールも含まれています。
「GNR検索」プロセッサでは、リアルタイム実行とバッチ実行の両方で機能する単一プロセッサを提供するために、EDQの標準参照データ機能を使用して参照データ(「検索リスト」)をメモリーに読み取り、レコードごとに問合せの氏名を照合します。
照合プロセッサを使用すると、同じソースまたは複数のソースからのレコードを照合したり、照合プロセスの結果をレビューすることができます。
これらの調整済プロセッサの指示に従うと、対象となるビジネス問題に適したデフォルト構成を使用して照合を構成できます。
配列、「グループ」および「マージ」以外の照合プロセッサはすべて複数のデータ・ソースを受け入れることに注意してください。照合のプロセスに複数のデータ・ソースを接続するには、照合に使用するデータ・ソースごとに(読取りまたは書込みファミリから)リーダーを追加します。
照合結果のレビュー
EDQには、すべての照合決定を自動化することはできないという重要な原則があるため、結果のレビューは照合プロセスの主要な一部となります。手動で照合結果をレビューすると、ユーザーは特定のインテリジェンスを個々のケースに適用して、照合プロセスを検証および調整できます。
EDQには、2つのレビュー・アプリケーション(「一致レビュー」と「ケース管理」)が用意されています。これらのアプリケーションは照合結果を様々な方法で分割するため、照合プロセッサは結果のレビューにどちらのレビュー・アプリケーションを使用するかを事前に選択する必要があります。照合プロセッサの定義と実行が完了したら、構成済のアプリケーションでその結果をレビューできます。
拡張照合プロセッサは、照合プロセッサに対する特別な事前設定が目的ではない、複数の入力データ・ソースからのデータを照合する手段を提供します。これにより、各ソースからデータを照合する方法を完全に管理でき、照合処理の構成方法を自由に変更できます。
拡張照合プロセッサは、照合プロセッサですべてのオプションを完全に管理する場合に使用します。
拡張照合は、照合プロセッサの1タイプです。照合プロセッサはいくつかのサブプロセッサで構成されており、各サブプロセッサは照合操作の異なるステップを実行するため個別に構成する必要があります。拡張照合プロセッサは次のサブプロセッサで構成されており、次に説明するように、それぞれが個別の機能を実行します。
次の表に、サブプロセッサを示します。
| サブプロセッサ | 説明 |
|---|---|
| 入力 |
照合プロセスに含まれるデータ・ストリームから属性を選択します。 |
| 識別 |
照合処理で使用する識別子を作成して属性にマップします。 |
| クラスタ |
データ・ストリームを複数のクラスタに分割します。 |
| 照合 |
実行する比較を選択し、一致ルールを使用して比較を解釈する方法を選択します。 |
| マージ |
オプションでルールを使用して照合レコードをマージし、出力レコードの「最適」なセットを作成します |
照合プロセスに含めるデータ・ストリームからの任意の属性。
入力は入力サブプロセッサで構成できます。
照合プロセッサの拡張オプションを除くすべてのオプションは、前述のサブプロセッサ内で構成します。
出力データ・ストリームとその属性は、前述の照合およびマージ・サブプロセッサで構成します。
拡張照合プロセッサは、構成によってはデータをバッチ処理する必要があるため、リアルタイム・レスポンスの実行には適していません。
|
注意: 拡張照合プロセッサには常に再実行マーカーが表示され、構成が変更されたかどうかに関係なく、プロセスが実行されるたびに完全に再実行されることを示します。これは、拡張照合プロセッサの下位プロセッサも再実行が必要であることを意味します。 |
結果の表示
拡張照合プロセッサでは、次に示す多数の結果ビューが作成されます。すべてのビューは、プロセス内の拡張照合プロセッサをクリックして表示できます。拡張照合プロセッサを展開してサブプロセッサを表示し、ビューを作成するサブプロセッサを選択して表示することもできます。
入力ビュー
入力ビューは、入力データ・ストリームごとに表示されます。ビューには、各セットから選択された属性が表示されます。
クラスタ・ビュー
クラスタ・ビューは、構成されたクラスタごとに表示されます。これらのビューを使用してクラスタリングの厳密度を評価し、不必要な比較が多数行われていないこと、および照合候補の漏れがないことを確認します。詳細は、クラスタリングの概要ガイドを参照してください。
次の表に、クラスタ・ビューによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| クラスタ | 個別のクラスタ・キー値。 |
| グループ・サイズ | クラスタ内のレコード合計数(つまり、個別のクラスタ・キー値が同じレコードの数)。 |
| 処理済? | このクラスタが実際に処理されたかどうかを示します。次の値を指定できます。
- はい - スキップ済 - クラスタ・サイズの限度 - スキップ済 - 比較制限 |
| [データ・ストリーム名] | 各入力データ・ストリームの次の値です。
各入力データ・ストリームの各クラスタ内に含まれるドリル可能なレコードの件数 |
照合ビュー(照合プロセッサによって作成される) [照合レビューのみ]
照合ビューでは、作業データ・ストリームから一致したレコードの数が集計されます。
| 統計 | 説明 |
|---|---|
| 一致するレコード | 他の作業セットからのレコードまたは参照レコードのいずれかと照合関係で一致した、作業データ・ストリームからのレコードの数。
これには、詳細オプションの「一致グループでのレビュー関係の使用」を選択しないかぎり、レビュー関係のみで他のレコードと一致したレコードは含まれないことに注意してください。 |
| 一致しないレコード | 他のレコードと一致しなかったレコードの合計数。 |
ルール・ビュー(照合により作成)
ルール・ビューには、各自動一致ルールによって作成された関係の数のサマリーが表示されます。
| 統計 | 説明 |
|---|---|
| ルールID | 一致ルールの数値識別子。 |
| ルール名 | 一致ルールの名称。 |
| リレーションシップ | 一致ルールによって作成された、レコード間の関係の数。レコードのペア(AとB)の間の各関係は、1つのルールのみによって作成できることに注意してください。上位のルールによって関係が作成されると、下位のルールは適用されません。また、別のルールによって、関係内の1つのレコードを別のレコードに関連付ける(たとえば、AとC)ことができます。 |
レビュー・ステータス・ビュー(照合により作成)
レビュー・ステータス・ビューでは、関係がレビュー・ステータス別に集計されます。
| 統計 | 説明 |
|---|---|
| レビュー・ステータス | レビュー・ステータス。可能なレビュー・ステータスごとに、次の行が表示されます。
- 自動照合 - 手動照合 - 保留中 - レビュー待ち - 手動照合なし |
| リレーションシップ | 指定されたレビュー・ステータスのレコード間の関係の数。後述の注意を参照してください。 |
|
注意: このビューの統計は、レビュー・プロセス時に行われた決定に基づいて自動的に更新されます。したがって、最上位レベルの統計には、各関係のレビュー・ステータスの最新ビューが常に表示されます。ただし、照合プロセッサが実行されるたびにデータへのドリルダウンが生成されるため、照合プロセッサの最後の実行以降に行われたレビュー決定は更新に反映されません。この状態が発生した場合、結果ブラウザには、表示されている生成済データが最新でないことが表示されます。 |
一致グループ・ビュー(照合により作成)[照合レビューのみ]
一致グループ・ビューでは、一致レコードのグループが集計されます。
| 統計 | 説明 |
|---|---|
| 一致グループ | 一致レコード・グループの合計数。ドリルダウンすると、グループのサマリーがグループ・サイズ(レコード数)別に表示されます。一致グループには、詳細オプションの「一致グループでのレビュー関係の使用」を選択しないかぎり、レビュー関係のみで他のレコードと一致したレコードは含まれないことに注意してください。 |
| 一致しない出力レコード | 出力された、作業表からの不一致レコードの合計数。
参照ソースからの不一致レコードは出力されないことに注意してください。 |
アラート・グループ・ビュー(照合により作成)[ケース管理のみ]
アラート・グループ・ビューでは、一致レコードのグループが集計されます。
| 統計 | 説明 |
|---|---|
| アラート・グループ | アラート・グループの合計数。ドリルダウンすると、グループのサマリーがグループ・サイズ(レコード数)別に表示されます。 |
| アラートにないレコード | アラートに含まれていなかった、作業データからのレコードの合計数。
参照ソースからの不一致レコードは出力されないことに注意してください。 |
グループ出力(照合により作成)[照合レビューのみ]
グループ出力は、照合プロセッサで作成された一致グループのデータ・ビューです。データ・ビューに出力されるグループ、およびビューの属性は、照合サブプロセッサのグループ出力のオプションに応じて異なる場合があります。たとえば、データ・ビューに、1レコードのみを含む「グループ」を含める場合と含めない場合があります。
アラート出力(照合により作成)[ケース管理のみ]
アラート出力は、照合プロセッサで作成されたアラートのデータ・ビューです。データ・ビューに出力されるアラート、およびビューの属性は、照合サブプロセッサのグループ出力のオプションに応じて異なる場合があります。
関係出力ビュー(照合により作成)
関係出力は、照合プロセッサで作成されたレコードのペアの各関係(リンク)を示すデータ・ビューです。データ・ビューに出力される関係、およびビューの属性は、照合サブプロセッサの関係出力のオプションに応じて異なる場合があります。たとえば、ビューに、特定のルールによって形成された関係を含める場合と含めない場合があります。
マージのサマリー(マージにより作成)
マージのサマリー・ビューでは、照合処理のマージ・ステージが集計されます。
| 統計 | 説明 |
|---|---|
| 成功 | マージ・プロセスで、エラーが発生せずに正常にマージされて出力されたグループの数。
ドリルダウンすると、成功したグループのサマリーがグループ・サイズ(レコード数)別に表示されます。 マージの構成で、関連付けられていないレコードを出力するように設定した場合は、1レコードのみを含む「グループ」が含まれることに注意してください。 |
| 含まれているエラー | 自動出力選択でエラーが発生し、手動による解決が必要であるため、正常にマージされなかったグループの数。ドリルダウンすると、失敗したグループのサマリーがグループ・サイズ(レコード数)別に表示されます。 |
マージ済出力ビュー(マージにより作成)
マージ済出力は、照合プロセッサからのマージ済出力(つまり、すべての入力データ・ストリームの重複レコードがマージされた後のレコード・セット)のデータ・ビューです。出力されるレコードとその属性は、マージ・サブプロセッサで設定するオプションに応じて異なります。
出力フィルタ
拡張照合プロセッサからは、次の出力フィルタが使用可能です。
グループ
リレーションシップ
マージ済
意思決定
グループ、関係、およびマージ済出力フィルタは、前述のグループ出力または(アラート出力)、関係出力およびマージ済出力に対応しています。
決定出力は、関係レビュー時に行われたすべての手動での照合決定およびレビュー・コメントが書き出された出力です。
決定の入力と出力
決定入力には、次の目的があります。
他の製品で行われた履歴一致決定のEDQへのインポート。これは1回かぎりのプロセスです。完了したら、データは、決定入力から関連が解除される必要があります。
外部レビュー・システムで行われた(および定期的に行われている)一致決定のインポート。これは、通常の実行プロセスの一環である必要があります。
決定出力により、一致決定の完全な監査証跡を外部に格納できます。
|
注意: 外部一致レビューでは、最新の一致決定を含む関係出力が使用されます。決定出力は、古い決定や現在の関係に関連付けられていない決定など、行われたすべての決定を含むため、様々です。このため、決定出力は、監査目的により適しています。 |
決定入力および出力の使用に関する詳細は、Oracle Fusion Middleware Oracle Enterprise Data Qualityの使用の一致決定のインポートおよび 一致決定のエクスポートに関する項を参照してください。
統合プロセッサは、同じビジネス・エンティティを表す複数のレコード・セットを結合するために使用します。
EDQにおける照合の詳細は、照合処理の概念ガイドを参照してください。
統合は、データ移行の一環として実行できます。重複レコードは、すべての入力データ・ストリーム内、および入力データ・ストリーム間で識別されます。新しい「最適」なレコードは、一致した入力レコードからデータをマージすることにより、重複レコードから作成できます。
統合プロセッサは、自動ルールと手動決定を組み合せて使用して、レコードを照合し、統合された適切な出力を作成する機能を備えています。
重複除外は、照合プロセッサの1タイプです。照合プロセッサはいくつかのサブプロセッサで構成されており、各サブプロセッサは照合操作の異なるステップを実行するため個別に構成する必要があります。「統合」プロセッサは次のサブプロセッサで構成されており、次に説明するように、それぞれが個別の機能を実行します。
| サブプロセッサ | 説明 |
|---|---|
| 入力 |
照合プロセスに含まれるデータ・ストリームから属性を選択します。 |
| 識別 |
照合処理で使用する識別子を作成して属性にマップします。 |
| クラスタ |
データ・ストリームを複数のクラスタに分割します。 |
| 照合 |
実行する比較を選択し、一致ルールを使用して比較を解釈する方法を選択します。 |
| マージ |
オプションでルールを使用して照合レコードをマージし、出力レコードの「最適」なセットを作成します |
入力
照合プロセスに含めるデータ・ストリームからの任意の属性。
入力は入力サブプロセッサで構成できます。
オプション
照合プロセッサの拡張オプションを除くすべてのオプションは、前述のサブプロセッサ内で構成します。
出力
出力データ・ストリームとそれらの属性は、前述の照合サブプロセッサおよびマージ・サブプロセッサで構成します。
実行
「統合」プロセッサは、データをバッチ処理するように設計されているため、リアルタイム・レスポンスの実行には適していません。
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム・モニタリング | はい |
| リアルタイム・レスポンス | いいえ |
|
注意: 「統合」プロセッサでは常に再実行マーカーが表示されていますが、このマーカーは、構成が変更されたかどうかに関係なくプロセスが実行のたびに完全に再実行されることを示します。これは、「統合」プロセッサの下位プロセッサも再実行が必要であることを意味します。 |
結果の表示
「統合」プロセッサでは、次に示す多数の結果ビューが作成されます。すべてのビューは、プロセス内の「統合」プロセッサをクリックして表示できます。「統合」プロセッサを展開してサブプロセッサを表示し、ビューを作成するサブプロセッサを選択して表示することもできます。
入力ビュー(入力により作成)
入力ビューは、入力データ・ストリームごとに表示されます。ビューには、各セットから選択された属性が表示されます。
クラスタ・ビュー(クラスタにより作成)
クラスタ・ビューは、構成されたクラスタごとに表示されます。これらのビューを使用してクラスタリングの厳密度を評価し、不必要な比較が多数行われていないこと、および照合候補の漏れがないことを確認します。詳細は、クラスタリングの概要ガイドを参照してください。
| 統計 | 意味 |
|---|---|
| クラスタ | 個別のクラスタ・キー値 |
| グループ・サイズ | クラスタ内のレコード合計数(つまり、個別のクラスタ・キー値が同じレコードの数) |
| 処理済? | このクラスタが実際に処理されたかどうかを示します。次の値を指定できます。
|
| [データ・ストリーム名] | 各入力データ・ストリームの次の値です。
各入力データ・ストリームの各クラスタ内に含まれるドリル可能なレコードの件数 |
照合ビュー(照合プロセッサによって作成される)[照合レビューのみ]
照合ビューでは、照合されたレコード数が集計されます。
| 統計 | 意味 |
|---|---|
| 一致するレコード | 他のレコードと一致したため、統合されるレコード数。
これには、詳細オプションの「一致グループでのレビュー関係の使用」を選択しないかぎり、レビュー関係のみで他のレコードと一致したレコードは含まれないことに注意してください。「一致グループでレビュー関係を使用[一致レビューのみ]」を参照してください。 |
| 一致しないレコード | 他のレコードと一致しなかった(そのため統合されない)レコードの合計数。 |
ルール・ビュー(照合により作成)
ルール・ビューには、各自動一致ルールによって作成された関係の数のサマリーが表示されます。
| 統計 | 意味 |
|---|---|
| ルールID | 一致ルールの数値識別子。 |
| ルール名 | 一致ルールの名称。 |
| リレーションシップ | 一致ルールによって作成された、レコード間の関係の数。レコードのペア(AとB)の間の各関係は、1つのルールのみによって作成できることに注意してください。上位のルールによって関係が作成されると、下位のルールは適用されません。また、別のルールによって、関係内の1つのレコードを別のレコードに関連付ける(たとえば、AとC)ことができます。 |
レビュー・ステータス・ビュー(照合により作成)
レビュー・ステータス・ビューでは、関係がレビュー・ステータス別に集計されます。
| 統計 | 意味 |
|---|---|
| レビュー・ステータス | レビュー・ステータス。可能なレビュー・ステータスごとに、次の行が表示されます。
|
| リレーションシップ | 指定されたレビュー・ステータスのレコード間の関係の数。後述の注意を参照してください。 |
|
注意: このビューの統計は、レビュー・プロセス時に行われた決定に基づいて自動的に更新されます。したがって、最上位レベルの統計には、各関係のレビュー・ステータスの最新ビューが常に表示されます。ただし、照合プロセッサが実行されるたびにデータへのドリルダウンが生成されるため、照合プロセッサの最後の実行以降に行われたレビュー決定は更新に反映されません。この状態が発生した場合、結果ブラウザには、表示されている生成済データが最新でないことが表示されます。 |
一致グループ・ビュー(照合により作成)[照合レビューのみ]
一致グループ・ビューでは、一致レコードのグループが集計されます。
| 統計 | 意味 |
|---|---|
| 一致グループ | 一致レコード・グループの合計数。ドリルダウンすると、グループのサマリーがグループ・サイズ(レコード数)別に表示されます。一致グループには、詳細オプションの「一致グループでのレビュー関係の使用」を選択しないかぎり、レビュー関係のみで他のレコードと一致したレコードは含まれないことに注意してください。「一致グループでレビュー関係を使用[一致レビューのみ]」を参照してください。 |
| 一致しない出力レコード | 出力された不一致レコードの合計数。 |
アラート・グループ・ビュー(照合により作成)[ケース管理のみ]
アラート・グループ・ビューでは、一致レコードのグループが集計されます。
| 統計 | 意味 |
|---|---|
| アラート・グループ | アラート・グループの合計数。ドリルダウンすると、グループのサマリーがグループ・サイズ(レコード数)別に表示されます。 |
| アラートにないレコード | アラートに含まれていなかった、作業データからのレコードの合計数。
参照ソースからの不一致レコードは出力されないことに注意してください。 |
グループ出力(照合により作成)[照合レビューのみ]
グループ出力は、照合プロセッサで作成された一致グループのデータ・ビューです。データ・ビューに出力されるグループ、およびビューの属性は、照合サブプロセッサのグループ出力のオプションに応じて異なる場合があります。たとえば、データ・ビューに、1レコードを含む「グループ」を含める場合と含めない場合があります。
アラート出力(照合により作成)[ケース管理のみ]
アラート出力は、照合プロセッサで作成されたアラートのデータ・ビューです。データ・ビューに出力されるアラート、およびビューの属性は、照合サブプロセッサのグループ出力のオプションに応じて異なる場合があります。
関係出力ビュー(照合により作成)
関係出力は、照合プロセッサで作成されたレコードのペアの各関係(リンク)を示すデータ・ビューです。データ・ビューに出力される関係、およびビューの属性は、照合サブプロセッサの関係出力のオプションに応じて異なる場合があります。たとえば、ビューに、特定のルールによって形成された関係を含める場合と含めない場合があります。
マージ・サマリー・ビュー(マージにより作成)
マージのサマリー・ビューでは、照合処理のマージ・ステージが集計されます。
| 統計 | 意味 |
|---|---|
| 成功 | マージ・プロセスで、エラーが発生せずに正常にマージされて出力されたグループの数。
ドリルダウンすると、成功したグループのサマリーがグループ・サイズ(レコード数)別に表示されます。 マージの構成で、関連付けられていないレコードを出力するように設定した場合は、1レコードのみを含む「グループ」が含まれることに注意してください。 |
| 含まれているエラー | 自動出力選択でエラーが発生し、手動による解決が必要であるため、正常にマージされなかったグループの数。ドリルダウンすると、失敗したグループのサマリーがグループ・サイズ(レコード数)別に表示されます。 |
マージ済出力ビュー(マージにより作成)
マージ済出力は、照合プロセッサからのマージ済出力(つまり、すべての入力データ・ストリームの重複レコードがマージされた後のレコード・セット)のデータ・ビューです。出力されるレコードとその属性は、マージ・サブプロセッサで設定するオプションに応じて異なります。
出力フィルタ
拡張照合プロセッサからは、次の出力フィルタが使用可能です。
グループ
リレーションシップ
マージ済
意思決定
グループ、関係、およびマージ済出力フィルタは、前述のグループ出力、関係出力およびマージ済出力に対応しています。
決定出力は、関係レビュー時に行われたすべての手動での照合決定およびレビュー・コメントが書き出された出力です。
決定の入力と出力
決定入力には、次の目的があります。
他の製品で行われた履歴一致決定のEDQへのインポート。これは1回かぎりのプロセスです。完了したら、データは、決定入力から関連が解除される必要があります。
外部レビュー・システムで行われた(および定期的に行われている)一致決定のインポート。これは、通常の実行プロセスの一環である必要があります。
決定出力により、一致決定の完全な監査証跡を外部に格納できます。
|
注意: 外部一致レビューでは、最新の一致決定を含む関係出力が使用されます。決定出力は、古い決定や現在の関係に関連付けられていない決定など、行われたすべての決定を含むため、様々です。このため、決定出力は、監査目的により適しています。 |
決定入力および出力の使用に関する詳細は、Oracle Fusion Middleware Oracle Enterprise Data Qualityの使用の一致決定のインポートおよび 一致決定のエクスポートに関する項を参照してください。
重複除外プロセッサは、元のレコードが正確に同じでなくても実行できる洗練された照合処理を使用して、1つのデータ・ストリーム内の重複レコード(つまり、同じエンティティを表すレコード)を識別します。
EDQにおける照合の詳細は、照合処理の概念ガイドを参照してください。
重複除外プロセッサは、1つのデータ・ストリーム内の重複レコードを識別するために使用します。すべての照合プロセッサと同様に、重複除外は、自動ルールと手動決定の両方を使用して、レコードを照合する機能を備えています。
必要に応じて、自動ルールと手動決定を組み合せて使用し、すべての重複レコードが削除され、重複が除外されたデータ・ストリームを作成することもできます。または、重複除外プロセッサの出力を使用して、システム内の重複レコードを相互にリンクできます。
重複除外は、照合プロセッサの1タイプです。照合プロセッサはいくつかのサブプロセッサで構成されており、各サブプロセッサは照合操作の異なるステップを実行するため個別に構成する必要があります。重複除外プロセッサは次のサブプロセッサで構成されており、次に説明するように、それぞれが個別の機能を実行します。
| サブプロセッサ | 説明 |
|---|---|
| 入力 |
照合プロセスに含まれるデータ・ストリームから属性を選択します。 |
| 識別 |
照合処理で使用する識別子を作成して属性にマップします。 |
| クラスタ |
データ・ストリームを複数のクラスタに分割します。 |
| 照合 |
実行する比較を選択し、一致ルールを使用して比較を解釈する方法を選択します。 |
| マージ |
オプションでルールを使用して照合レコードをマージし、出力レコードの「最適」なセットを作成します |
入力
照合プロセスに含める任意の属性。
入力は入力サブプロセッサで構成できます。
オプション
照合プロセッサの拡張オプションを除くすべてのオプションは、前述のサブプロセッサ内で構成します。
出力
出力データ・ストリームとそれらの属性は、前述の照合サブプロセッサおよびマージ・サブプロセッサで構成します。
実行
リアルタイム・レスポンス・プロセスに照合プロセッサが1つしかない場合、このプロセスで重複除外プロセッサを使用できます。
重複除外照合プロセッサをこのようにコールすると、レスポンス・インタフェースで特殊な動作が発生します。リアルタイム照合の概要ガイドを参照してください。
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム・モニタリング | はい |
| リアルタイム・レスポンス | はい |
|
注意: 重複除外プロセッサでは常に再実行マーカーが表示されていますが、このマーカーは、構成が変更されたかどうかに関係なくプロセスが実行のたびに完全に再実行されることを示します。これは、重複除外プロセッサの下位プロセッサも再実行が必要であることを意味します。 |
結果の表示
重複除外プロセッサでは、次に示す多数の結果ビューが作成されます。すべてのビューは、プロセス内の重複除外プロセッサをクリックして表示できます。重複除外プロセッサを展開してサブプロセッサを表示し、ビューを作成するサブプロセッサを選択して表示することもできます。
入力ビュー(入力により作成)
入力ビューでは、入力データ・ストリームの単純なビュー(重複除外される)とその選択済属性が表示されます。
クラスタ・ビュー(クラスタにより作成)
クラスタ・ビューは、構成されたクラスタごとに表示されます。これらのビューを使用してクラスタリングの厳密度を評価し、不必要な比較が多数行われていないこと、および照合候補の漏れがないことを確認します。詳細は、クラスタリングの概要ガイドを参照してください。
| 統計 | 意味 |
|---|---|
| クラスタ | 個別のクラスタ・キー値 |
| グループ・サイズ | クラスタ内のレコード合計数(つまり、個別のクラスタ・キー値が同じレコードの数) |
| 処理済? | このクラスタが実際に処理されたかどうかを示します。次の値を指定できます。
|
| [データ・ストリーム名] | 各入力データ・ストリームの次の値です。
各入力データ・ストリームの各クラスタ内に含まれるドリル可能なレコードの件数 |
照合ビュー(照合プロセッサによって作成される)[照合レビューのみ]
照合ビューでは、データ・ストリームで検出された重複レコード数が集計されます。
| 統計 | 意味 |
|---|---|
| 一致するレコード | 重複レコード、つまり照合関係により他のレコードと一致したレコードの合計数。
これには、詳細オプションの「一致グループでレビュー関係を使用」を選択しないかぎり、レビュー関係で他のレコードと一致したレコードは含まれないことに注意してください。「一致グループでレビュー関係を使用[一致レビューのみ]」を参照してください。 |
| 一致しないレコード | 他のレコードと一致しなかった(重複と識別されない)レコードの合計数。 |
ルール・ビュー(照合により作成)
ルール・ビューには、各自動一致ルールによって作成された関係の数のサマリーが表示されます。
| 統計 | 意味 |
|---|---|
| ルールID | 一致ルールの数値識別子。 |
| ルール名 | 一致ルールの名称。 |
| リレーションシップ | 一致ルールによって作成された、レコード間の関係の数。レコードのペア(AとB)の間の各関係は、1つのルールのみによって作成できることに注意してください。上位のルールによって関係が作成されると、下位のルールは適用されません。また、別のルールによって、関係内の1つのレコードを別のレコードに関連付ける(たとえば、AとC)ことができます。 |
レビュー・ステータス・ビュー(照合により作成)
レビュー・ステータス・ビューでは、関係がレビュー・ステータス別に集計されます。
| 統計 | 意味 |
|---|---|
レビュー・ステータス。可能なレビュー・ステータスごとに、次の行が表示されます。
|
|
| リレーションシップ | 指定されたレビュー・ステータスのレコード間の関係の数。後述の注意を参照してください。 |
|
注意: このビューの統計は、レビュー・プロセス時に行われた決定に基づいて自動的に更新されます。したがって、最上位レベルの統計には、各関係のレビュー・ステータスの最新ビューが常に表示されます。ただし、照合プロセッサが実行されるたびにデータへのドリルダウンが生成されるため、照合プロセッサの最後の実行以降に行われたレビュー決定は更新に反映されません。この状態が発生した場合、結果ブラウザには、表示されている生成済データが最新でないことが表示されます。 |
一致グループ・ビュー(照合により作成)[照合レビューのみ]
一致グループ・ビューでは、一致(重複)レコードのグループが集計されます。
| 統計 | 意味 |
|---|---|
| 一致グループ | 一致レコード・グループの合計数。ドリルダウンすると、グループのサマリーがグループ・サイズ(レコード数)別に表示されます。一致グループには、詳細オプションの「一致グループでのレビュー関係の使用」を選択しないかぎり、レビュー関係のみで他のレコードと一致したレコードは含まれないことに注意してください。「一致グループでレビュー関係を使用[一致レビューのみ]」を参照してください。 |
| 一致しない出力レコード | 出力された、作業表からの不一致レコード(重複していないレコード)の合計数。 |
アラート・グループ・ビュー(照合により作成)[ケース管理のみ]
アラート・グループ・ビューでは、一致レコードのグループが集計されます。
| 統計 | 意味 |
|---|---|
| アラート・グループ | アラート・グループの合計数。ドリルダウンすると、グループのサマリーがグループ・サイズ(レコード数)別に表示されます。 |
| アラートにないレコード | アラートに含まれていなかった、作業データからのレコードの合計数。
参照ソースからの不一致レコードは出力されないことに注意してください。 |
グループ出力(照合により作成)[照合レビューのみ]
グループ出力は、照合プロセッサで作成された一致グループのデータ・ビューです。データ・ビューに出力されるグループ、およびビューの属性は、照合サブプロセッサのグループ出力のオプションに応じて異なる場合があります。たとえば、データ・ビューに、1レコードを含む「グループ」を含める場合と含めない場合があります。
アラート出力(照合により作成)[ケース管理のみ]
アラート出力は、照合プロセッサで作成されたアラートのデータ・ビューです。データ・ビューに出力されるアラート、およびビューの属性は、照合サブプロセッサのグループ出力のオプションに応じて異なる場合があります。
関係出力ビュー(照合により作成)
関係出力は、照合プロセッサで作成されたレコードのペアの各関係(リンク)を示すデータ・ビューです。データ・ビューに出力される関係、およびビューの属性は、照合サブプロセッサの関係出力のオプションに応じて異なる場合があります。たとえば、ビューに、特定のルールによって形成された関係を含める場合と含めない場合があります。
マージ・サマリー・ビュー(マージにより作成)
マージのサマリー・ビューでは、照合処理のマージ・ステージが集計されます。
| 統計 | 意味 |
|---|---|
| 成功 | マージ・プロセスで、エラーが発生せずに正常にマージされて出力されたグループの数。
ドリルダウンすると、成功したグループのサマリーがグループ・サイズ(レコード数)別に表示されます。 マージの構成で、関連付けられていないレコードを出力するように設定した場合は、1レコードのみを含む「グループ」が含まれることに注意してください。 |
| 含まれているエラー | 自動出力選択でエラーが発生し、手動による解決が必要であるため、正常にマージされなかったグループの数。ドリルダウンすると、失敗したグループのサマリーがグループ・サイズ(レコード数)別に表示されます。 |
マージ済出力ビュー(マージにより作成)
「マージ済出力」は、照合プロセッサからマージされた出力のデータ・ビューです。つまり、重複レコードがマージされた後のレコード・セットです。出力されるレコードとその属性は、マージ・サブプロセッサで設定するオプションに応じて異なります。
出力フィルタ
重複除外プロセッサからは、次の出力フィルタが使用可能です。
グループ
リレーションシップ
重複除外済
クラスタ化
意思決定
「グループ」、「関係」、および「重複除外済」出力フィルタは、前述の「グループ出力」、「関係出力」および「マージ済出力」に対応しています。
「クラスタ化」出力フィルタは、追加された配列属性内の入力レコードおよびクラスタ値を、クラスタリング構成を使用して出力します。これは、通常、リアルタイム照合にのみ役立ちます。
決定の入力と出力
決定入力には、次の目的があります。
他の製品で行われた履歴一致決定のEDQへのインポート。これは1回かぎりのプロセスです。完了したら、データは、決定入力から関連が解除される必要があります。
外部レビュー・システムで行われた(および定期的に行われている)一致決定のインポート。これは、通常の実行プロセスの一環である必要があります。
決定出力により、一致決定の完全な監査証跡を外部に格納できます。
|
注意: 外部一致レビューでは、最新の一致決定を含む関係出力が使用されます。決定出力は、古い決定や現在の関係に関連付けられていない決定など、行われたすべての決定を含むため、様々です。このため、決定出力は、監査目的により適しています。 |
決定入力および出力の使用に関する詳細は、Oracle Fusion Middleware Oracle Enterprise Data Qualityの使用の一致決定のインポートおよび 一致決定のエクスポートに関する項を参照してください。
「強化」プロセッサを使用して、作業データと1つ以上の信頼できる参照ソースを照合し、参照ソースのデータをマージして作業データを強化します。
EDQにおける照合の詳細は、照合処理の概念ガイドを参照してください。
「強化」プロセッサの通常の使用方法は次のとおりです。
アドレス・データと信頼できる参照ソースと照合し、一致したアドレスを標準フォームで出力して、アドレスを拡張します。
マスター・データベースのレコードをセカンダリまたは新しいデータ・ソースに格納された情報を使用して強化します。
「強化」プロセッサは、自動ルールと手動判定の組合せを使用して、レコードを照合し、必要な強化済出力を作成する機能を備えています。
「強化」は、一種の照合プロセッサです。照合プロセッサはいくつかのサブプロセッサで構成されており、各サブプロセッサは照合操作の異なるステップを実行するため個別に構成する必要があります。重複除外プロセッサは次のサブプロセッサで構成されており、次に説明するように、それぞれが個別の機能を実行します。
| サブプロセッサ | 説明 |
|---|---|
| 入力 |
照合プロセスに含まれるデータ・ストリームから属性を選択します。 |
| 識別 |
照合処理で使用する識別子を作成して属性にマップします。 |
| クラスタ |
データ・ストリームを複数のクラスタに分割します。 |
| 照合 |
実行する比較を選択し、一致ルールを使用して比較を解釈する方法を選択します。 |
| マージ |
オプションでルールを使用して照合レコードをマージし、出力レコードの「最適」なセットを作成します |
入力
照合プロセスに含めるデータ・ストリームの属性。
入力は入力サブプロセッサで構成できます。
オプション
照合プロセッサの拡張オプションを除くすべてのオプションは、前述のサブプロセッサ内で構成します。
出力
出力データ・ストリームとそれらの属性は、前述の照合サブプロセッサおよびマージ・サブプロセッサで構成します。
実行
リアルタイム・レスポンス・プロセスに照合プロセッサが1つしかない場合、このプロセスで「強化」プロセッサを使用できます。
リアルタイム照合の概要ガイドを参照してください。
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム・モニタリング | はい |
| リアルタイム・レスポンス | はい |
|
注意: 「強化」プロセッサでは常に再実行マーカーが表示されていますが、このマーカーは、構成が変更されたかどうかに関係なくプロセスが実行のたびに完全に再実行されることを示します。これは、「強化」プロセッサの下位プロセッサも再実行が必要であることを意味します。 |
結果の表示
「強化」プロセッサでは、次に示す多数の結果ビューが作成されます。すべてのビューは、プロセス内の「強化」プロセッサをクリックして表示できます。「強化」プロセッサを展開してサブプロセッサを表示し、ビューを作成するサブプロセッサを選択して表示することもできます。
入力ビュー(入力により作成)
入力ビューは、各入力データ・ストリームに対して表示されます。つまり、強化される作業データ・ストリームと作業セットの強化に使用される参照ストリームの両方です。ビューには、各ストリームから選択された属性が表示されます。
クラスタ・ビュー(クラスタにより作成)
クラスタ・ビューは、構成されたクラスタごとに表示されます。これらのビューを使用してクラスタリングの厳密度を評価し、不必要な比較が多数行われていないこと、および照合候補の漏れがないことを確認します。詳細は、クラスタリングの概要ガイドを参照してください。
| 統計 | 意味 |
|---|---|
| クラスタ | 個別のクラスタ・キー値 |
| グループ・サイズ | クラスタ内のレコード合計数(つまり、個別のクラスタ・キー値が同じレコードの数) |
| 処理済? | このクラスタが実際に処理されたかどうかを示します。次の値を指定できます。
|
| [データ・ストリーム名] | 各入力データ・ストリームの次の値です。
各入力データ・ストリームの各クラスタ内に含まれるドリル可能なレコードの件数 |
照合ビュー(照合プロセッサによって作成される)[照合レビューのみ]
照合ビューでは、参照レコードに対して照合され、その結果強化される、作業データ・ストリームからのレコード数が集計されます。
| 統計 | 意味 |
|---|---|
| 一致するレコード | 照合関係により参照レコードと一致した作業データ・ストリームからのレコード数。つまり、強化されるレコード数。
これには、詳細オプションの「一致グループでレビュー関係を使用」を選択しないかぎり、レビュー関係で参照レコードと一致したレコードは含まれないことに注意してください。「一致グループでレビュー関係を使用[一致レビューのみ]」を参照してください。 |
| 一致しないレコード | 参照レコードと一致しなかった(そのため強化されない)レコードの合計数。 |
ルール・ビュー(照合により作成)
ルール・ビューには、各自動一致ルールによって作成された関係の数のサマリーが表示されます。
| 統計 | 意味 |
|---|---|
| ルールID | 一致ルールの数値識別子。 |
| ルール名 | 一致ルールの名称。 |
| リレーションシップ | 一致ルールによって作成された、レコード間の関係の数。レコードのペア(AとB)の間の各関係は、1つのルールのみによって作成できることに注意してください。上位のルールによって関係が作成されると、下位のルールは適用されません。また、別のルールによって、関係内の1つのレコードを別のレコードに関連付ける(たとえば、AとC)ことができます。 |
レビュー・ステータス・ビュー(照合により作成)
レビュー・ステータス・ビューでは、関係がレビュー・ステータス別に集計されます。
| 統計 | 意味 |
|---|---|
| レビュー・ステータス | レビュー・ステータス。可能なレビュー・ステータスごとに、次の行が表示されます。
|
| リレーションシップ | 指定されたレビュー・ステータスのレコード間の関係の数。後述の注意を参照してください。 |
|
注意: このビューの統計は、レビュー・プロセス時に行われた決定に基づいて自動的に更新されます。したがって、最上位レベルの統計には、各関係のレビュー・ステータスの最新ビューが常に表示されます。ただし、照合プロセッサが実行されるたびにデータへのドリルダウンが生成されるため、照合プロセッサの最後の実行以降に行われたレビュー決定は更新に反映されません。この状態が発生した場合、結果ブラウザには、表示されている生成済データが最新でないことが表示されます。 |
一致グループ・ビュー(照合により作成)[照合レビューのみ]
一致グループ・ビューでは、一致レコードのグループが集計されます。
| 統計 | 意味 |
|---|---|
| 一致グループ | 一致レコード・グループの合計数。ドリルダウンすると、グループのサマリーがグループ・サイズ(レコード数)別に表示されます。一致グループには、詳細オプションの「一致グループでのレビュー関係の使用」を選択しないかぎり、レビュー関係のみで他のレコードと一致したレコードは含まれないことに注意してください。「一致グループでレビュー関係を使用[一致レビューのみ]」を参照してください。 |
| 一致しない出力レコード | 出力された、作業表からの不一致レコードの合計数。
参照ソースからの不一致レコードは出力されないことに注意してください。 |
|
注意: 「強化」プロセッサ内の一致グループは、単一の作業レコードが他の作業レコードと同じグループに含まれないように形成されます。これは、作業レコードが、その照合参照レコードから常に強化されるようにし、他の作業レコードが同じ参照レコードに一致することがないようにするためです。 |
アラート・グループ・ビュー(照合により作成)[ケース管理のみ]
アラート・グループ・ビューでは、一致レコードのグループが集計されます。
| 統計 | 意味 |
|---|---|
| アラート・グループ | アラート・グループの合計数。ドリルダウンすると、グループのサマリーがグループ・サイズ(レコード数)別に表示されます。 |
| アラートにないレコード | アラートに含まれていなかった、作業データからのレコードの合計数。
参照ソースからの不一致レコードは出力されないことに注意してください。 |
グループ出力(照合により作成)[照合レビューのみ]
グループ出力は、照合プロセッサで作成された一致グループのデータ・ビューです。データ・ビューに出力されるグループ、およびビューの属性は、照合サブプロセッサのグループ出力のオプションに応じて異なる場合があります。たとえば、データ・ビューに、1レコードを含む「グループ」を含める場合と含めない場合があります。
アラート出力(照合により作成)[ケース管理のみ]
アラート出力は、照合プロセッサで作成されたアラートのデータ・ビューです。データ・ビューに出力されるアラート、およびビューの属性は、照合サブプロセッサのグループ出力のオプションに応じて異なる場合があります。
関係出力ビュー(照合により作成)
関係出力は、照合プロセッサで作成されたレコードのペアの各関係(リンク)を示すデータ・ビューです。データ・ビューに出力される関係、およびビューの属性は、照合サブプロセッサの関係出力のオプションに応じて異なる場合があります。たとえば、ビューに、特定のルールによって形成された関係を含める場合と含めない場合があります。
マージ・サマリー・ビュー(マージにより作成)
マージのサマリー・ビューでは、照合処理のマージ・ステージが集計されます。
| 統計 | 意味 |
|---|---|
| 成功 | マージ・プロセスで、エラーが発生せずに正常にマージされて出力されたグループの数。
ドリルダウンすると、成功したグループのサマリーがグループ・サイズ(レコード数)別に表示されます。 マージの構成で、関連付けられていないレコードを出力するように設定した場合は、1レコードのみを含む「グループ」が含まれることに注意してください。 |
| 含まれているエラー | 自動出力選択でエラーが発生し、手動による解決が必要であるため、正常にマージされなかったグループの数。ドリルダウンすると、失敗したグループのサマリーがグループ・サイズ(レコード数)別に表示されます。 |
マージ済出力ビュー(マージにより作成)
「マージ済出力」は、照合プロセッサからマージされた出力のデータ・ビューです。つまり、重複レコードがマージされた後のレコード・セットです。出力されるレコードとその属性は、マージ・サブプロセッサで設定するオプションに応じて異なります。
出力フィルタ
拡張照合プロセッサからは、次の出力フィルタが使用可能です。
グループ
リレーションシップ
マージ済
意思決定
グループ、関係、およびマージ済出力フィルタは、前述のグループ出力または(アラート出力)、関係出力およびマージ済出力に対応しています。
決定の入力と出力
決定入力には、次の目的があります。
他の製品で行われた履歴一致決定のEDQへのインポート。これは1回かぎりのプロセスです。完了したら、データは、決定入力から関連が解除される必要があります。
外部レビュー・システムで行われた(および定期的に行われている)一致決定のインポート。これは、通常の実行プロセスの一環である必要があります。
決定出力により、一致決定の完全な監査証跡を外部に格納できます。
|
注意: 外部一致レビューでは、最新の一致決定を含む関係出力が使用されます。決定出力は、古い決定や現在の関係に関連付けられていない決定など、行われたすべての決定を含むため、様々です。このため、決定出力は、監査目的により適しています。 |
決定入力および出力の使用に関する詳細は、Oracle Fusion Middleware Oracle Enterprise Data Qualityの使用の一致決定のインポートおよび 一致決定のエクスポートに関する項を参照してください。
「グループとマージ」プロセッサは、属性を使用してレコードをグループ化し、これらのレコードをマージし、選択したグループ化属性で固有のレコードを出力して、レコードを容易に重複解除できます。他の照合プロセッサとは異なり、これには複雑な照合を構成する機能がありません。レコードは、選択されたグループ化属性による完全一致で単純にグループ化されます。
「グループとマージ」をシンプルで効率的な方法として使用し、属性の固有の値を出力します。
たとえば、EDQをデータの抽出で使用する場合、実際に多数のデータベース表の結合として抽出データが生成されることがあります。これにより、キー列に重複した値が多数存在するかどうかがわかります。この場合、データ・セットを固有のキー値で作成して、データの結合を解除すると便利です。
「グループとマージ」は、EDQプロセスで参照データの生成時にも便利です。たとえば、多数のチェックを渡す、すべての固有のForename値でデータ・セットを作成する場合に便利なことがあります。チェックを渡すレコードは、レコードのグループ化に使用するForename属性とともに「グループとマージ」に挿入できます。出力された固有のForename値は、ステージング済データに書き込み、参照データに変換され、直接ルックアップで使用できます。MatchGroupSize属性は各値が発生する回数として機能することに注意してください。
レコードをグループ化する他の理由として、すべてのレコードを同じ属性値で合計するためにグループ化することもあります。これを実行するために、カスタム出力セレクタを作成する機能と組み合せて、「グループとマージ」を使用できます。
| サブプロセッサ | 説明 |
|---|---|
| 入力 |
グループ化するデータ・ストリームから属性を選択します。 |
| グループ |
レコードのグループ化基準となる属性を選択します。 |
| マージ |
ルールを使用して、グループ化されたレコードをマージします。 |
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 「グループとマージ」プロセッサは、配列を除くすべてのタイプの入力属性を受け入れます。他の照合プロセッサと同様に、入力された属性のみが出力されます。
入力は入力サブプロセッサで構成できます。 |
| オプション | すべてのオプションは前述のサブプロセッサで構成されます。
「グループとマージ」は、グループ化用の選択した属性の単純な連結を使用し、セパレータなしで値を連続して区切って、レコードをグループ化することに注意してください。これは、グループ化属性で同じデータを持つが異なる構造でグループ化される、次の2つの例のようなレコードが存在する可能性があるということです。 「グループとマージ」で、グループ化に基準として使用するすべての属性で完全に同じデータ値でレコードをグループ化する必要がある場合、連結プロセッサを使用して、グループ化キー属性を作成し、データ値に存在しないパイプ文字などの区切り文字を使用してデータ属性を区切ることをお薦めします。このキー属性を使用して、「グループとマージ」でレコードをグループ化できます。 |
| 出力 | マージ済出力データ・ストリームは、マージサブプロセッサで構成されます。 |
リアルタイム・レスポンス・プロセスに照合プロセッサが1つしかない場合、このプロセスで「グループとマージ」プロセッサを使用できます。ただし、同じ入力メッセージ内ではレコードのグループ化およびマージのみ実行されます。
「グループとマージ」プロセッサでは、次に示す結果のビューが作成されます。
「グループ」ビュー
「グループ」ビューでは、グループがサイズ別にまとめられます。
| 統計 | 説明 |
|---|---|
| グループ・サイズ | グループ・サイズ(レコード数) |
| カウント | リストされたグループの数。「件数」をドリルダウンすると、グループごとにマージされたレコードが表示されます。 |
「マージ済出力」ビュー
「マージ済出力」は、「グループとマージ」プロセッサからマージされた出力のデータ・ビューです。つまり、グループ化されたレコードがマージされた後のレコード・セットです。出力されるレコードとその属性は、マージ・サブプロセッサで設定するオプションに応じて異なります。
出力フィルタ
「グループとマージ」プロセッサには、1つの出力フィルタ(マージ済)があります。これは、前述の「マージ済出力」に対応しています。
例
たとえば、「グループとマージ」を使用して、氏名、生年月日および電子メール・アドレスが同一のすべてのレコードをグループ化してマージします。2レコードのグループが3つ作成されてマージされます。2レコードの3つのグループをドリルダウンすると、各グループのマージ済レコードが表示されます。
「グループ」は、「グループとマージ」プロセッサのサブプロセッサです。
「グループ」サブプロセッサを使用して、グループ化する基準となる属性を選択します。レコードは、選択した属性すべての値が完全に同じである場合にグループ化されます。「グループとマージ」を使用する前に、変換プロセッサを使用して、大文字/小文字や句読点の違いを解決しなければならない場合があります。
「グループとマージ」プロセッサへの入力属性から、レコードをグループ化する基準となる属性を選択します。
画面の下部にある「Nullの許可」チェック・ボックスは、選択したすべてのグループ化属性でNullであるレコードもグループ化するかどうかを指定します。多数のグループ化属性を使用する場合、Nullのレコードが存在することがありますが、すべての属性に存在するわけではなく、Null以外の属性値が同じであれば、グループ化されます。
「リンク」プロセッサは、同じエンティティを表すレコードを含むデータ・ストリームをリンクするために使用し、このために、元のレコードが正確に同じでなくても実行できる洗練された照合処理が使用されます。
「リンク」プロセッサは、データ・ストリーム間の一致するレコードをリンクするために使用します。すべての照合プロセッサと同様に、「リンク」は、自動ルールと手動判定の両方を使用して、レコードを照合する機能を備えています。
リンク・プロセスの出力を使用すると、外部ストリームのレコードをリンクできます。
「リンク」は、一種の照合プロセッサです。照合プロセッサはいくつかのサブプロセッサで構成されており、各サブプロセッサは照合操作の異なるステップを実行するため個別に構成する必要があります。次のサブプロセッサが「リンク」プロセッサを構成しており、それぞれ、次に示すように固有の機能を実行します。
| サブプロセッサ | 説明 |
|---|---|
| 入力 |
リンクするデータ・ストリームから属性を選択します。 |
| 識別 |
照合処理で使用する識別子を作成して属性にマップします。 |
| クラスタ |
データ・ストリームを複数のクラスタに分割します。 |
| 照合 |
実行する比較を選択し、一致ルールを使用して比較を解釈する方法を選択します。 |
入力
照合プロセスに含めるデータ・ストリームからの任意の属性。
入力は入力サブプロセッサで構成できます。複数の作業データ・ストリームおよび複数の参照データ・ストリームをリンク・プロセスに入力できることに注意してください。参照データ・ストリームは、相互に比較されることはなく、参照データ・ストリームからの関連のないレコードは照合プロセスから出力されません。
オプション
照合プロセッサの拡張オプションを除くすべてのオプションは、前述のサブプロセッサ内で構成します。
出力
出力データ・ストリームとそれらの属性は、前述の照合サブプロセッサおよびマージ・サブプロセッサで構成します。
実行
リアルタイム・レスポンス・プロセスに照合プロセッサが1つしかない場合、このプロセスでリンク・プロセッサを使用できます。
リンク照合プロセッサをこのようにコールすると、レスポンス・インタフェースで特殊な動作が発生します。リアルタイム照合の概要ガイドを参照してください。
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム・モニタリング | はい |
| リアルタイム・レスポンス | はい |
|
注意: 「リンク」プロセッサでは常に再実行マーカーが表示されていますが、このマーカーは、構成が変更されたかどうかに関係なくプロセスが実行のたびに完全に再実行されることを示します。これは、「リンク」プロセッサの下位プロセッサも再実行が必要であることを意味します。 |
結果の表示
「リンク」プロセッサでは、次に示す多数の結果ビューが作成されます。すべてのビューは、プロセス内の「リンク」プロセッサをクリックして表示できます。「リンク」プロセッサを展開してサブプロセッサを表示し、ビューを作成するサブプロセッサを選択して表示することもできます。
入力ビュー(入力により作成)
入力ビューは、入力データ・ストリームごとに表示されます。ビューには、各セットから選択された属性が表示されます。
クラスタ・ビュー(クラスタにより作成)
クラスタ・ビューは、構成されたクラスタごとに表示されます。これらのビューを使用してクラスタリングの厳密度を評価し、不必要な比較が多数行われていないこと、および照合候補の漏れがないことを確認します。詳細は、クラスタリングの概要ガイドを参照してください。
| 統計 | 意味 |
|---|---|
| クラスタ | 個別のクラスタ・キー値 |
| グループ・サイズ | クラスタ内のレコード合計数(つまり、個別のクラスタ・キー値が同じレコードの数) |
| 処理済? | このクラスタが実際に処理されたかどうかを示します。次の値を指定できます。
|
| [データ・ストリーム名] | 各入力データ・ストリームの次の値です。
各入力データ・ストリームの各クラスタ内に含まれるドリル可能なレコードの件数 |
照合ビュー(照合プロセッサによって作成される)[照合レビューのみ]
照合ビューでは、他の作業レコードまたは参照レコードのいずれかと照合され、リンクされる作業データ・ストリームからのレコード数が集計されます。
| 統計 | 意味 |
|---|---|
| 一致するレコード | 照合関係により他の作業レコードまたは参照レコードと一致した作業データ・ストリームからのレコード数。つまり、リンクされる作業レコード数。
これには、詳細オプションの「一致グループでレビュー関係を使用」を選択しないかぎり、レビュー関係で一致したレコードは含まれないことに注意してください。「一致グループでレビュー関係を使用[一致レビューのみ]」を参照してください。 |
| 一致しないレコード | 他のレコードと一致しなかった(そのためリンクされない)レコードの合計数。この数値には、参照データ・ストリームからの一致しないレコードが含まれます。 |
ルール・ビュー(照合により作成)
ルール・ビューには、各自動一致ルールによって作成された関係の数のサマリーが表示されます。
| 統計 | 意味 |
|---|---|
| ルールID | 一致ルールの数値識別子。 |
| ルール名 | 一致ルールの名称。 |
| リレーションシップ | 一致ルールによって作成された、レコード間の関係の数。レコードのペア(AとB)の間の各関係は、1つのルールのみによって作成できることに注意してください。上位のルールによって関係が作成されると、下位のルールは適用されません。また、別のルールによって、関係内の1つのレコードを別のレコードに関連付ける(たとえば、AとC)ことができます。 |
レビュー・ステータス・ビュー(照合により作成)
レビュー・ステータス・ビューでは、関係がレビュー・ステータス別に集計されます。
| 統計 | 意味 |
|---|---|
| レビュー・ステータス | レビュー・ステータス。可能なレビュー・ステータスごとに、次の行が表示されます。
|
| リレーションシップ | 指定されたレビュー・ステータスのレコード間の関係の数。後述の注意を参照してください。 |
|
注意: このビューの統計は、レビュー・プロセス時に行われた決定に基づいて自動的に更新されます。したがって、最上位レベルの統計には、各関係のレビュー・ステータスの最新ビューが常に表示されます。ただし、照合プロセッサが実行されるたびにデータへのドリルダウンが生成されるため、照合プロセッサの最後の実行以降に行われたレビュー決定は更新に反映されません。この状態が発生した場合、結果ブラウザには、表示されている生成済データが最新でないことが表示されます。 |
一致グループ・ビュー(照合により作成)[照合レビューのみ]
一致グループ・ビューでは、一致レコードのグループが集計されます。
| 統計 | 意味 |
|---|---|
| 一致グループ | 一致レコード・グループの合計数。ドリルダウンすると、グループのサマリーがグループ・サイズ(レコード数)別に表示されます。一致グループには、詳細オプションの「一致グループでのレビュー関係の使用」を選択しないかぎり、レビュー関係のみで他のレコードと一致したレコードは含まれないことに注意してください。「一致グループでレビュー関係を使用[一致レビューのみ]」を参照してください。 |
| 一致しない出力レコード | 出力された、作業表からの不一致レコードの合計数。
参照ソースからの不一致レコードは出力されないことに注意してください。 |
アラート・グループ・ビュー(照合により作成)[ケース管理のみ]
アラート・グループ・ビューでは、一致レコードのグループが集計されます。
| 統計 | 意味 |
|---|---|
| アラート・グループ | アラート・グループの合計数。ドリルダウンすると、グループのサマリーがグループ・サイズ(レコード数)別に表示されます。 |
| アラートにないレコード | アラートに含まれていなかった、作業データからのレコードの合計数。
参照ソースからの不一致レコードは出力されないことに注意してください。 |
グループ出力(照合により作成)[照合レビューのみ]
グループ出力は、照合プロセッサで作成された一致グループのデータ・ビューです。データ・ビューに出力されるグループ、およびビューの属性は、照合サブプロセッサのグループ出力のオプションに応じて異なる場合があります。たとえば、データ・ビューに、1レコードを含む「グループ」を含める場合と含めない場合があります。
アラート出力(照合により作成)[ケース管理のみ]
アラート出力は、照合プロセッサで作成されたアラートのデータ・ビューです。データ・ビューに出力されるアラート、およびビューの属性は、照合サブプロセッサのグループ出力のオプションに応じて異なる場合があります。
関係出力ビュー(照合により作成)
関係出力は、照合プロセッサで作成されたレコードのペアの各関係(リンク)を示すデータ・ビューです。データ・ビューに出力される関係、およびビューの属性は、照合サブプロセッサの関係出力のオプションに応じて異なる場合があります。たとえば、ビューに、特定のルールによって形成された関係を含める場合と含めない場合があります。
出力フィルタ
拡張照合プロセッサからは、次の出力フィルタが使用可能です。
グループ
リレーションシップ
マージ済
意思決定
グループ、関係、およびマージ済出力フィルタは、前述のグループ出力、関係出力およびマージ済出力に対応しています。
決定の入力と出力
決定入力には、次の目的があります。
他の製品で行われた履歴一致決定のEDQへのインポート。これは1回かぎりのプロセスです。完了したら、データは、決定入力から関連が解除される必要があります。
外部レビュー・システムで行われた(および定期的に行われている)一致決定のインポート。これは、通常の実行プロセスの一環である必要があります。
決定出力により、一致決定の完全な監査証跡を外部に格納できます。
|
注意: 外部一致レビューでは、最新の一致決定を含む関係出力が使用されます。決定出力は、古い決定や現在の関係に関連付けられていない決定など、行われたすべての決定を含むため、様々です。このため、決定出力は、監査目的により適しています。 |
決定入力および出力の使用に関する詳細は、Oracle Fusion Middleware Oracle Enterprise Data Qualityの使用の一致決定のインポートおよび 一致決定のエクスポートに関する項を参照してください。
照合プロセッサの一部の設定は拡張オプションとして格納されます。これらのオプションにアクセスするには、照合プロセッサを開いた後に「拡張オプション」リンクをクリックします。
これらの設定は通常、変更する必要はありませんが、調整が必要になる場合もあります。
次のオプションは「拡張」タブから使用できます。
一致グループは作業レコードを共有 [一致レビューのみ]
このオプションは、同じ一致グループに複数の作業レコードを含めるかどうかを決定します。たとえば、データを拡張またはリンクする際の目的は、多くの場合、各作業レコードのみを検討対象とし、それを単に1つ以上の参照データ・ソースと照合することです。この場合、オプションをオフにして、各一致グループに1つの作業データ・レコードのみが含まれるようにします。それ以外の場合は、作業レコードが直接、相互に比較されない場合でも、両方の作業レコードが同じ参照データ・レコードと一致するときは、それらを同じ一致グループに含めることができます。
クラスタ・サイズ制限
クラスタ・サイズ制限は、クラスタ内の最大レコード数のデフォルト上限です。この上限を超えると、照合サブプロセッサではクラスタ内のレコード間の比較が実行されません。この上限を超える各クラスタについては、実行時に照合プロセッサのプロセッサ・パネルに警告メッセージが表示され、ログ・ファイルに出力されます。
デフォルトのクラスタ・サイズ制限は500レコードです。特定のクラスタに対するこの設定は、クラスタ構成で上書きできることに注意してください。
|
注意: この方法でレコードを比較する際は、いくつかのグループをスキップすることが望ましい場合があります。たとえば、複数のクラスタを使用している場合は、クラスタ構成により1回のクラスタ機能で1つの大きいクラスタが生成され、すべてのレコードのクラスタ値がnullまたは非常に一般的な値(たとえば、姓がSMITH)になる場合があります。その場合、照合対象のレコードは、別のクラスタがあるために相互に比較されることがあります。 |
一致グループおよびレビュー・グループのサイズ制限
出力処理、レビューおよびケース生成のために一致グループおよびレビュー・グループをロードするときに照合プロセスがメモリー不足になることがあります。
「一致グループ・サイズ制限」フィールドおよび「レビュー・グループ・サイズ制限」フィールドは、生成できるグループ数の上限を設定します。デフォルトでは、両方のフィールドが5000に設定されています。フィールドをクリアすると、上限の設定がない状態になります。
一致グループ・サイズ制限フィールドおよびレビュー・グループ・サイズ制限フィールドは、生成できるグループ数の上限を設定します。デフォルトでは、両方のフィールドが5000に設定されています。フィールドをクリアすると、上限の設定がない状態になります。
クラスタ比較制限
クラスタ比較制限は、1つのクラスタで実行される比較の最大数のデフォルト上限です。この数値は、クラスタ内で実行される比較の数をそのクラスタの処理前に評価して計算されます。クラスタで実行される比較の数がこの制限を超える場合、そのクラスタはスキップされます。これは、複数データ・セットの使用時に、同じクラスタ内のレコードが必ずしもすべて相互に比較されるわけではない場合に、パフォーマンスの観点から最も負荷の高いクラスタを検出して処理から除外する合理的な方法です。たとえば、1つのクラスタに1000レコードが含まれ、その中の999レコードはレコードが相互に比較されない1つのデータ・セットからのレコードで、1レコードのみが2番目のデータ・セットのレコードの場合は、999の比較のみが実行されます。クラスタ内のすべてのレコードが相互に比較される場合、比較の数は非常に多くなります。たとえば、重複除外プロセッサでは、500レコードに対して249500(500*499)の比較が実行されます。
デフォルトでは、クラスタ比較制限に値は設定されません(つまり、適用制限はありません)。
特定のクラスタに対するこの設定は、クラスタ構成で上書きできることに注意してください。
クラスタ分割しきい値
1つの作業データと複数の参照データが入力されるマッチ・プロセッサでは、マルチスレッド環境でより効率的に処理できるように、大きいクラスタをサブクラスタに分割できます。このフィールドに設定された値を超えるクラスタは各しきい値ごとにより小さなグループへと自動的に分割され、複数のスレッドに割り当てられます。
しきい値のデフォルト設定は250です。これを0に設定すると、各クラスタが単一スレッドによって処理されます。
このオプションは、これらの条件を満たさないプロセッサでは使用できません。
nullクラスタを許可
このオプションは、Null値のクラスタを生成するかどうかを決定します。たとえば、Postcode属性についてクラスタを構成する場合は、郵便番号がNullのすべてのレコードを相互に比較して一致候補を検索するかどうかを決定する必要があります。
クラスタリングで使用する元の属性(1つまたは複数)がnullでない場合でも、変換によってすべての値が削除されたためにクラスタ値がnullになる場合もあります。たとえば、Trim Whitespace変換およびStrip Words変換を使用して、空白文字および「Company」や「Limited」などの単語をクラスタ値から削除すると、値「Company Limited」はNull値として索引付けされます。
デフォルトではNullのクラスタが作成されますが、グループに多数の(クラスタ・サイズ制限を超える)レコードが含まれている場合は、照合処理で無視されることに注意してください。
特定のクラスタに対するこの設定は、クラスタ構成で上書きできることに注意してください。
一致グループでレビュー関係を使用[一致レビューのみ]
デフォルトでは、一致グループは、一致として決定された関係、つまり、自動ルールまたは手動決定を使用して確定一致と判定された関係によって相互に関連するレコードのみで構成されます。
ただし、照合プロセスの開発時には、一致グループの最終的な構造(すべての関係がレビューされた後)が不明な場合があります。外部のレビュー・プロセスを支援し、照合プロセッサの出力によって照合処理で作成されるすべての関係の全体像を示すためには、一致グループのレポート時またはマージ時に、レビュー途中の関係を含めることもできます。
このオプションを選択すると、一致グループの形成方法が変わり、一致グループにレビュー待ちの関係が含まれます。このオプションはいつでも変更できますが、最終的にマージされる出力も含めて、照合プロセッサから作成されるすべてのタイプの出力に適用されます。このため、変更は、照合プロセスの開発時のみに限定する必要があります。
トークン属性の接頭辞
このオプションを適用できるのは、通常、リアルタイム重複防止のために重複除外照合プロセッサを使用する場合のみです。クラスタ・キー属性で使用する接頭辞を構成し、重複除外プロセッサからクラスタ化された出力フィルタに出力できます(新規レコードの適切なクラスタ・キー値を使用して呼出し側システムに初期応答を発行する目的で)。新しい属性名を形成するには、クラスタ名の前に指定の接頭辞を使用します。たとえば、'Name_Meta' クラスタの場合、デフォルト接頭辞'Clustered_'を使用すると、出力属性の名称は'Clustered_Name_Meta'になります。
ソートおよびフィルタ
一致レビューで照合プロセスの出力をソート、フィルタおよび検索する機能が不要な場合は、ソート/フィルタ・オプションを使用して、照合処理のパフォーマンスを向上させることができます。ケース管理を使用中の場合や、ユーザーが照合結果をレビューする必要がない場合がこれに該当します。
照合プロセッサごとに、3つの設定が可能です。
ソート/フィルタの有効化(デフォルト)
ソート/フィルタを有効にしない
インテリジェント・ソート/フィルタリングの使用
「ソート/フィルタの有効化」は、プロセスまたはジョブの実行プリファレンスの設定が上書きされないかぎり(「プロセス実行プリファレンス」を参照)、照合プロセッサからの出力に対して、一致レビューでのソートおよびフィルタを有効にします。ユーザーが一致レビューを使用して照合プロセスの結果をレビューするときには、この設定を使用します。
「ソート/フィルタを有効にしない」とは、一致プロセッサからの出力に対して、一致レビューでソートおよびフィルタが有効にならないという意味です(プロセスまたはジョブのレベル・オプションとは無関係)。これは、照合プロセッサの結果がレビューできないことを意味します。結果の処理にマッチ・レビューを使用しない場合に、この設定を使用します。
「インテリジェント・ソート/フィルタリングの使用」は、一致出力のデータ・サイズ(行と列の両方を使用)に応じて、一致レビューでソートおよびフィルタを有効にするかどうかを決定します。構成可能なシステム・プロパティを使用して、レビュー、ソート、フィルタおよび検索を有効にしないサイズを設定します。この設定は、サンプル・データ・セット(一般的に100,000行未満)に対して照合プロセスを設計し、設計段階では結果をレビューする必要があるが、完全データ・セット(数百万行が含まれる可能性がある)に対して照合プロセスをデプロイした後は、ユーザーがその結果を一致レビューでレビューする必要がない場合に使用します。
関係決定トリガー
このオプションを使用すると、関係決定が行われたときに、構成済トリガー・アクションの実行を選択できます。
任意のアクションをトリガーにできます。たとえば、トリガーには、JMSメッセージの送信、Webサービスの呼出し、通知電子メールの送信などがあります。トリガーには、関係および決定データを含めることができます。
トリガーは、管理者がEDQサーバーで設定する必要があります。トリガーを設定する必要がある場合(たとえば、一致レビュー・アプリケーションでの一致決定時に別のアプリケーションに通知する)、詳細はサポートに連絡してください。
レビュー・システム
「レビュー・システム」オプションを使用して、照合プロセッサからの結果の手動レビューを有効にするかどうか、および使用するレビューUIのタイプを制御します。3つのオプションがあります。
関係レビューなし - 照合プロセッサは、EDQでの手動レビュー用のデータを書き込みません。照合結果は書き込まれ、外部でレビューされます。
一致レビュー - 照合プロセッサは、ユーザーがEDQ一致レビューUIでレビューする最新実行の結果を書き込みます。
ケース管理 - 照合プロセッサは実行のたびに、結果をEDQケース管理UIに公開します。
使用するレビュー・システムの詳細は、「照合結果のレビュー」のトピックを参照してください。
リアルタイム・プロセスのキャッシュ参照レコード
リアルタイム参照照合サービスの実行中に、このオプションを有効にすると、リアルタイム照合プロセスの参照データは結果データベースに格納されて照合されるのではなく、EDQサーバーのメモリーにキャッシュされて照合されます。このオプションは、EDQに十分なメモリーが割り当てられているときにのみ有効にします。
決定キーの変更[一致レビューのみ]
決定キーは、手動の一致決定を再適用(保持)するためにハッシュ・アルゴリズムで使用される入力属性のセットで構成されます。これは、レコードのペアに対して行われた手動の一致決定は、決定キーを構成する属性のデータ値が同じであるかぎり、照合プロセスの後続の実行に再適用されることを意味します。
たとえば、氏名と住所の詳細を使用して個人を照合し、手動で照合したレコードの1つが変更された場合は、変更前のデータに基づいて行われた手動決定を適用するのではなく、そのレコードの再評価が必要になる場合があります。ただし、別な属性の値が変更された場合でも、照合処理で使用するレコードの詳細に実質的な変更はないと判断する場合があります。たとえば、金額が含まれるBalance属性は、出力の選択ロジックに使用される可能性があるため、照合プロセスに入力できますが、この属性値が変更されても、一致決定を再評価したり、レコードを相互に照合する必要はありません。
デフォルトでは、照合プロセッサが前バージョンからアップデートされていないかぎり(後述の注意を参照)、識別子にマップされたすべての属性は決定キーに含まれます。ただし、照合プロセッサに入力されたすべての属性を使用するように決定キーを変更したり、キーを構成する属性を選択してキーをカスタマイズすることはできます。たとえば、レコードのデータが変更されても、対象のレコードが同じであるかぎり、常に一致決定を再適用する場合は、一致処理に含まれるソースごとにレコードの主キー属性のみを選択できます。
|
注意: 入力属性のサブセットを使用するように決定キーを構成する機能はバージョン7.0の新機能であるため、古いバージョンのEDQを使用して構成した照合プロセッサではすべての属性が選択されますが、これは変更可能で、すでに行われた決定は失われません。 |
決定を行った後に決定キーを変更した場合
一般的には、決定キーの構成方法を決定してから、照合プロセスを運用可能にし、その結果をレビューのために割り当てます。ただし、決定キーの構成を変更する際にすでに決定が行われていた場合、EDQではその決定を可能なかぎり保持するように試みますが、次の制限があります。
決定キーで以前に使用された属性が照合プロセッサに入力されない場合、そのキーを使用して行われた決定は再適用できません。
これは、構成されたキー列に基づいて各決定が一意である場合、属性を決定キーに追加しても以前の決定は失われないことを意味します。
このタブで属性を決定キーから削除して以前の決定を移行することも可能ですが、前回の実行と同じデータ・セットを使用して少なくとも1回の実行が完了するまでは、照合プロセッサに入力属性が保持されることに注意してください。これが実行された後は、属性を照合プロセスから削除しても安全です。
ケース・ソースの構成[ケース管理のみ]
ケース・ソースは、ケース管理がアクティブなときに使用する権限、ワークフローおよびデータを定義するために使用します。ケース・ソースは、この画面の「ケース・ソース」タブで構成します。
ワークフロー・パラメータの構成[ケース管理のみ]
ケース管理では、ワークフロー・パラメータを使用して、ケースおよびアラートの拡張処理を行います。これらは、この画面の「ワークフロー・パラメータ」タブで構成します。
比較を使用して、各クラスタ内のレコード間で識別子値を比較します。
次の各表に、データ型別にEDQで提供される比較機能を示します。使用方法の詳細は、比較をクリックしてください。
照合変換を使用すると、比較する前に値を変換できることに注意してください。
文字列比較機能
| 比較 | 互換性のある識別子タイプ | 説明 | 可能な出力 |
|---|---|---|---|
| リストのすべて | 文字列 | 属性内に含まれているすべての値がリストに存在しているかどうかを判断します。 | TRUE: すべての値が存在する場合。
FALSE: 該当しない場合。 |
| 両方のフィールドNULL | 文字列 | 両方の属性がnullかどうかを判断します。 | TRUE: 両方の属性がnullである場合。
FALSE: 該当しない場合。 |
| 文字編集距離 | 文字列、文字配列 | 2つの値を比較し、値をもう一方の値に変換するために必要な文字編集の回数を返して、2つの値がどの程度一致しているかを判断します。 | 2つの文字列値の文字編集距離を示す数値。この比較では、結果バンドの使用がサポートされています。 |
| 文字の一致率 | 文字列、文字配列 | 2つの値の文字編集距離、および長い方の値の長さを使用して、2つの値の類似率を計算します。 | 文字一致率を示す数値。
この比較では、結果バンドの使用がサポートされています。 |
| 文字置換の一致 | 文字列、文字配列 | 値が置換されている場合は、2つの値を比較し、一致しているかどうかを判断します。 | TRUE: 値が一致する場合。FALSE: 値が一致しない場合。 |
| 次を含む | 文字列、文字配列 | 2つの値を比較し、一方の値にもう一方の値が含まれているかどうかを判断します。 | TRUE: 値が一致する場合。
FALSE: 値が一致しない場合。 |
| 同等または1つ/両方のフィールドNULL | 文字列 | 両方の属性が等しい、またはいずれかの属性がnullかを判断します。 | TRUE: 両方の属性が等しい、またはいずれかの属性がnullである場合。
FALSE: 該当しない場合。 |
| 文字列の完全一致 | 文字列、文字配列 | 2つの値を比較し、一致しているかどうかを判断します。 | TRUE: 値が一致する場合。
FALSE: 値が一致しない場合。 |
| リスト内 | 文字列、文字配列 | 別の指定された値または値のセットと2つの値を比較します。 | TRUE: 値が一致する場合。
FALSE: 値が一致しない場合。 |
| 配列内 | 文字列配列 | 別の指定された配列または配列のセットと2つの配列を比較します。 | TRUE: 配列が一致する場合。
FALSE: 配列が一致しない場合。 |
| 最長共通句 | 文字列、文字配列 | 2つの値を比較し、2つの値に共通する最長の連続する単語内の単語数を返します。 | 最長共通句を示す数値。
この比較では、結果バンドの使用がサポートされています。 |
| 最長共通句率 | 文字列、文字配列 | 2つの値の最長共通単語の連続を、2つの値の長い方または短い方の単語の長さに関連付けて、2つの値がどの程度一致しているかを計算します。 | 最長共通句率を示す数値。
この比較では、結果バンドの使用がサポートされています。 |
| 最長共通部分文字列 | 文字列、文字配列 | 2つの値を比較し、2つの値に共通する各値の最長部分の文字数を返します。 | 2つの文字列値に共通する最長部分文字列の長さを示す数値。
この比較では、結果バンドの使用がサポートされています。 |
| 最長共通部分文字列の比率 | 文字列、文字配列 | 2つの値の最長共通部分文字列を、2つの値の長い方または短い方の文字の長さに関連付けて、2つの値がどの程度一致しているかを計算します。 | 最長共通部分文字列率を示す数値。
この比較では、結果バンドの使用がサポートされています。 |
| 最長共通部分文字列の合計 | 文字列、文字配列 | 2つの値を比較し、2つの値に共通して指定の長さを超える部分文字列の合計文字数を返します。 | 文字数が指定の最小数以上の共通部分文字列の合計を示す数値。
この比較では、結果バンドの使用がサポートされています。 |
| 最長共通部分文字列の合計率 | 文字列、文字配列 | 最長共通部分文字列合計を計算し、長い方または短い方の文字列の長さに関連付けます。 | 最長共通部分文字列合計率を示す数値。
この比較では、結果バンドの使用がサポートされています。 |
| 次で始まる | 文字列、文字配列 | 2つの値を比較し、一方の値がもう一方の値で始まるかどうかを判断します | TRUE: 一方の値がもう一方の値で始まる場合。
FALSE: 該当しない場合。 |
| 単語編集距離 | 文字列、文字配列 | 2つの値を比較し、値をもう一方の値に遷移するために必要な単語編集の回数を返して、2つの値がどの程度一致しているかを判断します。 | 2つの文字列値の単語編集距離を示す数値。
この比較では、結果バンドの使用がサポートされています。 |
| 文字配列要素一致件数 | 文字列配列 | 同じ2つの配列の要素を比較します。 | 2つの配列内で一致した要素の正確な数によって異なる数値。 |
| 文字配列要素一致件数パーセンテージ | 文字列配列 | 同じ2つの配列の要素を比較します。 | 2つの配列内で一致した要素の正確な数によって異なるパーセンテージ値。 |
| 文字配列サブセット | 文字列配列 | 2つの配列を比較し、一方がもう一方のサブセットかどうかを判断します。 | TRUE: 1つの配列が別の配列のサブセットである場合。
FALSE: 該当しない場合。 |
| 単語一致数 | 文字列、文字配列 | 2つの値に共通する単語の数を返します。 | 2つの文字列値に共通する単語の数。
この比較では、結果バンドの使用がサポートされています。 |
| 単語一致率 | 文字列、文字配列 | 2つの値の単語編集距離、および長い方の値の長さを使用して、2つの値の類似率を計算します。 | 単語一致率を示す数値。
この比較では、結果バンドの使用がサポートされています。 |
日付比較機能
| 比較 | 互換性のある識別子タイプ | 説明 | 可能な出力 |
|---|---|---|---|
| 日付差異 | 日付、日付配列 | 2つの日付値/配列を比較し、2つの日付の差異を時間単位で返します。 | 2つの日付の差異を表す数値。オプション設定に応じて、差異は年、月、週または日単位で表現できます。
この比較では、結果バンドの使用がサポートされています。 |
| 日付編集距離 | 日付、日付配列 | 2つの日付値/配列を比較し、2つの値の日付編集距離を返します。 | 2つの日付の編集距離を示す数値。
この比較では、結果バンドの使用がサポートされています。 |
| 日付置換の一致 | 日付、日付配列 | 日と月を入れ替えた2つの日付値/配列を比較し、一致しているかどうかを判断します。 | TRUE: 値が一致する場合。
FALSE: 値が一致しない場合。 |
| 日付の完全一致 | 日付、日付配列 | 2つの日付値/配列を比較し、一致しているかどうかを判断します。 | TRUE: 値が一致する場合。
FALSE: 値が一致しない場合。 |
| 日付配列要素一致件数 | 日付配列 | 2つの日付配列を比較し、要素が同じかどうかを判断します。 | 同様と検出された要素の数を表す数値。 |
| 日付配列要素一致パーセンテージ | 日付配列 | 2つの日付配列を比較し、要素が同じかどうかを判断します。 | 2つの配列内で正確に一致した要素の数によって異なるパーセンテージ値。 |
| 日付配列サブセット | 日付配列 | 2つの日付配列を比較し、一方がもう一方のサブセットかどうかを判断します。 | TRUE: 1つの配列が別の配列のサブセットである場合。FALSE: 該当しない場合 |
| 同様の日付 | 日付、日付配列 | 2つの日付、日付配列を比較し、同じであるかどうかを判断します。 | TRUE: 日付が同様である場合。
FALSE: 該当しない場合。 |
数値比較機能
| 比較 | 互換性のある識別子タイプ | 説明 | 可能な出力 |
|---|---|---|---|
| 絶対差分 | 数値、番号配列 | 2つの数値または番号配列の絶対差分を計算して返します。 | 2つの数値および番号配列の絶対差分。
この比較では、結果バンドの使用がサポートされています。 |
| 等しい | 数値、番号配列 | 2つの数値、番号配列を比較し、等しいかどうかを判断します。 | TRUE: 値が等しい場合。
FALSE: 該当しない場合。 |
| 相違率 | 数値、番号配列 | 2つの数値または番号配列のパーセントの差を計算して返します。 | 2つの数値のパーセントの差。
この比較では、結果バンドの使用がサポートされています。 |
| 番号配列要素一致件数 | 番号配列 | 2つの番号配列を比較し、要素が同じかどうかを判断します。 | 同様と検出された要素の数を表す数値。 |
| 番号配列要素一致パーセンテージ | 番号配列 | 2つの番号配列を比較し、要素が同じかどうかを判断します。 | 同様と検出された要素の数を表すパーセンテージ値。 |
| 番号配列サブセット | 番号配列 | 2つの番号配列を比較し、一方がもう一方のサブセットかどうかを判断します。 | TRUE: 1つの配列が別の配列のサブセットである場合。FALSE: 該当しない場合。 |
「リストのすべて」比較は、属性内に含まれているすべての値がリストに存在しているかどうかを判断します。
リストの特定の値のみを含むレコードをチェックすることにより、データのサブセットのみに一致ルールを適用する方法として「リストのすべて」比較を使用します。
この比較では、結果バンドの使用はサポートされていません。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| デリミタ | フリー・テキスト | このフィールドは、使用する区切り文字を指定するために使用します。 | |
| リスト | 参照データ | 値リスト(一連の国コードなど)を含む参照データ・セット。 | クリア |
| 照合で両方のレコードのデータが必要 | はい/いいえ | 「はい」の場合、両方の入力識別子値にデータが含まれる必要があります。含まれない場合、比較は常にFalseになります。
「いいえ」の場合、1つのみの入力識別子値にデータが含まれる必要があります。 |
いいえ |
例
この例では、「リストのすべて」比較を使用し、比較対象の両方のレコードの国コード・トークンのカンマ区切りリストにあるすべての国コードが国コードリスト内に含まれている場合にのみ、一致ルールを適用しています。例として、リストには値USとUKが含まれていますが、DEは含まれていません。
結果例:
「両方のフィールドNULL (ソリューション)」比較は、両方の属性がnullであるかどうかを判断します。
特定の属性がnullである(でない)場合にのみ、データのサブセットに一致ルールを適用する方法として、「両方のフィールドNULL (ソリューション)」比較を使用します。
この比較では、結果バンドの使用はサポートされていません。
例
この例に、「両方のフィールドNULL (ソリューション)」比較を使用した結果を示します。
結果例:
「文字編集距離」比較では、2つの文字列/文字配列の値を比較し、値をもう一方の値に変換するために必要な文字編集(削除、挿入および置換)の最小回数を計算して、相互にどの程度一致しているかを判断します。
「文字編集距離」比較は、比較に使用される最も強力で汎用的な比較の1つです。「文字編集距離」比較を使用して、識別子の2つの値について完全一致または近似一致を検索します。「文字編集距離」比較は、スペルミスのために相互に1文字または2文字の差異があるテキスト値の照合に適しています。たとえば、「Matthews」と「Mathews」の編集距離は1です。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、完全一致(文字編集距離が0)の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。
たとえば、大文字/小文字を区別しない場合、「Oracle Corporation」と「ORACLE CORPORATION」は文字編集距離0で一致します。 |
はい |
例
この例では、「文字編集距離」比較を使用して電子メール・アドレスを照合します。次のオプションを指定します。
結果例:
表1-38 結果例: 文字編集距離
| 値A | 値B | 比較結果 |
|---|---|---|
|
john/smith@example.com |
john.smith@example.com |
1 |
|
John.Smith@example.com |
john.smith@example.com |
0 |
|
jhon_smith@hotmail.com |
john_smith@hotmail.com |
2 |
|
tom simpson@gmail.com |
tomsimpson@gmail.com |
1 |
|
andrew_johnson@email.net |
andrew.johnstone@email.net |
3 |
|
<null> |
andrew.johnstone@email.net |
データなし |
|
<null> |
<null> |
データなし |
「文字の一致率」比較では、2つの文字列値の文字編集距離を計算し、2つの値の長い方または短い方の長さ(文字数)を考慮して、2つの値(文字列、文字配列)が相互にどの程度一致しているかを判断します。
値が可変長(名前など)で元の値にスペル・ミスが存在する可能性のある場合に、「文字の一致率」比較を使用して一致を検索します。たとえば、会社名を照合する際、値「ABC」と「BBC」の文字編集距離は1で、他の比較では近似一致とみなされます。しかし、文字の一致率は66%にすぎません。これに対して、同じように文字編集距離が1の「Oracle」と「Oracles」の文字の一致率は90%で、高い一致率を示しています。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、完全一致(文字の一致率は100%)の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。
たとえば、大文字/小文字を区別しない場合、「Oracle Corporation」と「ORACLE CORPORATION」は文字の一致率が100%で一致します。 |
はい |
| より短い入力に関連付け | はい/いいえ | このオプションにより、「文字の一致率」比較で行われる計算が決定されます。
「はい」に設定すると、比較する2つの入力のうち、(文字数が)短い方の入力を使用して、その文字数のパーセントとして結果が計算されます。 「いいえ」に設定すると、比較する2つの入力のうち、(文字数が)長い方の入力を使用して、その文字数のパーセントとして結果が計算されます。 |
いいえ |
例
この例では、「文字の一致率」比較を使用して会社名を照合します。次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
より短い入力に関連付け= いいえ
次の変換が追加されます。
空白の切捨て。比較する前に、値からすべての空白を削除します。
単語の削除。*ビジネス接尾辞マップ(単語「Ltd」と「Limited」を含む)を使用します
次の表に、前述の構成を使用した比較結果の例を示します。
「文字置換の一致」比較は、文字置換が発生した文字列/文字配列を照合します。たとえば、値MichaelとMichealを比較する際、1回の置換がカウントされ、「最大許容置換」オプションが1以上に設定されている場合、2つの値が照合されます。
| オプション | タイプ | デフォルト値 |
|---|---|---|
| データなしのペアを照合 | はい/いいえ | いいえ |
| 大文字/小文字を区別しない | はい/いいえ | はい |
| 次で始まる | はい/いいえ | はい |
| 最大許容置換 | 値 |
例
この例では、「文字の一致率」比較を使用して会社名を照合します。次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
先頭から一致する? = はい
最大許容置換 = 1
次の表に、前述の構成を使用した比較結果の例を示します。
「次を含む」比較では、2つの値(文字列、文字配列)を比較し、一方の値の文字列の中にもう一方の値がすべて含まれているかどうかを判断します。したがって、完全に一致する場合と、一方の値にもう一方の値が含まれるが一致値の前または後にその他の情報が含まれる一致の場合があります。
「次を含む」比較を使用して、値の文字列のいずれかの端に高い頻度でその他の情報が含まれる文字列識別子について、一致を検索します。「次を含む」比較は、名称を照合する際に特に役立ちます。たとえば、個人の姓をメイン識別子として使用する場合があります。つまり、「John Richard Smith」や「J Richard Smith」は「Richard Smith」と一致するのが妥当で、「次で始まる」や「文字列の完全一致」比較を使用すると一致しません。
この比較操作では、結果バンドの使用はサポートされていません。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、完全一致(TRUE)の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。
たとえば、大文字/小文字を区別しない場合、「John Richard SMITH」と「Richard Smith」は一致し、それ以外の場合は一致しません。 |
はい |
例
この例では、「次を含む」比較を使用して個人の名前を照合します。
次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
また、「空白の切捨て」変換も追加され、値を比較する前に値からすべての空白を削除します。
結果例
次の表に、前述の構成を使用した比較結果の例を示します。
いずれかの値が空白の場合、「データなし」の比較結果が返されます。
表1-41 結果の例: 次を含む
| 値A | 値B | 比較結果 |
|---|---|---|
|
J Richard Smith |
Richard Smith |
TRUE (一致) |
|
John Richard Smith |
Richard Smith |
TRUE (一致) |
|
R Smith |
John R Smith |
TRUE (一致) |
|
R Smith |
J R Smith |
TRUE (一致) |
|
John Smith |
John Richard Smith |
FALSE (一致なし) |
|
R Smith |
Richard Smith |
FALSE (一致なし) |
|
David E Jones |
E J Jones |
FALSE (一致なし) |
|
Null |
Oracle |
データなし |
|
Null |
Null |
データなし |
「同等または1つ/両方のフィールドNULL (ソリューション)」比較は、両方の属性が等しいか、いずれかの属性がnullかを判断します。
特定の属性がnullであるか、データが欠落している場合にのみ、データのサブセットに一致ルールを適用する方法として、「同等または1つ/両方のフィールドNULL (ソリューション)」比較を使用します。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。
たとえば、大文字/小文字を区別しない場合、「Oracle Corporation」と「ORACLE CORPORATION」は一致し、それ以外の場合は一致しません。 |
いいえ |
例
この例に、「同等または1つ/両方のフィールドNULL (ソリューション)」比較を使用した結果を示します。
結果例:
「文字列の完全一致」比較は、2つの文字列/文字配列の値が一致しているかどうかを判断する単純な比較です。
「文字列の完全一致」比較を使用して、文字列識別子の2つの値について完全一致を検索します。多くの場合、「文字列の完全一致」比較はデシジョン表内で最上位の一致ルールとして使用し、最初にすべての完全一致を検索し、その後に部分一致を検索するルールを指定します。また、1つ以上の変換機能とともに使用して、変換された場合のみ同じになる値の一致を検索できます。たとえば、「イニシャルの生成」変換機能とともに「文字列の完全一致」を使用すると、「IBM」と「International Business Machines」は一致します。
この比較では、結果バンドの使用はサポートされていません。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、完全一致(TRUE)の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。
たとえば、大文字/小文字を区別しない場合、「Oracle Corporation」と「ORACLE CORPORATION」は一致し、それ以外の場合は一致しません。 |
はい |
例
「文字列の完全一致」比較を使用して、会社名を照合します。
次のオプションを指定します。
データなしのペアを照合= はい
大文字/小文字を区別しない = はい
次の変換が追加されます。
結果例
次の表に、「文字列の完全一致」比較の前述の構成を使用した比較結果をいくつか示します。
いずれかの値が空白の場合、または両方の値が空白の場合、「データなし」の比較結果が返されます。
表1-43 結果例: 文字列の完全一致
| 値A | 値B | 比較結果 |
|---|---|---|
|
Oracle |
ORACLE |
TRUE (一致) |
|
Price Waterhouse Coopers |
PriceWaterhouseCoopers |
TRUE (一致) |
|
Oracle Ltd |
Oracle |
TRUE (一致) |
|
Oracle Limited |
Oracle Ltd |
TRUE (一致) |
|
John Smith |
John Smith |
TRUE (一致) |
|
Oracle |
Oralce |
FALSE (一致なし) |
|
John Smith |
John A.Smith |
FALSE (一致なし) |
|
PWC |
Price Waterhouse Coopers |
FALSE (一致なし) |
|
George & Sons Construction |
George & Sons Confectioners |
FALSE (一致なし) |
|
Null |
Oracle |
データなし |
|
Null |
Null |
TRUE (一致) |
「リスト内」比較は、単一の値または値のリストを使用して照合する比較において、1つまたは両方の識別子値(文字列、文字配列)に条件付き一致ルールを適用する方法を提供します。
一致ルールを照合プロセスのデータのサブセットのみに適用する方法として、この比較を使用します。例:
一致ルールが中東の国の名前と照合するように設計されていると、国の識別子が中東の国のリストと一致する場合にのみ適用されます。
一致ルールが電気製品と照合するように設計されていると、製品カテゴリ識別子が単一の値と一致する場合にのみ適用されます。
この比較を使用して、「一致なし」結果とともに一致ルールで使用する場合、デシジョン表の下位の一致ルールで取得される一致を削除することもできます。たとえば、国または国籍の値が安全な値リストにない場合にのみ、特定のルールによる一致が表示されます。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| 両方のレコードのデータが必要 | はい/いいえ | 「はい」の場合、両方の入力識別子値にデータが含まれる必要があります。含まれない場合、比較は常にFalseになります。
「いいえ」の場合、1つのみの入力識別子値にデータが含まれる必要があります。 |
いいえ |
| 値に完全一致 | はい/いいえ | 「はい」の場合、指定した識別子値全体が一致する必要があります。
「いいえ」の場合、識別子内のトークンがリストと照合されます。この場合、次の関連フィールドで区切り文字を指定して、トークンを分割する方法を決定する必要があります。 |
いいえ |
| 必須値参照データ | 参照データ | 値リスト(一連の国コードなど)を含む参照データ・セット。 | クリア |
| 必要な値 | フリー・テキスト | 照合する対象の単一値。参照データ・セットと値が指定されている場合、その両方と照合されます。 | クリア |
| すべての値の一致が必要 | はい/いいえ | 「はい」の場合、識別子値のすべてのトークンを必須リストまたは必須値と照合する必要があります。「いいえ」の場合、いずれかのトークンが一致する必要があります。
このオプションは、「値に完全一致」が「いいえ」に設定されている場合にのみ使用されます。 |
いいえ |
| デリミタ文字参照データ | フリー・テキストまたは参照 | リストと照合する前に識別子値をトークン化するために使用される、区切り文字のリスト付きの参照データ・セットです。
このオプションは、「値に完全一致」が「いいえ」に設定されている場合にのみ使用されます。 |
なし |
| 区切り文字 | フリー・テキスト | このフィールドを使用して、
参照データ・セットにリンクするための代替として使用する区切り文字を指定します。このオプションは、「値に完全一致」が「いいえ」に設定されている場合にのみ使用されます。注意: 区切り文字と特定の文字の参照データ・リストがここに入力されている場合、両方が区切り文字として考慮されます。 |
なし |
例
この例では、「リスト内」比較を使用して、照合対象の両方のレコードの国識別子値が「UK」の場合にのみ一致ルールを適用しています。必要なオプションを次のように設定します(他のオプションは使用しません)。
表1-45 例1 結果: リスト内
| 値A | 値B | 比較結果 |
|---|---|---|
|
UK |
UK |
True |
|
UK |
US |
False |
|
US |
UK |
False |
|
UK |
データなし |
False |
|
UK, US |
UK |
False |
|
UK, UK |
UK |
False |
|
データなし |
UK |
False |
|
UK, UK |
データなし |
False |
この例では、「リスト内」比較を使用し、比較対象の両方のレコードで、国コード・トークンのカンマ区切りリスト内のすべての国コードが国コードのリストと一致する場合にのみ、一致ルールを適用しています。例として、リストには値USとUKが含まれていますが、IRとDEは含まれていません。
必要なオプションを次のように設定します(他のオプションは使用しません)。
「値(ソリューション)」比較は、指定した値がいずれかの属性に含まれているかどうかを判断します。
特定の値のみを含むレコードをチェックすることにより、データのサブセットのみに一致ルールを適用する方法として「値(ソリューション)」比較を使用します。
この比較では、結果バンドの使用はサポートされていません。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| デリミタ | フリー・テキスト | このフィールドは、使用する区切り文字を指定するために使用します。 | クリア |
| 値 | フリー・テキスト | 照合する対象の単一値。 | クリア |
例
この例では、「値(ソリューション)」比較を使用して、少なくとも1つのレコードに値Xが含まれている場合にのみ一致ルールを適用します。
結果例:
「最長共通句」比較では、2つの文字列値を比較し、両方の値に共通する最長句(その句が文字列値の全部か一部かに関係なく)の単語数を判断することにより、2つの値が一致しているかどうかを判断します。
句は、スペースで区切られた単語の連続として定義されます。
「最長共通句」比較を使用して、複数の単語が含まれ、その単語の順序が重要である文字列値の一致を検索します(たとえば、名称全体を照合する場合)。
「最長共通句」比較は、実質的に、「単語一致数」の順序に依存するバージョンです。デシジョン表内の下位の一致ルールでこれを使用すると、類似性はあるが他のルールを使用すると一致にならない(たとえば、一致しない単語が複数あるため)一致候補を検索してレビューできます。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、0の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。 | はい |
| 文字エラーの許容範囲 | 整数 | このオプションは、単語を相互に比較する際に許容される文字編集の回数を指定します。文字編集距離が指定された数値以下の単語はすべて、同じとみなされます。
たとえば、1に設定した場合、「95 Charnwood Court, Mile End, Parnham, Middlesex」と「95 Charwood Court, Mile End, Parnam, Middlesex」はこの許容範囲を考慮するとすべての単語が相互に一致するため、最長共通句の長さは7語になります。 |
0 |
| 数の許容範囲を無視 | はい/いいえ | このオプションを使用すると、すべてが数値で構成される単語に対して、文字エラーの許容範囲を無視できます。
たとえば、「はい」に設定して、文字エラーの許容範囲を1にした場合、数値95と96は異なるとみなされるため、1文字しか違わないにもかかわらず、「95 Charnwood Court, Mile End, Parnham, Middlesex」と「96 Charnwood Court, Mile End, Parnam, Middlesex」の最長共通句の長さは6語になります。 「いいえ」に設定した場合、数値は他の単語と同様に処理されるため、前述の例では95と96は同じとみなされ、最長共通句の長さは7語になります。 |
はい |
| 許容範囲値をパーセンテージ値で処理 | はい/いいえ | これを使用すると、文字エラーの許容範囲を、単語長(文字数)に対するパーセントとして処理できます。たとえば、1つの単語で5文字ごとに1つの文字エラーを許容するには、20%の値を使用します。
このオプションは、短い単語が1文字異なるだけで同じと処理されることを防ぐ一方で、長い単語では入力ミスとして許容できるようにする場合に役立ちます。たとえば、「Parnham」と「Parnam」は同じとみなしますが、「Bath」と「Batt」は別として処理されます。 「はい」に設定した場合、単語に差異があるが同じとみなすために、「文字エラーの許容範囲」オプションは、1つの単語内で差異を許容できる文字数の最大パーセントとして入力する必要があります。たとえば、Trueに設定した場合、文字エラーの許容範囲を20%とすると、ParnamとParnhamは同じとみなされます。これは、これらの編集距離が1であり、かつ、ワード長が7文字を超える場合は、1文字の一致エラーの割合が14%となり、20%のしきい値を下回るためです。一方、BathとBattという値は文字の一致エラーの割合が25% (4文字のうち1つがエラー)であるため、同じとはみなされません。 「いいえ」に設定した場合、「文字エラーの許容範囲」オプションは単語間の文字編集の許容範囲として処理されます。 |
いいえ |
例
この例では、「最長共通句」比較を使用して、顧客名の一致候補を識別します。次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
文字エラーの許容範囲= 0
数の許容範囲を無視= いいえ
許容範囲値をパーセンテージ値で処理= いいえ
結果例
次の表に、前述の構成を使用した比較結果をいくつか示します。
「最長共通句率」比較では、2つの文字列/文字配列の値を比較し、両方の値に共通する最長の単語の連続(スペースで区切られた)を判断して、それを単語数が多い方または少ない方の値の単語数に関連付けることにより、2つの値が一致しているかどうかを判断します。
「最長共通句率」比較は、値に多数の単語が含まれ、値の中の単語の順序が重要である場合に、2つの値が相互にどの程度近いかを判断するのに役立ちます。たとえば、会社名を照合する場合、正式名称内のいくつかの単語は、その名称をシステムに入力する際に除外されていることが多くあります。このため、意味のある単語の連続が含まれるが、一方の値にはその他の単語があまり多く含まれない場合、一致を識別するのに役立ちます。たとえば、「T D Waterhouse UK」と「Price Waterhouse UK」の最長共通句は2で、「Price Waterhouse」と「Price Waterhouse UK」も同様です。これに対して、最長共通句率は文字数を考慮するため、「T D Waterhouse UK」と「Price Waterhouse UK」はスコア50%で一致しますが、「Price Waterhouse」と「Price Waterhouse UK」は67%になり、より高い一致になります。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、0の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。 | はい |
| より短い入力に関連付け | はい/いいえ | このオプションでは、2つの値の最長共通句を、2つの値のうち長い方または短い方のどちらに関連付けるかを決定します。
「はい」に設定した場合、比較では2つの値の最長共通句を、2つの値のうち短い方(単語数が)に関連付けます。これにより、「T D Waterhouse UK」と「Price Waterhouse UK」のLCPPは67%になります。 「いいえ」に設定した場合、最長共通部分文字列は比較対象の2つの値のうち長い方に関連付けられます。そのため、「T D Waterhouse UK」と「Price Waterhouse UK」の照合結果は50%にしかなりません。 |
いいえ |
| 文字エラーの許容範囲 | 整数 | このオプションは、単語を相互に比較する際に許容される文字編集の回数を指定します。文字編集距離が指定された数値以下の単語はすべて、同じとみなされます。
たとえば、1に設定した場合、「95 Charnwood Court, Mile End, Parnham, Middlesex」と「95 Charwood Court, Mile End, Parnam, Middlesex」はこの許容範囲を考慮するとすべての単語が相互に一致するため、最長共通句率は100%になります。 |
0 |
| 数の許容範囲を無視 | はい/いいえ | このオプションを使用すると、すべてが数値で構成される単語に対して、文字エラーの許容範囲を無視できます。
たとえば、「はい」に設定して、文字エラーの許容範囲を1にした場合、数値95と96は異なるとみなされるため、1文字しか違わないにもかかわらず、「95 Charnwood Court, Mile End, Parnham, Middlesex」と「96 Charnwood Court, Mile End, Parnam, Middlesex」の最長共通句率は86%になります。 「いいえ」に設定した場合、数値は他の単語と同様に処理されるため、前述の例では95と96は同じとみなされ、最長共通句率は100%になります。 |
はい |
| 許容範囲値をパーセンテージ値で処理 | はい/いいえ | これを使用すると、文字エラーの許容範囲を、単語長(文字数)に対するパーセントとして処理できます。たとえば、1つの単語で5文字ごとに1つの文字エラーを許容するには、20%の値を使用します。
このオプションは、短い単語が1文字異なるだけで同じと処理されることを防ぐ一方で、長い単語では入力ミスとして許容できるようにする場合に役立ちます。たとえば、「Parnham」と「Parnam」は同じとみなしますが、「Bath」と「Batt」は別として処理されます。 「はい」に設定した場合、単語に差異があるが同じとみなすために、「文字エラーの許容範囲」オプションは、1つの単語内で差異を許容できる文字数の最大パーセントとして入力する必要があります。たとえば、Trueに設定した場合、文字エラーの許容範囲を20%とすると、ParnamとParnhamは同じとみなされます。これは、これらの編集距離が1であり、かつ、ワード長が7文字を超える場合は、1文字の一致エラーの割合が14%となり、20%のしきい値を下回るためです。一方、BathとBattという値は文字の一致エラーの割合が25% (4文字のうち1つがエラー)であるため、同じとはみなされません。 「いいえ」に設定した場合、「文字エラーの許容範囲」オプションは単語間の文字編集の許容範囲として処理されます。 |
いいえ |
例
この例では、「最長共通句率」比較を使用して、会社名の一致候補を識別します。
次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
より短い入力に関連付け= いいえ
文字エラーの許容範囲= 1
許容範囲値をパーセンテージ値で処理= いいえ
数の許容範囲を無視= はい
結果例
次の表に、前述の構成を使用した比較結果をいくつか示します。
表1-51 結果例: 最長共通句率
| 値A | 値B | 比較結果 |
|---|---|---|
|
Oracle Limited |
ORACLES LIMITED |
100% |
|
Accounting Software and Services Ltd |
Accounting Software and Services Ltd (E-Retail) |
83% |
|
The 365 Corporation |
The 364 Corporation |
33% |
|
Barclays Bank International |
Barrclays Bank |
67% |
|
Barclays |
Barclays Bank |
50% |
|
Oracle Professional Services Ltd |
Oracle Proffessional Services |
75% |
|
Marks and Spencer Financials |
Marks and Spencer |
75% |
|
Marks and Spencer Head Office |
Marks and Spencer |
60% |
「最長共通部分文字列」比較では、2つの文字列/文字配列の値を比較し、両方の値に共通する文字の連続(部分文字列、その部分文字列が文字列値の全部か一部かに関係なく)の最大長を判断することにより、2つの値が一致しているかどうかを判断します。
文字列の先頭または末尾に、単語の削除による比較では無視するのが困難なノイズがある場合、または、特定の長さを超える文字の共通する連続が文字列値に含まれ、それらが関連付けられている場合は、「最長共通部分文字列」比較を使用して、文字列値間の一致を検索します。たとえば、「Nomura Securities Co., Ltd.」と「Nomura Investor Relations Co., Ltd.」を照合すると、最長共通部分文字列は「Nomura」の6文字です。
多くの場合、「最長共通部分文字列」比較をデシジョン表内の下位の一致ルールで使用すると、類似性はあるが他のルールを使用すると一致にならない(たとえば、語順の問題や余分なノイズのため)一致候補を検索してレビューできます。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、0の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。 | はい |
例
この例では、「最長共通部分文字列」比較を使用して、顧客名の一致候補を識別します。
次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
「空白の切捨て」変換を使用して、値を比較する前に値からすべての空白を削除します。
結果例
次の表に、前述の構成を使用した比較結果をいくつか示します。
「最長共通部分文字列の比率」比較では、2つの値の最長共通部分文字列を検索し、その文字数を、入力値の長い方または短い方の文字数に関連付けることにより、2つの文字列/文字配列の値の相互の類似性を判断します。
「最長共通部分文字列の比率」比較は、「最長共通部分文字列」(指定の値の中の長い単語を単に照合し、値の中の他のデータは考慮されない)では正確な結果が出せない場合に使用します。たとえば、値「Ardent Design Birmingham」と「Britannia Design Birmingham」の最長共通部分文字列は17文字で、高い一致結果を示します。これに対して、最長共通部分文字列率は63%にすぎず、低い一致結果になります。
2つの文字列の短い方の値を使用する場合、「最長共通部分文字列の比率」比較では、2つの値について完全またはあいまいの「次を含む」一致も実行できます。たとえば、「最長共通部分文字列の比率」を使用して、短い方の値に関連付ける場合、値「Ardent」と「Ardent Design UK」はスコア100%で一致し、値「Ardent UK」と「Ardent Design UK」はスコア75%で一致します(すべての空白文字は削除されるとします)。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、0の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。 | はい |
| より短い入力に関連付け | はい/いいえ | このオプションでは、2つの値の最長共通部分文字列を、2つの値のうち長い方または短い方のどちらに関連付けるかを決定します。
「はい」に設定すると、短い方の値が使用されるため、「最長共通部分文字列の比率」は実質的に、一方の値がもう一方の値にどの程度含まれるかを測定します。たとえば、「Excel」と「Excel Europe」のLCSPは100%です。 「いいえ」に設定した場合、最長共通部分文字列は比較対象の2つの値のうち長い方に関連付けられます。このため、「Excel」と「Excel Europe」のLCSPは42%にすぎず、「Britannia Design」と「Britannia Desn.UK」は72%になります。 |
いいえ |
例
この例では、「最長共通部分文字列の比率」比較を使用して、住所の1行目で一致候補を識別します。
次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
より短い文字列に関連付け= はい
「空白の切捨て」変換を使用して、値を比較する前に値からすべての空白を削除します。
結果例
次の表に、前述の構成を使用した比較結果をいくつか示します。
「最長共通部分文字列の合計」比較は、2つの文字列/文字配列の値の類似性を判断できる強力な方法の1つで、特に、値に長い文字列や多くの単語が含まれる場合に使用します。
「最長共通部分文字列の合計」(LCSS)は、2つの値に共通する最長共通部分文字列の長さ(文字数)に、その他の重複しない共通部分文字列すべての長さを加えて計算されます。比較のオプションとして、部分文字列の最小長(文字数)を指定します。この比較では、各文字列値内で部分文字列が検出された順序は関係ありません。
これは、共通部分文字列長の可能な最大合計と必ずしも一致しないことに注意してください。
2つの文字列を比較するとき、重複しない部分文字列の複数の異なるセットを構築できる場合があります。「最長共通部分文字列の合計」比較では、可能な最大一致スコアにならない場合でも、2つの値に共通する最長共通部分文字列を含むセットが常に使用されます。
「最長共通部分文字列の合計」比較を使用して、一般的にデータ値に多数の文字や単語が含まれ、入力ミスやその他の差異(一方の値にその他の単語や略語が含まれる場合など)が存在する可能性がある文字列値の間で、あいまい一致を検索します。たとえば、会社名などのデータは値が長い場合があり、そのデータを固定長フィールドに格納するとき、ユーザーは一部の単語を短縮することがあります。このような問題を考慮せずに他のシステムと照合すると、一致を検索するのが困難になります。ただし、「最長共通部分文字列の合計」を使用して、最小文字列長プロパティを4に設定すると、値「Kingfisher Computer Services and Technology Limited」と「Kingfisher Comp Servs & Tech Ltd.」は一致スコアが23文字になり、高い一致を示します。つまり、文字列「Kingfisher Comp」(15文字)、「Serv」(4文字)および「Tech」(4文字)がすべて一致します。
部分文字列は重複できないため、文字列「Kingfisher Comp」は1回のみカウントされ、この文字列内の4文字以上の部分文字列(King、Kingf、Kingfi、ingfiなど)はカウントされません。
両方の値で部分文字列が検出され、その長さが条件を満たしている場合、他の部分文字列と比較して検出された順序は関係ありません。たとえば、最小文字列長プロパティを4に設定した場合、文字列「Kingfisher Servs & Tech」と「Kingfisher Tech & Servs」はスコア20で一致します。これは、部分文字列「Kingfisher」(11文字、スペースを含む)、「Tech」(4文字)および「Servs」(5文字)の合計です。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、0の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。 | はい |
| 長さを超える部分文字列を含めます | はい/いいえ | 「最長共通部分文字列の合計」の総合スコアに寄与するには、比較対象の2つの値の共通部分文字列が指定した値より大きい必要があります。
3に設定した場合、2つの値に共通する4文字以上の(重複しない)部分文字列がLCSS計算に含められます。たとえば、比較する前に空白文字が削除されると仮定した場合、値「Acme Micros Ltd Serv」と「Acme and Partners Micro Services Ltd」のLCSSは9です。これは、共通部分文字列「Acme」の4文字、共通部分文字列「Micro」の5文字から計算されます。共通部分文字列「Ltd」は長さが3文字を超えていないため、計算には含められません。 |
4 |
例
この例では、「最長共通部分文字列の合計」比較を使用して、会社名の一致候補を識別します。
次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
長さを超える部分文字列を含めます= 3
「空白の切捨て」変換を使用して、値を比較する前に値からすべての空白を削除します。
結果例
次の表に、前述の構成を使用した比較結果をいくつか示します。
表1-54 結果例: 最長共通部分文字列の合計
| 値A | 値B | 比較結果 |
|---|---|---|
|
Friars St Dental Practice |
Friar Street Dental Pract. |
18 |
|
Britannia Preservations |
Britannia Preservation Ltd |
21 |
|
Barraclough Partners |
Barraclough Stiles and Partners |
19 |
|
Gem Distribution Ltd |
Gem Distribution Ltd (Wildings) |
18 |
|
Think Consulting Ltd |
Think Training |
18 |
|
Logist Services and Distribution |
Consulting Ltd |
18 |
|
Logist Distribution & Services |
Logist Servs and Dist Logist Services & Distribution |
26 |
「最長共通部分文字列の合計率」比較は、2つの文字列/文字配列の値の類似性を判断できる強力な方法の1つで、特に、値に長い文字列や多くの単語が含まれる場合に使用します。
「最長共通部分文字列の合計率」(LCSSP)では、2つの文字列値の最長共通部分文字列合計を計算し、それを比較対象の文字列の長い方または短い方の文字数に関連付けます。
「最長共通部分文字列の合計率」比較は、複数の単語で構成されるテキスト文字列を照合する際に、単語の順序や空白文字の差異があり、文字列の長さに比例して類似性を判断する必要がある場合に特に役立ちます。
たとえば、アジア人の氏名を複数のソースから照合するときに、氏名が同じ順序で一貫性のある記述でない場合や、音訳の違いや入力ミスにより空白文字が異なる場合がこれに該当します。単語一致比較(「単語一致率」など)は一貫性のある方法で区切られた単語に依存しているため、空白文字の差異があると結果が弱められることに注意してください。
たとえば、次の氏名を考えてみます。
Mary Elizabeth Angus
Mary Elizabeth Francis
Mary Elizabeth
Xiaojian Zhong
ZHONG Xiao Jian
最後の2つの氏名は、両方の単語の順序やスペース設定が異なりますが、高い一致になります。「単語一致率」では高い結果になりません。これらは「最長共通部分文字列の合計」で高い結果になりますが、最初の2つの氏名の場合は高い一致になりません。
「最長共通部分文字列の合計率」では、2つの値の共通部分文字列の合計長を判断し、それを比較対象の合計文字数に関連付ける方法を提供します。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、0の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。 | はい |
| 長さを超える部分文字列を含めます | はい/いいえ | 「最長共通部分文字列の合計」の総合スコアに寄与するには、比較対象の2つの値の共通部分文字列が指定した値より大きい必要があります。
3に設定した場合、2つの値に共通する4文字以上の(重複しない)部分文字列がLCSS計算に含められます。たとえば、比較する前に空白文字が削除されると仮定した場合、値「Acme Micros Ltd Serv」と「Acme and Partners Micro Services Ltd」のLCSSは9です。これは、共通部分文字列「Acme」の4文字、共通部分文字列「Micro」の5文字から計算されます。共通部分文字列「Ltd」は長さが3文字を超えていないため、計算には含められません。 |
4 |
| より短い入力に関連付け | はい/いいえ | 「最長共通部分文字列の合計」を比較対象の2つの文字列のうち短い方または長い方のどちらに関連付けるかを設定します。短い方の入力に関連付けると、緩やかな一致ルールが可能になります。これは、短い方の文字列に含まれる部分文字列の大部分は長い方の文字列にも含まれ、長い方の文字列には他のデータも含めることができるためです。 | いいえ |
例
この例では、「最長共通部分文字列の合計率」比較を使用して氏名を比較します。
次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
長さを超える部分文字列を含めます= 3
より短い入力に関連付け= いいえ
「空白の切捨て」変換を使用して、値を比較する前に値からすべての空白を削除します。
結果例
次の表に、前述の構成を使用した比較結果をいくつか示します。
「同様の日付」比較は、入力として日付または日付配列を使用することで、2つの日付が同様かどうかを判断します。この比較では、日付が完全一致した場合、および日付の日と月が置換され年が一致した場合に、trueを返します。さらに、次の日付を照合するように構成することもできます。
構成可能な絶対数の日数が離れている日付
日と月のコンポーネントが同じで構成可能な年数が離れている日付
日と月のコンポーネントが同じで、年が競合している日付
日と年のコンポーネントが同じで、月が競合している日付
「同様の日付」比較を使用して、日付識別子に格納された日付、または文字列識別子に格納された日付の近い一致を検索します(epochからのミリ秒で表現)。
この比較では、結果バンドの使用はサポートされていません。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、完全一致(TRUE)の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 最大許容日数 | 整数 | 2つの日付の差異が指定した値以下である場合に、2つの日付を一致とみなす許容範囲。 | 5 |
| 最大許容年 | 整数 | 日と月が一致し、年の差異が指定した値以下である場合に、2つの日付を一致とみなす許容範囲。 | 5 |
| 年の競合を許可 | はい/いいえ | 日と月は同じであるが年が異なる場合に、2つの日付の一致を許可するかどうかを指定します。 | いいえ |
| 月の競合を許可 | はい/いいえ | 日と年は同じであるが月が異なる場合に、2つの日付の一致を許可するかどうかを指定します。 | いいえ |
例
この例に、「同様の日付」比較を使用した結果を示します。
結果例:
「次で始まる」比較では、2つの文字列/文字配列の値を比較し、一方の値がもう一方の値全体で始まるかどうかを判断します。したがって、完全に一致する場合と、一方の値がもう一方と同じ値で始まるがその他の情報も含まれる一致の場合があります。
「次で始まる」比較を使用して、値の文字列の後に高い頻度でその他の情報が含まれる文字列識別子について、一致を検索します。たとえば、会社名を照合するときに、「次で始まる」比較を使用して値「Oracle」と「Oracle Corporation」を照合します。
また、多くの場合、住所行を照合する際にも役立ちます(たとえば、「The Maltings」と「The Maltings, 10 Borough Road」、「10 Borough Road」と「10 Borough Road, Coventry」を比較する場合)。
この比較では、結果バンドの使用はサポートされていません。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、完全一致(TRUE)の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。 | はい |
例
この例では、「次で始まる」比較を使用して「名」識別子を照合します。次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
「空白の切捨て」変換を使用して、値を比較する前に値からすべての空白を削除します。
結果例
次の表に、前述の構成を使用した比較結果をいくつか示します。
いずれかの値が空白の場合、「データなし」の比較結果が返されます。
「単語編集距離」比較では、値をもう一方の値に変換するのに必要な単語編集(単語の挿入、削除および置換)の最小回数を計算して、複数の単語で構成される文字列/文字配列の値が相互にどの程度一致しているかを判断します。
「単語編集距離」比較は、複数の単語で構成される文字列値(フルネームなど)を照合する際に、文字列値は類似しているが、「文字編集距離」や「文字の一致率」などの文字ベースの一致プロパティを使用しても適切に一致しない場合に使用します。たとえば、値「Joseph Andrew Cole」と「Joseph Cole」は高い一致と考えられますが、文字編集距離は6、文字一致率は63%で、かなり低い一致を示します。同じ2つの値の単語編集距離は1ですが、最初と最後の数文字を照合する追加の比較も使用して、一致候補と判断することもできます。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「False」に設定されている場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「True」に設定されている場合、データなし値とデータなし値を比較した際、0の比較結果が返されます(一致する単語数が0であるため)。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。
たとえば、大文字/小文字を区別しない場合、「Joseph Andrew COLE」と「Joseph Andrew Cole」の単語編集距離は0です。大文字/小文字を区別する場合は1です。 |
はい |
| 文字エラーの許容範囲 | 整数 | このオプションは、単語を相互に比較する際に許容される文字編集の回数を指定します。文字編集距離が指定された数値以下の単語はすべて、同じとみなされます。
たとえば、1に設定した場合、この許容範囲を考慮するとすべての単語が相互に一致するため、「Parnham, Middlesex」と「Parnam, Middlesex」の単語編集距離は0になります。 |
0 |
| 数の許容範囲を無視 | はい/いいえ | このオプションを使用すると、すべてが数値で構成される単語に対して、文字エラーの許容範囲を無視できます。
たとえば、「はい」に設定して、文字エラーの許容範囲を1にした場合、数値95と96は異なるとみなされるため、1文字しか違わないにもかかわらず、「95 Charnwood Court, Mile End, Parnham, Middlesex」と「96 Charnwood Court, Mile End, Parnam, Middlesex」の単語編集距離は1になります。 「いいえ」に設定した場合、数値は他の単語と同様に処理されるため、前述の例では95と96は同じとみなされ、単語編集距離は0になります。 |
はい |
| 許容範囲値をパーセンテージ値で処理 | はい/いいえ | これを使用すると、文字エラーの許容範囲を、単語長(文字数)に対するパーセントとして処理できます。たとえば、1つの単語で5文字ごとに1つの文字エラーを許容するには、20%の値を使用します。
このオプションは、短い単語が1文字異なるだけで同じと処理されることを防ぐ一方で、長い単語では入力ミスとして許容できるようにする場合に役立ちます。たとえば、「Parnham」と「Parnam」は同じとみなしますが、「Bath」と「Batt」は別として処理されます。 「はい」に設定した場合、単語に差異があるが同じとみなすために、「文字エラーの許容範囲」オプションは、1つの単語内で差異を許容できる文字数の最大パーセントとして入力する必要があります。たとえば、Trueに設定した場合、文字エラーの許容範囲を20%とすると、ParnamとParnhamは同じとみなされます。これは、これらの編集距離が1であり、かつ、ワード長が7文字を超える場合は、1文字の一致エラーの割合が14%となり、20%のしきい値を下回るためです。一方、BathとBattという値は文字の一致エラーの割合が25% (4文字のうち1つがエラー)であるため、同じとはみなされません。 「いいえ」に設定した場合、「文字エラーの許容範囲」オプションは単語間の文字編集の許容範囲として処理されます。 |
いいえ |
| 単語の順序を無視 | はい/いいえ | 「はい」に設定した場合、各値内の単語の順序は結果に影響しません。たとえば、「Nomura International Bank」と「International Bank Nomura」の単語編集距離は0になります。
「いいえ」に設定した場合、各値内の単語の順序が考慮されます。そのため、「Nomura International Bank」と「International Bank Nomura」の単語編集距離は3になります。 |
はい |
例
この例では、「単語編集距離」比較を使用して会社名を照合します。次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
文字エラーの許容範囲= 1
数の許容範囲を無視= いいえ
許容範囲値をパーセンテージ値で処理= いいえ
単語の順序を無視 = はい
また、PLC、LIMITED、OFのエントリを含む参照データ・リストを使用して、「単語の削除」変換も追加されています
結果例
次の表に、前述の構成を使用した比較結果をいくつか示します。
表1-59 結果例: 単語編集距離
| 値A | 値B | 比較結果 |
|---|---|---|
|
International Bank of Nomura |
Nomura International Bank |
0 |
|
BA Systems Operations |
BA SYSTEMS OPERATIONS |
0 |
|
Oracle Limited |
Oracle |
0 |
|
Oracle Limited |
Oraccle |
0 |
|
George & Sons Plumbers Limited |
George Plumber & Sons |
0 |
|
Price Waterhouse Coopers |
Price Waterhouse |
1 |
|
British Telecom plc |
First Telecom |
1 |
|
Merrill Lynch |
Merrills |
1 |
|
Merrill Lynch |
Merrillion Software |
2 |
「単語一致数」比較を使用すると、共通するいくつかの単語(空白文字で区切られた)が含まれ、複数の単語で構成される文字列/文字配列の値を、それらの単語の検出順序に関係なく照合できます。
「単語一致数」比較は、複数の単語で構成される文字列識別子値(個人の氏名など)を照合する際に、共通する単語が含まれるが、値が必ずしも標準の順序でないために他の比較では一致にならない場合に使用します。たとえば、名前フィールドで「文字編集距離」比較を使用すると値「David SMITH」と「Smith, David」は一致しませんが、これらの値に含まれる2つの単語は共通しており、高い一致であることを示しています(特に、名前データが最大3単語である場合)。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「False」に設定されている場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「True」に設定されている場合、データなし値とデータなし値を比較した際、0の比較結果が返されます(一致する単語数が0であるため)。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。
たとえば、大/小文字を区別しない場合、「Joseph Andrew COLE」と「Joseph Andrew Cole」の単語一致数は3です。大/小文字を区別する場合は2です。 |
はい |
| 文字エラーの許容範囲 | 整数 | このオプションは、単語を相互に比較する際に許容される文字編集の回数を指定します。文字編集距離が指定された数値以下の単語はすべて、同じとみなされます。
たとえば、1に設定した場合、この許容範囲を考慮するとすべての単語が相互に一致するため、「95 Charnwood Court, Mile End, Parnham, Middlesex」と「95 Charwood Court, Mile End, Parnam, Middlesex」の単語一致数は7になります。 |
0 |
| 数の許容範囲を無視 | はい/いいえ | このオプションを使用すると、すべてが数値で構成される単語に対して、文字エラーの許容範囲を無視できます。
たとえば、「はい」に設定して、文字エラーの許容範囲を1にした場合、数値95と96は異なるとみなされるため、1文字しか違わないにもかかわらず、「95 Charnwood Court, Mile End, Parnham, Middlesex」と「96 Charnwood Court, Mile End, Parnam, Middlesex」の単語一致数は7ではなく6になります。 |
はい |
| 許容範囲値をパーセンテージ値で処理 | はい/いいえ | これを使用すると、文字エラーの許容範囲を、単語長(文字数)に対するパーセントとして処理できます。たとえば、1つの単語で5文字ごとに1つの文字エラーを許容するには、20%の値を使用します。
このオプションは、短い単語が1文字異なるだけで同じと処理されることを防ぐ一方で、長い単語では入力ミスとして許容できるようにする場合に役立ちます。たとえば、「Parnham」と「Parnam」は同じとみなしますが、「Bath」と「Batt」は別として処理されます。 「はい」に設定した場合、単語に差異があるが同じとみなすために、「文字エラーの許容範囲」オプションは、1つの単語内で差異を許容できる文字数の最大パーセントとして入力する必要があります。たとえば、Trueに設定した場合、文字エラーの許容範囲を20%とすると、ParnamとParnhamは同じとみなされます。これは、これらの編集距離が1であり、かつ、ワード長が7文字を超える場合は、1文字の一致エラーの割合が14%となり、20%のしきい値を下回るためです。一方、BathとBattという値は文字の一致エラーの割合が25% (4文字のうち1つがエラー)であるため、同じとはみなされません。 「いいえ」に設定した場合、「文字エラーの許容範囲」オプションは単語間の文字編集の許容範囲として処理されます。 |
いいえ |
例
この例では、「単語一致数」比較を使用して個人の名前を照合します。次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
文字エラーの許容範囲= 2
数の許容範囲を無視= いいえ
許容範囲値をパーセンテージ値で処理= いいえ
結果例
次の表に、前述の構成を使用した比較結果をいくつか示します。
表1-60 結果例: 単語一致数
| 値A | 値B | 比較結果 |
|---|---|---|
|
David Sheldon Turner |
TURNER David Shelldon |
3 |
|
David Sheldon Turner |
TURNER Sheldon David |
3 |
|
David Turner |
David Turner |
2 |
|
David Turner |
Dave Turner |
2 |
|
Mr David Sheldon Turner |
David Turner |
2 |
|
Alexander Graham Bell |
Alexander BELL |
2 |
|
Mrs Susan Chung |
Mrs Susane Chung |
3 |
|
Susan Smith |
Suzanne Smith |
1 |
|
Susan Simpson |
Susan Musslewhite |
1 |
|
Alexander Wallace |
Alex Walace |
1 |
|
Alexander Wallace |
Alex Wace |
0 |
「単語一致率」比較では、2つの文字列の単語編集距離を計算し、2つの値の長い方または短い方の長さ(単語数)を考慮して、複数の単語で構成される2つの文字列/文字配列の値が相互にどの程度一致しているかを判断します。
「単語一致率」比較は、複数の単語で構成される値(名称など)で一致を検索する際に、その他の情報(余分な単語など)が含まれているために、「文字の一致率」比較などを使用しても適切に一致しない場合に使用します。たとえば、値「Ali Muhammed Saadiq」と「Ali Saadiq」を照合する場合、文字一致率はわずか53%(空白文字は削除されるとします)で低い一致になりますが、単語一致率は66%(「より短い入力に関連付け」オプションを「はい」に設定すると100%)で高い一致になります。識別子値内で一致する単語数が多いほど、「単語一致率」比較の正確度が高くなります。単語数が少ない場合、単語一致率60%以上はかなり高い結果ですが、文字一致率60%はかなり低い結果を示すことに注意してください。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「False」に設定されている場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「True」に設定されている場合、データなし値とデータなし値を比較した際、0の比較結果が返されます(一致する単語数が0であるため)。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 大文字/小文字を区別しない | はい/いいえ | 値を比較する際に、大文字/小文字を区別しないかどうかを設定します。
たとえば、大文字/小文字を区別しない場合、「Joseph Andrew COLE」と「Joseph Andrew Cole」の単語一致率は100%です。大文字/小文字を区別する場合は67%です。 |
はい |
| 文字エラーの許容範囲 | 整数 | このオプションは、単語を相互に比較する際に許容される文字編集の回数を指定します。文字編集距離が指定された数値以下の単語はすべて、同じとみなされます。
たとえば、1に設定した場合、この許容範囲を考慮するとすべての単語が相互に一致するため、「95 Charnwood Court, Mile End, Parnham, Middlesex」と「95 Charwood Court, Mile End, Parnam, Middlesex」の単語一致率は100%になります。 |
0 |
| 数の許容範囲を無視 | はい/いいえ | このオプションを使用すると、すべてが数値で構成される単語に対して、文字エラーの許容範囲を無視できます。
たとえば、「はい」に設定して、文字エラーの許容範囲を1にした場合、数値95と96は異なるとみなされるため、1文字しか違わないにもかかわらず、「95 Charnwood Court, Mile End, Parnham, Middlesex」と「96 Charnwood Court, Mile End, Parnam, Middlesex」の単語一致率は86%になります。 「いいえ」に設定した場合、数値は他の単語と同様に処理されるため、前述の例では95と96は同じとみなされ、単語一致率は100%になります。 |
はい |
| 許容範囲値をパーセンテージ値で処理 | はい/いいえ | これを使用すると、文字エラーの許容範囲を、単語長(文字数)に対するパーセントとして処理できます。たとえば、1つの単語で5文字ごとに1つの文字エラーを許容するには、20%の値を使用します。
このオプションは、短い単語が1文字異なるだけで同じと処理されることを防ぐ一方で、長い単語では入力ミスとして許容できるようにする場合に役立ちます。たとえば、「Parnham」と「Parnam」は同じとみなしますが、「Bath」と「Batt」は別として処理されます。 「はい」に設定した場合、単語に差異があるが同じとみなすために、「文字エラーの許容範囲」オプションは、1つの単語内で差異を許容できる文字数の最大パーセントとして入力する必要があります。たとえば、Trueに設定した場合、文字エラーの許容範囲を20%とすると、ParnamとParnhamは同じとみなされます。これは、これらの編集距離が1であり、かつ、ワード長が7文字を超える場合は、1文字の一致エラーの割合が14%となり、20%のしきい値を下回るためです。一方、BathとBattという値は文字の一致エラーの割合が25% (4文字のうち1つがエラー)であるため、同じとはみなされません。 「いいえ」に設定した場合、「文字エラーの許容範囲」オプションは単語間の文字編集の許容範囲として処理されます。 |
いいえ |
| より短い入力に関連付け | はい/いいえ | このオプションにより、「単語一致率」比較で行われる計算が決定されます。
「はい」に設定すると、照合する2つの入力のうち、(単語数が)短い方の入力を使用して、その文字数のパーセントとして結果が計算されます。 「いいえ」に設定すると、照合する2つの入力のうち、(単語数が)長い方の入力を使用して、その文字数のパーセントとして結果が計算されます。 |
いいえ |
例
この例では、「単語一致率」比較を使用して会社名全体を照合します。次のオプションを指定します。
データなしのペアを照合= いいえ
大文字/小文字を区別しない = はい
より短い入力に関連付け= いいえ
文字エラーの許容範囲= 20
数の許容範囲を無視= はい
許容範囲値をパーセンテージ値で処理= はい
単語の順序を無視= いいえ
より短い入力に関連付け= はい
「ノイズ削除」変換が追加され、比較する値から句読点(カンマおよびピリオド)を削除します。
結果例
次の表に、前述の構成を使用した比較結果をいくつか示します。
表1-61 結果例: 単語一致率
| 値A | 値B | 比較結果 |
|---|---|---|
|
Federal Mogul Camshafts Ltd |
Federal Mogul Camshafts Castings Ltd |
100% |
|
Federal Mogul Camshafts Ltd |
Federal Mogul Eurofriction Ltd |
75% |
|
Stamford High School |
Stamford School |
100% |
|
Eurofleet Bodyshop Ltd |
Eurofleet Ltd |
100% |
|
Phoenix Food Ltd |
Phoenix Manufacturing Ltd |
66% |
|
Cumerland Wood and Chair Corp |
Cumberland Wood Corp |
100% |
「単語がIN共通で始まる」比較は、2つの文字列/文字配列識別子内の単語のいずれかに開始部分文字列の一致があるかどうかを判断します。
「単語がIN共通で始まる」比較を使用して、その他の情報が単語の末尾に高い頻度で出現する文字列識別子の一致を検索します。この比較は、名前のイニシャルや短縮した名前を照合する際に特に役立ちます。
この比較では、結果バンドの使用はサポートされていません。
オプション
なし。
例
この例では、「単語がIN共通で始まる」比較を使用して、イニシャルと短縮を許可する、共通の特定の名前を含むレコードを照合しています。
結果例:
「日付が異なりすぎます(ソリューション)」比較は、2つの日付値を比較し、構成オプションに基づき、大きく異なっている場合に、trueを返します。この比較では、計算時に値の入力ミスの編集距離と絶対距離を使用します。日付の入力ミスが多すぎて、かつ日数の絶対差異が構成済のしきい値を超えた場合に、異なりすぎると判断されます。
「日付が異なりすぎます(ソリューション)」比較を使用して、日付値に基づいた、明らかなレコードの不一致を削除します。
この比較では、結果バンドの使用はサポートされていません。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| 最大許容タイプ | 整数 | 2つの日付のレーベンシュタイン編集距離[ yyyyMMdd形式で示される場合]が指定した値以下である場合に、2つの日付を同様とみなす許容範囲。 |
2 |
| 最大差分(日数) | 整数 | 2つの日付の絶対差異が指定した値以下である場合に、2つの日付を同様とみなす許容範囲。 | 10 |
例
この例で、「日付が異なりすぎます(ソリューション)」比較を使用した結果を示します。
結果例:
「日付差異」比較では、2つの日付値の距離を判断します。オプション設定に応じて、差異は様々な方法(年、月、週または日単位)で表現できます。
「日付差異」比較を使用して、記述上の日付は異なるため、「日付編集距離」を使用すると高い一致にはならない場合に、相互に近い日付を検索します。たとえば、「31/12/1999」は「01/01/2000」に対して近似一致として一致します。
この比較では、結果バンドの使用がサポートされています。
構成例
この例では、時系列データに対して「日付差異」比較を使用して、相互に30日以内のすべてのレコードを照合します。一致ルールで日付差異が0から30日以内の一致を検索できます。
結果例
次の表に、前述の構成を使用した比較結果の例を示します。
「日付編集距離」比較では、2つの日付値および日付配列の文字編集距離を判断します。
「日付編集距離」比較を使用して、日付の完全一致または近似一致を検索します。「日付編集距離」は、日付を手動で(自動生成ではなく)システムに指定したために、入力ミスの可能性がある場合に使用します。たとえば、値「01/08/1972」と「01/08/1772」は日付編集距離が1で一致候補として識別されます。
この比較では、結果バンドの使用がサポートされています。
構成例
この例では、生年月日識別子に対して「日付編集距離」比較を使用して、個人を照合します。氏名も一致する場合、完全日付一致(編集距離が0)は一致として分類されます。また、氏名も一致する場合、近似日付一致(編集距離が1)は一致候補(レビューのため)として分類されます。
データなしのペアを照合= いいえ
日を無視 = いいえ
月を無視 = いいえ
年を無視= いいえ
世紀を無視= はい
タイム・ゾーン = ディレクタのタイム・ゾーン
結果例
次の表に、前述の構成を使用した比較結果の例を示します。
「日付置換の一致」比較では、日と月を入れ替えた(置換した)場合に2つの日付値/日付配列が一致するかどうかを判断します。これにより、同じ日付が異なる書式でシステムに入力される可能性があるレコードを照合できます。たとえば、アプリケーションが適切に国際化されていないと、英国のユーザーは1970年8月1日を「01/08/1970」と入力しますが、米国のユーザーは同じ日付を「08/01/1970」と入力する可能性があります。
「日付置換の一致」比較は他の比較と組み合せて使用し、日付が一貫性なく入力されている場合に一致候補を検索します。たとえば、姓、郵便番号および生年月日識別子を使用して個人を照合するとき、姓と郵便番号が同じで、生年月日は日と月を入れ替えると同じになる個人を一致候補として処理する場合があります。このような個人は、(日付一致比較を使用して)生年月日が完全一致になる必要があるルールには一致しません。
この比較では、結果バンドの使用はサポートされていません。
構成例
この例では、生年月日識別子に対して「日付置換の一致」比較を使用し、生年月日の日と月を入れ替えて個人を照合します。次のオプションを指定します。
データなしのペアを照合= いいえ
年を無視= いいえ
世紀を無視= はい
タイム・ゾーン = ディレクタのタイム・ゾーン
結果例
次の表に、比較結果を示します。
「日付の完全一致」比較は、2つの日付値/日付配列が一致しているかどうかを判断する単純な比較です。
「日付の完全一致」比較を使用して、日付一致を検索します。たとえば、生年月日識別子を使用して個人を照合します。「日付の完全一致」比較を使用すると、2つの日付をどの程度厳密に照合するかを構成できます。たとえば、年と世紀を無視すると、日と月が同じ場合に日付が一致するため、「11/01/1901」と「11/01/1970」は一致します。
この比較では、結果バンドの使用はサポートされていません。
構成例
この例では、生年月日識別子に対して「日付の完全一致」比較を使用し、生年月日の日と月を使用して個人を照合します。次のオプションを指定します。
データなしのペアを照合= いいえ
日を無視 = いいえ
月を無視 = いいえ
年を無視 = はい
世紀を無視= 任意の値(年を無視 = はいであるため適用不可)
タイム・ゾーン = ディレクタのタイム・ゾーン
結果例
次の表に、比較結果を示します。
「年が異なりすぎます」比較は、年のスペース区切りのリストを含む2つの文字列/文字配列の値を比較し、構成オプションに基づいて、比較対象の一方の側のすべての年がもう一方のすべての年と大きく異なっている場合に、trueを返します。この比較では、計算時に値の入力ミスの編集距離と絶対距離を使用します。年の入力ミスが多すぎて、かつ絶対差異が構成済のしきい値を超えた場合に、異なりすぎると判断されます。
「年が異なりすぎます」比較を使用して、日付値の年に基づき、明らかなレコードの不一致を削除します。これは、日付が不完全であるか、日付フィールドの日と月の信頼性が低い場合に役立ちます。
この比較では、結果バンドの使用はサポートされていません。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| 最大許容タイプ | 整数 | 2つの値のレーベンシュタイン編集距離が指定した値以下である場合に、2つの値を同様とみなす許容範囲。 | 2 |
| 最大差分 | 整数 | 2つの年の絶対差異が指定した値以下である場合に、2つの年を同様とみなす許容範囲。 | 3 |
例
この例に、「年が異なりすぎます」比較を使用した結果を示します。
結果例:
「絶対差分」比較では、相互に近い2つの数値を一致または一致候補とみなすことができるように、2つの数値/番号配列が相互にどの程度近いかを判断します。
「絶対差分」比較を使用して、近いが完全に同じではない数値を照合します。数値を正負に関係なく照合(たとえば、-0.5を0.5で照合)する場合は、この比較とともに「絶対値」変換機能も使用できることに注意してください。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、完全一致(絶対差分が0)の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
例
「絶対差分」比較を使用すると、ほぼ同一の数値を識別できます。たとえば、同じ製品の受注を単一の通貨値(受注は複数の通貨から変換される)によって検索するときに、(為替レートの変動を考慮して)受注金額の差異が5.00ポンド以内の受注は一致候補とみなすことができます。
この場合、「データなしのペアを照合」オプションは「いいえ」に設定します。
次の表に、前述の構成を使用した比較結果の例を示します。
「等しい」比較は、2つの数値/番号配列が相互に等しいかどうかを判断する単純な比較です。
「等しい」比較を使用して、等しい数値を照合します。数値を正負に関係なく照合(たとえば、-0.5を0.5で照合)する場合は、この比較とともに「絶対値」変換機能も使用できることに注意してください。
この比較では、結果バンドの使用はサポートされていません。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、完全一致(文字編集距離が0)の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 小数位の精度 | 整数 | このオプションを使用すると、数値を照合する小数桁数の精度を指定できます。整数以外の数値、つまり、45.678や45.622など小数点の後に値がある数値に対して、2つの値を照合する小数桁数を指定できます。たとえば、1に設定した場合、値45.6と45.6が比較されるため、値45.678と45.622は等しいとみなされます。2に設定した場合、値45.67と45.62が比較されるため等しいとはみなされません。変換として追加された場合を除き、端数処理は行われません(つまり、45.678は45.7ではなく45.6とみなされます)。 | 0 |
例
この例では、取引額と取引価格の2つの識別子に対して「等しい」比較を使用し、株取引が格納されているシステム内で重複した取引を検索します。
構成例
データなしのペアを照合= いいえ
小数位の精度= 2
結果例
次の表に、前述の構成を使用した比較結果の例を示します。
「パーセントの差」比較では、2つの数値/番号配列の大きい方の値を基準にして差異率を計算し、2つの数値がどの程度近いかを判断します。
2つの数値のパーセントの差(PD)は、次のいずれかの方法で計算されます。
分母としてより大きな数を使用(後述のオプションを参照) = 「はい」の場合:
または分母としてより大きな数を使用 = いいえ:
ここで:
PD = パーセントの差
n1 = 比較対象の2つの数値の小さい方の数値
n2 = 比較対象の2つの数値の大きい方の数値
したがって、「50」と「75」の値のペアの場合は次のようになります。
n1 = 50、および
n2 = 75
パーセントの差は、75-50 = 25/75 = 0.33 *100 = 33% (「分母としてより大きな数を使用」が「はい」の場合)になるか、
75-50 = 25/50 = 0.50*100 = 50%(「分母としてより大きな数を使用」が「いいえ」の場合)になります
「パーセントの差」比較を使用して、相対的に相互に近い数値を照合します。これは、非常に小さい値から非常に大きい値まで幅がある数値(受注金額など)を比較する場合に役立ちます。この場合、「絶対差分」比較を使用すると、2つの数値が相互にどの程度近いかを判断する際に誤った結果になる可能性があります。たとえば、値「0.5」と「1.20」は、値「8200」と「8300」よりかなり低い一致とみなされます。
この比較では、結果バンドの使用がサポートされています。
次の表に、構成オプションを示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| データなしのペアを照合 | はい/いいえ | このオプションは、識別子の2つのデータなし(Null、または空白文字のみを含む)値を比較した際に、比較結果を判断します。
「いいえ」に設定した場合、データなし値と別のデータなし値を比較した際、「データなし」の比較結果が返されます。 「はい」に設定した場合、データなし値と別のデータなし値を比較した際、完全一致(文字編集距離が0)の比較結果が返されます。「データなし」結果が返されるのは、データなし値と移入値を比較した場合のみです。 |
いいえ |
| 分母としてより大きな数を使用 | はい/いいえ | このオプションでは、前述した2つの数値のパーセントの差を計算する方法を変更できます。「はい」に設定すると、前述の最初の式が使用され、2つの数値の絶対差分は大きい方の数値に関連付けられます。たとえば、「25」と「75」のパーセントの差は67%になります。「いいえ」に設定すると、前述の2番目の式が使用され、2つの数値の絶対差分は小さい方の数値に関連付けられます。たとえば、「25」と「75」のパーセントの差は200%になります。 | はい |
例
この例では、「パーセントの差」比較を使用して、相対的に相互に近い数値を識別します。次のオプションを指定します。
構成例
データなしのペアを照合= いいえ
分母としてより大きな数を使用= はい
結果例
次の表に、比較結果の例を示します。
照合プロセッサ内で変換を使用すると、値をクラスタリングする際にも比較する際にも、ソース値を変換することでより正確な照合結果を得ることができます。これにより、照合前に一連の変換を構成しなくても、照合目的で変換を使用できます。
それぞれのクラスタ構成またはクラスタ比較内で、いくつかの変換を順番に使用できます。変換は、識別子のデータ型と互換性を持つ必要があります(ただし、変換を使用してそのデータ型を変更することもできます)。
EDQの一部として、次の照合変換が提供されています。これらはメインの変換プロセッサと似ていますが、照合プロセッサで値をクラスタリングまたは比較する際に簡便に使用できるよう設計されています。
照合変換
| 変換 | 互換性のある識別子タイプ | 説明 | 変換例 |
|---|---|---|---|
| 絶対値 | 数値、番号配列 | 数値を絶対値に変換(つまり、負の値を正の値に変換し、不要な桁を削除)します。 | "-1.5" -> "1.5"
"1.5" -> "1.5" "0001908" -> "1908" |
| 文字の置換 | 文字列、文字配列 | 文字列属性の個々の文字を置換します。 | "é"から"e" |
| 日付を文字列に変換 | 日付 | 日付書式を使用して日付値を文字列に変換します。 | 書式dd-MMM-yyyyを使用:
"23-Mar-2001 00:00:00" (日付) -> "23/03/2001" (文字列) |
| 数値を文字列に変換 | 数値 | 数値書式を使用して数値を文字列に変換します。 | 書式0.0を使用:
"175.66" (数値) -> "175.6" (文字列) "175.00" (数値) -> "175.0" (文字列) |
| 文字列を日付に変換 | 文字列 | 日付書式を使用して、文字列値を日付に変換します。 | 書式dd/MM/yyyyを使用:
"01/11/2001" (文字列) -> "01-Nov-2001 00:00:00" (日付) "10/04/1975" (文字列) -> "10-Apr-1975 00:00:00" (日付) |
| 文字列を数値に変換 | 文字列 | 数値書式を使用して、文字列値を数値に変換します。 | 書式0.0を使用:
"28" (文字列) -> "28.0" (数値) "68.22" (文字列) -> "68.2" (数値) |
| ノイズ削除 | 文字列、文字配列 | 文字列値からノイズ文字(#'<>,/?*%+など)を削除します。 | "Oracle (U.K.)" -> "Oracle UK"
"A+D Engineering" -> "AD Engineering" "John#Davison" -> "JohnDavison" "SIMPSON, David" -> "SIMPSON David" |
| 日付配列の重複除外 | 日付配列 | 配列での日付の重複除外。 | 入力: {Jun 22 2015 10:14:22 AM}{Feb 17, 1986 12:00:00 AM}{Jun 22 2015 10:14:22 AM} 出力: {Jun 22 2015 10:14:22 AM}{Feb 17, 1986 12:00:00 AM} |
| 番号配列の重複除外 | 番号配列 | 配列での番号の重複除外。 | 入力: {32}{14}{2}{32} 出力: {32}{14}{2} |
| 文字配列の重複除外 | 文字列配列 | 配列での文字要素の重複除外。 | 入力: {A}{B}{A} 出力: {A}{B} |
| 最初のN文字 | 文字列、文字配列 | 値が最初からn文字までになるように文字列値を削除します。 | 「文字数」が4の場合:
"Simpson" -> "Simp" "Simposn" -> "Simp" "Robertson" -> "Robe" |
| 最初のN語 | 文字列、文字配列 | 値が最初からn番目の単語までになるように文字列値を削除します。 | 「単語数」が2の場合:
"Barclays Bank (Sheffield)" -> "Barclays Bank" "Balfour Beatty Construction" -> "Balfour Beatty" |
| イニシャルの生成 | 文字列、文字配列 | 文字列値からイニシャルを生成します。 | 「次未満の語を無視」が4の場合:
"IBM" -> "IBM" "International Business Machines" -> "IBM" "Price Waterhouse Coopers" -> "PWC" "PWC" -> "PWC" "Aj Smith" -> "AS" "A j Smith" -> "AJS" |
| 最後のN語 | 文字列、文字配列 | 値が最後からn語までになるように文字列値を削除します。 | 「単語数」が2の場合:
"(Sheffield) Barclays Bank" -> "Barclays Bank" "Balfour Beatty Construction" -> "Beatty Construction" |
| 最後のN文字 | 文字列、文字配列 | 値が最後からn文字までになるように文字列値を削除します。 | 「文字数」が5の場合:
"01223 421630" ->"21630" "07771 821630"->"21630" "01223 322766"->"22766" |
| 小文字 | 文字列、文字配列 | 文字列値を小文字に変換します。 | "ORACLE" -> "oracle"
"Oracle" -> "oracle" "OraCle" -> "oracle" |
| 文字列から配列を作成 | 文字列 | 文字列を値の配列に変換し、その配列内の各値が個別の索引キーを構成するようにします。 | カンマおよびスペースのデリミタを使用:
"John Simpson" -> "John", "Simpson" "John R Adams" -> "John", "R", "Adams" "Adams, John" -> "Adams", "John" |
| Metaphone | 文字列、文字配列 | 文字列からmetaphone値を生成します。 | "John Murray" -> "JNMR"
"John Moore" -> "JNMR" "Joan Muir" -> "JNMR" |
| 空白の正規化 | 文字列、文字配列 | 連続する空白文字をすべて1つのスペースに変換します。 | "10 Harwood Road" -> "10 Harwood Road"
"3 Perse Row" -> "3 Perse Row" |
| 置換 | 文字列、文字配列 | たとえば、共通シノニムを標準化するために、参照データ・マップを使用して値を標準化します。 | 参照データ・マップに適切な置換が含まれる場合:
"Bill" -> "William" "Billy" -> "William" "William" -> "William" |
| 丸め | 数値、番号配列 | 数値を特定の小数点以下桁数にまで端数処理します。 | 小数点以下2桁に端数処理する場合:
"175.853" -> "175.85" "180.658" -> "180.66" |
| 余りの丸め | 数値 | 数値を端数処理し、複数の端数処理済の値を出力します。 | 10の位に端数処理し、3つの数値を出力する場合:
"45" -> "50", "40, "60" "23" -> "20", "10, "30" |
| スクリプト | 任意 | スクリプト化したカスタム照合変換を使用できます。 | カスタム・スクリプトにより指定された変換。 |
| 配列要素の選択 | 任意 | 値のクラスタリングまたは比較時に使用するために、配列内の任意の位置から個々の配列要素を選択できます。 | "11 Grange Road, Cambridge" -> "Cambridge" |
| Soundex | 文字列、文字配列 | 文字列からsoundex値を生成します。 | "Smith" -> "S530"
"Snaith" -> "S530" "Clark" -> "C462" "Clarke" -> "C462" "Clarke-Jones" -> "C462" |
| 数値の削除 | 文字列、文字配列 | 文字列からすべての数値を削除します。 | "CB37XL" -> "CBXL"
"7 Harwood Drive" -> " Harwood Drive" "Lemonade 300ML" -> "Lemonade ML" |
| 単語の削除 | 文字列、文字配列 | 単語の参照データ・リストを使用して、文字列から単語を削除します。 | 参照データ・リストに会社の接尾辞が含まれる場合:
"ORACLE CORP" -> "ORACLE" "VODAFONE GROUP PLC" -> "VODAFONE GROUP" "ORACLE CORPORATION" -> "ORACLE" |
| 空白の切捨て | 文字列、文字配列 | 文字列から空白(スペースおよび印刷不可能な文字)を削除します。 | "Nigel Lewis" -> "NigelLewis"
"Nigel Lewis" -> "NigelLewis" "Nigel Lewis" -> "NigelLewis" |
| 大文字 | 文字列、文字配列 | 文字列値を大文字に変換します。 | "Oracle" -> "ORACLE"
"OraCle" -> "ORACLE" "oracle" -> "ORACLE" |
「絶対値」変換は、数値をその絶対値に変換(つまり、プラス記号とマイナス記号を削除)し、不要な桁(値の先頭にあるゼロなど)を削除する単純な変換です。
「絶対値」変換は、数値が正か負か、あるいは数値が異なる書式で(異なる桁数が格納される書式で)格納されているかどうかに関係なく、数値の絶対値のみを問題とするような照合を行う目的で使用します。
例
この例では、「絶対値」変換を使用して量を照合します。量は正の数値であることが期待されますが、データに負の量が指定されているエラーが存在する可能性があります。
変換例
次の表に、「絶対値」変換の例を示します。
「文字の置換」は、文字列属性内の個々の文字を置換する単純な変換です。これにより、参照データ・マップと一致する文字を標準化または正規化できます。
アクセント付き文字や記号のバリアント(開始引用符と終了引用符など)のような一定でない文字を他の類似データでマスクできます。「文字の置換」を使用して、参照データ・マップの文字のすべてのインスタンスをその置換文字で置換します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを構成できます。
|
例
この例では、「文字の置換」変換を使用して、次の変換マップ参照データを使用して名属性のアクセント付き文字を標準化します。
変換例
次の表に、前述の構成を使用した文字置換を示します。
|
注意: 大文字のÉはEに変換され、小文字のéはeに変換されます。 |
「日付を文字列に変換」変換は、照合の際に値をクラスタリングする目的で日付データ型の識別子を文字列値に変換します。
これはメインの日付を文字列に変換プロセッサと同様に機能します。このヘルプ・ページでは、クラスタリングの際に変換を使用する例を示します。
「日付を文字列に変換」は比較内では使用できないことに注意してください。
「日付を文字列に変換」は、たとえば、値をその日、月または年の部分にまで切り捨てるために、日付値の文字列表現を必要とする場合に使用します。
この最も一般的な用途は、日付のみの部分(年など)を使用して日付値をクラスタリングする場合です。日付は、まず文字列書式に変換され、「最後のN文字」変換を使用して、年を表す関連する2文字または4文字が選択されます(「照合変換: 最後のN文字」を参照)。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
|
注意: 使用する日付書式は、標準のJava 1.5.0またはJava 1.6.0SimpleDateFormat APIに準拠している必要があります。日付が正しく出力されるように書式を指定する方法は、Javaのオンライン・ドキュメント(http://java.sun.com/javase/6/docs/api/java/text/SimpleDateFormat.html)を参照してください。 |
例
この例では、「最後のN文字」変換を使用して年の部分を抽出し、クラスタ内の年の値を使用する目的で、「日付を文字列に変換」を使用してDATE_OF_BIRTH属性を文字列型に変換します。
サンプル構成:
日付書式文字列: dd/MM/yyyy
変換例
次の表に、前述の構成を使用した変換の例を示します。
「数値を文字列に変換」変換は、照合の際に値をクラスタリングする目的で数値データ型の識別子を文字列値に変換します。
これは、メインの「数値を文字列に変換」プロセッサと同様に機能します。このヘルプ・ページでは、クラスタリングの際に変換を使用する例を示します。
「数値を文字列に変換」は比較内では使用できないことに注意してください。
「数値を文字列に変換」は、たとえば、数値を最後の数文字または最初の数文字にまで切り捨て、それをクラスタ・キーとして使用するために、数値の文字列表現を必要とする場合に使用します。
この最も一般的な用途は、数値のみの部分を使用して値をクラスタリングする場合です。たとえば、数値属性に格納された電話番号がソース・データに含まれる場合、まず数値が文字列書式に変換され、「最後のN文字」変換を使用して最後の数文字が抽出された後、これらの最後の数文字がクラスタ・キーとして使用されます。
オプション
なし。
例
この例では、「最後のN文字」変換を使用して最後の数桁をクラスタ・キーの一部として抽出する目的で、「数値を文字列に変換」を使用してTel_number属性を文字列型に変換します。
変換例
「文字列を日付に変換」変換を使用すると、クラスタリングの際に、文字列属性に格納された日付値を実際の日付属性値に変換できます。これはメインの文字列を日付に変換プロセッサとまったく同様に機能します。ただし、クラスタ化の目的でのみ適用することをお薦めします。
「文字列を日付に変換」は比較内では使用できないことに注意してください。
「文字列を日付に変換」変換は、(たとえば、データをテキスト・ファイルまたは特定のデータ型付けのない他の書式からインポートしたために)日付値が文字列識別子に格納されているときに、形式化された日付値に基づいてクラスタリングすることで、手動で入力した日付書式の差異を解決する場合に使用します。使用する参照リスト内の日付書式と一致しない日付の文字列表現はNull日付値に変換されることに注意してください。
テキスト・フィールドに数多くの日付の表現があり、変換の結果を確認する必要がある場合は、照合の前にメインの文字列を日付に変換プロセッサを使用する必要があります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
例
この例では、データはテキスト・ファイルからインポートされたため、すべての属性は文字列型です。データ型プロファイリング(「データ型プロファイラ」を参照)で、属性の1つに、照合の際に役立つ生年月日に対応する日付値が含まれることがわかりました。データは、特定の日付比較を使用できるように日付書式に変換されます。
サンプル構成:
認識される日付書式のリスト: *日付書式
提供された参照データ*「日付書式」には、日付値の様々な文字列表現を実際の日付属性用の値に変換する一連の共通日付書式が含まれています。
変換例
次の表に、前述の構成を使用した変換の例を示します。
「文字列を数値に変換」変換を使用すると、クラスタリングの際に、文字列属性に格納された数値を実際の数値属性に変換できます。
これはメインの文字列を数値に変換プロセッサとまったく同様に機能します。ただし、クラスタ化の目的でのみ適用することをお薦めします。
「文字列を数値に変換」は比較内では使用できないことに注意してください。
「文字列を数値に変換」変換は、(たとえば、データをテキスト・ファイルまたは特定のデータ型付けのない他の書式からインポートしたために)数値が文字列識別子に格納されているときに、形式化された日付値に基づいてクラスタリングする場合に使用します。数値として認識されない値はすべてNull値に変換されることに注意してください。
テキスト・フィールドに数多くの数値の表現があり、変換の結果を確認する必要がある場合は、照合の前にメインの文字列を数値に変換プロセッサを使用する必要があります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
例
この例では、データはテキスト・ファイルからインポートされたため、すべての属性は文字列型です。データ型プロファイリング(「データ型プロファイラ」を参照)で、属性の1つに、電話番号の市外局番に対応する数値が含まれることがわかりました。クラスタリングの際に、データは数値書式に変換されます。
サンプル構成:
数値書式参照データ: *数値書式
変換例
次の表に、前述の構成を使用した変換の例を示します。
「ノイズ削除」変換を使用すると、値をクラスタリングまたは比較する際に、メインの「ノイズ削除」プロセッサと同じようにノイズ文字を削除できます。ノイズ文字は一致するレコードの検出能力を低下させる可能性があるため、これによって照合の精度が上がります。たとえば、値"Castle (Investments) Ltd"と"Castle Investments Ltd"は高い一致ですが、前者の値からカッコを取り除かなければ、両者の文字編集距離は2になります。
「ノイズ削除」変換は、フリー・テキスト・フィールドを使用して値が入力された識別子を使用するレコードを照合する場合に使用します。フリー・テキスト・フィールドでは、同じデータが多く書式で入力されるうえ、入力エラーによって「(」や「)」などのノイズ文字が挿入される可能性があります。「ノイズ削除」変換を使用すると、照合の際にこのようなエラーを解決できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
例
この例では、データはテキスト・ファイルからインポートされたため、すべての属性は文字列型です。データ型プロファイリング(「データ型プロファイラ」を参照)で、属性の1つに、電話番号の市外局番に対応する数値が含まれることがわかりました。クラスタリングの際に、データは数値書式に変換されます。
サンプル構成:
この例では、「ノイズ削除」変換を使用して、照合の際に会社名からノイズ文字を削除します。使用するノイズ文字は次のとおりです。& + ( ) - *
変換例
次の表に、前述の構成を使用した変換の例を示します。
表1-81 「ノイズ削除」変換の例
| 値 | 変換済の値 |
|---|---|
|
Castle (Investments) Ltd |
Castle Investments Ltd |
|
Castle Investments Ltd |
Castle Investments Ltd |
|
Ipswich & Norwich Co-op |
Ipswich Norwich Coop |
|
Ipswich + Norwich Co-operative |
Ipswich Norwich Cooperative |
|
Barclays Bank - Cambridge |
Barclays Bank Cambridge |
|
Barclays Bank (Cambridge) |
Barclays Bank Cambridge |
|
George & Sons ***in administration*** |
George Sons in administration |
「最初のN文字」変換を使用すると、照合で比較を実行する際に、値の左側から読み取った文字数(N)にまで値を削除することにより、値の末尾を無視できます。
これは、値の最初の数文字にまで切り捨てるメインの文字の切捨てプロセッサを使用する場合と似ています。
「最初のN文字」変換は、識別子の最初の数文字を使用してクラスタリングする場合や、値の末尾がノイズ文字である識別子に対して照合を行う場合に使用します。多くの場合、これは、識別子のキー部分は同じであるが、残りの部分はまったく違うために、他の比較を使用して見つけることが困難な一致候補を見つける目的で、セカンダリ照合ルールで「文字列の完全一致」比較(「比較: 文字列の完全一致」を参照)により使用されます。たとえば、住所を照合する際、住所の1行目の最初の8文字が同じである場合、一方の値のデータに含まれるデータ量がもう一方よりもはるかに多かったとしても、一致の可能性は非常に高くなります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
|
注意: スペースや改行などの空白文字が値に含まれる場合は、他の文字と同様に文字としてカウントされます。データ文字を選択していることを確認するために、「空白の切捨て」変換を使用してからこの変換を使用することもできます。 |
サンプル構成:
この例では、「最初のN文字」変換を使用して、住所の1行目を照合します(1行目の一部に建物名より多くの情報が含まれることがわかっています)。
文字数: 8
無視する文字: 0
変換例
次の表に、前述の構成を使用した変換の例を示します。
「最初のN語」変換を使用すると、照合でクラスタリングまたは比較を実行する際に最初の数(N)単語のみを使用できます。
「最初のN語」変換は、識別子に多数の単語があるが、照合の際に値の先頭付近の単語よりも末尾付近の単語の有用性が低い場合に使用します。これは、会社名を照合する際に、会社名に付加される支店名やその他の補助語を照合時に無視する場合によく使用されます(ただし、この同じ単語が会社の識別に有用である場合もあるため、「単語の削除」変換を使用しても値から削除されません)。たとえば、"Barclays Bank Coventry"と"Barclays Bank Leicester Branch"を照合する場合などです。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
サンプル構成:
この例では、「文字編集距離」比較(「比較: 文字編集距離」を参照)内で「最初のN語」変換を使用して、(照合に必要でない余分な単語が値に含まれることが多い)会社名を照合します。
区切り文字参照データ: *区切り文字
区切り文字: なし
単語数: 2
変換例
次の表に、前述の構成を使用した変換の例を示します。
表1-83 「最初のN語」変換の例
| 値 | 変換済の値 |
|---|---|
|
Barclays Bank Plymouth Branch |
Barclays Bank |
|
Barclays Bank Coventry |
Barclays Bank |
|
Henkel Loctite |
Henkel Loctite |
|
Henkel Loctite Adhesives Limited |
Henkel Loctite |
|
Wingford Confectioners |
Wingford Confectioners |
|
Wingford Confectioners (in administration) - contact Mr J Alexander |
Wingford Confectioners |
「最後のN語」変換を使用すると、照合でクラスタリングや比較を実行する際に、最後の数(N)語のみを使用できます。
「最後のN語」変換は、識別子に多数の単語があるが、照合の際に値の先頭付近の単語よりも末尾付近の単語の有用性が高い場合に使用します。これは、会社名を照合する際に、会社名に付加される支店名やその他の補助語を照合時に考慮する場合によく使用されます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
構成例
この例では、「文字編集距離」比較(「比較: 文字編集距離」を参照)内で「最後のN語」変換を使用して、(照合に必要でない余分な単語が値に含まれることが多い)会社名を照合します。
区切り文字参照データ: *区切り文字
区切り文字: なし
単語数: 2
変換例
次の表に、前述の構成を使用した変換の例を示します。
「イニシャルの生成」変換を使用すると、たとえば、BMWとBayerische Motoren Werkeを照合するために、識別子からイニシャル変換した値を使用してレコードをクラスタリングまたは照合できます。これは、メインの「イニシャルの生成」プロセッサとまったく同様に機能します。
「イニシャルの生成」変換は、会社名や、識別子の形成時にイニシャル変換することが多いその他の名前を照合する場合に使用します。これは、最初に各値をイニシャル変換しないとコンピュータで照合することが困難な、"International Business Machines"と"IBM"のような一致を検索する場合に役立ちます。"IBM"のような短い単語が"I"にイニシャル変換されないようにするオプションも含まれています。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
|
注意: 通常、「イニシャルの生成」変換では、元の値の大/小文字は無視され、指定の区切り文字で区切られた各単語が検出されて大文字のイニシャルが生成されます。たとえば、値"A j Smith"、"ALAN JOHN SMITH"および"Alan john smith"はすべて"AJS"にイニシャル変換されます。ただし、"PWC"、"IBM"、"BT"のようにすでにイニシャルになっている値もあり、これらは"P"、"I"、"B"のようにさらにイニシャル変換されないようにする必要があります。 |
これらは次の条件によって区別できます。
1単語の値である。
すでに大文字になっている。
長さが数文字である。
「大文字の単語を無視」オプションを使用すると、値が大文字の1単語の場合、その単語が何文字以内のときにイニシャル変換しないかを指定できます。
たとえば、4に設定した場合、値"PWC"、"BT"、"RSPB"および"IBM"は、長さが4文字以内で、1単語の値で大文字であるため、イニシャル変換プロセスで無視されます。これに対して、"IAN JOHN SMITH"は、単語"IAN"の長さが4文字以内で大文字ですが、1単語の値でないため、"IJS"にイニシャル変換されます。また、"RSPCA"は長さが4文字を超えているため、"R"にイニシャル変換されます。
サンプル構成:
この例では、「文字列の完全一致」比較(「比較: 文字列の完全一致」を参照)内で「イニシャルの生成」変換を使用して、(値をイニシャル変換することが多い)会社名を照合します。
区切り文字参照データ: なし
区切り文字: <space>。
大文字の単語を無視: 5
「イニシャルの生成」変換の前に、次に示す2つの変換が使用されることに注意してください。
1. 大文字 - すべての値を大文字に変換します。
2. 単語の削除 - 値から特定の単語を削除します。使用する参照データには、'PLC'という単語が含まれています。
変換例
次の表に、前述の構成を使用した変換の例を示します。
表1-85 「イニシャルの生成」変換の例
| 値 | 「大文字」変換および「単語の削除」変換後の値 | 「イニシャルの生成」変換後の値 |
|---|---|---|
|
IBM |
IBM |
IBM |
|
I.B.M. |
I.B.M. |
IBM |
|
International Business Machines |
INTERNATIONAL BUSINESS MACHINES |
IBM |
|
PWC |
PWC |
PWC |
|
Price waterhouse coopers |
PRICE WATERHOUSE COOPERS |
PWC |
|
Price Waterhouse Coopers |
PRICE WATERHOUSE COOPERS |
PWC |
|
PRICE WATERHOUSE COOPERS |
PRICE WATERHOUSE COOPERS |
PWC |
|
British Telecom Plc |
BRITISH TELECOM |
BT |
|
BT plc |
BT |
BT |
|
BARKERS plc |
BARKERS |
B |
|
BARKERS & LEWIS plc |
BARKERS & LEWIS |
B&L |
「最後のN文字」変換を使用すると、照合で比較を実行する際に、値の右側から読み取った文字数(N)にまで値を削除することにより、値の先頭部分を無視できます。
また、これは識別子の最後の数文字をクラスタ・キーとして使用してクラスタリングする場合にも便利です。
「最後のN文字」変換は、値の先頭がノイズ文字である可能性のある識別子に対して照合を行う場合に使用します。多くの場合、これは、識別子のキー部分(値の最後)は同じであるが、残りの部分はまったく違うために、他の比較を使用して見つけることが困難な一致候補を見つける目的で、セカンダリ照合ルールで完全一致比較(「比較: 文字列の完全一致」を参照)により使用されます。たとえば、電話番号識別子に対する照合では、文字列の先頭の書式が(+44(0)1223、01223、1223のように)異なっていても、最後の5桁はかなり高い確率で電話番号を識別しているはずです。これらの文字のみを使用して照合すると、一致するレコードを特定するうえで便利です。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
|
注意: スペースや改行などの空白文字が値に含まれる場合は、他の文字と同様に文字としてカウントされます。データ文字を選択していることを確認するために、「空白の切捨て」変換を使用してからこの変換を使用することもできます。 |
サンプル構成:
この例では、「最後のN文字」変換を使用して、電話番号識別子の最後の5桁を照合します。
文字数: 5
無視する文字: 0
変換例
次の表に、前述の構成を使用した変換の例を示します。
「小文字」変換は、値をすべて小文字に変換し、大/小文字を区別しないクラスタリングを可能にする単純な変換です。
「小文字」変換は、大/小文字を区別しないクラスタリングを使用する場合に使用します。
たとえば、電子メール・アドレス識別子をクラスタリングする場合、電子メール・アドレスは通常は大/小文字を区別して使用されない(つまり、John.Smith@example.comは常にではないが通常はjohn.smith@example.comと同じアドレスである)ため、すべて小文字を使用してクラスタ値を作成します。この2つのレコードが同じクラスタに属するように、「小文字」変換を使用できます。
オプション
なし
例
この例では、電子メール・アドレスの最初の数文字に対してクラスタを作成する際に「小文字」変換を使用します。クラスタとして使用するいくつかの文字を選択する前に、値はすべて小文字に変換されます。
変換例
次の表に、前述の構成を使用した変換の例を示します。
「文字列から配列を作成」変換を使用すると、単一のテキスト値を可変数の固有の値に分割できます。作成された固有の値ごとにクラスタが作成されるため、これは照合のためにクラスタを作成する場合に便利です。これにより、一般的な単語が含まれる値はすべて、値の中の単語の順序に関係なく、照合目的で同じクラスタに入ります。たとえば、名前識別子に'John Simpson'と'Simpson, J'の値が含まれる場合、カンマとスペースの区切り文字を使用して配列を作成してクラスタリングすることで、2つのレコードは同じクラスタ('Simpson')に入ります。
「文字列から配列を作成」変換は、メインの文字列から配列を作成プロセッサと同様に機能しますが、特に、クラスタリングの際に値をクラスタ・キーとして使用する複数の単語に分割する場合に使用します。
「文字列から配列を作成」は比較内では使用できないことに注意してください。
複数のレコードに共通の単語が含まれる場合にそれらのレコードが同じクラスタに挿入されるように、「文字列から配列を作成」変換はクラスタリングの際の最後の変換として使用してください。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
例
この例では、Address1識別子に対するクラスタの構成に「文字列から配列を作成」変換を組み込みます。
サンプル構成:
クラスタを形成するために、次の変換をAddress1識別子に追加します。
大文字
数値の削除
単語の削除(The、House、Road、Street、Avenue、Laneなどのごく一般的な単語を除外します。)
空白の正規化
文字列から配列を作成
変換例
次の表に、前述の構成を使用した変換の例を示します。
表1-88 「文字列から配列を作成」変換の例
| 値 | 最初の4つの変換後の値 | 「文字列から配列を作成」変換後の値 |
|---|---|---|
|
The Maltings, 14 Appletree Lane |
MALTINGS, APPLETREE |
1 - MALTINGS 2 - APPLETREE |
|
14 Appletree Lane |
APPLETREE |
1 - APPLETREE |
|
The Maltings |
MALTINGS |
1 - MALTINGS |
|
32 Rushton Road, Coventry |
RUSHTON, COVENTRY |
1 - RUSHTON 2 - COVENTRY |
|
32 Rushton Rd |
RUSHTON |
1 - RUSHTON |
|
15 Stroud Green Road |
STROUD GREEN |
1 - STROUD 2 - GREEN |
|
14 Green End Avenue |
GREEN END |
1 - GREEN 2 - END |
変換後に共通の値を共有するレコードはすべて同じクラスタに挿入されます。たとえば、前述の最初の2つのレコードは'APPLETREE'クラスタに挿入され、最初のレコードと3番目のレコードは'MALTINGS'クラスタに挿入されます。
「Metaphone」変換は、発音が同じでもスペルミスなどが原因で異なる可能性のある値から共通のmetaphoneキーを作成します。
「Metaphone」変換は、クラスタリングや比較を実行する際、特に、名前などのスペルミスを含む可能性のあるデータを照合する場合に非常に便利です。
クラスタリングの際に、発音が同じ識別子を持つすべての値のグループを作成することによってレコードをクラスタ・グループに分割する便利な方法が提供されます。たとえば、姓「Gold」、「Gould」および「Gauld」すべてから同じmetaphoneキー(KLT)が生成されます。
比較を使用する場合、一致ルールを強化するために確定metaphone一致を含めると効果的なことがよくあります。たとえば、名前フィールドに対する編集距離が2文字または3文字の場合は非常に低い一致であっても、両方の値の発音が同じであれば、これによって一致を強化できます。たとえば、「John Clarke」は「Jon Clarke」と同一人物である可能性はありますが、「John Darke」と同一人物である可能性はそれよりはるかに低くなります。
これは、多くは名前を正しく聞き取らずにデータを入力したために発生したスペルミスを見つける方法を提供します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
例
この例では、「Metaphone」変換を使用して名前の一致を強化します。変換済の値に対して「文字列の完全一致」変換(「比較: 文字列の完全一致」を参照)が実行され、2つの値の発音が同じかどうかを判別する比較が形成されます。
変換例
次の表に、前述の構成を使用した変換の例を示します。
「空白の正規化」変換は、文字列の中のすべての空白を正規化して、単語間のすべてのス空白を1つのスペース文字に正規化します。さらに、先頭および末尾の空白も削除します。
EDQでは、空白文字は次のように定義されています。
スペース
改行、行送り、タブなどの印刷不可能な文字(および、その他のASCII文字0から31すべて)
「空白の正規化」変換は、データセット内に複数のスペースなどのキーイング・エラーが発生する可能性がある場合に使用します。たとえば、値の文字編集距離(「比較: 文字編集距離」を参照)で1つのスペースと複数のスペースの間で差異が認識されないようにする場合、比較内で空白を正規化すると便利です。スペース以外の空白(改行、タブ、その他の印刷不可能な文字など)のすべての書式を区切り文字として有効に使用できるように、クラスタ化時に「文字列から配列を作成」変換の前に使用することもできます。つまり、値"John[space]Simpson"と"John[tab][space]Simpson"では、後者のみ"John[tab]" ("John"ではない)というクラスタ値が生成されるのではなく、両方とも同じようにトークン化されます。
オプション
なし。
変換例
次の表に、変換の例を示します。
「置換」変換を使用すると、クラスタリングまたは照合の目的でデータを標準化するために、参照データ・マップを使用できます。
この変換は、EDQのメインの置換プロセッサとまったく同様に機能します。このヘルプ・ページでは、照合の際の「置換」変換の一般的な使用方法について説明します。
「置換」変換は、ユーザーがフリー・テキスト・フィールドによく入力する同じ値のバリエーションを解決する場合に非常に便利です。
同じ値がいくつかの異なる方法で表現される場合が多くあります。たとえば、「Bill」、「William」および「Billy」はすべて同じ名前の異なる形式であり、「Hse」、「House」および「Ho.」はすべて「House」という単語の形式です。参照データ・マップを使用すると、このようなシノニムを1つの値表現方法に標準化できます。
たとえば、次のエントリが参照データ・マップ内に存在し、照合目的で名前を標準化するためにこれらを使用するとします。
表1-91 「置換」変換の例
| 値 | 標準化 |
|---|---|
|
Bill |
William |
|
Billy |
William |
|
Willy |
William |
|
Mike |
Michael |
|
Mick |
Michael |
|
Mickey |
Michael |
|
Dave |
David |
|
Jim |
James |
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
例
この例では、「置換」変換を使用して、照合の目的で名前を標準化します。
サンプル構成:
参照データ:
表1-92 参照データの例
| 値 | マップ | アクティブ |
|---|---|---|
|
Bill |
William |
はい |
|
Billy |
William |
はい |
|
Willy |
William |
はい |
|
Will |
William |
はい |
|
Mike |
Michael |
はい |
|
Micheal |
Michael |
いいえ |
|
Mickey |
Michael |
はい |
|
Dave |
David |
はい |
|
Steven |
Stephen |
はい |
|
Steve |
Stephen |
はい |
|
Jim |
James |
はい |
最初に最長の値に一致: いいえ
大文字/小文字を区別しない: はい
一致基準: 全体の値
区切り文字: <space>
変換例
次の表に、前述の構成を使用した「置換」変換の例を示します。
表1-93 「置換」変換の例
| 値 | 変換済の値 |
|---|---|
|
Steven Lewis |
Stephen Lewis |
|
Stephen Lewis |
Stephen Lewis |
|
David Stevens |
David Stevens |
|
David Steven |
David Stephen |
|
Mike Davis |
Michael Davis |
|
Micheal Lewis |
Micheal Lewis |
|
Mickey Lewis |
Michael Lewis |
|
Jim Jones |
James Jones |
|
James Jones |
James Jones |
|
Bill Taylor |
William Taylor |
|
Will Taylor |
William Taylor |
「端数処理」変換を使用すると、レコードをクラスタリングまたは照合する目的で数値を端数処理できます。同一とみなすに足る近い数値は、共通の値に端数処理できます。
これはメインの端数処理プロセッサとまったく同様に機能します。ただし、クラスタ化または数値の比較時の照会内で特に役立ちます。
「端数処理」変換は、様々な精度の数値データがあるときに、各数値の概数を使用してクラスタリングまたは照合を行う場合に使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
|
注意: 「一番近い値に丸める」値を設定すると、「小数点以下桁数」オプションの値が上書きされ、値は指定の位(10の位など)の概数に端数処理されます(実質的に「小数点以下桁数」は0に設定されます)。 |
例
この例では、「端数処理」変換を使用して、一部の地理データのX座標を小数点以下1桁に端数処理します。
サンプル構成:
小数点以下桁数: 1
一番近い値に丸める(使用しない)
端数処理タイプ: 一番近い値
変換例
次の表に、前述の構成を使用した変換の例を示します。
「余りの丸め」変換を使用すると、互いに近い数値を同じクラスタに挿入できるように、数値を端数処理し、端数処理済の数値の両端に追加の数字を作成できます。
「余りの丸め」変換は比較内では使用できないことに注意してください。
「余りの丸め」変換は、様々な精度の数値データがあるときに、端数処理済の値の両端に追加のクラスタ値を付加して、各数値の概数を使用してクラスタリングする場合に使用します。
「余りの丸め」は、単一の数値に端数処理することに伴う問題を回避するために効果的です。たとえば、他の数値との差異が特定範囲内の数値を含むすべてのレコードを同じクラスタに挿入する場合、すべての数値を単一の値に端数処理すると、実現が難しくなる可能性があります。
たとえば、差異が10以内のすべての数値を同じクラスタに挿入するというルールがある場合、数値32と41は同じクラスタに属する必要があります。しかし、従来の「端数処理」変換を使用した場合、10の位に切り捨てまたは四捨五入を行うと、これらはそれぞれ30と40のグループに挿入され、切上げを行うと、それぞれグループ40と50に挿入されます。しかし、「余りの丸め」変換を使用すると、入力値ごとに複数のクラスタ値を生成して、これらを同じグループに挿入することができます。この場合、値32と41を10の位に端数処理すると、32はグループ20、30および40に挿入され、41はグループ30、40および50に挿入されます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
例
この例では、「余りの丸め」変換を使用して、互いの差異が10以内のすべての数値が常に同じクラスタに属するように整数値を端数処理します。
サンプル構成:
一番近い値に丸める: 5
端数処理タイプ: 一番近い値
トークンの数: 3
変換例
次の表に、前述の構成を使用した変換の例を示します。
表1-95 「余りの丸め」変換の例
| 値 | 変換後の値 |
|---|---|
|
1 |
1 - 0 2 - 5 3 - -5 |
|
11 |
1 - 10 2 - 5 3 - 15 |
|
14 |
1 - 15 2 - 10 3 - 20 |
|
26 |
1 - 25 2 - 20 3 - 30 |
|
36 |
1 - 35 2 - 30 3 - 40 |
|
44 |
1 - 45 2 - 40 3 - 50 |
|
61 |
1 - 60 2 - 55 3 - 65 |
|
70 |
1 - 70 2 - 65 3 - 75 |
変換後に共通のクラスタ値を共有するレコードはすべて同じクラスタに属します。たとえば、前述の最初の2つのレコードはクラスタ'5'に属し、最後の2つのレコードはクラスタ・グループ'65'に属します。
「スクリプト」照合変換を使用すると、照合内で使用するために独自のJavascriptまたはGroovy変換を作成できます。
「スクリプト」照合変換は、上級ユーザーのみを対象としたものです。スクリプトの構文は、メインのスクリプト・プロセッサと同じルールに準拠します。
「配列要素の選択」照合変換を使用すると、値のクラスタリングまたは値で使用するために、配列内の任意の位置から個々の配列要素を選択できます。
これは、メインの配列要素の選択プロセッサとまったく同様に機能します。ただし、値内の指定された位置にある単語(最後の単語、2番目の単語など)でクラスタ化するか、またはその単語を使用して比較する必要がある場合は、照合内で役立つ場合があります。
「配列要素の選択」照合変換は、値の中の特定の位置にある単語(2番目の単語、3番目の単語など)に対してクラスタリングする場合や、その単語を比較する場合に使用します。「文字列から配列を作成」を使用して、値を複数の単語を含む配列に分割してから、「配列要素の選択」を使用して、必要な単語をその位置に基づいて抽出します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
例
この例では、「配列要素の選択」変換を使用して、町識別子の最後の単語(単語がスペースで区切られている)を比較します。町識別子にマップされた属性には、町の前に他の住所情報('11 Grange Road, Cambridge'など)があるいくつかの値が含まれることがわかっています
サンプル構成:
比較の一部として、次に示す2つの変換を町識別子に追加します。
1. 文字列から配列を作成
区切り文字: 「スペース」および「カンマ」
2. 配列要素の選択
索引位置: 1
最後からカウント: はい
変換例
次の表に、前述の構成を使用した変換の例を示します。
表1-96 「配列要素の選択」変換の例
| 値 | 「文字列から配列を作成」後の値 | 「配列要素の選択」後の値 |
|---|---|---|
|
11 Grange Road, Cambridge |
1 - 11 2 - Grange 3 - Road 4 - Cambridge |
Cambridge |
|
Hardwick, Cambridge |
1 - Hardwick 2 - Cambridge |
Cambridge |
|
(London) |
1 - London |
(London) |
|
11 London Road, Hertford |
1 - 11 2 - London 3 - Road 4 - Hertford |
Hertford |
|
Cambridge |
1 - Cambridge |
Cambridge |
「Soundex」変換は、発音が同じでもスペルミスなどが原因で異なる可能性のある値から共通のsoundexキーを作成します。
「Soundex」変換は、「Metaphone」変換に似ていますが、別の方法を使用して2つの値の発音が同じかどうかを検出します。一般にこの変換は、同じキーを生成するために必要な2つの値の発音の類似性を判断する基準が緩く、たとえば、"Smith"と"Snaith"では同じキーが生成されます(metaphoneでは異なるキーが生成されます)。
さらに、「Soundex」変換は単一の単語(複数の単語からなる値の処理では最初の単語)に対してのみ機能するということも重要です。つまり、"Margaret Hawkins"と"Margaret Johnson"では同じsoundexキー(M626)が生成されますが、異なるmetaphoneキーが生成されます。
「Soundex」変換は、名や姓などの単一の名前識別子に対してクラスタリングまたは照合を行う場合に便利です。これは、名前のようにスペルミスがよくあるキー識別子で、同一である可能性のある名前を照合ルールで確実に捕捉する必要がある場合に使用します。
オプション
なし
例
この例では、「Soundex」変換を使用して、姓識別子の値をそのsoundexキーに変換することにより、小さなデータセットに初期クラスタを作成します。
変換例
次の表に、「Soundex」変換の例を示します。
「数値の削除」照合変換を使用すると、比較前に文字列値からすべての数値を削除できます。これは、メインの「数値の削除」プロセッサとまったく同様に機能します。
「数値の削除」変換は、正しい値に数値が含まれていてはならないのに、データに照合結果の質を低下させるような数値が残存している可能性がある識別子に対して照合を行う場合や、その他、文字列の数値でない部分を照合する必要のあるシナリオで使用します。
たとえば、在庫品目を照合する場合、一部の説明に、レコードの照合に使用するのに適さない非常に長いシリアル番号が含まれていることがあります。ユーザーが説明文のみを照合できるように、これらを削除できます。
オプション
なし
例
「数値の削除」変換は、在庫品目説明識別子に対する比較で使用します。
変換例
次の表に、「数値の削除」変換を使用した変換を示します。
「単語の削除」照合変換を使用すると、クラスタリングまたは比較の前に、文字列値から特定の単語を削除できます。これは、メインの「単語の削除」プロセッサとまったく同様に機能します。
「単語の削除」変換は、値の識別には必要ない特定単語の様々な形式が多数含まれるテキスト値をクラスタリングまたは比較する場合に非常に便利です。たとえば、会社名を照合する場合、識別子値の意味のある部分のみを照合するために、"LIMITED"、"LTD"、"GRP"、"GROUP"、"PLC"などの接尾辞を削除できます。
例
この例では、比較内で会社名識別子に対して「単語の削除」変換を使用します。
サンプル構成:
使用する参照データの一番左の列に、次の単語が含まれています。
CORP、CORPORATION、LIMITED、LTD、PLC、GROUP、GRP
区切り文字参照データ: *区切り文字
区切り文字: なし
大文字/小文字を区別しない: はい
変換例
次の表に、「単語の削除」変換の前述の構成を使用した変換例を示します。
「空白の切捨て」変換を使用すると、クラスタリングまたは比較の前に、文字列値からすべての空白を削除できます。
これはメインの空白の切捨てプロセッサとまったく同様に機能します。このヘルプ・ページでは、照合の際に「空白の切捨て」変換を使用する例を示します。
EDQでは、空白文字は次のように定義されています。
スペース
改行、行送り、タブなどの印刷不可能な文字(および、その他のASCII文字0から31すべて)
「空白の切捨て」変換は、値を照合する際に値の中の空白は不要であるが他の文字は有効であるようなテキスト値を比較する場合に非常に便利です。たとえば、郵便番号を照合する場合、照合や値のクラスタリングの際に、郵便番号の真ん中にスペースが存在するという事実は重要ではありません(つまり、"CB4 0WS"は"CB40WS"と同じです)。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| オプション | 次のオプションを指定します。
|
例
この例では、比較内で郵便番号識別子に対してデフォルト・オプションで「空白の切捨て」変換を使用して、識別子値からすべての空白を切り捨てます。
変換例
次の表に、「空白の切捨て」変換を使用した変換例を示します。
「大文字」変換は、値をすべて大文字に変換し、大/小文字を区別しないクラスタリングまたは照合を可能にする単純な変換です。
「大文字」変換は、大/小文字を区別しないクラスタリングを使用する場合に使用します。
たとえば、「最初のN文字」変換(「照合変換: 最初のN文字」を参照)を使用して姓識別子をクラスタ化する場合、Simpson、SIMPSON、simpsonなどの値がすべて同じクラスタ(クラスタ値SIMPを使用)になるように、すべての大文字を使用してクラスタ値を作成することもできます。
オプション
なし。
例
この例では、姓の最初の数文字に対してクラスタを作成する際に「大文字」変換を使用します。クラスタとして使用するいくつかの文字を選択する前に、値はすべて大文字に変換されます。
変換例
次の表に、前述の構成を使用した「大文字」変換の例を示します。
出力セレクタは、マージ対象のレコードのデータに基づいて、マージ済レコードのフィールドの値を1つ導出する機能です。
EDQには、次の出力セレクタが用意されています。新しい出力セレクタを追加することもできます。
| 出力セレクタ | 互換性のある入力列タイプ | 説明 | 出力選択の例 |
|---|---|---|---|
| 平均 | 数値 | 数値属性の入力値の平均を計算します。 | 入力: 1,5,8,10
出力: 6 |
| 配列の組合せ | 文字列配列、番号配列または日付配列 | 複数の配列を1つの配列にマージします | 入力: {1,2}{3,4} 出力: {1,2,3,4} |
| 区切りリスト | 文字列 | すべての入力値、または重複を除いたすべての入力値を区切りリストで出力します。 | 入力: lewistaylor@yahoo.com、lewist@hotmail.com、lewis@abco.com
出力: lewistaylor@yahoo.com、lewist@hotmail.com、lewis@abco.com |
| 最早値 | 文字列、数値または日付 | 日付属性を使用して、別の属性のマージされる値を選択します。指定された日付フィールドに最早値を含むレコードが選択され、選択されたレコードから別の属性の出力値が抽出されます。 | 入力: Johnson (01/05/2001), Johnston (06/01/1998)
出力: Johnston |
| 空でない最初の値 | 文字列、数値または日付 | 入力属性の順序に従って、属性から検出された空でない最初の値を選択します。 | 入力: null, Smith
出力: Smith 入力: Smith, Smyth 出力: Smith |
| 最大値 | 文字列、数値または日付 | 数値属性の場合は最大値、日付属性の場合は最新日付、文字列属性の場合はアルファベット順の最後の値を選択します。 | 入力: 9, 12, 14
出力: 14 |
| 最新の値 | 数値または日付 | 日付属性を使用して、別の属性のマージされる値を選択します。指定された日付フィールドに最新値を含むレコードが選択され、選択されたレコードから別の属性の出力値が抽出されます。 | 入力: Johnson (01/05/2001), Johnston (06/01/1998)
出力: Johnson |
| 最も長い文字列 | 文字列 | 最長文字列値(文字数の最も多い文字列値)を選択します。 | 入力: J、James、Jameson
出力: Jameson |
| 最小値 | 文字列、数値または日付 | 数値属性の場合は最小値、日付属性の場合は最早日付、文字列属性の場合はアルファベット順の最初の値を選択します。 | 入力: 8.2, 8.1, 7.6
出力: 7.6 |
| 最も一般的な値 | 文字列、数値または日付 | すべての入力レコードから、入力属性の最も一般的な値を選択します。 | 入力: Davis、Davis、Davies
出力: Davis |
| 配列での出力 | 文字列、数値または日付 | 入力を配列に結合します。 | 入力: Red, Green 出力: {Red}{Green} |
| 標準偏差 | 数値 | 数値属性の入力値の標準偏差を計算します。 | 入力: 1, 5, 8, 10, 12
出力: 3.87 |
| 合計値 | 数値 | すべての入力レコードの数値を加算します。 | 入力: 3,7,8,-2
出力: 16 |
| 最大からの値 | 文字列、数値または日付 | 数値属性を使用して、別の属性のマージされる値を選択します。指定された数値フィールドに最大値を含むレコードが選択され、選択されたレコードから別の属性の出力値が抽出されます。 | 入力: Johnston (50)、Johnson (40)、JOHNSON (35)
出力: Johnston |
| 最少からの値 | 文字列、数値または日付 | 数値属性を使用して、別の属性のマージされる値を選択します。指定された数値フィールドに最低値を含むレコードが選択され、選択されたレコードから別の属性の出力値が抽出されます。 | 入力: Johnston (50)、Johnson (40)、JOHNSON (35)
出力: JOHNSON |
「平均」出力セレクタでは、マージ対象の全レコードから入力されたすべての数値の平均を計算して出力します。
「平均」セレクタは、多くの場合、レコードを共通の属性値(複数可)でグループ化したり、複雑なルールを使用して照合して、データに関するレポートを作成する際に使用します。
たとえば、「グループとマージ」を使用して複数の受注レコードを製品識別子別にグループ化し、各製品の受注の平均受注額を計算して出力できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 入力データ・セットからの数値属性。 |
| オプション | 次のオプションを指定します。
|
例
この例では、「平均」出力セレクタを使用して、各レコードのOrderValue属性(数値)の平均を選択します。
サンプル構成:
Nullを0とみなす= いいえ
出力例
次の表に、「平均」セレクタを使用した出力選択の例を示します。
「区切りリスト」出力セレクタでは、すべての入力値、または重複を除いたすべての入力値を区切りリストで出力します。
「区切りリスト」出力セレクタは、レコードをマージするときに、特定フィールドの複数の値を保持する場合に使用します。たとえば、電子メール・アドレスや電話番号は重複している個人を識別する場合に役立ちますが、それらの個人の重複を除いたすべての電子メール・アドレスと電話番号をマージ済出力に含めます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 入力データ・セットからの文字列属性。 |
| オプション | 次のオプションを指定します。
|
例
この例では、「区切りリスト」出力セレクタを使用して、同じ製品を表す複数のレコードからすべての製品コードを出力します
サンプル構成:
個別値のみ= はい
デリミタ = |
空の値を無視= はい
出力例
次の表に、「区切りリスト」セレクタを使用した出力の例を示します。
「最早値」出力セレクタでは、各レコードの日付スタンプを評価して、別の属性で使用する値を選択します。
「最早値」出力セレクタは、レコードに日付スタンプがあり、最も早いスタンプのレコードの属性値が最適であることが多い場合に使用します。
たとえば、新しいシステムへの移行時にデータは慎重にチェックされてクレンジングされますが、エラーで重複したエントリが作成される場合があります。この場合、日付が早いレコードが適切なことがあります。マージされる値を決定する属性に加えて、出力セレクタへの入力として日付スタンプ列も選択する必要があります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 実際の出力値に対して、任意の入力データ・セットから任意のタイプの入力属性を構成できます。
どのレコードを「最早」とみなすかを決定するために、日付属性を構成する必要があります。 |
| オプション | 次のオプションを指定します。
|
例
この例では、「最早値」出力セレクタを使用して、レコードの日付スタンプに基づき、Company Nameフィールドの最早値を選択します。
サンプル構成:
関連付けられている場合、空でない値を最初に使用= いいえ
出力例
次の表に、「最早値」セレクタを使用した出力の例を示します。
表1-104 「最早値」セレクタを使用した出力の例
| 入力A (CompanyName, Date) | 入力B (CompanyName, Date) | 出力値(最早値) |
|---|---|---|
|
Barclays Bank plc, 10/01/1998 |
Barclays Bank (Bristol) PLC, 14/05/2002 |
Barclays Bank plc |
|
PriceWaterhouse Coopers, 10/01/1998 |
PWC, 24/03/2000 |
PriceWaterhouse Coopers |
|
Oracle Limited, 24/03/2003 |
Oracle, 24/03/2003 |
選択エラー(手動による解決が必要) |
|
Oracle, null |
Oracle, 24/01/1997 |
Oracle |
「空でない最初の値」出力セレクタでは、マージ対象のレコードを検索し、検出された空でない最初の値を出力属性の値として選択します。複数のデータ・ソースから入力レコードをマージする場合、マージされる値の優先ソースを指定するために、レコードが検査される順序を指定できます。
「空でない最初の値」出力セレクタは、あるデータ・ソースの値を他よりも優先する場合に使用します。たとえば、レコードを拡張するときに、参照データ表の値(空でない場合)を優先して使用する場合です。作業データの値が出力セレクタに入力されており、参照データ表の属性の値が空の場合は、作業データの値のみが選択されます。
また、特定のビジネス・ルールを使用してデータを選択する方法がなくても、各出力属性になんらかのデフォルト出力値を設定する必要があり、出力を手動でレビューして値が正しいことをチェックする必要がある場合も、「空でない最初の値」セレクタを使用できます。これにより、必要な出力を解決するための時間を短縮できます。
1つのデータ・ソースを使用し、各グループに複数のレコードが含まれる場合、「空でない最初の値」セレクタでは、数値属性の場合は最低値、日付属性の場合は最早日付、文字列属性の場合はアルファベット順にソートされた最初の値が選択されます。これにより、同じ照合プロセスが複数回実行されても、出力選択が確定的になります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 入力データ・セットからの任意のタイプの属性。 |
| オプション | なし。出力選択には、入力属性の順序が重要です。属性を順番に入力すると、選択では1番目の属性が優先され、1番目の属性に値がない場合のみ2番目の属性が使用されます。 |
例
この例では、信頼できる参照データ・ストリームから顧客の住所データを拡張する際に、「空でない最初の値」出力セレクタを使用してPostCode属性の値を選択します。参照データ・ストリームが使用可能な場合は、ここから郵便番号を選択します。使用不可の場合は、作業データ内の元の郵便番号値を保持します。このため、両方のPostCode属性を入力しますが、出力セレクタは参照データ・ストリームを最初に使用します。
出力例
次の表に、前述のように構成された「空でない最初の値」セレクタを使用した出力の例を示します。
表1-105 「空でない最初の値」セレクタを使用した出力の例
| 参照データ・ストリームからの入力値 | 作業データ・ストリームからの入力値 | 出力値 |
|---|---|---|
|
CB4 1UW |
CB4 1YW |
CB4 1UW |
|
CB4 3DD |
CB4 3DD |
CB4 3DD |
|
CB4 0WS |
null |
CB4 0WS |
|
null |
SW11 5QB |
SW11 5QB |
|
null |
null |
null (注意を参照) |
|
注意: 出力でnull値が選択されたとき、出力属性に対して「Nullの許可」設定の選択が解除されている場合のみ選択エラーとみなされます。そうでない場合、null値の選択は正しいとみなされます。 |
「最大値」出力セレクタでは、マージ対象のすべてのレコードから属性の「最大値」を選択します。これは、数値または日付属性の場合に、属性の最大値または最新日付を選択するときに最も役立ちます。文字列属性の場合は、データをアルファベット順にソートして最後の値を選択します。
「最大値」セレクタは、数値または日付値を選択する出力属性で、最大値または最新値が最適であることが多い場合に使用します。
たとえば、データの重複を除去するとき、Largest_Purchase (顧客が発注した1回の注文の最高金額を登録する)のような数値属性の最適値は一致するレコードの最大値で、Last_paymentのような日付属性の最適値は最新の日付値であることが多くなります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 入力データ・セットからの数値属性または日付属性。 |
| オプション | 次のオプションを指定します。
|
例
この例では、「最大値」出力セレクタを使用して、一致グループ内の各レコードのLargest_purchase属性(数値)の値から、この属性の最大値を選択します。
サンプル構成:
関連付けられている場合、空でない値を最初に使用= いいえ
出力例
次の表に、前述の構成を使用した出力選択の例を示します。
「最遅値」出力セレクタでは、各レコードの日付スタンプを評価して、別の属性で使用する値を選択します。
「最遅値」出力セレクタは、レコードに日付スタンプがあり、最新スタンプのレコードの列値が最適であることが多い場合に使用します。
たとえば、連絡先の重複を除去するとき、連絡先情報が2週間前にシステムに追加され、同じ連絡先の重複レコードには2年前に最終更新された異なる連絡先情報が含まれる場合、最近追加された情報の方が正しいことが多くなります。
値を選択する属性に加えて、出力セレクタへの日付入力として日付スタンプ列も選択する必要があります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 実際の出力値に対して、任意の入力データ・セットから任意のタイプの入力属性を構成できます。
どのレコードを最新とみなすかを決定するために、日付属性を構成する必要があります。 |
| オプション | 次のオプションを指定します。
|
例
この例では、「最遅値」出力セレクタを使用して、一致グループ内のレコードの電子メール・アドレスの中で最近更新されたアドレスを選択します。
サンプル構成:
関連付けられている場合、空でない値を最初に使用= はい
出力例
次の表に、出力例を示します。
表1-107 「最遅値」セレクタを使用した出力の例
| レコードA (電子メール、Last_modified_dat) | レコードB (電子メール、Last_modified_dat) | 出力値(最遅値) |
|---|---|---|
|
mike.lewis@hotmail.com, 10/01/1998 |
mike.lewis@aol.com, 14/05/2002 |
mike.lewis@aol.com |
|
steve_smith@yahoo.co.uk, 12/04/2006 |
smith_sst@capitagroup.co.uk, 01/08/2003 |
steve_smith@yahoo.co.uk |
|
dan.stewart@email.net, 10/01/1998 |
dan.stewart@email.net, 24/03/2000 |
dan.stewart@email.net |
|
dcole2000@hotmail.com, 24/03/2003 |
dcole@gmail.com, 24/03/2003 |
dcole2000@hotmail.com |
|
mikem@gmail.com, null |
mike.mills@gmail.com, 17/01/2009 |
mike.mills@gmail.com |
「最も長い文字列」出力セレクタでは、マージ対象の全レコードの入力属性値から、出力属性の最長文字列値を選択します。最長文字列とは、文字数の最も多い文字列です。
最長文字列は実際には、数値および日付値にも使用されます。
「最も長い文字列」出力セレクタは、最も完全または最長の値が属性の出力値に最適であることが多い場合に使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 入力データ・セットからの任意の属性(文字列、数値または日付)。 |
| オプション | 次のオプションを指定します。
|
例
この例では、「最も長い文字列」出力セレクタを使用して、各一致グループの全レコードからGiven Name属性の値を選択します。
サンプル構成:
関連付けられている場合、空でない値を最初に使用= はい
出力例
次の表に、「最も長い文字列」セレクタを使用した出力の例を示します。
「最小値」出力セレクタでは、マージ対象のすべてのレコードから属性の最小値を選択します。これは、数値または日付属性の場合に、属性の最小値または最早日付を選択するときに最も役立ちます。文字列属性の場合は、データをアルファベット順にソートして最初の値を選択します。
「最小値」セレクタは、数値または日付値を選択する出力属性で、最小値または最早値が最適であることが多い場合に使用します。
たとえば、データセットの重複を除去するとき、同じ顧客のレコードが複数ある場合があります。ソース・データに、Customer_Since_Dateなどの日付列がある場合、グループ内の最も早い日付値が適切なデータであると思われます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 入力データ・セットからの数値属性または日付属性。 |
| オプション | 次のオプションを指定します。
|
例
この例では、「最小値」出力セレクタを使用して、各一致グループ内の各レコードのCustomer_Since属性の値から、この属性の最早日付を選択します。
サンプル構成:
関連付けられている場合、空でない値を最初に使用= はい
出力例
次の表に、前述の構成を使用した出力選択の例を示します。
表1-109 「最小値」セレクタを使用した出力の例
| レコードA | レコードB | 出力値(最小値) |
|---|---|---|
|
01-Aug-1988 00:00:00 |
09-Mar-2001 00:00:00 |
01-Aug-1988 00:00:00 |
|
05-Sep-1982 00:00:00 |
02-Jun-1995 00:00:00 |
05-Sep-1982 00:00:00 |
|
01-Jan-1981 00:00:00 |
01-Jan-1982 00:00:00 |
01-Jan-1981 00:00:00 |
|
01-Sep-1980 00:00:00 |
Null |
01-Sep-1980 00:00:00 |
|
01-Sep-1980 00:00:00 |
01-Sep-1980 00:00:00 |
01-Sep-1980 00:00:00 |
「最も一般的な値」出力セレクタでは、マージ対象の全レコードの入力属性値から、最も一般的な値を出力属性として選択します。
「最も一般的な値」出力セレクタは、マージ対象のレコードで最もよく出現する値が属性の出力値に最適であることが多い場合に使用します。
「最も一般的な値」セレクタは、複数のレコードをマージするとき、最も一般的な値以外には意味のある定義がない場合に最も役立ちます。たとえば、Name属性の重複を除去して値を選択するとき、「John Lewis」と「John Louis」の最も一般的な値は判断できません。しかし、「John Lewis」、「John Lewis」、「John Louis」の最も一般的な値は簡単に判断できます。
また、このセレクタは、2つのレコードをマージするとき、レコード間で値が異なるために手動による選択が必要な場合に、選択エラーを発生させるためにも使用できます。
「最も一般的な値」セレクタは、Null値とデータを含む値から選択するときに、Null値を無視することに注意してください。ただし、すべての値がNull値の場合は、Null値を出力値として選択します。「Nullの許可」オプションを使用して、Null値が選択された場合にエラーを発生するかどうかを制御します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 入力データ・セットからの任意のタイプの属性。 |
| オプション | 次のオプションを指定します。
|
例
この例では、「最も一般的な値」出力セレクタを使用して、各一致グループの全レコードからSurname属性の値を選択します。
サンプル構成:
関連付けられている場合、空でない最初の値 = いいえ
出力例
次の表に、「最も一般的な値」セレクタを使用した出力の例を示します。
「標準偏差」出力セレクタでは、マージ対象の全レコードから入力された数値のセットの標準偏差を計算して出力します。
「標準偏差」セレクタは、レコードを共通の属性値(複数可)でグループ化したり、複雑なルールを使用してレコードを照合して、データの統計分析を実行する際に使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 入力データ・セットからの数値属性。特定のレコードに指定された属性がnullの場合、そのレコードは標準偏差の計算で無視されます。 |
| オプション | 次のオプションを指定します。
|
例
この例では、「標準偏差」出力セレクタを使用して、各レコードの数値属性の標準偏差を選択します。プロセッサは、入力を値の母集団全体として処理するように構成されています。
出力例
次の表に、「標準偏差」セレクタを使用した出力選択の例を示します。
「合計値」出力セレクタでは、マージ対象の全レコードから入力されたすべての数値の合計を計算して出力します。
「合計値」セレクタは、多くの場合、レコードを共通の属性値(複数可)でグループ化したり、複雑なルールを使用して照合して、データに関するレポートを作成する際に使用します。
たとえば、一般的な世帯の住宅ローン勘定レコードを照合するとき、「合計値」出力セレクタを使用して、その世帯の合計債務レベルを計算できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 入力データ・セットからの数値属性。 |
| オプション | なし。 |
例
この例では、「合計値」出力セレクタを使用して、一致グループの各レコードからBalance属性(数値)の合計を選択します。
出力例
次の表に、「合計値」セレクタを使用した出力選択の例を示します。
「最大からの値」出力セレクタでは、各レコードの数値属性を評価して、別の属性で使用する値を選択します。
「最大からの値」出力セレクタは、レコードに含まれる数値属性を使用して、様々な別の出力属性で使用する最適なレコードを選択する場合に使用します。
この出力セレクタは、複雑なロジックを使用して、同じエンティティを表す複数のレコードから、マージ済出力レコードとして使用するために最適なレコードを選択する必要がある場合に役立ちます。最初に複雑なロジックを使用して(照合する前に適用)、各レコードの完全性、妥当性および関連性を総合的に表す「選択スコア」数値属性を作成して移入できます。そのスコアをマージ時に使用して、最適なレコードを選択できます。
それ以外に、個人が予約した製品の数を表す属性など、選択で使用できる単純な数値属性がデータ内にすでに存在する場合もあります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 実際の出力値に対して、任意の入力データ・セットからの入力属性(同じデータ型であることが必要)を構成できます。
数値属性は、実際の「最高値」選択ロジックに対する |
| オプション | 次のオプションを指定します。
|
例
この例では、「最大からの値」出力セレクタを使用して、照合前にすべての入力レコードに追加されたSelectionScore属性に基づき、最適なレコードのOccupation値を選択します。
サンプル構成:
関連付けられている場合、空でない値を最初に使用= いいえ
Nullを0とみなす= いいえ
出力例
次の表に、「最大からの値」セレクタを使用した出力の例を示します。
表1-113 「最大からの値」セレクタを使用した出力の例
| 入力A (Occupation, SelectionScore) | 入力B (Occupation, SelectionScore) | 出力値(最大からの値) |
|---|---|---|
|
CEO, 45 |
Chief Executive Officer, 60 |
Chief Executive Officer |
|
Unknown, 0 |
Account Manager, 60 |
Account Manager |
|
Sales Executive, 60 |
Partner Manager, 60 |
選択エラー(手動による解決が必要) |
|
Nurse, 45 |
Chief Nurse, 60 |
Chief Nurse |
|
null, 0 |
Secretary, 50 |
Secretary |
|
Associate Analyst, null |
Business Analyst, 20 |
Business Analyst |
「最少からの値」出力セレクタでは、各レコードの数値属性を評価して、別の属性で使用する値を選択します。
「最少からの値」出力セレクタは、レコードに含まれる数値属性を使用して、様々な別の出力属性で使用する最適なレコードを選択する場合に使用します。
属性のタイプによっては、属性の最小値が最も重要な値である場合があります。たとえば、同じ個人の複数のレコードをマージして最高リスクのレコードを検出する場合、与信スコアが最も低い個人レコードが出力対象のレコードになります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 実際の出力値に対して、任意の入力データ・セットからの入力属性(同じデータ型であることが必要)を構成できます。
数値属性は、実際の「最小値」選択ロジックに対するチェック値属性として構成する必要があります。 |
| オプション | 次のオプションを指定します。
|
例
この例では、「最少からの値」出力セレクタを使用して、一致レコードのグループ内で与信スコアが最も低い個人の氏名を選択します。
サンプル構成:
関連付けられている場合、空でない値を最初に使用= いいえ
Nullを0とみなす= いいえ
出力例
次の表に、「最少からの値」セレクタを使用した出力の例を示します。
この場合、「関連付けられている場合、空でない値を最初に使用」オプションは「いいえ」に設定されています。
表1-114 「最少からの値」セレクタを使用した出力の例
| 入力A (Name, CredtScore) | 入力B (Name, CredtScore) | 出力値(最少からの値) |
|---|---|---|
|
Mr Bill Davis, 580 |
Mr William Davis, 690 |
Mr Bill Davis |
|
Mr Stephen Lewis, 720 |
Steve Lewis, 650 |
Steve Lewis |
|
null, 480 |
Mr F Johnson, 780 |
null |
|
Mr Brian Hamilton, 595 |
Mr B Hamilton, 595 |
選択エラー(手動による解決が必要) |
|
Andrew Taylor, null |
Andy Taylor, 0 |
Andy Taylor |
このセクションは、照合プロセッサに使用できるサブプロセッサについて説明します。
|
注意: すべてのサブプロセッサが、どの照合プロセッサにも使用できるとはかぎりません。該当するプロセッサについては、各サブプロセッサのセクションで説明します。 |
照合プロセッサの入力サブプロセッサは、入力データ・ストリームから照合プロセッサに属性をマップするために使用します。
入力サブプロセッサは照合処理に不可欠な部分で、照合プロセスで使用するデータの管理に使用します。
通常、照合プロセスには、各入力データ・ストリームのすべての属性が含まれています。ただし、照合処理で使用する属性は変更でき、照合対象の属性、照合候補のレビューで使用する属性、または出力選択で使用する属性のみを含めることができます。
|
注意: 7.0より古いバージョンのEDQでは、手動の照合決定の再適用(保持)に使用されるすべての入力属性が決定キーに含まれるため、入力属性の選択も慎重に構成する必要があります。ただし、現在は、決定キーでどの入力属性を使用するかを構成できます。 |
たとえば、一般的な顧客表からは、次の属性を照合プロセスに含めることができます。
| 目的 | 属性 |
|---|---|
| 照合に必要 | First_name
姓 Birth_date Address_1 Postcode Home_tel_number |
| 可能性のある照合レコードのレビューに必要 | 敬称
Address_2 Town County Customer_type |
| データ更新のための特定のレコードを特定するために必要 | Customer_ID |
| 出力の決定(たとえば、最新のレコードなど)に必要 | Last_modified_date
Has_active_account |
ソース・データ内のこれ以外の属性は、照合プロセスから除外できます。
データを照合処理に入力するには、最初にキャンバス上でデータ・ストリーム(1つまたは複数)を照合プロセッサに接続する必要があります。プロセッサが受け入れるデータ・ストリームの数とタイプは、次に示すように、プロセッサのタイプによって決まることに注意してください。
| 照合プロセッサのタイプ | アクセスする入力データ・ストリーム |
|---|---|
| グループとマージ | 単一の作業データ・ストリーム |
| 重複除外 | 単一の作業データ・ストリーム |
| 拡張 | 単一の作業データ・ストリーム、および任意の数の参照データ・ストリーム |
| リンク | 任意の数の作業データ・ストリームと参照データ・ストリーム |
| 統合 | 任意の数の作業データ・ストリーム |
| 拡張照合 | 任意の数の作業データ・ストリームと参照データ・ストリーム |
データ・ストリームは、照合プロセッサに、リーダーから直接または他のプロセッサの出力フィルタから接続されます。
データ・ストリームが接続されると、「入力」ダイアログを使用して属性を選択できます(方法はすべてのプロセッサで同じです)。
照合プロセッサ(グループとマージを除く)のオプションを構成するときは、2つの追加オプションが表示されます。
自身と比較 - このオプションを使用すると、照合プロセッサが該当するデータ・ストリーム内(データ・ストリーム間ではなく)で一致を検索するかどうかを変更できます。このオプションは、ほとんどの場合、照合プロセッサのタイプに応じたデフォルトに設定されます。作業データ・ストリームは常に相互に比較され、参照データ・ストリームは相互に比較されることはないことに注意してください。
有効 - このオプションを使用すると、入力データ・ストリームの構成は保持されますが、それを照合プロセスで使用するかどうかのオン/オフは切り替えることができます。
識別は、グループとマージを除くすべての照合プロセッサのサブプロセッサです。照合構成の識別ステップの目的は、ソース属性を識別子(後述の説明を参照)にマップし、その識別子を使用してデータ・ストリーム内またはデータ・ストリーム間のレコードを照合することです。
識別子
識別子を使用して、照合が必要な実社会のビジネス・エンティティ(例: 個人の氏名、住所、在庫品目)を表して識別します。
ビジネス・エンティテの識別方法は多数あるため、識別子の種類も多数あります。
システム識別子 - システム内で使用して、レコードまたはエンティティを識別します。多くの場合、データベースでは主キーになります。
実社会の識別子 - システムの外部で意味を持つエンティティの属性で、識別の目的で使用されます。
代替識別子 - システムの外部で意味を持つエンティティの属性で、必ずしも識別用ではないが識別の目的で使用できます。
たとえば、書籍に関する情報を格納するシステム内で、書籍は次の方法で識別できます。
主キー(システム識別子)
ISBN (実社会の識別子)
タイトル、著者および公開日の組合せ。(代替識別子)
EDQでは、これら各種の識別子は区別されません。照合対象のエンティティを識別するには、一部または全部のタイプの識別子を個別にまたは組み合せて使用できます。
EDQでは、エンティティを識別するために、そのエンティティの1つ以上の属性が識別子にマップされます。
識別子タイプ
様々なタイプのデータの照合に(例: 日付の比較、数値の照合)スペシャリストの比較を使用できるように、様々なタイプの識別子が存在しています。
識別子タイプのデフォルト・セットは基本型(日付、日付配列、文字列、文字配列、番号および番号配列)であることに注意してください。これらには、各ソース・データ・ストリームから1つの属性のみをマップできます。ただし、識別子タイプのセットは、特定の識別子や比較を追加するために拡張できます。たとえば、Address識別子タイプでは、スペシャリストの住所比較を使用して異なる構造の住所をマップできます。
「文字配列」を使用すると、単純な文字列を文字配列または別の文字配列を持つ文字配列と照合できます。「番号配列」と「日付配列」の両方でも同じことが適用されます。
使用
識別構成ステップを使用して、照合対象の属性を識別子にマップします。次に、識別子はクラスタリングおよび照合処理で使用されます。
これにより、データ・ストリーム間の属性名の差異を解決できます。たとえば、次に示すように、あるデータ・ストリーム内のlname属性と、別のデータ・ストリーム内のSURNAME属性は、両方ともsurname識別子にマップできます。
複数のデータ・ストリームを照合する場合は(リンクする場合など)、2つの識別子を作成することにより、あるデータ・ストリーム内の1つの属性を別のデータ・ストリーム内の複数の属性と照合できます。これにより、誤ったフィールドに入力されたデータに関する問題を照合プロセス内で解決できます。
識別子を追加するには、次の2つの方法があります。
構成ビュー・パネルから入力サブプロセッサを選択
識別子サブプロセッサ内から
重複除外照合プロセッサなどで1つのデータ・ストリームで作業しているときに、入力属性を表示しているときに、識別子を構成パネルから直接追加するのが最も簡単な方法です。統合、リンク、強化照合プロセッサなどで複数のデータ・ストリームを使用しているときは、各データ・ストリームの属性を、「識別」ダイアログで識別子にマップする必要があります。この場合、最初は入力属性ビューから必要な識別子を作成できますが、その識別子をマップするには前述の「識別」ダイアログを開く必要があります。
識別子の自動マッピング
自動マップ機能は、識別サブプロセッサ内で使用でき、入力サブプロセッサが選択されている場合は構成ビュー・パネルから使用できます。
自動マップが最も使用されるのは、入力データ・ストリーム内の全属性に対して識別子を作成する場合と、一貫性のある命名規則が使用されている場合です。自動マップでは、すべての作業データ入力ストリームと参照データ入力ストリーム内で検出された一意の属性名ごとに識別子が作成され、その名称のすべての入力属性が適切な名称にマップされます。
クラスタは、グループとマージを除くすべての照合プロセッサのサブプロセッサです。照合構成のクラスタ・ステージの目的は、照合処理でレコード間の不要な比較が実行されないようにクラスタリング・プロセスを構成することです。クラスタリングを使用しないと、各データ・ストリーム内の全レコードを他の全レコードと比較する必要があるため、データ・ストリームが小規模であっても照合プロセスは非常に効率が悪くなります。
クラスタは、共通のクラスタ・キーを使用して入力レコードをレコードのグループ(クラスタ・グループ)に分割するために使用し、そのグループ内ではレコードの比較が実行されます。
クラスタの構成には、1つ以上の識別子と、オプションでそれらの識別子の順序付けされた変換が含まれます。クラスタのクラスタ・キーが、その構成に基づいてレコードごとに生成され、そのクラスタ・キー別にレコードがグループ化されます。
1つのクラスタで複数の識別子が使用されている場合(複合クラスタ)、それらの識別子値(または変換された識別子値)は連結されて、各レコードのクラスタ・キーが形成されます。
1つのクラスタで使用されている配列タイプ識別子が1つのみの場合は、この配列のすべての要素に対してクラスタ・キーが生成されます。
1つのクラスタで複数の配列タイプ識別子が使用されている場合は、配列要素のすべての連結に対してクラスタ・キーが生成されます。たとえば、2つの属性の配列と2つの属性の別の配列も1つのクラスタで使用されている場合は、4つのクラスタ・キーが生成されます。
クラスタに識別子を追加するには「識別子の追加」ボタンを使用し、各識別子に変換を追加するには「変換の追加」ボタンを使用します。
識別子に有効に適用できる変換は、その識別子のデータ型(文字列、数値または日付)によって決まることに注意してください。識別子のデータ型は、いずれかの変換(日付を文字列に変換など)を使用して変更できます。無効な変換を構成すると、その変換は赤で表示されます。
前述の文字列を日付に変換を削除すると、最初のN文字変換が無効になります。
追加オプション - デフォルトの上書き
クラスタを構成するときは、3つの追加オプションを使用できます。通常、これらのオプションはデフォルト値から変更する必要はありませんが、特定の場合には変更可能です。オプションは次のとおりです。
クラスタ・グループ制限
クラスタ比較制限
Nullの許可
クラスタ・グループ制限
クラスタ・グループ制限は、1つのクラスタに含めることができるレコードの最大数です。デフォルトでは、クラスタ制限は500レコードです。
これを超えるレコードが1つのクラスタに含まれる場合は(たとえば、姓の最初の5文字による単純なクラスタリング構成を使用したとき、「SMITH」を含むレコードが500を超える場合)、実行される比較の数が多すぎるため、そのクラスタは照合処理で無視されます。このような場合、通常はクラスタリング構成がより厳密になるように変更して、より小さいグループを生成します。ただし、場合によっては、大きいクラスタが無視されないように、単純にサイズ制限を大きくすることもできます。
クラスタ比較制限
クラスタ比較制限は、当該クラスタを破棄する前に照合比較エンジンで実行できる比較の最大数です。デフォルトでは、クラスタ比較制限はnullに設定されています(つまり、制限はありません)。
クラスタで発生する比較の数は、クラスタ処理の開始前に計算できます。比較の数がクラスタ比較制限を超える場合、クラスタは処理の前に破棄され、そのクラスタに対する関係は生成されません。
Nullの許可
Nullの許可オプションを使用すると、すべてのレコードの構成済クラスタ・キーがNullの場合に、それらのレコードのクラスタを作成するかどうかを変更できます。
デフォルトでは、Nullのクラスタ・キーは許容され、グループが生成されます。
たとえば、クラスタが単純にEmail属性の値全体である場合は、Email属性の値がNullの全レコードを相互に比較しますか。しない場合は、このオプションを「False」に設定します。
設定をデフォルト設定の「True」のままにすると、クラスタ・キーがNullのクラスタが生成されますが、クラスタ制限(前述)を超える数のレコードが含まれる場合が多いため、いずれにしても照合処理では無視されます。
例
次の例では、「Surname」属性の最初の数文字(大文字に変換)、およびDate_of_Birth属性の年の部分を使用して、顧客データのセット内にクラスタを作成します。この場合、Date_of_Birthは日付属性であるため、最初に文字列(ddMMyyyy書式を使用)に変換され、最後の4文字が年を表すとみなされます。
この場合、デフォルトのクラスタ・サイズ制限の500が使用され、クラスタではNullのクラスタ・キーの生成が許容されます。
照合は、グループとマージを除くすべての照合プロセッサのサブプロセッサです。照合プロセッサ構成の照合ステージの目的は、メインの照合プロセスを構成することです。つまり、レコードの比較方法、およびその比較結果の解釈方法(自動的に一致、不一致、または手動レビューのための割当て)を構成します。
また、照合プロセスの結果(つまり、照合レコードのセット、およびレコード間で作成された関係)を出力する方法も構成できます。
照合構成のタブは次のとおりです。
関係(「関係出力」を参照)
一致グループ(「一致グループ出力[一致レビューのみ]」を参照)または
アラート・グループ(「アラート・グループ出力[ケース管理のみ]」を参照)
レコードの正確な照合に必要な比較と一致ルールのセットは、照合プロセスの要件と照合対象のデータの品質によって決まります。
一般的に、初めて照合プロセスを開発する際は、次のヒントが役立ちます。
確定一致(通常は、キー識別子間で完全に一致するレコード)の検索から始めます。これを行うには、完全一致比較を各識別子に追加し、それぞれ完全一致を検索するルールを追加します。完全一致比較には、レコード間の小さな相違(大/小文字の相違、識別子値内の余分な充填文字など)を解決するために、変換を含めることができることに注意してください。
完全一致ルールの下に、あいまい照合の程度を示すルール(たとえば、文字編集距離比較を使用して編集距離が1または2での一致)をさらに追加して、照合プロセスを拡張します。次に、照合処理を実行して、各ルールの有効性(一致が検索されたかどうか、誤った確定一致、つまり、一致したが同じエンティティを表していないレコードがないか)を確認します。
(多数の不一致の中から)確定一致を検出できる可能なかぎり緩やかな一致ルールを作成し、初期の照合決定をレビューに設定します。これにより、そのルールによって照合されたレコードの特性をレビューでき、確定一致のみを照合するためのより強力なルールを新たに作成できます。
照合プロセスを開発する際の一般的な目標は、照合候補のチェックに必要な手動レビューの量を最小限にすることです。ただし、照合が必要なレコードとそうでないレコードを自動的に区別できない場合があります。レコードの照合ペアを個々に照合する必要があるかどうかが明確でないルールは、レビュー・ルールにする必要があります。
EDQにおける照合の概要情報は、照合の概念ガイドを参照してください。
構成
照合サブプロセッサの構成には4つのステップがあり、各ステップに対応するタブが構成ダイアログに表示されます。
照合の主な構成は、「比較」タブおよび「一致ルール」タブにまとめられています。この2タイプの出力にはデフォルトの構成設定値があり、多くの場合は変更不要で、変更が必要になるのは照合プロセスの開発が完了間近な場合のみです。
比較
比較とは、指定の識別子に対して、どの程度2つのレコードが相互に一致しているかを決定する照合機能です。
EDQは比較のライブラリを備えており(「比較のリスト」を参照)、照合処理ニーズの大部分をカバーしています。新しい比較のスクリプトを作成してEDQに追加することもできます。
比較によって、クラスタ・グループ内のすべてのレコードが相互に比較され、比較結果が作成されます。考えられる比較結果は、比較の対象と識別子の型(文字列、数値、日付など)によって決まります。
たとえば、「文字列の完全一致」比較では(「比較: 文字列の完全一致」を参照)、実行する比較ごとに次のいずれかの結果が生成されます。
True - 識別子値のペアは一致しています
False - 識別子値のペアは一致していません
No Data - 一方または両方の識別子値に値がありませんでした
このため文字列の完全一致比較では、レコードのペアが一致しているかどうかを単に判断します。
これに対して、「文字編集距離」比較(「比較: 文字編集距離」を参照)では、レコードのペアがどの程度一致しているかが示され、このために、値をもう一方の値と照合するのに必要な文字編集の回数値が計算されます。たとえば、値「test」と「test」は完全に一致しており、文字編集距離の結果は0です。値「test」と「tast」は1文字が異なるため、文字編集距離は1です。値「test」と「mrtest」は2文字が異なるため、文字編集距離の結果は2です。
配列属性とともに使用した場合は、一般に、最初のレコードのすべての配列要素値が2番目のレコードのすべての配列要素値と比較され、最も一致率の高い結果が出力されます。たとえば、レコードAに'John'と'Jon'という要素を持つ配列があり、レコードBに'J'と'Jon'という要素を持つ配列がある場合、完全一致比較では'True'が返され、文字編集距離比較では'0'が返されます。これは、'Jon'が'Jon'と完全に一致するためです。
比較の追加と構成
比較を各識別子に追加するには、ダイアログの下部にある「比較の追加」ボタンを使用します。比較は、コピーして貼り付けることもできます(たとえば、別の識別子で同じ比較構成が必要な場合)。これを行うには、選択した比較をコピー([Ctrl]+[C])して識別子に貼り付けます([Ctrl]+[V])。比較は比較プロセッサ間でもコピーできるため、他の比較プロセッサで使用した比較構成は再使用できます。
比較はそれぞれ、ダイアログの右側を使用して構成します。
比較への変換の追加
比較に変換を追加すると、比較する前に識別子を変換できます。
たとえば、識別子値(名称など)は類似しているが完全には一致していない場合の一致ルールは、2つの値が同じ音に聞こえることを確認する比較を使用して、強化できます。これを行うには、文字列の完全一致比較を使用しますが、その比較にはMetaphone変換を追加します。これにより、個別の値ではなく、各識別子のmetaphoneキーを比較します。たとえば、「Jhon」と「John」は一致します。
比較変換には、使用する変換に応じた構成が必要です。詳細は、各変換のヘルプ・ページを参照してください。
比較オプション
比較オプションは、使用する比較に応じて異なります。使用可能なオプションの詳細は、各比較のヘルプ・ページを参照してください。たとえば、「文字列の完全一致」比較では次のオプションを使用できます(「比較: 文字列の完全一致」を参照)。
データなしのペアを照合 - データなし(null、空の文字列、または印刷不可能な文字のみ)を含む2つの値の照合で、「True」の結果(2つの値は一致)を返すか、または「No Data」の結果(該当データなし)を返すかを決定します。
大文字/小文字を区別しない- 照合で大/小文字を区別するかどうかを決定します。たとえば、これを設定すると「John」と「JOHN」は一致し、設定しないと一致しません。
結果バンド
数値結果が生成される比較(一致率、2つの識別子値の間の編集距離など)では結果バンドを使用します。これにより、レコードを自動的に照合するかどうかを決定するために、結果のバンドに対して個別の比較結果を構成できます。各比較ではデフォルトの結果バンドが表示されるため、結果バンドをいつも最初から構成する必要はありません。
異なるバンド結果が必要な場合は、比較用の結果バンドを変更できます。たとえば、文字編集距離比較を使用しているときに、編集距離が2以下の場合は、該当する識別子を照合する単純なルールを使用できます。
各結果バンドの右側の色にも注意してください。これらは「一致ルール」ペイン(キャンバス上に照合プロセッサが開き、照合サブプロセッサが選択されている場合に表示されます)で使用され、比較結果の強度へのクイック・ガイドを提供するため、複数の比較にまたがる各一致ルールの構成への視覚的なクイック・ガイドとなります。色の指示を変更するには、「色の反転」ティック・ボックスを使用します。高い一致率を示すには緑色、低い一致率を示すには赤色、その間は各種のグラデーションが使用されます。
複合比較
複合比較では、一致構成内に別個のグループを作成することで、より複雑な構成を作成できます。これらのグループに対して比較とスコアを別個に構成し、これらのグループの結果から全体スコアおよびその他のデータを計算できます。これにより、より効率的かつ柔軟な方法で一致を作成できます。
主なメリットは、次のとおりです。
一致構成の設定が容易 - 明示的に指定すべきルールがずっと少ないため、設定に必要な構成時間がずっと少なくて済みます
柔軟性 - ルールでは、ルール内のすべてのグループの一致または非一致を考慮できるため、一致でより正確な情報を返すことができます
外部化 - 新しいグループ間での重み付けが可能で、これらの外部化も可能であるため、一致の外部化構成に役立ちます。たとえば、論理グループにより高い重みを付与することで、このグループのスコアのスコア全体への貢献度を上げることができます。論理グループを完全に無効にすることもできます。
スコアリング
一致ルールを定義して、複合比較の出力から、または複数の複合比較の出力の組合せからそのスコアを取得できます。
たとえば、スコアを作成する複数の複合比較の出力と、それらすべての結果の組合せであるルール名の結果を結合することで、含まれるすべての複合比較全体で最適な一致の結果を得ることができます。たとえば、名前、住所および電話の複合比較を結合すると、2つのレコードが、スコア99のルール名"名前完全、住所完全、電話最後のN"に比較されます。
次に、スコアが90より大きい複合比較の出力の組合せから出力の組合せを取得するルールを定義すると、ルールのスコアが組合せのスコアとなるように定義することが可能になります。したがって、この例では、ルール名は"スコア>90"でスコアは99になります。
複数の複合比較のスコア出力による集計スコアを計算する場合、次の2つの方法があります。
重み付け平均
加重平均スコアを使用する場合、スコア全体に対する各複合比較の貢献度は、その加重に比例します。スコア全体は、関連するすべての複合比較それ自体が最大可能スコアを取得した場合に取得することが可能であった最大可能スコアの割合です。
ただし、特定の複合比較で"データなし"の場合は無視オプションが選択されており、カテゴリ結果が「データなし」の場合、その比較はスコア全体に貢献しません。
加重平均スコアの構成では、複合比較を構成する必要があります。各複合比較によって、加重および-100から100の間のスコアが提供されます。次の表に、各複合比較で構成可能なオプションの説明を示します。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| 加重 | 数値>0 | この一致が(他の複合比較を基準として)スコア全体にどの程度貢献するかを定義します | 1 |
| 有効 | チェックボックス | 複合比較がスコア全体に貢献するかどうかを定義します。このチェック・ボックスの選択を解除することは、スコアから複合比較を除外することと同じです。 | 選択済 |
| "データなし"の結果の場合に含める | チェックボックス | "データなし"の結果の場合に複合比較がスコアに貢献するかどうかを定義します | 選択済 |
スコアの結果について最小および最大スコアを正規化するために、次の構成オプションが用意されています。
| オプション | タイプ | 説明 | デフォルト値 |
|---|---|---|---|
| 範囲内で結果を正規化: 最小 | 数値 | 結果をその範囲内で正規化する最小スコア。これを0に設定すると、最小の結果スコアは0になります。ゼロより小さい場合、スコアはその負の値と最大スコアの間で正規化されますが、負の結果スコアはゼロとして返されます。 | 0 |
| 範囲内で結果を正規化: 最大 | 数値は最小スコアより大きくすることが必要。 | 結果を正規化する限度となる最大スコア。これを100に設定すると、最大の結果スコアは100になります。生成された結果スコアが100より大きい場合、値は100として返されます。 | 100 |
加重平均スコアを計算するには、次のアルゴリズムが適用されます。
i番目の複合比較のスコアがsi (-100から100の間)、加重がwiで、「範囲内で結果を正規化: 最大」を最大とし、「範囲内で結果を正規化: 最小」を最小とする場合、次のようになります。
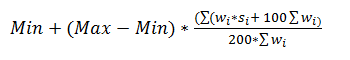
この式で、各合計は、"データなし"ではない結果を含む比較か、「"データなし"の場合に含める」に設定されている比較のみが対象です。
式の200の値は、加重された複合比較の結果の合計が含まれる可能性のある範囲です(各複合比較は-100から100の間の結果を含む可能性があるため)。加重とスコアの合計には、100が追加され、その範囲の割合として式の該当部分の分子になります。
例
次の例は、名前、住所、電話、電子メールおよび税番号の複合比較の構成および結果スコアを示しています。加重および「"データなし"の場合に含める」オプションは、スコアが複合比較の結果である場合の構成です。
| 複合 | ルール | スコア | 加重 | "データなし"の場合に含める |
|---|---|---|---|---|
| 名前 | 名前完全 | 100 | 5 | Y |
| 住所 | 住所完全 | 100 | 8 | Y |
| 電話 | 電話最後のN | 80 | 6 | N |
| 電子メール | 電子メール競合 | -5 | 7 | N |
| 税番号 | データなし | 0 | 10 | N |
範囲内で結果を正規化: 最小 = -20
範囲内で結果を正規化: 最大 = 120
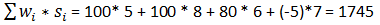
税番号は、"データなし"の結果であり、「データなしの場合に含める」オプションがNに設定されているため、無視されることになります。
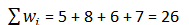
この式に基づいて(税番号は貢献なし)、結果は次のようになります。
-20 + (120-- 20)*(1745 + 2600)/5200 = 97
もう1つの例として、電子メール複合比較を電子メール競合ではなく"データなし"ルールと照合した場合、次の式に示すとおり、結果が大幅に変化します。
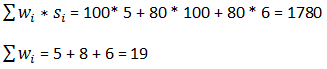
電子メールは貢献しなくなるため、結果は-20 + (120 - 20)*(1780 + 1900)/3800 = 116という式を使用して計算され、これは切り捨てられて100のスコアが返されます。
幾何平均
幾何平均スコアは、加重平均スコアのかわりになります。スコアは、コンポーネント複合比較のスコアの積から導出されるため、分散が生じ、線形性は低下します。結果として、少ない数の複合比較間の一致によって、すぐに高いスコアが生成される可能性があります。これに対して追加される他の一致比較は、貢献度が低く、スコアは徐々に増加します。これは、現在Customer Data Servicesで実行されるスコア付けの方法と同様です。たとえば、非常に高いスコアには、他のフィールドの内容に関係なく、2つの一致フィールドのみが必要です。
幾何平均を使用してスコアを計算する場合、スコアの構成に任意の数の複合比較を追加します。各複合比較には、次の表に説明されている構成オプションがあります。
| タイプ | 説明 | デフォルト | |
|---|---|---|---|
| 加重 | 数値>0 | この一致がスコア全体にどの程度貢献するかを定義します | 1 |
| 有効 | チェックボックス | 複合比較がスコア全体に貢献するかどうかを定義します。これをオフにすることは、スコアから複合比較を除外することと同じです。 | 選択済 |
|
注意: 「"データなし"の結果の場合に含める」オプションは、幾何平均スコアには関係ありません。 |
幾何平均スコアでは、次のアルゴリズムが適用されます。各複合比較で提供されるスコアは、-100から100の間であるとします。加重(wi)およびスコア(si)を持つ各複合比較iを使用します
最初に式を使用して、これらの値を複合比較の貢献度(ci)に変換します。si>=0 ci = 1 + wi *si/100の場合、結果は1から1 + wiの間になります。
si<0 ci= 1/(1-wi*si/100)の場合、結果は1/(1 +wi)から1の間になります。
スコア全体は次のように計算されます。
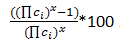
この式では、スコアの積が大きくなるほど100に近づき、結果が小さくなるほど負の無限大に近づくスコアが得られます。すべてのスコアが"データなし" (その結果ci= 1)の場合、スコアはゼロになります。最小可能スコアは、0に設定されます。結果スコアは、最も近い整数に端数処理されます。
この式で、xは、スコアがより大きくなるか小さくなるかを示すスコア・ファクタです。
スコア・ファクタは、幾何平均スコアの構成時に使用できるドロップダウン・リストから選択できます。次の表に示すとおり、それぞれ事前定義された値を持つ5つのオプションがあります。
| オプション | 値 |
|---|---|
| 標準 | 0.5 (デフォルト値) |
| 高い | 1 |
| より高い | 1/3 |
| より低い | 1/4 |
| 最低 | 1/5 |
例
次の表に、5つの複合比較のレコード・ペアの結果を示します。
| 複合 | ルール | スコア | 加重 | 計算された貢献度 |
|---|---|---|---|---|
| 名前 | 名前完全 | 100 | 5 | 1+ 5 *1 = 6 |
| 住所 | 不動産と郵便番号 | 80 | 8 | 1 + 0.8*8 = 7.4 |
| 電話 | 電話最後のN | 80 | 6 | 1 + 0.8*6 = 5.8 |
| 電子メール | 電子メール競合 | -5 | 7 | 1/(1 + 0.05*7) = 0.74 |
| 税番号 | データなし | 0 | 10 | 1 |
貢献度の積は、190.7556です。
x = 0.5を使用した結果は、次のとおりです。
100*(13.81143- 1)/ 13.81143 = 93%
一致ルール
照合プロセス中に解釈される比較結果の数は、一致ルールによって決まります。
一致ルールごとに1つの決定が生成されます。次の3つのいずれかになります。
一致
一致なし
レビュー
これらの決定は、複数の比較結果からの解釈です。たとえば、すべての比較結果が一致した場合、これは一致として分類されます。一部の比較のみが一致した場合は、ルールによってリンクされたレコードが一致かどうかを決定するために、一致レコードを手動でレビューできます。
一致ルールは、「一致ルール」ペインに表示されている論理順序に従って上位から下位に処理されます。複数の一致ルール・グループが使用されている場合は、最初の一致ルール・グループの一致ルールが上位から下位に処理され、その後に次のグループのルールが処理されます。
比較結果の決定表は、一致ルールの完全なセットによって形成されます。
レコードのペアが最上位の一致ルールの条件(たとえば、比較1 = True、比較2 = 近似一致)を満たしている場合は、一致ルールの判定がそのレコードのペアに適用されます。決定表内の下位の一致ルールは、上位のルールによってすでにリンクされているレコード(一致なし決定のルールの場合はリンクされなかったレコード)のペアには適用されません。
通常は、表の最上位にある最も強力な一致ルール(一致決定を行う)を使用するのが最適です。たとえば、すべての識別子を通じて完全な重複は非常に高い(完全)一致とみなされるため、最上位のルールの条件を満たします。表内を下位に移動するに従って、一致ルールは緩やかになります。
照合処理が実行された後は、各一致ルールによって形成されたリンク(「関係」と呼ばれます)が結果ブラウザの「ルール」ビューで使用可能になるため、関係出力をドリルダウンして関連するレコードを表示できます。
一致ルールの追加と構成
一致ルールは、一致ルール・リストの下部にあるボタンを使用して管理します。
ルールは、プラス記号を使用して追加し、マイナス記号を使用して削除します。リスト内の位置は、右側の矢印ボタンを使用して調整します。
一致ルールの左側のチェック・ボックスを使用すると、照合プロセッサの次回の実行から一致ルールを一時的に無効にできます(後で再度有効にできます)。これは、事前に構成された照合プロセッサで特に役立ち、設定されたルールの一部が特定のデータで不要な場合は、そのルールを削除せずに簡単に無効にできます。
一致ルールはそれぞれ、ダイアログの右側を使用して構成します。各比較はリスト表示されるため、一致決定(一致、一致なしまたはレビュー)を使用して解釈する比較結果を決定する必要があります。
また、既存のルールと一部のみ異なる新しいルールを作成する場合などは、右側で他のルールをコピーして貼り付け、その構成に小さい変更を加えることによって新しいルールを作成すると大変便利です。標準的なキーボード・ショートカット([Ctrl]+[C]および[Ctrl]+[V])や、右クリック・メニューも使用できます。
貼り付けたルールは、元のルールの直下に追加されます。その後は、ルール名の編集、構成の変更、およびルール表内の適切な位置への移動を実行できます。
ルールは、一致ルール・グループ間でコピーして貼り付けることができます。
一致ルールの比較結果の構成
構成された各比較に対して、一致ルールの比較結果を選択できます。比較ごとに結果が異なるため、比較結果も異なります。たとえば、文字列の完全一致比較では、次のいずれかの結果が返されます。
True (文字列は一致)
False (文字列は不一致)
No data (比較対象の一方または両方の値にデータなしが含まれる)
一致ルール内の比較の結果を選択するときは、前述のいずれかの結果を選択するか、またはすべての結果を意味する「*」を選択できます。
いずれの比較でも結果が「データなし」になる可能性があります。Nullまたは空の文字列値のデータを含む値を比較すると、結果は常に「データなし」になります。2つのNullまたは空の文字列の比較が「データなし」の結果となるのは、データなしのペアを照合オプション(すべての比較で同様)が「No」に設定されている場合のみです。
一致ルール・グループ
一致ルールは複数のグループにまとめられます。一致ルール・グループは、類似する機能を実行する一連の一致ルールで構成されます。一致ルール・グループ内の一致ルールは1つの単位として管理でき、次の操作を実行できます。
グループ内のルールの有効化または無効化。
グループ内の全ルールに対する決定の変更。
グループ内の全ルールで使用する比較の変更
決定表内のグループの位置の移動。
決定表内では、一致ルール・グループ内のルールが連続したルール・セットを形成します。つまり、特定グループのルールの間に、そのグループに含まれないルールが割り込むことはできません。
表示されている一致ルールは、選択したグループに関連付けられているルールです。
一致ルール・グループを完全に無視することも可能です。デフォルトでは、すべての照合プロセッサにデフォルトの一致ルール・グループがあり、すべての一致ルールはそのグループ内に配置されます。他の一致ルール・グループを作成しない場合、グループ化による一致ルール構成への影響はありません。
一致ルール・グループの管理
一致ルール・グループは、一致ルール自体と同様の方法で管理されます。一致ルール・グループを追加、削除および順序変更するには、ここでも、リストの下にあるボタンを使用します。
一致ルール・グループを削除すると、そのグループ内の一致ルールがすべて削除されます。
一致ルール・グループの右クリック・メニューを使用すると、グループ内のルールを一括変更できます。
たとえば、選択したグループ内の全ルールが無効化されます。このメカニズムによって、グループ内の全ルールの一致決定を変更したり、グループ内の全ルールに同じ比較を適用することができます。
関係出力
「関係」タブ使用すると、照合プロセスからの関係出力を構成できます。
関係とは2つのレコード間のリンクで、自動一致ルールおよび手動決定により作成されます。同じレコードを複数のレコードに関連付けることができるため、1つ以上の関係の中に存在する場合がありますが、関係はそれぞれ常に明確なレコードのペアと一対一対応です。
関係出力は、出力として各照合プロセッサから使用可能であり、外部のデータベースやファイルへの書込みおよびエクスポート、また後続の処理(プロファイリングなど)に使用できます。また、結果ブラウザのデータ・ビューとしても使用できます。最終的には、照合プロセッサの「ルール」および「レビュー・ステータス」サマリー・ビューからのドリルダウンで使用されます。
関係出力には、属性のデフォルト・セット、および出力レコードのデフォルト・セット(照合処理で形成される関係ごとに1つ)が含まれています。ただし、出力を構成する属性のセットや、出力する関係のセットを変更できます。
属性の変更
デフォルトの関係データを構成する属性は、構成ダイアログの左側にリストされます。
関係データは、照合プロセスで作成された関係ごと1つのレコードを出力します。このため、出力データ内の各レコードには2つの一致するレコードの情報が含まれます。
画面の左側に示すように、デフォルト・フォーマットにはデフォルトで次の属性が含まれます。
表1-115 デフォルトの関係データの属性
| 属性名 | 説明 | 属性値 |
|---|---|---|
|
ReviewGroup [一致レビューのみ] |
レビュー・グループID |
各関係が属するレビュー・グループの生成済ID。 レビュー・グループは相互に関係のあるレコードの完全グループです。このため、関係内の各レコードは同じレビュー・グループに含まれる必要があります。 |
|
MatchGroup [一致レビューのみ] |
一致グループID |
関係内の最初のレコードが属する一致グループの内部ID。 一致グループは、デフォルトではレビュー関係を考慮しません。このため、レビュー関係内の2つのレコードは別の一致グループに含まれます。 |
|
InternalId [一致レビューのみ] |
内部レコードID |
関係内の最初のレコードの内部レコードID。 |
|
DataStreamName [一致レビューのみ] |
レコードのデータ・ストリーム名 |
関係内の最初のレコードの入力データ・ストリーム名。 |
|
RelatedMatchGroup [一致レビューのみ] |
一致グループID |
関係内の2番目の(関連付けられた)レコードが属する一致グループの内部ID。 |
|
RelatedInternalId [一致レビューのみ] |
内部レコードID |
関係内の2番目の(関連付けられた)レコードの内部レコードID。 |
|
RelatedDataStreamName [一致レビューのみ] |
レコードのデータ・ストリーム名 |
関係内の2番目の(関連付けられた)レコードの入力データ・ストリーム名。 |
|
ルール |
一致ルール名 |
関係を作成した一致ルールの名前。 |
|
RuleDecision |
関係決定値 |
関係の一致決定。 |
|
ReviewStatus |
関係レビュー・ステータス |
関係のレビュー・ステータス(レビューは不要、レビュー待ち、レビュー済ユーザー)。 |
|
[識別子名] |
識別子: [識別子名]からの値 |
関係内の最初のレコードからの各識別子値の属性。 |
|
related_[識別子名] |
識別子: [識別子名]からの値 |
関係内の2番目の(関連付けられた)レコードからの各識別子値の属性。 |
|
[ComparisonName]_Element |
一致した属性と同じタイプの配列 |
最適な結果に関連する識別子に最初にマップされている属性からの要素。要素の複数のペアがベスト・マッチに関連している場合は、複数の値が含まれ、それらの値は下の属性の値の順にペアとなります。 |
|
[ComparisonName]_RelatedElement |
一致した属性と同じタイプの配列 |
最適な結果に関連する識別子に2番目にマップされている属性からの要素。要素の複数のペアがベスト・マッチに関連している場合は、複数の値が含まれ、それらの値は上の属性の値の順にペアとなります。 |
|
[ComparisonName]_Index |
番号配列 |
最適な結果に関連する識別子に対して、最初にマップされている属性からの要素の索引(1から始まる索引)。要素の複数のペアが最適な結果に関連している場合は、複数の値が含まれ、それらの値は下の属性の値の順にペアとなります。 |
|
[ComparisonName]_RelatedIndex |
番号配列 |
最適な結果に関連する識別子に対して、2番目にマップされている属性からの要素の索引(1から始まる索引)。要素の複数のペアが最適な結果に関連している場合は、複数の値が含まれ、それらの値は上の属性の値の順にペアとなります。 |
関係出力のデフォルト・フォーマットを保持するには、ダイアログの下部にある「自動属性選択」オプションを選択します。出力内の属性は識別子ごとに含まれているため、変更の可能性があることに注意してください。識別子を追加または削除すると、デフォルト出力内の属性が変更されます。
出力をカスタマイズする場合は、このボックスの選択を解除して、属性を追加または削除できます。いくつかの属性を追加できます。関係内の一方または両方のレコードに対して、任意の入力属性の値を照合プロセスに追加できます。また、REVIEW_USER (関係に対して最後の手動決定を行ったユーザー)、REVIEW_DATE (最後の手動決定の日付)、COMMENT (レビュー・プロセス中に関係に対して作成された最後のコメント)、COMMENT_USER (最後のコメントを作成したユーザー)およびケース管理の拡張属性(ケース管理が使用されている場合)など、照合プロセスから使用可能になるいくつかの属性も追加できます。
たとえば、属性を追加して出力をカスタム・フォーマットに変更すると、自動属性選択オプションが自動的に選択解除されることに注意してください。つまり、識別子が追加されても、属性は出力に自動的に追加されることはありませんが、属性は必要に応じて手動で追加できます。
関係のセットの変更
出力する関係のセットを変更する場合、いくつかのオプションを使用できます。
表1-116 関係のセットを変更するためのオプション
| オプション | 説明 | デフォルト設定 |
|---|---|---|
|
関係出力の生成 |
関係出力を生成するか、まったく生成しないかを決定します。たとえば、照合プロセスを完全に開発し、関係出力を使用しない場合は、関係出力を生成しないことでパフォーマンスを向上させることができます。 |
選択済 |
|
一致関係を出力 |
一致決定との関係を出力するかどうかを決定します。 |
選択済 |
|
レビュー関係を出力 |
レビュー決定との関係を出力するかどうかを決定します。 |
選択済 |
|
自動的にレビューされた関係を出力 |
自動ルールによってレビューされた関係を出力するかどうかを決定します。 |
選択済 |
|
手動でレビューされた関係を出力 |
手動でレビューされた関係を出力するかどうかを決定します。 |
選択済 |
|
レビュー待ちの関係を出力 |
レビュー待ちの関係を出力するかどうかを決定します。 |
選択済 |
|
手動照合なしの関係を出力 |
最初は(自動ルールによる)レビュー決定であったが、レビュー中に一致なし決定となった'関係'を出力するかどうかを決定します。たとえば、レビュー・プロセスで行われた決定の完全な監査証跡を出力する場合、このオプションを選択して前述のオプションの選択を解除できます。 |
未選択 |
|
含める一致ルール |
個々の一致ルールで作成された関係を出力するかどうかを選択できます |
すべてのルールを選択 |
一致グループのセットの変更
出力する一致グループのセットを変更する場合、いくつかのオプションを使用できます。
表1-117 一致グループのセットを変更するためのオプション
| オプション | 説明 | デフォルト設定 |
|---|---|---|
|
一致グループ・レポートの生成 |
一致グループの出力を生成するか、まったく生成しないかを決定します。たとえば、照合プロセスを完全に開発し、一致グループ出力を使用しない場合は、一致グループ出力を生成しないことでパフォーマンスを向上させることができます。 |
選択済 |
|
関連レコードを出力 |
関連するレコードのグループを出力するかどうかを決定します。 |
選択済 |
|
関連のないレコードを出力 |
関連のないレコードのグループを出力するかどうかを決定します。 |
重複除外プロセッサおよび統合プロセッサの場合は、選択済。 強化プロセッサ、リンク・プロセッサおよび照合プロセッサの場合は、選択しない。 |
一致グループ出力[一致レビューのみ]
「一致グループ」タブを使用すると、照合プロセスからの一致グループ出力を構成できます。
一致グループは、照合プロセスからのレコードの最終的なグループです。照合プロセスに入力された各作業レコードは、一致した他のレコードとともに(ある場合)、一致グループに出力されます。このグループは、一致決定によって関連付けられたレコードで構成されます。他と一致しなかった場合、グループに含まれるレコードは1つの可能性があります。このような関連付けられていないレコード(1のグループ)を出力するかどうかを選択できます。
一致グループ出力は、出力として各照合プロセッサから使用できます。外部のデータベースやファイルへの書込みおよびエクスポート、また後続の処理(プロファイリングなど)に使用できます。また、結果ブラウザのデータ・ビューとしても使用できます。最終的には、照合プロセッサの一致および「一致グループ」サマリー・ビューからのドリルダウンで使用されます。
一致グループ出力には、属性のデフォルト・セット、および出力レコードのデフォルト・セットが含まれます。ただし、出力を構成する属性のセットや、出力するグループのセットを変更できます。
属性の変更
デフォルトの一致グループ・データを構成する属性は、構成ダイアログの左側にリストされます。
一致グループ・データは照合プロセスに入力された作業レコードの出力で、他のレコードとの照合方法に従って複数のグループに編成されます。
|
注意: 参照データ・ストリームからのレコードは、作業レコードに関連する場合にのみ一致グループに含められます。一致グループに含まれるレコードが1つの場合、そのレコードは常に作業データ・ストリームからのレコードです。 |
画面の左側に示すように、デフォルト・フォーマットにはデフォルトで次の属性が含まれます。
表1-118 デフォルトの一致グループ・データの属性
| 属性名 | 説明 | 属性値 |
|---|---|---|
|
MatchGroup |
一致グループID |
各レコードが属する一致グループの内部ID 注意: 一致グループは、デフォルトではレビュー関係を考慮しません。これは、詳細オプションを使用して変更できます。 |
|
InternalId |
内部レコードID |
各レコードの内部レコードID。 |
|
InputName |
レコードの入力名 |
レコードの入力データ・ストリーム名。 |
|
MatchGroupSize |
一致グループ・サイズ |
レコードの一致グループ内のレコード合計数。 |
|
[識別子名] |
識別子: [識別子名]からの値 |
関係内の最初のレコードからの各識別子値の属性。 |
一致グループ出力のデフォルト・フォーマットを保持するには、ダイアログの下部にある「自動属性選択」オプションを選択します。出力内の属性は識別子ごとに含まれているため、変更の可能性があることに注意してください。識別子を追加または削除すると、デフォルト出力内の属性が変更されます。
出力をカスタマイズする場合は、このボックスの選択を解除して、属性を追加または削除できます。任意の入力属性の値を照合プロセスに追加できます。
たとえば、属性を追加して出力をカスタム・フォーマットに変更すると、自動属性選択オプションが自動的に選択解除されることに注意してください。つまり、識別子が追加されても、属性は出力に自動的に追加されることはありませんが、属性は必要に応じて手動で追加できます。
一致グループのセットの変更
出力する一致グループのセットを変更する場合、いくつかのオプションを使用できます。
表1-119 一致グループのオプション
| オプション | 説明 | デフォルト設定 |
|---|---|---|
|
一致グループ・レポートの生成 |
一致グループの出力を生成するか、まったく生成しないかを決定します。たとえば、照合プロセスを完全に開発し、一致グループ出力を使用しない場合は、一致グループ出力を生成しないことでパフォーマンスを向上させることができます。 |
選択済 |
|
関連レコードを出力 |
関連するレコードのグループを出力するかどうかを決定します。 |
選択済 |
|
関連のないレコードを出力 |
関連のないレコードのグループを出力するかどうかを決定します。 |
重複除外プロセッサおよび統合プロセッサの場合は、選択済。 強化プロセッサ、リンク・プロセッサおよび照合プロセッサの場合は、選択しない。 |
アラート・グループ出力[ケース管理のみ]
「アラート・グループ」タブを使用すると、照合プロセスからのアラート・グループ出力を構成できます。
グループ出力は、各照合プロセッサから使用できます。外部のデータベースやファイルへの書込みおよびエクスポート、また後続の処理(プロファイリングなど)に使用できます。また、結果ブラウザのデータ・ビューとしても使用できます。最終的には、照合プロセッサの一致および「一致グループ」サマリー・ビューからのドリルダウンで使用されます。
アラート・グループは、照合プロセスから収集したレコードのセットで、レビュー・プロセスで使用するアラートを形成します。照合プロセスによって関係に含められた各作業レコードは、一致したレコードとともに(ある場合)、アラート・グループに出力されます。このグループは、アラート・キーによって関連付けられたレコードで構成されます。
他と一致しなかったレコードはどのアラート・グループにも含められず、アラート・キーは割り当てられません。このようなシングルトン・レコードは、オプションでアラート・グループ出力に含めることができます。
アラート・グループ出力は、出力属性のデフォルト・セットおよび出力グループのデフォルト選択を使用して事前構成されています。これらのデフォルト構成は、照合プロセッサ・ダイアログの「アラート・グループ」タブで変更できます。
属性の変更
アラート・グループ・データに出力される属性は、構成ダイアログの左側にリストされます。
アラート・グループには照合プロセスに入力された作業レコードが含まれ、アラート・キーによって複数のグループに編成されます。
|
注意: 参照データ・ストリームからのレコードは、作業レコードに関連する場合にのみアラート・グループに含められます。 |
画面の左側に示すように、デフォルト・フォーマットにはデフォルトで次の属性が含まれます。
表1-120 デフォルトのアラート・グループ・データの属性
| 属性名 | 説明 | 属性値 |
|---|---|---|
|
CaseKey |
ケース・キー |
アラート・グループ内のレコードのケース・キー。 |
|
AlertKey |
アラート・キー |
レコードをアラート・グループに収集するのに使用されたアラート・キー。 |
|
InputName |
レコードの入力名 |
レコードの入力データ・ストリーム名。 |
|
InternalId |
内部レコードID |
レコードの内部識別子。 |
|
MatchGroupSize |
一致グループ・サイズ |
レコードのアラート・グループ内のレコード合計数。 |
|
[識別子名] |
識別子: [識別子名]からの値 |
関係内の最初のレコードからの各識別子値の属性。 |
アラート・グループ出力のデフォルト・フォーマットを保持するには、ダイアログの下部にある「自動属性選択」オプションを選択します。出力内の属性は識別子ごとに含まれているため、変更の可能性があることに注意してください。識別子を追加または削除すると、デフォルト出力内の属性が変更されます。
出力をカスタマイズする場合は、このボックスの選択を解除して、属性を追加または削除できます。任意の入力属性の値を照合プロセスに追加できます。
たとえば、属性を追加して出力をカスタム・フォーマットに変更すると、自動属性選択オプションが自動的に選択解除されることに注意してください。つまり、識別子が追加されても、属性は出力に自動的に追加されることはありませんが、属性は必要に応じて手動で追加できます。
アラート・グループの出力セットの変更
出力するアラート・グループを指定する場合、いくつかのオプションを使用できます。
表1-121 アラート・グループのオプション
| オプション | 説明 | デフォルト設定 |
|---|---|---|
|
アラート・グループ・レポートの生成 |
アラート・グループの出力を生成するか、まったく生成しないかを決定します。照合プロセスの開発が終了したら、アラート・グループ出力を無効にして、プロセスのパフォーマンスを向上させることができます。 |
選択済 |
|
関連レコードを出力 |
検出されたレコード(つまり、他のレコードと一致した)をアラート・グループに含めるかどうかを決定します。 |
選択済 |
|
関連のないレコードを出力 |
どのアラート・グループにも含まれないレコード(つまり、他のどのレコードとも一致しなかった)を出力するかどうかを決定します。 |
重複除外プロセッサおよび統合プロセッサの場合は、選択済。 強化プロセッサ、リンク・プロセッサおよび照合プロセッサの場合は、選択しない。 |
マージは、リンク(レコードのマージが発生しない)を除くすべての照合プロセッサのサブプロセッサです。
照合処理のオプション部分であるレコードのマージを使用すると、照合プロセスから「最適」な出力レコードを新たに作成できます。「最適」なレコードは、自動選択ルールと手動決定を組み合せて使用し、各照合グループの複数のレコードから構築されます。
たとえば、自動ルールを使用すると、照合プロセッサでは、照合グループで検出されたレコードの属性に対する最多値、入力日付を使用する最新値(「最終編集者」フィールドなど)、あるデータ・ソースを他のソースより優先させる空でない最初の値を出力できます。
属性の自動出力選択でエラーが発生すると、その属性は「Fail」ステータスとマークされます。失敗した属性が含まれるグループも「Fail」ステータスとマークされます。これらのエラーは、レビュー・ステージで手動で解決できます。たとえば、2つの異なるシステムから2つの重複レコードを統合するときに、自動ルールで値の選択に失敗した場合(照合グループ内のレコードに「最多」の値がない場合など)、ユーザーは、最適とみなされる値に応じて、一方のレコードから値(氏名など)を選択し、もう一方の関連レコードから別の値(電子メール・アドレスなど)を選択できます。「レビュー」画面から、選択エラーを含むレコードの出力をレビューできます。マージのサマリー結果ビューには、失敗した照合グループの数が示されるため、解決が必要なエラーの数を把握できます。
マージ・サブプロセッサの一般的な用途は、使用する照合プロセッサのタイプに応じて異なります。データ・ストリームの重複を除去したり、複数のデータ・ストリームを統合する場合(たとえば、データ移行プロジェクトの一環として行う場合、またはダイレクトメール用の顧客リストを準備するためにデータを再利用する場合など)は、自動マージ・ルールを使用して、重複のない出力レコードを作成するのが一般的です。
参照ソースからデータのセットを拡張する場合は、マージ・ルールを使用して、一致する参照レコードからデータを追加します。この場合、元の作業レコードは、信頼できる良質な情報で更新される場合と、単に新しい情報が追加される場合があります。
構成
重複除外照合プロセッサおよび統合照合プロセッサの場合、マージ構成に重複を除外した単純形式の出力を作成できるデフォルトの選択ルール・セットが含まれています。
強化プロセッサの場合、マージの構成に参照データから作業データを拡張するためのデフォルトの選択ルール・セットが含まれています。
これらのデフォルト構成はすべて単純で、照合プロセスから出力を簡単に作成できるように設計されています。マージ済出力レコードをより正確に構築する必要がある場合は、ニーズにあわせてルールを編集する必要があります。
マージ済出力のデフォルト・フォーマットを保持するには、ダイアログの下部にある「自動属性選択」オプションを選択します。出力内の属性は入力属性ごとに含まれているため、変更の可能性があることに注意してください。照合プロセッサから入力属性を追加または削除すると、デフォルト出力内の属性が変更されます。出力をカスタマイズするには、このボックスの選択を解除して、属性を追加または削除します。たとえば、属性を追加して出力をカスタム・フォーマットに変更すると、自動属性選択オプションが自動的に選択解除されることに注意してください。つまり、入力属性が変更されても、属性は出力に自動的に追加されることはありませんが、属性は必要に応じて手動で追加できます。
マージ済出力ルールの変更
マージ・ルールは、必要な出力属性ごとに個別に設定されます。
デフォルトでは、照合処理に入力されるすべてのデータ・ストリーム内にある同じ名称のどの属性にも、出力属性が含まれています。(重複除外の場合など、照合処理に提示されるデータ・ストリームが1つのみの場合は、すべての入力属性に対して出力属性が作成されます。)
|
注意: デフォルトの出力フォーマットで使用される出力セレクタは「最も一般的な値」です。これは、照合グループ内のすべてのレコードから、各属性の最も一般的な値が選択されることを意味します。最も一般的な値がない場合(たとえば、グループ内に2つのレコードがあり、1つのレコードは「FirstName」が「Jhon」で、もう1つのレコードは「John」の場合)、セレクタには、グループ内のレコードから空でない最初の値を選択するオプション(関連付けられている場合、空でない値を最初に使用)があります。デフォルトではこれが設定されていますが、設定を解除して、最も一般的な値がない場合はエラーが発生するようにもできます。 |
「MatchGroup」および「MatchGroupSize」には追加の出力属性があります。このため、すべての出力選択決定の完全な監査証跡を保持するために、マージ済出力と照合グループ出力を相互参照できます。これ以外にも、内部生成されたいくつかの属性を使用できます。
マージ済出力レコードのセットを変更する場合は、いくつかのオプションを使用できます。
| オプション | 説明 | デフォルト |
|---|---|---|
| マージ済出力の生成 | マージ済出力を生成するか、まったく生成しないかを決定します。たとえば、照合プロセスを完全に開発し、マージ済出力を使用しない場合は、マージ済出力を生成しないことでパフォーマンスを向上させることができます。 | 選択済 |
| 関連レコードを出力 | 関連付けられたレコードのグループのマージ済出力レコードを出力するかどうかを決定します。 | 選択済 |
| 関連のないレコードを出力 | 関連付けられていないレコードを出力するかどうかを決定します。 | 重複除外プロセッサおよび統合プロセッサの場合は、選択済。
強化プロセッサおよび照合プロセッサの場合は、選択しない。 |
属性の追加
新しい出力属性をマージ済出力に追加するには、ダイアログの下部にある「追加」ボタンを使用します。
これ以外にも、内部生成されたいくつかの出力属性を使用できます。
| 属性名 | 説明 | 属性値 |
|---|---|---|
| Match_Group_Status | 一致グループのステータス | 一致グループのステータス。
FAIL: 一致グループの出力選択時にエラーが発生した場合。 SUCCESS: 一致グループの出力選択時にエラーが発生しなかった場合。 |
| Reviewed_Flag | レビュー済ステータス | 一致グループのマージ済出力が手動でレビューされたかどうかを示す、一致グループのインジケータ。 |
| Review_User | レビューアの名前 | 一致グループのマージ済出力を最後にレビューしたユーザーの名前。 |
| Review_Date | 最新レビューの日付 | 一致グループのマージ済出力を最後にレビューした日付。 |
| コメント | 最新コメント | マージ済出力に対する最新コメント。 |
| Comment_User | 最新コメント提供者の名前 | 最新のコメントを記述したユーザーの名前。 |
| Comment_Date | 最新コメントの日付 | 最新コメントの日付。 |
これ以外に、新しいマージ済出力属性を作成(つまり、一致グループのレコードからデータをマージ)する手順は、次のとおりです。
出力属性の名称を指定します。
リストの下部からマージする値を選択します。
右側で、必要な出力セレクタを選択します。
データの選択元になる属性(1つまたは複数)を適切な順序で選択します。
|
注意: 使用可能な入力の数は、照合プロセッサに入力されるソース・データ・ストリームの数に応じて異なることに注意してください。出力セレクタには、特定の追加入力が必要な場合があります。たとえば、「最早値」および「最遅値」セレクタには、値の選択元になる最も古いレコードまたは最新のレコードの選択で使用する日付属性が必要です。 |
「オプション」タブで、出力セレクタのオプション(ある場合)を構成します。
Null値が含まれる出力属性を許容するかどうかを構成します。このオプションは、属性の出力が自動的に選択されたときにNull値の選択をエラーとみなすかどうかを決定します。出力属性でNullが許容(デフォルト)されている場合は、Null値が選択されても、出力セレクタのルールに従って属性に対してエラーは発生しません。
より複雑なルールを使用して出力データを選択する場合は、使用可能なセットに独自の出力セレクタを追加できます。
出力選択エラー
マージ済出力属性の出力セレクタで、一致グループの入力レコードから有効な値を1つ選択できない場合は、出力選択エラーが発生します。エラーなしのマージ済出力レコードが一致グループから出力できない場合(つまり、マージ済出力レコードに、すべての属性に対するすべての出力選択エラーが含まれる場合)、その一致グループには「失敗」グループとしてフラグが付けられます。この失敗フラグは、一致グループからのデータのマージには手動レビューが必要であることを示します。つまり、自動マージ・ルールで値を選択できなかった場合は、マージ済出力レコードを手動で解決できます。
値が正しく選択された場合でも(失敗したグループでも)出力されるため、選択エラーが発生したマージ済出力レコードが使用可能であることに注意してください。
出力選択エラーの例:
あいまいな選択
出力セレクタで出力値とみなすことができる値が複数検出され、自動的に選択する方法が設定されていない場合は、出力選択エラーが発生し、マージ済出力属性の値が選択されません。たとえば、一致グループの次のレコードから「Date of Birth」(生年月日)出力属性の最も一般的な値を選択する場合は、「関連付けられている場合、空でない値を最初に使用」オプションが選択されていないと、エラーが発生します。
| レコード | 生年月日 |
|---|---|
| A | 01/10/1975 |
| B | 01/10/1975 |
| C | 10/01/1975 |
| D | 10/01/1975 |
前述のケースでは、2つの値が2回ずつ発生しており、最も一般的な値が1つでないため、選択があいまいになります。
Null値を無効とする
マージ済出力属性にNull値を無効とするルールを適用すると、下流処理のためにこの属性の完全性を確保できます。
たとえば、出力セレクタの「Nullの許可」オプションを選択しないと、Postcode属性値が選択できなかったすべてのグループにフラグ付けできます。一致グループ内のすべてのレコードの「Postcode」属性がNull値の場合、Null以外の値は選択されないため、使用する出力セレクタに関係なく、選択エラーが発生します。
「計算」プロセッサを使用すると、数学演算を使用して数値を操作できます。計算プロセッサは、入力属性を操作し、操作の結果を使用して新しい出力属性を作成するため、変換プロセッサのファクト・タイプになります。
数値の検証には、数学的な計算が含まれる場合があります。たとえば、数量と単価を乗算した値は受注金額と等しい必要があるように、数値属性にはチェックが必要な数学的関係がある場合があります。
「計算」プロセッサを使用すると、このような値をチェックできる数学演算を作成できます。また、データのクレンジングや改善にも役立ちます。
「加算」プロセッサは数値を加算します。数値は、数値属性の数字から入力できます。定数値を合計に加算するか、配列をプロセッサに渡すこともできます。この場合、すべての要素が加算されます。
「加算」を使用して数値を合計したり、定数を数値に加算します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 数値属性の任意の数字。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「加算」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、各入力属性とともに、右側に新規のAddedValueが表示されます。
出力フィルタ
なし。
例
この例では、定数(25)がBALANCE属性に加算されます。
| BALANCE (昇順) | AddedValue |
|---|---|
| -74.28 | -49.28 |
| -11.6 | 13.4 |
| -0.01 | 24.99 |
| -0.01 | 24.99 |
| -0.01 | 24.99 |
「除算」プロセッサは、定数値で数値または番号配列属性を除算します。
除算で数値または番号配列属性を変換する必要がある場合に、「除算」を使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 定数値で除算する1つ以上の数値または番号配列属性。
|
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | 次のデータ属性が出力されます。
|
| フラグ | なし。 |
「除算」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、入力属性ともに、右側に新規のDividedValueが表示されます。
出力フィルタ
なし。
例
この例では、数値属性が2で除算されています。
| BALANCE (昇順) | DividedValue |
|---|---|
| 74.28 | 37.14 |
| 11.6 | 5.8 |
| 0.01 | 0.005 |
「乗算」プロセッサは、数値属性の値を乗算します。
「乗算」を使用して、数値を乗算します。
乗算した値は、ビジネス・ルールのチェックに使用できます。たとえば、Quantity属性とUnitPrice属性の値を乗算して、OrderValue属性の値が正しいことをチェックできます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 乗算する任意の数値属性または数値属性の配列(すべての要素が乗算されます)を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「乗算」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、各入力属性とともに、右側に新規のMultipliedValueが表示されます。
出力フィルタ
なし。
例
この例では、Units属性にPrice属性を乗算して、合計受注額を示す新しい属性(Order Value)を形成します。追加される属性のデフォルト名称(MultipliedValue)は、プロセッサ構成でOrder Valueに変更されています。
この新しい属性をチェックして、システムに格納されている受注の値と等しいかどうかを確認できます。
| 価格 | ユニット | 受注額 |
|---|---|---|
| 14.99 | 138.1 | 2070.119 |
| 14.99 | 138.15 | 2070.8685 |
| 14.99 | 138.33 | 2073.5667 |
| 14.99 | 138.4 | 2074.616 |
| 14.99 | 138.41 | 2074.7659 |
| 14.99 | 155.31 | 2328.0969 |
| 14.99 | 138.61 | 2077.7639 |
| 14.99 | 138.65 | 2078.3635 |
「端数処理」プロセッサを使用すると、数値または番号配列属性を指定の小数桁数に端数処理できます。
「端数処理」は、数値を低いレベルの精度に変換する必要がある場合(たとえば、異なる形式で数値を格納するシステムに数値を移行する場合)に使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 1つ以上の数値または番号配列属性。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | 次のデータ属性が出力されます。
|
| フラグ | なし。 |
|
注意: 「一番近い値に丸める」値を設定すると、「小数点以下桁数」オプションの値が上書きされ、値は指定の位(10の位など)の概数に端数処理されます(実質的に「小数点以下桁数」は0に設定されます)。 |
「端数処理」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、入力属性とともに、右側に新規に端数処理された値が表示されます。
出力フィルタ
なし。
例
この例では、顧客表のBALANCE属性を小数桁なしに端数処理します。
| BALANCE (昇順) | BALANCE.Rounded |
|---|---|
| 999999.99 | 1000000 |
| 74.28 | 74 |
| 11.6 | 12 |
| 0.01 | 0 |
「減算」プロセッサは、ある数値から別の数値を減算します。両方の数値は属性から入力されます。
「減算」を使用して、ある数値から別の数値を減算します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 減算される1つの数値属性、および減算する1つの数値属性を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「減算」トランスフォーマは、処理時にサマリー統計を表示しません。
「データ」ビューには、入力属性とともに、右側に新規に減算された値が表示されます。
出力フィルタ
なし。
例
この例では、Retail Price属性からDiscount属性を減算して、最終的な受注合計を求めます。デフォルトでは新しい属性の名称はSubtractedValueですが、この例ではOrder Totalに変更されています。
| Retail Price | Discount | Order Total |
|---|---|---|
| 211 | 20 | 191 |
| 189 | 18.9 | 170.1 |
| 149.99 | 29.99 | 120 |
| 204.99 | 18 | 186.49 |
「パーセンテージの計算」プロセッサは、ある数値の別の数値に対するパーセンテージ値を計算します。2つの数値の入力は、属性から取得されます。
「パーセンテージの計算」を使用して、ある数値を別のパーセンテージとして計算します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 計算される1つの数値属性、およびパーセンテージにする1つの数値属性を指定します。
|
| オプション | 次のデータ属性が出力されます。
|
| 出力 | 計算されたパーセンテージ値。入力がnullの場合、または最大値がゼロの場合、出力はnullになることがあります。 |
| フラグ | なし。 |
「パーセンテージの計算」トランスフォーマでは、処理に関するサマリー統計は表示されません。
出力フィルタ
なし。
例
| 値 | 最大 | 精度 | 出力値 |
|---|---|---|---|
| 50 | 100 | 0 | 50% |
| 5000 | 25000 | 0 | 20% |
| 22350 | 56800 | 2 | 39.35% |
| 198 | 0 | 2 | <Null> |
「製品データ」プロセッサ・ファミリを使用すると、EDQプロセスでOracle Enterprise Data Quality for Product Data (EDQ-P)の機能を使用できます。
これにより、単一環境でジョブ実行を処理し、単一の外部インタフェースを介して2つの製品をユニゾンで効率的に使用できます。
「製品データの処理」プロセッサは、Oracle Enterprise Data Quality for Product Data (EDQ-P)バージョン5.6.2のインスタンスにバージョン11gを介して接続し、本番のデータ・サービス・アプリケーション(DSA)を使用し、構造化されていない製品データの拡張や構造の追加などの製品データの処理をセマンティク・ルールによって行います。
|
注意: EDQサーバーがedqp.propertiesファイルを使用してEDQ-Pインスタンスに接続するように構成されている場合にのみ、このプロセッサが表示されます。このファイルは、次の設定を使用して、oedq_local_home/edqpフォルダで作成する必要があります。 |
server = [EDQ-Pサーバーの名前またはIPアドレス]
port = [EDQ-Pサーバーのhttpポート。インストール時のデフォルトでは、2229です]
batchsize = [一度にEDQ-Pに送信するレコード数。デフォルトは1000]
batchsizeが1000を超えると、メモリー不足エラーが発生する可能性があります。
「製品データの処理」プロセッサにより、EDQプロセス内でEDQ-Pを使用して、DSAによる製品データの解析および照合が可能になります。
次の表に、構成オプションを示します。
|
注意: このプロセッサでは常に再実行マーカーが表示されていますが、このマーカーは、構成が変更されたかどうかに関係なくプロセスが実行されるたびに完全に再実行されることを示します。これは、このプロセッサの後続のプロセッサも再実行が必要であることを意味します。これは、OEDQアプリケーションの外で変更が行われ、その変更に伴って後続の実行の結果が異なる可能性があるためです。 |
| 構成 | 説明 |
|---|---|
| 入力 | プロセッサへの入力は、選択したDSAに想定される入力に対応する必要があります。 |
| オプション | 次のオプションを指定します。
|
| 出力 | プロセッサからの出力属性は、「オプション」タブで選択されたDSAと出力ステップによって決定されます。属性のセットは、OEDQ-PのDSAの出力ステップの構成に対応します。 |
|
フラグ |
次のフラグが出力されます。
|
|
注意: このプロセッサはEDQ-Pを使用したレコードごとの処理に適しています。例: DSAを使用した製品説明の解析。照合など、レコード・セット全体で作業する必要のあるEDQ-P操作の場合、EDQ外部タスクを使用してEDQ-Pジョブを呼び出して、ファイルまたはデータベースのステージング済データ領域を使用してデータを共有することをお薦めします。EDQは本質的にマルチスレッドであるため、プロセッサは、EDQ-Pジョブのマルチインスタンス(スレッド当たり1つ)を呼び出すことで、使用するDSAを水平方向にスケール変更できると想定します。 |
「製品データの処理」プロセッサでは、処理に関するサマリー統計は表示されません。
「データ」ビューには、各入力属性とともに、右側に出力属性が表示されます。
出力フィルタ
出力フィルタを次に示します。
Returned – 選択したDSAおよび出力ステップから返されたレコード。
Not Returned – 入力したが、選択したDSAおよび出力ステップから返されなかったレコード。
例
この例では、OEDQ-P DSAを使用して、抵抗器に関連する構造化されていない製品説明を解析および拡張します。
| id | 説明 | edqp.Id | edqp.Description |
|---|---|---|---|
| 5001 | RESP ARY 5% 16 PIN 10OHM | 5001 | Resistor 10 Ohm 5% 16 Pin Array |
| 5002 | !gz9m;;) v!#Q 8jmASKqtfA7 | ||
| 5003 | mfax 75 ohm 1/4 w resp 20% | 5003 | Resistor 75 Ohm 20% 0.25 Watt Array |
| 5004 | array 16 pin 85 ohm 5% resp | 5004 | Resistor 85 Ohm 5% 16 Pin Array |
| 5005 | array 16 pin 62 Ohm 5% RESP | 5005 | Resistor 62 Ohm 5% 16 Pin Array |
| 5006 | array 16 pin 62 Ohm 5% RESP | 5006 | Resistor 62 Ohm 5% 16 Pin Array |
| 5007 | 1% 1/10 W THN CH2.21 OHM R... | 5007 | Resistor 2.21 Ohm 1% 0.1 Watt T... |
プロファイラは、データを理解するため、つまりデータの技術特性を検出し、データ内の問題を見つけ、ビジネス目的に適合しないデータを識別するために使用されます。
プロファイラは、データに固有のビジネス・ルールを使用しないという点で監査プロセッサとは異なります。むしろ、データを監査する際に使用できるビジネス・ルールの形成に使用できるデータ特性の検出に使用されます。
このため、プロファイラがデータをチェックすることはなく、出力フィルタ(有効レコードや無効レコードなど)もありません。単にデータを分析するためのもので、異なる特性を持つレコードを抽出するためのものではありません。
データ・プロファイリングは、データのビジネス・ルールとは何かまたはどうあるべきかという先入観なしに、データを最初から分析することで行われます。
|
注意: 本番環境でプロファイラを使用することはお薦めしません。また、データセットが500,000行および50列を超える場合、データセットのサンプリング後にプロファイラが使用される可能性があります。 |
文字プロファイラは、複数のテキスト属性に存在する重複しないすべての文字とその出現回数を検出するために使用します。
文字プロファイラは、テキスト属性内の予期しない文字を検出するのに特に役立ちます。このような文字に対しては、継続的なチェック(無効な文字のチェックを使用)、削除(ノイズ削除を使用)、または置換(文字の置換を使用)が必要になる場合があります。また、パースの前に、文字の不一致を正規化することも有益です。生成された結果は、前述の目的に応じて参照データに簡単に追加できます。また、データのソースに複数の国からのレコードが含まれる場合、文字プロファイラはデータ内の文字の種別を把握するのに役立ちます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 文字インスタンス検索の対象にする文字列属性を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
なし。 |
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 文字 | データ内で検出された文字。 |
| 10進数 | 10進数のUnicode文字参照。文字参照を参照データ内で直接使用できるように、文字参照の先頭にハッシュ文字が付いていることに注意してください。 |
| 16進数 | 16進数のUnicode文字参照。文字参照を参照データ内で直接使用できるように、文字参照の先頭に#xが付いていることに注意してください。 |
| 合計 | 選択したすべての入力属性で、当該の文字が出現した合計回数。 |
| レコード数 | 選択した入力属性で、その文字を含むレコードの数。 |
| [属性名] 合計 | 属性内での文字の出現回数。 |
| [属性名] レコード数 | その属性でその文字を含むレコードの数。 |
例
たとえば、文字プロファイラを使用して、Unicodeデータベースの複数言語データに含まれる異常な文字を検出しています。「合計」列を基準にして結果をソート(昇順)し、頻度の低い文字から順に表示しています。
含まれる属性プロファイラは、複数の属性があるレコードで、一方の属性値にもう一方の属性値が含まれることが多い属性のペアを検索します。しきい値オプションを使用して、一方の属性値にもう一方の属性値が含まれるレコードのパーセンテージに基づき、属性のペアに関連があるかどうかを判断します。
含まれる属性プロファイラは、関連がある属性、または関連がある必要がある属性を検索するために使用します。属性に強い関連性がある場合は、冗長な属性である可能性があります。
または、属性に関連があると考えられるが、その関係が壊れている場合、つまり、一方の列値は空白だが、もう一方の列値から導出できる場合もあります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 包含属性の関連性の調査対象にする属性を指定します。 |
| オプション | なし。 |
|
含まれる属性のしきい値(%) |
「次を含む」を使用して2つの属性を照合し、2つの属性に関連があるとみなされて結果に表示されるために必要な値の一致率を制御します。パーセントで指定します。デフォルト値は80%です。指定できる値は、50%以上、100%以下です。 |
|
大文字/小文字を区別しない |
一方の属性値にもう一方の属性値が含まれるかどうかをチェックするときに、大文字と小文字の別を無視するかどうかを制御します。「はい」または「いいえ」を指定します。デフォルトはYesです。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
なし。 |
含まれる属性プロファイラでは、統計を生成するためにレコードのバッチが必要です。つまり、属性のペアに意味のある関係があることを検出するには、完了まで実行される必要があります。したがって、データ・セット全体が処理されるまで結果が生成されないため、このプロセッサはリアルタイム・レスポンスが必要なプロセスには適していません。
リアルタイム・データ・ソースからのトランザクションのバッチに対して実行した場合、リーダー・プロセッサで構成されたコミット・ポイント(トランザクションまたは制限時間)に到達すると処理が終了します。
含まれる属性プロファイラでは、高頻度で一方の属性値にもう一方の属性値が含まれ、それぞれの値が関連しているパーセンテージが高い属性のペアについて、サマリー・ビューが表示されます。次の表に、最上位レベルのビューに表示される関連する属性の各ペアに関する統計を示します。
| 統計 | 説明 |
|---|---|
| 含まれる | 関連する両方の属性の値が同じであるレコードの数。 |
| 含まれない | 関連する属性の値が同じでないレコードの数。 |
「追加データ」ボタンをクリックすると、前述の統計が、分析対象レコードに対するパーセンテージとして表示されます。
属性のペアが完全に一致したレコードの数をドリルダウンすると、一致した各値の出現頻度の明細が表示されます。再度ドリルダウンすると、当該のレコードが表示されます。
あるいは、属性のペアが等しくないレコードの数をドリルダウンすると、当該のレコードが直接表示されます。属性の間に関係が存在する必要がある場合、それらのレコードでは関係が壊れています。
例
この例では、複数の属性の包含関係をチェックしています。EmailAddressにはFirstNameが含まれることが多いため、FirstName属性とEmailAddress属性の間に関係が検出されています。サマリー・データは次のとおりです。
| フィールド1 | フィールド2 | 含まれる(降順) | 含まれない |
|---|---|---|---|
| EmailAddress | FirstName | 1829 | 172 |
EmailAddress属性にFirstName属性が含まれる1829個のレコードをドリルダウンすると、次のビューに、関係が検出されたレコードの各ペアがすべて表示されます。
| EmailAddress | FirstName | カウント |
|---|---|---|
| LINDA.COOKSON@M-AND-I.COM | LINDA | 2 |
| PAUL.MARKAR@DISCOUNT-FEVER.COM | PAUL | 2 |
| SHEILA.ROBINSON@SUNRISE-HOLIDAYS.COM | SHEILA | 2 |
| NORMAN.SCANLON@ECA.COM | NORMAN | 2 |
| TONY.GIBSON@TOMBURN.COM | TONY | 2 |
| PAULINE.BEEDHAM@BLUEYONDER.CO.UK | PAULINE | 2 |
| ROWLAND.BROWN@BTINTERNET.COM | ROWLAND | 2 |
| JOHN@DARWINS.COM | JOHN | 2 |
| TEST@TEST.COM | TEST | 2 |
| EILEEN_BEARD@WILSONS_PENARTH.COM | EILEEN | 1 |
| BRIGETTE.WALLACE@UNIQUE-INTERIORS.COM | BRIGETTE | 1 |
| MICHAEL.CONNOLLY@GEMINI-VISUALS.COM | MICHAEL | 1 |
| JOYCE.AITKEN@RDM-ELECTRONICS.COM | JOYCE | 1 |
| JOANNA.TEMLETT@BTOPENWORLD.COM | JOANNA | 1 |
| MAHAJAN.DEBELLOTT@NTLWORLD.COM | MAHAJAN | 1 |
データ型プロファイラは、属性値が一貫したデータ型(テキスト、数値または日付)に準拠しているかどうかを評価するために、複数の属性の内容を分析します。
データ型プロファイラは、データ内の各属性で検出されたデータ型を把握し、データ型が一貫しているかどうかを評価するために使用します。これにより、たとえばデータが誤ったフィールドに入力されたり、データ型制約と異なるデータ型で入力された場合のように、データ型が正しくない値を検出します。
データ型プロファイラは、次の3つの基本データ型を探します。
日付: 構成可能な日付書式のリストと一致する値全体
数値: 完全な数値(12、56.2、-0.087など)
テキスト: その他の値(テキスト文字列、テキストと数値が混合した値など)。
Null値は、前述のデータ型とは別にカウントされます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | データ型の一貫性の分析対象にする属性を指定します。 |
| オプション | 指定できるオプションを記述します。 |
|
認識される日付書式のリスト |
様々な書式の日付を認識します。参照データ(日付書式カテゴリ)として指定します。デフォルト値は*「日付書式」です(注意を参照)。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
なし。 |
データ型チェックで使用する日付書式参照データは、標準のJava 1.6.0以降のSimpleDateFormat APIに準拠している必要があります。
日付が正しく認識されるように参照データ・エントリを追加する方法の詳細は、Javaのオンライン・ドキュメントを参照してください(http://java.sun.com/j2se/1.5.0/docs/api/java/text/SimpleDateFormat.html)。
|
注意: 日付書式参照データに含まれる有効な日付書式yyyyMMddは、このプロセッサでは認識されません。これは、この書式に英字やセパレータが含まれていないため、8桁の数値と区別できないためです。 |
|
注意: データ型プロファイラでは、プロセッサに入力されたレコードのセットについて計算された一貫性のパーセンテージの統計が生成されます。リアルタイム・モニタリング・プロセスでは、このセットはリーダーの構成可能なコミット・ポイント(複数のトランザクション、または制限時間として定義される)によって制限されます。データ型プロファイラを使用するプロセスがリアルタイム・レスポンス・プロセスとして実行されると、レコードは1つずつ処理されるため、この一貫性の測定は常に100%になります。 |
次の表に、このプロファイラによって生成される統計情報を示します。分析されたレコードの数に加えて、属性ごとに次の統計が結果ブラウザに表示されます。
| 統計 | 説明 |
|---|---|
| テキスト | テキスト書式として認識された値の数。 |
| 日付 | 日付書式として認識された値の数。 |
| 数値 | 数値書式として認識された値の数。 |
| %整合性 | 各属性のデータ型の一貫性の計算値。つまり、最も多いデータ型と一致したと認識された値のパーセンテージです。 |
例
この例では、顧客レコード表のすべての属性に対してデータ型プロファイラを実行します。
表1-123 データ型プロファイラの例
| 入力フィールド | 合計数 | テキスト書式 | 数値書式 | 日付/時刻書式 | Null値 | 整合性% |
|---|---|---|---|---|---|---|
|
CU_ACCOUNT |
2001 |
2000 |
0 |
0 |
1 |
>99.9 |
|
TITLE |
2001 |
1862 |
0 |
0 |
139 |
93.1 |
|
NAME |
2001 |
2000 |
0 |
0 |
1 |
>99.9 |
|
GENDER |
2001 |
1853 |
0 |
0 |
148 |
92.6 |
|
BUSINESS |
2001 |
1670 |
0 |
0 |
331 |
83.5 |
|
ADDRESS1 |
2001 |
1999 |
0 |
0 |
2 |
>99.9 |
|
ADDRESS2 |
2001 |
1922 |
0 |
0 |
79 |
96.1 |
|
ADDRESS3 |
2001 |
1032 |
0 |
0 |
969 |
51.6 |
|
POSTCODE |
2001 |
1765 |
0 |
0 |
236 |
88.2 |
|
電子メール |
2001 |
1936 |
0 |
0 |
65 |
96.8 |
|
ACC_MGR |
2001 |
1996 |
0 |
0 |
5 |
99.8 |
|
DT_PURCHASED |
2001 |
0 |
0 |
1998 |
3 |
99.9 |
|
DT_ACC_OPEN |
2001 |
0 |
0 |
1998 |
3 |
99.9 |
日付プロファイラは、日付属性を分析し、その属性の日付値の分布を次の単位で表示します。
該当週の日
該当月の日
年単位の日
月
年
「有効/Null」ビューも表示されます。日付属性のデータ値は有効な日付である必要があるため、無効な日付はNullになるように定義されています。
日付プロファイラは、日付属性に異常なトレンドがあるかどうかを調べるために使用します。たとえば、実際の日付値のかわりに一般的に使用されてきた「01/01/1970」のようなデフォルト日付があるかどうかを調べます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 単一の日付属性を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性があります。
前述の方法で日付値を分割すると、後続の処理で便利になる場合があります。たとえば、データを書き出して、各属性の日、月および年の値に基づいて照合処理を実行する場合などです。 |
|
フラグ |
なし。 |
日付プロファイラは、日付値を使用してレコードのバッチのトレンドを調べます。したがって、統計を生成するにはレコードのバッチが必要です。処理が完了するまで結果が生成されないため、このプロファイラはリアルタイム・レスポンスが必要なプロセスには適していません。
リアルタイム・データ・ソースからのトランザクションのバッチに対して実行した場合、リーダー・プロセッサで構成されたコミット・ポイント(トランザクションまたは制限時間)に到達すると処理が終了します。
次の表に、「曜日」ビューに表示される統計を示します。
| 統計 | 説明 |
|---|---|
| 曜日 | 曜日(Sunday - Saturday) |
| カウント | 日付がその曜日に当たるレコードの数。 |
| % |
日付がその曜日に当たるレコードのパーセンテージ。 |
次の表に、「日付」ビューに表示される統計を示します。
| 統計 | 説明 |
|---|---|
| 月における日 | 該当月の中での日付(1 - 31)。 |
| カウント | 日付がその日付(月)に当たるレコードの数。 |
| % |
日付がその日付(月)に当たるレコードのパーセンテージ。 |
次の表に、「日付(年)」ビューに表示される統計を示します。
| 統計 | 説明 |
|---|---|
| 年における日 | 該当年の中での日付(例: 1st Jan) |
| カウント | 日付がその日付(年)に当たるレコードの数。 |
| % |
日付がその日付(年)に当たるレコードのパーセンテージ。 |
次の表に、「月」ビューに表示される統計を示します。
| 統計 | 説明 |
|---|---|
| 月 | 月(January - December)。 |
| カウント | 日付がその月に属するレコードの数。 |
| % |
日付がその月に属するレコードのパーセンテージ。 |
次の表に、「年」ビューに表示される統計を示します。
| 統計 | 説明 |
|---|---|
| 年 | 年。 |
| カウント | 日付がその年に属するレコードの数。 |
| % |
日付がその年に属するレコードのパーセンテージ。 |
次の表に、「有効/Null」ビューに表示される統計を示します。
| 統計 | 説明 |
|---|---|
| 有効 | 分析対象の日付属性内の日付が有効なレコードの数。 |
| Null | 分析対象の日付属性内の日付がnull値のレコードの数。 |
「有効/Null」ビューで「追加情報」ボタンをクリックすると、分析されたレコードの総数に対するパーセンテージが統計として表示されます。
例
この例では、日付プロファイラは、顧客の最終支払日を格納している属性について、日付の分布を分析します。この場合、ユーザーは年ごとの日付の分布を把握することを最も重視しています。年ごとのサマリーを次に示します。
| 年 | カウント | % |
|---|---|---|
| 2003 | 369 | 18.4 |
| 2002 | 303 | 15.1 |
| 2001 | 250 | 12.5 |
| 2000 | 219 | 10.9 |
| 1999 | 174 | 8.7 |
| 1998 | 159 | 7.4 |
| 2004 | 152 | 7.6 |
| 1997 | 126 | 6.3 |
| 1996 | 103 | 5.1 |
| 1994 | 73 | 3.6 |
| 1995 | 42 | 2.1 |
| 1993 | 27 | 1.3 |
等しい属性プロファイラは、複数の属性があるレコードで、値が等しい頻度が高い属性のペアを検索します。たとえば、 FirstName属性とGivenName属性の両方が格納されている場合、これらの値は通常は同じです。しきい値オプションを使用して、各属性の値が同一であるケースのパーセンテージに基づき、属性のペアに関連があるかどうかを判断します。
等しい属性プロファイラは、冗長である可能性がある属性、または、通常は値が等しいが異なる場合もある属性のペアを見つけるために使用します。等しい属性プロファイラは、関連する2つの属性で、その2つの値が相互に関連している必要があるが実際には関連していない誤ったデータを検索する場合にも役立ちます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 等価属性の関連性の調査対象にする属性を指定します。 |
| オプション | 指定できるオプションを記述します。 |
|
等しい属性のしきい値 |
2つの属性に関連があるとみなされて結果に表示されるために必要な、2つの属性の値の同一率を制御します。パーセントで指定します。デフォルトは80%です。指定できる値は、50%以上、100%以下です。 |
|
nullを等しいものとして処理しますか。 |
Null値のペアを等しいとみなすかどうか、つまり、前述の等しい属性のしきい値を評価する際に対象とするかどうかを制御します。「はい」または「いいえ」で指定します。デフォルトは「はい」です。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
なし。 |
等しい属性プロファイラでは、統計を生成するためにレコードのバッチが必要です。つまり、属性のペアに意味のある関係があることを検出するには、完了まで実行される必要があります。したがって、データ・セット全体が処理されるまで結果が生成されないため、このプロセッサはリアルタイム・レスポンスが必要なプロセスには適していません。
リアルタイム・データ・ソースからのトランザクションのバッチに対して実行した場合、リーダー・プロセッサで構成されたコミット・ポイント(トランザクションまたは制限時間)に到達すると処理が終了します。
等しい属性プロファイラでは、値が等しい場合のパーセンテージが高い属性のペアについてサマリー・ビューが表示されます。次の表に、関連する(等しい)属性の各ペアに関する統計を示します。
| 統計 | 説明 |
|---|---|
| 等しい | 関連する両方の属性の値が同じであるレコードの数。 |
| Nullペア | 関連する両方の属性の値がnullであるレコードの数。
注意: 「nullを等しいものとして処理しますか。」オプションを選択した場合は、nullのペアが「等しい」統計に含まれるため、この統計はゼロになります。 |
| 等しくない | 関連する属性の値が同じでないレコードの数。 |
「追加データ」ボタンをクリックすると、前述の統計が、分析対象レコードに対するパーセンテージとして表示されます。
属性のペアが完全に一致したレコードの数をドリルダウンすると、一致した各値の出現頻度の明細が表示されます。再度ドリルダウンすると、当該のレコードが表示されます。
あるいは、属性のペアが等しくないレコードの数をドリルダウンすると、当該のレコードが直接表示されます。属性の間に関係が存在する必要がある場合、それらのレコードでは関係が壊れています。
例
この例では、デフォルト構成を使用して顧客表を分析し、相互に等しい頻度が高い属性があるかどうかを調べます。等しい属性プロファイラは、DT_PURCHASED属性とDT_ACC_OPEN属性が通常は等しいことを検出しています。
| フィールド1 | フィールド2 | 等しい | Nullペア | 等しくない |
|---|---|---|---|---|
| DT_PURCHASED | DT_ACC_OPEN | 1983 | 16 | 11 |
2つのフィールドが等しいレコードの数をドリルダウンすると、値が等しいすべてのペアを表示できます。
| DT_ACC_OPEN | DT_PURCHASED | カウント |
|---|---|---|
| 03/02/1997 | 03/02/1997 | 5 |
| 30/11/1993 | 30/11/1993 | 4 |
| 09/08/1996 | 09/08/1996 | 4 |
| 10/09/1993 | 10/09/1993 | 4 |
| 07/12/1992 | 07/12/1992 | 4 |
| 07/08/1996 | 07/08/1996 | 4 |
| 25/05/1993 | 25/05/1993 | 4 |
| 24/02/1994 | 24/02/1994 | 4 |
| 21/11/1996 | 21/11/1996 | 4 |
| 17/12/1996 | 17/12/1996 | 4 |
| 13/11/1992 | 13/11/1992 | 4 |
| 27/08/1992 | 27/08/1992 | 4 |
| 05/10/1992 | 05/10/1992 | 4 |
| 27/09/1992 | 27/09/1992 | 3 |
頻度プロファイラは、各属性を調べて、各属性に含まれる値を出現頻度に基づいて集計して返します。
頻度プロファイラは、データ内で出現頻度の高い値と低い値を検出するのに使用する、重要なプロファイリング・ツールの1つです。頻度プロファイリングの結果を使用して各データ属性の有効値と無効値の参照リストを構築し、検証に利用できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 値の出現頻度の分析対象にする属性を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
なし。 |
頻度プロファイラでは、統計を生成するためにレコードのバッチが必要です(たとえば、分析対象の各属性で値が出現する頻度を調べるために)。したがって、処理が完了するまで結果が生成されないため、これはリアルタイム・レスポンスが必要なプロセスには適していません。
リアルタイム・データ・ソースからのトランザクションのバッチに対して実行した場合、リーダー・プロセッサで構成されたコミット・ポイント(トランザクションまたは制限時間)に到達すると処理が終了します。
次の表に、頻度プロファイラの分析対象の各属性に関する統計を示します。結果ブラウザでは、各属性が個別のタブに表示されることに注意してください。
| 統計 | 説明 |
|---|---|
| 値 | 検出された値。 |
| カウント | 属性内でその値が出現する回数 |
| % |
分析対象のレコードの中で、属性にその値を含むレコードのパーセンテージ。 |
例
この例では、顧客レコード表のTitle属性に対して頻度プロファイラを実行しています。次のサマリー・ビューが表示されます。
| 値 | カウント | % |
|---|---|---|
| Mr | 816 | 40.8 |
| Ms | 468 | 23.4 |
| Mrs | 309 | 15.4 |
| Miss | 251 | 12.5 |
| 139 | 6.9 | |
| Dr | 15 | 0.7 |
| Prof. | 1 | <0.1 |
| Col. | 1 | <0.1 |
| Rev | 1 | <0.1 |
「カウント」列を基準にビューをソートすると、分析対象の各属性で出現頻度が最も高い値と最も低い値をすばやく把握でき、有効値と無効値の参照データ・リストを構築できます。
長さプロファイラは、任意の数の属性でデータ値を分析し、その長さを文字数で測定します。
長さプロファイラを使用すると、属性内に不適切な長さの値があるかどうかを簡単に検出できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 長さの測定の対象にする文字列属性を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。結果ブラウザでは、各属性が個別のタブに表示されることに注意してください。
| 統計 | 説明 |
|---|---|
| 値 | 検出された値。 |
| カウント | 属性内でその値が出現する回数 |
| % |
分析対象のレコードの中で、属性にその値を含むレコードのパーセンテージ。 |
例
この例では、顧客レコード表のCU_ACCOUNT属性で長さを測定しています。
サマリー・ビュー:
| 長さ | カウント | % (降順) |
|---|---|---|
| 13 | 332 | 16.5 |
| 12 | 304 | 15,1 |
| 14 | 293 | 14.6 |
| 15 | 243 | 11.9 |
| 11 | 217 | 10.8 |
| 16 | 197 | 9.8 |
| 10 | 136 | 6.8 |
| 17 | 103 | 5.1 |
| 9 | 60 | 3.0 |
| 18 | 44 | 2.2 |
| 19 | 20 | 1.0 |
| 8 | 13 | 0.6 |
| 20 | 11 | 0.5 |
| 7 | 10 | 0.5 |
| 21 | 9 | 0.4 |
| 6 | 6 | 0.3 |
| 22 | 4 | 0.2 |
ドリルダウン・ビュー:
| CU_ACCOUNT | CU_ACCOUNT.CharLength |
|---|---|
| 00-23603-JD | 11 |
| 00-23615-PB | 11 |
| 00-23624-PB | 11 |
| 00-23631-JD | 11 |
| 00-23642-SH | 11 |
| 00-23658-SH | 11 |
| 00-23667-SH | 11 |
| 00-23675-SH | 11 |
最大/最小プロファイラは、各属性のデータの極値を調べて、次の値を返します。
最短値
最長値
最低値
最高値
最大/最小プロファイラは、最初にデータの概要を把握するために使用します。最大/最小プロファイラを使用すると、データがその長さや有効値の制限に準拠しているかどうかについて概要をすばやく把握できます。これにより、たとえば想定より大きい/小さい数値、想定より早い/遅い日付値、「#」などの無効な文字のみで構成されたテキスト値、「aaa」や「zzz」のような不正データなどの外れ値(明らかに範囲外の値)を検出できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | データの最大値および最小値検出の対象にする属性を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
最大/最小プロファイラでは、有益な統計を生成するためにレコードのバッチが必要です。したがって、処理が完了するまで結果が生成されないため、これはリアルタイム・レスポンスが必要なプロセスには適していません。
リアルタイム・データ・ソースからのトランザクションのバッチに対して実行した場合、リーダー・プロセッサで構成されたコミット・ポイント(トランザクションまたは制限時間)に到達すると処理が終了します。
次の表に、このプロファイラによって各属性ごとに生成される統計を示します。
| 統計 | 説明 |
|---|---|
| 最小長 | 属性の最短値の文字数。 |
| 最大長 | 属性の最長値の文字数。 |
| 最小値 | 属性の最低値。
数値属性の場合は、最小の数値です。 日付属性の場合は、最早日付です。 テキスト属性の場合は、アルファベット順の最初の値です。 この分析ではNull値は無視されますが、その他のタイプの非データ(たとえばスペースのみで構成された値)は無視されません。 |
| 最大値 | 属性の最高値。
数値属性の場合は、最大の数値です。 日付属性の場合は、最新日付です。 テキスト属性の場合は、アルファベット順の最後の値です。 この分析ではNull値は無視されますが、その他のタイプの非データ(たとえばスペースのみで構成された値)は無視されません。 |
「追加情報」ボタンをクリックすると、前述の統計とともに、最短値、最長値、最小値および最大値を含むレコードの数とパーセンテージが表示されます。
例
この例では、顧客レコード表のすべての属性に対して最大/最小プロファイラを実行しています。
表1-124 最大/最小プロファイラ
| 入力フィールド | 合計数 | 最小長 | 最大長 | 最小値 | 最大値 |
|---|---|---|---|---|---|
|
CU_NO |
2010 |
2 |
6 |
10 |
875825 |
|
CU_ACCOUNT |
2010 |
7 |
12 |
00-0-XX |
OO-24282-LR |
|
TITLE |
2010 |
1 |
12 |
1 |
The Reverend |
|
NAME |
2010 |
4 |
29 |
# ADAMS |
aaaaaaaaa |
|
GENDER |
2010 |
1 |
1 |
1 |
M |
|
BUSINESS |
2010 |
2 |
41 |
Stoke Newington Town Hall |
e-sites.co.uk |
|
ADDRESS1 |
2010 |
1 |
50 |
(Brassfounders) LD, Coursington Road |
kjhkg |
|
ADDRESS2 |
2010 |
1 |
31 |
WARRINGTON |
jhgfhj |
|
ADDRESS3 |
2010 |
1 |
22 |
Aberdeen |
jhvgj |
|
POSTCODE |
2010 |
1 |
8 |
1P1 3HS |
gjhgj |
|
AREA_CODE |
2010 |
1 |
4 |
0 |
2920 |
|
TEL_NO |
2010 |
1 |
7 |
1 |
4227051 |
|
電子メール |
2010 |
1 |
50 |
5 |
zoe.peckham@btopenworld.com |
|
ACC_MGR |
2010 |
2 |
3 |
22 |
WH |
|
DT_PURCHASED |
2010 |
5 |
10 |
01/01/1995 |
Brian |
|
DT_ACC_OPEN |
2010 |
5 |
10 |
01/01/1995 |
Brian |
|
DT_LAST_PAYMENT |
2010 |
19 |
19 |
01-Jan-1970 00:00:00 |
21-Mar-2004 00:00:00 |
|
DT_LAST_PO_RAISED |
2010 |
19 |
19 |
01-Jan-1970 00:00:00 |
14-Feb-2004 00:00:00 |
|
BALANCE |
2010 |
1 |
10 |
-999999 |
410.5 |
数値プロファイラは、数値属性の数値をユーザー定義バンドにソートします。
このプロファイラは、数値の分布を把握して、想定範囲外にある値を検出するために、数値属性に対して使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 単一の数値属性を指定します。 |
| オプション | 次のオプションを指定します。
デフォルトの数値バンド参照データはサンプル目的であるため、ほとんどのタイプの数値データには適しません。これは、パーセント値を分析するときに役立つ場合があります。 特定のバンドに該当しない(つまり、そのバンドより低すぎるか高すぎる)数値は、「範囲外」に分類されることに注意してください。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| バンド最小値 | バンドの最小値。 |
| バンド名 | 参照データに定義されているバンドの名前。 |
| カウント | そのバンド内のレコードの数。 |
範囲外の数値(つまり、参照データ内に構成された数値バンド・セットの範囲外の数値)は、それぞれ結果ブラウザの個別の行に表示されます。
例
この例では、数値プロファイラがBALANCE属性の値を分析し、次のサマリー結果を出力しています。
デフォルトの*数値バンド参照データが使用されたことに注意してください。
サマリー・ビュー:
| バンド名 | バンド最小 | カウント | % |
|---|---|---|---|
| 0-9 | 0 | 1997 | 98.8 |
| 101-9999 | 101 | 1 | <0.1 |
| 範囲外 | 23 | 1.1 |
数値プロファイラは、データ内でバンド内の数値が1つ以上検出されたバンドの結果のみ出力します。これにより、多数のバンドを含む参照データを使用しながら、焦点を絞った結果を参照できます。
ドリルダウン・ビュー:
| AREA_CODE | BandName |
|---|---|
| 2070 | 100-9999 |
| 2070 | 100-9999 |
| 2070 | 100-9999 |
| 2070 | 100-9999 |
| 2070 | 100-9999 |
| 2070 | 100-9999 |
| 2070 | 100-9999 |
| 2070 | 100-9999 |
パターン・プロファイラは、任意の数の文字列属性でデータ値を分析し、文字タイプの順序に従ってパターンを割り当てます。たとえば、デフォルトのパターン・マップ参照リストを使用した場合、値「10 Lowestoft Lane」にはパターン「NN_aaaaaaaaa_aaaa」が割り当てられます。
|
注意: デフォルトの*基本のトークン化マップは、かわりの*Unicodeの基本のトークン化マップや*Unicode文字パターン・マップと同様に、Latin-1エンコード・データで使用するように設計されています。これらのマップがデータの文字エンコーディングに適していない場合は、たとえばマルチバイトのUnicode (16進数)文字参照などを考慮に入れた新しいマップを作成して使用できます。 |
このプロファイラは次に、各属性で各パターンが出現した回数をカウントして、その結果を表示します。
パターン・プロファイラは、データのパターンを特定し、有効パターンと無効パターンの参照リストを作成するために使用します。この参照リストは、パターン・チェック・プロセッサを使用してデータを継続的に検証するために利用できます。
次の各表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | データのパターンの分析対象にする文字列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
デフォルトの標準パターン・マップでは、文字が次のようにマップされます。
| 文字タイプ | パターンの表現 |
|---|---|
| 英字(a-zまたはA-Z) | a |
| 数字(0-9) | N |
| 句読点文字(セミコロン、カンマなど) | その文字のままで表されます。 |
| 制御文字(キャリッジ・リターンなど) | C |
| スペース | _ |
文字パターン・マップで認識されない文字は、各パターン内で疑問符(?)で表現されます。
必要に応じて、別の文字パターン・マップを使用して文字をマップできます。たとえば、「x」や「z」など出現頻度の低い文字は、出現頻度の高い文字とは異なる表現にできます。
| 構成 | 説明 |
|---|---|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって分析される各属性ごとに生成される統計を示します。
| 統計 | 説明 |
|---|---|
| パターン | 各値に対して生成されたパターン。 |
| 長さ | 生成された各パターンの長さ(つまり各値の文字数)。 |
| カウント | パターンと一致した属性の値を含むレコードの数。 |
| % |
パターンと一致した属性の値を含むレコードのパーセンテージ。 |
例
この例では、パターン・プロファイラを使用して、顧客レコード表のすべての属性でパターンを分析します。各属性ごとに、次のタイプのビューが生成されます。
| パターン | 長さ | カウント | % |
|---|---|---|---|
| NN-NNNNN-aa | 11 | 1681 | 84.0 |
| N-NNNN-aa | 10 | 310 | 15.5 |
| aa-NNNNN-aa | 11 | 4 | 0.2 |
| NN-NNN-aa | 9 | 2 | <0.1 |
| NN-N-aa | 7 | 1 | <0.1 |
| NN-NNNNN-Na | 11 | 1 | <0.1 |
| 10 | 1 | <0.1 | |
| NN-NNNNN | 9 | 1 | <0.1 |
「カウント」列を基準にビューをソートすると、データ内で出現頻度が最も高いパターンと最も低いパターンをすばやく把握でき、有効パターンと無効パターンのリストを構築してパターン・チェックで使用できます。
クイック統計プロファイルは、複数のレコードまたはトランザクションについて、次の点に関する基本的な品質メトリックを提供します。
候補キー列
完全性データと欠落データ
重複
値の一意性と多様性
各入力属性は個別にプロファイリングされます。
クイック統計は、データとその品質の基本的な全体像を把握するのに役立ちます。
ドキュメントやメタデータでは、情報が欠落したり、不完全な情報、古い情報または信頼できない情報が含まれていることがよくあります。データ自体を分析してデータの明確な全体像を把握することが重要です。これにより、誤った前提に基づいて誤った判断をすることを防ぎます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | クイック・プロファイリング統計の取得の対象にする属性を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
クイック統計プロファイラでは、統計を生成するためにレコードのバッチが必要です(たとえば、分析対象の属性ごとに重複値の数を調べるために)。したがって、処理が完了するまで結果が生成されないため、これはリアルタイム・レスポンスが必要なプロセスには適していません。
リアルタイム・データ・ソースからのトランザクションのバッチに対して実行した場合、リーダー・プロセッサで構成されたコミット・ポイント(トランザクションまたは制限時間)に到達すると処理が終了します。
次の表に、このプロファイラによって各属性ごとに生成される統計を示します。
| 統計 | 説明 |
|---|---|
| データあり | その属性にデータを含むレコードの数。 |
| データなし | その属性にデータを含まないレコードの数。これには、NULL値を含むレコードや、その他のタイプの非データ(スペースのみ、印刷不可能な文字など)を含むレコードも含まれます。数値をドリルダウンすると、検出された非データのタイプの明細が表示されます。 |
| シングルトン | その属性で1回のみ検出された値を含むレコードの数。 |
| 重複 | その属性で複数回検出された値を含むレコードの数。 |
| 個別 | その属性で検出された異なる値の数。数値をドリルダウンすると、これらの値の明細が出現頻度別に表示されます。 |
| コメント | クイック統計プロファイラの結果に基づいた自動コメント。後述の説明を参照してください。 |
「追加情報」ボタンをクリックすると、前述の統計が、分析対象レコードの総数に対するパーセンテージとして表示されます。
自動コメント
自動コメントは、データ内で関心を集める可能性がある部分を強調するために生成されます。例:
属性が100%完全で一意の場合は、候補キーとして識別されます
属性が100%完全に近く一意の場合は、破損した可能性があるキーとして強調表示されます
属性が100%完全に近い(空白を含むことはできない)場合は、ユーザーにnullの調査を要求するコメントが表示されます
属性が100%一意に近い(重複が許容されない)場合は、ユーザーに重複の調査を要求するコメントが表示されます
属性に重複しない値が1つのみ含まれている場合は、その属性が冗長である可能性があることを示すコメントが表示されます
これらのコメントが複数適用されると、各コメントが連結されます。
例
この例では、クイック統計プロファイラを使用して、最初に顧客レコード表の概要を把握します。
表1-125 クイック統計プロファイラの例
| 入力フィールド | レコード合計 | データあり | データなし | シングルトン | 重複 | 固有の値 |
|---|---|---|---|---|---|---|
|
CU_NO |
2001 |
2000 |
1 |
1997 |
3 |
1998 |
|
CU_ACCOUNT |
2001 |
2000 |
1 |
2000 |
0 |
2000 |
|
TITLE |
2001 |
1862 |
139 |
3 |
1859 |
8 |
|
NAME |
2001 |
2000 |
1 |
1980 |
20 |
1990 |
|
GENDER |
2001 |
1853 |
148 |
0 |
1853 |
2 |
|
BUSINESS |
2001 |
1670 |
331 |
1629 |
41 |
1649 |
|
ADDRESS1 |
2001 |
1999 |
2 |
1926 |
73 |
1954 |
|
ADDRESS2 |
2001 |
1921 |
80 |
554 |
1367 |
839 |
|
ADDRESS3 |
2001 |
1032 |
969 |
278 |
754 |
379 |
|
POSTCODE |
2001 |
1762 |
239 |
1604 |
158 |
1672 |
|
AREA_CODE |
2001 |
1884 |
117 |
64 |
1820 |
270 |
|
TEL_NO |
2001 |
1994 |
7 |
1875 |
119 |
1934 |
|
電子メール |
2001 |
1936 |
65 |
1904 |
32 |
1920 |
|
ACC_MGR |
2001 |
1996 |
5 |
0 |
1996 |
30 |
|
DT_PURCHASED |
2001 |
1998 |
3 |
1090 |
908 |
1499 |
|
DT_ACC_OPEN |
2001 |
1998 |
3 |
1093 |
905 |
1500 |
|
DT_LAST_PAYMENT |
2001 |
1997 |
4 |
1026 |
971 |
1425 |
|
DT_LAST_PO_RAISED |
2001 |
1998 |
3 |
1003 |
995 |
1433 |
|
BALANCE |
2001 |
1999 |
2 |
7 |
1992 |
10 |
ほとんどの場合、サマリー・ビューの数値をドリルダウンすると、レコードが直接表示されます。ただし、数値から中間ビューが表示される場合もあります。
サマリー・ビューで「BUSINESS」の重複数の値である41をドリルダウンすると、各重複値の頻度が表示されます。
サマリー・ビューで「TITLE」の固有の値の数である8をドリルダウンすると、各固有値の頻度が表示されます。
サマリー・ビューで「POSTCODE」のデータなしの数239をドリルダウンすると、検出された様々なデータなしのケースについてサマリー・ビューが表示されます(スナップショットでデフォルトの「データ処理なし」参照データ・マップが使用された場合は、これらすべてがNull値になることに注意してください)。
レコード完全度プロファイラを使用すると、データがどの程度完全か(または不完全か)について概要を把握できます。レコードを構成する属性のうちデータが含まれる属性の数が示され、完全な属性の数に従ってレコードが集計されます。
レコード完全度プロファイラは、適切な情報を含めずに入力されたダミー・レコードを検出するために使用します。この場合、ユーザーは最小限の必須データのみを入力していることが多く、完全な有効レコードと比べてレコードの完全性は低くなります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 完全性の分析に必要な任意の数の属性を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| レコード完全度% | 検出された完全性の各パーセンテージ。分析対象の属性のうちnullではないと分析された属性のパーセンテージが計算されます。 |
| 完全属性 | nullではない属性の数と、分析された属性の数。 |
| 一致するレコード | 特定の完全性(%)に該当するレコードの数。 |
|
注意: レコード完全度プロファイラは、各属性値がNullかNullでないかを評価します。空の文字列、スペースのみの値、その他の印刷不可能な文字を含む値は、デフォルトでリーダーでNull値に変換されます。これにより、各値に意味のあるデータが含まれるかどうかを示す一貫したビューが表示されます。ただし、このような非データ値がスナップショットまたはリーダーでNullに変換されない場合、これらは「完全」とみなされます。 |
例
この例では、レコード完全度プロファイラで顧客レコード表の4つの属性の完全性を評価し、次のサマリー結果を生成しています。
| レコード完全度% | 完全属性 | 一致するレコード |
|---|---|---|
| 50.0 | 2/4 | 4 |
| 75.0 | 3/4 | 130 |
| 100.0 | 4/4 | 866 |
ドリルダウンすると、特定の完全性レベルのレコードが表示されます。たとえば、レコード完全性が75%以上のレコードを表示するには、サマリー・グリッド内の該当する行をドリルダウンします。
| CU_NO | CU_ACCOUNT | 敬称 | 性別 | PercentPopulated | PopulatedAttributes |
|---|---|---|---|---|---|
| 13815 | 00-23615-PB | M | 75 | 3/4 | |
| 13840 | 00-23631-JD | Miss | 75 | 3/4 | |
| 13913 | 00-23719-LR | M | 75 | 3/4 | |
| 13989 | 00-23817-LR | Ms | 75 | 3/4 | |
| 14130 | 00-23900-JD | Ms | 75 | 3/4 | |
| 14166 | 00-23945-LR | Mr | 75 | 3/4 |
レコード重複プロファイラを使用すると、選択した属性に基づいて、相互に完全に重複しているレコードを検出できます。
レコード重複プロファイラは、データ・セット内で完全に重複している(たとえば、データ移行時のエラーが原因で)レコードがあるかどうかをチェックするために使用します。
重複チェックで使用する属性は選択可能なので、レコード全体のサブセットに基づいて重複したレコードを検索することもできます。たとえば、氏名、住所および郵便番号に基づいて重複した顧客レコードを検索できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 重複チェックで使用する属性を指定します。 |
| オプション | 次のオプションを指定します。
一部(全部ではない)の属性がNull値で、それらが他のレコードと完全に一致するレコードは、常に重複とみなされます。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
レコード重複プロファイラは、レコードのバッチについて重複を評価します。したがって、処理が完了するまで結果が生成されないため、これはリアルタイム・レスポンスが必要なプロセスには適していません。
リアルタイム・データ・ソースからのトランザクションのバッチに対して実行した場合、リーダー・プロセッサで構成されたコミット・ポイント(トランザクションまたは制限時間)に到達すると処理が終了します。返される統計は、トランザクションのバッチ内でのみの重複数を示します。
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 重複 | 分析対象の属性間で重複しているレコードの数。 |
| 重複なし | 分析対象の属性間で重複していないレコードの数。 |
例
この例では、レコード重複プロファイラを使用して、2つの属性ADDRESS1およびADDRESS2に基づいて顧客表内の重複を検出しています。
| 重複 | 重複なし |
|---|---|
| 8 | 1993 |
重複した値からレコードにドリルダウンできます。
| ADDRESS1 | ADDRESS2 | RecordDuplicate |
|---|---|---|
| Crescent Road, | 読込み | Y |
| Grange Road, | North Berwick | Y |
| Grange Road, | North Berwick | Y |
| Crescent Road, | 読込み | Y |
正規表現パターン・プロファイラは、いくつかの属性が正規表現のリストと一致しているかどうかを分析します。
正規表現パターン・プロファイラは、一般的に認識された書式と一致するデータ(複数の属性で一致する場合があります)を検出するために使用します。これは、郵便番号や国民保険番号など、固有のパターンを持つ値が誤ったフィールドに入力されている場合に役立ちます。
正規表現
正規表現は、パターンを表現し、文字列を操作するための標準の手法であり、一度習得すると非常に有用です。
正規表現に関するチュートリアルや参考資料はインターネットで入手できます。また、Jeffrey E. F. Friedl著、O'Reilly UK発行の『Mastering Regular Expressions』(ISBN: 0-596-00289-0)などの書籍も参考になります。
また、正規表現の習得に役立つソフトウェア・パッケージ(RegExBuddyなど)や、有益な正規表現のオンライン・ライブラリ(RegExLibなど)も使用できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 正規表現のリストと一致するデータの検索対象にする文字列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
次のフラグが出力されます。
|
次の表に、入力された各属性ごとに生成される統計を示します。
| 統計 | 説明 |
|---|---|
| 一致 | 属性内で参照リストの正規表現の1つと一致したレコードの数。
ドリルダウンすると、一致した正規表現別に一致の明細が表示されます。 |
| 不一致 | 属性内で参照リストのどの正規表現とも一致しなかったレコードの数。 |
例
この例では、正規表現パターン・プロファイラを使用して、いくつかの住所属性で郵便番号(英国)を検出しています。サマリー・データは次のとおりです。
| 属性 | 一致(降順) | 不一致 |
|---|---|---|
| POSTCODE | 1696 | 305 |
| ADDRESS3 | 169 | 1832 |
| ADDRESS1 | 0 | 2001 |
| ADDRESS2 | 0 | 2001 |
リスト内の正規表現の1つと属性が一致したレコードの数をドリルダウンすると、一致した正規表現別に明細が表示されます。この場合は、1つの正規表現のみ一致したため、ADDRESS3で一致した169レコードをドリルダウンすると、次のビューが表示されます。
| パターン | カウント | % |
|---|---|---|
| ([A-Z]{1,2}|[A-Z]{3}|[A-Z]{1,2}[0-9][A-Z])( +)([0-9][A-Z]{2}) | 169 | 8.4% |
リーダー(「リーダー」を参照)はプロセスの開始時に使用されて、そのプロセスで使用されるデータのソースに接続します。照合を含まないプロセス(「照合プロセッサ」を参照)では、通常、単一のリーダーが使用されます。
リーダーは、すべてのステージング済データ(スナップショット、つまり別のプロセスによって書き込まれた一連のステージング済データ)または参照データ、データ・インタフェース(ステージング済データがマッピングされている可能性がある)、あるいはメッセージのリアルタイム・プロバイダに接続できます。
ライター(「ライター」を参照)は、プロセスの任意の時点で使用して、ステージング済データ表、メッセージのリアルタイム・コンシューマまたはデータ・インタフェースに結果を書き込むことができます。1つのプロセスには任意の数のライターを含めることができ、ライターを含めないこともできます。
ライターは、書き込むレコードを決定するために他のプロセッサの出力フィルタに接続します。ライターは、すべての入力から受け取ったレコードをすべて書き出しますが、同じレコードを2回書き出すことはありません。ライターの構成内で、名前を選択してステージング済データの属性にプロセスの属性をマップすることができます。
ステージング済データ表に格納されたデータは、データ・ストア(「データ・ストア」を参照)にエクスポートできます。または、書き込まれたステージング済データ表に新しいプロセスのリーダーがアクセスできるように構成して、別のプロセスで使用できます。
データ・ストリームのマージ・プロセッサを使用すると、各ソースを属性の単一のターゲット・セットにマッピングして、複数のリーダーからのレコードのソースを結合できます。
これは、データを変換せずに、すべてのレコードをただ渡すことから、読取りと書込みのファミリに含まれます。
「データ・ストリームのマージ」プロセッサを使用すると、各入力データ・ストリームをターゲット構造にマップすることにより、複数の入力データ・ストリームを1つのストリームにマージできます。
「データ・ストリームのマージ」では、レコードの変換、照合またはマージは実行されません。すべての入力レコードが出力され、ターゲット構造にマップされます。
「データ・ストリームのマージ」は、同じタイプのエンティティを表すデータのソースが複数あり、すべてのソースの属性構造が似ているため、ターゲット構造に簡単にマップできる場合に使用します。データ・ストリームがマージされた後は、すべてのソースの全レコードが処理対象になるように定義できます。
入力
マージするデータ・ストリームからの任意の属性。
オプション
「データ・ストリームのマージ」構成画面は、各入力データ・ストリームを順番に操作して、任意の数のデータ・ストリームをターゲットまでマップできるように設計されています。各入力データ・ストリームをターゲットの出力データ・ストリームにマップするには、次の手順を実行します。
入力データ・ストリーム間を切り替えるには、画面上部のタブを使用します。「出力属性」のビューは同じままです。
ターゲット・データ・ストリームで、入力データ・セットの最新バージョンの属性に対応する新しい出力属性を作成するには、「すべての属性を追加します」ボタンをクリックします。 選択した入力属性が、対応する出力属性にマップされます。
選択した入力属性が、対応する出力属性にマップされます。
ターゲット・データ・ストリームに特定の属性を追加するには、1つ以上の入力属性を選択し、「出力属性を作成します」ボタンをクリックします。 選択した入力属性が、新しく作成した出力属性にマップされます。
選択した入力属性が、新しく作成した出力属性にマップされます。
既存の出力属性に入力属性をマップするには、「出力属性にマップします」ボタンを使用します。
出力属性を削除せずに出力属性から入力属性のマッピングを削除するには、マップされている入力属性を右側の画面で選択し、「出力属性をマップ解除または削除します」ボタンをクリックします。
ターゲット・データ・ストリームから出力属性を削除するには、出力属性を右側の画面で選択し、「出力属性をマップ解除または削除します」ボタンをクリックします。
ターゲット・データ・ストリームから出力属性をすべて削除するには、「すべての出力属性を削除します」ボタンをクリックします。
ターゲット・データ・ストリームで出力属性を並べ替えるには、上矢印と下矢印を使用します。

1つまたは複数の属性を既存の出力属性に名前でマップするには、入力属性を右側のペインで選択し、「名前でマップ」ボタンをクリックします。 選択した、既存の出力属性と同じ名前とタイプのすべての属性について、マッピングが作成されます。名前の照合では、大文字と小文字が区別されません。
選択した、既存の出力属性と同じ名前とタイプのすべての属性について、マッピングが作成されます。名前の照合では、大文字と小文字が区別されません。
デフォルトの「データ・ストリーム名」を「Merged」から変更し、出力データ・ストリームに意味のある名前を付けます。
プロセッサ接続に関する注意
「データ・ストリームのマージ」は、そこに入力されるストリームから完全に新しいデータ・ストリームを出力するので、「データ・ストリームのマージ」前のプロセッサは、「データ・ストリームのマージ」後のプロセッサに直接接続できません。
新しいデータ・ストリームが出力されるので(ただし完全に書き出されるとは限らない)、ドリルダウンして結果を見るときにリーダーで使用されたスナップショットまたはステージング済データに再リンクできません。つまり、「データ・ストリームのマージ」プロセッサのプロセッサ・ダウンストリームの結果をドリルダウンするときは、データ・セットのすべての属性ではなく、アクティブに処理された属性しか見えないということです。
出力
データ属性
「データ・ストリームのマージ」によって出力されたデータ属性は、構成画面を使用してユーザー定義されます。
フラグ
なし
実行
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム・モニタリング | はい |
| リアルタイム・レスポンス | はい |
進捗状況レポートに関する注意
「データ・ストリームのマージ」プロセッサは、入力レコードをすべて取得し、完全に新しいデータ・ストリームを出力します。したがって、「データ・ストリームのマージ」プロセッサを含むプロセスを実行するときは、進捗状況バーに予想より多い数のレコードが表示されることがあります。これは、EDQがすべての入力レコードを、出力レコード(新しいデータ・ストリームで)とは別にカウントするためです。照合プロセッサも新しいデータ・ストリームを出力するため、これは照合プロセッサの実行時でも同様です。
結果の表示
「データ・ストリームのマージ」では、ターゲット・データ・セットのビューのみが表示されます。入力データ・ストリームは表示されません。
出力フィルタ
「データ・ストリームのマージ」では、単一の「マージ済」出力フィルタが出力され、入力レコードはすべてターゲット構造にマップされます。
例
この例では、企業の連絡先を表すレコードの多数のソースが1つのデータ・ストリームにマージされます。
「データ・ストリームのマージ」構成
「リーダー」は、プロセスの開始時にデータを読み取るために使用される特別なタイプのプロセッサです。「リーダー」は、次のデータのソースに接続できます。
ステージング済データ(リポジトリ内に存在するデータのスナップショット、または別のプロセスによって作成された出力データ)
データ・インタフェース(マッピングを使用して異なるソースのデータにリダイレクトできます)
参照データのセット
メッセージのリアルタイム・プロバイダ(Webサービスのインバウンド・インタフェースなど)
プロセスには少なくとも1つのリーダーを含める必要がありますが、複数のソースのデータと照合する場合は、複数のリーダーを含めることができます。
リーダーはプロセスの開始時に使用され、プロセスで使用するデータのソースを選択し、作成するプロセスに固有のデータ・ソースからデータ属性を選択して順序変更できます。たとえば、特定のプロセス用にデータ・ソースから氏名フィールドと住所フィールドのみを選択し、プロセス全体でフィールドを表示する際の順序を変更できます。
プロセスには常に少なくとも1つのリーダーを含める必要があるため、1つのリーダーがプロセスに自動的に追加されます。
リーダー・ソース
読み込むデータの「タイプ」を、次のオプションから選択します。
ステージング済データ - データのスナップショット、またはEDQリポジトリにおける別のプロセスの名前付きプロセス
|
注意: リポジトリにスナップショットが存在する必要はありません。ストリーミング・モードでプロセスを実行している可能性もあり、その場合ソース・データはリポジトリにコピーされません。 |
データ・インタフェース - 一連のデータ属性の、構成済でソースから独立したインタフェース
参照データ - EDQリポジトリに存在する一連の参照データ
リアルタイム・プロバイダ - リアルタイムのメッセージ・ソースへの直接接続
選択したタイプで使用できるソースから、データの「ソース」を選択します。
データで使用できる属性がすべて、左側のペインに表示されます。矢印ボタンを使用して、プロセスで扱う属性を選択、または選択解除します。
| 矢印ボタン | 説明 |
|---|---|
 |
左側のペインで強調表示されている属性を、プロセスの入力として選択します。 |
 |
使用できる属性をすべて入力として選択します。 |
 |
右側のペインで選択されている入力の選択を解除します。 |
 |
すべての入力の選択を解除します。 |
右側のペインで、対象として選択した属性はドラッグ・アンド・ドロップで並べ替えることができます。
リーダーで指定した順序は、プロセス全体で結果の表示に利用されます。
|
注意: 特定のデータ・セットの属性をすべて扱う予定でないことがわかっている場合には、リーダーから除外することをお薦めします。こうすると、関心のある属性のみが表示されるので、プロセッサの構成や結果の閲覧がはるかにわかりやすくなります。 |
オプション
なし
実行
リーダーは、プロセスの送付先にかかわらず、どのプロセスでも必須の一部です。ただし、一部のプロセッサは特定タイプの実行に適していません。たとえば、リアルタイムのレスポンス・プロセスで複数のソースからのデータを照合および統合することはできませんが、リアルタイムのリーダー・ソースとして選択する(前述のように)と、プロセスの実行はそのリーダーおよびライターの構成方法によって決まるため、構成に使用できるプロセッサには何の制限も課されません。
一般的に、EDQは3つのモードで実行できるように設計されています。
バッチ実行。1つ以上のデータ・ソースの一連のレコードがバッチで処理されます。
リアルタイム・モニタリング実行。EDQがデータ・ソースのデータ品質プローブとして機能し、作成時に着信レコードの品質が監視されますが、各レコードに対するリアルタイム・レスポンスは想定されません。
リアルタイム・レスポンス事項。EDQがレコードを処理し、リアルタイム・レスポンス・インタフェースで追加のデータとともに返されます。
ライブラリの各プロセッサが、そのプロセッサで明らかに使用できる実行モードとともにリストされます。
結果の表示
リーダーの結果ブラウザには、プロセスを実行したときに基礎となるデータ・ストアに存在するすべてのレコードが表示されます。
出力フィルタ
リーダーに、出力フィルタは示されません。すべてのレコードは指定したソースから読み込まれ、プロセスの最後まで使用できます。
例
次の例は、顧客テーブルから読み込まれるレコードを示しています。
この場合、リーダーはすべてのデータ属性をソースから読み込み、順序は変えないように構成されています。それ以上の処理は定義されていません。
| CU_NO | CU_ACCOUNT | TITLE | NAME | GENDER | BUSINESS |
|---|---|---|---|---|---|
| 13810 | 00-23603-JD | Ms | Lynda BAINBRIDGE | F | Filling Station |
| 13815 | 00-23615-PB | William BENDALL | M | Edge Kamke & Ellis Ltd | |
| 13833 | 00-23624-PB | Ms | Karen SMITH | F | |
| 13840 | 00-23631-JD | Miss | Patricia VINER | Catchpole Engineering Products | |
| 13841 | 00-23642-SH | Mr | Colin WILLIAMS | M | Sanford Electical Co |
「ライター」は、ステージング済データ表、データ・インタフェース、参照データまたはリアルタイム・コンシューマ(リアルタイム・レスポンス用)にレコードを書き込むために使用される特別なタイプのプロセッサです。書き込む属性を選択して、ステージング済データ表、データ・インタフェースまたはリアルタイム・レスポンスの属性に別の名称でマップできます。
データがステージング済データ表に書き込まれた後は、データをデータ・ストアにエクスポートしたり、別のプロセスで使用したり、参照で使用できます。
ライター(1つまたは複数)をプロセスの最後で使用して、その結果をレポートしたり、外部システムにレスポンスを返します。
例:
バッチ監査プロセスから、すべての有効レコードを表に書き込み、すべての無効データを別の表に書き込みます。
バッチ・クレンジング・プロセスから、新規システムに移行予定のレコードをステージング済データ表に書き込み、エクスポートする前に、他のプロセスでそのデータをチェック(または再チェック)します。
リアルタイム・クレンジング・プロセスから、ライターを使用して各受信レコードへのレスポンス(様々な訂正を含む)を発行します。
入力
ステージング済データ表、参照データ、データ・インタフェースに、またはリアルタイム・レスポンスとして書き込まれる属性。
|
注意: 参照データに書き込んでいる場合、書き込むデータは参照データ・セットで定義されている一意性制約に従う必要があります。たとえば、ルックアップ列に一意性制約がある参照データ・セットを生成している場合、書き込むデータにはその列で重複する値がないようにしてください。データが適切に書き込まれるように、グループとマージ・プロセッサを使用してからデータを書き込む必要がある場合があります。参照データの構成の詳細は、「参照データの追加」を参照してください。 |
オプション
他のほとんどのプロセッサとは違い、キャンバスに接続したときにライターの構成ダイアログは表示されません。これは、ライターが複数のストリームに接続することが多いためです。ライターの構成ダイアログを開くには、キャンバスでプロセッサをダブルクリックしてください。
書き込みたいターゲットの「タイプ」を選択します。
ステージング済データ。EDQリポジトリの表に書き込む場合や、外部データ・ストアに直接書き込む場合。
データ・インタフェース。データ・インタフェース・マッピングを使用して、プロセスではなくジョブ構成でデータのターゲットを選択する場合。
参照データ。プロセスのデータを使用して参照データを書き込み、ディレクタで編集して他のプロセッサで使用する場合。
リアルタイム・コンシューマ。構成済のリアルタイム・コンシューマがあり、そこでレスポンス・メッセージが選択される場合。
次に、書き込む属性を左側から選択します。書き込む対象として選択した属性が中央ペインに表示され、ターゲットにマッピングできるようになります。属性リストの上には、詳細な情報を表示するオプションが2つあります。「実際の属性の表示」では、最新バージョンの属性を使用している実際の属性名が表示され、「データ型の表示」では属性のデータ型が表示されます。
書き込みできる「ステージング済データ」表または「参照データ」は、次のいずれかの可能性があります。
「新規」ボタンを使用して作成された(この場合は、選択した属性セットに対応する「ステージング済データ」表または「参照データ」が作成され、属性名は必要に応じて変更されることがあります)
既存の「ステージング済データ」表または「参照データ」のドロップダウンから選択した。
画面下部にある「自動」ボタンを使用すると、選択した属性がすべて、選択した「ステージング済データ」表または「参照データ」に直接マップされます。
「クリア」ボタンを使用すると、選択した属性と、「ステージング済データ」表または「参照データ」の属性の間のマッピングがすべてクリアされます。(属性と列は、削除されるまで残ります。)
中央列で属性をクリックしてドラッグすると、並べ替えられます。
「プロジェクト・ブラウザ」から、または「ライター構成」ダイアログの「編集」ボタン  でデータ・エディタを起動して、「ステージング済データ」表または「参照データ」の定義を編集することもできます。
でデータ・エディタを起動して、「ステージング済データ」表または「参照データ」の定義を編集することもできます。
実行
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム・モニタリング | はい |
| リアルタイム・レスポンス | はい |
結果の表示
ライターによって書き込まれるデータは、「結果ブラウザ」で表示できます。
例
この例では、無効なレコードの数が「検疫出力」という名前の「ステージング済データ」表に書き込まれます。

テキスト分析プロセッサは、テキスト・フィールドに格納されたデータを理解および改良するための拡張ツールです。通常、このようなデータは、新しい構造に変換するために、分析して内容を理解する必要があります。たとえば、大まかに分類された住所フィールドに手動で入力された住所データを、照合に適した構造に変換する必要があります。あるいは、複数のシステムから新しいシステムにデータを移行している場合に、新しいシステムで必要なデータ構造が移行元と異なる可能性があります。
テキスト分析プロセッサには、「フレーズ・プロファイラ」と「解析」の2つがあります。
「フレーズ・プロファイラ」はテキスト・フィールドの内容を分析して、データ内で最多の語とフレーズを返します。
「解析」では、内容の十分な理解、データの検証、および新しい構造への変換(必要な場合)を行うために、ユーザーがルールを作成して使用できます。
文字タグはトークン化の最初のステップとして使用され、(Unicode文字参照によって識別される)データの各文字に所定のタグを割り当てます。たとえば、すべての子文字に文字タグaを割り当てます。
文字タイプはデータの分割に使用されます。通常は、文字タイプが変わると別々の基本のトークンに分割されます。たとえば、文字列deluxe25mlはdeluxe、25およびmlの3つの基本のトークンに分割されます。これら3つの基本のトークンが文字タグとグループ・タグによってタグ付けされます。
このルールの例外は、デフォルトではALPHA_UPPERCASEからALPHA_LOWERCASEへの文字タイプの変化ではトークンが分割されないことです。これは、大/小文字が適切に使用されているトークンを維持するためです。たとえば、Michaelが2つのトークン(Mとichael)に分割されないようにします。
ユーザーは「大文字を小文字に対して分離」オプションを選択してこの動作を変更できます。
また、「小文字を大文字に対して分離」オプションの選択を解除すると、アルファベット文字のすべての文字列をまとめて保持することもできます。こうすることで、DelUXEを1つのトークンとして保持する効果があります。
また、WHITESPACEまたはDELIMITERのいずれかのタイプで特定の文字をマークできます。これらの文字は、トークンのシーケンスを照合する次のルールで無視できます。たとえば、「再分類」または「解決」で、<Token A>の後に<Token B>があるパターンを照合する場合に、2つの間に空白文字または区切り文字があるかどうかを気にする必要がありません。
文字タイプには、NUMERIC、CONTROL、PUNCTUATION、SYMBOL、ALPHA_UPPERCASE、ALPHA_LOWERCASEおよびUNDEFINEDがあります。
「解析」の「分類」サブプロセッサでは、ルールを使用してトークンを分類することにより、データに意味を加えます。
「分類」では、いくつかのトークン・チェックをデータに適用します。各トークン・チェックでは、特定の意味(たとえば、郵便番号)によって、基本のトークンまたは基本のトークンのシーケンスを分類します。
各トークン・チェック内で、複数のルールを使用できます。各ルールでは、リストに対してデータを照合するなどの方法でデータをチェックし、チェックに合格したデータを、トークン・チェックの名称および信頼レベル(「有効」または「可能性のあるもの」)に対応するタグを使用して分類します。
特定のトークンが複数のトークン・チェックと一致する場合は、可能な意味が複数になることに注意してください。たとえば、トークン「Scott」は、「valid Forename」(有効な名前)と「valid Surname」(有効な姓)の両方に分類できます。選択サブプロセッサでは、後で、データ内のトークンのコンテキストに基づき、可能性のあるすべての意味から最適なものを各トークンに割り当てることを試みます。
分類は、解析の中で不可欠な部分です。分類ルールを使用して、データ内のトークン(数値、単語、フレーズなど)に意味を与えます。後続のステップでは、トークン分類のパターンを使用して、データを検証し、新しい出力構造に解決できます(該当する場合)。
多くの場合、分類ルールでは、フレーズ・プロファイラおよび頻度プロファイラの結果を使用してデータ自体から作成された単語やフレーズのリストを使用します。
「分類」の「構成」ウィンドウには、「トークン・チェック」と「属性」の2つのタブがあります。
「トークン・チェック」タブは、様々なトークンに対するいくつかのチェックを組み合せて分類ルールを構成するために使用します。
「属性」タブは、これらのトークン・チェックを入力属性に関連付けるために使用します。
トークン・チェック
トークン・チェックは、特定の意味を持つデータを識別するための1つ以上のルールで構成されます。
一般的に、トークン・チェックは、値のリストを使用してデータを識別する単一のルールで構成されます。たとえば、「Title」トークン・チェックの場合、1つのリスト・チェック・ルールが、有効な敬称(「さん」、「様」、「殿」など)の参照リストとともに使用されます。
ただし、さらに複雑なタイプのトークン・チェックを構成できます。これは、有効なトークン値のリストを維持できない場合(有効な値が多すぎる場合など)に、必要なことがあります。
たとえば、人名を解析するときに次のトークン・チェックが使用されます。
表1-126 トークン・チェック: Forename
| 順序 | ルール・タイプ | 条件 | 決定 |
|---|---|---|---|
|
1 |
リスト・チェック |
一般的なForenameのリストと一致 |
有効 |
|
2 |
基本のトークン・チェック |
基本のトークン・タグと一致: A |
可能性あり |
表1-127 トークン・チェック: Surname
| 順序 | ルール・タイプ | 条件 | 決定 |
|---|---|---|---|
|
1 |
リスト・チェック |
一般的なSurnameのリストと一致 |
有効 |
|
2 |
リスト・チェック |
不正データ・トークンのリストと一致 |
無効 |
|
3 |
属性ワード長チェック |
3語以上 |
無効 |
|
4 |
基本のトークン・チェック |
基本のトークン・パターンと一致: A (例: Davies) A-A (例: Smith-Davies) A_A (例: Taylor Smith) |
可能性あり |
|
注意: デフォルトではすべてのトークン・チェックが表示されます。適用対象の属性によってフィルタ処理するには、トークンのリストの上にあるドロップダウン選択フィールドで必要な属性を選択します。 |
各トークン・チェック内のルールは順序どおりに処理されることが重要です。つまり、チェックの上位のルールに該当する場合、下位のルールは処理されません。そのため、たとえば、トークンSmithが前述のSurnameトークン・チェックの上位ルールを使用して有効なSurnameとして分類された場合は、ルール4により可能性があるSurnameに分類されることはありません。同様に、トークンUnknownがルール2でSurnameとしての分類から除外された場合、ルール4によって可能性があるSurnameに分類されることはありません。
このように、トークン・チェックは肯定または否定のいずれでも使用できます。リストを照合して有効なトークンまたは可能性のあるトークンを識別する(肯定)か、無効なトークンを識別(否定)してから、それ以外のトークンを有効または可能性のあるものとして分類できます。
次のタイプの分類ルールを各トークン・チェックで使用できます。
表1-128 トークン・チェックでの分類ルール
| ルール・タイプ | 説明 |
|---|---|
|
リスト・チェック |
属性についてリストまたはマップと一致するデータをチェックします。 マップが使用されるときは、一致したトークンの置換(標準化)をパーサー内で実行できます。「出力で置換を使用」オプションが選択されると、マップされた値(存在する場合)が、出力内の一致した値よりも優先して使用されます。 ノイズ文字(リストとの照合を試行する前に削除する文字)の参照データ・セットを指定できます。 |
|
正規表現チェック |
属性について正規表現と一致するデータをチェックします。 |
|
属性完全性チェック |
意味があるデータ(空白文字以外)が属性に含まれていることをチェックします。 |
|
パターン・チェック |
属性について、文字パターンまたは文字パターン・リストと一致する基本のトークンをチェックします。このチェックでは大/小文字が区別されます。 |
|
属性文字長チェック |
属性のデータの長さを文字数でチェックします。 |
|
属性ワード長チェック |
属性のデータの長さを単語数でチェックします。 |
|
基本のトークン・チェック |
属性について、所定の基本のトークン・タグ(Aなど)と一致するトークンまたは所定の基本のトークン・タグのパターン(A-Aなど)と一致するトークンのパターンをチェックします。 次の「特殊文字」の「注意」を参照してください。 |
特殊文字
ピリオドを含む基本のトークン・パターン(www.example.comなどの値に対してA.A.Aなど)をチェックしようとする場合、ピリオドは解析においては特殊文字であるため、参照データではピリオドの前に\を入力する必要があります。そのため、たとえば、基本のトークン・パターンA.A.Aをチェックする場合は、A\.A\.Aと入力する必要があります。
注意: ピリオドを、デフォルトの基本のトークン・タグPではなく文字(.)としてタグ付けするには、解析で使用されるデフォルトの基本のトークン化マップを編集する必要があります。
属性へのトークン・チェックの適用
トークン・チェックを属性に適用するには、「属性」タブで矢印ボタン(またはドラッグ・アンド・ドロップ)を使用して、「属性」に対する「トークン・チェック」を選択し、選択を解除します。同じトークン・チェックを多数の属性に適用したり、1つの属性に多数のトークン・チェックを適用したりするケースは一般的です。
どのトークン・チェックをどの属性に適用するかを決定するには、多くの場合、フレーズ・プロファイルの結果が役立ちます。どのタイプのトークンがどこにあるかがわかりやすいためです。
どの属性にも関連していないトークン・チェックを追加した場合(つまり効果がない場合)は、「分類」の「構成」ダイアログを終了する前に警告が表示されます。
例
この例では、TITLE属性とNAME属性がいくつものトークン・チェックを使用して解析されています。TITLE属性ではTitleトークンのみがチェックされます。NAME属性では、Forenames、Surnames、Initials、Name QualifiersおよびName Suffixesがチェックされます。
「トークン・チェック」ビュー
「トークン・チェック」ビューには、各属性内のそれぞれのトークン・チェックのサマリーが表示され、分類レベル(「有効」または「可能性のあるもの」)ごとに分類済トークンの個別値の数が示されます。
表1-129 「トークン・チェック」ビュー
| 属性 | トークン・チェック | 有効 | 可能性あり |
|---|---|---|---|
|
NAME |
<Forename> |
772 |
72 |
|
NAME |
<Initial> |
19 |
0 |
|
NAME |
<Surname> |
1623 |
70 |
|
NAME |
<Qualifier> |
7 |
0 |
|
NAME |
<Suffix> |
0 |
0 |
|
TITLE |
<Title> |
10 |
0 |
これをドリルダウンして、個別のトークンや各トークンを含むレコードの数を確認できます。たとえば、有効な名前として分類されたトークンをドリルダウンできます。
さらにドリルダウンすると、関連するトークンを含むレコードが表示されます。1つのレコードに同じトークンが2つ含まれる可能性もあることに注意してください(この場合1つとしてカウントされます)。
「分類」ビュー
「分類」ビューには、分類ステップの後で生成されたトークン・パターン(データの説明)がすべて表示されます。1つの入力レコードに対して複数のトークン・パターンが生成される可能性があります。同一のトークンが様々なチェックで分類されることがあるためです。つまり、同じレコードが複数のトークン・パターンの下に表示されることがあります。
最も一般的なトークン・パターン(<valid Title><valid Forename>_<valid Surname>など)が含まれている一部のレコードには、2番目に一般的なトークン・パターン(<valid Title><valid Surname>_<valid Surname>など)も含まれていることに注意してください。ただし、1つ目のパターンの方が多いため、選択サブプロセッサのパターン頻度選択を使用して、このパターンをこれらのレコードに最も可能性の高い説明として選択できます。または、状況依存の「再分類」ルール(「再分類」を参照)を使用して、状況に依存しないトークン・チェックを渡す場合でも、TitleとSurnameの間のトークンが別のsurnameである可能性が低いというインテリジェンスを追加することができます。
「未分類のトークン」ビュー
「未分類のトークン」ビューには、トークン・チェックで分類されなかった各属性内の(基本の)トークンの数が表示されます。これは、分類で使用されたリストに追加する必要がある値を探すために役立ちます。
前述の例では、次のような「未分類のトークン」ビューが表示されます。
ドリルダウンすると、個別の各トークンと出現頻度が示されます。たとえば、前述のNAMEフィールドの55個の未分類トークンにドリルダウンできます。これにより、一般的でない文字、ダミー値およびスペルミスを確認できます。
ここでこのビューを使用して、分類リストに追加したり、新しいリストを作成したりできます(たとえば、ダミー値を認識するリストを作成します)。
解析プロセッサを構成する次のステップとして、オプションで、データを再分類します。
グループ・タグはトークン化の2番目のステップで使用され、文字タグのシーケンスを同じグループ・タグでグループ化します。
同じグループ・タグが付いた文字タグのシーケンスと同じ文字タイプが、1つのトークンを形成します。
たとえば、トークン化の最初のフェーズでは、文字タグを使用してデータ103をNNNとタグ付けする可能性があります。ただし、同じグループ・タグ(N)で同じ文字タイプ(NUMERIC)の文字が3つ並んでいることから、これらはグループ化されて、基本のトークン・タグNの基本のトークン(103)が1つ形成されます。
英字の動作は少し異なることに注意してください。ユーザーは、小文字と大文字のシーケンスがある場合にトークンを分割するかどうかを選択できます。デフォルトでは、トークンは小文字から大文字に遷移するときに分割されますが、大文字から小文字への遷移では分割されません。たとえば、データ「Michael」は文字タグのシーケンス「Aaaaaaa」ですが、最初の文字の後で文字タイプがALPHA_UPPERCASEからALPHA_LOWERCASEに遷移しています。ユーザーがデフォルト設定の「大文字を小文字に対して分離」オプションを設定していない場合、これはグループ化されて、ベース・トークン・タグAの1つのベース・トークン(Michael)を形成します。文字タグaとAはどちらも同じグループ・タグを使用しており、ユーザーが文字タイプの変化に対してデータを分割しないためです。
「解析」の「入力」サブプロセッサは、解析プロセスに対して入力属性を選択するために使用されます。
このサブプロセッサを使用して、ダッシュボード公開オプションを構成し、プロセッサについてのノートを追加できます(他のユーザーへの配布用にパーサーを設計する場合のオーサーシップ詳細など)。
標準の入力画面を使用して、「解析」プロセッサの入力属性を選択します。
「解析」のサブプロセッサは、選択した入力属性を「解析」プロセッサが使用する内部属性にマップするために使用されます。
内部属性を使用すると、内部属性の実際の名前と関係なく、「解析」プロセッサを開発および構成できます。これは、同じ「解析」プロセッサを複数のデータ・ソースで使用できるので、便利です。これにより、新規入力属性を既存の内部属性にマップすることで、別々の名前の入力属性を指定できます。他のオプション(属性を適用するための分類および再分類ルールなど)を再構成する必要がありません。
各内部属性には、名前(Title、Forename、Surnameなど)とタグ(通常はa1、a2、a3など)があります。タグを使用すると、解析の解決フェーズで、トークン・パターンがどの入力属性に基づいているかを「解析」プロセッサで区別できるようになります。詳細は、「属性タグの使用方法」を参照してください。
パーサーに必要な属性が左側に表示されます。選択した入力属性を右側の列の属性にマップします。
「解析」プロセッサは、データを理解して構造を改善するための強力なツールです。手動で構成したビジネス・ルールおよび人工知能の両方を適用して、1つまたは複数の属性内のデータの意味を分析して理解できます。さらに、ルール内でその意味を使用して、データを検証し、必要に応じてデータを再構築できます。たとえば、「解析」を使用すると、誤って住所属性に取得された名前データを認識でき、必要に応じて、そのデータを異なる構造の新しい属性にマップできます。
「解析」プロセッサは、任意のタイプのデータを認識して変換するように構成できます。EDQにおける解析の詳細は、「解析の概念ガイド」を参照してください。
「解析」プロセッサには多様な用途があります。たとえば、「解析」を使用して次のことができます。
特定のビジネス目的に応じて改善された構造をデータに適用します。たとえば、正確な照合処理を行うのに適した構造にデータを変換します。
構造化されていない、または半構造化された形式のデータに構造を適用します。たとえば、1つのNotes属性に含まれるデータをすべて、複数の出力属性の固有項目に取得します。
複数の属性内のデータが目的に対して意味的に適しているかどうか(バッチ・ベースまたはリアルタイム・ベースのいずれか)をチェックします。
複数の入力属性からのデータの構造を変更します。たとえば、複数の異なるソース形式から単一のターゲット形式にデータを移行します。
解析の概要
パーサーは複数の段階で実行されます。各段階は、次の「構成」の項で詳細に説明しています。パーサーの処理の概要は、次のとおりです。
入力データ >
トークン化: データの構文分析。データを最小の単位(基本のトークン)に分割します
分類: データの意味分析。意味をトークンに割り当てます
再分類: トークン・シーケンスで新しく分類されたトークンを調べます
パターン選択: 可能な場合に、データの最適な説明を選択します
解決: データを必要な構造に解決し、結論を出します
> 出力データとフラグ
「解析」プロセッサの動作を全体的に理解するには、サンプル・レコードを確認するのが便利です。この例では「肩書き」、「名」、「姓」の3つの属性から個人名を解析しています。
入力レコードの例
次のレコードが入力です。
| 敬称 | 名 | 姓 |
|---|---|---|
| Mr | Bill Archibald | SCOTT |
トークン化
トークン化によって、レコードは次のようにトークン化されます。トークン「Mr」、「Bill」、「Archibald」および「SCOTT」が認識され、トークン・タグ<A>が割り当てられます。また、「Bill」と「Archibald」の間のスペースもトークンとして認識され、トークン・タグ<_>が割り当てられます。トークン化では、常に、基本のトークンの単一パターンが出力されます。この場合、パターンは次に示すとおりとなります(「トークン化」ビューより)。
| 敬称 | 名 | 姓 |
|---|---|---|
| <A> | <A>_<A> | <A> |
分類
次の「分類」では、名前と肩書きのリストに分類ルールを使用して、レコードのトークンを分類します。複数のリストに出現する名前もあるので、トークンによっては複数の形で分類されます。たとえば、トークン「Archibald」は<possible forename>と<possible surname>のどちらにも分類され、トークン「SCOTT」は<possible forename>と<valid surname>のどちらにも分類されます。そのため「分類」では、次の「分類」ビューに示すように複数の分類パターンが出力されます。
| 敬称 | 名 | 姓 |
|---|---|---|
| <valid title> | <valid forename>_<possible_surname> | <possible forename> |
| <valid title> | <valid forename>_<possible_forename> | <possible forename> |
| <valid title> | <valid forename>_<possible_surname> | <valid surname> |
| <valid title> | <valid forename>_<possible_forename> | <valid surname> |
再分類
ここまでで、データについて複数の記述ができました。しかし、「名」属性には次の「再分類」ルールを適用する必要がある場合があります。トークン'Archibald'は名としても有効なので、それが間違いなくミドル・ネームを表すことを示すためです。
| 名前 | 検索 | 再分類基準 | 結果 |
|---|---|---|---|
| 名の後にミドルネーム | <valid forename>(<possible forename>) | middlename | 有効 |
このルールは「名」属性の「<valid forename>(<possible forename>)」というパターンに対して機能し、上の2番目と4番目の分類パターンに影響します。「再分類」では新しいパターンを追加しますが、既存のパターンを削除するわけではないので、次の表に示すように元の4つのパターンと新しい2つのパターンが並びます。
| 敬称 | 名 | 姓 |
|---|---|---|
| <valid title> | <valid forename>_<possible_surname> | <possible forename> |
| <valid title> | <valid forename>_<possible_forename> | <possible forename> |
| <valid title> | <valid forename>_<possible_surname> | <valid surname> |
| <valid title> | <valid forename>_<valid_middlename> | <valid surname> |
| <valid title> | <valid forename>_<valid_middlename> | <possible forename> |
| <valid title> | <valid forename>_<possible_forename> | <valid surname> |
|
注意: 「再分類」ビューには、「選択」プロセスの入力として事前選択されていたパターンしか表示されません。事前選択は、選択プロセスの最初の段階では構成できず、未分類のトークンが多すぎるパターンは除外されます。事前選択プロセスは、まずこれまでに生成されたパターンをすべて調査し、いずれかのパターンに存在する未分類のトークンの最小数を決定します。次に、未分類のトークンがその数より多いパターンがあれば除外されます。上の例では、どのパターンにも未分類のトークンは含まれていないため、未分類トークンの最小数はゼロです。どのパターンにも1つ以上の未分類トークンは含まれていないので、どのパターンも事前選択プロセスで除外されることはありません。 |
選択
「選択」に進むと、6つの可能性から最適なパターンを選ぼうとします。上の例では、すべてのトークン分類で結果が「有効」になっているので、4番目のパターンが最も強力だとわかります。したがって、デフォルトの選択ルールを使用して各パターンにスコアを付けることによって最初のパターンが選択され、「選択」ビューに表示されます。
| 敬称 | 名 | 姓 |
|---|---|---|
| <valid title> | <valid forename>_<valid_middlename> | <valid surname> |
解決内容
選択パターンがレコードの適切な説明であることを確認すると、パターンを出力属性に解決して結果を割り当てることができます。この場合は、上で選択したパターンを右クリックして「解決」を選択し、「完全」解決ルールを追加します。
ここではデフォルトの出力割当て(実行した分類に従う)を使用し、「既知の氏名書式」というコメントを付けて、このパターンに「成功」の結果を割り当てます。
このルールで「解析」を再実行すると、このルールで入力レコードが解決されていることがわかります。
| Id | ルール | 結果 | コメント | カウント |
|---|---|---|---|---|
| 1 | 完全ルール | 成功 | 既知の氏名書式 | 1 |
最後に、レコードをドリルダウンすると、この解決ルールに従ってデータが正しく出力属性に割り当られたことが確認できます。
| 敬称 | 名 | 姓 | UnclassifiedData.Parse | title.Parse | forename.Parse | surname.Parse |
|---|---|---|---|---|---|---|
| Mr | Bill Archibald | SCOTT | Mr | Bill | SCOTT |
構成
「解析」は、複数のサブプロセッサを備えた拡張プロセッサです。各サブプロセッサは、解析の異なるステップを実行し、個別に構成する必要があります。次のサブプロセッサが「解析」プロセッサを構成しており、それぞれ、次に示すように固有の機能を実行します。
| サブプロセッサ | 説明 |
|---|---|
| 入力 |
解析する入力属性を選択し、ダッシュボード公開オプションを構成できます。有効な入力は文字列属性のみであることに注意してください。 |
| マップ |
入力属性を、パーサーで必要な入力属性にマップします。 |
| トークン化 |
「トークン化」では、データを構文的に分析し、ルールを使用してデータを最小単位(ベース・トークン)に分割します。各ベース・トークンにはタグが指定されます。たとえば、<A>は英字の完全なシーケンスに対して使用されます。 |
| 分類 |
「分類」では、データを意味的に分析し、ベース・トークンまたはベース・トークンのシーケンスに意味を割り当てます。各分類には、「建物」などのタグと分類レベル(「有効」または「可能性のあるもの」)があり、あいまいなデータに対して最適な説明を選択するときに使用されます。 |
| 再分類 |
「再分類」はオプションのステップで、分類されたトークンと未分類(ベース)トークンのシーケンスを新しい単一のトークンとして再分類できます。 |
| 選択 |
「選択」では、レコードに可能な説明(つまり、トークン・パターン)が複数ある場合に、調整可能なアルゴリズムを使用してデータの最適な説明を選択します。 |
| 解決 |
「解決」では、ルールを使用して、データの選択された説明(トークン・パターン)を、結果(「成功」、「レビュー」または「失敗」)および「コメント」(オプション)に関連付けます。また、選択されたトークン・パターンに従って、データを新しい構造に出力するためのルールを構成できます。 |
詳細オプション
一部の結果ビューが不要な場合、最適なパフォーマンスを得るために、パーサーには2つの実行モードがあります。
次の2つのモードがあります。
解析とプロファイル
解析
「解析とプロファイル」(デフォルト・モード)は、最初にデータを解析するときに使用する必要があります。これは、パーサーによって出力される「トークン・チェック」および「未分類のトークン」結果ビューが、分類で使用されるリストを作成および追加して解析ルールを定義する過程で役立つためです。
「解析」モードは、パーサーの分類構成が完了し、パフォーマンスの最適化が必要な場合に使用します。このモードで実行すると、「トークン・チェック」および「未分類のトークン」ビューは作成されないことに注意してください。
オプション
すべてのオプションはサブプロセッサごとに構成可能です。
出力
データ属性
出力データ属性は解決サブプロセッサで構成します。
フラグ
| フラグ属性 | 目的 | 使用可能な値 |
|---|---|---|
| [属性名].SelectedPattern | レコードに選択されたトークン・パターンを示します | 選択したトークン・パターン |
| [属性名].BasePattern | トークン化から出力されたレコードの基本のトークン・パターンを示します(パーサーを使用して純粋にこのパターンを生成する場合) | 基本のトークン・パターン |
| ParseResult | レコードに対するパーサーの結果を示します。 | 「不明」/「成功」/「レビュー」/「失敗」 |
| ParseComment | レコードの解決ルールのユーザー指定のコメントを追加します。 | レコードを解決した解決ルールに対するコメント |
ダッシュボードへの公開
「解析」プロセッサの結果は、ダッシュボードに公開できます。
デフォルトでは、結果について次の解釈が使用されます。
| 結果 | ダッシュボードの解釈 |
|---|---|
| 成功 | 成功 |
| レビュー | 警告 |
| 失敗 | アラート |
実行
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム・モニタリング | はい |
| リアルタイム・レスポンス | はい |
結果の表示
「解析」プロセッサでは、次に示す多数の結果ビューが作成されます。すべてのビューは、プロセス内の「解析」プロセッサをクリックして表示できます。「解析」プロセッサを展開してサブプロセッサを表示し、ビューを作成するサブプロセッサを選択して表示することもできます。
「基本のトークン化」ビュー(「トークン化」により作成)
このビューには、「トークン化」サブプロセッサの結果が表示され、すべての入力属性にわたって「基本のトークン」の個別パターンがすべて示されます。パターンは、頻度別に編成されます。
|
注意: 各レコードは、1つだけ基本のトークン・パターンを持ちます。多くのレコードには、同じ基本のトークン・パターンがあります。 |
| 統計 | 意味 |
|---|---|
| 入力属性ごと | 入力属性のある基本のトークンのパターン
すべての属性にわたって個別の基本のトークン・パターンごとに、ビューの行が存在します |
| カウント | すべての属性にわたって個別の基本のトークン・パターンごとのレコード数 |
| % |
すべての属性にわたって個別の基本のトークン・パターンごとのレコードのパーセンテージ |
「トークン・チェック」ビュー(「分類」により作成)
このビューには、「分類」サブプロセッサの結果が表示され、入力属性ごとのトークン・チェックの結果。
| 統計 | 意味 |
|---|---|
| 属性 | トークン・チェックを適用した属性 |
| 分類子 | トークンの分類に使用されるトークン・チェックの名前 |
| 有効 | トークン・チェックによって「有効」と分類された個別のトークンの数 |
| 可能性あり | トークン・チェックによって「可能性のあるもの」と分類された個別のトークンの数 |
「有効」または「可能性のあるもの」の統計をドリルダウンすると、分類した個別のトークンのサマリーと、それを含むレコードの数がわかります。再度ドリルダウンすると、これらのトークンを含むレコードが表示されます。
「未分類のトークン」ビュー(「分類」により作成)
| 統計 | 意味 |
|---|---|
| 属性 | 入力属性 |
| 未分類のトークン | その属性で未分類のトークンの合計数 |
「未分類のトークン」をドリルダウンすると、分類されたトークンとその頻度がすべてリスト表示されます。再度ドリルダウンすると、これらのトークンを含むレコードが表示されます。
「分類」ビュー(「分類」により作成)
このビューには、分類後(ただし再分類の前)に生成されたすべてのトークン・パターンのリストが表示されます。入力レコードごとに、可能性のあるパターンは多数ある可能性があります。
| 統計 | 意味 |
|---|---|
| 入力属性ごと | 属性全体でのトークンのパターン。
すべての属性にわたって個別のトークン・パターンごとに、ビューの行が存在します。 |
| カウント | トークン・パターンがデータの可能な説明であるレコードの数。同じレコードが可能性のある多くのトークン・パターンを持つ場合があり、各トークン・パターンが多くのレコードを説明する場合もあります。 |
| % |
データ・セットにわたって可能性のあるすべてのトークン・パターンのパーセンテージとして表されるカウント。 |
「再分類ルール」ビュー(「再分類」により作成)
このビューには、すべての再分類ルールのリストと、それがデータにどう影響するかが示されます。
| 統計 | 意味 |
|---|---|
| ルールID | 再分類ルールのID。IDは自動的に割り当てられます。ルール間に依存関係がある場合にはIDが便利です。後述する「前例」の統計を参照してください。 |
| ルール名 | 再分類ルールの名前。 |
| 属性 | 再分類ルールが適用された属性。 |
| 検索 | ルールの照合に使用されたトークン・パターン |
| 再分類基準 | 再分類ルールのターゲット・トークン |
| 結果 | 再分類ルールの分類レベル(有効または可能性がある) |
| 影響を受ける結果 | ルールによって影響されるレコードの数 |
| 影響を受けるパターン | ルールによって影響される分類パターンの数 |
| 前例 | このルールに先行して適用されるその他の再分類ルールの数。たとえば、<A>を1つのルールで<B>として再分類し、<B>を別のルールで<C>として再分類する場合は、最初のルールが2番目のルールよりも優先されます。レコードに影響を与えなかった再分類ルールであっても、論理的に計算されるため、優先される場合があります。 |
「再分類」ビュー(「再分類」により作成)
このビューには、再分類後(ただし選択の前)に生成されたすべてのトークン・パターンのリストが表示されます。入力レコードごとに、可能性のあるパターンは多数ある可能性があります。このビューには、「選択」ステップで入力レコードごとに最適なパターンを選択しようとする前に、データ・セット全体にわたって可能性のあるすべてのパターンとその頻度が示されます。
|
注意: このビュー自体のデータは、どのパターンを選択するかを制御するために使用されることがあります。つまり、データ・セット全体での共通度を表することによって、レコードのパターンを選択するように「選択」ステップを構成できるということです。選択サブプロセッサの構成を参照してください。 |
| 統計 | 意味 |
|---|---|
| 入力属性ごと | 属性全体でのトークンのパターン。
すべての属性にわたって個別のトークン・パターンごとに、ビューの行が存在します。 |
| カウント | トークン・パターンがデータの可能な説明であるレコードの数。同じレコードが可能性のある多くのトークン・パターンを持つ場合があり、各トークン・パターンが多くのレコードを説明する場合もあります。 |
| % |
データ・セットにわたって可能性のあるすべてのトークン・パターンのパーセンテージとして表されるカウント。 |
「選択」ビュー(「選択」により作成)
「選択」ステップの後で、各入力レコードは選択したトークン・パターンを持ちます。
このビューには、データ・セット全体で選択したパターンのビューと、その出現頻度が表示されます。
|
注意: 選択にあいまいさがあるために、レコードを説明する単一のトークン・パターンを選択できない場合、あいまいさがあるパターンが、同じあいまいさを持つレコードの数とともに表示されます。つまりこれは、選択されなかったが可能性のあるパターンの同じセットです |
| 統計 | 意味 |
|---|---|
| 入力属性ごと | 属性にわたるトークンのパターン
すべての属性にわたって個別のトークン・パターンごとに、ビューの行が存在します。 |
| 完全ルール | トークン・パターンを解決した完全な解決ルール(ある場合)の数値識別子 |
| あいまいルール | トークン・パターンを解決したあいまいな解決ルール(ある場合)の数値識別子 |
| カウント | データの最適な説明としてトークン・パターンが選択されたレコードの数 |
| % |
トークン・パターンが選択されたレコードのパーセンテージ |
「解決ルール」ビュー(「解決」により作成)
このビューには、各「解決ルール」によって実行された解決のサマリーが表示されます。これは、ルールが予定どおりに動作していることを確認するときに便利です。
| 統計 | 意味 |
|---|---|
| ID | 構成中に設定されたルールの数値識別子。 |
| ルール | ルールのタイプ(「完全」ルールまたは「あいまい」ルール) |
| 結果 | ルールの「結果」(「成功」、「レビュー」、「失敗」) |
| コメント | ルールの「コメント」 |
| カウント | このルールを使用して解決されたレコードの数。結果ブラウザで「追加情報」ボタンをクリックすると、これがパーセンテージとして表示されます。 |
「結果」ビュー(「解決」により作成)
| 統計 | 意味 |
|---|---|
| 成功 | 結果が「成功」のレコードの合計数 |
| レビュー | 結果が「レビュー」のレコードの合計数 |
| 失敗 | 結果が「失敗」のレコードの合計数 |
| 不明 | 「解析」で結果を割り当てられなかったレコードの数 |
出力フィルタ
「解析」プロセッサからは、次の出力フィルタが使用可能です。
成功 - 「成功」の結果に割り当てられたレコード
レビュー - 「レビュー」の結果に割り当てられたレコード
失敗 - 「失敗」の結果に割り当てられたレコード
不明 - どの解決ルールにも一致せず、そのために個別の結果がないレコード
例
この例では、単一のNAME属性のデータを理解し、構造化された名前を出力するために完全な「解析」構成が使用されています。
「基本のトークン化」ビュー
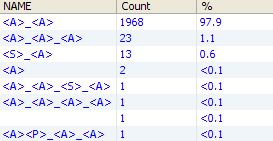
「トークン・チェック」ビュー
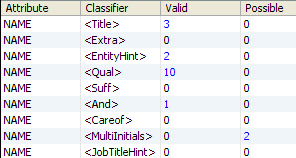
「分類」ビュー
「未分類のトークン」ビュー

「再分類ルール」ビュー
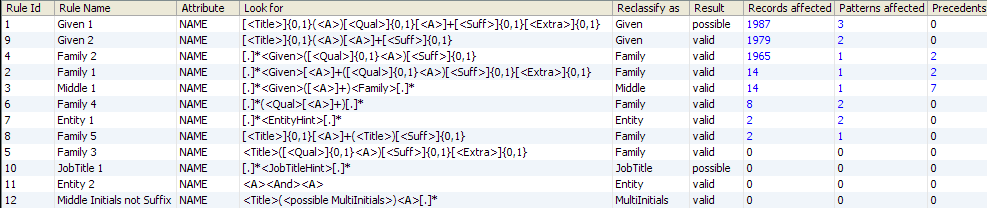
「再分類」ビュー
「選択」ビュー
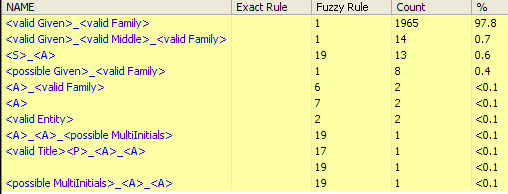
「解決ルール」ビュー
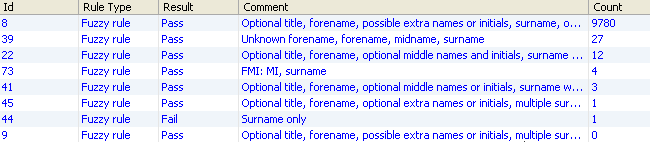
「結果」ビュー
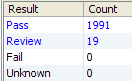
「成功」結果のドリルダウン
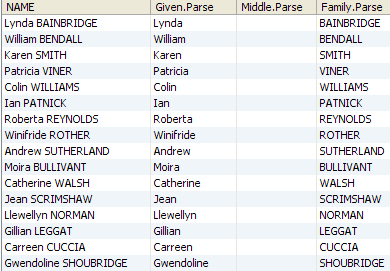
「フレーズ・プロファイラ」では、複数の属性を分析し、共通する単語やフレーズを検索します。
すべての入力属性内で出現する単語やフレーズが頻度順に返されます。
「フレーズ・プロファイラ」を使用すると、データ内で最も頻出する重要な単語やフレーズ、およびその出現場所を簡単に検出できます。さらに、フレーズ・プロファイリングの結果を使用して、「解析」プロセッサの構成を決定できます。たとえば、検出された単語やフレーズを、データの分類に使用する参照データ・リストに追加したり、属性内で出現する単語やフレーズを調べることにより、どのトークン・チェックをどの属性に適用するかを決定できます。
したがって、「フレーズ・プロファイラ」は、テキスト・フィールドの内容を理解するとき、特にデータの構造を改善したり変更する場合(たとえば、データを移行するため)に使用する重要なツールです。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 共通する単語またはフレーズについて分析する文字列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
なし。 |
|
フラグ |
なし。 |
実行
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム・モニタリング | はい |
| リアルタイム・レスポンス | いいえ |
通常、フリー・テキストを含む大きなデータセットには異なるフレーズが多数含まれており、データセットの内容を理解するために重要なものはごくわずかです。
「フレーズ・プロファイラ」には、重要でない結果を消去するために、切捨て頻度と許容変動という2つの設定が用意されています。
切捨て頻度
通常、「フレーズ・プロファイラ」では、多数のレコードに出現する比較的少数のフレーズ(潜在的に重要)と、少数のレコードに出現する非常に多数のフレーズ(重要性は低い)が一緒に生成されます。頻度が少ないフレーズをこの結果に含めたくない場合があります。絶対的な切捨て頻度はデータセットのサイズに応じて変わるため、切捨て頻度設定を入力レコード100万件当たりの頻度として指定すると便利です。
許容変動
1フレーズが多くの単語で構成される場合(または1つの部分文字列が多くの文字で構成される場合)、長いフレーズには短いフレーズが含まれるため、フレーズNewcastle Upon Tyneを含むデータには、部分フレーズNewcastle UponとUpon Tyneも同じ数だけ含まれます。
この2つの部分フレーズがフレーズ全体とまったく同じ頻度出現し、その頻度に変動がない場合、フレーズ全体は重要(最上位フレーズ)ですが、部分フレーズは重要ではありません。この場合、部分フレーズは結果から除外されます。
ただし、部分フレーズの出現頻度がフレーズ全体よりも多い場合は、部分フレーズの重要性が高くなります。フレーズと部分フレーズの頻度の変動(差)が部分フレーズの独立した重要性を表します。つまり、許容変動を指定すると、頻度の変動(差)がその値を下回る部分フレーズを除くことができます。やはり、絶対的な変動(差)はデータセットのサイズに応じて変わるため、許容変動設定を入力レコード100万件当たりの変動(差)として指定すると便利です。
例
次のパラメータを検討してみてください。
100万件のレコードが「フレーズ・プロファイラ」で分析されます
切捨て頻度は100 ppm (100万分の1)に設定されます
許容変動は50 ppmに設定されます
フレーズNewcastle Upon Tyneは400回出現します
フレーズNewcastel Upon Tyneは50回出現します
フレーズNewcastle Upon Tyneは結果に表示されますが、Newcastel Upon Tyneは切り捨てられるため表示されません。部分フレーズUpon Tyneの頻度は450であり切捨ての影響を受けませんが、フレーズ全体との頻度の変動(差) 50は許容制限にちょうど該当するため、結果に表示されません。データ内にUpon Tyneが含まれるレコードがもう1件あれば、これは潜在的に重要であるとして結果に表示されます。通常は、切捨て頻度と許容変動を同じ値に設定することが適当です。
最上位フレーズとしてマーク
フレーズが、他のフレーズの部分フレーズか最上位フレーズかがわかると役立つ場合があります。前述の例では、Newcastle Upon Tyneが最上位フレーズになり、おそらく市を表すと考えることができます。ただし、フレーズNewcastle Upon Tyne Borough Councilが1回のみ出現して、この出現が結果に含まれる場合(切捨てまたは許容変動オプションで除外されなかった場合)、Newcastle Upon Tyneは最上位フレーズではなくなり、市以外を表す可能性が出てきます。「フレーズ・プロファイラ」によって、結果内の最上位フレーズにフラグが立てられます。
次の表に、このプロファイラによって生成される統計情報を示します。「フレーズ・プロファイラ」では結果のサマリー・ビューが生成され、入力属性で検出された単語とフレーズが出現頻度の順に表示されます。
| 統計 | 説明 |
|---|---|
| サイズ | フレーズのサイズ(単語数)。 |
| 最上位フレーズ | フレーズが最上位フレーズかどうかを示します。許容変動の設定について説明している前述の「注意」を参照してください。 |
| フレーズ | データで検出された単語またはフレーズ。 |
| 頻度 | フレーズまたは単語の出現回数。データにドリルダウンすると、表示されるレコードがこの頻度より少ない場合があります。同じフレーズまたは単語が同じレコードに複数回出現することがあるためです。 |
| [Attribute].freq | 入力属性ごとのフレーズまたは単語の出現回数。 |
例
この例では、顧客の名前と住所のデータをビューで分析し、構造上の問題を解決するために解析します。「フレーズ・プロファイラ」を実行して、名前と住所の属性で最も多い単語とフレーズを検出します。構成されるオプションは次のとおりです。
切捨て頻度: 5000
許容変動: 5000
フレーズ内の最大語数: 10
追加の単語デリミタ: カンマ(,)
単語デリミタの正規表現: 未使用
大文字/小文字を区別しない: いいえ
たとえば、Mr、Ms、MrsおよびMissの各単語が頻繁に出現する有効なTitleである場合は、解析でそれらを分類するための参照データ・リストを作成することをお薦めします。その後、Title属性で結果をソートして、出現する他の値を見つけることができます。
「解析」の「再分類」サブプロセッサは、オプションのステップで、分類済および未分類のトークンのシーケンス、または特定のコンテキストのトークンを認識し、特定の信頼レベル(「有効」または「可能性のあるもの」)を使用してそれらを新しいトークンに再分類することにより、データ内のトークンの各種パターンの合計数を減らすことができます。
「再分類」は、トークンのシーケンスを出力でまとめる場合、および属性内のトークンの類似する複数のパターンを同じとみなす場合に使用します。
たとえば、住所を解析するとき、最初の分類後のAddress1属性のデータは、次のような異なるパターンに分類されます。
<N>_<A>_<valid Road Hint> (例: 10 Harwood Street)
<N>_<A>_<A>_<valid Road Hint> (例: 15 Long End Road)
<A>_<valid Road Hint> (例: Nuttall Lane)
これらの異なるトークンのシーケンスはすべて「valid Thoroughfares」(有効な大通り)として再分類できます。
また、「分類」ステップではデータの特定の断片が検出される属性以外にコンテキストは考慮されないため、「再分類」ステップが役立ちます。再分類ルールを使用して、コンテキスト内で不正確に分類されたトークンを再分類できます。たとえば、データ「London Road」は、<valid Town> <valid Road Hint>に分類されます。このトークンのシーケンスを「valid Thoroughfare」として再分類するか、または、ルール内で<valid Town>部分をカッコで囲み、この部分を「ThoroughfareName」(大通り名)として再分類するかを選択できます。
構成
各再分類ルールでは、構成された式を使用して、分類後のトークンのパターンを照合し、一致した各パターンの一部を新しいトークンとして再分類します。
ルールは、ルールの再分類ダイアログにあるチェック・ボックスを使用して、簡単に有効または無効にできます。ルールは、「属性」タブで、必要な入力属性に関連付ける必要があります。
次の表では、再分類で使用される式の構文のガイドを示しています。
| 文字 | 使用 | 例 |
|---|---|---|
| [ ] | シーケンスが発生する回数を指定するために、トークンのシーケンスをグループ化するために使用されます。必ず範囲(中カッコで囲む)か、*または+が続きます。
グループにピリオド(.)が含まれている場合、これはトークン(1つまたは複数)を表します。 |
<A>
トークン<A>と一致します |
| { } | 前のグループ(大カッコで囲む)のインスタンスがパターンつまりシーケンスで出現する回数を表す範囲を指定します。範囲は最小値と最大値で指定し、カンマで区切ります。 | [<A>]{1,3}
シーケンス内でトークン<A>が1から3回出現する場合に一致します [<A>]{2,2} シーケンス内でトークン<A>が2回出現する場合に一致します |
| ? | グループがオプションであることを示します。これは{0,1}と指定するのと同じ意味です。つまり、グループが出現しないか、1回のみ出現する場合に一致します。 | [<title>]?
タイトル・トークンが出現しないか、1回出現する場合に一致します |
| + |
中カッコ(前述)の中で数字のかわりに使用し、前のグループが1回以上出現する必要があり、何回出現してもよいことを示します。 | <A>
シーケンス内でトークン<A>が出現(任意の回数)する場合に一致します |
| * |
中カッコの中で数字のかわりに使用し、前のグループが任意の回数出現するか、まったく出現しないことを示します。 | [.]* |
| [.] | ワイルドカードを表し、任意のトークンに一致します。
これは、トークンの回数に関するルールと一緒に使用します。たとえば、[.]*とすると、任意の回数出現するトークンを表します。 |
[.]*(<N><valid RoadHint>)[.]*
シーケンス<N><valid RoadHint>が出現した場合にこのシーケンスを再分類し、パターン内の他のトークンは再分類しません |
| ( ) | パターンのうち、実際に再分類したい部分を囲みます。再分類自体ではなく、「再分類ルール」の照合でパターン・コンテキストを使用できます。 | (<N><valid RoadHint>)<valid Town>
シーケンス<N><valid RoadHint>が「valid Town」トークンの前に出現した場合に、このシーケンスを再分類します。 |
| " " | トークンのかわりにルールで使用される完全なデータを囲みます。 | [-] |
その他の注意点
次の再分類ルールに注意してください。
ワイルドカードを使用しないかぎり、各ルールでは属性内のトークン・パターン全体を照合します。
ルールを順序付ける必要はなく、すべてのルールがデータ・セットに適用されます。相互に依存するルールは自動的に順序付けされます。たとえば、<A>_<valid Road Hint>を<valid Thoroughfare>に再分類し、<N>_<valid Thoroughfare>を再分類する別のルールを追加すると、後者のルールは最初のルールの後に処理されます。循環するルールは許可されません。たとえば、あるルールで<A>を<B>に再分類し、別のルールで<B>を<A>に分類することはできません。
区切り文字または空白文字を表す基本のトークン(「トークン化」ステップの構成から導出される)を、再分類ルールで指定するかどうかを選択できます。これを含めないと、ルールに対してパターンを照合するときに無視されます。これをルールに含める場合は、完全に一致する必要があります。たとえば、ルール<N><valid Road Hint>は<N>_<valid Road Hint>と<N>___<valid Road Hint>の両方と一致しますが、ルール<N>_<valid Road Hint>は前者のパターンとのみ一致します。
照合するトークンの有効性レベルを指定するかどうかを選択できます。たとえば、ルール<N><Road Hint>は<N><valid Road Hint>と<N><possible Road Hint>の両方と一致します。
トークンの様々なシーケンスを同じターゲット・トークンに再分類する、複数の再分類ルールを使用できます。
例
この例では、2つの再分類ルールを使用し、Acacia AvenueやLondon Roadのような大通りを表すトークンのシーケンスを識別して、住所を解析するときに解決するパターンの合計数を少なくしています。
| ルール名 | 検索 | 再分類基準 | 結果 |
|---|---|---|---|
| 大通り | [.]*([<A>]+<RoadHint>)[.]* | 大通り | 有効 |
| 町を道路名で再分類 | [.]*([<Town>]+<RoadHint>)[.]* | 大通り | 有効 |
これら2つのルールは、どちらもAddress1属性に適用されます。ルールの結果は、プロセスの実行後に確認できます。
こうすると、影響されるレコードとパターンをドリルダウンし、各ルールが正しく動作することを確認できます。再分類ルールはそれぞれ、適用した属性内の多くのパターンに影響することがあり、それが分類パターン全体の多くに影響することがあります(複数の属性を解析する場合)。同じ入力レコードが複数の分類パターンを持つこともあるので(単一のトークンが複数の方法で分類されることがあるため)、同じレコードが、同じルールに影響される複数の分類パターンを持つ場合もあります。
前述の再分類ルールが適用された後は、「再分類」ビューで、いくつかのパターン内の<thoroughfare>トークンの外観を確認できます。
解析プロセッサを構成する次のステップとして、入力データの最適な説明を選択します。
「解決」は、「解析」の最後のサブプロセッサです。このステップでは、各レコードの選択されたトークン・パターンを使用して、解析の結果(「成功」、「レビュー」または「失敗」)、およびデータの出力方法(たとえば、新しい構造への出力)を決定します。選択されたパターンが同じレコードは、すべて同じ方法で解決されます。
「解析」を使用してデータを検証したり、データを新しい構造に変換する場合に、「解決」ステップは不可欠です。
データのタイプによっては、単純なルール・セットを使用して初期の「解析」プロセッサを構成するのが適切な場合があるため、最も頻出するパターンを解決したり、トークンを出力属性にマップしてデータを新しい構造に解決できます。次に、残りのレコードを「レビュー」のままにして、より複雑な構成を使用する2番目の「解析」プロセッサに渡します。これにより、すでに解決済のレコードに影響を与えずに、2番目のパーサーの処理を迅速に繰り返すことができます。
結果の解決
解析でレコードを解決する方法は3つあります。
完全ルール - 1つのトークン・パターンが完全に一致します。該当するパターンを含むレコードは、1つの結果およびコメント(オプション)によって解決され、ルールで指示されている方法で出力されます。
あいまいルール - 複数のトークン・パターンが一致する場合があります。一致するトークン・パターンを含むレコードは、1つの結果およびコメント(オプション)によって解決され、ルールで指示されている方法で出力されます。
自動抽出 - 特定の完全ルールまたはあいまいルールと一致しなかったパターンのトークンは、対応する出力属性に自動的に抽出されます。これらの不一致パターンを含むレコードに関連付けられた結果やコメントはありません。デフォルトでは自動抽出が使用されますが、必要に応じてオフにできます。
これらの3つの方法は優先度順に処理されます。つまり、完全ルールはあいまいルールより優先され、あいまいルールは自動抽出より優先されます。パターンが完全ルールと一致した場合は、あいまいルールで処理されません。パターンがあいまいルールと一致した場合は、自動抽出で処理されません。
「分類」および「再分類」を使用して、トークンを適切な出力属性に実質的に解決した場合、特定の解決ルールは必要なく、自動抽出で十分です。ただし、これは、特定のトークン・パターンに従ってデータの出力方法を決定できるため、よく使用されます。この場合、使用する特定の解決ルール(完全またはあいまい)のタイプは、処理対象のデータ量、および解決が必要なトークン・パターンの数によって決定できます。パターンの数が少ない場合は、完全ルールを使用して簡単に解決できます。パターンの数が多い場合、最多パターンを完全一致で解決し、残りのパターンはあいまいルールを使用して解決できます。
完全ルール
完全ルールを作成するには、選択されたトークン・パターンを「選択」ビュー(「選択」サブプロセッサで作成)で参照し、右クリックして「解決」を選択します。複数のパターンを一度に解決することもできます。
上部の矢印ボタンを使用して、トークン・パターン間を移動します。
マジック・ワンド・ボタンを使用すると、トークンのマッピングをデフォルト属性にリセットできます。つまり、出力属性名と一致するトークン・タグを含むすべてのトークンは一致する出力属性にマップされ、その他のトークンはすべてUnclassifiedData出力属性(削除されていない場合)にマップされます。
出力属性を追加したり削除するには、「出力」タブに移動し、属性を追加または削除します。次に、「完全」タブに戻り、パターンのトークンをそれらの属性にマップします。
パーサーが再実行されると、完全ルールによって解決されたパターンがルール識別子への参照とともに結果ブラウザに表示され、緑色の背景色を使用してパターンが解決済であることが強調表示されます。
あいまいルール
各あいまいルールでは、構成された式を使用して、複数のトークン・パターンを照合します。構成された式は、「再分類」で使用する式と似ていますが、次の2つの点が異なります。
あいまい解決ルールと照合する際に、特定のレコードのデータ自体を使用するための引用符" "は使用できません。これは、解決がトークン・パターンごとに実行される必要があるためです。
再分類ルールで再分類するパターンの一部を示すために使用する通常のカッコ()は使用できません。解決は、全入力属性のパターン全体に対して実行されます。
次の表では、あいまい解決ルールで使用される式の構文のガイドを示しています。
| 文字 | 使用 | 例 |
|---|---|---|
| [ ] | シーケンスが発生する回数を指定するために、トークンのシーケンスをグループ化するために使用されます。必ず範囲(中カッコで囲む)か、*または+が続きます。
グループにピリオド(.)が含まれている場合、これはトークン(1つまたは複数)を表します。 |
<A>
トークン<A>と一致します |
| { } | 前のグループ(大カッコで囲む)のインスタンスがパターンつまりシーケンスで出現する回数を表す範囲を指定します。範囲は最小値と最大値で指定し、カンマで区切ります。 | [<A>]{1,3}
シーケンス内でトークン<A>が1から3回出現する場合に一致します [<A>]{2,2} シーケンス内でトークン<A>が2回出現する場合に一致します |
| ? | グループがオプションであることを示します。これは{0,1}と指定するのと同じ意味です。つまり、グループが出現しないか、1回のみ出現する場合に一致します。 | [<title>]?
タイトル・トークンが出現しないか、1回出現する場合に一致します |
| + | 中カッコ(前述)の中で数字のかわりに使用し、前のグループが1回以上出現する必要があり、何回出現してもよいことを示します。 | <A>
シーケンス内でトークン<A>が出現(任意の回数)する場合に一致します |
| * |
中カッコの中で数字のかわりに使用し、前のグループが任意の回数出現するか、まったく出現しないことを示します。 | [.]* |
| [.] | ワイルドカードを表し、任意のトークンに一致します。
これは、トークンの回数に関するルールと一緒に使用します。たとえば、[.]*とすると、任意の回数出現するトークンを表します。 |
[.]*(<A><valid Surname>)[.]*
<A><valid Surname>を含むすべてのパターンと一致します |
その他の注意点
次の注意事項が、あいまいルールに適用されます。
ワイルドカードを使用しないかぎり、各ルールではすべての属性内のトークン・パターン全体を照合します。パターンは順序に依存しますが、各トークンが出現した属性には依存しません。
ルールは順序に依存します。トークン・パターンが上位のあいまいルールと一致した場合は、下位のあいまいルールで処理されません。
区切り文字または空白文字を表す基本のトークン(「トークン化」ステップの構成から導出される)を、あいまい解決ルールで指定するかどうかを選択できます。これを含めないと、ルールに対してパターンを照合するときに無視されます。これをルールに含める場合は、完全に一致する必要があります。たとえば、ルール<A><valid Surname>は<A>_<valid Surname>と<A>___<valid Surname>の両方と一致しますが、ルール<A>_<valid Surname>は前者のパターンとのみ一致します。
照合するトークンの分類信頼レベルを指定するかどうかを選択できます。たとえば、ルール<A><Surname>は<A><valid Surname>と<A><possible Surname>の両方と一致します。
属性タグを使用して、トークンが出現する属性を指定できます。属性タグは、マップ時に自動的に割り当てられ、a1、a2、a3のような形式です。surname入力属性のタグがa3の場合、この属性内で検出された有効な姓は、他の属性内で検出された有効な姓より信頼するとします。これを行うには、<valid a3.Surname>トークンを使用してルールを指定します。詳細は、属性タグの使用方法に関する項を参照してください。
パーサーが再実行されると、あいまいルールによって解決されたパターンがルール識別子への参照とともに結果ブラウザに表示され、黄色の背景色を使用してパターンが解決済であることが強調表示されます。
あいまい解決ルールの例
この例では、あいまい解決ルールを使用して、Company Namesを含むBUSINESS属性を解析するとき、類似したトークン・パターンの数を照合します
次のパターンがすべて、データに存在します。
<A>_<valid Suffix> (例: Dixie Associates)
<A>_<A>_<valid Suffix> (例: Payless Tyres Ltd)
<A>_<A>_<A>_<valid Suffix> (例: B W P Partners)
<A>_<A>_<A>_<A>_<valid Suffix> (例: Shire Support and Services Ltd)
接尾辞をBusiness Suffix出力属性に出力し、名前の残りはBusiness Name出力に出力するなど、単純にこれらすべてのパターンを解決したいとします。
これを実行するには、次のあいまい解決ルールを使用します。<valid Suffix>トークンの前に、未分類の語が最大4つあり、すべてがBusiness Name出力にマップされると想定しています。
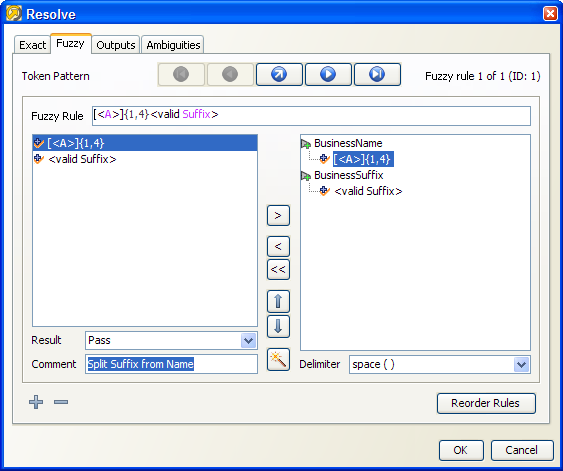
これは次のように動作します(「解決ルール」ビューでルールをドリルダウン)。
入力属性または出力属性を削除した場合の、解決に対する影響について
入力属性または出力属性を「解析」プロセッサから削除すると、その属性を使用している解決ルールに影響します。
出力属性を削除した場合は、完全またはあいまいの解決ルールからも削除されます。ただし、ルール自体は削除されません。これは、ユーザーの指定に応じてレコードを解決しようとする試みを保持し、まだ有効な可能性がある他の属性に対するマッピングを削除しないためです。
極端な場合は、すでに存在しない属性に対するトークン・マッピングしか含まれていないため、解決ルールが空になることがあります。ルールで一部のデータがマップされないのが一般的です。
入力属性を削除した場合は、当然ながらデータで生成されたトークン・パターンに影響するため、解決ルールが有効である可能性は低くなります。
一般的には、分類と再分類がすべて完了したときに解決ルールの作成と変更を始めるようにする必要があります。出力属性を追加する(または名前を変更する)必要があるのは普通ですが、解決ルール内で使用してからは、削除することはほとんどありません。
自動抽出
自動抽出は、特定の解決ルールを使用せずに、解析から有益な出力を作成するために使用するオプションの機能です。また、完全解決ルールまたはあいまい解決ルール(あるいはその両方)とともに使用すると、特定のルールと一致しない残りのパターンについて可能な最適な出力を作成する場合に役立ちます。自動抽出の目的は、入力データの各種トークン分類を「解析」プロセッサの出力に直接反映させることです。
これを使用すると、「分類」および「再分類」ステージで使用されるトークン分類タグごとに、出力属性が自動的に作成されます。これらのタグと一致するトークンは、各トークン・パターンからこの出力属性に自動的に抽出されます。パターンに同じタグのトークンが複数含まれる場合(たとえば、<valid Forename><valid Forename>...)、これらはすべて同じ出力属性にマップされ、選択した区切り文字(デフォルトはカンマ)を使用して区切られます。
追加の出力属性(Parse.UnclassifiedData)も作成されます。分類ルールまたは再分類ルールを使用して特に分類されなかったすべてのトークンはこの属性に抽出され、選択した区切り文字を使用して再度区切られます。
自動抽出は、「解決」サブプロセッサの「出力」タブから有効または無効にできます。特定のレコードの複数のトークンが同じタグで分類されている場合は、トークン間の区切り文字も変更できます。
自動抽出の例
デフォルトでは、つまり完全解決ルールまたはあいまい解決ルールを使用しない場合、自動抽出によって分類済のトークンはすべて同じ名前の出力属性にマップされ(NAME属性で「解析」プロセッサによるチェックとデータの分割を行うため)、残りの未分類トークンはすべて、Parse.UnclassifiedDataにマッピングされます。
「成功」レコードのドリルダウン
ドリルダウンして、「解析」プロセッサからの出力データを確認するときは、結果ブラウザでフラグを表示のトグルを使用し、選択したトークン・パターンと割り当てられた結果およびコメントを含め、パーサーで追跡されるフラグ属性をすべて確認すると便利です。
「選択」は、「解析」のサブプロセッサの1つです。「選択」ステップでは、各レコードを説明する生成済の可能なトークン・パターンをすべて取得し、条件を組み合せて使用して、データを最もよく理解できるパターンが選択されます。
使用される条件は次のとおりです。
未分類のトークンの数
データ・セット内での可能な各説明の出現頻度(オプション)
分類の信頼レベル(「有効」または「可能性のあるもの」)
「選択」では、調整可能なアルゴリズムを使用して、データを最もよく説明するトークン・パターンが選択されます。場合によっては、1つのトークン・パターンを選択できないことがあります。たとえば、未分類トークンの数、データ・セット内での出現回数、および分類での信頼レベルがすべての同じ候補パターンが2つ以上ある場合です。この場合、そのレコードは、パターン選択であいまいなパターンがあるとマークされます。レコードにパターン選択であいまいなパターンが1つ以上ある場合、(「解決」ステップであいまいなパターンのオプションに従って)そのレコードに結果を割り当てることはできますが、そのデータを出力形式にマップすることはできません。
「解析」プロセッサでは、選択を実行して各入力レコードを最もよく理解できるトークンを取得し、それを「解決」ステップで使用して結果を割り当て、データを新しい出力形式に解決します。
たとえば、単一の「NAME」フィールドを解析するとき、データ「ADAM SCOTT」は、「<valid Forename>_<valid Surname>」または「<valid Surname>_<valid Forename>」のいずれかの単純な分類ルールで認識できます。正しい答えは、データ・セット内のデータの形式によって決まる場合があります。残りの氏名のほとんどが「<Forename> <Surname>」の形式の場合、これが最も可能性の高いパターンとみなされ、この個人の氏名は「Adam Scott」である可能性が高くなります。ただし、残りの氏名が一般的に「<Surname> <Forename>」の形式の場合、この個人の氏名は「Scott Adam」である可能性が高くなります。
また、トークンが2つの異なるトークン・チェックによって2つの異なる信頼レベルに分類された場合(たとえば、トークン「ADAM」が<valid Forename>と<possible Surname>に指定された場合)、暗黙的に、<valid Forename>である可能性が高くなります。
「選択」サブプロセッサの構成方法を理解するには、最適なパターンの選択に使用されるロジックを理解することが重要です。
区切り文字の扱い
このオプションは、選択プロセスでの区切り文字トークンの扱いを定義します。8.1より前のバージョンのEDQでは、区切り文字は選択プロセスで未分類トークンとしてカウントされていました。これ以降のバージョンのEDQで作成された新しいプロセッサでは、デフォルトで、区切り文字は未分類トークンのカウントに含まれていません。
未分類トークンの数が最小のパターンのみ最終選択アルゴリズムに渡されるため、区切り文字の分類によってプロセッサの動作が変わる可能性があります。
未分類トークンが多いパターンの無視
選択では、他より未分類トークンが多いパターンは自動的に無視されます。たとえば、住所を解析するとき、Town属性のデータ「Newcastle Upon Tyne」からは次のトークン・パターンが生成されるため(「Newcastle」と「Newcastle Upon Tyne」の両方が「valid Town」のリストに含まれていると仮定した場合)、<valid Town>トークンとして分類されます。
たとえば、住所を解析するとき、Town属性のデータ「Newcastle Upon Tyne」からは次のトークン・パターンが生成されるため(「Newcastle」と「Newcastle Upon Tyne」の両方が「valid Town」のリストに含まれていると仮定した場合)、<valid Town>トークンとして分類されます。
<valid Town>_<A>_<A>
<valid Town>
この場合、2番目のパターンの方が未分類トークンが少ないため、「解析」では常に2番目のパターンが優先されます。
アルゴリズムによる選択
「選択」では、次のアルゴリズムを使用して、特定のレコードに対して最適なトークン・パターンを選択します。アルゴリズムは特定のポイント(後述)で調整可能で、選択の厳密度を調整できます。
調整可能なすべてのパラメータは、「拡張」タブで調整できます。
| ステップ | オプション | 使用する基準 | ロジック | 調整可能なパラメータ |
|---|---|---|---|---|
| 1 | はい(次を参照) | サンプル・データにおけるトークン・パターンの出現頻度(結果から生成) | a) 可能性のある他のパターンよりn % (変更可能)低い頻度で出現する場合に、最も頻度の高いパターンを選択します。
可能性のあるパターンが2つ以上残る場合は、bに進みます。 b) 最も頻度の高いパターンよりp % (変更可能)低い頻度のパターンがあれば、割り引きます 可能性のあるパターンが2つ以上残る場合は、ステップ2に進みます。 |
n (デフォルトは10%)
p (デフォルトは20%) |
| 2 | いいえ | パターンにおけるトークン分類の信頼レベル(「有効」または「可能性のあるもの」) | 可能性のある各パターンに、次のようにスコアを付けます。
100ポイントから開始して: a) 未分類のトークン1つごとにqポイントを引く b) 信頼レベルが「可能性のあるもの」のトークン1つごとにrポイントを引く。 次に、sポイント高い場合に、最も高いスコアのパターンを選択します。 |
q (デフォルトは10)
r (デフォルトは5) s (デフォルトは5) |
頻度のサンプルを使用してパターンを選択(上の表のステップ1)
このステップはオプションですが、複雑な解析が必要な場合は推奨です。
「解析」プロセッサを初めて実行するときは、データ・セット全体での頻度を解析して最適なトークン・パターンを選択することはできません。「解析」では、可能性のあるすべてのパターンを最初に生成する必要があるためです。
「解析」プロセッサを少なくとも1回実行した後には、次のようになります。
「+」ボタンをクリックすると、最新の結果(「再分類」ビューのデータ)から、新しいパターン頻度サンプルを作成できます。
「^」ボタンをクリックすると、最新の結果から選択したパターン頻度サンプルを更新できます。
実行するたびに生成される事前選択パターン・データを自動的に使用するかわりに、統計サンプルを使用すると、入力データ・セットのサイズにかかわらず、「解析」プロセッサに予測可能な選択を保証できます。こうすると、サンプルが同じ場合に、特定のレコードに対しては常に同じ説明が選択されます。
満足のいく説明のセットが生成されるまでにはパーサーの実行と、分類および再分類ルールの変更を何度も繰り返す必要があるため、結果の更新が必要なことは少なくありません。
その他のオプション
上の項で説明したパターン選択アルゴリズムで使用されるパラメータは、オプションで調整できます。オプションを変更すると、パーサーの情報に大きく影響する場合があるので、これらのオプションの変更は必ず熟練したユーザーが行ってください。
この例では、選択したアルゴリズムで調整可能なすべてのパラメータはデフォルト値を使用しています(前述)。
単一のNAME属性を解析するとき、"DR Adam FOTHERGILL ESQ"という値を持つレコードからは次のトークン・パターンが生成される可能性があります(他の可能性もある)。
1. <valid Title>_<possible Surname>_<possible Surname>_<valid Honorific> 2. <valid Title>_<valid Forename>_<possible Surname>_<valid Honorific> 3. <valid Title>_<valid Forename>_<possible Surname>_<possible Surname> 4. <A>_<A>_<A>_<A>
その他
まず、他のパターンより未分類のトークンが多いため、パターン4が割引きされます。
次に、残り3つのトークン・パターンが選択アルゴリズムに渡されます。
ステップ1aでは、いずれかのパターンの頻度がサンプル・データの他のパターンより10%以上高い場合に、このパターンが選択されます。そうでない場合、ロジックはステップ1bに進みます。
ステップ1bでは、いずれかのパターンの頻度が、最も頻度の高いパターンより20%以上低い場合に、このパターンが割り引かれます。複数のパターンが残った場合、ロジックはステップ2に進みます。
ステップ2では、残ったパターンにスコアが付けられます。パターン1、2、3がすべて残ったと仮定すると、スコアは次のようになります。
Pattern 1: 100 points – 10 points for 2 Possible tokens = 90 points Pattern 2: 100 points – 5 points for 1 Possible token = 95 points Pattern 3: 100 points – 10 points for 2 Possible tokens = 90 points
そのため、この場合はデフォルトしきい値の差である5ポイントを使用するので(それ以上高い値は使用しない)、パターン2が選択されます。
トークン・パターンの選択方法が適切であることを確認した後、解析プロセッサを構成する最後のステップとして、データを解決します。
「トークン化」は、「解析」のサブプロセッサの1つです。「トークン化」サブプロセッサでは、データを構文的に基本のトークンの初期セットに分割し、データ内の文字および文字のシーケンスを分析して、解析の最初のステップを実行します。
解析のコンテキストでは、トークンとは「解析」プロセッサが理解できるデータの任意の単位です。「トークン化」手順では、トークンの最初のセット(基本のトークン)を形成します。基本のトークンは、同じタイプの文字(文字、数字など)のシーケンスを他のタイプの文字(句読点や空白)で区切ったものであるのが普通です。たとえば、次のようなデータが入力されるとします
| Address1 |
|---|
| 10 Harwood Road |
| 3Lewis Drive |
この場合の「トークン化」手順では、デフォルトのルールを使用してデータを次のような基本のトークンに分解します。
| Address1 | 基本のトークン | 基本のトークンのパターン |
|---|---|---|
| 10 Harwood Road | "10" - 'N'のタグを付け数字であることを示す
"." - '_'のタグを付け空白であることを示す "Harwood" - 'A'のタグを付け単語であることを示す "." - '_'のタグを付け空白であることを示す "Road" - 'A'のタグを付け単語であることを示す |
N_A_A |
| 3Lewis Drive | "3" - 'N'のタグを付け数字であることを示す
"Lewis" - 'A'のタグを付け単語であることを示す "." - '_'のタグを付け空白であることを示す "Drive" - 'A'のタグを付け単語であることを示す |
NA_A |
ただし、データをさらに分析するときには特定の基本のトークンを無視することがあります。たとえば、前述の空白文字は分類しないので、解決ルールの照合時に無視するとします。この場合は、基本のトークンの参照データで、無視する文字をWHITESPACEまたはDELIMITERのタイプとして指定できます。次の「構成」を参照してください。
「トークン化」は、解析するデータ属性の内容を最初に把握し、データを理解する方法を決定する場合に使用します。通常は、トークン化ルールのデフォルト・セットを使用して内容を把握し、必要に応じてルールを調整できます。たとえば、データ内で特定の文字が特定の意味を持つため、その他の文字とは異なるタグ付けをする場合です。多くの場合、デフォルトのトークン化ルールを変更する必要はありません。
構成
トークン化ルールは、次のオプションで構成されます。
| オプション | タイプ | 目的 | デフォルト値 |
|---|---|---|---|
| 文字マップ | 文字トークン・マップ | 文字(Unicode参照)を文字タグ、グループ化した文字タグおよび文字タイプにマップします。
後述する「注意」を参照してください。 |
*基本のトークン化マップ |
| 小文字を大文字に対して分離 | はい/いいえ | 小文字から大文字への変化がある文字のシーケンスを、別々のトークンに分離します(たとえば、「HarwoodRoad」を「Harwood」と「Road」の2つの基本のトークンに分離します)。 | はい |
| 大文字を小文字に対して分離 | はい/いいえ | 大文字から小文字への変化がある文字のシーケンスを、別々のトークンに分離します(たとえば、「SMITHjohn」を「SMITH」と「john」の2つの基本のトークンに分離します)。 | いいえ |
文字マップ参照データに関する注意
データのトークン化に使用される参照データは特殊な形式であり、トークン化の動作にとって重要です。
デフォルトの参照データの次のスクリーンショットで、各列の目的を説明します。表示される列は、次のとおりです。
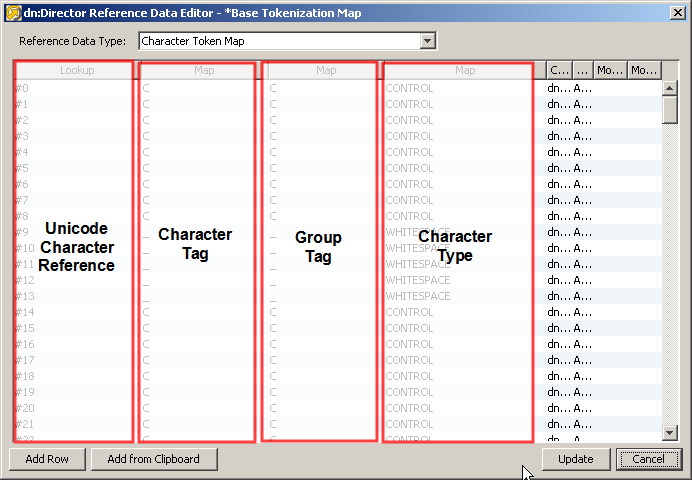
Unicode文字参照: Unicode文字参照はトークン化で使用され、トークン化の最初のステップで所定の文字タグにマップされる文字を識別します。たとえば、スペース文字を表す文字参照#32はデフォルトでは「_」の文字タグにマップされています。
|
注意: デフォルトの*基本のトークン化マップは、かわりの*Unicodeの基本のトークン化マップや*Unicode文字パターン・マップと同様に、Latin-1エンコード・データで使用するように設計されています。これらのマップがデータの文字エンコーディングに適していない場合は、たとえばマルチバイトのUnicode (16進数)文字参照などを考慮に入れた新しいマップを作成して使用できます。 |
文字タグ: 文字タグはトークン化の最初のステップとして使用され、(Unicode文字参照によって識別される)データの各文字に所定のタグを割り当てます。たとえば、すべての子文字に文字タグaを割り当てます。
グループ・タグ: グループ・タグはトークン化の2番目のステップで使用され、文字タグのシーケンスを同じグループ・タグでグループ化します。グループ・タグが同じで文字タイプも同じである文字タグのシーケンスはグループ化されて1つのトークンを形成します。たとえば、トークン化の最初のフェーズでは文字タグを使用してデータ103をNNNというタグにしますが、同じグループ・タグ(N)の3文字と、同じ文字タイプ(NUMERIC)がシーケンスにあるため、これらはグループ化されてNという基本のトークン・タグで1つの基本のトークン(103)となります。
英字の動作は少し異なることに注意してください。ユーザーは、小文字と大文字のシーケンスがある場合にトークンを分割するかどうかを選択できます。デフォルトでは、トークンは小文字から大文字に遷移するときに分割されますが、大文字から小文字への遷移では分割されません。たとえば、データ「Michael」は文字タグのシーケンス「Aaaaaaa」ですが、最初の文字の後で文字タイプがALPHA_UPPERCASEからALPHA_LOWERCASEに遷移しています。ユーザーが「大文字を小文字に対して分離」オプションのデフォルト設定を設定していない場合、これはグループ化されて、基本のトークン・タグAで1つの基本のトークン(Michael)を形成します。文字タグaとAはどちらも同じグループ・タグを共有しており、ユーザーが文字タイプの遷移に対してデータを分割しないためです。
文字タイプ: 文字タイプはデータの分割に使用されます。通常は、文字タイプが変わると別々の基本のトークンに分割されます。たとえば、文字列deluxe25mlはdeluxe、25およびmlの3つの基本のトークンに分割されます。これら3つの基本のトークンが文字タグとグループ・タグによってタグ付けされます。このルールの例外は、デフォルトではALPHA_UPPERCASEからALPHA_LOWERCASEへの文字タイプの変化ではトークンが分割されないことです。これは、大/小文字が適切に使用されているトークンを維持するためです。たとえば、Michaelが2つのトークン(Mとichael)に分割されないようにします。
ユーザーは「大文字を小文字に対して分離」オプションを選択して、この動作を変更できます。
また、「小文字を大文字に対して分離」オプションの選択を解除すると、アルファベット文字のすべての文字列をまとめて保持することもできます。こうすることで、DelUXEを1つのトークンとして保持する効果があります。
また、WHITESPACEまたはDELIMITERのいずれかのタイプで特定の文字をマークできます。これらの文字は、トークンのシーケンスを照合する次のルールで無視できます。たとえば、「再分類」または「解決」で、<Token A>の後に<Token B>があるパターンを照合する場合に、2つの間に空白文字または区切り文字があるかどうかを気にする必要がありません。文字タイプには、NUMERIC、CONTROL、PUNCTUATION、SYMBOL、ALPHA_UPPERCASE、ALPHA_LOWERCASEおよびUNDEFINEDがあります。
参照データの「コメント」列では、Unicode文字参照が表す実際の文字が説明されています(たとえば、#32は空白文字である、など)。
異なる入力属性ごとに異なるルールを使用
デフォルトでは、「解析」プロセッサに入力されるすべての属性に対して同じトークン化ルールが適用されます。通常、属性固有のトークン化ルールは必要ありません。ただし、ペインの左側で属性を選択し、「属性固有の設定を有効化」オプションを選択すれば、これを変更できます。分析する属性が多く、異なる文字が意味のある区切りになっていると、これが必要な場合があります。
属性固有のルールを指定するときは、属性間で設定をコピーすることも、「コピー元」オプションを使用してデフォルトの「グローバル」設定を再適用することもできます。
例
この例では、デフォルトのルールを使用して住所データをトークン化しており、結果は次のようになります。
(この場合、「空白の切捨て」プロセッサを使用して解析する前に、各属性から先頭と末尾の空白が切り捨てられたことに注意してください。)
次の表は、すべての入力属性における基本のトークンの個別のパターンをまとめたものです。
| ADDRESS1.trimmed | ADDRESS2.trimmed | ADDRESS3.trimmed | POSTCODE.trimmed | カウント | % |
|---|---|---|---|---|---|
| <A>_<A><,> | <A> | <A><N>_<N><A> | 119 | 5.9 | |
| <A>_<A><,>_<A>_<A> | <A> | <A><N>_<N><A> | 95 | 4.7 | |
| <A>_<A><,> | <A> | <A> | <A><N>_<N><A> | 73 | 3.6 |
| <A>_<A><,>_<A>_<A> | <A> | <A> | <A><N>_<N><A> | 58 | 2.9 |
| <N>_<A>_<A><,> | <A> | <A><N>_<N><A> | 55 | 2.7 | |
| <A>_<A><,>_<A> | <A> | <A><N>_<N><A> | 49 | 2.4 | |
| <A>_<A><,> | <A> | <A><N>_<N><A> | <A><N>_<N><A> | 40 | 2.0 |
| <N>_<A>_<A><,> | <A> | <A> | <A><N>_<N><A> | 35 | 1.7 |
次の表は、一番上の基本のトークン・パターンをドリルダウンした結果を示しています。
| ADDRESS1.trimmed | ADDRESS2.trimmed | ADDRESS3.trimmed | POSTCODE.trimmed |
|---|---|---|---|
| Tempsford Hall, | Sandy | SG19 2DB | |
| West Thurrock, | Purfleet | RM19 1PA | |
| Hayes Lane, | Stourbridge | DY9 8PA | |
| Middleton Road, | Oswestry | SY11 2RB | |
| Freshwater Road, | Dagenham | RM8 1RU | |
| College Road, | Birmingham | B8 3TE | |
| Ranelagh Gdns, | (London) | SW6 3PR | |
| Trumpington Road, | Cambridge, | CB2 2AG |
解析プロセッサを構成する次のステップとして、データを分類します。
Unicode文字参照はトークン化で使用され、トークン化の最初のステップで所定の文字タグにマップされる文字を識別します。たとえば、スペース文字を表す文字参照#32はデフォルトでは「_」の文字タグにマップされています。
|
注意: デフォルトの*基本のトークン化マップは、かわりの*Unicodeの基本のトークン化マップや*Unicode文字パターン・マップと同様に、Latin-1エンコード・データで使用するように設計されています。これらのマップがデータの文字エンコーディングに適していない場合は、たとえばマルチバイトのUnicode (16進数)文字参照などを考慮に入れた新しいマップを作成して使用できます。 |
「解析」プロセッサの「マップ」サブプロセッサは、「解析」プロセッサのために内部属性を定義し、実際の入力属性を内部属性にマップします。「解析」プロセッサのその他の機能は、内部属性に対応して定義されるため、構成された「解析」プロセッサは、入力を再マップするだけで様々な入力データ・ソースに対して再利用できます。各内部属性は、「解析」プロセッサを構成するユーザーが定義する名前と、自動的に生成され編集できない属性タグによって識別されます。属性タグは、a1、a2、a3のような形式です。
属性タグを使用して、別の入力属性に基づく同じトークンのインスタンスを区別することができます。たとえば、名前データの分析に使用されている「解析」プロセッサは、Title、ForenameおよびSurnameという3つの内部属性を定義できます。属性タグを使用すると、Titleフィールドから抽出された有効な敬称の処理方法を、Forenameフィールドから抽出された有効な敬称の処理方法と別のものにすることができます。
この区別は「解決」サブプロセッサで行われます。次のトークン・パターンのみに可能性があるとします。
<valid Title> <valid Forename> <valid Surname>
この場合、入力ステージで各トークンが含まれていた属性に対する参照がないことがすぐにわかります。属性タグを使用しないと、次の4つの入力パターンはすべて同様に解決されます。
表1-132 入力パターンの解決
| パターン | Title (a1) | Forename (a2) | Surname (a3) |
|---|---|---|---|
|
1 |
<valid Title> |
<valid Forename> |
<valid Surname> |
|
2 |
<valid Title> <valid Forename> |
<valid Surname> |
|
|
3 |
<valid Title> <valid Forename> <valid Surname> |
||
|
4 |
<valid Title> |
<valid Forename> <valid Surname> |
通常、フィールドが適切に設定された正しいデータを含むレコードは、フィールド設定が適切でない正しいデータを含むレコードよりも品質が高いとみなされます。この基準に従って、検索基準に属性タグを含めて、最初のパターンをその他のパターンと区別する解決ルールを定義できます。パターン1に対応する検索条件は次のようになります。
<valid a1.Title> <valid a2.Forename> <valid a3.Surname>
次の解決ルールには具体的でない検索条件を含めることで、パターン2、3および4に対応します。これらには低いフォーマット品質に基づいて別の解決結果が割り当てられます。
|
注意: 解決ルールは順序どおりに適用されるため、具体的なルールを一般的なルールよりも先にテストする必要があります。そうしないと、一般的なルールがすべてのパターンに適用され、具体的な一致パターンが処理されなくなります。 |
詳細な例
次の表では、解決ルールの検索文字列の詳しい例を示し、前述のパターンのどれと一致するかを説明します。
サード・パーティ・プロセッサは、サード・パーティ製品との統合を使用してデータの分析と変換を実行します。通常、プロセッサで必要なサード・パーティ・ソフトウェアの有効なインストールがEDQによって検出されたときに、サード・パーティ・プロセッサが有効化されます。
「住所の検証」プロセッサ(AV)を使用して、任意の国の住所データを検証および標準化します。地域コードも提供されています。
|
注意: プロセッサが正しくインストールされていない場合でも、動作しますが、精度コード(値は-1.0)以外の出力フィールドが空白のままになります。 |
「住所の検証」プロセッサを使用して、次のことを実行します。
住所を1つの形式に標準化します。
住所が正しいかどうかをチェックします。
不完全な住所を補完します。
地域コードを使用して、住所データを拡張します。
構成
このプロセッサでは常に再実行マーカーが表示されていますが、このマーカーは、構成が変更されたかどうかに関係なくプロセスが実行されるたびに完全に再実行されることを示します。これは、このプロセッサの後続のプロセッサも再実行が必要であることを意味します。これは、EDQアプリケーションの外で変更が行われ、その変更に伴って後続の実行の結果が異なる可能性があるためです。
入力
入力属性に特定のデータ型が含まれている可能性があるため、初期構造の住所データに従って、このプロセッサでは入力属性のマッピングがヒントとして使用されます。通常は、「住所の検証」にデータを指定する前に、住所をすべての異なる入力属性に完全に解析する必要はありません。多くの場合、住所データを入力住所行に追加すれば十分です(国が指定されている場合)。これは、「住所の検証」プロセッサが内部で住所を解析してから、国固有の参照データと照合するためです。ただし、住所の構造が正しい場合、対応する入力属性マッピングが使用されると、さらに効果的な検証結果を表示できます(たとえば、通常、入力属性に郵便番号が含まれている場合、これを単純に住所行にマップするのではなく、郵便番号入力属性にマップすることをお薦めします)。
組織
最大8つの住所行の値
二重従属地域
従属地域
場所
管理領域
郵便番号
国
私書箱
サブ建物
建物
不動産
大通り
従属大通り
スーパー管理領域
サブ管理領域
|
注意: 「国」の入力は、国名または国コードとともに指定する必要があります。指定しないと、「住所の検証」では住所の検証または精度コードの作成を行うことができません。 |
オプション
| オプション | 説明 | 設定 |
|---|---|---|
| 処理モード | 入力された住所を検証するか、インストールされているすべてのデータを検索して複数の結果を返すか。 | 検証(ベスト・マッチ): 1対1 - 参照データを確認し、最適な一致を返します。
検証(複数の結果を許容): 入力された住所の1対1の検証を試行しますが、入力された住所で検証結果が「あいまい」な場合には、「住所の検証」によって複数の結果が返されることもあります。 検索: 1対多 - 参照データを確認し、複数の一致を返します。たとえば、複数の国にまたがる検索が可能です。 |
| 結果の最大数 | 返すことのできる結果の数の上限(オプション)。
注意: 「検証(ベスト・マッチ)」を選択した場合、このフィールドはグレー・アウト表示されます。 |
数値フィールド、最大15文字。 |
| ジオコード | 一致するジオコードを返すかどうか。 | はい
いいえ |
| 出力住所の区切り文字 | 住所要素の区切りに使用する記号。 | 一部の句読点記号と特殊文字。 |
| 出力スクリプト | 出力が、選択したスクリプトに変換されます。 | 使用可能なスクリプトのドロップダウン・リスト。ネイティブ(デフォルト) - 出力を元のスクリプトの形で返します。 |
| 出力の大/小文字 | 出力を返すときの大/小文字。 | 使用可能なオプションは「タイトル」(デフォルト - 各単語の最初の文字が大文字で、その他の文字は小文字)、「大文字」または「小文字」です。 |
| その他のオプション | フリー・テキスト・フィールド。 | There are additional options available that are not listed on the 「住所の検証: オプション」タブにリストされていない追加のオプションがあります。
これらのオプションを使用するには、フリー・テキスト・フィールドにそのオプションと指定値を入力します。例:
注意:
|
出力
次の表に、使用可能なAV出力フィールドをすべてリストします。各データ・セットの完全な出力は、AVプロセッサの設定、元の住所データ、および国ごとに使用可能な情報によって異なります。
|
注意: CASS、AMASおよびSERPのオプションが機能するには、適切なLoqateライブラリとデータが追加でインストールされている必要があります。 |
| 出力フィールド | 説明 |
|---|---|
| av.Address | 完全な住所。該当する国の郵便制度に応じて照合/検証され、適切に書式設定されます。 |
| av.CountryName | 完全な国名。 |
| av.ISO3166-2 | ISO3166による2文字の国コード。 |
| av.ISO3166-3 | ISO3166による3文字の国コード。 |
| av.ISO3166-N | ISO3166による3桁数字の国コード。 |
| av.SuperAdministrativeArea | 1つの国で最大の地理的データ要素。 |
| av.AdministrativeArea | 1つの国で最も一般的な地理的データ要素。たとえば米国やカナダの州など。 |
| av.SubAdministrativeArea | 最小の地理的データ要素。米国の群など。 |
| av.Locality | 1つの国で最も一般的な人口集中地域のデータ要素。たとえば市や地方自治体など。 |
| av.DependentLocality | さらに小さい人口集中地域のデータ要素。トルコの近隣(neighborhood)など。 |
| av.DoubleDependentLocality | LocalityおよびDependentLocalityフィールドに応じて最も小さい人口集中地域のデータ要素。英国の村など。 |
| av.Thoroughfare | 1つの国で最も一般的な番地またはブロックのデータ要素。たとえばストリートなど。 |
| av.ThoroughfarePreDirection | Thoroughfareフィールドの先頭に含まれる方向。たとえば、Thoroughfareに"N MAIN ST"が含まれている場合、ThoroughfarePreDirectionは"N"を含みます。 |
| av.ThoroughfareLeadingType | Thoroughfareフィールドの先頭にある大通りタイプのインジケータ。たとえば、Thoroughfareに"RUE DE LA GARE"が含まれている場合、ThoroughfareLeadingTypeは"RUE"を含みます。 |
| av.ThoroughfareName | Thoroughfareフィールドにおける名前インジケータ。たとえば、Thoroughfareに"N MAIN ST"が含まれている場合、ThoroughfareNameは"MAIN"を含みます。 |
| av.ThoroughfareTrailingType | Thoroughfareフィールドの末尾にある大通りタイプのインジケータ。たとえば、Thoroughfareに"N MAIN ST"が含まれている場合、ThoroughfareTrailingTypeは"ST"を含みます。 |
| av.ThoroughfarePostDirection | Thoroughfareフィールドの末尾に含まれる方向。たとえば、Thoroughfareに"MAIN ST N"が含まれている場合、ThoroughfarePostDirectionは"N"を含みます。 |
| av.DependentThoroughfare | 1つの国における独立した番地またはブロックのデータ要素。たとえば英国の従属番地。 |
| av.DependentThoroughfarePreDirection | DependentThoroughfareフィールドの先頭に含まれる方向。たとえば、DependentThoroughfareに"N MAIN ST"が含まれている場合、DependentThoroughfarePreDirectionは"N"を含みます。 |
| av.DependentThoroughfareLeadingType | DependentThoroughfareフィールドの先頭にある大通りタイプのインジケータ。たとえば、DependentThoroughfareに"RUE DE LA GARE"が含まれている場合、DependentThoroughfareLeadingTypeは"RUE"を含みます。 |
| av.DependentThoroughfareName | DependentThoroughfareフィールドにおける名前インジケータ。たとえば、DependentThoroughfareに"N MAIN ST"が含まれている場合、DependentThoroughfareNameは"MAIN"を含みます。 |
| av.DependentThoroughfareTrailingType | DependentThoroughfareフィールドの末尾にある大通りタイプのインジケータ。たとえば、DependentThoroughfareに"N MAIN ST"が含まれている場合、DependentThoroughfareTrailingTypeは"ST"を含みます。 |
| av.DependentThoroughfarePostDirection | DependentThoroughfareフィールドの末尾に含まれる方向。たとえば、DependentThoroughfareに"MAIN ST N"が含まれている場合、DependentThoroughfarePostDirectionは"N"を含みます。 |
| av.Building | 個々の場所を識別する説明的な名前。 |
| av.BuildingLeadingType | Buildingフィールドの先頭にある建物タイプのインジケータ。たとえば、Buildingに"BLOC C"が含まれている場合、BuildingLeadingTypeは"BLOC"を含みます。 |
| av.BuildingName | Buildingフィールドにおける名前インジケータ。たとえば、Buildingに"WESTMINSTER HOUSE"が含まれている場合、BuildingNameは"WESTMINSTER"を含みます。 |
| av.BuildingTrailingType | Buildingフィールドの末尾にある建物タイプのインジケータ。たとえば、Buildingに"WESTMINSTER HOUSE"が含まれている場合、BuildingTrailingTypeは"HOUSE"を含みます。 |
| av.Premise | 個々の場所を識別する英数字のコード。 |
| av.PremiseType | Premiseフィールドの先頭にある不動産タイプのインジケータ。たとえば、Premiseに"Plot 7/7A"が含まれている場合、PremiseTypeは"Plot"を含みます。 |
| av.PremiseNumber | Premiseフィールドにおける英数字インジケータ。たとえば、Premiseに"Plot 7/7A"が含まれている場合、PremiseNumberは"7/7A"を含みます。 |
| av.SubBuilding | 特定の配達地点、たとえば"FLAT 1"や"SUITE 212"のセカンダリID。 |
| av.SubBuildingType | SubBuildingフィールドの先頭にある建物タイプのインジケータ。たとえば、SubBuildingに"FLAT 1"が含まれている場合、SubBuildingTypeは"FLAT"を含みます。 |
| av.SubBuildingNumber | SubBuildingフィールドにおける英数字インジケータ。たとえば、SubBuildingに"FLAT 1"が含まれている場合、SubBuildingNumberは"1"を含みます。 |
| av.SubBuildingName | SubBuildingフィールドにおける説明的な名前。たとえば、SubBuildingに"BASEMENT FLAT"が含まれている場合、SubBuildingNameは"BASEMENT FLAT"を含みます。 |
| av.PostalCode | 特定の配達地点の完全な郵便番号。 |
| av.PostalCodePrimary | 特定の国で使用されるプライマリの郵便番号。たとえば、米国のZIP、カナダの郵便番号、インドのピンコードなど。 |
| av.PostalCodeSecondary | セカンダリの郵便番号情報(たとえば米国のZip Plus 4)。 |
| av.Organization | 特定の配達地点に関連付けられている企業名。 |
| av.OrganizationName | Organizationフィールドにおける名前インジケータ。たとえば、Organizationに"Loqate Inc"が含まれている場合、国に十分なレベルの解析詳細が存在すれば、OrganizationNameは"Loqate"を含みます。 |
| av.OrganizationType | Organizationフィールドの末尾にあるタイプのインジケータ。たとえば、Organizationに"Loqate Inc"が含まれている場合、国に十分なレベルの解析詳細が存在すれば、OrganizationTypeは"Inc"を含みます。 |
| av.PostBox | PostBoxフィールドにあるタイプのインジケータ。たとえば、PostBoxに"PO BOX 1234"が含まれている場合、国に十分なレベルの解析詳細が存在すれば、PostBoxTypeは"PO BOX"を含みます。 |
| av.PostBoxNumber | PostBoxフィールドにおける英数字インジケータ。たとえば、PostBoxに"PO BOX 1234"が含まれている場合、国に十分なレベルの解析詳細が存在すれば、PostBoxNumberは"1234"を含みます。 |
| av.Latitude | 10進の角度書式で表すWGS 84緯度。 |
| av.Longitude | 10進の角度書式で表すWGS 84経度。 |
| av.DeliveryAddress | 完全な住所からOrganization、Locality階層、AdministrativeArea階層およびPostalCode階層の各フィールドを引き、該当する国の郵便制度に応じて正しく書式設定したもの。AddressLineSeparatorを使用して指定した改行も含める。 |
| av.Geodistance | 複数地点の平均として計算したジオコーディング結果で可能性のある半径(メートル単位)。 |
| av.Contact | 連絡先の名前。 |
| av.Function | 権限または役職名。 |
| av.Department | 組織の部門情報。 |
| av.Unmatched | 特定の住所コンポーネントに一致しない単語。 |
| avverify.amas.DPID | 配布ポイントID: 新しい住所ごとに、ソース・アドレス・データベースに割り当てられる一意の8桁の数 |
| avverify.amas.FloorType | フロアまたはレベルのタイプ |
| avverify.amas.FloorNumber | フロアまたはレベルの数(英字を含む場合もある) |
| avverify.amas.LotNumber | 配分数 |
| avverify.amas.PostBoxNum | 住所が郵便配達タイプの場合の郵便配達番号 |
| avverify.amas.PostBoxNumberPrefix | 郵便配達番号に関連する郵便配達番号接頭辞 |
| avverify.amas.PostBoxNumberSuffix | 郵便配達番号に関連する郵便配達番号接尾辞 |
| avverify.amas.PrimaryPremise | 不動産の大通り番号(不動産の範囲付き住所の最初の数) |
| avverify.amas.PrimaryPremiseSuffix | 大通り番号の接尾辞 |
| avverify.amas.SecondaryPremise | 2番目の大通り番号(不動産に範囲付き住所がある場合のみ使用されます。たとえば23-25など) |
| avverify.amas.SecondaryPremiseSuffix | 2番目の大通り番号の接尾辞 |
| avverify.amas.PreSortZone | バーコード・ソート・プラン(BSP)番号とも言います。オーストラリアで使用される54種類の地域の1つ。オーストラリアの郵便のPreSort Letters Serviceとして有効なためには、この番号に基づいて手紙をソートする必要があります。 |
| avverify.amas.PrintPostZone | 仕分けインジケータとも言います。オーストラリアの郵便のPrint Post Serviceとして有効なためには、この番号に基づいて手紙をソートする必要があります。 |
| avverify.amas.Barcode | DPIDに基づくバーコード |
| avverify.amas.PrimaryAddressLine | 標準書式でのプライマリの住所 |
| avverify.amas.SecondaryAddressLine | 標準書式でのセカンダリの住所 |
| avverify.cass.AutoZoneIndicator | 次の自動ゾーン・インジケータ
|
| avverify.cass.CarrierRoute | 5桁の郵便コード内で、郵便配達または収集順路に割り当てられる配達順路コード。CRIDとも言います。5つのタイプがあります。
|
| avverify.cass.CMRAIndicator | 住所が民間私書箱(CMRA)に関連付けられていることを示します。
|
| avverify.cass.CongressionalDistrict | 住所が所属する下院議員選挙区 |
| avverify.cass.DefaultFlag | 値が"Y"の場合、レコードがZIP+4ファイルにおける高層のデフォルト、地方無料配達経路のデフォルト、または番地のデフォルト・レコードに一致することを示します。 |
| avverify.cass.DeliveryPointBarCode | 2桁の配達地点と1桁の検証桁で構成される3桁のコード。これを使用して作成される12桁のPOSTNETバーコードは、5桁のZIPコード、4桁のZIP+4コード、およびこの3桁のコードで構成されます。 |
| avverify.cass.DPVConfirmedIndicator | 次のいずれかの値を使用して、住所の配達率を示します。
|
| avverify.cass.DPVFootnotes | 配達地点検証統計の脚注。このフィールドはDPVConfirmedIndicatorとともに使用され、入力された住所の有効性と配達率がこれで決まります。
|
| avverify.cass.eLOTCode | eLOT方向インジケータ。詳細は、eLOTNumberフィールドを参照してください。値:
|
| avverify.cass.eLOTNumber | eLOT (Enhanced Line of Travel)を表す4桁の順序番号。この番号は、eLOTCodeフィールドと組み合せてメールのソートに使用されます。eLOT処理を郵便事業者が使用すると、拡張配達経路の事前ソート割引が有効になります。 |
| avverify.cass.EWSFlag | 値が"Y"の場合、住所がEWS (Early Warning System)ファイルのレコードに一致し、ZIP+4には一致しません |
| avverify.cass.FalsePositiveIndicator | 誤検知の表によって、誤検知の住所がフラグ設定されます。郵便一覧が生成中か、検証中に作成されるかが、このフラグによって決まります。USPSでは、DPV証明を通じて郵便リストを作成することはできません。
|
| avverify.cass.FIPSCountyCode | 国を一意に識別する5桁のFIPS (連邦情報処理標準)コード。 |
| avverify.cass.Footnotes | 脚注の文字列
|
| avverify.cass.LACSLinkCode | LACSLinkデータベースに対する問合せの後でLACSLinkによって返されるコード。
|
| avverify.cass.LACSLinkIndicator | LACSLinkデータベースに対する問合せの後でLACSLinkによって返されるインジケータ。
|
| avverify.cass.LACSStatus | 値が"L"の場合、入力された住所がLocatable Address Conversion Service (LACS)データベースのエントリに一致し、入力された住所が地域形式の住所から市町村形式の住所に変換されていることを示します。 |
| avverify.cass.NoStatIndicator | 住所に配達が届いておらず、その住所が可能性のある配達先として信頼できないことを示します。これらの住所に配達が届かないのは、1)配達が確立していない、2)顧客が削除の一部としてメールを受信する、または3)業者がすべてのメールを破棄または返却したため、この住所はすでに有効な配達先ではないためです。
|
| avverify.cass.PMBNumber | PMB指示に続く、解析済のPMB番号 |
| avverify.cass.PMBType | Parsed Private Mailbox (PMB)の指示 |
| avverify.cass.PrimaryAddressLine | プライマリの配達住所。次のいずれかを含むことがあります。
|
| avverify.cass.RecordType | 有効な配達住所として確認されている住所のレコード・タイプ。値:
|
| avverify.cass.ReturnCode |
|
| avverify.cass.ResidentialDelivery | このフィールドは、入力された住所が住居の住所か事業所の住所かを示します。値:
注意: このフィールドを使用できるのは、RDIデータ・パックがCASSとともにインストールされている場合のみです。 |
| avverify.cass.SecondaryAddressLine | セカンダリの配達住所(存在する場合)。 |
| avverify.cass.SUITELinkFootnote | SuiteLinkデータベースに対する問合せの後でSuiteLinkによって返されるコード。値:
|
| avverify.cass.VacantIndicator | 配達地点が、過去には有効だったが現在は空き(ほとんどの場合90日以上使用されていない)で、配達物を受け取っていないことを示します。値:
|
| avverify.serp.SerpStatusEx | V (有効)
C (修正可能): 修正可能なフィールドは、出力で正しい値に修正されます。 N (無効) |
| avverify.serp.Questionable | QR ("不審-農村部"の意味)
QU ("不審-都市部"の意味) 空 - 住所に不審な点はない。 |
| avverify.serp.DeliveryInstallationAreaName | 郵便支局/郵便施設の地域名 |
| avverify.serp.DeliveryInstallationType | 郵便支局/郵便施設/出力タイプ |
| avverify.serp.DeliveryInstallationQualifierName | 郵便施設の名前 |
| avverify.serp.RouteType | ルート・アドレスのタイプ: 農村部ルート、軍用ルートなど。 |
| avverify.serp.RouteNumber | ルート・アドレスのルート番号を示す |
| avverify.serp.AdditionalContentType | サイトまたはコンポーネントの指定子を含む |
| avverify.serp.AdditionalContentNumber | サイトまたはコンポーネントの番号を含む |
フラグ
| フラグ名 | 詳細 |
|---|---|
| av.AccuracyCode | 各住所が識別および照合された精度を示すコード。
注意: 複数の出力オプションがある場合(検証: 複数の結果と検索を許可)は、見つかった結果ごとに精度コードが返されます。 |
| av.ResultCount | 戻された住所の数。「確認」モードの場合は常に"1"です。 |
| av.MatchScore | 入力と最も近い参照一致との間の一致(パーセンテージ単位)。これは、精度コードから抽出されます。 |
| av.GeoAccuracy | 住所に関連付けられている1つ以上のジオコードが識別済かどうかを示すコード。 |
|
注意: プロセッサの「オプション」タブにある「フィールド・ステータス・フラグを返す」オプションが「はい」に設定されている場合は、出力属性ごとに追加のフラグが、それぞれの検証ステータスを示す数値とともに生成されます。 |
| コード | 説明 |
|---|---|
| 0 | 適用不可: フィールドは戻りフィールド・ステータスに適用されません。 |
| 1 | 検証済で変更なし: 該当する参照データを使用してフィールドを検証済で、変更は必要ありませんでした。 |
| 2 | 検証済で別名を変更: 該当する参照データを使用してフィールドを検証済で、解析中の別名の変更がありました(「7: 別名を識別済」を参照)。 |
| 3 | 検証済で若干の変更: 該当する参照データを使用してフィールドを検証済で、綴りが若干変更されました。 |
| 4 | 検証済で大幅な変更: 該当する参照データを使用してフィールドを検証済で、綴りが大幅に変更されました。 |
| 5 | 追加: 該当する参照データを使用してフィールドが追加されました。 |
| 6 | 識別済で変更なし: 該当する辞書データを使用してフィールドを識別済で、変更は必要ありませんでした。たとえば、入力値"PO Box 1234"はPostBoxとして識別されますが、検証できない場合には、ステータス6が返されます。 |
| 7 | 別名を識別済: 該当する辞書データを使用してフィールドを識別済で、別名の変更がありました。たとえば、入力値'Avnue'は、ThoroughfareType 'Ave'の別名として識別できます。 |
| 8 | コンテキストを識別済: 該当するコンテキスト・ルールを使用してフィールドは識別済です。たとえば、入力された住所"123 sdovnsdv San Bruno CA USA"では、"sdovnsdv"という語がThoroughfareとして識別されますが、それは出現するコンテキストのためにすぎません(識別可能な不動産番号より後で、識別可能な地域の前)。 |
| 9 | 空フィールドが空です。 |
| 10 | 未認識: フィールドは認識されていません。 |
AccuracyCode
このコードは、次の要素で構成されています。

A.検証ステータス - 検証のレベル。
V: 検証済 - 入力データと、利用可能な参照データからの1つのレコードとの間で完全に照合が実行されました。
P: 部分的に検証済 - 入力データと、利用可能な参照データからの1つのレコードとの間で部分的に照合が実行されました。
U: 未検証 - 検証できません。出力フィールドには入力データが含まれます。
A: あいまい - 近い参照データが複数一致します。
C: 競合 - 複数の近い参照データが競合する値に一致します。
R: 反転 - 指定した最小許容レベルでレコードを検証できませんでした。出力フィールドには入力データが含まれます。
B.事後処理された検証一致レベル - 検証プロセス後に、入力データが使用可能な参照データと一致する範囲。
5: 配達地点 (PostBoxまたはSubBuilding)。
4: 不動産 (PremiseまたはBuilding)。
3: 大通り。
2: 地域。
1: 管理領域。
0: なし。
C.事前処理された検証一致レベル - 検証プロセスの前に、入力データが利用可能な参照データと一致する範囲。
5: 配達地点 (PostBoxまたはSubBuilding)。
4: 不動産 (PremiseまたはBuilding)。
3: 大通り。
2: 地域。
1: 管理領域。
0: なし。
D.解析ステータス - すべてのデータを解析できるかどうか。
I: 識別済で解析済 - 入力データは識別が可能で、コンポーネントに配置されています
U: 解析不可 - 一部の入力データは識別が不可で、解析できません。
E.辞書識別一致レベル - 入力データがパターンおよび辞書の一致を通じて形成したレベル。
5: 配達地点 (PostBoxまたはSubBuilding)。
4: 不動産 (PremiseまたはBuilding)。
3: 大通り。
2: 地域。
1: 管理領域。
0: なし。
F.コンテキスト識別一致レベル - コンテキスト識別一致レベルは、出現するコンテキストに基づいて入力データを認識できるレベルを示します。
5: 配達地点 (PostBoxまたはSubBuilding)。
4: 不動産 (PremiseまたはBuilding)。
3: 大通り。
2: 地域。
1: 管理領域。
0: なし。
G.郵便番号ステータス - 郵便番号が検証された範囲。
P8: PostalCodePrimaryとPostalCodeSecondaryが検証済。
P7: PostalCodePrimaryが検証済、PostalCodeSecondaryが追加または変更。
P6: PostalCodePrimaryが検出済。
P5: PostalCodePrimaryが検出済で若干の変更。
P4: PostalCodePrimaryが検出済で大幅な変更。
P3: PostalCodePrimaryが追加。
P2: PostalCodePrimaryが辞書によって識別済。
P1: PostalCodePrimaryがコンテキストによって識別済。
P0: PostalCodePrimaryが空。
H.一致スコア - 入力データと、最も近い参照データとの一致の類似度。0 (一致なし)から100 (完全一致)までのパーセンテージで表します。
GeoAccuracy
ジオコードとも言い、このフラグは2つの値で構成されます。
| 値 | 説明 | 設定 |
|---|---|---|
| ジオコーディングのステータス | 住所のジオコードが見つかったかどうかを示します。 | P: ポイント - 入力された住所に一致するジオコードが1つだけ見つかりました
I: 補間 - ジオコードは、入力された住所の場所の範囲から補間されます A: 複数平均 - 入力された住所に一致する複数のジオコード候補が見つかり、その平均が返されました U: ジオコード不可 - 入力された住所に対してジオコーディングを生成できませんでした |
| ジオコーディングのレベル | ジオコードの地理的な精度を示します。 | 5: 配達地点 (PostBoxまたはSubBuilding)
4: 不動産 (PremiseまたはBuilding) 3: 大通り。 2: 地域。 1: 管理領域。 0: なし。 |
実行
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム監視 | はい |
| リアルタイム・レスポンス | はい |
結果の表示
「住所の検証」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、各入力属性とともに、右側に出力属性が表示されます。
出力フィルタ
なし。
「Capscan一致コード」プロセッサでは、Capscan Matchcode APIのインストールを使用して、住所を検証して標準化します。EDQでは、Capscan Matchcode APIで使用するために購入されたデータ・セットをサポートします。
住所は、Capscanが提供する参照データに対して検証されます。「Capscan一致コード」プロセッサを使用するには、Capscan Matchcode APIのライセンスを取得してインストールする必要があります。
「Capscan一致コード」を使用して、次のことを実行します。
住所の検証
住所のエラーおよび欠落した情報を修正します
Capscanの商号および氏名のデータを使用して、住所に関連付けられた組織および個人が、Capscanの参照データのその住所にリストされていることをチェックします
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 住所データを含む、任意の数の入力属性を指定します。
「Capscan一致コード」のパフォーマンスが最適になるのは、住所属性が論理的な順序で入力された場合です(例: UK住所の場合、Address1、Address2、Town、County、Postcode)。住所によっては、データを減らすこともできます(例: Address1およびPostcode)。特に、住所フィールドに含まれる情報が国別住所ファイルにない可能性が高い場合です。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性があります。
|
|
フラグ |
次のフラグがあります。
|
「Capscan一致コード」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、各入力属性とともに、右側に出力属性が表示されます。
出力フィルタ
なし。
例
この例では、「Capscan一致コード」を使用して、英国の住所と郵政省のPAF (Postal Address File)とを照合しています。
| Address1 | Address2 | Address3 | アドレス 4 | ZipCode | capscan.MatchScore | capscan.OutputStatus |
|---|---|---|---|---|---|---|
| 2 Thrornham Drive | NORWICH | NR7 8HX | 99 | V | ||
| KILCREGGAN | 15 Seafield Street | ELGIN | IV30 1QZ | 80 | V | |
| 24 Kirkham Road | Heald Green | CHEADLE | SK8 3DT | 100 | V | |
| Lynmar | Temple Road | SOUTHAMPTON | SO19 9FE | 99 | V | |
| 1 Longfield Crescent | ILKESTON | DE7 4DE | 99 | V | ||
| 9 Cornwalis Drive | SHIFNAL | TF11 8UB | 86 | V | ||
| 3 Doonview Wynd | Doonfoot | Ayr | KA7 4HY | 99 | V | |
| 12 Canons Gate | HARLOW | CM20 1QE | 99 | V |
「Experian QAS」プロセッサでは、Experian QAS Batch API (以前のQAS QuickAddress Batch API)のインストールを使用して、住所を検証し標準化します。EDQでは、Experian QAS Batch APIで使用するために購入されたデータ・セットをサポートします。特定の国に応じたデフォルトの構成(レイアウト)が用意されています。ユーザー作成による住所の出力に対してデータを標準化することもできます。
住所は、Experian QASが提供する参照データに対して照合することで検証されます。使用される参照データは、国に依存する様々なソースに基づいています。詳細は、Experian QAS国情報のガイドを参照してください。
名称もExperian QASにより提供されるデータに対して検証されます。この提供されるデータは特定の国に使用可能なデータ・セットで、たとえば、QAS GBN名のデータを使用します。
「Experian QAS」プロセッサを使用するには、Experian QAS Batch APIのライセンスを取得してEDQサーバーにインストールする必要があります。
|
注意: Experian QAS Batch APIとEDQがともに正しく機能するためには、EDQサーバーでいくつかのシステム設定の構成が必要となる場合があります。 |
このプロセッサは、Experian QAS Batch APIバージョン6.1以降と互換性があります。
「Experian QAS」プロセッサを使用して、次のことを実行します。
郵便本局所在町と郵便番号が指定の属性に配置されるように、指定の形式に住所を標準化します。
住所が正しいかどうかをチェックし、正しくない場合は住所がどのように間違っているかをチェックします(後述のMatchCodeの意味を参照)。
指定の住所に対して名称が正しく最新かどうかをチェックします(QASデータ・セットがある場合)。
データを拡張し、QASからのデータ・ファイルで使用できる情報(グリッド照合など)をさらに追加します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 名前または住所データを含む、任意の数の属性を指定します。
注意: 「Experian QAS」プロセッサを「すべて」モードで使用するとき、多数の国の住所データを検証できるようにするには、住所の国名をそのAPIに入力して、対応する国に基づいて検索を行うように支援できます。データに国名が含まれない場合は、住所データまたはISOコードを使用してデータを拡張して国名を追加できます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
出力データ属性は使用されるレイアウトによって異なります(レイアウトはExperian QASインストールのQAWORLD.iniファイルに定義されています)。有効なすべてのレイアウトは、「Experian QAS」プロセッサの「オプション」で選択できます。 |
|
フラグ |
次のフラグがあります。
|
実行
| 実行モード | サポート |
|---|---|
| バッチ | はい |
| リアルタイム・モニタリング | はい |
| リアルタイム・レスポンス | はい |
|
注意: このプロセッサでは常に再実行マーカーが表示されていますが、このマーカーは、構成が変更されたかどうかに関係なくプロセスが実行されるたびに完全に再実行されることを示します。これは、このプロセッサの後続のプロセッサも再実行が必要であることを意味します。これは、EDQアプリケーションの外で変更が行われ、その変更に伴って後続の実行の結果が異なる可能性があるためです。 |
結果の表示
「Experian QAS」プロセッサは、処理時にサマリー統計を表示しません。
「データ」ビューには、各入力属性とともに、右側に出力属性が表示されます。
| MatchCodeの意味 |
|---|
| Experian QASが次のいずれかの結果を返す場合のレコード番号は次のとおりです。
R - 完全な住所と郵便番号が見つかった Q - 完全な住所が見つかったが、郵便番号が見つからなかった P - 部分的な住所と郵便番号が見つかった O - 部分的な住所が見つかったが、郵便番号が見つからなかった N - 複数の住所と郵便番号が見つかった M - 複数の住所が見つかったが、郵便番号が見つからなかった L - 郵便番号が見つかったが、住所が取得できなかった K - 住所も郵便番号も取得できなかった D - 認識されない国 C - 国が使用できない B - 空欄 A - 未処理 |
| 後続のプロセッサを使用して、有効な住所を分類できます。たとえば、「論理チェック」プロセッサを使用すると、MatchSuccessがOより大きく(つまりP、Q、R)、MatchConfidenceLevelが9の場合のレコードを渡すことができます |
出力フィルタ
なし。
例
この例では、英国の住所の番号が、GBRレイアウトに対するExperian QAS Batch APIを使用してチェックされます。
| 完全な住所 | qas.MatchCode | qas.MatchSuccess |
|---|---|---|
| Filling Station, Ilkley Road(A65), Burley in Wharfedale, North Yorkshire, LS29 7BT | R013701a2020024390000000000 | R |
| Orbis, Cathedral Gardens, Manchester, Lancashire, M4 3PG | R53340000020040001000000000 | R |
| Moor End Livery, Tempsford Hall,, Sandy, SG19 2BD | P91300000024020000000000000 | P |
| C T V Services, CTV House, Lichfield Road Industrial Estate, Tamworth, Staffordshire, B79 7TA | P91300000024020400000000000 | P |
| 195 Temple Way ,,Bristol,BS99 7HD | O9030000002406000000000000 | O |
EDQで提供されるデフォルトの構成では、次の出力データ属性が生成されます。
| 属性 | 値 |
|---|---|
| AddressLine1 | 一致した組織 |
| AddressLine2 | 一致した私書箱 |
| AddressLine3 | 一致した建物または通りの初期要素 |
| AddressLine4 | 一致した建物または通りの最終要素 |
| AddressLine5 | 一致した村 |
| AddressLine6 | 一致した町/市区 |
| AddressLine7 | 一致した郡/州/県 |
| AddressLine8 | 一致した郵便番号 |
| AddressLine9 | 一致した3文字の国コード |
出力データ属性には、(混在した国際データを使用できるように)汎用値が使用されるため、AddressLine1などの汎用名が割り当てられます。
EDQで提供されるデフォルトの構成では、次の出力データ属性が生成されます。
| データ属性 | 値 |
|---|---|
| qas.Organization | 一致した組織 |
| qas.Department1 | 一致した最初の部門 |
| qas.Department2 | 一致した2番目の部門 |
| qas.POBox | 一致した私書箱タイプ |
| qas.Street | 一致した番地 |
| qas.BuildingNumber | 一致した家屋番号 |
| qas.PostalCode | 一致した郵便番号 |
| qas.Town | 一致した町 |
| qas.TownRegion | 一致した町の地域(同じ公式郵便名を持つ異なる町を区別するために使用) |
| qas.District | 一致した地区 |
| qas.StateName | 一致した州 |
| qas.Country | 一致した国 |
| qas.UnusedInput | APIによって、ターゲットの住所と照合されなかった住所要素のすべてを含む配列 |
EDQで提供されるデフォルトの構成では、次の出力データ属性が生成されます。
| データ属性 | 値 |
|---|---|
| qas.BuildingNumber | 一致した家屋番号 |
| qas.BuildingName | 一致した家屋名 |
| qas.Floor | 一致したフロア* |
| qas.ApartmentNumber | 一致したアパート番号 |
| qas.ApartmentName | 一致したアパート名* |
| qas.Street | 一致した番地 |
| qas.PostalCode | 一致した郵便番号 |
| qas.PostalDistrict | 一致した郵便地域 |
| qas.Town | 一致した町 |
| qas.Country | 一致した国 |
| qas.UnusedInput | APIによって、ターゲットの住所と照合されなかった住所要素のすべてを含む配列 |
* ここで使用したコードの意味は、QASのドキュメントを参照してください。
EDQで提供されるデフォルトの構成では、次の出力データ属性が生成されます。
| データ属性 | 値 |
|---|---|
| qas.BuildingNumber | 一致した家屋番号 |
| qas.Street | 一致した番地 |
| qas.PostalCode | 一致した郵便番号 |
| qas.Region | 一致した地域 |
| qas.Province | 一致した県 |
| qas.Town | 一致した町 |
| qas.UnusedInput | APIによって、ターゲットの住所と照合されなかった住所要素のすべてを含む配列 |
EDQで提供されるデフォルトの構成では、次の出力データ属性が生成されます。
| データ属性 | 値 |
|---|---|
| qas.CEDEXOrganisation | 一致したCEDEX組織 |
| qas.CEDEXDepartment | 一致したCEDEX部門 |
| qas.POBoxType | 一致した私書箱タイプ |
| qas.Location | 一致した場所。たとえばCentre Commercial |
| qas.Number | 一致した家屋番号 |
| qas.Street | 一致した番地 |
| qas.Locality | 一致した地域 |
| qas.Postcode | 一致した郵便番号 |
| qas.Town | 一致した町 |
| qas.Departement | 一致した部門 |
| qas.INSEECode | 一致したINSEEコード(地域を示す5文字の英数字コード) |
| qas.Country | 一致した国 |
| qas.UnusedInput | APIによって、ターゲットの住所と照合されなかった住所要素のすべてを含む配列 |
EDQで提供されるデフォルトの構成では、次の出力データ属性が生成されます。
| データ属性 | 値 |
|---|---|
| qas.Organisation | 一致した組織 |
| qas.POBox | 一致した私書箱 |
| qas.SubBuildingName | 一致したサブ建物名 |
| qas.BuildingName | 一致した家屋名 |
| qas.BuildingNumber | 一致した家屋番号 |
| qas.DependentThoroughfare | 一致した従属大通り |
| qas.Thoroughfare | 一致した大通り |
| qas.DoubleDependentLocality | 一致した二重従属地域 |
| qas.DependentLocality | 一致した従属地域 |
| qas.Town | 一致した町 |
| qas.SubmittedPNRLocality | 一致した地域(大きい町や市の一部の識別に使用されるのが一般的) |
| qas.County | 一致した郡 |
| qas.Postcode | 一致した郵便番号 |
| qas.UnusedInput | APIによって、ターゲットの住所と照合されなかった住所要素のすべてを含む配列。 |
EDQで提供されるデフォルトの構成では、次の出力データ属性が生成されます。
| データ属性 | 値 |
|---|---|
| qas.BuildingNumber | 一致した家屋番号 |
| qas.BuildingName | 一致した家屋名 |
| qas.Street | 一致した番地 |
| qas.PostalCode | 一致した郵便番号 |
| qas.POBoxNumber | 一致した私書箱番号 |
| qas.Locality | 一致した地域 |
| qas.Country | 一致した国 |
| qas.UnusedInput | APIによって、ターゲットの住所と照合されなかった住所要素のすべてを含む配列 |
EDQで提供されるデフォルトの構成では、次の出力データ属性が生成されます。
| データ属性 | 値 |
|---|---|
| qas.Postbus | 一致した郵便バス(私書箱に相当) |
| qas.HouseNumber | 一致した番地 |
| qas.Street | 一致した番地 |
| qas.TownCity | 一致した町/市区 |
| qas.Province | 一致した県 |
| qas.PostalCode | 一致した郵便番号 |
| qas.Country | 一致した国 |
| qas.UnusedInput | APIによって、ターゲットの住所と照合されなかった住所要素のすべてを含む配列 |
次に示す機能は、Experian QASの上級ユーザーまたはEDQ管理者のみの使用を想定しています。これらの機能は、QASインストールに含まれるQAWorld.ini構成ファイルの編集を伴います。また、Experian QAS Batch APIのカスタマイズに習熟している必要があります。
これらの変更を有効にするためにはサーバーでEDQアプリケーション・サービスを再起動する必要があることに注意してください。
独自のレイアウトの作成
Experian QAS Batch APIで使用するために独自のレイアウトを作成できます。たとえば、Experian QASから新たに購入したデータ・セットに対してAPIを使用するため、またはAPIから返される住所の形式を変更するためです。最も簡単な方法は、QAWorld.iniファイルにある既存のファイルをコピーし、そのコピーを編集することです。新しいレイアウトには新しい名前を付けてください。また、住所行の数が指定した住所行の数と一致し、出力属性マッピングの数が住所行の数と一致することを確認します。
住所行の数は変更できます。これは、選択した情報のみを出力する場合や、住所の要素を1行にまとめる場合に対応します。この例では、住所の要素P22、P21、P12およびP11が同じ属性について出力されます。これらの住所要素以外の要素がレコードに含まれている場合、同じ住所行に表示されます(例: Unit1, Cornwall House)。
APIによって出力される住所行の要素のコードや意味は、Experian QAS Batch APIのドキュメントを参照してください。
ユーザー作成レイアウトの例:
[GBR ADD STAND]
CountryBase=GBR
CleaningAction=Address
AddressLineCount=7
AddressLine1=W40,P22,P21,P12,P11
AddressLine2=W40,S11
AddressLine3=W40,L41
AddressLine4=W40,L31
AddressLine5=W40,L21
AddressLine6=W40,L11
AddressLine7=W40,C11
SeparateElements=Yes
ElementSeparator={, } C11{ ^ } P11{, ^ } P21{, ^ } X11{ ^ } A11{ ^ }
CapitaliseItem=L21
複数の国が含まれるデータの使用
Experian QAS APIを使用して、複数の国が含まれるデータの住所を複数の国別住所ファイルに対してチェックする場合、[ALL]セクションの各行から最初の文字を削除してQAWorld,iniファイルの既存の[ALL]レイアウトを使用できます。あるいは、独自の国際レイアウトを作成することもできます。
国際レイアウトでは、CountryBase行に、対応する国の3文字のISOコードを表示する必要があります。
[ALL]
CountryBase=NUL GBR DEU LUX ESP DNK NLD FRA
初期コードNULを使用すると次のように暗黙に指定されます。
変換プロセッサは、1つ以上の入力属性を受け取って変換し、変換した値を新しい属性として出力します。
EDQの変換プロセッサは入力データを決して直接変更しないことを理解することが重要です。EDQでは、適用する変換の効果を確認してから、変換データを使用する方法を決めることができます。たとえば、データ・クレンジング・プロセスからデータを掻き出す前に、元のデータよりも変換済データを優先して使用するように選択できます。
変換プロセッサの最も一般的な用途は、データを新システムに移行する前に、あるいはデータの監査や照合を行う前にデータ品質を詳しく分析するためにデータを変換することです。したがって、変換プロセッサはプロセス・フローのどの時点でも使用できます。たとえば、分析を実行する前にすべてのテキスト・データを大文字または小文字に変換することもできます。そうすると、大/小文字を区別する必要がなくなります。
多くの場合、データに適用する必要がある変換は、プロファイリングおよび監査の際に明らかになります。したがって、EDQでは、変換ルールをデータそのものから直接作成することができます。たとえば、属性の値が無効な一連のレコードが見つかったとします。その場合、誤った値を正しい値で置き換えるために参照データ・マップをデータから直接作成できます。さらに、新しい参照データ・マップを使用して、不正な値が置換された新しい属性を作成するように、「置換」プロセッサを構成できます。
変換プロセッサで作成される属性は、プロセッサに応じて導出または追加になります。これはデータ・フローの動作に影響するため、違いを理解することが重要です。
導出属性
導出属性は、各入力属性を個別に処理して、各入力属性の変換済バージョンを新しく生成する変換プロセッサによって作成されます。新しい導出属性には、入力属性のデータの変換済バージョンが含まれます。導出属性の名前は、常にデフォルト形式[Input Attribute Name].Transformationになります(例: Forename.Upper)。
表1-135 導出属性
| プロセッサ | デフォルト名での導出属性の作成 |
|---|---|
|
大文字 |
[Attribute Name].Upper |
|
空白の切捨て |
[Attribute Name].Trimmed |
|
ノイズ削除 |
[Attribute Name].Denoise |
|
文字の切捨て |
[Attribute Name].Substring |
|
置換 |
[Attribute Name].Replaced |
|
適切な大小文字 |
[Attribute Name].Proper |
導出属性を追加するプロセッサによって属性が変換されると、出力属性には変換を反映する名前が付けられます。
デフォルトでは後続のプロセッサは入力属性として属性の最新値を使用します。たとえば、「ノイズ削除」プロセッサを「リーダー」プロセッサと「大文字」プロセッサの間に挿入した場合、「大文字」プロセッサで入力として使用されるNAME属性は、オリジナルのNAME属性ではなくNAME.Denoiseバージョンになります。
属性が処理されたすべての変換の中から、使用される最新バージョン属性が青い矢印で示されます。
つまり、処理の順序をあらかじめ確認する必要はありません。変換処理を別の変換処理の前に挿入しても、他のプロセッサにはほとんど影響しません。
導出属性は、名前がデフォルトの名前形式から変更された場合でも、結果ブラウザで導出元属性の横に表示されます(たとえば、NAME.UpperがNew_nameに変更されることがあります)。
定義された属性は緑色の丸印で示されます。これは属性の最新バージョンではなく、属性の特定のバージョン(NAME.Denoiseなど)を示します。
|
注意: 後続のプロセッサの入力として、最新バージョンのかわりに定義済属性を選択できます。プロセッサの構成において、青矢印アイコンの下で各属性を展開すると、使用可能な定義済属性を表示できます。前述の例では、NAME (オリジナル・ソースの属性)とNAME.Denoiseが使用可能です。表示される属性はどれもプロセッサの入力として選択できます。 |
追加属性
追加属性は、新しい属性が1つの入力属性に直接対応していない場合やデータ型が変更される場合に、変換プロセッサによって作成されます。追加属性が作成されるのは次のケースです。
変換で複数の入力属性が使用される場合(連結など)
複数の出力属性が同一の入力属性から作成される場合(分割など)
入力属性のデータ型が変更される場合(データ型の変換など)
追加属性には変換操作に基づいてデフォルト名が割り当てられます。たとえば、連結の場合はConcatが使用されます。追加属性を追加するプロセッサの例を次に示します。
表1-136 追加属性
| プロセッサ | デフォルト名での追加属性の作成 |
|---|---|
|
連結 |
Concat |
|
入力から配列を作成 |
配列 |
|
乗算 |
MultipliedValue |
|
加算 |
AddedValue |
|
文字列から配列を作成 |
ArrayFromString |
出力属性の命名
[Input Attribute].[Output]という形式で名前が付けられるように属性(導出または追加)を追加するプロセッサを構成すると、プロセッサによって作成される出力属性の名前は、入力属性が変更された場合に変更されます。これは、導出属性を追加するすべてのプロセッサと、追加属性を追加する一部のプロセッサ(出力が入力属性に関連しているが、導出属性を追加する理由がないケース)に該当します。一般的な理由としては、データ型の変更により導出属性ではなく追加属性を作成する必要があるためです。そうしないと、後続のプロセッサへの入力が無効になってしまうためです。
これは次のプロセッサに該当します。
表1-137 出力属性の命名
| プロセッサ | デフォルト名での追加属性の作成 |
|---|---|
|
数値を文字列に変換 |
[Input Attribute].NumberToString |
|
日付を文字列に変換 |
[Input Attribute].DateToString |
|
文字列を日付に変換 |
[Input Attribute].StringToDate |
|
文字列を数値に変換 |
[Input Attribute].StringToNumber |
「現在の日付の追加」プロセッサは、現在のサーバー処理日付/時刻を値として使用して、プロセスに日付属性を追加します。
オプションを使用して、同じ日付と時間をプロセス内のすべてのレコードに追加するか(後述の「注意」を参照)、各レコードが処理されるたびに正確な時間を追加するかを制御します。たとえば、データ・セットの生年月日属性を現在の日付/時刻と比較する場合は、日付の比較がすべてのレコードで一貫するように同じ日付/時刻をすべてのレコードに追加できます。一方、実行が長時間になるプロセスで、EDQが処理した日付と時間を各レコードにスタンプする場合は、各レコードが処理された正確な時間を追加します。
|
注意: プロセスを間隔モードで実行し、すべてのレコードに同じ日付と時間を追加するオプションが選択されている場合は、同じ間隔のすべてのレコードに同じ日付と時間が追加されますが、別の間隔のレコードには追加されません。 |
「現在の日付の追加」は、処理時間に注意する必要がある日付/時刻の計算に使用します。たとえば、プロセスの実行時に、昨年更新されたレコードを分離して操作できます。そのためには、現在の日付と時間をプロセスに追加し、「日付差異」を使用して今回の日付とデータ内の最終変更日との差異を計算し、「値のチェック」を使用して必要なレコードを分離します。
「現在の日付の追加」プロセッサのその他の用途は、次のとおりです。
現在の日付と生年月日属性を比較して、個人の現在の年齢を計算します
EDQがレコードを処理した時点でレコードにタイムスタンプを設定します
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | このプロセッサは、プロセッサに入力されたすべてのレコードに属性を追加するため、入力は必要ありません。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「現在の日付の追加」プロセッサには常に再実行マーカーが表示され、構成が変更されたかどうかに関係なく、プロセスが実行されるたびに完全に再実行されることを示します。このことは、「現在の日付の追加」プロセッサの後続のプロセッサ、および追加された日付値(またはそれに依存する別の属性値)を使用するプロセッサも再実行が必要であることを意味します。これは、「現在の日付の追加」が実行のたびに異なる日付/時刻値を追加するため、一貫した結果を確保するには、すべての依存プロセッサを再実行する必要があることを意味します。
「現在の日付の追加」プロセッサは、サマリー・データを出力しません。新しい日付属性は、データ・ビューのその他すべての属性の左側に表示されます。
出力フィルタ
なし。
例
この第1の例では、「現在の日付の追加」ですべてのレコードに同じ日付/時刻値を追加します。時刻は午前0時に設定されることに注意してください。
| 処理日 | ID |
|---|---|
| 05-Jun-2008 00:00:00 | 49956 |
| 05-Jun-2008 00:00:00 | 49837 |
| 05-Jun-2008 00:00:00 | 49505 |
| 05-Jun-2008 00:00:00 | 49491 |
| 05-Jun-2008 00:00:00 | 49415 |
| 05-Jun-2008 00:00:00 | 49346 |
| 05-Jun-2008 00:00:00 | 49149 |
| 05-Jun-2008 00:00:00 | 48554 |
この第2の例では、「現在の日付の追加」で各レコードに正確な処理日付/時刻を追加します。
| 処理日 | ID |
|---|---|
| 05-Jun-2008 15:16:31 | 49956 |
| 05-Jun-2008 15:16:31 | 49837 |
| 05-Jun-2008 15:16:31 | 49505 |
| 05-Jun-2008 15:16:31 | 49491 |
| 05-Jun-2008 15:16:31 | 49415 |
| 05-Jun-2008 15:16:31 | 49346 |
| 05-Jun-2008 15:16:31 | 49149 |
| 05-Jun-2008 15:16:32 | 48554 |
「日付属性の追加」プロセッサは、プロセッサに入力されたすべてのレコードに、指定の値で新しい日付属性を追加します。
EDQでは、すべての日付値が時間コンポーネントを持ちますが、時間コンポーネントが常に処理で使用されるとはかぎりません。
「日付属性の追加」プロセッサの主要な用途は、別のプロセッサが処理するためのテスト用の日付値を作成することです。これを使用して、特定の日付または日付/時刻で一連のレコードをタグ付けすることもできますが、この値は構成内で固定です。レコードの処理時に日付/時刻スタンプを追加するには、「現在の日付の追加」を使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | このプロセッサは、プロセッサに入力されたすべてのレコードに属性を追加するため、入力は必要ありません。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「日付属性の追加」プロセッサは、サマリー・データを出力しません。新しい属性は、データ・ビューのその他すべての属性の左側に表示されます。
出力フィルタ
なし。
例
この第1の例では、「日付属性の追加」を使用して、後続プロセッサで使用するテスト用の日付値を追加します。
| 日付 |
|---|
| 28-Oct-2011 16:27:28 |
| 28-Oct-2011 16:27:28 |
| 28-Oct-2011 16:27:28 |
| 28-Oct-2011 16:27:28 |
| 28-Oct-2011 16:27:28 |
| 28-Oct-2011 16:27:28 |
| 28-Oct-2011 16:27:28 |
| 28-Oct-2011 16:27:28 |
「数値属性の追加」プロセッサは、プロセッサに入力されたすべてのレコードに、指定の値で新しい数値属性を追加します。
「数値属性の追加」プロセッサには多くの用途があります。例:
値がどのように処理されるかを確認するために、別のプロセッサに対するテスト数値の値を作成します。たとえば、「計算」プロセッサへの新しい入力を作成するために使用します。
別のプロセッサから出力されたデータ・レコードに特定の属性と値でタグ付けします
これは、別のプロセッサを使用して一致したすべてのデータを変換する簡易的な方法として使用してください
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | このプロセッサは、プロセッサに入力されたすべてのレコードに属性を追加するため、入力は必要ありません。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「数値属性の追加」プロセッサは、サマリー・データを出力しません。新しい属性は、データ・ビューのその他すべての属性の左側に表示されます。
出力フィルタ
なし。
例
この例では、「数値属性の追加」を使用して、後続の「減算」プロセッサで使用するための固定の値(2)が設定された新しい属性(属性名は'ValueToSubtract'に変更)を作成します。
| ValueToSubtract | CU_NO |
|---|---|
| 2 | 13810 |
| 2 | 13815 |
| 2 | 13833 |
| 2 | 13840 |
| 2 | 13841 |
| 2 | 15531 |
| 2 | 13861 |
| 2 | 13865 |
「文字列属性の追加」プロセッサは、プロセッサに入力されたすべてのレコードに、指定の値で新しい文字列属性を追加します。
「文字列属性の追加」プロセッサには多くの用途があります。例:
値がどのように処理されるかを確認するために、別のプロセッサに対するテスト文字列値を作成します。
別のプロセッサから出力されたデータ・レコードに特定の属性と値でタグ付けします(たとえば、DuplicateRecord属性を'Yes'の値で追加)。
別のプロセッサを使用して一致したすべてのデータを変換する簡易的な方法として使用します(たとえば、特定のリストに一致しなかったすべての値を'Other'として分類)。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | このプロセッサは、プロセッサに入力されたすべてのレコードに属性を追加するため、入力は必要ありません。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「文字列属性の追加」プロセッサは、サマリー・データを出力しません。新しい属性は、データ・ビューのその他すべての属性の左側に表示されます。
出力フィルタ
なし。
例
この例では、「文字列属性の追加」を使用して、タイトル属性にデータがあるレコードすべてをタグ付けし、そのデータが有効なタイトルのリストと一致しない場合は、NewTitle属性に'Other'の値を設定します。「データなしチェック」および「リスト・チェック」を使用して、レコードを必要なセットにフィルタ処理します。
| NewTitle | CU_NO | CU_ACCOUNT | TITLE |
|---|---|---|---|
| その他 | 13440 | 99-22730-SH | Col. |
| その他 | 13467 | 99-23255-PB | Rev |
| その他 | 15631 | 01-24993-SH | Prof. |
「文字の置換」プロセッサは、個々の文字を置換します。これにより、参照データ・マップと一致する文字を標準化または正規化できます。
アクセント付き文字や記号のバリアント(開始引用符と終了引用符など)のような一定でない文字を他の類似データでマスクできます。「文字の置換」プロセッサを使用して、参照データ・マップの文字のすべてのインスタンスを、その置換文字で置換します。
場合によっては、ある記述体系から別の記述体系に文字をマッピングすることで、「文字の置換」を文字から文字への単純な音訳に使用することもあります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 文字を置換する文字列または文字列配列型の属性を指定します。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、単一の配列属性が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「文字の置換」プロセッサでは、処理に関するサマリー統計は表示されません。データ・ビューには、入力属性とともに、右側に文字置換後の文字列が含まれた新しい属性が表示されます。
出力フィルタ
なし。
例
この例では、「文字の置換」プロセッサを使用して、名(姓名の名)属性のアクセント付き文字を標準化します。
変換マップ参照データ:
| ルックアップ | マップ | コメント |
|---|---|---|
| É |
E | E揚音 |
| È |
E | E抑音 |
| ô |
o | o曲折アクセント記号 |
大文字/小文字を区別しない = はい
結果:
| アクセント名 | accent names.CharReplace |
|---|---|
| élise | elise |
| Aimée | Aimee |
| Marie-élise | Marie-elise |
| Cécile | Cecile |
|
注意: 大文字のÉはEに変換され、小文字のéはeに変換されます。 |
「連結」プロセッサは、オプションのユーザー定義文字または文字列を列値と列値の接着剤として使用して、2つ以上の属性値を連結します。
「連結」プロセッサを使用して、詳細な分析を実行する他のプロセッサに供給するために、複数の属性から連結キーまたは連結値を作成します。
また、照合のためにデータをクレンジングする際のデータの連結(たとえば、住所の全体に対して単一の属性を作成)にも役立ちます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 単一の属性に連結する文字列または文字配列属性を指定します。
単一の配列属性を入力した場合、配列要素の値が連結されて文字列の出力が形成されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「連結」トランスフォーマでは、処理に関するサマリー統計は表示されません。「データ」ビューには、入力属性とともに、右側に新しく追加された連結後の属性が表示されます。
出力フィルタ
なし。
例
この例では、カンマ・セパレータ文字列を使用して複数の住所属性を連結し、WholeAddressという名前に変更した新しい属性を形成します。
| Address_Line1 | Address_Line2 | POSTCODE | WholeAddress |
|---|---|---|---|
| Bonds Lane, Garstang | Preston | PR3 1RA | Bonds Lane, Garstang, Preston, PR3 1RA |
| Temsford Hall | Sandy | SG19 2BD | Temsford Hall, Sandy, SG19 2BD |
| West Thurrock | Purfleet | RM19 1PA | West Thurrock, Purfleet, RM19 1PA |
「日付を文字列に変換」トランスフォーマは、任意の数の日付または日付配列属性を取得し、文字列型または文字配列型にそれぞれ変換します。
「日付を文字列に変換」は、処理上、日付をテキストとして扱う必要がある場合に使用します。たとえば、照合のために属性を分割して日付の日、月および年の部分を抽出するために、日付を文字列型に変換し、次に「文字の切捨て」を使用して異なる部分を抽出できます。
日付は、日付の国際的な標準書式(dd-MMM-yyyy、例: 25-Apr-2006)で文字列値に変換されます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 文字列型または文字配列型に変換する任意の数の日付または日付配列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | 属性入力ごとに、新しい属性が次の形式で作成されます。
|
| フラグ | なし。 |
「日付を文字列に変換」トランスフォーマでは、処理に関するサマリー統計は表示されません。「データ」ビューには、各入力属性とともに、右側に新しく導出された文字列型属性が表示されます。
出力フィルタ
なし。
例
この例では、「日付を文字列に変換」を使用して、DT_LAST_PAYMENT属性を文字列型に変換します。この例では、出力形式から時間要素(HH:mm:ss)を削除することにより、日付の変換時に時間要素が削除されます。
| DT_LAST_PAYMENT | DT_LAST_PAYMENT.DateToString |
|---|---|
| 11-Mar-2000 00:00:00 | 11-Mar-2000 |
| 16-Sep-2003 00:00:00 | 16-Sep-2003 |
| 15-Mar-2000 00:00:00 | 15-Mar-2000 |
| 05-Oct-2001 00:00:00 | 05-Oct-2001 |
| {05-Oct-2001 00:00:00}{12-Apr-2000 00:00:00} | {05-Oct-2001}{12-Apr-2000} |
「数値を文字列に変換」トランスフォーマは、任意の数の数値または番号配列属性を取得し、それらを文字列型または文字配列型にそれぞれ変換します。
「数値を文字列に変換」は、処理上、数値をテキストとして扱う必要がある場合や、異なるデータ型でターゲット・システムにデータを移行するために使用します(たとえば、電話番号を数値ではなくテキスト・フィールドとして格納する場合など)。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 文字列型または文字配列型に変換する数値属性の任意の数値または番号配列を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | 属性入力ごとに、新しい属性が次の形式で作成されます。
|
| フラグ | なし。 |
「数値を文字列に変換」トランスフォーマでは、処理に関するサマリー統計は表示されません。「データ」ビューには、各入力属性とともに、右側に新しく導出された文字列型属性が表示されます。
出力フィルタ
なし。
例
この例では、ターゲット・システムの単一のHOME_TELテキストベース・フィールドへの移行に備えて、「日付を文字列に変換」を使用してAREA_CODE属性とTEL_NO属性を文字列形式に変換します。
| AREA_CODE | AREA_CODE.NumberToString | TEL_NO | TEL_NO.NumberToString |
|---|---|---|---|
| 0 | 0 | 508341 | 508341 |
| 1133 | 1133 | 349597 | 349597 |
| 1133 | 1133 | 717299 | 717299 |
| 1133 | 1133 | 704790 | 704790 |
| 1133 | 1133 | 618464 | 618464 |
| 1133 | 1133 | 877808 | 877808 |
| 1133 | 1133 | 969155 | 969155 |
| 1133 | 1133 | 693764 | 693764 |
「数値を日付に変換」プロセッサは、実際に日付の値を表している数値または番号配列の値を正式な日付型または日付配列型にそれぞれ変換します。
日付は、データベースに数値として内部的に格納され、指定された基準日/時間からの単位数(日、秒またはミリ秒)としてカウントされることがよくあります。
これらの値を日付値または日付/時間値として書式設定する場合、大半は数値を取得して日付として表示する関数を使用して処理されます。
ソース・データベースからのデータの抽出方法によっては、これらの日付値は数値として取得されます。EDQにデータベース抽出のアクセス権限のみが付与され、ソース・データベースについては付与されていない場合、値は数値としてスナップショットされることになります。その後、日付を正しく処理するには、数値を標準の日付書式に変換する必要があります。
したがって、「数値を日付に変換」プロセッサは、構成された基準日といくつかの単位を使用して、数値から日付値を計算します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 日付型または日付配列型に変換する1つ以上の数値または番号配列属性を指定します。文字列属性および日付属性は有効な入力ではありません。
複数の属性が変換のために送信されたが、そのうち1つが失敗した場合、レコード全体に失敗のマークが付きますが、有効な属性は正しく変換されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | 次のデータ属性が出力されます。
|
| フラグ | 次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 成功 | 数値から日付への変換が成功した(つまり、日付が計算された)レコードの数。 |
| 失敗 | 数値から日付への変換が失敗した(つまり、日付を計算できなかった)レコードの数。 |
出力フィルタ
次の出力フィルタを使用できます。
変換が成功したレコード
変換が失敗したレコード
例
この例では、日付値がExcelスプレッドシートに間違って数値として書式設定されています。EDQユーザーが保持するスプレッドシートへの権限は読取り専用アクセスで、書式を変更できないため、このプロセッサとデフォルトの構成を使用して数値を日付に変換します。
| DateOfBirth | DateOfBirth.NumberToDate |
|---|---|
| 18639 | 11-Jan-1951 00:00:00 |
| 19003 | 10-Jan-1952 00:00:00 |
| 17126 | 20-Nov-1946 00:00:00 |
| 28885 | 30-Jan-1979 00:00:00 |
| {28885}{24800} | {30-Jan-1979 00:00:00}{24-Nov-1967 00:00:00} |
「文字列を日付に変換」トランスフォーマは、文字列または配列属性の値を取得し、その値を日付書式の参照リストを使用して認識し、標準の日付型または日付配列型への変換を試みます。
「文字列を日付に変換」は、文字列または文字配列属性に日付値が格納されている場合に、たとえば、日付プロファイラを介した実行など、その値に対して日付固有の処理を実行するときに使用します。
文字列属性内の日付値を検索するには、データ型プロファイラを実行します。指定の属性から想定したデータ型以外のレコードを分離するには、「データ型チェック」を実行します。
|
注意: 参照リストを使用して日付と認識されない値は、「文字列を日付に変換」プロセッサによる変換が失敗となる(nullに変換される)ため、このプロセッサ自体が単独で分離を実行できます。これには、無効な日付(日付の月の部分に日の値がある日付など)が含まれます。 |
文字列または文字配列属性を日付型または日付配列型に変換するために、プロセッサは日付の値を正しく認識する必要があります。そのために日付書式の参照リストが使用されます。日付の暗黙の書式はロケール固有である可能性があり、たとえば、英国書式で取得される日付では01/04/2001を1st-Apr-2001に変換し、米国書式で取得される日付では4th-Jan-2001に変換する必要があります。日付を正しく認識するために、参照リストで日付の正しい書式を使用する必要があります。書式のデフォルト・リストはEDQに付属しています。認識する必要がある書式がこのリストにない場合は、標準Java APIが認識する(したがってEDQの日付プロセッサが認識する)日付書式を指定した独自のリストを作成できます(http://java.sun.com/javase/6/docs/api/java/text/SimpleDateFormat.htmlを参照)。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 日付型または日付配列型に変換する1つ以上の文字列または文字配列属性を指定します。
複数の属性が変換のために送信されたが、そのうち1つが失敗した場合、レコード全体に失敗のマークが付きますが、有効な属性は正しく変換されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | 次のデータ属性が出力されます。
|
| フラグ | 次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 成功 | 文字列から日付への変換に成功したレコードの数。 |
| 失敗 | 文字列から日付への変換に失敗したレコードの数。
入力された値が日付として(まったく)認識されなかったり、無効な日付(うるう年でない年の2月29日のような存在しない日付など)として認識されたりすることで発生する可能性があります。 |
「追加情報」ボタンをクリックすると、前述の統計がパーセントとして表示されます。
出力フィルタ
次の出力フィルタを使用できます。
変換が成功したレコード
変換が失敗したレコード
例
顧客表には、文字列として格納され、日付属性として管理されていないDT_PURCHASED属性があります。
日付値を認識するために標準の「*日付書式」参照リストを使用し、文字列から日付に変換した結果を次に示します。
| 成功 | 失敗 |
|---|---|
| 2003 99.7% | 7 0.3% |
「成功」または「失敗」にドリルダウンできます。
|
注意: 値がnullのため、または日付として認識されない値が含まれているために、値が日付として認識されない場合、変換された日付値はnullになります。 |
「文字列を数値に変換」トランスフォーマは、文字列または文字配列属性の値を取得し、その値を数値書式の参照リストを使用して認識し、それぞれ数値型または番号配列型への変換を試みます。
「文字列を数値に変換」は、文字列または文字配列属性に数値が格納されている場合に、たとえば、数値プロファイラを介した実行など、その値に対して数値固有の処理を実行するときに使用します。
文字列属性内の数値を検索するには、データ型プロファイラを実行します。指定の属性から想定したデータ型以外のレコードを分離するには、「データ型チェック」を実行します。
|
注意: 参照リストを使用して数値と認識されない値は、「文字列を数値に変換」プロセッサによる変換が失敗となる(nullに変換される)ため、このプロセッサ自体が単独で分離を実行できます。 |
文字列または文字配列属性を数値書式に変換するために、プロセッサは数値を正しく認識する必要があります。これは標準的な一連の数値書式の参照リストを使用することで対応しています。そのためにデフォルトの標準数値書式リストが用意されています。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 数値型または番号配列型に変換する1つ以上の文字列または文字配列属性を指定します。
複数の属性が変換のために送信されたが、そのうち1つが失敗した場合、レコード全体に失敗のマークが付きますが、有効な属性は正しく変換されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 成功 | 文字列から数値への変換に成功したレコードの数。 |
| 失敗 | 文字列から数値への変換に失敗したレコードの数。 |
「追加情報」ボタンをクリックすると、前述の統計がパーセントとして表示されます。
出力フィルタ
次の出力フィルタを使用できます。
変換が成功したレコード
変換が失敗したレコード
例
従業員表には、数値の内線番号を保持する必要がある内線番号属性がありますが、文字列として格納され、数値属性として管理されていません。
数値を認識するために標準の「*数値書式」参照リストを使用し、文字列から数値に変換した結果を次に示します。
| 成功 | 失敗 |
|---|---|
| 7 | 2 |
失敗へのドリルダウン。
| 拡張 | Extension.StringToNumber |
|---|---|
| x188 | |
| xtn 204 |
「日付差異」プロセッサは、2つの日付/日付配列の値を比較し、その差異を返します。差異は、指定したオプションに従って、年、月、週または日、あるいはこれらの組合せで返されます。
「日付差異」は、2つの日付の差異を導出するために使用します。たとえば、生年月日属性が指定された個人のデータ・セットがある場合は、「現在の日付の追加」の後に「日付差異」を使用して、各個人の現在の年齢を計算できます。
次の表に、構成オプションを示します。
オプションを使用して、「日付差異」が各レコードの2つの日付値の差異を出力する方法を決定します。年、月、週および日に対して個別の出力属性が出力されますが、オプションは組み合せて使用できます。たとえば、「日付全体」オプションのみを「はい」に設定すると、日付の差異は単純に日数で出力されますが、すべてのオプションを「はい」に設定すると、差異は、年数、月数、週数および日数で構成され、この場合、日数は必ず0から6までの値になります(7日は1週間に該当するため)。
| 構成 | 説明 |
|---|---|
| 入力 | 2つの日付属性を正しく指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
比較する日付の一方がNullの場合、「日付差異」プロセッサでは日付の差異を計算できないため、選択したすべての出力属性にnull値が出力されます。
「日付差異」プロセッサは、サマリー・データを出力しません。新しい日付差異属性は、データ・ビューのその他すべての属性の左側に表示されます。
出力フィルタ
なし。
例
この例では、日付差異を使用して、Date of Birth属性と現在のProcessing Dateを比較することで、顧客の年齢を年で導出します。出力属性は、WholeYearsからAgeという名前に変更されています。
| ProcessingDate | 生年月日 | 年齢 |
|---|---|---|
| 05-Jun-2008 16:03:14 | 07-Jul-1984 00:00:00 | 23 |
| 05-Jun-2008 16:03:14 | 21-Jun-1933 00:00:00 | 74 |
| 05-Jun-2008 16:03:14 | 08-Jun-1913 00:00:00 | 94 |
| 05-Jun-2008 16:03:14 | 12-Jul-1952 00:00:00 | 55 |
| 05-Jun-2008 16:03:14 | 02-Jul-1919 00:00:00 | 88 |
| 05-Jun-2008 16:03:14 | 03-Jan-1915 00:00:00 | 93 |
| 05-Jun-2008 16:03:14 | 14-Sep-1914 00:00:00 | 68 |
| 05-Jun-2008 16:03:14 | 17-Feb-1940 00:00:00 | 68 |
「ノイズ削除」プロセッサは、テキスト属性からユーザー定義のノイズ文字を削除し、その値を新しい出力属性で返します。
ノイズ文字のリストは、画面上でリストとして入力するか、参照リストを使用できます(両方を使用することも可能です)。
一貫していない書式、句読点、誤った制御文字など、データ内で一貫性のない値をマスクできます。
テキスト属性に「リスト・チェック」を実行する前など、他の処理の前に「ノイズ削除」プロセッサを使用して、これらのノイズ文字をテキスト属性から削除します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | ノイズを削除する文字列または文字列配列型の属性を指定します。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「ノイズ削除」トランスフォーマでは、処理に関するサマリー統計は表示されません。「データ」ビューには、各入力属性とともに、右側に新しく導出されたノイズを削除した属性が表示されます。
出力フィルタ
なし。
例
この例では、「ノイズ削除」プロセッサを使用して、NAME属性からハッシュ文字(#)をすべて削除します。
| NAME (昇順) | NAME.Denoise |
|---|---|
| # MCAULAY | MCAULAY |
| # RAE | RAE |
| # SWAN | SWAN |
| # WILLIAM | WILLIAM |
| A Test | A Test |
| Abigail Anderson | Abigail Anderson |
「マップから拡張」プロセッサを使用すると、既存の属性から一致する値をマップして、データに新しい属性を追加できます。
「マップから拡張」は、既存のデータから新しいデータを導出できる場合に使用します。たとえば、性別がなく、性別固有の敬称(Mr、Mrsなど)があるレコードに、次のようなエントリがある参照データを使用して新規に性別属性を追加できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | マップ内のルックアップ列と照合する単一の属性を指定します。 |
| オプション | 次の「値マップ」オプションを指定します。
次の照合オプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 拡張済 | 参照リストと一致したために新しい属性値で拡張されたレコードの数。 |
| 未拡張 | 参照リストと一致しなかったために拡張されなかったレコードの数。 |
出力フィルタ
次の出力フィルタを使用できます。
「参照データの参照」を使用して拡張されたレコード
「参照データの参照」を使用して拡張されなかったレコード
例
この例では、「マップから拡張」を使用して、レコードに性別固有の敬称が設定されたTitleGenderという名前に変更した属性を追加します。
| 敬称 | TitleGender |
|---|---|
| Ms | F |
| Ms | F |
| Miss | F |
| Mr | M |
| Mr | M |
| Ms | F |
| Miss | F |
| Mr | M |
「値の抽出」プロセッサは、参照リストと一致した値または値の一部を新しい属性に抽出します。
リストとの照合は、次の5つのいずれかの方法で実行できます。
全体の値
次で始まる
次で終わる
次を含む
区切り文字の一致
これは、値が抽出される方法を制御します。たとえば、会社名属性からビジネス接尾辞を抽出する場合は、リストの値で終了している場合にのみ値を抽出します。
「値の抽出」は、個別に処理する必要がある入力属性の明確な部分が格納された新しい属性を作成する場合に使用します。
たとえば、製品の単位を表す値(PINTS、PNTS、PTSなど)が含まれているProduct_Description属性がある場合は、これらの値を個別の属性に抽出できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | リストと一致する値を抽出する1つ以上の文字列または文字配列属性を指定します。 |
| オプション | 次の「値マップ」オプションを指定します。
次の照合オプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | 次のデータ属性が出力されます。
|
| フラグ | 次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 抽出済 | リストと一致したために抽出が実行されたレコードの数。 |
| 未抽出 | リストと一致しなかったために抽出が実行されなかったレコードの数。 |
出力フィルタ
次の出力フィルタを使用できます。
リストと一致したレコード
リストと一致しなかったレコード
例
この例では、通常は郡のみが格納され、一部に郡とその他の追跡情報(郵便番号など)の両方が格納されることがあるADDRESS3属性から郡の値を「値の抽出」を使用して抽出します。この場合、「次で始まる」オプションを使用してリストを照合し、一致する値をCountyという出力属性に抽出します。
| ADDRESS3.trimmed | County |
|---|---|
| Cheshire | Cheshire |
| Kent | Kent |
| Surrey, CB0 8YN | Surrey |
| Herts, AL1 3HL | Herts |
| Cambridgeshire | Cambridgeshire |
| Essex, SS2 5QN | Essex |
| London, WC2E 8JG | (London) |
「イニシャルの生成」プロセッサは、値をイニシャルに変換します(たとえば、"Bayerische Motoren Werke"を"BMW"に変換します)。
「イニシャルの生成」変換は、略称と非略称の両方の名称(またはその他の用語)が使用される場合に、データを一致させる(または一致処理のためのレコードのクラスタリング)に最も一般的に使用されます。これは、最初に各値をイニシャル変換しないとコンピュータで照合することが困難な、"International Business Machines"と"IBM"のような一致を検索する場合に役立ちます。"IBM"のような短い単語が"I"にイニシャル変換されないようにするオプションも含まれています。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | イニシャルに変換する文字列または文字列配列型の属性を指定します。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
通常、「イニシャルの生成」変換では、元の値の大/小文字は無視され、指定の区切り文字で区切られた各単語が検出されて大文字のイニシャルが生成されます。たとえば、値"A j Smith"、"ALAN JOHN SMITH"および"Alan john smith"はすべて"AJS"にイニシャル変換されます。ただし、"PWC"、"IBM"、"BT"のようにすでにイニシャルになっている値もあり、これらは"P"、"I"、"B"のようにさらにイニシャル変換されないようにする必要があります。
これらは次の条件によって区別できます。
1単語の値である。
すでに大文字になっている。
長さが数文字である。
「大文字の単語を無視」オプションを使用すると、値が大文字の1単語の場合、その単語が何文字以内のときにイニシャル変換しないかを指定できます。
たとえば、4に設定した場合、値"PWC"、"BT"、"RSPB"および"IBM"は、長さが4文字以内で、1単語の値で大文字であるため、イニシャル変換プロセスで無視されます。これに対して、"IAN JOHN SMITH"は、単語"IAN"の長さが4文字以内で大文字ですが、1単語の値でないため、"IJS"にイニシャル変換されます。また、"RSPCA"は長さが4文字を超えているため、"R"にイニシャル変換されます。
「イニシャルの生成」トランスフォーマでは、処理に関するサマリー統計は表示されません。データ・ビューには、各入力属性とともに、右側に新しく導出されたイニシャル変換した属性が表示されます。
出力フィルタ
なし。
例
この例では、「イニシャルの生成」変換を使用して次のデフォルトの構成で会社名をイニシャルの値に変換します。
区切り文字参照データ: 未使用
区切り文字: スペース
大文字の単語を無視: 4
'BMW'は大文字で構成される3文字の単一語であるため、すでにイニシャルで表現されているとみなされ、'B'にイニシャル変換されないことに注意してください。
| BusName.Parse | BusName.Initials (昇順) |
|---|---|
| BMW | BMW |
| Bayerische Motorren Werke | BMW |
| Bayerishe Motorren Werke | BMW |
| Broad Oak Woodcraft | BOW |
| Brunswick Properties | BP |
| Body Perfect | BP |
| Byron Pawnbrokers | BP |
「ハッシュ・ジェネレータ」プロセッサは、各入力属性のハッシュ・キーを作成します。出力されるハッシュ・キーは、入力される個々のデータ値ごとに同じ(かつ一意)になります。
「ハッシュ・ジェネレータ」プロセッサは、入力属性が同じ値を保持しているかぎり保持されるキーをデータ・セット内に作成する場合に使用します。
ハッシュ・キーは、たとえば、最後の処理以降に重要な属性で変更されたレコードに対して各種プロセッサを実行するのみのプロセスを作成する場合など、データを'diff'する際によく使用されます。
通常は、「ハッシュ・ジェネレータ」プロセッサの前に「連結」プロセッサを使用して複数の属性を単一の属性に連結し、その単一の属性を使用してハッシュ・キーを生成します。これにより、「連結」プロセッサに渡されたすべての属性の正確な値が同じであるかぎり、ハッシュ・キーは常に同じになります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | ハッシュ・キーの生成に使用する文字列または文字列配列型の属性を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「ハッシュ・ジェネレータ」トランスフォーマでは、処理に関するサマリー統計は表示されません。データ・ビューには、各入力属性とともに、右側に新しく導出されたハッシュ・キー属性が表示されます。
出力フィルタ
なし。
例
この例では、すべての名前および住所属性から導出されて連結されたNAMEANDADDRESS属性を使用して、各レコードのハッシュ・キーを生成します。
| NAMEANDADDRESS | NAMEANDADDRESS.Hash |
|---|---|
| Mr|Jonathan BINIAN|Warrington HDC|Warrington| | 207dff53331d004b207b7e03cf9c63be |
| Ms|Rosemary THORP|Benton Square|Benton| | 764fd23a622bf3cd30379caae9d7cd95 |
| Ms|Margaret|ROBERTSON|23 High Street|Leicester| | a41958f76d398b809f740f4e0c064914 |
「ルックアップと戻り」プロセッサを使用すると、参照データ・ソースで関連データをルックアップし、後続の処理で使用するデータを返すことができます。
参照データの関連レコードを数多く返す必要がある場合、一致するデータは配列属性で返されます。その後、これらの配列属性に対して「配列からレコードを分割」を使用して、このデータを分割(作業データと参照データにわたる結合を効果的に作成)することもできます。
「ルックアップと戻り」は、各顧客レコードに関連する住所レコードをすべてを返すなど、プロセスに関連データを追加する場合に使用します。
また、「ルックアップと戻り」を「ルックアップ・チェック」と同様の方法で使用して、許容範囲内の数の関連レコードが別の表またはシステムに存在するかどうかをチェックし、一致する参照データの一部(たとえば、一致するレコードのID)を返すことでチェックの結果がわかるようにできます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 参照データに対するルックアップに使用する属性を指定します。これらは、参照データのルックアップ列を構成する属性と対応している必要があります。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
出力属性は、選択された参照データの戻り列ごとに返されます(さらに相応の名前が付けられます)。「最大一致数」オプションが1に設定されている(各レコードについて単一の一致するレコードのみが返される)場合、出力属性のデータ型には戻り列のデータ型が反映されます。複数のレコードが返される場合、出力属性は配列になります。 |
|
フラグ |
次のフラグが出力されます。
|
外部データ(ステージングされていないデータ)をルックアップする場合、ルックアップのパフォーマンスの適切なレベルは、選択した参照データのルックアップ列に適切な索引があるかどうかによって決まります。また、外部参照データをルックアップする場合、「ルックアップと戻り」プロセッサには常に再実行マーカーが表示され、実際のプロセッサの構成が変更されたかどうかに関係なく、プロセスが実行されるたびに完全に再実行されることを示します。このことは、「ルックアップと戻り」プロセッサの後続のプロセッサも再実行が必要であることを意味します。これは、EDQでは外部参照データが変更されたかどうかを検出できないため、変更があったとみなし(外部参照は一般的に、動的変更参照データに使用されるため)、ルックアップを再実行して依存する結果の一貫性を確保する必要があるためです。
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 変換済データ | データが返されたレコードの数。
これは、構成されたオプションに応じて、参照データの関連レコード数が許容範囲内の作業データからのレコードの数です。 |
| 未変換データ | データが返されなかったレコードの数。
これは、構成されたオプションに従って、参照データの関連レコード数が許容範囲を超える作業データからのレコードの数です。 |
出力フィルタ
次の出力フィルタを使用できます。
変換済レコード
未変換レコード
例
この例では、「ルックアップと戻り」プロセッサを使用して、Customerレコードに関連する(Workorder表の)受注レコードを(CU_ID属性を参照キーとして)参照し、各受注を識別できる十分な(Workorder表からの)情報を返します。少なくとも1件の受注レコードが一致する場合は、データが返されます。
サマリー・ビュー:
| 変換済レコード | 未変換レコード |
|---|---|
| 1718 | 283 |
「変換済レコード」のドリルダウン。
| CU_NO | LookupCount | LookupReturnValid | Return Value1 | Return Value2 |
|---|---|---|---|---|
| 13815 | 1 | Y | {13815} | {26107} |
| 15531 | 2 | Y | {15531}{15531} | {26688}{26031} |
| 13861 | 1 | Y | {13861} | {25247} |
| 13870 | 3 | Y | {13870}{13870}{13870} | {26037}{25910}{24857} |
前述の例の多くは、多数のレコードがルックアップ列と一致し、結果的にデータが配列属性で返されています。
「小文字」プロセッサは、すべての入力属性値を小文字に変換し、変換した値を新しい属性で返します。
「小文字」プロセッサは、大/小文字を区別しない検証ルールを使用する場合や、データ・クレンジングの一環として大/小文字を標準化するために使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 小文字に変換する文字列または文字列配列型の属性を指定します。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、単一の配列属性が出力されます。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「小文字」プロセッサでは、処理に関するサマリー統計は表示されません。
データ・ビューには、各入力属性とともに、右側に新しく導出された小文字属性が表示されます。
出力フィルタ
なし。
例
この例では、電子メール・アドレス属性の値がすべて小文字に変換されています。
| 電子メール | EMAIL.Lower |
|---|---|
| A.SHELBURNE@BTOPENWORLD.COM | a.shelburne@btopenworld.com |
| DAROBE@Tinyworld.co.uk | darobe@tinyworld.co.uk |
| k.smith@yahoo.co.uk | k.smith@yahoo.co.uk |
| N SHARP@BEEB.NET | n sharp@beeb.net |
「入力から配列を作成」プロセッサは、入力された属性から配列を作成します。
「入力から配列を作成」は、その後の処理のために、入力属性の配列が格納された単一の属性を作成する場合に使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 配列を作成する複数の文字列属性または文字列配列属性を指定します。配列内の要素の決定に使用される入力の順序(つまり、最初に入力された属性が配列の最初の要素になり、2番目の属性が2番目の要素になり、それ以降も同様に続く) |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「入力から配列を作成」プロセッサでは、処理に関するサマリー統計は表示されません。
データ・ビューには、入力属性とともに、右側に新しく追加された配列属性が表示されます。
出力フィルタ
なし。入力されたすべてのレコードが出力されます。
例
「入力から配列を作成」を使用して、AddressArray属性を作成できます。
配列属性にドリルダウンすると、配列のデータ全部が表示されます。
「文字列から配列を作成」プロセッサは、区切り文字を使用して、属性内のデータを配列に分割します。配列の各要素は、その後の処理のために、「配列要素の選択」を使用して個々の属性に抽出できます。
「配列要素の選択」は、属性内のデータを分割する簡易的な方法として使用してください。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 配列に分割する単一の文字列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「文字列から配列を作成」トランスフォーマでは、処理に関するサマリー統計は表示されません。
データ・ビューには、入力属性とともに、右側に新しく追加された配列属性が表示されます。
出力フィルタ
なし。入力されたすべてのレコードが出力されます。
例
この例では、「文字列から配列を作成」を使用して、単一のNAME属性を配列に分割します。その後、配列内の様々な要素を抽出して検証できます。
| 名前 | ArrayFromString |
|---|---|
| Yvonne CHIN-YOUNG CHUNG | {Yvonne}{CHIN-YOUNG}{CHUNG} |
| Lynda BAINBRIDGE | {Lynda}{BAINBRIDGE} |
| William BENDALL | {William}{BENDALL} |
| Karen SMITH | {Karen}{SMITH} |
| Patricia VINER | {Patricia}{VINER} |
| Colin WILLIAMS | {Colin}{WILLIAMS} |
| Ian PATNICK | {Ian}{PATNICK} |
| Roberta REYNOLDS | {Roberta}{REYNOLDS} |
| Winifride ROTHER | {Winifride}{ROTHER} |
配列属性をドリルダウンすると、配列のデータ全部が表示されます(次の例を参照)。
| 索引(昇順) | 属性 |
|---|---|
| 1 | Yvonne |
| 2 | CHIN-YOUNG |
| 3 | CHUNG |
「属性のマージ」プロセッサを使用すると、複数の入力属性から空でない最初の値を選択することにより、複数の属性を単一の属性にマージできます。
属性のマージは、次の場合に使用します。
無効なレコードに適用した修正および元の値(レコードが有効とみなされた場合)を使用して、クレンジングされた値を保持する単一のマージ済属性を作成するために、データをクレンジングする場合
元の同じ属性の異なるレコードに対して、異なるプロセッサで多数の修正を適用した後、すべてのレコードを対象とした単一のクレンジング済属性を作成するために、これらをマージする必要がある場合
別のシナリオとして、順番に並んだ入力属性セットの値に基づいて、新しい属性の値を選択する必要がある場合
「属性のマージ」は、レコードごとに選択内容を実行し、この並べられた属性のリストから空でない最初の値を選択します。
|
注意: 空白またはその他の非テキスト文字のみを含む文字列(折返し線など)は、空の文字列と同じではありません。テキスト以外の文字が最初に受信された場合に、その文字を含む文字列が選択されないようにするには、まず、「データなしの正規化」プロセッサを介してマージする属性を渡して、これらの文字をNullに変更してから「属性のマージ」プロセッサに渡す必要があります。これにより、「属性のマージ」プロセッサはNullを無視します。 |
いくつかの属性をすべて同じマージ済属性に順番にマップできます。このようにして、たとえば、元のfirstname属性があり、「リスト・チェック」を使用してこの属性に有効な名が含まれているかどうかを確認した場合は、無効なレコードに対してのみ(たとえば、「置換」プロセッサを使用して)修正を適用できます。その結果、2つの属性を保持することになり、これを単一のMergedFirstname属性にマージすることが望まれます。「属性のマージ」プロセッサを使用すると、たとえば次のように、空でない最初の値を選択し、複数の属性を順に考慮することで、これを実行できます。
修正された名前(firstname.Replaced)が空でない場合は、それを選択します。
修正された名前が空の場合、元の名(firstname)を選択します(修正されなかったレコードがすべて選択されます)。
単一の「属性のマージ」プロセッサで、いくつかのマージされた属性を作成できます。
たとえば、前述の例と同様の方法で敬称属性の値に修正を適用した場合は、同じプロセッサでMergedFirstnameとMergedTitleの両方を作成できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 新しい属性を作成するためにマージする属性を指定します。マージされた新しい属性を作成するための選択に使用する属性は、同じデータ型(文字列、数値または日付)を共有する必要があります。
マージされた新しい属性を作成するために入力属性をマップするには、マージする属性を左側で選択し、「マージ」ボタンを使用します。ダイアログの上矢印および下矢印ボタンを使用して、マージされる各属性内で入力属性の選択の順序を変更します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「属性のマージ」では、結果のサマリー・ビューは生成されません。データ・ビューを使用して、構成されたマージの選択が期待どおり機能していることを確認します。
出力フィルタ
なし。入力されたすべてのレコードが出力されます。
例
この例では、titleとfirstnameの値に対する置換を、(リスト・チェックで有効と認識されなかった敬称や名を含む)レコードのサブセットに適用します。使用可能な場合は、置換された値が使用されます。使用可能でない場合は、titleとfirstnameの元の値が使用されます。
| title.Replaced | タイトル | MergedTitle | firstname.Replaced | firstname | MergedFirstname |
|---|---|---|---|---|---|
| Miss | Miss | Cindy | Sindy | Cindy | |
| Ms | Ms | Rebecca | Rebecca | ||
| Mr | Mister | Mr | Paul | Paul | |
| Ms | Ms | Lorraine | Lorraine | ||
| Rev | The Reverend | Rev | Claudia | Cluadia | Claudia |
| Professor | Prof. | Professor | Geoffrey | Geoffry | Geoffrey |
属性をマージした後は、たとえば、前述の例のMergedFirstnameおよびMergedTitleの両方に有効なデータが格納されていることを確認するなど、マージされた属性を再チェックできます。
「Metaphone」プロセッサは、Double Metaphoneアルゴリズムを使用して、文字列属性の値を元の文字列の音声発音を表すコードに変換します。
Double Metaphoneアルゴリズムは、(特に個人名に対応できるように設計されている) Soundexより一般的な発音技術で、元のMetaphoneアルゴリズムより精巧で状況依存に対応しています。
|
注意: このドキュメントでは、これ以降、「Metaphoneコード」とします。ただし、Double Metaphoneアルゴリズムは全体を通して使用します。 |
Metaphoneコードは、たとえば、情報を電話で取得した場合など、同じ発音の単語でスペルの相違が発生する可能性がある場合に特に役立ちます。正確な文字列値のかわりに、文字列の発音を考慮することで、軽微な差異の多くを克服できます。したがって、Metaphoneコードは、重複チェックを実行する際に生のデータ値にかわる優れたコードであり、重複の可能性がある値または等価値を簡単に識別できるようになります。
このプロセッサを使用すると、Metaphoneコードの最大長(最大12文字)を指定することにより、列全体ではなく最初の数音節または複合データの最初の数単語のみに集中したり、双方の値の発音類似性の厳密度を制御できるようになります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 文字列または文字列配列属性を指定します。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「Metaphone」変換プロセッサでは、処理に関するサマリー統計は表示されません。
データ・ビューには、各入力属性とともに、右側に新しく導出されたMetaphone属性が表示されます。
出力フィルタ
なし。入力されたすべてのレコードが出力されます。
例
この例では、「Metaphone」プロセッサを使用して、サービス管理データ例から顧客表のNAME属性を変換します。この場合、デフォルトの最大長である12文字が使用されました。
| NAME (昇順) | NAME.Metaphone |
|---|---|
| James TODTENHAUPT | JMSTTNPT |
| James WYLIE | JMSL |
| James WYLLIE | JMSL |
| Jane MCCULLOCH | JNMKLK |
| Jane MCLACHAN | JNMKLKN |
| Jane MCWILLAIM | JNMKLM |
| Jane MILLIGAN | JNMLKN |
James WYLIEとJames WYLLIEに同じMetaphoneコードが設定されていることに注意してください。
「データなしの正規化」プロセッサを使用すると、データの属性に存在する様々なタイプの空白値をNull値または独自に選択した特定の値に正規化できます。これは、データなしの値を一貫して処理するために重要です。たとえば、空白文字のみが格納された属性がある場合、他のプロセッサ(「一致」プロセッサによる比較など)では、これらの値がNULL値に正規化されていないかぎりデータなしとして処理されません。
「データなしの正規化」プロセッサでは、「データ処理なし」と同じ機能(Nullに正規化する場合)を実行できますが、実行できるのは1つのプロセス内のみです。これは、プロファイリング時にソースに存在する様々なタイプのデータなしを把握しておく必要がある一方で、後続のプロセッサでは引き続き空白値(Null)として処理する場合や、空白文字のみの構成になるまで値を値のノイズ削除やトリミングを行うなど、他の変換を介して属性内に空白値が生じ、これらをNullとして処理する必要がある場合に便利です。
「データなしの正規化」プロセッサは、空白文字のみが格納された属性値があることをパターン・プロファイリングで検出し、結果的に使用するデータがないとみなす必要がある場合に使用します。後続のプロセッサには、これらの値をNullとして処理することが保証されます。たとえば、「一致」プロセッサによる比較で、Null文字列とデータ値を比較した場合は、データなしの比較結果が返されます。
あるいは、元からNull (正規化前)であった値と区別するために、データなし値を独自に選択した値に明確に変換できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | データなし値をNullまたは特定の値に正規化する任意の数の文字列または文字配列属性を指定します。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「データなしの正規化」トランスフォーマでは、処理に関するサマリー統計は表示されません。
「データ」ビューには、各入力属性とともに、右側に新しく正規化された属性が表示されます。
出力フィルタ
なし。
例
この例では、データなしノーマライザを使用して、TITLE属性のすべての空白値をカスタム文字列’#NO DATA#’に正規化します。
| TITLE | TITLE.NoDataNormalized |
|---|---|
| Ms | Ms |
| #NO DATA# | |
| Mr | Mr |
| Miss | Miss |
| #NO DATA# | |
| Ms | Ms |
| #NO DATA# |
「空白の正規化」プロセッサは、文字列値の中の空白文字をすべて正規化して、単語間の複数のスペースを1つのスペース文字に正規化します。さらに、先頭および末尾の空白文字も削除します。
EDQでは、空白文字は次のように定義されています。
スペース
改行、行送り、タブなどの印刷不可能な文字(および、その他のASCII文字0から31すべて)
「空白の正規化」は、すべての値が通常のスペース設定になるように、フリー・テキスト・フィールドを解析する前によく使用されます。また、余分なスペースが残存している可能性がある他の変換の後にもよく使用されます。たとえば、テキスト・フィールドから単語または数値を除去した場合は、単語間に余分なスペースが残っている可能性があります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 空白文字を正規化する文字列または文字列配列型の属性を指定します。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | 次のデータ属性が出力されます。
|
| フラグ | なし。 |
「空白の正規化」トランスフォーマでは、処理に関するサマリー統計は表示されません。
データ・ビューには、各入力属性とともに、右側に新しく導出された空白文字を正規化した属性が表示されます。
出力フィルタ
なし。
例
この例では、「空白の正規化」プロセッサを使用して、住所の1行目にある属性の単語間のスペースを正規化します。
| Address1 | Address1.WhitespaceNormalized |
|---|---|
| Medway House[space][space][space], Bridge Street | Medway House[space], Bridge Street |
| Monarch Mill[space][space], Jones Street | Monarch Mill[space], Jones Street |
| Unit 1[space][space], Barnard Road | Unit 1[space], Barnard Road |
| Alston Street[space][space][space][space], | Alston Street[space], |
「パターン変換」プロセッサは、正規表現を使用して文字列または文字配列属性のデータの書式を変換するかわりとなる、単純でわかりやすい手段を提供します。
「パターン変換」は、2つの列で構成される参照データ・セット(パターン・マップ)を使用して、いくつかのパターン(1つ目のルックアップ列)を新しい1つ以上の書式(2つ目のマップ列)と照合し、データを再書式化します。
たとえば、郵便番号、口座番号、製品シリアル番号の属性など、データが少数の標準形式に従っていることが望まれ、実際はそのようになっていない場合に、「パターン変換」を使用して属性のデータの書式を標準化します。
データに存在する可能性がある無効なパターンを見つけるには、パターン・プロファイラ(同じ文字パターン・マップを使用、つまり、文字パターン生成方法が同じ)を使用すると便利です。これらは、無効な各パターンが有効なパターンにマップされた状態で、このプロセッサで使用されるパターン・マップに追加できます。
「パターン変換」は、ある文字パターンから別のパターンへの単純なマップを使用する範囲内で、可能なかぎり多くの柔軟性を提供することを目指します。テキスト変換のタイプによっては、正規表現の特別な複雑さを必要とするものもあります(「正規表現の置換」を参照)。
プロセッサの完全なロジックは次のとおりです。
| ステップ | アクション |
|---|---|
| 1 | 値のパターンを生成するために、構成された文字パターン・マップを使用して、入力値のすべての文字をパターン文字にマップします(AB1243-ZXをaaNNNN-aaなど)。 |
| 2 | 生成されたパターンをパターン・マップのルックアップ列に対して照合します。
|
| 3 | パターン文字がルックアップ列にあり、マップ列にない場合は、基礎となる文字が値から削除されます(たとえば、NN-aからNNaへのマップを使用すると、12-Aの値は12Aに変換されます)
パターン文字がマップのルックアップ列になく、マップ列にある場合は、そのパターン文字が出力値のリテラル文字として追加されます(たとえば、NNaaからNN-aaへのマップを使用すると、12ABの値は12-ABに変換されます) パターン文字がパターン・マップのルックアップ列とマップ列の両方にある場合は、次のようになります。
|
|
注意: 同じパターン文字にマップするすべての文字は、最終的なパターンで常に同じ順序で表示される必要があります(たとえば、デフォルトの文字パターン・マップを使用して、AB123CDから123ABCDまたは1ABC23への変換は可能ですが、AB123CDからBA123CDまたはAB213CDへは変換できません)。 |
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | パターン・マップを使用して値を置換する1つ以上の文字列または文字配列属性を指定します。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
次のデータ属性が出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 変換済 | パターン・マップを使用して変換されたレコードの数。 |
| 未変換 | パターン・マップを使用して変換されなかったレコードの数。 |
出力フィルタ
「パターン変換」プロセッサからは、次の出力フィルタが使用可能です。
変換済の値を持つレコード
未変換の値を持つレコード
例
この例では、パターンの生成にデフォルトの文字パターン・マップを使用し、英国の郵便番号に関する共通書式の問題を解決するために、次のパターン・マップを使用します。
| ルックアップ | マップ |
|---|---|
| aaN-_Naa | aaN Naa |
| aaN._Naa | aaN Naa |
| aaNN._Naa | aaNN Naa |
| aaNNaa | aaN Naa |
| aaN__Naa | aaN Naa |
これにより、次に示すように値が変換されます。
| Postcode | Postcode.PatternTransformed |
|---|---|
| OL6 9HX | OL6 9HX |
| CW96HF | CW9 6HF |
| PR7 3RB | PR7 3RB |
| CH7 6DZ | CH7 6DZ |
| CH7 6BD | CH7 6BD |
| CH40BE | CH4 0BE |
| SK87NG | SK8 7NG |
「適切な大小文字」プロセッサは、テキスト属性の値を、各単語の最初の文字を大文字に、単語の後続する文字を小文字に変換します。
「適切な大小文字」プロセッサは、ダイレクト・メールの名前や住所など、単語の表示を標準化する場合に使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 適切な大/小文字に変換する文字列または文字列配列型の属性を指定します。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「適切な大小文字」トランスフォーマでは、処理に関するサマリー統計は表示されません。データ・ビューには、各入力属性とともに、右側に新しく導出された適切な大/小文字の属性が表示されます。
出力フィルタ
なし。
例
次のオプションを使用して、様々な大/小文字指定の名前を変換します。
区切り文字: '.- (スペース、アポストロフィ、ピリオドおよびハイフン)
大小文字が混合する単語を保持: はい。
例外: 参照データ・リスト('van'は指定され、'de'は指定されていない)。
例外に一致する場合大小文字を区別しない: はい
例外時のアクション: 小文字への変換。
| 名前 | name.Proper |
|---|---|
| Tess De'Suiza | Tess De'Suiza |
| O'FLAHERTY | O'Flaherty |
| James De-lacey | James De-lacey |
| FRED DE LA TOUR | Fred De La Tour |
| Charles DeQuincey | Charles DeQuincey |
| ARTHUR DENTFORD | Arthur Dentford |
| John De'SUIZA | John De'Suiza |
「正規表現の一致」プロセッサは、正規表現に対して属性のデータを照合し、一致するデータを新しい属性に出力します。また、正規表現の中で一致したグループすべての配列が設定された属性を追加します。
「正規表現の一致」は、正規表現と一致するデータを抽出する簡単な方法として使用してください。これはグループの配列を作成する場合に特に便利です。
正規表現のグループは、カッコの中に記載することに注意してください。1つの正規表現に多数のグループが存在する可能性があります。
「正規表現の一致」は、正規表現全体に対して一致した値が格納された属性と、正規表現の中で一致するグループの配列が格納された属性の2つの属性を追加します。一致するものがなかった場合、新しい属性は両方ともnullになります。
正規表現
正規表現は、パターンを表現し、文字列を操作するための標準の手法であり、一度習得すると非常に有用です。
正規表現に関するチュートリアルや参考資料はインターネットで入手できます。また、Jeffrey E. F. Friedl著、O'Reilly UK発行の『Mastering Regular Expressions』(ISBN: 0-596-00289-0)などの書籍も参考になります。
また、正規表現の習得に役立つソフトウェア・パッケージ(RegExBuddyなど)や、有益な正規表現のオンライン・ライブラリ(RegExLibなど)も使用できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 単一の文字列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 一致 | 正規表現と一致したレコードの数。 |
| 不一致 | 正規表現と一致しなかったレコードの数。 |
出力フィルタ
「正規表現の一致」プロセッサからは、次の出力フィルタが使用可能です。
正規表現と一致したレコード
正規表現と一致しなかったレコード
例
この例では、ADDRESS3属性内の値を、次の英国郵便番号の正規表現と照合します。
([A-Z]{1,2}[0-9]{1,2}|[A-Z]{3}|[A-Z]{1,2}[0-9][A-Z]) +([0-9][A-Z]{2})
| 一致した値 | 不一致の値 |
|---|---|
| 170 | 1831 |
「一致した値」へのドリルダウン:
値が一致すると、区別された各グループ(つまり、外側コードと内側コード)に一致する値で配列が作成されます。
| ADDRESS3 | RegExMatchFull | RegExMatchGroups |
|---|---|---|
| SP7 9QJ | SP7 9QJ | {SP7}{9QJ} |
| BA16 0BB | BA16 0BB | {BA16}{0BB} |
| LA9 7BT | LA9 7BT | {LA9}{7BT} |
| E16 2AG | E16 2AG | {E16}[2AG} |
| SN1 5BB | SN1 5BB | {SN1}{5BB} |
「正規表現の置換」プロセッサは、文字列または文字配列属性を正規表現と照合して、一致する値を指定の値または一致したテキストから導出した値で置換する(たとえば、正規表現と一致した文字列全体を、正規表現の最初のグループのみで置換する)ことで、高度なテキスト置換を実行する手段を提供します。
「正規表現の置換」は、たとえば、正規表現に従って特定のパターンに一致する文字列を特定の値で置換する必要がある場合や、テキストの一部のコンテキストを検討してから標準化するかどうかを判断する必要がある場合など、高度なテキスト変換に使用します。
たとえば、一定数の有効値が設定された属性に対して、有効な特定の値のリストと一致しない、数文字の長さを超える英文字のすべての値を'Other'に変換できます。これは、「リスト・チェック」を実行し、一致しなかった値を「正規表現の置換」を使用して変換することで対応できます。
円記号(\)とドル記号($)は、置換文字列の特殊文字であることに注意してください。ドル記号は、照合に使用する正規表現の中のグループに対する参照として使用されます。円記号は、置換文字列内でエスケープ・リテラル文字に使用されます。
正規表現
正規表現は、パターンを表現し、文字列を操作するための標準の手法であり、一度習得すると非常に有用です。
正規表現に関するチュートリアルや参考資料はインターネットで入手できます。また、Jeffrey E. F. Friedl著、O'Reilly UK発行の『Mastering Regular Expressions』(ISBN: 0-596-00289-0)などの書籍も参考になります。
また、正規表現の習得に役立つソフトウェア・パッケージ(RegExBuddyなど)や、有益な正規表現のオンライン・ライブラリ(RegExLibなど)も使用できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 1つ以上の文字列または文字配列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 変換済 | 正規表現と一致したために変換が適用されたレコードの数。 |
| 未変換 | 正規表現と一致しなかったために変換が行われなかったレコードの数。 |
出力フィルタ
次の出力フィルタを使用できます。
変換済の値を持つレコード
未変換の値を持つレコード
例
この例では、正規表現の置換を使用して、3桁とその後に続くスペースおよび<anything>が<anything><space><the three digits>で置き換えられます。
正規表現: ^(\d{3}) (.*)$
置換文字列: $2 $1
結果(成功した置換):
| 文字列 | 置換 |
|---|---|
| 123 24ACB | 24ACB 123 |
| 435 GBRSDF | GBRSDF 435 |
| 789 X | X 789 |
「正規表現分割」プロセッサは、正規表現を使用して分割が発生する場所を定義し、属性のデータを配列に分割する手段を提供します。
区切り文字を使用する方法より高度なデータの分割方法が必要な場合は、「正規表現分割」を使用してデータを分割します。たとえば、一連の文字のいずれかが発生した場合または一連の文字の可変長が発生した場合にデータを分割することがあります。
正規表現
正規表現は、パターンを表現し、文字列を操作するための標準の手法であり、一度習得すると非常に有用です。
正規表現に関するチュートリアルや参考資料はインターネットで入手できます。また、Jeffrey E. F. Friedl著、O'Reilly UK発行の『Mastering Regular Expressions』(ISBN: 0-596-00289-0)などの書籍も参考になります。
また、正規表現の習得に役立つソフトウェア・パッケージ(RegExBuddyなど)や、有益な正規表現のオンライン・ライブラリ(RegExLibなど)も使用できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 1つ以上の文字列または文字配列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 成功 | 正規表現を使用して分割されたレコードの数。 |
| 失敗 | 正規表現を使用して分割されなかったレコードの数。 |
出力フィルタ
次の出力フィルタを使用できます。
分割が成功したレコード
分割が失敗したレコード
例
この例では、「正規表現分割」を使用して、従業員表のNotes属性から個人のイニシャル(シーケンス内で検出された2または3文字の大文字)の左右どちら側でもデータを分割します。
正規表現: ([A-Z]{2,3})
結果(成功した置換):
| 注意 | RegExSplit |
|---|---|
| started 14/10/1995 JBM ref557 | {started 14/10/1995 }{ ref557} |
| started 15/5/95 JBM ref557 | {started 15/5/95 }{ ref557} |
| start date 15/6/1998 HM etn247 | {start date 15/6/1998 }{ etn247} |
| started 2/1/2004 RLJ ref-1842 | {started 2/1/2004 }{ ref-1842} |
| started 8/10/2000 JBM ref557 | {started 8/10/2000 }{ ref557} |
| started 10/6/2001 JBM ref557 | {started 10/6/2001 }{ ref557] |
「置換」プロセッサは、たとえばデータを標準化するために、参照データ・マップを使用してデータを変換します。マップの1列目は値の照合に使用され、2列目は置換の制御に使用されます。
実行される置換は、値全体の単純な置換('Oracle Ltd'の値を'Oracle Limited'に置換するなど)、または入力された値の一部の置換(CompanyName属性の最後が'ltd'の場合に'limited'に置換する、'decsd'の文字列を検出するたびに'deceased'に置換するなど)になります。参照データの照合方法、つまりデータの置換方法は、次のいずれかのオプションを使用して制御します。
全体の値
次を含む
次で始まる
次で終わる
区切り文字の一致
また、参照データとの照合では、大/小文字を区別または無視できます。
「次を含む」、「次で始まる」または「後方から一致する」オプションを使用する場合は、参照データのルックアップ列に対して複数の一致が存在する可能性があります。この場合、「置換」では置換が常に1回のみ発生します。たとえば、'PT'という値を'PINT'で置換する「次を含む」置換を実行すると、'10PT - APTITUDE BITTER'の値は'10PINT APINTITUDE BITTER'ではなく'10PINT - APTITUDE BITTER'に変換されます。
「区切り文字の一致」オプションを使用し、照合する前に区切り文字を使用してデータを区切るように選択すると、入力された値に多数の一致がある場合も、置換マップのルックアップ列と一致する分割された値が置換されます。
複数の一致がある場合の「置換」プロセッサによる置換方法の判断は、構成オプションを使用して制御できます。
デフォルトでは、単純にマップが順にチェックされ、入力データからのマップに対する最初の一致が置換に使用されます。たとえば、置換マップに'Lyn'および'Lynda'の値があり、リストの先頭に'Lyn'がある場合、'Lynda'という入力値は、マップのルックアップ値'Lyn'を使用して置換されます。
ただし、これは「最長の値に一致」オプションを使用して制御できます。このオプションを選択すると、一致した各参照エントリの長さが評価され、最も長い一致が使用されます。したがって、前述の例では、マップの'Lynda'というルックアップ値を使用して置換が実行されます。
「置換」プロセッサを使用して、同じものを意味する異なる接尾辞(LtdとLimited、AssocとAssc、CnclとCouncilなど)が標準的な様式で表されるように標準化(たとえば、CompanyName名の値をすべて標準化)します
日付の置換
「置換」を使用して、日付値を置換できます。ただし、機能させるためには、参照データ・マップの日付値がISOの標準書式、つまり、YYYY-MM-DD (例: 1900-01-01)またはYYYY-MM-DD HH:mm:ss (例: 1900-01-01 00:00:00)である必要があります。日付はNull値で置換でき、これにより、たとえば無効な日付を削除できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 参照データ・マップを使用して値を置換する単一の属性を指定します。属性は文字列または文字列配列です。
配列を入力すると、置換は配列要素レベルで適用され、(置換実行後のデータを含む)配列が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 変換済 | 置換が実行されたレコードの数。数値をドリルダウンすると、レコードが表示されます。 |
| 未変換 | 置換が実行されなかったレコードの数。 |
| 無効 | 入力データ型に対して置換値が無効であったために置換に失敗したレコードの数。 |
|
注意: 「置換」プロセッサでは、任意のデータ型の属性(文字列、配列、数値または日付)を使用できます。ただし、「置換」は入力属性のデータ型を常に出力属性に対して使用するため、選択可能な変換の中には、置換された値が出力属性のデータ型では無効になる変換があります。たとえば、マップを使用して'2006-04-14'という日付値を'Bad date'で置換しようとすると、'Bad date'という値は有効な日付ではないため、置換は失敗します。無効な置換が存在する場合は、置換を実行する前に元の属性を異なるデータ型に変換するか、参照データ・マップを変更して無効な置換を削除する必要があります。 |
出力フィルタ
次の出力フィルタを使用できます。
変換済の値を持つレコード
未変換の値を持つレコード
無効な置換があるレコード
例
この例では、「置換」プロセッサを使用して、顧客表からAddress3属性の英国の郡およびその他同様のデータを標準化します。出力属性は、Address3.standという名前になっています。
この場合、「全体の値」置換を使用しました。次の図は、変換されたレコードのドリルダウン・ビューからの抜粋です。
| ADDRESS3 | ADDRESS3.stand | CU_NO |
|---|---|---|
| Lancs | Lancashire | 13841 |
| Cambs | Cambridgeshire | 14053 |
| OXON | Oxfordshire | 14068 |
| Leics | Leicestershire | 14130 |
| Linc | Lincolnshire | 14207 |
| Beds | Bedfordshure | 14506 |
「すべて置換」プロセッサは、参照データ・マップを使用して、複数の属性間でデータを変換します。マップの1列目に指定された値は、2列目の対応する値で置換されます。
置換の実行では、単純に値全体が置換されたり(たとえば、国名'France'をISO標準国コード'FR'に置換する場合など)、区切り文字を使用して入力属性のデータを個別に考慮されるトークンに分割されたりします。参照データの照合方法、つまりデータの置換方法は、次のいずれかのオプションを使用して制御します。
全体の値
区切り文字の一致
また、参照データとの照合では、大/小文字を区別または無視できます。
「区切り文字の一致」オプションを使用し、照合する前に区切り文字を使用してデータを区切るように選択すると、入力された値に多数の一致がある場合も、置換マップのルックアップ列と一致する分割された値が置換されます。
「すべて置換」プロセッサは、複数の属性にわたって1つの値を他の値で置換する場合に使用します。たとえば、データなしを表す意図の文字列に変換したり、複数のフィールドにわたって国名をISO標準国コードに変換するなどが一般的な例です。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 参照データ・マップを使用して値を置換する属性のセットを指定します。属性は文字列または文字列配列です。
配列を入力すると、置換は配列要素レベルで適用され、(置換実行後のデータを含む)配列が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 変換済 | 置換が実行されたレコードの数。数値をドリルダウンすると、レコードが表示されます。 |
| 未変換 | 置換が実行されなかったレコードの数。 |
出力フィルタ
次の出力フィルタを使用できます。
変換済の値を持つレコード
未変換の値を持つレコード
例
この例では、「すべて置換」プロセッサを使用して、ISO標準の2文字の国コードを標準化された国名に変換します。置換操作は同時に2つの属性に適用されるため、複数の「置換」プロセッサを使用する必要はありません。次の図は、変換されたレコードのドリルダウン・ビューからの抜粋です。
| AddressCountryCode | AddressCountryCode.AllReplaced | OperatingCountryCode | OperatingCountryCode.AllReplaced |
|---|---|---|---|
| GL | GREENLAND | GR | GREECE |
| US | UNITED STATES | FI | FINLAND |
| CZ | CZECH REPUBLIC | MG | MADAGASCAR |
| PL | POLAND | JO | JORDAN |
| HN | HONDURAS | RS | SERBIA |
| UG | UGANDA | KG | KYRGYZSTAN |
| KI | KIRIBATI | ZA | SOUTH AFRICA |
| MH | MARSHALL ISLANDS | MG | MADAGASCAR |
「戻り配列サイズ」プロセッサは、配列属性を受け取り、新しい属性に配列のサイズを返します。配列のサイズは、配列に含まれる要素の数です。
このプロセッサからの出力は数学的な計算に使用され、その後、配列を分割したり配列の要素を処理するために他のプロセッサに適用されます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 単一の配列属性を指定します。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「戻り配列サイズ」トランスフォーマでは、処理に関するサマリー統計は表示されません。
「データ」ビューには、入力配列属性とともに、右側に新しい配列サイズ属性が表示されます。
出力フィルタ
なし。入力されたすべてのレコードが出力されます。
例
この例では、「戻り配列サイズ」を使用して配列属性のサイズを返します。
| 配列 | ArraySize |
|---|---|
| { Orbis, Cathedral Gardens}{Manchester}{Lancashire}{M4 3Pg} | 4 |
| {Capability Green,}{ Luton}{Bedfordshire}{LU1 3LU} | 4 |
| { Bonds Lane, Garstang}{Preston}{ Lancs}{PR3 1RA} | 4 |
| { Tempsford Hall,}{ Sandy}{}{SG19 2BD} | 4 |
「配列要素の選択」プロセッサは、1つ以上の配列属性から番号付き要素を同等のタイプの新しい属性に抽出します。
このプロセスを使用して、その後の処理のために配列から単一の要素を選択します。たとえば、「文字列から配列を作成」を使用して属性の値を配列に分割した場合は、「配列要素の選択」を使用して要素を新しい属性に抽出できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 配列要素を選択する1つ以上の配列属性を指定します。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | 次のデータ属性が出力されます。
|
| フラグ | なし。 |
「配列要素の選択」トランスフォーマでは、処理に関するサマリー統計は表示されません。
「データ」ビューには、入力配列属性とともに、右側に新しい配列サイズ属性が表示されます。
出力フィルタ
なし。入力されたすべてのレコードが出力されます。
例
この例では、配列要素の選択はNAME配列の最初の要素を新しい属性に抽出します。
| 配列(昇順) | 配列要素 |
|---|---|
| { 1 King Edward Road,}{Brentwood}{Essex}{CM14 4HG} | 1 King Edward Road, |
| { 1-3 Dufferin St,}{LONDON}{}{EC1Y 8NA} | 1-3 Dufferin St, |
| { 1-5 Call Lane,}{ Leeds}{ West Yorkshire}{LS1 7DM} | 1-5 Call Lane, |
| { 10 Ballater Street,}{Glasgow}{G5 9PS}{} | 10 Ballater Street, |
「Soundex」プロセッサは、指定属性内の各値にsoundexコードを生成します。Soundexは発音が似ている名称を同一コードとして表す抽象キーです。Soundexは、特に苗字/姓に適用されます(他のドメインでの使用には注意が必要です)。
Soundexコードは発音が同じでも綴りが異なる場合に使用されます。soundexコードを作成すると、重複チェックのときに生データ値のかわりにSoundexを頻繁に使用できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | soundexコードを作成する文字列属性または文字配列属性を指定します。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「Soundex」トランスフォーマでは、処理に関するサマリー統計は表示されません。
「データ」ビューには、入力配列属性とともに、右側に新しい配列サイズ属性が表示されます。
出力フィルタ
なし。入力されたすべてのレコードが出力されます。
例
この例では、Surname属性に対してSoundex変換を使用します。Surname属性は、顧客表の中のNAME属性から作成されました。それには、「文字列から配列を作成」プロセッサを使用して属性をスペース区切りで分割し、「配列要素の選択」プロセッサを使用して配列内の2番目の要素を選択することでSurnameを出力します。
| Surname (昇順) | Surname.Soundex |
|---|---|
| ADAMSKI | A352 |
| AHMED | A530 |
| AITKEN | A325 |
| ALLAN | A450 |
| ALLEN | A450 |
同じ値と考えられるALLANとALLENのような誤字の場合でも、同一のsoundexコードが生成されます。
「配列からレコードを分割」プロセッサを使用すると、入力配列内の各要素ごとにレコードを新たに分割することで、1つのレコードから複数のレコードを作成できます。
「配列からレコードを分割」は、複数のレコードで表現される必要があるデータが間違って1つのレコードのみにキャプチャされた場合に使用します。つまり、間違って非正規化されたデータを正規化するために使用します。
分割が必要な非正規化データは通常、このプロセッサを使用する前に前処理する必要があります。たとえば、次の受注表ではフリー・テキスト・フィールドを使用して複数の受注(複数の注文番号と製品説明を持つ)が誤って次の受注表の1つのレコードに入力されました。
| Order_ID | Order_Number | Product_Desc |
|---|---|---|
| O574112 | 2788143 / 2788144 | Home PC Package / Color Printer |
この場合、Order_Number属性およびProduct_Desc属性の両方に簡単な前処理が必要です。文字列から配列を作成プロセッサを使用して/文字を区切り文字に使用して配列を作成します。次に「配列からレコードを分割」プロセッサに配列を入力すると、次のようにレコードが分割されます。
| Order_ID | Order_Number.normalized | Product_Desc.normalized |
|---|---|---|
| O574112 | 2788143 | Home PC Package |
| O574112 | 2788144 | Color Printer |
前述の例では、多数の配列属性がこのプロセッサに入力されました。この場合、各入力レコード当たりの出力レコード数は要素数が最も多い配列属性の要素数と一致します。各属性の入力ではないデータは、各入力レコードから作成された出力レコードのすべてに単にコピーされます。たとえば、Title.arrayとFirstName.arrayを入力して、次のレコードを分割する場合。
| Cust_ID | Title.array | FirstName.array | 姓 |
|---|---|---|---|
| 13451 | {Mr}{Mrs} | {John}{Dorothy}{James} | Smith |
出力レコードは次のとおりです。
| Cust_ID | Title.array | FirstName.array | 姓 |
|---|---|---|---|
| 13451 | Mr | John | Smith |
| 13451 | Mrs | Dorothy | Smith |
| 13451 | James | Smith |
Title.arrayの配列にFirstName.arrayの3番目の要素と対応する要素がないため、Title.array.normalizedの最後のレコードはNullになります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | レコードの分割に使用する配列属性を1つ以上指定します。入力された配列の各要素が単一値として出力されます。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
次のフラグが出力されます。
|
次の表に、このプロファイラによって生成される統計情報を示します。
| 統計 | 説明 |
|---|---|
| 入力レコード | 入力されたレコードの数(分割前)。 |
| 出力レコード | 出力されたレコードの数(分割後)。
ドリルダウンすると、すべての出力レコードが表示されます。 |
| 分割% | 複数の出力レコードに分割された入力レコードのパーセント値。
ドリルダウンすると、分割された出力レコード(入力配列属性が複数の要素を持つレコード)が表示されます。 |
出力フィルタ
なし。
例
この例では、照合のために個人名のデータ・セットを準備します。データには、別名や異なる綴りを持つ個人名が多数含まれます。これらは、単一のAliases.Array属性へと前処理され、次に、配列からレコードを分割を使用してそれぞれの名前が別々に照合できるように分割されます。
| Aliases.Array | Aliases.Array.Split |
|---|---|
| {Jose Angel Veron}{Jose Veron} | Jose Veron |
| {Jose Angel Veron}{Jose Veron} | Jose Angel Veron |
| {Namik Zouahi}{Namiq Zouahi}{Namig Zouahi} | Namik Zouahi |
| {Namik Zouahi}{Namiq Zouahi}{Namig Zouahi} | Namiq Zouahi |
| {Namik Zouahi}{Namiq Zouahi}{Namig Zouahi} | Namig Zouahi |
| {Christine Moss}{Christine Lee}{Christine Graham} | Christine Moss |
| {Christine Moss}{Christine Lee}{Christine Graham} | Christine Lee |
| {Christine Moss}{Christine Lee}{Christine Graham} | Christine Graham |
「数値の削除」プロセッサを使用すると、テキスト属性からすべての数値を速やかに削除できます。
数値の削除は通常、照合用のデータを準備するために(または照合プロセッサでの照合変換として)使用されます。テキスト・データに不要な数値が含まれている場合、照合する前にそれらを削除するときに便利です。
たとえば、商品説明を照合するときに、一部の説明に非常に長いシリアル番号が含まれていることがあります。これらを削除して、説明文のみを使用できます。
また、電話番号など、大半が数値だと思われるテキスト属性内で数値以外の文字列や文字を見つけるときにも使用できます。これはデータの解析や、標準化のときに役立ちます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 数値を削除する文字列型または文字配列型の属性を指定します。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
「数値の削除」トランスフォーマは、処理に関するサマリー統計を表示しません。
「データ」ビューには、各入力属性が、その右に数値が削除され新しく導出された属性とともに表示されます。
出力フィルタ
なし。
例
この例では、電話番号を含む属性からすべての数値が削除されます。これにより、電話番号に関する追加情報を示す様々な方法がデータに含まれていることがわかります。それらの追加情報は標準化し、たとえば電話帳に表示されない(ex-directory)番号を示すためのフラグを新しい属性内に設定するために使用する必要がある場合もあります。
| PhoneNumber | PhoneNumber.StrippedNumbers (降順) |
|---|---|
| 01240 904346(w) | (w) |
| 043408 37440(landlord'sno) | (landlord'sno) |
| 01266 310270(ex directory) | (ex directory) |
| 01266 317153(ex directory) | (ex directory) |
| 01266 371080(ex directory) | (ex directory) |
| 01918441231 (H) | (H) |
単語の削除変換プロセッサは、参照データリストと一致するすべての単語を属性値から削除します。
単語の削除は、多くの場合、照合する値を作成する目的で、属性から無関係な単語を削除するために使用されます。たとえば、Company Nameフィールドを使用して会社を照合するときに、LTD、LIMITED、UK、PLCなど様々な形式で発生したり、一部の値でのみ発生するあまり重要でない単語を削除するのに役立ちます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 単語を削除する文字型または文字配列型の属性を指定します。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
単語の削除トランスフォーマでは、処理に関するサマリー統計は表示されません。
「データ」ビューには、各入力属性が、その右に数値が削除され新しく導出された属性とともに表示されます。
出力フィルタ
なし。
例
この例では、単語の削除を使用して、会社名が含まれるフィールドから、「Limited」、「Ltd.」、「Services」、「Associates」などの比較的重要性の低い単語を削除します。
| BUSINESS | Business.StrippedWords |
|---|---|
| Kamke & Ellis Ltd. | Kamke & Ellis |
| Sanford Electrical Co | Sanford Electrical |
| C T V Services | C T V |
| W F Electrical Contractors Limited | W F Electrical Contractors |
| Eco-Systems Group | Eco-Systems |
| Milbourne Associates | Milbourne |
文字変換プロセッサは、ある記述体系(アラビア語など)から別の記述体系(ラテン語など)に文字列を変換します。これは大部分は音声操作で、文字列が表す音声に基づいて、その文字列に相当する語をターゲットの記述体系で作成しようとする操作です。文字列の翻訳を目的とするものではありません。たとえば、アラビア語の氏名の一般的な構成要素である文字列に、音読すると「bin」のように聞こえる文字列がありますが、これはラテン語の文字列「bin」に文字変換され、文字どおりの意味である「son of」には翻訳されません。
元の記述体系の単一の文字列には、有効な文字変換が複数ある場合があります。たとえば、「bin」は「ben」にも文字変換できます。一部の氏名には非常に多くの代替文字変換があります。文字変換プロセッサの目的は、元の文字列に対して、可能性のあるすべての代替文字変換を提供するのではなく、単一の標準形式を提供することです。代替文字変換は照合プロセスの一環として認識され、文字変換されていない氏名の代替つづりと同様の認識方法で管理されます。
EDQの文字変換プロセッサは、ICUにより提供されるICU4Jライブラリを中心に構築されています。ICUは制限のないオープン・ソース・ライセンスでリリースされており、市販のソフトウェアは言うまでもなく、他のオープン・ソースやフリー・ソフトウェアと組み合せて使用する際に適しています。ICUおよびICUのライセンスの詳細は、ICUのWebサイトを参照してください。
文字変換プロセッサは、ある記述体系から別の記述体系へと発音的に適した方法で文字列を変換するために使用します。これは、ある記述体系で提供された文字列を別の記述体系で提供された参照データと照合する場合に役立ちます。たとえば、国際的なウォッチ・リストはラテン語のスクリプトでのみ提供されることがよくあります。
|
注意: 文字変換プロセッサは、EDQで代替記述体系を処理するために使用可能な唯一のツールではありません。文字変換要件の複雑性とICU4Jの多様な記述体系のサポートによっては、他のアプローチの方が確実な場合があります。たとえば、ソース記述体系とターゲット記述体系の適切な参照データ・セットとともに、置換プロセッサと文字の置換プロセッサの組合せを使用して文字変換を実装できます。 |
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 文字変換する任意の数の文字列属性または文字列属性の配列を指定します。数値および日付属性は、特定の記述体系とは独立した形式で格納されるため文字変換する必要はありません。数値または日付が含まれる文字列は、最も適切な方式でターゲット記述体系に変換されますが、これは音声操作ではありません。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
文字変換プロセッサは、サマリー・データを出力しません。文字変換された入力値は入力属性とともにデータ・ビューに表示されます。
出力フィルタ
なし。
例
次の例では、入力データの氏名がギリシャ語(Original Script Name)からラテン語(Original Script Name.Transliterated)に文字変換されます。
「文字の切捨て」プロセッサでは、指定のオプションに従って、文字列または文字配列属性を元の値の左、中央または右から設定された文字数に切り捨てます。
切捨て結果は追加属性として出力されます。
「文字の切捨て」は、テキスト値を設定された文字数に切り捨てるために使用します。たとえば、照合する前にデータを操作したり、ある属性の最初の数文字と別の属性の最後の数文字で構成された新しい照合クラスタを作成できます。この場合、「文字の切捨て」を2度使用することになり、1度目で属性の最初の数文字を取得し、2度目で別の属性の最後の数文字を取得します。
複数の属性にまったく同じ切捨て操作を実行する場合は、「文字の切捨て」プロセッサの1回の使用で実行できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 設定された文字数に切り捨てる、文字列または文字配列型の属性を指定します。数値および日付属性は、標準的な単一のテキスト表現がないため、有効な入力ではありません。日付属性または数値属性を切り捨てる場合は、最初に「数値を文字列に変換」または「日付を文字列に変換」を使用して、文字列データ型の標準的な表現(たとえば、日付の場合はDD/MM/YYYY)に変換する必要があります。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
| データ属性 | 次のデータ属性が出力されます。
|
| フラグ | なし。 |
「文字の切捨て」トランスフォーマでは、処理に関するサマリー統計は表示されません。
「データ」ビューには、各入力属性が、その右に数値が削除され新しく導出された属性とともに表示されます。
出力フィルタ
なし。
例
この例では、「文字の切捨て」プロセッサを使用して、顧客表のDT_PURCHASED属性の日付の日部分(最初の2文字)が返されます。
ここでは、DT_PURCHASED 属性はすでに文字列属性として格納されています。必要な場合は、日付を文字列に変換プロセッサを使用してDATE属性を文字列に変換します。
変換の結果を次に示します。
| DT_PURCHASED | DT_PURCHASED.Substring |
|---|---|
| 03/01/2000 | 03 |
| 06/01/2000 | 06 |
| 10/01/2000 | 10 |
| 14/01/2000 | 14 |
| 16/01/2000 | 16 |
| 16/01/2000 | 16 |
| 23/01/2000 | 23 |
| 23/01/2000 | 23 |
空白の切捨てプロセッサでは、テキスト属性の値から空白文字(つまり、スペースおよびその他の印刷不可能な文字)を切り捨てます。空白文字を値の左側のみ(先頭の空白文字)、値の右側のみ(末尾の空白文字)、両側から、または元の値全体にわたって切り捨てるかを制御できます。
切捨て結果は追加属性として出力されます。
空白の切捨ては、テキスト値をその本来の値に正規化するために使用します。たとえば、重複チェックで使用する属性から誤った余分なスペースを削除できます。
空白の切捨てでは、空白文字の固定の定義(属性値からすべての空白文字および印刷不可能な文字を削除する)が使用されることに注意してください。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 空白を削除する文字型または文字配列型の属性を指定します。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | 次のオプションを指定します。
|
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
空白の切捨てトランスフォーマでは、処理に関するサマリー統計は表示されません。
「データ」ビューには、各入力属性が、その右に数値が削除され新しく導出された属性とともに表示されます。
出力フィルタ
なし。
例
この例では、空白の切捨てを使用して、ADDRESS3属性の左から先頭の空白文字をすべて切り捨てます。
| ADDRESS3 (昇順) | ADDRESS3.Trimmed |
|---|---|
| Avon | Avon |
|
Avon |
Avon |
| Bedford | Bedford |
|
Bedfordshire |
Bedfordshire |
| Berks | Berks |
|
Berks |
Berks |
| Berks | Berks |
大文字プロセッサでは、テキスト属性値を大文字に変換し、変換した値を新しい属性に返します。
大文字プロセッサは、大/小文字を区別しない検証ルールを使用する場合や、データ・クレンジングの一環として大/小文字を標準化するために使用します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 大文字に変換する文字列または文字配列型の属性。数値属性および日付属性は有効な入力ではありません。数値属性および日付属性は有効な入力ではありません。
配列属性を入力すると、変換はすべての配列要素に適用され、1つの配列属性が出力されます。 |
| オプション | なし。 |
| 出力 | データ属性またはフラグ属性の出力を記述します。 |
|
データ属性 |
次のデータ属性が出力されます。
|
|
フラグ |
なし。 |
大文字トランスフォーマでは、処理に関するサマリー統計は表示されません。
「データ」ビューには、各入力属性が、その右に数値が削除され新しく導出された属性とともに表示されます。
出力フィルタ
なし。
例
この例では、処理の最初に大文字プロセッサを使用して、その後の処理のためにすべての文字列属性を大文字に変換します。
| TITLE | TITLE.Upper | NAME | NAME.Upper |
|---|---|---|---|
| Ms | MS | Lynda BAINBRIDGE | LYNDA BAINBRIDGE |
| William BENDALL | WILLIAM BENDALL | ||
| Ms | MS | Karen SMITH | KAREN SMITH |
| Miss | MISS | Patricia VINER | PATRICIA VINER |
| Mr | MR | Colin WILLIAMS | COLIN WILLIAMS |
| Mr | MR | Ian PATNICK | IAN PATNICK |
| Ms | MS | Robera REYNOLDS | ROBERTA REYNOLDS |
| Miss | MISS | Winifride ROTHER | WINIFRIDE ROTHER |
「日付配列属性の追加」トランスフォーマは、複数の要素と要素値属性を取得し、一致する新しい日付配列属性を追加します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 次の入力は任意で、指定するとオプションよりも優先されます。
|
| オプション | 次のオプションを指定します。
|
| 出力 | 属性入力またはオプション値ごとに、NewDateArray属性が作成されます。 |
|
注意: このプロセッサは、最大100個の要素を作成できます。特定の数の要素を作成するために入力属性を使用する場合、およびその値が100を超える場合、空の配列が出力となります。 |
出力フィルタ
なし。
例
| 要素値 | 配列長 | 出力 |
|---|---|---|
| 29-April-2015 | <Null> | <Null> |
| 29-April-2015 | -1 | <Null> |
| 29-April-2015 | 1.5 | <Null> |
| 29-April-2015 | 0 | 0 |
| 29-April-2015 | 1 | (29-April-2015) |
| 29-April-2015 | 3 | (29-April-2015)
(29-April-2015) (29-April-2015) |
「数値配列属性の追加」プロセッサは、後続の処理で使用できる新しい数値配列属性を作成します。新しい配列は構成可能なサイズ(要素の数)にすることができます。各要素値は、最初に作成されたときはブランクですが、必要に応じて、すべての要素に単一の値を設定できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 次の入力は任意で、指定するとオプションよりも優先されます。
|
| オプション | 次のオプションを指定します。
|
| 出力 | このプロセッサは、出力として新しい番号配列属性を作成します |
|
注意: このプロセッサは、最大100個の要素を作成できます。特定の数の要素を作成するために入力属性を使用する場合、およびその値が100を超える場合、空の配列が出力となります。 |
出力フィルタ
なし。
例
| 要素値 | 配列長 | 出力 |
|---|---|---|
| 42 | 0 | {} |
| 42 | 1 | {42} |
| 42 | 3 | {42}
{42} {42} |
「文字配列属性の追加」プロセッサは、後続の処理で使用できる新しい文字配列属性を作成します。新しい配列は構成可能なサイズ(要素の数)にすることができます。各要素値は、最初に作成されたときはブランクですが、必要に応じて、すべての要素に単一の値を設定できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 次の入力は任意で、指定するとオプションよりも優先されます。
|
| オプション | 次のオプションを指定します。
|
| 出力 | NewStringArray属性が作成されます。 |
|
注意: このプロセッサは、最大100個の要素を作成できます。特定の数の要素を作成するために入力属性を使用する場合、およびその値が100を超える場合、空の配列が出力となります。 |
出力フィルタ
なし。
例
| 要素値 | 配列長 | 出力 |
|---|---|---|
| 赤 | 0 | () |
| 赤 | 1 | (赤) |
| 赤 | 3 | (赤)
(赤) (赤) |
「配列の連結」プロセッサは、2つ以上の配列属性を1つの配列属性に連結します。
たとえば、異なる入力フィールドから導出された2つの電話番号配列があり、それらを組み合せて1つの配列属性を作成して照合で使用する場合などです。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 連結する2つ以上の配列属性を指定します。配列の型は同じであることが必要です。 |
| オプション | 次のオプションを指定します。
|
| 出力 | 入力の連結後の結果配列。値の順序は入力属性のとおりです。 |
出力フィルタ
なし。
例
| 入力値A | 入力値B | 空の値の削除 | 出力値 |
|---|---|---|---|
| (John) | (Smith) | いいえ | (John)(Smith) |
| (London) | () | いいえ | (London) |
| (Cambridge) | (CB40WZ) | いいえ | (Cambridge)(CB40WZ) |
| (2)(5)(7) | (3)(4)(6) | いいえ | (2)(5)(7)(3)(4)(6) |
| (Sydney) | (<Null>) (Australia) | はい | (Sydney)(Australia) |
「配列への文字列の連結」プロセッサは、文字列属性を文字配列の各要素に連結します。
このプロセッサの使用例としては、配列内の各電話番号の先頭に市外局番を付ける場合があげられます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 |
|
| オプション | 次のオプションを指定します。
|
| 出力 | 入力の連結後の結果配列。 |
出力フィルタ
なし。
例
| 配列 | 文字列 | セパレータ | 空を無視 | 追加または先頭に追加 | 出力値 |
|---|---|---|---|---|---|
| (London,)(Cambridge,) | United Kingdom | <未設定> | N/A | 追加 | (London,United Kingdom)(Cambridge,United Kingdom) |
| (John)(Smith) | <Null> | <未設定> | はい | 追加 | (John)(Smith) |
| (Sydney)(Perth) | <Null> | ", " | N | 追加 | (Sydney,)(Perth,) |
| (A)(B) | C | <未設定> | N/A | 先頭に追加 | (CA)(CB) |
このプロセッサは、同時に2つの配列を処理するように設計されています。一方の配列はチェック配列、もう一方は更新する配列であり、2つ目の配列は最初の配列のコンテンツに基づいて変更されます。
これを使用する場合の一般的な状況は、実行する2つの異なる操作が存在し、2つの異なる配列が出力となる場合です。場合によっては、配列は最初にチェックしてから更新/操作する必要があります。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 |
|
| オプション | 次のオプションを指定します。
|
| 出力 | 入力の連結後の結果配列。 |
出力フィルタ
なし。
例
| チェック配列 | 更新配列 | チェック値(入力) | 更新値(入力) | チェック値(プロパティ) | 値(プロパティ)の更新 | 比較演算子 | 一致要素の削除 | 更新後の配列 | 更新実行済 |
|---|---|---|---|---|---|---|---|---|---|
| (London, Cambridge, Cambridge, London) | (USA, UK, Argentina, Australia) | Cambridge | ターゲット | (無効) | (無効) | 次と等しい | (無効) | (USA, Target, Target, Australia) | Y |
| (Y, Y, Y, Y, Y) | (ABC, 1235, AB1, WER, TXT) | 未設定 | 未設定 | N | (空白) | 次と等しい | いいえ | (ABC, 1235, AB1, WER, TXT) | N |
| () | () | (空白) | 無効 | (無効) | (無効) | 次と等しい | (無効) | () | N |
| (Null) | () | (空白) | 無効 | (無効) | (無効) | 次と等しい | (無効) | () | N |
このプロセッサは、任意の配列型の1つ以上の配列の重複を除外します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | 重複を除外する配列を選択します。文字配列型、番号配列型または日付配列型を指定できます。各配列の重複は個別に除外されます(つまり、複数の配列に重複が存在する可能性があります)。 |
| 出力 | 入力の重複除外後の結果配列(入力ごとに1つ)。
|
出力フィルタ
| 構成 | 説明 |
|---|---|
| 重複除外済 | 要素が削除されたすべてのレコード。 |
| 一意 | すべての要素がすでに一意であり、変更が行われなかったすべてのレコード。 |
例
単一の配列
| 配列 | 文字列 | セパレータ |
|---|---|---|
| (John)(Smith) | (John)(Smith) | 一意 |
| (Bank)(Automobile)(Bank) | (Bank)(Automobile) | 重複除外済 |
| (Zipcode)(<Null>)(<Null>)(<Null>) | (Zipcode)(<Null>) | 重複除外済 |
| (London)(空白)(Null)(空白) | (London)(<空白>)(<Null>) | 重複除外済 |
| <Null> | (<Null>) | 一意 |
2つの配列
| 入力値A | 入力値B | 出力値A | 出力値B | 出力フィルタ |
|---|---|---|---|---|
| (A)(B) | (B)(C) | (A)(B) | (B)(C) | 一意 |
| (C)(A)(B)(A)(A) | (D)(D)(D) | (C)(A)(B) | (D) | 重複除外済 |
「一致配列要素の検索」プロセッサは2つ以上の配列内で共通の値を検索します。結果には一意の値のみが含まれ、これらの値は最初の配列に出現した順序で表示されます。すべての入力配列の中で重複する要素がある場合は、それらが出力配列に出現します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 |
|
| オプション | 大文字/小文字を区別しないかどうか。デフォルトのオプションは「はい」です。 |
| 出力 | 入力の連結後の結果配列。
|
出力フィルタ
| フィルタ | HasCommonElements |
|---|---|
| 共通要素あり | はい |
| 不一致要素 | いいえ |
例
2つの入力。
| 選択した属性A | 選択した属性B | 一致要素 | HasCommonElements | 出力フィルタ |
|---|---|---|---|---|
| (A)(B)(C) | (B) | (B) | Y | 一致 |
| (A) | (B) | () | N | 不一致 |
| (A)(B)(C) | () | () | N | 不一致 |
| () | () | () | N | 不一致 |
| (<空白>) | (<空白>) | (<空白>) | Y | 一致 |
| (<Null>) | (<Null>) | (<Null>) | Y | 一致 |
| (<空白>) | (<Null>) | () | N | 不一致 |
| () | <Null> | () | N | 不一致 |
| <Null> | () | () | N | 不一致 |
| <Null> | <Null> | () | N | 不一致 |
|
注意: 空の配列とnullの配列を比較すると、結果は1つの空の配列となり、不一致の値となるため、これらは同等であるとみなされます。 |
3つの入力。
| 選択した属性A | 選択した属性B | 選択した属性C | 一致要素 | HasCommonElements | 出力フィルタ |
|---|---|---|---|---|---|
| (A)(B)(C) | (B) | () | () | N | 不一致 |
| (A) | (B) | (A)(B) | () | N | 不一致 |
| (A)(B)(C) | (B) | (A)(B) | (B) | Y | 一致 |
| (A)(B)(C)(D) | (D)(B)(E) | (D)(A)(F)(B) | (B)(D) | Y | 一致 |
| (A)(B)(C) | (B) | <Null> | () | N | 不一致 |
|
注意: 共通の値は、入力のペアではなく、すべての入力の結合に基づきます |
「メッセージのヘッダー番号の取得」プロセッサは、Webサービス・リクエストのXML要素の属性から数値属性を抽出します。これは、レコード全体で値を指定する際に役立ちます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | ありません(すべての値はXMLから取得されます。) |
| オプション |
|
| 出力 | 入力の連結後の結果配列。
|
出力フィルタ
次の表に、構成オプションを示します。
| フィルタ | HeaderValid |
|---|---|
| ヘッダー有効 | Y |
| ヘッダー無効 | N |
例
次の例は、ヘッダーの値(デフォルト値またはNull)を示しています。
| ヘッダー | 値 | デフォルト | 出力値 | ヘッダー有効 | フィルタ |
|---|---|---|---|---|---|
| max_edit_distance | 2 | 3 | 2 | Y | 有効 |
| max_edit_distance | Null | 3 | 3 | Y | 有効 |
| max_edit_distance | Banana | 3 | 3 | N | 無効 |
| max_edit_distance | Banana | 未設定 | Null | N | 無効 |
| max_edit_distance | Null | 未設定 | Null | Y | 有効 |
「メッセージのヘッダー文字列の取得」プロセッサは、Webサービス・リクエストのメッセージ・ヘッダーに存在する文字列値を抽出して属性として出力します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 | なし |
| オプション | 次の構成オプションがあります。
|
| 出力 |
|
出力フィルタ
なし
例
次の例は、何も指定されない場合のヘッダーの値(デフォルト値またはNull)を示しています。
| ヘッダー | 値 | デフォルト値 | 出力値 |
|---|---|---|---|
| email_append | @gmail.com | @example.com | @gmail.com |
| email_append | (<空白>) | @example.com | (<空白>) |
| email_append | <Null> | @example.com | @example.com |
| email_append | <Null> | <未設定> | <Null> |
「配列属性のマージ」プロセッサは、複数の配列入力の要素をマージして、最長の配列と同じ長さの配列として出力します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 |
|
| オプション |
|
| 出力 |
|
出力フィルタ
なし
例
| 入力 | 空の要素の選択 | 出力 |
|---|---|---|
| 配列1: {Cambridge, , ,London}
配列2: {CB21 5dz, WR14 2SZ, , W3 2ln } 配列3: {Cambs, Worcs, London, Lincs, Wilts} |
はい | マージ配列: {Cambridge, , ,London, Wilts} |
| 配列1: {Cambridge, , ,London}
配列2: {CB21 5dz, WR14 2SZ, , W3 2ln } 配列3: {Cambs, Worcs, London, Lincs} |
いいえ | マージ配列: {Cambridge, WR14 2SZ, London, London} |
「配列のソート」プロセッサは、配列のデータ型に従って、昇順または降順に配列内の要素の値をソートします。すべての番号配列属性は数値でソートされますが、文字配列属性は文字でソートされます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 |
|
| オプション |
|
| 出力 |
|
出力フィルタ
なし
例
| 入力値 | ソート順序 | 出力 |
|---|---|---|
| (A)(D)(C)(B) | 昇順 | (A)(B)(C)(D) |
| (2) (5) (7) (3) (4) (6) (12) | 昇順 | (2) (3) (4) (5) (6) (7) (12) |
| (2) (5) (7) (3) (4) (6) (12) | 降順 | (12) (7) (6) (5) (4) (3) (2) |
| (18-Feb-2015 12:00:00)
(2-Mar-2015 12:00:00) (20-Jan-2015 12:00:00) (1-Dec-2014 12:00:00) |
昇順 | (01-Dec-2014 12:00:00)
(20-Jan-2015 12:00:00) (18-Feb-2015 12:00:00) (02-Mar-2015 12:00:00) |
| (A) (D) (C) (<空白>) (<Null>) (B) | 昇順 | (<Null>) (<空白>) (A) (B) (C) (D) |
|
注意: 配列のすべてのnullエントリは他のすべての値より上にソートされます。 |
「配列の分割」プロセッサは、配列入力のタイプに従って、文字列、数値または日付など、多数の標準属性に入力配列属性を分割します。これを使用することで、「配列要素の選択」プロセッサの多くのインスタンスを使用するより迅速に配列要素値を個別の属性に抽出できます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 |
|
| オプション |
|
| 出力 |
|
|
注意: 入力配列の要素が空白またはnullの場合は、デフォルト出力としてではなく空白またはnullとして出力されます。 |
出力フィルタ
なし
例
| 入力値 | 属性数 | デフォルト 出力 |
出力 | |||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| (Apple) (Grape) (Jack) (Matt) (Ginger) (Carrot) (Tom) | 3 | <未設定> | Apple | Grape | Jack | N/A |
| (Apple) (Grape) (Jack) (Matt) (Ginger) (Carrot) (Tom) | 4 | <未設定> | Apple | Grape | Jack | Matt |
| (<空白>) (Grape) (Jack) (Matt) (Ginger) (Carrot) (Tom) | 4 | <未設定> | (<空白>) | Grape | Jack | Matt |
| (<Null>) (Grape) (Jack) (Matt) (Ginger) (Carrot) (Tom) | 4 | <未設定> | <Null> | Grape | Jack | Matt |
| (<空白>) (Grape) (Jack) (Matt) (Ginger) (Carrot) (Tom) | 4 | <未設定> | (<空白>) | Grape | Jack | Matt |
| (Apple) (Grape) | 3 | <未設定> | Apple | Grape | (<空白>) | N/A |
| (Apple) (Grape) | 3 | Jack | Apple | Grape | Jack | N/A |
| () | 3 | <未設定> | (<空白>) | (<空白>) | (<空白>) | N/A |
| () | 3 | Jack | Jack | Jack | Jack | N/A |
| <Null> | 3 | Jack | Jack | Jack | Jack | N/A |
| <Null> | 3 | <未設定> | (<空白>) | (<空白>) | (<空白>) | N/A |
| (<空白>) (<空白> | 4 | Jack | (<空白>) | (<空白>) | Jack | Jack |
| (<Null>) (<空白>) | 4 | Jack | <Null> | (<空白>) | Jack | Jack |
「長さによる配列からの文字列の削除」プロセッサは、特定の値よりも大きいか、小さいか、あるいは等しい長さに基づいて配列から文字列要素を削除します。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 |
|
| オプション |
|
| 出力 |
|
出力フィルタ
次の出力フィルタを使用できます。これらは、StrippedValuesFlag出力属性フラグによってレコード全体に定義されます。
| フィルタ | StrippedValuesFlag |
|---|---|
| 削除されたレコード | Y |
| 未変更のレコード | N |
例
| Input | Min | Max | Out | 削除された値フラグ | 出力フィルタ |
|---|---|---|---|---|---|
| (A) (Bob) (John) | <未設定> | <未設定> | (A) (Bob) (John) | N | 変更なし |
| (A) (Bob) (John) | 3 | <未設定> | (Bob) (John) | Y | 削除済 |
| (<Null>) (Bob) (John) | 3 | <未設定> | (<Null>) (Bob) (John) | N | 変更なし |
| <Null> | 3 | <未設定> | <Null> | N | 変更なし |
| () | 3 | <未設定> | () | N | 変更なし |
| (A) (Bob) (John) | <未設定> | 3 | (A) (Bob) | Y | 削除済 |
| (A) (Bob) (John) | 3 | 3 | (Bob) | Y | 削除済 |
| (A) (Bob) (John) | 4 | 2 | () | Y | 削除済 |
「配列の切捨て」プロセッサは、配列内から要素の範囲を選択するために使用します。これを使用するのは、配列の先頭または末尾から要素を切り捨てて、配列を要素のサブセットに変換する必要がある場合です。次の要素が配列形式で返されます。
次の表に、構成オプションを示します。
| 構成 | 説明 |
|---|---|
| 入力 |
|
| オプション |
|
| 出力 |
|
出力フィルタ
なし
例
| 入力配列 | 結果入力の長さ | 開始位置入力 | 結果プロパティの長さ | 開始位置プロパティ | 最後からカウント・プロパティ | 出力配列 |
|---|---|---|---|---|---|---|
| FirstNames: {Apple, Grape, Jack}
LastNames: (Orange, Goom, Garlic) |
1 | <未設定> | <無効> | 1 | いいえ | FirstNames: SubArray: (Apple)
LastNames: SubArray: (Orange) |
| FirstNames: (Apple, Grape, Jack, Matt, Ginger, Carrot, Tom)
LastNames: (Orange, Onion, Garlic, Potatoes, Smith, Banana, Evans) |
5 | 2 | <無効> | 無効化> | いいえ | FirstNames: SubArray: (Grape, Jack, Matt, Ginger, Carrot)
LastNames: SubArray: (Onion, Garlic, Potatoes, Smith, Banana) |
| FirstNames: {Apple, Grape, Jack, Matt, Ginger, Carrot, Tom}
LastNames: {Orange, Onion, Garlic, Potatoes, Smith, Banana, Evans} |
<未設定> | 2 | 2 | 無効化> | はい | FirstNames: SubArray: {Carrot, Tom}
LastName: SubArray: {Banana, Evans} |
| FirstNames: {Apple, Grape}
LastNames: {Orange, Onion} |
-1 | -1 | <無効> | 無効化> | いいえ | FirstNames: SubArray: {Apple, Grape}
LastNames: SubArray: {Orange, Onion} |
| FirstNames: {Apple, Grape}
LastNames: {Orange, Onion} |
3 | <未設定> | <無効> | 1 | いいえ | FirstNames: SubArray: {Apple, Grape}
LastNames: SubArray: {Orange, Onion} |
| FirstNames: {Apple, Grape}
LastNames: {Orange, Onion} |
1 | 5 | <無効> | 無効化> | いいえ | FirstNames.SubArray: {}
LastNames.SubArray: {} |
値
すべての式は、なんらかの種類の値を使用します。これらの値は、式に追加されてその一部として使用される場合もあれば、「式」プロセッサへの入力である属性から読み込まれる場合もあります。
式における値は文字列、数値、または文字列か数値の配列です。数値はIEEEの倍精度フォーマットで格納され、最大値は約1.8 x 10308です。式で日付値を使用する場合、その値は等価のJavaタイムスタンプ(1970年1月1日00:00から数えたミリ秒)で表されます。
式
式は、演算子で結んだ項目で構成されます。サポートされる項は次のとおりです。
数値: 数値は単純な整数で表されるか、浮動小数点と、指数のオプションを使用して複素数を書き込むこともできます。
例:
1000 2.1212 0.1 1.2321e-20 1e10
Null: 特殊な名前nullは、未定義の値を表します。
文字列定数: 文字列定数は、一重(')または二重(")の引用符で囲みます。文字列の中の特殊な文字には、次のようにJavaスタイルの円記号(\)を使用できます。
\nまたは\nnまたは\nnn: 8進コードのNで表した文字
\n: ライン・フィード(新規行)(コード10)
\r: キャリッジ・リターン(コード13)
\a: ベル(コード7)
\t: タブ(コード9)
\b: バックスペース(コード8)
\f: フォームフィード(コード12)
\v: 垂直タブ(コード11)
例:
"the cat slept on the mat" "this is a line feed: \n" 'this is also a string'
属性名: 式の中で使用する名前には、文字、数字、ドル記号($)、アンダースコア(_)、ピリオド(.)のみを使用し、数字で始めることはできません。その他の文字を使用する必要がある場合には、特殊な構文@'name'または@"name"を使用すると、式に入力できます。たとえば、名前に空白が含まれている場合は、次のように入力する必要があります。
@"a name with spaces"
配列値: 配列値は、中カッコ({ })で囲んだ値のリストとして入力できます。
例:
{1, 2, 3}
{a+2, b-5}
配列選択: 配列の要素は、大カッコで囲んだインデックス式([ ])を使用して選択できます。最初の要素がインデックス1になります。サブ配列は、配列スライスを使用して選択できます。スライスは、コロンで示されます([lwb:upb])。
例:
arr[1]
arr[x+1]
z[2:3+m]
{1,2,3}[2]
次の演算子を使用でき、優先度はこの順になります。
| 演算子 | 優先度 | 意味 |
|---|---|---|
| ^ |
8 | 累乗(例: ^ 0.5は平方根の値を求めます) |
| * |
7 | 乗算 |
| / |
7 | 除算 |
| % |
7 | 係数 |
| + |
6 | 加算 |
| - | 6 | 減算 |
| || |
6 | 文字列連結 |
| > | 5 | より大きい |
| < |
5 | より小さい |
| >= | 5 | 以上 |
| <= |
5 | 以下 |
| = or == | 4 | 次と等しい |
| != or <> | 4 | 次と等しくない |
| & |
3 | 論理積(AND) |
| | |
2 | 論理和(OR) |
| ! | 1 | 単一の論理否定(NOT) |
比較演算子は、比較が成り立つ場合に1に評価され、成り立たない場合に0に評価されます。
優先度の高い演算子は、優先度の低い演算子より結合度が強くなります。例:
a = b + c * d ^ e
これは次に相当します。:
a = (b + (c * (d ^ e)))
ファンクション
式の言語では、次の関数を使用できます。
| ファンクション | 引数 | 結果 | 意味 |
|---|---|---|---|
| floor (x) | 数値 | 数値 | 切下げ |
| ceil (x) | 数値 | 数値 | 切上げ |
| round (x) | 数値 | 数値 | 一番近い値に丸める |
| abs (x) | 数値 | 数値 | 絶対値 |
| length (x) | 文字列または配列 | 数値 | 文字列の長さ(文字数)、または配列の長さ(要素数) |
| isset (x) | 任意 | 数値 | 引数に等しい場合は1、等しくない場合は0。nullは等しいとして比較されます。 |
| equals (a,b) | スカラー | 数値 | 引数に等しい場合は1、等しくない場合は0。nullは等しいとして比較されます。 |
| substr (string, start)または
substr (string, start, length) |
文字列、数値、数値 | 文字列 | 部分文字列 - 開始値を負にすると末尾から開始 |
| trimleft (string, start)または
trimleft (string, start, length) |
文字列、数値、数値 | 文字列 | 左からの部分文字列 |
| trimright (string, start)または
trimright (string, start, length) |
文字列、数値、数値 | 文字列 | 右からの部分文字列 |
| chartonumber (string) | 文字列 | 数値 | 文字列の最初の文字を、対応する数値コードに変換します。文字列が空の場合、結果はnullになります。 |
| indexof (string, sub)または
indexof (string, sub, start) |
文字列、数値、数値 | 数値 | startで始め、文字列の中で部分文字列の最初のインデックスを検索します。見つからない場合は0 |
| upper (string) | 文字列 | 文字列 | 大文字 |
| lower (string) | 文字列 | 文字列 | 小文字 |
| stringify (x) | 文字列または数値 | 文字列 | 数値または文字列を文字列に変換して格納します |
| digest (x) | 文字列または数値 | 文字列 | 引数からダイジェストを生成します |
| format (num)またはformatdate (num, format) | 数値、文字列 | 文字列 | デフォルトまたは指定した数字フォーマットを使用して数値を書式設定します(java.text.DecimalFormatを参照) |
| parsedate (string)またはparsedate (string, format) | 文字列、文字列 | 数値 | デフォルトまたはサプライヤの日付書式を使用して日付を解析します。解析に失敗した場合、結果はnullです |
| soundex (string) | 文字列 | 文字列 | Soundex |
| refinedsoundex (string) | 文字列 | 文字列 | 高精度のsoundex |
| metaphone (string) | 文字列 | 文字列 | 基本のmetaphone |
| doublemetaphone (string)またはdoublemetaphone (string, length) | 文字列、数値 | 文字列 | オプションで長さを指定するmetaphone (デフォルトは12) |
| regexsplit (string, regex)またはregexsplit (string, regex, limit) | 文字列、文字列、数値 | 文字列配列 | regexを使用して配列に分割 - java.lang.String.splitを参照してください。 |
| regexreplace (string, regex, replace) | 文字列、文字列、文字列 | 文字列 | 文字列で出現するregexをすべて、置換文字列で置換します |
| trim (string) | 文字列 | 文字列 | 文字列の先頭および末尾から空白文字を削除します |
| mult (number, number, ...) | 数字 | 数値 | すべての引数の積 |
| sum (number, number, ...) | 数字 | 数値 | すべての引数の和。nullが1つでもあると、結果はnullになります |
| zsum (number, number, ...) | 数字 | 数値 | すべての引数の和。nullはゼロとみなします |
| concat (string, string, ...) | 文字列 | 文字列 | すべての引数を結合します |
| concat2 (delimiter, string, string, ...) | 文字列 | 文字列 | 最初の文字を区切り文字として、すべての引数を結合します |
| concat3 (delimiter, noblanks, string, string, ...) | 文字列、数値、文字列 | 文字列 | 最初の文字を区切り文字として、すべての引数を結合します。2番目の引数がゼロ以外の場合は、空白文字列を無視します。 |
| array (value, value, ...) | 任意 | 配列 | 引数から配列を作成します |
| trim2 (string, code) | 文字列、文字列 | 文字列 | 左(code = 'l')、右(code = 'r')、両方(code = 'b')、または任意の位置(code = 'a')から空白を切り捨てます |
| nodatacheck (string) | 文字列 | 文字列 | データ分類なし - 文字列が移入されている場合は'-'を返すか、次のようにデータなしのコード('a' - 'f')を返します。
a = null b = 空文字列 c = 制御文字 d = シングル・スペース e = 複数のスペース f = 他の空白 |
式コンテキスト
式は、EDQの様々なコンテキストで使用されます。コンテキストごとに、異なるセットの名前を使用できます。コンテキストの一部を次にあげておきます。
「式」および「式フィルタ」プロセッサ: 式の中の名前がそれぞれ、プロセッサの入力として選択した属性に一致する必要があります。照合では大/小文字が区別され、属性名に接尾辞(属性名でピリオドの後の部分)がある場合には接尾辞が無視されます。
属性名が式の名前として有効でない場合、たとえば空白を含む場合などには、@"name"構文を使用して入力する必要があります。たとえば、属性が住所1 (番地)の場合、次のように入力します。
@"address line 1 (street)"
計算機プロセッサ: com.datanomic.director.runtime.widgets.common.Calculatorクラスを使用して、多数の標準プロセッサが実装されます。これは、プロセッサのパラメータから(XMLから)の式であり、入力属性を使用して評価されます。
式のパラメータは、プロセッサの各出力に対して定義する必要があります。ID Nの出力のパラメータ名はexpr.Nです。出力が1つしかない場合は、かわりにもっと単純な名前exprも使用できます。
式の中で、入力属性はiNとして参照できます。NはXMLからの入力IDです。入力に複数の属性が関連付けられている場合、その名前は集計のコンテキストのみで使用できます。
出力はID順に評価され、出現が早い出力はoNとして参照できます。NはXMLからの出力IDです。
また作業中の式は、出力の式の複数の場所で使用できる値を格納するように定義することもできます。これらの作業中の式は、出力式より前に評価されます。作業中の式のパラメータ名はexpr.t1、expr.t2、などとなります。
計算機プロセッサでは、プロセッサのオプションを使用できます。オプションの名前を使用するだけです。
例:
「大文字」プロセッサの式は、次のように定義されます。
<parameters>
<parameter name="expr">upper(i1)</parameter>
</parameters>
「連結」プロセッサの式は、次のように定義されます。
<parameters>
<parameter name="expr">concat2(separator, i1)</parameter>
</parameters>
separatorプロパティの使用方法に注意してください。
「文字の切捨て」プロセッサの式は、次のように定義されます。
<parameters>
<parameter name="expr.o1">side == 'l' ? trimleft(i1, start, length) : trimright(i1, start, length)</parameter>
</parameters>
「配列要素の選択」プロセッサの式は、次のように定義されます。
<parameters>
<parameter name="expr.t1">fromend ? (length(i1) - index) + 1 : index</parameter>
<parameter name="expr.o1">i1[t1]</parameter>
</parameters>
「正規表現の置換」プロセッサの式は、次のように定義されます。
<parameters>
<parameter name="expr.o1">regexreplace(i1, regex, replace)</parameter>
<parameter name="expr.o2">o1 != i1 ? 'Y' : 'N'</parameter>
</parameters>
この場合、最初の式が置換を実行し、2つ目の式がsuccessフラグを計算します。
高度な機能
条件式: 次の構文を使用すると、条件式を指定できます。
a ? b : c
結果は'a'が真であれば'b'になり、それ以外であれば'c'になります。
イテレータ式: イテレータ式は、SumやConcatenateなどの集計関数で使用する特殊な機能です。構文は次のとおりです。
{a : expr}
ここで、aが配列または複数属性の名前(任意の数の実属性が割り当てられている入力属性),であり、exprがaを含む式です。式は、名前で連続した値によって置換されて評価され、結果が集計関数に渡されます。
わかりやすいように、例で示します。
例1
sum({ a : a ^ 2 })
これは、aのすべての引数の2乗を合計します。
例2
sum( { a : a < 0 ? 1 : 0 })
aの引数のうち、負のものをすべてカウントします。
例3
sum({ i1 : nodatacheck(i1) = '-'}) > 0 ? 'Y' : 'N'
i1 (入力属性1)の要素について移入された要素をカウントし、いずれかにデータがあればY、「データなし」であればNを返します。
キャンバスでプロセッサをグループ化するには、複数のプロセッサを選択し、右クリックして「グループ」を選択します。
「グループ名」をダブルクリックすると、目的に応じてグループの名前を変更できます。
グループ化すると、関連するプロセッサのグループを閉じることによってキャンバス上のスペースを有効に使用でき、作成するプロセスが読みやすくなります。グループをコピーして貼り付ければ、プロセッサを長く続けるより簡単です。
プロセッサのグループを解除するには、閉じたグループを右クリック、または展開したグループのグループ名を右クリックして「グループ解除」オプションを選択します。
EDQには、データを理解して改良するために、幅広いプロセッサが用意されています。これらはツール・パレットのいくつかのファミリに編成され、プロセッサの各ファミリには同じようなタイプのプロセッサが含まれます。
プロセッサを発行すれば、新しいプロセッサ・ファミリを追加することもできます。
デフォルトのファミリは次のとおりです。詳細は、各ファミリをクリックしてください。
お気に入り
ツール・パレットの「お気に入り」セクションには、これまでに「お気に入り」としてマークしたプロセッサが表示されます。
プロセッサを「お気に入り」リストに追加するには、右クリックして「お気に入りに追加」を選択してください。
保存したグループ
ツール・パレットの保存したグループ・セクションは、以前のバージョンのEDQでツール・パレットに保存したグループのために使用します。
|
注意: バージョン7.2以上のEDQでは、グループをツール・パレットに保存することはできなくなったため、この機能は新しいプロセッサの作成および公開機能に移行しました。ただし、アップグレードを実行しても、以前のバージョンでツール・パレットに保存してあったグループは維持されます。 |
保存されたグループは、すべてのユーザーのパレットに表示されます。
公開されたプロセッサ
公開したが、カスタムのファミリ・アイコンを定義していない(したがってカスタム・ファミリがない)プロセッサがあれば、ツール・パレットのこの部分に公開されます。
プロセッサには、多くの状態があります。プロセッサの外見は、その状態によって変化します。
次の表に、「クイック統計プロファイラ」プロセッサのすべての状態と、その状態の説明をまとめました。
| アイコン | プロセッサの状態 | 説明 |
|---|---|---|
 |
切断 | プロセッサは切断されています。 |
 |
接続済で構成済ですが、実行済ではありません | プロセッサは接続され、有効に構成されていますが、まだ実行されていません。結果を生成するには実行する必要があるため、再実行マーカーが表示されます。 |
 |
接続済で構成済で、結果が最新です | プロセッサは接続され、有効に構成されていて、実行されています。その結果は最新なので、再実行マーカーは表示されません。 |
 |
接続済で構成済で、結果が最新ではありません | プロセッサは接続され、有効に構成されていて、実行されています。前回のプロセス実行後に構成が変更されて結果に影響したため、プロセッサの結果が最新ではなく、再実行マーカーが表示されます。
注意: プロセッサを使用するジョブを削除した場合、そのプロセッサは最新でないとマークされることがあります。 |
 |
エラー | プロセッサは接続されていますが、構成が無効です。つまり必要な構成がない、または無効なため実行できない状態です。プロセッサの上にカーソルを置くと、エラーを説明するツールチップが表示されます。構成してエラーを修正するには、プロセッサをダブルクリックします。 |
EDQにおけるプロジェクトとは、共有参照データを使用して共通のデータ・セットを処理する関連プロセスのグループです。プロジェクトに関する主要情報を共有するためのプロジェクト・メモや、EDQを使用してプロジェクトで実行した作業を追跡するための問題など、追加の作業情報もプロジェクトに対して保存されます。プロジェクトで生成された結果は、リンク付きの結果ブックにまとめられます。
プロジェクトは、EDQサーバー間で移動したり、システムのアップグレード前にバックアップするためにパッケージ化できます。
データ・ストアは、データの格納先がデータベースか1つ以上のファイルかどうかに関係なく、データのストアに接続します。データ・ストアはプロセス用のデータのソースとして使用することができ、プロセスの書き込まれたステージング済データ結果をデータ・ストアにエクスポートすることも、またはその両方をすることもできます。
通常は、サーバー経由でデータ・ストアに接続することをお薦めします。これは、ファイルへの接続時にサーバーがそのファイルに必ずアクセスできるように、サーバー・ランディング領域にファイルが存在している必要があることを意味します。ただし、クライアント接続を使用してデータをサーバーにプルすることも可能です。詳細は、「クライアント側データ・ストア」を参照してください。
EDQでは、次のタイプのデータ・ストアへのネイティブ接続がサポートされています。
データベース
Oracle
PostgreSQL
DB2
DB2 for i5/OS (詳細は、次を参照)
MySQL
Microsoft SQL Server
Sybase
Microsoft Access
JNDI Datasources
注意:
EDQでは、Teradataシステムへの接続もサポートできます(Teradata JDBCドライバを購入している場合)。
JNDIデータソース・オプションを使用して、WebLogicなどのアプリケーション・サーバー上の構成済の接続に接続します。
OracleデータベースへのEDQの接続
デフォルトでは、EDQは直接JDBC接続を使用してOracleデータベースに接続します。アプリケーション・サーバー上で構成されているJNDI接続を介してOracleに接続したり、tnsnames.oraファイルまたはLDAPサーバーで指定された接続文字列を介して接続を使用するようにEDQサーバーを構成することもできます。
この代替方法は、Oracle ExadataなどのRAC対応データベースで論理スキーマに接続する場合に便利です。tnsnamesまたはLDAPを介してOracleに接続できるようにEDQを構成する方法の詳細は、EDQリリース12.2.1ドキュメント・ライブラリの『Oracle Enterprise Data Qualityの管理』を参照してください。
DB2 for i5/OSへのEDQの接続
DB2 for i5/OSデータベースにEDQを接続するには、DB2 for iSeriesドライバをダウンロードする必要があります。
次の手順を実行します。
http://jt400.sourceforge.net/からToolbox for Java/JTOpenをダウンロードします
ダウンロードしたファイルを抽出します。ファイル名はjtopen_N_n.zip形式で、Nとnはバージョン番号の1桁目と2桁目を表します。
oedq_local_home/dbconnectorsディレクトリにdb2i5というフォルダを作成します。
手順2で抽出したzipファイルからdb2i5フォルダにjt400.jarファイルをコピーします。
EDQ (Datanomic)アプリケーション・サーバーを再起動します。
Accessデータベースへの接続
Accessデータベースに接続する場合は、次の点を考慮します。
サーバー側データ・ストア接続を使用したEDQでのAccessデータベースへの接続は、Windows EDQサーバーでのみ可能です。
Windows EDQサーバーでのAccessデータベースへのサーバー側接続を可能にするには、そのサーバーにAccessドライバをインストールする必要があります。これらは、Access 2010の一部としてインストールされます。Access 2010をインストールしない場合、必要なドライバを別個にインストールできます。
Microsoft Access Database Engine 2010再頒布可能(Microsoft.ACE.OLEDB.12.0)を、次のMicrosoft Webサイトからインストールします
http://www.microsoft.com/en-gb/download/details.aspx?id=13255
EDQサーバーがLinuxまたはUNIXで実行されている場合でも、Accessを持つWindowsクライアントを使用して、または前述のインストール済ドライバを使用して、Accessデータベースへのクライアント側接続を作成できます。また、クライアント側データ・ストア接続の制限を確認する必要があります。「クライアント側データ・ストア」を参照してください。
|
注意: 64ビットJava仮想マシン(JVM)を使用してMDBファイルに接続する場合、64ビットMicrosoft Jetデータベース・エンジンをインストールする必要があります。 |
テキスト・ファイル
テキスト・ファイル(CSVファイルまたはその他のデリミタ付きテキスト・ファイル)。
デリミタ付きテキスト・ファイルのディレクトリ。
固定幅テキスト・ファイル。
XMLファイル
スタイルシート付きXML (XMLファイルをEDQが認識するフォーマットに変換する方法を定義したXSLTスタイルシート・ファイル付きのXMLファイル)
単純なXMLファイル(単純な2レベル構造のXMLファイルで、最上位レベルのタグはエンティティを表し、下位レベルのタグはそのエンティティの属性を表します。Microsoft AccessからエクスポートしたXMLがその一例です。)
MS Officeファイル
Microsoft Accessファイル
Microsoft Excelファイル
その他
EDQでは、JDBCやODBCなどの標準を使用したその他データ・ストアへの接続がサポートされています。ODBC接続は、クライアントからのみ実行できます。
JDBC URLを使用してデータ・ストアに接続する際に役立つ情報は、OracleのJDBC FAQを参照してください。
データ・ストアへの接続詳細はEDQサーバーに保存されます。このサーバーおよび関連プロジェクトへのアクセス権があるユーザーは、そのデータ・ストアを使用できます。
参照データは、作業データのチェックおよび改良時に様々なプロセッサによって参照で使用されるデータです。参照データの例は次のとおりです。
有効または無効な値、文字、パターンのリスト
単語の標準化、文字の置換またはパターンの生成に使用するマップ
参照データの各セットの作成、編集および管理は、EDQ自体で行うことも、外部ソースから行うこともできます。たとえば、インターネット上で保存および更新されているファイルをダウンロードしてスナップショットを作成し、参照データとして使用することも、独自の参照データ・データベースを保守し、このデータベースに対して参照を実行することもできます。
EDQで管理される参照データも、ステージング済データと同じ方法でプロセスで使用できます。プロファイリング、チェック、変換、照合などを実行できます。
参照データ定義には2つの側面があります。
データ自体
参照の定義、そのデータへの参照を実行する方法の定義(つまり、参照でどの列を使用してどの列(ある場合)を返すか)
参照データ・セットを作成する際は、「新規参照データ」オプションによって、データ・セット(EDQで管理される)と、そのデータに対するデフォルトの参照定義が作成されます。新規参照オプションでは、次の3つのソースのいずれかである既存のデータ・セットへの参照が作成されます。
既存の参照データ・セット(デフォルトには異なる参照定義を使用する場合)
ステージング済データ(スナップショット、またはプロセスから書き込まれたステージング済データ・セットのいずれか)
外部データ(構成済のサーバー側データ・ストア接続の1つを使用)
プロセッサ・オプションで参照データを使用する場合、参照と参照データに違いはありません。
EDQで管理される参照データ
値およびパターンの検証に使用されるデータのリストやマップを使用するとき、一般的にそのデータのリストやマップがメモリーにロードできる程度に小さく(後述の説明を参照)、結果を使用して作成または更新する必要がある場合は、それらのデータ・セットをEDQで管理することをお薦めします。
|
注意: ガイドとして、50,000行未満の参照データ・セットは、最小推奨RAMが1GBのEDQサーバー上のメモリーにロード可能であるため、プロセッサで使用するために参照データを選択する際は、これがロード可能としてマークされます。これより大きい参照データ・セットはデフォルトではメモリーにロードできませんが、使用可能な追加メモリーがあることがわかっている場合、管理者はサーバーに対する50,000行の制限を変更できます。 |
たとえば、次のタイプの参照データは通常EDQで管理されます。
データのチェックに使用する有効および無効な値、パターンおよび正規表現の参照リスト
データの変換に使用する標準化マップ
パターンの生成に使用する文字マップ
日付と数値を認識して変換するために使用する日付と数値の書式リスト
参照データのスタータ・パックがEDQに付属していますが、新しい参照データは、結果ブラウザを使用して、独自のデータから迅速かつ簡単に作成および変更できます。
参照データのカテゴリ
EDQで管理される参照データ・セットを作成する際は、必要に応じてカテゴリを割り当てることができます。
カテゴリは、プロセッサから参照データを選択する際、そのプロセッサ・オプションに特定タイプの参照データ(文字、パターンまたは正規表現のリストなど)が必要なときに、参照データ・セットの簡潔なリストを提供するために使用します。
次のカテゴリはすべてプロセッサ・ライブラリのプロセッサで使用されているため、参照データ・セットの作成時に選択可能です。新しいプロセッサが作成され、プロセッサ・ライブラリに追加された場合は、これらによってカテゴリがさらに追加され、リストにも表示される場合があります。
ステージング済データ参照
ステージング済データ参照は、リポジトリ内の既存のステージング済データ・セット(スナップショット、または別のプロセスから書き込まれたデータのいずれか)への参照です。
ステージング済データ参照を設定する際は、参照でどの列を使用してどの列を返すかを選択する必要があります。
異なる参照列と戻り列を使用して、同じデータに対する複数の異なる参照を構成できます。
ステージング済データ参照は、プロジェクト・ブラウザの「参照データ」ノードの下に表示されますが、ステージング済データ・アイコンによって、この参照は編集可能な参照データや外部データではなくステージング済データへの参照であることが示されます。
外部データ参照
外部データ参照は、ステージングされていないデータ(たとえば、EDQの外部に存在し、頻繁に更新される可能性がある大規模なデータ・セットなど、ステージングを望まないデータ)への参照です。
外部データ参照は、ステージング済データ参照と同じ方法で構成され、参照で使用する列と返す列が選択されます。ただし、外部データ・セットはEDQリポジトリにステージングされません。
異なる参照列と戻り列を使用して、同じデータに対する複数の異なる参照を構成できます。
外部データ参照は、プロジェクト・ブラウザの「参照データ」ノードの下に表示されますが、データ・ストア・アイコンによって、この参照は編集可能な参照データやステージング済データではなく外部データへの参照であることが示されます。
参照データのレベル
参照データは、2つの異なるレベルで存在する場合があります。システム・レベルの参照データは、サーバー上でグローバルに共有され、多数のプロジェクトで使用できます。プロジェクト・レベルの参照データは、そのデータが保存されているプロジェクトでのみ使用できます。
公開されたプロセッサとは、拡張パック(Customer Data Packなど)からインストールされた、またはEDQユーザーによってサーバーに公開された追加のプロセッサ(プロセッサ・ライブラリのプロセッサに加えた)です。これらはプロジェクト・ブラウザに表示されるため、他のオブジェクトと同様にパッケージ化できます。
公開されたプロセッサには、テンプレート、参照およびロックされた参照の3つのタイプがあります。
参照公開済プロセッサは、プロセッサ・アイコンの左上にある緑の四角形で示されます。ロックされた参照公開済プロセッサは、同じ位置にある赤い四角形で示されます。
テンプレート公開済プロセッサ
テンプレート公開済プロセッサは、他のプロセッサと同様に使用できます。デフォルトでは、公開元プロセスであるかのように構成オプションが設定されていますが、これらは必要に応じて変更できます。
|
注意: テンプレート公開済プロセッサ・アイコンは、アイコン上の特別なラベルによっては示されません。 |
参照公開済プロセッサ
参照公開済プロセッサの主な機能は次のとおりです。
集中管理されているため、オリジナルに加えられた変更は、システムの他の場所にあるプロセッサのすべてのインスタンスにロール・アウトされます。
ユーザーはこれらのプロセッサの構成を表示できますが、必要なセキュリティ権限を持っている場合を除き、変更することはできません。
エンド・ユーザーは、その権限レベルに関係なく、ロックされた参照公開済プロセッサをロック解除できません。編集できるのは、オリジナルのみです。
EDQでは、すべてのプロセッサ・インスタンスのアイコンをカスタマイズできます。これは、特殊な目的を持つ可能性のある構成済プロセッサを、基礎となる汎用プロセッサと区別するための1つの方法です。
たとえば、「ルックアップ・チェック」プロセッサで特定の購入済または無料で使用可能な参照データ・セットとデータをチェックする場合、プロセス内でその参照データをグラフィカルに示すと便利です。
プロセッサ・アイコンのカスタマイズも、新しいプロセッサの作成および公開時に便利です。プロセッサが公開されている場合、ツール・パレットからプロセッサを使用する際、そのカスタマイズ済アイコンがデフォルトのアイコンになります。
詳細は、「プロセッサ・アイコンのカスタマイズ」を参照してください。
|
注意: カスタム・プロセッサ・アイコンとして使用するイメージの使用権は、必ず確認してください。 |
カスタム・イメージは、プロジェクト・ブラウザのイメージ・ノードに格納されています。
OEDQでは、すべてのプロセッサ・インスタンスのアイコンをカスタマイズできます。これは、特殊な目的を持つ可能性のある構成済プロセッサを、基礎となる汎用プロセッサと区別するための1つの方法です。たとえば、「ルックアップ・チェック」プロセッサで特定の購入済または無料で使用可能な参照データ・セットとデータをチェックする場合、プロセス内でその参照データをグラフィカルに示すと便利です。
プロセッサ・アイコンのカスタマイズも、新しいプロセッサの作成および公開時に便利です。プロセッサが公開されている場合、ツール・パレットからプロセッサを使用する際、そのカスタマイズ済アイコンがデフォルトのアイコンになります。
プロセッサ・アイコンをカスタマイズする手順は、次のとおりです。
キャンバスでプロセッサをダブルクリックします
「アイコンとファミリ」タブを選択します
プロセッサ・アイコン(イメージの右上に表示される)を変更するには、画面の左側を使用します。
ファミリ・アイコンを変更するには画面の右側を使用します(プロセッサを公開すると、これが選択したグループに公開されます。あるいは、存在していない場合は新しいファミリが作成されます)
プロセッサ・アイコンとファミリ・アイコンどちらの場合も、ダイアログが開いてサーバーのイメージ・ライブラリが表示されます。既存のイメージを選択するか、新しいイメージを作成できます。
新しいイメージを追加する場合は、ダイアログが表示され、イメージの参照(またはドラッグ・アンド・ドロップ)、サイズ変更、名前や説明(オプション)の入力を行うことができます。
サーバー上でイメージが作成されるとサーバーのイメージ・ライブラリに追加され、アイコンをカスタマイズする際にいつでも使用できるようになります。サーバー上のイメージ・ライブラリは、プロジェクト・ブラウザの「イメージ」ノードの下に子ノードとして表示されます。
ステージング済データは、EDQリポジトリで保持されるデータのコピーです。
ステージング済データには、2つのタイプがあります。各タイプは異なる方法で作成されます。
スナップショット。つまり、データ・ストア内のソース・ファイルまたはデータベースからのデータのコピーです。
書き込まれたステージング済データ。つまり、ライターによって書き出されたデータまたはEDQプロセス内の公開された結果ビューです。
いずれのタイプのステージング済データに対しても、次のことができます。
プロセスの開始時にリーダーを使用して読み取る
ステージング済データ参照で使用する
データ・インタフェースにマップする、またはデータ・インタフェースからマップする
データ・ソース内のターゲット表またはファイルにエクスポートする
削除済
編集済
ステージング済データの削除
ステージング済データ・セットは削除できます。
|
注意: ステージング済データ・セットが他の構成オブジェクトによって使用された場合、たとえば、任意のプロセスによって読み取られたり書き込まれたりした場合、または参照で使用された場合、警告が送信されます。 |
ステージング済データを削除するには、ステージング済データ・セットを右クリックしてステージング済データの削除を選択するか(ライターによって書き込まれたステージング済データの場合)、「スナップショットの削除」を選択します(スナップショットの場合)。
ステージング済データの編集
ステージング済データは、次のように編集できます。
スナップショットの場合は、そのスナップショットの作成時に定義した初期設定情報を変更できます。たとえば、初期調査の一環として1000行のみが使用されている初期設定を変更するには、スナップショットを編集して再実行します。
書き込まれたステージング済データの場合は、ステージング済データ表の構造を変更できます。つまり、列を追加/削除し、列のデータ型を編集できます。書き込まれたステージング済データを編集するには、通常、そのステージング済データ表に書き込むライターの再構成が必要です。
|
注意: ステージング済データ表の構造は、そのステージング済データ表に書き込むライターからも編集できるため、書き込む属性(プロセスを編集する場合に変更できる)にあわせてステージング済データ表を変更できます。 |
EDQのデータ・インタフェースは、データのソースまたはターゲットに直接読取りまたは書込みを行うのではなく、インタフェースから読み取るプロセスまたはインタフェースに書き込むプロセスの作成に使用する、特定のエンティティを表す属性セットのテンプレートです。
データ・インタフェース・マッピングを使用して、ソース・データをデータ・インタフェースにマップするか、ターゲット・データをデータ・インタフェースからマップします。実際に使用するマッピング(データ・インタフェースを使用するプロセスの実行時に)は、ジョブで定義されます。これにより、様々なジョブが異なるデータで同じプロセスを使用できます。たとえば、1つのプロセスをバッチ・モード(ステージング済データ・マッピングを使用)またはリアルタイム(WebサービスまたはJMSマッピングを使用)の両方で使用できます。
データ・インタフェースを使用するスタンドアロン・プロセスの実行時に使用するマッピングを指定することもできます。詳細は、「プロセス実行プリファレンス」を参照してください。
|
注意: データ・インタフェースは、Oracle Enterprise Data Qualityバージョン8.1以前に存在した「ビュー」という概念に取ってかわるものです。ビューはデータ・インタフェースのより簡易なフォームで、プロセスへのデータの読込みにのみ使用されており、ビューへのソース・データの一度に1つのマッピングのみがサポートされていました。古いバージョンのEDQを使用して作成されたパッケージ・ファイルからビューをインポートする場合、ビューをデータ・インタフェース・ノードにドラッグする必要があります。これにより、ビューの属性がデータ・インタフェースとしてインポートされます。ビューを使用するプロジェクト全体をインポートする場合、ビューはデータ・インタフェースに移行され、ビューへのデータのマップに使用されたマッピングがデータ・インタフェース・マッピングとして追加されます。ただし、以前にビューからデータを読み取ったジョブは、編集して、データ・インタフェースに使用するマッピングを(1つのみであっても)指定する必要があることに注意してください。 |
データ・インタフェースは多くの場合、プロセス・テンプレートの作成に使用され、同じようなタイプのデータ(顧客、運用、財務など)を使用して多くの異なるクライアントを扱う可能性のあるシステム・インテグレータやコンサルタントによって使用されます。プロセス・テンプレートは、特定のデータ・ソースまたはデータ・ターゲットに対して定義されるわけではないため、新しいクライアントの新しいデータをすばやくマップして、テンプレートから作成されたプロセスを実行できます。
また、データ・インタフェースを使用するとプロセスの効率的な再利用が可能になります。これにより、潜在的に複雑なプロセスを、それぞれが固有の機能を実行する多数の再利用可能なプロセスに細分できます。その後、必要に応じて、ジョブの構成時にこれらのプロセスをつなぎ合せることができます。
たとえば、Oracle Enterprise Data Quality Customer Data Services Packには、バッチおよびリアルタイム照合サービスの両方で使用される住所、個人およびエンティティを標準化するためのプロセスが含まれます。
プロセスは、構成された一連のプロセッサであり、プロジェクト内で使用されて特定のデータ・セット(1つまたは複数)を処理します。
各プロセスには通常、表のプロファイリング、発生したデータ・トランザクションの監査、データの照合など、特定の目的があります。
プロセスは、リーダー・プロセッサで開始します。ツール・パレットから、使用可能なその他のプロセッサをプロセスに追加できます。
プロセスの状態
プロセスには、4つの状態が考えられます。この状態に応じてキャンバスの背景色が変化します。次の表に、4つの状態と、それによって背景色がどのように変化するかを示します。
| 背景色 | 意味 |
|---|---|
| 白 | 標準 |
| 青 | 実行中 |
| ピンク | エラー |
| 灰色 | 読取り専用 |
グレーの背景色のプロセスは、実行中(実行開始後にプロセスが開かれた)か、または現行バージョンのプロセスでないために読取り専用になっている可能性があることに注意してください。
プロセスの実行とスケジュール
プロセスを実行するには4つの方法があります。
ツールバーのクイック実行ボタンを使用
プロセスを右クリックして「実行」を選択
ツールバーのプロセス実行プリファレンスを使用してプロセスを実行
プロセスがタスクとして含まれているジョブを定義して実行(またはスケジュール)
これらのオプションのいずれを使用しても、プロセスは常に接続先のEDQサーバーで実行されます。サーバーが常に実行されている場合は、プロセスの実行を設定したり、クライアント・セッションを閉じてプロセスの完了時に再度開いたり、都合のよい時間(深夜など)にプロセスを実行するようにスケジュールすることもできます。または、プロセスをまだ開発中の場合は、プロセスを実行してその進行状況を監視してから結果を評価できます。
クイック実行
クイック実行ボタンを使用すると、プロセスの現在の実行プリファレンスを使用してプロセスが即時に実行されます。プロセスが以前に実行されたことがない場合は、プロセス実行のデフォルト・オプションが使用されます。デフォルト・オプションでは、スナップショットのリフレッシュ、ダッシュボードへの結果の公開、エクスポートの実行は行われません。サーバーで必要な処理量を最小化して最新の結果を提供するように、インテリジェント実行が使用されます。
クイック実行オプションを使用するには、実行するプロセスを開き、ツールバーのボタンをクリックします。
プロセス実行プリファレンス
プロセス実行プリファレンス・ボタンを使用すると、次のようなプロセス実行オプションを定義できます。
入力データの(すべてではなく)サンプルでプロセスを実行する
プロセスを高速化するために結果のドリルダウンを制限する
プロセスを対話形式で実行できるように、データ・インタフェースからの読み取りまたはデータ・インタフェースへの書き込みを行うプロセスの、データ・インタフェース・マッピングを追加する
間隔モードで実行して、リアルタイム・プロセスの結果を定期的に書き込む
結果をダッシュボードに公開する
その後、この画面からプロセスを直接実行できます。ここで作成した設定は保存され、今後クイック実行オプションを使用するたびに使用されます。
プロセス実行プリファレンスを変更するには、プロセスを開いてツールバーのボタンをクリックし、オプションを変更します。リーダー、プロセスおよびライター用の個別のタブがあり、EDQの様々な実行オプションに完全にアクセスできます。たとえば、ソース・データをリポジトリにコピーしないことを選択する一方、ステージング済データはリポジトリと外部の両方に書き込むことを選択できます。
プロセス実行プリファレンスは、将来スケジュールできるようにジョブとして昇格する(ジョブとして保存)ことが可能です。「ジョブの定義とスケジュール」を参照してください。
プロセスの実行時に使用可能なオプションの詳細は、「実行オプション」を参照してください。
ジョブの定義とスケジュール
ジョブの定義とスケジュールでは、次の追加機能を使用できます。
ジョブを将来的に実行したり、繰り返して実行する
複数のタスクで構成されるジョブを定義する
これらのタスクの前後に外部タスクを実行する。
プロセスの取消
実行中のプロセスは、ユーザー・インタフェースを使用して取り消すことができます。それには、プロセスで右クリック・オプションを使用するか、キャンバスの左下にある停止アイコン(プロセスの実行中に表示される)を押します。
実行中のタスクは、タスク・ウィンドウから取り消すこともできます。
プロセスを取り消す際のオプションは次のとおりです。
できるだけ早く取り消す
これまで生成された結果を保存して取り消す
Webサービスとして実行中のリアルタイム・プロセスの場合は、3番目のオプションを使用できます。
Webサービスの停止
「Webサービスの停止」オプションでは、Webサービスを閉じ、開いている結果間隔を閉じて結果を保持する適切な方法が提供されます。
取り消されたプロセスは、プロジェクト・ブラウザではそのプロセスが取り消されたことを示す黄色の停止アイコン付きで表示されるため、その結果が欠落していたり不完全である理由がわかります。「プロジェクト・ブラウザ・オブジェクトの状態」を参照してください。
プロセスの変更管理
サブバージョンと統合して、プロセスの変更管理を実装することをお薦めします。詳細は、Oracle EDQ統合バージョン管理ガイドを参照してください。
以前のプロセス・バージョンを開く
以前のプロセス・バージョンを開き、その構成をキャンバスで表示できます。古いプロセス・バージョンの結果も保持され、(プロセスまたはプロジェクトの結果をすべてパージするか、プロセスを削除することによって)パージするまで保存されます。
以前のプロセス・バージョンに戻す
プロセスの構成を誤って変更した場合は、すでに保存されているバージョンのプロセスに戻すことができます。それには、プロセスを右クリックして「バージョンに戻す」を選択します。これにより、選択した以前の保存ポイントを使用して、プロセスの新しいバージョンが実際に作成されます。
プロセスの削除またはパージ
プロセスを削除するには、プロジェクト・ブラウザでプロセスを右クリックし、「作成」を選択するか、または[Delete]キーを押します。
プロセスの結果をパージするには、プロセスを右クリックして「結果のパージ」を選択します。場合によっては、プロセスの結果データが大量に存在することがあります。この場合、サーバーで実行中のパージ操作がタスク・ウィンドウに表示されます。
結果ブックでは、データ品質プロジェクトにおける結果の主要ページのインスタント・ビューが提供されます。結果ブックの結果ページは、プロジェクト内の複数のプロセスから表示できます。
1つのプロジェクトで複数の結果ブックを使用できます(プロジェクト内の異なるタイプの処理や異なるフェーズの結果を区分する場合など)。たとえば、プロファイリング結果用、データ・クレンジング用および照合結果用にそれぞれ結果ブックを作成し、それらを単一の結果ブックにまとめることができます。
結果ブックの作成
結果ブックは、プロジェクト・ブラウザで作成することも、結果ブラウザで一連の結果を新しい結果ブックにリンクして作成することもできます。
プロジェクト・ブラウザで結果ブックを作成するには、「結果ブック」を右クリックし、「新規結果ブック」を選択します。
結果ブラウザで複数の結果をリンクして結果ブックを作成するには、結果ブックにページを追加ボタンをクリックし、ダイアログの下部にある「新規結果ブック」ボタンをクリックします。
結果ブックへのページの追加
結果ブラウザおよび結果ブックにページを追加ボタンを使用して、結果ブックにページを追加できます。
結果ページの構成では、表示する列を選択したり、列に別の名前を指定することによって結果ページの表示を調整できます。プロセスの最新バージョンにページをリンクするか、ページが作成されたプロセスのバージョンにそのページを永続的にリンクするかも選択できます。
プロセス・バージョンへのリンク
EDQでは、ユーザーが設計したプロセスにバージョン管理を適用する機会が提供されます。プロセスの新しいバージョンを作成することで効率的に元のバージョンを凍結し、元のバージョンを損わずにその後の開発を実行できます。結果ブックでページに「最新バージョンにリンク」チェック・ボックスが選択されている場合、そのページは常に、プロセスの最新バージョンの最新の結果を参照します。このチェック・ボックスが選択されていない場合、結果ブックは、作成時にアクティブであったプロセッサのバージョンの最新の結果を参照します。
|
注意: リーダーおよびライターはバージョン管理されません。これらは常に現在のデータ・セットから直接読み取り、履歴データは保存されません。したがって、このチェック・ボックスが選択されていない場合でも、常にプロセスの最新バージョンにリンクされているかのように動作します。 |
たとえば、2つの結果ページによって参照されるプロセスがあるとします。
ページAはプロセスの最新バージョンにリンクされていませんが、ページBはリンクされています。この時点では、プロセスのバージョンは1つのみであるため、2つのページの動作に差異はありません。
しかし、プロセスの新しいバージョンが作成された場合、ページBは常に最新バージョンにリンクされるため、新しいバージョンを参照します。ページAは最新バージョンにリンクされていないため、引き続きバージョン1の最新の結果を参照します。
両方のオプションとも、結果ブックで予期しない動作になる場合があります。
ページがプロセスの最新バージョンにリンクされていても、データの参照先のプロセッサがプロセスから削除された場合は、ページでレポートするデータがないため、結果ページは無効となります。
ページがプロセスの前のバージョンにリンクされていて、プロセスがパッケージ化されて新しいプロジェクトに移動された場合は、ページのデータがないため、ページは無効となります。プロセスのこのインスタンスは新しいコンテキストでは実行されていないため、ページでレポートするデータはありません。
結果ブックの表示
結果ブックを表示するには、プロジェクト・ブラウザで「結果ブック」を選択します。結果ブックの各ページが、結果ブラウザの各タブとして表示されます。
結果ブックの外部との共有
結果ブックを外部と共有する(EDQにアクセスできない同僚に結果ブックを送信するなど)最も簡単な方法は、結果ブックのすべてのページをワークシートとして含むMicrosoft Excelワークブックを作成することです。これを実行するには、結果ブラウザの最も右にあるアイコンを使用します。
現在のページのみを含むExcelワークブックを作成するには、「Excelにエクスポート」を選択します。
結果ブックのエクスポート
結果ブックの結果をファイルまたはデータベースに反復的または定期的に書き込む場合は、結果ブック・エクスポートを設定し、ジョブの一部としてスケジュールできます。これにより、プロセスまたはプロセスのセットが実行されるたびに、選択した結果を自動的に出力できます。これは、入力データを継続的に変更していて、データを分析するたびにメトリックを保存する必要がある場合に役立ちます。
結果ブックのエクスポートを設定するには、「結果ブック」を右クリックして「エクスポート」を選択するか、または「エクスポート」を右クリックして「結果ブックのエクスポート」を選択します。
外部タスクとは、EDQジョブの一環として実行されるが、EDQアプリケーション内では発生しないタスクの詳細を保存したものです。
外部タスクは、ファイルのダウンロードまたは外部実行ファイルのいずれかである場合があります。
ファイルのダウンロード
ファイル・ダウンロードは、EDQで処理するファイルをサーバー・ランディング領域に取得するために使用します。ファイルは、インターネットや他のネットワーク・ソースからダウンロードできます。必要な場合は、ユーザー認証の詳細やプロキシ/ファイアウォールの設定をファイル・ダウンロード・タスクの一部として設定できます。
ファイル・ダウンロード・タスクに設定できるオプション一式は次のとおりです。
URL: ソース・ファイルの場所を指定します。内部の場所かサーバーが接続できる別のネットワーク・ファイルの場所を指定できます。
ユーザー名: ユーザー名を指定します(ファイルをダウンロードするために認証の詳細が必要な場合)。
パスワード: パスワードを指定します(ファイルをダウンロードするために認証の詳細が必要な場合)。
プロキシ・ホスト: プロキシ/ファイアウォール・サーバーの名前またはIPアドレス(サーバーがインターネット/ネットワークに直接接続されない場合)。
プロキシ・ポート: プロキシ/ファイアウォール・サーバーへの接続に使用されるポート。
プロキシ・ユーザー名: プロキシ/ファイアウォール・サーバーの認証に使用されるユーザー名。
プロキシ・パスワード: プロキシ/ファイアウォール・サーバーの認証に使用されるパスワード。
ファイル名: ファイルがランディング領域にダウンロードされたときにダウンロードされたファイルに付ける名前。ランディング領域のサブフォルダにファイルを格納しない場合は、スラッシュを使用してディレクトリ構造を指定してください(例: DownloadedData/downloadedfile.csv)。
プロジェクト専用フォルダを使用: このオプションを選択すると、ファイルがプロジェクト専用のランディング領域に自動的に格納されます。通常これが使用されるのは、ランディング領域にアクセスできるのが同じプロジェクト内のプロセスのみになるようにプロジェクト権限が設定されている場合です。
SSLホスト名の不一致を許可: このオプションを選択すると、SSL証明書に指定されたホスト名と証明書が適用されるサーバー名の矛盾をダウンロード・タスクが無視できます。
無効なSSL証明書を無視: このオプションを選択すると、ホストの未確認のSSL証明書をダウンロード・タスクが無視できます。
ファイル・ダウンロード・タスクには名前を付けて、説明(オプション)を付けることができます。
外部実行ファイル・タスクには次のオプションを設定できます。
コマンド: このオプションでは実行するコマンドを指定します。コマンドのパスがEDQサーバーのシステム・パスにない場合は、コマンドのフルパスを指定する必要があります。
引数: このオプションでは、コマンドに指定する追加の引数を指定します。
作業ディレクトリ: このオプションでは、コマンドが実行されるEDQサーバー上の作業ディレクトリを指定します。コマンドが読み取る必要があるすべてのファイルはこのディレクトリに存在する必要があります。また、コマンドによって書き出されるすべてのファイルはこのディレクトリに書き出されます。このオプションを空にしておくと、コマンドの作業ディレクトリはサーバー・ファイル・ランディング領域(デフォルト・インストールでは[Install Path]\oedq_local_home\landingareaに設定)になります。
実行ファイル・タスクには名前を付けて、説明(オプション)を付けることができます。
実行ファイル・タスクのセキュリティの考慮事項
externaltasks.restrictedという名前のプロパティを使用して、外部タスクのスコープを制御します。このプロパティはデフォルトではdirector.propertiesファイルでtrueに設定されています。
externaltasks.restrictedがtrueに設定されているとき、外部タスクで使用されるコマンドはEDQコマンド領域に存在する必要があります。デフォルトでは、コマンド領域はoedq_local_home/commandareaにあります。この場所は、director.propertiesでcommandareaプロパティを設定して上書きできます。
外部実行ファイルでスクリプト(Perlスクリプトなど)を実行する必要がある場合、呼出しをコマンド領域のバッチ・ファイルにラップする必要があります。
|
警告: externaltasks.restrictedがfalseに設定されると、外部実行ファイル・メカニズムは潜在的なセキュリティ・ハザードにつながります。理論上は、ディレクタ・アプリケーションにアクセスする誰もが、サーバーに対する無制限のアクセス権(ファイルの削除や機密データの読取りなど)を備えた外部ジョブを作成できます。 |
ジョブは、順序付けられた1つ以上のタスクが編成された構成です。タスクとは、スナップショット、プロセス、エクスポート、結果ブックのエクスポートまたは外部タスクを実行することです。
ジョブは、プロジェクト内にあります。
ジョブ内のタスクは複数のフェーズに編成でき、これを使用してタスクの実行順序を制御します。たとえば、タスクAをタスクBの前に完了するには、タスクAをフェーズ1に、タスクBをそれより後のフェーズに配置します。1つのフェーズ内では、すべてのタスクが可能なかぎり迅速に実行され、(可能な場合は)使用可能なスレッドを共有してパラレルに実行されます。同じフェーズ内で複数のチェーン・プロセスを実行することもでき、その場合は、単一のプロセスとして効率的に実行されます。
フェーズおよびタスクは有効または無効にできますが、これはサーバー・コンソールUIからジョブを実行するときに実行プロファイルを使用して、またはEDQコマンドライン・インタフェースのrunopsjobコマンドを使用して、上書きできます。
ジョブにはトリガーを含めることもでき、これを使用して、リアルタイム・プロセスを停止したり、フェーズ内の他のタスクの実行開始前、または他の全タスクの完了後に、他のジョブを開始できます。
ジョブの完了時に送信されるジョブ通知電子メールを構成できます。電子メールにはジョブのステータス(成功したか失敗したか)が示され、実行中に発生した警告やエラーの詳細も記載されます。
ジョブは、コマンドライン・インタフェースを使用してディレクタUI、サーバー・コンソールUIまたは外部スケジューラを使用して実行するようにスケジュールできます。
ジョブ・キャンバス
ジョブは、ジョブ・キャンバスを使用して作成および管理されます。ジョブ・キャンバスを開くには、プロジェクト・ブラウザでプロジェクトの「ジョブ」ノードに移動して、ダブルクリックします。
ジョブ・キャンバス自体は、「フェーズ」リスト(左側)と右側の「キャンバス」に分割されています。「キャンバス」には、現在選択されているフェーズのタスクが表示されます。
「プロジェクト・ブラウザ」は、ディレクタのツールバーでジョブ・キャンバスの最大化ボタンを切り替えて非表示にすることができます(ジョブ・キャンバスに使用できる領域を最大化)。
ジョブ・キャンバス・ツールバーには次のボタンがあります。
表1-138 ジョブ・キャンバス・ツールバー
| 名前 | 説明 |
|---|---|
|
ジョブの実行 |
現在表示されているジョブを実行します。 |
|
実行プロファイル付きジョブの実行 |
「プロファイルの実行」を選択するようにユーザーに求めた後で、現在表示されているジョブを実行します。 |
|
通知 |
電子メール通知を構成します。詳細は、「ジョブ通知」を参照してください。 |
|
フェーズ・リストの表示/非表示 |
フェーズ・リストの表示と非表示を切り替えます。 |
|
ツール・パレット・アイテムの切替え |
「フィルタ」がアクティブ化されている場合、ツール・パレットには、現在選択されているタスクに結び付けられるタスクしか表示されません。 |
|
ジョブ外部化 |
現在選択されているジョブの「ジョブ外部化」ダイアログが開きます。 |
|
ノートの追加 |
ジョブ・キャンバスにノートを追加します。ノートは、クリックしてからドラッグすると移動でき、選択して[Delete]を押すと削除できます。 |
|
ズーム・インおよびズーム・アウト |
これらのボタンを使用して、ジョブ・キャンバスのズーム・インまたはズーム・アウトを行います。 |
このトピックでは、次の項目について説明します。
ジョブの作成
ジョブの編集
ジョブの削除
ジョブ・キャンバスの右クリック・メニュー
ジョブ・フェーズの編集および構成
|
注意: 現在実行中のジョブは編集または削除できません。変更を試行する前に必ずジョブのステータスを確認してください。ジョブのスナップショット・タスクおよびエクスポート・タスクは、クライアント側のデータ・ストアではなくサーバー側のデータ・ストアを使用する必要があります。 |
ジョブを作成する手順は、次のとおりです。
プロジェクト・ブラウザで必要なプロジェクトを展開します。
プロジェクトの「ジョブ」ノードを右クリックして、「新規ジョブ」を選択します。
「新規ジョブ」ダイアログが表示されます。名前と説明(必須の場合)を入力して、「終了」をクリックします。
ジョブが作成され、ジョブ・キャンバスに表示されます。
フェーズ・リストで「新規フェーズ」を右クリックし、「構成」を選択します。
フェーズの名前を入力し、次に示す他のオプションを必要に応じて選択します。
表1-139 新規フェーズのオプション
| フィールド | 説明 |
|---|---|
|
有効? |
フェーズを有効化または無効化します。デフォルトの状態では選択されています(有効化)。 注意: フェーズのステータスは実行プロファイルで上書きできます。または、EDQコマンドライン・インタフェースでrunopsjobコマンドを使用して上書きできます。 |
|
実行条件 |
前のフェーズの成功または失敗に応じてフェーズを実行するように条件設定します。 オプションは次のとおりです。
注意: エラー・フラグが存在することはできません。残っているエラー・フラグは前のフェーズで削除しておく必要があります。 |
|
エラーのクリア? |
ジョブのエラー状態をクリアするかそのまま残します。 ジョブ・フェーズでエラーが発生すると、エラー・フラグが適用されます。 「成功で実行」フェーズでは、「成功で実行」フェーズを実行するために以前のエラー・フラグをクリアする必要があります。 デフォルトの状態では選択されていません。 |
|
トリガー |
フェーズの実行前または実行後にトリガーをアクティブ化するように構成します。詳細は、「ジョブ・トリガーの使用」を参照してください。 |
「OK」をクリックして設定を保存します。
ツール・パレットでタスクをクリックしてドラッグし、必要に応じてタスクの構成とリンクを行います。
さらにフェーズを追加するには、「フェーズ」領域下部のジョブ・フェーズの追加ボタンをクリックします。フェーズを選択し、「フェーズの移動」ボタンを使用してリスト内で上下に動かすと、フェーズの順序を変更できます。フェーズを削除するには「フェーズの削除」ボタンをクリックします。
必要に応じてジョブが構成されたら、「ファイル」 > 「保存」をクリックします。
ジョブを編集する手順は、次のとおりです。
ジョブを実行するには、プロジェクト・ブラウザでジョブを探し、ダブルクリックするか、右クリックして「編集...」を選択します。
ジョブがジョブ・キャンバスに表示されます。必要に応じてフェーズまたはタスク(あるいは両方)を編集します。
「ファイル」 > 「保存」をクリックします。
ジョブを削除しても、そのジョブに含まれていたプロセスは削除されません。そのジョブに関連する結果も削除されません。ただし、ジョブに含まれていたいずれかのプロセスが最後に実行されたのがそのジョブだった場合、そのプロセスの最新結果セットは削除されます。これによって、そのプロセス内のプロセッサが最新ではないとマークされます。
ジョブを削除するには次のいずれかを実行します。
プロジェクト・ブラウザでジョブを選択し、[Delete]キーを押します。
ジョブを右クリックし、「削除」を選択します。
現在実行中のジョブは削除できないことに注意してください。
ジョブを作成または編集するときには、右クリック・メニューからアクセスできるその他のオプションがあります。
キャンバスでタスクを選択して右クリックするとメニューが表示されます。次の2通りの場合があります。
有効 - 選択したタスクが有効化されると、このオプションの横にチェックマークが表示されます。必要に応じて選択または選択解除します。
タスクの構成...- このオプションでは「タスクの構成」ダイアログが表示されます。
削除 - 選択したタスクを削除します。
開く - 選択したタスクをプロセス・キャンバスで開きます。
切取り、コピー、貼付け - これらのオプションを使用して、必要に応じてジョブ・キャンバスでタスクの切取り、コピー、貼付けを行います。
ジョブ・トリガーは他のジョブを開始または中断するために使用されます。デフォルトでは次の2種類のトリガーが用意されています。
「ジョブの実行」トリガー: ジョブを開始するために使用されます。
「Webサービスの停止」トリガー: リアルタイム・プロセスを停止するために使用されます。
管理者はJMSメッセージの送信やWebサービスの呼出しなど他のトリガーを構成できます。これらは「フェーズ構成」ダイアログを使用して構成されます。
トリガーはフェーズの前または後に設定できます。前のトリガーはフェーズ名の上の青色矢印で示され、後のトリガーはフェーズ名の下の赤色矢印で示されます。
トリガーをブロック・トリガーとして指定することもできます。ブロック・トリガーは、トリガーされたタスクが完了するまで、後続のトリガーまたはフェーズの開始を防ぎます。
トリガーを構成する手順は、次のとおりです。
対象のフェーズを右クリックし、「構成」を選択します。「フェーズ構成」ダイアログが表示されます。
「トリガー」領域で、必要に応じて「フェーズ前」または「フェーズ後」リストの下の「トリガーの追加」ボタンをクリックします。「トリガーの選択」ダイアログが表示されます。
ドロップダウン・フィールドでトリガーの種類を選択します。
リスト領域で特定のトリガーを選択します。
「OK」をクリックします。
必要な場合は、トリガーの横の「ブロック中」チェックボックスを選択します。
必要に応じて他のトリガーを設定します。
すべてのトリガーが設定されたら、「OK」をクリックします。
ジョブ内のタスクには、外部化できる設定がいくつも含まれています。
タスクの設定を外部化する手順は、次のとおりです。
タスクを右クリックして「タスクの構成」を選択します。
対象の設定の横にある「外部化」ボタンをクリックします。
「外部化」ポップアップ内のチェック・ボックスを選択します。
設定のデフォルト名が表示されます。これは必要に応じて編集できます。
「OK」をクリックします。
この後、これらの設定は「ジョブ外部化」ダイアログで管理されます。このダイアログを開くには、ジョブ・キャンバス・ツールバーの「ジョブ外部化」ボタンをクリックします。
ジョブの外部化は、「外部化の有効化」ボックスを選択または選択解除して有効と無効を切り替えることができます。
「外部化されたオプション」領域に外部化に対応するオプションが表示されます。
オプションを削除するには、そのオプションを選択して、「削除」(「外部化されたオプション」領域の下)をクリックします。
オプションの名前を変更するには、そのオプションを選択して、「名前変更」をクリックします。「名前変更」ポップアップで名前を編集し、「OK」をクリックします。
「外部化されたオプション」領域では、選択されたオプションはそれが関連付けられているタスクの横に表示されます。1つのオプションが複数のタスクに関連付けられている場合は、タスクそれぞれに対して1回表示されます。前述の例のダイアログでは、「有効」オプションがUK顧客のタスクとUS顧客のタスクに関連付けられています。
オプションとタスクの関連付けを解除するには、この領域でオプションを選択して「削除」をクリックします。
EDQでは、GUIで対話型操作として(プロジェクト・ブラウザでオブジェクトを右クリックして「実行」を選択)、またはスケジュール済ジョブの一部として、次の種類のタスクを実行できます。
タスクには様々な実行オプションが含まれます。詳細は、次のタスクをクリックしてください。
また、ジョブを設定する際に、フェーズの実行前または実行後に実行するようにトリガーを設定することもできます。
ジョブを設定するときに、タスクをいくつかのフェーズに分割できます。これによって、処理順序を制御したり、含まれるタスクの成功または失敗によってジョブの実行方法を変えたい場合に条件付きの実行を使用したりすることができます。
スナップショット
ジョブの一部として「スナップショット」を実行するように構成する際には、1つのオプション「有効」があり、デフォルトで設定されています。
このオプションを無効化すると、ジョブ定義は保持されますが、スナップショットのリフレッシュが一時的に無効になります。たとえば、スナップショットをすでに実行したため、ジョブのタスクのみを後で再実行しようとしている場合に該当します。
プロセス
ジョブの一部として、またはクイック実行オプションとプロセス実行プリファレンスを使用して、プロセスを実行する際には、様々なオプションを使用できます。
リーダー(処理するレコードのオプション)
プロセス(プロセスによる結果の書込み方法のオプション)
実行モード(リアルタイム・プロセスのオプション)
ライター(プロセスのレコードの書込み方法のオプション)
リーダー
プロセスのリーダーごとに次のオプションを設定できます。
サンプル?
「サンプル」オプションではジョブ固有のサンプリング・オプションを指定できます。たとえば、通常は数百万件のレコードに対して実行されるプロセスがあるとします。ただし、テスト目的などで、ある特定のレコードのみを処理するように特定のジョブを設定したい場合があります。
「サンプリング」の下のオプションを使用して必要なサンプリングを指定し、「サンプル」オプションを使用して有効にします。
使用可能なサンプリング・オプションはリーダーの接続方法によって異なります。
リアルタイム・プロバイダに接続しているリーダーの場合、「カウント」オプションを使用して指定レコード数で終了するようにプロセスを制限できます。または「期間」オプションを使用して期間を制限してプロセスを実行できます。たとえば、リアルタイム・モニタリング・プロセスを1時間のみ実行できます。
ステージング済データ構成に接続しているリーダーの場合、スナップショットの構成に使用できるのと同じサンプリングとフィルタのオプションを使用して、定義済レコード・セットのサンプルのみに対して実行するようにプロセスを制限できます。たとえば、データ・ソースの最初の1000レコードのみを処理するプロセスを実行できます。
「サンプリング・オプション」のフィールドを次に示します。
すべて - すべてのレコードをサンプリングします。
カウント - nレコードをサンプリングします。選択するサンプリング順序に応じて、最初のnレコードまたは最後のnレコードになります。
パーセンテージ - レコードの合計数のn%をサンプリングします。
サンプリング・オフセット - この数よりも後のレコードに対してサンプリングを実行します。
サンプリング順序 - 「降順」(最初のレコードから)または「昇順」(最後から)。
|
注意: たとえば、2000件のレコード・セットに対してサンプリング・オフセットに1800が指定されると、「カウント」または「パーセンテージ」フィールドに指定された値にかかわらず200レコードしかサンプリングされません。 |
プロセス
プロセス実行プリファレンスの一部として、またはジョブの一部として、プロセスを実行するときに次のオプションを使用できます。
表1-140 プロセス・オプション
| オプション | 説明 |
|---|---|
|
インテリジェント実行を使用? |
「インテリジェント実行の使用」は、プロセスの現在の構成に基づく最新結果を得ているプロセッサは、その結果を再生成しないことを意味します。最新結果がないプロセッサは、再実行マーカーによってマークされます。インテリジェント実行はデフォルトで選択されています。プロセス内のリーダーでレコードのサンプリングまたはフィルタを選択した場合は、インテリジェント実行の設定にかかわらずすべてのプロセッサが再実行します。プロセスが異なるセットのレコードに対して実行されるためです。 |
|
照合プロセッサでのソート/フィルタを有効化? |
このオプションは、プロセスの任意の照合プロセッサに指定されたソート/フィルタ有効化設定(各照合プロセッサの「拡張オプション」)が、プロセス実行の一部として実行されることを意味します。このオプションはデフォルトで選択されます。大容量のデータが一致する場合は、ソート/フィルタ有効化タスクを実行して一致結果の確認を許可すると、長い時間がかかる可能性があるため、このオプションの選択を解除して後に延ばすことをお薦めします。たとえば、一致結果を外部にエクスポートする場合、「ソート/フィルタの有効化」プロセスが実行するのを待たずに、照合プロセスが完了したらすぐにデータのエクスポートを開始できます。照合プロセスの結果を確認する必要がない場合には、設定を完全にオーバーライドすることもできます。 |
|
結果のドリル・ダウン |
このオプションでは、「結果のドリル・ダウン」の必要なレベルを選択できます。
|
|
ダッシュボードに公開? |
このオプションでは、結果をダッシュボードに公開するかどうかを設定します。結果を公開するためには、プロセスの1つ以上の監査プロセッサでダッシュボードの公開をあらかじめ有効にしておく必要があることに注意してください。 |
実行モード
必要な実行タイプをサポートするために、EDQでは3種類の実行モードが用意されています。
リアルタイム・プロバイダに接続しているリーダーがプロセスにない場合、プロセスは常に標準モード(以下を参照)で実行します。
リアルタイム・プロバイダに接続しているリーダーが少なくとも1つプロセスに含まれる場合、プロセスの実行モードを次の3つのオプションから選択できます。
標準モード
標準モードでは、プロセスはレコードのバッチを完了するまで実行します。レコードのバッチはリーダーの構成によって定義されます。さらに、その他のサンプリング・オプションがプロセス実行プリファレンスまたはジョブ・オプションで設定されることもあります。
準備モード
準備モードが必要なのは、プロセスがリアルタイム・レスポンスを提供する必要がある場合です。ただし、これが可能になるのは、プロセスのリアルタイムでない部分がすでに実行された場合、つまりプロセスの準備が完了した場合のみです。
準備モードが最も使用されるのはリアルタイム参照照合です。この場合、同じプロセスが別のジョブおよび別のモードで実行するようにスケジュールされます。最初のジョブは、プロセスのリアルタイム以外の部分(たとえば、照合用の参照データに対するすべてのクラスタ・キーの作成など)をすべて実行して、リアルタイム・レスポンス実行のためにプロセスを準備します。2番目のジョブはリアルタイム・レスポンス・プロセスとして実行します(おそらく間隔モード)。
間隔モード
間隔モードでは、プロセスが長期間(絶え間なく)実行しますが、処理の結果は間隔ごとに書き込まれます。レコードまたは時間の制限に達すると、1つの間隔が完了して新しい間隔が始まります。レコードと時間両方のしきい値が指定されている場合は、いずれかのしきい値に達すると新しい間隔が始まります。
間隔モードのプロセスは長時間実行できるため、結果を保存しておく間隔の数を構成できることが重要です。これは、間隔の数または期間によって定義できます。
たとえば、連続して実行し、毎日新しい間隔が開始するようにリアルタイム・レスポンス・プロセスのオプションを設定できます。たとえば、最大10の間隔(つまり10日分の結果)を保存できます。
連続実行するプロセスもダッシュボードに結果を公開できることに注意してください。時間とレコードの間隔に対して傾向分析をプロットできます。
間隔モードでの処理結果の参照
プロセスが間隔モードで実行しているとき、完了した間隔の結果を参照できます(間隔を保存するために指定されているオプションに対して古すぎない場合)。
結果ブラウザには単純なドロップダウン選択ボックスがあり、各間隔の開始日時と終了日時が表示されます。デフォルトでは最後に完了した間隔が表示されます。間隔を選択して結果を参照します。
プロセスを開いているときに新しい結果セットが表示可能になると、ステータス・バーに通知が示されます。その後、ドロップダウン選択ボックスで新しい結果を選択できます。
ライター
プロセスのライターごとに次のオプションを設定できます。
Write Data? このオプションは、ライターが実行されるかどうかを設定します。つまり、書き込んでデータをステージングするライターの場合、このオプションを選択解除するとステージング済データが書き込まれません。リアルタイム・コンシューマに書き込むライターの場合、このオプションを選択解除するとリアルタイム・レスポンスが書き込まれません。
これは次の2つのケースで役立ちます。
1. 書き込まれたデータをリポジトリにステージングせずに、データを直接エクスポート・ターゲットにストリームする場合。ライターは、書き込む属性を選択するためのみに使用されます。このケースでは、データの書込みオプションの選択を解除し、エクスポート・タスクをジョブ定義のこのプロセスの後に追加します。
2. ライターを一時的に無効にする場合。たとえば、テストのためにプロセスをリアルタイム実行からバッチ実行に切り替える場合に、リアルタイム・レスポンスを発行するライターを一時的に無効化することがあります。
Enable Sort/Filter? このオプションでは、「ステージング済データ」ライターによって書き込まれたデータのソートとフィルタを有効化するかどうかを設定します。通常、ライターによって書き込まれたステージング済データに対してソートとフィルタを有効にする必要があるのは、ユーザーが結果のソートとフィルタを望む別のプロセスによってデータが読み取られる予定がある場合、またはライターの結果そのもののソートとフィルタを行う必要がある場合です。
このオプションはリアルタイム・コンシューマに接続しているライターには影響しません。
外部タスク
プロジェクトに構成されているすべての外部タスク(ファイルのダウンロードまたは外部実行ファイル)は、同じプロジェクト内のジョブに追加できます。
ジョブの一部として実行するように「外部タスク」を構成する際には、1つのオプション「有効」があります。
エクスポート・オプションの有効化または無効化では、ジョブ定義を維持したままで、データのエクスポートを一時的に有効化または無効化できます。
エクスポート
ジョブの一部として実行するように「エクスポート」を構成するとき、エクスポートを有効化または無効化できます(ジョブ定義を維持したままで、データのエクスポートを一時的に有効化または無効化できます)。また、次のオプションを使用して、ターゲット・データ・ストアにデータを書き込む方法を指定できます。
現在のデータおよび挿入の削除(デフォルト)
EDQでは、ターゲットの表またはファイルの現在のデータすべてを削除し、適用範囲内データをエクスポートに挿入します。たとえば、外部データベースに書き込んでいる場合は、表を切り捨ててデータを挿入します。または、ファイルに書き込んでいる場合は、ファイルを再作成します。
現在のデータに追加
EDQでは、ターゲットの表またはファイルのデータを削除せずに、適用範囲内データをエクスポートに追加します。UTF-16ファイルに追加する場合は、バイト順序マーカーが新しいデータの先頭に書き込まれないように、UTF-16LEまたはUTF-16-BE文字セットを使用してください。
主キーを使用してレコードを置換します
EDQでは、エクスポートの適用範囲データにも存在するレコード(主キーの照合によって判別)をすべてターゲット表から削除し、適用範囲内データを挿入します。
|
注意: エクスポートがディレクタでスタンドアロン・タスクとして実行される場合(「エクスポート」を右クリックして「実行」を選択する場合)、常に「現在のデータおよび挿入の削除」モードで実行します。「現在のデータおよび挿入の削除」モードと「主キーを使用してレコードを置換します」モードでは、削除操作の後で挿入操作を行います。更新ではありません。ターゲット・データベースの参照整合性ルールによってレコードの削除が妨げられ、そのためにエクスポート・タスクが失敗する可能性があります。このようなケースでかわりに更新操作を実行するためには、専用のデータ統合製品(Oracle Data Integratorなど)の使用をお薦めします。 |
結果ブックのエクスポート
ジョブの一部として実行するように「結果ブックのエクスポート」を構成する際には、エクスポートを有効化または無効化する1つのオプションがあります。必要な場合には同じ構成を維持したままで一時的にエクスポートを無効にできます。
トリガー
トリガーは、処理の特定の時点でEDQが実行できるアクションが具体的に構成されたものです。
ジョブでフェーズの前に実行
ジョブでフェーズの後に実行
手動の照合決定を行うとき(たとえば、ある人物がウォッチリストと完全に一致するかなど、別のアプリケーションに影響する決定が行われたときにそのアプリケーションに通知する場合)。
ジョブが実行を完了するたびに、1ユーザー、特定の複数ユーザーまたはユーザー・グループ全体に電子メールの通知を送信するようにジョブを構成できます。これにより、EDQユーザーはEDQにログオンしなくてもスケジュール済ジョブのステータスをモニターできます。
また、電子メールが送信されるのは、有効なSMTPサーバーの詳細がoedq_local_homeディレクトリのnotification/smtpサブフォルダにあるmail.propertiesファイルに指定されている場合のみです。同じSMTPサーバー詳細が問題の通知にも使用されます。
デフォルト通知テンプレート(default.txt)はEDQのconfig/notification/jobsディレクトリにあります。追加のテンプレートを構成するには、このファイルをコピーして同じディレクトリに貼り付け、名前を変更して、内容を必要に応じて変更します。新しいファイルの名前は「電子メール通知構成」ダイアログの「通知テンプレート」フィールドに表示されます。
ジョブ通知を構成する手順は、次のとおりです。
ジョブを開き、ジョブ・キャンバス・ツールバーの「通知の構成」ボタンをクリックします。「電子メール通知構成」ダイアログが表示されます。
「有効」ボックスを選択します。
ドロップダウン・リストから通知テンプレートを選択します。
通知を送信するユーザーとグループをクリックして選択します。ユーザーまたはグループ(あるいは両方)を複数選択する場合は、[Ctrl]キーを押したままでクリックします。
「OK」をクリックします。
|
注意: 「ユーザー構成」に有効な電子メール・アドレスが構成されているユーザーのみが電子メールを受信します。 |
デフォルト通知内容
デフォルトの通知には、次のようにジョブの各フェーズで実行されたすべてのタスクのサマリー情報が含まれます。
スナップショット・タスク
通知には、ジョブの実行でのスナップショット・タスクのステータスが表示されます。ステータスには、次のものがあります。
STREAMED - プロセスが実行されるときに、データをプロセスに直接送ってステージングすることにより、スナップショットのパフォーマンスが最適化されました
FINISHED - スナップショットが独立タスクとして完了するまで実行しました
CANCELLED - スナップショット・タスク中にユーザーによってジョブが取り消されました
WARNING - スナップショット完了まで実行しましたが、1つ以上の警告が生成されました(たとえば、スナップショットがデータ・ソースのデータを切り捨てる必要がありました)
ERROR - エラーのためにスナップショットが完了できませんでした
スナップショット・タスクがFINISHEDステータスの場合、スナップショットされたレコード数が表示されます。
処理中に検出された警告とエラーの詳細が含まれます。
プロセス・タスク
通知には、ジョブの実行でのプロセス・タスクのステータスが表示されます。ステータスには、次のものがあります。
FINISHED - プロセスが完了するまで実行しました
CANCELLED - プロセス・タスク中にユーザーによってジョブが取り消されました
WARNING - プロセス完了まで実行しましたが、1つ以上の警告が生成されました
ERROR - エラーのためにプロセスが完了できませんでした
プロセスが正しい数のレコードに対して実行されたことを確認するために、プロセス・タスクのリーダーとライターごとにレコード数が含まれます。処理中に検出された警告とエラーの詳細が含まれます。これには警告の生成プロセッサによって生成された警告またはエラーが含まれる場合があることに注意してください。
エクスポート・タスク
通知には、ジョブの実行でのエクスポート・タスクのステータスが表示されます。ステータスには、次のものがあります。
STREAMED - プロセスからのデータを直接実行してデータ・ターゲットに書き込むことにより、エクスポートのパフォーマンスが最適化されました
FINISHED - エクスポートが独立タスクとして完了するまで実行しました
CANCELLED - エクスポート・タスク中にユーザーによってジョブが取り消されました
ERROR - エラーのためにエクスポートが完了できませんでした
エクスポート・タスクがFINISHEDステータスの場合、エクスポートされたレコード数が表示されます。
処理中に検出されたエラーの詳細が含まれます。
結果ブックのエクスポート・タスク
通知には、ジョブの実行での結果ブックのエクスポート・タスクのステータスが表示されます。ステータスには、次のものがあります。
FINISHED - 結果ブックのエクスポートが完了するまで実行されました
CANCELLED - 結果ブックのエクスポート・タスク中にユーザーによってジョブが取り消されました
ERROR - エラーのために結果ブックのエクスポートが完了できませんでした
処理中に検出されたエラーの詳細が含まれます
外部タスク
通知には、ジョブの実行での外部タスクのステータスが表示されます。ステータスには、次のものがあります。
FINISHED - 外部タスクが完了するまで実行しました
CANCELLED - 外部タスク中にユーザーによってジョブが取り消されました
ERROR - エラーのために外部タスクが完了できませんでした
処理中に検出されたエラーの詳細が含まれます
コマンドライン・ユーティリティのコレクションがEDQによってファイルjmxtools.jarに用意されています。
jmxtools.jarのコマンドはEDQがインストールされている場所で使用できます。コマンド構文は次のとおりです。
java.exe -jar jmxtools.jar <command> <arguments> <argument options>
各コマンドには多様な引数を指定できます(引数は大/小文字が区別されます)。
コマンド、引数およびオプション
この項では、コマンドライン・ツールで使用できるすべてのコマンドと、各コマンドで使用されるすべての引数を示します。
droporphans
droporphansコマンドを使用して、親がない結果表を削除します。
droporphansコマンドには次の引数を指定できます。
listorphans
listorphansコマンドを使用して、親がない結果表を識別します。詳細は、Oracle Fusion Middleware Oracle Enterprise Data Qualityサーバー管理者ガイドの親のない表の識別と削除に関する項を参照してください。listorphansコマンドには、前述のdroporphansコマンドと同じ引数を指定できます。
scriptorphans
scriptorphansコマンドは、親のない結果表を削除するためにSQLコマンドのリストを作成します。これは、表を削除するときに結果データベースに対して実行するコマンドが正確かどうかを確認する場合、または表を手動で削除する場合に役立ちます。
list
listコマンドは、使用可能なすべてのコマンドをリスト表示します。
runjob
runjobコマンドは、ディレクタUIを使用してジョブを実行する場合と同じ方法で、指定されたジョブを実行します。runjobコマンドには次の引数を指定できます。
runopsjob
runopsjobコマンドは、サーバー・コンソールUIを使用してジョブを実行する場合と同じ方法で、指定されたジョブを実行します。これは、runjobコマンドに対して、実行ラベルと実行プロファイルを使用する機能が追加されたものです。実行ラベルを使用すると、結果を同じジョブの他の実行結果と分けて保存することができます。実行プロファイルを使用すると、外部化された構成設定を実行時に上書きできます。
runopsjobコマンドには次の引数を指定できます。
shutdown
shutdownコマンドは、リアルタイム・レコード・プロバイダ(WebサービスまたはJMS)で実行しているすべてのリアルタイム・ジョブを停止します。
これには次の引数を指定できます。
コマンド例
次のコマンド例では、コマンドライン・インタフェースからジョブが実行されます。
java.exe -jar jmxtools.jar runjob -job Job1 -project ClientProject -u adminuser -p adminpassword server:9005
このコマンドの指定内容は次のとおりです。
ジョブ名: Job1
プロジェクト名: ClientProject
ユーザー: adminuser
パスワード: adminpassword
サーバー名: server
コマンドライン・インタフェースのポート: 9005
|
注意: 名前(プロジェクトまたはユーザー名)にスペースが含まれる場合、コマンド構文内で二重引用符で囲む必要があります。たとえば、プロジェクトに含まれるジョブの名前をMaster Data Analysisにする場合、コマンドに「...-project "Master Data Analysis"...」と指定する必要があります |
終了ステータス
ジョブが完了すると終了ステータス(0または1)が返されます。終了ステータス0はジョブが正常に完了したことを示し、終了ステータス1はジョブにエラーがあったことを示します。
Windowsバッチ・ファイルの例
次のWindowsバッチ・ファイルの構文例は、指定したジョブをEDQで呼び出し、返される終了ステータスを使用してジョブが失敗した場合にエラー・メッセージを表示する単純なケースを示しています。
@ECHO OFF java -jar jmxtools.jar runjob -job [Job Name] -project [Project Name] -u [User Name] -p [Password] [Server Name]:9005 IF ERRORLEVEL 1 GOTO error ECHO Job ran successfully GOTO end :error ECHO An error occurred running the job :end
エクスポートには、2つのタイプがあります。
保存済の構成を使用する準備済エクスポート(ステージング済データ・エクスポートまたは結果ブック・エクスポート)。
結果ブラウザからExcelファイルへの現在の結果の非定型エクスポート。
準備済エクスポート
準備済エクスポートとは、ステージング済データまたは結果ブックをデータ・ストア(データベースの表またはファイル)に出力するための保存済の構成を指します。
ステージング済データのエクスポート
ステージング済データのエクスポートでは、ステージング済データの属性を外部のデータベース表やファイルの属性にマップしたり、ターゲットのデータベース表やファイルを実行時に自動作成できます。データを表に追加するかどうか、データを上書きするかどうか、またはステージング済データ・セットで一致する主キーが指定されたターゲット・レコードのみを置換するかどうかを定義できます。
柔軟性を確保するために、エクスポートは、プロセスのライターとは別に定義します。たとえば、プロセスではステージング済データの同じセットを複数のターゲットにエクスポートし、外部のデータベースやファイルで使用されている属性名の別のセットをEDQで使用できます。
結果ブックのエクスポート
結果ブックのエクスポートでは、ターゲットのデータベース表やファイルを実行時に自動作成したり、同じ名前の既存の表やファイルを置換できます。表やファイルがすでに存在する場合は、データが上書きされます。
準備済エクスポートの実行
準備済エクスポートは、次の2つの方法で実行できます。
手動。つまり、ユーザーがステージング済データや保存済の結果ブックを外部に書き込む場合です。エクスポートを手動で実行するには、プロジェクト・ブラウザで「エクスポート」を右クリックし、エクスポートの実行を選択します。
自動。つまり、スケジュールされたジョブの一環としてデータをエクスポートする場合です。スケジュールされたジョブの一環としてエクスポートを実行するには、ジョブを定義し、エクスポートをタスクとして追加し、スケジューラを使用してジョブをスケジュールします。
|
注意: ステージング済データのエクスポートをジョブの一環として実行する場合は、EDQリポジトリにデータをステージングする必要はありません。ジョブにエクスポート・タスクを含める一方、ジョブ定義でステージング済データを無効にすると、出力データはエクスポート・ターゲットに直接ストリーミングされます。 |
特別エクスポート
特別エクスポートでは、結果ブラウザからExcelファイルへの1回かぎりのデータ・エクスポートを実行できます。選択したデータがエクスポート対象となり、データが選択されていない場合は、現在の「結果ブラウザ」タブに表示可能なすべての結果がエクスポート対象となります。
「全タブをExcelにエクスポート」によって、結果ブラウザにあるすべてのタブの特別エクスポートが有効になります。結果ブラウザの各タブがExcelファイルのワークシートに書き込まれます。
特別エクスポートは、次を定義するユーザー定義可能なプリファレンス(「編集」メニューの「プリファレンス」)に従います。
エクスポート可能な最大行数
結果ブラウザの列名をヘッダーとしてエクスポートするかどうか
ファイルへの書き込み後にExcelファイルを開くかどうか。
ディレクタでは、ユーザーはプロジェクト進捗の全体を通じてノートを取得できます。ノートの使用により、ディレクタをプロジェクトに関連するすべての情報の完全なリポジトリとして使用できます。プロジェクトに従事するすべてのユーザーに対して使用可能にする必要がある情報をノートとして追加できます。
各ノートには、次の情報を保存できます。
タイトル
フリー・テキスト・ノート
(オプション)ファイル添付
ノートの作成ユーザーおよび日付/時間は、ノートの最終変更ユーザーおよび日付/時間と同様に自動的に取得されます。
次に、ノートの使用例を示します。
メイン・プロジェクト・スポンサの簡潔な担当者詳細の提供
プロジェクト計画の添付
プロジェクト定義文書の添付
複数のユーザー間に割り当てられた作業を区分するスプレッドシートの添付
プロジェクトの初期ディスカッションが含まれた電子メール・スレッドの添付
|
注意: 各添付ファイルの最大サイズは2MBです。 |
添付ファイルはデータベースにインポートされます。添付ファイルを共通ネットワーク・ディレクトリに保存して、常に最新バージョンが使用されるようにする場合は、プロジェクト・メモを追加して、プロジェクトに関連するすべての文書にアクセスする場所をユーザーに通知します。
ディレクタ内に構成されたEDQプロセスは、リアルタイム・データ監査、クレンジングおよび照合(リアルタイム重複防止など)のために、Webサービスとしてデプロイし、ソース・システムと容易に統合できます。
これにより、データに関する問題を統合データ品質Webサービスを使用してデータ入力時に防ぎ、レコードをその入力時にチェックできます。
Webサービスの作成
プロジェクト・ブラウザで「Webサービス」を右クリックし、「新規Webサービス」を選択します。
ウィザードを使用して、Webサービスのインバウンドとアウトバウンドのインタフェースを定義します。これらのインタフェースを定義した後は、リーダーがリアルタイム・プロバイダ(インバウンド・インタフェース)から読み取るように構成し、ライターがリアルタイム・コンシューマ(アウトバウンド・インタフェース)に書き込むように構成することで、Webサービスとして機能するようにプロセスを変更できます。アウトバウンド・インタフェースは、たとえば、レコードの入力時にはそのレコードをチェックするが、レスポンスは発行しないリアルタイム・モニタリング・プロセスのオプションであることに注意してください。
複数レコードの処理
一部のWebサービスでは、複数のレコードを同じメッセージの一部とみなすと便利です。たとえば、重複したレコードのシステムへの入力を防止するために、Webサービスを設定してリアルタイムでレコードを照合する場合は、Webサービスのインバウンドとアウトバウンド両方のインタフェースで「複数レコード」オプションを選択する必要があり、これによって、すべての候補レコードとともに単一のメッセージを受信し、重複の可能性があるレコードおよびその一致レベルとともに単一のメッセージを送信できます。
インバウンド・インタフェースとアウトバウンド・インタフェースで、異なる「複数レコード」オプションを設定することもできます。たとえば、単一のインバウンド・レコードを、EDQで管理されている参照データ・セットと照合する場合(顧客レコードをウォッチリストと照合する場合など)、インバウンド・インタフェースは単一のレコードの場合がありますが、アウトバウンド・インタフェースは、入力レコードが複数のリストと一致する可能性があるため、複数レコードの場合があります。
Webサービス詳細の表示
Webサービスに対するWSDLファイルのURLをコピーするには、右クリックして「WSDL URLをクリップボードにコピー」を選択します。
EDQサーバーで設定されたWebサービスはすべて1つのページから参照できるため、統合者はそれらを使用するのに必要なWSDLファイルに簡単にアクセスできます。
サーバーですべてのWebサービスを表示するには:
EDQ Launchpadに移動します。
「Webサービス」をクリックします。
通常のユーザー名とパスワードを使用してログインします。
このページからは、WebサービスのサービスURLを表示したり、可能な操作(プロバイダとコンシューマ)に生成されたWSDLファイルを表示し、自動生成されたGUIを使用してWebサービスをテストできます(サービスが実行されている場合)。
サーバー上のWebサービスをテストするための個別のJavaアプリケーションは、「(テスト)」オプションによって起動されます。これには、Webサービスのレスポンス時間をテストするためのオプションが含まれます。
|
注意: プロジェクト・アクセスに制限があるユーザーの場合、表示してテストできるのは、アクセス権があるプロジェクトのWebサービスのみです。 |
Webサービスに対するプロセスの設定
Webサービスを定義した後は、プロセスのリーダーを構成してインバウンド・インタフェース(リアルタイム・プロバイダ)からメッセージを読み取り、(必要に応じて)プロセスのライターを構成し、アウトバウンド・インタフェース(リアルタイム・コンシューマ)に接続してレスポンスを発行できます。
バッチ処理とリアルタイム処理を簡単に切り替える(たとえば、プロセスをテストするためにバッチ・モードに切り替える)には、データをデータ・インタフェースから読み取るようにプロセスを構成し、データ・インタフェース・マッピングを使用してステージング済データ・ソース(スナップショットなど)とリアルタイム・プロバイダ(Webサービスなど)を切り替えると便利です。
リアルタイム・プロセスを設計し、それをテストするためにバッチとリアルタイム実行を切り替える際の他の便利な方法は、そのプロセスに2つのライター(1つは、リアルタイム・レスポンスを発行するライター、もう1つは、インバウンド・レコードとレスポンスの両方の監査証跡をステージング済データ表に書き込むライター)を追加することです。これにより、2つの異なるジョブ(1つは、リアルタイム・ライターを有効にし、ステージング済データ・ライターを無効にするジョブ、もう1つは、ステージング済データ・ライターを有効にし、リアルタイム・ライターを無効にするジョブ)を構成できます。詳細は、「実行オプション」を参照してください。
Webサービスにリンクされるプロセスは、リアルタイム・レスポンス・プロセス(インバウンド・メッセージを受け入れて、リアルタイム・レスポンスを発行する)またはリアルタイム・モニタリング・プロセス(レコードの追加時にそのレコードをチェックするが、レスポンスは発行しない)のいずれかになります。プロセスは連続して実行される可能性が高いため、定期的に結果が書き込まれる間隔モードで実行することをお薦めします。
Webサービスのテスト
EDQ Launchpadからアクセス可能なJavaアプリケーションを使用すると、統合作業の前に、実行中のWebサービスをテストできます。このアプリケーションにアクセスするには、LaunchpadからWebサービスを表示する際に「(テスト)」オプションをクリックします。有効なEDQユーザー名とパスワードを使用して、再度ログインする必要があります。
Launchpadで選択したWebサービスがデフォルトで選択されますが、上部の「設定」セクションにある「プロジェクト」ドロップダウンと「Webサービス」ドロップダウンで異なるサービスを選択してテストできます。
Webサービスが変更されている場合は、「WSDLの取得」ボタンで最新のWSDLファイルを取得します。これにより、テスト・アプリケーションを続行しながらWebサービスの定義を編集できます。
残りの画面には、「イン」セクションと「アウト」セクションが表示されます。ここでは、リクエストを設定して、Webサービスに送信し、レスポンスを確認できます。
リクエストに応答するためのサービスのレスポンス時間は、ミリ秒で測定されます。
リクエストは必要に応じて複数回送信でき、レスポンスの平均時間は図で示すことができます。それには、「タイミング・テスト」ボタンをクリックしてリクエストの送信回数を入力し、(必要に応じて)リクエストの送信間隔をミリ秒で入力します。次に、「実行」ボタンをクリックしてリクエストを送信します。「ステータス」セクションは、リクエストの送信に従って更新されます。
次に、「チャート」リンクをクリックしてレスポンスを示す図を生成すると、最も遅いレスポンスと最も早いレスポンスの発生時期を確認できます。
レコードの追加
複数レコードが予測されるWebサービス、つまり、「複数レコード」オプションが選択された状態で作成されたWebサービス(たとえば、一連の候補から一致レコードを識別するためのWebサービス)の場合は、「レコードの追加」ボタンを使用して、必要な数のレコードをリクエストの送信前に追加できます。「レコードの追加」ボタンは、単一のレコードが予測されるWebサービスが選択されている場合は無効です。
代替統合方法(JMS)
EDQでは、JMS (Java Messaging Service)を介したリアルタイム機能を使用した統合もサポートされています。この場合、リアルタイム・プロバイダとコンシューマは手動で設定する必要があります。
問題を使用することで、EDQのユーザーはデータ分析時の主要な結果レコードを保持でき、プロジェクトで作業を複数のユーザーに割り当てて追跡する方法も提供されます。
問題の一般的な使用方法は、データ監査の実行時に検出されたインテリジェンスを取得して、完了が必要なアクション(たとえば、クレンジングによる解決が必要なデータ品質問題における複数の方法)のリストと照合することです。
特に、EDQの様々なユーザーを様々なアクティビティに特化させることができます。たとえば、監査ユーザーはデータを分析し、情報および未処理の問題を専門のデータ・クレンジング・ユーザーに渡すことができます。
現在ログオンしているユーザーに割り当てられている問題は、ディレクタのツールバーに示されます。
この通知をクリックすると、問題マネージャ・アプリケーションが開きます。詳細は、「問題マネージャ」を参照してください。
問題は、結果ブラウザの結果から作成され、レビューする照合結果が割り当てられます。たとえば、郵便番号属性に対するQuickstatsプロファイラの結果に基づいて問題を作成するには、結果を右クリックして「問題の作成」を選択します。
問題作成ダイアログが表示されます。問題は、その問題を作成したプロセッサに自動的にリンクされます。その後、問題を別のユーザーに割り当てると、そのユーザーが関連プロセッサの結果に直接リンクできるようになります。
照合結果レビュー時の問題の使用[一致レビューのみ]
問題は、一致レビュー・アプリケーションでレビューする照合結果を割り当てるときにも使用されます。この場合、レビューする結果を割り当てるユーザーが問題を作成し、特定ユーザーまたはユーザーのグループに割り当てます。問題には、スタンドアロンのレビュー・アプリケーションを開く際に使用できるURLが含まれているため、レビュー担当ユーザーには、結果の生成に使用するプロセスの構成へのアクセス権はありません。
詳細は、「一致レビューの使用」を参照してください。
問題に関する電子メール通知
管理者は、ユーザーが自分に関係する問題が作成または変更された場合に電子メールを受信するようにEDQを構成できます。
これを実行するには、管理者は、oedq_local_homeディレクトリのnotification/smtpサブフォルダにあるmail.propertiesファイルに有効なSMTPサーバー詳細を設定する必要があります。同じSMTPサーバー詳細がジョブ通知にも使用されます。EDQサーバー管理者ガイドを参照してください。
問題に関する電子メール通知のレイアウトと内容を定義した、デフォルト・テンプレートが用意されています。これは必要に応じて変更できます。
電子メールには、問題を開くためのリンクが含まれます。結果から発生した問題の場合は、リンクによってEDQ問題マネージャが開き、照合結果をレビューするために割り当てられた問題の場合は、関連する結果が選択された状態で一致レビュー・アプリケーションが開きます。
問題に関する電子メールが有効な場合、EDQ (ユーザー構成ページ)で設定された電子メール・アドレスを持つユーザーは、次の表に示す電子メールを受信します。これらのイベントの多くが単一のアクションで発生する場合(たとえば、問題がユーザーによって作成され、そのユーザーに割り当てられた場合)は、単一の電子メールのみが送信されます。
スナップショットは、データ・ストアにステージングされたデータのコピーで、1つ以上のプロセスで使用されます。
操作するデータをコピーする必要はありませんが、コピーすると、プロセッサのメトリックをドリルダウンして、処理の各ステージでデータ自体を確認できるため、ディレクタの結果ブラウザの表示機能へのアクセスが大幅に改善されます。
一般的に、監査プロセスで作業するときやデータ・クレンジングのルールを定義するときはデータのコピーを作成しますが、本番でデータ・クレンジング・プロセスを実行するときは、実行時間を短縮するためにストリーミング・モードで(つまり、リポジトリにデータをコピーせずに)プロセスを実行します。
スナップショットに関する次のプロパティを定義できます。
ソース・データのデータ・ストア(EDQホストに登録済の接続先データ・ストアのリスト)
スナップショットを作成する表またはデータ・インタフェース(または、新しいデータ・インタフェースのスナップショットを作成するSQLを指定できます)
スナップショットに含める列
スナップショットでソートおよびフィルタを有効にするかどうか。およびどの列で有効にするか。詳細は、「スナップショットでのソートおよびフィルタの有効化」を参照してください。
スナップショットでの基本的なフィルタ・オプション(または、データベース表からスナップショットを作成する独自のSQL WHERE句を記述できます)
(オプション)データのサンプリング(最初のnレコード、オフセット後の最初のnレコード、100レコードごとに1レコードなど)
(オプション)非データ処理
スナップショット構成を追加した後は、プロジェクト・ブラウザでスナップショットを右クリックし、スナップショットの実行を選択することでスナップショットを実行できます。
または、そのスナップショットを使用する最初のプロセスの実行時にスナップショットの実行を選択できます。
スナップショットの共有
スナップショットは、プロジェクト・レベルで共有されます。これは、同じプロジェクトの多数のプロセスで同じスナップショットが使用されるが、異なるプロジェクトのプロセスでは使用されないことを意味します。スナップショット構成をコピーして新しいプロジェクトに貼り付けた場合は、独立したスナップショットとなり、プロセスでステージング済データを使用するには、そのスナップショットを実行する必要があります(データ・ソースからデータをストリーミングしていない場合)。
スナップショットの編集/削除
スナップショットを編集するには(操作するサンプルのサイズを変更するなど)、右クリック・メニューのオプションを使用します。
スナップショット名の変更を選択し、そのスナップショットがプロセスで使用されている場合は、そのプロセスが無効になることに注意してください。名前が変更されたスナップショットが自動的に参照されることはありません。プロセスではスナップショットが名前で参照されるため、内部IDが異なっていてもサーバー間で構成を簡単に移動できます。
必要に応じて、右クリック・メニューのオプションを使用してスナップショットを削除することもできます。スナップショットが他の構成オブジェクトで使用されている場合、それらのオブジェクトでエラーが発生している可能性があるため、警告が表示されます。
通常はすべての列のスナップショットを作成し、リーダーを構成することによって、特定のプロセスで使用する列を選択することをお薦めします。
非データ処理
スナップショットの一環としてデータをリポジトリにコピーする際は、様々な形式の非データを正規化できます。これを実行するには、非データとみなされる複数の文字をリストした参照データ・マップを指定します。通常、これらの文字は印刷不可能な文字です(ASCII文字の0-32など)。データ値が非データ文字のみで構成されている場合は、常に単一値に正規化されます。デフォルトの非データ処理参照データでは、すべての非データ値がNULL値に正規化されます。これにより、特定の種類の値が含まれているデータと、値が含まれていないデータを明確に区別できます。
スナップショット・タイプ
スナップショットには、2つのタイプがあります。
サーバー側スナップショット(サーバーベースのデータ・ストアからのスナップショット)。
クライアント側スナップショット(クライアントベースのデータ・ストアからのスナップショット)。
サーバー側スナップショットは、EDQホスト・サーバーがコピーする必要があるデータにアクセスできる場合(たとえば、同じマシン上に存在するか、ホストとのローカル・ネットワーク接続がある別のマシンに存在する場合)に使用されます。
サーバー側スナップショットは、サーバーがデータ・ソースにアクセスできるときはいつでも、手動でまたは自動的に(たとえば、スケジュールされたジョブの一環として)再ロードできます。これは、プロセスの実行がスケジュールされている場合は、スナップショットが自動的に再実行され、データの変更内容が必要に応じて取得されることを意味します。
クライアント側スナップショットは、サーバー経由ではなくクライアント経由でアクセスされるデータのソースに対して使用されます。たとえば、操作するデータが、EDQホストがインストールされていないクライアント・マシン(つまり、クライアントはネットワーク上のEDQホストにアクセスする)に格納されている場合です。この場合、データはクライアント上のコネクタ経由でEDQホストのリポジトリにコピーされます。
クライアント側スナップショットは、接続されたクライアント・マシン上で、データ・ソースへのアクセス権があるユーザーが手動でのみ(つまり、スナップショットを右クリックして「実行」を選択することで)再ロードできます。
スナップショットの取消
実行中のスナップショットは、右クリック・オプションを使用して取り消すことができます。取り消すと、プロジェクト・ブラウザ・ツリーのスナップショット・アイコン上に、取消インジケータが重なって表示されます。そのスナップショットが後で正常に再実行されると、取消インジケータが削除されます。