| Oracle® Fusion Middleware Oracle Data Integratorの管理 12c (12.2.1.2.0) E82750-01 |
|

 前 |
 次 |
この章では、Oracle Data Integratorにおけるトポロジの設定方法について説明します。
この章には次の項が含まれます:
|
関連項目: 『Oracle Data Integratorでの統合プロジェクトの開発』の「Oracle Data Integratorトポロジの概要」。 |
次のステップは、トポロジを作成するためのガイドラインです。初期設定後にトポロジをいつでも変更できます。
様々な環境に対応するコンテキストを作成します。「コンテキストの作成」を参照してください。
Oracle Data Integratorで使用されるサーバーに対応するデータ・サーバーを作成します。「データ・サーバーの作成」を参照してください。
データ・サーバーごとに、Oracle Data Integratorと統合されるデータが含まれるスキーマに対応する物理スキーマを作成します。「物理スキーマの作成」を参照してください。
論理スキーマを作成し、コンテキストでこれらを物理スキーマと関連付けます。「論理スキーマの作成」を参照してください。
情報システムにインストールされたスタンドアロン・エージェント、スタンドアロン・コロケート・エージェントまたはJava EEエージェントに対応する物理エージェントを作成します。「物理エージェントの作成」を参照してください。
論理エージェントを作成し、コンテキストでこれらを物理エージェントと関連付けます。「論理エージェントの作成」を参照してください。
|
注意: 「新規モデルとトポロジ・オブジェクト」ウィザードを使用して、モデルを作成し、それをトポロジ・オブジェクトと関連付けることができます(作業リポジトリに接続されている場合)。詳細は、『Oracle Data Integratorでの統合プロジェクトの開発』のモデルおよびトポロジ・オブジェクトの作成に関する項を参照してください。 |
コンテキストを作成するには:
トポロジ・ナビゲータで、「コンテキスト」ナビゲーション・ツリーを展開します。
ナビゲーション・ツリー・ヘッダーで「新規コンテキスト」をクリックします。
次の各フィールドに値を入力します。
名前: Oracle Data Integratorグラフィカル・インタフェースに表示されるコンテキストの名前。
コード: 様々なリポジトリ間でのコンテキストの参照および識別を可能にする、コンテキストのコード。
パスワード: グラフィカル・インタフェースでユーザー・リクエストがこのコンテキストに切り替わった場合にリクエストされるパスワード。クリティカル・コンテキスト(本番データを示すコンテキストなど)にはパスワードを使用することをお薦めします。
デザイナ・ナビゲータまたはオペレータ・ナビゲータの各種リストで、このコンテキストをデフォルトで表示する必要がある場合は、「デフォルト」を選択します。
「ファイル」メニューから「保存」をクリックします。
データ・サーバーは、統合フローでOracle Data Integratorによりアクセスされるデータベース、JMSサーバー・インスタンス、スクリプト・エンジンまたはファイル・システムなどに対応します。データ・サーバーでは、物理スキーマの形式で下位区分が作成されます。
|
注意: よく使用されるテクノロジのデータ・サーバー作成方法の詳細は、『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』を参照してください。 |
データ・サーバーの作成時には、次のガイドラインに従うことをお薦めします。
テクノロジ固有の要件の確認
一部のテクノロジでは、次のような要素のインストールおよび構成が必要です。
JDBCドライバのインストール。詳細は、『Oracle Data Integratorのインストールと構成』を参照してください。
クライアント・コネクタのインストール
データ・ソースの構成
データ・サーバーによって接続しているテクノロジのドキュメントおよび『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』を参照してください。接続情報は、テクノロジに応じて変更される場合があります。提供されているサーバー・ドキュメントを参照し、接続方法を定義するようサーバー管理者に連絡してください。
Oracle Data Integratorユーザーの作成
Oracle Data Integratorで使用される各データベース・エンジンについて、このデータ・サーバー上にODI専用のユーザーを作成することをお薦めします(通常はODI_TEMP)。
ユーザー権限を付与して、次の操作を実行します。
自分のスキーマでオブジェクトを作成または削除したり、データ操作を実行します。
統合プロセスに必要な操作に従って、このデータ・サーバーのその他のスキーマのオブジェクトにデータを取り込みます。
このユーザーは、次のように使用する必要があります:
このユーザーの名前/パスワードをデータ・サーバーのユーザー/パスワード定義で使用します。
このユーザーのスキーマを、このサーバー上のすべてのデータ・スキーマの作業スキーマとして使用します。
データ・サーバーを作成するには:
トポロジ・ナビゲータで、「物理アーキテクチャ」ナビゲーション・ツリーにある「テクノロジ」ノードを展開します。
|
ヒント: 「物理アーキテクチャ」ナビゲーション・ツリーに表示されるテクノロジのリストは、非常に長くなる可能性があります。表示されるテクノロジ・リストを絞り込むために、「トポロジ・ナビゲータ」ツールバー・メニューから「未使用のテクノロジを非表示」を選択して、未使用のテクノロジを非表示することができます。 |
データ・サーバーを作成するテクノロジを選択します。
右クリックして「新規データ・サーバー」を選択します。
「定義」タブで、次のフィールドに値を入力します:
名前: Oracle Data Integratorに表示されるデータ・サーバーの名前。
データ・サーバーの名前を付ける場合は、命名標準の<TECHNOLOGY_NAME>_<SERVER_NAME>を使用することをお薦めします。
...(データ・サーバー): これは他のデータ・サーバーで識別のために使用されるデータ・サーバーの物理名です。データ・サーバーを自然な方法で相互接続できる場合はこの名前を入力します。このパラメータは、一部のテクノロジでは必須ではありません。
たとえば、Oracleの場合、この名前はインスタンス名に相当しており、DBLinkを使用して別のOracleデータ・サーバーからこのデータ・サーバーにアクセスする際に使用されます。
ユーザー/パスワード: データ・サーバーに接続するためのユーザー名およびパスワード。このパラメータは、ファイル・テクノロジなど一部のテクノロジでは必須ではありません。
テクノロジに応じて、ログイン、ユーザーまたはアカウントを指定できます。JNDIプロトコルを使用した一部の接続については、ユーザー名およびそれに関連するパスワードはオプションです(LDAPディレクトリで指定されている場合)。
データ・サーバーに対して接続パラメータを定義します。
JDBCによって直接テクノロジにアクセスできます。あるいは、このデータ・サーバーへのJDBC接続がJNDIディレクトリから提供される場合もあります。
JNDIディレクトリによってテクノロジにアクセスする場合、次の操作を行います。
「定義」タブで「JNDI接続」を選択します。
「JNDI」タブに移動し、次のフィールドに入力します:
| フィールド | 説明 |
|---|---|
| JNDI認証 |
|
| JNDIユーザー/パスワード | JNDIディレクトリに接続するユーザー/パスワード |
| JNDIプロトコル | 接続に使用されるプロトコル
最も一般的なプロトコルのみをここにリストしています。これは完全なリストではありません。
|
| JNDIドライバ | JNDI接続を可能にするドライバ
Sun LDAPディレクトリの例: |
| JNDI URL | JNDI接続を可能にするURL
例: |
| JNDIリソース | 接続パラメータを含むディレクトリ要素
例: |
JDBCによってテクノロジに接続する場合、次の操作を行います。
「JNDI接続」ボックスを選択解除します。
「JDBC」タブに移動し、次のフィールドに入力します:
| フィールド | 説明 |
|---|---|
| JDBCドライバ | データ・サーバーへの接続に使用されるJDBCドライバの名前 |
| JDBC URL | データ・サーバーに接続できるURL |
事前定義済のJDBCドライバおよびURLのリストを取得するには、使用可能なドライバの表示または「URLサンプルの表示」をクリックします。
「定義」タブで、残りの各フィールドに値を入力します。
配列フェッチ・サイズ: 大量のデータをデータ・サーバーから読み取る際、Oracle Data Integratorは連続的なレコードのバッチをフェッチします。この値は、Oracle Data Integratorがデータ・サーバーとの1回の通信でリクエストする行(読み取るレコード)の数です。
バッチ更新サイズ: 大量のデータをデータ・サーバーに書き込む際、Oracle Data Integratorは連続的なレコードのバッチを挿入します。この値は、Oracle Data Integratorが1回のINSERTコマンドでリクエストする行(書き込むレコード)の数です。
|
注意: 配列フェッチおよびバッチ更新のパラメータは、JDBCの使用時のみアクセス可能です。ただし、すべてのJDBCドライバが同じ値を受け付けるとは限りません。場合によっては、これらのパラメータを空白にすることが望ましい場合もあります。 |
|
注意: 配列フェッチおよびバッチ更新の値に指定する数字が大きいほど、データ・サーバーとOracle Data Integrator間のやりとりが少なくなります。ただし、各やりとりでリカバリされるデータ量が増加するのに伴い、Oracle Data Integratorマシンにかかる負荷が大きくなります。配列フェッチの管理と同じように、バッチ更新の管理は最適化の範囲に含まれます。デフォルト値(30)から始めて、それ以上のパフォーマンス向上が認められないところまで値を10ずつ増やすことをお薦めします。 |
ターゲットの並列度: ロード・タスクに対して許可されるスレッドの数を示します。デフォルト値は1です。許可される最大スレッド数は99です。
|
注意: 「ターゲットの並列度」を大きくした場合、ターゲット環境や、ターゲット・スレッド/接続の最大数をサポートするだめのリソースが十分にあるかどうかによって、その結果は異なります。配列フェッチおよびバッチ更新のサイズに関しては、環境に最も適した値を決定するためのベンチマークを実行する必要があります。個々のソース・スレッドおよびターゲット・スレッドのパフォーマンスの詳細は、オペレータのロード・タスクの「実行の詳細」セクションに表示されます。「実行」の値はJDBC操作の実行にかかった時間であり、待機の値は、ソースがターゲットによる行のロードを待機している時間、またはターゲットがソースによる行の提供を待機している時間です。また、行のロード順序に依存している場合、たとえば、順序やタイムスタンプなどを使用している場合は、「ターゲットの並列度」の値を1より大きくしないでください。これは、ソース行の処理とロードが、多数のターゲット・スレッドの1つによって中間的に行われるためです。 |
「ファイル」メニューで、「保存」をクリックしてデータ・サーバーの作成を検証します。
次の操作はオプションです。
接続プロパティの追加
これらのプロパティは、オプションの構成パラメータを指定するために、接続の作成時に渡されます。各プロパティは(キー、値の)ペアです。
JDBCの場合: これらのプロパティは、使用されるドライバによって決まります。使用可能なプロパティのリストについては、ドライバのドキュメントを参照してください。JDBCでは、接続用のユーザーおよびパスワードを「定義」タブではなくここで指定できます。
JNDIの場合: これらのプロパティは、使用されるリソースによって決まります。
データ・サーバーに接続プロパティを追加するには:
「プロパティ」タブで、「プロパティを追加」をクリックします。
このプロパティを識別するキーを指定します。このキーは大/小文字が区別されます。
プロパティの値を指定します。
「ファイル」メニューから「保存」をクリックします。
データソースの定義
「データソース」タブでは、アプリケーション・サーバーにデプロイされたOracle Data Integrator Java EEエージェントでこのデータ・サーバーへの接続に使用されるJDBCデータソースを定義できます。スタンドアロン・エージェントにはデータソースは適用されません。
データソースの定義は必須ではありませんが、定義することで、Java EEエージェントはアプリケーション・サーバーで使用可能なデータソースおよび接続プーリングの機能の恩恵を受けることができます。接続プーリングにより、複数セッション間で接続を再利用できます。Java EEエージェントで指定のデータ・サーバーに対してデータソースが宣言されていない場合、このJava EEエージェントは常に直接JDBC接続を使用してデータ・サーバーに接続します。アプリケーション・サーバーのデータソースはいずれも使用しません。
Oracle Data Integratorでデータソースを定義する前に、次の点に注意してください。
WebLogic Serverのデータソースは、接続プール構成で「文キャッシュ・サイズ」パラメータを0に設定して作成する必要があります。文キャッシュはデータ統合のパフォーマンスに若干の影響を及ぼし、一部のJDBCドライバでデータの切捨てなどの予期しない結果を招く可能性があります。これはソースおよびターゲットのデータ・サーバーへのデータ接続にのみ影響し、リポジトリ接続には影響しません。
接続プーリングをデータソースで使用する場合、プロシージャおよびナレッジ・モジュールでALTER SESSION文を使用しないことをお薦めします。接続でALTER SESSION文が必要な場合は、関連データソースでの接続プーリングを無効化することをお薦めします。
データ・サーバーに対してJDBCデータソースを定義するには:
データ・サーバー・エディタの「データソース」タブで、「データソースの追加」をクリックします。
「エージェント」フィールドで物理エージェントを選択します。
「JNDI名」フィールドにデータソース名を入力します。
この名前は、アプリケーション・サーバーのデータソース名と一致する必要があるので注意してください。
環境命名コンテキスト(ENC)を使用する場合は、「JNDI標準」を選択します。
「JNDI標準」を選択した場合、Oracle Data Integratorでは、アプリケーション・サーバーのJNDIディレクトリでデータソースを識別するために、データソース名の前に文字列java:comp/env/が自動的に付けられます。
JNDI標準は、Oracle WebLogic Serverではサポートされておらず、グローバル・データ・ソースに対してはサポートされていないことに注意してください。
「ファイル」メニューから「保存」をクリックします。
Java EEエージェントに対してデータソースを定義した後、Java EEエージェントがデプロイされているアプリケーション・サーバーでデータソースを作成する必要があります。アプリケーション・サーバーでデータソースを作成するには、次のような複数の方法があります。
アプリケーション・サーバー・コンソールからデータ・ソースを構成します。詳細は、アプリケーション・サーバーのドキュメントを参照してください。
エージェントのアプリケーション・サーバーにおけるOracle Data Integratorからのデータソースのデプロイ。
接続時または切断時のコマンドの設定
「接続/切断時」タブでは、物理アーキテクチャに定義されているデータ・サーバーへの接続の作成時またはクローズ時に実行するSQLコマンドを定義できます。
接続時のコマンドは、ODIコンポーネント(ODIクライアント・コンポーネントを含む)がこのデータ・サーバーに接続されるたびに実行されます。
切断時のコマンドは、ODIコンポーネント(ODIクライアント・コンポーネントを含む)がこのデータ・サーバーから切断されるたびに実行されます。
これらのSQLコマンドは、データ・サーバー定義とともにマスター・リポジトリに格納されます。
接続時または切断時のコマンドを設定する前に、次にことに注意してください。
接続時および切断時のコマンドは、テクノロジ・タイプが「データベース」(JDBC)のデータ・サーバーでのみサポートされます。
接続時および切断時のコマンドは、データソースを使用している場合も実行されます。この場合、コマンドは、接続プールに対して接続を取得および解放するときに実行されます。
置換APIがサポートされています。設計時タグ<%はサポートされていません。実行時タグ<?および<@はサポートされています。
置換モードではグローバル変数(#GLOBAL.<VAR_NAMEまたは#<VAR_NAME)のみがサポートされています。詳細は、変数の有効範囲を参照してください。式エディタには、現在のデータ・サーバーに有効な変数のみが表示されます。
接続時および切断時のコマンドに使用される変数は、実行時にのみ置換され、その時点でセッションが開始します。データ・サーバーの接続をテストする場合や、このデータ・サーバーでデータの表示操作を実行する場合、変数を使用するコマンドは失敗となります。これらの変数はシナリオで宣言してください。
Oracle Data Integratorの順序は、接続時および切断時のコマンドではサポートされていません。
接続時および切断時のコマンドには、次の使用方法があります。
セッションが実行されると、データ・サーバーへの接続が開きます。コマンド「接続時」が定義されているデータ・サーバーで接続が開くたびに、「接続時のコマンド」と呼ばれる特定のステップの下にタスクが作成されます。このタスクには、接続の確立先となるデータ・サーバー、およびこのデータ・サーバーへの接続を作成するステップとタスクに基づいて名前が設定されます。このタスクには、接続時のコマンドのコードが格納されます。
セッションが完了すると、データ・サーバーへの接続はすべてクローズされます。切断時のコマンドが定義されているデータ・サーバーで接続がクローズされるたびに、「切断時のコマンド」という特定のステップにタスクが作成されます。このタスクには、切断されるデータ・サーバー、およびこのデータ・サーバーへの接続を切り離したステップとタスクに基づいて名前が設定されます。これには、切断時のコマンドのコードが格納されます。
ODI StudioまたはODIコンソールで行われる操作が、データベース・サーバーへの接続を必要とする場合(データの表示、テスト接続など)、このコマンドに「クライアント・トランザクション」を選択すると、接続時/切断時のコマンドも実行されます。
|
注意: オペレータ・ナビゲータに接続時および切断時ステップを表示するかどうかを指定できます。ユーザー・パラメータ「接続時および切断時ステップを非表示」をYesに設定すると、接続時および切断時ステップは表示されません。 |
接続時または切断時のコマンドを設定するには:
データ・サーバー・エディタの「接続/切断時」タブで、「接続時」セクションまたは「切断時」セクションの「式エディタを起動します」をクリックします。
式エディタで、SQLコマンドを入力します。
|
注意: 式エディタには、データ・サーバーのテクノロジで使用可能な置換メソッドとキーワードのみが表示されます。グローバル変数が表示されるのは、作業リポジトリへの接続が使用できる場合のみであることに注意してください。 |
「OK」をクリックします。「コマンド」フィールドにSQLコマンドが表示されます。
オプションで、コマンドの実行後に接続をコミットする場合は「コミット」を選択します。「実行」リストで「自動コミット」または「クライアント・トランザクション」が選択されている場合、この値は無視されます。
オプションで、コマンド実行時に発生した例外を無視する場合は、「エラーの無視」を選択します。「エラーの無視」が選択されていない場合、コール操作はエラー・ステータスで終了します。セッションの途中で失敗となった、「エラーの無視」が選択されているコマンドは、警告状態のタスクとして表示されます。
「ログ・レベル」リストから、接続または切断コマンドのログ・レベル(1から6)を選択します。実行時には、コマンドのログ・レベルに基づいてコマンドをセッション・ログに保存できます。デフォルトは3です。
「実行」リストから、コマンドを実行するトランザクションを選択します。
|
注意: 0から9のトランザクションおよび「自動コミット」トランザクションは、(プロシージャまたはナレッジ・モジュールによる)セッションで作成された接続に相当します。「クライアント・トランザクション」は、クライアント・コンポーネント(ODI ConsoleおよびStudio)に相当します。 |
すべてのトランザクションを選択または選択解除する場合は、「すべて選択」または「すべて選択解除」を選択できます。
「ファイル」メニューから「保存」をクリックします。
接続をテストする準備が整いました。詳細は、「データ・サーバー接続のテスト」を参照してください。
トポロジの定義を続行する前に、データ・サーバー接続をテストすることをお薦めします。
データ・サーバーへの接続をテストするには:
トポロジ・ナビゲータで、「物理アーキテクチャ」ナビゲーション・ツリーの「テクノロジ」ノードを展開してから、データ・サーバーが含まれるテクノロジを展開します。
テストするデータ・サーバーをダブルクリックします。データ・サーバー・エディタが開きます。
「テスト接続」をクリックします。
「テスト接続」ダイアログが表示されます。
テストを実行するエージェントを選択します。「ローカル(エージェントなし)」は、ローカル・ステーションが接続を試行することを示します。
「詳細」をクリックし、データベースおよびJDBCドライバの特性および能力を取得します。
「テスト」をクリックし、テストを起動します。
テストが機能した場合、「接続が正常に実行されました」というウィンドウが表示され、機能しない場合、エラー・ウィンドウが表示されます。接続失敗の原因の詳細を取得するには、このエラー・ウィンドウの「詳細」ボタンを使用します。
Oracle Data Integratorの物理スキーマは、次のスキーマのペアに相当します。
(データ)スキーマ。ここで、Oracle Data Integratorはマッピングのソースおよびターゲット・データ構造を検索します。
作業スキーマ。ここで、Oracle Data Integratorはデータ・スキーマに含まれるソースおよびターゲットに関連付けられた一時作業データ構造を作成し、操作できます。
よく使用されるテクノロジの物理スキーマ作成方法の詳細は、『Oracle Data Integrator接続およびナレッジ・モジュール・ガイド』を参照してください。
物理スキーマを作成する前に、次の点に注意してください。
テクノロジの中には、複数のスキーマをサポートしないものがあります。一部のテクノロジでは、1つのデータ・サーバーのスキーマが1つのみであるため、作業スキーマおよびデータ・スキーマを指定しません。
一部のテクノロジでは、一時構造の作成をサポートしていません。これらのテクノロジでは、作業スキーマは使用できません。
物理スキーマが関連付けられているデータ・サーバーで指定されたユーザーには、このデータ・サーバーに関連付けられたスキーマでの適切な権限が必要です。
OWBテクノロジの物理スキーマでは、OWBワークスペースのみが表示され、選択可能になります。
物理スキーマを作成するには:
データ・サーバーを選択し、右クリックして「新規物理スキーマ」を選択します。物理スキーマ・エディタが表示されます。
テクノロジが複数のスキーマをサポートしている場合、次の操作を行います。
...(スキーマ)で、このData Integrator物理スキーマについてデータ・スキーマを選択または入力します。テクノロジがスキーマ・リストをサポートしている場合、スキーマのリストが表示されます。
...(作業スキーマ)で、このData Integrator物理スキーマについて作業スキーマを選択または入力します。テクノロジがスキーマ・リストをサポートしている場合、スキーマのリストが表示されます。
このスキーマをこのデータ・サーバーのデフォルト・スキーマにする場合は、「デフォルト」ボックスを選択します(最初の物理スキーマが常にデフォルト・スキーマとなります)。
「コンテキスト」タブに移動します。
「追加」をクリックします。
この新規物理スキーマに対して、コンテキストおよび既存の論理スキーマを選択します。
このテクノロジの論理スキーマが存在しない場合、このエディタから作成できます。
論理スキーマを作成するには:
左側の列で既存のコンテキストを選択します。
右側の列で論理スキーマ名を入力します。
このエディタを保存する際に、この論理スキーマは自動的に作成され、このコンテキスト内のこの物理スキーマに関連付けられます。
「ファイル」メニューから「保存」をクリックします。
論理スキーマを作成するには:
トポロジ・ナビゲータで、「論理アーキテクチャ」ナビゲーション・ツリーにある「テクノロジ」ノードを展開します。
論理スキーマを関連付けるテクノロジを選択します。
右クリックして「新規論理スキーマ」を選択します。
「スキーマ名」を入力します。
左側の列の各コンテキストについて、右側の列で既存の物理スキーマを選択します。この物理スキーマはこのコンテキストの論理スキーマと自動的に関連付けられます。必要なすべてのコンテキストについてこの操作を繰り返します。
「ファイル」メニューから「保存」をクリックします。
物理エージェントを作成するには:
トポロジ・ナビゲータで、「物理アーキテクチャ」ナビゲーション・ツリーにある「エージェント」ノードを右クリックします。
「新規エージェント」を選択します。
次の各フィールドに値を入力します。
名前: Javaグラフィカル・インタフェースで使用されるエージェントの名前。
|
注意: Internalというエージェント名は使用しないでください。Oracle Data Integratorでは、内部エージェントを使用してセッションを実行するときに「内部」エージェントを使用するため、「内部」というエージェント名は予約されています。 |
ホスト: エージェントが起動されるマシンのネットワーク名またはIPアドレス。
ポート: エージェントで使用されるリスニング・ポート。デフォルトでは、このポートは20910です。
Webアプリケーション・コンテキスト: アプリケーション・サーバーにデプロイされたJava EEエージェントに対応するWebアプリケーションの名前。スタンドアロン・エージェントおよびスタンドアロン・コロケート・エージェントの場合、このフィールドはoraclediagentに設定する必要があります。
「プロトコル」はエージェント接続に使用するプロトコルです。使用可能な値は、httpまたはhttpsです。デフォルトはhttpです。
このエージェントでサポートされる最大セッション数。
スレッドの最大数: ODIエージェントが任意の時点で使用できる最大スレッド数を制御します。お使いのシステム・リソースおよびCPUの容量にあわせて調整してください。
セッション当たりの最大スレッド数: ODIでは複数のスレッドを持つセッションの実行をサポートしています。この値は、単一セッション実行時の最大並列度を制限します。
セッション・ブループリント・キャッシュ管理:
最大キャッシュ・エントリ: パフォーマンスの場合、セッション・ブループリントはキャッシュされます。このパラメータを調整して、ブループリント・キャッシュによるJVMメモリー消費を制御します。
未使用ブループリント・ライフタイム(秒): キャッシュからブループリントをフラッシュするためのアイドル時間間隔。
ロード・バランシングを設定する場合、「ロード・バランシング」タブに移動し、現在のエージェントが実行を委任できるリンク済物理エージェントのセットを選択します。詳細は、「ロード・バランシングの設定」を参照してください。
エージェントが起動されている場合、「テスト」をクリックします。「接続に成功」ダイアログが表示されます。
「はい」をクリックします。
Oracle Data Integratorを使用すると、ビッグ・データの統合、Oozieワークフローのデプロイと実行、およびPig LatinやSparkなどの言語でのコードの生成を行うことができます。
次のステップは、ビッグ・データを使用するためのトポロジを設定するためのガイドラインです。
表3-1 ビッグ・データの使用
| タスク | ドキュメント |
|---|---|
|
Hadoopデータを統合する環境の設定 |
『Oracle Data Integratorとのビッグ・データの統合』のHadoopデータを統合するための環境の設定に関する項を参照してください。 |
|
Hive、HDFSおよびHBaseなどのビッグ・データ・テクノロジ用のデータ・サーバーの設定 |
『Oracle Data Integratorとのビッグ・データの統合』の次の各項を参照してください。 ファイル・データソースの設定 Hiveデータソースの設定 HBaseデータソースの設定 |
|
Oracle Data Integrator内でOozieワークフローを実行するためのOozieエンジンの設定 |
『Oracle Data Integratorとのビッグ・データの統合』のOozieランタイム・エンジンの設定および初期化に関する項を参照してください。 |
|
Pig LatinおよびSparkコードを生成するためのHive、PigおよびSparkトポロジ・オブジェクトの設定 |
『Oracle Data Integratorとのビッグ・データの統合』の次の各項を参照してください。 Hiveデータ・サーバーの設定 Hive物理スキーマの作成 Pigデータ・サーバーの設定 Pig物理スキーマの作成 Sparkデータ・サーバーの設定 Spark物理スキーマの作成 |
この項では、スタンドアロン・エージェント、スタンドアロン・コロケート・エージェントおよびJava EEエージェントの使用方法と、ロード・バランシングの処理方法について説明します。Oracle Data Integratorエージェントの詳細は、『Oracle Data Integratorの理解』のランタイム・エージェントに関する項を参照してください。
スタンドアロン・エージェントの管理では、次の各項で説明するアクションを実行します。
|
注意: この項で説明するタスクの実行に必要なエージェント・コマンド行スクリプトは、Oracle Data Integratorスタンドアロン・エージェントがインストールされている場合のみ使用できます。スタンドアロン・エージェントのインストール方法の詳細は、『Oracle Data Integratorのインストールと構成』を参照してください。 |
スタンドアロン・エージェントの構成については、『Oracle Data Integratorのインストールと構成』に説明があります。次を参照してください。
「Oracle Data Integratorのインストール」
「Oracle Data Integratorマスターおよび作業リポジトリ・スキーマの作成」
「スタンドアロン・エージェントのドメインの構成」
スタンドアロン・エージェントは、事前定義済のスケジュールどおりに、または要求に応じて、シナリオを実行できます。スタンドアロン・エージェントを起動する手順は、『Oracle Data Integratorのインストールと構成』のノード・マネージャを使用したスタンドアロン・エージェントの起動に関する項を参照してください。
スタンドアロン・コロケート・エージェントの管理では、次の各項で説明するアクションを実行します。
|
注意: スタンドアロン・コロケート・エージェントは、WebLogicドメイン内に構成されて管理サーバーにより管理されるスタンドアロン・エージェントです。WebLogicドメインでは、Oracle Fusion Middleware Infrastructureのサービスをエージェントの管理に使用できます。詳細は、『Oracle Data Integratorのインストールと構成』のスタンドアロン・コロケート・エージェントの標準インストール・トポロジの理解に関する項を参照してください。 |
スタンドアロン・コロケート・エージェントの構成については、『Oracle Data Integratorのインストールと構成』に説明があります。次を参照してください。
「Oracle Data Integratorのインストール」
「Oracle Data Integratorマスターおよび作業リポジトリ・スキーマの作成」
「スタンドアロン・コロケート・エージェントのドメインの構成」
スタンドアロン・コロケート・エージェントを起動する手順は、『Oracle Data Integratorのインストールと構成』のスタンドアロン・コロケート・エージェントの起動に関する項を参照してください。
スタンドアロン・コロケート・エージェントを停止する手順は、『Oracle Data Integratorのインストールと構成』のOracle Data Integratorエージェントの停止に関する項を参照してください。
Java EEエージェントの管理は、次の各項で説明するアクションを伴います。
Java EEエージェントの構成については、『Oracle Data Integratorのインストールと構成』に説明があります。次を参照してください。
「Oracle Data Integratorのインストール」
「Oracle Data Integratorマスターおよび作業リポジトリ・スキーマの作成」
「Java EEエージェントのドメインの構成」
Oracle Data Integratorでは、ランタイム・エージェント用のサーバー・テンプレートの作成に役立つサーバー・テンプレート生成ウィザードが用意されています。
|
注意: サーバー・テンプレートの生成機能を使用するには、ODI Studioはエンタープライズ・インストール・オプションを使用してインストールする必要があります。ODI Studioおよびインストール・タイプの詳細は、『Oracle Data Integratorのインストールと構成』のOracle Data Integratorのインストールに関する項を参照してください。 |
サーバー・テンプレート生成ウィザードを開くには:
物理エージェント・エディタのツールバー・メニューから、「サーバー・テンプレートの生成」を選択します。これにより、図3-1に示すテンプレート生成ウィザードが開始されます。
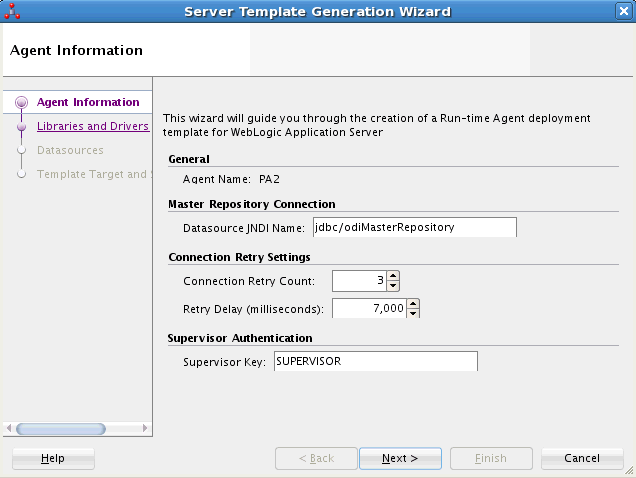
「エージェント情報」タブで、エージェント情報を確認し、必要に応じてデフォルト構成を変更します。
「エージェント情報」には次のパラメータが含まれます。
一般
エージェント名: デプロイするエージェントの名前が表示されます。
マスター・リポジトリ接続
データソースJNDI名: マスター・リポジトリに接続するためにJava EEエージェントで使用されるデータソースの名前。テンプレートには、このデータソースの定義を含めることができます。デフォルトはjdbc/odiMasterRepositoryです。
接続の再試行設定
接続の再試行回数: エージェントによるリポジトリへの接続が切断された場合の再試行回数。ODIリポジトリがOracle RACデータベースに存在する場合、このパラメータをゼロ以外の値に設定すると、高可用性接続再試行機能が有効になります。この機能が有効である場合、1つ以上のOracle RACノードが使用不可になっても、エージェントは中断もなく引き続きセッションを実行できます。
再試行の遅延(ミリ秒): 各接続再試行の間隔(ミリ秒)。
スーパーバイザ認証
スーパーバイザ・キー: スーパーバイザ権限を持つODIユーザーのログインおよびパスワードが含まれるアプリケーション・サーバー資格証明ストアのキーの名前。このエージェントはこのユーザー資格証明を使用してリポジトリに接続します。
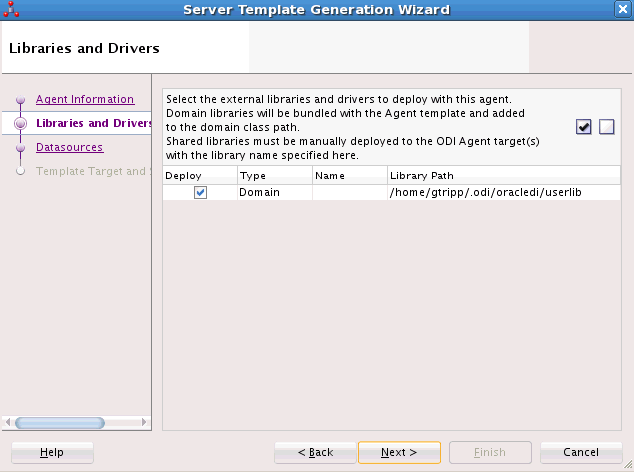
「次」をクリックします。図3-2に示すような「ライブラリおよびドライバ」タブが表示されます。
「ライブラリおよびドライバ」タブで、このエージェントとともにデプロイする外部ライブラリおよびドライバをリストから選択します。ユーザーが追加したライブラリのみがここに表示されます。
ライブラリは、このエージェントに必要なJARファイルまたはZIPファイルとなる点に注意してください。ソースおよびターゲット・データ・サーバーにアクセスするための追加JDBCドライバまたはライブラリをここで選択する必要があります。
また、「タイプ」列で、「ドメイン」ライブラリまたは「共有」ライブラリを選択することもできます。「ドメイン」を選択すると、各JARがシステム・クラス・パスの一部として追加されて、そのドメイン内のすべてのアプリケーションで表示できるようになります。「共有」を選択した場合、JARをデプロイ時に選択して共有ライブラリにすることができます。JARを共有ライブラリとして選択した場合、「名前」列が有効になり、JARファイルの参照名(MANIFESTファイルでExtension-Name属性に対して指定されている名前)が表示されます。JARファイルに参照名がない場合、選択した共有ライブラリはODI Studioで指定されている名前でWebLogic Serverにデプロイされるため、「名前」列に一意の名前を追加する必要があります。
|
注意: 「共有」タイプには、必ず「OpenTool JAR」を選択してください。また、共有として選択したJARは、共有ライブラリとして手動でWeblogic Serverにデプロイする必要があります。これにより、これらのJARはアプリケーション・クラス・パスの一部として追加されます。 |
ツールバーの対応するボタンを使用して、リスト内のすべてのライブラリまたはドライバ(あるいはその両方)を選択または選択解除できます。
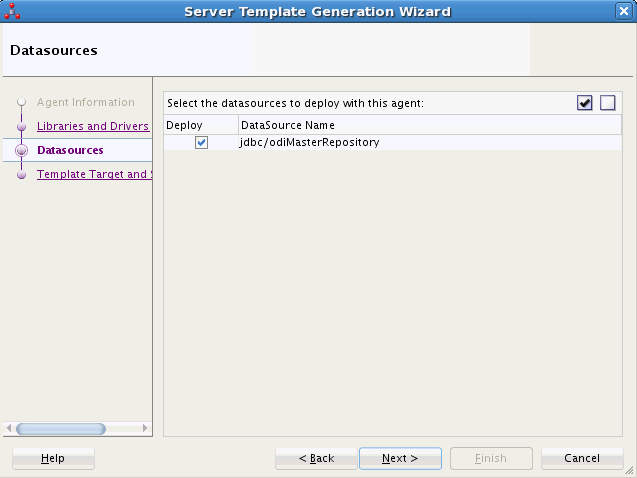
「次」をクリックします。図3-3に示すような「データソース」タブが表示されます。
「データソース」タブで、このエージェント・テンプレートに含めるデータソース定義を選択します。ウィザードからはデータソースの選択のみ可能です。これらのデータソースの命名および追加は、物理エージェント・エディタの「データソース」タブで行います。
「次」をクリックします。図3-4に示すような「テンプレート・ターゲットおよびサマリー」タブが表示されます。
図3-4 サーバー・テンプレート生成ウィザード - 「テンプレート・ターゲットおよびサマリー」タブ
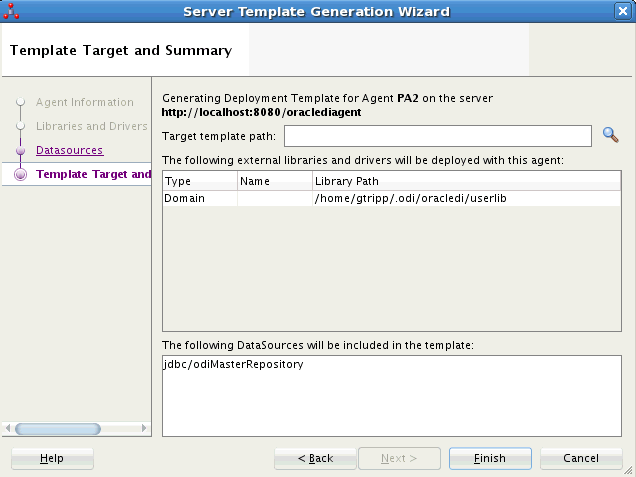
「テンプレート・ターゲットおよびサマリー」タブで、サーバー・テンプレートが生成される「ターゲット・テンプレート・パス」を入力します。
「終了」をクリックしてウィザードを閉じ、サーバー・テンプレートを生成します。
「テンプレート生成情報」ダイアログが表示されます。
「OK」をクリックし、ダイアログを閉じます。
生成されたテンプレートは、それぞれの構成ウィザードを使用したWLSまたはWASでのエージェントのデプロイに使用できます。詳細は、『Oracle Data Integratorのインストールと構成』を参照してください。
資格証明ストアでのスーパーバイザの宣言
テンプレートのデプロイ後、スーパーバイザをWLSまたはWAS資格証明ストアに宣言する必要があります。詳細は、『Oracle Data Integratorのインストールと構成』を参照してください。
トポロジ・ナビゲータから、Java EEエージェントを構成するアプリケーション・サーバーにデータソースをデプロイできます。データソースはOracle WebLogic Serverにのみデプロイできます。
アプリケーション・サーバーでデータソースをデプロイするには:
データソースをデプロイするアプリケーション・サーバー用に構成された物理エージェント・エディタを開きます。
「データソース」タブに移動します。
ソース/ターゲット・データ・サーバーを、トポロジ・ナビゲータの「物理アーキテクチャ」ツリーから「データソース」タブにドラッグ・アンド・ドロップします。
これらのデータソースの「JNDI名」を指定します。
いずれかのデータソースを右クリックし、「サーバーにおけるデータソースのデプロイ」を選択します。
「データソース・デプロイ」ダイアログで、データソースをデプロイするサーバーを選択します。使用可能な値は、WLSまたはWASサーバーです。
「デプロイメント・サーバー詳細」セクションで、次の各フィールドに入力します。
ホスト: アプリケーション・サーバーのホスト名またはIPアドレス。
ポート: デプロイメント・マネージャのブートストラップ・ポート。
ユーザー: サーバーのユーザー名。
パスワード: このユーザーのパスワード。
「データソース・デプロイ」セクションで、データソースをデプロイするサーバーの名前(たとえばodi_server1)を指定します。
「OK」をクリックします。
|
注意: この操作では、Oracle WebLogic Serverにデータソース定義が作成されるのみです。これらのデータソースが機能するために必要なドライバ・ファイルまたはライブラリ・ファイルはインストールされません。Studioクラスパスに追加されたドライバはエージェント・テンプレートに含めることができます。詳細は、「Java EEエージェント用のサーバー・テンプレートの作成」を参照してください。 |
WLSデータソース構成および使用方法
WebLogic ServerでOracle Data Integrator用にデータソースを設定する場合、次の点に注意してください。
データソースは、接続プール構成で「文キャッシュ・サイズ」パラメータを0に設定して作成する必要があります。文キャッシュはデータ統合のパフォーマンスに若干の影響を及ぼし、一部のJDBCドライバでデータの切捨てなどの予期しない結果を招く可能性があります。
接続プーリングをデータソースで使用する場合、プロシージャおよびナレッジ・モジュールでALTER SESSION文を使用しないことをお薦めします。接続でALTER SESSION文が必要な場合は、変更された接続が使用後に接続プールに戻されるため、関連データソースでの接続プーリングを無効化することをお薦めします。
Oracle Data Integratorでは、物理エージェント間でパラレル・セッション実行のロード・バランシングを実行できます。
各物理エージェントは次で定義されます:
作業リポジトリから同時に実行できる最大セッション数。
最大セッション数の値は、エージェントが動作するマシンの能力に応じて設定する必要があります。また、Oracle Data Integratorエージェントに対して指定する処理能力に応じて設定することもできます。
オプションで、セッションの実行を委任できるリンク先物理エージェントの数
エージェントの負荷は、指定時間にこのエージェントの比率(実行中のセッション数 / セッションの最大数)で決定されます。
リンク先エージェントを持つエージェントでセッションが開始されると、Oracle Data Integratorでは負荷のより少ないリンク先エージェントが判別され、このリンク先エージェントにセッションが委任されます。
エージェントは、他のエージェントにすべての着信セッションを委任するのではなく、自身にリンクして一部の着信セッションを実行できます。自身にリンクしていないエージェントは、リンク先エージェントへのセッションの委任のみが可能であり、セッションの実行は不可である点に注意してください。
委任はリンク先エージェントの階層内でカスケードします。エージェントAにエージェントB1およびB2がリンクされており、エージェントB1にエージェントC1がリンクされている場合、エージェントAで開始したセッションはエージェントB2またはC1により実行されます。エージェント・リンクをループさせないようにすることをお薦めします。
ユーザー・パラメータ「新しいロード・バランシングの使用」がはいに設定されている場合、セッション終了ごとにセッションのロード・バランシングも再実行されます。これは、エージェントがセッションを終了した場合、すでに別のエージェントに割り当てられているセッションが再割当される可能性があることを意味します。
指定のエージェントについて、実行中のセッション数が最大セッション数に到達した場合、そのエージェントは実行中のセッション数が最大セッション数を下回るまで、着信セッションを「キュー」ステータスにします。
エージェントが(クラッシュしたなどで)使用できず、ユーザー・パラメータ「新しいロード・バランシングの使用」が「はい」に設定されている場合、キュー内のセッションはすべて、セッションを実行しておらずキューにセッションがない別のロード・バランシング済エージェントに再割当されます。
ロード・バランシングを設定するには:
物理エージェントのセットを定義し、これらをエージェントの階層にリンクします(詳細は、「物理エージェントの作成」を参照してください)。
トポロジで定義されたエージェントに対応する物理エージェントをすべて開始します。
階層のルート・エージェントで実行を開始します。Oracle Data Integratorにより、リンク先エージェント間で実行のロード・バランシングが行われます。