| Oracle® Health Sciences Clinical Development Analytics Administrator's Guide for Informatica Release 3.2.1 E86402-01 |
|
|
PDF · Mobi · ePub |
| Oracle® Health Sciences Clinical Development Analytics Administrator's Guide for Informatica Release 3.2.1 E86402-01 |
|
|
PDF · Mobi · ePub |
This chapter contains the following topics:
To load data from the source systems to the data warehouse, OHSCDA uses Extract Transform and Load (ETL) programs that
Identify and read desired data from different data source systems,
Clean and format data uniformly, and
Write it to the target data warehouse.
In OHSCDA, Oracle Clinical, Oracle's Siebel Clinical, and InForm are the source systems for which Oracle provides predefined ETL.
ETL is the process by which data is copied from a source database and placed in warehouse tables, available for analytic queries.
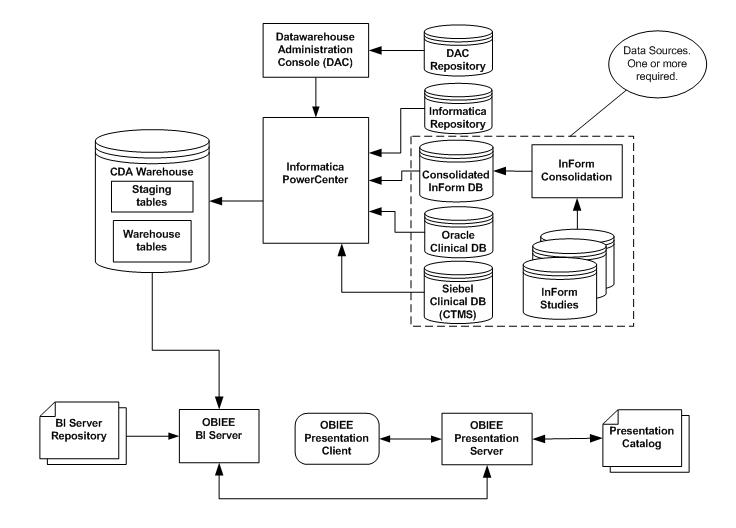
OHSCDA supports the extraction of data from one or more transactional application source databases. In OHSCDA, ETL is performed by execution of Informatica Mappings. A mapping is a program that selects data from one or more tables, performs transformations and derivations on the data, and inserts or updates the results in a target table. Mappings are stored in the Informatica Repository. Oracle uses the Oracle Data Warehouse Admin Console (DAC) to schedule and supervise the execution of the entire set of ETL necessary to populate the CDA warehouse.
Because data can be extracted from databases managed by different applications, the ETL mappings to load any given warehouse table are composed of two parts. The first part is a mapping that reads from a specific application's database and writes to a common warehouse staging table. This mapping is referred to as SDE, for Source-Dependent Extract. Records in the staging table have a common format, regardless of the source from which they were extracted. For a given warehouse table, there must be one SDE for each supported source application. The second mapping for the given warehouse table reads from its staging table and writes to the final warehouse table. This part is called as the SIL, for Source-Independent Load.
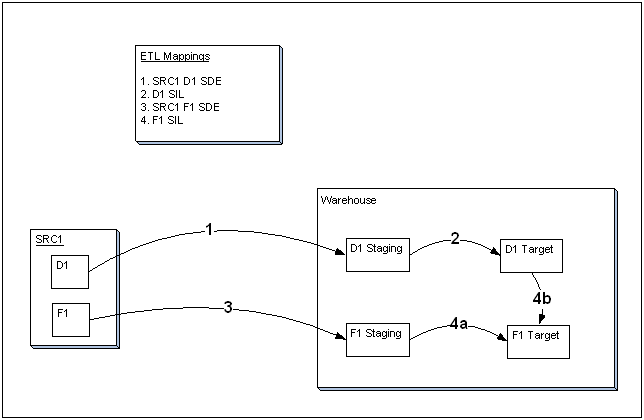
Figure 2-2 shows the ETL process for extracting data from two tables (one dimension D1 and one fact F1) in one source application database.
Each numbered arrow represents the execution of a Mapping. The Mappings are executed in the order indicated by the numbers. Mapping 4, the SIL that loads fact F1 into the warehouse target table for the fact, has two components. The first part (4a) represents the copy, transformation, and derivation of the staged data for the fact. The second part (4b) represents the setting of the values of each record's foreign key to dimension D1. The result is that dimension D1 can be queried as one of the dimensions in the star-schema centered on fact F1.
OHSCDA provides SIL for each of its warehouse tables. It provides SDE to stage data for these tables from InForm, Oracle Clinical, and Siebel Clinical database. The execution of the mappings is under the control of the Oracle DAC.
The OHSCDA ETL architecture is flexible. It allows you to integrate data from multiple databases instances for one application (for example, multiple Oracle Clinical databases), or databases from different source applications (for example, one Oracle Clinical and one Siebel Clinical), or any combination of these.
The OHSCDA ETL architecture is extensible. OHSCDA provides SDE mappings for InForm, Oracle Clinical, and Siebel Clinical. You can add data from another application to the OHSCDA warehouse by creating the SDE to map its database tables to the OHSCDA staging tables.
For each source application there is one SDE mapping for each warehouse table. This SDE extracts data from the source system and loads it to the staging tables. SDEs have the following features:
Incremental submission mode: OHSCDA-supplied ETL uses timestamps and journal tables in the source transactional system to optimize periodic loads.
Bulk and normal load: Bulk load uses block transfers to expedite loading of large data volume. It is intended for use during initial data warehouse population. Bulk load is faster, if data volume is sufficiently large. However, if load is interrupted (for example, disk space is exhausted, power failure), load can be re-started from task that failed in DAC.
Normal load writes one record at a time. It is intended to be used for updates to the data warehouse, once population has been completed. Normal load is faster, if data volume is sufficiently small. You can also restart load if the load is interrupted.
Setting Bulk or Normal load option should be done at Workflow session in Informatica. Perform the following steps to set the load option:
Navigate to Session in a workflow and edit the task properties.
Navigate to the Mappings subtab and select 'Bulk/Normal' under Target Load type.
Save the workflow.
There is one SIL mapping for each warehouse target table. The SIL extracts the normalized data from the staging table and inserts it into the data warehouse star-schema target table. SILs have the following attributes:
Concerning changes to dimension values over time, OHSCDA overwrites old values with new ones. This strategy is termed as Slowly Changing Dimension approach 1.
OHSCDA's data model includes aggregate tables and a number of indexes, designed to minimize query time.
By default, bulk load is disabled for all SILs.
The results of each ETL execution are logged by Informatica. The logs hold information about errors encountered, during execution.
Informatica provides the following four error tables:
PMERR_DATA
PMERR_MSG
PMERR_SESS
PMERR_TRANS
During ETL execution, records which fail to be inserted in the target table (for example, some records violate a constraint) are placed in the Informatica PowerCenter error tables. You can review which records did not make it into the data warehouse, and decide on appropriate action with respect to them.
As you read data from different database instances, you need to specify the source of the data. OHSCDA provides the W_RXI_DATASOURCE_S table (in RXI schema) that stores all information about all data sources from which data is extracted for OHSCDA. The following are some of the columns in this table:
ROW_WID: A unique ID for each record in the table.
DATASOURCE_NUM_ID: The ID for the database. Must be coordinated with the value given to the database in DAC when ETL is run.
DATASOURCE_NAME: A meaningful name of the database.
DATASOURCE_TYPE: Application system that manages the database.
DESC_TEXT: Optional text describing the purpose of the database.
INTEGRATION_ID: Set this to the same values as DATASOURCE_NUM_ID
See Also:
Oracle Health Sciences Clinical Development Analytics Electronic Technical Reference Manual, for more information about the W_RXI_DATASOURCE_S table.
Section 2.1.3, "Adding a New Data Source" for more information on how to add a new data source to OHSCDA.
OHSCDA provides an optional feature to manage hard deletion of records in Siebel Clinical. You create triggers in the source system to handle deletion of records. To do this:
Navigate to the temporary staging location where the OHSCDA installer copies the installation files.
Connect to the Siebel Clinical data source and run the ocda_sc_del_trigger.sql script delivered with OHSCDA. This script creates the RXI_DELETE_LOG_S table and triggers on tables provided as input. The following are the tables in Siebel Clinical for which OHSCDA supports creating triggers:
S_CL_PTCL_LS
S_PROD_INT
S_CL_SUBJ_LS
S_CONTACT
S_CL_PGM_LS
S_PTCL_SITE_LS
S_EVT_ACT
S_ORG_EXT
Provide a list of comma separated values of table names for which the triggers need to be created as the script's input. For example, S_CL_PTCL_LS, S_PROD_INT, and S_CL_SUBJ_LS. The tables names that you provide can only be a subset of the tables listed above.
Note:
When you delete a record in the table, the primary key of the deleted record is inserted in the RXI_DELETE_LOG_S table on the Siebel source system.Set the value of the DELETE_FLOW submission parameter to Y in DAC, on the Source System Parameters tab under CDA_Warehouse container within the Design view.
Execute the ETLs as listed in the Section 2.2, "Executing the ETL Execution Plans".
The Siebel Clinical related SDE mappings read the above instance of the RXI_DELETE_LOG_S table.
Note:
Records that are deleted in the source system are soft deleted in the data warehouse.OHSCDA provides predefined source-dependent extract (SDE) mappings for InForm, Oracle Clinical, and Siebel Clinical. Enter your source system related information in W_RXI_DATASOURCE_S table in Section 2.1.1, "Adding Data Source Information" where structure of w_rxi_datasource_s table is described. If you want to add another database (whether for one of these applications or for another application), perform the following tasks:
Create a new SDE programs to load the tables from source system to the staging area. For more information about creating a new SDE program, see Section 2.4, "Creating an ETL Execution Plan".
Insert a record into the W_RXI_DATASOURCE_S table, assigning the source a unique DATASOURCE_NUM_ID. Set this value to a number greater than 100.
Important:
When calling an SDE mapping to read from a particular database instance, ensure that you pass in the value of DATASOURCE_NUM_ID that corresponds to that database. Also, pass ENTERPRISE_ID (normally 0) to the SDE.
If you write new SDE, ensure that it sets the value of DATASOURCE_NUM_ID in the staging table to which it writes.
In DAC, navigate to the Setup view, and then select the Physical Data Sources tab.
Enter values in the following fields:
Name: Logical name for the database connection.
Type: Select Source for the database connection for a database.
Connection Type: Type of database.
Dependency Priority: Number used to generate dependencies when designing execution plans.
Data Source Number: Unique number assigned to the data source category so that the data can be identified in the data warehouse. Enter the same value as you have given in the W_RXI_DATASOURCE_S table.
For source applications other than Siebel Clinical, it is necessary to load data into CDA's LOV seed table for each database instance from which CDA is sourced. So, if the database you are adding is not a Siebel Clinical database, perform the following steps:
Make a copy of OCDA_W_RXI_LOV_S_seed.sql.
In the copy, modify the value of datasource_num_id to the value that you specified in W_RXI_DATASOURCE_S for the source database that you are adding.
Connect to the RXI account.
Run the modified copy of OCDA_W_RXI_LOV_S_seed.sql.
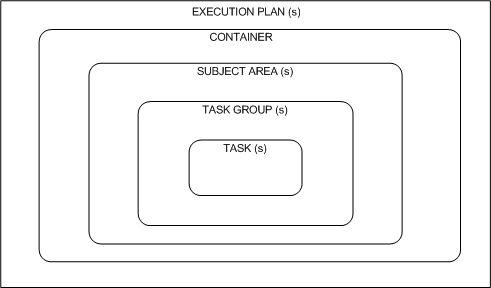
This section describes the hierarchy that organizes the ETL mappings in DAC. Figure 2-3 displays the OHSCDA hierarchy.
The following is the OHSCDA hierarchy:
CONTAINER (CDA_Warehouse): A single container that holds all objects used for OHSCDA.
EXECUTION PLAN: A data transformation plan defined on subject areas that need to be transformed at certain frequencies of time. An execution plan is defined based on business requirements for when the data warehouse needs to be loaded. Single Execution Plan to Load Complete Warehouse.
SUBJECT AREAS: A logical grouping of tables related to a particular subject or application context. It also includes the tasks that are associated with the tables, as well as the tasks required to load the tables. Subject areas are assigned to execution plans, which can be scheduled for full or incremental loads.
TASK GROUPS: This is a group of tasks that should be run in a given order.
TASKS: A unit of work for loading one or more tables. A task comprises the following: source and target tables, phase, execution type, truncate properties, and commands for full or incremental loads. Each task is a single Informatica workflow.
To load data from the source to their target tables in the data warehouse, run the Execution Plan packaged with OHSCDA. Perform the following tasks in DAC:
Note:
Before executing the ETL load plans, you must create a validation procedure to populate the Patient Statuses table for each study using two packaged procedures provided with Oracle Clinical. For information on how to create a validation procedure, see Oracle Clinical Creating a Study.Navigate to the Execute view.
Select the CDA â Complete Warehouse execution plan.
Set the parameter values under the Parameter tab.
Build the execution plan.
Click Run.
Note:
The prune_days parameter is used to determine the extraction end date for the incremental load. By default, the value of this parameter is 1. This indicates that the source extraction end date is a day less than the ETL program run date. For example, if the ETL program run date is 28 July, 2010 the source extraction end date is 27 July, 2010.If Oracle Clinical is your only data source:
Navigate to the Execution Plans tab.
Click the CDA - Oracle Clinical Warehouse execution plan.
Set the required parameters.
Build the execution plan.
Click Run.
If Siebel Clinical is your only data source:
Navigate to the Execution Plans tab.
Click the CDA - Siebel Clinical Warehouse execution plan.
Set the required parameters.
Build the execution plan.
Click Run.
If InForm is your only data source:
Navigate to the Execution Plans tab.
Click the CDA - Inform Warehouse execution plan.
Set the required parameters.
Build the execution plan.
Click Run.
Note:
Execution of the ETL (specifically theOCDA_ETL_RUN_S_POP program) populates W_ETL_RUN_S.LOAD_DT with the timestamp for the execution of the ETL. This ETL execution timestamp is used in the calculation of OHSCDA measures concerning the amount of time that currently open discrepancies have been open.
While the timestamp is captured in CURRENT_ETL_LOAD_DT, it is only available for calculation of discrepancy intervals through the OBIEE Dynamic Repository Variable CURRENT_DAY. CURRENT_DAY is refreshed from LOAD_DT at a fixed interval, by default 5 minutes, starting each time the Oracle BI Service is started. Between the time that the ETL is run, and the time that CURRENT_DAY is refreshed, calculations of intervals that currently open discrepancies have been open will be inaccurate.
The following are the two remedies:
Restart the Oracle BI Server after every execution of the ETL. This will cause CURRENT_DAY to be refreshed to the correct value.
If this is inconvenient, you can modify the intervals between refreshes of the value of CURRENT_DAY. For more information on how to modify the refresh interval for CURRENT_DAY, see Section 1.1, "Maintaining the Oracle Health Sciences Clinical Development Analytics OBIEE Repository".
Tip:
You can schedule the jobs to execute at regular intervals. For more information on scheduling jobs, see Section 2.6, "Scheduling an ETL Execution Plan".If InForm is your data source, with automerge, to execute the CDA - Complete Inform Automerge execution plan:
Set the value of AUTO_MERGE_FLG to Y in the Source System Parameters tab under CDA_Warehouse container within the Design view.
Navigate to the Execution Plans tab.
Click the CDA - Complete Inform Automerge execution plan.
Set the required parameters.
Build the Execution Plan.
Click Run.
When you customize an ETL Execution Plan, it is your responsibility to maintain version control over changes to ETL mappings.
Oracle recommends that you carefully track the changes you make to Oracle-supplied ETL so that you can re-apply these changes in subsequent releases.
Though OHSCDA includes ETL Execution Plans for extracting data from InForm, Oracle Clinical, and Siebel Clinical to OHSCDA data warehouse, you may want to create your own ETL to extract data from other data sources.
Note:
The value of DATASOURCE_NUM_ID is set to 1 for Oracle Clinical, 2 for Siebel Clinical, and 3 for InForm. If you want to add your own data sources, set this value to a number greater than 100.See Also:
Informatica PowerCenter Online Help
You may also want to modify an existing ETL load plan to meet your reporting requirements.
See Also:
Informatica PowerCenter Online Help
To modify an ETL without any changes to the associated tables or columns, perform the following tasks:
Identify the Execution Plan that needs to be modified in Informatica repository.
Open and modify the ETLs (transformation and/or workflow).
Test and save the changes in repository.
Connect to DAC and navigate to the corresponding task.
Right-click the task and synchronize it.
Navigate to the execution plan and execute ETL to verify the changes.
The ETL execution plans that extract data for the warehouse fact tables assume that the dimensions to which each fact is related are up-to-date at the time the fact ETL Execution Plans are executed. This assumption is the basis for certain fact calculations that would provide erroneous results if the assumption were not true. For example, in the received CRFs fact, the value of the pCRF entry complete measure depends on whether or not the study requires second pass entry. But that piece of information -- second pass entry required -- is obtained from an attribute of the Study dimension. So, if the second-pass requirement for a study changes, and the change is not applied to the Study dimension, the Received CRF fact attributes will contain incorrect values.
As shipped, OHSCDA ETL workflows ensure this interlock by executing the ETL for related dimensions immediately before running the ETL for a fact. This is standard warehouse management practice, but especially important given the interdependence of the dimensions and the fact. The need to execute dimension ETL immediately before corresponding fact ETL, and the danger of not doing it, is emphasized here because it is possible (though discouraged) to modify these shipped workflows.
To modify one or more tables or columns without any changes to the associated ETL programs (typically to widen a column):
Change the table properties as needed.
Save the mapping and refresh the workflow.
Connect to DAC and navigate to corresponding task and refresh it.
Note:
If the changes to the tables or columns are not compatible with the table that is installed in the data warehouse schema, you will get a warning while making the change. For example, if you are reducing the length of a number column from 15 to 10, the change is not compatible with the existing data in the table.When you submit an Execution Plan for execution in DAC, you can schedule it execute at regular intervals. To schedule an Execution Plan, perform the following tasks:
Navigate to the Scheduler tab within the Execute view.
Create a new schedule plan.
Enter the required details and click Save.
|
Copyright © 2010, 2017, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|