BDDでは、多くの異なるクラスタ構成がサポートされています。次の各項では、デモ環境、開発環境および本番環境に適した3つの構成、およびそれらの考えられるバリエーションを説明します。
ユーザーはこれらの例に制限されておらず、リソースおよびデータ処理のニーズに適した任意の構成をインストールできます。
単一ノードのデモ環境
BDDは、単一の物理または仮想マシンで稼働しているデモ環境にインストールできます。この構成は、処理できるデータの量にかぎりがあるため、製品の機能を小さいサンプル・データベースでデモンストレーションする場合にのみお薦めします。
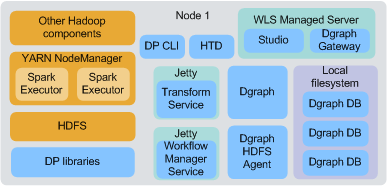
単一ノード・デプロイメントでは、すべてのBDDおよび必要なHadoopコンポーネントは同一ノードでホストされ、Dgraphデータベースはローカル・ファイルシステムに格納されます。
単一ノード・インストールの場合、BDDはデフォルト構成ですばやくインストールできるクイックスタート・オプションを提供しています。詳細は、クイックスタート・インストールを参照してください。
ノード2つのデプロイメント環境
BDDは、2つのノードで稼働している開発環境にインストールできます。この構成では、単一ノード・デプロイメントよりもやや大きいデータベースを処理できますが、処理容量はまだ制限されており、BDDコンポーネントの高可用性は提供されません。
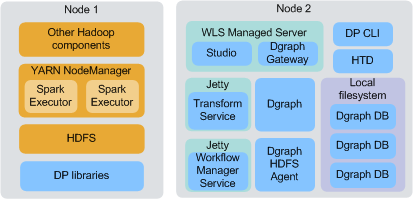
2ノード構成では、すべてのHadoopコンポーネントおよびデータ処理ライブラリが1つのノードでホストされ、残りのBDDコンポーネントがもう1つのノードでホストされます。前述の図では、Dgraphデータベースがローカル・ファイル・システムに格納されていますが、ノード1のHDFSに格納することもできます。
マルチノードの本番環境
本番環境では、BDDはマルチノード・クラスタにインストールする必要があります。クラスタのサイズは、処理で計画しているデータ量、および特定の時点でデータを問い合せることが予想されるエンド・ユーザーの数によって異なります。ただし、最低6個のノードを使用すると、すべてのコンポーネントの高可用性が保証されます。
一般的なBDDクラスタは、次のようなノードで構成されます。
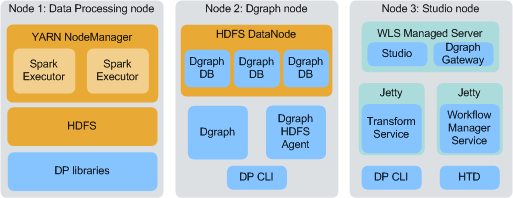
- ノード1では、データ処理ライブラリ、YARN NodeManagerサービス、Spark on YARNおよびHDFSが実行されており、データ処理が機能するためにそのすべてが必要となります。クラスタに含めるデータ処理ノードの数は、データ量およびそのサイズによって異なりますが、最低3つのノードを使用すると、高可用性が保証されます。
- ノード2は、Dgraph、Dgraph HDFSエージェント、DP CLIおよびHDFS DataNodeサービスを実行しています。DgraphデータベースはHDFSに格納されています(本番環境にお薦めします)。(NFSに格納することもできます。その場合、DataNodeサービスは必要ありません。)一般的なクラスタには複数のDgraphノードが含まれています。
- ノード3は、StudioとDgraph Gateway (WebLogic Managed Serverコンテナ内)、変換サービスとワークフロー・マネージャ・サービス(Jettyコンテナ内)、DP CLIおよびHive表ディテクタを実行しています。一般的なクラスタには、同時問合せを行うユーザー数に応じて、1つ以上のStudioノードが含まれています。複数のStudioノードを持つクラスタでは、ワークフロー・マネージャ・サービスおよびHive表ディテクタはそれらのいずれかにのみそれぞれインストールされます。また、クラスタ内の1つのStudioノードは管理サーバーとして機能する必要があります。
コンポーネントの併置
BDDクラスタを構成する1つの方法は、異なるコンポーネントを同じノードに併置することです。ノード全体を特定のコンポーネント専用にする必要がないため、これは、より効率的なハードウェア使用方法となります。
ただし、併置されたコンポーネント間でメモリーおよび他のリソースが競合し、パフォーマンスに悪影響を及ぼす可能性があることに注意してください。異なるコンポーネントを同じノードでホストするかどうかは、現場の本番要件およびハードウェア能力によります。
- HDFS DataNodeサービス以外のHadoopコンポーネントとDgraphを併置しないでください。特に、Sparkと同じノードでホストしないでください。どちらも多くのメモリーを必要とするためです。これを行う必要がある場合は、cgroupを使用して、それぞれが十分なリソースにアクセスできるようにします。詳細は、cgroupの設定を参照してください。
- 同様に、Dgraphを変換サービスと併置しないでください。変換サービスでも多くのメモリーが必要となります。
- 管理対象サーバーをDgraphまたはHadoopコンポーネントと併置することはできますが、WebLogic Serverが消費できるメモリー量を制限して、他のコンポーネントが必要なリソースにアクセスできるようにする必要があります。
