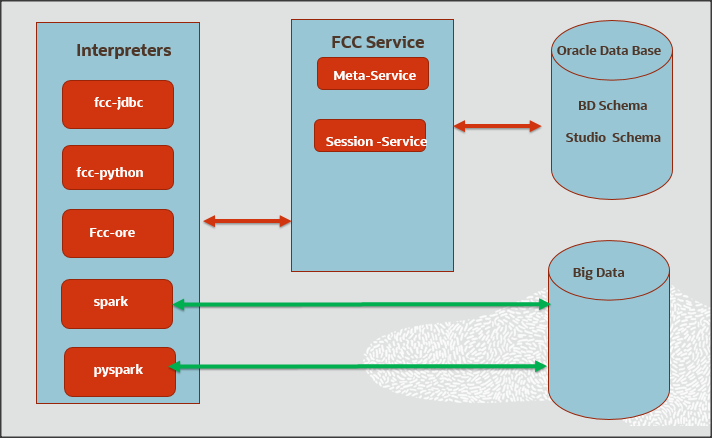
An interpreter is a program that directly executes instructions written in a programming or scripting language, without requiring them previously to be compiled into a machine language program. Interpreters are plug-ins, which enable users to use a specific language to process data in the back-end. Examples of Interpreters are, jdbc-interpreter, spark-interpreters, python-interpreters, and so on. Interpreters allow you to define customized drivers, URLs, passwords, connections, SQL result to display, and so on.
In FCC Studio, Interpreters are used in Notebooks to execute code in different languages. Each interpreter has a set of properties that are adjusted and applied across all notebooks. For example, by using the python-interpreter, it is possible to change between versions, whereas the jdbc-interpreter offers to customize the URL, schema, or credentials. In FCC Studio, you can either use a default interpreter variant or create a new variant for an interpreter. You can create more than one variant for an interpreter. The benefit of creating multiple variants for an Interpreter is to connect different versions of interpreters (Python ver:3, Python ver:2, and so on ), this helps to connect a different set of users, database schema. For example, FCC Studio schema, BD schema, and so on. FCC Studio provides secure and safe credential management such as Oracle Wallet (jdbc wallet) Password (jdbc password), or KeyStores to link to interpreter variants to access secured data.
The following image illustrates the examples of interpreters used in FCC Studio and database connections.
Topics:
· Create a New Interpreter Variant
· Create an Interpreter Variant
· Modify the Python Docker Images
· Configure Spark Query Parameters
FCC Studio has ready-to-use interpreters such as fcc-jdbc, fcc-spark-scala Interpreter, fcc-python Interpreter, and so on. You can configure them based on the use case. Additional variants of interpreters are created as multiple users might require different settings to access the database securely. Interpreters such as fcc-jdbc and jdbc are linked using credentials to enable secure data access.
Interpreters are configured when you want to modify URL, data location, drivers, enable or disable connections, and so on.
To configure ready-to-use interpreters, follow these steps:
1. In the Crime & Compliance Studio menu list, click Interpreters. By default, the Interpreters page lists all the available interpreters.

2. Click the interpreter that you want to view from the list displayed on the LHS. The default configured interpreter variant is displayed on the RHS.

3. Modify the values in the fields as per requirement. For example, to modify the limit of a parameter, to connect to a different schema, PGX server, and so on.
4. Click Update. The modified values are updated in the interpreter.
Table 2 lists the Ready-to-use interpreter in FCC Studio:
The fcc- jdbc is a ready-to-use Interpreter variant in FCC Studio that connects BD and ECM database schema and is used for scenario notebooks. The parameters are configured to connect different schemas. It filters results based on security attributes mapped to the user.
NOTE |
If it is used to connect to another schema, Virtual Private Database (VPD) must be configured. Alternatively, you can use the jdbc Interpreter. |
In the fcc-jdbc Interpreter, you can configure the connection to pull or push data to the desired location, set the default jdbc authentication type, link credentials, and so on. To access additional access permissions for the fcc-jdbc Interpreter, you can link with credentials too.
Use this section to perform the following activities:
· Configure a fcc-jdbc Interpreter Variant
· Link Wallet Credentials to fcc-jdbc Interpreter
To configure a fcc-jdbc Interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select fcc-jdbc. The fcc-jdbc interpreter pane is displayed.
2. Enter the following information in the fcc-jdbc Interpreter variant pane as tabulated in Table 3.
FCC Studio provides secure and safe credential management. Examples for credentials are passwords, Oracle Wallets, or KeyStores.
Oracle Wallet is a file that stores database authentication and signing credentials. It allows users to securely access databases without providing credentials to third-party software, and easily connect to Oracle products.
A Keytab is a file containing pairs of Kerberos principals and encrypted keys (which are derived from the Kerberos password). You can use a keytab file to authenticate various remote systems using Kerberos without entering a password. However, when you change your Kerberos password, you must recreate all your keytab files.
Use this section to link credentials (a wallet or a password) to the fcc-jdbc interpreter variant to enable secure data access. This linking enables the fcc-jdbc interpreter to securely connect to the specified Oracle database. For more information to link Wallet Credentials to the fcc-jdbc Interpreter, see Linking Credentials to Interpreters.
NOTE |
The Credentials' section is enabled if an interpreter variant can accept credentials. |
You can also create new credentials and link to the fcc-jdbc Interpreter. For more information, see Creating Credentials.
The fcc- ore (ORE: Oracle R Enterprise) is a ready-to-use interpreter to connect to BD schema. This interpreter is used to write a notebook in R language, to perform R based analytics on data from database schema on the business table.
Additional configuration is required and must be done as a prerequisite or post-installation with a manual update in the interpreter setting. In the fcc-ore interpreter, you can configure the Oracle system identifier (SID) of the database server to connect the fcc-ore Interpreter, configure to the display the output number of rows, set the hostname of the database server to connect the fcc-ore interpreter, schema details, and so on.
To configure the fcc-ore interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select fcc-ore. The fcc-ore interpreter pane is displayed.
2. Enter the following information in the fcc-ore interpreter variant pane as tabulated in Table 4.
The fcc-pyspark Interpreter is a ready-to-use interpreter used to connect to Big data server from the livy server. After it is connected, you can write in the pyspark language to query and perform analytics on data present in the Big data. In the fcc-pyspark interpreter, you can configure the number of executors to launch for the current session, cached execution timeout, amount of memory to use for the executor process, and so on.
To configure the fcc-pysprk interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select fcc-pyspark. The fcc-pyspark interpreter pane is displayed.
2. Enter the following information in the fcc-pyspark interpreter variant pane as tabulated in Table 5.
The fcc-python interpreter is used to write Python code in a notebook to analyze data from different sources, machine learning, and artificial intelligence, and so on. In the fcc-python interpreter, you can configure the python installed path, set the maximum number of results that must be displayed, change the Python version, add Python Packages, and so on. When FCC Studio stops supporting any of the outdated Python versions, you can add or change the Python version. For example, Python 3.6.0, Python 3.6.6, Python 3.6.7, and so on.
Topics:
· Configure an fcc-python Interpreter
· Change Python Version in the fcc-python Interpreter
· Add or Modify Python Packages to the fcc-python Interpreter
To configure an fcc-python interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select fcc-python. The fcc-python interpreter pane is displayed.
2. Enter the following information in the fcc-python interpreter variant pane as tabulated in Table 6.
Field |
Description |
|---|---|
zeppelin.python |
Enter the Python installed path. The value points to the default Python version set for the interpreter. NOTE: To use a different Python version, see Changing Python Version in the fcc-python Interpreter |
zeppelin.python.useIPython |
Set to 'True' to use IPython, else set to 'False'. |
zeppelin.python.maxResult |
Enter the maximum number of results that must be displayed. |
In the fcc-python interpreter, the Linux console uses the default python version in. /user/fccstudio/python_user/bin/python as value. If you want to modify the python version, either you can create an interpreter variant or modify the existing python version in the same interpreter variant.
NOTE |
Python2 is the default version used in the Linux console and it is no more supported. Hence, you can use any version of python3 or any virtual environment with a specific python version or a specific version of python packages. |
To use a different version of Python, follow these steps:
1. Navigate to the fcc-python Interpreter Settings page.
2. Change the default Python version in the zeppelin.python parameter to the new version. For example, python3.6.
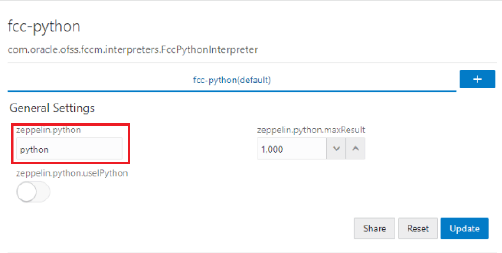
Create a new interpreter variant and configure the version in the zeppelin.python parameter. For information on creating a new interpreter variant, see Creating a New Interpreter Variant. For example, to use Python 3.6, create a new fcc-python interpreter variant and enter the value as python3.6.
When a user wants to write something in Python but the packages are not present. Use case: ML or AI code. By default, the Linux server (or docker image) has a limited number of packages present inside it.
To add desired Python packages to the fcc-python interpreter, follow these steps:
· For FCC Studio installed on-premise:
To add or modify Python libraries to the fcc-python interpreter, contact System Administrator to install the required additional Python libraries on the Processing Server (Studio Notebook Server). The newly added Python libraries must be accessible to the Linux user for FCC Studio.
To add the python packages for python3, follow these steps:
1. Navigate to the <Studio_Installation_Path>/python-packages/bin directory.
2. Execute the following command:
python3 -m pip install <package name> --user
· For FCC Studio installed using Kubernetes:
To install additional Python libraries to the fcc-python interpreter, see Modify the Python Images for the Python Interpreter.
fcc-spark-scala Interpreter is a ready-to-use interpreter using the livy server to connect to the Big data server. It is used to perform analytics on data present in Big data using the Scala language. fcc-spark-scala interpreter does not connect to any schema by default. Users must write code for connection either in the Initialization section or in the notebook’s paragraph. In the fcc-spark-scala interpreter, you can configure the number of executors to launch for the current session, set the Livy URL, and configure keytab location, and so on.
To configure the fcc-spark-scala interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select fcc-spark-scala. The fcc-spark-scala interpreter pane is displayed.
2. Enter the following information in the fcc-spark-scala interpreter variant pane as tabulated in Table 7.
The fcc-spark-sql Interpreter is a ready-to-use interpreter uses livy server to connect Big data cluster. It is used to perform analytics on data present in Hive schema using Hive queries. In the fcc-spark-sql interpreter, you can configure the number of executors to launch for the current session, data pull interval in milliseconds, and so on.
To configure the fcc-sprk-sql interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select fcc-sprk-sql. The fcc-sprk-sql interpreter pane is displayed.
2. Enter the following information in the fcc-sprk-sql interpreter variant pane as tabulated in Table 8.
The jdbc Interpreter is a ready-to-use interpreter used to connect Studio schema without OFSAA. This interpreter is used to connect and write SQL queries on any schema without any restriction. The jdbc interpreter has no security attributes, it can be used to access any schema. In jdbc interpreter, you can configure schema details, link Wallet Credentials to the jdbc Interpreter, and so on.
Topics:
· Configure jdbc Interpreter Variant
· Link Wallet Credentials to jdbc Interpreter
To configure a jdbc interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select jdbc. The jdbc interpreter pane is displayed.
2. Enter the following information in the jdbc interpreter variant pane as tabulated in Table 9.
FCC Studio provides secure and safe credential management. Examples for credentials are passwords, Oracle Wallets, or KeyStores. Use this section to link credentials (a wallet and a password) to jdbc interpreter variant to enable secure data access. This linking enables the jdbc interpreter to securely connect to the specified Oracle database. For more information to link Wallet Credentials to jdbc Interpreter, see Link Credentials.
NOTE |
The Credentials' section is enabled if an interpreter variant can accept credentials. |
You can also create new credentials and link to jdbc Interpreter. For more information, see Create Credentials.
This interpreter is used to display text based on Markdown, which is a lightweight markup language. In the md interpreter, you can configure the markdown parser type. Markdown (md) is a plain text formatting syntax designed so that it can be converted to HTML. Use this section to configure the markdown parser type.
To configure the md interpreter variant, follow these steps:
1. On the md Interpreter page LHS menu, select md. The md interpreter pane is displayed.
2. Enter the markdown parser type and click Update. To confirm the modified configuration.
The pgql Interpreter is a ready-to-use interpreter used to connect the configured PGX server. This interpreter is used to perform queries on the graph in FCC Studio. In the pgql Interpreter, you can configure the class which implements the formatting of the visualization the output, the size of the output message, and so on.
PGQL is a graph query language built on top of SQL, bringing graph pattern matching capabilities to existing SQL users and to new users who are interested in graph technology but who do not have an SQL background.
To configure the pgql interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select pgql. The pgql interpreter pane is displayed.
2. Enter the following information in the pgql interpreter variant pane as tabulated in Table 10.
The pgx-algorithm Interpreter is a ready-to-use interpreter used to connect to the configured PGX server. This interpreter is used to write an algorithm on the graph, and it is also used in the pgx-java interpreter. In the pgx-algorithm Interpreter, you can configure the class which implements the PGQL driver, the size of the output message, and so on.
To configure pgx-algorithm interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select pgx-algorithm. The pgx-algorithm interpreter pane is displayed.
2. Enter the following information in the pgx-algorithm interpreter variant pane as tabulated in Table 11.
The pgx-java Interpreter is a ready-to-use interpreter used to connect to the configured PGX server. This interpreter is used to write an algorithm on the graph and also used in the pgx-java interpreter. In the pgx-java Interpreter, you can configure the class which implements the formatting of the visualization output, the class which implements the PGQL driver, and so on.
PGX-java interpreter is Java11 based interpreter with PGX client embedded in it to query on graph present in the PGX server.
To configure the pgx-java interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select pgx-java. The pgx-java interpreter pane is displayed.
2. Enter the following information in the pgx-java interpreter variant pane as tabulated in Table 12.
Users must write for connection either in the Initialization section or in the notebook’s paragraph. This interpreter is used to write the pyspark language to query and perform analytics on data present in big data. This requires additional configuration, which must be performed as a prerequisite or as post-installation with the manual change of interpreter settings.
In the pyspark interpreter, you can configure the Python binary executable to use for PySpark in both driver and workers, set 'True' to use IPython, else set to 'False', and so on.
To configure the pyspark interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select pyspark. The pyspark interpreter pane is displayed.
2. Enter the following information in the pyspark interpreter variant pane as tabulated in Table 13.
The spark Interpreter does not connect to any schema by default. Users must write for connection either in the Initialization section or in a notebook’s paragraph. This interpreter is used to perform analytics on data present in Big data clusters in the Scala language. This requires additional configuration, which must be performed as pre-requisite or as post-installation with the manual change of interpreter settings.
In spark interpreter, you can configure the cluster manager to connect, print the Read–eval–print loop (REPL) output, the total number of cores to use, and so on.
To configure the spark interpreter variant, follow these steps:
1. On the Interpreter page LHS menu, select spark. The spark interpreter pane is displayed.
2. Enter the following information in the spark interpreter variant pane as tabulated in Table 14.
FCC Studio provides secure and safe credential management. Examples for credentials are passwords, Oracle Wallets, or KeyStores. Use this section to link credentials (a wallet and a password) to fcc-jdbc or jdbc interpreter variant to enable secure data access. This linking enables the fcc-jdbc or jdbc interpreter to securely connect to the specified Oracle Database. You can also create new credentials, based on your requirement to connect to the new interpreter variants. For more information, see Create Credentials.
NOTE |
You can link credentials only to fcc-jdbc and jdbc interpreters. The Credentials' section is enabled if an Interpreter variant can accept credentials. |
To link ready-to-use credentials to the required interpreters, follow these steps:
1. On the Interpreters page, select the required interpreters. For example, fcc-jdb or jdbc.
2. Go to the Credentials section.

3. To select Oracle Wallet (jdbc wallet) credential that you want to link to the Interpreter variant, click Select. The Select Credential dialog is displayed.

4. Select the required Oracle Wallet (jdbc wallet).
5. To select Password (jdbc password) that you want to link to the Interpreter variant, click Select. The Select Credential dialog is displayed.

6. Select the required Password (jdbc password). Click Select.
7. Click Update to save the changes. The required password and Oracle Wallet are linked to the fcc-jdbc or jdbc Interpreter.
New credentials are created when database details are changed or updated. For example, change in Transparent Network Substrate (TNS) due to hostname change or compulsory periodic update of passwords of the schema.
Oracle Wallet provides a simple and easy method to manage database credentials across multiple domains. It allows you to update database credentials by updating the Wallet instead of having to change individual data source definitions.
Use this section to add a new credential to the interpreters.
To create a credential, follow these steps:
1. On the FCC Studio workspace LHS Menu, click Credentials. The Credentials page is displayed.
2. Click Create. The Create Credential dialog is displayed.

3. Enter the following information in the Create Credential dialog box as tabulated in Table 15:
4. Click Create. The wallet credential is created and displayed on the Credentials page.
To create a new password credential for the wallet, follow these steps:
1. Click Create. The Create Credential dialog is displayed.

2. Enter the following information in the Create Credential dialog as tabulated in Table 16.
3. Click Create. The password is created for the wallet and displayed on the Credentials page.
4. To download the credential files, click the credential file name on the Credentials page.
5. To
delete a required credential, click Delete
 . The credential is removed from the
list.
. The credential is removed from the
list.
In FCC Studio, you can either use a default interpreter variant or create a new variant for an interpreter. You can create more than one variant for an interpreter. Multiple variants for an interpreter are created to connect different versions of interpreters (Python ver:3, Python ver:2 ), connect a different set of users, database schema. For example, FCC Studio schema, BD schema, and so on.
To create a new interpreter variant, follow these steps:
1. On the Interpreters page, click the required interpreters from the LHS list. For example, fcc-jdbc interpreter.
The default interpreter variant is displayed on the RHS.
2. On
the default interpreter, click Add
 to create a new variant. The Create Interpreter Variant dialog
box is displayed.
to create a new variant. The Create Interpreter Variant dialog
box is displayed.
3. Enter the Name for the new interpreter variant. Click Create. A new variant is created with a name, <Interpreter Type>.<Variant Name>.
4. Provide the new schema details such as the default.url, default.user, and default.password.
NOTE |
Steps: 5 and 6 are applicable only for fcc-jdbc |
5. The Oracle Database schema that you have created must be granted with the same permissions that are granted to the BD or ECM atomic schema.
For more information, see the Prerequisite Environmental Settings section in the OFS Crime and Compliance Studio Installation Guide (On-Premise).
6. Navigate to the <Studio_Installation_Path>/ficdb/bin directory. Run the following script after modifying the schema name with the newly created schema:
../OFS_FCCM_STUDIO/metaservice/model/SQLScripts/Atomic_Schema/FCC_JRSDCN_CONTEXT_ATOMIC.sql
../OFS_FCCM_STUDIO/metaservice/model/SQLScripts/Atomic_Schema/PKG_FCC_STUDIO_JURN_VPD.sql
../OFS_FCCM_STUDIO/metaservice/model/SQLScripts/Atomic_Schema/PKG_FCC_STUDIO_JURN_VPD_BODY_ATOMIC.sql
7. Configure the required values for the properties.
8. Click Update. A new variant is created for the selected interpreter.
9. For using the new interpreter variant in the notebook paragraphs, use the following format:
%fcc-jdbc.<VariantName>
Interpreter variants do not apply to Spark or PySpark interpreter. Hence, you must enable an additional set of interpreters.
To enable a second Spark or PySpark interpreter, see Enabling a Second Spark or PySpark Interpreter chapter in the OFS Crime and Compliance Studio Installation Guide (On-Premise).
Use this section to modify the Python Docker images in the Kubernetes environment. A Docker image is built by a series of layers. Each layer represents an instruction in the image’s Docker file. Each layer except the very last one is read-only.
When the FCC studio is installed and started, the image is loaded on the local node and pushed into a docker repository. The image can be modified on the local node or any machine which can pull in and push to the Docker repository.
To modify the Python packages or change the Python version, you must modify the Python image.
NOTE |
· This section is applicable for FCC Studio installed using Kubernetes. · This section can be used as an example to understand the steps involved to modify the Python images for the Python interpreter in FCC Studio. |
Topics:
· Prerequisite to Build a Python Interpreter Docker Image
· Replace Python Image in FCC Studio
To build Python images, you can either modify the Python packages in the Python interpreter or add different versions of Python to the Python interpreter.
Python packages are present inside the python interpreter image, FCC Studio allows you to modify the version or upgrade to a new Python package in the Python interpreter.
The following Python libraries are part of the fcc-python interpreter images for Python 3.6 version:
· pandas 0.25.3
· numpy 1.17.4
· scipy 1.3.2
· scikit-learn 0.21.3
· matplot-lib 3.1.1
· seaborn 0.9.0
· cx-oracle 7.2.2
· sqlalchemy 1.3.11
To modify the Python packages in the Python interpreter, follow these steps:
NOTE |
This process adds the Python packages to Python 3.6. |
1. Navigate to the Studio Installation Path directory.
2. Create a directory in the same location as the <Studio_Installation_Path> and create a file inside the directory as Dockerfile.
3. Copy and paste the following information as a template into the Dockerfile:
FROM ofsaa-fccm-docker-release-local.dockerhub-den.oraclecorp.com/fcc-studio/fcc-python:8.0.8.0.0
RUN pip3 --no-cache-dir install scipy pandas cx_oracle --user
4. Modify the Dockerfile depending on the following installation method:
a. If Internet connectivity is available, follow these steps:
Depending on the version of the Python package, install the scipy and cx_oracle Python packages using the following command:
RUN pip install scipy cx_oracle
b. If Internet connectivity is unavailable, follow these steps:
i. Download the Python package files.
ii. Create a directory besides the Dockerfile file.
For example, packages
iii. Place the downloaded files in the newly created packages directory.
iv. Modify the Dockerfile using the following commands:
For example, to install using Python3:
COPY packages /var/olds-python-interpreter/packages
RUN cd /var/olds-python-interpreter/packages
RUN pip3 --no-cache-dir install --no-deps numpy-1.17.4-cp36-cp36m-manylinux1_x-86_64.whl
NOTE |
For more information on how to write Dockerfile, visit https://docs.docker.com/engine/reference/builder/. |
5. Build and push the image to the Docker registry. For more information, see Build and Push an Image
6. Replace the Python image in FCC Studio. For more information, see Replace a Python Image in FCC Studio
Python packages are present inside the python interpreter image, FCC Studio allows you to add a new version or upgrade to a new Python package in the Python interpreter. Use this section to add different versions or upgrade to a new Python version to a Python interpreter.
To add a different version of Python to Python interpreter in FCC Studio, follow these steps:
1. Navigate to the Studio Installation Path directory.
2. Create a directory at the same location as the <Studio_Installation_Path> and create a file inside the directory with the file name, Dockerfile.
3. Copy and paste the following information as a template into the Dockerfile:
FROM ofsaa-fccm-docker-release-local.dockerhub-den.oraclecorp.com/fccstudio/ fcc-
python:8.0.8.0.0
USER root
RUN yum install -y python3.5
USER interpreteruser
RUN python3.5 -m pip install scipy pandas cx_oracle --user
4. Modify the Dockerfile based on the preferred way of installing Python in the RHEL server.
For more information on how to modify the Dockerfile, visit https://docs.docker.com/engine/reference/builder/.
5. Build on LINUX and push the image to the Docker Registry . For more information, see Build and Push an Image
6. Replace the Python image in FCC Studio. For more information, see Replace a Python Image in FCC Studio
An image is built on LINUX and pushed to a docker Registry.
To build and push an image, follow these steps:
1. Navigate to the Studio Installation Path directory.
2. Build the docker image using the following command:
docker build . --build-arg http_proxy=http://<proxy-url>:<port> --build-arg https_proxy=http://<proxy_url>:<port> -t <my.docker-registry.com:port>/ofsaa-fccm-docker-release-local.dockerhub-den.oraclecorp.com/fcc-studio/fcc-python:<version>
Where:
§ <my.docker-registry.com:port> is the docker-registry URL with port number.
§ <version> is the custom tag for this image.
For example,
docker build . --build-arg http_proxy=http://my-proxy-url:80 --build-arg https_proxy=http://my-proxy-url:80 -t my.docker-registry.com:5000/ofsaa-fccm-docker-release-local.dockerhub-den.oraclecorp.com/fcc-studio/fcc-python:8.0.8.0.0-C1
NOTE |
build-arg can be skipped if proxy is not required or if packages are placed locally. |
3. Push the images using the following command:
docker push <my.docker-registry.com:port>/ofsaa-fccm-docker-releaselocal.dockerhub-den.oraclecorp.com/fcc-studio/fcc-python:<version>
Python packages are present inside the python interpreter image, but if you want to replace the Python images, FCC Studio allows you to perform this activity. Use this section to replace a Python image in the FCC Studio.
To replace the Python images in FCC Studio, follow these steps:
1. Navigate to the <Studio_Installation_path>/deployments/ directory.
2. Update the image name in the fcc-python.yml file as follows:
spec:
spec:
containers:
- name: python-interpreter
image: ofsaa-fccm-docker-release-local.dockerhub-den.oraclecorp.com/fcc-studio/fcc-python:<version>
3. To restart the FCC Studio application, follow these steps:
a. Execute the following command from the Kubernetes master node:
kubectl delete namespace <Namespace>
b. Navigate to the <Studio_Installation_Path>/bin directory.
c. Execute the following command:
./fcc-studio.sh --registry <registry URL>:<registry port>