Understanding the Planning Process
This topic discusses:
Table-based systems.
Normalized relational databases.
Record definition planning.
Effective dates.
Control tables.
TableSets.
Planning is the first step in the application development process. As a system designer, you must consider how to store, retrieve, manipulate, and process data that is stored in the tables in your application database.
PeopleTools-based applications are table-based systems. A database for a PeopleTools application contains three major sets of tables:
System Catalog tables store physical attributes of tables and views, which your database management system uses to optimize performance.
PeopleTools tables contain information that you define using PeopleTools.
Application Data tables house the actual data that your users enter and access through PeopleSoft application pages.
This diagram shows PeopleSoft database tables and sample names:
Image: Tables in a PeopleSoft database
The following image explains about the different tables in a PeopleSoft database
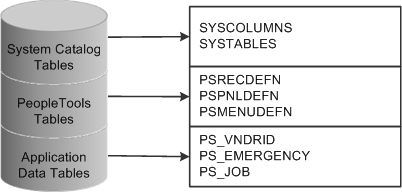
Like a spreadsheet, each of these tables contains columns and rows. Columns define the structure of how the data is stored. Rows represent the actual data that is stored in the database.
Every time that you create a new definition using PeopleTools, the system inserts rows of data into various PeopleTools tables. The entries in these tables determine the online processing of the system and what happens during imports. PeopleSoft maintains the structure of these tables. You maintain data in the PeopleTools tables related to definitions that you create or adapt using PeopleTools. You can view the PeopleTools tables in the PPLTOOLS project using the PeopleSoft Application Designer.
To create the application data tables that store the rows of data that your users manipulate:
Create a record definition.
In doing so you determine the structure of the table, the characteristics of the fields, and any online processing that you want to occur behind the scenes when a user enters data.
Apply the SQL Create option to build the SQL table in which your application data will reside based on a subset of parameters in your record definition.
During this process, the system automatically gives the application data table the same name as your record definition, prefaced with PS_.
To better understand the structure of your PeopleSoft system, you should be familiar with the concept of a normalized relational database. A normalized table adheres to standards that are designed to improve the productivity of the database user. Normalization makes the database more flexible, allowing data to be combined in many different ways.
The standards for a normalized database are called forms, such as first normal form, second normal form, and so on.
First Normal Form
The first normal form requires that a table contain no repeating groups of nonkey fields. In other words, when you set up a record definition, if you encounter a field that could have multiple occurrences, put that field in a separate record that is subordinate to the primary record definition (a child record). This setup allows unlimited occurrences of a repeating field rather than a specified number. Each row of data is uniquely identified by a primary key, which can be a single field or a group of fields that, when concatenated together, form a unique key.
For example, look at the record definition structure of the tables that we use to schedule exam times for different locations in our training database. Here are the necessary fields, in order of importance:
LOCATION
EXAM_DT
EXAM_TIME
You know that you have multiple exam dates and times per location. You could set up record definitions to accommodate this data as follows:
|
Record Definition |
Fields |
Key? |
|---|---|---|
|
LOCATION |
LOCATION |
Yes |
|
EXAM |
LOCATION EXAM_DT |
Yes Yes |
|
EXAM_TIME |
LOCATION EXAM_DT EXAM_TIME |
Yes Yes Yes |
Because multiple exam dates per location might exist, we added exam dates to the second record definition (child record) that is subordinate to the first (parent) record. Similarly, because one date could have multiple exam times, exam times are located in a third record definition that is subordinate to the second.
Second Normal Form
The second normal form dictates that every nonkey field in a table must be completely dependent on the primary key. If two fields make up the key to a table, every nonkey field must be dependent on both keys together. For example, if a table has the Employee ID and the Department ID fields as keys, you would not put the Department Name field in the table because this field is dependent only on the Department ID field and not on the Employee ID field.
Third Normal Form
The third normal form is a corollary to the second; it requires that a nonkey field not be dependent on another nonkey field. For example, if a table is keyed by the Employee ID field and Department ID is a nonkey field in the table, you would not put the Department Name field in the record because this field is dependent on a nonkey field (Department ID). You would find the Department Name field only in the table that is keyed by the Department ID field, not in any other table that contains Department ID.
With the third normal form, you store shared fields in tables of their own and reference them elsewhere. For example, you would not put the Department Name field in every record definition in which the Department ID field appears. Instead, you would create a prompt table of department IDs and department names. Similarly, you would create a prompt table of job codes and job titles instead of putting a job title in every employee’s record.
Note: When designing record definitions, you should adhere to the third normal form to increase flexibility and reduce data redundancy.
Before you begin to create record definitions, you should know how you plan to use the record definition, the fields that it will contain, special edits that you would like to see performed on the record definition, or specific fields in the definition.
You define two layers of information:
Record level
Field level
At the record level, determine the ultimate purpose of the record definition and how it will be used in the system. Is it destined to define an underlying SQL table to hold data? Are you building a view to join or retrieve information from other tables? Do you need a temporary work record where you can store derived data?
You can audit record-level changes, as opposed to individual fields contained in the record definition, which is an efficient alternative if you plan to audit several fields. You can also establish a more sophisticated use of record definitions, such as sharing information in TableSets and multilanguage controls, at the record level.
At the field level, plan the details of what types of fields to add. Should they be character fields or number fields? Should automatic formatting be used? What are the keys to the data stored in the database? Which fields should you audit? Do you want to specify prompt tables so that users can select from lists of valid values that are stored elsewhere in the database?
In most cases, if you are creating a record definition for a SQL table, you do nt have to worry about record-level definitions for parameters and conditions. Unless you change how a record definition is used, the system automatically assumes that you are defining a record definition for an underlying SQL table.
Effective dates enable you to keep historical, current, and future information in tables. You can use the information to review the past and plan for the future. Three types of effective dates are available:
|
Field or Control |
Definition |
|---|---|
| Future |
Data rows that have effective dates that are after the system date, which is usually today’s date. |
| Current |
Data row with the most recent effective date that is closest to today’s (system) date, but not a future date. Only one row is the current row. |
| History |
Data rows that have effective dates before the current data row. |
The EFFDT (Effective Date) field has special properties related to the processing of effective dates on rows and should be used only when needed.
Unlike regular date fields, which you can use anywhere in the system, use the EFFDT field only in record definitions for which you want to maintain data history—future, current, and past—to store rows of data in sequence. Using EFFDT fields only for this circumstance enables you to store multiple occurrences of data based on when it goes into effect.
For effective-dated rows, you can have multiple occurrences of future and history but only one current row of data.
EFFDT is almost always a key and almost never a list item. Activate the Descending Key attribute so that the row with the most recent effective date appears first on pages. You might enter %DATE (current system date) as the default constant for this field.
Note: Alternatively, you can use %CLIENTDATE as the default constant for the date field. %CLIENTDATE adjusts the date as appropriate to the time zone of the browser.
To enable you to track an accurate history of your effective-dated information, the system invokes special logic when you access a record definition that contains EFFDT. The action that you select dictates whether you can access the row type and what you can do with each type of row:
|
Action Type |
View |
Change |
Insert New Rows |
|---|---|---|---|
|
Update/Display |
Current, Future |
Future Only |
Effective Date Greater Than the Current Row |
|
Update/Display All |
History, Current, Future |
Future Only |
Effective Date Greater Than the Current Row |
|
Correction |
History, Current, Future |
All Existing Rows |
Add New Rows with No Effective Date Restrictions |
Note: For records that do not contain EFFDT, all actions (Update/Display, Update/Display All, and Correction) operate the same way: they retrieve all existing rows for the specified keys.
When you run a page with effective-dated records and you insert a row, the system copies the contents of the previous row into the new row to save you keying time. In a large effective-dated table, you do not want to reenter all of the data when only a single field changes. Also, anytime you insert an effective-dated row using PeopleCode, the system copies the contents of the previous row.
|
Field or Control |
Definition |
|---|---|
| Effective Status |
In prompt tables, EFF_STATUS (Effective Status) usually accompanies EFFDT. When used with EFFDT, it is part of the mechanism that enables the system to select the appropriate effective-dated rows. You can also use EFF_STATUS by itself as a simple status field, but do not change the translate values. They must be A (active) and I (inactive) for EFFDT to work properly. If you need a status field with different values, use or define a different field. |
| Effective Sequence |
The EFFSEQ (Effective Sequence) field serves different purposes, depending on whether it is paired with EFFDT. If EFFSEQ is not paired with EFFDT, then EFFSEQ has no special function and can be used as a simple sequencing field wherever you need one. If EFFSEQ is paired with EFFDT, it enables you to enter more than one row with the same effective date. You assign a unique sequence number to each row that has the same effective date. Do not make EFFSEQ a required field; a value of unrequired allows the first EFFSEQ to be zero. Select Display Zero in the page definition to have zeros appear on the page. For example, suppose that you want to enter both a transfer and a pay rate change for an employee, and both actions are effective on the same day. Enter the transfer on the job data pages as usual, and leave the Effective Sequence Number field as 0 (zero). Then, insert a row to enter the change in pay rate. This time, the effective date is identical to the previous row, but enter 1 in the Effective Sequence Number field. |
Control tables store information that controls the processing of an application. This type of processing might be consistent throughout an organization (in which case the entire organization shares the same control information), or it might be used only by portions of the organization for more limited sharing of data.
Sharing One Set of Common Values
The first type of sharing is to create one table that everyone shares; it stores common information that is valid for all users, such as a country table to store country codes or a department table to store department codes. Such control tables are ordinarily maintained centrally because the data is shared throughout the entire organization.
Sharing Common Values in Overlapping Plans
What do you do if the codes that are stored in a table are valid only for some users? Consider benefit plans, for example. Typically, you store information for benefits plans in a plan table. However, not all plans are valid for all employees; their validity might depend on whether the employee is full-time or part-time, union or nonunion. Some plans might overlap; some might be appropriate for all employees and others only for some. In a relational database, you do not want to define the same plan value—and associated data—more than once.
In this case, you can easily resolve the problem by using two tables. The first is the plan table, which stores the relevant data for each plan. The second table defines which plans are valid for various benefit programs or groups of plans. For example, one benefit program might be valid for nonunion employees, and another benefit program might contain the plans as negotiated with a union.
This table shows how you might set up the two tables to reflect the benefits offered:
|
Benefit Program Table |
Benefit Plan Table |
||||
|---|---|---|---|---|---|
|
Key |
Valid Values |
Key |
Description |
Field |
Field |
|
Nonunion Program |
Plan 1 Plan 2 |
Plan 1 Plan 2 |
Health Life |
... ... |
... ... |
|
Union Program |
Plan 2 Plan 3 Plan 4 |
Plan 3 Plan 4 |
Savings Health-Union |
... ... |
... ... |
These tables are ordinarily centrally maintained because the data is shared by various groups in the organization.
When none of the information stored in control tables is valid for all users, but the structure of these common tables is the same, you can set up a way to share multiple sets of values. For example, a multicompany organization must store completely different sets of accounting codes for its various operating entities, and the data for these accounting codes is maintained in a set of relevant control tables. The actual data values differ, but the structure of the control tables remains the same. PeopleTools enables you to share sets of values in a control table through TableSets.
To better understand TableSets, consider an organization that has two retail stores with common accounting codes, two pharmaceutical firms with another set of accounting codes, and two shipping firms with yet another set of codes.
Image: Maintaining multiple account codes for multiple companies
The following image explains about maintaining multiple account codes for multiple companies
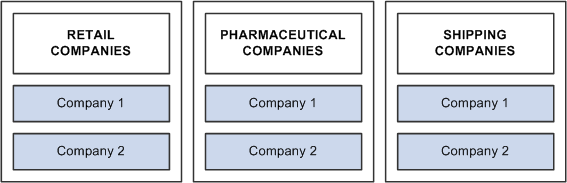
If each of these companies has completely different accounting codes, you can establish six different sets of account codes to be maintained by each company. If they all have exactly the same accounting codes, you can limit them to one set of values. However, the reality is usually somewhere in between. That is, there is one set of account codes for each type of business: retail, pharmaceutical, and shipping. Rather than having six different companies maintaining separate copies of this common data, you can reduce the number to three sets:
Image: Sharing multiple account codes among companies
The following image illustrates the concept of sharing multiple account codes among companies
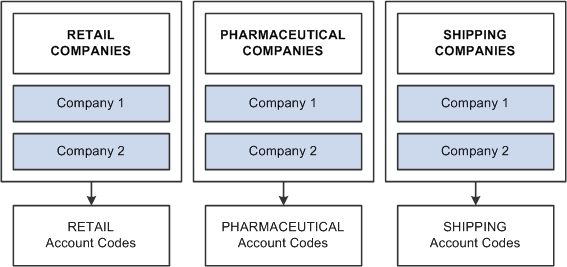
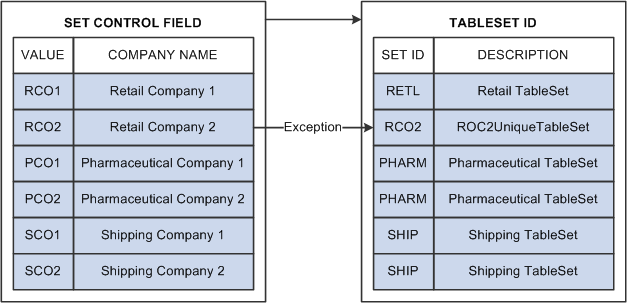
You can also handle exceptions. Suppose that Retail Company 2, a recently acquired company, has its own unique set of account codes. A separate set of values should be maintained for this company as an exception to the retail rule:
Image: Sharing account codes among companies with exceptions
The following image explains sharing account codes among companies with exceptions
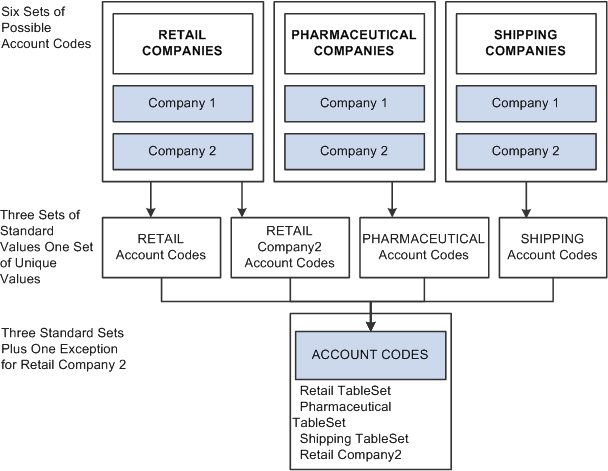
When you share tables in PeopleTools applications, you add the setID field as an additional key or unique identifier to the table that you want to share. This key identifies the sets of information in the table that are shared by multiple companies or business units under your corporate umbrella. You then specify a set control field, which identifies which fields map between the original key and the TableSets. You can specify any field that logically identifies the TableSet. In this example, you might assign the Company field as the set control:
Image: Linking set controls and TableSets
The following diagram illustrates Linking set controls and TableSets where in you can specify any field that logically identifies the TableSet
Sharing Groups of Record Definitions
While this example illustrates how you might share data values for a single table—Account Codes—you typically share data that is stored in many tables that are based on the same TableSets. To minimize the overhead of defining TableSets, you can define record groups that share table data in a similar manner. For example, rather than using the TableSets that you establish for accounting codes solely for the Accounting Code table, you can group all accounting related tables into one record group.
TableSets and PeopleSoft Applications
Some PeopleSoft applications already take full advantage of TableSets and table sharing. Throughout the PeopleSoft Financials and HCM product lines, TableSets are used extensively, in most cases triggered by business unit.