| Oracle® Fusion Middleware Oracle Business Intelligence Publisher開発者ガイド 12c (12.2.1) E70034-01 |
|

 前へ |
 次へ |
| Oracle® Fusion Middleware Oracle Business Intelligence Publisher開発者ガイド 12c (12.2.1) E70034-01 |
|
前へ |
次へ |
この章では、カスタム・アプリケーションからコールしてドキュメントを生成して処理できるBI Publisher Java APIについて説明します。
内容は次のとおりです。
|
注意: この章の情報は、Oracle Fusion Middleware Business Intelligenceドキュメント・ライブラリで入手できるOracle Fusion Middleware Oracle Business Intelligence Publisher Java APIリファレンスで使用されます。またこの章では、Javaプログラミング、XMLおよびXSLテクノロジの知識があることを前提として記載されています。 |
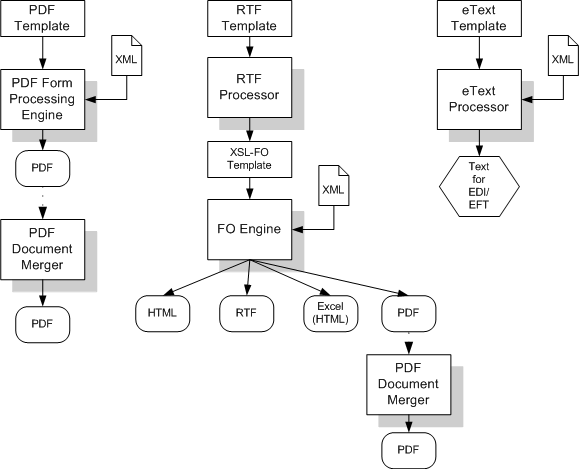
BI Publisherは、次のコアAPIコンポーネントで構成されています。
PDFフォーム処理エンジン
PDFテンプレートをXMLデータ(およびオプションのメタデータ)とマージしてPDFドキュメント出力を作成します。第7.4項「PDFフォーム処理エンジン」を参照してください。
RTFプロセッサ・エンジン
FOエンジンに対する入力用にRTFテンプレートをXSLに変換します。第7.5項「RTFプロセッサ・エンジン」を参照してください。
FOプロセッサ・エンジン
XSLとXMLをマージして、Excel(HTML)、PDF、RTFまたはHTMLのいずれかの出力形式を作成します。第7.6項「FOプロセッサ・エンジン」を参照してください。
PDFドキュメント・マージ機能
ドキュメントのマージ、ページ番号の追加および透かしの設定など、PDFファイルのオプションの後処理機能を提供します。第7.7項「PDFドキュメントのマージ機能」を参照してください。
eTextプロセッサ
RTF eTextテンプレートをXSLに変換し、XSLとXMLをマージしてEDIおよびEFT伝送用のテキスト出力を作成します。第7.10項「eTextプロセッサ」を参照してください。
ドキュメント・プロセッサ・エンジン(XML API)
テンプレート名、データソース、言語、出力タイプ、出力名および出力先を指定する単一のXMLファイルを渡すことによって、単一のAPIまたは複数のAPIにアクセスするバッチ処理機能を提供します。第7.11項「ドキュメント・プロセッサ・エンジン」を参照してください。
次の図に、各コア処理エンジンに対するテンプレート・タイプおよび出力タイプのオプションを示します。
BI Publisher APIを使用するには、xdocore.jarがクラス・パス内にあることを確認します。xdocore.jarにはBI Publisher APIのメイン・ライブラリが格納されています。
さらに、次のライブラリが必要です。
aolj.jar - 様々なBI Publisher機能をサポート
collections.jar - 配信APIまたはバースト・エンジンを操作する場合のみ必要
dvt-jclient.jar - チャート・ライブラリ
dvt-utils.jar - チャート・ライブラリ
groovy-all-1.6.3.jar - Groovy
i18nAPI_v3.jar - ローカライゼーション関数で使用されるi18nライブラリ
jewt4.jar - チャート・サポート・ライブラリ
mail.jar - SMTP配信に使用
ojdl.jar - Oracle Diagnostic Loggingに使用
orai18n-collation.jar - XDKにより使用
orai18n-mapping.jar - XDKにより使用
orai18n.jar - XDKにより使用されるキャラクタ・セット・ファイルおよびグローバリゼーション・サポート・ファイルを含む
osdt_cert.jar - SMIMEサポートのセキュリティ・ライブラリ
osdt_cms.jar - SMIMEサポートのセキュリティ・ライブラリ
osdt_core.jar - SMIMEサポートのセキュリティ・ライブラリ
osdt_smime.jar - SMIMEサポートのセキュリティ・ライブラリ
share.jar - チャート・サポート・ライブラリ
versioninfo.jar - BI Publisherのバージョン情報を含む
xdoparser.jar - スケーラブルなXMLパーサーおよびXSLT 2.0エンジン(10g)
xdoparser11g.jar - スケーラブルなXMLパーサーおよびXSLT 2.0エンジン(11g以降)
xmlparserv2.jar - XDK (SAXおよびDOM)
Oracle JDeveloperを使用している場合は、チャート作成ライブラリとXMLパーサー・ライブラリが使用可能になっています。ただし、すべての必要なJARファイルでディレクトリを作成してプロジェクトのカスタム・ライブラリとして使用するようにお薦めします。これにより、デプロイ後の予期しないエラーを回避できます。
ライブラリを取得する最も簡単な方法は、Template Builder for Microsoft Wordアドインをダウンロードしてインストールします。ホームページからTemplate Builder for Wordをダウンロードするには、「はじめに」でBI Publisherツールのダウンロード→Template Builder for Wordをクリックします。
JARファイルは、Template Builderを使用してインストール・ディレクトリの下のjlibライブラリ内にパッケージ化されます。
jlibへのサンプル・パスは次のようになります。
C:\Program Files\Oracle\BI Publisher\BI Publisher Desktop\Template Builder for Word\jlib
この項では、PDFフォーム処理エンジンの使用法を説明します。次のトピックが含まれます。
PDFフォーム処理エンジンは、PDFテンプレートとXMLデータ・ファイルをマージしてPDFドキュメントを作成します。これには、ファイル名、ストリームまたはXMLデータ文字列を使用します。
PDF処理エンジンの入力として、XMLベースのテンプレート・メタ情報(.xtm)ファイルを必要に応じて組み込むことができます。このファイルは、オーバーフロー・データの配置を定義する補足テンプレートです。
FO処理エンジンにも、PDFテンプレートに関する情報を提供するユーティリティが組み込まれています。次の操作を実行できます。
PDFテンプレートからのフィールド名リストの取得
XSLTを使用したXMLデータのXFDFへの変換
XMLデータをPDFテンプレートとマージしてPDF出力ドキュメントを作成するには、次の3つの方法があります。
入力/出力ファイル名を使用する方法
入力/出力ストリームを使用する方法
入力XMLデータ文字列を使用する方法
入力:
テンプレート・ファイル名(文字列)
XMLファイル名(文字列)
出力:
PDFファイル名(文字列)
例7-1 入力/出力ファイル名を使用したXMLデータとPDFテンプレートのマージのサンプル・コード
import oracle.xdo.template.FormProcessor;
.
.
FormProcessor fProcessor = new FormProcessor();
fProcessor.setTemplate(args[0]); // Input File (PDF) name
fProcessor.setData(args[1]); // Input XML data file name
fProcessor.setOutput(args[2]); // Output File (PDF) name fProcessor.process();
入力:
PDFテンプレート(入力ストリーム)
XMLデータ(入力ストリーム)
出力:
PDF(出力ストリーム)
例7-2 入力/出力ストリームを使用したXMLデータとPDFテンプレートのマージのサンプル・コード
import java.io.*; import oracle.xdo.template.FormProcessor; . . . FormProcessor fProcessor = new FormProcessor(); FileInputStream fIs = new FileInputStream(originalFilePath); // Input File FileInputStream fIs2 = new FileInputStream(dataFilePath); // Input Data FileInputStream fIs3 = new FileInputStream(metaData); // Metadata XML Data FileOutputStream fOs = new FileOutputStream(newFilePath); // Output File fProcessor.setTemplate(fIs); fProcessor.setData(fIs2); // Input Data fProcessor.setOutput(fOs); fProcessor.process(); fIs.close(); fOs.close();
入力:
テンプレート・ファイル名(文字列)
XMLデータ(文字列)
出力:
PDFファイル名(文字列)
例7-3 XMLデータ文字列とPDFテンプレートのマージのサンプル・コード
import oracle.xdo.template.FormProcessor; . . . FormProcessor fProcessor = new FormProcessor(); fProcessor.setTemplate(originalFilePath); // Input File (PDF) name fProcessor.setDataString(xmlContents); // Input XML string fProcessor.setOutput(newFilePath); // Output File (PDF) name fProcessor.process();
PDFテンプレートからフィールド名を取得するには、FormProcessor.getFieldNames() APIを使用します。このAPIでは、フィールド名が列挙オブジェクトに戻されます。
入力:
PDFテンプレート
出力:
列挙オブジェクト
例7-4 フィールド名リストの取得のサンプル・コード
import java.util.Enumeration;
import oracle.xdo.template.FormProcessor;
.
.
.
FormProcessor fProcessor = new FormProcessor();
fProcessor.setTemplate(filePath); // Input File (PDF) name
Enumeration enum = fProcessor.getFieldNames();
while(enum.hasMoreElements())
{
String formName = (String)enum.nextElement();
System.out.println("name : " + formName + " , value : " + fProcessor.getFieldValue(formName));
}
XML Forms Data Format(XFDF)は、PDFドキュメント内のフォーム・データと注釈を表すための形式です。XFDFは、Forms Data Format(FDF)のXMLバージョンであり、フォーム・データと注釈を表すためのPDFの簡易バージョンです。PDFドキュメント内のフォーム・フィールドには、編集ボックス、ボタンおよびラジオ・ボタンが含まれます。
このクラスを使用してXFDFデータを生成します。このクラスのインスタンスを作成すると、内部XFDFツリーが初期化されます。append()メソッドを使用して、文字列の名前と値のペアを渡すことによって、FIELD要素をXFDFツリーに追加します。データは必要なだけ追加できます。
このクラスでは、appendXML()メソッドをコールしてXMLデータを追加することもできます。appendXML()メソッドをコールする前に、setStyleSheet()メソッドをコールして適切なXSLスタイルシートを設定する必要があることに注意してください。XMLデータは必要なだけ追加できます。
toString()、toReader()、toInputStream()またはtoXMLDocument()のいずれかのメソッドをコールすると、内部XFDFドキュメントをいつでも取得できます。
次に、XFDFデータのサンプルを示します。
例7-5 サンプルXFDFデータ
<?xml version="1.0" encoding="UTF-8"?> <xfdf xmlns="http://ns.adobe.com/xfdf/" xml:space="preserve"> <fields> <field name="TITLE"> <value>Purchase Order</value> </field> <field name="SUPPLIER_TITLE"> <value>Supplie</value> </field> ... </fields>
次のコード例は、APIの使用法を示しています。
例7-6 内部XFDFドキュメントの取得のサンプル・コード
import oracle.xdo.template.FormProcessor; import oracle.xdo.template.pdf.xfdf.XFDFObject; . . . FormProcessor fProcessor = new FormProcessor(); fProcessor.setTemplate(filePath); // Input File (PDF) name XFDFObject xfdfObject = new XFDFObject(fProcessor.getFieldInfo()); System.out.println(xfdfObject.toString());
XSLスタイルシートを使用して、標準のXMLをXFDF形式に変換します。次に、サンプルのXMLデータをXFDFに変換する例を示します。
次のように、開始時のXMLはROWSET/ROW形式であるとします。
<ROWSET>
<ROW num="0">
<SUPPLIER>Supplier</SUPPLIER>
<SUPPLIERNUMBER>Supplier Number</SUPPLIERNUMBER>
<CURRCODE>Currency</CURRCODE>
</ROW>
...
</ROWSET>
このXMLから次のXFDF形式を生成するとします。
<fields>
<field name="SUPPLIER1">
<value>Supplier</value>
</field>
<field name="SUPPLIERNUMBER1">
<value>Supplier Number</value>
</field>
<field name="CURRCODE1">
<value>Currency</value>
</field>
...
</fields>
次のXSLTは変換を実行します。
例7-7 XMLデータのXFDF形式への変換のサンプルXLST
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<fields>
<xsl:apply-templates/>
</fields>
</xsl:template>
<!-- Count how many ROWs(rows) are in the source XML file. -->
<xsl:variable name="cnt" select="count(//row|//ROW)" />
<!-- Try to match ROW (or row) element.
<xsl:template match="ROW/*|row/*">
<field>
<!-- Set "name" attribute in "field" element. -->
<xsl:attribute name="name">
<!-- Set the name of the current element (column name)as a value of the current name attribute. -->
<xsl:value-of select="name(.)" />
<!-- Add the number at the end of the name attribute value if more than 1 rows found in the source XML file.-->
<xsl:if test="$cnt > 1">
<xsl:number count="ROW|row" level="single" format="1"/>
</xsl:if>
</xsl:attribute>
<value>
<!--Set the text data set in the current column data as a text of the "value" element. -->
<xsl:value-of select="." />
</value>
</field>
</xsl:template>
</xsl:stylesheet>
この結果、次のようにXSLTを使用すると、XFDFObjectを使用してXMLをXFDF形式に変換できます。
例7-8 XMLデータのXFDF形式への変換実行のサンプル・コード
import java.io.*; import oracle.xdo.template.pdf.xfdf.XFDFObject; . . . XFDFObject xfdfObject = new XFDFObject(); xfdfObject .setStylesheet(new BufferedInputStream(new FileInputStream(xslPath))); // XSL file name xfdfObject .appendXML( new File(xmlPath1)); // XML data file name xfdfObject .appendXML( new File(xmlPath2)); // XML data file name System.out.print(xfdfObject .toString());
この項では、RTPプロセッサ・エンジンの使用法を説明します。次のトピックが含まれます。
RTFProcessorはペアとなるXLIFFファイルを生成できます。APIの例は次のとおりです。
例7-9 ペアリングXLIFFファイル生成のサンプル・コード
public static void main(String[] args)
{
RTFProcessor rtfp = new RTFProcessor(args[0]); //input RTF template
rtfp.setOutput(args[1]); // XSL output file
rtfp.setXLIFFOutput(args[2]); // XLIFF output file
rtfp.process();
System.exit(0);
}
翻訳されたレポートを生成するには、次のようにFOProcessorをコールします。
RTFプロセッサ・エンジンは、入力としてRTFテンプレートを使用します。プロセッサは、テンプレートを解析し、XSL-FOテンプレートを作成します。このテンプレートをデータソース(XMLファイル)とともにFOエンジンに渡すと、PDF、HTML、RTFまたはExcel(HTML)の出力を作成できます。
次の例に示すように、入力/出力ファイル名または入力/出力ストリームのいずれかを使用します。
入力:
RTF(入力ストリーム)
出力:
XSL(出力ストリーム)
例7-12 入力/出力ストリームを使用したXSLの生成のサンプル・コード
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
FileInputStream fIs = new FileInputStream(args[0]); //input template
FileOutputStream fOs = new FileOutputStream(args[1]); // output
RTFProcessor rtfProcessor = new RTFProcessor(fIs);
rtfProcessor.setOutput(fOs);
rtfProcessor.process();
// Closes inputStreams outputStream
System.exit(0);
}
この項では、FOプロセッサ・エンジンの使用法を説明します。次のトピックが含まれます。
FOプロセッサ・エンジンには、次の機能が備わっています。
BI Publisherでは、BiDiレイアウトに関してUnicode BiDiアルゴリズムを利用します。FOプロセッサでは、プロパティwriting-mode、directionおよびunicode bidiに対する特定の値に基づいてBiDiレイアウトがサポートされます。
writing-modeプロパティでは、テキストにおける行の語順、および行の順序が定義されます。つまり、right-to-left, top-to-bottom(右から左、上から下)またはleft-to-right, top-to-bottom(左から右、上から下)のいずれかを指定します。directionプロパティでは、テキスト文字列の書込み方法が決まります。つまり、right-to-left(右から左)またはleft-to-right(左から右)などの方向を指定します。unicode bidiでは、上書き動作が制御および管理されます。
FOプロセッサでは、2つのレベルのフォント代替メカニズムがサポートされています。このメカニズムでは、指定したフォントまたは絵文字が検出されない場合に使用するデフォルト・フォントが制御されます。BI Publisherでは、適切なデフォルト代替フォントが自動的に提供され、構成は必要ありません。また、使用するデフォルト・フォントを指定するユーザー定義構成ファイルもサポートされています。絵文字の代替の場合、デフォルト・メカニズムでは絵文字のみが置換され、文字列全体は置換されません。
ヘッダーおよびフッターがテンプレートで定義されているより多くの領域を必要とする場合は、FOプロセッサによって、ページのヘッダーおよびフッターの値と本文領域余白の値との差異に基づいて、ヘッダーおよびフッターの領域が拡張され、本文の領域が縮小されます。
この機能では、Zスタイルの水平方向の表区切りがサポートされます。水平方向の表区切りは列の拡張に影響されないため、拡張された列のセルがページ(または領域の幅)を超えた場合は、FOプロセッサによってセルが分割され、分割セルに対してインテリジェント書式設定は適用されません。
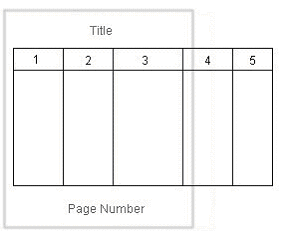
次の図に、幅が広すぎるために1ページに表示できない表を示します。
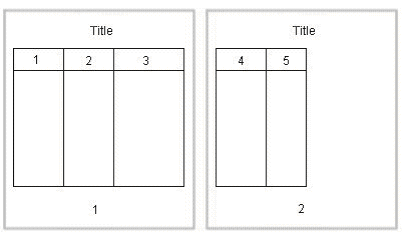
次の図に、幅の広い表を水平方向の表区切りで処理する方法の1つのオプションを示します。この例では、3列目の後で水平方向の表区切りが行われます。
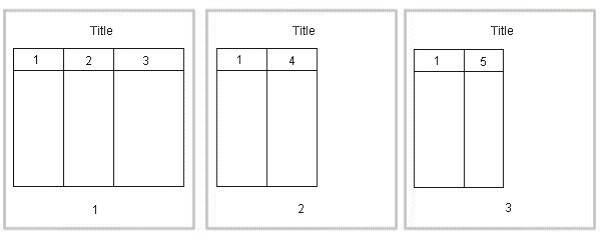
次の図に、別のオプションを示します。3列目の後で表が区切られますが、新しい各ページに1列目が表示されます。
FOプロセッサ・エンジンは、BI PublisherでW3C XSL-FOの標準実装となっています。XSL-FOコンポーネントごとに完全実装であることが示されていません。
FOプロセッサは、次に示す入力タイプのいずれかから、PDF、RTF、HTMLまたはExcel(HTML)の出力を生成できます。
テンプレート(XSL)およびデータ(XML)の組合せ
FOオブジェクト
入力タイプをファイル名、ストリームまたは配列で渡すことができます。setOutputFormatメソッドを次のいずれかに設定して出力形式を設定します。
FORMAT_EXCEL
FORMAT_HTML
FORMAT_PDF
FORMAT_RTF
FORMAT_PPTX
FORMAT_MHTML
FORMAT_PPTMHT
FORMAT_EXCEL_MHTML
FORMAT_PDFZ
次の入力からXSL-FOを作成するXSL-FOユーティリティも提供されています。
XSLファイルおよびXMLファイル
2つのXMLファイルおよび2つのXSLファイル
2つのXSL-FOファイル(マージ)
XSL-FOユーティリティからのFOオブジェクト出力は、FOプロセッサの入力として使用できます。
次の例は、FOプロセッサでファイル名を使用して出力ファイルを作成する方法を示しています。
入力:
XMLファイル名(文字列)
XSLファイル名(文字列)
出力:
出力ファイル名(文字列)
例7-13 ファイル名を使用した出力生成のサンプル・コード
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
FOProcessor processor = new FOProcessor();
processor.setData(args[0]); // set XML input file
processor.setTemplate(args[1]); // set XSL input file
processor.setOutput(args[2]); //set output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
次の例に示すように、入力/出力ストリームを指定してプロセッサを使用することもできます。
入力:
XMLデータ(入力ストリーム)
XSLデータ(入力ストリーム)
出力:
出力ストリーム(出力ストリーム)
例7-14 ストリームを使用した出力生成のサンプル・コード
import java.io.InputStream;
import java.io.OutputStream;
import oracle.xdo.template.FOProcessor;
.
.
.
public void runFOProcessor(InputStream xmlInputStream,
InputStream xslInputStream,
OutputStream pdfOutputStream)
{
FOProcessor processor = new FOProcessor();
processor.setData(xmlInputStream);
processor.setTemplate(xslInputStream);
processor.setOutput(pdfOutputStream);
// Set output format (for PDF generation)
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
データとテンプレートの配列の組合せを処理して、複数の入力から1つの出力ファイルを生成できます。入力データソースの数は、データに適用されるテンプレートの数と一致する必要があります。たとえば、File1.xml、File2.xml、File3.xmlとFile1.xsl、File2.xsl、File3.xslの入力から単一のFile1_File2_File3.pdfが作成されます。
入力:
XMLデータ(配列)
XSLデータ(テンプレート)(配列)
出力:
ファイル名(文字列)
例7-15 XSLテンプレート配列およびXMLデータからの出力生成のサンプル・コード
import java.io.InputStream;
import java.io.OutputStream;
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
String[] xmlInput = {"first.xml", "second.xml", "third.xml"};
String[] xslInput = {"first.xsl", "second.xsl", "third.xsl"};
FOProcessor processor = new FOProcessor();
processor.setData(xmlInput);
processor.setTemplate(xslInput);
processor.setOutput("/tmp/output.pdf); //set (PDF) output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF); processor.process();
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
}
入力XMLおよびXSLファイルからXSL-FO出力ファイルを作成するか、または2つのXSL-FOファイルをマージするには、XSL-FOユーティリティを使用します。このユーティリティで出力を使用して、最終出力を生成できます。第7.6.2項「XMLファイルおよびXSLファイルからの出力の生成」を参照してください。
入力:
XMLファイル
XSLファイル
出力:
XSL-FO(入力ストリーム)
例7-16 XMLファイルとXSLファイルからからのXSL-FO作成のサンプル・コード
import oracle.xdo.template.fo.util.FOUtility;
.
.
.
public static void main(String[] args)
{
InputStream foStream;
// creates XSL-FO InputStream from XML(arg[0])
// and XSL(arg[1]) filepath String
foStream = FOUtility.createFO(args[0], args[1]);
if (mergedFOStream == null)
{
System.out.println("Merge failed.");
System.exit(1);
}
System.exit(0);
}
入力:
XMLファイル1
XMLファイル2
XSLファイル1
XSLファイル2
出力:
XSL-FO(入力ストリーム)
例7-17 2つのXMLファイルおよび2つのXSLファイルからのXSL-FO作成のサンプル・コード
import oracle.xdo.template.fo.util.FOUtility;
.
.
.
public static void main(String[] args)
{
InputStream firstFOStream, secondFOStream, mergedFOStream;
InputStream[] input = InputStream[2];
// creates XSL-FO from arguments
firstFOStream = FOUtility.createFO(args[0], args[1]);
// creates another XSL-FO from arguments
secondFOStream = FOUtility.createFO(args[2], args[3]);
// set each InputStream into the InputStream Array
Array.set(input, 0, firstFOStream);
Array.set(input, 1, secondFOStream);
// merges two XSL-FOs
mergedFOStream = FOUtility.mergeFOs(input);
if (mergedFOStream == null)
{
System.out.println("Merge failed.");
System.exit(1);
}
System.exit(0);
}
入力:
2つのXSL-FOファイル名(配列)
出力:
1つのXSL-FO(入力ストリーム)
例7-18 2つのXSL-FOファイルのマージのサンプル・コード
import oracle.xdo.template.fo.util.FOUtility;
.
.
.
public static void main(String[] args)
{
InputStream mergedFOStream;
// creates Array
String[] input = {args[0], args[1]};
// merges two FO files
mergedFOStream = FOUtility.mergeFOs(input);
if (mergedFOStream == null)
{
System.out.println("Merge failed.");
System.exit(1);
}
System.exit(0);
}
FOプロセッサは、FOオブジェクトを処理して最終出力を生成するためにも使用できます。FOオブジェクトは、XMLデータにXSL-FOスタイルシートを適用した結果です。これらのオブジェクトは、サード・パーティのアプリケーションから生成でき、FOプロセッサの入力として使用できます。
プロセッサのコール方法は前述の方法と同じですが、書式設定の指示はFOに含まれているため、テンプレートは必要ありません。
入力:
FOファイル名(文字列)
出力:
PDFファイル名(文字列)
例7-19 ファイル名を使用した出力生成のサンプル・コード
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args) {
FOProcessor processor = new FOProcessor();
processor.setData(args[0]); // set XSL-FO input file
processor.setTemplate((String)null);
processor.setOutput(args[2]); //set (PDF) output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
入力:
FOデータ(入力ストリーム)
出力:
出力(出力ストリーム)
例7-20 ストリームを使用した出力生成のサンプル・コード
import java.io.InputStream;
import java.io.OutputStream;
import oracle.xdo.template.FOProcessor;
.
.
.
public void runFOProcessor(InputStream xmlfoInputStream,
OutputStream pdfOutputStream)
{
FOProcessor processor = new FOProcessor();
processor.setData(xmlfoInputStream);
processor.setTemplate((String)null);
processor.setOutput(pdfOutputStream);
// Set output format (for PDF generation)
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
}
複数のFO入力を配列として渡して単一の出力ファイルを生成できます。テンプレートは必要でないため、次の例に示すように、テンプレート配列のメンバーはnullに設定します。
入力:
FOデータ(配列)
出力:
出力ファイル名(文字列)
例7-21 FOデータの配列を使用した出力生成のサンプル・コード
import java.lang.reflect.Array;
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
String[] xmlInput = {"first.fo", "second.fo", "third.fo"};
String[] xslInput = {null, null, null}; // null needs for xsl-fo input
FOProcessor processor = new FOProcessor();
processor.setData(xmlInput);
processor.setTemplate(xslInput);
processor.setOutput("/tmp/output.pdf); //set (PDF) output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF); processor.process();
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
}
PDFドキュメント・マージ機能クラスでは、PDFドキュメントを操作するための一連のユーティリティが提供されます。これらのユーティリティを使用すると、ドキュメントのマージ、ページ番号の追加、背景の設定および透かしの追加を実行できます。
多くのビジネス・ドキュメントが、最終的に1つのドキュメントにマージする必要がある別個の複数のドキュメントで構成されています。PDFDocMergerクラスでは、複数ドキュメントをマージして単一のPDFドキュメントを作成する機能がサポートされています。また、さらに操作して、ページ番号、透かしまたはその他の背景イメージを追加できます。
次のコードは、物理ファイルを使用して2つのPDFドキュメントをマージ(連結)して、単一の出力ドキュメントを生成する方法を示しています。
入力:
PDF_1ファイル名(文字列)
PDF_2ファイル名(文字列)
出力:
PDFファイル名(文字列)
例7-22 入力/出力ファイル名を使用したPDFドキュメントのマージのサンプル・コード
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public static void main(String[] args)
{
try
{
// Last argument is PDF file name for output
int inputNumbers = args.length - 1;
// Initialize inputStreams
FileInputStream[] inputStreams = new FileInputStream[inputNumbers];
inputStreams[0] = new FileInputStream(args[0]);
inputStreams[1] = new FileInputStream(args[1]);
// Initialize outputStream
FileOutputStream outputStream = new FileOutputStream(args[2]);
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
// Closes inputStreams and outputStream
}
catch(Exception exc)
{
exc.printStackTrace();
}
}
入力:
PDFドキュメント(入力ストリーム配列)
出力:
PDFドキュメント(出力ストリーム)
例7-23 入力/出力ストリームを使用したPDFドキュメントのマージ
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public boolean mergeDocs(InputStream[] inputStreams, OutputStream outputStream)
{
try
{
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
return true;
}
catch(Exception exc)
{
exc.printStackTrace();
return false;
}
}
次のコードは、入力ストリームを使用して2つのPDFドキュメントをマージし、単一のマージ出力ストリームを生成する方法を示しています。
ページ番号を追加する手順は、次のとおりです。
最終出力PDFドキュメントでページ番号を表示する位置にPDFフォーム・フィールドを組み込んだ背景用PDFテンプレート・ドキュメントを作成します。
フォーム・フィールドに@pagenum@という名前を設定します。
フィールドに、ページ番号の開始番号を入力します。フィールドに値を入力しない場合、開始ページ番号はデフォルトで1に設定されます。
入力:
PDFドキュメント(入力ストリーム配列)
背景用PDFドキュメント(入力ストリーム)
出力:
PDFドキュメント(出力ストリーム)
例7-24 ページ番号を配置するための背景とPDFドキュメントとのマージのサンプル・コード
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public static boolean mergeDocs(InputStream[] inputStreams, InputStream backgroundStream, OutputStream outputStream)
{
try
{
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
// Set Background
docMerger.setBackground(backgroundStream);
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
return true;
}
catch(Exception exc)
{
exc.printStackTrace();
return false;
}
}
FOプロセッサでは、XSL-FOテンプレートによってページ番号がネイティブでサポートされていますが、複数のドキュメントをマージしている場合、完成したドキュメントに最初から最後まで番号を付けるにはこのクラスを使用する必要があります。
次に示すコード例では、次のメソッドを使用して、ページ上の特定位置へのページ番号配置、番号の書式設定、および開始値の設定が実行されます。
setPageNumberCoordinates (x, y) - ページ番号の位置のxおよびy座標を設定します。次に示す例では、座標は300, 20に設定されます。
setPageNumberFontInfo (font name, size) - ページ番号のフォントとサイズを設定します。このメソッドをコールしない場合は、デフォルトのHelvetica、サイズ8が使用されます。次に示す例では、フォントはCourier、サイズは8に設定されます。
setPageNumberValue (n, n) - 開始番号および番号付けを開始するページを設定します。このメソッドをコールしない場合は、デフォルト値1, 1が使用されます。
入力:
PDFドキュメント(入力ストリーム配列)
出力:
PDFドキュメント(出力ストリーム)
例7-25 マージPDFドキュメントへのページ番号の追加のサンプル・コード
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public boolean mergeDocs(InputStream[] inputStreams, OutputStream outputStream)
{
try
{
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
// Calls several methods to specify Page Number
// Calling setPageNumberCoordinates() method is necessary to set Page Numbering
// Please refer to javadoc for more information
docMerger.setPageNumberCoordinates(300, 20);
// If this method is not called, then the default font"(Helvetica, 8)" is used.
docMerger.setPageNumberFontInfo("Courier", 8);
// If this method is not called, then the default initial value "(1, 1)" is used.
docMerger.setPageNumberValue(1, 1);
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
return true;
}
catch(Exception exc)
{
exc.printStackTrace();
return false;
}
}
草案段階の一部のドキュメントでは、ドキュメント全体に「DRAFT」という透かしが表示される必要があります。また、ドキュメントに背景イメージが必要な場合もあります。次のコード・サンプルは、PDFDocMergerクラスを使用して透かしを設定する方法を示しています。
SetTextDefaultWatermark()メソッドを使用して、次の属性でテキストの透かしを設定します。
テキストの角度(度): 55
色: 明るい灰色(0.9, 0.9, 0.9)
フォント: Helvetica
フォント・サイズ: 100
開始位置は、テキストの長さに基づいて計算されます。
または、SetTextWatermark()メソッドを使用して、各属性を別々に設定する方法もあります。SetTextWatermark()メソッドを次のように使用します。
SetTextWatermark ("Watermark Text", x, y) - 透かしテキストを宣言し、開始位置のxおよびy座標を設定します。次に示す例では、透かしテキストは「Draft」、座標は200f, 200fです。
setTextWatermarkAngle (n) - 透かしテキストの角度を設定します。このメソッドをコールしない場合は、0(ゼロ)が使用されます。
setTextWatermarkColor (R, G, B) - RGBカラーを設定します。このメソッドをコールしない場合は、明るい灰色(0.9, 0.9, 0.9)が使用されます。
setTextWatermarkFont ("font name", font size) - フォントとサイズを設定します。このメソッドをコールしない場合は、Helvetica, 100が使用されます。
次の例は、これらのプロパティを設定し、PDFDocMergerをコールする方法を示しています。
入力:
PDFドキュメント(入力ストリーム)
出力:
PDFドキュメント(出力ストリーム)
例7-26 PDFドキュメントでのテキストの透かしの設定のサンプル・コード
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public boolean mergeDocs(InputStream inputStreams, OutputStream outputStream)
{
try
{
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
// You can use setTextDefaultWatermark() without these detailed setting
docMerger.setTextWatermark("DRAFT", 200f, 200f); //set text and place
docMerger.setTextWatermarkAngle(80); //set angle
docMerger.setTextWatermarkColor(1.0f, 0.3f, 0.5f); // set RGB Color
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
return true;
}
catch(Exception exc)
{
exc.printStackTrace();
return false;
}
}
イメージの透かしは、ドキュメントの背景全体または特定の領域(例: ロゴ表示領域)に表示されるように設定できます。次のように、長方形の座標を使用して、イメージの配置とサイズを指定します。
float[] rct = {LowerLeft X, LowerLeft Y, UpperRight X, UpperRight Y}
次に例を示します。
float[] rct = {100f, 100f, 200f, 200f}
イメージは、定義された長方形の領域にあわせてサイズが変更されます。
サイズを変更せずに実際のイメージ・サイズを使用するには、左下Xと左下Yの位置で配置を定義し、右上Xと右上Yの座標は-1fと指定します。次に例を示します。
float[] rct = {100f, 100f, -1f, -1f}
入力:
PDFドキュメント(入力ストリーム)
イメージ・ファイル(入力ストリーム)
出力:
PDFドキュメント(出力ストリーム)
例7-27 PDFドキュメントでのイメージの透かしの設定のサンプル・コード
import java.io.*;
import oracle.xdo.common.pdf.util.PDFDocMerger;
.
.
.
public boolean mergeDocs(InputStream inputStreams, OutputStream outputStream, String imageFilePath)
{
try
{
// Initialize PDFDocMerger
PDFDocMerger docMerger = new PDFDocMerger(inputStreams, outputStream);
FileInputStream wmStream = new FileInputStream(imageFilePath);
float[] rct = {100f, 100f, -1f, -1f};
pdfMerger.setImageWatermark(wmStream, rct);
// Merge PDF Documents and generates new PDF Document
docMerger.mergePDFDocs();
docMerger = null;
// Closes inputStreams
return true;
}
catch(Exception exc)
{
exc.printStackTrace();
return false;
}
}
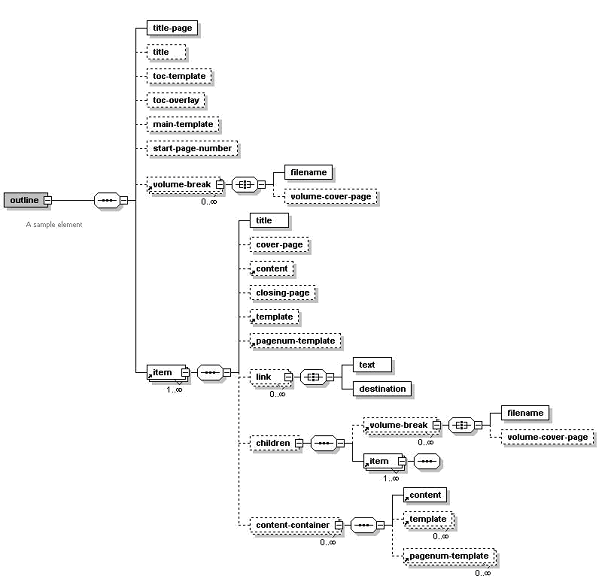
PDFBookBinderプロセッサは、複数のPDFドキュメントをマージして、章、項および節の階層構造と目次で構成された単一のドキュメントにする場合に便利です。このプロセッサではPDFスタイルの「しおり」も生成され、アウトライン構造は章および項の階層によって決まります。非常に強力な機能を備えており、組み合されたドキュメントを完全に管理できます。
目次の書式設定とスタイルは、Microsoft Wordで作成されたRTFテンプレートで定義されます。各章は独立したPDFファイル(1つの章、項または節が1つのPDFに対応します)としてプログラムに渡されます。テンプレートは、ドキュメント内への動的または静的コンテンツの挿入、ページ番号付けおよびハイパーリンクの配置のために章レベルで指定することもできます。
テンプレートの形式は、RTFまたはPDFのどちらでもかまいません。RTFテンプレートのほうが、BI Publisherの動的コンテンツのサポートを活用できるのでより柔軟性があります。PDFテンプレートは、柔軟性がはるかに低く、ページ番号やその他のタイプの動的コンテンツを挿入したときのテキスト領域の再構成といった必要な効果を得ることが難しくなります。
テンプレートは、(90度単位で)回転したり、透過にすることができます。PDFテンプレートは、ブック・レベルで指定してグローバルなページ番号付けや、その他、背景および透かしなどのコンテンツの指定を可能にすることもできます。表題ページや各章や項ごとの中扉もパラメータとして渡すことができます。
ブックの章、項および節の構造は、XMLとして表され、コマンドライン・パラメータとして渡すことも、APIレベルで渡すこともできます。章および項のファイルは、すべてのテンプレート・ファイルおよびそのパラメータと同じように、すべてこのXML構造内に指定されます。したがって、必要なパラメータはXMLファイルとPDF出力ファイルの2つのみです。
また、ブック構造内に分冊の区切りを指定することもできます。これにより、内容が別々の出力ファイルに分割され、ファイルおよび印刷の管理が簡単になります。
次の図に、XML制御ファイルの構造を示します。
XML構造内でのテンプレートおよびコンテンツ・ファイルの位置を指定するには、ローカル・ファイル・システムへの相対パスまたはテンプレートやコンテンツの位置を指すURLを指定します。Secure HTTPプロトコルの他、特別に認識される次のようなBI Publisherプロトコルもサポートされています。
「xdoxsl:///」はサブテンプレートのロードに使用します。
「xdo://」は、イメージなど、その他のリソースのロードに使用します。
コマンドラインの使用例を次に示します。
例7-28 コマンドライン・オプションのサンプル
java oracle.xdo.template.pdf.book.PDFBookBinder [-debug <true or false>] [-tmp <temp dir>] -xml <input xml> -pdf <output pdf>
説明:
-xml <file>: 目次XML構造を含む入力XMLファイルのファイル名です。
-pdf <file>: 生成される最終のPDF出力ファイルです。
-tmp <directory>: メモリー管理を向上させるための一時ディレクトリです。(これは任意の指定で、指定しない場合はシステムの環境変数"java.io.tmpdir"が使用されます。)
-log <file>: 出力ログ・ファイルを設定します(任意指定で、デフォルトはSystem.outです)。
-debug <true or false>: デバッグをオフまたはオンにします。
この項では、PDFデジタル署名エンジンの使用法を説明します。次のトピックが含まれます。
PDFデジタル署名エンジンは、署名されていないPDFドキュメントを署名フィールド名とパスワードで保護されたPFX(Personal Information Exchange)ファイルで処理して、署名済PDFドキュメントを作成します。PFXファイルは、Public Key Cryptography Standards #12(PCKS-12)の形式に従っており、ファイルにはデジタル証明と対応する秘密鍵が格納されています。
署名済PDFドキュメントの作成は、第7.9.2項「PDFドキュメントの署名」を参照してください。
署名済PDFを配信するには、スケジュール・サービスを使用します。第3章「ScheduleService」を参照してください。
署名済PDFドキュメントの検証は、第7.9.4項「署名済PDFドキュメントの検証」を参照してください。
PDFドキュメントの署名には、次の項目が必要です。
デジタル証明書。デジタル証明書を取得するには、Oracle Fusion Middleware Oracle Business Intelligence Publisher開発者ガイドのデジタル署名の実装に関する項を参照してください。
デジタル証明書を格納したPFXファイル。PFXファイルを作成するには、Oracle Fusion Middleware Oracle Business Intelligence Publisher開発者ガイドのデジタル署名の実装に関する項を参照してください。
署名フィールドを備えたPDFファイル。PDFファイルに署名フィールドがない場合、addSignatureField()メソッドを使用してフィールドを追加できます。例7-30にPDFファイルへの署名フィールド追加のサンプル・コードを示します。このメソッドは署名フィールドをPKCS-1 Secure Hash Algorithm #1 (SHA-1)形式で保存します。
前述の項目を取得または作成すれば、PDFドキュメントに署名できます。
PDFドキュメントに署名するには、Oracle BI Publisher付属のPDFSignature Java APIを使用して、PDFファイルをPFXファイルで処理します。例7-30にそのためのサンプル・コードを示します。
例7-30 署名済PDFドキュメント作成のサンプル・コード
String workDir = "C:/projects/";
String inPDF = workDir + "VerySimpleContent.pdf";
String outPDF = workDir + "VerySimpleContent_signed.pdf";
String pkcs12File = workDir + "YourName.pfx";
try
{
PDFSignature pdfSignature = new PDFSignature(inPDF, outPDF);
pdfSignature.init("password123", pkcs12File);
// If your PDF document does not have a signature field, uncomment the
// following line of code, which adds a signature field with the name
// "Signature1".
// pdfSignature.addSignatureField(1, PDFSignature.PDF_SIGNFIELD_UPPER_RIGHT, "Signature1", -1, -1);
pdfSignature.sign("Signature1", "Reason to Sign");
pdfSignature.cleanup();
}
catch(Throwable t)
{
t.printStackTrace();
}
署名済PDFを配信するには、スケジュール・サービスを使用します。第3章「ScheduleService」を参照してください。
署名済PDFドキュメントを検証するには、デジタル証明を使用して処理します。例7-31にそのためのサンプル・コードを示します。
例7-31 署名済PDFドキュメント検証のサンプル・コード
String workDir = "C:/projects/";
String inPDF = workDir + "VerySimpleContent_signedWithAcrobat.pdf";
String trustedRootCert = workDir + "VerisignFreeCertificate.cer";
File trustedRootCertFile = new File(trustedRootCert);
Vector trustedCerts = new Vector();
trustedCerts.addElement(trustedRootCertFile);
try
{
PDFSignature pdfSignature = new PDFSignature(inPDF);
pdfSignature.init();
SignatureFields signFields = pdfSignature.getSignatureFields();
Vector signedFieldNames = signFields.getSignatureFieldNames();
int size = signedFieldNames.size();
for(int i = 0 ; i < size ; i++)
{
String signFieldName = (String)signedFieldNames.elementAt(i);
SignatureField signField = signFields.getSignatureField(signFieldName);
boolean isValid = signField.verifyDocument();
System.out.println("Valid? : " + isValid);
boolean isCertValid = signField.verifyCertificates(trustedCerts, null);
System.out.println("Trusted? : " + isCertValid);
}
}
catch(Throwable t)
{
t.printStackTrace();
}
eTextプロセッサを使用すると、RTF eTextテンプレートをXSLに変換し、XSLとXMLをマージしてEDIおよびEFT伝送用のテキスト出力を作成できます。
RTF eTextテンプレートをXSLに変換するAPIメソッドのコールの例は、次のとおりです。
例7-32 RTF eTextテンプレートのXSLへの変換のサンプル・コード
String rtf = "test.rtf"; // etext template filename
String xsl = "out.xsl"; // xsl-fo filename
Properties prop = new Properties();
try
{
EFTProcessor p = new EFTProcessor();
p.setTemplate(rtf);
p.setConfig(prop);
p.setOutput(xsl);
p.process();
}
catch (Exception e)
{
e.printStackTrace();
}
XSLとXMLをマージしてeText出力を作成するAPIメソッドのコールの例は、次のとおりです。
例7-33 EDIおよびEFT伝送用のテキスト出力の作成のサンプル・コード
String rtf = "test.rtf"; // etext template filename
String xml = "data.xml"; //xml data filename
String etext = "etext.txt"; //etext output filename
Properties prop = new Properties();
try
{
EFTProcessor p = new EFTProcessor();
p.setConfig(prop);
p.setTemplate(rtf);
p.setData(xml);
p.setOutput(etext);
p.process();
}
catch (Exception e)
{
e.printStackTrace();
}
次のAPIを使用すると、eTextテンプレートの順序番号を取得できます。
EFTProcessor.getPeriodicSequenceNumbers() - 順序の名前や、順序の最後の順序番号を含むハッシュ表を返します。
EFTProcessor.getPeriodicSequenceNames() - eTextテンプレートに定義されるすべてのPERIODIC_SEQUENCE順序名を含むベクターを返します。
次の例に、これらのAPIを使用する方法を示します。
図7-34 順序番号を取得するためのサンプル・コード
try{
EFTProcessor eftp = new EFTProcessor();
eftp.setConfig(prop); // set property
eftp.setTemplate(rtf); // set template
eftp.setOutput(etext); // set etext output
eftp.setXSL(xsl);
eftp.setData(xml); // set xml data
eftp.process();
// Vector sequenceNames = eftp.getPeriodicSequenceNames();
// get periodic sequence names
Hashtable seqNumbers = eftp.getPeriodicSequenceNumbers();
// get periodic sequence numbers
Enumeration keys = seqNumbers.keys();
while (keys.hasMoreElements()) {
String key = keys.nextElement().toString();
String value = seqNumbers.get(key).toString();
System.out.println("EFT test: key=" + key + " value=" + value);
}
}
catch( Exception e)
{
e.printStackTrace();
}
ドキュメント・プロセッサ・エンジンは、テンプレート名、データソース、言語、出力タイプ、出力名および出力先を指定する単一のXMLインスタンスドキュメントを渡すことによって、単一のAPIまたは複数のAPIにアクセスするバッチ処理機能を提供します。
このソリューションを使用すると、BI Publisherを使用したバッチ印刷が可能になります。単一のXMLドキュメントを使用して、複数の顧客に対する一連の請求書について、顧客ごとの優先出力形式や配信チャネルなども含めて定義できます。XML形式は非常に柔軟性があり、複数ドキュメントの作成または単一のマスター・ドキュメントの作成が可能です。
この項の内容は、次のとおりです。
ドキュメント・プロセッサXMLファイルの階層と要素の説明
特定の処理オプションの例を示すサンプルXMLファイルの提供
プロセッサを起動するサンプル・コードの提供
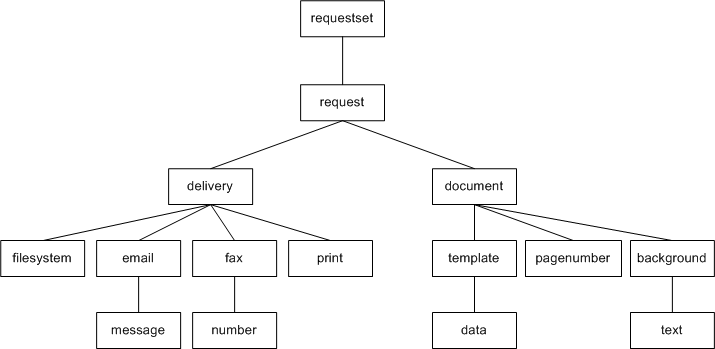
ドキュメント・プロセッサXMLファイルの要素の階層は、次のとおりです。
Requestset
request
delivery
filesystem
print
fax
number
email
message
document
background
text
pagenumber
template
data
この階層を図に表すと、次のようになります。
次の表で、各要素について説明します。
表7-1 ドキュメント・プロセッサXMLファイルの階層内の要素
| 要素 | 属性 | 説明 |
|---|---|---|
|
|
|
ルート要素には、[
|
|
|
なし |
データおよびテンプレート処理定義が含まれる要素。 |
|
|
なし |
生成された出力の送信先を定義します。 |
|
|
|
出力を1つ指定します。この出力には複数のテンプレート要素を設定できます。 pdf(デフォルト) rtf html excel text |
|
|
|
出力をファイル・システムに保存する場合はこの要素を指定します。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
特定のページに背景テキストが必要な場合は、 |
|
|
|
|
|
|
|
ページ番号のフォントにはHelveticaが使用されます。
|
|
|
|
テンプレート情報が記述されます。
rtf xsl-fo etext デフォルトはpdfです。 |
|
|
|
|
この項では、次の例を示す各サンプルXMLファイルを提供します。
単純なXML形式
2つのデータ・セットの定義
複数のテンプレートおよびデータの定義
HTTPを介したテンプレートの取得
HTTPを介したデータの取得
複数出力の生成
ページ番号の定義
次の例は、2つのデータソースを定義して1つのテンプレートとマージし、ファイル・システムに送信される1つの出力ファイルを作成する方法を示しています。
例7-35 2つのデータ・セットを定義するサンプルXML
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\tmp\outfile.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="d:\mywork\template1.pdf">
<xapi:data>
<field1>The first set of data</field1>
</xapi:data>
<xapi:data>
<field1>The second set of data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>
次の例は、前述の例を基に、2つのデータソースを1つのテンプレートに、さらに2つのデータソースを2番目のテンプレートに適用し、これら2つを1つの出力ファイルにマージする方法を示しています。ドキュメントをマージするときは、output-typeが"pdf"であることが必要です。
例7-36 複数のテンプレートとデータを定義するサンプルXML
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\tmp\outfile3.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="d:\mywork\template1.pdf">
<xapi:data>
<field1>The first set of data</field1>
</xapi:data>
<xapi:data>
<field1>The second set of data</field1>
</xapi:data>
</xapi:template>
<xapi:template type="pdf"
location="d:\mywork\template2.pdf">
<xapi:data>
<field1>The third set of data</field1>
</xapi:data>
<xapi:data>
<field1>The fourth set of data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>
このサンプルは、前述の例とほぼ同じですが、2つのテンプレートがHTTPを介して取得されている点が異なります。
例7-37 HTTPを介したテンプレートを取得するサンプルXML
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out4.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="http://your.server:9999/templates/template1.pdf">
<xapi:data>
<field1>The first page data</field1>
</xapi:data>
<xapi:data>
<field1>The second page data</field1>
</xapi:data>
</xapi:template>
<xapi:template type="pdf"
location="http://your.server:9999/templates/template2.pdf">
<xapi:data>
<field1>The third page data</field1>
</xapi:data>
<xapi:data>
<field1>The fourth page data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>
このサンプルは、前述の例を基に、2つのデータソースを使用する1つのテンプレートを示しています。これらはすべてHTTPを介して取得されます。さらに、HTTPを介して取得される2番目のテンプレートがXMLに埋め込まれた2つのデータソースとともに示されています。
例7-38 HTTPを介したデータを取得するサンプルXML
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out5.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="http://your.server:9999/templates/template1.pdf">
<xapi:data location="http://your.server:9999/data/data_1.xml"/>
<xapi:data location="http://your.server:9999/data/data_2.xml"/>
</xapi:template>
<xapi:template type="pdf"
location="http://your.server:9999/templates/template2.pdf">
<xapi:data>
<field1>The third page data</field1>
</xapi:data>
<xapi:data>
<field1>The fourth page data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>
次のサンプルは、2つの出力out_1.pdfとout_2.pdfの生成を示しています。各出力に対してrequest要素が定義されていることに注意してください。
例7-39 複数出力を生成するサンプルXML
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out_1.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="d:\mywork\template1.pdf">
<xapi:data>
<field1>The first set of data</field1>
</xapi:data>
<xapi:data>
<field1>The second set of data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out_2.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="d:mywork\template2.pdf">
<xapi:data>
<field1>The third set of data</field1>
</xapi:data>
<xapi:data>
<field1>The fourth set of data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>
次のサンプルは、PDF出力ドキュメントにページ番号を定義するpagenumber要素の使用方法を示しています。生成される最初のドキュメントは、初期ページ番号値1で始まります。2番目の出力ドキュメントは、初期ページ番号値3で始まります。pagenumber要素は、document要素タグ内の任意の場所に配置できます。
pagenumber要素を使用して適用されるページ番号は、テンプレートで定義されているページ番号を置換しません。
例7-40 ページ番号を定義するサンプルXML
<?xml version="1.0" encoding="UTF-8"?>
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi">
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out7-1.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:pagenumber initial-value="1" initial-page-index="1"
x-pos="300" y-pos="20" />
<xapi:template type="pdf"
location="d:\mywork\template1.pdf">
<xapi:data>
<field1>The first page data</field1>
</xapi:data>
<xapi:data>
<field1>The second page data</field1>
</xapi:data>
</xapi:template>
</xapi:document>
</xapi:request>
<xapi:request>
<xapi:delivery>
<xapi:filesystem output="d:\temp\out7-2.pdf"/>
</xapi:delivery>
<xapi:document output-type="pdf">
<xapi:template type="pdf"
location="d:\mywork\template2.pdf">
<xapi:data>
<field1>The third page data</field1>
</xapi:data>
<xapi:data>
<field1>The fourth page data</field1>
</xapi:data>
</xapi:template>
<xapi:pagenumber initial-value="3" initial-page-index="1"
x-pos="300" y-pos="20" />
</xapi:document>
</xapi:request>
</xapi:requestset>
次のコード・サンプルは、入力ファイル名と入力ストリームを使用してドキュメント・プロセッサ・エンジンを起動する方法を示しています。
入力:
データ・ファイル名(文字列)
一時ファイルのディレクトリ(文字列)
例7-41 入力ファイル名を使用したプロセッサの起動のサンプル・コード
import oracle.xdo.batch.DocumentProcessor;
.
.
.
public static void main(String[] args)
{
.
.
.
try
{
// dataFile --- File path of the Document Processor XML
// tempDir --- Temporary Directory path
DocumentProcessor docProcessor = new DocumentProcessor(dataFile, tempDir);
docProcessor.process();
}
catch(Exception e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
入力:
データ・ファイル(入力ストリーム)
一時ファイルのディレクトリ(文字列)
例7-42 入力ストリームを使用したプロセッサの起動のサンプル・コード
import oracle.xdo.batch.DocumentProcessor;
import java.io.InputStream;
.
.
.
public static void main(String[] args)
{
.
.
.
try
{
// dataFile --- File path of the Document Processor XML
// tempDir --- Temporary Directory path
FileInputStream fIs = new FileInputStream(dataFile);
DocumentProcessor docProcessor = new DocumentProcessor(fIs, tempDir);
docProcessor.process();
fIs.close();
}
catch(Exception e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
FOプロセッサでは、最終的なドキュメントに適用可能なPDFセキュリティおよびその他のプロパティがサポートされています。セキュリティ・プロパティには、ドキュメントを印刷不可にする機能、および暗号化ドキュメントにパスワード・セキュリティを適用する機能があります。
その他のプロパティでは、フォントのサブセット化および埋込みを定義できます。通常実行時にBI Publisherで使用できないフォントがテンプレートで使用されている場合は、フォント・プロパティを使用してフォントの格納場所を指定できます。BI Publisherは、実行時にフォントを取得し、最終的なドキュメントで使用します。たとえば、このプロパティは、小切手の口座番号と銀行支店コードにMICRフォントを使用している場合に、その小切手の印刷に使用される場合があります。
このプロパティは、次の方法で設定できます。
実行時に、Javaプロパティ・オブジェクトとしてプロパティを指定し、FOプロセッサに渡します。
構成ファイルにプロパティを設定します。
テンプレートにプロパティを設定します(RTFテンプレートのみ)。
プロパティをプロパティ・オブジェクトとして渡すには、FOプロセッサをコールする前にプロパティの名前/値のペアを設定します。次に例を示します。
入力:
XMLファイル名(文字列)
XSLファイル名(文字列)
出力:
PDFファイル名(文字列)
例7-43 FOエンジンへのプロパティの受渡しのサンプル・コード
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
FOProcessor processor = new FOProcessor();
processor.setData(args[0]); // set XML input file
processor.setTemplate(args[1]); // set XSL input file
processor.setOutput(args[2]); //set (PDF) output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
Properties prop = new Properties();
/* PDF Security control: */
prop.put("pdf-security", "true");
/* Permissions password: */
prop.put("pdf-permissions-password", "abc");
/* Encryption level: */
prop.put("pdf-encription-level", "0");
processor.setConfig(prop);
// Start processing
try
{
processor.generate();
}
catch (XDOException e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
次のコードは、構成ファイルの格納場所を渡す例を示しています。
入力:
XMLファイル名(文字列)
XSLファイル名(文字列)
出力:
PDFファイル名(文字列)
例7-44 FOプロセッサへの構成ファイルの受渡しのサンプル・コード
import oracle.xdo.template.FOProcessor;
.
.
.
public static void main(String[] args)
{
FOProcessor processor = new FOProcessor();
processor.setData(args[0]); // set XML input file
processor.setTemplate(args[1]); // set XSL input file
processor.setOutput(args[2]); //set (PDF) output file
processor.setOutputFormat(FOProcessor.FORMAT_PDF);
processor.setConfig("/tmp/xmlpconfig.xml");
// Start processing
try
{
processor.generate();
} catch (XDOException e)
{ e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
入力:
データ・ファイル名(文字列)
一時ファイルのディレクトリ(文字列)
出力:
PDFファイル
例7-45 ドキュメント・プロセッサへのプロパティの受渡しのサンプル・コード
import oracle.xdo.batch.DocumentProcessor;
.
.
.
public static void main(String[] args)
{
.
.
.
try
{
// dataFile --- File path of the Document Processor XML
// tempDir --- Temporary Directory path
DocumentProcessor docProcessor = new DocumentProcessor(dataFile, tempDir);
Properties prop = new Properties();
/* PDF Security control: */
prop.put("pdf-security", "true");
/* Permissions password: */
prop.put("pdf-permissions-password", "abc");
/* encryption level: */
prop.put("pdf-encription-level", "0");
processor.setConfig(prop);
docProcessor.process();
}
catch(Exception e)
{
e.printStackTrace();
System.exit(1);
}
System.exit(0);
}
拡張書式設定をテンプレートで機能させるには、実行時にデータの書式を設定する適切なメソッドをJavaクラスに提供する必要があります。多くのフォント・ベンダーは、書式設定を実行するために、フォントとともにコードを提供しています。これらのコードは、実行時にBI Publisherの書式設定ライブラリで使用可能なクラスにメソッドとして組み込む必要があります。エンコーディングに対して正しいメソッドをコールするために、ライブラリのクラスに固有のインタフェースを用意する必要があります。
BI Publisherに備わっている3つのバーコードのいずれかを使用すれば、Javaクラスを提供する必要はありません。詳細は、『Oracle Fusion Middleware Oracle Business Intelligence Publisherレポート・デザイナーズ・ガイド』のBI Publisherに付属のバーコード・フォントの使用方法に関する項を参照してください。
このクラスには、次のメソッドを実装する必要があります。
/** * Return a unique ID for this barcode encoder * @return the id as a string */ public String getVendorID(); /** * Return true if this encoder support a specific type of barcode * @param type the type of the barcode * @return true if supported */ public boolean isSupported(String type); /** * Encode a barcode string by given a specific type * @param data the original data for the barcode * @param type the type of the barcode * @return the formatted data */ public String encode(String data, String type);
このクラスをBI Publisherが動作している中間層JVMのクラスパスに配置してください。
E-Business Suiteユーザーは、中間層および存在しているコンカレント・ノードのクラスパスに、クラスを配置する必要があります。
register-barcode-vendorコマンドにbarcode_vendor_idが指定されていない場合、BI PublisherはgetVendorID()をコールして、このメソッドの結果をベンダーIDとして使用します。
code128a、code128bおよびcode128cエンコーディングをサポートするクラスの例は次のとおりです。
次のコード・サンプルは、ご使用のシステムにコピーして貼付けることができます。公開上の制約のため、改行を修正し、スマート引用符として表示される引用符を削除して単純な引用符に置換する必要があります。
例7-46 バーコードの拡張書式設定のサンプル・コード
package oracle.xdo.template.rtf.util.barcoder;
import java.util.Hashtable;
import java.lang.reflect.Method;
import oracle.xdo.template.rtf.util.XDOBarcodeEncoder;
import oracle.xdo.common.log.Logger;
// This class name will be used in the register vendor
// field in the template.
public class BarcodeUtil implements XDOBarcodeEncoder
// The class implements the XDOBarcodeEncoder interface
{
// This is the barcode vendor id that is used in the
// register vendor field and format-barcode fields
public static final String BARCODE_VENDOR_ID = "XMLPBarVendor";
// The hashtable is used to store references to
// the encoding methods
public static final Hashtable ENCODERS = new Hashtable(10);
// The BarcodeUtil class needs to be instantiated
public static final BarcodeUtil mUtility = new BarcodeUtil();
// This is the main code that is executed in the class,
// it is loading the methods for the encoding into the hashtable.
// In this case we are loading the three code128 encoding
// methods we have created.
static {
try {
Class[] clazz = new Class[] { "".getClass() };
ENCODERS.put("code128a",mUtility.getClass().getMethod("code128a", clazz));
ENCODERS.put("code128b",mUtility.getClass().getMethod("code128b", clazz));
ENCODERS.put("code128c",mUtility.getClass().getMethod("code128c", clazz));
} catch (Exception e) {
// This is using the BI Publisher logging class to push
// errors to the XMLP log file.
Logger.log(e,5);
}
}
// The getVendorID method is called from the template layer
// at runtime to ensure the correct encoding method are used
public final String getVendorID()
{
return BARCODE_VENDOR_ID;
}
//The isSupported method is called to ensure that the
// encoding method called from the template is actually
// present in this class.
// If not then XMLP will report this in the log.
public final boolean isSupported(String s)
{
if(s != null)
return ENCODERS.containsKey(s.trim().toLowerCase());
else
return false;
}
// The encode method is called to then call the appropriate
// encoding method, in this example the code128a/b/c methods.
public final String encode(String s, String s1)
{
if(s != null && s1 != null)
{
try
{
Method method = (Method)ENCODERS.get(s1.trim().toLowerCase());
if(method != null)
return (String)method.invoke(this, new Object[] {
s
});
else
return s;
}
catch(Exception exception)
{
Logger.log(exception,5);
}
return s;
} else
{
return s;
}
}
/** This is the complete method for Code128a */
public static final String code128a( String DataToEncode )
{
char C128_Start = (char)203;
char C128_Stop = (char)206;
String Printable_string = "";
char CurrentChar;
int CurrentValue=0;
int weightedTotal=0;
int CheckDigitValue=0;
char C128_CheckDigit='w';
DataToEncode = DataToEncode.trim();
weightedTotal = ((int)C128_Start) - 100;
for( int i = 1; i <= DataToEncode.length(); i++ )
{
//get the value of each character
CurrentChar = DataToEncode.charAt(i-1);
if( ((int)CurrentChar) < 135 )
CurrentValue = ((int)CurrentChar) - 32;
if( ((int)CurrentChar) > 134 )
CurrentValue = ((int)CurrentChar) - 100;
CurrentValue = CurrentValue * i;
weightedTotal = weightedTotal + CurrentValue;
}
//divide the WeightedTotal by 103 and get the remainder,
//this is the CheckDigitValue
CheckDigitValue = weightedTotal % 103;
if( (CheckDigitValue < 95) && (CheckDigitValue > 0) )
C128_CheckDigit = (char)(CheckDigitValue + 32);
if( CheckDigitValue > 94 )
C128_CheckDigit = (char)(CheckDigitValue + 100);
if( CheckDigitValue == 0 ){
C128_CheckDigit = (char)194;
}
Printable_string = C128_Start + DataToEncode + C128_CheckDigit + C128_Stop + " ";
return Printable_string;
}
/** This is the complete method for Code128b ***/
public static final String code128b( String DataToEncode )
{
char C128_Start = (char)204;
char C128_Stop = (char)206;
String Printable_string = "";
char CurrentChar;
int CurrentValue=0;
int weightedTotal=0;
int CheckDigitValue=0;
char C128_CheckDigit='w';
DataToEncode = DataToEncode.trim();
weightedTotal = ((int)C128_Start) - 100;
for( int i = 1; i <= DataToEncode.length(); i++ )
{
//get the value of each character
CurrentChar = DataToEncode.charAt(i-1);
if( ((int)CurrentChar) < 135 )
CurrentValue = ((int)CurrentChar) - 32;
if( ((int)CurrentChar) > 134 )
CurrentValue = ((int)CurrentChar) - 100;
CurrentValue = CurrentValue * i;
weightedTotal = weightedTotal + CurrentValue;
}
//divide the WeightedTotal by 103 and get the remainder,
//this is the CheckDigitValue
CheckDigitValue = weightedTotal % 103;
if( (CheckDigitValue < 95) && (CheckDigitValue > 0) )
C128_CheckDigit = (char)(CheckDigitValue + 32);
if( CheckDigitValue > 94 )
C128_CheckDigit = (char)(CheckDigitValue + 100);
if( CheckDigitValue == 0 ){
C128_CheckDigit = (char)194;
}
Printable_string = C128_Start + DataToEncode + C128_CheckDigit + C128_Stop + " ";
return Printable_string;
}
/** This is the complete method for Code128c **/
public static final String code128c( String s )
{
char C128_Start = (char)205;
char C128_Stop = (char)206;
String Printable_string = "";
String DataToPrint = "";
String OnlyCorrectData = "";
int i=1;
int CurrentChar=0;
int CurrentValue=0;
int weightedTotal=0;
int CheckDigitValue=0;
char C128_CheckDigit='w';
DataToPrint = "";
s = s.trim();
for(i = 1; i <= s.length(); i++ )
{
//Add only numbers to OnlyCorrectData string
CurrentChar = (int)s.charAt(i-1);
if((CurrentChar < 58) && (CurrentChar > 47))
{
OnlyCorrectData = OnlyCorrectData + (char)s.charAt(i-1);
}
}
s = OnlyCorrectData;
//Check for an even number of digits, add 0 if not even
if( (s.length() % 2) == 1 )
{
s = "0" + s;
}
//<<<< Calculate Modulo 103 Check Digit and generate
// DataToPrint >>>>
//Set WeightedTotal to the Code 128 value of
// the start character
weightedTotal = ((int)C128_Start) - 100;
int WeightValue = 1;
for( i = 1; i <= s.length(); i += 2 )
{
//Get the value of each number pair (ex: 5 and 6 = 5*10+6 =56)
//And assign the ASCII values to DataToPrint
CurrentChar = ((((int)s.charAt(i-1))-48)*10) + (((int)s.charAt(i))-48);
if((CurrentChar < 95) && (CurrentChar > 0))
DataToPrint = DataToPrint + (char)(CurrentChar + 32);
if( CurrentChar > 94 )
DataToPrint = DataToPrint + (char)(CurrentChar + 100);
if( CurrentChar == 0)
DataToPrint = DataToPrint + (char)194;
//multiply by the weighting character
//add the values together to get the weighted total
weightedTotal = weightedTotal + (CurrentChar * WeightValue);
WeightValue = WeightValue + 1;
}
//divide the WeightedTotal by 103 and get the remainder,
//this is the CheckDigitValue
CheckDigitValue = weightedTotal % 103;
if((CheckDigitValue < 95) && (CheckDigitValue > 0))
C128_CheckDigit = (char)(CheckDigitValue + 32);
if( CheckDigitValue > 94 )
C128_CheckDigit = (char)(CheckDigitValue + 100);
if( CheckDigitValue == 0 ){
C128_CheckDigit = (char)194;
}
Printable_string = C128_Start + DataToPrint + C128_CheckDigit + C128_Stop + " ";
Logger.log(Printable_string,5);
return Printable_string;
}
}
クラスを作成して正しいクラスパスに配置すると、テンプレート作成者は、そのクラスを使用してバーコードのデータを書式設定できるようになります。テンプレート・コマンドに次の情報を指定することをテンプレート作成者に伝える必要があります。
クラス名とパス
この例では、次のとおりです。
oracle.xdo.template.rtf.util.barcoder.BarcodeUtil
作成したバーコード・ベンダーID
この例では、XMLPBarVendorです。
使用可能なエンコーディング・メソッド
この例では、コード128a、コード128bおよびコード128cです。これらのコードはこの情報を使用して、データをバーコード出力にエンコードできます。
テンプレート作成者は、この情報を使用してバーコード出力用データを正しくエンコーディングできます。