The diagram in this topic shows data sets loaded by Data Processing component of BDD, from Hive. The diagram illustrates how you can update this data set using DP CLI, and increase its size from sample to full.
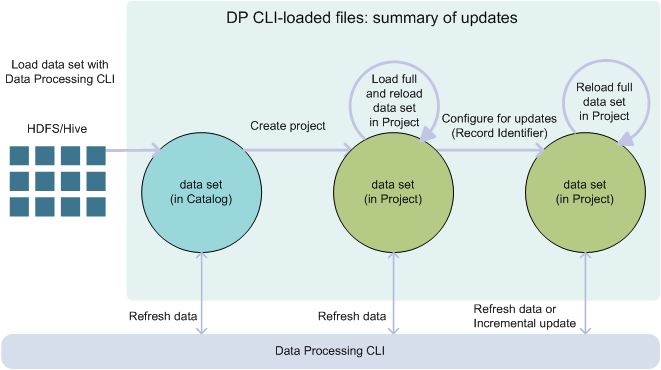
- You load a data set from Hive using the Data Processing workflow (DP CLI). The data set appears in Catalog in Studio.
- You can now create a BDD project from this data set. Notice that a data set in your project does not eliminate this data set in Catalog. That is, other users may still see this data set in Catalog, if they have permissions. However, you have now taken this data set with you into your project. You can think of it as a different version of the data set, or your project's private version of the data set.
- In a project, you can load full data into it with the Load full data set action in Studio.
- Using Data Processing CLI,
you can also run scripted updates to this data set. Two types of scripted
updates exist:
Refresh Data and
Incremental Update.
To run scripted updates, you need a data set logical name, found in the data set's properties in Studio. It is important to provide the correct data set logical name to the DP CLI. If the data set is in Catalog, it is not the same data set that you have in your project. Note the correct data set logical name.
- You cannot run an Incremental Update with DP CLI for a data set in Catalog; you can only run it when you add the data set to a project.
- You can run an Incremental Update with DP CLI after you specify a record identifier. For this, you must move the data set into a project in Studio.
- Because this data set arrived from Hive, you cannot update it within Studio. Instead, you can use DP CLI for data set updates.
- Once you load full data, this does not change the data set that appears in Catalog. Moving a data set to a project and loading full data is similar to creating a personal version of the data set. Next, you can write scripted updates to this data set, using DP CLI commands Refresh data and Incremental update. You can run these updates periodically, as cron jobs. The updates will run on your personal version of this data set in this project. This way, your version of this data set is independent of the data set's version that appears in Catalog.
With this workflow, you create a project of your own, based on this data set, where you can run scripted updates with DP CLI. This approach works well for BDD projects that you want to keep around and populate with newer data.
This way, you can continue using the configuration and visualizations you built in Studio before, and analyze newer data as it arrives.
