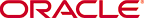| Siebel CRM Performance Tuning Guide Siebel 2018 E24801-01 |
|


 Previous |
 Next |
View PDF |
| Siebel CRM Performance Tuning Guide Siebel 2018 E24801-01 |
|
Previous |
Next |
View PDF |
This topic describes Siebel EIM tuning tips for the database platforms supported by Siebel Business Applications. It contains the following information:
This topic is part of "Database Guidelines for Optimizing Siebel EIM".
The information that follows describes Siebel EIM tuning tips for Microsoft SQL Server.
Table and index fragmentation occurs on tables that have many insert, update, and delete activities. Because the table is being modified, pages begin to fill, causing page splits on clustered indexes. As pages split, the new pages might use disk space that is not contiguous, hurting performance because contiguous pages are a form of sequential input/output (I/O), which is faster than nonsequential I/O.
Before running Siebel EIM, it is important to defragment the tables by executing the DBCC DBREINDEX command on the table's clustered index. This applies especially to those indexes that will be used during Siebel EIM processing, which packs each data page with the fill factor amount of data (configured using the FILLFACTOR option) and reorders the information on contiguous data pages. You can also drop and recreate the index (without using the SORTED_DATA option). However, using the DBCC DBREINDEX command is recommended because it is faster than dropping and recreating the index, as shown in the following example:
DBCC SHOWCONTIG scanning '**S_GROUPIF' table... Table: '**S_GROUPIF' (731969784); index ID: 1, database ID: 7 TABLE level scan performed. Pages Scanned................................: 739 Extents Scanned..............................: 93 Extent Switches..............................: 92 Avg. Pages per Extent........................: 7.9 Scan Density [Best Count:Actual Count].......: 100.00% [93:93] Logical Scan Fragmentation ..................: 0.00% Extent Scan Fragmentation ...................: 1.08% Avg. Bytes Free per Page.....................: 74.8 Avg. Page Density (full).....................: 99.08% DBCC execution completed. If DBCC printed error messages, contact the system administrator.
To determine whether you need to rebuild the index because of excessive index page splits, look at the Scan Density value displayed by DBCC SHOWCONTIG. The Scan Density value must be at or near 100%. If it is significantly below 100%, then rebuild the index.
When purging data from the EIM table, use the TRUNCATE TABLE statement. This is a fast, nonlogged method of deleting all rows in a table. DELETE physically removes one row at a time and records each deleted row in the transaction log. TRUNCATE TABLE only logs the deallocation of whole data pages and immediately frees all of the space occupied by that table's data and indexes. The distribution pages for all indexes are also freed.
Microsoft SQL Server allows data to be bulk copied into a single EIM table from multiple clients in parallel, using the bcp utility or BULK INSERT statement. Use the bcp utility or BULK INSERT statement when the following conditions are true:
SQL Server is running on a computer with more than one processor.
The data to be bulk copied into the EIM table can be partitioned into separate data files.
These recommendations can improve the performance of data load operations. Perform the following tasks, in the order in which they are presented, to bulk copy data into SQL Server in parallel:
Set the database option truncate log on checkpoint to TRUE using sp_dboption.
Set the database option select into/bulkcopy to TRUE using sp_dboption.
In a logged bulk copy all row insertions are logged, which can generate many log records in a large bulk copy operation. These log records can be used to both roll forward and roll back the logged bulk copy operation.
In a nonlogged bulk copy, only the allocations of new pages to hold the bulk copied rows are logged. This significantly reduces the amount of logging that is needed and speeds the bulk copy operation. Once you do a nonlogged operation, immediately back up so that transaction logging can be restarted.
Make sure that the table does not have any indexes, or, if the table has an index, make sure that it is empty when the bulk copy starts.
Make sure that you are not replicating the target table.
Make sure that the TABLOCK hint is specified using bcp_control with eOption set to BCPHINTS.
|
Note: Using ordered data and theORDER hint will not affect performance because the clustered index is not present in the EIM table during the data load. |
After data has been bulk copied into a single EIM table from multiple clients, any clustered index on the table must be recreated using DBCC DBREINDEX.
This is the database that Microsoft SQL Server uses for temporary space needed during execution of various queries. Set the initial size of the TEMPDB to a minimum of 100 MB, and configure it for auto-growth, which allows SQL Server to expand the temporary database as needed to accommodate user activity.
Additional parameters have a direct impact on SQL Server performance and must be set according to the following guidelines:
SPIN COUNTER. This parameter specifies the maximum number of attempts that Microsoft SQL Server will make to obtain a given resource. The default settings are adequate in most configurations.
MAX ASYNC I/O. This parameter configures the number of asynchronous inputs/outputs (I/Os) that can be issued. The default is 32, which allows a maximum of 32 outstanding reads and 32 outstanding writes per file. Servers with nonspecialized disk subsystems do not benefit from increasing this value. Servers with high-performance disk subsystems, such as intelligent disk controllers with RAM caching and RAID disk sets, can gain some performance benefit by increasing this value because they have the ability to accept multiple asynchronous I/O requests.
MAX DEGREE OF PARALLELISM. This option is used to configure Microsoft SQL Server's use of parallel query plan generation. Set this option to 1 to disable parallel query plan generation. This setting is mandatory to avoid generating an unpredictable query plan.
LOCKS. This option is used to specify the number of locks that Microsoft SQL Server allocates for use throughout the server. Locks are used to manage access to database resources such as tables and rows. Set this option to 0 to allow Microsoft SQL Server to dynamically manage lock allocation based on system requirements.
AUTO CREATE STATISTICS. This option allows SQL Server to create new statistics for database columns as needed to improve query optimization. Make sure that this option is enabled.
AUTO UPDATE STATISTICS. This allows Microsoft SQL Server to automatically manage database statistics and update them as necessary to achieve proper query optimization. Make sure that this option is enabled.
This topic is part of "Database Guidelines for Optimizing Siebel EIM".
The subtopics that follow provide Siebel EIM tuning tips for Oracle Database.
Before running Siebel EIM, consult an experienced DBA in order to evaluate the amount of space necessary to store the data to be inserted in the EIM tables and the Siebel base tables. Also, for example with Oracle Database, you can make sure that the extent sizes of those tables and indexes are defined accordingly.
Avoiding excessive extensions and keeping a small number of extents for tables and indexes is important because extent allocation and deallocation activities (such as truncate or drop commands) can be demanding on CPU resources.
To check whether segment extension is occurring in Oracle Database
Use the SQL statement that follows to identify objects with greater than 10 extents.
|
Note: Ten extents is not a target number for segment extensions. |
SELECT segment_name,segment_type,tablespace_name,extents FROM dba_segments WHERE owner = (Siebel table_owner) and extents > 10;
To reduce fragmentation, the objects can be rebuilt with appropriate storage parameters. Always be careful when rebuilding objects because of issues such as defaults or triggers on the objects.
When purging data from an EIM table, use the TRUNCATE command as opposed to the DELETE command. The TRUNCATE command releases the data blocks and resets the high water mark while the DELETE command does not, which causes additional blocks to be read during processing. Also, be sure to drop and recreate the indexes on the EIM table to release the empty blocks.
It is recommended that Archive Logging be disabled during initial data loads. You can enable this feature to provide for point-in-time recovery after completing the data loads.
Multiple Siebel EIM processes can be executed against an EIM table provided that they all use different batches or batch ranges. The concern is that you might experience contention for locks on common objects. To run multiple jobs in parallel against the same EIM table, make sure that the FREELIST parameter is set appropriately for the tables and indexes used in the Siebel EIM processing.
|
Note: If you are using Auto Segment Space Mgmt (ASSM) as part of defining tablespaces, then thePCTUSED and FREELIST parameters (and FREELIST groups) are ignored. |
Applicable database objects include EIM tables and indexes, as well as base tables and indexes. The value of the FREELIST parameter specifies the number of block IDs that will be stored in memory which are available for record insertion. Generally, you set the value to at least half of the intended number of parallel jobs to be run against the same EIM table (for example, a FREELIST setting of 10 permits up to 20 parallel jobs against the same EIM table).
This parameter is set at the time of object creation and the default for this parameter is 1. To check the value of this parameter for a particular object, the following query can be used:
SELECT SEGMENT_NAME, SEGMENT_TYPE, FREELISTS
FROM DBA_SEGMENTS
WHERE SEGMENT_NAME='OBJECT NAME TO BE CHECKED';
To change this parameter, the object must be rebuilt. Again, be careful when rebuilding objects because of issues such as defaults or triggers on the objects.
To rebuild an object
Export the data from the table with the grants.
Drop the table.
Recreate the table with the desired FREELIST parameter.
Import the data back into the table.
Rebuild the indexes with the desired FREELIST parameter.
Another method to improve performance is to put small tables that are frequently accessed in cache. The value of BUFFER_POOL_KEEP determines the portion of the buffer cache that will not be flushed by the LRU algorithm. This allows you to put certain tables in memory, which improves performance when accessing those tables. This also makes sure that, after accessing a table for the first time, it will always be kept in the memory. Otherwise, it is possible that the table will get pushed out of memory and will require disk access the next time it is used.
Be aware that the amount of memory allocated to the keep area is subtracted from the overall buffer cache memory (defined by DB_BLOCK_BUFFERS). A good candidate for this type of operation is the S_LST_OF_VAL table. The syntax for keeping a table in the cache is as follows:
ALTER TABLE S_LST_OF_VAL CACHE;
This topic is part of "Database Guidelines for Optimizing Siebel EIM". It describes Siebel EIM tuning tips for an IBM DB2 database.
Review the following list of tuning tips for Siebel EIM:
Use the IBM DB2 load replace option when loading EIM tables.
|
Note: You can also use the IBM DB2 load option to purge EIM tables. To do this, run the load option with an empty (null) input file inLOAD REPLACE mode. This purges the specified EIM table(s) instantly. |
Use separate tablespaces for EIM tables and the base tables.
For large Siebel EIM loads or where many Siebel EIM tasks execute in parallel, place individual EIM tables in separate tablespaces.
Use large page sizes for EIM tables and for the larger base tables. Previous experience has determined that a page size of 16 KB or 32 KB provides good performance. The larger page sizes allow more data to be fitted on a single page and also reduces the number of levels in the index B-tree structures.
Similarly, use large extent sizes for both EIM tables and the large base tables.
Make sure that the tablespace containers are equitably distributed across the logical and physical disks and across the input/output (I/O) controllers of the database server.
Use separate bufferpools for EIM tables and the target base tables. Since initial Siebel EIM loads are quite large and there are usually no online users, it is recommended to allocate a significant amount of memory to the EIM table and base table bufferpools.
After you load new data, reorganize the tables if the data on a disk is out of cluster. If the results of executing the RUNSTATS command indicate that clustering has deteriorated (clustering index is less than 80% clustered) and that a reorganization of tables is required, then check the system catalog to see if tables need to be reorganized. See also 477378.1 (Article ID) on My Oracle Support. This article contains sample SQL that you can use to determine which tables are out of cluster and need reorganization.
|
Note: Allocate time to conversion schedules to allow for the reorganization of tables and the gathering of statistics prior to allowing end users access to a system containing new data. |
Use IBM DB2 snapshot monitors to make sure that performance is optimal and to detect and resolve any performance bottlenecks.
You can turn off logretain during the initial load. However, you must turn it back on before moving into a production environment.
|
Note: When logretain is enabled, you must make a full cold backup of the database. |
For the EIM tables and the base tables involved, alter the tables to set them to VOLATILE. This makes sure that indexes are preferred over table scans.
Executing Siebel EIM processes in parallel will cause deadlock and timeout on IBM DB2 databases if multiple Siebel EIM processes attempt to update the same catalog table simultaneously. To avoid this, set the UPDATE STATISTICS parameter to FALSE in the Siebel EIM configuration file (IFB file).
Executing UPDATE STATISTICS in each Siebel EIM process consumes significant database server resources. It is recommended that the database administrator updates statistics outside of the Siebel EIM process using the RUNSTATS command.
Consider the settings for IBM DB2 registry values in Table 10-3:
Table 10-3 IBM DB2 Registry Settings
| Registry Value | Setting |
|---|---|
|
DB2_CORRELATED_PREDICATES = |
YES |
|
DB2_HASH_JOIN = |
NO |
|
DB2_PARALLEL_IO = |
"*" |
|
DB2_STRIPPED_CONTAINERS = |
When using RAID devices for tablespace containers |
Consider the settings for the IBM DB2 database manager configuration parameters in Table 10-4:
Table 10-4 IBM DB2 Database Manager Configuration Parameter Settings
| Registry Value | Setting |
|---|---|
|
INTRA_PARALLEL = |
NO (can be used during large index creation) |
|
MAX_QUERYDEGREE = |
1 (can be increased during large index creation) |
|
SHEAPTHRES = |
100,000 (depends upon available memory, SORTHEAP setting, and other factors) |
Consider the settings for the IBM DB2 database parameters in Table 10-5:
Table 10-5 IBM DB2 Database Parameter Settings
| Registry Value | Setting |
|---|---|
|
CATALOGCACHE_SZ = |
6400 |
|
DFT_QUERYOPT = |
3 |
|
LOCKLIST = |
5000 |
|
LOCKTIMEOUT = |
120 (between 30 and 120) |
|
LOGBUFSZ = |
512 |
|
LOGFILESZ = |
8000 or higher |
|
LOGPRIMARY = |
20 or higher |
|
MAXLOCKS = |
30 |
|
MINCOMMIT = |
1 |
|
NUM_IOCLEANERS = |
Number of CPUs in the database server |
|
NUM_IOSERVERS = |
Number of disks containing DB2 containers |
|
SORTHEAP = |
10240 (This setting is only for initial Siebel EIM loads. During production, set it to between 64 and 256.) The value you specify for SORTHEAP impacts the result of changing the value for SHEAPTHRES. For example, if SORTHEAP = 10000, then you can execute no more than nine Siebel EIM batches if you set SHEAPTHRES = 100000. If executing concurrent Siebel EIM batches, then make sure to allocate sufficient physical memory so that memory swapping or memory paging do not occur. |
|
STAT_HEAP_SZ = |
8000 |
This topic is part of "Database Guidelines for Optimizing Siebel EIM".
For IBM DB2 for z/OS configuration settings, you can find a listing (from the JCL) of the Database Manager Configuration Parameters (DSNZPARM) in Implementing Siebel Business Applications on DB2 for z/OS.
More IBM DB2 for z/OS information is provided in the following topics:
This topic is part of "Database Guidelines for Optimizing Siebel EIM".
Figure 10-1 illustrates the load process for IBM DB2 for z/OS. For more information, see Siebel Enterprise Integration Manager Administration Guide.
This topic is part of "Database Guidelines for Optimizing Siebel EIM".
The following general recommendations apply when performing the IBM DB2 for z/OS loading process for Siebel EIM:
Use the ONLY BASE TABLES and IGNORE BASE TABLES parameters or ONLY BASE COLUMNS and IGNORE BASE COLUMNS parameters in the IFB files to reduce the amount of processing performed by Siebel EIM. By using the IGNORE BASE COLUMNS option, you allow foreign keys to be excluded, which reduces both processing requirements and error log entries for keys which cannot be resolved. Remember that the key words ONLY and IGNORE are mutually exclusive. For example, the following settings exclude the options IGNORE BASE TABLES and ONLY BASE COLUMNS:
ONLY BASE TABLES = S_CONTACT IGNORE BASE COLUMNS = S_CONTACT.PR_MKT_SEG_ID
Import parents and children separately. Wherever possible, load data such as accounts, addresses, and teams at the same time, using the same EIM table.
Use batch sizes that allow all of the EIM table data in the batch to be stored in the database cache (approximately 5,000 records for IBM DB2 for z/OS). Siebel EIM can be configured through the use of an extended parameter to use a range of batches. Remember to put the variable name into the IFB file.
Multiple Siebel EIM processes can be executed against an EIM table, provided they all use different batches or batch ranges. However, the main limit to Siebel EIM performance is not the application server but the database. Contention for locks on common objects can occur if multiple Siebel EIM streams are executed simultaneously for the same base table. Multiple Siebel EIM job streams can run concurrently for different base tables, for example, S_ORG_EXT and S_ASSET.
Run Siebel EIM during periods of minimum user activity, outside of business hours, if possible. This reduces the load for connected users and makes sure that the maximum processing capacity is available for the Siebel EIM processes.
Set the system preference that disables transaction logging during the initial database load. This setting (in the Administration - Siebel Remote screen, and Remote System Preferences view) is a check box labeled Enable Transaction Logging. Unchecking this preference reduces transaction activity to the Siebel docking tables, which are used for synchronizing mobile clients.
Disable the database triggers by removing them through the Server Administration screens. Doing this can also help to improve the throughput rate. Remember to reapply the triggers after the Siebel EIM load has completed, because the lack of triggers will mean that components, such as Workflow Policies and Assignment Manager, will not function for the new or updated data.
Make sure that the required columns ROW_ID, IF_ROW_STAT, and IF_ROW_BATCH_NUM are correctly populated in the EIM table to be processed. The most efficient time to do this is when populating the EIM table from the data source or staging area, after cleansing the data.
Unless there are specific processing requirements, make sure that the EIM table is empty before loading data into it for Siebel EIM processing. Always make sure that suitable batch numbers are being used to avoid conflicts within the EIM table. If you are using an automated routine, then truncating the EIM table between loads from the data source helps to preserve performance.
When running Siebel Business Applications on an IBM DB2 for z/OS database, Siebel EIM can sometimes stop responding when updating the S_LST_OF_VAL base table. This is due to a data issue. The BU_ID column in the S_LST_OF_VAL base table might have only one or very few distinct values. That makes the DB2 optimizer perform a table scan through all rows in the S_LST_OF_VAL table when most or all rows have the same BU_ID column value.
To avoid this problem and speed up the query, modify the statistics data by running the following SQL statements:
update sysibm.sysindexes set firstkeycard=1000 where name='S_LST_OF_VAL_M2'; update sysibm.syscolumns set colcard = 1000 where tbname='S_LST_OF_VAL' and name='BU_ID';
|
Note: Depending on the data with which you are working, you might need to run other SQL statements beforehand. |