| Oracle® TimesTen In-Memory Databaseレプリケーション・ガイド リリース18.1 E98633-04 |
|


 前 |
 次 |
Oracle Clusterwareは、アプリケーションを監視および制御して高可用性を実現します。Oracle Clusterwareは、クラスタに参加しているソフトウェア・コンポーネントの可用性を管理および監視する汎用のクラスタ・マネージャです。次の各項では、Oracle Clusterwareを使用して、アクティブ・スタンバイ・ペア・レプリケーション・スキームに含まれるデータベースの可用性を管理する方法を説明します。
Oracle Clusterwareを使用して管理できるのは次の構成です。
読取り専用サブスクライバを持つ(または持たない)アクティブ・スタンバイ・ペア
AWTキャッシュ・グループおよび読取り専用キャッシュ・グループが構成された(読取り専用サブスクライバを持つ(または持たない))アクティブ・スタンバイ・ペア
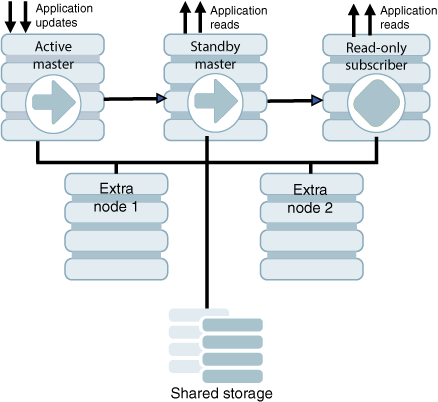
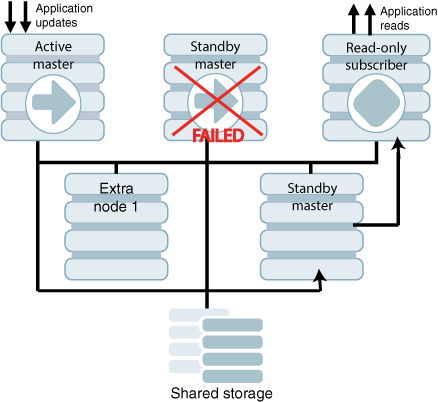
図8-1に、同じローカル・ネットワークに1つの読取り専用サブスクライバを持つアクティブ・スタンバイ・ペアを示します。アクティブ・マスター、スタンバイ・マスターおよび読取り専用サブスクライバは異なるノードにあります。TimesTenを実行しているがアクティブ・スタンバイ・ペアの一部ではないノードが2つあります。アクティブ・データベースの更新は、アプリケーションによって行われます。スタンバイおよびサブスクライバからの読取りもアプリケーションによって行われます。すべてのノードは共有記憶域に接続されています。
Oracle Clusterwareを使用すると、ノード障害およびその他のイベントに対応して、TimesTenデータベースおよびアプリケーションの起動、監視および自動フェイルオーバーを行うことができます。詳細は、「Clusterwareによる管理」および「障害からのリカバリ」を参照してください。
Oracle Clusterwareは、TimesTenの2つの可用性レベルで実装できます。
基本的な可用性レベルでは、クラスタ内の、アクティブ・スタンバイ・ペアとして構成された2つのマスター・ノードおよび最大127の読取り専用サブスクライバ・ノードが管理されます。アクティブ・スタンバイ・ペアは、ローカル・ホスト名またはIPアドレスを使用して定義されます。両方のマスター・ノードに障害が発生すると、ユーザーが介入してアクティブ・スタンバイ・スキームを新しいホストに移行する必要があります。両方のマスター・ノードに障害が発生すると、Oracle Clusterwareによってユーザーへの通知が行われます。
高度な可用性レベルでは、アクティブ、スタンバイおよび読取り専用サブスクライバ・データベースの仮想IPアドレスが使用されます。初期アクティブ・スタンバイ・ペアの一部ではない追加のノードをクラスタに含めることもできます。障害が発生した場合、仮想IPアドレスを使用することで、追加のノードの1つが、障害の発生したノードの役割を自動的に引き継ぐことができます。
|
ノート: アプリケーションがクライアント/サーバー構成のTimesTenに接続している場合、自動クライアント・フェイルオーバーによって、クライアントは障害が発生した後アクティブ・データベースに自動的に再接続できます。詳細は、「アクティブ・スタンバイ・ペアの自動クライアント・フェイルオーバーの使用」を参照してください。また、『Oracle TimesTen In-Memory Databaseリファレンス』のTTC_FailoverPortRangeも参照してください。 |
ttCWAdminユーティリティを使用して、Oracle Clusterwareで管理されているクラスタ内のTimesTenアクティブ・スタンバイ・ペアを管理します。各アクティブ・スタンバイ・ペアの構成は、cluster.oracle.iniという初期化ファイルに手動で作成されます。このファイルの情報は、Oracle Clusterwareのリソースを作成する場合に使用されます。リソースは、TimesTenデーモン、TimesTenデータベース、TimesTenプロセス、ユーザー・アプリケーションおよび仮想IPアドレスの管理に使用されます。クラスタ内のホストからcluster.oracle.iniファイルへのアクセスおよび読取りが可能な間は、ttCWAdminユーティリティをこのホストから実行できます。ttCWAdminユーティリティの詳細は、『Oracle TimesTen In-Memory Databaseリファレンス』のttCWAdminに関する説明を参照してください。cluster.oracle.iniファイルの詳細は、「cluster.oracle.iniファイルによるOracle Clusterware管理の構成」を参照してください。
次の各項では、クラスタを作成する際の要件とインストール・ステップについて説明します。
ttCWAdminコマンドの実行に必要な権限の詳細は、『Oracle TimesTen In-Memory Databaseリファレンス』のttCWAdminに関する説明を参照してください。
TimesTenでは、Linuxプラットフォーム上のClusterwareはサポートされますが、Windowsプラットフォーム上のClusterwareはサポートされません。
TimesTenは、TimesTenアクティブ・スタンバイ・ペア・レプリケーションを備えたOracle Clusterwareをサポートします。ネットワークと記憶域の要件およびOracle Clusterware構成ファイルの情報は、『Oracle Clusterware管理およびデプロイメント・ガイド』を参照してください。
Oracle ClusterwareおよびTimesTenは、すべてのノードで同じ場所にインストールされている必要があります。TimesTenインスタンス管理者は、同じUNIXまたはLinuxのプライマリ・グループにOracle Clusterwareインストール所有者として属している必要があります。
各ホストのクロックの誤差が250ミリ秒以内であるように、すべてのホストがネットワーク・タイム・プロトコル(NTP)または同様のシステムを使用する必要があります。各ノードのシステム・クロックの同期がとられるように調整する場合は、時間をさかのぼって設定しないでください。
Oracle Clusterwareをインストールします。デフォルトでは、すべてのホストで同時にインストールが実行されます。ご使用のプラットフォーム用のOracle Clusterwareのインストール・ドキュメントを参照してください。たとえば、Gridインフラストラクチャ・インストレーション・ガイド for Linuxを参照してください。
インストールが正常に完了すると、Oracle Clusterwareは自動的に起動します。
|
ノート: 次を実行すると、Oracle Clusterwareがクラスタ内のすべてのホストで実行されているかどうかを確認できます。crsctl check crs -all |
ttInstanceCreateコマンドを使用して、追加のホストを含め、クラスタ内の各ホスト上の同じ場所にTimesTenをインストールします。ttInstanceCreateコマンドからのプロンプトに従う方法の詳細は、Oracle TimesTen In-Memory Databaseインストレーション、移行およびアップグレード・ガイドのOracle Clusterware用の対話型インスタンスの作成を参照してください。
様々なプロンプトに応答する場合は、次の点に注意してください。
インスタンス名は各ホストで同じである必要があります。
インスタンス管理者のユーザー名は、すべてのホストで同じである必要があります。
TimesTenインスタンス管理者は、同じUNIXまたはLinuxのプライマリ・グループにOracle Clusterwareインストール所有者として属している必要があります。
さらに、次の質問に「yes」と回答すると、
Would you like to use TimesTen Replication with Oracle Clusterware?
ttInstanceCreateコマンドで、Oracle Clusterwareに使用されている値の入力を求められ、そのそれぞれがttcrsagent.optionsファイルに格納されます。
TimesTenクラスタ・エージェント(ttCRSAgent)に関連付けられているTCP/IPポート番号。ポート番号は、クラスタ内のすべてのノードで同じである必要があります。ポート番号を指定しない場合、TimesTenはデフォルトのTimesTenデーモンのポート番号に6を加えて、TimesTenクラスタ・エージェントに関連付けられたTCP/IPポート番号にします。したがって、TimesTenクラスタ・エージェントに関連付けられたデフォルトのデーモンのポート番号は、64ビット・システムでは3754になります。
Oracle Clusterwareの場所。場所は各ホストで同じである必要があります。
スペア・ホストを含むクラスタ内のホスト(ホスト名はカンマで区切ります)。このリストは各ホストで同じである必要があります。
詳細は、Oracle TimesTen In-Memory Databaseインストレーション、移行およびアップグレード・ガイドのOracle Clusterwareで使用するためのOracle Clusterwareのインストールおよび「Oracle Clusterware用の対話型インスタンスの作成」を参照してください。
TimesTenインスタンスのOracle Clusterwareサポートの有効化の詳細は、Oracle TimesTen In-Memory Databaseインストレーション、移行およびアップグレード・ガイドのOracle Clusterware用の対話型インスタンスの作成を参照してください。
ttCWAdmin –initコマンドおよびttCWAdmin –shutdownコマンドでは、TimesTenクラスタを開始および停止するために、ttcrsagent.optionsファイルが使用されます。ttcrsagent.optionsファイルは、TimesTenデーモンのホーム・ディレクトリにあります。
ttcrsagent.optionsファイルを手動で変更しないでください。かわりに、TimesTenクラスタの開始後にttInstanceModify -crsコマンドを使用して、このファイル内の情報を作成または変更します。また、setup.shに-recordオプションおよび-batchオプションを使用して、追加ホストに同じインストールを実行できます。
|
ノート: レプリケーションにOracle Clusterwareを使用するためのTimesTen構成の変更の詳細は、Oracle TimesTen In-Memory Databaseインストレーション、移行およびアップグレード・ガイドのインスタンスのOracle Clusterware構成の変更を参照してください。 |
Oracle Clusterwareの現在のホーム・ロケーションはCRS_HOME環境変数に設定されています。また、ttInstanceModify -crsコマンドは、プロンプトの一部としてOracle Clusterwareホームの現在の場所を示します。
|
ノート: ttcrsagent.optionsファイルの詳細は、「TimesTenクラスタ・エージェントの起動」を参照してください。ttInstanceCreateおよびttInstanceModifyの詳細は、Oracle TimesTen In-Memory DatabaseリファレンスのttInstanceCreateおよびttInstanceModifyをそれぞれ参照してください。 |
次の例は、ttcrsagent.optionsファイルの各項目を変更するときに表示されるttInstanceModify -crsプロンプトを示しています。
% ttInstanceModify -crs Cannot find instance_info file : /etc/TimesTen/instance_info Would you like to modify the existing TimesTen Replication with Oracle Clusterware configuration? [ no ] yes This TimesTen instance is configured to use an Oracle Clusterware installation located in : /mydir/oracle/crs/app/11.2.0 Would you like to change this value? [ no ] no The TimesTen Clusterware agent is configured to use port 54504 Would you like to change this value? [ no ] no The TimesTen Clusterware agent is currently configured with these nodes : node1 node2 node3 node4 Would you like to change these values? [ no ] Overwrite the existing TimesTen Clusterware options file? [ no ] no
Oracle ClusterwareをTimesTenと組み合せて使用する場合、アクティブ・スタンバイ・ペア・レプリケーション・スキームはアクティブ・データベース上で作成(ttCWAdmin -createコマンドを使用)および削除(ttCWAdmin -dropコマンドを使用)されます。ttCWAdmin -createコマンドとttCWAdmin -dropコマンドの間では、次のコマンドまたはSQL文のいずれも実行できません。ただし、これらのコマンドまたはSQLステートメントは、ttCWAdmin -beginAlterSchemaコマンドとttCWAdmin -endAlterSchemaコマンドを使用する場合に実行できます(「スキーマの変更」を参照)。
CREATE ACTIVE STANDBY PAIR、ALTER ACTIVE STANDBY PAIRおよびDROP ACTIVE STANDBY PAIRのSQL文によるアクティブ・スタンバイ・ペアの作成、変更または削除。
ttAdminユーティリティの-repStartオプションおよび-repStopオプション、またはttRepStartまたはttRepStopの組込みプロシージャのいずれかによる、レプリケーション・エージェントの起動または停止。詳細は、「レプリケーション・エージェントの起動と停止」を参照してください。
ttAdminユーティリティの-cacheStartオプションおよび-cacheStopオプション、またはttCacheStartおよびttCacheStopの組込みプロシージャのいずれかによる、アクティブ・スタンバイ・ペア作成後のキャッシュ・エージェントの起動または停止。
ttRepAdminユーティリティの-duplicateオプションによるデータベースの複製。
また、ttCWAdmin -shutdownをコールする前にttDaemonAdmin -stopをコールしないでください。
Oracle Clusterwareと統合されたTimesTenでは、このような操作は、ttCWAdminユーティリティおよびcluster.oracle.iniファイルで指定された属性によって行われます。
組込みやユーティリティの詳細は、『Oracle TimesTen In-Memory Databaseリファレンス』を参照してください。SQL文の詳細は、『Oracle TimesTen In-Memory Database SQLリファレンス・ガイド』を参照してください。
クラスタを作成および初期化するには、次の手順を実行します。
クラスタで複数のアクティブ・スタンバイ・ペアを使用する予定の場合は、「クラスタへの複数のアクティブ・スタンバイ・ペアの挿入」を参照してください。
リモート障害時リカバリ・サブスクライバとしてOracle Databaseを構成する場合は、「障害時リカバリ・サブスクライバとしてのOracle Databaseの構成」を参照してください。
Oracle Clusterwareによって管理されていない読取り専用サブスクライバを設定する場合は、「Oracle Clusterwareによって管理されていない読取り専用サブスクライバの構成」を参照してください。
ttCWAdmin -initコマンドを実行して、クラスタ内のすべてのホストで、TimesTenクラスタ・エージェント(ttCRSAgent)およびTimesTenクラスタ・デーモン・モニター(ttCRSDaemon)を起動します。このコマンドは、ttcrsagent.optionsファイルで定義された、クラスタ内のどのホストででも実行できます。
次に例を示します。
ttCWAdmin -init
ttCWAdmin -initコマンドによって、次の操作が実行されます。
ttcrsagent.optionsファイルを読み取り、このファイルに定義されている各ホストでTimesTenメイン・デーモンを起動します。
クラスタ内のすべてのホストで、TimesTenクラスタ・エージェント(ttCRSAgent)およびTimesTenクラスタ・デーモン・モニター(ttCRSDaemon)が開始および登録されます。各ホストには、TimesTenのインストールのために1つのTimesTenクラスタ・エージェントと1つのTimesTenクラスタ・デーモン・モニターがあります。TimesTenクラスタ・エージェントが起動すると、Oracle Clusterwareによって各ホストでのTimesTenデーモンの監視が開始され、障害が発生するとTimesTenデーモンが再起動されます。
TimesTenクラスタ・エージェントおよびTimesTenクラスタ・デーモン・モニターをクラスタ内の特定のホストで起動および登録するには、-hostsコマンドを使用して、クラスタ内の希望のホストを指定し、起動します。
ttCWAdmin -init -hosts "host1, host2"
アクティブ・データベースを配置するホストにデータベースを作成します。DSNはデータベース・ファイル名と同じである必要があります。
表、AWTキャッシュ・グループおよび読取り専用キャッシュ・グループなどのスキーマ・オブジェクトを作成し、適切なデータを使用して設定します。ただし、キャッシュ・グループを作成する前に、まず、キャッシャ・グループをロードするタイミングを決定する必要があります。
最高のパフォーマンスを達成するには、ttCWAdmin -createコマンドを実行する前に、キャッシュ・グループ表をOracle Database表からロードします。複製がアクティブ・データベース上で実行されてスタンバイ・データベース(およびすべてのサブスクライバ・データベース)が作成される前に初期データをキャッシュ・グループにロードすると、パフォーマンスのオーバーヘッドがより小さくなります。
このオプションでは、次の手順を実行します。
キャッシュ・エージェントを次のように起動します。
Command> call ttCacheStart;
|
ノート: この時点では、ttCWAdmin -startコマンドは実行されていないため、キャッシュ・エージェントを起動できます。ttCWAdmin -startコマンドを実行すると、キャッシュ・エージェントはすでに起動されており、処理を継続することを示すメッセージが表示されます。 |
LOAD CACHE GROUP文を使用し、Oracle Database表からキャッシュ・グループ表をロードします。
自動リフレッシュ・キャッシュ・グループを使用している場合、ALTER CACHE GROUP SET AUTOREFRESH STATE PAUSED文を使用して、自動リフレッシュ状態をPAUSEDに設定します。自動リフレッシュの状態は、ttCWAdmin -startコマンドの処理の一環として、ONに設定されます。
次の例は、読取り専用自動リフレッシュ・キャッシュ・グループを作成してデータをロードし、その後に自動リフレッシュの状態をpauseに設定する方法を示します。
Command> call ttCacheStart; Command> CREATE READONLY CACHE GROUP my_cg AUTOREFRESH MODE INCREMENTAL INTERVAL 60 SECONDS FROM t1 (c1 NUMBER(22) NOT NULL PRIMARY KEY, c2 DATE, c3 VARCHAR(30)); Command> LOAD CACHE GROUP my_cg COMMIT EVERY 100 ROWS PARALLEL 4; Command> ALTER CACHE GROUP my_cg SET AUTOREFRESH STATE PAUSED;
または、ttCWAdmin -startが実行されるまで、キャッシュ・グループ表のロードを待機します(「キャッシュ・グループのロード」を参照)。データは、スタンバイ・データベースとすべてのサブスクライバ・データベースにレプリケートされます。
クラスタに含められるすべてのホストで、システムDSN (sys.odbc.ini)ファイルを作成します。DataStore属性とData Source Nameは、cluster.oracle.iniファイルのエントリ名として同じである必要があります。sys.odbc.iniファイルの内容の詳細は、「cluster.oracle.iniファイルによるOracle Clusterware管理の構成」を参照してください。
cluster.oracle.iniファイルをテキスト・ファイルとして作成します。ファイルの内容と許容可能な場所の詳細は、「cluster.oracle.iniファイルによるOracle Clusterware管理の構成」を参照してください。
高度な可用性を実現するには、予備のマスター・ホストまたはサブスクライバ・ホストを構成します。これらのホストは、アクティブ・スタンバイ・ペア・レプリケーション・スキームで使用されるマスター・ホストまたはサブスクライバ・ホストが予期しないシャットダウンやリカバリ不能なエラーの発生により置換えが必要になるまで、アイドル状態に維持されます。これはオプションのステップで、高度な可用性を構成することを決定した場合のみ実行する必要があります。
高度な可用性を実装するために追加のマスター・ホストまたはサブスクライバ・ホストを提供することを計画している場合、仮想IPアドレスを構成する必要があります(アクティブ・スタンバイ・ペアでアクティブに使用されている各マスター・ホストおよび各サブスクライバに1つずつ)。作成する必要のある仮想IPアドレスの数は、「高度な可用性の構成」を参照してください。
この場合、次の手順を実行します。
Oracle Clusterwareにより管理されているTimesTenレプリケーション環境の複数のホストを管理するためのみに使用される、ネットワーク上の新しい仮想IPアドレスを指定(または作成)します。
高度な可用性を構成する複数のホストを管理するために使用されるこれらのVIPアドレスを、cluster.oracle.iniファイルで構成します(「高度な可用性の構成」を参照)。
これらのVIPアドレスを管理するOracle Clusterwareリソースを、クラスタ内の任意のホストでrootユーザーとしてttCWAdmin -createVIPsコマンドを実行して作成します。
次に例を示します。
ttCWAdmin -createVIPs -dsn myDSN
このコマンドで作成されるVIPアドレスの名前は、network_で始まり、その後に、TimesTenインスタンス名、TimesTenインスタンス管理者およびDSNが続きます。一方、Oracle Clusterwareによる使用のために作成されるVIPアドレスは、oraで始まります。
|
ノート: ttCWAdmin -createVIPsコマンドを実行した後に、ttCWAdmin -createコマンドを実行する必要があります。ttCWAdmin -createコマンドの実行後に、VIPアドレスを高度な可用性のために使用することを決定した場合、次の手順を実行する必要があります。
|
VIPアドレスを管理するOracle Clusterwareリソースを作成すると、これを削除するための唯一の方法は、ttCWAdmin -dropVIPsコマンドを実行することです。最初にttCWAdmin -dropコマンドを実行してから、仮想IPアドレスを削除します。
次に、仮想IPアドレスを削除する方法の例を示します。
ttCWAdmin -dropVIPs -dsn myDSN
ttCWAdmin -dropVIPsコマンドを使用する状況の例は、「クラスタからのアクティブ・スタンバイ・ペアの削除」を参照してください。
クラスタ内の任意のホストでttCWAdmin -createコマンドを実行し、アクティブ・スタンバイ・ペアのレプリケーション・スキームを作成します。
|
ノート: cluster.oracle.iniファイルにはttCWAdmin -createコマンドの実行に必要な構成が含まれているため、ttCWAdmin実行可能ファイルがこのファイルにアクセスできることが必要です。詳細は、「cluster.oracle.iniファイルによるOracle Clusterware管理の構成」を参照してください。 |
次に例を示します。
ttCWAdmin -create -dsn myDSN
ttCWAdmin -createコマンドにより、次のプロンプトが表示されます。
ADMIN権限を持つTimesTenユーザーの名前を求めるプロンプト。キャッシュ・グループがOracle Clusterwareにより管理されている場合は、TimesTenキャッシュ・マネージャ・ユーザー名を入力します。
前の手順で入力したユーザー名のTimesTenパスワードを求めるプロンプト。
キャッシュ・グループが使用されている場合は、キャッシュ・マネージャ・ユーザーと同じ名前のOracleユーザーのパスワードが求められます。このパスワードは、キャッシュ・マネージャ・ユーザーが接続したときにOraclePWD接続属性で指定されます。
前の手順の情報を暗号化するために使用するランダム文字列を求めるプロンプト。
cluster.oracle.iniファイルとして使用するファイルのパスと名前を指定する場合は、ttCWAdmin -createコマンドの-ttclusteriniオプションを使用します。
ttCWAdmin -create -dsn myDSN -ttclusterini path/to/cluster/mycluster.ini
アクティブ・スタンバイ・ペアを削除するには、ttCWAdmin -dropコマンドを次のように使用します。
ttCWAdmin -drop -dsn myDSN
|
ノート: アプリケーションが仮想IPアドレスを使用してTimesTenデータベースに接続する場合、仮想IPアドレスはOracle Clusterwareにより管理されるため、この接続はttCWAdmin -dropコマンドを使用して削除できます。ただし、アプリケーションがホスト名を使用してTimesTenデータベースに接続する場合、接続は削除されません。 |
ttCWAdmin -createコマンドとttCWAdmin -dropコマンドを使用する順序を示す例は、「クラスタでのアクティブ・スタンバイ・ペアの管理」および「アクティブ・スタンバイ・ペアでの読取り専用サブスクライバの管理」を参照してください。
ttCWAdmin -startコマンドを任意のホストで実行し、アクティブ・スタンバイ・ペアのレプリケーション・スキームでクラスタを起動します。これによって、アクティブ・データベースでキャッシュ・エージェント(まだ起動していない場合)とレプリケーション・エージェントが起動され、複製が実行されてスタンバイ・データベース(およびすべてのサブスクライバ・データベース)が作成され、スタンバイ(およびすべてのサブスクライバ)でキャッシュ・エージェントとレプリケーション・エージェントが起動されます。
-noAppオプションを指定しなかった場合は、アプリケーションも起動されます。-noAppオプションを指定する場合は、-startAppsまたは-stopAppsオプションを使用してアプリケーションを起動または停止できます。
次に例を示します。
ttCWAdmin -start -dsn myDSN
このコマンドは、アクティブ・スタンバイ・ペアの次のプロセスを開始します。
アプリケーションAppNameの監視
次の例では、キャッシュ・エージェントおよびレプリケーション・エージェントを起動しますが、-noappオプションが含まれているため、アプリケーションは起動されません。
ttCWAdmin -start -noapp -dsn myDSN
アプリケーションを起動および停止するには、次に示すとおり、ttCWAdmin -startAppsおよび-stopAppsコマンドを使用します。
ttCWAdmin -startapps -dsn myDSN ... ttCWAdmin -stopapps -dsn myDSN
TimesTenデータベース・モニター(ttCRSMaster)、キャッシュ・エージェントおよびレプリケーション・エージェントを停止し、アプリケーションを両方のデータベースから切断するには、ttCWAdmin -stopコマンドを実行します。
ttCWAdmin -stop -dsn myDSN
|
ノート: アプリケーションが仮想IPアドレスを使用してTimesTenデータベースに接続する場合、仮想IPアドレスはOracle Clusterwareにより管理されるため、この接続はttCWAdmin -stopコマンドを使用して削除できます。ただし、アプリケーションがホスト名を使用してTimesTenデータベースに接続する場合、接続は削除されませんが、スタンバイへのレプリケーションは発生しません。 |
ttCWAdmin -startおよび-stopコマンドを使用する順序を示す例については、「クラスタでのアクティブ・スタンバイ・ペアの管理」および「アクティブ・スタンバイ・ペアでの読取り専用サブスクライバの管理」を参照してください。
アクティブ・スタンバイ・ペアにキャッシュ・グループが含まれており、キャッシュ・グループがすでにロードされていない場合(「1つのホストでのTimesTenデータベースの作成および移入」を参照)、LOAD CACHE GROUP文を使用し、Oracle Database表からキャッシュ・グループ表をロードします。
キャッシュ・グループをロードする状況の詳細は、「1つのホストでのTimesTenデータベースの作成および移入」を参照してください。
Oracle Clusterwareを使用してクラスタ内の複数のアクティブ・スタンバイ・ペアを管理する場合、cluster.oracle.iniファイルに追加の構成を含めます。すべてのTimesTenデータベースが単一ホストの同じTimesTenインスタンスに含まれる場合のみ、Oracle Clusterwareはクラスタ内の1つ以上のアクティブ・スタンバイ・ペアを管理できます。
たとえば、次のcluster.oracle.iniファイルには、同一ホストの2つのアクティブ・スタンバイ・ペアのレプリケーション・スキームの構成情報が含まれます。
[advancedSubscriberDSN] MasterHosts=host1,host2,host3 SubscriberHosts=host4, host5 MasterVIP=192.168.1.1, 192.168.1.2 SubscriberVIP=192.168.1.3 VIPInterface=eth0 VIPNetMask=255.255.255.0 [advSub2DSN] MasterHosts=host1,host2,host3 SubscriberHosts=host4, host5 MasterVIP=192.168.1.4, 192.168.1.5 SubscriberVIP=192.168.1.6 VIPInterface=eth0 VIPNetMask=255.255.255.0
追加のレプリケーション・スキームに対して次の手順を実行します。
データベースを作成および移入します。
仮想IPアドレスを作成します。ttCWAdmin -createVIPsコマンドを使用します。
アクティブ・スタンバイ・ペアのレプリケーション・スキームを作成します。ttCWAdmin -createコマンドを使用します。
アクティブ・スタンバイ・ペアを開始します。ttCWAdmin -startコマンドを使用します。
プライマリ・サイトにリモート障害時リカバリ・サブスクライバとしてOracle Databaseを持つアクティブ・スタンバイ・ペアを作成できます。(詳細は、「アクティブ・スタンバイ・ペアでの障害時リカバリ・サブスクライバの使用」を参照してください。)Oracle Clusterwareは、アクティブ・スタンバイ・ペアは管理しますが、障害時リカバリ・サブスクライバは管理しません。プライマリ・サイトに障害が発生した場合、ユーザーは、リモート・サイトを使用するよう明示的に切り替える必要があります。
Oracle Clusterwareを使用してリモート障害時リカバリ・サブスクライバを持つアクティブ・スタンバイ・ペアを管理するには、次の手順を実行します。
RepDDLまたはRemoteSubscriberHosts Clusterware属性を使用し、リモート障害時リカバリ・サブスクライバに関する情報を提供します。次に例を示します。
[advancedDRsubDSN] MasterHosts=host1,host2,host3 SubscriberHosts=host4, host5 RemoteSubscriberHosts=host6 MasterVIP=192.168.1.1, 192.168.1.2 SubscriberVIP=192.168.1.3 VIPInterface=eth0 VIPNetMask=255.255.255.0 CacheConnect=y
ttCWAdmin -createを使用し、プライマリ・サイトにアクティブ・スタンバイ・ペアのレプリケーション・スキームを作成します。この操作では障害時リカバリ・サブスクライバは作成されません。
ttCWAdmin -startを使用し、アクティブ・スタンバイ・ペアのレプリケーション・スキームを開始します。
アクティブ・スタンバイ・ペアによってレプリケートされるキャッシュ・グループをロードします。
「障害時リカバリ・サブスクライバのローリング・アウト」の手順に従って、障害時リカバリ・サブスクライバを設定します。
Oracle Clusterwareによって管理されていない読取り専用のTimesTenサブスクライバ・データベースを含めることができます。次のタスクを実行します。
cluster.oracle.iniファイルにRemoteSubscriberHosts Clusterware属性を含めます。次に例を示します。
[advancedROsubDSN] MasterHosts=host1,host2,host3 RemoteSubscriberHosts=host6 MasterVIP=192.168.1.1, 192.168.1.2 SubscriberVIP=192.168.1.3 VIPInterface=eth0 VIPNetMask=255.255.255.0
ttCWAdmin -createを使用し、プライマリ・サイトにアクティブ・スタンバイ・ペアのレプリケーション・スキームを作成します。
ttCWAdmin -startを使用し、アクティブ・スタンバイ・ペアのレプリケーション・スキームを開始します。これによって、読取り専用サブスクライバは作成されません。
ttRepStateGet組込みプロシージャを使用して、スタンバイ・データベースの状態がSTANDBYであることを確認します。
サブスクライバ・ホストで、ttRepAdmin -duplicateオプションを使用して、スタンバイ・データベースを読取り専用サブスクライバに複製します。詳細は、「データベースの複製」を参照してください。
サブスクライバ・ホストでレプリケーション・エージェントを起動します。
読取り専用サブスクライバを既存の構成に追加または既存の構成から削除する方法については、「Oracle Clusterwareによって管理されていない読取り専用サブスクライバの追加または削除」を参照してください。
読取り専用サブスクライバを再作成する方法については、「Oracle Clusterwareによって管理されていない読取り専用サブスクライバの再作成」を参照してください。
cluster.oracle.iniファイルの情報は、TimesTenデータベース、TimesTenプロセス、ユーザー・アプリケーションおよび仮想IPアドレスを管理するOracle Clusterwareリソースの作成に使用されます。cluster.oracle.iniという初期化ファイルをテキスト・ファイルとして作成します。
ttCWAdmin -createコマンドはこのファイルを読み取って構成情報を参照するので、このテキスト・ファイルの場所はttCWAdminによってアクセス可能かつ読取り可能であることが必要でます。ttCWAdminユーティリティを使用して、Oracle Clusterwareで管理されているクラスタ内のTimesTenアクティブ・スタンバイ・ペアを管理します。
このファイルは、アクティブ・データベースのホストにあるTimesTenデーモン・ホーム・ディレクトリに置くことをお薦めします。ただし、ttCWAdmin -createコマンドを実行するホストと同じホストにある任意のディレクトリまたは共有ドライブにこのファイルを置くこともできます。
このファイルのデフォルトの場所は、timesten_home/confディレクトリです。このファイルを別の場所に置く場合は、-ttclusteriniオプションを指定して場所のパスを識別します。
cluster.oracle.iniファイルのエントリ名は、sys.odbc.iniファイルの既存のシステムDSNと同じである必要があります。たとえば、[basicDSN]は、「基本的な可用性の構成」で説明されているcluster.oracle.iniファイル内のエントリ名です。また、[basicDSN]は、各ホストのsys.odbc.iniファイル内のDataStoreおよびData Source Nameデータ・ストア属性である必要があります。たとえば、host1にあるDSN basicDSNのsys.odbc.iniファイルは次のようになります。
[basicDSN] DataStore=/path1/basicDSN LogDir=/path1/log DatabaseCharacterSet=AL32UTF8 ConnectionCharacterSet=AL32UTF8
host2にあるbasicDSNのsys.odbc.iniファイルには異なるパスを指定できますが、その他すべての属性は同じである必要があります。
[basicDSN] DataStore=/path2/basicDSN LogDir=/path2/log DatabaseCharacterSet=AL32UTF8 ConnectionCharacterSet=AL32UTF8
次の項では、cluster.oracle.iniファイルのサンプル構成を示します。
この例では、サブスクライバを持たないアクティブ・スタンバイ・ペアを示します。アクティブ・データベースのホストは最初のMasterHostで定義されており(host1)、スタンバイ・データベースのホストはリストの2つ目のMasterHost (host2)です。リスト内の各ホストはカンマで区切ります。必要に応じて、読みやすくするために空白を含めることができます。
[basicDSN] MasterHosts=host1,host2
次の例では、host3にある、1つのサブスクライバを持つアクティブ・スタンバイ・ペアのcluster.oracle.iniファイルを示します。
[basicSubscriberDSN] MasterHosts=host1,host2 SubscriberHosts=host3
高度な可用性を実現するには、予備のマスター・ホストまたはサブスクライバ・ホストを構成します。これらのホストは、アクティブ・スタンバイ・ペア・レプリケーション・スキームで使用されるマスター・ホストまたはサブスクライバ・ホストが予期しないシャットダウンやリカバリ不能なエラーの発生により置換えが必要になるまで、アイドル状態に維持されます。
「基本的な可用性の構成」で説明されているように、cluster.oracle.iniファイルのMasterHosts属性は、マスター・ノードとして使用されるホストを構成します。アクティブ・スタンバイ・ペア・レプリケーション・スキームでは、2つのマスター・ホストのみ必要です(1つはアクティブ、もう1つはスタンバイになります)。障害が発生すると、停止しなかったホストがアクティブになり(まだアクティブでない場合)、停止したホストはリカバリ後にスタンバイになります。ただし、停止したホストをリカバリできず、cluster.oracle.iniファイルで3つ以上のホストをマスター・ホストとして指定している場合、リスト内の次のマスター・ホストがリカバリ不能なマスター・ポストを置き換えるようにインスタンス化されます。
たとえば、次の例は複数マスター・ホストの構成を示します。最初の2つのマスター・ホスト(host1とhost2)はアクティブとスタンバイになります。次の2つのマスター・ホスト(host3とhost4)は、リカバリ不能な障害が発生した場合にhost1またはhost2のいずれかと入れ替えるために使用できます。
MasterHosts=host1,host2,host3,host4
3つ以上のホストを構成する場合、TimesTenリソースを管理するOracle Clusterwareリソースのみで使用される2つの仮想IP (VIP)アドレスも構成する必要があります。これらのVIPアドレスを使用することにより、レプリケーションを管理するTimesTen内部プロセスは、リカバリ不能なホスト・エラーにより発生するいずれのマスター・ホスト変更の影響も受けなくなります。
|
ノート: 「仮想IPアドレスを管理するためのOracle Clusterwareリソースの作成」で説明されているように、これらのVIPアドレス(高度な可用性で使用される)を管理するOracle Clusterwareリソースは、ttCWAdmin -createVIPsコマンドを使用して作成されます。 |
これらのVIPアドレスは、Oracle Clusterwareで使用するために定義されている他のいずれのVIPアドレスまたはユーザー・アプリケーションにより使用されるいずれのVIPアドレスとも異なる必要があります。さらに、アプリケーションがこれらのVIPアドレスを使用すると、マスター・ホストで障害(リカバリ可能またはリカバリ不可能)が発生したときにアプリケーションでエラーが発生することがあります。ユーザー・アプリケーションは、クライアント・フェイルオーバーの方法として、またはアクティブ・データベースとスタンバイ・データベースが切り替わったときに自身を隔離するための方法として、これらのVIPアドレスを使用することはできません。
2つのVIPアドレスをMasterVIPパラメータに指定します。アクティブ・スタンバイ・ペアのレプリケーション・スキームの各マスター・ホストに1つずつです。TimesTenクラスタに指定されたVIPアドレスは、Oracle Clusterwareですでに定義および使用されているVIPアドレスとは異なる必要があります。特に、Oracle Clusterwareのインストール時に指定されたVIPアドレスをTimesTenで使用することはできません。
MasterVIP=192.168.1.1, 192.168.1.2
次のパラメータも、cluster.oracle.iniファイル内で高度な可用性に関連付けられます。
MasterHostsに類似するSubscriberHostsは、サブスクライバ・データベースを含むことができるホストの名前をリストします。
MasterVIPに類似するSubscriberVIPは、サブスクライバ・ノードを管理するためにTimesTenが内部で使用できるVIPアドレスを提供します。
VIPInterfaceは、パブリック・ネットワーク・アダプタの名前です。
VIPNetMaskは、仮想IPアドレスのネットマスクを定義します。
次の例では、アクティブ・データベースおよびスタンバイ・データベースのホストは、それぞれhost1およびhost2です。リカバリ不能なエラーが発生した場合にインスタンス化できるホストは、host3およびhost4です。サブスクライバ・ノードはありません。VIPInterfaceは、パブリック・ネットワーク・アダプタの名前です。VIPNetMaskは、仮想IPアドレスのネットマスクを定義します。
[advancedDSN] MasterHosts=host1,host2,host3,host4 MasterVIP=192.168.1.1, 192.168.1.2 VIPInterface=eth0 VIPNetMask=255.255.255.0
次の例では、単一のサブスクライバがhost4上に構成されます。SubscriberHostsには、マスター・データベースのフェイルオーバーに使用できる追加のホストが1つと、サブスクライバ・データベースのフェイルオーバーに使用できる追加のノードが1つ定義されます。MasterVIPおよびSubscriberVIPは、マスター・データベースおよびサブスクライバ・ホストに対して定義されている仮想IPアドレスを指定します。
[advancedSubscriberDSN] MasterHosts=host1,host2,host3 SubscriberHosts=host4,host5 MasterVIP=192.168.1.1, 192.168.1.2 SubscriberVIP=192.168.1.3 VIPInterface=eth0 VIPNetMask=255.255.255.0
追加のマスター・ノードが次のようになっていることを確認します。
TimesTenがインストールされている。
ダイレクト・モードのアプリケーションがインストールされている(構成の一部である場合)。「アプリケーション・フェイルオーバーの実装」を参照してください。
アクティブ・スタンバイ・ペアが1つ以上のAWTまたは読取り専用キャッシュ・グループをレプリケートする場合、CacheConnect属性をyに設定します。
この例では、高度な可用性構成で1つのサブスクライバを持つアクティブ・スタンバイ・ペアを指定します。アクティブ・スタンバイ・ペアによって、1つ以上のキャッシュ・グループがレプリケートされます。
[advancedCacheDSN] MasterHosts=host1,host2,host3 SubscriberHosts=host4, host5 MasterVIP=192.168.1.1, 192.168.1.2 SubscriberVIP=192.168.1.3 VIPInterface=eth0 VIPNetMask=255.255.255.0 CacheConnect=y
Oracle Clusterwareと統合されたTimesTenでは、アクティブ・スタンバイ・ペアの任意のデータベースにリンクされたTimesTenアプリケーションのフェイルオーバーを簡素化できます。TimesTenは、Oracle ClusterwareおよびTimesTenと同じホストにある、ダイレクト・モードのアプリケーションとクライアント/サーバー・モードのアプリケーションの両方を管理できます。
TimesTenアプリケーションのフェイルオーバーに必要なcluster.oracle.iniファイルの属性は、次のとおりです。
AppName: Oracle Clusterwareで管理されるアプリケーションの名前。
AppStartCmd: アプリケーションを起動するコマンドライン。
AppStopCmd: アプリケーションを停止するコマンドライン。
AppCheckCmd: AppNameで指定されたアプリケーションのステータスを確認するアプリケーションを実行するためのコマンドライン。
AppType: アプリケーションのリンク先となるデータベースを定義します。使用可能な値は、Active、Standby、DualMaster、Subscriber (all)およびSubscriber[index]です。
AppFailureThreshold、DatabaseFailoverDelay、AppScriptTimeoutなど、構成可能なオプションの属性が複数あります。表A-3「オプション属性」は、すべてのオプション属性とそのデフォルト値の一覧および説明を示します。
TimesTenアプリケーション・モニター・プロセスは、ユーザー指定のスクリプトまたはAppCheckCmdで指定されたプログラムを使用して、アプリケーションを監視します。アプリケーションのステータスを確認するスクリプトは、成功の場合は0を返し、失敗の場合は0以外を返すように記述されている必要があります。0(ゼロ)以外の値が検出されると、Oracle Clusterwareは、障害が発生したアプリケーションをリカバリするためのアクションを実行します。
この例では、サブスクライバを持たないアクティブ・スタンバイ・ペアに対して構成されている高度な可用性を示します。readerアプリケーションは、スタンバイ・データベースのデータを問い合せるアプリケーションです。AppStartCmd、AppStopCmdおよびAppCheckCmdには、start、stopおよびcheckコマンドなどの引数を含めることができます。
|
ノート: AppStartCmd、AppStopCmdおよびAppCheckCmdの値に引用符を使用しないでください。 |
[appDSN] MasterHosts=host1,host2,host3,host4 MasterVIP=192.168.1.1, 192.168.1.2 VIPInterface=eth0 VIPNetMask=255.255.255.0 AppName=reader AppType=Standby AppStartCmd=/mycluster/reader/app_start.sh start AppStopCmd=/mycluster/reader/app_stop.sh stop AppCheckCmd=/mycluster/reader/app_check.sh check
2つ以上のアプリケーションのフェイルオーバーを構成できます。AppNameを使用してアプリケーションを指定し、AppName属性のすぐ後に続くAppType、AppStartCmd、AppStopCmdおよびAppCheckCmdの値を指定します。読みやすくするために空白行を含めることができます。次に例を示します。
[app2DSN] MasterHosts=host1,host2,host3,host4 MasterVIP=192.168.1.1, 192.168.1.2 VIPInterface=eth0 VIPNetMask=255.255.255.0 AppName=reader AppType=Standby AppStartCmd=/mycluster/reader/app_start.sh AppStopCmd=/mycluster/reader/app_stop.sh AppCheckCmd=/mycluster/reader/app_check.sh AppName=update AppType=Active AppStartCmd=/mycluster/update/app2_start.sh AppStopCmd=/mycluster/update/app2_stop.sh AppCheckCmd=/mycluster/update/app2_check.sh
AppTypeをDualMasterに設定すると、アプリケーションはアクティブ・ホストとスタンバイ・ホストの両方で起動します。アクティブ・ホストでアプリケーションが停止すると、そのホスト上のアクティブ・データベースおよびその他すべてのアプリケーションがスタンバイ・ホストにフェイルオーバーします。AppFailureInterval、AppRestartAttemptsおよびAppUptimeThreshold属性を設定することによって、障害間隔、再起動の試行回数および稼働時間のしきい値を構成できます。これらの属性にはデフォルト値があります。次に例を示します。
[appDualDSN] MasterHosts=host1,host2,host3,host4 MasterVIP=192.168.1.1, 192.168.1.2 VIPInterface=eth0 VIPNetMask=255.255.255.0 AppName=update AppType=DualMaster AppStartCmd=/mycluster/update/app2_start.sh AppStopCmd=/mycluster/update/app2_stop.sh AppCheckCmd=/mycluster/update/app2_check.sh AppRestartAttempts=5 AppUptimeThreshold=300 AppFailureInterval=30
両方のマスター・ノードに障害が発生し、その後復旧した場合、Oracle Clusterwareは、自動的にマスター・データベースをリカバリできます。一時的な二重の障害から自動リカバリするには、次の条件が満たされている必要があります。
アクティブ・スタンバイ・ペアにRETURN TWOSAFEが指定されていない。
AutoRecoverがyに設定されている。
RepBackupDirが共有記憶域のディレクトリを指定している。
RepBackupPeriodが0より大きい値に設定されている。
両方のマスター・ノードに永続的な障害が発生した場合、Oracle Clusterwareは、自動的にマスター・データベースを2つの新しいノードにリカバリできます。次の条件が満たされている必要があります。
高度な可用性(仮想IPアドレスおよび少なくとも4つのホスト)が構成されている。
アクティブ・スタンバイ・ペアがキャッシュ・グループをレプリケートしていない。
RETURN TWOSAFEが指定されていない。
AutoRecoverがyに設定されている。
RepBackupDirが共有記憶域のディレクトリを指定している。
RepBackupPeriodが0より大きい値に設定されている。
TimesTenは最初にアクティブ・データベースの全体バックアップを実行し、次に増分バックアップを実行します。オプションの属性RepFullBackupCycleを指定すると、TimesTenがその後の全体バックアップを実行するタイミングを管理できます。デフォルトでは、TimesTenは、増分バックアップを5回実行するたびに完全バックアップを1回実行します。
RepBackupDirおよびRepBackupPeriodをバックアップに構成している場合、TimesTenは、アクティブになるすべてのマスター・データベースのバックアップを実行します。データベースが再度アクティブにならないかぎり、かつてアクティブとして使用され今はスタンバイになっているデータベースに対して実行されたバックアップは削除されません。2つの完全なデータベース・バックアップ用に十分な共有記憶域が必要です。ttCWAdmin -restoreコマンドによって、正しいバックアップ・ファイルが自動的に選択されます。
増分バックアップでは、トランザクション・ログ・ファイルのログ・レコードの量が増えます。RepBackupPeriodおよびRepFullBackupCycleの値を十分に小さくし、トランザクション・ログ・ファイルのログ・レコードが大量にならないようにします。
[autorecoveryDSN]
MasterHosts=host1,host2,host3,host4
MasterVIP=192.168.1.1, 192.168.1.2
VIPInterface=eth0
VIPNetMask=255.255.255.0
AutoRecover=y
RepBackupDir=/shared_drive/dsbackup
RepBackupPeriod=3600
アクティブ・スタンバイ・ペアにキャッシュ・グループがある場合、または両方のマスター・ホストの障害から手動でリカバリする場合は、AutoRecoverがn(デフォルト)に設定されていることを確認します。手動リカバリでは、次のこと必要です。
RepBackupDirが共有記憶域のディレクトリを指定している
RepBackupPeriodが0より大きい値に設定されている。
この例では、手動リカバリの属性設定を示します。AutoRecoverのデフォルト値はnであるため、このファイルには含まれていません。
[manrecoveryDSN]
MasterHosts=host1,host2,host3
MasterVIP=192.168.1.1, 192.168.1.2
VIPInterface=eth0
VIPNetMask=255.255.255.0
RepBackupDir=/shared_drive/dsbackup
RepBackupPeriod=3600
RepDDL属性は、アクティブ・スタンバイ・ペアを作成するSQL文を表します。RepDDL属性はオプションです。これは、アクティブ・スタンバイ・ペアから表、キャッシュ・グループおよび順序を除外する場合に使用できます。
RepDDLをcluster.oracle.iniファイルに含める場合は、ReturnServiceAttribute、MasterStoreAttributeまたはSubscriberStoreAttributeをcluster.oracle.iniファイルに指定しないでください。これらのレプリケーション設定は、RepDDL属性に含めるようにしてください。
RepDDLの値を指定する場合、データベース・ファイル名の接頭辞に<DSN>マクロを使用します。マスター・ホスト名を指定するには、<MASTERHOST[1]>および<MASTERHOST[2]>マクロを使用します。TimesTenは、構成で仮想IPアドレスが使用されているかどうに応じて、MasterHostsまたはMasterVIP属性の正しい値に置換します。同様に、サブスクライバ・ホスト名を指定するには、<SUBSCRIBERHOST[n]>マクロを使用します(ここで、nは、1からSubscriberHosts属性値の合計数までの数値、仮想IPアドレスが使用されている場合は1からSubscriberVIP属性値の合計数までの数値です)。
RepDDL属性を使用して、アクティブ・スタンバイ・ペアから表、キャッシュ・グループおよび順序を除外します。
[excludeDSN] MasterHosts=host1,host2,host3,host4 SubscriberHosts=host5,host6 MasterVIP=192.168.1.1, 192.168.1.2 SubscriberVIP=192.168.1.3 VIPInterface=eth0 VIPNetMask=255.255.255.0 RepDDL=CREATE ACTIVE STANDBY PAIR \ <DSN> ON <MASTERHOST[1]>, <DSN> ON <MASTERHOST[2]> SUBSCRIBER <DSN> ON <SUBSCRIBERHOST[1]>\ EXCLUDE TABLE pat.salaries, \ EXCLUDE CACHE GROUP terry.salupdate, \ EXCLUDE SEQUENCE ttuser.empcount
レプリケーション・エージェントのトランスミッタは、次の方法でルート情報を取得します(優先順に示します)。
RepDDL設定のROUTE句から(ROUTE句が指定されている場合)。高度な可用性を構成している場合は、ROUTE句を指定しないでください。
ローカル・ホストとリモート・ホストのプライベート・ホスト名およびパブリック・ホスト名を提供するとともに、リモート・デーモンのポート番号を提供するOracle Clusterwareから。プライベート・ホスト名は、パブリック・ホスト名より優先されます。レプリケーション・エージェントのトランスミッタがIPCソケットに接続できない場合、Oracle Clusterwareがレプリケーション・スキームに関して保持している情報を使用してリモート・デーモンへの接続を試行します。
アクティブ・ホストおよびスタンバイ・ホストから。失敗した場合、レプリケーション・エージェントはホスト名に基づいた接続方法を選択します。
この例では、RepDDLにROUTE句を指定します。
[routeDSN] MasterHosts=host1,host2,host3,host4 RepDDL=CREATE ACTIVE STANDBY PAIR \ <DSN> ON <MASTERHOST[1]>, <DSN> ON <MASTERHOST[2]>\ ROUTE MASTER <DSN> ON <MASTERHOST[1]> SUBSCRIBER <DSN> ON <MASTERHOST[2]>\ MASTERIP "192.168.1.2" PRIORITY 1\ SUBSCRIBERIP "192.168.1.3" PRIORITY 1\ MASTERIP "10.0.0.1" PRIORITY 2\ SUBSCRIBERIP "10.0.0.2" PRIORITY 2\ MASTERIP "140.87.11.203" PRIORITY 3\ SUBSCRIBERIP "140.87.11.204" PRIORITY 3\ ROUTE MASTER <DSN> ON <MASTERHOST[2]> SUBSCRIBER <DSN> ON <MASTERHOST[1]>\ MASTERIP "192.168.1.3" PRIORITY 1\ SUBSCRIBERIP "192.168.1.2" PRIORITY 1\ MASTERIP "10.0.0.2" PRIORITY 2\ SUBSCRIBERIP "10.0.0.1" PRIORITY 2\ MASTERIP "140.87.11.204" PRIORITY 3\ SUBSCRIBERIP "140.87.11.203" PRIORITY 3\
次の項では、クラスタのステータスの取得方法を説明します。
ttCWAdmin -statusコマンドでは、同じインスタンス管理者によって管理されているTimesTenインスタンスのすべてのアクティブ・スタンバイ・ペアの情報がレポートされます。DSNを指定すると、ユーティリティによってそのDSNとアクティブ・スタンバイ・ペアに関する情報がレポートされます。
例8-1 アクティブ・スタンバイ・ペアの作成後のステータス
アクティブ・スタンバイ・ペア・レプリケーション・スキームを作成した後ttCWAdmin -statusコマンドを実行したがレプリケーションをまだ開始していない場合、ステータスは次のようになります。
% ttCWAdmin -status TimesTen Cluster status report as of Thu Nov 11 13:54:35 2010 ==================================================================== TimesTen daemon monitors: Host:HOST1 Status: online Host:HOST2 Status: online ==================================================================== ==================================================================== TimesTen Cluster agents Host:HOST1 Status: online Host:HOST2 Status: online ==================================================================== Status of Cluster related to DSN MYDSN: ==================================================================== 1. Status of Cluster monitoring components: Monitor Process for Active datastore:NOT RUNNING Monitor Process for Standby datastore:NOT RUNNING Monitor Process for Master Datastore 1 on Host host1: NOT RUNNING Monitor Process for Master Datastore 2 on Host host2: NOT RUNNING 2.Status of Datastores comprising the cluster Master Datastore 1: Host:host1 Status:AVAILABLE State:ACTIVE Master Datastore 2: Host:host2 Status:UNAVAILABLE State:UNKNOWN ==================================================================== The cluster containing the replicated DSN is offline
例8-2 アクティブ・データベースが稼働している場合のステータス
レプリケーション・スキームを開始してアクティブ・データベースが実行されているがスタンバイ・データベースがまだ実行されていない場合、ttCWAdmin -statusは次の値を返します。
% ttCWAdmin -status TimesTen Cluster status report as of Thu Nov 11 13:58:25 2010 ==================================================================== TimesTen daemon monitors: Host:HOST1 Status: online Host:HOST2 Status: online ==================================================================== ==================================================================== TimesTen Cluster agents Host:HOST1 Status: online Host:HOST2 Status: online ==================================================================== Status of Cluster related to DSN MYDSN: ==================================================================== 1. Status of Cluster monitoring components: Monitor Process for Active datastore:RUNNING on Host host1 Monitor Process for Standby datastore:RUNNING on Host host1 Monitor Process for Master Datastore 1 on Host host1: RUNNING Monitor Process for Master Datastore 2 on Host host2: RUNNING 2.Status of Datastores comprising the cluster Master Datastore 1: Host:host1 Status:AVAILABLE State:ACTIVE Master Datastore 2: Host:host2 Status:AVAILABLE State:IDLE ==================================================================== The cluster containing the replicated DSN is online
例8-3 アクティブ・データベースとスタンバイ・データベースが稼働している場合のステータス
レプリケーション・スキームを開始してアクティブ・データベースとスタンバイ・データベースの両方が実行されている場合、ttCWAdmin -statusは次の値を返します。
% ttcwadmin -status TimesTen Cluster status report as of Thu Nov 11 13:59:20 2010 ==================================================================== TimesTen daemon monitors: Host:HOST1 Status: online Host:HOST2 Status: online ==================================================================== ==================================================================== TimesTen Cluster agents Host:HOST1 Status: online Host:HOST2 Status: online ==================================================================== Status of Cluster related to DSN MYDSN: ==================================================================== 1. Status of Cluster monitoring components: Monitor Process for Active datastore:RUNNING on Host host1 Monitor Process for Standby datastore:RUNNING on Host host2 Monitor Process for Master Datastore 1 on Host host1: RUNNING Monitor Process for Master Datastore 2 on Host host2: RUNNING 2.Status of Datastores comprising the cluster Master Datastore 1: Host:host1 Status:AVAILABLE State:ACTIVE Master Datastore 2: Host:host2 Status:AVAILABLE State:STANDBY ==================================================================== The cluster containing the replicated DSN is online
監視プロセスでは、ttcwerrors.logおよびttcwmsg.logファイルにイベントとエラーがレポートされます。これらのファイルはdaemon_home/infoディレクトリにあります。これらのファイルのデフォルト・サイズはユーザー・ログのデフォルトの最大サイズと同じです。ログ・ファイルの最大数はユーザー・ログのデフォルトのファイル数と同じです。ファイルの最大数が書き込まれると、その他のエラーおよびメッセージによってファイルが上書きされ、最も古いファイルで開始されます。
ログ・ファイル数およびログ・ファイル・サイズのデフォルト値は、『Oracle TimesTen In-Memory Databaseオペレーション・ガイド』のエラー、警告および情報メッセージに関する項を参照してください。
クラスタを正常に停止するには、次の手順を実行します。
ttCWAdmin -stopコマンドで、TimesTenデーモン・モニター(ttCRSmaster)、キャッシュ・エージェントおよびレプリケーション・エージェントを停止し、データベース(使用中でない場合)をアンロードします。
% ttCWAdmin -stop -dsn myDSN
ttCWAdmin -dropコマンドを使用して、アクティブなスタンバイ・ペアを削除します。このコマンドは、ClusterwareからTimesTenデーモン・モニター(ttCRSmaster)リソースを登録解除します。
% ttCWAdmin -drop -dsn myDSN
ttCWAdmin -shutdownコマンドを使用して、クラスタ内のすべてのホストで、TimesTenクラスタ・エージェント(ttCRSAgent)およびTimesTenクラスタ・デーモン・モニター(ttCRSDaemon)を停止します。
% ttCWAdmin -shutdown
rootまたはOS管理者としてOracle Clusterwareのcrsctl disable crsコマンドを実行し、サーバー起動時にOracle Clusterwareが自動起動しないようにします。
% crsctl disable crs
オプションで、すべてのアプリケーションを切断してから各ホストで次のコマンドを実行することにより、アクティブ、スタンバイおよびサブスクライバの各ホストで各TimesTenデータベースを正常に停止できます。
% ttDaemonAdmin -stop
Oracle Clusterwareは、様々な種類の障害から自動的にリカバリできます。次の項では、いくつかの障害の例と、Oracle Clusterwareによる障害の管理方法を示します。
TimesTenデータベース・モニター(ttCRSmasterプロセス)がリカバリを実行します。forceconnectオプションを使用せずに、障害の発生したデータベースへの接続を試行します。エラー994 ("Data store connection terminated")で接続に失敗した場合、データベース・モニターは再接続を10回試行します。エラー707 ("Attempt to connect to a data store that has been manually unloaded from RAM")で接続に失敗した場合、データベース・モニターはRAMポリシーを変更して接続を再試行します。データベース・モニターは、接続できない場合、接続障害エラーを返します。
データベース・モニターがデータベースに接続できた場合、次のタスクが実行されます。
TTREP.REPLICATIONSレプリケーション表のCHECKSUM列を問い合せます。
CHECKSUM列の値がOracle Cluster Registryに保存されているチェックサムと一致する場合は、データベース・モニターはデータベースのロールを確認します。役割がACTIVEの場合、リカバリは完了です。
役割がACTIVEでない場合、データベース・モニターは、ローカル・データベースのレプリケーションのコミット・チケット番号(CTN)とアクティブ・データベースのCTNを問い合せて、レプリケートされていないトランザクションがあるかどうかを確認します。すべてのトランザクションがレプリケートされていれば、リカバリは完了です。
チェックサムが一致しなかった場合、または一部のトランザクションがレプリケートされていない場合には、データベース・モニターはリモート・データベースから複製操作を実行し、ローカル・データベースを再作成します。
エラー8110または8111(マスター・キャッチアップが必要またはマスター・キャッチアップを実行中)により、データベース・モニターがデータベースへの接続に失敗した場合、forceconnect=1オプションを使用して接続を行い、マスター・キャッチアップを開始します。マスター・キャッチアップが完了すると、リカバリは完了です。エラー8112 ("Operation not permitted")によりマスター・キャッチアップが失敗した場合、データベース・モニターはリモート・データベースから複製操作を実行します。マスター・キャッチアップの詳細は、「障害が発生したマスター・データベースの自動キャッチアップ」を参照してください。
その他のエラーにより接続に失敗した場合には、データベース・モニターはリモート・データベースから複製操作の実行を試みます。
複製操作では、次のことを確認します。
リモート・データベースが使用できる。
レプリケーション・エージェントが稼働している。
リモート・データベースに適切なロールが設定されている。スタンバイ・データベースの作成のために複製操作が試行される場合、役割はACTIVEに設定されている必要があります。読取り専用サブスクライバの作成のために複製操作が試行される場合、役割はSTANDBYまたはACTIVEに設定されている必要があります。
複製操作の条件が満たされている場合は、障害が発生した既存のデータベースは破棄され、複製操作が開始されます。
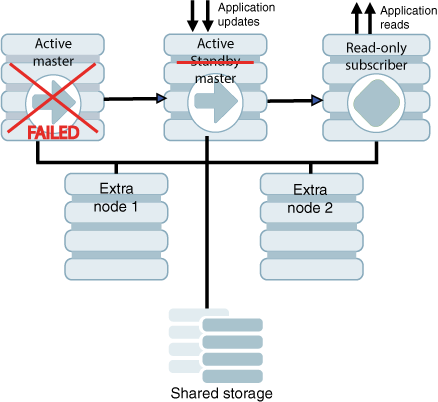
アクティブ・データベースが存在するノードで障害が発生した場合、Oracle Clusterwareでは、スタンバイ・データベースの状態が自動的にACTIVEに変更されます。アプリケーション・フェイルオーバーが構成されている場合は、アプリケーションによって新しいアクティブ・データベースの更新が開始されます。
図8-2では、スタンバイ・データベースの状態がACTIVEに変更され、アプリケーションによって新しいアクティブ・データベースが更新されています。
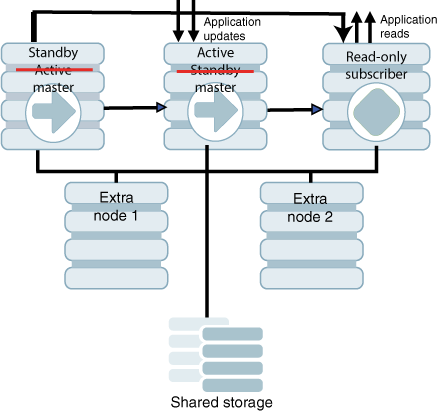
Oracle Clusterwareによって、障害が発生したデータベースまたはホストの再起動が試行されます。成功すると、そのデータベースがスタンバイ・データベースになります。
図8-3に、前のアクティブ・マスターがスタンバイ・マスターになったクラスタを示します。
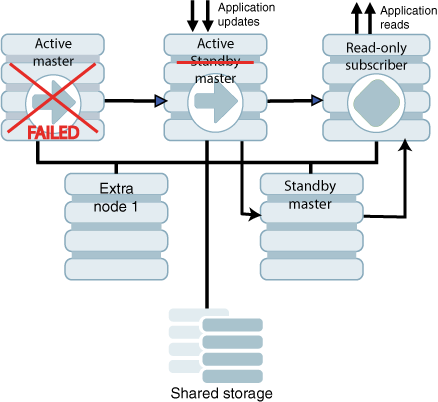
前のアクティブ・マスターの障害が永続的であり、高度な可用性が構成されている場合は、Oracle Clusterwareでは追加のノードの1つでスタンバイ・マスターが起動されます。
図8-4に、追加のノードの1つでスタンバイ・マスターが起動されたクラスタを示します。
これらの自動アクションの実行を待機しない場合は、「アクティブ・データベースまたはそのホストで障害が発生した場合の強制的なスイッチオーバーの実行」を参照してください。
スタンバイ・マスターで障害が発生した場合、Oracle Clusterwareによって、まず、そのデータベースまたはホストの再起動が試行されます。スタンバイ・マスターを同じホストで再起動できず、高度な可用性が構成されている場合は、追加のノードでスタンバイ・マスターが起動されます。
図8-5に、追加のノードの1つでスタンバイ・マスターが起動されたクラスタを示します。
サブスクライバ・ノードで障害が発生した場合、Oracle Clusterwareによって、まず、そのデータベースまたはホストの再起動が試行されます。データベースを同じホストで再起動できず、高度な可用性が構成されている場合は、追加のノードでサブスクライバ・データベースが起動されます。
この項の内容は次のとおりです。
Oracle Clusterwareでは、次のような場合に、両方のマスター・ノードで一時的な障害が発生し、その後ノードが復旧した後に自動リカバリを実行できます。
アクティブ・スタンバイ・ペアにRETURN TWOSAFEが指定されていない。
AutoRecoverがyに設定されている。
RepBackupDirが共有記憶域のディレクトリを指定している。
RepBackupPeriodが0より大きい値に設定されている。
Oracle Clusterwareでは、次のような場合に、両方のマスター・ノードで発生した永続的な障害からの自動リカバリを実行できます。
高度な可用性(仮想IPアドレスおよび少なくとも4つのホスト)が構成されている。
アクティブ・スタンバイ・ペアがキャッシュ・グループをレプリケートしていない。
アクティブ・スタンバイ・ペアにRETURN TWOSAFEが指定されていない。
AutoRecoverがyに設定されている。
RepBackupDirが共有記憶域のディレクトリを指定している。
RepBackupPeriodが0より大きい値に設定されている。
cluster.oracle.iniファイルの例については、「両方のマスター・ノードが恒久的に失敗した場合のリカバリの構成」を参照してください。
この項では、障害が発生したマスター・ノードが、TimesTenおよびOracle Clusterwareがインストールされている新しいホストにリカバリされることを想定しています。次のステップでは、例としてmanrecoveryDSNデータベースおよびcluster.oracle.iniファイルを使用します。
高度な可用性構成で手動リカバリを実行するには、次の手順を実行します。
TimesTenクラスタ・エージェント(ttCRSAgent)がローカル・ホストで実行されていることを確認します。
ttCWAdmin -init -hosts localhost
バックアップ・データベースをリストアします。リストアするデータベースと同じDSNを持つデータベースがホストにないことを確認します。
ttCWAdmin -restore -dsn manrecoveryDSN
データベースにキャッシュ・グループがある場合、そのキャッシュ・グループを削除して再度作成します。
新しいホストがcluster.oracle.iniファイルのMasterHostsおよびSubscriberHostsで指定されていない場合、新しいホストが含まれるようにファイルを変更します。
このステップでは、manrecoveryDSNを使用します。cluster.oracle.iniファイルにはすでに追加のホストが指定されているため、manrecoveryDSNにはこのステップは必要はありません。
アクティブ・スタンバイ・ペアのレプリケーション・スキームを再度作成します。
ttCWAdmin -create -dsn manrecoveryDSN
アクティブ・スタンバイ・ペアのレプリケーション・スキームを開始します。
ttCWAdmin -start -dsn manrecoveryDSN
この項では、障害が発生したマスター・ノードが、TimesTenおよびOracle Clusterwareがインストールされている新しいホストにリカバリされることを想定しています。次のステップでは、例としてbasicDSNデータベースおよびcluster.oracle.iniファイルを使用します。
基本的な可用性構成で手動リカバリを実行するには、次のステップを実行します。
アクティブ・スタンバイ・ペアのデータベース用に新しいホストを取得します。
TimesTenクラスタ・エージェント(ttCRSAgent)がローカル・ホストで実行されていることを確認します。
ttCWAdmin -init -hosts localhost
バックアップ・データベースをリストアします。リストアするデータベースと同じDSNを持つデータベースがホストにないことを確認します。
ttCWAdmin -restore -dsn basicDSN
データベースにキャッシュ・グループがある場合、そのキャッシュ・グループを削除して再度作成します。
cluster.oracle.iniファイルのMasterHostsおよびSubscriberHostsエントリを更新します。この例では、basicDSNデータベースを使用します。MasterHostsエントリはhost1からhost10に変更されます。SubscriberHostsエントリはhost2からhost20に変更されます。
[basicDSN] MasterHosts=host10,host20
アクティブ・スタンバイ・ペアのレプリケーション・スキームを再度作成します。
ttCWAdmin -create -dsn basicDSN
アクティブ・スタンバイ・ペアのレプリケーション・スキームを開始します。
ttCWAdmin -start -dsn basicDSN
両方のマスター・ノードで障害が発生し、データベースが破損する場合があります。同じマスター・ノードにリカバリするには、次のステップを実行します。
TimesTenデーモン・モニター(ttCRSmaster)、レプリケーション・エージェントおよびキャッシュ・エージェントが停止し、アプリケーションが両方のデータベースから切断されていることを確認します。この例では、basicDSNデータベースを使用します。
ttCWAdmin -stop -dsn basicDSN
ttDestroyユーティリティを使用し、新しいアクティブ・データベースを配置するノードでデータベースを破棄します。
ttDestroy basicDSN
バックアップ・データベースをリストアします。
ttCWAdmin -restore -dsn basicDSN
データベースにキャッシュ・グループがある場合、そのキャッシュ・グループを削除して再度作成します。
アクティブ・スタンバイ・ペアのレプリケーション・スキームを再度作成します。
ttCWAdmin -create -dsn basicDSN
アクティブ・スタンバイ・ペアのレプリケーション・スキームを開始します。
ttCWAdmin -start -dsn basicDSN
cluster.oracle.iniファイルでReturnServiceAttribute Clusterware属性を使用し、RETURNサービスRETURN TWOSAFEを利用できるようにアクティブ・スタンバイ・ペアを構成できます。RETURN TWOSAFEが構成されている場合、両方のノードで障害が発生した後、いずれかまたは両方のノードでデータベース・ログを利用できることがあります。
次のcluster.oracle.iniの例では、データベース・ログを利用できなかった場合のバックアップ構成を示します。
[basicTwosafeDSN]
MasterHosts=host1,host2
ReturnServiceAttribute=RETURN TWOSAFE
RepBackupDir=/shared_drive/dsbackup
RepBackupPeriod=3600
次のリカバリ手順を実行します。
TimesTenデーモン・モニター(ttCRSmaster)、レプリケーション・エージェントおよびキャッシュ・エージェントが停止し、アプリケーションが両方のデータベースから切断されていることを確認します。
ttCWAdmin -stop -dsn basicTwosafeDSN
アクティブ・スタンバイ・ペアを削除します。
ttCWAdmin -drop -dsn basicTwosafeDSN
前のアクティブ・データベースまたはスタンバイ・データベースのどちらがより新しいかを判断し、新しい方のデータベースを使用してアクティブ・スタンバイ・ペアを再度作成します。アクティブ・データベースを配置するホストを選択するように要求されます。
ttCWAdmin -create -dsn basicTwosafeDSN
どちらのデータベースも使用できない場合、バックアップからデータベースをリストアします。
ttCWAdmin -restore -dsn basicTwosafeDSN
アクティブ・スタンバイ・ペアのレプリケーション・スキームを開始します。
ttCWAdmin -start -dsn basicTwosafeDSN
二重のホスト障害のより極端なケースとして、3つ以上のマスター・ホストの障害対応について説明します。次のガイドラインを使用します。
停電やネットワーク障害などの場合は、障害の根本原因に対処します。
アクティブ・データベースおよびスタンバイ・データベース用の少なくとも2つの正常なホストを識別または取得します。
cluster.oracle.iniファイルのMasterHostsおよびSubscriberHostsエントリを更新します。
その後実行するアクションのガイドラインは、「高度な可用性の場合の手動リカバリ」および「基本的な可用性の場合の手動リカバリ」を参照してください。
TimesTenおよびOracle Clusterwareによって自動リカバリが実行されるまで待機せずに、スタンバイ・データベースに強制的にスイッチオーバーする場合は、Oracle Clusterwareコマンドを使用してアプリケーションを作成します。
次のことを行います。
crsctl stop resourceコマンドを使用して、アクティブ・データベースでTimesTenデーモン・モニター(ttCRSmaster)リソースを停止します。これにより、スタンバイ・データベースのロールがアクティブに変更されます。
以前のアクティブ・データベースでttCRSmasterリソースを再起動するには、crsctl start resourceコマンドを使用します。これにより、データベースがリカバリされ、スタンバイ・データベースになります。
次の例は、host1のアクティブ・データベースからhost2のスタンバイ・データベースへの強制スイッチオーバーを示しています。
crsctl status resourceコマンドを使用して、すべてのTimesTenリソースを検索します。
% crsctl status resource | grep TT NAME=TT_Activeservice_tt181_ttadmin_REP1 NAME=TT_Agent_tt181_ttadmin_HOST1 NAME=TT_Agent_tt181_ttadmin_HOST2 NAME=TT_App_tt181_ttadmin_REP1_updateemp NAME=TT_Daemon_tt181_ttadmin_HOST1 NAME=TT_Daemon_tt181_ttadmin_HOST2 NAME=TT_Master_tt181_ttadmin_REP1_0 NAME=TT_Master_tt181_ttadmin_REP1_1 NAME=TT_Subservice_tt181_ttadmin_REP1
ttCRSActiveServiceリソースのステータスを取得して、アクティブ・データベースが存在するホストを検索します。
% crsctl status resource TT_Activeservice_tt181_ttadmin_REP1 NAME=TT_Activeservice_tt181_ttadmin_REP1 TYPE=application TARGET=ONLINE STATE=ONLINE on host1
初期ステータス・レポートには2つのttCRSmasterリソースがリストされています。どのttCRSmasterリソースがアクティブ・データベースと同じホストにあるかを確認します。
% crsctl status resource TT_Master_tt181_ttadmin_REP1_0 NAME=TT_Master_tt181_ttadmin_REP1_0 TYPE=application TARGET=ONLINE STATE=ONLINE on host1 % crsctl status resource TT_Master_tt181_ttadmin_REP1_1 NAME=TT_Master_tt181_ttadmin_REP1_1 TYPE=application TARGET=ONLINE STATE=ONLINE on host2
アクティブ・データベースが存在するホストのttCRSmasterリソースを停止します。
% crsctl stop resource TT_Master_tt181_ttadmin_REP1_0 CRS-2673: Attempting to stop 'TT_Master_tt181_ttadmin_REP1_0' on 'host1' CRS-2677: Stop of 'TT_Master_tt181_ttadmin_REP1_0' on 'host1' succeeded
最初のアクティブ・データベースでttCRSmasterリソースを再起動します。
% crsctl start resource TT_Master_tt181_ttadmin_REP1_0 CRS-2672: Attempting to start 'TT_Master_tt181_ttadmin_REP1_0' on 'host1' CRS-2676: Start of 'TT_Master_tt181_ttadmin_REP1_0' on 'host1' succeeded
アクティブ・サービスttCRSActiveServiceおよびスタンバイ・サービスttCRSsubserviceリソースがある場所を確認して、強制スイッチオーバーが成功していることを確認します。
% crsctl status resource TT_Activeservice_tt181_ttadmin_REP1 NAME=TT_Activeservice_tt181_ttadmin_REP1 TYPE=application TARGET=ONLINE STATE=ONLINE on host2 % crsctl status resource TT_Subservice_tt181_ttadmin_REP1 NAME=TT_Subservice_tt181_ttadmin_REP1 TYPE=application TARGET=ONLINE STATE=ONLINE on host1
crsctl start resourceおよびcrsctl stop resourceコマンドの詳細は、『Oracle Clusterware管理およびデプロイメント・ガイド』を参照してください。
この項の内容は次のとおりです。
ttCWAdmin -createコマンドでアクティブ・スタンバイ・ペアのレプリケーション・スキームを作成する場合、TimesTen環境を管理するために必要なユーザー名とパスワードを求めるプロンプトがOracle Clusterwareで表示されます。Oracle Clusterwareはこれらのユーザー名とパスワードを保存します。ユーザー名やパスワードを変更した後には、ttCWAdmin -reauthenticateコマンドを実行して、これらの新しいユーザー名とパスワードをOracle Clusterwareが保存できるようにする必要があります。
DDLReplicationLevel接続属性が3に設定されていることを確認します。この値であれば、アクティブ・データベース上のユーザー名やパスワードへの変更がスタンバイ・データベースにレプリケートされます。
同じ方法(および同じ制限)を使用して、ユーザー名やパスワードを変更します(「レプリケーションで使用されるユーザー名またはパスワードの変更」を参照)。
アクティブ・データベースで、スタンバイ・データベースのDSNおよびホストを使用してttRepSubscriberWait組込みプロシージャ(またはttRepAdmin -waitコマンド)をコールし、すべてのパスワード変更がスタンバイ・データベースにレプリケートされていることを確認します。たとえば、すべてのトランザクションがhost2ホストのmaster2スタンバイ・データベースレプリケートされるようにするには、次のようにします。
Command> CALL ttRepSubscriberWait(NULL, NULL, 'master2', 'host2', -1);
ttCWAdmin -reauthenticateコマンドを実行して、Oracle Clusterwareに新しいパスワードを保存します。
ttCWAdmin -reauthenticate -dsn myDSN
このコマンドを実行すると、ttCWAdmin -createコマンドで要求される情報と同じ情報を求めるプロンプトが表示されます(「アクティブ・スタンバイ・ペアのレプリケーション・スキームの作成」を参照)。
次の項では、クラスタ使用時のホストの追加または削除方法を説明します。
ホストを追加するには、クラスタが高度な可用性用に構成されている必要があります。この項の例では、advancedSubscriberDSNを使用しています。
クラスタに2つのスペア・マスター・ホストを追加するには、次のようなコマンドを入力します。
ttCWAdmin -addMasterHosts -hosts "host8,host9" -dsn advancedSubscriberDSN
クラスタに1つのスペア・サブスクライバ・ホストを追加するには、次のようなコマンドを入力します。
ttCWAdmin -addSubscriberHosts -hosts "subhost1" -dsn advancedSubscriberDSN
ホストをクラスタから削除するには、クラスタが高度な可用性用に構成されている必要があります。マスター・ホストの1つを削除するには、MasterHostsに3つ以上のホストがリストされている必要があります。サブスクライバ・ホストの1つを削除するには、サブスクライバ・データベースの数よりも少なくとも1つ多いホストがSubscriberHostsにリストされている必要があります。
この項の例では、advancedSubscriberDSNを使用しています。
クラスタから2つのスペア・マスター・ホストを削除するには、次のようなコマンドを入力します。
ttCWAdmin -delMasterHosts "host8,host9" -dsn advancedSubscriberDSN
クラスタから1つのスペア・サブスクライバ・ホストを削除するには、次のようなコマンドを入力します。
ttCWAdmin -delSubscriberHosts "subhost1" -dsn advancedSubscriberDSN
次の項では、クラスタに対するアクティブ・スタンバイ・ペアの追加または削除方法を説明します。
すでにアクティブ・スタンバイ・ペアを管理しているクラスタに(サブスクライバを持つ(または持たない))アクティブ・スタンバイ・ペアを追加するには、次の手順を実行します。
最初にアクティブ・データベースを配置するホストに、データベースを作成して移入を行います。詳細は、「1つのホストでのTimesTenデータベースの作成および移入」を参照してください。
cluster.oracle.iniファイルを変更します。この例では、advancedSubscriberDSNの構成がすでに含まれたcluster.oracle.iniファイルに、advSub2DSNを追加します。新しいアクティブ・スタンバイ・ペアは、元のアクティブ・スタンバイ・ペアとは異なるホストにあります。
[advancedSubscriberDSN] MasterHosts=host1,host2,host3 SubscriberHosts=host4, host5 MasterVIP=192.168.1.1, 192.168.1.2 SubscriberVIP=192.168.1.3 VIPInterface=eth0 VIPNetMask=255.255.255.0 [advSub2DSN] MasterHosts=host6,host7,host8 SubscriberHosts=host9, host10 MasterVIP=192.168.1.4, 192.168.1.5 SubscriberVIP=192.168.1.6 VIPInterface=eth0 VIPNetMask=255.255.255.0
rootユーザーとして、新しい仮想IPアドレスを作成します。
ttCWAdmin -createVIPs -dsn advSub2DSN
新しいアクティブ・スタンバイ・ペアのレプリケーション・スキームを作成します。
ttCWAdmin -create -dsn advSub2DSN
新しいアクティブ・スタンバイ・ペアのレプリケーション・スキームを開始します。
ttCWAdmin -start -dsn advSub2DSN
(サブスクライバを持つ(または持たない))アクティブ・スタンバイ・ペアをクラスタから削除するには、次の手順を実行します。
アクティブ・スタンバイ・ペアのすべてのデータベースで、レプリケーション・エージェントを停止します。この例では、「クラスタへのアクティブ・スタンバイ・ペアの追加」で追加されたadvSub2DSNを使用します。
ttCWAdmin -stop -dsn advSub2DSN
アクティブ・スタンバイのレプリケーション・スキームを削除します。
ttCWAdmin -drop -dsn advSub2DSN
アクティブ・スタンバイ・ペアの仮想IPアドレスを削除します。
ttCWAdmin -dropVIPs -dsn advSub2DSN
cluster.oracle.iniファイルを変更します(オプション)。advSub2DSNのエントリを削除します。
データベースを破棄する場合、このアクティブ・スタンバイ・ペアの構成に含まれる各ホストにログオンし、ttDestroyユーティリティを使用します。
ttDestroy advSub2DSN
ttDestroyの詳細は、『Oracle TimesTen In-Memory Databaseリファレンス』のttDestroyに関する説明を参照してください。
次の項では、Oracle Clusterwareが管理するアクティブ・スタンバイ・ペアでの読取り専用サブスクライバの管理方法を説明します。
Oracle Clusterwareによって管理される読取り専用サブスクライバをアクティブ・スタンバイ・ペアのレプリケーション・スキームに追加するには、次のステップを実行します。
すべてのデータベースでレプリケーション・エージェントを停止します。この例では、すでにサブスクライバが含まれており、高度な可用性が構成されているadvancedSubscriberDSNを使用します。
ttCWAdmin -stop -dsn advancedSubscriberDSN
アクティブ・スタンバイ・ペアを削除します。
ttCWAdmin -drop -dsn advancedSubscriberDSN
cluster.oracle.iniファイルを変更します。
SubscriberHosts属性にサブスクライバを追加します。
クラスタが高度な可用性用に構成されている場合、仮想IPアドレスをSubscriberVIP属性に追加します。
これらの属性を使用する例については、「高度な可用性の構成」を参照してください。
アクティブ・スタンバイ・ペアのレプリケーション・スキームを作成します。
ttCWAdmin -create -dsn advancedSubscriberDSN
アクティブ・スタンバイ・ペアのレプリケーション・スキームを開始します。
ttCWAdmin -start -dsn advancedSubscriberDSN
Oracle Clusterwareによって管理される読取り専用サブスクライバをアクティブ・スタンバイ・ペアから削除するには、次のステップを実行します。
すべてのデータベースでレプリケーション・エージェントを停止します。この例では、サブスクライバが含まれており、高度な可用性が構成されているadvancedSubscriberDSNを使用します。
ttCWAdmin -stop -dsn advancedSubscriberDSN
アクティブ・スタンバイ・ペアを削除します。
ttCWAdmin -drop -dsn advancedSubscriberDSN
cluster.oracle.iniファイルを変更します。
SubscriberHosts属性からサブスクライバを削除するか、アクティブ・スタンバイ・ペアにサブスクライバが残っていない場合は属性全体を削除します。
SubscriberVIP属性から仮想IPアドレスを削除するか、アクティブ・スタンバイ・ペアにサブスクライバが残っていない場合は属性全体を削除します。
アクティブ・スタンバイ・ペアのレプリケーション・スキームを作成します。
ttCWAdmin -create -dsn advancedSubscriberDSN
アクティブ・スタンバイ・ペアのレプリケーション・スキームを開始します。
ttCWAdmin -start -dsn advancedSubscriberDSN
Oracle Clusterwareによって管理されている既存のアクティブ・スタンバイ・ペアのレプリケーション・スキームに、Oracle Clusterwareによって管理されていない読取り専用サブスクライバを追加または削除できます。ttCWAdmin -beginAlterSchemaコマンドを使用すると、レプリケーション・スキームを削除および再作成せずに、サブスクライバを追加できます。サブスクライバはOracle Clusterware管理用に設定された構成の一部ではないため、Oracle Clusterwareでは管理されません。
次のステップを実行します。
ttCWAdmin -beginAlterSchemaコマンドを実行し、アクティブ・データベースとスタンバイ・データベースでレプリケーション・エージェントを停止します。
ttIsqlを使用してアクティブ・データベースに接続し、ALTER ACTIVE STANDBY PAIR文を使用して、レプリケーション・スキームにサブスクライバを追加、または削除します。たとえば、サブスクライバを追加するには次のコマンドを実行します。
ALTER ACTIVE STANDBY PAIR ADD SUBSCRIBER ROsubDSN ON host6;
サブスクライバを削除するには、次のコマンドを実行します。
ALTER ACTIVE STANDBY PAIR DROP SUBSCRIBER ROsubDSN ON host6;
変更したレプリケーション・スキームを登録するttCWAdmin -endAlterSchemaコマンドを実行して、レプリケーションを開始します。サブスクライバを追加する場合は、これにより、スタンバイ・データベースへの複製も開始されます。
ttIsql repschemesコマンドを入力して、読取り専用サブスクライバがレプリケーション・スキームに追加、または削除されていることを確認します。
ttRepStateGet組込みプロシージャを使用して、スタンバイ・データベースの状態がSTANDBYであることを確認します。
サブスクライバを追加した場合は、サブスクライバ・ホストでttRepAdmin -duplicateを実行し、スタンバイ・データベースを読取り専用サブスクライバに複製します。「データベースの複製」を参照してください。
サブスクライバを追加した場合は、サブスクライバ・エージェントでレプリケーション・エージェントを起動します。
サブスクライバを追加した場合は、「Oracle Clusterwareによって管理されていない読取り専用サブスクライバの構成」のステップ1の説明に従って、cluster.oracle.iniファイルに読取り専用サブスクライバのOracle Clusterware属性RemoteSubscriberHostsを追加し、クラスタが削除されて再作成された場合に読取り専用サブスクライバを確実に含むようにします。また、サブスクライバを削除した場合は、cluster.oracle.iniファイルから、削除したサブスクライバのOracle Clusterware属性RemoteSubscriberHostsを削除します(構成されている場合)。
次のタスクを実行して、Oracle Clusterwareによって管理されない読取り専用サブスクライバを破棄および再作成します。
サブスクライバ・ホストでレプリケーション・エージェントを停止します。
ttDestroyユーティリティを使用して、サブスクライバ・データベースを破棄します。
サブスクライバ・ホストで、ttRepAdmin -duplicateを使用して、スタンバイ・データベースを読取り専用サブスクライバに複製します。詳細は、「データベースの複製」を参照してください。
フェイルオーバー後、アクティブ・データベースおよびスタンバイ・データベースはフェイルオーバー前とは異なるホストに配置されます。元の構成をリストアするには、ttCWAdminユーティリティの-switchオプションを使用します。また、必要に応じて、-timeoutオプションと-switchオプションを使用して、アクティブおよびスタンバイ・データベースの切替えが完了するまで待機するタイムアウトの秒数を設定できます。
次に例を示します。
ttCWAdmin -switch -dsn basicDSN
-switchオプションを使用する前に、オープン・トランザクションが存在しないことを確認してください。オープン・トランザクションが存在する場合、コマンドは失敗します。
|
ノート: -switchおよび-timeoutオプションの詳細は、『Oracle TimesTen In-Memory Databaseリファレンス』の「ttCWAdmin」を参照してください。 |
図8-6に、アクティブ・スタンバイ・ペアのホストを示します。アクティブ・データベースはホストAに存在し、スタンバイ・データベースはホストBに存在します。
ttCWAdmin -switchコマンドによって次のタスクが実行されます。
ホストA (アクティブ・マスター)でTimesTenクラスタ・エージェント(ttCRSAgent)を非アクティブにする。
ホストAでTimesTenデータベース・モニター(ttCRSmaster)を無効にする。
ホストAで組込みプロシージャttRepSubscriberWait、ttRepStopおよびttRepDeactivateをコールする。
ホストAでアクティブ・サービス(ttCRSActiveService)を停止し、Oracle ClusterwareのCRSDプロセスに失敗イベントをレポートする。
ホストAで監視を有効にし、アクティブ・サービスをホストBに移動する。
ホストAでレプリケーション・エージェントを開始し、ホストBでスタンバイ・サービス(ttCRSsubservice)を停止して、ホストBでOracle ClusterwareのCRSDプロセスに失敗イベントをレポートする。
ホストAでスタンバイ・サービス(ttCRSsubservice)を開始する。
サブスクライバを持つアクティブ・スタンバイ・ペアの間で接続属性を変更した場合、この構成に含まれるすべてのホストで接続属性を変更する必要があります。
|
ノート: DATASTORE接続属性は、データ・ストアの作成時にのみ設定が許可されているため、すべて変更できません。たとえば、次のプロシージャはPermSize値を変更するために使用できます。 |
ttCWAdmin -beginAlterSchemaおよび-endAlterSchemaコマンドを使用すると、アクティブおよびスタンバイ・データベースとすべてのサブスクライバの接続属性値を簡単に変更できます。
変更の準備のため、ttCWAdmin -beginAlterSchemaコマンドを使用して、Oracle Clusterware管理を一時停止し、アクティブおよびスタンバイ・データベースとすべてのサブスクライバ・データベースのレプリケーション・エージェントを停止します。
すべての変更が完了したら、ttCWAdmin -endAlterSchemaコマンドを使用して、Oracle Clusterware管理を再開し、アクティブおよびスタンバイ・データベースとすべてのサブスクライバ・データベースのすべてのレプリケーション・エージェントを再起動します。
Oracle Clusterwareを使用している場合にアクティブ・スタンバイ・ペアの接続属性を変更するには、次のタスクを実行します。
ttCWAdmin -beginAlterSchemaコマンドを使用して、Oracle Clusterwareを一時停止し、アクティブおよびスタンバイ・データベースのすべてのレプリケーション・エージェントを停止します。
アクティブ・データベースはリクエストと更新を引き続き受け付けますが、レプリケーション・エージェントが再起動されるまでは、スタンバイ・データベースとすべてのサブスクライバにはいかなる変更も伝播されません。
また、ttCWAdmin -beginAlterSchemaコマンドは、スタンバイ・データベースとすべてのサブスクライバ・データベースのRAMポリシーを一時的にInUse with RamGraceに変更します。このポリシーにより、TimesTenがこれらのデータベースをアンロードできるようにするための60秒の猶予期間が設定されます。スタンバイおよびサブスクライバ・データベースがメモリーからアンロードされると、これらのデータベースの接続属性が変更可能になります。
ttCWAdmin -beginAlterSchema -dsn advancedDSN
すべてのアプリケーション接続を切断し、(RAMポリシーに基づいて)スタンバイおよびサブスクライバ・データベースがメモリーからアンロードされるのを待機します。
スタンバイおよびサブスクライバ・データベースがメモリーからアンロードされたら、それぞれのsys.odbc.iniファイル内のスタンバイ・データベースおよびすべてのサブスクライバ・データベースのホストで、PermSizeなどの任意の接続属性を変更します。
ttCWAdmin -endAlterSchemaコマンドを使用して、Oracle Clusterwareを再開し、アクティブおよびスタンバイ・データベースのすべてのレプリケーション・エージェントを再起動します。各TimesTenデータベースの構成済のRAMポリシーは、alwaysに戻されます。アクティブ・データベースは、スタンバイ・データベースとサブスクライバが停止していた間に発生したすべてのトランザクションを伝播します。
ttCWAdmin -endAlterSchema -dsn advancedDSN
|
ノート: 次のステップを実行する前に、アクティブ・データベースからスタンバイ・データベースとすべてのサブスクライバにすべての変更が伝播されるまで、しばらく待機します。接続属性をまだ変更していないホストは、アクティブ・データベースのみです。このホストで接続属性を変更できるようにするため、アクティブ・データベースとスタンバイ・データベースを切り替えます。 |
すべてのアプリケーション・ワークロードを一時停止して、アクティブ・データベースのすべてのアプリケーションを切断します。
ttCWAdmin -switchコマンドを使用して、アクティブ・データベースとスタンバイ・データベースを切り替えます。
ttCWAdmin -switch -dsn advancedDSN
ttCWAdmin -beginAlterSchemaコマンドを使用して、Oracle Clusterwareを一時停止し、すべてのデータベースのすべてのレプリケーション・エージェントを停止します。
新しいアクティブ・データベースは引き続きリクエストと更新を受け付けますが、新しいスタンバイ・データベースとすべてのサブスクライバにはいかなる変更も伝播されません。
新しいスタンバイ・データベース(およびすべてのサブスクライバ・データベース)のRAMポリシーがinUse with RamGraceに変更されます。このポリシーにより、TimesTenがこれらのデータベースをアンロードできるようにするための60秒の猶予期間が設定されます。
ttCWAdmin -beginAlterSchema -dsn advancedDSN
新しいスタンバイ・データベースがメモリーからアンロードされるを待機します。アンロードが完了したら、sys.odbc.iniファイルに含まれる新しいスタンバイ・データベースで、同じ接続属性(PermSizeなど)を変更します。これで、すべてのホストで接続属性が変更されました。
ttCWAdmin -endAlterSchemaコマンドを実行して、Oracle Clusterware管理を再開し、アクティブおよびスタンバイ・データベースのレプリケーション・エージェントを再起動します。構成済のRAMポリシーはalwaysに戻されます。
ttCWAdmin -endAlterSchema -dsn advancedDSN
すべてのアプリケーション・ワークロードを一時停止して、アクティブ・データベースのすべてのアプリケーションを切断します。
必要であれば、ttCWAdmin -switchコマンドを使用してアクティブ・データベースとスタンバイ・データベースを切り替え、アクティブ・スタンバイ・ペアを元の構成に戻します。
ttCWAdmin -switch -dsn advancedDSN
Oracle ClusterwareでTimesTenデータベースを管理する場合、TimesTenデータベースのRAMポリシーはデフォルトでalwaysに設定されています。ただし、Oracle Clusterware管理を停止すると、TimesTenデータベースのRAMポリシーはinUseに設定されます。
TimesTenの管理にOracle Clusterwareを今後使用しない場合は、ご使用の環境に合ったTimesTen RAMポリシーを設定する必要があります。一般的に推奨される設定はmanualです。
TimesTenデータベースのRAMポリシーの詳細は、『Oracle TimesTen In-Memory Databaseオペレーション・ガイド』のRAMポリシーの指定に関する説明を参照してください。
Oracle Clusterwareを使用してアクティブ・スタンバイ・ペアを管理する場合は、Oracle Clusterwareですべてのレプリケーション・エージェントを起動および停止する必要があることを除いて、通常のレプリケーション環境と同様に必要に応じてDDL文を実行しスキーマを変更できます。
したがって、スキーマを変更する際には次のことに気をつけてください。
自動的にレプリケートされるオブジェクトに対するDDL文については、レプリケーション・エージェントを停止する必要はありません。この場合、DDL文が自動的に伝播され、スタンバイ・データベースとすべてのサブスクライバに適用されるため、それ以上のアクションは必要ありません。DDLReplicationLevel接続属性によって、レプリケートされるDDL文を制御します。
レプリケーション・スキームに含まれるが、オブジェクトに対して実行されるDDL文がレプリケートされないオブジェクト(これらのオブジェクトは「アクティブ・スタンバイ・ペアへのその他の変更」にリストされています)については、アクティブ・データベースでOracle ClusterwareのttCWAdmin -beginAlterSchemaコマンドを実行して、Oracle Clusterware管理をすべて一時停止し、レプリケーション・スキームの各ノード上のレプリケーション・エージェントを停止します。その後、レプリケーション・スキームのアクティブ・データベースでDDL文を実行します。最後に、アクティブ・データベースでOracle ClusterwareのttCWAdmin -endAlterSchemaコマンドを実行して、すべてのレプリケーション・エージェントを再起動します。
これらのオブジェクトはレプリケーション・スキームに含まれますが、DDL文がレプリケートされないため、ttCWAdmin -endAlterSchemaコマンドの実行後に複製が行われ、これらのスキーマ変更がスタンバイ・データベースとすべてのサブスクライバに伝播されます。これは、複製がスキーマの変更を伝播するために使用される唯一のシナリオです。
手順については、「Oracle Clusterwareのスキーマ変更の簡素化」を参照してください。
自動的にレプリケートされない、レプリケーション・スキームに含まれないオブジェクトに対するDDL文については、アクティブ・データベースでOracle ClusterwareのttCWAdmin -beginAlterSchemaコマンドを実行して、Oracle Clusterware管理をすべて一時停止し、すべてのノード上のレプリケーション・エージェントを停止します。その後、「アクティブ・スタンバイ・ペアのDDLの変更」で説明するように、手動でこれらのDDL文を実行して、すべてのノードを同期できます。最後に、アクティブ・データベースでOracle ClusterwareのttCWAdmin -endAlterSchemaコマンドを実行して、すべてのレプリケーション・エージェントを再起動します。
手順については、「Oracle Clusterwareのスキーマ変更の簡素化」を参照してください。
|
ノート: 「アクティブ・スタンバイ・ペアのDDLの変更」および「アクティブ・スタンバイ・ペアへのその他の変更」という項では、どのDDL文がアクティブ・スタンバイ・ペア用に自動的にレプリケートされるか、どの文がレプリケートされないかを説明しています。これらの項では、どのオブジェクトがレプリケーション・スキームの一部かも説明しています。 |
ttCWAdmin -beginAlterSchemaおよび-endAlterSchemaコマンドを使用すると、アクティブおよびスタンバイ・データベースでのスキーマ変更が簡単にできます。
スキーマ変更の準備のため、ttCWAdmin -beginAlterSchemaコマンドを使用して、Oracle Clusterware管理を一時停止し、アクティブ・データベースとスタンバイ・データベースの両方でレプリケーション・エージェントを停止します。
すべてのスキーマ変更が完了した後、ttCWAdmin -endAlterSchemaコマンドを実行します。レプリケーション・スキームに含まれるがオブジェクトに対して実行されるDDL文が自動的にレプリケートされないオブジェクトについては、ttCWAdmin -endAlterSchemaコマンドの実行後に複製が行われ、これらのスキーマ変更のみがスタンバイ・データベースとすべてのサブスクライバに伝播されます。このコマンドは、変更されたレプリケーション・スキームを登録し、アクティブおよびスタンバイ・データベースのレプリケーション・エージェントを再起動し、Oracle Clusterwareの制御を回復します。
Oracle Clusterwareの使用時にアクティブ・スタンバイ・ペアのスキーマを変更するには、次のタスクを実行します。
Oracle Clusterwareを一時停止し、アクティブ・データベースとスタンバイ・データベースの両方でレプリケーション・エージェントを停止します。
ttCWAdmin -beginAlterSchema -dsn advancedDSN
必要なスキーマ変更を行います。
また、オブジェクトに対するDDLがレプリケートされないオブジェクトを作成、変更または削除する場合は、レプリケーション・エージェントが非アクティブになっている間に、スタンバイ・データベースとサブスクライバで同じオブジェクトを手動で作成、変更または削除して、同じオブジェクトがレプリケーション・スキーム内のすべてのデータベースに存在するようにする必要があります。たとえば、アクティブ・データベースでマテリアライズド・ビューを作成する場合は、スタンバイ・データベースとサブスクライバ・データベースでも同時にそのマテリアライズド・ビューを作成します。
レプリケーション・スキームの一部であるが、自動的にはレプリケートされないオブジェクト(順序など)をアクティブ・スタンバイ・ペアのレプリケーション・スキームに含める場合は、アクティブ・スタンバイ・ペアを変更します。
ALTER ACTIVE STANDBY PAIR INCLUDE samplesequence;
オブジェクトがキャッシュ・グループである場合、キャッシュ・グループを作成、変更または削除する手順については、「キャッシュ・グループに対するスキーマ変更」を参照してください。
ttCWAdmin -endAlterSchemaコマンドを実行して、Oracle Clusterwareを再開し、アクティブおよびスタンバイ・データベース上のレプリケーション・エージェントを再起動します。レプリケーション・スキームに含まれるがオブジェクトに対して実行されるDDL文が自動的にレプリケートされないオブジェクトを変更した場合は、ttCWAdmin -endAlterSchemaコマンドの実行後に複製が行われ、これらのスキーマ変更のみがスタンバイ・データベースとすべてのサブスクライバに伝播されます。
ttCWAdmin -endAlterSchema -dsn advancedDSN
ttCWAdmin -beginAlterSchemaおよび-endAlterSchemaコマンドを使用すると、キャッシュ・グループに対するスキーマ変更が簡単にできます。
アクティブ・スタンバイ・ペアのアクティブ・データベースについて、次のステップを実行します。
ttCWAdmin -beginAlterSchemaコマンドを使用して、Oracle Clusterware管理を一時停止し、レプリケーション・エージェントを停止します。
ttCWAdmin -beginAlterSchema -dsn advancedDSN
キャッシュ・グループを作成します。
キャッシュ・グループが読取り専用の場合は、読取り専用キャッシュ・グループを含めるようにアクティブ・スタンバイ・ペアを変更します。
ALTER ACTIVE STANDBY PAIR INCLUDE CACHE GROUP samplecachegroup;
ttCWAdmin -endAlterSchemaコマンドを実行して、Oracle Clusterwareを再開し、レプリケーション・エージェントを起動します。キャッシュ・グループ・オブジェクトを追加したので、複製が行われ、これらのスキーマ変更がスタンバイ・データベースに伝播されます。
ttCWAdmin -endAlterSchema -dsn advancedDSN
キャッシュ・グループを作成すると、いつでもそのキャッシュ・グループをロードすることができます。
キャッシュ・グループを削除するには、次のステップを実行します。
キャッシュ・グループをアンロードします。
UNLOAD CACHE GROUP samplecachegroup;
アクティブ・スタンバイ・ペアのアクティブ・データベースで、キャッシュ・グループの削除を有効にします。
ttCWAdmin -beginAlterSchema -dsn advancedDSN
キャッシュ・グループが読取り専用の場合は、読取り専用キャッシュ・グループを除外するようにアクティブ・スタンバイ・ペアを変更します。
ALTER ACTIVE STANDBY PAIR EXCLUDE CACHE GROUP samplecachegroup;
キャッシュ・グループが読取り専用の場合は、自動リフレッシュの状態をPAUSEDに設定します。
ALTER CACHE GROUP samplecachegroup SET AUTOREFRESH STATE PAUSED;
キャッシュ・グループを削除します。
DROP CACHE GROUP samplecachegroup;
キャッシュ・グループが読取り専用キャッシュ・グループだった場合は、Oracle Databaseでキャッシュ管理ユーザーとしてSQL*Plusスクリプトtimesten_home/install/oraclescripts/cacheCleanUp.sqlを実行し、自動リフレッシュ操作の実装に使用されるOracle Databaseオブジェクトを削除します。
ttCWAdmin -endAlterSchemaコマンドを実行して、Oracle Clusterwareを再開し、レプリケーション・エージェントを再起動します。キャッシュ・グループ・オブジェクトを削除したので、複製が行われ、これらのスキーマ変更がスタンバイ・データベースに伝播されます。
ttCWAdmin -endAlterSchema -dsn advancedDSN
既存のキャッシュ・グループを変更するには、「キャッシュ・グループの削除」で説明されているように、まず既存のキャッシュ・グループを削除します。その後、「キャッシュ・グループの追加」で説明されているように、キャッシュ・グループに目的の変更を追加します。
クラスタで高度な可用性が構成されている場合、ttCWAdmin -relocateコマンドを使用して、ローカル・ホストから、cluster.oracle.iniファイルのMasterHosts属性で指定されている次に利用可能なスペア・ホストにデータベースを移動できます。ローカル・ホストのデータベースがアクティブな役割を持っている場合、-relocateオプションでは、まず役割の入替えが行われます。したがって、新しく移行されたアクティブ・データベースがスタンバイ・データベースになり、元のスタンバイ・データベースが新しいアクティブ・データベースになります。
ttCWAdmin -relocateコマンドは、ホストをオフラインにすることを決定した場合にデータベースを再配置するのに役立ちます。このコマンドを使用する前に、オープン・トランザクションが存在しないことを確認してください。
ttCWAdmin -relocateコマンドで役割の切替えが必要な場合は、-timeoutオプションと-relocateオプションを使用し、役割の切替えが完了するまで待機するタイムアウトの秒数を設定できます。
次に例を示します。
ttCWAdmin -relocate -dsn advancedDSN
|
ノート: ttCWAdmin -relocateと-timeoutオプションの詳細は、『Oracle TimesTen In-Memory Databaseリファレンス』のttCWAdminを参照してください。 |
Oracle Clusterwareソフトウェアのローリング・アップグレードを実行する場合の完全な手順については、『Oracle Clusterware管理およびデプロイメント・ガイド』を参照してください。
Oracle Clusterwareの使用時にすべてのホストでTimesTenをアップグレードする方法の詳細は、次を参照してください。
Oracle TimesTen In-Memory Databaseインストレーション、移行およびアップグレード・ガイドのOracle Clusterware使用時のオフラインTimesTenアップグレードの実行
Oracle TimesTen In-Memory Databaseインストレーション、移行およびアップグレード・ガイドのOracle Clusterware使用時のオンラインTimesTenアップグレードの実行
ホストまたはネットワークのメンテナンスを実行する必要がある場合は、Oracle Clusterwareリソースを停止し、クラスタ内のTimesTenデータベースを1つ以上停止する必要があります。データベースのデータの一貫性を維持するため、トランザクションが失われないように、アクティブ・スタンバイ・ペアに含まれるTimesTenデータベースを適切に停止する必要があります。
メンテナンスの実行中に行う決定の1つに、Oracle Clusterwareを有効なままにするか無効にするかがあります。Oracle Clusterwareを有効なままにすると、システムの再起動後に、すべてのOracle ClusterwareおよびTimesTenプロセスが自動的に再起動します。Oracle Clusterwareを無効にすると、これらのプロセスはすべて自動的には再起動しません。
次の項では、以下について説明します。
クラスタ内のすべてのホストでメンテナンスを実行する場合、停止時間を最小にするため、次の操作を実行できます。
|
ノート: アクティブ、スタンバイおよび1つ以上のサブスクライバ・データベースがある場合は、指定されたデータベースを含む各ホストで、これらのタスクの一部を実行する必要があります。 |
アクティブ、スタンバイおよびサブスクライバ・データベースを含む各ホストで、rootまたはOS管理者として、Oracle Clusterwareのcrsctl stop crsコマンドを実行し、Oracle Clusterwareとレプリケーション・エージェントを停止します。
アクティブ・データベースが停止しているため、レプリケーション・エージェントが再起動されるまで、すべてのリクエストが拒否されます。
% crsctl stop crs
crsctl stop crsコマンドは、アクティブ、スタンバイおよびすべてのサブスクライバ・データベースのRAMポリシーを一時的にinUse with RamGraceに変更します。このポリシーにより、TimesTenがこれらのデータベースをアンロードできるようにするための60秒の猶予期間が設定されます。
必要に応じて、クラスタ内のすべてのホストでrootまたはOS管理者としてOracle Clusterwareのcrsctl disable crsコマンドを実行することにより、サーバー起動時にOracle ClusterwareおよびTimesTenが自動起動されるのを防止できます。
% crsctl disable crs
すべてのアプリケーション接続を切断し、アクティブ、スタンバイおよびサブスクライバ・データベースがメモリーからアンロードされるのを待機します。
アクティブ・スタンバイ・ペアの各TimesTenデータベースを正常に停止するには、アクティブ、スタンバイおよびサブスクライバ・データベースを含む各ホストで次のコマンドを実行します。
% ttDaemonAdmin -stop
|
ノート: TimesTenメイン・デーモン・プロセスは同じTimesTenインストールに属するすべてのデータベースを管理しているので、前述のコマンドを実行する前にすべてのデータベースを切断してください。『Oracle TimesTen In-Memory Databaseオペレーション・ガイド』のTimesTenアプリケーションの停止に関する説明を参照してください。 |
アクティブ、スタンバイおよびサブスクライバ・データベースを含むホストでメンテナンスを実行します。
メンテナンスが完了したら、次のいずれかを実行します。
Oracle ClusterwareおよびTimesTenの自動起動を無効にしなかった場合は、すべてのホストを再起動してから、Oracle ClusterwareおよびTimesTenプロセスが実行されるまで待機します(これには数分かかる場合があります)。
再起動後のOracle ClusterwareおよびTimesTenの自動起動を無効にした場合、または、自動起動が有効になっているがメンテナンス後にホストを再起動していない場合は、クラスタ内の各ホストで次のタスクを実行します。
次のコマンドを実行してTimesTenデータベースを起動します。
% ttDaemonAdmin -start
rootまたはOS管理者としてcrsctl enable crsを実行し、サーバー起動時のOracle Clusterwareの自動起動を有効にします。
% crsctl enable crs
rootまたはOS管理者としてcrsctl start crsを実行し、ローカル・サーバーのOracle Clusterwareを起動します。次のステップに進む前に、すべてのOracle Clusterwareリソースが稼働するまで待機します。
% crsctl start crs
すべてが稼働したら、アプリケーションを再接続できます。アクティブは、スタンバイおよびサブスクライバ・データベースへのすべての更新のレプリケートを開始します。構成済のRAMポリシーはalwaysに戻されます。
クラスタ内のすべてのホストでメンテナンスを実行する場合、停止時間を最小にするため、次の操作を実行できます。
|
ノート: アクティブ、スタンバイおよび1つ以上のサブスクライバ・データベースがある場合は、指定されたデータベースを含む各ホストで、これらのタスクの一部を実行する必要があります。 |
スタンバイおよびサブスクライバ・データベースを含む各ホストで、rootまたはOS管理者としてOracle Clusterwareのcrsctl stop crsコマンドを実行し、Oracle Clusterwareとレプリケーション・エージェントを停止します。
アクティブ・データベースはリクエストと更新を引き続き受け付けますが、レプリケーション・エージェントが再起動されるまでは、スタンバイ・データベースとすべてのサブスクライバにはいかなる変更も伝播されません。
% crsctl stop crs
また、crsctl stop crsコマンドは、スタンバイおよびすべてのサブスクライバ・データベースのRAMポリシーを一時的にInUse with RamGraceに変更します。このポリシーにより、TimesTenがこれらのデータベースをアンロードできるようにするための60秒の猶予期間が設定されます。
必要に応じて、スタンバイおよびサブスクライバ・データベースを含む各ホストでrootまたはOS管理者としてOracle Clusterwareのcrsctl disable crsコマンドを実行することにより、サーバー起動時にOracle ClusterwareおよびTimesTenが自動起動されるのを防止できます。
% crsctl disable crs
すべてのアプリケーション接続を切断し、スタンバイおよびサブスクライバ・データベースがメモリーからアンロードされるのを待機します。
TimesTenデータベースを正常に停止するには、スタンバイおよびサブスクライバ・データベースを含む各ホストで次のコマンドを実行します。
% ttDaemonAdmin -stop
|
ノート: TimesTenメイン・デーモン・プロセスは同じTimesTenインストールに属するすべてのデータベースを管理しているので、前述のコマンドを実行する前にすべてのデータベースを切断してください。『Oracle TimesTen In-Memory Databaseオペレーション・ガイド』のTimesTenアプリケーションの停止に関する説明を参照してください。 |
スタンバイおよびサブスクライバ・データベースを含むホストでメンテナンスを実行します。
メンテナンスが完了したら、次のいずれかを実行します。
Oracle ClusterwareおよびTimesTenの自動起動を無効にしなかった場合は、すべてのホストを再起動してから、Oracle ClusterwareおよびTimesTenプロセスが実行されるまで待機します(これには数分かかる場合があります)。
再起動後のOracle ClusterwareおよびTimesTenの自動起動を無効にした場合、または、自動起動が有効になっているがメンテナンス後にホストを再起動していない場合は、クラスタ内の各ホストで次のタスクを実行します。
次のコマンドを実行してTimesTenデータベースを起動します。
% ttDaemonAdmin -start
rootまたはOS管理者としてcrsctl enable crsを実行し、サーバー起動時のOracle Clusterwareの自動起動を有効にします。
% crsctl enable crs
rootまたはOS管理者としてcrsctl start crsを実行し、ローカル・サーバーのOracle Clusterwareを起動します。次のステップに進む前に、すべてのOracle Clusterwareリソースが稼働するまで待機します。
% crsctl start crs
すべてが稼働したら、アクティブはすべての更新をスタンバイおよびサブスクライバ・データベースにレプリケートします。
アクティブ・データベースのホストで同じメンテナンスを実行できるように、ttCWAdmin -switchコマンドを使用してアクティブ・データベースとスタンバイ・データベースを切り替えます。
ttCWAdmin -switch -dsn advancedDSN
新しいスタンバイ・データベースのホストでrootまたはOS管理者としてOracle Clusterwareのcrsctl stop crsコマンドを実行し、Oracle Clusterwareとレプリケーション・エージェントを停止します。
新しいアクティブ・データベースは引き続きリクエストと更新を受け付けますが、レプリケーション・エージェントが再起動されるまで、新しいスタンバイ・データベースとすべてのサブスクライバにはいかなる変更も伝播されません。
% crsctl stop crs
すべてのアプリケーション接続を切断し、スタンバイおよびサブスクライバ・データベースがメモリーからアンロードされるのを待機します。
TimesTenデータベースを正常に停止するには、新しいスタンバイ・データベースを含むホストで次のコマンドを実行します。
% ttDaemonAdmin -stop
新しいスタンバイ・データベースを含むホストでメンテナンスを実行します。これで、クラスタ内のすべてのホストでメンテナンスが実行されました。
メンテナンスが完了したら、次のいずれかを実行します。
Oracle ClusterwareおよびTimesTenの自動起動を無効にしなかった場合は、すべてのホストを再起動してから、Oracle ClusterwareおよびTimesTenプロセスが実行されるまで待機します(これには数分かかる場合があります)。
再起動後のOracle ClusterwareおよびTimesTenの自動起動を無効にした場合、または、自動起動が有効になっているがメンテナンス後にホストを再起動していない場合は、クラスタ内の各ホストで次のタスクを実行します。
次のコマンドを実行してTimesTenデータベースを起動します。
% ttDaemonAdmin -start
rootまたはOS管理者としてcrsctl enable crsを実行し、サーバー起動時のOracle Clusterwareの自動起動を有効にします。
% crsctl enable crs
rootまたはOS管理者としてcrsctl start crsを実行し、ローカル・サーバーのOracle Clusterwareを起動します。次のステップに進む前に、すべてのOracle Clusterwareリソースが稼働するまで待機します。
% crsctl start crs
すべてが稼働したら、アクティブはすべての更新をスタンバイおよびサブスクライバ・データベースにレプリケートします。RAMポリシーはalwaysに戻されます。
ttCWAdmin -switchコマンドを使用して、アクティブ・スタンバイ・ペアのアクティブとスタンバイの役割を元の構成に戻します。
ttCWAdmin -switch -dsn advancedDSN